Криптографические методы защиты информации
Работа с бинарными данными и реестром Windows на
платформе .NET.
Описание библиотеки классов AcedUtils.NET.
Андрей Дрязгов
В
статье описывается набор классов, которые могут использоваться для быстрой
работы с бинарными данными, в том числе, для записи данных различного типа в
поток, чтения из потока, сжатия, шифрования, контроля целостности данных, а
также для облегчения работы с реестром Windows из приложений на платформе .NET.
Исходный код библиотеки AcedUtils.NET и демонстрационное приложение прилагаются
к статье.
Предисловие
Основной
целью разработки AcedUtils.NET было стремление создать классы для эффективного
выполнения основных операций с данными, включая сжатие, шифрование, работу с
бинарным потоком. Весь код библиотеки написан на языке C# и максимально
оптимизирован по быстродействию.
Библиотека
AcedUtils.NET содержит следующие классы, принадлежащие пространству имен
AcedUtils:
AcedBinary
– содержит статические методы и функции для работы с бинарными данными, в том
числе для вычисления контрольной суммы Адлера, для копирования массивов байт и
работы с массивами чисел типа Int32.
AcedRipeMD
– используется для вычисления значения односторонней хеш-функции RipeMD-160
массива байт или строки символов. Включает методы для копирования и сравнения
цифровой сигнатуры, преобразования ее в значение типа Guid, очистки массива,
содержащего цифровую сигнатуру.
AcedCast5
– предназначен для шифрования и дешифрования массива байт методом CAST-128 в
режиме CFB (64 бита). Блочный алгоритм шифрования реализован в соответствии с
RFC 2144. Алгоритм отличается высоким быстродействием и надежностью.
AcedDeflator,
AcedInflator – используются для сжатия и распаковки массива байт с помощью
алгоритма LZ+Huffman.
AcedMemoryReader,
AcedMemoryWriter – предназначены для помещения данных в бинарный поток и чтения
из потока. При использовании этих классов бинарный поток представляется
массивом типа byte[], размер которого динамически увеличивается по мере
добавления новых данных. При этом сами данные могут быть упакованы с
применением оригинального алгоритма сжатия, зашифрованы методом CAST-128 и
защищены значением цифровой сигнатуры RipeMD-160.
AcedStreamReader,
AcedStreamWriter – предназначены для помещения данных в бинарный поток и чтения
данных из потока. Здесь, в отличие от классов AcedMemoryReader и
AcedMemoryWriter, размер бинарного потока не ограничивается объемом оперативной
памяти. Данные помещаются в поток и читаются из потока типа System.IO.Stream,
который ассоциируется, соответственно, с экземпляром класса AcedStreamWriter
или AcedStreamReader.
AcedReaderStream,
AcedWriterStream – классы-оболочки, позволяющие работать с перечисленными выше
классами бинарных потоков так, как будто они являются потомками класса
System.IO.Stream.
AcedRegistry
– объединяет методы для сохранения в реестре Windows значений различного типа,
в том числе, строк, массивов байт, значений типа Boolean, DateTime, Decimal,
Double и т.д. Кроме того, в AcedRegistry находятся методы для чтения
соответствующих значений из реестра Windows.
Рассмотрим
подробнее каждый из перечисленных классов.
Класс
AcedBinary
В
AcedBinary собраны функции для работы с бинарными данными, которые используются
другими классами в составе AcedUtils.NET. Однако, они могут вызываться и из
прикладной программы. Например, функция SwapBytes() обращает порядок следования
байт в значении типа System.UInt32, функция ReverseBits() выполняет аналогичное
действие с битами в составе двойного слова. Точнее, размер исходного значения
может варьироваться от 1 до 32 бит. Функция Adler32() вычисляет значение
контрольной суммы Адлера в соответствии с RFC 1950 для массива байт или его
фрагмента. Данный алгоритм расчета контрольной суммы отличается от CRC32 большей
производительностью. В этом классе есть еще несколько unsafe-методов,
предназначенных для копирования массива байт, быстрого заполнения массива чисел
типа System.Int32 и копирования одного такого массива в другой.
Класс
AcedRipeMD
Смысл
односторонней хеш-функции заключается в том, что практически невозможно
подобрать другой набор байт, для которого значение цифровой сигнатуры совпадало
бы с исходным значением. Кроме того, невозможно восстановить состояние исходных
данных по известному значению цифровой сигнатуры. Класс AcedRipeMD реализует
алгоритм расчета односторонней хеш-функции RipeMD-160 в полном соответствии с
документом: "RIPEMD-160: A Strengthened Version of RIPEMD" (Hans
Dobbertin, Antoon Bosselaers, Bart Preneel), April 18, 1996. Длина получаемой
сигнатуры составляет 20 байт (160 бит). Цифровую сигнатуру удобно представить в
виде массива из 5 элементов типа System.Int32.
Чтобы
получить значение односторонней хеш-функции для массива байт или строки
символов, можно воспользоваться функцией Compute() класса AcedRipeMD. При
передаче в нее массива байт указывается смещение и длина обрабатываемого
фрагмента массива. Имеется также unsafe-вариант этой функции, принимающий в
качестве параметра указатель на массив байт. Иногда, например, при работе с потоком
данных, требуется рассчитать цифровую сигнатуру для массива байт,
представленного в виде нескольких фрагментов. В этом случае можно применить
функции для поточного расчета сигнатуры RipeMD-160. Для этого сначала
вызывается функция Initialize, которая возвращает или заполняет служебный
массив hashData. Затем нужно последовательно вызвать метод Update для каждого
фрагмента данных. В этот метод передается массив hashData, а также ссылка на
первый или следующий фрагмент данных в виде массива байт или строки символов,
для которого вычисляется значение сигнатуры. После того, как функция Update
была вызвана для каждого фрагмента, можно получить само значение цифровой
сигнатуры вызовом метода Finalize().
Алгоритм
шифрования CAST-128, используемый при работе с бинарным потоком классами
Aced(…)Writer/Aced(…)Reader, предполагает, что длина ключа шифра составляет 128
бит. Цифровая сигнатура RipeMD-160 как нельзя лучше подходит для использования
ее в качестве ключа при шифровании данных. Однако, она представляется числом
размером 160 бит, а не 128. Для решения этой проблемы в класс AcedRipeMD
добавлена функция ToGuid(). Она принимает значение 20-байтной цифровой
сигнатуры и возвращает соответствующее ему значение типа System.Guid, размер
которого составляет 128 бит.
В
классе AcedRipeMD есть еще несколько вспомогательных методов, облегчающих
работу с цифровой сигнатурой, представленной в виде массива из 5 значений типа
System.Int32. Например, функция Copy() позволяет быстро скопировать значение
хеш-функции в массив байт или, наоборот, считать его из массива байт. Функция
Equals() используется для проверки равенства двух значений цифровой сигнатуры,
одно из которых может быть представлено массивом байт. Функция Clear() обнуляет
5 элементов массива типа System.Int32[], предназначенного для хранения
сигнатуры RipeMD-160.
Класс
AcedCast5
В
AcedCast5 реализован алгоритм CAST-128 (CAST5) в соответствии с RFC 2144. Это
незапатентованный алгоритм шифрования с ключом размером 128 бит, отличающийся
высоким быстродействием и стойкостью к различным видам криптоанализа. При
применении шифра к данным используется режим обратной загрузки шифротекста
(CFB) с размером блока входных данных 64 бита. Класс AcedCast5 используется при
шифровании и дешифровании бинарного потока данных, представленного классами
Aced(…)Writer/Aced(…)Reader. Кроме того, он может применяться самостоятельно
для шифрования произвольных данных.
Два
основных метода класса AcedCast5, методы Encrypt() и Decrypt(), предназначены,
соответственно, для шифрования и дешифрования массива байт или его фрагмента с
ключом, который задается параметром keyBytes в виде 16-байтного массива. Если в
программе ключ представляется значением типа System.Guid, то соответствующий
ему массив байт можно получить вызовом функции Guid.ToByteArray(). Одновременно
с шифрованием в классе AcedCast5 вычисляется значение односторонней хеш-функции
RipeMD-160 для шифруемых данных. Функция Encrypt() возвращает массив из 5
значений типа System.Int32, представляющих собой цифровую сигнатуру фрагмента
данных, рассчитанную до того, как данные были зашифрованы. Функция Decrypt()
возвращает аналогичный массив, представляющий цифровую сигнатуру фрагмента
данных, рассчитанную после того, как данные были расшифрованы. Если при
шифровании и дешифровании использован один и тот же ключ и данные в массиве не
были повреждены, функции Encrypt() и Decrypt() должны вернуть одно и тоже
значение хеш-функции RipeMD-160. Имеются также unsafe-варианты этих функций, в
которые передается указатель на массив шифруемых байт. Кроме того, функции
Encrypt() и Decrypt() могут принимать параметр iv, задающий начальный вектор
для шифрования или дешифрования данных.
