Построение регрессионной модели по панельным данным в пакете STATISTICA
Министерство
образования Республики Беларусь
Учреждение
образования
«Гомельский
государственный университет
имени
Франциска Скорины»
Математический
факультет
Кафедра
экономической кибернетики и теории вероятностей
Построение
регрессионной модели по панельным данным в пакете STATISTICA
Курсовой
проект
Гомель
2013
Содержание
Введение
1.
Построение регрессионной модели по панельным данным
1.1
Панельные данные
1.2
Скрытые переменные и индивидуальные эффекты
1.3
Модель с фиксированными эффектами
1.4
Модель со случайными эффектами
2.
Построение регрессионной модели по панельным данным
2.1
Постановка задачи
2.2
Построение регрессионной модели по панельным данным и проверка адекватности
модели в пакете STATISTICA
Заключение
Список
использованных источников
Введение
На
практике часто встречаются экономические данные, которые имеют два измерения.
Одно измерение 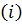 соответствует
принадлежности отдельным экономическим единицам, а другое
соответствует
принадлежности отдельным экономическим единицам, а другое 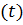 -
принадлежности тому или иному моменту времени. В таких случаях одномерные
данные за разные временные периоды составляют один большой набор данных. Можно
выделить два частых случая такого объединения одномерных данных:
-
принадлежности тому или иному моменту времени. В таких случаях одномерные
данные за разные временные периоды составляют один большой набор данных. Можно
выделить два частых случая такого объединения одномерных данных:
независимое
объединение (разные единицы, независимые выборки);
панельные
данные (одни и те же единицы в динамике).
Целью
курсового проекта являются построение регрессионной модели по основным
экономическим показателям деятельности пяти предприятий на основе панельных данных.
Для достижения поставленной цели необходимо решить следующие задачи:
изучить
теоретико-методологический подход к построению регрессионных моделей по
панельным данным;
провести
расчет коэффициентов однонаправленной модели с фиксированными эффектами по
панельным данным в MS Excel и оценить качество модели.
Структура
работы представлена двумя разделами, введением и заключением. В первой главе
раскрываются теоретические основы построения регрессионной модели по панельным
данным. Во второй главе проводится построение однонаправленной модели с
фиксированными эффектами по статистическим данным.
Построение
регрессионной модели по панельным данным
.1
Панельные данные
Панельные
данные можно представить в виде таблицы «объект-признак». При этом придерживаются
следующего соглашения. Признаки располагаются по столбцам, по строкам - данные
о первом объекте за Т периодов (строки 1, 2, 3, ...,7), затем о втором объекте
(строки Т+1, Т+ 2, ...,) и т. д.
Объекты
Признаки
Объект
1 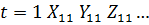
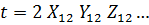
…
… … …
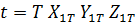 …
…
____________________________________________
Объект
2 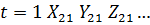
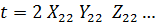
…
… … …
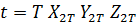 …
…
…..
…. …. …. ……
_____________________________________________
Объект
N 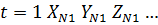
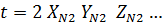
…
… … …
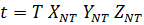 …
…
_____________________________________________
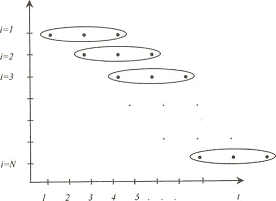
Панель
бывает сбалансированная и несбалансированная. Если данные присутствуют по всем
объектам за все периоды времени, то панель называется сбалансированной (рисунок
1).
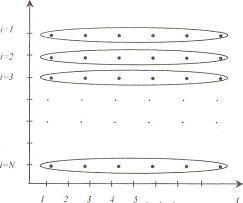
Рисунок
1 - Сбалансированная панель
Достаточно
часто из-за технических, организационных или иных причин в некоторые периоды
времени не удается собрать сведения для всех объектов, включенных в выборку
первоначально (смерть, отъезд, болезнь и т. п.). Чтобы сохранить
репрезентативность, отсутствующие объекты приходится заменять другими. В
результате получим несбалансированную панель (рисунок 2).
При
исследовании проблем занятости и безработицы в международной практике
распространены так называемые ротационные панели. Объект (человек
трудоспособного возраста) участвует в шести последовательных ежеквартальных
опросах, а затем исключается из панели. Таким образом, 1/6 часть всей выборки
обновляется (рисунок 3).
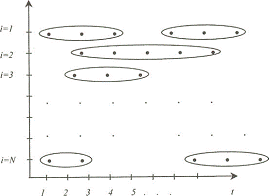
Рисунок
2. - Несбалансированная панель Рисунок 3 - Ротационная панель
Возможны
и иные модификации панельных данных. Но наибольшее распространение получили
сбалансированные и несбалансированные панели.
.2
Скрытые переменные и индивидуальные эффекты
Использование
панельных данных позволяет более полно учесть особенности объектов, попавших в
выборку. Каждый человек или хозяйствующий субъект обладает некоторыми
признаками, которые могут воздействовать на результативный показатель, но плохо
поддаются регистрации, т. е. являются неучтенными, скрытыми или ненаблюдаемыми.
Если их значения различны для разных объектов, но постоянны во времени, их
влияние можно учесть, вводя в модель индивидуальные уровни для каждого объекта.
Существует
несколько способов сформировать панельный массив данных. Первый - во времени,
опрашивая несколько лет подряд одну и ту же группу людей. Но есть интересная
альтернатива, состоящая в том, что можно попытаться отыскать достаточное
количество пар близнецов, провести единовременный опрос и сравнить их доходы в
текущем году. Так как близнецы генетически идентичны, можно предположить, что
способности у них одинаковы. Тогда в качестве объекта выступает пара близнецов,
а аналога «времени» - номер близнеца в паре.
Пусть
к = 1, 2, ... К - соответствует номеру пары, у = 1,2 - номеру близнеца. Тогда
общее число наблюдений N = 2К.
