Статистический анализ зарегистрированных абонентских терминалов сотовой связи
Московский
Государственный Строительный Университет
Институт
фундаментального образования
Факультет
общенаучных кафедр
Курсовая
работа по дисциплине:
«Теория
вероятности и математическая статистика»
Выполнил:
Студент
ИФО 3-2
Плаксина
С.С.
Проверила:
Доцент
Кирьянова Л.В.
Москва 2011
Введение
Математическая статистика -
наука, изучающая методы раскрытия закономерностей, свойственных большим
совокупностям однородных объектов, на основании их выборочного обследования.
Задачей математической статистики является построение методов оценки
вероятности или принятия решений о характере событий на основе статистических
данных. Математическая статистика делится на статистику чисел, многомерный
статистический анализ, анализ функций (процессов) и временных рядов, статистику
объектов нечисловой природы.
Задача.
Провести первичную обработку статистических
данных по количеству зарегистрированных абонентских терминалов сотовой связи за
2008 год на 1000 населения в регионах России. Сделать выводы.
Решение.
Первая часть
ЧИСЛО АБОНЕНТСКИХ ТЕРМИНАЛОВ СОТОВОЙ СВЯЗИ на
1000 человек населения ПО СУБЪЕКТАМ РОССИЙСКОЙ ФЕДЕРАЦИИ (на конец года; штук)
2008 год.
|
1
|
Белгородская
область
|
1211,9
|
30
|
Кабардино-Балкарская
Республика
|
956,7
|
59
|
Челябинская
область
|
1522,1
|
|
2
|
Брянская
область
|
1103,6
|
31
|
Республика
Калмыкия
|
1255
|
60
|
Республика
Алтай
|
1006,2
|
|
3
|
Владимирская
область
|
1343,2
|
32
|
Карачаево-Черкесская
Республика
|
1203,1
|
61
|
Республика
Бурятия
|
1244
|
|
4
|
Воронежская
область
|
983,1
|
33
|
Республика
Северная Осетия - Алания
|
1027,6
|
62
|
Республика
Тыва
|
916,2
|
|
5
|
Ивановская
область
|
1400,9
|
34
|
Чеченская
Республика
|
812,5
|
63
|
Республика
Хакасия
|
1408,6
|
|
6
|
Калужская
область
|
1420,4
|
35
|
Краснодарский
край
|
1417,4
|
64
|
Алтайский
край
|
1125,1
|
|
7
|
Костромская
область
|
1392
|
36
|
Ставропольский
край
|
1109,3
|
65
|
Забайкальский
край
|
1018,9
|
|
8
|
Курская
область
|
1217,5
|
37
|
Астраханская
область
|
1490,1
|
66
|
Красноярский
край
|
1385,9
|
|
9
|
Липецкая
область
|
1106,5
|
38
|
Волгоградская
область
|
1296,8
|
67
|
Иркутская
область
|
1505,7
|
|
10
|
Орловская
область
|
1186
|
39
|
Ростовская
область
|
1100,2
|
68
|
Кемеровская
область
|
1235
|
|
11
|
Рязанская
область
|
1400,5
|
40
|
Республика
Башкортостан
|
1283
|
69
|
Новосибирская
область
|
1337,9
|
|
12
|
Смоленская
область
|
1532,2
|
41
|
Республика
Марий Эл
|
1313,5
|
70
|
Омская
область
|
1244,1
|
|
13
|
Тамбовская
область
|
1209,6
|
42
|
Республика
Мордовия
|
1287,7
|
71
|
Томская
область
|
1232,2
|
|
14
|
Тверская
область
|
1483,4
|
43
|
Республика
Татарстан
|
1366,3
|
72
|
Республика
Саха (Якутия)
|
957,2
|
|
15
|
Тульская
область
|
1237,3
|
44
|
Удмуртская
Республика
|
1161
|
73
|
Камчатский
край
|
1421,1
|
|
16
|
Ярославская
область
|
1448
|
45
|
Чувашская
Республика
|
1299,8
|
74
|
Приморский
край
|
1531
|
|
17
|
г.
