Паралельне виконання операцій множення матриць
МІНІСТЕРСТВО ОСВІТИ І НАУКИ
УКРАЇНИ
Національний
університет «Львівська політехніка»
Кафедра
ЕОМ
КУРСОВА РОБОТА
з дисципліни
«Паралельні та розподілені
обчислення»
на тему
«Паралельне виконання
операцій множення матриць»
Виконав:
Ст. гр. КІ - 45
Гончаренко
О.С.
Прийняв:
Грицик І.В.
Львів
- 2014р.
Завдання
Розробити схему та описати процедуру перемноження матриці А
(розмірністю N1*N2) на матрицю В (розмірністю N2*N3) на структурі з восьми
процесорів. Для цієї структури визначити час виконання алгоритму, відсоток
послідовної частини алгоритму та ефективність алгоритму.
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
21
|
22
|
23
|
|
Г
|
О
|
Н
|
Ч
|
А
|
Р
|
Е
|
К
|
О
|
О
|
Л
|
Е
|
К
|
С
|
А
|
Н
|
Д
|
Р
|
С
|
Е
|
Р
|
Г
|
І
|
|
3
|
8
|
|
4
|
5
|
7
|
1
|
2
|
|
6
|
|
|
|
|
|
|
|
|
|
|
|
|
= 190=88= 149
Таблиця 1. Часові параметри
|
Співвідношення
часових параметрів
|
Пояснення
|
|
tu=2tz
|
час виконання
однієї операції множення
|
|
tS=1/5tZ
|
час виконання
однієї операції сумування
|
|
tP =1/3tZ
|
час виконання
однієї операції пересилання даних між процесорами
|
|
tz
|
час виконання
операції завантаження одних даних
|
|
tW=1/5tz
|
час виконання
операції вивантаження одних даних
|
Таблиця 2. Кодування букв
|
К
|
О
|
Н
|
Р
|
Е
|
Л
|
С
|
Ч
|
|
47
|
250
|
134
|
93
|
171
|
212
|
82
|
49
|
|
2F
|
FA
|
86
|
5D
|
AB
|
D4
|
52
|
31
|
Таблиця 3. Матриця суміжності
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
1
|
0
|
0
|
1
|
0
|
1
|
1
|
1
|
1
|
|
2
|
1
|
0
|
1
|
1
|
1
|
0
|
1
|
0
|
|
3
|
1
|
0
|
0
|
0
|
0
|
1
|
1
|
0
|
|
4
|
0
|
1
|
0
|
0
|
1
|
1
|
0
|
1
|
|
5
|
1
|
0
|
1
|
0
|
0
|
0
|
1
|
1
|
|
6
|
1
|
1
|
0
|
1
|
0
|
0
|
0
|
0
|
|
7
|
0
|
1
|
0
|
1
|
0
|
0
|
0
|
0
|
|
8
|
0
|
0
|
1
|
1
|
0
|
0
|
0
|
0
|
Type = ( i)mod3
+ 1= 1109519.= 3 Розподілена пам'ять.
i)mod3
+ 1= 1109519.= 3 Розподілена пам'ять.
Анотація
В даній курсовій роботі проведено розробку програмної реалізації восьми
процесорної паралельної системи зі розподіленою пам’яттю, яка виконує множення
двох матриць розмірами А(190*88) та В(88*149). Також наводяться числові
значення характеристик даної системи таких як ефективність, коефіцієнт
відношення часу виконання паралельної частини програми і часу виконання всієї
програми. Проведено також порівняння даного алгоритму з простим послідовним за
такими основним ознаками, як час виконання однакової задачі на різних
алгоритмах, ефективність.
Алгоритм виконання множення 2-ох матриць реалізований на С++ з
консольним інтерфейсом, та з використанням MPI.
Annotation
this course work developed program of eight parallel processor system
with distributed memory, which performs multiplication with dimensions
А(190*88) and В(88*149). There are numerical values of the characteristics of the system such as
efficiency, the ratio of the execution time of the parallel program and the
execution time of parallel applications and runtime. Comparing this algorithm
with a simple serial to such basic functions as performing the same task on
different performance algorithms.algorithm of two matrices implemented in C + +
with a console interface, and using MPI.
Вступ
Паралельні обчислювальні системи - комп'ютерні системи, що
реалізовують тим або іншим способом паралельну обробку даних на багатьох
обчислювальних вузлах для підвищення загальної швидкості розрахунку. Ідея
розпаралелення обчислень базується на тому, що більшість завдань можуть бути
розділені на набір менших завдань, які можуть бути вирішені одночасно. Зазвичай
паралельні обчислення вимагають координації дій.
Паралельні алгоритми досить важливі з огляду на постійне
вдосконалення багатопроцесорних систем і збільшення числа ядер у сучасних
процесорах. Зазвичай простіше сконструювати комп'ютер з одним швидким процесором,
ніж з багатьма повільними з тією ж продуктивністю. Однак збільшення
продуктивності за рахунок вдосконалення одного процесора має фізичні обмеження,
такі як досягнення максимальної щільності елементів та тепловиділення.
Зазначені обмеження можна подолати лише шляхом переходу до багатопроцесорної
архітектури, що виявляється ефективним навіть у малих обчислювальних системах.
