Основные способы обработки большого количества текстовой информации
Санкт-Петербургский
Государственный
морской технический университет
Факультет
морского приборостроения.
Кафедра
САУ и БВТ
РЕФЕРАТ
ПО
ДИСЦИПЛИНЕ
“ИНФОРМАТИКА”
НА
ТЕМУ:
“Основные
способы обработки большого количества текстовой информации”.
Выполнил:
студентка гр. 31ВМ1 (3111)
Жаркова
А.Н.________
Проверил:
Д.Т.Н., профессор
Жуков
Ю.И.________
Санкт
- Петербург
2000
г.
Реферат составлен на страницах. Содержит 2 рисунка, 3
таблицы и 2 приложения.
Ключевые слова: адресация, автокоррекция, сжатие.
Целью
реферата является разработка и описание трех практических задач современной
информатики:
ü адресации элементов баз данных, множества или списка,
для определения по первичному ключу местоположения элемента в блоке информации;
ü автокоррекции языковых текстов для обнаружения и
исправления ошибок в текстах;
ü сжатии данных, для хранения данных в предельно
компактной форме.
АННОТАЦИЯ.. 2
СОДЕРЖАНИЕ.. 3
Введение. 4
ЧАСТЬ 1. МЕТОДЫ АДРЕСАЦИИ.. 5
ВВЕДЕНИЕ.. 5
1. Теоретическая часть. 5
1.1. Последовательное сканирование списка. 5
1. 2. Блочный поиск.. 5
1.3. Двоичный поиск.. 5
1.4. Индексно-последовательная организация.. 6
1.5. Индексно-произвольная организация.. 6
1.6. Адресация с помощью ключа, эквивалентного адресу.. 7
1.7. Алгоритм преобразования ключа в адрес.. 8
Выводы по части 1. 10
ЧАСТЬ 2. АВТОКОРРЕКЦИЯ ТЕКСТА.. 11
ВВЕДЕНИЕ.. 11
1. Теоретическая часть. 11
1.1. Методы обнаружения ошибок.. 11
1.2. Автоматизация процесса исправления.. 11
1.3. Диалоговый и пакетный режимы... 12
Выводы по части 2. 13
ЧАСТЬ 3. СЖАТИЕ ИНФОРМАЦИИ.. 13
ВВЕДЕНИЕ.. 13
1. Теоретическая
часть. 13
1.1. Сжатие числовых данных.. 13
1.2. Сжатие словарей.. 13
1.3. Сжатие специальных текстов.. 14
1.4. Сжатие структурированных данных.. 15
1.5. Сжатие текстовой информации общего вида. 15
1.5.1. Адаптивные алгоритмы... 16
1.5.2. Статистические алгоритмы. 16
1.5.2.1. Кодирование фрагментов фиксированной длины... 16
1.5.2.2. Кодирование фрагментов переменной длины... 17
Выводы по части 3. 17
ПРИЛОЖЕНИЕ 1. Методы сжатия
данных. 18
Метод Шеннона-Фано.. 18
Метод Хаффмена. 18
Заключение. 20
Список литературы.. 20
Настоящий реферат состоит из трех самостоятельных частей, в которых
излагаются три практические задачи современной информатики – адресация
элементов данных линейного списка, автокоррекция естественно языковых текстов,
сжатие данных.
Они призваны, с одной стороны, для ознакомления с некоторыми
практическими задачами информатики, а с другой – закрепить навыки прикладного
программирования и составления блок-схем.
Первая задача нашла
свое применение в таких программных продуктах, как системы управления базами
данных, операционные системы (организация поисковых операций в системных
данных), компиляторы (работа с таблицами идентификаторов) и многих других.
Алгоритмы адресации имеют универсальный характер и используются практически во
всех задачах, в которых ведется организация и поиск информации в одномерных
массивах, независимо от места ее нахождения – основная память или внешняя.
Вторая задача носит
более частный характер, а изложенные методы используются при проверке
орфографии в текстовых и табличных процессорах, издательских системах, а также
как средство верификации результатов работы сканера – после распознавания
текста для устранения возможных ошибок выполняется его орфографический анализ.
Проблема сжатия
данных решается в современных архиваторах. Они, как правило, используют
комбинацию методов, изложенных в третьей части.
Задачи
программируются на языке программирования, который изучается в курсе «Алгоритмические
языки и программирование», и, тем самым, закрепляют навыки, полученные в этой
дисциплине. Кроме этого, требование подготовки блок-схем средствами WinWord
позволяет углубить знания, связанные, с одной стороны, с логическим проектированием
алгоритма, а с другой – с правилами начертания блок-схем.
Запрограммированные
и отлаженные задачи должным образом оформляются, что также способствует умению
правильно и аккуратно закреплять результат работы на бумажном носителе информации.
Основную проблему при адресации
элементов списков можно сформулировать следующим образом: как по первичному
ключу определить местоположение элемента с данным ключом (задача поиска)?
Существует несколько различных способов адресации. Они рассматриваются далее.
Иногда бывает необходимо объединить несколько
полей, чтобы образовать уникальный ключ, называемый в этом случае сцепленным
ключом: например, ключ, идентифицирующий студента в институте, является
комбинацией номера группы, фамилии, имени и отчества студента (есть случаи,
когда в одной группе учатся студенты с одинаковыми фамилиями и именами).
