Методика разработки программного продукта для поиска причин в изменениях трендов в данных
Реферат
Объем работы: 123 страницы, 9 иллюстраций, 4 приложения, 1 таблица
Ключевые слова: алгоритм классификации, анализ данных, data mining, машинное обучение
Дипломная работа посвящена методике разработки программного продукта для
поиска причин в изменениях трендов в данных. Рассмотрено создание системы
предобработки данных и разработка системы классификации на базе различных
алгоритмов машинного обучения. В работе определяется область применения
разработанной программы. Для разработки системы предобработки данных
использован язык программирования C#, Фреймворк .Net, а также СУБД MS SQL Server 2008R2.
Для разработки системы классификации использован язык программирования Python и библиотека Scikit-Learn. Для системы классификации была использована стратегия
One-vs-Rest для
алгоритмов классификации Машина Опорных Векторов (с различными ядрами) и
Наивный Байесовский Классификатор. Разработка велась под операционной системой Windows 7. Осуществлены эксперименты по
проверке точности объяснений, даваемых системой на тестовых данных.
Оглавление
Реферат
Введение
Постановка задачи
1. Методы машинного обучения
и алгоритмы машинного обучения
1.1 Задача классификации
1.2 Multiclass классификация
1.2.1 Стратегия One-vs.-rest
1.3 Multi-label классификация
Выводы
2. Методы и алгоритмы,
реализованные в программной системе
2.1 TF-IDF
2.2 Наивный Байесовский
Классификатор
2.3 SVM
2.3.1 Стохастический
Градиентый Спуск
Выводы
3. Реализация системы
3.1 Предобработка информации
3.1.1 Инструкция пользователя
3.2 Система классификации
3.2.1 Рабочий режим
3.2.2 Тестовый режим
3.2.3 Инструкция пользователя
Выводы
4. Машинный эксперимент
Выводы
Заключение
Список использованных
ресурсов
Приложение 1. Система
предобработки информации
Program.cs
FactMiner.cs
Logger.cs
Приложение 2. Файл
конфигурации системы предобработки информации
Приложение 3. Хранимые
процедуры и табличные представления базы данных FactEventAnalysisDB
usp_populateCoraxFactsTable
usp_clearFactsTables
SpikeFactsHypothesis
PriceFactsHypothesis
Приложение 4. Система классификации
Введение
В современном мире особенно сложной является задача по поиску причины в
изменении поведения комплексной системы. Например:
Что послужило причиной скачка энергопотребления города?
Почему резко выросла заболеваемость гриппом в определенной стране?
По какой причине цена некой ценной бумаги резко упала в конкретный день?
Одной из самых сложных проблем при выявлении и разработке законов
развития комплексных систем и принятия решений является формирование понимания
внутренних связей и механизмов тех или иных процессов в системах. Как правило,
этих связей и механизмов много, разные элементы системы могут быть связаны
между собой самыми разными прямыми и обратными связями, при этом каждый элемент
так или иначе связан с функциями системы и очень часто - с вредными или
нежелательными эффектами. Учитывать и использовать все эти связи в работе очень
сложно.
В самом деле, в любом из упомянутых выше случаев на динамику системы
(уровень энергопотребления, заболеваемость, цена ценной бумаги) могут влиять
сотни тысяч различных событий. Выявить какое из событий вызвало изменение в
динамике чрезвычайно сложно. Согласно исследованиям психологов, нормальный
человек способен удерживать в зоне своего внимания 7 ± 2 объекта. А в реальных
системах объектов и связей во много раз больше. В результате при попытке все
это «охватить в уме» внимание нарушается, случайным образом «прыгает» от
объекта к объекту, преувеличивает одни и преуменьшает или просто пропускает
другие элементы и связи и т.п. Цельную и объективную картину увидеть не
удается.
Например, ниже представлен график цен некой нефтедобывающей компании по
месяцам.
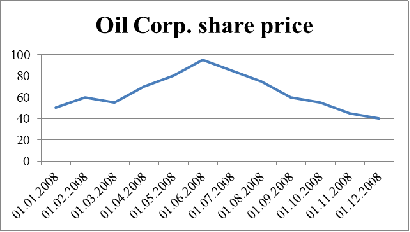
Рис. 1. Пример слома тренда
На данном графике явно виден рост цены акций данной компании вплоть до
6.1.2008, который сменился ее стабильным спадом после этого момента времени.
Опытный специалист в анализе ценных бумаг может проверить события, которые
произошли 6.1.2008 и выяснить, что в этот день был опубликован отчет о
перспективах китайской экономики, который был негативным. Цена акций
нефтедобывающих компаний сильно зависит от экономики Китая, ибо данная страна
является крупнейшим в мире потребителем нефти, и проблемы в ее экономике могут
сильно снизить доходы нефтедобывающих компаний.
Однако для выполнения анализа, который позволит найти объяснение
произошедшему изменению в динамике цены ценной бумаги требуются обширные знания
в предметной области, хорошо разбираться в характеристиках компаний, а также
быть в состоянии изучить колоссальные объемы данных - ибо в тот же день,
6.1.2008, в мире произошли миллионы событий, каждое из которых могло повлиять
на динамику цены.
Очевидно, одним из способов помочь эксперту в определении причин
изменения динамики системы будет решение задачи по сокращению списка событий,
связанных с системой, которые эксперту нужно рассмотреть. Вместо десятков тысяч
событий эксперт сможет сосредоточиться на рассмотрении лишь их небольшого
подмножества и применив свою компетенцию в предметной области сможет ответить
на вопрос, что же вызвало изменение в динамике системы. Именно данная задача
выделения наиболее вероятных объяснений причин некоего изменения и будет решена
в данной работе.
В первой главе производится постановка задачи, ее более подробное
описание, а также описание исходных данных.
Во второй главе приводится описание алгоритмов и методов, примененных при
разработке данной системы.
В третьей главе описывается реализация системы с помощью языков
программирования T-SQL, C# и Python, а также библиотеки scikit-learn.
В четвертой главе приводится описание методов оценки качества работы
полученной системы, и делаются выводы о качестве работы системы на тестовых
данных.
Постановка
задачи
Решить задачу по идентификации наиболее интересных для рассмотрения
событий может помочь Интеллектуальный Анализ Данных.
Интеллектуальный анализ данных (также известный как Data Mining) -
собирательное название, используемое для обозначения совокупности методов
обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и
доступных интерпретации знаний, необходимых для принятия решений в различных
сферах человеческой деятельности. Данный термин был введен в обиход Григорием
Пятецким-Шапиро в 1989 году.
Основу методов Data Mining составляют всевозможные методы классификации,
моделирования и прогнозирования, основанные на применении деревьев решений,
искусственных нейронных сетей, генетических алгоритмов, эволюционного
программирования, ассоциативной памяти, нечёткой логики. К методам Data Mining
нередко относят статистические методы (дескриптивный анализ, корреляционный и
регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный
анализ, дискриминантный анализ, анализ временных рядов, анализ выживаемости,
анализ связей). Такие методы, однако, предполагают некоторые априорные
представления об анализируемых данных, что несколько расходится с целями Data
Mining (обнаружение ранее неизвестных нетривиальных и практически полезных
знаний). Одними из важнейших инструментов, позволяющих решать задачи Data
Mining являются методы Машинного Обучения.
Машинное обучение или Machine Learning - обширный подраздел
искусственного интеллекта, изучающий методы построения моделей, способных
обучаться, и алгоритмов для их построения и обучения. Различают два типа
обучения. Обучение по прецедентам, или индуктивное обучение, основано на
выявлении закономерностей в эмпирических данных. Дедуктивное обучение
предполагает формализацию знаний экспертов и их перенос в компьютер в виде базы
знаний. Дедуктивное обучение принято относить к области экспертных систем,
поэтому термины машинное обучение и обучение по прецедентам можно считать
синонимами.
Машинное обучение находится на стыке математической статистики, методов
оптимизации и дискретной математики, но имеет также и собственную специфику,
связанную с проблемами вычислительной эффективности и переобучения. Многие
методы индуктивного обучения разрабатывались как альтернатива классическим
статистическим подходам.
Задачу машинного обучения можно описать следующим образом. Имеется
множество объектов (ситуаций) и множество возможных ответов (откликов,
реакций). Существует некоторая зависимость между ответами и объектами, но она
неизвестна. Известна только конечная совокупность прецедентов - пар «объект,
ответ», называемая обучающей выборкой. На основе этих данных требуется
восстановить зависимость, то есть построить алгоритм, способный для любого
объекта выдать достаточно точный ответ. Для измерения точности ответов
определённым образом вводится функционал качества.
Данная постановка является обобщением классических задач аппроксимации
функций. В классических задачах аппроксимации объектами являются действительные
числа или векторы. В реальных прикладных задачах входные данные об объектах
могут быть неполными, неточными, нечисловыми, разнородными. Эти особенности
приводят к большому разнообразию методов машинного обучения. Раздел машинного
обучения, с одной стороны, образовался в результате разделения науки о
нейросетях на методы обучения сетей и виды топологий архитектуры сетей, а с
другой, вобрал в себя методы математической статистики. Подобное разнообразие
позволяет нам подобрать инструмент для решения озвученной задачи по поиску
событий, вызвавших изменения в динамике систем.
Итак, имеется набор данных о ценах на ценные бумаги и о корпоративных
событиях (таких как выплата дивидендов, изменения рейтинга компаний, собраниях
акционеров) которые хранятся в базе данных MS SQL Server.
Задача делится на три части:
) Извлечь из информации о ценах данные о том, для каких ценных бумаг
когда наблюдалось изменение в тренде в цене (если цена на бумагу росла
некоторое время, то в какой момент она начала снижаться или стала неизменной).
2) Разработать систему, которая сможет обучиться на информации о
предшествующих событиях и изменениях в трендах
) После обучения система получив на вход информацию о некотором
изменении в динамике цены какой-либо ценной бумаги должна будет предоставлять
информацию о том, какое событие наиболее вероятно вызвало данное изменение
(какими характеристиками должно обладать такое событие).
С учетом этого описания и анализа имеющейся литературы в данной области
определим направления работы:
) Разработка программы, которая будет преобразовывать информацию о
ценах на ценные бумаги в информацию об изменениях в трендах цен на ценные
бумаги.
2) Рассмотрение различных методов машинного обучения, выбор наиболее
подходящего алгоритма машинного обучения с точки зрения его математической
модели
) Реализация выбранных алгоритмов в коде
) Проверка работы системы на тестовых данных
Система должна быть способна к масштабируемости, а ее архитектура должна
быть легко изменяемой. Легче всего этого добиться использую библиотеку scikit-learn, которая предоставляет большое количество различных
модулей, которые можно легко использовать в других системах.
1. Методы
машинного обучения и алгоритмы машинного обучения
Задачу, стоящую перед нами, можно отнести к задаче классификации, где в
ответ на набор значений параметров (страна, тип бумаг, тип изменения в
динамике) система должна возвращать несколько меток классов, которые описывают
событие, которое предположительно вызвало данное изменение в динамике. Ниже
проводится информация о задаче классификации и ее подвидах.
.1 Задача
классификации
Задача классификации - формализованная задача, в которой имеется
множество объектов (ситуаций), разделённых некоторым образом на классы. Задано
конечное множество объектов, для которых известно, к каким классам они
относятся. Это множество называется выборкой. Классовая принадлежность
остальных объектов неизвестна. Требуется построить алгоритм, способный
классифицировать (см. ниже) произвольный объект из исходного множества.
Классифицировать объект - значит, указать номер (или наименование)
класса, к которому относится данный объект.
Классификация объекта - номер или наименование класса, выдаваемый
алгоритмом классификации в результате его применения к данному конкретному
объекту.
В машинном обучении задача классификации решается, как правило, с помощью
методов искусственных нейронных сетей при постановке эксперимента в виде
обучения с учителем.
Математически данную задачу можно описать следующим образом:
Пусть 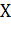 - множество описаний объектов,
- множество описаний объектов, 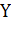 - множество номеров (или
наименований) классов. Существует неизвестная целевая зависимость - отображение
- множество номеров (или
наименований) классов. Существует неизвестная целевая зависимость - отображение
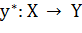 , значения которой известны только на
объектах конечной обучающей выборки
, значения которой известны только на
объектах конечной обучающей выборки 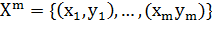 . Требуется построить алгоритм
. Требуется построить алгоритм 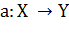 , способный классифицировать
произвольный объект
, способный классифицировать
произвольный объект 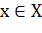 .
.
Более общей считается вероятностная постановка задачи. Предполагается,
что множество пар «объект, класс» 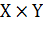 является вероятностным пространством
с неизвестной вероятностной мерой
является вероятностным пространством
с неизвестной вероятностной мерой 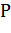 . Имеется конечная обучающая выборка
наблюдений , сгенерированная согласно вероятностной мере . Требуется построить алгоритм , способный классифицировать
произвольный объект .
. Имеется конечная обучающая выборка
наблюдений , сгенерированная согласно вероятностной мере . Требуется построить алгоритм , способный классифицировать
произвольный объект .
Признаком называется отображение 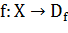 , где
, где 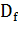 - множество допустимых значений
признака. Если заданы признаки
- множество допустимых значений
признака. Если заданы признаки 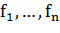 ,то вектор
,то вектор 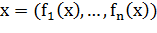 называется признаковым описанием объекта . Признаковые описания допустимо
отождествлять с самими объектами. При этом множество
называется признаковым описанием объекта . Признаковые описания допустимо
отождествлять с самими объектами. При этом множество 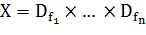 называют признаковым пространством.
называют признаковым пространством.
В зависимости от множества признаки делятся на следующие типы:
. Бинарный признак: 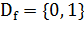
2. Номинальный признак: - конечное множество
. Порядковый признак: - конечное упорядоченное множество
. Количественный признак: - множество действительных чисел
Часто встречаются прикладные задачи с разнотипными признаками, для их
решения походят далеко не все методы.
