Современные поисковые системы
Министерство образования и науки
Российской Федерации
Федеральное государственное бюджетное
образовательное учреждение высшего профессионального образования
"Московский государственный технологический университет
"СТАНКИН"
Кафедра: информационные технологии
и вычислительные системы
Курсовая работа
по дисциплине
"Математическое моделирование
процессов и систем"
СОВРЕМЕННЫЕ ПОИСКОВЫЕ СИСТЕМЫ
Выполнил: студент группы ИДМ-13-06
Блажко Сергей
Проверил: к. т. н., доцент
Пителинский К. В.
Москва 2013
Оглавление
Введение
1. Организация хранения данных
1.1 База данных и система управления базами данных
1.2 Хранение данных
2.1 Поиск информации в базах данных
2.2 Понятие индекса
3. Поисковые системы
3.1 Понятие поисковой системы
3.2 Особенности работы поискового движка
3.3 Использование индексов в поисковых системах
3.4 Особенности поиска текстовой информации
3.5 Особенности поиска графической информации
3.6 Особенности поиска аудио информации
3.7 Обзор популярных текстовых поисковых систем
3.8 Обзор популярных поисковых систем, предназначенных для поиска
изображений
3.9 Обзор популярных поисковых систем, предназначенных для поиска
аудио композиций
3.10 Обзор специализированных поисковых систем
Список использованной литературы
Введение
Сеть Интернет растет очень быстрыми темпами, и найти нужную
информацию среди миллиардов Web-страниц и файлов становится все сложнее. Для
поиска информации используются специальные поисковые серверы, которые содержат
более или менее полную и постоянно обновляемую информацию о Web-страницах,
файлах и других документах, хранящихся на десятках миллионов серверов
Интернета.
Тем не менее, всякий рядовой пользователь наловчился находить
нужную ему информацию при помощи поисковых систем. Казалось бы, что может быть
проще - зайти при помощи веб-браузера на необходимый поисковый сайт и ввести в
строку поиска необходимую комбинацию слов после чего получить несколько сотен
тысяч подходящих результатов.
Однако технологии не стоят на месте. С появлением компактных
цифровых мультимедийных устройств, таких как цифровых фотоаппаратов, плееров,
видеокамер, мобильных телефонов, совмещающих предыдущие устройства, появилась
возможность загружать на просторы интернета необходимые данные (музыкальные
файлы, изображения, электронные документы). И если до недавнего времени стоял
вопрос, можно ли находить мультимедийные данные в интернете таким же образом,
как мы находим текстовую информацию, то сейчас даже это не является проблемой.
Итак, целью реферата является знакомство с организацией и
основными методами хранения и поиска данных, которые востребованы в настоящее
время, а именно данных, представленными в текстовом и мультимедийном
(графическом и аудио) виде.
поисковая система информация база
1.
Организация хранения данных
1.1 База
данных и система управления базами данных
В настоящее время каждая серьезная система, целью которой
является сбор и обработка информации не может обойтись без собственных баз
данных (БД) и систем управления базами данных (СУБД).
Системы управления базами данных (СУБД) дают полный контроль
над определением и обработкой и совместным использованием данных. Такие системы
предоставляют все возможности управления и каталогизации больших объемов
информации во множестве таблиц. СУБД обеспечивает три основные возможности:
определение данных, обработка данных и управление данными. [1]
· Определение данных. Можно определить,
какие данные будут храниться в базе данных, тип данных (например, текст или
число) и связи между ними. В некоторых случаях можно задать способы
форматирования и проверки допустимости данных.
· Обработка данных. Допускается любое
манипулирование данными. Можно выбирать необходимые поля данных, фильтровать и
сортировать данные. Также можно выполнять слияние связанной информации и
выводить итоговые данные. Имеется возможность выделить подмножество данных и
попросить СУБД обновить, удалить или скопировать его в другую таблицу либо
создать новую таблицу с этими данными.
· Управление данными. Можно определять, кому
разрешено просматривать, обновлять и добавлять информацию. В большинстве
случаев имеется возможность определить порядок совместного использования и
обновления данных несколькими пользователями.
Существует много видов и классов БД (и соответственно СУБД),
которые различаются, как и в способе хранения данных, так и в способе доступа к
ним и обработки, но рассмотрим только классы БД, которые используются в
поисковых системах:
· Объектно-реляционная СУБД;
· Графовая СУБД;
Объектно-реляционная СУБД - реляционная СУБД
(РСУБД), поддерживающая некоторые технологии, реализующие
объектно-ориентированный подход: объекты, классы и наследование реализованы в
структуре баз данных и языке запросов.
Объектно-реляционными СУБД являются, к примеру, широко
известные Oracle Database, Informix, DB2, PostgreSQL. [2]
Пожалуй, самый распространенный класс СУБД, хорошо себя
зарекомендовал и используется практически повсеместно для различных целей,
начиная с организации телефонного справочника, заканчивая обработкой
сверхбольших объемов данных. Также представители данного класса имеют самые
высокие показатели производительности при выполнении задач общего назначения.
Графовая база данных - разновидность баз
данных с реализацией сетевой модели в виде графа и его обобщений.
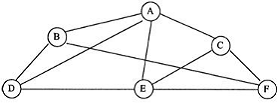
Модель хранения информации в виде графов, графов со
свойствами в узлах и гиперграфов сложилась в 1990-2000 годах. Хотя
использование графов в виде модели представления данных сложилась гораздо
раньше, уже в 80-х годах 20-го века. Первую графовую СУБД создали уже в 2007
году (Neo4j). На настоящий момент существует более десятка графовых СУБД и это
направление бурно развивается.
Графовую модель данных обычно рассматривают как обобщение
RDF-модели или сетевой модели данных. Основными элементами модели являются узлы
и связи. В зависимости от реализации узлов и ребер граф-модель данных разделяют
на несколько подтипов. [3]
Данный вид баз данных применяется для моделирования
социальных графов (социальных сетей), в биоинформатике, а также для
семантического веб. [4] [5]
По мнению некоторых авторов, для задач с естественной
графовой структурой данных графовые СУБД могут существенно превосходить
реляционные по производительности, а также иметь преимущества в наглядности
представления и внесения изменений в схему БД.
1.2 Хранение
данных
Как и любые другие данные, обрабатываемые компьютером,
информация в базах данных на низком уровне хранится в двоичной форме. От
данного способа представления данных пока что уйти не получится. Тем не менее,
в каждой из двух представленных баз данных возможно представление, понятное
пользователю или программе, работающей с базой данных (которая все же делает
данные понятные человеку).
В большинстве БД текстовую (строковую информацию) можно
хранить напрямую, без каких-либо модификаций, потому что БД имеют встроенные типы
и алгоритмы для этих целей. [6]
Что же касается мультимедийной информации (изображения,
аудио-видео и пр.), то "удобном" виде такие данные хранить не
получится, потому что чаще всего СУБД не имеет ни малейшего представления каким
образом эту информацию обрабатывать. Поэтому одним из решений является хранение
таких данных в битовых полях без возможности представить их в удобочитаемом
виде (эту возможность оставляют программному обеспечению, работающему с СУБД).
Иногда, в случае, если БД не может (из каких-либо соображений) хранить подобную
информацию, её представляют в знакомом нам, тестовом виде, например, используя BASE64 систему счисления
(кодирование Base64). [7]
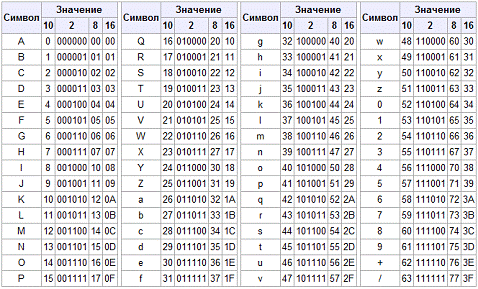
Схема соответствия "символ ↔
значение" в Base64
В каком бы виде не хранилась бы информация, необходимо
обеспечить взаимосвязь её с иной информацией. В объектно-реляционных СУБД эта
взаимосвязь устанавливается при помощи связи отношений, действуют законы и
операции теории множеств. В графовых БД данные данная связь изображается в виде
ребер графов или гиперграфов (что предпочтительнее в нашем случае).
