Применение статистической системы R для разработки алгоритмов диагностирования АЭС
Введение
Очень важную роль в системах диагностики играют
методы обработки и анализа данных. Вообще, на АЭС существует огромное
количество технологических параметров, контролируемых с различной
периодичностью, в то время как для описания различных эксплуатационных режимов
достаточно иметь гораздо меньший набор параметров. Таким образом, ставится
задача выделить из огромного потока информации именно ту ее часть, которая
является необходимой для решения нашей конкретной задачи диагностирования.
Исходя из типа задачи, выбираются конкретные методы. В данной работе мы
подробно рассмотрели такие большие классы методов, как кластерный и факторный
анализ.
Глава
1.
Методы анализа данных, применяемые в диагностике
1.1 Роль диагностики
За последние полвека роль технической
диагностики в самых различных технических областях значительно выросла. Это в
первую очередь связано с тем, что очень сильно возросла техническая сложность
объектов диагностики, которые зачастую работают на пределе допустимых
возможностей или вообще в запредельных режимах. Естественно, все это влечет за
собой и рост вероятности возникновения внештатных ситуаций, которые могут
перерасти в аварии и катастрофы, сопровождаемые полным выходом из строя объекта
контроля и его разрушением. Более того, характер многих объектов диагностики
(АЭС, химическое производство, нефтегазовые объекты, объекты
военно-промышленного комплекса и т.д.) таков, что при возникновении аварии на
них возможный ущерб может намного превысить стоимость самого этого объекта за
счет того, что зона влияния аварии может составлять десятки и сотни километров
и в этой зоне могут оказаться густонаселенные районы, важные промышленные
объекты и т.д. Ряд крупнейших аварий во всем мире подтвердил важность и
необходимость постоянного диагностирования многих технических объектов на всем
протяжении их работы с целью раннего выявления каких-либо аномалий и
дальнейшего прогнозирования их безопасной эксплуатации.
Среди важнейших объектов промышленного значения
атомные электростанции (АЭС) занимают особое место. Они являются средством для
выработки большого количества недорогой электроэнергии и одними из самых
экологически чистых среди предприятий энергетического комплекса, но авария на
АЭС может иметь совершенно катастрофические последствия. Это было со всей
очевидностью продемонстрировано крупнейшими авариями на АЭС "Three Mile
Island " (США, 1979 г.) и на Чернобыльской АЭС (СССР, 1986 г.), не считая
десятков менее крупных инцидентов. После этого основные усилия были направлены
на
обеспечение безопасности АЭС. Наряду с
конструктивными и другими мерами, важное положение здесь занимают разработка и
внедрение систем и средств технического диагностирования АЭС. Задачами
технического диагностирования являются [27]:
обнаружение отклонения от нормального режима
эксплуатации ЯЭУ (аномальной
ситуации) на возможно более ранней стадии развития;
определение причин аномальной ситуации;
прогнозирование хода развития аномальной
ситуации;
выбор мер по устранению или локализации
аномальной ситуации.
Важнейшим звеном системы диагностирования
является оператор. На него ложатся
задачи восприятия текущей информации, ее переработки и анализа, сравнения
текущего состояния с имеющимся описанием нормального или одного из аномальных
состояний и принятия решения о состоянии установки, принятия решения о
необходимом управляющем воздействии на систему. Уменьшить нагрузку на оператора
и повысить эффективность системы диагностирования можно за счет формализации
этих действий. За счет этого появляется возможность существенно повысить быстродействие
и надежность принимаемых решений, увеличить точность описания системы за счет
расширения состава диагностических признаков.
Важнейшую роль в развитии систем
диагностирования играет вычислительная техника. С появлением современных
персональных и промышленных компьютеров стало возможным создавать системы,
работающие в непосредственном (онлайновом) режиме, когда время между получением
информации с датчика и представлением обработанных данных на экран оператора
составляет доли секунды. Таким образом, резко возрастает скорость принятия
решений, повышается надежность и эффективность работы системы в целом,
становится возможным применение сложных алгоритмов обработки диагностической
информации при высоком быстродействии. Все это выводит системы технической
диагностики АЭС на качественно новый уровень. В качестве примеров таких систем
можно привести компьютерные системы поддержки оператора CAMLS, CSPM, ChemAND
для реакторов CANDU и акустическую систему обнаружения течи ALUS фирмы Siemens.
1.2 Методы обработки и анализа
данных
Очень важную роль в системах диагностики играют
методы обработки и анализа данных. Вообще, на АЭС существует огромное
количество технологических параметров, контролируемых с различной
периодичностью, в то время как для описания различных эксплуатационных режимов
достаточно иметь гораздо меньший набор параметров. Использовать единственный
набор из большинства параметров для описания всех режимов работы не
целесообразно не только по причинам технического характера (огромный объем данных,
увеличение времени обработки и т.д.), но и вследствие того факта, что многие
параметры не только могут иметь неверное значение (вероятность чего для
большего числа параметров растет), затрудняя работу алгоритма диагностирования,
но и быть для данного режима попросту избыточными. Таким образом, ставится
задача выделить из огромного потока информации именно ту ее часть, которая
является необходимой для решения нашей конкретной задачи диагностирования.
Решением такого рода задач занимается область знания, называемая Data Mining
(дословно, "добыча, откапывание данных"), образовавшаяся на стыке
многих научных дисциплин. Дальнейший выбор конкретных методов зависит от
выбранной задачи диагностирования и соответствующей ей задачи Data Mining.
Примером задач диагностирования успешно
применены к ряду задач, таких как идентификация частиц, распознавание лиц,
распознавание текста, биоинформатика и многим другим
могут
являться контроль герметичности оболочек, диагностирование режима кипения по
акустическим шумам и т.д. Решение этих задач может сводиться к решению таких
проблем, как распознавание образов, предсказание временных рядов, регрессионный
анализ зависимостей и т.д.
Наряду с другими подходами, в качестве
математического аппарата для формализации действий оператора при диагностике
ЯЭУ используется теория распознавания образов. В основе методологии ее
применения лежит аналогия между действиями оператора и задачами и методами их
решения в теории распознавания образов. Задачами теории являются отсеивание
случайных, избыточных и ошибочных данных, сжатие и редуцирование описания
состояния установки, выделение существенных диагностических признаков. Для
решения этих задач применяются методы поиска и формирования информативных
признаков. Выделив существенные диагностические признаки, оператор
классифицирует текущую ситуацию на основе приведенных в эксплуатационной
документации описаний классов и правил принятия решений, полагаясь также на
собственный опыт. В качестве примера описания класса можно привести набор
установок для ряда технологических параметров, соответствующих нормальной
работе реакторной установки на номинальном уровне мощности. Пример решающего
правила: "Если при работе на постоянном уровне мощности происходит
снижение давления в первом контуре, то произошел разрыв первого контура".
Ряд таких решающих правил лежит в основе сигналов аварийной защиты (A3). С
помощью теории распознавания образов возможно автоматизированное (с помощью
ЭВМ) решение следующих задач, возникающих при технической диагностике ЯЭУ:
Минимизации описания ЯЭУ;
Отбора и формирования существенных для
диагностики признаков;
Выработки на основе обучения или самообучения
решающих правил;
Автоматического распознавания эксплуатационных
ситуаций;
Прогнозирования развития аномальных режимов.
Можно выделить такие большие классы методов, как
кластерный анализ и построение оптимальных правил принятия решения.
Кластерный анализ рассматривает обучение без
учителя, т.е. подразумевается, что мы не имеем выборки данных с заранее
известной принадлежностью каждого измерения к тому или иному режиму. К
кластерному анализу относятся такие методы, как алгоритм цепных расстояний,
метод К внутригрупповых средних, центроидный метод (или "Форель"),
агломеративная иерархическая процедура кластеризации и др..
К методам построения решающих правил или методам
классификации относятся такие методы как перцептрон, дискриминант Фишера,
процедура Хо-Кашьяпа, метод К ближайших соседей, нейронные сети, деревья
классификации и др.
Глава
2.