Классической задачей классификации считается двухклассовая классификация,
то есть задача определения принадлежит ли объект лишь одному из двух классов,
которая служит основой для решения более сложных задач.
.2 Multiclass классификация
Multiclass classification
(многоклассовая классификация) - частный случай задачи классификации при
которой требуется классифицировать объекты в более чем один из двух классов.
Когда число классов достигает многих тысяч задача существенно вырастает в
сложности.
В то время как некоторые алгоритмы классификации по определению допускают
использования нескольких классов другие могут не иметь такой возможности, в то
же время они могут быть использованы в задачах многоклассовой классификации с
помощью различных стратегий. Классической считается стратегия One-vs.-rest
(один-против-всех, OvA или OvR).
.2.1
Стратегия One-vs.-rest
Стратегия One-vs.-rest включает в себя тренировку одного классификатора для
каждого класса, при котором мы считаем примеры с нужным классом позитивными
примерами, а все остальные примеры - негативными. Стратегия требует чтобы
базовые классификаторы возвращали меру уверенности (confidence score) своего решения, а не просто метку класса. Дискретные
метки класса могут привести к двусмысленности, так как несколько классов могут
быть предсказаны для одного примера.
Примерное описание алгоритма для стратегии OvA, которая использует бинарный классификатор L представлено ниже:
Вход:
· L, алгоритм обучения для бинарного классификатора
· Примеры
· Метки 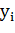 где
где 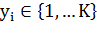 является меткой для примера
является меткой для примера 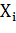
Выход:
· Набор обученных классификаторов 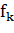 для
для 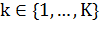
Процесс:
· Для каждого 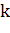 из
из 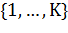
o Создать новый вектор меток 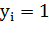 где
где 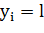 , 0 - в противном случае
, 0 - в противном случае
o Применить 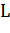 к
к 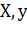 чтобы получить
чтобы получить
Для принятия решения необходимо применить все классификаторы к новому
примеру 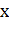 и назначить ему метку для которой соответствующий
классификатор демонстрирует наибольшую меру уверенности:
и назначить ему метку для которой соответствующий
классификатор демонстрирует наибольшую меру уверенности:
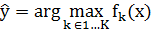
Данная стратегия является чрезвычайно популярной но во многом является
эвристикой, которая страдает от нескольких проблем. Во-первых, масштаб меры
уверенности может значительно отличаться между различными бинарными
классификаторами. Во-вторых, даже если распределение различных классов
сбалансированно во всем тренировочном наборе данных, алгоритмы обучения
бинарных классификаторов наблюдают несбалансированное распределение, так как,
как правило, количество отрицательных примеров намного превышает количество
позитивных примеров. В процессе изучения данного класса задач были созданы
методы для решения задачи Multi-label классификации, речь о которой пойдет ниже.
.3 Multi-label классификация
Multi-label классификация (примерный перевод - «многотемная
классификация») - один из видов задач классификации, где каждому примеру
необходимо присвоить сразу несколько меток принадлежности к определенному
классу. Формально задача может быть описана как нахождение модели, которая
будет ставить в соответствие входные примеры бинарным векторам 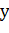 , а не скалярным значениям, как в
классической задаче классификации.
, а не скалярным значениям, как в
классической задаче классификации.
Существует два основных подхода для решения данной задачи - методы
трансформации проблемы и методы адаптации алгоритмов. Методы трансформации
проблемы преобразуют проблему к набору проблем бинарной классификации, которые
могут быть решены с помощью классификаторов, способных решать бинарные задачи
классификации. Методы адаптации алгоритмов, в свою очередь, модифицируют
алгоритмы классификации так, чтобы они могли напрямую решать задачу multi-label классификации. Таким образом, вместо
того, чтобы упрощать проблему они пытаются непосредственно решать проблему multi-label классификации.
В области machine
learning классическими считаются методы
трансформации проблемы, которые демонстрируют наилучшее качество предсказаний.
Среди них самым распространенным и популярным считается метод двоичных
отношений (binary relevance method). Данный метод предполагает создание и обучения
одного бинарного классификатора для каждой возможной метки. Далее, когда модели
подается новый пример, она присваивает данному примеру все метки для которых
соответствующие классификаторы дали положительный ответ. Метод превращения
задачи в набор бинарных задач классификации имеет много общего с методом one-vs.-all
мультиклассовой классификации. Тем не менее, надо учитывать что это не идеально
тот же метод - он тренирует отельный классификатор для каждой метки, но не для
каждого возможного значения этой метки.
Мерой «многотемности» данного набора данных можно оценить с помощью двух
статистических формул:
· Кардинальность меток (label cardinality) -
среднее количество меток, присвоенных каждому примеру в наборе данных:
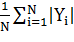
· Плотность меток - количество меток на каждый пример из набора данных
деленное на общее количество различных меток, усреднённое по всем примерам:
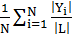 ,
,
где 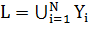
Методы оценки производительности multi-label
классификации в корне отличаются от используемых в многоклассовой или бинарной
классификации, в связи с естественными отличиями данной задачи классификации.
Если 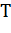 - правильный набор меток для данного
примера, а - набор предсказанных меток, то можно определить следующие
метрики для такого примера:
- правильный набор меток для данного
примера, а - набор предсказанных меток, то можно определить следующие
метрики для такого примера:
· Hamming loss - доля ошибочных меток во всем наборе меток. Является
функцией потерь, потому ее оптимальное значение равно 0. Тесно связанная с ней
метрика Hamming Score, также именуемая «точность в многотемной задаче» (accuracy in the multi-label setting),
определяется как количество правильных меток деленное на объединение
предсказанных и правильных меток: 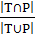
· Precision, recall и F1-метрика (F1-score). Precision (точность) равна доле правильно предсказанных меток от
общего количества предсказанных меток - 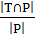 . Recall (полнота) характеризует все ли правильные ответы
вернул классификатор, равна доле правильно предсказанных меток от общего
количества правильных меток -
. Recall (полнота) характеризует все ли правильные ответы
вернул классификатор, равна доле правильно предсказанных меток от общего
количества правильных меток - 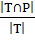 . Метрика F1 -
фактически является гармоническим средним от Precision и Recall,
. Метрика F1 -
фактически является гармоническим средним от Precision и Recall, 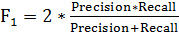
· Метрика точного соответствия (Exact Match Metric). Самая строгая метрика, представляет собой долю примеров
для которых классификатор смог верно указать все метки.
Выводы
Суммируя все вышесказанное мы можем указать, что задача, которая стоит
перед нами является гибридом multi-label и multiclass классификации. Для каждого примера
нам требуется предсказывать одну или несколько меток (например, страна, в
которой произошло событие, или индустрия, с которой связано произошедшее
событие), каждой метке может быть присвоено несколько различных значений.
Подобные задачи имеют название multi-task классификация или multiclass - multi-output
классификация. Задачи, подобные этой относительно успешно решаются в такой
области как Document classification (классификация документов), что
позволяет предположить, что ее методы могут быть успешно адаптированы для
решения стоящей перед нами задачи. Рассмотрим некоторые методы применяемые в
рамках классификации документов, а также применяемые в этой области
классификаторы.
2. Методы
и алгоритмы, реализованные в программной системе
.1 TF-IDF
TF-IDF (TF - term frequency, IDF - inverse document frequency) - статистическая мера, используемая
для оценки важности слова в контексте документа, являющегося частью коллекции
документов или корпуса. Вес некоторого слова пропорционален количеству
употребления этого слова в документе, и обратно пропорционален частоте
употребления слова в других документах коллекции.
Мера TF-IDF часто используется в задачах анализа текстов и
информационного поиска, например, как один из критериев релевантности документа
поисковому запросу, при расчёте меры близости документов при кластеризации.
TF
(term frequency - частота слова) - отношение числа вхождения некоторого слова к
общему количеству слов документа. Таким образом, оценивается важность слова 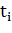 в пределах отдельного документа.
в пределах отдельного документа.
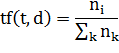
где 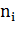 есть число вхождений слова в документ, а в знаменателе -
общее число слов в данном документе.
есть число вхождений слова в документ, а в знаменателе -
общее число слов в данном документе.
IDF
(inverse document frequency - обратная частота документа) - инверсия частоты, с
которой некоторое слово встречается в документах коллекции. Основоположником
данной концепции является Карен Спарк Джонс. Учёт IDF уменьшает вес
широкоупотребительных слов. Для каждого уникального слова в пределах конкретной
коллекции документов существует только одно значение IDF.
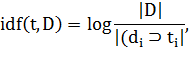
Где:
· 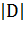 - количество документов в корпусе
- количество документов в корпусе
· 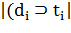 - количество документов, в которых
встречается (когда
- количество документов, в которых
встречается (когда 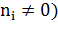
Выбор основания логарифма в формуле не имеет значения, поскольку
изменение основания приводит к изменению веса каждого слова на постоянный
множитель, что не влияет на соотношение весов.
Таким образом, мера TF-IDF является произведением двух сомножителей:
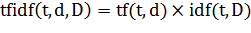
Большой вес в TF-IDF получат слова с высокой частотой в пределах
конкретного документа и с низкой частотой употреблений в других документах.
Мера TF-IDF часто используется для представления документов коллекции в виде
числовых векторов, отражающих важность использования каждого слова из
некоторого набора слов (количество слов набора определяет размерность вектора)
в каждом документе. Подобная модель называется векторной моделью (Vector space
model) и даёт возможность сравнивать тексты, сравнивая представляющие их
вектора в какой либо метрике (евклидово расстояние, косинусная мера,
манхэттенское расстояние, расстояние Чебышёва и др.), то есть производя
кластерный анализ.
В контексте рассматриваемой в данной работе задачи, мера TF-IDF может быть применена для решения двух задач:
· «Уравнивание» влияния событий которые имеют большое количество параметров
с теми событиями, которые имеют малое количество параметров
· Придание большего веса тем значениям параметров событий,
которые встречаются реже, чем те, которые встречаются часто. В самом деле,
если, например, большая часть событий ассоциирована с определенной страной, это
означает что наличие данной страны в параметрах события имеет малую
информационную ценность.
Таким образом, использовав подсчет меры TF-IDF мы сможем
преобразовать наш список событий и изменений параметров в формат числовых
векторов, то есть мы сможем преобразовать входные данные к векторной модели, в
которой большей вес будет предоставлен значениям параметров, которые
встречаются редко, а также уравняет важность событий с большим и малым числом
параметров. После этого мы сможем применить методы multiclass - multi-label
классификации с помощью какого-либо классификатора. В рамках Document classification отлично себя показали два
классификатора - SVM (с алгоритмом
обучения SGD) и Наивный Байесовский
классификатор. Оба этих классификатора рассматриваются ниже.
.2 Наивный
Байесовский Классификатор
Наивный байесовский классификатор - простой вероятностный классификатор,
основанный на применении Теоремы Байеса со строгими (наивными) предположениями
о независимости.
В зависимости от точной природы вероятностной модели, наивные байесовские
классификаторы могут обучаться очень эффективно. Во многих практических
приложениях, для оценки параметров для наивных байесовых моделей используют
метод максимального правдоподобия; другими словами, можно работать с наивной
байесовской моделью, не веря в байесовскую вероятность и не используя
байесовские методы.
Несмотря на наивный вид и, несомненно, очень упрощенные условия, наивные
байесовские классификаторы часто работают намного лучше во многих сложных
жизненных ситуациях.
Достоинством наивного байесовского классификатора является малое
количество данных для обучения, необходимых для оценки параметров, требуемых
для классификации.
Вероятностная модель для классификатора - это условная модель 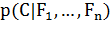 над зависимой переменной класса
над зависимой переменной класса 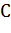 с малым количеством результатов или
классов, зависимая от нескольких переменных
с малым количеством результатов или
классов, зависимая от нескольких переменных 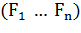 . Проблема заключается в том, что
когда количество свойств
. Проблема заключается в том, что
когда количество свойств 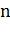 очень велико или когда свойство может принимать большое
количество значений, тогда строить такую модель на вероятностных таблицах
становится невозможно. Поэтому мы переформулируем модель, чтобы сделать её
легко поддающейся обработке.
очень велико или когда свойство может принимать большое
количество значений, тогда строить такую модель на вероятностных таблицах
становится невозможно. Поэтому мы переформулируем модель, чтобы сделать её
легко поддающейся обработке.
Используя теорему Байеса, запишем
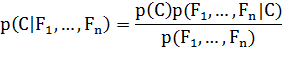
На практике интересен лишь числитель этой дроби, так как знаменатель не
зависит от и значения свойств 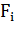 даны, так что знаменатель -
константа.
даны, так что знаменатель -
константа.
Числитель эквивалентен совместной вероятности модели 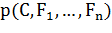 которая может быть переписана
следующим образом, используя повторные приложения определений условной
вероятности:
которая может быть переписана
следующим образом, используя повторные приложения определений условной
вероятности:
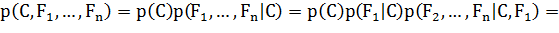
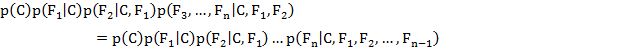
и т.д. Теперь можно использовать «наивные» предположения условной
независимости: предположим, что каждое свойство условно независимо от любого другого
свойства 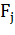 при
при 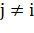 . Это означает:
. Это означает:
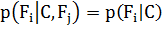
таким образом, совместная модель может быть выражена как:
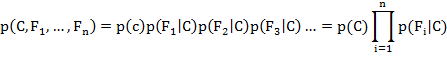
Это означает, что из предположения о независимости, условное
распределение по классовой переменной может быть выражено так:
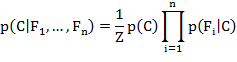
где 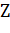 - это масштабный множитель, зависящий только от
- это масштабный множитель, зависящий только от  , то есть константа, если значения
переменных известны.
, то есть константа, если значения
переменных известны.
Все параметры модели могут быть аппроксимированы относительными частотами
из набора данных обучения. Это оценки максимального правдоподобия вероятностей.