Складність послідовних алгоритмів виявляється в обсязі використаної пам'яті та
часу (число тактів процесора), необхідних для виконання алгоритму. Розподілені
обчислення - спосіб розв'язання трудомістких обчислювальних завдань з
використанням двох і більше комп'ютерів, об'єднаних в мережу. Розподілені
обчислення є окремим випадком паралельних обчислень, тобто одночасного
розв'язання різних частин одного обчислювального завдання декількома
процесорами одного або кількох комп'ютерів. Тому необхідно, щоб завдання, що
розв'язується було сегментоване розділене на підзадачі, що можуть обчислюватися
паралельно. При цьому для розподілених обчислень доводиться також враховувати
можливу відмінність в обчислювальних ресурсах, які будуть доступні для
розрахунку різних підзадач. Проте, не кожне завдання можна «розпаралелити» і
прискорити його розв'язання за допомогою розподілених обчислень.
1. Теоретичний
розділ
Основна ідея розпаралелювання обчислень - мінімізація часу
виконання задачі за рахунок розподілу навантаження між декількома
обчислювальними пристроями. Цими «обчислювальними пристроями» можуть бути як
процесори одного суперкомп'ютера, так і кілька комп'ютерів, об’єднаних за
допомогою комунікаційної мережі в єдину обчислювальну структуру - кластер.
Паралельна модель програмування сильно відрізняється від
звичайної - послідовної. Існують дві моделі паралельного програмування: модель
паралелізму даних і модель паралелізму задач. Модель паралелізму даних має на
увазі незалежну обробку даних кожним процесом (наприклад, векторні операції з
масивами). Модель паралелізаму задач передбачає розбиття основної задачі на
самостійні підзадачі, кожна з яких виконується окремо й обмінюється даними з
іншими. Це більш трудомісткий, у порівнянні з паралелізмом даних, підхід.
Перевагою є велика гнучкість і велика воля, надана програмісту в розробці
програми, що ефективно використовує ресурси паралельної системи. При цьому
можуть застосовуватися спеціалізовані бібліотеки, що беруть на себе всі
«організаційні» задачі. Приклади таких бібліотек: MPI (Message Passing
Interface) і PVM (Parallel Virtual Machine).
При множенні матриць А(mxn) і В(nxl) отримаємо матрицю С(),
кожен елемент якої визначається відповідно до виразу
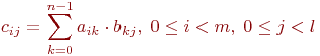 (1.1)
(1.1)
Як випливає з даної формули, кожен елемент результуючої
матриці С є скалярний добуток відповідних рядка матриці A та стовпця матриці B:
Цей алгоритм передбачає виконання mxnxl операцій множення і mx(2n-1)xl операцій
додавання елементів вихідних матриць.
Послідовний алгоритм множення матриць видається трьома
вкладеними циклами:
Алгоритм 1. Послідовний алгоритм множення двох квадратних
матриць
(i = 0; i <n; i + +) {(j = 0; j <l; j + +) {[i] [j] =
0;(k = 0; k <m; k + +) {[i] [j] = MatrixC [i] [j] + MatrixA [i] [k] *
MatrixB [k] [j];
}
}}
Цей алгоритм є ітеративним і орієнтований на послідовне
обчислення рядків матриці С. Дійсно, при виконанні однієї ітерації зовнішнього
циклу (циклу за змінною i) обчислюється один рядок результуючої матриці (Рис.
1.1).
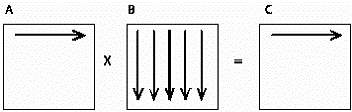
Рис. 1.1 Обчислення одного рядка результуючої матриці
На першій ітерації циклу за змінною i використовується перший
рядок матриці A і всі стовпці матриці B для того, щоб обчислити елементи
першого рядка результуючої матриці С.
Оскільки кожен елемент результуючої матриці є скалярний
добуток рядка та стовпця вихідних матриць, то для обчислення всіх елементів
матриці з розміром nxl необхідно виконати n*(2n-1)*l скалярних операцій .
З визначення операції матричного множення випливає, що
обчислення усіх елементів матриці С може бути виконано незалежно один від
одного. Як результат, можливий підхід для організації паралельних обчислень
полягає у використанні в якості базової підзадачі процедури визначення одного
елемента результуючої матриці С. Для проведення всіх необхідних обчислень кожна
підзадача повинна містити по одному рядку матриці А і одному стовпцю матриці В.
Для обчислення одного рядка матриці С необхідно, щоб у кожній
підзадачі містилася рядок матриці А і був забезпечений доступ до всіх стовпцях
матриці B. Можливі способи організації паралельних обчислень полягають у
наступному.
Алгоритм являє собою ітераційну процедуру, кількість ітерацій
якої збігається з числом підзадач. На кожній ітерації алгоритму кожна підзадача
містить по одному рядку матриці А і одному стовпцю матриці В. При виконанні
ітерації проводиться скалярне множення, що призводить до отримання відповідних елементів
результуючої матриці С. Після завершення обчислень в кінці кожної ітерації
стовпці матриці В повинні бути передані між підзадачами з тим, щоб у кожній
підзадачі виявилися нові стовпці матриці В і могли бути обчислені нові елементи
матриці C. При цьому дана передача стовпців між підзадачами повинна бути
організована таким чином, щоб після завершення ітерацій алгоритму в кожній
підзадачі послідовно опинилися всі стовпці матриці В.