Описание методов
2.1 Метод кластерного анализа
Термин кластерный анализ (впервые ввел Tryon,
1939) Кластерный анализ - это совокупность методов, позволяющих
классифицировать многомерные наблюдения, каждое из которых описывается набором
исходных переменных Х1,Х2,..., Хm. Целью кластерного анализа является
образование групп схожих между собой объектов, которые принято называть
кластерами. Слово кластер английского происхождения (cluster), переводится как
сгусток, пучок, группа. Родственные понятия, используемые в литературе, -
класс, таксон, сгущение.
В отличие от комбинационных группировок
кластерный анализ приводит к разбиению на группы с учетом всех группировочных
признаков одновременно. Например, если каждый наблюдаемый объект
характеризуется двумя признаками Х1 и Х2, то при выполнении комбинационной
группировки вся совокупность объектов будет разбита на группы по Х1, а затем
внутри каждой выделенной группы будут образованы подгруппы по Х2. Такой подход
получил название монотетического. Определить принадлежность каждого объекта к
той или иной группе можно, последовательно сравнивая его значения Х1 и Х2 с
границами выделенных групп. Образование группы в этом случае всегда связано с
указанием ее границ по каждому группировочному признаку отдельно. В кластерном
анализе используется иной принцип образования групп, так называемый
политетический подход. Все группировочные признаки одновременно участвуют в
группировке, т.е. они учитываются все сразу при отнесении наблюдения в ту или
иную группу. При этом, как правило, не указаны четкие границы каждой группы, а
также неизвестно заранее, сколько же групп целесообразно выделить в исследуемой
совокупности.
Кластерный анализ - одно из направлений
статистического исследования. Особо важное место он занимает в тех отраслях
науки, которые связаны с изучением массовых явлений и процессов. Необходимость
развития методов кластерного анализа и их использования, продиктована прежде
всего тем, что они помогают построить научно обоснованные классификации,
выявить внутренние связи между единицами наблюдаемой совокупности. Кроме того,
методы кластерного анализа могут использоваться с целью сжатия информации, что
является важным фактором в условиях постоянного увеличения и усложнения потоков
статистических данных.
Первые публикации по кластерному анализу
появились в конце 30-х годов нашего столетия, но активное развитие этих методов
и их широкое использование началось в конце 60-х - начале 70-х годов. В
дальнейшем это направление многомерного анализа очень интенсивно развивалось.
Появились новые методы, новые модификации уже известных алгоритмов, существенно
расширилась область применения кластерного анализа. Если первоначально методы
многомерной классификации использовались в психологии, археологии, биологии, то
сейчас они стали активно применяться в социологии, экономике, статистике, в
исторических исследованиях. Особенно расширилось их использование в связи с
появлением и развитием ЭВМ и, в частности, персональных компьютеров. Это
связано прежде всего с трудоемкостью обработки больших массивов информации
(вычисление и обращение матриц больших размерностей).
Методы кластерного анализа позволяют решать
следующие задачи:
• проведение классификации объектов с учетом
признаков, отражающих сущность, природу объектов. Решение такой задачи, как
правило, приводит к углублению знаний о совокупности классифицируемых объектов;
• проверка выдвигаемых предположений о наличии
некоторой структуры в изучаемой совокупности объектов, т.е. поиск существующей
структуры;
• построение новых классификаций для
слабоизученных явлений, когда необходимо установить наличие связей внутри
совокупности и попытаться привнести в нее структуру.
2.1.1 Иерархическое дерево
Назначение этого алгоритма состоит в объединении
объектов в достаточно большие кластеры, используя некоторую меру сходства или
расстояние между объектами. Рассмотрим горизонтальную древовидную диаграмму.
Диаграмма начинается с каждого объекта в классе (в левой части диаграммы).
Теперь представим себе, что постепенно (очень малыми шагами) вы
"ослабляете" ваш критерий о том, какие объекты являются уникальными,
а какие нет. Другими словами, вы понижаете порог, относящийся к решению об
объединении двух или более объектов в один кластер.
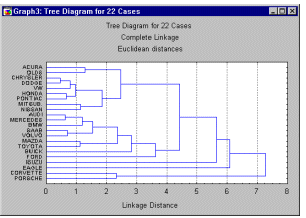
Рис. 1
-
Дендрограма
иерархических группировок
В результате, вы связываете вместе всё большее и
большее число объектов и объединяете все больше и больше кластеров, состоящих
из все сильнее различающихся элементов. Окончательно, на последнем шаге все
объекты объединяются вместе. На этих диаграммах горизонтальные оси представляют
расстояние объединения (в вертикальных древовидных диаграммах вертикальные оси
представляют расстояние объединения). Так, для каждого узла в графе (там, где
формируется новый кластер) вы можете видеть величину расстояния, для которого
соответствующие элементы связываются в новый единственный кластер. Когда данные
имеют ясную "структуру" в терминах кластеров объектов, сходных между
собой, тогда эта структура, скорее всего, должна быть отражена в иерархическом
дереве различными ветвями. В результате успешного анализа методом объединения
появляется возможность обнаружить кластеры (ветви) и интерпретировать их.
Меры расстояния:
Объединение или метод древовидной кластеризации
используется при формировании кластеров несходства или расстояния между
объектами. Эти расстояния могут определяться в одномерном или многомерном
пространстве. Наиболее прямой путь вычисления расстояний между объектами в
многомерном пространстве состоит в вычислении евклидовых расстояний. Если вы
имеете двух- или трёхмерное пространство, то эта мера является реальным
геометрическим расстоянием между объектами в пространстве (как будто расстояния
между объектами измерены рулеткой). Однако алгоритм объединения не
"заботится" о том, являются ли "предоставленные" для этого
расстояния настоящими или некоторыми другими производными мерами расстояния,
что более значимо для исследователя; и задачей исследователей является
подобрать правильный метод для специфических применений.
Евклидово расстояние
Это, по-видимому, наиболее общий тип расстояния.
Оно попросту является геометрическим расстоянием в многомерном пространстве и
вычисляется следующим образом:
расстояние(x,y) = { i
(xi - yi)2}1/2
i
(xi - yi)2}1/2
Заметим, что евклидово расстояние (и его
квадрат) вычисляется по исходным, а не по стандартизованным данным. Это обычный
способ его вычисления, который имеет определенные преимущества (например,
расстояние между двумя объектами не изменяется при введении в анализ нового
объекта, который может оказаться выбросом). Тем не менее, на расстояния могут
сильно влиять различия между осями, по координатам которых вычисляются эти
расстояния. К примеру, если одна из осей измерена в сантиметрах, а вы потом
переведете ее в миллиметры (умножая значения на 10), то окончательное евклидово
расстояние (или квадрат евклидова расстояния), вычисляемое по координатам,
сильно изменится, и, как следствие, результаты кластерного анализа могут сильно
отличаться от предыдущих.
Квадрат евклидова расстояния
Иногда может возникнуть желание возвести в
квадрат стандартное евклидово расстояние, чтобы придать большие веса более
отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом
(см. также замечания в предыдущем пункте): расстояние
(x,y) = i
(xi - yi)2
Расстояние городских кварталов (манхэттенское
расстояние)
Это расстояние является просто средним разностей
по координатам. В большинстве случаев эта мера расстояния приводит к таким же
результатам, как и для обычного расстояния Евклида. Однако отметим, что для
этой меры влияние отдельных больших разностей (выбросов) уменьшается (так как
они не возводятся в квадрат). Манхэттенское расстояние вычисляется по формуле:
расстояние
(x,y) = i
|xi - yi|
Расстояние Чебышева
Это расстояние может оказаться полезным, когда
желают определить два объекта как "различные", если они различаются
по какой-либо одной координате (каким-либо одним измерением). Расстояние
Чебышева вычисляется по формуле: расстояние
(x,y) = Максимум|xi - yi|
Степенное расстояние
Иногда желают прогрессивно увеличить или
уменьшить вес, относящийся к размерности, для которой соответствующие объекты
сильно отличаются. Это может быть достигнуто с использованием степенного
расстояния. Степенное расстояние вычисляется по формуле: расстояние
(x,y) = (i |xi - yi|p)1/r
где r и p - параметры, определяемые
пользователем. Несколько примеров вычислений могут показать, как
"работает" эта мера. Параметр p ответственен за постепенное
взвешивание разностей по отдельным координатам, параметр r ответственен за
прогрессивное взвешивание больших расстояний между объектами. Если оба
параметра - r и p, равны двум, то это расстояние совпадает с расстоянием
Евклида.