Непрерывные свойства, как правило, оцениваются через нормальное распределение.
В качестве математического ожидания и дисперсии вычисляются статистики -
среднее арифметическое и среднеквадратическое отклонение соответственно.
Если данный класс и значение свойства никогда не встречаются вместе в
наборе обучения, тогда оценка, основанная на вероятностях, будет равна нулю.
Это проблема, так как при перемножении нулевая оценка приведет к потере
информации о других вероятностях. Поэтому предпочтительно проводить небольшие поправки
во все оценки вероятностей так, чтобы никакая вероятность не была строго равна
нулю.
Наивный байесовский классификатор объединяет модель с правилом решения.
Одно общее правило должно выбрать наиболее вероятную гипотезу; оно известно как
апостериорное правило принятия решения (MAP). Соответствующий классификатор - это функция 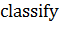 определённая следующим образом:
определённая следующим образом:
2.3 SVM
Метод опорных векторов (англ. SVM, support vector machine) - набор схожих
алгоритмов обучения с учителем, использующихся для задач классификации и
регрессионного анализа. Принадлежит к семейству линейных классификаторов, может
также рассматриваться как специальный случай регуляризации по Тихонову. Особым
свойством метода опорных векторов является непрерывное уменьшение эмпирической
ошибки классификации и увеличение зазора, поэтому метод также известен как
метод классификатора с максимальным зазором.
Основная идея метода - перевод исходных векторов в пространство более
высокой размерности и поиск разделяющей гиперплоскости с максимальным зазором в
этом пространстве. Две параллельных гиперплоскости строятся по обеим сторонам
гиперплоскости, разделяющей наши классы. Разделяющей гиперплоскостью будет
гиперплоскость, максимизирующая расстояние до двух параллельных
гиперплоскостей. Алгоритм работает в предположении, что чем больше разница или
расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя
ошибка классификатора.
Часто в алгоритмах машинного обучения возникает необходимость
классифицировать данные. Каждый объект данных представлен как вектор (точка) в 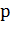 -мерном пространстве
(последовательность p чисел). Каждая из этих точек принадлежит только одному из
двух классов. Нас интересует, можем ли мы разделить точки гиперплоскостью
размерностью
-мерном пространстве
(последовательность p чисел). Каждая из этих точек принадлежит только одному из
двух классов. Нас интересует, можем ли мы разделить точки гиперплоскостью
размерностью 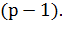 Это типичный случай линейной разделимости. Таких
гиперплоскостей может быть много. Поэтому вполне естественно полагать, что
максимизация зазора между классами способствует более уверенной классификации.
То есть можем ли мы найти такую гиперплоскость, чтобы расстояние от неё до
ближайшей точки было максимальным. Это бы означало, что расстояние между двумя
ближайшими точками, лежащими по разные стороны гиперплоскости, максимально.
Если такая гиперплоскость существует, то она нас будет интересовать больше
всего; она называется оптимальной разделяющей гиперплоскостью, а
соответствующий ей линейный классификатор называется оптимально разделяющим классификатором.
Это типичный случай линейной разделимости. Таких
гиперплоскостей может быть много. Поэтому вполне естественно полагать, что
максимизация зазора между классами способствует более уверенной классификации.
То есть можем ли мы найти такую гиперплоскость, чтобы расстояние от неё до
ближайшей точки было максимальным. Это бы означало, что расстояние между двумя
ближайшими точками, лежащими по разные стороны гиперплоскости, максимально.
Если такая гиперплоскость существует, то она нас будет интересовать больше
всего; она называется оптимальной разделяющей гиперплоскостью, а
соответствующий ей линейный классификатор называется оптимально разделяющим классификатором.
Формально можно описать задачу следующим образом.
Полагаем, что точки имеют вид: 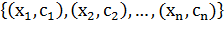 , где
, где 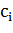 принимает значение 1 или −1, в
зависимости от того, какому классу принадлежит точка
принимает значение 1 или −1, в
зависимости от того, какому классу принадлежит точка 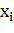 . Каждое - это -мерный вещественный вектор, обычно
нормализованный значениями
. Каждое - это -мерный вещественный вектор, обычно
нормализованный значениями 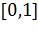 или
или 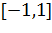 . Если точки не будут нормализованы, то точка с большими
отклонениями от средних значений координат точек слишком сильно повлияет на
классификатор. Мы можем рассматривать это как учебную коллекцию, в которой для
каждого элемента уже задан класс, к которому он принадлежит. Мы хотим, чтобы
алгоритм метода опорных векторов классифицировал их таким же образом. Для этого
мы строим разделяющую гиперплоскость, которая имеет вид:
. Если точки не будут нормализованы, то точка с большими
отклонениями от средних значений координат точек слишком сильно повлияет на
классификатор. Мы можем рассматривать это как учебную коллекцию, в которой для
каждого элемента уже задан класс, к которому он принадлежит. Мы хотим, чтобы
алгоритм метода опорных векторов классифицировал их таким же образом. Для этого
мы строим разделяющую гиперплоскость, которая имеет вид: 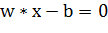
Вектор 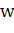 - перпендикуляр к разделяющей гиперплоскости. Параметр
- перпендикуляр к разделяющей гиперплоскости. Параметр 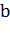 равен по модулю расстоянию от
гиперплоскости до начала координат. Если параметр равен нулю, гиперплоскость проходит
через начало координат, что ограничивает решение.
равен по модулю расстоянию от
гиперплоскости до начала координат. Если параметр равен нулю, гиперплоскость проходит
через начало координат, что ограничивает решение.
Так как нас интересует оптимальное разделение, нас интересуют опорные
вектора и гиперплоскости, параллельные оптимальной и ближайшие к опорным
векторам двух классов. Можно показать, что эти параллельные гиперплоскости
могут быть описаны следующими уравнениям (с точностью до нормировки).
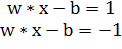
Если обучающая выборка линейно разделима, то мы можем выбрать
гиперплоскости таким образом, чтобы между ними не лежала ни одна точка
обучающей выборки и затем максимизировать расстояние между гиперплоскостями.
Ширину полосы между ними легко найти из соображений геометрии, она равна 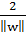 , таким образом наша задача
минимизировать
, таким образом наша задача
минимизировать 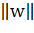 . Чтобы исключить все точки из полосы, мы должны убедиться
для всех
. Чтобы исключить все точки из полосы, мы должны убедиться
для всех 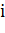 , что
, что
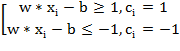
Это может быть также записано в виде:
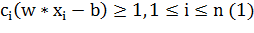
В случае линейной разделимости классов, проблема построения оптимальной
разделяющей гиперплоскости сводится к минимизации при условии (1). Это задача
квадратичной оптимизации, которая имеет вид:
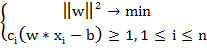
По теореме Куна - Таккера эта задача эквивалентна двойственной задаче
поиска седловой точки функции Лагранжа.
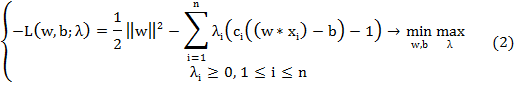
Где 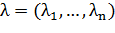 - вектор двойственных переменных
- вектор двойственных переменных
Сведем эту задачу к эквивалентной задаче квадратичного программирования,
содержащую только двойственные переменные:
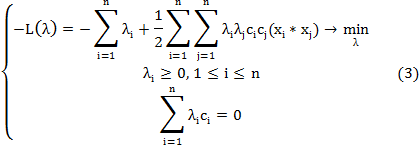
Допустим мы решили данную задачу, тогда и можно найти по формулам:
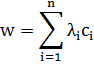
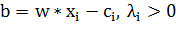
В итоге алгоритм классификации может быть записан в виде:
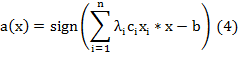
При этом суммирование идет не по всей выборке, а только по опорным
векторам, для которых 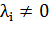
В случае линейной неразделимости классов, для того, чтобы алгоритм мог
работать, позволим ему допускать ошибки на обучающей выборке. Введем набор
дополнительных переменных 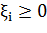 , характеризующих величину ошибки на объектах
, характеризующих величину ошибки на объектах 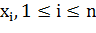 . Возьмем за отправную точку (2),
смягчим ограничения неравенства, так же введём в минимизируемый функционал
штраф за суммарную ошибку:
. Возьмем за отправную точку (2),
смягчим ограничения неравенства, так же введём в минимизируемый функционал
штраф за суммарную ошибку:
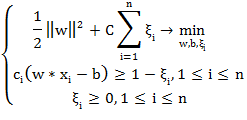
Коэффициент - параметр настройки метода, который позволяет регулировать
отношение между максимизацией ширины разделяющей полосы и минимизацией
суммарной ошибки.
Аналогично, по теореме Куна-Таккера сводим задачу к поиску седловой точки
функции Лагранжа:
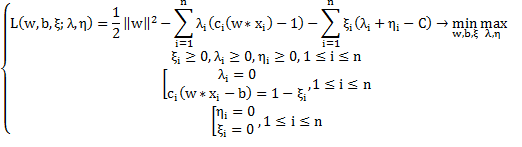
По аналогии сведем эту задачу к эквивалентной:
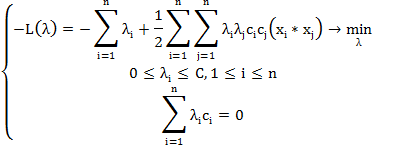
На практике для построения машины опорных векторов решают именно эту
задачу, а не (3), так как гарантировать линейную разделимость точек на два
класса в общем случае не представляется возможным. Этот вариант алгоритма
называют алгоритмом с мягким зазором (soft-margin SVM), тогда как в линейно
разделимом случае говорят о жёстком зазоре (hard-margin SVM).
Для алгоритма классификации сохраняется формула (4), с той лишь разницей,
что теперь ненулевыми 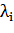 обладают не только опорные объекты, но и объекты-нарушители.
В определённом смысле это недостаток, поскольку нарушителями часто оказываются
шумовые выбросы, и построенное на них решающее правило, по сути дела, опирается
на шум.
обладают не только опорные объекты, но и объекты-нарушители.
В определённом смысле это недостаток, поскольку нарушителями часто оказываются
шумовые выбросы, и построенное на них решающее правило, по сути дела, опирается
на шум.
Константу обычно выбирают по критерию скользящего контроля. Это
трудоёмкий способ, так как задачу приходится решать заново при каждом значении .
Если есть основания полагать, что выборка почти линейно разделима, и лишь
объекты-выбросы классифицируются неверно, то можно применить фильтрацию
выбросов. Сначала задача решается при некотором C, и из выборки удаляется
небольшая доля объектов, имеющих наибольшую величину ошибки 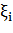 . После этого задача решается заново
по усечённой выборке. Возможно, придётся проделать несколько таких итераций,
пока оставшиеся объекты не окажутся линейно разделимыми.
. После этого задача решается заново
по усечённой выборке. Возможно, придётся проделать несколько таких итераций,
пока оставшиеся объекты не окажутся линейно разделимыми.
Алгоритм построения оптимальной разделяющей гиперплоскости, предложенный
в 1963 году Владимиром Вапником и Алексеем Червоненкисом - алгоритм линейной
классификации. Однако в 1992 году Бернхард Босер, Изабелл Гийон и Вапник предложили
способ создания нелинейного классификатора, в основе которого лежит переход от
скалярных произведений к произвольным ядрам, так называемый kernel trick
(предложенный впервые М.А. Айзерманом, Э.М. Браверманном и Л.В. Розоноэром для
метода потенциальных функций), позволяющий строить нелинейные разделители.
Результирующий алгоритм крайне похож на алгоритм линейной классификации, с той
лишь разницей, что каждое скалярное произведение в приведённых выше формулах
заменяется нелинейной функцией ядра (скалярным произведением в пространстве с
большей размерностью). В этом пространстве уже может существовать оптимальная
разделяющая гиперплоскость. Так как размерность получаемого пространства может
быть больше размерности исходного, то преобразование, сопоставляющее скалярные
произведения, будет нелинейным, а значит функция, соответствующая в исходном
пространстве оптимальной разделяющей гиперплоскости, будет также нелинейной.
Стоит отметить, что если исходное пространство имеет достаточно высокую
размерность, то можно надеяться, что в нём выборка окажется линейно разделимой.
Наиболее распространённые ядра:
. Линейное ядро: 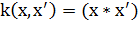
2. Полиномиальное (однородное): 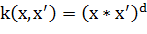
3. RBF функция:
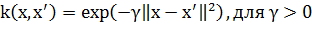
4. Сигмоид:
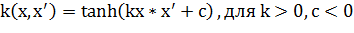
В рамках поставленной перед нами задачи будем использовать линейное
однородное ядро. Данное ядро показало отличные результаты в задачах Document Classification, хотя по сравнению с Наивным
Байесовским Классификатором обучение данного классификатора занимается
сравнительно большой промежуток времени. Также проверена работа всех остальных
ядер из данного списка и выявлено, что их обучение занимает значительно больший
промежуток времени, при этом не привнося особых улучшений в точности
классификации.
Для ускорения обучения мы будем использовать метод под названием
Стохастический Градиентный Спуск, который позволяет значительно ускорить
обучение классификатора, не сильно жертвуя его точностью.
.3.1
Стохастический Градиентный Спуск
Градиентные методы - это широкий класс оптимизационных алгоритмов,
используемых не только в машинном обучении. Здесь градиентный подход будет
рассмотрен в качестве способа подбора вектора синаптических весов в линейном классификаторе. Пусть 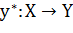 - целевая зависимость, известная
только на объектах обучающей выборки:
- целевая зависимость, известная
только на объектах обучающей выборки:
Найдём алгоритм 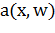 , аппроксимирующий зависимость
, аппроксимирующий зависимость 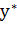 . В случае линейного классификатора
искомый алгоритм имеет вид:
. В случае линейного классификатора
искомый алгоритм имеет вид:
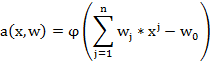
где 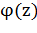 играет роль функции активации (в простейшем случае можно
положить
играет роль функции активации (в простейшем случае можно
положить 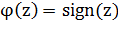 ).