2. Поиск
данных
2.1 Поиск
информации в базах данных
Процедура поиска является одной из центральных процедур в
системах автоматической обработки информации. При решении любой задачи
требуется выбирать исходные данные из некоторых заранее подготовленных массивов
информации и записывать результаты решения в эти или другие массивы. Проблемы
поиска информации в формализованных базах данных заслуживают самого серьезного
внимания. Поиск информации в базах данных - это процесс отбора из них множества
описаний объектов, удовлетворяющих сформулированным в запросе условиям. При
этом в качестве результатов поиска могут выдаваться не все признаки объектов, а
только часть их - в соответствии с условиями запроса. Объект может выбираться
из массива по значению одного идентифицирующего его (ключевого) признака или по
сочетанию значений нескольких ключевых признаков. Он может также выбираться по
сочетанию любых других (неключевых) признаков, если это сочетание однозначно
выделяет его из множества всех объектов массива.
Важной методологической проблемой прикладной компьютерной
лингвистики является правильная оценка необходимого соотношения между
декларативной и процедурной компонентами систем автоматической обработки
текстовой информации. Чему отдать предпочтение: мощным вычислительным
процедурам, опирающимся на относительно небольшие словарные системы с богатой
грамматической и семантической информацией, или мощной декларативной компоненте
при относительно простых процедурных средствах. И высказали мнение, что второй
путь предпочтительнее. Можно представить себе крайний случай такого
предпочтения, когда лингвистическая задача решается путем создания большого
словаря и поиска в этом словаре необходимой информации. Однако более реальна
ситуация, когда задача решается путем последовательного поиска в небольшом
количестве достаточно представительных словарей и выполнения несложных процедур
преобразования результатов поиска.
Будем различать первичные и производные (в частности,
обобщенные) признаки объектов. Первичные признаки назначаются при
первоначальном описании объектов, а производные являются функциями первичных.
Поиск может вестись как по первичным, так и по производным признакам. Чаще
всего в процессе поиска информации выбирается не один объект, а множество
объектов. Оно может быть задано различными способами:
) перечнем значений ключевых признаков или сочетаний
ключевых признаков;
2) значением или интервалом (перечнем) значений одного
неключевого признака;
) булевой функцией значений или интервалов (перечней)
значений любых признаков объекта (как ключевых, так и неключевых);
) отношением между признаками, выраженным с помощью
арифметических и логических операции (операций типа "И”, "ИЛИ”,
"НЕ”), а также отношений =, >, < и их отрицаний. Условия выборки
признаков у найденных объектов задаются в виде перечней наименований этих
признаков.
Важной проблемой, возникающей при реализации процедур поиска
информации, является проблема отождествления признаков объектов и установления
парадигматических отношений между ними (отношений типа род-вид, целое-часть и
др.). Общее решение этой проблемы связано с возможностью распознавания
смыслового тождества и парадигматических отношений различных форм наименований
понятий на основе их морфологического, синтаксического и семантического
анализа. Но на практике широко применяются и другие решения, основанные на
унификации форм представления наименований понятий в базах данных и
использования систем меню, в которых пользователю предлагается делать выбор
наименований понятий только из числа рекомендованных.
· композиция запросов - запросы выполняются
в строго определенной последовательности, а результаты поиска по предыдущему
запросу используются в качестве исходных данных для формирования следующего за
ним запроса. При этом первый запрос в серии запросов определяется полностью, а
остальные - не полностью и доопределяются в процессе поиска.
· объединение запросов - когда результаты
поиска по нескольким запросам объединяются в одну общую выдачу.
· разветвление запросов - когда после
выполнения очередного запроса есть возможность перехода к одному из нескольких
запросов в зависимости от выполнения тех или иных условий. Перечисленные
способы организации процесса выполнения запросов могут применяться в различных
сочетаниях, что позволяет строить различные процедуры многошагового поиска. [8]
2.2 Понятие
индекса
Создание или внедрение СУБД обусловлено в первую очередь
большими объемами хранимых и обрабатываемых данных. Немаловажной операцией с
данными является их поиск. Современные СУБД используют индексы для хранимых
данных, то есть производится их индексация. Индекс - объект базы данных,
создаваемый с целью повышения производительности поиска данных. Таблицы в базе
данных могут иметь большое количество строк, которые хранятся в произвольном
порядке, и их поиск по заданному критерию путем последовательного просмотра
таблицы строка за строкой может занимать много времени. Индекс формируется из
значений одного или нескольких столбцов таблицы и указателей на соответствующие
строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие
критерию поиска. Ускорение работы с использованием индексов достигается в
первую очередь за счёт того, что индекс имеет структуру, оптимизированную под
поиск.
Существует два типа индексов: кластерные и некластерные. При
наличии кластерного индекса строки таблицы упорядочены по значению ключа этого
индекса. Если в таблице нет кластерного индекса, таблица называется кучей.
Некластерный индекс, созданный для такой таблицы, содержит только указатели на
записи таблицы. Кластерный индекс может быть только одним для каждой таблицы,
но каждая таблица может иметь несколько различных некластерных индексов, каждый
из которых определяет свой собственный порядок следования записей.
Индексы могут быть реализованы различными структурами.
Наиболее частоупотребимы B*-деревья, B+-деревья, B-деревья и хеши.
Для эффективной работы многомерными данными самыми
популярными типами индекса являются: GIST (Generalized Search Tree) и GIN (Generalized Inverted
Index). GIN индекс, или обобщенный обратный индекс - это структура данных, у
которой ключом является лексема, а значением - сортированный список
идентификаторов документов, которые содержат эту лексему. Так как в обратном
индексе используется бинарное дерево для поиска ключей, то он слабо зависит от
их количества и потому хорошо шкалируется. Этот индекс используется практически
всеми большими поисковыми машинами, однако его использование в базах данных для
индексирования изменяющихся документов затруднено, так как любые изменения
приводят к большому количеству обновлений индекса. Этот индекс лучше всего
подходит для неменяющихся коллекций документов. В тоже время, GIST индекс
является "прямым" индексом, т.е. для каждого документа ставится в
соответствие битовая сигнатура, в которой содержится информация обо всех
лексемах, которые содержаться в этом документе, поэтому добавление нового
документа приводит к добавлению только одной сигнатуры.
Для определения области применения каждого из индексов
необходимо знать их основные различия:
· создание индекса - GIN требует в 3 раза
больше времени чем GIST;
· размер индекса - GIN-индекс в 2-3 раза
больше GIST-индекса;
· время поиска - GIN-индекс в 3 раза
быстрее, чем GIST-индекс;
· обновление индекса - GIN-индекс
обновляется в 10 раз медленнее.
3. Поисковые
системы
3.1 Понятие
поисковой системы
Ранее неоднократно упоминалось понятие поисковой системы,
однако не было сказано, что эта сама поисковая система из себя представляет.
Поисковая система - программно-аппаратный
комплекс с веб-интерфейсом, предоставляющий возможность поиска информации в
интернете. Под поисковой системой обычно подразумевается сайт, на котором
размещён интерфейс (фронт-энд) системы. Программной частью поисковой системы
является поисковая машина (поисковый движок) - комплекс программ,
обеспечивающий функциональность поисковой системы и обычно являющийся
коммерческой тайной компании-разработчика поисковой системы.
Поисковая машина (поисковый движок) -
комплекс программ, предназначенный для поиска информации. Обычно
является частью поисковой системы. [9]
Основными критериями качества работы поисковой машины
являются релевантность (степень соответствия запроса и найденного, т.е.
уместность результата), полнота индекса, учёт морфологии языка.
Поисковый движок выполняет следующие функции:
· Поиск ссылок на страницы и другие
документы сайтов;
· Извлечение из документов информации,
важной для поиска, преобразование этой информации в формат, удобный для
поисковой машины и сохранение этой информации в базу данных поисковой машины
(индексация данных);
· Поиск по базе данных проиндексированных
документов;
· Ранжирование (сортировка) документов в
соответствии с их релевантностью поисковым запросам;
· Кластеризация документов.
Чаще всего (текстовый) поисковый движок состоит из следующих
компонентов:
· Spider (англ. паук) он же робот -
программа очень похожая на браузер, но разница в том, что она скачивает HTML
тексты и не работает с графической частью;
· Crawler (англ. обходчик) - программа
обрабатывает найденные ссылки и как поводырь ведет паука по ссылкам;
· Indexer (англ. индексатор) - программа
занимается анализом документов;
· Database (англ. база данных) - база данных
всех найденных и обработанных документов;
· Search engine, results engine (англ.
система обработки результатов) - именно данная программа решает какая страница
соответствует введенному запросу, в каком порядке должны быть отсортированы
html страницы. Все расчеты происходят исходя из внутреннего алгоритма, с
которым и имеет дело оптимизатор;
· Web server (англ. веб-сервер) - сервер,
предназначенный для взаимодействия между пользователем и поисковой системой.