В
классе AcedCast5 есть функций для шифрования данных, представленных несколькими
фрагментами, т.е. поточного шифрования. В частности, функция ScheduleKey() на
основе ключа шифра keyBytes создает или заполняет специальный массив key,
содержащий ключевую информацию, который передается затем в качестве ключа в
остальные функции, относящиеся к данному разделу. Таким образом, ключевой
массив создается только однажды, а не перед каждым шифрованием следующего
фрагмента данных. Функция GetOrdinaryIV() возвращает значение, которое может
использоваться в качестве начального вектора. Это значение получается
шифрованием нулевого вектора с помощью текущего ключа шифра. Функции Encrypt()
и Decrypt(), которые принимают параметр key, используются непосредственного для
шифрования и дешифрования данных в поточном режиме. Каждая из этих функций,
кроме ключа и ссылки на шифруемые или дешифруемые данные, принимает параметр
iv, в котором передается значение начального вектора. Новое значение вектора,
которое может использоваться при следующем вызове функций Encrypt()/Decrypt(),
возвращается как результат функции. Когда все данные зашифрованы или расшифрованы,
нужно вызвать метод ClearKey() для очистки массива key, содержащего ключевую
информацию. А можно вместо или после этого передать массив key в метод
ScheduleKey() для заполнения его информацией о новом ключе для шифрования
других данных с другим ключом без пересоздания массива key.
Классы
AcedDeflator и AcedInflator
Эти
классы предназначены для сжатия и распаковки данных, представленных массивом
байт или его фрагментом. Применяемый алгоритм сжатия аналогичен описанному в
RFC 1951 и реализованному в библиотеке zlib, но имеет ряд отличий, в частности,
использует другой формат блока данных. Формат описан в исходном коде библиотеки
в начале файла Compressor.cs.
Упаковка
данных производится методом Compress() класса AcedDeflator, распаковка –
методом Decompress() класса AcedInflator. Особенность работы с этими классами
заключается в том, что их экземпляры не следует создавать напрямую вызовом
конструктора. Лучше вместо этого использовать ссылку на единственный экземпляр
каждого класса, которую можно получить, обратившись к статическому свойству
Instance. Это ограничение связано с тем, что при создании экземпляров этих
классов, особенно класса AcedDeflator, выделяется значительный объем памяти под
внутренние массивы. Обычно не требуется использовать параллельно несколько
экземпляров архиватора. Кроме того, частое перераспределение памяти ведет к
снижению производительности. При первом обращении к свойству Instance создается
один экземпляр соответствующего класса. Ссылка на него сохраняется в
статическом поле класса и возвращается при каждом следующем обращении к
свойству Instance. Когда возникает необходимость освобождения памяти, занятой
внутренними массивами архиватора, можно вызвать статический метод Release для
обнуления внутренней ссылки на экземпляр соответствующего класса. Тогда, если
нет других ссылок на этот экземпляр, при следующей "сборке мусора"
память будет возвращена операционной системе.
Для
сжатия данных функцией AcedDeflator.Compress() в нее передается ссылка на
массив байт с указанием смещения и длины сжимаемого фрагмента данных. Есть два
варианта этой функции. В первом случае память под массив для сохранения
упакованных данных распределяется самой функцией Compress(). Параметры
beforeGap и afterGap этой функции задают отступ, соответственно, в начале и в
конце выходного массива на случай, если кроме упакованных данных в него должна
быть помещена еще какая-то информация. Во втором случае в функцию Compress()
передается ссылка на уже существующий массив, в который должны быть записаны
упакованные данные, а также смещение в этом массиве, с которого начинается
запись. Максимальный размер упакованного фрагмента в случае, если данные
несжимаемы, равен длине исходного фрагмента плюс 4 байта. Таким образом, длина
приемного массива должна быть достаточна для хранения исходного фрагмента
данных плюс 4 байта и плюс смещение в этом массиве. Функция Compress()
возвращает размер сжатого фрагмента, т.е. число байт, сохраненное в выходном
массиве.
Параметр
типа AcedCompressionMode, передаваемый в функции Compress(), выбирает режим
сжатия данных. Он принимает одно из следующих значений: NoCompression – данные
не сжимаются, а просто копируются в входной массив с добавлением 4-байтной
длины фрагмента для последующей его распаковки; Fastest – самый быстрый режим
сжатия, который, тем не менее, может быть эффективен для некоторых типов
данных; Fast – используется режим быстрого сжатия, когда максимальное
расстояние между повторяющимися последовательностями во входном потоке
принимается равным 65535 байтам; Normal – обычное сжатие, когда максимальное
расстояние между последовательностями составляет 131071 байт;
MaximumCompression – максимальное сжатие, доступное данному архиватору,
предполагающее, что максимальное расстояние между повторяющимися
последовательностями составляет 262143 байта.
Сжатые
данные распаковываются методом AcedInflator.Decompress(). Прежде чем вызывать
этот метод необходимо подготовить область памяти, достаточную для хранения
результата. Узнать первоначальный размер сжатых данных можно вызовом статической
функции GetDecompressedLength() класса AcedInflator. В нее передается ссылка на
массив байт и смещение в этом массиве, с которого начинаются упакованные
данные. Функция возвращает длину фрагмента данных после его распаковки. Затем
можно создать массив байт достаточного размера и передать его в функцию
Decompress() для заполнения распакованными данными. Эта функция принимает
ссылку на исходный массив, содержащий сжатые данные, смещение в этом массиве, а
также ссылку на приемный массив, в который выполняется распаковка, и смещение в
приемном массиве. Функция возвращает число байт сохраненное в выходном массиве.
Есть еще другой вариант функции Decompress(), в котором память под выходной
массив распределяется самой функцией. Эта функция принимает параметры beforeGap
и afterGap, которые задают число байт, которое надо зарезервировать,
соответственно, в начале и в конце выходного массива.
Класс
AcedMemoryWriter
Позволяет
сохранять разнотипные данные в массиве байт, длина которого динамически
увеличивается по мере добавления в него данных. Затем эти данные представляются
в виде массива типа System.Byte[], который, кроме самих данных, содержит их
контрольную сумму и, возможно, значение цифровой сигнатуры. Возвращаемый массив
может быть упакован для экономии места и зашифрован для ограничения доступа к
информации.
При
создании экземпляра класса AcedMemoryWriter можно указать предполагаемое число
байт, которое будет помещено в бинарный поток. Таким образом удается избежать
лишнего перераспределения памяти под внутренний массив. В AcedMemoryWriter есть
методы, названия которых начинаются с "Write", предназначенные для
помещения в поток значений следующих типов: Boolean, Byte, Byte[], Char,
DateTime, Decimal, Single, Double, Guid, Int16, Int32, Int64, SByte, String,
TimeSpan, UInt16, UInt32, UInt64. Кроме того, можно добавлять сразу фрагменты
массивов с элементами стандартных value-типов с помощью перегруженных методов
Write(). При этом указывается индекс первого сохраняемого элемента массива и
число записываемых элементов. Общее число байт, помещенное в бинарный поток,
возвращается свойством Length класса AcedWriter. Метод Reset() обнуляет длину
потока, позволяя заполнить его новыми данными без пересоздания экземпляра
класса AcedMemoryWriter.
Текущая
длина внутреннего массива возвращается и устанавливается свойством Capacity.
Ссылку на внутренний массив можно получить вызовом функции GetBuffer(). Правда,
эта ссылка изменяется при каждом перераспределении памяти, т.е. при каждом
изменении свойства Capacity. В некоторых случаях, например, при чтении данных
из файла с помощью FileStream.Read(), удобнее передать ссылку на внутренний
массив непосредственно в метод FileStream.Read(), вместо того, чтобы считывать
данные в промежуточный массив, а затем переписывать их в поток методом Write().
Чтобы сделать это быстрее, нужно сохранить во временной переменной текущую
длину потока, т.е. значение свойства Length, затем вызвать метод Skip(),
передавая в него число байт, которое будет прочитано из файла. При этом длина
потока увеличится на указанное число байт без фактического заполнения их
данными. Теперь можно получить ссылку на внутренний массив из функции
GetBuffer(), а затем вызвать метод FileStream.Read(), передавая в него
полученную ссылку на массив и значение, сохраненное во временной переменной, в
качестве смещения в массиве.