Кроме простого и сцепленного, ключ может
быть первичным – определять максимум один элемент в списке или вторичным –
определять множество (в общем случае не одноэлементное) элементов в списке.
Например, фамилия студента в учебной группе, как правило, является первичным
ключом, а пол студента – вторичный ключ, поскольку одному значению этого ключа
(мужской или женский) соответствует, в общем случае, группа студентов.
 Если элементы упорядочены по ключу, то при
сканировании списка не требуется чтение каждого элемента. Компьютер мог бы,
например, просматривать каждый n-ный элемент в последовательности возрастания
ключей. При нахождении элемента с ключом, большим, чем ключ, используемый при
поиске, просматриваются последние n-1 элементов, которые были пропущены.
Этот способ называется блочным поиском: элементы группируются в блоки, и
каждый блок проверяется по одному разу до тех пор, пока ни будет найден
нужный блок. Вычисление оптимального для блочного поиска размера блока выполняется
следующим образом: в списке, содержащем N элементов, число просмотренных
элементов минимально при длине блока, равной ÖN. При этом в среднем анализируется
ÖN элементов.
Если элементы упорядочены по ключу, то при
сканировании списка не требуется чтение каждого элемента. Компьютер мог бы,
например, просматривать каждый n-ный элемент в последовательности возрастания
ключей. При нахождении элемента с ключом, большим, чем ключ, используемый при
поиске, просматриваются последние n-1 элементов, которые были пропущены.
Этот способ называется блочным поиском: элементы группируются в блоки, и
каждый блок проверяется по одному разу до тех пор, пока ни будет найден
нужный блок. Вычисление оптимального для блочного поиска размера блока выполняется
следующим образом: в списке, содержащем N элементов, число просмотренных
элементов минимально при длине блока, равной ÖN. При этом в среднем анализируется
ÖN элементов.
При двоичном поиске рассматривается
элемент, находящийся в середине области, в которой выполняется поиск, и его
ключ сравнивается с поисковым ключом. Затем поисковая область делится пополам,
и процесс повторяется. При этом, если N велико, то в среднем будет просмотрено
примерно log2N-1 элементов. Это число меньше, чем число просмотров
для случая блочного поиска.
В общем случае сканирование
(последовательный поиск) в списках для нахождения в них элемента является
процессом, требующим много времени, если он выполняется над всем списком.
Однако его можно использовать для точной локализации элемента в небольшой
области, если эта область найдена некоторым другим способом.
Если список упорядочен по ключам, то
обычно при адресации используется таблица, называемая индексом. При
обращении к таблице задается ключ искомого элемента, а результатом процедуры
поиска в таблице является относительный или абсолютный адрес элемента.
Индекс можно определить как таблицу, с
которой связана процедура, воспринимающая на входе информацию о некоторых значениях
атрибутов и выдающая на выходе информацию, способствующую быстрой локализации
элемента или элементов, которые имеют заданные значения атрибутов. Индекс
использует в качестве входной информации ключ и дает на выходе информацию,
относящуюся к физическому адресу данного элемента.
Если для адресации используется
индекс, ЭВМ в основном производит поиск в индексе, а не в списке. При этом
существенно экономится время, но требуется память для хранения индекса. Это похоже
на использование картотеки в библиотеке. Пользователь отыскивает название
требуемой книги в картотеке и находит номер книги по каталогу, который является
как бы относительным адресом положения книги на полках.
Если элементы списка упорядочены по
ключу, индекс обычно содержит не ссылки на каждый элемент, а ссылки на блоки
элементов, внутри которых можно выполнить поиск или сканирование.
Хранение ссылок на блоки элементов, а не
на отдельные элементы в значительной степени уменьшает размер индекса. Причем
даже в этом случае индекс часто оказывается слишком большим для поиска и
поэтому используется индекс индекса. В больших списках может быть больше двух
уровней индекса.
Для ускорения поиска сегменты нижнего
уровня индекса могут находиться среди данных, на которые они указывают.
Например, в файле на диске обычно имеется на каждом цилиндре индекс дорожек,
содержащий ссылки на записи, хранящиеся на этом цилиндре.
Индексно-последовательные файлы
представляют собой наиболее распространенную форму адресации файлов.
Произвольный (непоследовательный)
список можно индексировать точно так же, как и последовательный
список. Однако при этом требуется значительно больший по размерам индекс, так
как он должен содержать по одному элементу для каждого элемента списка, а не
для блока элемента. Более того, в нем должны содержаться полные абсолютные
(или относительные) адреса, в то время как в индексе последовательного списка
адреса могут содержаться в усеченном виде, так как старшие знаки последовательных
адресов будут совпадать.
По сравнению с произвольным доступом
индексно-последовательный список более экономичен как с точки зрения размера
индекса, так и с точки зрения времени, необходимого для поиска в нем. Произвольные
списки в основном используются для обеспечения возможности адресации
элементов списка с несколькими ключами. Если список упорядочен по одному
ключу, то он не упорядочен по другому ключу. Для каждого типа ключей может
существовать свой индекс: для упорядоченных ключей индексы будут более
длинными, так как должны будут содержать по одному данному для каждого элемента.