Правила объединения или связи:
На первом шаге, когда каждый объект представляет
собой отдельный кластер, расстояния между этими объектами определяются
выбранной мерой. Однако когда связываются вместе несколько объектов, возникает
вопрос, как следует определить расстояния между кластерами? Другими словами,
необходимо правило объединения или связи для двух кластеров. Здесь имеются
различные возможности: например, вы можете связать два кластера вместе, когда
любые два объекта в двух кластерах ближе друг к другу, чем соответствующее
расстояние связи. Другими словами, вы используете "правило ближайшего
соседа" для определения расстояния между кластерами; этот метод называется
методом одиночной связи. Это правило строит "волокнистые" кластеры,
т.е. кластеры, "сцепленные вместе" только отдельными элементами, случайно
оказавшимися ближе остальных друг к другу. Как альтернативу вы можете
использовать соседей в кластерах, которые находятся дальше всех остальных пар
объектов друг от друга. Этот метод называется метод полной связи. Существует
также множество других методов объединения кластеров, подобных тем, что были
рассмотрены.
Одиночная связь (метод ближайшего соседа)
Как было описано выше, в этом методе расстояние
между двумя кластерами определяется расстоянием между двумя наиболее близкими
объектами (ближайшими соседями) в различных кластерах. Это правило должно, в
известном смысле, нанизывать объекты вместе для формирования кластеров, и
результирующие кластеры имеют тенденцию быть представленными длинными
"цепочками".
Полная связь (метод наиболее удаленных соседей)
В этом методе расстояния между кластерами
определяются наибольшим расстоянием между любыми двумя объектами в различных
кластерах (т.е. "наиболее удаленными соседями"). Этот метод обычно
работает очень хорошо, когда объекты происходят на самом деле из реально
различных "рощ". Если же кластеры имеют в некотором роде удлиненную
форму или их естественный тип является "цепочечным", то этот метод
непригоден.
Невзвешенное попарное среднее
В этом методе расстояние между двумя различными
кластерами вычисляется как среднее расстояние между всеми парами объектов в
них. Метод эффективен, когда объекты в действительности формируют различные
"рощи", однако он работает одинаково хорошо и в случаях протяженных
("цепочного" типа) кластеров.
Взвешенное попарное среднее
Метод идентичен методу невзвешенного попарного
среднего, за исключением того, что при вычислениях размер соответствующих
кластеров (т.е. число объектов, содержащихся в них) используется в качестве
весового коэффициента. Поэтому предлагаемый метод должен быть использован
(скорее даже, чем предыдущий), когда предполагаются неравные размеры кластеров.
Невзвешенный центроидный метод
В этом методе расстояние между двумя кластерами
определяется как расстояние между их центрами тяжести.
Взвешенный центроидный метод (медиана)
тот метод идентичен предыдущему, за исключением
того, что при вычислениях используются веса для учёта разницы между размерами
кластеров (т.е. числами объектов в них). Поэтому, если имеются (или
подозреваются) значительные отличия в размерах кластеров, этот метод оказывается
предпочтительнее предыдущего.
Метод Варда
Этот метод отличается от всех других методов,
поскольку он использует методы дисперсионного анализа для оценки расстояний
между кластерами. Метод минимизирует сумму квадратов (SS) для любых двух
(гипотетических) кластеров, которые могут быть сформированы на каждом шаге.
Подробности можно найти в работе Варда (Ward, 1963). В целом метод
представляется очень эффективным, однако он стремится создавать кластеры малого
размера.
2.1.2
Метод
K средних
Общая логика. Предположим,
вы уже имеете гипотезы относительно числа кластеров (по наблюдениям или по
переменным). Вы можете указать системе- образовать ровно три кластера так,
чтобы они были настолько различны, насколько это возможно. Это именно тот тип
задач, которые решает алгоритм
<#"700969.files/image003.gif">
Рис. 2
-
3М
диаграмма рассеяния
Для случая более трех переменных, становится
невозможным представить точки на диаграмме рассеяния, однако логика вращения
осей с целью максимизации дисперсии нового фактора остается прежней.
Ортогональные факторы
После того, как вы нашли линию, для которой
дисперсия максимальна, вокруг нее остается некоторый разброс данных. И
процедуру естественно повторить. Таким образом, факторы последовательно
выделяются один за другим. Так как каждый последующий фактор определяется так,
чтобы максимизировать изменчивость, оставшуюся от предыдущих, то факторы
оказываются независимыми друг от друга. Другими словами, некоррелированными или
ортогональными.
Анализ главных факторов
Прежде, чем продолжить рассмотрение различных
аспектов вывода анализа главных компонент, введем анализ главных факторов.
Вернемся к примеру вопросника об удовлетворенности жизнью, чтобы сформулировать
другую "мыслимую модель". Вы можете представить себе, что ответы
субъектов зависят от двух компонент. Сначала выбираем некоторые подходящие
общие факторы, такие как, например, "удовлетворение своим хобби",
рассмотренные ранее. Каждый пункт измеряет некоторую часть этого общего аспекта
удовлетворения. Кроме того, каждый пункт включает уникальный аспект
удовлетворения, не характерный для любого другого пункта.
Общности
Если эта модель правильна, то вы не можете
ожидать, что факторы будут содержать всю дисперсию в переменных; они будут
содержать только ту часть, которая принадлежит общим факторам и распределена по
нескольким переменным. На языке факторного анализа доля дисперсии отдельной
переменной, принадлежащая общим факторам (и разделяемая с другими переменными)
называется общностью. Поэтому дополнительной работой, стоящей перед
исследователем при применении этой модели, является оценка общностей для каждой
переменной, т.е. доли дисперсии, которая является общей для всех пунктов. Доля
дисперсии, за которую отвечает каждый пункт, равна тогда суммарной дисперсии,
соответствующей всем переменным, минус общность. С общей точки зрения в
качестве оценки общности следует использовать множественный коэффициент
корреляции выбранной переменной со всеми другими
Вы хотите найти 0, Люгнт. Ниже приведена таблица
нагрузок на повернутые факторы (Табл.3).
Табл. 3
-
Нагрузки
на повернутые факторы
|
STATISTICA
ФАКТОРНЫЙ АНАЛИЗ
|
Факторные
нагрузки (Варимакс нормализ.) Выделение: Главные компоненты
|
|
Переменная
|
Фактор
1
|
Фактор
2
|
|
РАБОТА_1
РАБОТА_2 РАБОТА_3 ДОМ_1 ДОМ_2 ДОМ_3
|
.862443.890267.886055.062145.107230.140876
|
.051643.110351.152603.845786.902913.869995
|
|
Общая
дисперсия Доля общей дисп.
|
2.356684.392781
|
2.325629.387605
|
Интерпретация факторной структуры
Теперь картина становится более ясной. Как и
ожидалось, первый фактор отмечен высокими нагрузками на переменные, связанные с
удовлетворенностью на работе, а второй фактор - с удовлетворенностью домом. Из
этого вы должны заключить, что удовлетворенность, измеренная вашим вопросником,
составлена из двух частей: удовлетворенность домом и работой, следовательно, вы
произвели классификацию переменных.
Рассмотрим следующий пример, здесь к предыдущему
примеру добавились четыре новых переменных Хобби.
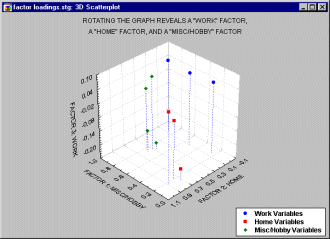
Рис. 3
- Диаграмма
рассеяния факторных нагрузок
На этом графике (Рис.3) 10 переменных были
сведены к трем факторам - фактор удовлетворенности работой (work), фактор
удовлетворенности домом (home), и фактор удовлетворенности хобби (hobby/misc).