).
Согласно принципу минимизации эмпирического риска для этого достаточно
решить оптимизационную задачу:
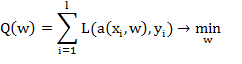
Где 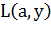 - заданная функция потерь.
- заданная функция потерь.
Для минимизации применим метод градиентного спуска (gradient descent).
Это пошаговый алгоритм, на каждой итерации которого вектор изменяется в направлении наибольшего
убывания функционала 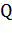 (то есть в направлении антиградиента):
(то есть в направлении антиградиента):
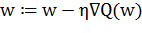
Где 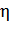 - положительный параметр, называемый темпом обучения
(learning rate).
- положительный параметр, называемый темпом обучения
(learning rate).
Возможны 2 основных подхода к реализации градиентного спуска:
. Пакетный (batch), когда на каждой итерации обучающая выборка
просматривается целиком, и только после этого изменяется . Это требует больших
вычислительных затрат.
2. Стохастический (stochastic/online), когда на каждой итерации
алгоритма из обучающей выборки каким-то (случайным) образом выбирается только
один объект. Таким образом вектор настраивается на каждый вновь
выбираемый объект.
Можно представить алгоритм стохастического градиентного спуска в виде
псевдокода следующим образом:
Вход:
· 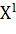 - обучающая выборка
- обучающая выборка
· - темп обучения
· 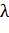 - параметр сглаживания функционала
- параметр сглаживания функционала
Выход:
1. Вектор весов
Тело:
1) Инициализировать веса 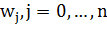
2) Инициализировать текущую оценку функционала:
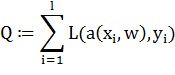
3) Повторять:
. Выбрать объект из случайным образом
2. Вычислить выходное значение алгоритма 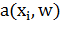 и ошибку:
и ошибку:
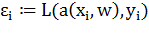
3. Сделать шаг градиентного спуска
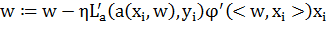
4. Оценить значение функционала:
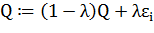
4) Пока значение не стабилизируется и/или веса не перестанут изменяться.
Главным достоинством SGD
можно назвать его скорость обучения на избыточно больших данных. Именно это
интересно для нас в рамках поставленной перед нами задачи ибо объем входных
данных будет весьма велик. В то же время, алгоритм SGD в отличие от классического пакетного градиентного
спуска дает несколько меньшую точность классификации. Также алгоритм SGD неприменим при обучении машины
опорных векторов с нелинейным ядром.
Выводы
В рамках решаемой задачи нам потребуется воспользоваться алгоритмом
преобразования исходных данных TF-IDF, который позволит нам повысить
весомость редких событий и снизить вес частых событий. Полученные после
преобразования данные мы будем передавать классификаторам, которые подходят для
решения стоящей перед нами задачи, а именно: Наивный Байесовский Классификатор
или Машина Опорных Векторов с Линейным ядром, обученная по методу
стохастического градиентного спуска. Также мы осуществим проверку эффективности
Машины Опорных Векторов с нелинейными ядрами, обученной по методу пакетного градиентного
спуска. Однако, данный тип классификатора не кажется подходящим для
поставленной задачи в силу слишком сложного ядра и склонности к
переобучаемости, при которой классификатор плохо справляется с данными, которые
не использовались для обучения классификатора.
программный машинный предобработка данные
3.
Реализация системы
Работа системы состоит из двух этапов. На первом этапе производится
извлечение информации о трендах в ценах, устанавливаются периоды роста,
снижения и постоянства цен на ценные бумаги. Разработка системы, способной
выполнить данный этап не является основной темой данной работы, потому
примененная для предобработки данных программа будет описана кратко.
На втором этапе добытая информация о трендах применяется для тренировки
классификатора и выполнения предсказаний о причинах анализируемых изменений в
трендах цен.
.1
Предобработка информации
Для извлечения информации о трендах в ценах используется приложение
FactEventAnalyzer.exe, разработанное на C#. Текст программы доступен в Приложении 1.
Программа работает с набором данных о ценах на ценные бумаги и о
корпоративных событиях (таких как выплата дивидендов, изменения рейтинга
компаний, собраниях акционеров) которые хранятся в базе данных MS SQL Server.
Примеры доступных данных продемонстрированы ниже.
Информация о ценных бумагах:
|
SecId
|
Ticker
|
Issuer
|
Sec Type
|
Inv Type
|
Price Currency
|
Region
|
Issuer Country
|
Exchange
|
Industry Sector
|
|
1283450
|
IBM
|
International
Business Machines Corp
|
EQTY
|
EQTY
|
USD
|
American
|
USA
|
XNYS
|
IT Consulting
& Other Services
|
|
1283451
|
ADVS
|
Advent Software
Inc
|
EQTY
|
EQTY
|
USD
|
American
|
USA
|
XNGS
|
Application
Software
|
|
1283454
|
MSFT US Equity
|
Microsoft Corp
|
EQTY
|
EQTY
|
USD
|
American
|
USA
|
XNGS
|
Systems Software
|
|
1283456
|
WIL SP
|
Wilmar
International Ltd
|
EQTY
|
EQTY
|
SGD
|
Asian
|
SGP
|
XSES
|
Agricultural
Products
|
|
1283457
|
ADM
|
Archer-Daniels-Midland
Co
|
EQTY
|
EQTY
|
USD
|
American
|
USA
|
XNYS
|
Agricultural
Products
|
|
1283459
|
AGU
|
Agrium Inc
|
EQTY
|
EQTY
|
USD
|
American
|
CAN
|
XNYS
|
Fertilizers
& Agricultural Chemicals
|
|
1283460
|
BG
|
Bunge Ltd
|
EQTY
|
EQTY
|
USD
|
American
|
BMU
|
XNYS
|
Agricultural
Products
|
|
1283462
|
GGR SP
|
Golden
Agri-Resources Ltd
|
EQTY
|
EQTY
|
SGD
|
Asian
|
MUS
|
XSES
|
Agricultural
Products
|
|
1283463
|
INGR
|
Ingredion Inc
|
EQTY
|
EQTY
|
USD
|
American
|
XNYS
|
Agricultural
Products
|
|
1283464
|
VT
|
Viterra Inc
|
EQTY
|
EQTY
|
CAD
|
American
|
CAN
|
XTSE
|
Agricultural
Products
|
1. SecId. Внутренний уникальный идентификатор бумаги
2. Ticker. Идентификатор, под которым бумага торгуется на бирже
3. Issuer. Компания, выпустившая данную бумагу
4. SecType. Код типа ценной бумаги
5. InvType. Код подтипа ценной бумаги
6. PriceCurrency. Валюта, в которой торгуется данная бумага
7. Region. Регион, с которым ассоциирована данная бумага
8. IssuerCountry. Страна регистрации компании, выпустившей данную бумагу
9. Exchange. Биржа, на которой торгуется данная бумага
10. IndustrySector. Индустрия, в которой работает компания, выпустившая данную
бумагу
Информация о ценах:
|
Date
|
DateTick
|
SecId
|
Price
|
AskPrice
|
BidPrice
|
|
1/24/12 0:00
|
40930
|
1287491
|
196
|
195
|
196
|
|
2/20/12 0:00
|
40957
|
1289220
|
26.5
|
20
|
20
|
|
3/5/12 0:00
|
40971
|
1289817
|
0.028375
|
0.022
|
0.0265
|
|
3/12/12 0:00
|
40978
|
1283601
|
37.14
|
37.12
|
37.23
|
|
3/20/12 0:00
|
40986
|
1289231
|
1.49
|
1.45
|
1.45
|
|
4/9/12 0:00
|
41006
|
1290160
|
1800
|
2200
|
1800
|
|
4/20/12 0:00
|
41017
|
1301676
|
0.195
|
0.013
|
0.12
|
|
5/2/12 0:00
|
41029
|
1290181
|
1500
|
1400
|
1500
|
|
5/14/12 0:00
|
41041
|
1289360
|
3.4
|
2.8
|
2.8
|
|
5/21/12 0:00
|
41048
|
1361228
|
0.0024
|
0.0005
|
0.00175
|
1. Date.
Информация о дате, на которую была актуальна указанная цена
2. DateTick. Информация о да, на которую была актуальна цена,
представленная в виде числа дней с 1-го января 1900 года
3. SecId. Внутренний уникальный идентификатор бумаги, для которой актуальна
данная цена
4. Price. Значения цены закрытия
5. Ask. Значение цены
6. Bid. Значение цены
Информация о корпоративных событиях:
|
SecId
|
UniqueCoraxId
|
EffectiveDate
|
EventType
|
EventMajorType
|
|
1283525
|
4625097
|
2/4/14 0:00
|
Merger
|
Standard
|
|
1283679
|
4626420
|
4/3/14 0:00
|
Stock Split
|
Standard
|
|
1284173
|
4627461
|
2/4/14 0:00
|
Merger
|
Standard
|
|
1284756
|
4629913
|
12/12/13 0:00
|
Cash Dividend
|
Standard
|
|
1284756
|
4629915
|
3/13/14 0:00
|
Cash Dividend
|
Standard
|
|
1284900
|
4630130
|
2/27/14 0:00
|
Merger
|
Standard
|
|
1285138
|
4630535
|
3/27/14 0:00
|
Cash Dividend
|
Standard
|
|
1285590
|
4631157
|
12/23/13 0:00
|
Divestiture
|
Standard
|
|
1285590
|
4631162
|
3/30/14 0:00
|
Merger
|
Standard
|
|
1285590
|
4631163
|
3/30/14 0:00
|
Divestiture
|
Standard
|
1. SecId. Внутренний уникальный идентификатор бумаги, для которой актуально
данное событие
2. UniqueCoraxId. Уникальный идентификатор данного события.
3. EffectiveDate. Дата события.
4. EventType. Подтип события.
5. EventMajorType. Глобальный тип события.
Приложение вызывается из командной строки, после чего выполняет следующий
процесс:
) Считываются стартовые параметры из xml-файла Config.xml (доступен в Приложении 2).
2) Запускается процесс runFactMiner, которые извлекает информацию о трендах из исходных данных с
помощью предоставленных параметров. Данная задача выполняется следующим
образом:
1. Для каждой ценной бумаги удовлетворяющей переданным параметрам
программа перебирает каждую имеющуюся запись о ее цене в хронологическом
порядке.
2. Если цена в текущей записи выше чем в предыдущей - предполагаем
что цена растет, если она меньше - падает. При этом изменение должно превзойти
заранее заданный параметр чувствительности changeThreshold (например 0.2 процента изменения) в
противном случае считаем что цена неизменна.
. В том случае если изменение цены превышает некоторый наперед
заданный уровень (например, более 3%) то считаем что произошел «всплеск» (spike) и создаем об этом запись. Значение
этого уровня хранится в параметре spikeThreshold.
. Если тренд изменяется на очередной записи о цене - предполагаем
что тренд мог быть сломлен.
. В том случае если мы предполагаем слом тренда программа
проверяет некоторое количество следующих записей о ценах (количество также
задается параметром dateThreshold).
Если при сравнении текущей записи данных и той, на которой произошел слом
тренда, видим, что слом тренда подтвержден - создаем запись о начале тренда и
его окончании. Если слом тренда не подтвержден - продолжаем перебор
3) По окончанию такого перебора в базе данных FactEventAnalysisDB, с
помощью табличных представления PriceFactsHypothesis извлекается информация о
трендах на ценные бумаги а с помощью представления SpikeFactsHypothesis - о
«всплесках» и сохраняются в локальный файл формата csv.
Диаграмма классов системы приведена ниже:

Рис. 2. Диаграмма классов приложения Fact Event Analyzer
Краткое описание классов надо ниже:
1) CoraxesSource, CoraxFactsTable, PricesSource,
SecuritiesSource, PriceFactsTable, SpikeFactsTable. Классы, обеспечивающий доступ к
источникам данных - одноименным таблицам в базе данных FactEventAnalysisDB.
2) FactEventAnalysisDBDataContext. Служебный класс, обеспечивающий
коммуникацию приложения с базой данных FactEventAnalysisDB.
3) FactMiner. Класс, выполняющий функции извлечения информации о трендах
с помощью переданных ему параметров, и запись информации о трендах в файлы.
4) Logger. Класс, выполняющий ведение журнала работы приложения.
5) PriceFactsHypothesi. Класс, обеспечивающий вызов табличного представления
PriceFactsHypothesis в базе FactEventAnalysisDB.
6) SpikeFactHypothesi. Класс, обеспечивающий вызов табличного представления SpikeFactsHypothesis в базе FactEventAnalysisDB.
7) Program. Главный класс, объединяющий все остальные классы и
вызывающий методы других классов по ходу выполнения программы. Также
обеспечивает чтение параметров программы из файла параметров.
8) Settings. Служебный класс, хранящий информацию о приложении.
9) Parameters. Структура, обеспечивающая хранение параметров программы,
считанных из файла параметров.
В процессе работы система базу данных FactEventAnalysisDB, ее диаграмма приведена ниже:
Также используется две хранимых процедуры из базы FactEventAnalysisDB, код которых доступен в Приложении
3. Их описание приведено ниже:
1) usp_ClearFactsTables. Очищает таблицы CoraxFactsTable и SpikeFactsTable, от старых данных, которые могли
остаться от предыдущих выполнений программы
2) usp_populateCoraxFactsTable. Осуществляет предобработку данных в
таблице CoraxesSource и переносит обработанные данные в
таблицу CoraxFactsTable.