[10]
Пользователь, осуществляя поиск необходимой информации,
отправляет поисковый запрос в поисковую систему.
Поисковый запрос - исходная информация для
осуществления поиска с помощью поисковой системы. Формат поискового запроса
зависит как от устройства поисковой системы, так и от типа информации для
поиска.
Чаще всего поисковый запрос задаётся в виде набора слов или
фразы, иногда - используя расширенные возможности языка запросов поисковой
системы. Но бывают и совсем иные виды запросов. В некоторых поисковых системах
запросом является изображение, а результатом поиска - страницы в интернете, на которых
это изображение встречается.
.2
Особенности работы поискового движка
В целом, принцип работы поисковой системы не является тайной за
семью печатями. Выглядит он примерно так: поисковые роботы, блуждая по гиперпространству,
индексируют информацию, размещённую в виде html-документов и, собирают её в
базы данных, располагая в определённом порядке. При вводе запроса в строке
поисковой системы автоматически формируется обращение к необходимой базе данных
(поисковый запрос). Система, на основании этого поискового запроса, выдаёт
наиболее релевантные ответы, ранжируя сайты в определённом порядке, т.е.
присваивая им позиции в поисковой выдаче в зависимости от их значимости.
Поисковые машины постоянно совершенствуют свои алгоритмы поиска.
Для более релевантной выдачи поисковики учитывают поведенческие факторы
пользователей, своего рода искусственный интеллект, который построен на более
сложных вычислительных методах информационного поиска. И сейчас уже сложно
представить, что изначально поисковые системы использовались лишь для
управления информацией в научной литературе и осуществляли довольно примитивный
поиск по ключевым словам.
Алгоритмы поисковых машин - это (зачастую) коммерческая, а поэтому
закрытая информация. То, что именно учитывают поисковые системы при
ранжировании сайтов, знают лишь разработчики этих систем. Каждая поисковая
система использует свои алгоритмы для поиска, которые время от времени
обновляются с целью осуществления более качественной, релевантной выдачи. [11]
3.3
Использование индексов в поисковых системах
Поисковый индекс - структура данных,
которая содержит информацию о документах и используется в поисковых системах.
Индексирование (или индексация), совершаемое поисковой
машиной, - процесс сбора, сортировки и хранения данных с целью обеспечить
быстрый и точный поиск информации. Создание индекса включает междисциплинарные
понятия из лингвистики, когнитивной психологии, математики, информатики и
физики. Веб-индексированием называют процесс индексирования в контексте
поисковых машин, разработанных, чтобы искать веб-страницы в Интернете.
Одной из основных задач при проектировании поисковых систем
является управление последовательными вычислительными процессами. Существует
ситуации, в которых возможно создание состояния гонки и когерентных отказов.
Например, новый документ добавлен к корпусу, и индекс должен быть обновлен, но
в то же время индекс должен продолжать отвечать на поисковые запросы. Это
коллизия между двумя конкурирующими задачами. Считается, что авторы являются
производителями информации, а поисковый робот - потребителем этой информации,
захватывая текст и сохраняя его в кэше (или корпусе). Прямой индекс является
потребителем информации, произведенной корпусом, а инвертированный индекс - потребителем
информации, произведенной прямым индексом. Это обычно упоминается как модель
производителя-потребителя. Индексатор является производителем доступной для
поиска информации, а пользователи, которые ее ищут, - потребителями. Проблема
усиливается при распределенном хранении и распределенной обработке. Чтобы
масштабировать большие объемы индексированной информации, поисковая система
может основываться на архитектуре распределенных вычислений, при этом поисковая
система состоит из нескольких машин, работающих согласованно. Это увеличивает
вероятность нелогичности и делает сложнее поддержку полностью синхронизируемой,
распределенной, параллельной архитектуры
Популярные поисковые машины сосредотачиваются на
полнотекстовой индексации документов, написанных на естественных языках.
Мультимедийные документы, такие как видео и аудио и графика также могут
участвовать в поиске.
Метапоисковые машины используют индексы других поисковых
сервисов и не хранят локальный индекс, в то время как поисковые машины,
основанные на кешированных страницах, долго хранят как индекс, так и текстовые
корпусы. В отличие от полнотекстовых индексов, частично-текстовые сервисы
ограничивают глубину индексации, чтобы уменьшить размер индекса. Большие
сервисы, как правило, выполняют индексацию в заданном временно́м интервале из-за необходимого времени и затрат на обработку, в то
время как поисковые машины, основанные на агентах, строят индекс в масштабе
реального времени.
Архитектура поисковой системы различается по способам
индексирования и по методам хранения индексов, удовлетворяя факторы. Индексы
бывают следующих типов:
· Прямой индекс. Прямой индекс хранит
список слов для каждого документа.
Пример прямого индекса
· Инвертированный индекс. Хранилище списка
вхождений каждого критерия поиска, обычно в форме хеш-таблиц или бинарного
дерева.
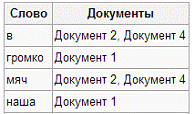
Пример инвертированного индекса
· Индекс цитирования. Хранилище цитат или
гиперссылок между документами для поддержки анализа цитирования, предмет
библиометрии.
· N-грамма. Хранилище последовательностей длин
данных для поддержки других типов поиска или анализа документов.
· Матрица термов документа. Используется в
латентно-семантическом анализе (ЛСА), хранит вхождения слов в документах в
двумерной разреженной матрице.
Инвертированный индекс заполняется путем слияния или
восстановления. Архитектура может быть спроектирована так, чтобы поддерживать
инкрементную индексацию, где слияние определяет документ или документы, которые
будут добавлены или обновлены, а затем анализирует каждый документ в слова. Для
технической точности, слияние объединяет недавно индексированные документы,
обычно находящиеся в виртуальной памяти, с индексным кэшем, который находится
на одном или нескольких жестких дисках компьютера.
После синтаксического анализа индексатор добавляет указанный
документ в список документов для соответствующих слов. В более крупной
поисковой системе процесс нахождения каждого слова для инвертированного индекса
может быть слишком трудоемким, поэтому его как правило разделяют на две части:
· разработка прямого индекса,
· сортировка прямого индекса в
инвертированный индекс.
Инвертированный индекс называется так из-за того, что он
является инверсией прямого индекса.
Для получения данных для индексов используется синтаксический
анализ документов. Синтаксический анализ (или парсинг) документа предполагает
разбор документа на компоненты (слова) для вставки в прямой и инвертированный
индексы. Найденные слова называют токенами (анг. tokens), и в контексте
индексации поисковых систем и обработки естественного языка парсинг часто
называют токенизацией (то есть разбиением на токены). Синтаксический анализ
иногда называют частеречной разметкой (анг. tagging), морфологическим анализом,
контент-анализом, текстовым анализом, анализом текста, генерацией согласования,
сегментацией речи, лексическим анализом. Термины "индексация",
"парсинг" и "токенизация" взаимозаменяемы в корпоративном
сленге.
Обработка естественного языка является предметом постоянных исследований
и технологических улучшений. Токенизация имеет проблемы с извлечением
необходимой информации из документов для индексации, чтобы поддерживать
качественный поиск. Токенизация для индексации включает в себя несколько
технологий, реализация которых может является коммерческой тайной.
3.4
Особенности поиска текстовой информации
Так или иначе, поиск информации сводится к поиску
необходимого в базе проиндексированных документов (чаще всего имеются в виду HTML документы).
Рассмотрим алгоритмы поисковых систем как способы поиска
информации в собранной поисковиками базе html-документов, такие как прямой
поиск и алгоритм обратных индексов.
Метод простого перебора всех html-страниц содержащихся в
базах данных поисковых систем называется алгоритмом прямого поиска, но даже
притом, что этот метод позволяет, точно найти нужную информацию, не пропустив
ничего важного, он совершенно не подходит для работы с большими объемами данных
из-за длительности обработки. И поэтому более результативным методом поиска, является
алгоритм обратных индексов, на котором основан полнотекстовый поиск. Именно
этот алгоритм используется всеми крупными поисковыми системами в мире. Прямые
индексы, содержащие оригинальный текст документов, поисковики тоже сохраняют,
но только для составления сниппетов.