Заметим, что факторные нагрузки для каждого фактора имеют сильно различающиеся
значения для остальных двух факторов, но большие значения именно для этого
фактора. Например, факторные нагрузки для переменных, относящихся к хобби
(выделены зеленым цветом) имеют и большие, и малые значения для
"дома" и "работы", но все четыре переменные имеют большие
факторные нагрузки для фактора "хобби".
Косоугольные факторы
Некоторые авторы (например, Харман (Harman,
1976), Дженнрих и Сэмпсон (Jennrich, Sampson, 1966); Кларксон и Дженнрих
(Clarkson, Jennrich, 1988)) обсуждали довольно подробно концепцию косоугольных
(не ортогональных) факторов, для того чтобы достичь более простой интерпретации
решений. В частности, были развиты вычислительные стратегии, как для вращения
факторов, так и для лучшего представления "кластеров" переменных без
отказа от ортогональности (т.е. независимости) факторов. Однако косоугольные
факторы, получаемые с помощью этих процедур, трудно интерпретировать.
Возвратимся, к примеру, обсуждавшемуся выше, и предположим, что вы включили в
вопросник четыре пункта, измеряющих другие типы удовлетворенности (Хобби).
Предположим, что ответы людей на эти пункты были одинаково связаны как с
удовлетворенностью домом (Фактор 1), так и работой (Фактор 2). Косоугольное
вращение должно дать, очевидно, два коррелирующих фактора с меньшей, чем ранее,
выразительностью, то есть с большими перекрестными нагрузками.
Иерархический факторный анализ
Вместо вычисления нагрузок косоугольных
факторов, для которых часто трудно дать хорошую интерпретацию, вы можете
использовать стратегию, впервые предложенную Томсоном (Thompson, 1951) и
Шмидтом и Лейманом (Schmidt, Leiman, 1957), которая было подробно развита и
популяризирована Верри (Wherry, 1959, 1975, 1984). В соответствии с этой
стратегией, вначале определяются кластеры и происходит вращение осей в пределах
кластеров, а затем вычисляются корреляции между найденными (косоугольными)
факторами. Полученная корреляционная матрица для косоугольных факторов затем
подвергается дальнейшему анализу для того, чтобы выделить множество
ортогональных факторов, разделяющих изменчивость в переменных на ту, что
относятся к распределенной или общей дисперсии (вторичные факторы), и на
частные дисперсии, относящиеся к кластерам или схожим переменным (пунктам
вопросника) в анализе (первичные факторы). Применительно к рассматриваемому
примеру такой иерархический анализ может дать следующие факторные нагрузки:
Табл. 4
-
Вторичные
и первичные факторные нагрузки
|
STATISTICA
ФАКТОРНЫЙ АНАЛИЗ
|
Вторичные
и первичные факторные нагрузки
|
|
Фактор
|
Вторич.
1
|
Первич.
1
|
Первич.
2
|
|
РАБОТА_1
РАБОТА_2 РАБОТА_3 ДОМ_1 ДОМ_2 ДОМ_3 ХОББИ_1 ХОББИ_2 ХОББИ_3 ХОББИ_4
|
.483178.570953.565624.535812.615403.586405.780488.734854.776013.714183
|
.649499.687056.656790.117278.079910.065512.466823.464779.439010.455157
|
.187074.140627.115461.630076.668880.626730.280141.238512.303672.228351
|
Внимательное изучение позволяет сделать следующие
заключения:
Имеется общий (вторичный) фактор
удовлетворенности, которому, по-видимому, подвержены все типы
удовлетворенности, измеренные для 10 пунктов;
Имеются, вероятно, две первичные уникальных
области удовлетворения, которые могут быть описаны как удовлетворенностью
работой, так и удовлетворенностью домашней жизнью.
Верри (Wherry, 1984) обсудил подробно примеры
такого иерархического анализа и объяснил, каким образом могут быть получены
значимые и интерпретируемые вторичные факторы.
Глава
3.
Разработка программного обеспечения
.1 Система статистического анализа R
Все расчеты, приведенные, в данной работе
выполнялись с использованием статистической системы R [7], представляющую собой
язык программирования и среду для статистических расчетов и графики. R
предлагает широкие вычислительные возможности, включая линейное и нелинейное
моделирование, статистические тесты, анализ временных рядов, методы
классификации, кластеризации, искусственного интеллекта и многое другое. Эта
система является свободно-распространяемым программным продуктом и доступна
бесплатно для основных платформ, включая операционные системы Windows и Linux.
К основных достоинствам R относятся следующие:
• модульность - базовая установка системы
обеспечивает только наиболее общую, минимально необходимую функциональность.
Функции, реализующие специфические методы и алгоритмы, свойственные тем или
иным областям анализа и обработки данных, доступны через подгружаемые модули -
так называемые пакеты, которые также предназначены для свободного использования
и доступны на официальном сайте R;
широкие графические возможности, включая
3-хмерную графику;
открытый интерфейс, обеспечивающий простую
интеграцию R с другими языками программирования, системами обработки данных,
системами управления базами данных и пр. [8];
высокие темпы «эволюционирования» - наличие
исходного кода, а также прав на свободное использование данного программного
продукта приводят к тому, что в работе над созданием, тестированием и
оптимизацией R принимают участие тысячи разработчиков и пользователей со всего
мира, что обеспечивает высокое качество и надежность программ, а так же высокие
темпы появление новых исправленных и оптимизированных версий как самой системы
R, так и подгружаемых модулей.
По мнению авторов, в настоящее время система К
является наиболее мощной и удобной системой для всестороннего анализа и
обработки данных.
В этой связи вполне логичным можно считать
утверждение, что для решения задач подобного рода выбор, очевидно, ложиться на
R. В действительности это не совсем так. R действительно прост и удобен в
задачах, когда исследователь точно знает последовательность своих действий. Во
многом это означает, что исследователь досконально знает данные, с которыми он
работает, а также их особенности. Это в свою очередь означает, что
исследователь знает и методы, которые ему понадобятся для получения требуемого
результата. В таком случае, все что требуется это вызвать соответствующую R
функцию. В действительности, в самом начале работы с данными нам известно о них
либо очень мало, либо совсем ничего и поэтому стадии применения конкретных
методов предшествует огромная работа, связанная с разведочным анализом. Это
подразумевает работу не со статистическими методами, а с самими данными -
реализацией большого числа различных предположений по их преобразованию,
предварительной обработке и т. д. В таких условиях весьма актуальными
становятся такие вопросы как уровень владения используемым средством
манипуляции с данными, эффективность используемых средств с точки зрения быстроты
их реализации, степень их ориентации на работу с целыми массивами данных, а не
с отдельными скалярными значениями-числами и т. д. Решением подобной
конфликтной ситуации может служить следующий подход: «подключить»
функциональность R к уже знакомому и эффективному средству манипуляции с
данными. Таким образом имея функциональность базового языка программирования в
неизменном виде мы дополнительно получаем доступ к функциональности R!
Подобное решение становиться возможным в силу
следующей особенности R. Подавляющее большинство методов и алгоритмов,
доступных для использования в R реализованы в виде оптимизированных,
скомпилированных и готовых к использованию библиотек функций, написанных на
языках С и Fortran. Таким образом, если базовая платформа анализа содержит в
себе возможности вызова внешних библиотек, становится возможным построение
мощного совместного средства анализа данных, сочетающего в себе быстроту и
отлаженность функций R с эффективностью предварительной манипуляции данными в
знакомой среде. В качестве одного из вариантов базовой платформы авторами
использован язык программирования Dyalog APL.
3.2 Язык программирования APL
АПЛ (APL, от A Programming Language,
- язык программирования) был в основном разработан в 1962 году Кеннетом
Айверсоном, в прошлом профессором Гарвардского университета, который перешел в
фирму IBM <#"700969.files/image005.gif">
Рис. 4
-
Кластеры,
полученные после применения kmeans
Для сравнения проведем аналогичные действия на
языке APL
Вначале передаем значение матрицы х в APL сессию
x„rget 'x'
получаем матрицу, размерностью
½x
100 2
Далее применим APL функцию kmean, аналогичную
функции в R
m„2 kmean ›[2]s
получаем 2 класса:„mclass›[2]s c
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2
строим график с помощью APL
функции
plot
0 plot ›[1]¨(›[2]1
2°.=c)š¨›x
Рис. 5
-
Кластеры,
полученные после применения kmean
Матрица центров
определяется в APL сессии следующим образом:
œm
.04238166514 ¯0.01510380116
0.9453574183 1.006225326
размеры классов:
+/c=2
+/c=1
Как видим, результаты абсолютно идентичны!