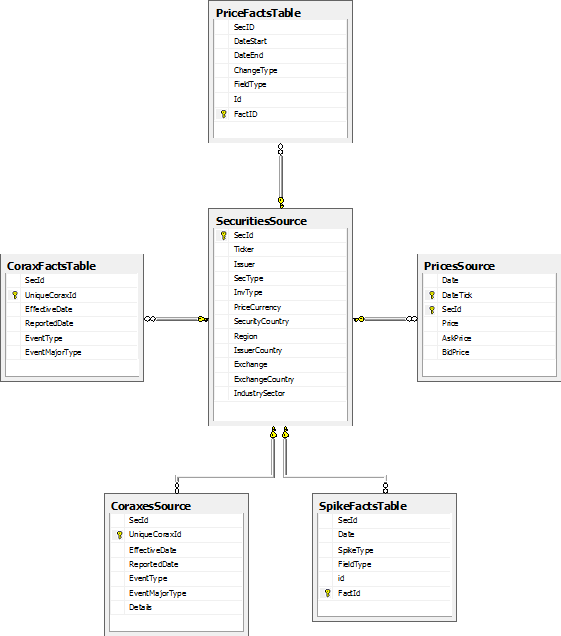
Рис. 3. Диаграмма базы данных FactEventAnalysisDB
Помимо этого используются два табличных представления, описание которых
дано ниже:
1) PriceFactsHypothesis. Представление извлекающее все пары «корпоративное событие -
изменение в тренде цены» из таблиц PriceFactsTable и CoraxFactsTable на каждую дату.
2) SpikeFactsHypothesis. Представление извлекающее все пары «корпоративное
событие - всплеск в цене» из таблиц SpikeFactsTable и CoraxFactsTable на каждую дату.
Код данных представлений также доступен в Приложении 3.
Задача извлечения трендов не является главной темой работы, потому
упомянута кратко.
По результатам работы система производит два файла - SpikeFacts.csv и PriceFacts.csv, которые используются в дальнейшем. Данные файлы
представляют собой список пар «Характеристика события» - «Характеристика
изменения» на каждую дату.
Ниже представлена инструкция по использованию системы предобработки.
.1.1
Инструкция пользователя
Для использования системы необходимо убедиться, что база с исходными
данными FactEventAnalysisDB развернута на компьютере
пользователя. После этого необходимо скопировать файл FactEventAnalyzer в любую папку на пользовательском
компьютере. В ту же папку нужно положить файл Config.xml
(доступен в Приложении 2). В данном файле необходимо указать актуальные
параметры для следующих переменных:
. logFolder. Указать папку, в которой будет храниться журнал выполнения
программы
2. changeThreshold. Указать значение (в процентах) на которое должна измениться
цена, чтобы система предположила что тренд в изменении цены был сломлен.
3. Dates (from и to). Даты с которой и по которую будут проанализированы цены
(можно использовать для ограничения объема данных, которые будут обработаны.
4. spikeThreshold. Значение (в процентах) на которое должна измениться цена,
чтобы система сделала вывод о наличии «всплеска» в цене.
5. dateThreshold. На сколько дней вперед система будет проверять цены для
проверки гипотезы об изменении в тренде цены.
6. filesForMl. Папка, в которую будут сохранены результаты работы
программы.
Пример использования программы продемонстрирован ниже.
Программа скопирована в папку D:\DiplomaProject\PreProcessing
Рис. 4. Программа скопирована в папку
Двойной щелчок мыши по FactEventAnalyzer.exe запускает
предобработчик. Так как это консольное приложение то появляется окно консоли,
которое будет оставаться открытым на все время работы программы.
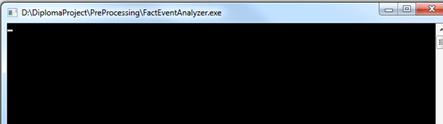
Рис. 5. Работа системы предобработки данных
После завершения работы программы в подпапке Log доступен журнал работы программы:
Рис. 6. Журнал работы системы предобработки данных
А в указанной ранее в файле Config.xml папке хранятся результаты работы
программы предобработки:

Рис. 7. Результат работы системы предобработки данных
.2 Система
классификации
Полученные в предыдущем шаге файлы используются системой FactGeneralyzer, код которой доступен в Приложении
4.
Данная система разработана с помощью языка Python и пакета Scikit-learn, которые предоставляют реализацию
упомянутых в предыдущих разделах методов и алгоритмов машинного обучения.
Система позволяет выбрать классификатор, который будет использоваться при
работе. Система способна работать в двух режимах - тестовом и рабочем. Описание
обоих режимов представлено ниже.
.2.1
Рабочий режим
Данный режим предназначен для обучения классификаторов на основе
информации о прошлых событиях и изменениях. Обученные классификаторы
применяются для анализа предложенных изменений, после чего система делает
предположение о причине данных изменений.
После запуска программы вызывается функция main(), которая записывает дату и время запуска программы,
после чего определяет в каком режиме должна работать система - тестовом или
рабочем. Для рабочего режима вызывается функция workMode, которой передается информация о
файлах с данными для обучения и для выполнения предсказаний, информация о
выбранном классификаторе, а также информация о папке в которую надо записать
результаты предсказаний.
Функция workMode загружает данные для обучения и
данные ля выполнения предсказаний из файлов и трансформирует их в формат Pandas.DataFrame, который удобен для обработки
данных, которые можно представить в виде таблицы. Затем система формирует 3
набора данных:
1. X_train - информация о событиях из
тренировочных данных
2. y_train - информация о изменениях в трендах
в тренировочных данных
3. X_test - информация о изменениях в трендах,
объяснение которым должна найти система
После формирования данных наборов, набор y_train (информация
о произошедших изменениях в тренировочных данных) проходит через трансформацию
с помощью функции preprocessing. MultiLabelBinarizer().
Данная трансформация преобразовывает матрицу текстовых меток (информацию
об изменениях в трендах - страну выпуска ценной бумаги, тип изменения в тренде,
биржу, на которой торгуется бумага) в формат бинарной матрицы, содержащей метки
о присутствии или отсутствии определенного класса в примере. Данное
преобразование необходимо, так как использованные в дальнейшем алгоритмы
ожидают именно такой формат на вход для выполнения предсказаний.
После этого система тренирует классификатор на базе выбранного алгоритма
классификации.
Для этого система сначала выполняет преобразование исходного набора пар
текстовых меток о событиях и произошедших одновременно с ними изменениях
(напомним, информация о произошедших изменениях уже была преобразована функцией
MultiLabelBinarizer) в формат бинарных разряженных
матриц, содержащих количество появления каждой из меток с помощью функции
CountVectorizer().
Полученные матрицы передается функции TfidfTransformer(). Данная функция
выполняет TF-IDF преобразование над переданными матрицами, которое
было разобрано ранее. Преобразование выполняется для того, чтобы повысить вес
редких параметров событий и понизить вес часто встречающихся характеристик.
Например, если подавляющее большинство событий в наборе данных связано с
российскими ценными бумагами то событие связанное с ценными бумагами другой
страны будет иметь больший вес при обучении классификатора.
Полученные матрицы, содержащие информацию о изменениях и о произошедших
одновременно с ними событиях, после преобразования TF-IDF передаются
метаклассификатору OneVsRestClassifier(). Данный метаклассификатор использует
переданные ему матрицы для выполнения задачи многоклассовой\многотемной
классификации с помощью выбранного нами классификатора и стратегии One-vs-all.
Для облегчения задачи последовательного вызова функций CountVectorizer(),
TfidfTransformer() и передачи результатов метаклассификатору
OneVsRestClassifier() мы воспользуемся так называемым конвейером - Pipeline(). Конвейер просто последовательно
применяет переданные ему функции и передает их результат выбранному
классификатору.
После обучения классификатора на тестовых данных (команда fit()) мы выполняем предсказание для
данных в X_test, то есть пытаемся объяснить изменения в трендах,
хранимые в данной переменной. Полученные предсказания проходят обратное
преобразование из формата бинарной матрицы, содержащей метки о присутствии или
отсутствии определенного класса в примере в формат обычной текстовой информации
с помощью функции inverse_transform(). Полученные предсказания
сохраняются в текстовый файл. Пример результата:
,"NegSpike,AAB,Apple Inc,EQTY,REIT,USD,Asian,JPN,XTKS,Internet
Software & Services","(American, Bought Back, EQTY, FOX, Movies
& Entertainment, Standard, Twenty-First Century Fox Inc, USA, USD,
XNGS)"
. 0 - порядковый номер результата
2. Следом идем набор меток изменения, которое мы пытаемся объяснить,
разделенные запятыми.
. Далее в скобках перечисляются характеристики события, которое
предположительно вызвало данное изменение.
По результатам системы производится файл с предсказаниями выполненными с
помощью выбранного алгоритма классификации.
.2.2
Тестовый режим
В тестовом режиме оценивается производительность системы на переданном ей
файле с данными с помощью выбранного классификатора. Для оценки
производительности системы и качества ее предсказаний попробуем оценивать
метрику Precision (доля правильно предсказанных меток
от общего количества предсказанных меток). Ожидается, что система будет
способна выделить наиболее вероятные причины изменения в трендах цены и сможет
предсказать, какие события, скорее всего, происходили одновременно с
происходящими изменениями в трендах, то есть сможет указать максимальное
количество меток таких корпоративных событий.
В тестовом режиме системе передается файл с тестовыми парами событий и
изменений в трендах, после чего данный файл разделяется на два случайных
подмножества - тренировочный набор данных (90% исходных пар событий и трендов)
и тестовый набор данных (10% исходных пар). После чего выбранный классификатор
тренируется на тренировочном наборе данных (процесс полностью аналогичен
таковому в рабочем режиме). Затем обученный классификатор запускается для
каждого описания изменения тренда в тестовом наборе данных, и система делает предсказания
о причинах изменения этого тренда. После этого подсчитывается, сколько из меток
предсказанного описания события присутствуют в реально существовавшей паре
событие - изменение в тренде. Путем деления полученного количества на общее
количество предсказанных меток получаем Precision системы.
По результатам работы системы получаем файл Results.csv,
который содержит следующую информацию:
. Порядковый номер тестового примера
2. Описание тренда, для которого выполнялись предсказания в виде
набора меток, разделенных запятыми
. Какое событие на самом деле происходило одновременно с данным
изменением в трендах, заключенное в квадратные скобки.
. Какой набор меток был предсказан системой, заключенный в скобки.
Пример одной такой записи:
, PosSpike, ICPT, Intercept Pharmaceuticals Inc, EQTY, REIT,
USD, American, USA, XNGS, Biotechnology, [Merger, Standard, ETE, Energy
Transfer Equity LP, UNIT, EUNT, USD, American, USA, XNYS, Oil & Gas Storage
& Transportation], (American, EQTY, Standard, USA, USD)
.2.3
Инструкция пользователя
Тестовый
режим
Необходимо скопировать файл с программой FactGeneralizer.py в любую папку на пользовательском компьютере. Также
необходимо скопировать нужные для работы файлы в любую папку на
пользовательском компьютере. В случае работы программы в тестовом режиме
необходим один файл с парами событие - изменение в тренде. Далее необходимо
открыть командную строку и с помощью команды cd перейти в папку, в которой хранится файл FactGeneralizer.py. Для запуска программы в тестовом режиме необходимо ввести в
командной строке следующую команду и нажать Enter:
python FactGeneralizer.py “test” “PriceFacts.csv” “Results.csv” “linear”
Значение параметров приведено ниже:
) “test” - метка, обозначающая что программа
будет работать в тестовом режиме
2) “PriceFacts.csv” - имя файла, содержащего исходные
данные
) “Results.csv” - имя файла, в котором будут
сохранены результаты работы программы
) “linear” - алгоритм
классификации, который будет использован программой. Поддерживаются следующие алгоритмы:
1. linear - Машина опорных векторов с линейным ядром и обучением пакетным методом
2. linearWithSGD - Машина опорных векторов с линейным ядром и
обучением по методу стохастического градиентного спуска
3. rbf - Машина опорных векторов с Радиальной базисной функцией в качестве
ядра, обучение пакетным методом
4. poly - Машина опорных векторов с Полиномиальным ядром, обучение пакетным
методом
5. sigmoid - Машина опорных векторов с Сигмоидной функцией в качестве
ядра, обучение пакетным методом
6. bayes - Наивный байесовский классификатор
После завершения программы в командной строке будет выведена информация о
времени работы программы и информация о precision (точности) программы на тестовых
данных. Также в файл результатов будут сохранены тестовые примеры и сделанные
системой предсказания.
Ниже приведен пример запуска и получения результатов программы в тестовом
режиме.
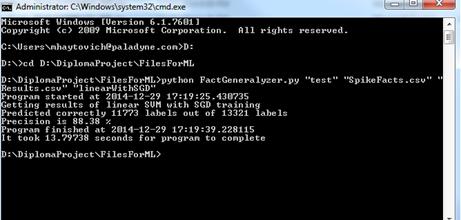
Рис. 8. Работа системы классификации в тестовом режиме
Рабочий
режим
Необходимо скопировать файл с программой FactGeneralizer.py в любую папку на пользовательском компьютере. Также
необходимо скопировать нужные для работы файлы в любую папку на
пользовательском компьютере. В случае работы программы в рабочем режиме
необходимы два файла. Первый из них, содержащий пары «событие - изменение в
тренде» будет использован для обучения классификатора. Второй должен содержать
записи об изменениях в трендах, которые система попытается объяснить. Далее
необходимо открыть командную строку и с помощью команды cd перейти в папку, в которой хранится
файл FactGeneralizer.py. Для запуска программы в тестовом режиме необходимо ввести в
командной строке следующую команду и нажать Enter:
python FactGeneralizer.py “work” “PriceFacts.csv”
“ToPredict.csv”
“Results.csv” “linear”
Значение параметров приведено ниже:
) “test” - метка, обозначающая что программа
будет работать в тестовом режиме
2) “PriceFacts.csv” - имя файла, содержащего исходные
данные для тренировки классификатора
) “ToPredict.csv” - имя файла, содержащего записи об
изменениях в тренде, которые система попытается объяснить
) “Results.csv” - имя файла, в котором будут
сохранены результаты работы программы
) “linear” - алгоритм
классификации, который будет использован программой. Поддерживаются следующие
алгоритмы:
1. linear - Машина опорных векторов с линейным ядром и обучением пакетным методом
2. linearWithSGD - Машина опорных векторов с линейным ядром и
обучением по методу стохастического градиентного спуска
3. rbf - Машина опорных векторов с Радиальной базисной функцией в качестве
ядра, обучение пакетным методом
4. poly - Машина опорных векторов с Полиномиальным ядром, обучение пакетным
методом
5. sigmoid - Машина опорных векторов с Сигмоидной функцией в качестве
ядра, обучение пакетным методом
6. bayes - Наивный байесовский классификатор
После завершения программы в командной строке будет выведена информация о
времени работы программы. В файл результатов будет записана информация о каждом
изменении в тренде, которое система пыталась объяснить, и описание вероятной
причины в данном изменении в тренде. Ниже приведен пример запуска программы в
рабочем режиме.