Можлива проста схема організації необхідної послідовності
передач стовпців матриці В між підзадачами полягає в представленні топології
інформаційних зв'язків підзадач у вигляді кільцевої структури. У цьому випадку
на кожній ітерації підзадача i, 0 <= i <n, буде передавати свій стовпець
матриці В підзадачі з номером i +1 - Рис. 1.2. Після виконання всіх ітерацій
алгоритму необхідна умова буде забезпечена в кожній підзадачі по черзі
опиняться всі стовпці матриці В.
На рис. 1.2 представлені ітерації алгоритму матричного
множення для випадку, коли матриці складаються з чотирьох рядків і чотирьох
стовпців. На початку обчислень в кожній підзадачі i, 0 <= i <n,
розташовуються i-й рядок матриці A і i-й стовпець матриці B. В результаті їх
перемножування підзадача отримує елемент Сіi результуючої матриці С. Далі
підзадачі здійснюють обмін стовпцями, в ході якого кожна підзадача передає свій
стовпець матриці B наступної підзадачі відповідно до кільцевої структури
інформаційної взаємодії. Далі виконання описаних дій повторюється до завершення
всіх ітерацій паралельного алгоритму.
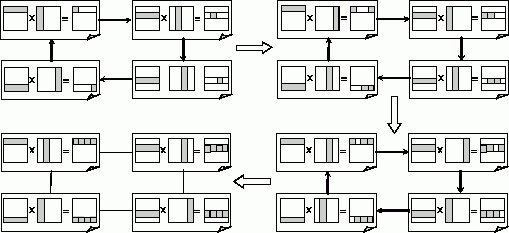
Рис. 1.2. Загальна схема передачі даних для паралельного
алгоритму матричного множення при стрічковій схемі розділення даних
. Проектування граф-схеми виконання алгоритму
Згідно з заданим варіантом будуємо структуру зв’язків між
процесорами. Зв'язок між процесорами ми зобразили у вигляді графа з 8-ма
вершинами.
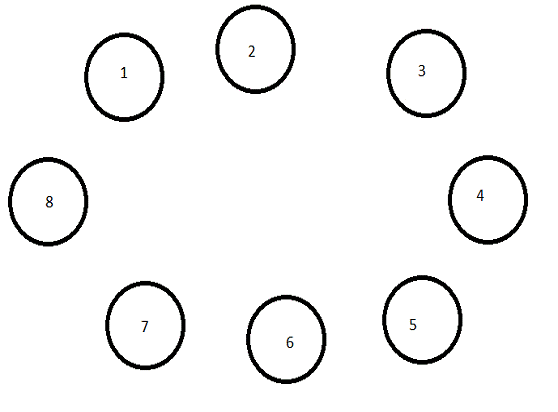
Рис. 2.1 Граф обміну даними між процесорами
Оскільки в нас розподілена пам'ять то завантаження вхідних та
вивантаження вихідних даних буде виконуватись паралельно.
Зробивши аналіз графа я прийшов до висновку що дане завдання
можна розв’язати організувавши кільцеву структуру звязків між процесорами.
Граф-схема кільцевої структури наведена на Рис.2.2.
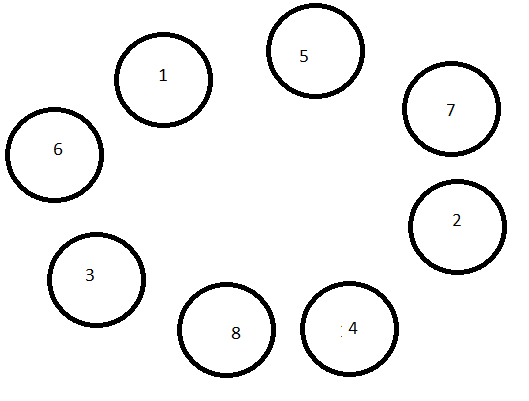
Рис.2.2 Граф-схема кільцевого зв’язку між процесорами
Завантаження даних в процесори відбуваються через розподілену
пам’ять. Визначемо розмірності підматриць А та В для кожного з процесорів. Для
цього ми ділимо кількість рядків матриці А на кількість процесорів(в даному
випадку 8) та кількість стовпців матриці В на кількість процесорів. Якщо під
час виконання розподілу, не вдається отримати однакову розмірність підматриць,
то розділяємо їх таким чином, щоб різниця між ними не була більша за 1.
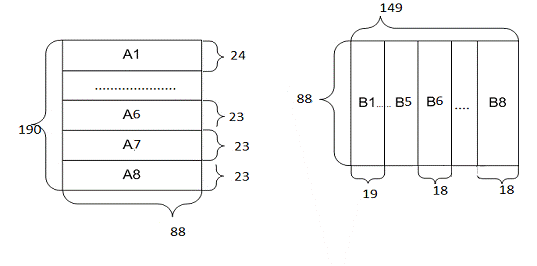
Рис. 2.3 Розбиття матриць
Кожен процесор має свою пам'ять. На початку роботи туди буде
завантажено для кожного і-го процесора під матриці Аі та Ві. Після перемноження
під матриць відбудеться обмін Ві під матрицями по кільці, структура якого була
показана вище. Після обміну знову відбудеться перемноження підматриць. Обмін
відбуватиметься доти, доки кожен і-тий процесор не виконає множення Аі*В. Після
виконання перемножень буде відбуватись збір результату в 1-ий процесор.