Когда
все необходимые данные записаны в бинарный поток, вызывается функция ToArray(),
возвращающая результирующий массив данных. Имеется несколько вариантов этой
функции, которые отличаются набором принимаемых параметров. Наиболее
функциональным является вариант, принимающий два параметра: compressionMode
типа AcedCompressionMode и keyGuid типа System.Guid. Вызов функции ToArray() с
одним параметром эквивалентен передаче значения Guid.Empty в параметре keyGuid.
Вызов этой функции без параметров эквивалентен передаче значения NoCompression
в параметре compressionMode и значения Guid.Empty в параметре keyGuid.
Рассмотрим подробнее, чем управляют эти параметры и как они влияют на
сохраняемый формат данных.
Параметр
типа AcedCompressionMode выбирает режим сжатия данных. Его значение
соответствует одной из констант, рассмотренных выше при описании класса
AcedDeflator. Если этот параметр равен значению NoCompression, данные бинарного
потока не сжимаются. Параметр keyGuid задает ключ шифрования для выходного
массива байт. Если этот параметр равен Guid.Empty, шифрование не выполняется.
Значение типа System.Guid используется в качестве ключа шифра по нескольким
причинам. Во-первых, легко сгенерировать новое уникальное значение ключа
вызовом функции Guid.NewGuid(). Во-вторых, значения такого типа имеют
общепринятое строковое представление. В-третьих, Guid легко получить из
значения односторонней хеш-функции RipeMD-160. Если ключ шифра вводится
пользователем с клавиатуры в виде строки символов, необходимо преобразовать эту
строку в цифровую сигнатуру вызовом AcedRipeMD.Compute(), а затем в значение
типа System.Guid вызовом метода ToGuid() класса AcedRipeMD. Шифрование данных
выполняется методами классом AcedCast5. Но прежде, чем шифровать данные, для
них вычисляется значение 20-байтной сигнатуры RipeMD-160, которое помещается в
выходной массив вместе с данными и используется при последующем чтении из
потока для проверки того, что данные в потоке расшифрованы с правильным ключом
и что они не были повреждены.
Последовательность
действий при вызове метода ToArray() класса AcedMemoryWriter следующая. Сначала
выполняется упаковка данных классом AcedDeflator. Затем для полученного массива
рассчитывается значение односторонней хеш-функции RipeMD-160 методами класса
AcedRipeMD. Это значение помещается в выходной массив перед данными. Потом
данные шифруются методами класса AcedCast5. Значение цифровой сигнатуры не
шифруется. На заключительном этапе для всего содержимого выходного массива
рассчитывается контрольная сумма Адлера вызовом метода AcedBinary.Adler32(),
которая размещается в первых 4-х байтах выходного массива. Заполненный таким
образом массив возвращается как результат функции ToArray(). В зависимости от
параметров, могут опускаться этапы упаковки и/или расчета цифровой сигнатуры и
шифрования данных.
Пример
использования класса AcedMemoryWriter:
private
byte[] PutData()
{
AcedMemoryWriter w = new AcedMemoryWriter();
w.WriteByteArray(new byte[] {5, 6, 7, 8, 9});
w.WriteInt16(10000);
int[] otherValues = new int[120];
for (int i = 0; i < 120; i += 3)
{
otherValues[i] = 1;
otherValues[i + 1] = 2;
otherValues[i + 2] = 3;
}
w.Write(otherValues, 10, 100);
w.WriteString("Hello
world!");
//////////////////////////////////////////////////////
//
Вариант 1: данные возвращаются как есть с
//
добавлением контрольной суммы Адлера.
//////////////////////////////////////////////////////
return
w.ToArray();
/*
//////////////////////////////////////////////////////
//
Вариант 2: данные сжимаются и защищаются
//
контрольной суммой Адлера.
//////////////////////////////////////////////////////
return w.ToArray(AcedCompressionMode.Fast);
*/
/*
//////////////////////////////////////////////////////
//
Вариант 3: данные сжимаются, шифруются и защищаются
//////////////////////////////////////////////////////
return
w.ToArray(AcedCompressionMode.Fast,
new Guid("CA761232-ED42-11CE-BACD-00AA0057B223"));
*/
}
В
данном примере функция PutData() помещает в бинарный поток массив байт как
целый объект, потом значение типа Int16, затем фрагмент массива элементов типа
Int32, а в конце – строку символов. Результатом функции может быть просто
массив байт, содержащий данные, записанные в поток, защищенные контрольной
суммой Адлера. Размер этого массива составляет 443 байта. Если передать в
функцию AcedMemoryWriter.ToArray() параметр compressionMode со значением
AcedCompression.Fast, данные бинарного потока будут упакованы и размер полученного
массива составит 51 байт. Если, кроме того, передать некоторое непустое
значение типа Guid в параметре keyGuid, сжатые данные будут защищены цифровой
сигнатурой RipeMD-160 и зашифрованы методом CAST-128. За счет добавления
сигнатуры размер выходного массива увеличится при этом на 20 байт и составит 71
байт.
Класс
AcedMemoryReader
Предназначен
для чтения данных из массива байт, созданного экземпляром класса
AcedMemoryWriter. В конструктор класса AcedMemoryReader передается ссылка на
массив байт с указанием фрагмента, содержащего данные бинарного потока. Если
данные зашифрованы, в последнем параметре конструктора необходимо передать
значение типа System.Guid, соответствующее ключу шифра, который использовался
при вызове метода ToArray() класса AcedMemoryWriter. Отдельные значения могут
быть прочитаны из потока методами, названия которых состоят из префикса
"Read" и наименования типа читаемого значения. Фрагменты массивов,
состоящих из элементов стандартных value-типов, считываются методом Read(). Для
возвращения текущей позиции на начало потока, чтобы заново прочитать данные,
используется метод Reset(). Чтобы пропустить некоторое количество байт во
входном потоке вызывается метод Skip(). При попытке чтения данных за пределами
потока возникает исключение типа AcedReadBeyondTheEndException.
Свойство
Position класса AcedMemoryReader возвращает индекс следующего считываемого
байта во внутреннем массиве, ссылка на который возвращается функцией
GetBuffer(). Размер внутреннего массива определяется свойством Size. Смещение
во внутреннем массиве, с которого начинаются данные потока – свойством Offset.
Если исходный массив байт, переданный в конструктор класса, является
упакованным, в памяти создается новый массив для распакованных данных. Тогда
функция GetBuffer() возвращает ссылку на этот временный массив, а свойство
Offset всегда равно нулю. Если же исходный массив не является упакованным,
функция GetBuffer() возвращает ссылку на массив, переданный параметром bytes в
конструктор класса AcedMemoryReader. Если данные потока зашифрованы, массив
байт, передаваемый в конструктор этого класса, расшифровывается на месте. Это
означает, что один и тот же зашифрованный массив байт нельзя использовать для
инициализации нескольких экземпляров класса AcedMemoryReader.
Если
при создании экземпляра класса AcedMemoryReader в конструктор передан массив
недостаточной длины или рассчитанная для него контрольная сумма Адлера не
совпадает с сохраненным в потоке значением контрольной суммы, возникает
исключение AcedDataCorruptedException. Если после дешифрования данных
оказывается, что рассчитанное значение цифровой сигнатуры RipeMD-160 для данных
потока не совпадает со значением сигнатуры, сохраненным в начале массива
данных, возникает исключение AcedWrongDecryptionKeyException, которое является
потомком от класса AcedDataCorruptedException.
Пример
использования класса AcedMemoryReader:
private void GetData(byte[] dataBytes, out byte[] bytes,
out short n, out string s, out int[] otherValues)
{
AcedMemoryReader r = new AcedMemoryReader(dataBytes,
0, dataBytes.Length);
/*
AcedMemoryReader r = new AcedMemoryReader(dataBytes,
0, dataBytes.Length,
new Guid("CA761232-ED42-11CE-BACD-00AA0057B223"));
*/
bytes = r.ReadByteArray();
n = r.ReadInt16();
otherValues = new int[120];
r.Read(otherValues, 10, 100);
s
= r.ReadString();
}
Предполагается,
что массив байт, передаваемый параметром dataBytes в функцию GetData(), получен
как результат функции PutData(), код которой приведен выше в разделе,
описывающем класс AcedMemoryWriter. Используемый здесь конструктор класса
AcedMemoryReader предполагает, что данные в бинарном потоке не зашифрованы.
Закомментированный фрагмент кода содержит вызов конструктора с передачей в него
ключа шифра, соответствующего варианту 3 функции PutData().
Классы
AcedStreamWriter, AcedStreamReader
Эти
классы аналогичны описанным выше классам AcedMemoryWriter, AcedMemoryReader.
При их использовании, однако, данные помещаются не в массив байт, а в поток
типа System.IO.Stream, ассоциированный с экземпляром класса AcedStreamWriter, и
читаются не из массива байт, а из потока типа System.IO.Stream,
ассоциированного с классом AcedStreamReader.