3.5 Программная реализация
Для автоматизации работы с функциями R в APL
сессии, строят оболочку
3.5.1 Кластерный анализ
Функция r_kmean
Назначение: передает в R матрицу данных, разделяет
ее на кластеры и возвращает результат в APL.
Аргументы:матрица исходных данных,
k-задаваемое количество кластеров.
Результат: cu-вектор,
показывающий какая точка к какому кластеру относится
ce-матрица
центров кластеров.
Текст функции
y„k r_kmean mat;cu;ce
'mat'rput mat
'k'rput k'cl <- kmeans(mat, k,
20)''cu<-cl$cluster'„rget'cu'
rexec'ce<-cl$centers'„rget'ce'„cu
ce
Функция n_clust
Назначение: показывает,
сколько точек в каждом кластере.
Аргументы: x-вектор,
показывающий, какая точка к какому кластеру относится.
Результат: n-количество
точек, попавших в каждый кластер.
Текст функции:
n„n_clust x
n„{¾[“¾]}žx
n„n,[1.5]+/n°.=x
Функция hclust_war
Назначение: передает
в R матрицу данных и разделяет ее на кластеры, строит дерево классификации.
Аргументы:матрица исходных данных,
k-задаваемое количество кластеров,
m-определяет, строить дерево, либо нет.
Результат: h-вектор,
показывающий какая точка к какому кластеру относится.
Текст функции:
h„l hclust_war mat;k;m
(k m)„l
rexec'library(cluster)'
'mat'rput mat
'k'rput k
'm'rput m' hc <-
hclust(dist(mat), "war")'' memb <- cutree(hc, k = k) '„rget'memb'
…(m=0)/0' plot(hc, hang = -1)'
3.5.2 Факторный анализ
Функция factanal
Назначение: передает
в R матрицу данных и определяет факторные нагрузки для заданного количества
факторов
Аргументы:матрица исходных данных,
n-задаваемое количество факторов.
Результат:-матрица факторов,
f2-вектор специфических нагрузок.
Текст функции:
f„n factanal mat
'mat'rput mat
'n'rput n'f<-factanal(mat,
factors = n)''f1<-f$loadings''f2<-f$uniquenesses '
f1„rget'f1'„rget'f2'„f1 f2
Функция factanal_promax
Назначение: производит
вращение promax факторных нагрузок для наглядного представления.
Аргументы:матрица исходных данных,
n-задаваемое количество факторов.
Результат:-матрица факторов,
f2-вектор специфических нагрузок.
Текст функции:
f„n factanal_promax mat
'mat'rput mat
'n'rput n'f<-factanal(x=mat,
factors = n, rotation =
"promax")''f1<-f$loadings''f2<-f$uniquenesses
'„rget'f1'„rget'f2'„f1 f2
Глава
4.
Кластерный и факторный анализ результатов УЗК
В работе АЭС с реакторами РБМК-1000 важную роль
играют трубопроводы Ду-300. Они входят в состав контура многократной
принудительной циркуляции (опускные и напорные трубопроводы), системы продувки
и расхолаживания и системы аварийного охлаждения реактора. Диаметр
трубопроводов из аустенитной стали составляет 325 мм, толщина стенки - 16 мм.
Контроль состояния сварных соединений трубопроводов проводится с помощью
ультразвукового метода неразрушающего контроля по методике, разработанной
специалистами Инженерного центра диагностики при НИКИЭТ им. Н.А. Доллежаля.
4.1 Установка для проведения
контроля сварных соединений
Для проведения ультразвукового контроля (УЗК)
служит установка, представленная на Рис. 6.
В ее состав входят 8 преобразователей,
располагающихся по обе стороны сварного шва. Часть из них является
генераторами, а часть - приемниками (усилителями) акустического сигнала
(обозначены буквами Г и У), два преобразователя совмещают эти функции. Для
обнаружения дефектов используется два метода ультразвукового контроля:
эхо-метод и теневой метод. При эхо-методе преобразователи располагаются с одной
стороны сварного соединения. Метод основан на том, что генератор излучает
ультразвуковую волну, которая отражается от дефекта и принимается усилителем. В
отсутствие дефекта сигнал на приемнике отсутствует. При теневом методе
генератор и приемник располагаются с разных сторон шва. Если дефекта нет, волна
без потерь проходит от генератора к приемнику. При наличии дефекта сигнал на
приемнике ослаблен из-за рассеивания ультразвуковой волны на дефекте.
Табл. 6
-
Характеристики
тактов прозвучивания
|
№
такта
|
Генератор
|
Приемник
|
Схема
|
Выявляемые
дефекты
|
|
0
|
Г0
|
У0
|
Хордовая
|
Продольные
сторона А
|
|
1
|
Г2
|
У2
|
Хордовая
|
Продольные
сторона Б
|
|
2
|
Г5
|
У5
|
РC
|
Продольные
сторона А
|
|
3
|
Г6
|
У6
|
РC
|
Продольные
сторона Б
|
|
4
|
Г5
|
У6
|
Теневая
РС
|
Продольные
сторона А
|
|
5
|
Г6
|
У5
|
Теневая
РС
|
Продольные
сторона Б
|
|
6
|
Г0
|
У2
|
Хордовая
|
Поперечные
|
|
7
|
Г2
|
У0
|
Хордовая
|
Поперечные
|
|
8
|
Г5
|
У5
|
РС
|
Продольные
+6дБ (А)
|
|
9
|
Г6
|
У6
|
РС
|
Продольные
+6дБ (Б)
|
|
10
|
Г0
|
У0
|
Хордовая
|
Продольные
+6дБ (А)
|
|
11
|
Г2
|
У2
|
Хордовая
|
Продольные
+6дБ (Б)
|
|
12
|
Г2
|
У3
|
Теневая
хордовая
|
Продольные
сторона А
|
|
13
|
Г3
|
У0
|
Теневая
хордовая
|
Продольные
сторона Б
|
|
14
|
Г0
|
У2
|
Хордовая
|
Поперечные
+6дБ
|
|
15
|
Г2
|
У0
|
Хордовая
|
Поперечные
+6дБ
|
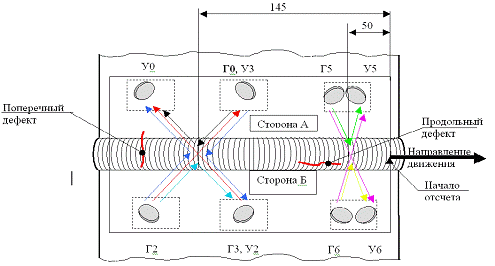
Рис. 6 - Схема
установки для проведения УЗК
Всего реализовано 16 различных схем
прозвучивания материала сварного шва. Основными являются 4 схемы с
использованием эхо-метода (эхо-такты, например, с генератором Г0 и приемником
У0) и 4 с использованием теневого метода (теневые такты, например, Г6-У5). С их
помощью осуществляется выявление продольных дефектов. Еще 2 схемы предназначены
для обнаружения поперечных дефектов. На случай недостаточного акустического
контакта эхо-такты повторяются с усилением +6дБ (6 схем). Такое количество
преобразователей и реализуемых с их помощью схем прозвучивания обеспечивает
более надежное выявление дефектов.
Конструктивно все преобразователи
объединены в так называемый сканер, в который также входят двигатель и датчик
пути. Для проведения контроля сканер с помощью специального кольца
устанавливается на сварное соединение и при помощи двигателя делает один оборот
вокруг трубопровода с шагом 1мм. При этом каждый миллиметр материала шва прозвучивается
по всем 16 схемам, а датчик пути измеряет пройденное расстояние. С помощью
кабеля сканер соединен с ультразвуковым дефектоскопом, на который в процессе
контроля передается вся полученная информация. По окончании контроля данные с
дефектоскопа переносятся на персональный компьютер для дальнейшего анализа.