На рис. 2.4. наведена граф-схема виконання алгоритму множення
двох матриць з розподіленою пам’яттю в загальному випадку.
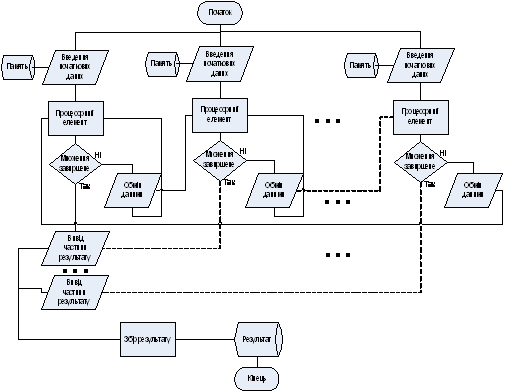
Рис. 2.4. Граф-схема виконання алгоритму множення двох матриць з
розподіленою пам’яттю.
3. Розробка функціональної схеми
|
Процесор1
|
Процесор2
|
Процесор3
|
Процесор4
|
Процесор5
|
Процесор6
|
Процесор7
|
Процесор 8
|
|
Завантажен А1,В1.
|
Завантажен А2,В2.
|
Завантажен А3,В3.
|
Завантажен А4,В4.
|
Завантажен А5,В5.
|
Завантажен А6,В6.
|
Завантажен А7,В7.
|
Завантажен А8,В8.
|
|
Множення А1хВ1
|
Множення А2хВ2
|
Множення А3хВ3
|
Множення А4хВ4
|
Множення А5хВ5
|
Множення А6хВ6
|
Множення А7хВ7
|
Множення А8хВ8
|
|
Перес.В1-P5,отрим.В6
з P6
|
Перес.В2-P4,отрим.В7
З P7
|
Перес.В3-P6,отрим.В8
З P8
|
Перес.В4-P8,отрим.В2
З P2
|
Перес.В5-P7,отрим.В1
З P1
|
Перес.В6-P1,отрим.В3
З P3
|
Перес.В7-P2,отрим.В5
З P5
|
Перес.В8-P3,отрим.В4
З P4
|
|
Множення А1хВ6
|
Множення А2хВ7
|
Множення А3хВ8
|
Множення А4хВ2
|
Множення А5хВ1
|
Множення А6хВ3
|
Множення А7хВ5
|
Множення А8хВ4
|
|
Перес.В6-P5,отрим.В3
P6
|
Перес.В7-P4,отрим.В5
З P5
|
Перес.В8-P6,отрим.В4
З P8
|
Перес.В2-P8,отрим.В7
З P2
|
Перес.В1-P7,отрим.В6
З P1
|
Перес.В3-P1,отрим.В8
З P3
|
Перес.В5-P2,отрим.В1
З P5
|
Перес.B4-P3,отрим.В2
З P4
|
|
Множення А1хВ3
|
Множення А2хВ5
|
Множення А3хВ4
|
Множення А4хВ7
|
Множення А5хВ6
|
Множення А6хВ8
|
Множення А7хВ1
|
Множення А8хВ2
|
|
Перес.В3-P5,отрим.В8
з P6
|
Перес.В5-P4,отрим.В1
З P7
|
Перес.В4-P6,отрим.В2
З P8
|
Перес.В7-P8,отрим.В5
З P2
|
Перес.В6-P7,отрим.В3
З P1
|
Перес.В8-P1,отрим.В4
З P3
|
Перес.В1-P2,отрим.В6
З P5
|
Перес.В2-P3,отрим.В7
З P4
|
|
Множення А1хВ8
|
Множення А2хВ1
|
Множення А3хВ2
|
Множення А4хВ5
|
Множення А5хВ3
|
Множення А6хВ4
|
Множення А7хВ6
|
Множення А8хВ7
|
|
Перес.В8-P5,отрим.В4
з P6
|
Перес.В1-P4,отрим.В1
З P7
|
Перес.В2-P6,отрим.В7
З P8
|
Перес.В5-P8,отрим.В1
З P2
|
Перес.В3-P7,отрим.В8
З P1
|
Перес.В4-P1,отрим.В2
З P3
|
Перес.В6-P2,отрим.В3
З P5
|
Перес.В7-P3,отрим.В5
З P4
|
|
Множення А1хВ4
|
Множення А2хВ6
|
Множення А3хВ7
|
Множення А4хВ1
|
Множення А5хВ8
|
Множення А6хВ2
|
Множення А7хВ3
|
Множення А8хВ5
|
|
Перес.В4-P5,отрим.В2
з P6
|
Перес.В6-P4,отрим.В3
З P7
|
Перес.В7-P6,отрим.В5
З P8
|
Перес.В1-P8,отрим.В6
З P2
|
Перес.В8-P7,отрим.В4
З P1
|
Перес.В2-P1,отрим.В7
З P3
|
Перес.В3-P2,отрим.В8
З P5
|
Перес.В5-P3,отрим.В1
З P4
|
|
Множення А1хВ2
|
Множення А2хВ3
|
Множення А3хВ5
|
Множення А4хВ6
|
Множення А5хВ4
|
Множення А6хВ7
|
Множення А7хВ8
|
Множення А8хВ1
|
|
Перес.В2-P5,отрим.В7
з P6
|
Перес.В3-P4,отрим.В8
З P7
|
Перес.В5-P6,отрим.В1
З P8
|
Перес.В6-P8,отрим.В3
З P2
|
Перес.В4-P7,отрим.В2
З P1
|
Перес.В7-P1,отрим.В5
З P3
|
Перес.В8-P2,отрим.В4
З P5
|