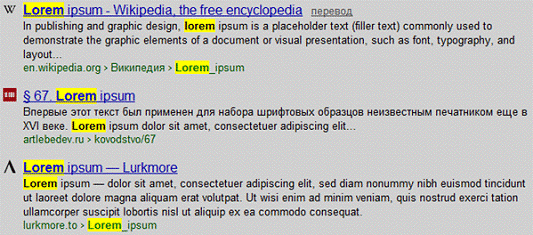
При использовании алгоритма обратных индексов, поисковые
системы преобразовывают html-документы в текстовые файлы, которые содержат
полный список имеющихся в документе слов. Эти слова располагаются в алфавитном
порядке, а рядом с ними указаны координаты мест, где они встречаются. Кроме
этого для каждого слова приводятся еще некоторые параметры (которые являются
секретной информацией), определяющие его значение в документе. На примере это
выглядит как список слов используемых в книге, с указанием номеров страниц, где
эти слова встречаются. При вводе запроса поисковые системы выдают информацию не
сразу из сети, а из собственных баз данных на основе обратных индексов. [12]
Так же в последнее время поисковые системы осваивают
искусственный интеллект, направленный на развитие методов построения алгоритмов
на основе машинного обучения, которые тесно связаны с извлечением информации и
интеллектуальным анализом данных. В 2009 году Яндекс внедрил новый метод машинного
обучения Матрикснет, который учитывает очень много факторов ранжирования и при
этом не увеличивает количество оценок асессоров. [13]
При вводе одного и того же поискового запроса в разных
поисковых системах результаты выдачи будут отличаться, потому что каждая
поисковая система использует свои алгоритмы ранжирования.
Некоторые поисковые системы, занимающиеся поиском именно
текстовой информации строятся на основе графовых баз данных, то есть
структурами для хранения индексов являются графы (или чаще гиперграфы). Это
обосновано тем, что такие структуры намного нагляднее отражают все возможные
связи, а определения компонуются в области, что позволяет вести поиск не только
по точным соответствиям, но и по смежным определениям.
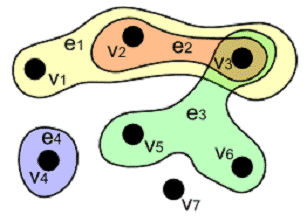
Пример гиперграфа
3.5
Особенности поиска графической информации
Современные поисковые системы способны производить поиск
также и графической информации. В отличие от текстовой информации, поиск
графических документов затруднен хотя бы тем, что графические документы можно
преобразовывать в различные форматы и изменять их размеры, что делает
затруднительным их прямой и индексный поиск ввиду различия в низкоуровневой
организации.
Так например, любое изображение хранящееся без какого-либо
сжатия возможно преобразовать в сжатое, тем самым изменив место, занимаемое
документом на жестком диске и, возможно, удалив часть незначительной информации
(при сжатии алгоритмами, предусматривающими потери). С точки зрения
"анатомии" эти графические файлы хоть и не имеют (а если и имеют то
незначительные) визуальных отличий, но их структура будет кардинально
отличаться.
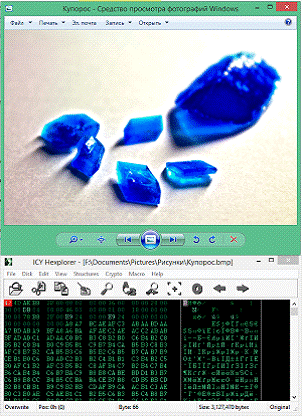
Визуальное и внутренне сравнение графических файлов
в форматах jpeg (слева) и bmp (справа)
Дело обстоит иначе, в случае, когда графические файлы имеют
некоторую дополнительную информацию (метаданные или EXIF). Такой информацией
может являться:
· Дата и время создания изображения;
· Имя автора;
· Параметры съемки и наименование цифровой
аппаратуры (программы) при помощи которой было получено изображение;
· Координаты места, где было получено
изображение (геометка);
· Иная информация.
Также допускается внесение дополнительной информации
непосредственно на веб-страницах без внесения оной непосредственно в
графический документ (контекстуальная информация).
Такую информацию довольно легко можно получить из
графического документа и занести её в базу данных и тем самым совершать поиск
изображения аналогично поиску текстовой информации.
Вышеуказанный способ поиска называется прямым, то есть мы
ищем непосредственное изображение по ключевым признакам. Существует также т. н.
реверсивный поиск изображений, который заключается как в поиске подобных
изображений, так и в поиске метаданных об изображении.
На данный момент существует довольно много сервисов,
обеспечивающих такую возможность. В общем случае принцип таких систем не
отличается от принципа работы тестовых поисковых систем. Все различие
заключается в алгоритмах индексации и поиска, которые, опять же, чаще всего
являются закрытыми.
В общем случае не трудно представить, каким образом
производится реверсивный поиск изображений. Как и в случае с текстовыми
поисковыми системами, поисковые роботы исследуют просторы интернета с целью
нахождения различных изображений. Также, для ускорения поиска происходит
индексация найденных изображений, однако данными для индексации являются уже не
слова (то есть определения), а признаки, применимые исключительно к графическим
документам. Такими признаками могут быть: цветовая гамма изображения, параметры
анализа цветового контраста и пр. То есть формируется скелет изображения или,
лучше сказать, его оттиск.

Пример извлечения признаков
Далее пользователь загружает необходимое ему изображение, тем
самым формируя поисковый запрос. Поисковый движок по тому же принципу, по
которому производилось извлечение признаков у изображений подлежащих
индексации, получает признаки загруженного пользователем изображения, после
чего происходит поиск вариантов аналогично поиску текстовой информации.
Такой способ поиска также иногда называют компьютерным
зрением.
Также иногда поисковая система позволяет комбинировать прямой
и реверсивный способы поиска для более точного результата.

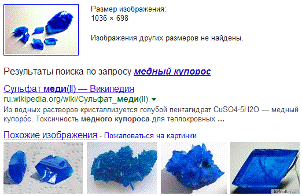
Примеры результатов поиска: слева - реверсивный,
справа комбинированный
3.6
Особенности поиска аудио информации
Каждый из нас бывал в такой ситуации, когда в голове вертится
какая-то мелодия, но название никак не вспоминается. Или композиция была
услышана по радио или просто на улице, а кто поет и как называется - не
известно. В таких случаях очень кстати приходятся поисковые системы, способные
производить поиск аудио информации.
Аналогично поиску графической информации, существует
несколько техник в опознании песни, применение каждой из них зависит от того,
что, собственно, знает человек об искомой композиции.
У каждого аудиофайла есть два главных идентификатора - название
и исполнитель.
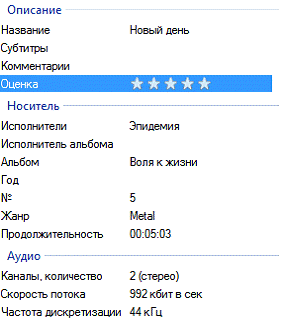
Пример метаданных аудиофайла
Другое дело, что с комбинацией "название и
исполнитель" далеко не всегда все ясно. Даже вполне официальные источники
порой путаются в правильном написании названий музыкальных групп или их песен.
Чего уж говорить об обычных людях.
Простейший случай - человек помнит название песни, но не
помнит исполнителя. Или наоборот. В этом случае поисковая система должна иметь
доступ к базам данных по исполнителям и их творчеству. Производится
обыкновенный тестовый поисковый запрос. Пользователь посмотрит предложенные
варианты, послушает их фрагменты в потоковом формате и выберет нужное.

Пример результата поиска по названию композиции
Для создания подобной базы точкой опоры пока даже в Интернете
остаются музыкальные CD. Ведь подавляющее число аудиозаписей по-прежнему
выходит в первую очередь в этом формате. Все выпущенные диски каталогизируются,
заносятся в классификаторы с соответствующими индексами.
С технической точки зрения, у поисковых систем, работающих с
аудио информацией структура индекса немного различается и чаще всего
представляется в виде N-грамм. С семантической точки зрения, это может быть
последовательность звуков, слогов, слов или букв. На практике чаще встречается
N-грамма как ряд слов. Целью построения N-граммных моделей является определение
вероятности употребления заданной фразы. Эту вероятность можно задать формально
как вероятность возникновения последовательности слов в неком корпусе (наборе
текстов). К примеру, вероятность фразы "счастье есть удовольствие без
раскаяния" можно вычислить как произведение вероятностей каждого из слов
этой фразы:
= P (счастье) * P (есть|счастье) * P (удовольствие|счастье
есть) * P (без|счастье есть удовольствие) * P (раскаяния|счастье есть
удовольствие без)
Рассчитать вероятность P (счастье) дело нехитрое: нужно всего
лишь посчитать сколько раз это слово встретилось в тексте и поделить это
значение на общее число слов. Но рассчитать вероятность P (раскаяния|счастье
есть удовольствие без) уже не так просто. К счастью, мы можем упростить эту
задачу.