Москва и Московская область
|
1972,1
|
46
|
Пермский
край
|
1335,2
|
75
|
Хабаровский
край
|
1315,6
|
|
18
|
Республика
Карелия
|
1462,1
|
47
|
Кировская
область
|
1152,5
|
76
|
Амурская
область
|
1295,9
|
|
19
|
Республика
Коми
|
1495,4
|
48
|
Нижегородская
область
|
1422
|
77
|
Магаданская
область
|
1370,6
|
|
20
|
Архангельская
область
|
1476,2
|
49
|
Оренбургская
область
|
1215,5
|
78
|
Сахалинская
область
|
1329,9
|
|
21
|
Вологодская
область
|
1523,1
|
50
|
Пензенская
область
|
1267,6
|
79
|
Еврейская
автономная область
|
730,5
|
|
22
|
Калининградская
область
|
1581,2
|
51
|
Самарская
область
|
1570,3
|
80
|
Чукотский
автономный округ
|
767,8
|
|
23
|
Мурманская
область
|
1790,1
|
52
|
Саратовская
область
|
1317,1
|
|
|
|
|
24
|
Новгородская
область
|
1546,6
|
53
|
Ульяновская
область
|
1361,4
|
|
|
|
|
25
|
Псковская
область
|
1404,7
|
54
|
Курганская
область
|
1180,6
|
|
|
|
|
26
|
г.
Санкт-Петербург и Ленинградская область
|
1863,4
|
55
|
Свердловская
область
|
1285,9
|
|
|
|
|
27
|
Республика
Адыгея
|
707,4
|
56
|
Тюменская
область
|
1528,8
|
|
|
|
|
28
|
Республика
Дагестан
|
930
|
57
|
Ханты-Мансийский
автономный округ - Югра
|
1593
|
|
|
|
|
29
|
Республика
Ингушетия
|
877,5
|
58
|
Ямало-Ненецкий
автономный округ
|
1732,9
|
|
|
|
Теория
Объем выборки - это количество
проведенных измерений или наблюдений.
Вариационный ряд - это
упорядоченные по возрастанию числовые значения элементов выборки.
Статистическая совокупность -
это совокупность предметов или явлений, объединенных каким-либо общим
признаком.
Генеральная совокупность - это
совокупность объектов или явлений, все элементы которой подлежат изучению при
статистическом анализе.
Выборочная совокупность
(выборка) - это множество результатов наблюдений, случайно отобранных из
генеральной совокупности.
Размах выборки - это разность
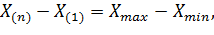
где выбранные точки называются
экстремальными значениями (только для отсортированных данных).
Интервалом варьирования 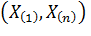 называется
промежуток между экстремальными значениями. Составим
интервальную таблицу частот. Обычно число интервалов группировки
называется
промежуток между экстремальными значениями. Составим
интервальную таблицу частот. Обычно число интервалов группировки 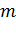 рассчитывают
по формуле Стерджеса:
рассчитывают
по формуле Стерджеса: 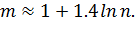
Ширина интервала равна:
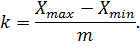
Частота 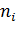 -
это число, равное количеству элементов, попавших в данный интервал. Сумма всех
частот должна равняться объему выборки:
-
это число, равное количеству элементов, попавших в данный интервал. Сумма всех
частот должна равняться объему выборки:
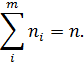
Относительная частота - это
отношение частоты к объему выборки, т.е. 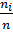 .
.
Относительная накопленная
частота - это отношение количества элементов, оказавшихся меньше какого-то
определенного значения, к объему выборки.
Расчет
|
n=80
|
x
max=1972,1
|
x
min=707,4
|
Запишем число интервалов группировки по формуле
Стёрджеса
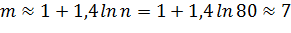
Ширина интервала равна
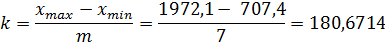
Частоту посчитаем как количество значений,
попавших в каждый интервал.
Относительную частоту возьмем по формуле ,
то есть отношение частоты к объему выборки.
Накопленная частота - это отношение количества
элементов, оказавшихся меньше какого-то определенного значения, к объему
выборки.