Перес.В1-P3,отрим.В6
З P4
|
|
Множення А1хВ7
|
Множення А2хВ8
|
Множення А3хВ1
|
Множення А4хВ3
|
Множення А5хВ2
|
Множення А6хВ5
|
Множення А8хВ6
|
|
Перес.В7-P5,отрим.В5
з P6
|
Перес.В8-P4,отрим.В4
З P7
|
Перес.В1-P6,отрим.В6
З P8
|
Перес.В3-P8,отрим.В8
З P2
|
Перес.В5-P7,отрим.В7
З P1
|
Перес.В5-P1,отрим.В1
З P3
|
Перес.В4-P2,отрим.В2
З P5
|
Перес.В6-P3,отрим.В3
З P4
|
|
Множення А1хВ5
|
Множення А2хВ4
|
Множення А3хВ6
|
Множення А4хВ8
|
Множення А5хВ7
|
Множення А6хВ1
|
Множення А7хВ2
|
Множення А8хВ3
|
|
Вив. С1
|
Перес. С2- Р1
Отрим. С7
|
Перес. С3- Р6
|
Перес. С4- Р8
|
Перес. С5-Р1
|
Перес. С6- Р1
Отрим.С3
|
Перес. С7- Р2
|
Перес. С8- Р1
Отрим.С4
|
|
Вив.(С2,С5,С6,С8)
|
Перес. С7- Р1
|
|
|
|
Перес. С3- Р1
|
|
Перес. С4- Р1
|
|
Вив.(С3,С4,С7)
|
|
|
|
|
|
|
|
Рис 3.1 Схема планування обчислень
Операція обміну підматрицями Ві.буде відбуватися паралельно.
Також паралельно буде виконуватися операція звертання до памяті(оскільки в нас
розподілена пам’ять) і операція множення.
Відповідно до цього по заверщенні множень на кожному з
процесорів буде підматриця Сі = А*Ві. Дана схема максимально показує
розпаралелення виконання процесу множення матриць на 8-ми процесорах.
Кожен процесор виконує моження підматриць і зберігає проміжні
дані, а також обмінюється підматрицею В з сусідім процесором по кільцевій
структурі. Пересилання підматриці відбувається по колу між сусідніми
процесорами, причому операція відсилання і прийому даних буде виконуватись
паралельно. Процесори в цьому випадку завантажені найбільш рівномірно.
. Розрахунковий
розділ
Для процесорних елементів визначимо такі розміри підматриць:
А1-A5[24,88], А6-A8[23,88], B1-B5[88, 19], B6-B8[88, 18].
Для визначення точних характеристик системи врахуємо
співвідношення часових параметрів (згідно з завданням). Насамперед, зведемо
часи виконання різних операцій до спільного знаменника, тобто визначимо базову
операцію для знаходження часів виконання інших операцій.
Виразимо інші операції через час Tz:
TW=1/5TZ , TP =1/3TZ, TS=1/5TZ, Tu=2Tz.
Оскільки пам’ять розподілена, то це означає що завантаження
буде відбуватися паралельно, а отже за час завантаження ми беремо час
завантаження процесора, який виконує завантаження підматриць з більшим
розміром:
TZ = (24 * 88 + 88 * 19) * tZ = 3784* tZ
Операція пересилання також буде виконуватися паралельно, а
отже, обраховуємо пересилку найбільшої підматриці Ві також враховуємо, що
пересилка буде відбуватися в 7 тактів:
TP = 7 * 88 * 19 * tP =11704 * tP = 3902 * tZ
Операція множення також буде виконуватися паралельно на
процесорах і займе 8 тактів:
TU = TU1 +TU2 +TU3 +TU4 +TU5 +TU6 +TU7 +TU8 = 619696*tz
такт:= 24 * 88 * 19 * tU = 40128 * tU = 80256 * tZ
такт:= 24 * 88 * 19 * tU = 40128 * tU = 80256 * tZ