Модель
зависимости текущей заработной платы от образования имеет вид
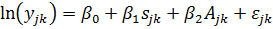
где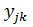 - заработная
плата,
- заработная
плата,
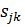 - уровень
образования (число лет обучения),
- уровень
образования (число лет обучения),
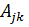 -
способности индивида.
-
способности индивида.
Так
как, по предположению, способности у близнецов совпадают, то для любого 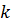 :
:
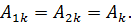
Хотя
способности не поддаются непосредственному измерению, естественно допустить,
что более талантливые люди получают лучшее образование:
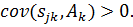
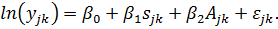
Способности
индивида не поддаются прямому измерению, т.е. мы не располагаем сведениями о
величинах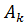 . Так как
уравнение включает ненаблюдаемую переменную, мы не можем оценить все
коэффициенты модели.
. Так как
уравнение включает ненаблюдаемую переменную, мы не можем оценить все
коэффициенты модели.
Наиболее
простой вариант состоит в том, чтобы вообще исключить переменную 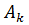 из
рассмотрения:
из
рассмотрения:
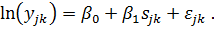
Использование
панельных данных позволяет устранить это смещение. Введём 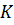 фиктивных
переменных:
фиктивных
переменных:
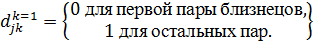
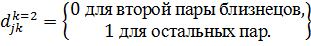
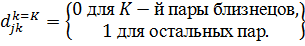
В
этом случае:
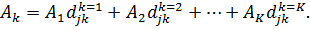
Если
включить в уравнение регрессии все фиктивных переменных и свободный
член 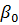 , будет
строгая мультиколлениарность. Поэтому один из параметров следует исключить из
модели, например, свободный член . Перепишем уравнение регрессии без
свободного члена:
, будет
строгая мультиколлениарность. Поэтому один из параметров следует исключить из
модели, например, свободный член . Перепишем уравнение регрессии без
свободного члена:
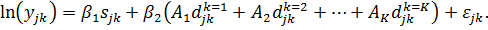
Получим
модель с 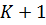 независимой
переменной:
независимой
переменной:
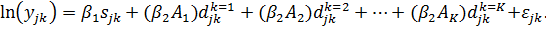
Обозначим
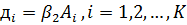 . Тогда
неизвестные величины
. Тогда
неизвестные величины 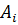 - включаются
в уравнение как часть параметров подлежащих оценке:
- включаются
в уравнение как часть параметров подлежащих оценке:
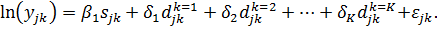
В
результате модель не содержит неизменяемых переменных. Оценив коэффициенты
модели методом наименьших квадратов, получим несмещенную оценку параметра 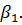
Коэффициент
при каждой фиктивной переменной 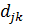 соответствует влиянию способностей
каждой отдельной пары близнецов на их доход. А его произведение на фиктивную
переменную - индивидуальный эффект, соответствующей паре:
соответствует влиянию способностей
каждой отдельной пары близнецов на их доход. А его произведение на фиктивную
переменную - индивидуальный эффект, соответствующей паре:
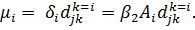
Поэтому
предыдущее уравнение эквивалентно введению в модель К индивидуальных эффектов:
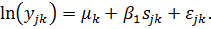
Данный
подход получил название модели с фиксированными эффектами (fixed effects
model). Использование панельных данных позволило ввести в модель индивидуальные
эффекты для того, чтобы избавиться от влияния ненаблюдаемой переменной
(постоянной во времени) и получить несмещенную оценку интересующего нас
параметра.
Введение
фиктивных переменных вовсе не единственная возможность. Того же результата
можно добиться и иным путем. Запишем исходную модель для каждой пары близнецов:
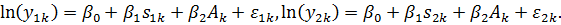
Найдем
разность между ними:
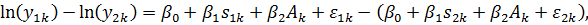
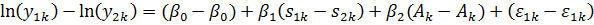
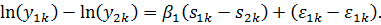
Полученное
уравнение содержит лишь одну объясняющую переменную (s) - уровень образования.
Для
преобразованного уравнения можно получить несмещенную оценку интересующего нас
параметра 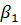 , методом
наименьших квадратов. Этот прием оценивания обычно называют переходом к первым
разностям (first differences). В общем виде получили:
, методом
наименьших квадратов. Этот прием оценивания обычно называют переходом к первым
разностям (first differences). В общем виде получили:
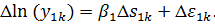
Найдём
МНК-оценку:
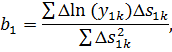
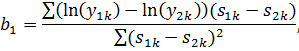
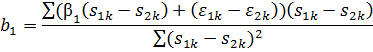
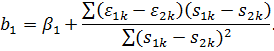
Найдем
МНК-оценку:
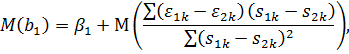
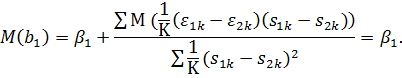
Следовательно,
оценка не смещена. Таким образом, использование панельных данных позволяет
элиминировать эффект ненаблюдаемых переменных и получить несмещенную оценку
отдачи от образования.
Оценки
коэффициента 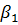 , метода
первых разностей и фиксированных эффектов совпадают.
, метода
первых разностей и фиксированных эффектов совпадают.
Для
метода первых разностей число наблюдений 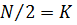 . Соответственно число степеней
свободы равно К минус число оцениваемых параметров:
. Соответственно число степеней
свободы равно К минус число оцениваемых параметров:
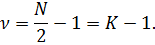
Для
модели фиксированных эффектов число наблюдений равно 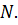 Однако
число параметров
Однако
число параметров 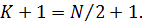 Число
степеней свободы:
Число
степеней свободы:
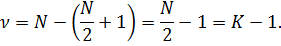
Число
степеней свободы для методов первых разностей и фиксированных эффектов
совпадает. То есть в рассматриваемом примере оценки, полученные путем перехода
к разностям и фиксированных эффектов, полностью эквивалентны.