Ключ, который чаще всего используется при адресации списка, обычно служит
для его упорядочения, поскольку наиболее быстрый доступ возможен в том случае,
когда применяется короткий последовательный индекс.
Аналогия с картотекой библиотеки скорее
соответствует индексно-последовательному доступу, чем произвольному. В
картотеке используются два ключа - название книги и фамилия автора, и, как
правило, ни тот, ни другой ключ не применяются при упорядочивании книг на
полках, следовательно, оба индекса должны содержать по элементу для каждой
книги. Книги упорядочиваются по номеру в каталоге. После того как
пользователь нашел номер интересующей его книги в каталоге, он отыскивает
книгу на рядах полок. В каждом ряду обычно указаны начальный и конечный
номера книг в нем. Пользователь сравнивает номер, который он получил из
каталога (индекса), с номерами, указанными в рядах. Найдя нужный ряд, он ищет
полку, на которой стоит книга. Аналогично ЭВМ выполняет поиск в файлах,
начиная, например, с главного индекса, далее просматривая индекс цилиндров, а
затем индекс дорожек.
В картотеке библиотеки не указывается
физическое местоположение книги на полках. Вместо этого в ней содержится номер
в каталоге, который может рассматриваться как символический адрес. Символический
адрес указывается потому, что книги переставляются, и, если бы использовался
физический адрес, это потребовало бы частой корректировки картотеки
библиотеки. По той же причине в индексно-произвольных списках часто
используются символические, а не абсолютные адреса. При добавлении новых или
удалении старых элементов изменяется местоположение остальных элементов.
Если имеется несколько ключей, то индекс вторичного ключа может содержать в
качестве выхода первичный ключ записи. При определении же местоположения
элемента по его первичному ключу можно использовать какой-нибудь другой способ
адресации. По этому методу поиск осуществляется медленнее, чем поиск, при
котором физический адрес элемента определяется по индексу. В списках, в
которых положение элементов часто изменяется, символическая адресация может
оказаться предпочтительнее.
Другой причиной для непоследовательного
размещения элементов могут служить частые изменения списка. Интенсивное
включение новых и удаление старых элементов в последовательно
упорядоченном списке связано с большими трудностями и значительным расходом
машинного времени. Если бы книги хранились на полках библиотеки в алфавитном
порядке, то обеспечение такого порядка занимало бы излишне много времени, так
как каждый раз при добавлении новой книги требовалось бы передвигать много
книг.
Известно много методов преобразования
ключа непосредственно в адрес в файле. В тех случаях, когда такое преобразование
возможно, оно обеспечивает самую быструю адресацию; при этом нет необходимости
организовывать поиск внутри файла или выполнять операции с индексами.
Наиболее простое решение задачи
адресации - указывать во входном сообщении относительный машинный адрес
запрашиваемой записи. В некоторых ранних банковских системах номера счетов
видоизменялись так, чтобы новый номер или его часть являлись бы адресом
элемента для данного счета в списке. Таким образом, адрес был равен ключу или
определялся по нему простым способом.
Во многих приложениях такой прямой
подход невозможен. Номера изделий на заводе не могут изменяться только ради
удобства использования ЭВМ, поскольку для работников фирмы они имеют в
запросе определенный смысл.
Иногда во входном сообщении
используется внутренний машинный код; при этом не требуется, чтобы он был
равен номеру клиента или номеру изделия. Например, адрес записи счета в
файле может печататься в банковской расчетной книжке клиента сберкассы и
указываться далее в запросе с терминала.
Такие схемы называются прямой
адресацией, хотя обычно этот термин используется в более широком смысле для
обозначения любого алгоритма, преобразующего ключ непосредственно в машинный
адрес.
Способ преобразования ключа в адрес дает
почти ту же скорость поиска, что и способ, в котором используется ключ, эквивалентный
адресу. В некоторых приложениях адрес может быть вычислен на основе
идентификаторов объекта, таких как адрес улицы и номер дома или номер рейса
и его дата. Для таких приложений рассматриваемый метод адресации
является наиболее простым и быстрым. Чаще всего данный способ применяется в
диалоговых системах, где критичным является время поиска в списке, и
называется хешированием, перемешиванием или рандомизацией.
К недостаткам данного способа относится
малое заполнение списка: в списке остаются свободные участки, поскольку
ключи преобразуются не в непрерывное множество адресов.
При этом методе вся область памяти для
размещения списка делится на участки – бакеты размером несколько десятков
элементов списка. Сам алгоритм хеширования по первичному ключу определяет, в
отличие от других методов, не адрес одного элемента списка, а адрес бакета,
содержащего целую группу элементов. При размещении элемента в списке каждый
новый элемент добавляется в конец уже имеющихся в бакете элементов; при поиске
- после определения адреса бакета поиск нужного элемента выполняется методом
последовательного сканирования.
Алгоритм хеширования выполняется в три
этапа:
1) первый этап
выполняется только для нечисловых значений ключей и заключается в замене их
числовыми значениями. Для этого составляется таблица соответствия символов
алфавита, в котором записываются значения ключей, с цифрами от 1 до 9. Затем
каждый символ нечислового значения ключа заменяется своим цифровым
эквивалентом. Например, если нечисловые значения ключей определены на русском
алфавите, такая таблица будет иметь вид:
а 1 и 9 р 8 ш 7
б 2 й 1 с 9 щ 8
в 3 к 2 т 1 э 9
г 4 л 3 у 2 ю 1
д 5 м 4 ф 3 я 2
е 6 н 5 х 4 ь 3
ж 7 о 6 ц 5 ъ 4
з 8 п 7 ч 6 ы 5
Очевидно, разным
символам присваивается один цифровой код, что ведет к потере информации.