такт:= 24 * 88 * 19 * tU = 40128 * tU = 80256 * tZ
такт:= 24 * 88 * 19 * tU = 40128 * tU = 80256 * tZ
такт:= 24 * 88 * 18 * tU = 38016 * tU = 76032 * tZ
такт:= 23 * 88 * 19 * tU = 38456 * tU = 76912 * tZ
такт:= 23 * 88 * 18 * tU = 36432 * tU = 72864 * tZ
такт:= 23 * 88 * 18 * tU = 36432 * tU = 72864 * tZ
Час додавання також виконується паралельно:
TS = TS1 +TS2 +TS3 +TS4 +TS5 +TS6 +TS7 +TS8 = 61265,4 * tZ
такт:= 24 * (88 - 1) * 19 * tS = 39672 * tS = 7934,4 * tZ
такт:= 24 * (88 - 1) * 19 * tS = 39672 * tS = 7934,4 * tZ
такт:= 24 * (88 - 1) * 19 * tS = 39672 * tS = 7934,4 * tZ
такт:= 24 * (88 - 1) * 19 * tS = 39672 * tS = 7934,4 * tZ
такт:= 24 * (88 - 1) * 18 * tS = 37584 * tS = 7516,8 * tZ
такт:= 23 * (88 - 1) * 19 * tS = 38019 * tS = 7603,8 * tZ
такт:= 23 * (88 - 1) * 18 * tS = 36018 * tS = 7203,6 * tZ
такт:= 23 * (88 - 1) * 18 * tS = 36018 * tS = 7203,6 * tZ
Збір результату, на кожному етапі операції, що показані нище
на графі де зображено вивантаження та пересилання виконуються паралельно:
комп'ютер пам’ять паралельний матриця
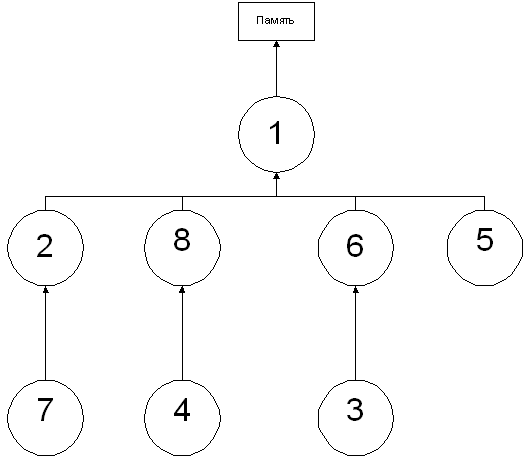
Рис 4.1. Граф вивантаження та пересилання між процесорами
1-ий етап:
Вивантажуємо С1, а також пересилаємо С2, С5, С6, С8:= 24 * 149 * tw =
3576 * tw = 715,2 * tZ= 88 * 19 * 4 * tP = 6688* tP = 2230* tZ
-ий етап:
Вивантажуємо С2, С5, С6, С8 та пересилаємо С3, С4, С7:= 24 * 149 * 4
=14208 tw = 2841,6 * tz= 88 * 19 * 3 * tP = 5016 * tP = 1672 * tZ
-ій етап:
Вивантажуємо тільки С3, С4, С7:= 24 * 149 * 3 * tw = 2145,6 * tZ= 2230
+ 2841,6 +2145,6 = 7212,2 * tZ
Загальний час:пар= 3784 + 3902 + 619696 +61265,4 +7212,2 = 695859,6 * Z
Для порівняння обчислимо умовний час виконання послідовного
алгоритму:пос = n1 * n2 + n2 * n3 = 29832* tZ
Пересилань не буде, тому TPпос =0.пос 2491280*tu = 4982560 * tZпос =
2462970 * tS = 492594 * tZпос = 190 * 149 * tW = 28310 * tZПОС = TZпос + TSпос
+ TWпос = 29832 +4982560 +492594 +28310 =5533296 * tZ
Ефективність: E= TПОС / (8Tпар)= 5533296 / (8 * 695859,6) = 0,99
5. Розробка програми
Граф-схема програми наведена на рис. 5.1. Лістинг програми
наведений в додатку А. Дана програма містить консольний інтерфейс, розроблена
за допомогою мови програмування С++.
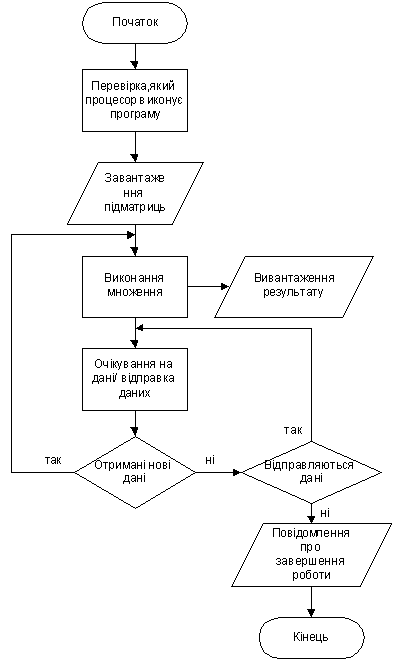
Рис. 5.1 Граф-схема алгоритму перемноження матриць на заданій
структурі
Завдяки тому, що при написанні коду програми були використані
засоби технології MPI, дана програма не просто імітує роботу
паралельноїсистеми, а дійсно є цілком працездатною і може бути запущеною на
паралельній системі, яка досліджується у цій курсовій роботі.
Для
тестування достовірності результатів паралельної програми, я розробив ще й
послідовну, де множаться ці ж матриці.