Когда
панель строится по времени, часто удается обосновать, что некоторые скрытые
параметры не изменяются от периода к периоду. Пусть, например, цель
исследования состоит в оценке влияния налоговых скидок на инвестиции (ПС) на
стоимость акций. Исходная модель формулируется следующим образом:
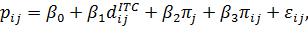
где
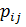 - цена одной
акции;
- цена одной
акции;
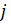 - номер
фирмы;
- номер
фирмы;
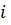 - номер года
(1 или 2);
- номер года
(1 или 2);
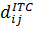 - фиктивная
переменная, равная 1;
- фиктивная
переменная, равная 1;
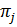 - внутренние
скрытые факторы прибыльности;
- внутренние
скрытые факторы прибыльности;
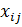 - прочие
наблюдаемые характеристики фирмы или рынка;
- прочие
наблюдаемые характеристики фирмы или рынка;
Проблема
состоит в том, что величины. неизвестны и их нельзя оценить по данным
отчетности. Кроме того, только те фирмы, которые имели прибыль, могут получить
налоговые скидки. Поэтому 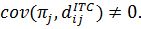
Допустим
мы хотим оценить склонность домохозяйств к сбережению. Запишем исходную модель 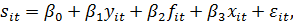 где
где 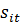 -
сбережения -го домохозяйства в год, t;
-
сбережения -го домохозяйства в год, t; 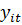 - доход
- доход 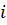 -го
домохозяйства в год,
-го
домохозяйства в год,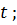
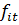 -
ненаблюдаемые характеристики -го домохозяйства в год,
-
ненаблюдаемые характеристики -го домохозяйства в год, 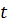 (склонности,
способность к предвидению и т. д.);
(склонности,
способность к предвидению и т. д.); 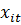 - прочие характеристики -го
домохозяйства в год,
- прочие характеристики -го
домохозяйства в год, 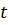 (возраст
главы семьи, количество детей и т. п.).
(возраст
главы семьи, количество детей и т. п.).
Величины
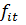 не поддаются
непосредственному измерению и коррелированны с доходом:
не поддаются
непосредственному измерению и коррелированны с доходом: 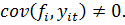
Перейдя
к первым разностям, получим:
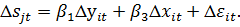
Полученное
уравнение не содержит ненаблюдаемых переменных. Используя метод наименьших
квадратов, можно найти несмещенную оценку склонности к сбережению 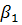 ,
Альтернативный метод оценивания - введение в исходную модель фиктивных
переменных - приведет к аналогичному результату.
,
Альтернативный метод оценивания - введение в исходную модель фиктивных
переменных - приведет к аналогичному результату.
В
рассмотренных примерах все совокупности содержат некоторую внутреннюю
неоднородность. Некоторые факторы скрыты, их не удается измерить и включить в
модель. Панельные данные позволяют частично учесть эту неоднородность за счет
того, что индивидуальные эффекты отражают влияние всех (наблюдаемых или
ненаблюдаемых) переменных, которые принимают разные значения для разных
объектов, но не меняются во времени. Аналогично если добавить в модель
фиктивные переменные для каждого момента времени, то коэффициенты при них
вберут в себя влияния всех наблюдаемых или ненаблюдаемых переменных, которые
зависят только от времени, но одинаковы для всех единиц совокупности.
Если
ненаблюдаемые переменные коррелированны с регрессорами, то оценки коэффициентов
сокращенной модели будут смещены (из-за эффекта пропущенных переменных).
Использование панельных данных позволяет устранить это смещение. То есть оценки
параметров, рассчитанные по панельным данным, более робастны - устойчивы по
отношению к неполной спецификации модели. Соответствующие методы получили
названия метода первых разностей (FD), вторых разностей (DD), модели с
фиксированными эффектами (fixed effects).
Если
допустить, что пропущенные переменные не коррелированны с остальными
регрессорами, тогда их влияние можно учесть иначе - рассматривать как
компоненты ошибок наблюдения. Тогда для панельных данных используют модели со
случайными эффектами (random effects models). Основанием такого допущения могут
быть положения экономической теории или особенности организации выборки. Если
пропущенные переменные являются одной из составляющих ошибок, получим:
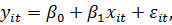
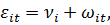
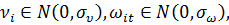
где
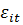 , -
суммарная ошибка;
, -
суммарная ошибка;
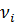 , - ошибка
объекта и не зависящая от времени;
, - ошибка
объекта и не зависящая от времени;
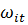 - случайная
ошибка регистрации.
- случайная
ошибка регистрации.
Это
модель линейной регрессии при гетероскедастичности ошибок. Дисперсия ошибок
зависит от номера объекта. Поэтому для оценивания следует использовать
обобщенный метод наименьших квадратов.
.3
Модель с фиксированными эффектами
Рассмотрим
модель линейной регрессии для панельных данных, включающую индивидуальные
уровни для каждого объекта:
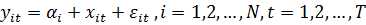 (1)
(1)
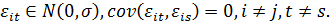
Для
каждого объекта 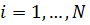 индивидуальный
эффект, остается постоянным в течение всех периодов
индивидуальный
эффект, остается постоянным в течение всех периодов 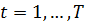 . Вектор
регрессоров
. Вектор
регрессоров 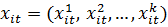 не включает
свободного члена. Таким образом, в (1)
не включает
свободного члена. Таким образом, в (1) 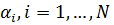 - неизвестные параметры, которые
необходимо оценить.
- неизвестные параметры, которые
необходимо оценить.