Тогда, например,
для ключа со значением КОМПЬЮТЕР цифровой эквивалент имеет вид 264731168.
2) формируется
относительный адрес элемента списка. Для этого числовое значение адреса приводится
к порядку, равному порядку адресов памяти, где размещен список. Например,
список размещен на диске в кластерах с номерами от 10 до 999, т.е. в адресах с
порядком, равным 3. Тогда для ключа, полученного на предыдущем этапе, надо
выполнить такое преобразование, чтобы из девятизначного числа превратить его в
трехзначное. Подобные преобразования выполняются разными способами. Рассмотрим
некоторые из них:
- возведение в
квадрат. Числовое значение ключа возводится в квадрат и в полученном числе по
центру выбирается нужное количество цифр. Для нашего случая 2647311682
= 70082591310644200, центральными цифрами являются 131. Таким образом,
относительный адрес для ключа КОМПЬЮТЕР равен 131,
- метод
складывания (не путать со сложением). Числовое значение ключа делится на три
части: средняя часть (размещается по центру) имеет количество цифр, равное
порядку адресов памяти, где размещен список; оставшиеся правая и левая части
«заворачиваются» к средней и совпавшие цифры складываются до образования цифр.
Например, для ключа 264731168 этот способ дает следующий результат:
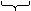 264 731 168
264 731 168
левая средняя правая
часть часть часть
После
складывания:
731-
средняя часть
462
- левая часть, «завернутая» по месту стыка со средней частью
861
- правая «завернутая» часть.
После сложения
совпавших цифр (сложение идет до достижения значения цифры):
(7+4+8)(3+6+6)(1+2+1) = (19)(15)(4) = (1+9)(1+5)(4) = (10)(6)(4) = (1+0)(6)(4)
= 164
Таким образом,
относительный адрес для ключа КОМПЬЮТЕР, полученный вторым способом, равен
164,
- метод деления.
Числовое значение ключа делится на количество адресов памяти, в которой
размещается список. Остаток от деления – относительный адрес. Например, для
ключа 264731168 и для числа адресов 989 (999 – 10) остаток от деления равен
593. Это и есть относительный адрес для ключа КОМПЬЮТЕР,
- метод сдвига.
Числовое значение ключа делится на две равные части, которые смещаются друг
навстречу другу так, чтобы общее число разрядов стало равно порядку адресов
памяти. Совпавшие разряды складываются. Например, для ключа 264731168 и для тех
же адресов:
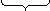 02647[1] 31168
02647[1] 31168
левая правая
часть часть
 направление
движения
направление
движения
правой
и левой частей числа
 02647 после
сдвига
02647 после
сдвига


 31168
31168
3 3 7 (10)(15) = 337(1+0)(1+5)=33716
Поскольку
полученное число имеет порядок, больший трех, процедура сдвига повторяется:
 033 716
033 716
левая часть правая часть
 033 после
сдвига
033 после
сдвига
749 – конечный
результат – относительный адрес для ключа КОМПЬЮТЕР.
Очевидно,
и этот этап дает потерю информации.
3) вычисление
абсолютного адреса. Исходная информация – диапазон изменения относительных
адресов (очевидно, от 0 до 999) и адреса размещения элементов списка в памяти
(напомним, что список занимает кластеры с адресами от 10 до 999). Тогда
абсолютный адрес для элементов списка получается по формуле:
<начальный
адрес размещения списка> + <относительный адрес элемента> * const,
где
const – константа, получаемая по формуле:
число
доступных адресов / максимальный относительный адрес, причем число доступных
адресов – разность между максимальным и минимальным адресами размещения списка
в памяти.
Для
нашего случая const = 989 / 999 = 0,989
Тогда,
например, для относительного адреса 199 абсолютный адрес (читай – номер
кластера) равен 10 + 199*0,989 = 10+197 = 207.
Программы автоматического обнаружения и
исправления ошибок в текстах на естественных языках (назовем их
автокорректорами - АК, хотя терминология ещё не сложилась) получают все большее
распространение. Они используются, в частности, в пакетах WINWORD и EXCEL для
проверки орфографии текстовой информации.
Говоря точнее, АК производят
автоматически лишь обнаружение ошибок, а собственно коррекция ведется обычно
при участии человека.
Известны, по крайней мере,
три метода автоматизированного обнаружения орфографических ошибок в текстах -
статистический, полиграммный и словарный.
При статистическом методе из текста одна
за другой выделяются составляющие его словоформы, а их перечень по ходу проверки
упорядочивается согласно частоте встречаемости. По завершении просмотра текста
упорядоченный перечень предъявляется человеку для контроля, например, через экран
дисплея. Орографические ошибки и описки в сколь-нибудь грамотном тексте несистематичны
и редки, так что искаженные ими слова оказываются где-то в конце перечня.