Для обміну інформацією між процесами використовуються функції
бібліотеки MPI 2.0 MPI_Send() та MPI_Recv(). Це парні функції, які призначені
відповідно для відправки та прийому повідомлень.
int MPI_Send(void *buf, int count, MPI_Datatype type, int
dest, int tag, MPI_Commcomm)
buf - адреса буфера пам'яті, в якому розташовуються дані
повідомлення, що відправляється;- кількість елементів даних в повідомленні;-
тип елементів даних повідомлення, що пересилається;- ранг процесу, якому
відправляється повідомлення;- значення-тег, що використовується для
ідентифікації повідомлення;- комунікатор, в рамках якого виконується передача
даних.
int MPI_Recv(void *buf, int count, MPI_Datatype type, int
source,tag, MPI_Comm comm, MPI_Status *status)
де buf,
count, type - буфер пам'яті для прийому повідомлення, призначення кожного
окремого параметра відповідає опису в MPI_Send.- ранг процесу, від якого
повинен бути виконаний прийом повідомлення.- тег повідомлення, яке повинне бути
прийняте для процесу.- комунікатор, в рамках якого виконується передача даних.-
вказівник на структуру даних з інформацією про результат виконання операції
прийому даних.
.
Результат роботи програми
Рис. 6.1 Результат виконання множення
Висновок
Під час виконання курсового проекту я оволодів технологією
написання програм для багатопроцесорних систем. Розробив восьми процесорну
систему з розподіленою пам’яттю множення двох матриць. Також було проведено
деякі обчислення, які дають уявлення про характеристики даного паралельного
алгоритму, та порівняно його з послідовним. В результаті проведеної роботи
можна зробити такі висновки: для восьми процесорної системи та матриць з
розмірами 190х88 88х149 умовний час виконання програми в інтервалах виконання
операції виявився рівним 695859,6 tZ, а для послідовної структури 5533296 tZ .
Ефективність при цьому рівна E = 99% , що є досить хорошим показником.
Список літератури
1. Корнеев
В.В. Параллельные вычислительные системы. М.: Нолидж, 1999
. Воеводин
В.В., Воеводин Вл.В. Параллельные вычисления. - СПб: БХВ-Петербург, 2002.
. Ортега
Дж. Введение в параллельные и векторные методы решения линейных систем. М.:Мир,
1991.
. Программирование
на параллельных вычислительных системах: Пер с англ./Под ред. Р.Бэбба.М.:Мир,
1991.
. Бройнль
Т. Паралельне програмування: Початковий курс: Навчальний посібник. - К.:Вища
школа.,1997.
. Воеводин
В.В. Математические основы параллельных вычислений.- М.: Изд-во МГУ, 1991.
. Векторизация
программ: теория, методы, реализация: Пер. с англ. и нем. /Под ред. Г.Д.Чинина.
- М:. Мир, 1991.
. Організація
паралельних обчислень : Навчальний посібник з дисципліни “Паралельні та
розподілені обчислення” для студентів базового напрямку 6.0915
"Комп'ютерна інженерія" / Укладачі: Є. Ваврук, О. Лашко - Львів:
Національний університет “Львівська політехніка”, 2007, 70 с.
Додаток
Текст програми на C++ з використанням бібліотеки МРІ:
#include <stdio.h>
#include <iostream>
#include <stdlib.h>
#include <iostream>
#include "mpi.h"
#include <Windows.h>
#include <conio.h>
namespace std;
int route=0;int circle[] = {0,4,6,1,3,7,2,5};int
procNumber=8;int N1=190;int N2=88;int N3=149;procRank;int root=0;_Status
Status;A{row;n1;n2;arr[N1/8+N1][N2];
};B{col;n2;n3;arr[N2][N3/8+N3];
};R{n1;n3;arr[N1/8+N1][N3];
};matrixA[N1][N2]={0};matrixB[N2][N3]={0};Res[N1][N3]={0};subA[procNumber];subB[procNumber];procA;procB;procBtmp;procRes;result[procNumber];NextProc;PrevProc;procSize;
//ЗбірDataReplication(){(procRank==7||procRank==5||procRank==1||procRank==4){_Send(&procRes,sizeof(procRes),MPI_BYTE,root,0,MPI_COMM_WORLD);(procRank==1){_Recv(&procRes,sizeof(procRes),MPI_BYTE,6,0,MPI_COMM_WORLD,&Status);_Send(&procRes,sizeof(procRes),MPI_BYTE,root,0,MPI_COMM_WORLD);
}(procRank==7){_Recv(&procRes,sizeof(procRes),MPI_BYTE,3,0,MPI_COMM_WORLD,&Status);_Send(&procRes,sizeof(procRes),MPI_BYTE,root,0,MPI_COMM_WORLD);