4.2 Постановка задачи
Описанная выше система в течение
нескольких лет используется на российских АЭС с реакторами РБМК. Анализ
результатов контроля выполняется экспертом, который выдает заключение о наличии
дефектов в данном сварном соединении и их координатах. Основным признаком
дефекта является одновременное повышение уровня эхо-сигнала (пик) и падение
амплитуды теневого сигнала (провал) хотя бы по одной паре тактов. Таким
образом, основная задача эксперта состоит в выделении пиков и провалов сигнала
на фоне помех. После определения координат дефекта, его высота определяется по
величине падения теневого сигнала.
В идеале амплитуда эхо-сигнала при
отсутствии дефекта должна равняться нулю, а амплитуда теневого сигнала - 255
усл.ед. При наличии дефекта должно наблюдаться обратное соотношение сигналов по
эхо и теневым тактам.
В реальности, анализ сигналов
затруднен наличием целого ряда мешающих факторов. Даже при отсутствии дефекта,
ультразвуковая волна отражается на границах зерен структуры материала. Поэтому
в сигнале всегда присутствует так называемый структурный шум [3]. Свое влияние
оказывают электрические помехи и ошибки амплитудного квантования сигналов.
Поведение сигналов УЗК существенно зависит от размера, ориентации и положения
дефекта относительно измерительного блока. Наконец сильнейшее влияние на сигнал
оказывает непостоянство акустического контакта датчиков и контролируемой
поверхности.
Таким образом, эксперт должен
проводить одновременный анализ и сопоставление, в условиях шумов и мешающих
факторов, 16-и сигналов, изменяющихся при изменении координат сканера, поэтому
точность анализа не высока. Наша задача состоит в проведении анализа данных
контроля с помощью статистических методов анализа (факторный и
кластерный), применяемых в диагностике и сопоставить с результатом анализа,
проведенного высококвалифицированными экспертами.
4.3 Исходные данные
Результаты УЗК сварного соединения
представляют собой файл данных, в котором записана служебная информация (номер
соединения, условия контроля и т.д.) и таблица измеренных значений сигналов. В
первом столбце таблицы записываются показания датчика пути (расстояние вдоль
сварного шва в миллиметрах), а в остальных - значения амплитуд сигналов по всем
16 схемам прозвучивания. Длина окружности трубопровода составляет 1020 мм. Для
надежного контроля начального участка сканирование проводиться с нахлестом.
Амплитуда сигнала изменяется в диапазоне 0-255 условных единиц.
Будем представлять результаты УЗК в
виде матрицы 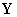 размерностью
размерностью
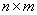 :
:
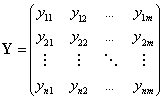 , (1)
, (1)
В качестве исходных данных для
анализа использовались результаты УЗК 31-ого сварного соединения (шва)
трубопроводов Курской АЭС. Имеющиеся для этих швов экспертные заключения
указывают на наличие в каждом шве от 1 до 4 выявленных дефектов.
4.4 Анализ данных
Определение типа дефектов
Из общего файла данных выделим
результаты УЗК представленные в виде матрицы:
½cr„cracks[;2‡¼18]
1579 16
а также теоретический вектор
классификации дефектов, полученный в результате анализа, проведенного
экспертами
½t„cracks[;19]
1579
4.4.1 Кластерный анализ
Проведем кластерный анализ данных методом К
средних. Применим функцию r_kmean для того, чтобы поделить данные на кластеры.
Количество кластеров взяли равное трем, т к подозреваем дефекты трех видов.
(u v )„ 3 r_kmean cr
после применения получили вектор кластеризации
u.
½ u
1579
Посмотрим, сколько точек попало в каждый кластер
n_clust u
334
510
735
Для наглядного представления кластеров построим
их, спроецировав на оси Орлочи (Рис2)
orl„›[2]Orloci cr
0
ap207.plot›[2]¨(›[2](¼3)°.=œu)/¨›œorl
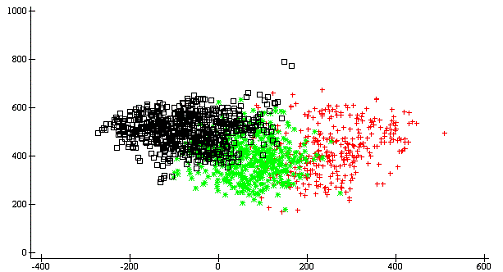
Рис.
7 - Кластеры,
полученные после применения функции r_kmean
Для сравнения с результатами экспертов построим
матрицу сходства
œ{+/(¼3)°.=¾}¨(›[2]('hvn'°.=t))/¨›u
23 459 730
0 2
Проведем кластерный анализ данных иерархическим
методом кластеризации. В данном случае наилучший результат показало применение
метода Варда. Применим функцию hclust_war для того, чтобы поделить данные на
кластеры.
h„3 hclust_war cr
получим вектор кластеризации h и дерево
кластеризации, на котором наглядно видно поэтапное распределение точек по
кластерам (Рис 8).
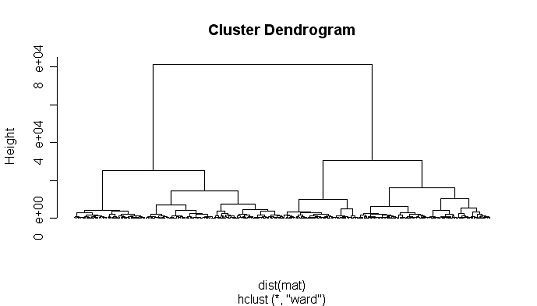
Рис. 8 -
Дендрограмма иерархических скоплений
посмотрим, сколько точек попало в каждый кластер
n_clust h
793
503
283
Для наглядного представления кластеров построим
их, спроецировав на оси Орлочи (Рис 9)
0
ap207.plot›[2]¨(›[2](¼3)°.=œh)/¨›œorl
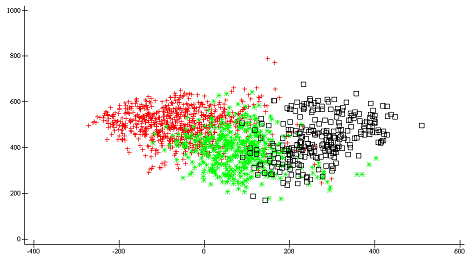
Рис.
9 - Кластеры,
полученные после применения hclust_war
Для сравнения с результатами экспертов построим
матрицу сходства
œ{+/(¼3)°.=¾}¨(›[2]('hvn'°.=t))/¨›h
787 415 10
88 187
0 86
Посмотрим, сколько точек должно относиться к
вертикальным и горизонтальным дефектам и сколько к неоднородности материала
n_clust t
h 1212 -горизонтальные89 -неоднородность материала278
-вертикальные
а так же построим эти классы, спроецировав на
оси Орлочи (Рис 10).
0 ap207.plot›[2]¨(›[2]'hvn'°.=t)/¨›œorl
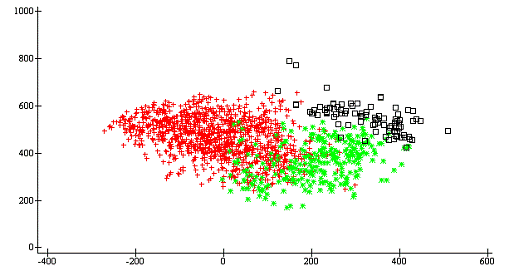
Рис. 10 - Теоретическое
распределение классов
В итоге, мы видим, что применение функций kmean
и hclust дало нам три кластера, схожих между собой по количеству точек. При
сравнении их с данными экспертного заключения мы увидели, что наши кластеры
соответствуют типам дефектов. Следовательно, с помощью кластерного анализа мы
научились автоматически находить объективное различие между типами дефектов.
4.4.2 Факторный анализ
Применим факторный анализ для
результата УЗК сварных соединений с искусственно внесенными дефектами. Данные
представлены в виде матрицы  .
.
строк - т.к. сканирование
проводилось чере 1 мм, а длина окружности трубопровода составляет 1020 мм.
столбцов - т.к. сканер состоит из 16
датчиков.
Для определения физического смысла
полученных факторов приведена табл. 6.