Заметив их здесь, контролирующее лицо может автоматизированно найти их в тексте
и исправить.
При полиграммном методе все
встречающиеся в тексте двух- или трехбуквенные сочетания (биграммы и триграммы)
проверяются по таблице их допустимости в данном естественном языке. Если в
словоформе не содержится недопустимых полиграмм, она считается правильной, а
иначе - сомнительной, и тогда предъявляется человеку для визуального контроля
и, если нужно, исправления.
При словарном методе все входящие в
текст словоформы, после упорядочения или без него, в своем исходном текстовом
виде или после морфологического анализа, сравниваются с содержимым заранее
составленного машинного словаря. Если словарь такую словоформу допускает, она
считается правильной, а иначе предъявляется контролеру. Он может оставить слово
как есть; оставить его и вставить в словарь, так что далее в сеансе подобное
слово будет опознаваться системой без замечаний; заменить (исправить) слово в
данном месте; потребовать подобных замен по всем дальнейшему тексту;
отредактировать слово вместе с его окружением. Операции над сомнительным
участком текста, указанные или иные возможные, могут комбинироваться исходя из
замысла проектировщика АК.
Результаты неоднократных исследований
показали, что только словарный метод экономит труд человека и ведет к минимуму
ошибочных действий обоих родов - пропуска текстовых ошибок, с одной стороны, и
отнесения правильных слов к сомнительным, с другой. Поэтому словарный метод
стал доминирующим, хотя полиграммный метод иногда и применяют как вспомогательный.
Можно предложить три степени
автоматизации процесса коррекции текста:
1) только обнаружение ошибок,
2) обнаружение их и выдвижение гипотез
(альтернатив, кандидатов) по исправлению;
3) обнаружение ошибок, выдвижение
гипотез и принятие одной из них (если хотя бы одна выдвинута системой) в качестве автоматически вносимого
исправления.
Без первой степени АК немыслим.
Вторая и третья степень возможны только
при словарном методе. Уже вторая существенно облегчает внесение исправлений,
ибо в большинстве случаев исключает перенабор сомнительного слова. Особенно
полезны найденные альтернативы, когда контролирующее текст лицо нетвердо знает
данный естественный язык или конкретную терминологическую область. Однако
выдвижение гипотез требует больших переборов с поиском по словарю. Поэтому
современные АК часто имеют средство выдвижения гипотез лишь в качестве
факультативного, запускаемого, если требуется, избирательно для данного
сомнительного слова.
Третья степень автоматизации заманчива и
одновременно опасна. Заманчивость заключается в полной автоматизации процесса
исправления. Опасность же в том, что ни один словарь, в том числе - заключенный
в человеческом мозгу, никогда не бывает исчерпывающе полным. Когда незнакомое
слово встречает система, основанная на неполном словаре, она может
"исправить" его на ближайшее ей знакомое, порой резко исказив исходный
смысл текста. Особо опасно править собственные имена лиц, фирм, изделий,
Заманчиво уметь пропускать (обходить) собственные имена и сугубо специальные
термины, априори полагая их правильными, но безошибочные способы обхода, особенно
- терминов, нам не известны.
Чисто автоматическому исправлению мог бы
способствовать автоматический синтаксический и семантический анализ проверяемого
текста, но он ещё не стал принадлежностью обычных АК. И даже при его наличии
лишь человек сможет диагностировать быстро меняющиеся совокупности собственных
имен, терминов и аббревиатур, а также окказионализмы - случайно появляющиеся
словесные новации.
В связи со сказанным полная
автоматизация исправлений может применяться лишь в любом из следующих
ограничительных условий:
I) Текст имеет вид перечня терминов и
терминологических словосочетаний в стандартной их форме, так что в АК
достаточно иметь словарь, замкнутый по объему и проблематике. При этом все
термины между собой "непохожи" (например, в словаре нет одновременно
АДСОРБЦИЯ и АБСОРБЦИЯ).
2) Ошибки носят характер замены кодов
исходных букв на коды литер, совпадающих или близких к исходным по
начертанию. Например, заменяются коды ASCII русских букв А, В, С, Е, У на коды
латинских букв А, В, С, Е, У; латинские буквы I и 0 - на цифры I и 0 и
т.п. Сюда же отнесем повторы одной и той же литеры, возникающие из-за продленного
нажима клавиши дисплея или его неисправности. В подавляющем большинстве, если в
словоформе более 2 -3 букв, такие исправления абсолютно правильны.
Возможны, в общем случае, два режима
работы АК: диалоговый, когда текст проверяется слово за словом и пользователю
предоставляется возможность снять очередное затруднение по мере его возникновения,
и пакетный, когда готовые большие тексты анализируются в отсутствии
пользователя.
Во втором случае ненайденные словоформы
либо как-то отмечаются в исходном тексте, либо запоминаются отдельно в виде
своих адресов (в качестве адреса может использоваться, например, номер строки и
номер символа, с которого начинается слово, в строке). Подобная проверка
ведется до конца проверяемого файла без вмешательства человека. Далее файл
вызывается снова и предъявляется для контроля тех строк, где были замечены
сомнительные слова.