При
работе с классом AcedStreamWriter в памяти создается буфер размером 2МБ,
который постепенно заполняется данными. При достижении конца буфера, вызове
методов Flush() или Close() класса AcedStreamWriter содержимое буфера
упаковывается методом Compress() класса AcedDeflator. Сжатые данные сохраняются
в другом буфере, размер которого также составляет 2МБ. Для упакованных данных
вычисляется цифровая сигнатура RipeMD-160, после чего данные шифруются методом
CAST-128. Длина фрагмента данных, контрольная сумма Адлера, цифровая сигнатура
RipeMD-160 и сами сжатые и зашифрованные данные записываются в выходной поток
типа System.IO.Stream. После этого содержимое буфера очищается и в него можно
записывать следующие данные. При вызове метода Close() класса AcedStreamWriter,
если ассоциированный с ним поток поддерживает операцию Seek, поток
позиционируется на начало записанных данных и в потоке сохраняется общая длина
(в байтах) данных, помещенных в поток классом AcedStreamWriter. Этот размер
представляется значением типа System.Int64. Если операция Seek не
поддерживается потоком типа System.IO.Stream, длина остается равной значению
-1, записанному в поток при его ассоциации с классом AcedStreamWriter. Метод
AssignStream класса AcedStreamWriter используется, чтобы связать данный
экземпляр класса с потоком System.IO.Stream. Кроме ссылки на поток в этот метод
передается константа, выбирающая режим сжатия данных, а также значение типа
System.Guid, которое, если оно отлично от Guid.Empty, задает ключ для
шифрования данных. Таким образом, в зависимости от параметров, переданных в
метод AssignStream, этапы сжатия данных, расчета цифровой сигнатуры и
шифрования данных могут опускаться.
Чтобы
прочитать данные, сохраненные в потоке System.IO.Stream классом
AcedStreamWriter, нужно воспользоваться классом AcedStreamReader. Экземпляр
этого класса может быть ассоциирован с потоком типа System.IO.Stream с помощью
метода AssignStream. Если данные, помещенные в поток, зашифрованы, при вызове
метода AssignStream следует указать ключ шифра в виде значения типа
System.Guid. В методе AssignStream сразу считывается длина фрагмента данных, помещенного
в поток классом AcedStreamWriter. Это значение возвращается свойством Length
класса AcedStreamReader. Длина может быть равна значению -1, если не было
возможности сохранить в потоке настоящее значение длины. В экземпляре класса
AcedStreamReader также имеется два буфера, каждый размером по 2МБ. Первый
предназначен для данных, считанных из потока System.IO.Stream, второй – для
распакованных данных. Когда вызывается один из методов Read… класса
AcedStreamReader, сначала предпринимается попытка считать значение из буфера
распакованных данных. Если достигнут конец буфера, из потока System.IO.Stream
считывается следующий фрагмент данных. Для этого фрагмента проверяется значение
контрольной суммы Адлера. Затем, если данные зашифрованы, выполняется их дешифрование
и проверка цифровой сигнатуры RipeMD-160. Потом, если данные упакованы,
производится их распаковка во второй буфер. Теперь значение может быть
прочитано и возвращено функцией Read.… При чтении из потока длинных массивов
перегруженным методом Read() класса AcedStreamReader возможна ситуация, когда
для считывания всего массива приходится несколько раз заполнять внутренний
буфер данными из потока System.IO.Stream.
Так
как экземпляры классов AcedStreamWriter и AcedStreamReader занимают собой
значительный объем памяти (каждый свыше 4МБ), создавать их при каждом чтении из
потока нерационально. Сборщик мусора в .NET Framework автоматически относит
блоки памяти свыше 85000 байт ко второму поколению (об этом см. в книге Джеффри
Рихтера "Программирование на платформе .NET Framework" – M.:
Издательско-торговый дом "Русская Редакция", 2003). Такие блоки лучше
использовать для ресурсов с длительным временем существования. В противном
случае, частое пересоздание больших блоков памяти отрицательно сказывается на
общей производительности приложения. Для решения этой проблемы в классах
AcedStreamWriter и AcedStreamReader имеется статическое свойство Instance,
которое при первом обращении к нему создает экземпляр соответствующего класса,
а при следующих обращениях просто возвращает ссылку на существующий экземпляр.
Тогда, вместо того, чтобы создавать новые экземпляры классов вызовом
соответствующих конструкторов, лучше воспользоваться единственным экземпляром,
возвращаемым свойством Instance. Этот подход аналогичен тому, который
применяется в классах AcedDeflator и AcedInflator. Чтобы освободить занимаемую
память можно вызвать статический метод Release(), освобождающий ссылку на
экземпляр соответствующего класса.
После
помещения всех данных в поток AcedStreamWriter, а также после чтения
необходимых данных из потока AcedStreamReader, нужно вызвать метод Close() для
выполнения завершающих действий. Если в параметре closeStream метода Close()
передано значение True, поток типа System.IO.Stream, ассоциированный с данным
экземпляром класса AcedStreamWriter или AcedStreamReader, закрывается вызовом
метода Close() потока.
Классы
AcedWriterStream, AcedReaderStream
Эти
классы представляют собой оболочку над другими классами, предназначенными для
работы с бинарным потоком. Они используются, когда надо представить экземпляры
других классов в виде объектов, производных от класса System.IO.Stream.
Класс
AcedWriterStream является потомком класса System.IO.Stream и предназначен для
записи данных в потоки типа AcedMemoryWriter и AcedStreamWriter. В его
конструктор передается ссылка на интерфейс IAcedWriter, который поддерживается
классами AcedMemoryWriter и AcedStreamWriter. Класс AcedWriterStream
используется только для записи данных в поток, поэтому его свойства CanRead и
CanSeek возвращают значение False, а свойство CanWrite – значение True. Вызов
методов Write(), WriteByte(), Flush(), Close() перенаправляется соответствующим
методам объекта, реализующего интерфейс IAcedWriter. При чтении свойств Length
и Position возвращается число байт, помещенное в выходной бинарный поток.
Однако, присвоение значения свойству Position или вызов методов Read(),
ReadByte(), Seek(), SetLength() приводит к возникновению исключения типа
System.NotSupportedException. Свойство Writer класса AcedWriterStream
возвращает ссылку на объект, реализующий интерфейс IAcedWriter, которая была
передана в конструктор класса при его создании.
Аналогичным
образом применяется класс AcedReaderStream, который также является потомком
класса System.IO.Stream. Этот класс предназначен для чтения данных из потоков
типа AcedMemoryReader и AcedStreamReader, реализующих интерфейс IAcedReader.
Класс AcedReaderStream предназначен исключительно для чтения данных, поэтому
его свойство CanRead возвращает значение True, а свойства CanWrite и CanSeek
возвращают значение False. Вызов методов Read(), ReadByte(), Close()
перенаправляется соответствующим методам объекта, реализующего интерфейс
IAcedReader. При чтении свойства Position возвращается текущая позиция в потоке
относительно начала данных. Свойство Length возвращает общее число байт,
которое может быть прочитано из потока. В некоторых случаях количество байт,
помещенное в поток, неизвестно. Тогда свойство Length возвращает значение -1.
Попытка присвоения значения свойству Position или вызова одного из следующих
методов: Seek(), SetLength(), Write(), WriteByte() заканчивается возникновением
исключения типа System.NotSupportedException. Свойство Reader класса
AcedReaderStream возвращает интерфейс IAcedReader, переданный в конструктор класса.
Подробную информацию о свойствах и методах интерфейсов IAcedWriter, IAcedReader
можно найти в файле Interfaces.cs исходного кода.
Класс
AcedRegistry
AcedRegistry
восполняет собой отсутствие в .NET Framework класса, подобного классу TRegistry
в Borland Delphi. Его особенностью по сравнению со стандартным классом
Microsoft.Win32.Registry является наличие специальных методов для помещения в
реестр значений различного типа и для чтения соответствующих значений из
реестра. Класс AcedRegistry включает методы для работы с данными, которые
представлены значениями следующих типов: String, Byte[], Int32, Boolean,
DateTime, Decimal, Double, Guid, Int64.
Работа
с классом AcedRegistry начинается с вызова конструктора, который принимает три
параметра: первый (registryBaseKey) – выбирает ветвь реестра, такую как
HKEY_CURRENT_USER или HKEY_LOCAL_MACHINE; второй параметр (registryKey)
указывает наименование ключа реестра, с которым предполагается работать; третий
параметр задает режим работы: только чтение или чтение/запись. Если указанный
ключ не существует, то при открытии его в режиме "только для чтения"
ошибка не возникает. Тогда каждое обращение к функциям Get() для чтения
значений ключа вернет False, а при вызове GetDef() будет возвращаться значение
по умолчанию. При открытии ключа в режиме, допускающем запись, если он
отсутствует, соответствующий ключ немедленно создается в реестре. Обратиться к
объекту типа Microsoft.Win32.RegistryKey, представляющему открытый ключ
реестра, можно через свойство RegistryKey класса AcedRegistry.