Примем, что вероятность слова в тексте зависит только от
предыдущего слова. Тогда наша формула для расчета фразы примет следующий вид:
= P (счастье) * P (есть|счастье) * P (удовольствие|есть) * P
(без|удовольствие) * P (раскаяния|без)
Уже проще. Рассчитать условную вероятность P (есть|счастье)
несложно. Для этого считаем количество пар 'счастье есть' и делим на количество
в тексте слова 'счастье'.
В результате, если мы посчитаем все пары слов в некотором
тексте, мы сможем вычислить вероятность произвольной фразы. Этот набор
рассчитанных вероятностей и будет биграммной моделью. [14]
Именно такая структура наиболее полно позволяет индексировать
как контекстуальные (текстовые) признаки аудиофайлов, так и исключительно
музыкальные признаки (будут рассмотрены позже).
Вернемся к базам данных. В Интернете уже довольно долго
существуют онлайн-базы музыкальных данных. В таких базах содержится справочная
информация о множестве исполнителей, альбомов, композиций. Их называют CDDB.
Большинство музыкальных сервисов и поисковых систем использует эти первичные
данные.
Если сравнивать песню с человеком, то информацию,
содержащуюся в базах CDDB, можно сравнить с паспортными данными. Название
композиции, альбом, в состав которого она входит, имя исполнителя или название
группы - это ее ФИО. Но нужен номер паспорта. Его роль играет уникальный
идентификатор CD, с тем отличием, что он относится не к одному треку, а к их группе.
Откуда берется этот идентификатор? Так как создатели стандарта
аудио-CD в свое время никак не могли планировать существования треков с CD вне
самого CD, то они не предусмотрели на диске никакой идентификационной информации.
Таким образом, компакт-диск по умолчанию - человек без паспорта. Его самого
надо опознать.
Если продолжить аналогию с человеком, то сделать это можно по его
приметам. Для CD это будет сочетание числа аудиофайлов и их продолжительности.
Вместе они дают достаточно уникальную картину. Так и работают CDDB - в их базах
хранятся уникальные идентификаторы CD, рассчитанные на основании данных о
числе, последовательности и продолжительности треков - "фоторобот"
диска. Программа-клиент на ПК пользователя создает такой "фоторобот"
для диска, подлежащего идентификации, соединяется через Интернет с базой и ищет
в ней совпадающий по приметам диск. Подобным образом могут опознаваться как
физические CD-диски, так и их сжатые в MP3 и другие форматы копии, главное,
чтобы сохранилась уникальная структура.
В идеале у музыки должны быть "устанавливающие личность
документы" или "особые приметы". Для композиций на носителе - CD
- это уникальные параметры диска, позволяющие восстановить все данные по базам
CDDB. Для оцифрованной музыки это метаданные.
В реальности же все не так просто. Что делать, если аудиофайл
лишен каких-либо примет? Таких ситуаций может быть немало: запись с радио,
безвестный файл, скачанный из интернета, запись с диктофона, оцифрованная
аналоговая запись.
В случае с человеком на помощь приходят отпечатки пальцев. Это
работает и для песен.
Акустические "отпечатки пальцев" - это выжимка из
цифрового аудиофайла, минимальный объем информации, по которой его можно
достоверно установить. Обычно это небольшой массив данных, до 10 КБ.
Принципиально, что "отпечатки", содержат чисто музыкальные
характеристики - ритм, окраску звучания, информацию о мелодии - и не зависят от
конкретного файла, из которого получены. Стоит также заметить, что способ получения
таких отпечатков может отличаться у различных поисковые систем, и часто
является закрытой информацией, хотя есть и представители с открытым кодом
(например, The Echo Nest Musical Fingerprint). [15]

Анализ звукового файла
Далее все делается очень похоже на технологии CDDB:
программа-клиент через интернет сверяет передаваемую ей композицию с базой
данных таких "отпечатков". Если обнаруживается совпадение, значит, файл
опознан.
В итоге мы можем алгоритмизировать процесс опознания музыки и
разбить его на степени сложности:
-ая степень - известно имя песни и/или автор, но неточно. Здесь
вполне может помочь система автокоррекции ошибок, поиск по базам CDDB по
названию - чтобы найти исполнителя или наоборот.
-ая - нет информации о песне, но есть аудиоматериал. Это запись с
радио, диктофона, оцифровка аналога. Здесь на помощь придет опознание по
акустическим отпечаткам пальцев. [16]
3.7 Обзор
популярных текстовых поисковых систем
Для обзора выберем некоторые популярные в Российской
Федерации системы текстовой информации:
· Google;
· Bing;
· Яндекс;
· DataparkSearch;
· Sphinx;
· Lucene.
Данный выбор обоснован как популярностью использования среди
пользователей Интернета, так и популярностью внедрения в порталы, в том числе и
в корпоративные.
Google (произносится как "Гугл", производное
от слова гугол - числа, равного 10100) - Крупнейшая в интернете
поисковая система, принадлежащая корпорации Google Inc.
Первая по популярности система [17] (79,65 %), обрабатывает
41 млрд 345 млн запросов в месяц (доля рынка 62,4 %), индексирует более 25 млрд
веб-страниц, может находить информацию на 195 языках.
Поисковый робот Google - Googlebot, является основным роботом, сканирующим содержание
страницы для поискового индекса. Также существует робот для сканирования
страниц, предназначенных для мобильных устройств (Googlebot-Mobile). Робот
соблюдает стандартные Интернет-приёмы для запросов, такие как использование
файлов robot. txt, Sitemap, мета-теги, noindex, nofollow . Поддерживает поиск в документах форматов PDF,
RTF, PostScript, Microsoft Word, Microsoft Excel, Microsoft PowerPoint и
других.
Существует возможность выполнения в интерфейсе сложных
запросов на внутреннем языке, что также позволяет использовать поисковую
систему как сканер уязвимостей. [18]
Также система позволяет встраивать поиск в собственных
сайтах, благодаря открытому API.
Bing
Популярность данной поисковой системы обуславливается в
первую очередь большим числом пользователей ОС Windows (не Windows Phone), в стандартном браузере
которой Bing является поисковым сервисом по умолчанию.
Основой для поисковой системы служит поисковый движок Kumo
(произносится "Кумо" - яп. паук или облако).
Возможности поисковой системы больше направлены на визуальное
оформление, такие как:
· ежедневно изменяющиеся темы оформления
стартовой страницы с информационными блоками;
· вывод уточняющих вариантов поисковых
запросов по отдельным категориям;
· видео с автоматически запускающимся
предварительным просмотром;
· дополнительные данные по каждому
результату поиска;
· встроенный сервис для поиска маршрутов
(другие специальные поисковые сервисы появятся в скором времени);
· функции, повышающие удобство в использовании
при поиске информации, изображений и видео.
Яндекс
Поисковая система "Яндекс" (также "Яндекс.
Поиск") является четвёртой среди поисковых систем мира по количеству
обработанных поисковых запросов (4,84 млрд, 2,8 % от мирового количества,
статистика за декабрь 2012 года). Причём, нужно отметить, "Яндекс"
является самым быстрорастущим поисковиком из первой пятёрки, с 28 % за 2012
год. Доля на рынке Рунета составляет 60,5 %.
Поиск Яндекса позволяет искать документы на русском,
татарском, украинском, белорусском, казахском, турецком, английском, немецком и
французском языках с учётом морфологии этих языков и близости слов в
предложении.
С 23 июня 2011 года поиск "Яндекса" установлен на
портале Rambler (произносится "рамблер").
Помимо веб-страниц в формате HTML, Яндекс индексирует
документы в форматах PDF (Adobe Acrobat), Rich Text Format (RTF), двоичных
форматах Word (. doc), Excel (. xls), PowerPoint (. ppt), RSS (блоги и форумы).
Поисковая система способна также индексировать текст внутри объектов Shockwave Flash (если текст не помещен
на само изображение), если эти элементы передаются отдельной страницей, имеющей
MIME-тип application/x-shockwave-flash, и файлы с расширением. swf. [19]
Отличительная особенность Яндекса - возможность точной
настройки поискового запроса. Стоит отметить, что язык менее гибкий, но более
простой в отличие от языка запросов Google.
Поисковый движок по аналогии с Google соблюдает стандартные
Интернет-приёмы для запросов, однако именно Яндекс впервые предложил
использование тега noindex.Engine (произносится "Дэйта-Парк-Сёрч Энжин") -
поисковая машина (не система) с открытым исходным текстом, написанная на языке
С. Распространяется по лицензии GNU GPL. Предназначена для организации поиска
на одном или многих веб-серверах.самостоятельно может индексировать текст,
HTML, а также многие другие данные, используя внешние парсеры.