Уравнение
(1) можно записать в векторной и матричной форме. Обозначим 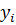 - вектор
размерности
- вектор
размерности 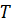 значений
независимых переменных;
значений
независимых переменных; 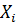 - матрица
значений регрессоров для i-го объекта размерности
- матрица
значений регрессоров для i-го объекта размерности 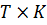 и пусть
и пусть 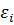 - вектор
ошибок размерности
- вектор
ошибок размерности 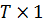 . Тогда (1)
можно переписать в виде
. Тогда (1)
можно переписать в виде

где
- вектор,
состоящий из единиц, размерности Т.
Объединяя
уравнения в единую систему, получим:
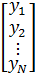 =
=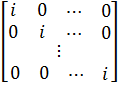 *
*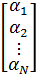 +
+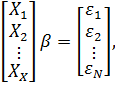
или
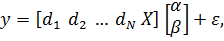 (2)
(2)
где
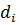 - фиктивная
переменная, соответствующая i-му объекту.
- фиктивная
переменная, соответствующая i-му объекту.
Если
обозначить 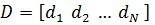 - матрица
размером
- матрица
размером 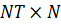 , получим
матричную запись:
, получим
матричную запись:
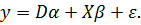 (3)
(3)
Матрица
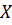 содержит
j-столбцов, матрица D -
содержит
j-столбцов, матрица D - 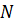 -столбцов,
всего модель содержит
-столбцов,
всего модель содержит 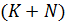 оцениваемых
параметров. Если число объектов N невелико, то оценки параметров
оцениваемых
параметров. Если число объектов N невелико, то оценки параметров 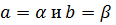 можно
получить с помощью стандартных формул регрессионного анализа. Система
нормальных уравнений имеет вид
можно
получить с помощью стандартных формул регрессионного анализа. Система
нормальных уравнений имеет вид
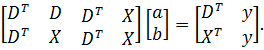
Для
того чтобы было возможно найти решение системы уравнений, необходимо, чтобы
матрица системы имела полный ранг. Это означает, что регрессоры не должны быть
коллинеарные с фиктивными переменными. . В частности, матрица X не должна
включать признаков, которые не изменяются во времени. Например, таких как год
рождения или пол респондента. Если это требование выполнено, то оценки можно
найти по формуле
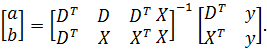
Но
если число единиц наблюдения составляет несколько сотен или тысяч, вычисление
обратной матрицы потребует слишком больших затрат времени и объемов оперативной
памяти. Чтобы избежать этого, учитывают, что матрица D состоит из значений N
фиктивных переменных, а регрессионная модель является моделью регрессии с
фиктивными переменными.
Для
моделей с фиктивными переменными известно, что МНК-оценку b для вектора
параметров можно найти из линейной регрессии для преобразованных переменных
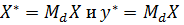
где
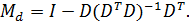
Оценка
b вычисляется по формуле
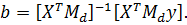 (4)
(4)
Так
как столбцы матрицы D ортогональны, то матрица 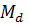 является блочно-диагональной:
является блочно-диагональной:
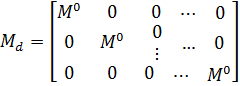
где
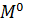 - матрица
вида
- матрица
вида
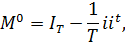
где
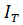 - единичная
матрица размером
- единичная
матрица размером 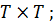
- вектор
размерности T, все элементы которого равны единице.
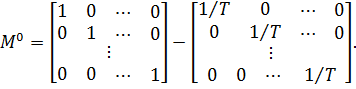
Для
любого вектора z, размерности 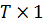 умножение на
умножение на 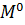 , означает
вычитание из каждого его элемента среднего значения:
, означает
вычитание из каждого его элемента среднего значения:
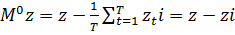 .
.
То
есть преобразование 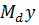 и
и 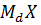 означает
вычитание из каждого элемента вектора у и матрицы
означает
вычитание из каждого элемента вектора у и матрицы 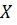 среднего
значения:
среднего
значения: 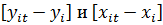 , где
, где 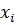 - среднее
значение зависимой переменной для i-го объекта, - вектор средних значений
независимых переменных для -го объекта.
- среднее
значение зависимой переменной для i-го объекта, - вектор средних значений
независимых переменных для -го объекта.
После
того как по формуле (4) найдены оценки 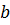 , легко получить и оценки
индивидуальных эффектов а из уравнения:
, легко получить и оценки
индивидуальных эффектов а из уравнения:
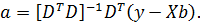 (5)
(5)
Формула
(5) означает, что для каждого объекта индивидуальный эффект можно найти по
формуле
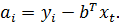 (6)
(6)
Индивидуальный
эффект а, равен среднему остатку в i-й группе. Оценка ковариационной матрицы
вектора b может быть получена по обычной формуле
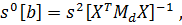 (7)
(7)
где
 несмещённая
оценка остаточной дсперсии:
несмещённая
оценка остаточной дсперсии:
 (8)
(8)
Оценки
выборочных дисперсий индивидуальных эффектов можно получить по формуле
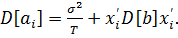 (9)
(9)
Оценки
модели с фиксированными эффектами можно получить, переходя к отклонениям от
групповых средних. Рассмотрим, как взаимосвязаны оценки трех различных
регрессий.