Перегруженный
метод Put() предназначен для записи в реестр значений различного типа. Функция
Get() считывает значение с указанным именем и сохраняет его в переменной,
передаваемой как ref-параметр. Если запрашиваемое значение присутствует в
реестре, функция возвращает True. Функция GetDef() отличается от Get() тем, что
она возвращает прочитанное значение как результат функции. Если соответствующее
значение отсутствует в реестре, GetDef() возвращает значение по умолчанию,
которое задается вторым параметром при вызове этой функции.
В
конце работы с экземпляром класса AcedRegistry для него обязательно надо
вызвать метод Dispose(). При использовании языка C# удобно поместить создание
класса AcedRegistry в блок using для гарантированного освобождения
unmanaged-ресурсов.
Пример
использования класса AcedRegistry:
private const string
DemoRegistryKey = "Software\\AcedUtils.NET\\Demo",
cfgStreamFileName = "StreamFileName",
cfgCompressionMode = "CompressionMode";
private static string _streamFileName = String.Empty;
private static AcedCompressionMode _compressionMode;
private static void LoadConfig()
{
using (AcedRegistry config = new AcedRegistry
(AcedBaseKey.CurrentUser, DemoRegistryKey, false))
{
config.Get(cfgStreamFileName, ref
_streamFileName);
_compressionMode = (AcedCompressionMode)
config.GetDef(cfgCompressionMode, 0);
}
}
private static void SaveConfig()
{
using (AcedRegistry config = new AcedRegistry
(AcedBaseKey.CurrentUser, DemoRegistryKey, true))
{
config.Put(cfgStreamFileName, _streamFileName);
config.Put(cfgCompressionMode, (int)
_compressionMode);
}}
}
Описание
демонстрационного проектаа
Чтобы
проиллюстрировать различные способы работы с бинарными данными с помощью
рассмотренных выше классов, разработано небольшое приложение, которое
представляет собой примитивный аналог архиватора файлов. Верхняя часть главной
формы используется для помещения в бинарный поток данных произвольных файлов.
При нажатии на кнопку "Добавить файл" пользователю предлагается
выбрать на диске файл, который будет добавлен в поток. После помещения в поток
одного или нескольких файлов можно сохранить весь поток на диске в виде одного
файла. Причем данные при этом могут быть упакованы и зашифрованы. Чтобы
проверить механизм контроля целостности данных, можно немного повредить данные
в выходном потоке при сохранении его на диске. Для этого нужно пометить опцию
"Инвертировать третий байт". Нижняя часть формы позволяет загрузить
данные потока из файла на диске. Если поток зашифрован, перед чтением с диска
надо установить опцию "Расшифровывать с паролем" и указать
соответствующий пароль в поле ввода. Кроме данных, в бинарном потоке
сохраняются имена и размеры файлов, которые отображаются в соответствующем
списке после чтения потока с диска. Отдельные файлы из этого списка можно
пометить и выгрузить нажатием кнопки "Сохранить отмеченный файл".
Информация
об имени файла потока, а также об использованном режиме сжатия сохраняется в
реестре с помощью класса AcedRegistry и восстанавливается при следующем запуске
программы. При добавлении очередного файла в бинарный поток сначала
записывается его имя методом AcedMemoryWriter.WriteString(), потом длина файла
в байтах методом AcedMemoryWriter.WriteInt32(), затем в потоке резервируется
место для самих данных вызовом AcedMemoryWriter.Skip(). Фактическое заполнение
данными происходит при вызове метода FileStream.Read(), в который передается
ссылка на внутренний массив экземпляра класса AcedMemoryWriter, возвращаемый
функцией GetBuffer(), и смещение, соответствующее длине потока до вызова метода
Skip(). При сохранении потока на диске ключ шифрования получается как значение
односторонней хеш-функции RipeMD-160 для строки символов, введенной
пользователем в качестве пароля. Это значение преобразуется к типу System.Guid
вызовом метода AcedRipeMD.ToGuid() и передается в метод ToArray() класса
AcedMemoryWriter.
В
момент загрузки потока с диска проверяется его контрольная сумма. Затем данные
потока расшифровываются и для них проверяется сигнатура RipeMD-160, после чего
данные распаковываются. Из потока читаются имена и размеры файлов методами
AcedMemoryReader.ReadString() и AcedMemoryReader.ReadInt32(). Для каждого файла
вычисляется значение сигнатуры RipeMD-160. Эта информация помещается в список
типа ListView. Сами данные пропускаются вызовом метода AcedMemoryReader.Skip().
В свойстве Tag каждого элемента типа ListViewItem списка сохраняется
соответствующее ему смещение данных относительно начала потока. Когда
пользователь выбрал элемент списка и нажал кнопку "Сохранить отмеченный
файл", поток позиционируется на начало методом AcedMemoryReader.Reset(), а
затем текущая позиция смещается на число байт, соответствующее значению
свойства Tag элемента списка. После создания соответствующего файла на диске,
данные выгружаются в файл напрямую из бинарного потока, минуя промежуточные массивы.
Для этого в метод FileStream.Write() передается ссылка на внутренний массив
экземпляра класса AcedMemoryReader с указанием смещения, равного текущей
позиции в потоке.
В
этом приложении демонстрируются также способы работы с потоками на базе классов
AcedStreamWriter и AcedStreamReader. При нажатии кнопок в нижней части главной
формы приложения вызывается функция TestStreams(). Если параметр useAcedStreams
этой функции равен False, в качестве основного хранилища данных используется
стандартный класс System.IO.MemoryStream. Функция TestStreams() подготавливает
некоторые разнотипные данные, а затем передает их в метод PutData(), который
должен поместить их в поток типа System.IO.Stream (в данном случае
MemoryStream). Метод PutData() ассоциирует экземпляр класса AcedStreamWriter с
переданным в нее потоком типа Stream. При этом указывается, что сохраняемые
данные должны сжиматься в режиме Fast и шифроваться с ключом, который
передается как последний параметр в функцию AssignStream(). Затем данные
помещаются в поток с помощью методов класса AcedStreamWriter. Последним
вызываемым методом является Close(), которые помещает в поток все
буферизованные изменения. После выхода из PutData() заполненный бинарный поток
типа MemoryStream превращается в массив байт, а его размер в байтах выводится в
окне сообщения. Следующим этапом работы функции TestStreams() является загрузка
данных из потока MemoryStream, созданного на основе полученного массива байт.
Чтение данные выполняется методом GetData() с помощью экземпляра класса
AcedStreamReader, ассоциированного с потоком типа System.IO.Stream (в данном
случае MemoryStream).
Если
в параметре useAcedStreams функции TestStreams() передано значение True, в
качестве хранилища данных вместо MemoryStream используется экземпляр класса
AcedMemoryWriter. Так как метод PutData() работает только с потоками типа
System.IO.Stream, необходимо создать класс-оболочку AcedWriterStream, который
является потомком класса System.IO.Stream и в то же время инкапсулирует
экземпляр класса AcedMemoryWriter. Ссылка на класс-оболочку передается в метод
PutData(), и через него данные записываются в поток AcedMemoryWriter. В
завершении, данные из AcedMemoryWriter превращаются в массив байт вызовом
функции ToArray() аналогично предыдущему случаю. На этапе чтения данных в
качестве хранилища выступает экземпляр класса AcedMemoryReader, который
создается на основе полученного массива байт. Так как метод GetData() загружает
данные только из потоков типа System.IO.Stream, создается класс-оболочка
AcedReaderStream на основе экземпляра AcedMemoryReader. Ссылка на
AcedReaderStream передается в метод GetData(). Таким образом, данные
считываются из потока типа AcedMemoryReader посредством класса-оболочки
AcedReaderStream, являющегося потомком класса System.IO.Stream.
Заключение
В
статье описываются классы, которые могут быть полезны разработчику на платформе
.NET. Некоторые из них, такие как AcedRipeMD, AcedDeflator, являются аналогами
классов, добавленных в .NET 2.0. Однако, реализация этих алгоритмов в
библиотеке AcedUtils.NET представляется все же более эффективной.
Взаимодействие
Microsoft Excel с приложениями .NET. Позднее связывание.
Гасанов
Ровшан Закариевич
ведущий
.NET-разработчик компании PFSoft
Microsoft Certified Application Developer
Содержание:
Вступление
Запуск
и завершение работы Excel.