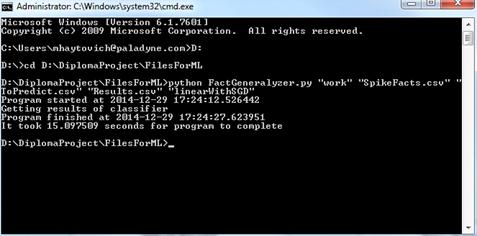
Рис. 9. Работа системы классификации в рабочем режиме
Выводы
Реализована система, осуществляющая предобработку исходных данных о ценах
на ценные бумаги и корпоративных событиях, связанных с ценными бумагами.
Предобработка создает файл, содержащий информацию о том, какие корпоративные
события происходили одновременно с какими изменениями в трендах цен. Далее
данная информация передается системе классификации, которая производит
преобразование по алгоритму TF-IDF и тренирует классификатор на базе
одного из поддерживаемых алгоритмов. В ходе тренировки классификатор
определяет, какие параметры корпоративных событий сопутствуют конкретным
параметрам в изменениях трендов. Например, классификатор способен обнаружить,
что в большинстве случаев одновременно со сломом тренда для ценных бумаг,
торгующихся на московской бирже и выпущенных металлургическими компаниями,
обычно происходит корпоративное событие связанное с китайскими
автопроизводителями.
Обученный классификатор используется далее для поиска причин слома тренда
цен переданных классификатору ценных бумаг.
4.
Машинный эксперимент
В ходе машинного эксперимента этап предобработки информации был запущен
на следующем наборе тестовых данных:
. 8542 ценных бумаги.
2. 1576688 записей о ценах на эти ценные бумаги, данные записи
содержат информацию о ценах за год.
. 53154 записи о корпоративных событиях, связанных с этими ценными
бумагами.
Были установлены следующие параметры работы для предобработчика данных:
1. changeThreshold = 0.3. При изменении цены на эту величину за день считаем,
что возможен слом тренда.
2. spikeThreshold = 6. При изменении цены на эту величину за день
считаем, что произошел всплеск в цене.
. dateThreshold = 3. При предположении о том, что произошел слом
тренда, система сравнит последнюю цену с ценой через 3 дня чтобы проверить
гипотезу о сломе тренда.
Системе предобработки данных понадобилось около 19 часов работы для
завершения предобработки исходных данных. По результатам было получено 26975
пар событие - изменение в тренде. Полученные пары были использованы для работы
системы классификации в тестовом режиме.
Система была запущена три раза для каждого из поддерживаемых
классификаторов. Тренировка классификаторов производилась на случайно выбранных
90% данных (24280) и далее тестировалась на 2695 оставшихся записях.
Ниже представлена таблица с результатами тестирования:
Таблица 1
Результаты тестирования различных классификаторов
|
Тип
классификатора
|
Всего
предсказано меток
|
Корректно
предсказано меток
|
Precision, %
|
Время выполнения
программы, сек.
|
|
SVM с линейным ядром, SGD обучение
|
15047
|
12119
|
81
|
21
|
|
15217
|
12424
|
82
|
23
|
|
14977
|
12121
|
81
|
19
|
|
SVM с линейным ядром, обучение пакетным градиентным
спуском
|
15157
|
12192
|
80
|
159
|
|
15286
|
12471
|
82
|
146
|
|
15218
|
12200
|
80
|
147
|
|
SVM с ядром RBF
|
1765880
|
28073
|
1.59
|
9985
|
|
1765880
|
28083
|
1.59
|
9950
|
|
1765880
|
28050
|
1.59
|
9949
|
|
SVM с
полиномиальным ядром
|
1765880
|
28128
|
1.59
|
8620
|
|
1765880
|
28118
|
1.59
|
9639
|
|
1765880
|
28081
|
1.59
|
9960
|
|
SVM с ядром -
сигмоид
|
1765880
|
1.59
|
9685
|
|
1765880
|
28112
|
1.59
|
8739
|
|
1765880
|
28084
|
1.59
|
8677
|
|
Наивный
Байесовский классификатор
|
17904
|
12627
|
70.53
|
12
|
|
18141
|
12672
|
69.85
|
12
|
|
16790
|
12812
|
76
|
12
|
Выводы
Как и предполагалось ранее, машина опорных векторов с нелинейным ядром (RBF, полиномиальное ядро или сигмоид) не
подходит для решения данной задачи. Каждый из этих трех классификаторов сильно
переучивается на тестовых данных и дает практически одинаковые прогнозы для
всех тестовых примеров. Данные классификаторы требуют значительное время для
обучения (порядка 3 часов каждый) и демонстрируют одинаковую точность, равную
примерно 1,5%.
Как и предполагалось ранее, наилучшую точность демонстрирует машина
опорных векторов с линейным ядром. При этом обучение по методу стохастического
градиентного спуска дает резкий прирост в скорости обучения - средняя время
тренировки по методу стохастического градиентного спуска равно 20 секундам,
против 150 секунд при обучении по методу пакетного градиентного спуска. При
этом переход на стохастический градиентный спуск не снижает точности
классификатора - она все также близка к 80%.
Наивный Байесовский классификатор также хорошо показал себя в машинном
эксперименте. Его отличительной чертой можно назвать большую агрессивность при
выполнении предсказаний (если машина опорных векторов в среднем предсказывала
около 15000 меток то Наивный Байесовский Классификатор предсказывал около 17500
меток). Также можно отметить больший разброс точности данного классификатора -
если результаты SVM отличаются
друг от друга примерно на 1% то результаты NBC колеблются в более широких пределах и могут
отличаться друг от друга почти на 7%. Тем не менее, данный алгоритм обучается
гораздо быстрее, чем SVM,
даже при ее обучении по методу стохастического градиентного спуска. NBC в среднем потребовалось 12 секунд на
тренировку, в то время как SVM в
среднем обучалась около 20 секунд. Также следует отметить, что NBC до лучше масштабируется до больших
объемов данных, соответственно с ростом объема обучающих данных время,
необходимое на его обучение, будет расти медленнее, чем для SVM.
Таким образом, применение классификаторов NBC и SVM
действительно позволяет достичь поставленной нами задачи. Данные классификаторы
способны с большой точностью (примерно 70-80%) предсказывать, какими
характеристиками обладают события, которые должны одновременно происходить с
переданными им записями о сломах в трендах цен.
Заключение
В рамках данной работы нам удалось решить задачу по поиску наиболее
вероятных причин в изменениях в трендах данных. Задача, которая стояла перед
нами является гибридом multi-label и multiclass классификации. Для каждого
примера нам требуется предсказывать одну или несколько меток (например, страна,
в которой произошло событие, или индустрия, с которой связано произошедшее
событие), каждой метке может быть присвоено несколько различных значений.
Подобные задачи имеют название multi-task классификация или multiclass -
multi-output классификация. Задачи, подобные этой относительно успешно решаются
в такой области как Document classification (классификация документов), что
позволило нам использовать методы, традиционно применяемые в рамках
классификации документов
Задача состояла из двух частей:
) Извлечение из информации о ценах данные о том для каких ценных бумаг
когда наблюдалось изменение в тренде в цене (если цена на бумагу росла
некоторое время, то в какой момент она начала снижаться или стала неизменной).
) Разработка системы, которая сможет обучиться на информации о
предшествующих событиях и изменениях в трендах выявляя наиболее вероятные характеристики
событий - причин, и далее сумеет предсказать, какими характеристиками наиболее
вероятно обладает событие, которое вызвало переданный системе слом в тренде.
Первая часть задачи была решена с помощью языка программирования C#.
Вторая задача была решена с помощью языка python и открытой библиотеки программного обеспечения для
машинного обучения scikit-learn. Данная библиотека имеет открытый
исходный код, предлагает эффективную реализацию всех популярных алгоритмов
машинного обучения и поддерживается большим сообществом разработчиков и
исследователей из университетов и лабораторий всего мира. При решении второй
части задачи мы использовали алгоритм TF-IDF который позволил нам повысить
весомость редких событий и снизить вес частых событий. Далее были применены
алгоритмы классификации Машина Опорных Векторов и Наивный Байесовский
Классификатор. Проверена эффективность различных ядер для Машины Опорных
Векторов, а также эффективность пакетного градиентного спуска и стохастического
градиентного спуска. Установлено, что наилучшей точностью обладают SVM с линейным ядром и Наивный
Байесовский Классификатор. Нам удалось получить точность классификации около
80%. Также установлено, что обучение по методу стохастического градиентного
спуска позволяет значительно ускорить тренировку SVM классификатора без каких-либо жертв в точности.
Реализованная система обладает приемлемой производительностью. И
достаточной точностью для ее практического применения. Архитектура
разработанной программы позволяет включить её в состав более сложной системы.
Список
использованных ресурсов
1. Scikit-learn:
Machine Learning in Python, Pedregosa et al., JMLR 12, 2011, pp. 2825-2830.
2. C#
5.0 in a Nutshell 5th Edition, Albahari J., Albahari B., 2012, pp.319 - 423.
3. Нейронные
сети. Полный курс, Хайкин С., Издательский дом "Вильямс", 2006, с.