Таблица сгруппированных данных:
|
№
|
интервал
|
X-сер.инт.
|
частоты
|
отн.част.
|
|
1
|
[707,4;
888,07)
|
797,736
|
5
|
0,0625
|
|
2
|
[888,07;
1068,74)
|
978,407
|
8
|
0,1
|
|
3
|
[1068,74;
1249,41)
|
1159,079
|
19
|
0,2375
|
|
4
|
[1249,41;
1430,09)
|
1339,750
|
28
|
0,35
|
|
5
|
[1430,09;
1610,76)
|
1520,421
|
16
|
0,2
|
|
6
|
[1610,76;
1791,43)
|
1701,093
|
2
|
0,025
|
|
7
|
[1791,43;
1972,10)
|
1881,764
|
2
|
0,025
|
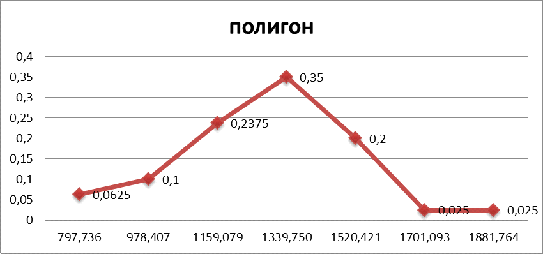
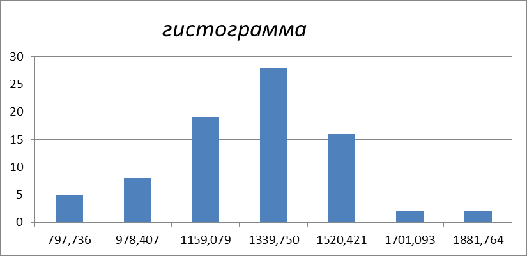
Представим эти данные графически с помощью
гистограммы и полигона частот.
Гистограмма - это способ
графического представления табличных данных некоторого показателя в виде
прямоугольников, площади которых пропорциональны. При построении гистограммы мы
на каждом интервале строим прямоугольник площадью 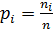 ,
то есть высота прямоугольника
,
то есть высота прямоугольника 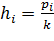 . Таким образом,
общая площадь равна единице. С увеличением объема выборки и уменьшением длины
интервала гистограмма будет приближаться к кривой плотности распределения,
поэтому гистограмму используют в качестве оценки для плотности распределения.
. Таким образом,
общая площадь равна единице. С увеличением объема выборки и уменьшением длины
интервала гистограмма будет приближаться к кривой плотности распределения,
поэтому гистограмму используют в качестве оценки для плотности распределения.
Полигон частот - это ломаная,
концы отрезков которой имеют координаты 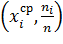 .
.
Выборочные
характеристики.
Выборочное (эмпирическое)
среднее.
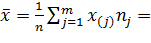 1285,55
1285,55
Выборочная медиана
Это значение признака,
приходящееся на середину вариационного ряда.
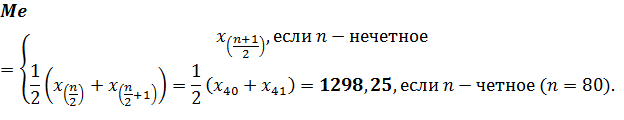
Медиану, как меру средней
величины, используют в том случае, если крайние члены вариационного ряда по
сравнению с остальными, оказались чрезмерно большими или малыми.
Выборочная мода
Это выборочное значение,
которому соответствует наибольшая частота. Моду легко найти графическим путем с
помощью гистограммы. В моем случае:
 1323
1323
Выборочная (эмпирическая) дисперсия
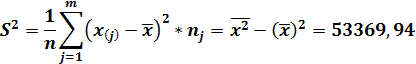
Выборочное среднеквадратическое
отклонение
Это арифметический квадратный
корень из выборочной дисперсии
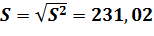 .
.
Эмпирический коэффициент
асимметрии
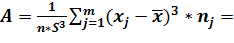 - 0,0725
- 0,0725
Если 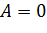 ,
то распределение имеет симметричную форму.
,
то распределение имеет симметричную форму.
Если 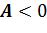 (мой
случай), то распределение имеет отрицательную (левостороннюю) асимметрию.
(мой
случай), то распределение имеет отрицательную (левостороннюю) асимметрию.
Эмпирический эксцесс
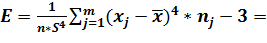 0,162
0,162
Если 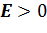 (мой
случай), то полигон вариационного ряда имеет более
крутую вершину по сравнению с нормальной кривой.
(мой
случай), то полигон вариационного ряда имеет более
крутую вершину по сравнению с нормальной кривой.
Если 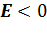 ,
то полигон вариационного ряда имеет более пологую вершину по сравнению с
нормальной кривой.