Машина готова для индексирования мультиязычных сайтов:
поддерживается множество различных кодировок и языков, а также их
автоматическое определение; использует технологию согласования содержимого для
индексирования копий одной и той же страницы на разных языках; может искать без
учёта акцентов символов (диакритических знаков); а также разбивать на слова и
фразы китайского, корейского, тайского и японского языков. Возможно
использование синонимов, акронимов и всех морфологических форм слова для
расширения результатов поиска.
Использует собственную технологию ссылочного ранжирования,
основанную на нейронной сети. Эта технология называется Neo Popularity Rank
(произносится "Нио Попьюларити Ранк"). Результаты поиска могут
сортироваться по релевантности, популярности, дате последнего изменения и по
важности (произведению релевантности на популярность).
Для уточнения ранжирования сайтов может автоматически строить
рефераты индексируемых страниц, состоящие из трёх наиболее важных предложений.
[20](от англ. SQL Phrase Index - индекс фраз (фразовый индекс) SQL) - система
полнотекстового поиска, разработанная Андреем Аксеновым и распространяемая по
лицензии GNU GPL. Отличительной особенностью является высокая скорость
индексации и поиска, а также интеграция с существующими СУБД (MySQL,
PostgreSQL) и API для распространённых языков веб-программирования (официально
поддерживаются PHP, Python, Java; существуют реализованные сообществом API для
Perl, Ruby,.net и C++).
По технологии SphinxSE осуществляется поиск на популярном
блоге Хабрахабр, проекте Викимапия, популярном книжном интернет-магазине
Буквоед, BitTorrent-трекере Пиратская бухта и других высоконагруженных
проектах. [21]
The Apache Lucene (произносится "Апач Люцен") - это
свободная библиотека (не система) для высокоскоростного полнотекстового поиска,
написанная на Java. Может быть использована для поиска в интернете и других областях
компьютерной лингвистики (аналитическая философия). Например, Lucene используется как
компонента в децентрализованной поисковой системе YaCy. [22]
Возможности:
· Масштабируемая и высокоскоростная
индексация
· свыше 95GB в час на современном
оборудовании;
· требуется малый объем оперативной памяти -
размер поджкачки всего 1MB;
· размер индекса примерно 20-30 % от размера
исходного текста.
· Мощный, точный и эффективный поисковый
алгоритм
· ранжированный поиск - лучшие результаты
показываются первыми;
· множество мощных типов запросов: запрос
фразы, шаблонные запросы, поиск интервалов и т.д.;
· поиск основанный на "полях"
(таких как заголовок, автор, текст);
· возможность сортировать по различным
полям;
· множественный индексный поиск с
возможностью объединения результатов;
· возможность одновременного поиска и
обновления индекса.
· Кроссплатформное решение
· исходный код полностью написан на Java;
· наличие портов на другие языки
программирования (С, С++, Perl и др.).
Таблица
|
Наименование
поисковой системы (движка)
|
Тип
|
Лицензия
|
Назначение
|
Типы индексируемых
документов
|
Тип индекса
|
API/ протоколы
|
Варианты поиска
|
Производительность
(предполагаемая)
|
|
Google
|
Поисковая
система
|
Проприентарная
|
Интернет поиск
|
Html,
xml, PDF, RTF, PostScript, doc (x), xls (x), ppt (x) и др.
|
Информация
закрыта
|
Открытый API, возможно встраивание в сайт
|
Собственный
мощный язык запросов
|
Индексирует
>45 млрд страниц, среднее время вывода 0.12 сек. /терм.
|
|
Bing
|
Поисковая
система
|
Проприентарная
|
Интернет поиск
|
Html,
xml, PDF, RTF, PostScript, doc (x), xls (x), ppt (x) и др.
|
Информация
закрыта
|
Закрытый API
|
Упрощенный язык
запросов
|
Индексирует
>18 млрд страниц, среднее время вывода 0.2 сек. /терм.
|
|
Яндекс. Поиск
|
Поисковая
система
|
Специальная, с
закрытым исходным кодом
|
Интернет поиск
|
Html,
xml, PDF, RTF, PostScript, doc (x), xls (x), ppt (x) и др.
|
Монолитный +
индекс цитирования + распределенный поиск
|
Собственный
язык запросов
|
Индексирует
>12 млрд страниц, среднее время вывода 0.11 сек. /терм.
|
|
DataparkSearch
|
Поисковая
машина
|
Свободное ПО с
открытым исходным кодом (GNU
GPL)
|
Поиск на одном
или нескольких веб-серверах
|
Html,
xml и др.
|
Монолитный GIST.
|
SQL
DB
|
Булевый поиск,
поиск по фразам, учёт близости слов
|
Точные данные
неизвестны
|
|
Sphinx
|
Поисковая
система
|
Свободное ПО с
открытым исходным кодом (GNU
GPL)
|
Поиск на одном
или нескольких веб-серверах
|
Только текст
или SQL DB
|
Монолитный +
дельта-индекс, возможность распределённого поиска
|
SQL DB, собственный XML-протокол,
встроенные API для РНР, Ruby, Python, Java, Perl
|
Полнотекстовый
поиск, булевый поиск, возможно использование синонимов, акронимов и всех
морфологических форм слова.
|
Среднее время
0.1 сек. при 4 ГиБ индекса.0.5 сек при 100 ГиБ. Есть примеры работ на базах
данных объемом несколько ТиБ.
|
|
Lucene
|
Библиотека для
организации поиска
|
Свободное ПО с
открытым исходным кодом (Apache License 2.0)
|
Построение
поисковых систем для интернета, в P2P сетях
|
Текст, возможна
индексация базы данных через JDBC
|
Инкрементный
индекс, но требующий оптимизации
|
Java API
|
Булевый поиск,
поиск по фразам, нечёткий поиск, учёт близости слов, поиск по маске
|
Известна лишь
скорость индексации: около 20 МиБ/минута
|
3.8 Обзор
популярных поисковых систем, предназначенных для поиска изображений
Для обзора поисковых систем для изображений были выбраны
следующие популярные сервисы:
· Tineye;
· Google картинки;
· Поиск Mail.ru;
· Яндекс. Картинки.
Tineye (произносится "Тин-Ай" - дословно
оловянный глаз) - Поиск дубликатов фотографий. Ищет точно такие же фотографии
или фотографии более высокого разрешения. Кроме того, TinEye может использоваться
тогда, когда нужно найти одного и того же человека на разных фотографиях.
Пользователь может загрузить свою фотографию в поисковик или же указать адрес
картинки, размещенной в интернете. После этого система произведет поиск похожих
и в поисковой выдаче представит список фотографий с указанием сайтов, на
которых фото размещено, и имен найденных графических файлов.
Google картинки
Google использует технологии компьютерного зрения,
чтобы сопоставить картинку с другими изображениями в индексе Google Картинок и других
коллекциях. Поисковая система подбирает похожие графические файлы, а также
наиболее точное текстовое описание запроса. Поэтому в результатах поиска есть
изображения, похожие на картинку запроса или соответствующие ее описанию.
Страница результатов Поиска по картинке отличается от страницы результатов
обычного поиска и поиска изображений. Главное отличие в том, что здесь показаны
не только картинки, но и веб-страницы, имеющие отношение к запросу. Иными
словами, результаты подбираются на основе поискового запроса и связанной с ним
информации.
Поиск Mail.ru
Аналогично обычному поиску, Mail.ru позволяет находить
изображения согласно введенному запросу. Поддерживается только прямой способ
поиска, то есть поиск изображения согласно текстовому запросу.
Яндекс. Картинки
На начальном этапе своего существования поиск изображений
основывался исключительно на извлечении и анализе метаданных, связанных
непосредственно с изображениями: атрибутов alt, заголовков страниц и текстов
ссылок на изображения. Постепенно для поиска изображений стали учитывать также
и текст, расположенный на той же веб-странице, что и картинка. Параллельно с
поиском изображений по метаданным развивалось, и продолжает успешно
развиваться, другое направление - поиск изображений по их содержанию. Этот вид
поиска основывается на технологии компьютерного зрения. Она призвана обучить
машину смотреть на изображение глазами человека, понимать и анализировать его
содержимое: цвета и формы объектов, их текстуру, взаимное расположение. Набор
метаданных, характеризующих изображение, ограничен, а компьютерное зрение
позволяет значительно расширить количество атрибутов, которые учитываются при
поиске картинок и ранжировании результатов.