417 - 458
4. Python manual [Электронный ресурс]
. Причинно-следственный
анализ [Электронный ресурс]
. Инвестиции
- Учебник, Уильям Ф. Шарп, Инфра-М, 2001
Приложение
1
Система
предобработки информации
Program.cs
using
System;System.Collections.Generic;System.Linq;System.Text;System.Threading.Tasks;System.Xml.Linq;FactEventAnalyzer
{struct Parameters
{double ChangeThreshold;int SecIdFrom;int SecIdTo;int
DateFrom;int DateTo;double SpikeThreshold;Logger fileLogger;int
minerDateThreshold;string folderForMLFiles;
}Program
{void Main()
{startDate = System.DateTime.Now;curParam =
readInitialParams(AppDomain.CurrentDomain.BaseDirectory);.fileLogger.writeToLog("Fact-Event
analysis tool started");.runFactMiner(CurParam:
curParam);.fileLogger.writeToLog("Fact-Event analysis tool completed, it
took " + (System.DateTime.Now -
startDate).TotalSeconds.ToString() + " .");
}Parameters readInitialParams(string paramPass)
{curParam = new Parameters();config = XElement.Load(paramPass
+ "\\Config.xml");LogConfig =
config.Element("logging").Element("logFolder");.fileLogger
= new
Logger(LogConfig.Attribute("path").Value.ToString());factMinerSettings
= config.Element("factMinerSettings");.ChangeThreshold = (double)
factMinerSettings.Element("changeThreshold").Attribute("value");.SecIdFrom
=
(int)factMinerSettings.Element("securities").Attribute("from");.SecIdTo
=
(int)factMinerSettings.Element("securities").Attribute("to");.DateFrom
=
(int)factMinerSettings.Element("dates").Attribute("from");.DateTo
=
(int)factMinerSettings.Element("dates").Attribute("to");.SpikeThreshold
=
(double)factMinerSettings.Element("spikeThreshold").Attribute("value");.minerDateThreshold
=
(int)factMinerSettings.Element("dateThreshold").Attribute("value");.folderForMLFiles
=
(string)factMinerSettings.Element("filesForMl").Attribute("value");copyConfigFile
= paramPass+"\\Log\\Config" +
curParam.fileLogger.composeDateString(mode: 0) +
".xml";.IO.File.Copy(paramPass + "\\Config.xml",
copyConfigFile);.fileLogger.writeToLog("Config loaded, copy of loaded
config
file:\n " + copyConfigFile);curParam;
}
}
}
FactMiner.cs
using
System;System.Collections.Generic;System.Linq;System.Text;System.Threading.Tasks;System.Reflection;FactEventAnalyzer
{class FactMiner
{ChangeType
{= 0,= 1,= 2,= 3,= 4
}FieldType
{= 0,= 1,= 2
}static void runFactMiner(Parameters CurParam)
{startDate = DateTime.Now;.fileLogger.writeToLog("Mining
of Facts started");dbContext = new
FactEventAnalysisDBDataContext();.usp_clearFactsTables(dateFrom:
CurParam.DateFrom, dateTo:
CurParam.DateTo, secIdFrom: CurParam.SecIdFrom, secIdTo:
CurParam.SecIdTo, isPrices: true, isCorax: false, isSpike:
true);.fileLogger.writeToLog("Price Facts and Spike Facts are cleared,
it took " + (DateTime.Now -
startDate).TotalSeconds);SecurityQuery = from security in
dbContext.SecuritiesSourcessecurity.SecIdsecurity.SecId >=
CurParam.SecIdFrom && security.SecId <=
CurParam.SecIdTo && dbContext.PricesSources.Any(p
=> (p.SecId ==
security.SecId && p.DateTick >= CurParam.DateFrom
&& p.DateTick <=
CurParam.DateTo))security;totalSecs =
SecurityQuery.Count();curSecNum = 0;(FactEventAnalyzer.SecuritiesSource curSec
in SecurityQuery)
{++;.fileLogger.writeToLog(curSecNum.ToString() +
"/" +
totalSecs.ToString() + ", SecId is " +
curSec.SecId);(DbContext: dbContext, CurSec: curSec, curParam:
CurParam);.fileLogger.writeToLog("Price
completed");(DbContext: dbContext, CurSec: curSec, curParam:
CurParam);.fileLogger.writeToLog("Ask
completed");(DbContext: dbContext, CurSec: curSec, curParam:
CurParam);.fileLogger.writeToLog("Bid
completed");(CurParam.SpikeThreshold > 0)
{(DbContext: dbContext, CurSec: curSec, curParam:
CurParam);.fileLogger.writeToLog("Spikes analyzed");
}
}.fileLogger.writeToLog("Price Facts are produced.\n
Start time: "
+ startDate.ToString() +
"\n Finish time: " + System.DateTime.Now.ToString()
+
"\n Securities processed: " + totalSecs.ToString()
+
"\n Total runtime: " + (System.DateTime.Now - ).TotalSeconds.ToString());.fileLogger.writeToLog("Starting
Corax Facts production");(curParam:
CurParam);.fileLogger.writeToLog("Corax Facts are produced.Starting to
save results to file.\n");hypothesisQuery = from
hypothesis in dbContext.PriceFactsHypothesishypothesis;resultsFile =
CurParam.folderForMLFiles + "\\PriceFacts_" +
CurParam.fileLogger.composeDateString(mode: 0) +
".csv";delimiter = ",";type =
typeof(PriceFactsHypothesi);[] properties = type.GetProperties();line =
"";(PropertyInfo property in properties)
{+= property.Name + delimiter;
}.IO.StreamWriter file = new
System.IO.StreamWriter(resultsFile,
true);.WriteLine(line);.Close();(var hypothesis in
hypothesisQuery)
{= type.GetProperties();= "";(PropertyInfo property
in properties)
{value = property.GetValue(hypothesis) != null
? property.GetValue(hypothesis).ToString()
: string.Empty; // or whatever you want the default text to
be+= value + delimiter;
}= new System.IO.StreamWriter(resultsFile,
true);.WriteLine(line);.Close();
}hypothesisQuery2 = from hypothesis in
dbContext.SpikeFactsHypothesishypothesis;=
CurParam.folderForMLFiles + "\\SpikeFacts_" +
CurParam.fileLogger.composeDateString(mode: 0) +
".csv";= typeof(SpikeFactsHypothesi);= type.GetProperties();=
"";(PropertyInfo property in properties)
{+= property.Name + delimiter;
}= new System.IO.StreamWriter(resultsFile,
true);.WriteLine(line);.Close();(var hypothesis in hypothesisQuery2)
{= type.GetProperties();= "";(PropertyInfo property
in properties)
{value = property.GetValue(hypothesis) != null
? property.GetValue(hypothesis).ToString()
: string.Empty; // or whatever you want the default text to
be+= value + delimiter;
}= new System.IO.StreamWriter(resultsFile,
true);.WriteLine(line);.Close();
}.fileLogger.writeToLog("Fact mining have completed.\n
Start
time: " + startDate.ToString() +
"\n Finish time: " + System.DateTime.Now.ToString()
+
"\n Total runtime of Fact Miner: " +
(System.DateTime.Now - ).TotalSeconds.ToString());
}void analyzePriceField(FactEventAnalysisDBDataContext
DbContext,
FactEventAnalyzer.SecuritiesSource CurSec, Parameters
curParam)
{PriceQuery = from price in
DbContext.PricesSourcesprice.SecId.Equals(CurSec.SecId) &&
price.DateTick >=
curParam.DateFrom && price.DateTick <=
curParam.DateToprice.DateTickprice;isFirst = true;previousPrice = new
FactEventAnalyzer.PricesSource();startPrice = new
FactEventAnalyzer.PricesSource();lastPrice = new
FactEventAnalyzer.PricesSource();isSkip = false;isSecond = false;skipNum =
0;curChange = ChangeType.Unchanged;(FactEventAnalyzer.PricesSource curPrice in
PriceQuery)
{= curPrice;(isFirst == true)
{= curPrice;= false;= true;
}
{(isSecond == true)
{= determineChangeType(prevPrice: startPrice.Price, curPrice:
curPrice.Price, changeThreshold: curParam.ChangeThreshold);=
curPrice;= false;
}
{(isSkip == false)
{(determineChangeType(prevPrice: previousPrice.Price,
curPrice:
curPrice.Price, changeThreshold: curParam.ChangeThreshold) !=
curChange)
{= true;
}
{= curPrice;
}
}
{(skipNum < (curParam.minerDateThreshold - 1))
{++;
}
{= 0;= false;(determineChangeType(prevPrice:
previousPrice.Price, curPrice:
curPrice.Price, changeThreshold: curParam.ChangeThreshold) !=
curChange)
{(curChange, dateStart: startPrice.DateTick, dateEnd:
previousPrice.DateTick, secId: CurSec.SecId, fieldType:
FieldType.Price);= determineChangeType(prevPrice: previousPrice.Price,
curPrice: curPrice.Price, changeThreshold:
curParam.ChangeThreshold);= previousPrice;= curPrice;
}
{= curPrice;
}
}
}
}
}
}(isSkip == true)
{(changeType: curChange, dateStart: startPrice.DateTick,
dateEnd: previousPrice.DateTick, secId: CurSec.SecId,
fieldType: .Price);(changeType:
determineChangeType(previousPrice.Price, curPrice:
lastPrice.Price,
changeThreshold: curParam.ChangeThreshold), dateStart:
previousPrice.DateTick, dateEnd: lastPrice.DateTick, secId:
CurSec.SecId,
fieldType: FieldType.Price);
}
{(isFirst != true)
{(changeType: curChange, dateStart: startPrice.DateTick,
dateEnd: lastPrice.DateTick, secId: CurSec.SecId, fieldType:
.Price);
}
}
}void analyzeAskField(FactEventAnalysisDBDataContext
DbContext,
FactEventAnalyzer.SecuritiesSource CurSec, Parameters
curParam)
{PriceQuery = from price in
DbContext.PricesSourcesprice.SecId.Equals(CurSec.SecId) &&
price.DateTick >=
curParam.DateFrom && price.DateTick <=
curParam.DateToprice.DateTickprice;isFirst = true;previousPrice = new
FactEventAnalyzer.PricesSource();startPrice = new
FactEventAnalyzer.PricesSource();lastPrice = new
FactEventAnalyzer.PricesSource();isSkip = false;isSecond = false;skipNum =
0;curChange = ChangeType.Unchanged;(FactEventAnalyzer.PricesSource curPrice in
PriceQuery)
{= curPrice;(isFirst == true)
{
= curPrice;= false;= true;
}
{(isSecond == true)
{= determineChangeType(prevPrice: startPrice.AskPrice,
curPrice: curPrice.AskPrice, changeThreshold:
curParam.ChangeThreshold);= curPrice;= false;
}
{(isSkip == false)
{(determineChangeType(prevPrice: previousPrice.AskPrice,
curPrice:
curPrice.AskPrice, changeThreshold: curParam.ChangeThreshold)
!= curChange)
{= true;
}
{= curPrice;
}
}
{(skipNum < (curParam.minerDateThreshold - 1))
{++;
}
{= 0;= false;(determineChangeType(prevPrice:
previousPrice.AskPrice, curPrice:
curPrice.AskPrice, changeThreshold: curParam.ChangeThreshold)
!=
curChange)
{(curChange, dateStart: startPrice.DateTick, dateEnd:
previousPrice.DateTick, secId: CurSec.SecId, fieldType:
FieldType.Ask);= determineChangeType(prevPrice: previousPrice.AskPrice,
curPrice: curPrice.AskPrice, changeThreshold:
curParam.ChangeThreshold);= previousPrice;= curPrice;
}
{= curPrice;
}
}
}
}
}
}(isSkip == true)
{(changeType: curChange, dateStart: startPrice.DateTick,
dateEnd: previousPrice.DateTick, secId: CurSec.SecId,
fieldType: .Ask);(changeType:
determineChangeType(previousPrice.AskPrice, curPrice:
lastPrice.AskPrice,
changeThreshold: curParam.ChangeThreshold), dateStart:
previousPrice.DateTick, dateEnd: lastPrice.DateTick, secId:
CurSec.SecId,
fieldType: FieldType.Ask);
}
{(isFirst != true)
{(changeType: curChange, dateStart: startPrice.DateTick,
dateEnd: lastPrice.DateTick, secId: CurSec.SecId, fieldType:
.Ask);
}
}
}void analyzeBidField(FactEventAnalysisDBDataContext
DbContext,
FactEventAnalyzer.SecuritiesSource CurSec, Parameters
curParam)
{PriceQuery = from price in
DbContext.PricesSourcesprice.SecId.Equals(CurSec.SecId) &&
price.DateTick >=
curParam.DateFrom && price.DateTick <=
curParam.DateToprice.DateTickprice;isFirst = true;previousPrice = new
FactEventAnalyzer.PricesSource();startPrice = new
FactEventAnalyzer.PricesSource();lastPrice = new
FactEventAnalyzer.PricesSource();isSkip = false;isSecond = false;skipNum =
1;curChange = ChangeType.Unchanged;(FactEventAnalyzer.PricesSource curPrice in
PriceQuery)
{= curPrice;(isFirst == true)
{
= curPrice;= false;= true;
}
{(isSecond == true)
{= determineChangeType(prevPrice: startPrice.BidPrice,
curPrice:
curPrice.BidPrice, changeThreshold:
curParam.ChangeThreshold);= curPrice;= false;
}
{(isSkip == false)
{(determineChangeType(prevPrice: previousPrice.BidPrice,
curPrice:
curPrice.BidPrice, changeThreshold: curParam.ChangeThreshold)
!=
curChange)
{= true;
}
{= curPrice;
}
}
{(skipNum < (curParam.minerDateThreshold - 1))
{++;
}
{= 1;= false;(determineChangeType(prevPrice:
previousPrice.BidPrice, curPrice:
curPrice.BidPrice, changeThreshold: curParam.ChangeThreshold)
!=
curChange)
{(curChange, dateStart: startPrice.DateTick, dateEnd:
previousPrice.DateTick, secId: CurSec.SecId, fieldType: FieldType.Bid);=
previousPrice;= curPrice;= determineChangeType(prevPrice: startPrice.BidPrice,
curPrice:
previousPrice.BidPrice, changeThreshold:
curParam.ChangeThreshold);
}
{= curPrice;
}
}
}
}
}
}(isSkip == true)
{(changeType: curChange, dateStart: startPrice.DateTick,
dateEnd: previousPrice.DateTick, secId: CurSec.SecId,
fieldType: .Bid);(changeType:
determineChangeType(previousPrice.BidPrice, curPrice:
lastPrice.BidPrice,
changeThreshold: curParam.ChangeThreshold), dateStart:
previousPrice.DateTick, dateEnd: lastPrice.DateTick, secId:
CurSec.SecId,
fieldType: FieldType.Bid);
}
{(isFirst != true)
{(changeType: curChange, dateStart: startPrice.DateTick,
dateEnd: lastPrice.DateTick, secId: CurSec.SecId, fieldType:
.Bid);
}
}
}void insertNewPriceFact(ChangeType changeType, int
dateStart, int
dateEnd, int secId, FieldType fieldType)
{dbContext = new
FactEventAnalysisDBDataContext();.PriceFactsTable newFact =
new
FactEventAnalyzer.PriceFactsTable();.ChangeType =
changeType.ToString();.DateStart = dateStart;.DateEnd = dateEnd;.SecID =
secId;.FieldType =
fieldType.ToString();.PriceFactsTables.InsertOnSubmit(newFact);.SubmitChanges();
}void insertNewSpikeFact(ChangeType changeType, int date, int
secId,