Управление
книгами и страницами.
Работа
со страницами. Объект Range. Использование записи макросов для автоматизации
Excel.
Перехват
событий Excel.
Заключение.
Литература
Примеры
классов.
1.
Вступление.
Многим
разработчикам рано или поздно приходится сталкиваться с задачами, которые
подразумевают использование Microsoft Excel (далее по тексту просто Excel) в
своей работе. Не будем перечислять подобные задачи, думаю, читатель сам уже с
этим столкнулся. Многие вопросы покажутся Вам очень знакомыми, кое-кто скажет,
а зачем такие сложности? Ведь можно применить утилиту tlbimp.exe, импортировать
библиотеку типов, создать RCW сборку, добавить на нее ссылку и вам станет
доступно пространство имен Excel, со всеми RCW классами, которые отображают в
себя "внутренности" Excel. Или еще проще, просто добавить ссылку на
COM-объекты Excel в Visual Studio, и она сделает все сама. Все это хорошо,
конечно. И просто. Но иногда возникают условия, когда описанное вкратце "раннее
связывание" неприемлемо. И тогда на помощь приходит т.н. "позднее
связывание", когда типы становятся известными не на этапе компиляции, а на
этапе выполнения.
Описывать
позднее связывание в этой статье нет смысла, в литературе, как и в Интернете
достаточно материала по этой теме. По поводу языка, то все примеры приведены с
использованием C#, но, надеюсь программисты, использующие в своей работе другие
.NET языки, смогут разобраться в коде без особого труда.
2.
Запуск и завершение работы Excel.
Запуск
Excel и его корректное завершение - это самая первая задача, которую нужно
решить программисту, если он собрался использовать Excel в своем приложении.
Возможно, Excel уже запущен, и операция запуска уже не нужна, достаточно
получить на него ссылку, и начать с ним работу. В получении ссылки на уже
работающую копию Excel кроется один неприятный момент, связанный с ошибкой в
самом приложении Excel (которую вроде бы исправлена в MSOffice 2003)[2]. Эта
ситуация подробно описана в конце этой главы.
А
сейчас по порядку.
В
первую очередь Вы должны подключить к своему приложению два пространства имен:
using System.Runtime.InteropServices;
using System.Reflection;
Типы,
которые необходимы для организации позднего связывания, описаны в этих
пространствах имен. Один из них: класс Marshal, который предоставляет богатые
возможности для организации взаимодействия между кодом с автоматически
управляемой памятью (managed code), и объектами "неуправляемым кодом"
(unmanaged code).
Для
получения ссылки на процесс Excel, нужно знать GUID Excel. Однако можно
поступить намного проще, зная программный идентификатор Excel:
"Excel.Application".
Для
получения ссылки на работающий Excel, воспользуйтесь статическим методом
GetActiveObject(), класса Marshal:
string sAppProgID = "Excel.Application";
object oExcel = Marshal.GetActiveObject(sAppProgID);
Если
Excel уже запущен (COM-объект Excel присутствует), то вызов данного метода
вернет ссылку на объект-отображение Excel в .NET, которые Вы сможете
использовать для дальнейшей работы. Если Excel не запущен, то возникнет
исключение.
Для
запуска Excel необходимо воспользоваться классом Activator, описанным в
пространстве имен System.
string sAppProgID = "Excel.Application";
// Получаем ссылку на интерфейс IDispatch
Type tExcelObj = Type.GetTypeFromProgID(sAppProgID);
// Запускаем Excel
object oExcel = Activator.CreateInstance(tExcelObj);
После
того, как Вы получили ссылку на работающее приложение Excel, или же запустили
его, Вам становится доступно вся объектная модель Excel. С точки зрения
программиста она выглядит так:
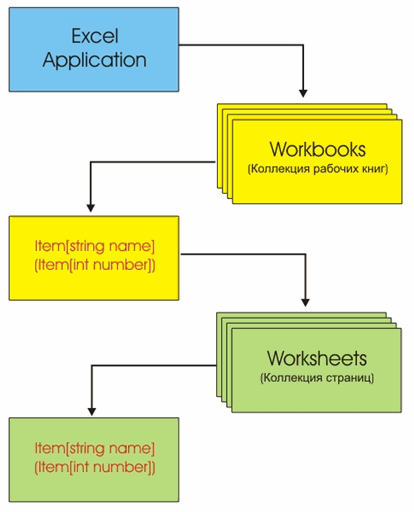
Рис.
1. Объектная модель Excel
Нам
для работы необходимо получить вместе с объектом Excel, ссылку на его коллекцию
книг, и с ее помощью мы можем получить доступ к любой книге. У каждой книги
есть коллекция страниц, ссылку на которую мы также должны получить для доступа
к конкретной странице. Хочу сразу заметить, что доступ к книгам и к страницам
мы можем получить как по их имени, так и по их порядковому номеру, причем, что
самое важное: нумерация книг и страниц в коллекции начинается с единицы, а не с
нуля (как принято нумеровать массивы в .NET). Отмечу, что хотя в Visual Basic
for Excel есть директива Option Base, на порядок нумерации в коллекциях в наше
случае он не влияет.
Для
того, чтобы корректно завершить работу с приложением Excel, для всех объектов,
которые мы получаем поздним связыванием, нам необходимо применить метод
ReleaseComObject класса Marshal:
// Уничтожение объекта Excel.
Marshal.ReleaseComObject(oExcel);
//
Вызываем сборщик мусора для немедленной очистки памяти
GC.GetTotalMemory(true);
Отмечу
сразу, что если вызов GC.Collect() не помогает, то попробуйте очистку памяти
этим способом. Если проигнорировать эту операцию, то в памяти останутся объекты
Excel, которые будут существовать даже после того, как Вы завершите свое
приложение и Excel. Если после этого запустить приложение NET и попытаться
получить ссылку на работающий Excel, то мы без проблем ее получим. Но если мы
заходим сделать Excel видимым (Установив ему свойство Visible в true), то при
наличии MSExcel версии ранней, чем 2003, основное окно Excel прорисовывалось не
полностью. На экране присутствовали только панели инструментов и окантовка
основного окна. В MS Excel 2003 вроде бы такого не наблюдается.
Но,
тем не менее, если Ваша программа получает ссылки на какие-либо объекты Excel,
Вы обязательно должны вызвать для них ReleaseComObject() класса Marshal.
А
перед завершением работы с Excel обязательно произведите очистку памяти:
GC.GetTotalMemory(true);
3.
Управление книгами и страницами.
Позднее
связывание подразумевает, что нам неизвестен тип объекта, с которым мы хотим
работать, а это значит, что мы не можем применять непосредственно обращаться к
его методам и полям, используя оператор ".". Поэтому для вызова
метода, нам необходимо знать его название и список формальных параметров,
которые он принимает. Для вызова метода в классе Type предусмотрен метод
InvokeMember(). Поэтому нам достаточно получить ссылку на экземпляр класса
Type, описывающий тип объекта, с которым мы устанавливаем позднее связывание, и
вызвать метод InvokeMember()/ Я не буду останавливаться подробно на этом
методе, он достаточно хорошо описан в технической документации. Отмечу только
самое необходимое, с которым мы будем непосредственно работать.
Метод
InvokeMember() перегружен, и имеет три модификации.
public object InvokeMember(string name, BindingFlags flags, Binder
binder, object target, object[] args);
public object InvokeMember(string name, BindingFlags flags, Binder
binder, object target, object[] args, CultureInfo info);
public abstract object InvokeMember(string name, BindingFlags flags,
Binder binder, object target, object[] args, ParameterModifier[] modifiers,
CultureInfo info, string[] namedParameters);
В
нашей работе мы будем использовать только первую модификацию метода. В качестве
первого параметра метод получает строковое название метода, поля, свойства того
объекта, с которым мы устанавливаем связь. При этом в названии не должно быть
пробелов или лишних символов, кроме того, этот параметр чувствителен к
регистру.
Второй
параметр принимает на вход флаги, характеризующие связывание. Нам понадобятся
только следующие флаги:
BindingFlags.InvokeMethod
- Найти метод, определить его точку входа, и выполнить передав ему массив
фактических параметров.
BindingFlags.GetProperty
- Установить свойство
BindingFlags.SetProperty
- Получить значение свойства.
Третий
параметр - binder - мы устанавливаем в null - он нам не нужен.
Через
четвертый параметр - target - мы передаем ссылку на объект, к методу которого
мы хотим обратиться.
Пятый
параметр - args - это массив с параметрами, который принимает на вход
вызываемый поздним связыванием метод, или массив, который содержит один элемент
- значение свойство, которое мы устанавливаем.