Во-первых,
с единственным свободным членом:
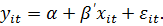 (10а)
(10а)
Во-вторых,
построенной по отклонениям от групповых средних:
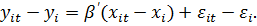 (10b)
(10b)
В-третьих,
по групповым средним:
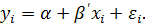 (10c)
(10c)
Каждая
из этих возможностей играет важную роль при анализе панельных данных и
используется напрямую либо на промежуточных этапах. В (10а) перекрестные
произведения находятся от общих средних, у и х:
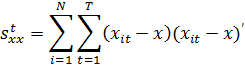
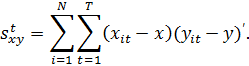
В
случае модели (10b) данные представлены в виде отклонений от групповых средних,
поэтому выборочные средние 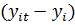 и
и 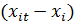 равны нулю. Матрицы перекрестных
произведений рассчитываются по отклонениям групповых средних и отражают
внутригрупповые суммы квадратов:
равны нулю. Матрицы перекрестных
произведений рассчитываются по отклонениям групповых средних и отражают
внутригрупповые суммы квадратов:
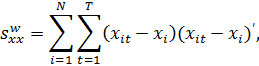
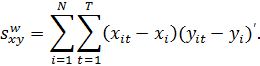
В
(10с) среднее групповых средних является общим средним. Матрицы моментов равны:
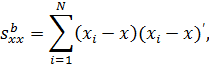
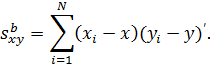
Легко
проверить, что выполняются равенства:
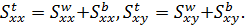
Найдём
оценки неизвестных параметров 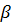 каждым из трёх способов. Оценки
стандартной регрессии:
каждым из трёх способов. Оценки
стандартной регрессии:
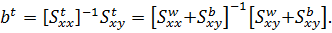 (11)
(11)
Основываясь
на отклонениях от групповых средних, получим оценки:
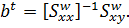 (12)
(12)
Эта
формула соответствует модели с фиксированными эффектами.
Оценки
наименьших квадратов для уравнения (10с), рассчитываемые по N групповым
средним:
и
называют between оценками, или межгрупповыми (between-groups estimator).
Из
выражений (12) и (13) следует, что:
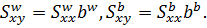
Включая
их в (11), мы видим, что МНК-оценка есть взвешенная сумма внутригрупповых и
межгрупповых оценок:
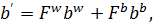 (15)
(15)
Где
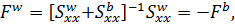
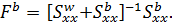
Фиктивные
переменные могут использоваться и для учета временного фактора. Это необходимо,
если средний уровень явления существенно изменяется во времени.
Тогда
модель может быть записана следующим образом:
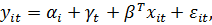 (16)
(16)
где
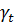 - эффект
специфический для каждого периода.
- эффект
специфический для каждого периода.
Данная
модель получена из предыдущей включением дополнительных (Т - 1) фиктивных
переменных. Из-за строгой коллинеарности нельзя включить все Т-эффекты для
каждого периодов времени. На практике обычно исключают эффект для первого 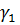 или
последнего периода
или
последнего периода 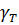 .
.
Модель
также можно переписать в симметричной форме:
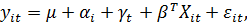
с
ограничениями
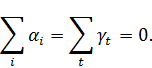
Будем
считать, что для выполнения ограничений мы не включаем в модель эффекты 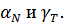 То есть
полагаем:
То есть
полагаем:

Обозначив
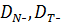 множества из
(N-1) и (Т- 1) фиктивных переменных, получим матричную запись:
множества из
(N-1) и (Т- 1) фиктивных переменных, получим матричную запись:
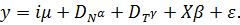 (17)
(17)
При
этом матрица 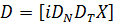 должна
иметь ранг N+T+K- 1. Это накладывает ограничения на состав регрессоров.
Использование прямых формул предполагает вычисление обратной матрицы
должна
иметь ранг N+T+K- 1. Это накладывает ограничения на состав регрессоров.
Использование прямых формул предполагает вычисление обратной матрицы 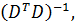 что при
большом числе объектов может потребовать слишком много времени. Однако вместо
этого можно использовать свойства модели с фиктивными переменными и перейти к
отклонениям от групповых средних. Для этого вычислим:
что при
большом числе объектов может потребовать слишком много времени. Однако вместо
этого можно использовать свойства модели с фиктивными переменными и перейти к
отклонениям от групповых средних. Для этого вычислим:
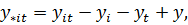
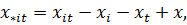
Где
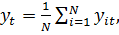
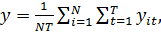
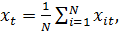
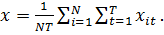
Найдем
коэффициенты регрессии 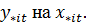 В
результате получим оценку вектора . Оценки коэффициентов при фиктивных
переменных рассчитаем по формулам
В
результате получим оценку вектора . Оценки коэффициентов при фиктивных
переменных рассчитаем по формулам
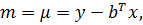
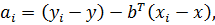 (18)
(18)
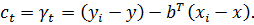
Для
вычисления оценки ковариационной матрицы для вектора 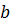 используют
суммы квадратов и перекрестных произведений
используют
суммы квадратов и перекрестных произведений 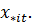 Оценка дисперсии ошибок s2
находится по формуле
Оценка дисперсии ошибок s2
находится по формуле
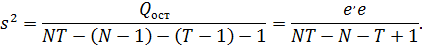
Если
число периодов наблюдения невелико, то нет необходимости переходить к
отклонениям от средних. Проще ввести в модель Т-1 фиктивную переменную для
каждого из периодов за исключением первого или последнего.