Таблица
|
Наименование
поисковой системы
|
Возможность
производить прямой поиск
|
Возможность
производить инверсный поиск
|
Поиск
изображения по цветовой гамме
|
Тип поиска
|
Ограничения
|
Поддержка
поисковых ограничений
|
Использование API, количество индексированных изображений
|
|
Tineye
|
отсутствует
|
Изображение, URL
|
присутствует
|
Поиск по
метаданным, полное или частичное совпадение, коррекция размера
|
Ограничение
количества поисковых запросов (для бесплатного сервиса), форматы файлов: JPEG, PNG, GIF объемом до 20 МиБ
|
Только robot. txt
|
Использование API разрешено только при использовании
оплаченного сервиса. Индексировано более 4 млрд. изображений
|
|
Google картинки
|
присутствует
|
Изображение, URL
|
отсутствует
|
Поиск по
метаданным, полное и частичное совпадение, поиск подобного изображения (по
цветовой гамме, форме и т.п.), коррекция размера
|
Форматы файлов:
JPEG, PNG, BMP, GIF размер не более 8000x6000 пикс. объем файла ограничивается
объемом, разрешенным для разовой передачи по HTTP
|
robot.
txt, nofollow
|
Открытый API. Количество индексированных изображений
зависит от индексированных веб-страниц и количества загруженных изображений
на сервисы Google
|
|
Поиск Mail.ru
|
присутствует
|
отсутствует
|
отсутствует
|
-
|
robot. txt
|
Зависит от
количества изображений, загруженных на сервисы Mail.ru
|
|
Яндекс.
Картинки
|
присутствует
|
Изображение, URL
|
присутствует
|
Поиск по
метаданным, полное и частичное совпадение, коррекция размера
|
Форматы файлов:
JPEG, PNG, BMP, GIF объемом до 20 МиБ
|
robot. txt, nofollow, noindex
|
Открытый API. Количество индексированных изображений
зависит от индексированных веб-страниц и количества загруженных изображений
на сервисы Yandex
|
3.9 Обзор
популярных поисковых систем, предназначенных для поиска аудио композиций
Поисковые системы, предназначенные для идентификации
аудиокомпозиций в том или ином случае обращаются к базам данных CD. Существуют сервисы
работающие как по принципу веб-сервисов, так и с использованием специфического
ПО. Рассмотрим наиболее популярные:
· TrackID (MusicID);
· Tunatic;
· Shazam;
· Last. fm;
· Яндекс. Музыка;
· ThankYou.
TrackID (от англ. Track Identification - идентификация дорожки
(звуковой)) - сервис, созданный в начале 2006 года калифорнийской компанией Gracenote (произносится
"Грейсноут") для телефонов серии Walkman (англ. Плеер) компании Sony Ericsson (кроме ранних моделей
серии - W200,
W300, W550, W700 и W800), позволяющий
узнавать исполнителя и название музыкального произведения по его короткому
отрывку, записанному на микрофон телефона. На данный момент приложение доступно
для аппаратов на базе ОС Android (произносится "Андроид"). Для
распознавания музыкального произведения пользователь запускает программу - она
записывает отрывок (10-12 секунд) музыкального произведения с помощью
встроенного микрофона телефона в формате AMR и отсылает на Web-сервис Sony
Ericsson, где он сравнивается с образцами, существующими в базе данных, и через
несколько секунд, в случае успеха, на экране высвечивается информация о песне.
Tunatic
Tunatic (произносится "Тьюнатик") - Бесплатное
программное обеспечение для онлайн-идентификации музыки, разработанное Sylvain Demongeot для операционных систем Windows и Mac OS. Принцип распознавания
песни таков: снимается акустический отпечаток, со сравнительно небольшого
участка аудио материала, через любой канал аудиокарты (канал можно выбрать в
настройках микшера, будь то микрофон, или линейный вход, или даже общий) и
отправляет данные в базу данных Tunatic, где происходит поиск совпадений с
аудиоотпечатками уже опознанных композиций. Если совпадение будет найдено, Tunatic вернёт название песни и
имя автора вместе с ссылкой для получения более подробной информации. По ссылке
можно перейти на страницу веб-сайта, где также уже будут указан исполнитель и
название композиции, а также приглашение скачать её в iTunes или рингтон, поискать
упоминание композиции в Google.
Shazam
Shazam (произносится "Шазам") - это
коммерческий кроссплатформенный проект (ранее был доступен только для мобильных
устройств, в данный момент существует приложение для Windows 8), осуществляющий поиск
информации о песнях. Пользователь Shazam использует микрофон своего мобильного
телефона для записи фрагмента музыки, которая играет где-либо. Затем фрагмент
сравнивается с центральной базой данных и при успешном сопоставлении выдается
информация о треке. Shazam может идентифицировать записанные звуки, которые передаются из
любых источников, таких, как радио - или телетрансляция, музыка в кинофильме
или клубе, при условии, что уровень фонового шума не слишком высок. Shazam хранит каталог аудио,
опознанных при помощи программы, давая прямые ссылки на данные треки на YouTube, если таковые там
имеются.. fm
Last. fm - интернет-портал музыкальной тематики, основным
сервисом которого является сбор информации о музыке, которую слушает
пользователь, и её каталогизация в индивидуальных и общих чартах. Регистрация
бесплатна. Функция интернет-радио бесплатна только для граждан США, Германии,
Великобритании, от остальных требуется подписка за $3, €3 или £3 в месяц.
Компания с такими амбициями на рынке музыкальных услуг, как Last. fm, не может зависеть от сторонних
провайдеров данных, в том числе акустических отпечатков пальцев. Поэтому Last. fm разрабатывает свою
технологию, используя внушительное комьюнити как источник данных и рабочую
силу. Пока технология находится в бета-версии, но компания заявляет, что ее
база уже содержит свыше 10 миллионов отпечатков.
Яндекс. Музыка
"Яндекс. Музыка" - сервис компании Яндекс,
позволяющий искать и легально бесплатно прослушивать музыкальные композиции,
альбомы и подборки музыкальных треков. Доступен посетителям из России, Украины,
Белоруссии и Казахстана. Сервис "Яндекс. Музыка" даёт возможность
пользователям:
· прослушивать лицензионную музыку с
использованием Adobe Flash-плеера или HTML 5 (для мобильных устройств);
· искать музыку с помощью простого поиска
или хорошо структурированного каталога;
· вставлять треки в блоги и страницы
социальных сетей;
· составлять свои плей-листы;
· получать музыкальные рекомендации;
· отправлять статистику в Last. fm
("скробблинг");
· импортировать аудиозаписи из своих
коллекций в соцсети "ВКонтакте".
ThankYou
ThankYou (англ. Спасибо) - интернет-портал,
распространяющий творческий контент по схеме "pay what you want" ("плати,
сколько хочешь"). В настоящее время на сайте работают музыкальный и
литературный разделы. Музыку и книги, размещенные на сайте, можно свободно
скачать, а затем, при желании, заплатить их правообладателям, нажав кнопку
"Спасибо". Создатели проекта считают самой справедливой моделью
оплаты творческого труда схему "pay what you want" ("плати,
сколько хочешь"), когда пользователи сначала свободно скачивают интересный
им контент, а затем платят (или не платят) за него по желанию.
Таблица
|
Наименование
поисковой системы
|
Используемая CDDB
|
Платформа
|
Тип поискового
запроса
|
Способ
получения результатов
|
|
TrackID
|
Gracenote
|
Java (SEMC), Android
|
Звук в формате AMR
|
Переадресация в
интернет-магазин
|
|
Tunatic
|
Собственная
(Sylvain Demongeot)
|
Windows,
Mac OS
|
Звуковой
отрывок (формат неизвестен)
|
Переадресация
на страницу веб-сайта, где будут указан исполнитель и название композиции, а
также приглашение скачать её в iTunes или
поискать упоминание композиции в Google
|
|
Shazam
|
Собственная
|
Windows
Phone, iOS, BlackBerry, Symbian, Android, Windows 8
|
Fingerprint+AMR
|
Представление
метаданных
|
|
Last. fm
Fingerprinter
|
Собственная
|
Web-based,
Windows, Mac OS, Linux
|
Fingerprint
или метаданные
|
Представление
упоминаний о композиции на сайте Last. fm и приглашение посетить веб-страницы с
упоминанием
|
|
Яндекс. Музыка
|
Собственная,
возможен импорт из других источников
|
Web-based, Android, iOS
|
Метаданные
|
Страница с
возможными результатами и возможностью прослушать результаты.
|
|
ThankYou
|
Собственная,
импорт из официальных источников
|
Web-based
|
Страница с
возможными результатами и возможностью прослушать и/или скачать результаты.
|
3.10 Обзор
специализированных поисковых систем
Помимо систем, занимающихся поиском полнотекстовой
информации, существуют системы, позволяющие находить текстовые документы
(электронные публикации с имеющимся текстовым слоем), в которых данная
информация присутствует. Отличие таких систем от систем обычного текстового
поиска в том, что движок старается найти наиболее точное соответствие всем
имеющимся термам в запросе с учетом их положения и, как правило, поисковые
запрос в таких системах гораздо объемнее. Многие поисковые системы,
рассмотренные ранее (Yandex, Google, Bing) позволяют находить упоминание информации в
ограниченном наборе типов публикаций, поэтому они рассматриваться не будут.