,
то полигон вариационного ряда имеет более пологую вершину по сравнению с
нормальной кривой.
Интервальное
оценивание параметров
статистический регрессионный
интервальный
Доверительный интервал
Это статистическая оценка
параметра вероятностного распределения, имеющая вид интервала, границами
которого служат функции от результатов наблюдений и который с высокой
вероятностью «накрывает» неизвестный параметр.
При этом вероятность называют
доверительной вероятностью или уровнем надежности.
Величину называют нижней
доверительной границей, аналогично - верхняя доверительная граница.
Если установить большое
значение уровня надежности, то доверительный интервал будет шире, и увеличится
«уверенность» в оценке, и наоборот. Ширина доверительного интервала также
зависит от объема выборки и «степени разброса» наблюденных значений.
Различают два вида задания
доверительных границ:
. Симметрично относительно
оценки параметра, т.е.
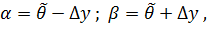
где 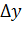 -
величина абсолютной погрешности или предельная ошибка.
-
величина абсолютной погрешности или предельная ошибка.
Для симметричного относительно
точечной оценки интервала величина абсолютной погрешности оценивания равна
половине доверительного интервала.
. Из условия равенства
вероятностей выхода за верхнюю и нижнюю границу, т.е.
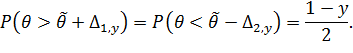
В общем случае 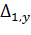 ,
тогда предельная ошибка выборки равна наибольшему отклонению выборочного значения
параметра от его истинного значения.
,
тогда предельная ошибка выборки равна наибольшему отклонению выборочного значения
параметра от его истинного значения.
Интервальная оценка для
математического ожидания нормального распределения при известной дисперсии.
Для использования этой оценки
на практике требуется, чтобы распределение генеральной случайной величины было
нормальным и параметрами 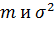 , либо, чтобы объем
выборки был достаточно велик. Тогда
, либо, чтобы объем
выборки был достаточно велик. Тогда  -
доверительный интервал имеет вид:
-
доверительный интервал имеет вид:
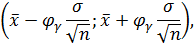
где 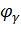 -
квантиль стандартного нормального распределения уровня
-
квантиль стандартного нормального распределения уровня 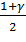 ,
,
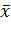 -
выборочное среднее.
-
выборочное среднее.
Интервальная оценка для
математического ожидания нормального распределения при неизвестной дисперсии (мой
случай).
Если дисперсия неизвестна, то
ее заменяют на оценку:
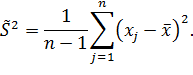
Поэтому симметричный -
доверительный интервал будет иметь вид:
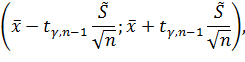
Зададим уровень доверия 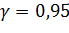 .
Тогда
.
Тогда 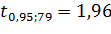 .
Имея формулу
.
Имея формулу
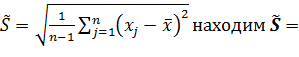 108,76
108,76
и получаем доверительный интервал для нашего
случая: (1261,72; 1309,38)
Это означает, что вероятность
нахождения математического ожидания в данном интервале равна уровню доверия:
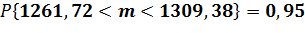
Отметим так же, что если 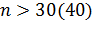 ,
распределение Стьюдента близко к нормальному и можно пользоваться таблицами
нормального распределения.
,
распределение Стьюдента близко к нормальному и можно пользоваться таблицами
нормального распределения.
Интервальная оценка для
среднеквадратического отклонения нормального распределения.
В этом случае эффективной
оценкой дисперсии является статистика
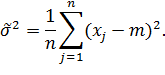
Тогда -
доверительный не симметричный интервал будет иметь вид:
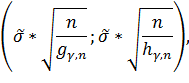
где 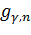 -
квантиль уровня
-
квантиль уровня 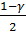 распределения
распределения 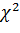 с
с
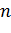 степенью
свободы,
степенью
свободы, 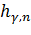 -
квантиль уровня распределения с
степенью
свободы.
-
квантиль уровня распределения с
степенью
свободы.