Для
проверки значимости индивидуальных и временных эффектов
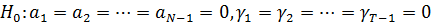 используют
T-критерий:
используют
T-критерий:
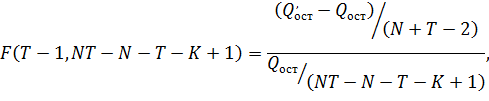
где
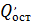 - сумма квадратов
остатков обычной регрессии
- сумма квадратов
остатков обычной регрессии 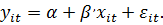
Для
тестирования на временные эффекты:
проверим
гипотезу 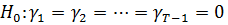 . Найдем
статистику:
. Найдем
статистику:
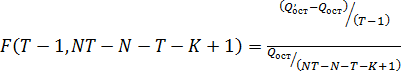 ,
,
где
- сумма
квадратов остатков регрессии с фиксированными эффектами 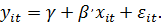
Для
тестирования на индивидуальные эффекты:
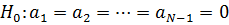 . Вычислим:
. Вычислим:
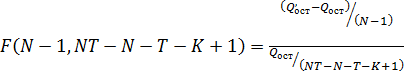 ,
,
где
- сумма
квадратов остатков регрессии с фиксированными временными эффектами 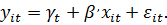
Для
проверки гипотезы о значимости коэффициентов при факторах:
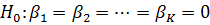
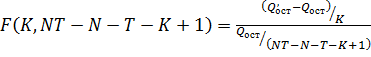 ,
,
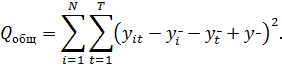
При
исчислении групповых средних необходимо использовать соответствующие размеры
групп 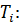
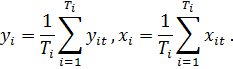
Матрица
перекрестных произведений 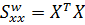 заменяется
суммой матриц сумм квадратов и перекрестных произведений:
заменяется
суммой матриц сумм квадратов и перекрестных произведений:
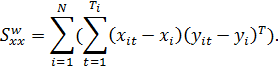
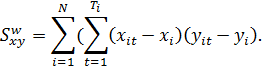
Оценки
коэффициентов регрессии получаются из уравнения 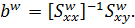 Within-оценка по-прежнему совпадает
с МНК-оценкой, вычисленной по отклонениям от средних:
Within-оценка по-прежнему совпадает
с МНК-оценкой, вычисленной по отклонениям от средних:
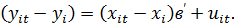
.4
Модель со случайными эффектами
Иногда
есть основания предполагать, что индивидуальные эффекты не коррелированны с
регрессорами. Например, если данные являются случайной выборкой из большой
популяции. Тогда индивидуальные эффекты можно рассматривать как одну из
составляющих ошибки.
Переформулируем
модель, включающую K-регрессоров, в виде
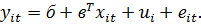 (19)
(19)
Компонента
является случайным отклонением (случайной ошибкой), соответствующей i-му
объекту и постоянной во времени. Эта величина может соответствовать, например,
суммарному влиянию факторов, специфических для отдельной фирмы, семьи,
индивидуума и т. п. и не включенных в число регрессоров. Допустим, что
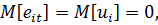
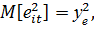
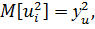
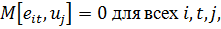 (20)
(20)
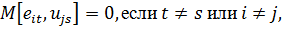
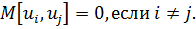
Рассмотрим
T-наблюдений, соответствующих i-му объекту. Обозначим суммарную ошибку 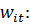
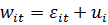 ,
, 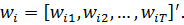
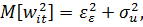
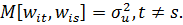
Ковариационная
матрица наблюдений для i-го объекта 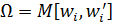 равна:
равна:
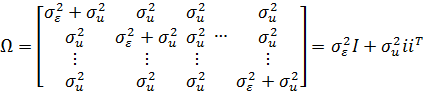 (21)
(21)
где
I-единичная матрица;единичный вектор размерности 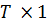 .
.
Так
как ошибки для объектов i и j независимы, ковариационная матрица всех NT
наблюдений будет иметь ввиду
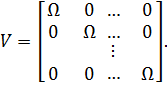 (22)
(22)
Таким
образом, модель случайных эффектов соответствует молол и линейной регрессии при
гетероскедастичности ошибок.
Эффективными,
как известно, являются оценки обобщенного метода наименьших квадратов
(GLS-оценки). Для уравнения регрессии GLS-оценки рассчитываются по формуле
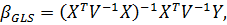
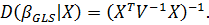
-оценки
можно также найти из преобразованного уравнения
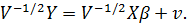
Для использования обобщенного метода наименьших
квадратов (GLS), необходимо найти матрицу 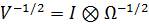 ,
где
,
где  -
символ произведения Кронекера. Следовательно, нам необходимо найти матрицу
-
символ произведения Кронекера. Следовательно, нам необходимо найти матрицу 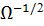 .
Матрица
.
Матрица 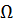 имеет
достаточно простую структуру. Если допустить, что дисперсии
имеет
достаточно простую структуру. Если допустить, что дисперсии 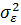 и
и
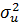 известны,
можно выписать явное выражение для
известны,
можно выписать явное выражение для 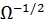 :
: 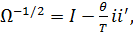 где
параметр, зависящий:
где
параметр, зависящий:
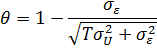
Умножение на означает
следующее преобразование
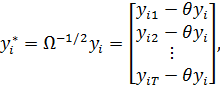 (23)
(23)
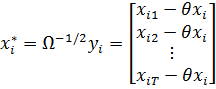
Можно показать, что оценки обобщенного метода
наименьших квадратов, подобно МНК-оценкам, могут быть вычислены как матричные
взвешенные межгрупповых и внутригрупповых:
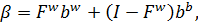 (24)
(24)
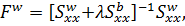

Формула (24) позволяет проанализировать, к чему
сводятся GLS-оценки в зависимости от параметра 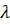 .
.
Если ,
то GLS-оценки совпадают с оценками простой регрессии. Из формулы (24) видно,
что это возможно, когда
,
то GLS-оценки совпадают с оценками простой регрессии. Из формулы (24) видно,
что это возможно, когда 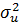 , равно нулю, т. е.
индивидуальных эффектов вовсе не существует. Но, если
, равно нулю, т. е.
индивидуальных эффектов вовсе не существует. Но, если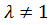 ,
то МНК-оценки становятся неэффективными. По сравнению с обобщенным обычный
метод наименьших квадратов придает слишком большой вес вариации между
объектами. Он объясняет ее целиком изменениями независимых переменных, вместо
того чтобы допустить, что некоторые колебания значений признака объясняется
случайной ошибкой
,
то МНК-оценки становятся неэффективными. По сравнению с обобщенным обычный
метод наименьших квадратов придает слишком большой вес вариации между
объектами. Он объясняет ее целиком изменениями независимых переменных, вместо
того чтобы допустить, что некоторые колебания значений признака объясняется
случайной ошибкой 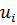 .
.