Рассмотрим следующие системы:
· Антиплагиат;
· Turtle (проект Дмитрия Крюкова);
· БД ВИНИТИ РАН;
· elibrary.
Антиплагиат
Антиплагиат (Антиплагиат. Ру) - российский интернет-проект,
программно-аппаратный комплекс для проверки текстовых документов на наличие
заимствований из открытых источников в сети Интернет и других источников.
Проект доступен как для рядовых пользователей, так и (в специальной версии) для
высших учебных заведений. С технической точки зрения система сочетает в себе
обыкновенную поисковую систему и систему полнотекстового поиска в электронных
публикациях. Существует несколько типов поиска согласно используемой лицензии.
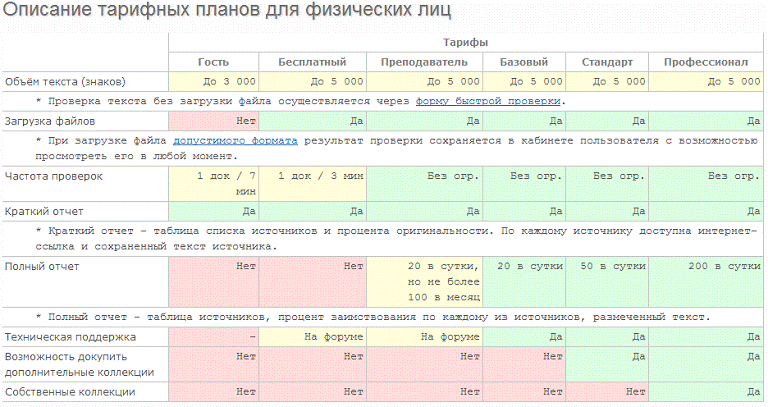
Существует возможность развертывания локальной версии системы
вне зависимости от доступа к Интернету.
Тем не менее, не смотря на популярность данной системы, её
работа вызывает много критики, как со стороны преподавателей, так и со стороны
учеников/студентов. Так неоднократно были замечены случаи, при которых данная
система кэшировала поисковый запрос и оставляла его для собственных целей,
после чего они (запросы) появлялись в интернете (на сайтах, на которых не
ведется поиск Антиплагиат-ом). Также до сих пор ведутся споры о правомерности
системы проверки, на основе которой построена система. Антиплагиат не имеет
никакого отношения ни к Минобрнауки России, ни к Высшей аттестационной
комиссии. Система разработана в инициативном порядке; какой-либо аттестации или
аккредитации при министерстве, либо ВАК данная система не проходила.
Turtle или Черепаха (turtle.ru) - проект Крюкова
Дмитрия, автора поисковой системы Rambler. Отличительной особенностью Turtle является
"Поиск по фрагменту", т.е. поиск с помощью технологии сравнения
похожих документов с заданным фрагментом текста, хотя также доступен
стандартный алгоритм поиска. Главная цель этой функции - обеспечить возможность
быстрого поиска "плагиата", т.е. материалов, которые
несанкционированно копируются с одного сайта на другой. Данная система имеет
своего поискового робота, который автоматически добавляет сайты в собственную
базу данных.
Поисковая система поддерживает стандартные приемы поиска,
однако в ней отсутствует собственный язык запросов. Также поддерживается поиск
по синонимам и поиск по всем формам слова.
По причине смерти Дмитрия Крюкова (14 апреля 2009) проект
временно приостановлен.
БД ВИНИТИ РАН
ВИНИТИ (Всероссийский Институт Научной и Технической
Информации) - крупнейший информационный центр России, основан в 1952г. с целью
улучшения информационного обеспечения ученых и специалистов. База данных (БД)
ВИНИТИ РАН - Федеральная база отечественных и зарубежных публикаций по
естественным, точным и техническим наукам, генерируется с 1981 г., обновляется
ежемесячно, пополнение составляет около 1 млн. документов в год. БД ВИНИТИ РАН
включает 28 тематических фрагментов, состоящих из 217 разделов. Для проведения
поиска одновременно по нескольким тематическим фрагментам, а также с целью
навигации по БД ВИНИТИ генерируется единая Политематическая БД. Также
существует возможность проведения специализированного on-line поиска: диалоговый поиск
и поиск специалистами ВИНИТИ.(от англ. Electronic Library - электронная
библиотека) − российский информационный портал в области науки, медицины,
технологии и образования. На платформе аккумулируются полные тексты и рефераты
научных статей и публикаций. По состоянию на январь 2012 в базе данных
eLIBRARY.ru насчитывается более 15 млн статей. Ресурс создан в 1998 году
компанией "Научная электронная библиотека". Старт проекта был связан
с необходимостью разработки единой web-платформы с интегрированным поисковым
аппаратом для обеспечения доступа российского научного сообщества к электронным
версиям ведущих мировых научных изданий, подписку на которые осуществлял
Российский фонд фундаментальных исследований. Существует возможность публикации
и полнотекстового и контекстуального поиска загруженной информации. Возможен
поиск с учетом морфологии и поиск похожего текста.
Проект аналогичен Google Scholar.
Список
использованной литературы
1. Когаловский
М.Р. Энциклопедия технологий баз данных. - М.: Финансы и статистика, 2002. -
800 с. - ISBN 5-279-02276-4.
2. Материалы
на сайте Центра информационных технологий CITForum -
http://citforum.ru/database/articles/ordbms10.
3. Renzo
Angles, Claudio Gutierrez Survey of Graph Database Models. - ACM Computing
Surveys, Vol.40, No.1, Article 1, 2008.
4. Материалы
на сайте Ibuildings - http://ibuildings.
nl/blog/2009/09/07/graphs-in-the-database-sql-meets-social-networks.
. Материалы
на сайте High Scalability http://highscalability.com/paper-graph-databases-and-future-large-scale-knowledge-management.
. Материалы
на сайте Мариупольского строительного колледжа
http://msk.edu.ua/ivk/Informatika/kolomna-school7-ict/st40401. htm.
7. Josefsson
S. The Base16, Base32, and Base64 Data Encodings. - The Internet Society, 2006
8. Материалы
на сайте Компьютерной лингвистики http://www.secreti. info/kl15.html.
. Захаров
Н.В. Информационно-поисковые системы в филологических науках [электронный
ресурс] http://www.zpu-journal.ru/e-zpu/2008/5/Zakharov_ISS/.
. Поисковая
система, релевантность, компоненты, алгоритмы поисковых систем [электронный
ресурс] http://www.web-analyst.ru/search_system.html.
. Поисковые
системы [электронный ресурс] - http://www.smartincom.ru/search-engines/.
. Материалы
на сайте Google https: // www.google.ru/insidesearch/howsearchworks/crawling-indexing.html.
. Материалы
на сайте Яндекс http://company. yandex.ru/technologies/matrixnet/.
14. Proceedings
of the 7th Annual Conference ZNALOSTI 2008, Bratislava, стр.54-65, Словакия, фев. 2008. - ISBN 978-80-227-2827-0.
15. EchoPrint
- открытая система распознавания музыки [электронный ресурс] http://habrahabr.ru/post/122969/.
. Музыкальные
сервисы в Интернете: опознание музыки [электронный ресурс]
http://www.mobile-review.com/mp3/articles/music-recognition. shtml.
17. Top
15 Most Popular Search Engines December 2013 [электронный ресурс]
http://www.ebizmba.com/articles/search-engines.
18. Взлом
при помощи Google на SecurityLab [электронный ресурс]
http://www.securitylab.ru/contest/212086. php.
. Поисковая
система Яндекс [электронный ресурс] http://dataword. info/poiskovaya-sistema-yandeks.
php.
. Материалы
на официальном сайте проекта DataparkSearch http://www.dataparksearch.org/.
. Материалы
на официальном сайте проекта Sphinx http://sphinxsearch.com/info/powered/.
. Материала
на официальном сайте проекта Lucene
http://lucene. apache.org/.