Табл. 7
|
№
такта
|
Генератор
|
Приемник
|
Схема
|
Выявляемые
дефекты
|
|
0
|
Г0
|
У0
|
Хордовая
|
Продольные
сторона А
|
|
1
|
Г2
|
У2
|
Хордовая
|
Продольные
сторона Б
|
|
2
|
Г5
|
У5
|
РC
|
Продольные
сторона А
|
|
3
|
Г6
|
У6
|
РC
|
Продольные
сторона Б
|
|
4
|
Г5
|
У6
|
Теневая
РС
|
Продольные
сторона А
|
|
5
|
Г6
|
У5
|
Теневая
РС
|
Продольные
сторона Б
|
|
6
|
Г0
|
У2
|
Хордовая
|
Поперечные
|
|
7
|
Г2
|
У0
|
Хордовая
|
Поперечные
|
|
8
|
Г5
|
У5
|
РС
|
Продольные
+6дБ (А)
|
|
9
|
Г6
|
У6
|
РС
|
Продольные
+6дБ (Б)
|
|
10
|
Г0
|
У0
|
Хордовая
|
Продольные
+6дБ (А)
|
|
11
|
Г2
|
У2
|
Хордовая
|
Продольные
+6дБ (Б)
|
|
12
|
Г2
|
У3
|
Теневая
хордовая
|
Продольные
сторона А
|
|
13
|
Г3
|
У0
|
Теневая
хордовая
|
Продольные
сторона Б
|
|
14
|
Г0
|
У2
|
Хордовая
|
Поперечные
+6дБ
|
|
15
|
Г2
|
У0
|
Хордовая
|
Поперечные
+6дБ
|
проведем факторный анализ - применим функцию
factanal. Выделив различное число факторов, убедились в том, что значимых два
фактора.
Для первого измерения:
½x1„(1œSOP)[;1+¼16]
1020 16
P1„2 factanal x1
Получим матрицу факторных нагрузок для первого
измерения.
F1
¯0.006909217585
0.3570403632
.9359667383 ¯0.05613298544
¯0.02516413007
0.9591901485
0.7562349696 0.04619627057
¯0.2184879084 ¯0.1619798794
¯0.2454979435 ¯0.4093254292
¯0.04533917083 ¯0.01122230633
¯0.05946685351 ¯0.03547559663
0.01979887715 0.9693684672
.7431416704 0.1227686242
¯0.0503300375
0.5688344585
.9632744079 ¯0.08902034789
¯0.2377305689 ¯0.3422272036
¯0.2351652602 ¯0.3879201117
¯0.05944048362 ¯0.1324745156
¯0.1204646179 ¯0.1131851983
Для второго измерения:
½x2„(2œSOP)[;1+¼16]
1020 16P2„2 factanal x2
Получим матрицу факторных нагрузок для второго
измерения
F2
¯0.01774647929
0.1261071226
.9418428664 ¯0.04329535857
¯0.01335442054
0.8991667839
.7080867772 0.03021178612
¯0.1508099056 ¯0.01082638453
¯0.2526317668 ¯0.1788843203
0.03386485305 0.02306466543
¯0.04682266494 ¯0.004369314023
0.03002790398 0.9970478696
.5807746141 0.05048395747
¯0.05242975831
0.2681249588
.969271625 ¯0.07814245605
¯0.2307022961 ¯0.3115868269
¯0.2133557114 ¯0.2504969228
¯0.06376167053 ¯0.07865004072
¯0.02711297381 ¯0.07289307416
Для третьего измерения:
½x3„(3œSOP)[;1+¼16]
1020 16P3„2 factanal x3
Получим матрицу факторных нагрузок для третьего
измерения
F3
¯0.06173261452
0.2209860597
.9482804904 ¯0.02449341725
¯0.01916873987
0.9440920134
.6860583853 ¯0.05033583345
¯0.4319492371 ¯0.4910195695
¯0.2913828348 ¯0.4019039741
¯0.06273700292 ¯0.07848261359
¯0.07742280882 ¯0.05917609123
.08791287748 0.9585300715
0.8353926321 0.01762185365
¯0.06515918939
0.4798130015
.9683122709 ¯0.02864040503
¯0.3289923074 ¯0.376728623
¯0.4275474516 ¯0.4767345645
¯0.1194326319 ¯0.1272951144
¯0.1628641866 ¯0.1320746183
Метод вращения promax
Для удобства проведения анализа применим
вращение факторных нагрузок.
Рассмотрев несколько методов вращения убедились
в тои, что они дают аналогичный результат. Для примера возьмем метод promax
f1 p1„2 factanal_promax x1
f1
¯0.05592957379
0.3651255429
.9581964752 ¯0.1397515425
¯0.1569600498
0.9814925811
.7616539906 ¯0.01944808371
¯0.1996914431 ¯0.1461266624
¯0.193235767 ¯0.3962726089
¯0.04450608249 ¯0.007463679651
¯0.05553063278 ¯0.0309804313
¯0.1126929525
0.9879235454
.737867204 0.0598810328
¯0.129039812 0.585179358
.9904337853 ¯0.1757329333
¯0.1945399045 ¯0.3284534916
¯0.1856750092 ¯0.3753291916
¯0.04221541012 ¯0.1300128759
¯0.1068300776 ¯0.1049444197
p1
.8724475921 0.1208137683 0.07932221815
0.4259613704 0.9260392347 0.7721803705 0.997806947
.9952200526 0.05993327418 0.4326499305
0.6739039422 0.06417676201 0.8263539244
.7942226275 0.9789256631 0.9726817954
Рассмотрим матрицу факторных нагрузок f1. видим,
что в первом факторе наибольшие коэффициенты нагрузок соответствуют дефектам
стороны “Б”, а во втором - дефектам стороны “А”.Для подтверждения сравним
коэффициенты с порогом. Первый
фактор
.195<|f1[;1]
1 0 1 1 0 0 0 0 1 0 1 0 0 0 0
Второй фактор
.35<|f1[;2]
0 1 0 0 1 0 0 1 0 1 0 0 1 0 0
Построим наглядное изображение первого фактора и
вектора классификации(Рис.11)
½s1„x1+.×f1[;1]
1020
cl1„1œclassSOP
((cl1=3)/cl1)„0
ap207.plot(¼1020)(cl1)s1
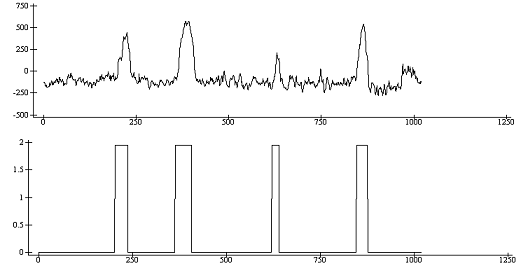
Рис. 11
-
Изображение
первого фактора и вектора классификации для первого измерения
кластерный анализ интерфейс соединение
А так же второго фактора и вектора классификации
½s1„x1+.×f1[;2]
1020
ap207.plotn(¼1020)(cl1)s1
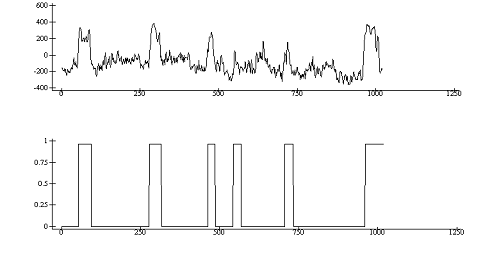
Рис. 12
-
Изображение
второго фактора и вектора классификации для первого измерения
Из Рис.11,12 наглядно видно, что пики фактора
соответствуют пикам вектора классификации.
Проделаем тот же анализ для данных второго и
третьего измерения, а так же для общей матрицы.