В высокофлективных языках, к которым
относятся, в частности, все славянские, от одной основы могут образовываться
до нескольких сот различных словоформ. В этих условиях в АК неизбежны
средства морфологического анализа той или иной сложности, а непосредственное
использование западных АК и перенос методов их работы на неанглоязычные
тексты едва ли даст удовлетворительные результаты, если исключить метод
"грубой силы" - неограниченное наращивание объема оперативной памяти
(ОП) и быстродействия ЭВМ.
Объектами сжатия являются:
- числовые данные,
- упорядоченные текстовые данные
(словари),
- специальные тексты на
формализованных языках,
- естественно-языковые тексты
общего вида,
- структурированные данные.
В качестве количественной меры
сжатия используется коэффициент сжатия - отношение
длины первоначального к сжатому тексту, а также продолжительность требуемых
преобразований.
Наиболее распространены методы:
разностное кодирование, кодирование повторений и подавление незначащих нулей.
Суть разностного кодирования
заключается в хранении вместо абсолютных значений разностей двух смежных чисел
или отклонения чисел от их среднего значения. Например, для последовательности
чисел 2, 14, 18, 27, 34
первый способ даст последовательность 2, 12, 4, 9, 7. Второй способ порождает
последовательность: -17, -5, -1, 8, 15 (среднее значение для исходной
последовательности - 19).
Первый вариант эффективен для медленно
меняющихся последовательностей, второй - когда максимальное отклонение от среднего
значительно меньше абсолютного значения среднего.
Кодирование повторений
заключается в замене цепочки одинаковых символов кодом этого числа и числом
повторений. Например, для последовательности 5555 6666 888888 применение этого
способа даст последовательность 5(4) 6(4) 8(6).
Подавление незначащих нулей означает отбрасывание незначащих нулей в старших разрядах целой части числа и в младших разрядах дробной
части. Например, применение этого способа сжатия к последовательности 0010
01,100 011 011 даст последовательность: 10 1,1 11 11.
1.2. Сжатие словарей
Под словарями понимают списки
неповторяющихся цепочек символов в алфавитном или ином строгом порядке. Такой
словарь можно рассматривать как монотонную последовательность чисел и для его сжатия применять метод разностного
кодирования (см. п.1.1). Здесь он заключается в
отбрасывании у каждого слова начальных букв, совпадающих с начальными символами
предыдущего слова и замене их на число отброшенных букв. Например, словарь:
вычислитель
вычислительный
вычислять
в результате
рассматриваемого способа кодирования будет заменен словарем:
вычислитель
11ный
6ять.
Такой метод, однако, неудобен
тем, что при декодировании любого конкретного слова требуется последовательно
декодировать все предшествующие
слова. Поэтому порой используются отдельные перечни наиболее
часто встречающихся частей слов (суффиксы, префиксы), где каждой из них
ставится в соответствие более короткий код, заменяющий её в словаре. Например,
словарь:
встречающийся
заменяющий
с помощью этого способа сжатия
заменится на совокупность словарей:
основной вспомогательный
встреча1ся
1- ющий
заменя1
Важнейшим здесь является
алгоритм выбора достаточно длинных и часто встречающихся подцепочек. При его
разработке используются эвристические алгоритмы, поскольку эффективного
алгоритма поиска оптимального решения не существует.
Когда составляющие словаря образуют сильно обособленные группы слов, можно разделить
весь словарь на подсловари, присвоив каждому из них свой индекс, и кодировать слова независимо в каждом
из них кодами минимальной длины, а слова из различных подсловарей
различать этими индексами. Такой метод является модификацией описанного в п.
1.1 метода сжатия числовых данных через их среднее значение.
К специальным относятся тексты
на формальных языках, отличающихся ограниченным словарем, замкнутой
грамматикой. Сюда прежде всего относятся тексты на языках программирования, машинные
коды, различные формулы и обозначения, а также ограниченные подмножество фраз естественного языка в таких четко
формализованных задачах как организация реплик в
интерактивных системах, выдача сообщений при компиляции и т.п.
Для данного типа информации
пригодны методы, описанные в п. 1.5. В то же время специфика этих текстов позволяет осуществить экономное хранение, основанное на
выделении длинных часто повторяющихся фрагментов.
Например, текст Фортран-программы:
ТYРЕ *,’ФОРТРАН’
ТYРЕ *,’ПРОГРАММА'
может быть представлен с
использованием кодового словаря:
программа словарь
1,'ФОРТРАН' 1
- ТУРЕ *
1,'ПРОГРАММА'
Структурированные данные
содержат текстовую и иную информацию и хранятся в определенном формате,
приемлемом для тех или иных прикладных задач,
например, для документального или фактографического поиска информации. Пример
структурированных данных - библиографические описания.
Разнородность
данных структурированного типа обуславливает различные
типы информационной избыточности, поэтому необходимо использовать комбинацию
методов, приспособленных к своим подгруппам данных. Так, для числовых полей
целесообразно применять методы п. 1.1, для текстовых - описанные в п. 1.5. По
некоторым оценкам комбинация этих методов дает сокращение объема данных в 1,5-4
раза, по другим оценкам - даже до 6 раз.