Если же математическое ожидание
- неизвестно (мой случай), то количество степеней свободы уменьшается на
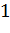 ,
и доверительный интервал имеет вид
,
и доверительный интервал имеет вид
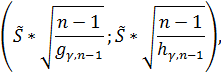
Здесь 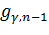 -
это квантиль уровня распределения
-
это квантиль уровня распределения 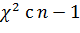 степенями
свободы и
степенями
свободы и 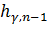 - это квантиль
уровня распределения
- это квантиль
уровня распределения
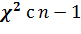 степенями
свободы. Берем
степенями
свободы. Берем 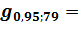 100,74862
и
100,74862
и 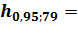 59,52295.
Тогда наш доверительный интервал будет: (96,31;
125,30)
59,52295.
Тогда наш доверительный интервал будет: (96,31;
125,30)
Гипотеза о виде
распределения
Предположим, что наша выборка
имеет нормальное распределение. Проверим эту гипотезу с помощью критерия
согласия - критерия (Пирсона).
Проверка этой гипотезы состоит
из следующих пунктов:
. Воспользуемся ранее
составленным разбиением диапазона значений случайной величины на интервалы 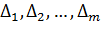 ,
но при этом объединим последние 2 интервала, так как в них попало достаточно
мало значений в сравнении с подсчитанным числом наблюдений, попавших в каждый
интервал.
,
но при этом объединим последние 2 интервала, так как в них попало достаточно
мало значений в сравнении с подсчитанным числом наблюдений, попавших в каждый
интервал.
. Предположив справедливость
основной гипотезы, подсчитаем вероятность попадания в каждый интервал:
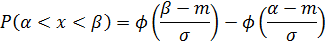
3. Примем следующие значения
для 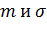 :
:
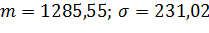 .
.
|
№
|
интервал
|
частоты
|
Рi
|
(ni-n*pi)^2/(n*pi)
|
χ^2(m-k-1)
|
|
1
|
[707,4;
888,07)
|
5
|
0,0365
|
1,096
|
4,207
|
|
2
|
[888,07;
1068,74)
|
8
|
0,1335
|
1,189
|
|
|
3
|
[1068,74;
1249,41)
|
19
|
0,3424
|
1,607
|
|
|
4
|
[1249,41;
1430,09)
|
28
|
0,2197
|
0,685
|
|
|
5
|
[1430,09;
1610,76)
|
16
|
0,1835
|
0,579
|
|
|
6
|
[1610,76;
1972,10)
|
4
|
0,0789
|
0,078
|
|
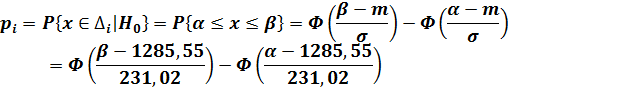
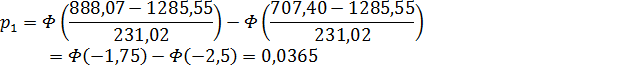
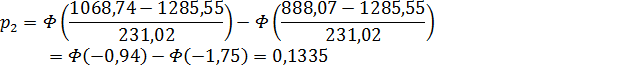
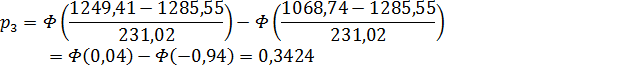
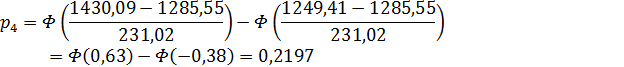
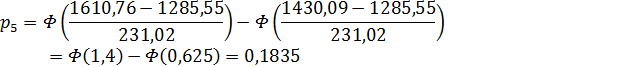
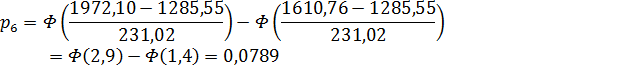
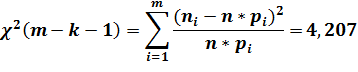
4. Задавшись уровнем значимости
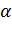 ,
строят критическую область, используя предельную теорему: при выполнении
основной гипотезы распределение статистики критерия сходится к -
распределению с
,
строят критическую область, используя предельную теорему: при выполнении
основной гипотезы распределение статистики критерия сходится к -
распределению с 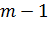 степенью свободы.
степенью свободы.
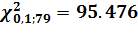
5. Если значение статистики
критерия меньше критического значения, т.е.
 а
а
у нас 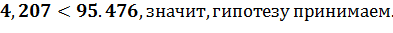
Сформулируем задачи статистического
анализа
· Задачи регрессионного анализа -
задачи, связанные с установлением аналитических зависимостей между переменным Y
и одним или несколькими переменными 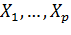 .