Метод
InvokeMember() возвращает результат выполнения метода или значение свойства.
object oWorkbooks = oExcel.GetType().InvokeMember("Workbooks",
BindingFlags.GetProperty, null, oExcel, null);
Объект
oWorkbooks и есть managed-ссылка на коллекцию книг.
Для
получения доступа к конкретной книге выполняем следующий код, используя
коллекцию книг:
//
Доступ к книге по ее порядковому номеру
//
Создаем массив параметров
object[]
args = new object[1];
//
Мы хотим получить доступ к первой книге Excel
args[0]
= 1;
//
Получаем ссылку на первую книгу в коллекции Excel
object oWorkbook =
oWorkbooks.GetType().InvokeMember("Item", BindingFlags.GetProperty,
null, oWorkbooks, args);
//
Доступ к книге по ее названию
//
(обратите внимание, что расширение в
//
названии не указывается)
object[]
args = new object[1];
//
Указываем название книги, к которой мы хотим получить доступ
args[0]
= "Книга1";
//
Получаем ссылку на первую книгу в коллекции Excel
object oWorkbook =
oWorkbooks.GetType().InvokeMember("Item", BindingFlags.GetProperty,
null, oWorkbooks, args);
Если
книг с указанным названием не существует, то данный код выбрасывает исключение.
Для
того, чтобы открыть, закрыть или создать книгу, воспользуемся соответствующими
методами коллекции книг oWorkbooks, ссылку на которую мы уже успешно получили.
Для
создания новой книги у объекта oWorkbooks есть несколько модификаций метода
Add. Если мы вызовем этот метод без параметров, то будет создана новая книга,
имеющая имя, принятое по умолчанию, и содержащая количество страниц, также
принятое по умолчанию.
//Создаем
новую книгу
object
oWorkbook = oWorkbooks.GetType().InvokeMember("Add",
BindingFlags.InvokeMethod, null, oWorkbooks, null);
Для
создания книги на основе шаблона, достаточно передать полное имя файла,
содержащее этот шаблон:
//
Заносим в массив параметров имя файла
object[] args = new object[1]; args[0] =
"D:\MyApp\Templates\invoice.xls";
//Создаем новую книгу
object oWorkbook =
oWorkbooks.GetType().InvokeMember("Add", BindingFlags.InvokeMethod,
null, oWorkbooks, args);
Для
открытия файла с книгой, воспользуемся методом Open объекта oWorkbooks:
//
Открытие файла d:\book1.xls
//
Заносим в массив параметров имя файла
object[] args = new object[1];
args[0] = "D:\book1.xls";
// Пробуем открыть книгу
object oWorkbook =
oWorkbooks.GetType().InvokeMember("Open", BindingFlags.InvokeMethod,
null, oWorkbooks, args);
Закрытие
книги возможно с помощью метода Close объекта oWorkbook. При этом он принимает
несколько необязательных параметров. Рассмотрим два варианта (Обратите
внимание, что мы вызываем метод Close книги, а не коллекции книг, и
target-объектом у нас выступает oWorkbook, а не oWorkbooks):
//
Вариант 1. Закрываем книгу с принятием всех изменений
object[]
args = new object[1];
//
с принятием всех изменений
args[0]
= true;
//
Пробуем закрыть книгу
oWorkbook.GetType().InvokeMember("Close",
BindingFlags.InvokeMethod, null, oWorkbook, args);
//
Вариант 2. Закрываем книгу с принятием всех изменений
object[] args = new object[2]; args[0] = true;
//
И под определенным названием
args[1]
= @"D:\book2.xls";
//
Пробуем закрыть книгу
oWorkbook.GetType().InvokeMember("Close",
BindingFlags.InvokeMethod, null, oWorkbook, args);
Отмечу
сразу, что сохранение произойдет только в том случае, если вы произвели
какие-либо изменения в рабочей книге. Если Вы создали рабочую книгу и ходите ее
сразу же закрыть, причем с сохранением под другим именем - у Вас ничего не
выйдет. Excel просто закроет книгу и все.
Для
того, чтобы просто сохранить изменения в книге, достаточно вызвать для нее
метод Save или SaveAs, передав последнему в качестве параметра имя файла, под
которым нужно сохранить книгу.
//
Просто сохраняем книгу
oWorkbook.GetType().InvokeMember("Save",
BindingFlags.InvokeMethod, null, oWorkbook, null);
//
Задаем параметры метода SaveAs - имя файла
object[] args = new object[2];
args[0] = @"d:\d1.xls";
//
Сохраняем книгу в файле d:\d1.xls
oWorkbook.GetType().InvokeMember("SaveAs",
BindingFlags.InvokeMethod, null, oWorkbook, args);
//
Просто сохраняем рабочую книгу. По умолчанию новая книга без
//
изменений будет сохранена в папку «Мои Документы»
//
текущей учетной записи Windows
oWorkbook.GetType().InvokeMember("Save",
BindingFlags.InvokeMethod, null, oWorkbook, null);
Для
работы со страницами нам необходимо получить доступ к их коллекции.
Естественно, мы уже должны иметь ссылку на рабочую книгу. Для получения ссылки
на коллекцию страниц, нужно вызвать свойство Worksheets рабочей книги:
object oWorksheets =
oWorkbook.GetType().InvokeMember("Worksheets",
BindingFlags.GetProperty, null, oWorkbook, null);
Объект
oWorksheets - это managed-ссылка на коллекцию страниц текущей книги. Зная
ссылку на эту коллекцию мы можем получить доступ к конкретной странице по ее
имени или порядковому номеру (Аналогично коллекции рабочих книг):
//Задаем
порядковый номер страницы - 1
object[]
args = new object[1];
args[0]
= 1;
//
Получаем ссылку на эту страницу
object oWorksheet =
oWorksheets.GetType().InvokeMember("Item", BindingFlags.GetProperty,
null, oWorksheets, args);
//Задаем имя страницы
args[0]
= "Лист1";
//Получаем
ссылку на страницу с именем Лист1
oWorksheet = oWorksheets.GetType().InvokeMember("Item",
BindingFlags.GetProperty, null, oWorksheets, args);
4.
Работа со страницами. Объект Range. Использование записи макросов для
автоматизации Excel.
Страница
имеет ссылку на объект Range, который, по сути представляет собой объект-диапазон
ячеек. Через объект Range мы получаем доступ к любой ячейке, а также к ее
свойствам. Но объект Range содержит массу методов, и и для позднего связывания
нужно знать не только формат передаваемых им формальных параметров, но и точное
название метода (или свойства, которое по сути дела является комбинацией
методов). Иными словами, нужно знать сигнатуру метода, чтобы успешно вызвать
его через позднее связывание. До сих пор мы использовали простые методы типа
Open, Close, Save, с которыми, в принципе, все понятно. Они не содержат большое
количество параметров, и список параметров интуитивно ясен.
Для
того, чтобы узнать, какие методы поддерживает объект Range, можно
воспользоваться утилитой tlbimp.exe, и импортировав через нее библиотеку типов
Excel, открыть эту библиотеку в дизассемблере IL-кода ildasm.exe. Дизассемблер
покажет нам объект Range и все его методы. Можно использовать более продвинутые
утилиты сторонних разработчиков (например, всем известный Anakrino).
Но
есть более простой способ, который позволит нам существенно сэкономить время.
Это сам Excel, а точнее его запись макросов. Например, нам нужно
отформатировать ячейки определенным образом, хотя бы так, как показано на рис.:
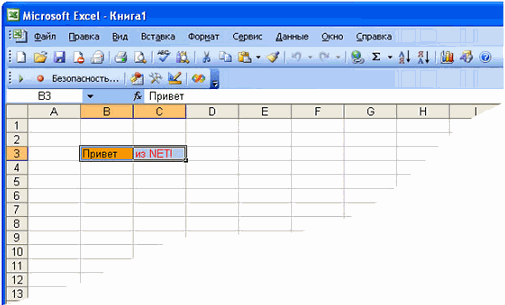
Рис.
2. Результат работы макроса.
Для
этого открываем Excel, включаем запись макросов и форматируем указанные ячейки
как нам вздумается. Полученный макрос будет выглядеть следующим образом:
Sub
Макрос1()
'
'
Макрос1 Макрос
' Макрос записан 17.04.2005 (Powerful)
'
Range("B3").Select
With Selection.Interior
.ColorIndex = 45
.Pattern = xlSolid
End With
Range("C3").Select
Selection.Font.ColorIndex = 3
Range("B3").Select
ActiveCell.FormulaR1C1 = "Привет"
Range("C3").Select
ActiveCell.FormulaR1C1 = "из NET!"