½x2„(2œSOP)[;1+¼16]
1020 16
выделим два фактора
f2 p2„2 factanal_promax x2
½f2
16 2
.03292670544 0.1279759517
.9507526522 ¯0.07172310148
¯0.1211449101
0.9091310771
.707265171 0.009507354872
¯0.1501086935 ¯0.006463440314
¯0.2321963365 ¯0.1732861321
0.03123509011 0.02230450737
¯0.04648417883 ¯0.003025455845
¯0.08931920141 1.006765491
.5770208696 0.03377563908
¯0.08476355845
0.2725348386
.9824651708 ¯0.1077554645
¯0.194279853 ¯0.3080518568
¯0.1841844763 ¯0.2468270034
¯0.05458984787 ¯0.07759359383
¯0.01848611256 ¯0.07286361441
p2
.9837939936 0.1110523435 0.1912965821
0.4977106561 0.977160959 0.9041831454 0.9983258635
.9977970042 0.005 0.6602073742 0.9253673322
0.05440472144 0.8496830564 0.8917249377
.9897656496 0.9939596452
сравним их с порогом
195<|f2[;1]
1 0 1 0 1 0 0 0 1 0 1 0 0 0 0
.2<|f2[;2]
0 1 0 0 0 0 0 1 0 1 0 1 1 0 0
построим наглядное изображение
½s2„x2+.×f2[;1]
1020
cl2„2œclassSOP
((cl2=3)/cl2)„0
ap207.plot(¼1020)(cl2)s2
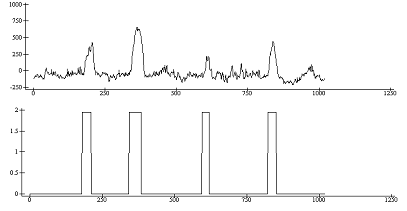
Рис. 13
-
Изображение
первого фактора и вектора классификации для второго измерения
½s2„x2+.×f2[;2]
ap207.plotn(¼1020)(cl2)s2
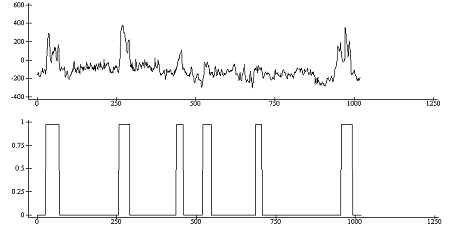
Рис. 14
-
Изображение
второго фактора и вектора классификации для второго измерения
½x3„(3œSOP)[;1+¼16]
1020 16p3„2 factanal_promax x
½f3
16 2
¯0.1164410283
0.2414955489
.9895609518 ¯0.1509911971
¯0.2437443759
0.9994415315
.7236574319 ¯0.1436787408
¯0.331679119
¯0.461494662
¯0.2069851582
¯0.3859412221
¯0.04647440852 ¯0.07459530049
¯0.06628744236 ¯0.05227079456
¯0.1360805978
1.000557748
.8624640815 ¯0.09162388802
¯0.1813675891
0.5152555126
.011325383 ¯0.1580134326
¯0.2519709619
¯0.354394716
¯0.3304998663
¯0.4469912619
¯0.09371668632 ¯0.1186576722
¯0.1376396091
¯0.1179737039
p3
.947339383 0.1001673995 0.1083174701
0.5268077291 0.572294458 0.7535637085 0.9899305145
.9905998687 0.07348868126
0.3018134122 0.7654740059 0.06155078676 0.7498271829
.5898911365 0.9694998234
0.9560571775
.3<|f3[;1]
1 0 1 1 0 0 0 0 1 0 1 0 1 0 0
.4<|f3[;2]
0 1 0 1 0 0 0 1 0 1 0 0 1 0 0
½s3„x3+.×f3[;1]
1020
cl3„3œclassSOP
((cl3=3)/cl3)„0
ap207.plot(¼1020)(cl3)s3
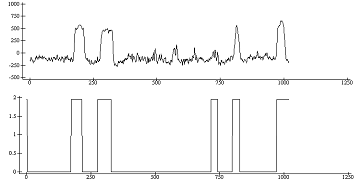
Рис. 15
-
Изображение
первого фактора и вектора классификации для третьего измерения.
½s3„x3+.×f3[;2]
1020
ap207.plotn(¼1020)(cl3)s3
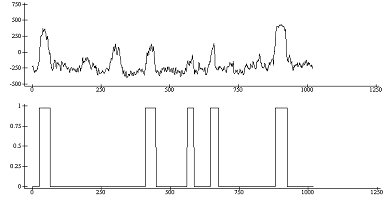
Рис. 16
-
Изображение
второго фактора и вектора классификации для третьего измерения
½x„(³œ,/³¨SOP)[;1+¼16]
3060 16p„2 factanal_promax x
f
¯0.05571849886
0.2275861717
.9313076253 ¯0.09293534522
¯0.1355065684
0.9479679539
.6502338318 ¯0.02316863571
¯0.1596401602 ¯0.2278044176
¯0.2189112935 ¯0.2415878718
¯0.01323876793 ¯0.03477674488
¯0.06259359568 ¯0.03725793743
¯0.0888114694
0.9866743929
.7445202821 0.0107660438
¯0.1009405034
0.4541082642
.989789383 ¯0.1241682624
¯0.1963755045 ¯0.3261338268
¯0.1236407107 ¯0.348180213
¯0.00719190266 ¯0.1435936437
¯0.1153982131 ¯0.1034168126
p
.9499552412 0.1569778698 0.1318923248
0.5824197349 0.9087945954 0.8735855878 0.9984277153
.9938423353 0.05194250421 0.4425196921
0.8010357889 0.05168209202 0.8306811049
.8470901723 0.9789498367 0.971464143
.2<|f[;1]
1 0 1 0 1 0 0 0 1 0 1 0 0 0 0
.3<|f[;2]
0 1 0 0 0 0 0 1 0 1 0 1 1 0 0
Проведя факторный анализ данных, мы увидели, что
у нас имеются два наиболее информативных фактора, следовательно, один фактор
отвечает за один тип датчиков, второй за другой тип датчиков. Значит, имеется
два типа датчиков. Для того, чтобы определить, какие это датчики, рассмотрели
факторы. Оказалось, что наибольшие коэффициенты факторных нагрузок в первом
факторе соответствуют датчикам со стороны “В”, а во втором со стороны “А”. В
итоге оказалось, что мы можем представить результат УЗК в виде двух факторов,
что заметно облегчает анализ полученных данных и выявление дефектов.
Заключение
В ходе выполнения данной работы мы рассмотрели
факторный и кластерный анализ результатов УЗК сварного шва. Факторный анализ
позволил нам выявить основные влияющие признаки в данных и произвести их
интерпретацию. При применении к данным УЗК метод позволил выявить влияние
расположения дефектов по стороне сварного соединения.
Метод кластерного анализа предназначен для
выявления группировки данных. В данной работе применялось два вида кластерного
анализа: К средних и иерархические группировки. С помощью этих методов был
разработан алгоритм автоматического определения типов дефектов, который был
проверен в соответствии с правилами, предложенными экспертами.
В качестве среды исследования и разработки
применялась система статистических вычислений R, совместно с языком
программирования Dyalog APL посредством соответствующего интерфейса. По результатам
данной работы можно сделать вывод, что такое сочетание средств разработки
прекрасно подходит для решения рассмотренных задач.
Список литературы
1. Методика
полуавтоматизированного ультразвукового контроля аустенитных сварных соединений
трубопроводов Ду 300 и РГК энергоблоков типа РБМК-1000.
№ 840.11М-01. М.-ГУП ИЦД НИКИЭТ, 2003 г.
2. Система
полуавтоматизированного ультразвукового контроля аустенитных сварных соединений
трубопроводов Ду 300 и РГК с ограниченным доступом
и автоматической записью результатов контроля. Техническое
описание
и инструкция по эксплуатации. № 840.04ИЭ. М.-ГУП ИЦД НИКИЭТ, 2003 г.
. Подсекин
А.К. Основы неразрушающих методов контроля сварных соединений АЭС. Учеб.
пособие. - Обнинский институт атомной энергетики, 1990
г.
. Скоморохов
A.O. Модели теории распознавания образов в диагностировании АЭС. Обнинск,
ОИАТЭ, 1988.
. Окунь
Я. Факторный анализ. Статистика, Москва, 1974.
7. A.O.
Skomorokhov, V.N. Kutinsky. Cooperative Computing based on Dyalog
APL and the R Statistical System. APL Quote
Quad, Vol.33, Num.2, 2004.