В структурированных данных
наряду с типами информационной избыточности, характерных для текстовых или
нетекстовых данных, существует особый позиционный тип избыточности. Он связан с
дублированием информации для идентификации структуры данных. Например, если
записи файла имеют структуру:
Ф.И.О. студента
отношение к воинской обязанности
домашний адрес
специальность
оценки за сессию,
причем поля имеют длину,
соответственно, 40, 20, 50, 15, 10 байт, то при различных значениях тех или
иных полей для конкретных студентов часть области памяти, отводимой под
отдельные поля, не будет использоваться. Тогда, если поле «Отношение к воинской
обязанности» пусто, его можно исключить из конкретной записи и вся запись будет
иметь следующий вид:
(Ф.И.О. студента)1(домашний
адрес)3(специальность)4(оценки за сессию)5,
где индексы означают
принадлежность того или иного значения соответствующему полю.
Принципиальная возможность сжатия текстовой информации связана с тем, что составляющие текста - буквы и
словоформы - различаются по частоте встречаемости в
тексте, в то время как их длины слабо связаны с частотой.
Методы кодирования можно разделить на четыре класса в зависимости
от того, какие группы символов кодируются (постоянной или переменной длины), и
какие коды используются
(постоянной или переменной длины).
По использованию статистики и грамматики алгоритмы сжатия можно
разделить на семантически зависимые и семантически независимые.
Первые (лингвистические) методы опираются на грамматику естественного языка для выделения в текстах элементов, подлежащих
кодированию (как правило, это отдельные слова –
словоформы).
Семантически независимые методы
сжатия в свою очередь можно разделить на те, которые не используют, и те, которые используют
априорные сведения о статистике текста. В соответствии с этим существуют два
типа алгоритмов сжатия: одно - и двухфазные, которые будем называть
соответственно адаптивными и статистическими.
Семантически зависимые методы не
используют для сжатия никаких априорных сведений о статистике текста.
Кодирование производится в процессе однократного
сканирования текста. Оно сводится к замене цепочек символов текста на
встроенные указатели, адресованные к той части текста, где такие цепочки уже
встречались. В этом случае говорят о внутренней адресации, а сами методы называются
адаптивными.
В алгоритмах второго типа
выполняется ссылка на таблицу кодов, которая может создаваться заново для
каждого текста или использоваться одна на все гипотетические тексты. В этом
случае говорят о внешней адресации и локальных или глобальных кодовых таблицах.
Строят код постоянной длины для
фрагментов переменной длины.
Сжимают текст в процессе
однократного его сканирования. Кодирование заключается в нахождении
повторяющихся участков текста и замене каждого участка указателем, адресованным
к той части текста, где такой участок уже встречался. Для декодирования в этом
случае кодовой таблицы не требуется. В качестве указателя может использоваться
структура (m, n), где m – количество символов назад или вперед по тексту,
переместившись на которые можно найти подобный фрагмент текста; n – длина
фрагмента в символах.
Существует два типа встроенных
указателей, указывающих на предшествующие или последующие участки. Алгоритмы,
использующие указатели назад, могут работать с
непрерывным входным потоком данных, генерируя
непрерывный выходной поток сжатой информации. На каждом шаге алгоритма входной
текст заполняет буфер фиксированной длины, внутри
которого производится идентификация одинаковых подстрок максимально возможной
длины. При нахождении двух таких подстрок вторая заменяется
указателем, адресованным в начало первой.
Алгоритмы с указателями вперед
могут работать лишь с текстами конечной длины, поскольку требуют обратного
сканирования текста. Здесь также используется поиск совпадающих подстрок в буфере
переменной длины с уже закодированным текстом.
Одной из характерных черт адаптивных алгоритмов является достаточная
их универсальность, т.е. возможность работать с любыми, не только текстовыми
данными, ненужность начальной информации о характере данных и их статистике.
Эта черта снижает эффективность сжатия и достигаемое сжатие, как правило,
меньше полученного другими методами. Но часто адаптивные алгоритмы просты и
все же приемлемы по эффективности.
Коэффициент сжатия текстовых
данных этим методом лежит в пределах 1,8 - 2,5.
Простейшей
формой словаря в этом случае является кодовая таблица символов алфавита, ставящая
в соответствие каждому символу свой код. Коды выбираются с таким расчетом,
чтобы общая длина закодированного ими текста была
минимальной. Такую же таблицу можно составить для
всех или наиболее часто встречающихся комбинаций из двух, трех и т.д. букв,
т.е. фрагментов с фиксированным числом символов. Ниже приведены частоты букв в
русском языке:
пробел 0,174 ы 0,016
о 0,080 з 0,016
е, ё 0,071 ъ 0,014
а 0,061 ь 0,014
и 0,061 б 0,014
т 0,052 г 0,013
м 0,052 ч 0,012
с 0,045 й 0,010
р 0,040 у 0,009
в 0,038 ж 0,007
л 0,035 ю 0,006
к 0,028 ш 0,006
н 0,026 ц 0,003
д 0,025 щ 0,003
п 0,023 э 0,003
у 0,021 ф 0,002
я 0,018 х 0,002
Сами коды рассчитываются на
основании частот отдельных символов (в случае таблицы символов) или их
комбинаций (в этом случае общая частота рассчитывается как произведение частот
отдельных символов, входящих в комбинацию) с помощью методов Шеннона-Фано или
Хаффмена (описание методов см. в приложении 1).