}(procRank==5){_Recv(&procRes,sizeof(procRes),MPI_BYTE,2,0,MPI_COMM_WORLD,&Status);_Send(&procRes,sizeof(procRes),MPI_BYTE,root,0,MPI_COMM_WORLD);
}
}(procRank==2)MPI_Send(&procRes,sizeof(procRes),MPI_BYTE,5,0,MPI_COMM_WORLD);(procRank==6)MPI_Send(&procRes,sizeof(procRes),MPI_BYTE,1,0,MPI_COMM_WORLD);(procRank==3)MPI_Send(&procRes,sizeof(procRes),MPI_BYTE,7,0,MPI_COMM_WORLD);(procRank==root){[root]=procRes;_Recv(&result[7],sizeof(procRes),MPI_BYTE,7,0,MPI_COMM_WORLD,&Status);_Recv(&result[5],sizeof(procRes),MPI_BYTE,5,0,MPI_COMM_WORLD,&Status);_Recv(&result[1],sizeof(procRes),MPI_BYTE,1,0,MPI_COMM_WORLD,&Status);_Recv(&result[4],sizeof(procRes),MPI_BYTE,4,0,MPI_COMM_WORLD,&Status);_Recv(&result[2],sizeof(procRes),MPI_BYTE,5,0,MPI_COMM_WORLD,&Status);_Recv(&result[6],sizeof(procRes),MPI_BYTE,1,0,MPI_COMM_WORLD,&Status);_Recv(&result[3],sizeof(procRes),MPI_BYTE,7,0,MPI_COMM_WORLD,&Status);
}
}
//початкова розсилкаDataDistribution(){(procRank==root){=
subA[root];= subB[root];(int i=0;i<procNumber;i++)(i!=root){_Send(&subA[circle[i]],sizeof(subA[circle[i]]),MPI_BYTE,circle[i],0,MPI_COMM_WORLD);_Send(&subB[circle[i]],sizeof(subB[circle[i]]),MPI_BYTE,circle[i],0,MPI_COMM_WORLD);
}
}_Status
Status;(procRank!=root){_Recv(&procA,sizeof(procA),MPI_BYTE,root,0,MPI_COMM_WORLD,&Status);_Recv(&procB,sizeof(procB),MPI_BYTE,root,0,MPI_COMM_WORLD,&Status);
}
}
//пересилка підматриці і перемноженняmull(){(int
i=0;i<procA.n1;i++)(int j=0;j<procB.n3;j++)(int
k=0;k<procA.n2;k++).arr[i][j+procB.col]+=procA.arr[i][k]*procB.arr[k][j];
}DataSend(){.n1=procA.n1;.n3=N3;
//mull();(int k=0;k<procNumber;k++){(int
i=0;i<procNumber;i++){(procRank==circle[i]){( i % 2==0 )
{_Send(&procB,sizeof(B),MPI_BYTE,circle[(i+1)%procSize],0,MPI_COMM_WORLD);_Recv(&procBtmp,sizeof(B),MPI_BYTE,circle[(i+procSize-1)%procSize],0,MPI_COMM_WORLD,&Status);=procBtmp;
} else
{_Recv(&procBtmp,sizeof(B),MPI_BYTE,circle[(i-1)%procSize],0,MPI_COMM_WORLD,&Status);_Send(&procB,sizeof(B),MPI_BYTE,circle[(i+1)%procSize],0,MPI_COMM_WORLD);=procBtmp;
}
}
}();
}
}
SetRank()
{(procRank==0)
{= 4;= 5;
}(procRank==1)
{= 3;= 6;
}(procRank==2)
{= 5;= 7;
}(procRank==3)
{= 7;= 1;
}(procRank==4)
{= 6;= 0;
}(procRank==5)
{= 0;= 2;
}(procRank==6)
{= 1;= 4;
}(procRank==7)
{= 2;= 3;
}
}
main(int argc, char* argv[])
{_Init(&argc,
&argv);_Comm_rank(MPI_COMM_WORLD,&procRank);_Comm_size(MPI_COMM_WORLD,&procSize);(procSize!=8){<<"Must
be 8 process"<<endl;_Finalize();1;
}(procRank==root){
//заповнення А(int i=0;i<N1;i++)(int
j=0;j<N2;j++)[i][j]=rand()%9+1;<<"Matrix A"<<endl;(int
i=0;i<N1;i++){(int j=0;j<N2;j++)<<matrixA[i][j]<<"
";<<endl;
}
//заповнення В(int i=0;i<N2;i++)(int
j=0;j<N3;j++)[i][j]=rand()%9+1;<<endl<<"Matrix
B"<<endl;(int i=0;i<N2;i++){(int
j=0;j<N3;j++)<<matrixB[i][j]<<" ";<<endl;
}
//перемноження матриць(int i=0;i<N1;i++)(int
j=0;j<N3;j++)(int
k=0;k<N2;k++)[i][j]+=matrixA[i][k]*matrixB[k][j];<<endl<<"Result"<<endl;(int
i=0;i<N1;i++){(int j=0;j<N3;j++)<<Res[i][j]<<"
";<<endl;
}
//розбиття на підматриці
//АrowsSum=0;restRows = N1;restProc = procNumber;(int i=0;i<procNumber;i++)
{[i].row=rowsSum;[i].n1 = restRows/restProc;[i].n2 = N2;(int
k=0;k<subA[i].n1;k++)(int j=0;j<subA[i].n2;j++)[i].arr[k][j] =
matrixA[k+rowsSum][j];+=subA[i].n1;-= restRows/restProc;-;
}
//В=0;= procNumber;= N3;(int i=0;i<procNumber;i++)
{[i].col = rowsSum;[i].n2 = N2;[i].n3 =
restRows/restProc;(int k= 0;k<subB[i].n2;k++)(int
j=0;j<subB[i].n3;j++)[i].arr[k][j] = matrixB[k][j+rowsSum];+=subB[i].n3;-=
restRows/restProc;-;
}
}
//cout<<"SetRank"<<endl;();
//cout<<"DataDistribution()"<<endl;();();
//cout<<"DataReplication()"<<endl;();
(procRank==root){<<endl<<"Paralel
rez"<<endl;(int k=0;k<procNumber;k++)(int
i=0;i<result[k].n1;i++){(int
j=0;j<result[k].n3;j++)<<result[k].arr[i][j]<<"
";<<endl;
}
}_Finalize();0;
}