.
В этой части работы я проведу исследование
влияния всех имеющихся у нас факторов на количество абонентских терминалов
сотовой связи.
Регрессионный анализ - частный случай
статистической зависимости и подразумевает зависимость среднего значения
величины Yот другой величины
Х (одномерной или многомерной).Методы множественного анализа позволяют решать
задачу исследования зависимости одной переменной Y
от нескольких переменных X1,
X2,…,Xk.
Для
построения уравнения множественной регрессии чаще используют функции:
1) 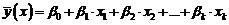 - линейную;
- линейную;
) 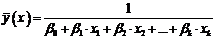 - гиперболическую;
- гиперболическую;
) 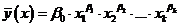 - степенную;
- степенную;
) 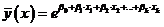 - экспоненту.
- экспоненту.
Можно использовать и другие функции,
приводимые к линейному виду.
Выбрать форму связи между переменными
довольно сложно. Эта задача на практике основывается на априорном теоретическом
анализе изучаемого явления. Для оценки параметров уравнения множественной
регрессии применяют метод наименьших квадратов. Рассмотрим более подробно
линейное уравнение множественной регрессии. Если связь между результирующим
признаком и анализируемыми факторами нелинейная, то она может быть сведена к
линейной путём линеаризации (с помощью замены переменной). Если ввести в
рассмотрение матрицы:
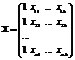
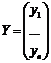
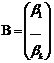 ,
,
то систему нормальных уравнений
можно записать в матричном виде: 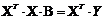 . Решением последней системы
является вектор - столбец:
. Решением последней системы
является вектор - столбец:
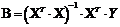 .
.
Для того, чтобы установить,
соответствует ли выбранная регрессионная модель экспериментальным данным,
используют критерий Фишера. По заданному уровню значимости a находят критическое значение
распределения Фишера 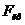 при числе
степеней свободы
при числе
степеней свободы 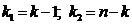 . Если
значение статистики
. Если
значение статистики
F=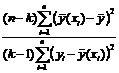 >,
>,
то уравнение считают значимым (т.е.
соответствующим экспериментальным данным на уровне a). При этом выборочная
остаточная дисперсия (с её помощью оценивают неучтённые в модели случайные
факторы) будет равна:
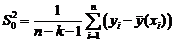 .
.
Среднеквадратическое отклонение
коэффициента регрессии равно:
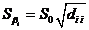
(здесь 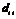 -
диагональный элемент матрицы
-
диагональный элемент матрицы 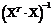 ).
).
Соответствующий коэффициент
уравнения регрессии считают значимым, если 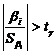 , где
, где 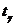 - критическое значение распределения
Стьюдента, определённое на уровне доверия g = 1 -a(где a - уровень значимости) при
числе степеней свободы, равном n-k- 1 (т.е.
квантиль уровня
- критическое значение распределения
Стьюдента, определённое на уровне доверия g = 1 -a(где a - уровень значимости) при
числе степеней свободы, равном n-k- 1 (т.е.
квантиль уровня 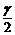 распределения
Стьюдента с n-k- 1 степенями
свободы).
распределения
Стьюдента с n-k- 1 степенями
свободы).
Доверительный интервал для истинного
коэффициента имеет вид: 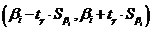 .
.