Избыточность
информации заключается ещё в корреляции между символами (словами). Метод
Хаффмена сохраняет эту избыточность. Существуют модификации метода,
позволяющие учесть взаимозависимости. Наиболее простая из них используется,
когда все символы можно разделить на небольшое число групп с сильной
корреляцией внутри групп и слабой - между ними. Это иногда имеет место для
числовых и буквенных символов текста.
К другим недостаткам хаффменовских методов относится относительная
сложность декодирования - необходимость анализа битовой структуры префиксных
кодов, замедляющая процесс декодирования.
Дальнейшим
развитием метода Хаффмена являются арифметические
коды. Они происходят из так называемых конкатенационных, или
блочных, кодов. Суть их заключается в том, что выходной код генерируется для
цепочки входных символов фиксированной длины без
учета межсимвольных корреляций. В основе метода лежит представление вероятности
каждой цепочки К входных символов (А1, А2, ... АК
) в виде числа, получаемого как сумма К слагаемых
вида
p(А1)p(А2)..р(АI-1)P(АI), I=1, 2, 3, …… K
где р
(S) - вероятность
символа S,
Р(S)-
куммулятивная вероятность символа S, равная сумме вероятностей всех символов AI,
для которых р(АI)
больше р(S).
Другой формой словаря может
являться словарь фрагментов переменной длины. Словари фрагментов переменной
длины строятся из словоформ, которые выделяются в тексте по естественным разделителям
– пробелам и знакам пунктуации. Затем рассчитываются частоты каждой словоформы
как отношение числа ее повторений к
общему количеству словоформ. Используя эти частоты, применяют метод Хаффмена
или Шеннона-Фано для кодирования словоформ кодом переменной длины.
В процессе ускоренной компьютеризации общества объемы данных, хранимых на машинных носителях,
быстро растут. Ещё совсем недавно они измерялись килобайтами и мегабайтами, а
теперь - гигабайтами и более крупными единицами. Естественно желание хранить
эти данные предельно компактно. Причем интересны обратимые методы,
устраняющие избыточность информации при сжатии и восстанавливающие её при разжатии. Описанные в реферате методы обратимы.
Знаки упорядочиваются по
возрастанию их частот и образуют частичные суммы Si = Spj (j = 1, 2, 3, ….. i), где рj -
частота j-того знака. Далее процесс
разбивается на несколько шагов. В первом шаге столбец знаков рассекается на две
части так, чтобы частичная сумма сечения была близка к 0,5. Процесс деления подстолбцов повторяется так, чтобы каждый раз
частичная сумма в точке сечения оказывалась ближе к среднему арифметическому
частичных сумм на нижнем и верхнем краях разделяемого подстолбца.
При каждом разбиении элементам верхней части ставится в соответствие 1,
нижней - 0. Например: пусть
знаки рi
A 0,11
B 0,15
C 0,20
D 0,24
E 0,30
Тогда процедура разбиения
складывается из шагов:
 Знаки pi коды
Знаки pi коды
 A 0,11 1
1 111
A 0,11 1
1 111

 B 0,15 1
0 110
B 0,15 1
0 110
C 0,20
0 10

 D 0,24 0 1
01
D 0,24 0 1
01
E 0,30
0 00
шаг1 шаг2 шагЗ
Знаки упорядочиваются по
возрастанию частоты. Два
самых редких знака объединяются в один класс, и их
частоты складываются. Полученные частоты переупорядочиваются
и процесс повторяется до тех пор, пока все знаки ни будут объединены в один
класс.
Например,

Знаки pi Знаки pi
A 0,11 (0) C 0,20
(0)
 B 0,15
(1) D 0,24 (1)
B 0,15
(1) D 0,24 (1)
C 0,20 F 0,26
D 0,24 E 0,30
E 0,30

Знаки pi Знаки pi
F 0,26
(0) G 0,44 (0)
E 0,30
(1) H 0,56 (1)
G 0,44
Тогда коды исходных символов
(они «собираются» из частных кодов дополнительных обозначений – F, G, H- в
обратном относительно хода кодировки порядке):
символы
A 100
(А вошел в F с кодом 0; F вошел в H с кодом 0; у H код 1. Тогда обратный
порядок - 100)
B 101
(B вошел в F с кодом 1; F вошел в H с кодом 0; у H код 1. Тогда обратный
порядок – 101)
С 00
(С вошел в G с кодом 0; у G код 0)
D
01 (D вошел в G с кодом 1; у G код 0. Тогда обратный порядок – 01)
E
11 (E вошел в H с кодом 1, у H код 1)
Я думаю, что эти вопросы,
определяющие часть информатики, посвященную обработке информации, помогают
профессиональному программисту, с одной стороны, ознакомится с некоторыми практическими
задачами информатики, а с другой стороны, закрепить навыки прикладного
программирования и составления блок-схем. Эта довольно сложная часть
информатики нуждается в более полном освещении, а о пользе улучшения навыков
обработке текстовой информации, а также работы с базами данных нечего и
говорить. Говоря коротко, и профессионал, и начинающий пользователь может найти
для себя много полезного в предоставленной выше информации.
Каган
и Каневский “Цифровые вычислительные машины и системы”.
Газета
“Компьютер - инфо”.
[1]
Добавление незначащего нуля обусловлено требованием четности числа цифр