Если 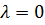 ,
получим within-оценки (фиксированных эффектов). Если число периодов наблюдения
Т конечно, то, чтобы параметр равнялся нулю,
необходимо, чтобы дисперсия была равна нулю,
т. е. все различия между объектами объяснялись случайными величинами которые
постоянны во времени. Другой возможный случай, когда число периодов наблюдения
стремится к бесконечности:
,
получим within-оценки (фиксированных эффектов). Если число периодов наблюдения
Т конечно, то, чтобы параметр равнялся нулю,
необходимо, чтобы дисперсия была равна нулю,
т. е. все различия между объектами объяснялись случайными величинами которые
постоянны во времени. Другой возможный случай, когда число периодов наблюдения
стремится к бесконечности: 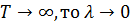 и оценка модели со
случайными эффектами стремится к оценке фиксированных эффектов.
и оценка модели со
случайными эффектами стремится к оценке фиксированных эффектов.
Запишем исходное уравнение 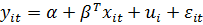 и уравнение для групповых средних
и уравнение для групповых средних
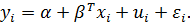 (25)
(25)
Вычитание из каждого уравнения среднего по
группе позволяет избавиться от неоднородности:
 (26)
(26)
Это модель within-регрессии, и она не содержит
значений индивидуальных эффектов 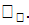 Следовательно,
оценку
Следовательно,
оценку 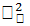 можно
найти на основании остатков модели с фиксированными эффектами:
можно
найти на основании остатков модели с фиксированными эффектами:
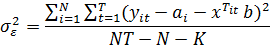
Рассмотрим далее средние ошибки для каждой
группы:
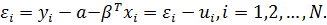 (27)
(27)
Средние ошибки для объектов взаимно независимы,
их дисперсия равна:
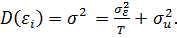 (28)
(28)
Оценка дисперсии (30) является несмещенной, но
на практике может быть отрицательной, что необходимо учитывать.
Для проверки гипотезы
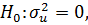
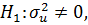
используется тестовая статистика:
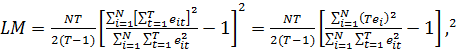 (31)
(31)
остатки в стандартной регрессионной модели.
При нулевой гипотезе LM подчиняется закону
распределения Хи-квадрат с одной степенью свободы. Тогда
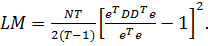 (32)
(32)
. Построение регрессионной модели по панельным
данным
.1 Постановка задачи
Имеются данные об объёмах продаж (Y, тыс.шт.),
затратах на рекламу (X1, тыс. ден. ед.) и затраты на сырье (X2, тыс. ден. ед.)
для пяти предприятий за 2010-2012 года (таблица 1).
Таблица 1 - Исходные данные
|
Исходные
данные
|
|

|
|
|
|
|
|
|
|
|
|
|
ОАО
« 8 Марта»
|
ОАО
« 8 Марта»
|
ОАО
« 8 Марта»
|
ОАО
« 8 Марта»
|
ОАО
« 8 Марта»
|
|
|
|
|
|
|
«Гомельский
вагоноремонтный
|
«Гомельский
вагоноремонтный
|
«Гомельский
вагоноремонтный
|
«Гомельский
вагоноремонтный
|
«Гомельский
вагоноремонтный
|
|
Завод»
Бел ЖД РУП
|
Завод»
Бел ЖД РУП
|
Завод»
Бел ЖД РУП
|
Завод»
Бел ЖД РУП
|
Завод»
Бел ЖД РУП
|
|
|
|
|
|
|
|
|
|
|
|
ОАО
«Гомельпромстрой»
|
ОАО
«Гомельпромстрой»
|
ОАО
«Гомельпромстрой»
|
ОАО
«Гомельпромстрой»
|
|
|
|
|
|
|
ОАО
«Гомельский
|
ОАО
«Гомельский
|
ОАО
«Гомельский
|
ОАО
«Гомельский
|
ОАО
«Гомельский
|
|
мясокомбинат»
|
мясокомбинат»
|
мясокомбинат»
|
мясокомбинат»
|
мясокомбинат»
|
|
|
|
|
|
|
|
|
|
|
|
ЗАО
«ГомельЭнергоСервис»
|
ЗАО
«ГомельЭнергоСервис»
|
ЗАО
«ГомельЭнергоСервис»
|
ЗАО
«ГомельЭнергоСервис»
|
ЗАО
«ГомельЭнергоСервис»
|
|
|
|
|
|
Требуется построить однонаправленную модель с
фиксированными эффектами зависимости объемов продаж У от факторов Х1 и Х2 .
2.2 Построение регрессионной модели по панельным
данным и проверка адекватности модели в пакете STATISTICA
Модель имеет вид
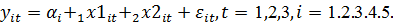
Исходные данные представим в пакете STATISTICA,
изображено на рисунке 3.
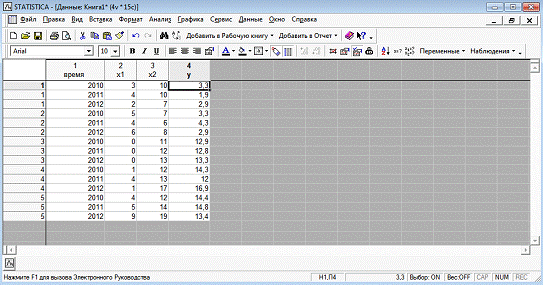
Рисунок 3 - Исходные данные
Оценки коэффициентов данной модели находятся при
помощи анализа STATISTICI, изображенном на рисунке 4.
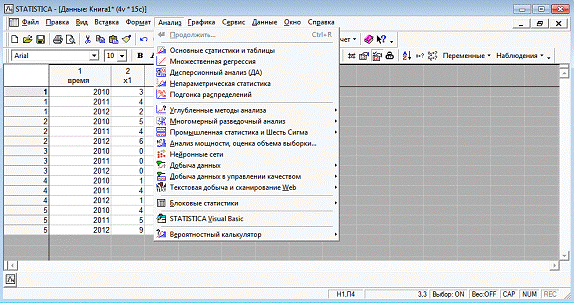
Рисунок 4 - Анализ STATISTICA
Выбираем переменные для построения модели с
фиксированными эффектами зависимости 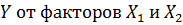 ,
изображенные на рисунке 5.