Доверительный интервал для значения
случайной величины Y имеет вид:
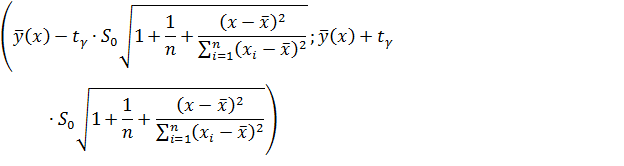
|
Центральный
федеральный округ
|
x1
|
x2
|
х3
|
х4
|
у
|
|
1
|
Белгородская
область
|
1519
|
74
|
12757,9
|
276,3
|
1211,9
|
|
2
|
Брянская
область
|
1309
|
59,4
|
10042,6
|
253,8
|
1103,6
|
|
3
|
Владимирская
область
|
1449
|
76,6
|
9596,2
|
252,6
|
1343,2
|
|
4
|
Воронежская
область
|
2280
|
68,8
|
10304,8
|
417,1
|
983,1
|
|
5
|
Ивановская
область
|
1080
|
61,4
|
8353,8
|
221,8
|
1400,9
|
|
6
|
Калужская
область
|
1006
|
63,2
|
11755,9
|
311,7
|
1420,4
|
|
7
|
Костромская
область
|
697
|
60,9
|
9413,2
|
516,9
|
1392
|
|
8
|
Курская
область
|
1162
|
49,5
|
11411
|
241,9
|
1217,5
|
|
9
|
Липецкая
область
|
1169
|
68,8
|
12274,4
|
302,7
|
1106,5
|
|
10
|
Московская
область и г. Москва
|
16000
|
93,3
|
37500
|
264,8
|
1972,1
|
|
11
|
Орловская
область
|
822
|
58,8
|
9814,5
|
283
|
1186
|
|
12
|
Рязанская
область
|
1165
|
72,9
|
11311,3
|
287,6
|
1400,5
|
|
13
|
Смоленская
область
|
983
|
50,9
|
11522,7
|
313,7
|
1532,2
|
|
14
|
Тамбовская
область
|
1106
|
61,8
|
11252,8
|
284,8
|
1209,6
|
|
15
|
Тверская
область
|
1380
|
70,2
|
10856
|
236,2
|
1483,4
|
|
16
|
Тульская
область
|
1566
|
63,5
|
11388,5
|
294,1
|
1237,3
|
|
17
|
Ярославская
область
|
1315
|
75,5
|
12587,2
|
276,6
|
1448
|
|
|
Северо-Западный
федеральный округ
|
|
|
|
|
|
|
18
|
Республика
Карелия
|
691
|
89,9
|
12228,6
|
299,6
|
1462,1
|
|
19
|
Республика
Коми
|
968
|
64
|
18636,4
|
308,2
|
1495,4
|
|
20
|
Архангельская
область
|
1272
|
80,4
|
14823,6
|
279,2
|
1476,2
|
|
21
|
Вологодская
область
|
1223
|
60
|
12193,5
|
284,7
|
1523,1
|
|
22
|
Калининградская
область
|
937
|
82
|
12922,3
|
265,5
|
1581,2
|
|
23
|
Мурманская
область
|
851
|
79
|
18773,2
|
326,1
|
1790,1
|
|
24
|
Новгородская
область
|
652
|
76,5
|
11645,6
|
325,1
|
1546,6
|
|
25
|
Псковская
область
|
706
|
68,5
|
10290,9
|
301,8
|
1404,7
|
|
26
|
г.
Санкт-Петербург и Ленинградская область
|
5540
|
95,8
|
20000
|
432,7
|
1863,4
|
|
|
Южный
федеральный округ
|
|
|
|
|
|
|
27
|
Республика
Адыгея
|
441
|
81,5
|
7986,3
|
235,4
|
707,4
|
|
28
|
Республика
Дагестан
|
2688
|
76,5
|
10962
|
82,3
|
930,0
|
|
29
|
Республика
Ингушетия
|
499
|
54
|
37,5
|
877,5
|
|
30
|
Кабардино-Балкарская
Республика
|
891
|
69,9
|
8589,3
|
10,9
|
956,7
|
|
31
|
Республика
Калмыкия
|
286
|
56,2
|
5651,2
|
213,9
|
1255,0
|
|
32
|
Карачаево-Черкесская
Республика
|
427
|
57,2
|
8676,1
|
236,5
|
1203,1
|
|
33
|
Республика
Северная Осетия - Алания
|
702
|
67,9
|
9837,7
|
228,8
|
1027,6
|
|
34
|
Чеченская
Республика
|
1209
|
45,8
|
...