Range("B3:C3").Select
Selection.Borders(xlDiagonalDown).LineStyle = xlNone
Selection.Borders(xlDiagonalUp).LineStyle = xlNone
With Selection.Borders(xlEdgeLeft)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
With Selection.Borders(xlEdgeTop)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
With Selection.Borders(xlEdgeBottom)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
With Selection.Borders(xlEdgeRight)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
With Selection.Borders(xlInsideVertical)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End
With
End
Sub
Как
видно, здесь очень часто используется вызов метода Select у объекта Range. Но
нам это не нужно, ведь мы можем работать с ячейками напрямую, минуя их
выделение. Метод Select просто переопределяет ссылки, которые будут
возвращаться объектом Selection. Сам объект Selection - это тот же самый Range.
Таким образом, наша задача существенно упрощается, так как нам нужно просто
получить ссылки на нужные объекты Range, получить доступ к их внутренним
объектам и произвести вызов соответствующих методов или свойств, используя уже
известный нам метод InvokeMember().
Возьмем,
например следующий участок кода:
...
Range("B3").Select
With Selection.Interior
.ColorIndex = 45
.Pattern = xlSolid
End With
Range("C3").Select
Selection.Font.ColorIndex
= 3
...
Данный
код окрашивает цвет фона ячейки B3 в оранжевый, причем заливка ячейки -
сплошная, а цвет текста ячейки C3 устанавливает в красный.
Попробуем
реализовать этот участок в нашем приложении. Допустим, что мы успешно получили
ссылки на нужную книгу и страницу.
Ссылка
на страницу у нас храниться в переменной oWorksheet.
//
Получаем ссылку на ячейку B3 (точнее на объект Range("B3")),
// Получаем ссылку на объект Interior
object oInterior =
oRange.GetType().InvokeMember("Interior", BindingFlags.GetProperty,
null, oRange, null);
// Устанавливаем заливку (Аналог вызова
// Range("B3").Interior.ColorIndex)
oInterior.GetType().InvokeMember("ColorIndex",
BindingFlags.SetProperty, null, oInterior, new object[]{45});
//
Устанавливаем способ заливки (Pattern = xlSolid)
/*
Для того, чтобы узнать значение константы xlSolid, можно посмотреть
документацию, использовать описанный выше импорт библиотеки типов, а можно
просто прогнать наш макрос в Visual Basic по шагам и посмотреть значение в
контроле переменных, что существенно сэкономит Ваше время. */
//
Задаем параметр xlSolid = 1;
object[]
args = new object[]{1}
//
Устанавливаем свойство Pattern в xlSolid
oInterior.GetType().InvokeMember("Pattern",
BindingFlags.SetProperty, null, oInterior, args);
Для
того, чтобы задать текст, можно использовать свойство Value объекта Range.
oRange.GetType().InvokeMember("Value",
BindingFlags.SetProperty, null, oRange, new object[]{"Привет"});
Далее
разбирать код я не буду, советую читателям самим поэкспериментировать с
установкой свойств Excel из приложений .NET, по аналогии с приведенными здесь
примерами. А сейчас перейдем к событиям Excel и их перехвату, используя позднее
связывание.
5.
Перехват событий Excel
Перехватывая
события Excel, Вы получаете возможность отслеживать его состояние и
контролировать некоторые действия. Например, Вы можете отследить закрытие
рабочей книги и корректно отключиться от Excel, произведя очистку памяти и
прочие завершающие процедуры. Для того, чтобы понять, как перехватывать
события, проведем небольшой экскурс в события COM объектов. В этом отступлении
я предполагаю, что читатель немного знаком с COM архитектурой, хотя это не
обязательно, в конце статьи я приведу уже готовое решение, которое можно
использовать в своих приложениях, даже не задумываясь о тонкостях COM.
Если
объект (будь-то СОМ или RCW объекта .NET) хочет получать события другого COM
объекта, то он должен уведомить об этом источник событий, зарегистрировав себя
в списке объектов-получателей уведомлений о событиях. Для этого СОМ
предоставляет интерфейс IConnectionPointContainer, содержащий метод FindConnectionPoint.
С помощью вызова метода FindConnectionPoint, объект-получатель события получает
"точку подключения" - интерфейс IConnectionPoint и регистрирует c
помощью метода Advise свою реализацию интерфейса IDispatch, методы которого будут
реализовываться при возникновении тех или иных событий. Excel определяет
интерфейс, который должен реализовываться классом-приемником событий.
interface
["00024413-0000-0000-C000-000000000046"]
{
DispId(0x61d)]
void NewWorkbook(object Wb);
DispId(0x616)]
void SheetSelectionChange(object Sh, object Target);
DispId(0x617)]
void SheetBeforeDoubleClick(object Sh, object Target, ref bool
Cancel);
DispId(1560)]
void SheetBeforeRightClick(object Sh, object Target, ref bool
Cancel);
DispId(0x619)]
void SheetActivate(object Sh);
DispId(0x61a)]
void SheetDeactivate(object Sh);
DispId(0x61b)]
void SheetCalculate(object Sh);
DispId(0x61c)]
void SheetChange(object Sh, object Target);
DispId(0x61f)]
void WorkbookOpen(object Wb);
DispId(0x620)]
void WorkbookActivate(object Wb);
DispId(0x621)]
void WorkbookDeactivate(object Wb);
DispId(1570)]
void WorkbookBeforeClose(object Wb, ref bool Cancel);
DispId(0x623)]
void WorkbookBeforeSave(object Wb, bool SaveAsUI, ref bool Cancel);
DispId(0x624)]
void WorkbookBeforePrint(object Wb, ref bool Cancel);
DispId(0x625)]
void WorkbookNewSheet(object Wb, object Sh);
DispId(0x626)]
void WorkbookAddinInstall(object Wb);
DispId(0x627)]
void WorkbookAddinUninstall(object Wb);
DispId(0x612)]
void WindowResize(object Wb, object Wn);
DispId(0x614)]
void WindowActivate(object Wb, object Wn);
DispId(0x615)]
void WindowDeactivate(object Wb, object Wn);
DispId(0x73e)]
void SheetFollowHyperlink(object Sh, object Target);
DispId(0x86d)]
void SheetPivotTableUpdate(object Sh, object Target);
DispId(2160)]
void WorkbookPivotTableCloseConnection(object Wb, object Target);
DispId(0x871)]
void WorkbookPivotTableOpenConnection(object Wb, object Target); }
Таким
образом наш класс - приемник событий должен реализовывать этот интерфейс и
регистрировать себя используя IConnectionPointContainer и IConnectionPoint.
Библиотека базовых классов .NET уже определяет managed-версии интерфейсов: для
IConnectionPointContainer это UCOMIConnectionPointContainer, а для
IConnectionPoint - UCOMIConnectionPoint, которые определены в пространстве имен
- System.Runtime.InteropServices.
Регистрация
класса-приемника событий будет выглядеть так:
// и на IConnectionPoint
UCOMIConnectionPoint icp;
// Получаем ссылку на Excel
FExcel = Marshal.GetActiveObject("Excel.Application");
// Получаем ссылку на интерфейс
IConnectionPointContainer
icpc = FExcel as UCOMIConnectionPointContainer;
//
Получаем «точку подключения»
Guid
guid = new Guid("00024413-0000-0000-C000-000000000046");
icpc.FindConnectionPoint(ref guid, out icp);
//
Регистрируем класс - приемник событий, который реализует
//
интерфейс с GUID ["00024413-0000-0000-C000-000000000046"]
//
При этом наш класс получает уникальный идентификатор
//
cookie, который нужно сохранить, чтобы иметь
//
возможность отключиться от источника событий
icp.Advise(ExcelEventSink, out cookie);
Для
отключения от событий достаточно вызвать метод Unadvise(), и передать ему в
качестве параметра идентификатор cookie, который мы получили при регистрации
нашего класса-приемника событий методом Advise:
icp.Unadvise(cookie);
6.
Заключение.
Мы
рассмотрели в статье на примере с MS Excel взаимодействие COM и NET, используя
позднее связывание. Используя аналогичный подход, можно организовать управление
любым COM сервером. (Чаще всего автоматизируют приложения пакета MS Office и MS
Internet Explorer).
В
приложенном к данной статье файле находится класс, с помощью которого можно
организовать обработку событий Excel в любом приложении .NET.
7.
Литература
Эндрю
Троелсен. С# и платформа .NET. Библиотека программиста. - СПб. Питер, 2004.
Н.
Елманова, С. Трепалин, А. Тенцер. Delphi 6 и технология СОМ. - СПб. Питер,
2002.
Техническая
документация MSDN.
Список литературы
Для
подготовки данной работы были использованы материалы с сайта http://www.citforum.ru/