Разработка транслятора-интерпретатора учебного языка программирования
Оглавление
Введение
. Постановка задачи
. Описание методов решения задачи
.1 Лексический анализатор
.2 Синтаксический анализатор
.3 Формирование ПОЛИЗа
.4 Формирование триад
.5 Оптимизация списка триад
.6 Интерпретация программы
. Описание программы
. Тестовые примеры
.1 Тестирование лексического анализатора
.2 Тестирование синтаксического анализатора
.3 Тестирование модуля формирования ПОЛИЗа
.4 Тестирование модуля формирования триад
.5 Тестирование модуля формирования триад
.6 Тестирование модуля интерпретации
Заключение
Введение
Простой интерпретатор анализирует и тут же выполняет (собственно
интерпретация) программу покомандно (или построчно), по мере поступления её
исходного кода на вход интерпретатора. Достоинством такого подхода является
мгновенная реакция. Недостаток - такой интерпретатор обнаруживает ошибки в
тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор - программа трансляции, которая постоянно находится
в памяти. Переводит команды языка высокого уровня в машинные коды
последовательно в ходе работы программы.
Если некоторая задача возникает часто, то имеет смысл представить ее
конкретные проявления в виде предложений на простом языке. Затем можно будет
создать интерпретатор, который решает задачу, анализируя предложения этого
языка.
Например, поиск строк по образцу - весьма распространенная задача.
Регулярные выражения - это стандартный язык для задания образцов поиска. Вместо
того чтобы программировать специализированные алгоритмы для сопоставления строк
с каждым образцом, не проще ли построить алгоритм поиска так, чтобы он мог
интерпретировать регулярное выражение, описывающее множество строк-образцов.
Процесс компиляции, как правило, состоит из нескольких этапов:
лексического, синтаксического и семантического анализов, генерации
промежуточного кода, оптимизации и генерации результирующего машинного кода.
В ходе данного курсового проекта будет разработан интерпретатор учебного
языка программирования, в состав которого входят лексический, синтаксический
анализ, а также посторонние триад, их оптимизация и интерпретация.
1. Постановка
задачи
Требуется разработать транслятор-интерпретатор по заданной грамматике
языка. Модуль требуется реализовать на языке высокого уровня, а именно на языке
программирования Java.
Грамматика языка Logic5
<prog>::=<block>
<block>::=<oper>|<oper>;<block>
<oper>::=<ident>:=<vur>
<oper>::=if<ident>?<oper>:<oper>
<vur>::=<fact>|<vur>#<fact>
<fact>::=<perv>|<fact>&<perv>
<perv>::=<ident>|<c.const>|(<vur>)
<c.const>::=<num>|+<num>|-<num>
<num>::=<dig>|<num><dig>
<dig>::=0|1|2|3|4|5|6|7|8|9
<ident>::=<lett>|<ident><lett>
<lett>::=
A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z
Метод синтаксического анализа - нисходящий синтаксический анализ методом LR(1).
Согласно данной грамматике необходимо разработать
транслятор-интерпретатор, выполняющий следующие действия:
) лексический анализ;
) синтаксический анализ;
) преобразование грамматики в ПОЛИЗ;
) построение триад и их оптимизация;
) выполнение программы.
2. Описание
методов решения задачи
2.1
Лексический анализатор
В заданной грамматике выделим все типы лексем и определим их коды
(Таблица 2.1)
Таблица 2.1 - Типы и коды лексем
|
Лексема
|
Код
|
|
Ключевое слово
|
-
|
|
IF
|
0
|
|
Ограничители
|
-
|
|
;
|
10
|
|
:=
|
11
|
|
?
|
12
|
|
:
|
13
|
|
#
|
14
|
|
&
|
15
|
|
(
|
16
|
|
)
|
17
|
|
+
|
18
|
|
-
|
19
|
|
Идентификаторы
|
-
|
|
A...Z
|
30...54
|
|
Константы:
|
-
|
|
0...9
|
60...70
|
Граф переходов и выходов, согласно которому происходит разбор исходной
грамматики на лексемы изображен в приложении А.
По полученному графу построим таблицу переходов и выходов (Таблица 2.2)
Таблица 2.2 - Таблица переходов и выходов
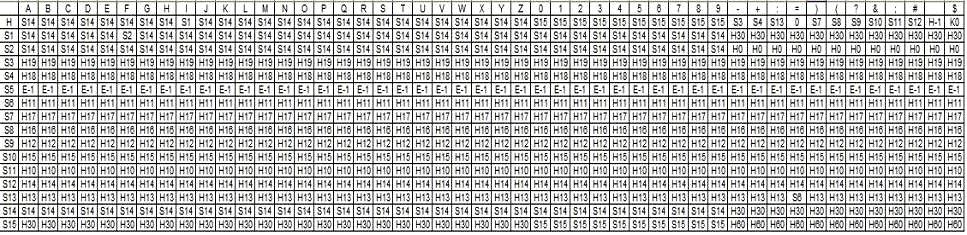

Кодировать состояния будем следующим образом:
Столбцу соответствует определенный символ;
Строке соответствуют состояния переходов.
Пересечение строки и столбца в результате дают символ следующего
состояния и код перехода.