|
293,6
|
812,5
|
|
35
|
Краснодарский
край
|
5122
|
84,5
|
12023,9
|
256,3
|
1417,4
|
|
36
|
Ставропольский
край
|
2705
|
87,5
|
9952,5
|
251,5
|
1109,3
|
|
37
|
Астраханская
область
|
1001
|
72,8
|
11120,4
|
264,9
|
1490,1
|
|
38
|
Волгоградская
область
|
2609
|
69,4
|
10866,4
|
265
|
1296,8
|
|
39
|
Ростовская
область
|
4255
|
80
|
12160,5
|
256,1
|
1100,2
|
Шаг
1
|
ВЫВОД
ИТОГОВ
|
|
|
|
|
|
|
|
|
|
|
|
|
Регрессионная
статистика
|
|
|
|
|
|
Множественный
R
|
0,796435939
|
|
|
|
|
|
R-квадрат
|
0,634310205
|
|
|
|
|
|
Нормированный
R-квадрат
|
0,591287876
|
|
|
|
|
|
Стандартная
ошибка
|
176,8575146
|
|
|
|
|
|
Наблюдения
|
39
|
|
|
|
|
|
|
|
|
|
|
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
|
Регрессия
|
4
|
1844653,538
|
461163,3845
|
14,74374404
|
4,40742E-07
|
|
Остаток
|
34
|
1063471,736
|
31278,58048
|
|
|
|
Итого
|
38
|
2908125,274
|
|
|
|
|
|
Коэффициенты
|
Стандартная
ошибка
|
t-статистика
|
P-Значение
|
|
|
Y-пересечение
|
581,3210031
|
196,6962844
|
2,955424425
|
0,005637418
|
|
|
Переменная
X 1
|
-0,035268095
|
0,018433848
|
-1,913224813
|
0,064170699
|
|
|
Переменная
X 2
|
0,481742142
|
2,903126362
|
0,165939088
|
0,869187718
|
|
|
Переменная
X 3
|
0,046016513
|
0,009465295
|
4,861603493
|
2,59455E-05
|
|
|
Переменная
X 4
|
0,80898839
|
0,341120441
|
2,371562333
|
0,023518416
|
|
Исходя из полученных данных, а именно:
Множественный R
близок к 1 (0.796),
F больше Fкр
(14,74>2.87) -мы можем сделать вывод о значимости нашего уравнения
регрессии.
Далее, используя распределение Стьюдента,
находим критическую точку, которая определяет какие из переменных Х нам
необходимо отсеять. В нашем случае t-статистика
должна по модулю быть больше 2,03. Отсеиваем переменные Х1 и Х2 и для повышения
точности анализа повторяем расчет.
Шаг
2
|
ВЫВОД
ИТОГОВ
|
|
|
|
|
|
|
|
|
|
|
|
|
Регрессионная
статистика
|
|
|
|
|
|
Множественный
R
|
0,771318015
|
|
|
|
|
|
R-квадрат
|
0,59493148
|
|
|
|
|
|
Нормированный
R-квадрат
|
0,572427673
|
|
|
|
|
|
Стандартная
ошибка
|
180,8920797
|
|
|
|
|
|
Наблюдения
|
39
|
|
|
|
|
|
|
|
|
|
|
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
|
Регрессия
|
2
|
1730135,272
|
865067,6361
|
26,43692633
|
8,62011E-08
|
|
Остаток
|
36
|
1177990,002
|
32721,9445
|
|
|
|
|
|
|
|
|
|
|
Коэффициенты
|
Стандартная
ошибка
|
t-статистика
|
P-Значение
|
|
|
Y-пересечение
|
670,6745952
|
103,9132726
|
6,454176432
|
1,72536E-07
|
|
|
Переменная
X 3
|
0,032798818
|
0,005519879
|
5,941945079
|
8,30834E-07
|
|
|
Переменная
X 4
|
0,936914637
|
0,342066894
|
2,738980751
|
0,009523646
|
|
Множественный R
близок к 1 (0.77),
F больше Fкр
(26,44>4,1) -уравнение регрессии значимое.
t-статистика должна
по модулю быть больше 2,028, значит теперь все оставшиеся переменные Х нам
подходят, так как по модулю их t-статистики
больше нашего значения.
Будем учитывать в регрессионном анализе только
значимые коэффициенты, 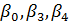 .
.
Тогда уравнение множественной регрессии примет
вид:
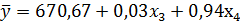
Вывод
Мы выяснили, что количество населения и
количество организаций, использующих интернет, не влияют на количество
абонентских терминалов сотовой связи в регионах РФ. Наибольшее же влияние, что
логично, оказывают денежные доходы населения.
Список использованной литературы
1. Э.Леман
«Проверка статистических гипотез», Москва, 1979
2. В.Е.
Гмурман «Руководство к решению задач по теории вероятности и математической
статистике», Москва, «Высшая школа», 2001
3. Н.И.
Чернова «Математическая статистика, пособие», Новосибирск, 2007
4. Г.И.
Ивченко, Ю. И. Медведев «Математическая статистика», Москва «Высшая школа»,
1984