FieldType fieldType)
{dbContext = new
FactEventAnalysisDBDataContext();.SpikeFactsTable
newSpikeFact = new
FactEventAnalyzer.SpikeFactsTable();.Date = date;.FieldType =
fieldType.ToString();.SecId = secId;.SpikeType = changeType.ToString();
.SpikeFactsTables.InsertOnSubmit(newSpikeFact);.SubmitChanges();
}void produceCoraxFacts(Parameters curParam)
{? insertedSecs = 0, insertedCoraxes = 0;startDate =
DateTime.Now;dbContext = new
FactEventAnalysisDBDataContext();.usp_clearFactsTables(dateFrom:
curParam.DateFrom, dateTo:
curParam.DateTo, secIdFrom: curParam.SecIdFrom, secIdTo:
curParam.SecIdTo, isPrices: false, isCorax: true, isSpike:
false);.fileLogger.writeToLog("Corax Facts are cleared, it took " +
(DateTime.Now -
startDate).TotalSeconds);.usp_populateCoraxFactsTable(curParam.DateFrom,
curParam.DateTo, curParam.SecIdFrom, curParam.SecIdTo, ref
insertedSecs, ref insertedCoraxes);
.fileLogger.writeToLog("Corax Facts are produced.\n
Start time: "
+ startDate.ToString() +
"\n Finish time: " + System.DateTime.Now.ToString()
+
"\n Securities processed: " +
insertedSecs.ToString() +
"\n Facts inserted: " + insertedCoraxes.ToString()
+
"\n Total runtime: " + (System.DateTime.Now -
).TotalSeconds.ToString());
}void produceSpikeFacts(FactEventAnalysisDBDataContext
DbContext, FactEventAnalyzer.SecuritiesSource CurSec,
Parameters )
{PriceQuery = from price in
DbContext.PricesSourcesprice.SecId.Equals(CurSec.SecId) &&
price.DateTick >=
curParam.DateFrom && price.DateTick <= curParam.DateToprice.DateTickprice;isFirst
= true;.PricesSource prevPrice = new
FactEventAnalyzer.PricesSource();(FactEventAnalyzer.PricesSource
curPrice in PriceQuery)
{(isFirst == true)
{= curPrice;= false;
}
{changeAmount = (double)(100 * (curPrice.Price - prevPrice.Price)
/
prevPrice.Price);(Math.Abs(changeAmount) >
curParam.SpikeThreshold)
{(changeAmount < 0)
{(changeType: ChangeType.NegSpike, date:
curPrice.DateTick, secId: CurSec.SecId, fieldType:
FieldType.Price);
}
{(changeType: ChangeType.PosSpike, date:
curPrice.DateTick, secId: CurSec.SecId, fieldType:
FieldType.Price);
}
}= (double)(100 * (curPrice.AskPrice - prevPrice.AskPrice) /
prevPrice.AskPrice);(Math.Abs(changeAmount) >
curParam.SpikeThreshold)
{(changeAmount < 0)
{(changeType: ChangeType.NegSpike, date:
curPrice.DateTick, secId: CurSec.SecId, fieldType:
FieldType.Ask);
}
{(changeType: ChangeType.PosSpike, date:
curPrice.DateTick, secId: CurSec.SecId, fieldType:
FieldType.Ask);
}
}= (double)(100 * (curPrice.BidPrice - prevPrice.BidPrice) /
prevPrice.BidPrice);(Math.Abs(changeAmount) >
curParam.SpikeThreshold)
{(changeAmount < 0)
{(changeType: ChangeType.NegSpike, date:
curPrice.DateTick, secId: CurSec.SecId, fieldType:
FieldType.Bid);
}
{(changeType: ChangeType.PosSpike, date:
curPrice.DateTick, secId: CurSec.SecId, fieldType:
FieldType.Bid);
}
}= curPrice;
}
}
}ChangeType determineChangeType(decimal prevPrice, decimal
curPrice, double changeThreshold)
{changeAmount = (double)(100 * (curPrice - prevPrice) /
prevPrice);(Math.Abs(changeAmount) < changeThreshold)
{ChangeType.Unchanged;
}
{(changeAmount < 0)
{ChangeType.Decreasing;
}
{ChangeType.Growing;
}
}
}
}
}
Logger.cs
using
System;System.Collections.Generic;System.Linq;System.Text;System.Threading.Tasks;FactEventAnalyzer
{class Logger
{Logger() { }logFile;Logger(string logFolder)
{.logFile = logFolder + "\\FactMiner_" +
composeDateString(mode: 0) +
".log";
}string composeDateString(int mode=1)
{tempDate = System.DateTime.Now;(mode == 0)
{(tempDate.Year.ToString() + tempDate.Month.ToString("D2")
+
tempDate.Day.ToString("D2")
+ "T" + tempDate.Hour.ToString("D2") +
tempDate.Minute.ToString("D2")
+ "_" +
tempDate.Millisecond.ToString("D3"));
}
{(tempDate.Year.ToString() + "." +
tempDate.Month.ToString("D2") +
"." + tempDate.Day.ToString("D2")
+ "T" + tempDate.Hour.ToString("D2") +
":" +
tempDate.Minute.ToString("D2") + ":" +
tempDate.Second.ToString("D2")
+ "." +
tempDate.Millisecond.ToString("D3"));
}
}void writeToLog(string logMessage)
{
.IO.StreamWriter file = new
System.IO.StreamWriter(this.logFile,
true);.WriteLine(composeDateString() + " " +
logMessage);.Close();
}
}
}
Приложение
2. Файл конфигурации системы предобработки информации
<factEventAnalyzer>
<logging>
<logFolder path="D:\DiplomaProject\AnalyzingWorkFolder\log"/>
</logging>
<factMinerSettings>
<changeThreshold value="0.3"/>
<securities from="0"
to="99999999"/>
<dates from="0" to="99999"/>
<spikeThreshold value="6"/>
<dateThreshold value = "3"/>
<filesForMl value="D:\DiplomaProject\FilesForML"/>
</factMinerSettings>
</factEventAnalyzer>
Приложение 3. Хранимые процедуры и табличные представления базы данных FactEventAnalysisDB
_populateCoraxFactsTable
USE [FactEventAnalysisDB]ANSI_NULLS ONQUOTED_IDENTIFIER ONPROCEDURE
[dbo].[usp_populateCoraxFactsTable]
@DateFrom int = 0,
@DateTo int = 999999999,
@SecIdFrom int = 0,
@SecIdTo int = 999999999,
@SecuritiesInserted int = 0 output,
@CoraxesInserted int = 0 outputtable #Inserted
(int not null,int not null
)into dbo.CoraxFactsTable
(,,,,,
).UniqueCoraxId,.SecId#Inserted.SecId as SecId,.UniqueCoraxId
as UniqueCoraxid,(c.EffectiveDate as int) as EffectiveDate,(c.ReportedDate as
int) as ReportedDate,.EventType as EventType,.EventMajorType as
EventMajorType.CoraxesSource as c.SecId >= @SecIdFromc.SecId <= @SecIdTo(
(c.ReportedDate>=@DateFromc.ReportedDate<=@DateTo)
(c.EffectiveDate>=@DateFromc.EffectiveDate<=@DateTo)
)@CoraxesInserted = COUNT(*)
#Inserted
@SecuritiesInserted = COUNT(t.SecId)
(select distinct SecId from #Inserted) as t
usp_clearFactsTables
USE [FactEventAnalysisDB]ANSI_NULLS ONQUOTED_IDENTIFIER
ONPROCEDURE [dbo].[usp_clearFactsTables]
@DateFrom int = 0,
@DateTo int = 999999999,
@SecIdFrom int = 0,
@SecIdTo int = 999999999,
@IsPrices bit = 0,
@IsCorax bit = 0,
@IsSpike bit = 0(@IsPrices = 1)from.PriceFactsTable>=
@SecIdFromSecId <= @SecIdTo(
(DateStart >= @DateFromDateStart <=@DateTo)
(DateEnd <= @DateToDateEnd >= @DateFrom))(@IsSpike =
1)from.SpikeFactsTable>= @SecIdFromSecId <= @SecIdTo[Date] >=
@DateFrom[Date] <= @DateTo(@IsCorax = 1)from.CoraxFactsTable>=
@SecIdFromSecId <= @SecIdTo(
(ReportedDate>=@DateFromReportedDate<=@DateTo)
(EffectiveDate>=@DateFromEffectiveDate<=@DateTo))
SpikeFactsHypothesis
USE [FactEventAnalysisDB]ANSI_NULLS ONQUOTED_IDENTIFIER
ONview [dbo].[SpikeFactsHypothesis] as.EventType as [CoraxEventType]
,cf.EventMajorType as [CoraxEventMajorType]
,csec.Ticker as [CoraxTicker]
,csec.Issuer as [CoraxIssuer]
,csec.SecType as [CoraxSecType]
,csec.InvType as [CoraxInvType]
,csec.PriceCurrency as [CoraxPriceCurrency]
,csec.Region as[CoraxRegion]
,csec.IssuerCountry as [CoraxIssuerCountry]
,csec.Exchange as [CoraxExchange]
,csec.IndustrySector as [CoraxIndustrySector]
,sf.SpikeType as [ChangeType]
,ssec.Ticker as [ChangeTicker]
,ssec.Issuer as [ChangeIssuer]
,ssec.SecType as [ChangeSecType]
,ssec.InvType as [ChangeInvType]
,ssec.PriceCurrency as [ChangePriceCurrency]
,ssec.Region as [ChangeRegion]
,ssec.IssuerCountry as [ChangeIssuerCountry]
,ssec.Exchange as [ChangeExchange]
,ssec.IndustrySector as
[ChangeIndustrySector].CoraxFactsTable as cfdbo.SecuritiesSource as csec on
cf.SecId = csec.SecIddbo.Spikefactstable as sf on cf.EffectiveDate =
sf.[Date]dbo.SecuritiesSource as ssec on sf.SecId = ssec.SecId.FieldType =
'Price'
PriceFactsHypothesis
USE [FactEventAnalysisDB]ANSI_NULLS ONQUOTED_IDENTIFIER ON
view [dbo].[PriceFactsHypothesis] as.EventType as
[CoraxEventType]
,cf.EventMajorType as [CoraxEventMajorType]
,csec.Ticker as [CoraxTicker]
,csec.Issuer as [CoraxIssuer]
,csec.SecType as [CoraxSecType]
,csec.InvType as [CoraxInvType]
,csec.PriceCurrency as [CoraxPriceCurrency]
,csec.Region as[CoraxRegion]
,csec.IssuerCountry as [CoraxIssuerCountry]
,csec.Exchange as [CoraxExchange]
,csec.IndustrySector as [CoraxIndustrySector]
,sf.ChangeType as [ChangeType]
,ssec.Ticker as [ChangeTicker]
,ssec.Issuer as [ChangeIssuer]
,ssec.SecType as [ChangeSecType]
,ssec.InvType as [ChangeInvType]
,ssec.PriceCurrency as [ChangePriceCurrency]
,ssec.Region as [ChangeRegion]
,ssec.IssuerCountry as [ChangeIssuerCountry]
,ssec.Exchange as [ChangeExchange]
,ssec.IndustrySector as
[ChangeIndustrySector].CoraxFactsTable as cfdbo.SecuritiesSource as csec on
cf.SecId = csec.SecIddbo.PriceFactstable as sf on cf.EffectiveDate = sf.[DateStart]dbo.SecuritiesSource
as ssec on sf.SecId = ssec.SecId.FieldType = 'Price'
Приложение 4
Система классификации
__future__ import divisionsyscsv as csvnumpy as nppandas as
pdpandas import DataFramesklearnsklearn.preprocessing import LabelEncodersklearn.cross_validation
import train_test_splitsklearn.grid_search import GridSearchCVsklearn.metrics
import classification_reportsklearn.svm import SVCsklearn.svm import
LinearSVCsklearn import cross_validation, svm, treesklearn.naive_bayes import
MultinomialNBsklearn.pipeline import Pipelinesklearn.feature_extraction.text
import CountVectorizersklearn.neighbors import
KNeighborsClassifiersklearn.feature_extraction.text import
TfidfTransformersklearn.multiclass import OneVsRestClassifiersklearn import preprocessingsklearn.linear_model
import SGDClassifierrandomwarningsdatetime import datetimesklearn.grid_search
import GridSearchCV.filterwarnings("ignore")= {
'linear': LinearSVC(),
'linearWithSGD': SGDClassifier(),
'rbf': SVC(kernel='rbf', probability=True),
'poly': SVC(kernel='poly', probability=True),
'sigmoid': SVC(kernel='sigmoid', probability=True),
'bayes': MultinomialNB()
}= {
'linearWithSGD': 'linear SVM with SGD training',
'linear': 'linear SVM without SGD training',
'rbf': 'SVM with RBF kernel',
'poly': 'SVM with polynomial kernel',
'sigmoid': 'SVM with sigmoid kernel',
'bayes': 'Naive Bayes classifier'
}replacer(text):str(str(text).replace("u'",'').replace("'",
''))workMode(fileIn, toPredict, fileOut, classif):= pd.read_csv(fileIn, header
= 0, encoding='utf-8-sig')_test = pd.read_csv(toPredict, header = 0,
encoding='utf-8-sig')_train = []_train = []_test = []i in work[[i for i in
list(work.columns.values) if
i.startswith('Change')]].values:_train.append(','.join(i.T.tolist()))_train
= np.array(X_train)i in work[[i for i in list(work.columns.values) if
i.startswith('Corax')]].values:_train.append(list(i))i in
work_test[[i for i in list(work_test.columns.values) if
i.startswith('Change')]].values:_test.append(','.join(i.T.tolist()))_test
= np.array(X_test)= preprocessing.MultiLabelBinarizer()=
lb.fit_transform(y_train)("Getting results of classifier")=
Pipeline([('vectorizer', CountVectorizer()),('tfidf',
TfidfTransformer()),('clf', OneVsRestClassifier(selClassifiers[classif]))]).fit(X_train,
Y)= classifier.predict(X_test)_labels = lb.inverse_transform(predicted)=
DataFrame.from_items([('Change', X_test),
('Prediction',all_labels)]).Prediction =
df.Prediction.map(replacer).to_csv(fileOut)testMode(fileIn, fileOut, classif):=
pd.read_csv(fileIn, header = 0, encoding='utf-8-sig')=
random.sample(list(df.index), int(len(df) * 0.9))= df.ix[rows]_test =
df.drop(rows)_train = []_train = []_test = []_test = []i in work[[i for i in
list(work.columns.values) if
i.startswith('Change')]].values:_train.append(','.join(i.T.tolist()))_train
= np.array(X_train)i in work[[i for i in list(work.columns.values) if
i.startswith('Corax')]].values:_train.append(list(i))i in
work_test[[i for i in list(work_test.columns.values) if
i.startswith('Change')]].values:_test.append(','.join(i.T.tolist()))_test
= np.array(X_test)i in work_test[[i for i in list(work_test.columns.values) if
i.startswith('Corax')]].values:_test.append(list(i))=
preprocessing.MultiLabelBinarizer()= lb.fit_transform(y_train)("Getting
results of %s" % classifierDescriptions[classif])=
Pipeline([('vectorizer', CountVectorizer()),('tfidf',
TfidfTransformer()),('clf',
OneVsRestClassifier(selClassifiers[classif]))]).fit(X_train, Y)=
classifier.predict(X_test)_labels = lb.inverse_transform(predicted)=
DataFrame.from_items([('Test', X_test), ('RealAnswer', y_test),
('Prediction',all_labels)])= 0= 0classifying, item, labels in
zip(X_test, y_test, all_labels):res in labels:res in
item:+=1+=len(labels)('Predicted correctly %s labels out of %s labels' %
(CorPred, Total))('Precision is %.2f %%' %
(100*float(CorPred)/float(Total))).Prediction =
df.Prediction.map(replacer).RealAnswer =
df.RealAnswer.map(replacer).to_csv(fileOut)main():=
datetime.now()("Program started at %s" % start)sys.argv[1] ==
'test':(sys.argv[2], sys.argv[3], sys.argv[4])sys.argv[1] ==
'work':(sys.argv[2], sys.argv[3], sys.argv[4], sys.argv[5]):('Unknown mode,
only test or work modes are available')= datetime.now()("Program finished
at %s" % end)("It took %s seconds for program to complete" %
(end - ).total_seconds())__name__ == '__main__':
main()