,
изображенные на рисунке 5.
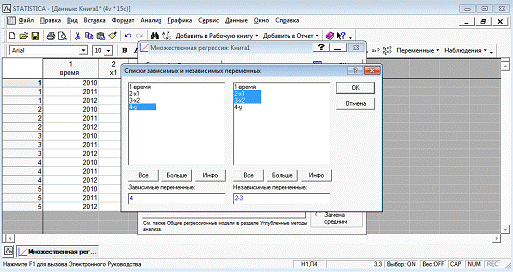
Рисунок 5 - Выбор переменных для построения
регрессии
регрессионная модель данный excel
На стартовой панели отображен диалог определения
оценивания модели, выбрав итоговую таблицу регрессии, были получены оценки
коэффициентов, изображенные на рисунке 6. Так же данная модель проверена на
адекватность, представлена на рисунке 7.
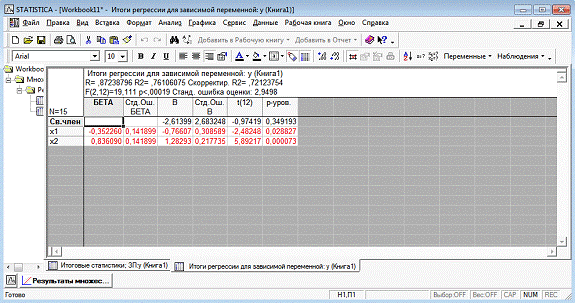
Рисунок 6 - Результаты оценки множественной
линейной регрессии с
фиктивными
переменными
В таблице приведены значения остатков для
уравнения регрессии
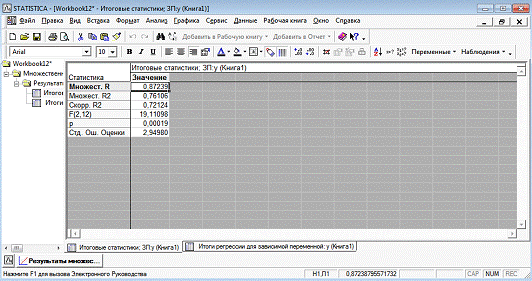
Рисунок 7 - Показатели адекватности уравнения
регрессии с фиктивными переменными
Согласно данным, приведенным на рисунке 6 и
рисунке 7, модель статистически значима по F-критерию Фишера, при этом R2=0.76,
что указывает на высокую адекватность модели.
Заключение
Панельными называют данные, содержащие сведения
об одном и том же множестве объектов за ряд последовательных периодов времени.
Этот метод используют при изучении потребительского поведения, занятости,
безработицы, доходов и заработной платы, производственных функций и политики
дивидендов фирм, в международных и межрегиональных сопоставлениях. Традиционно
выборочные данные представляют в виде таблиц «объект-признак»: по строкам
располагают объекты, по столбцам - признаки. Для панельных данных добавляется
еще одно измерение - время. Преимущества панельных данных следующие. Во-первых,
большее число наблюдений  обеспечивает
большую эффективность оценивания параметров эконометрической модели. Во-вторых,
появляется возможность контроля над неоднородностью объектов. В-третьих,
возможностью идентифицировать эффекты, недоступные в анализе пространственных
данных.
обеспечивает
большую эффективность оценивания параметров эконометрической модели. Во-вторых,
появляется возможность контроля над неоднородностью объектов. В-третьих,
возможностью идентифицировать эффекты, недоступные в анализе пространственных
данных.
В работе рассмотрены методы построения
регрессионной модели по панельным данным. Изучены методы построения
регрессионных моделей по панельным данным. Построена однонаправленная модель с
фиксированными эффектами по данным об экономической деятельности предприятия.
Список использованных источников
Айвазян
С. А. Прикладная статистика. Основы эконометрики. Том 2. - М.: Юнити-Дана,
2001. - 432 с.
Бабешко
Л. О. Основы эконометрического моделирования: Учеб. пособие. - 2-е,
исправленное. - М.: КомКнига, 2006. - 432 с
Берндт
Э. Практика эконометрики: классика и современность. - М.: Юнити-Дана, 2005. -
848 с
Доугерти
К. Введение в эконометрику: Пер. с англ. - М.: ИНФРА-М, 1999. - 402 с.
Кремер
Н. Ш., Путко Б. А. Эконометрика. - М.: Юнити-Дана, 2003-2004. - 311 с.
Леонтьев
В. В. Экономические эссе. Теория, исследования, факты и политика: Пер. с англ.
- М.: Политиздат, 1990. - 324 с.
Магнус
Я. Р., Катышев П. К., Пересецкий А. А. Эконометрика. Начальный курс. - М.:
Дело, 2007. - 504 с.
Моргенштерн
О. О точности экономико-статистических наблюдений. - М.: Статистика, 1968. -
324 с.
Суслов
В. И., Ибрагимов Н. М., Талышева Л. П., Цыплаков А. А. Эконометрия. -
Новосибирск: СО РАН, 2005. - 744 с.
Тутубалин
В.Н.
<http://ru.wikipedia.org/wiki/%D0%A2%D1%83%D1%82%D1%83%D0%B1%D0%B0%D0%BB%D0%B8%D0%BD,_%D0%92%D0%B0%D0%BB%D0%B5%D1%80%D0%B8%D0%B9_%D0%9D%D0%B8%D0%BA%D0%BE%D0%BB%D0%B0%D0%B5%D0%B2%D0%B8%D1%87> Границы
применимости (вероятностно-статистические методы и их возможности). - М.:
Знание, 1977. - 64 с.
Эконометрика.
Учебник / Под ред. Елисеевой И. И. - 2-е изд. - М.: Финансы и статистика, 2006.
- 576 с.