Алгоритм работы:
1) Начальное состояние H;
2) Берем следующий символ;
) По таблице определяется номер следующего состояния;
) Если следующее состояние: S, то присваиваем текущему состоянию
номер найденного состояния;
) Если следующее состояние: H, то переходим в начальное
состояние, и в зависимости от полученного кода лексемы добавляем лексему к
нужному списку
) Если следующее состояние: E, переходим в начальное состояние, выставляем флаг ошибки
) Если есть еще лексемы, то переходим к пункту 2, иначе к пункту
8
) Конец
.2 Синтаксический анализатор
Алгоритм синтаксического анализа на основе LR(k)-грамматики относится к
классу алгоритмов восходящего разбора.
Строкам управляющей таблицы М (LR-таблицы разбора) ставятся в
соответствие состояния, в которых может находиться анализатор, столбцам -
элементы множества.
Каждая запись рабочего стека представляет собой пару: (символ, номер
состояния). Перед началом работы алгоритма в рабочий стек заносится пара ($,1).
Возможные значения элементов таблицы и их интерпретация алгоритмом
разбора приведены в таблице 2.3.
Таблица 2.3
|
N п/п
|
Значение элемента таблицы
|
Интерпретация алгоритмом
разбора
|
|
1
|
Номер i порождающего
правила грамматики
|
Удаление из рабочего стека
n записей (n - количество символов в правой части правила номер i); имитация
считывания в качестве следующего входного символа нетерминала левой части
правила номер i.
|
|
2
|
("Сдвиг", номер j
состояния)
|
Запись текущего входного
символа в выходной стек и в паре с номером j - в рабочий стек; если этот
символ нетерминал, установка указателей на него в ближайших к нему n записях
выходного стека с пустыми указателями.
|
|
3
|
“допуск”
|
конец работы
|
|
4
|
"ошибка"
|
Вывод сообщения об ошибке;
Конец работы.
|
Для построения управляющей таблицы М может быть выполнена разметка
порождающих правил грамматики номерами состояний анализатора. Номера состояний
устанавливаются в правой части каждого правила: перед первым символом, между
любыми двумя символами и после последнего символа. При этом номер состояния,
непосредственно справа от которого находится не терминал, следует
распространить на позиции перед первыми символами всех правых частей правил для
данного не терминала (и т. д. рекурсивно). А если непосредственно слева от
одного и того же символа в каких-либо правилах установлены одинаковые множества
меток, то и непосредственно справа от этого символа в этих правилах следует
поставить одну и ту же метку. После разметки грамматики выполняется построение
таблицы М по следующему алгоритму.
. Если символ А в правой части правила имеет непосредственно слева от
себя метку k, а непосредственно справа от себя - метку j, то(k,A) =
("сдвиг",j).
. Если метка j размещается за последним символом правой части правила
номер i (если правая часть правила - "lambda", j совпадает с меткой
состояния, непосредственно справа от которого находится не терминал левой части
правила i), то определяется множество Q символов, которые в какой-либо
сентенциальной форме могут следовать за не терминалом левой части правила номер
i, и M(j,q)=i для всех q, принадлежащих Q.
. M(1,<S>)="допуск".
Так как грамматика не удовлетворяет требованиям, то преобразуем ее, и
получим эквивалентную грамматику, пригодную для анализа по LR(1) методу:
Приведем грамматику языка Logic5:
<prog>::=<block>
<block>::=<oper>|<oper>;<block>
<oper>::=<ident>:=<vur>
<oper>::=if<ident>?<oper>:<oper>
<vur>::=<fact>|<vur>#<fact>
<fact>::=<perv>|<fact>&<perv>
<perv>::=<ident>|<c.const>|(<vur>)
<c.const>::=<num>
<num>::=<dig>|<num><dig>
<dig>::=0
<ident>::=<lett>|<ident><lett>
<lett>::=A
Распишем грамматику:
<prog>::=<block>
<block>::=<oper>
<block>::=<oper> 10 <block>
<oper>::=<ident> 11 <vur>
<oper>::=0 <ident> 12 <oper> 13
<oper>
<vur>::=<fact>
<vur>::=<vur> 14 <fact>
<fact>::=<perv>
<fact>::=<fact> 15 <perv>
<perv>::=<ident>
<perv>::=<c.const>
<perv>::=16 <vur> 17
<c.const>::=<num>
<c.const>::=18 <num>
<c.const>::=19 <num>
<num>::=<dig>
<num>::=<num> <dig>
<dig>::=60
<ident>::=<lett>
<ident>::=<ident> <lett>
21 <lett>::=30
Разметим грамматику:
<prog>::= 1 <block> 2
<block>::= 1,4 <oper> 3
<block>::= 1,4 <oper> 3 10 4 <block> 5
<oper>::= 1,4,12,14 <ident> 23 11 8 <vur> 9
<oper>::= 1,4,12,14 0 10 <ident> 11 12 12
<oper> 13 13 14 <oper> 15
<vur>::= 8,25 <fact> 16
<vur>::= 8,25 <vur> 9 14 18 <fact> 19
<fact>::= 8,18,25 <perv> 20
<fact>::= 8,18,25 <fact> 16 15 21 <perv> 22
<perv>::= 8,18,21,25 <ident> 23
<perv>::= 8,18,21,25 <c.const> 24
<perv>::= 8,18,21,25 16 25 <vur> 9 17 27
<c.const>::= 8,18,21,25 <num> 28
<num>::= 8,18,21,25,29,31 <dig> 33
<num>::= 8,18,21,25,29,31 <num> 28 <dig> 34
<dig>::= 8,18,21,25,28,29,31 60 35
<ident>::= 6,8,10,18,21,25,1,4,12,14 <lett> 36
<ident>::= 6,8,10,18,21,25,1,4,12,14 <ident> 23
<lett> 37
19 <lett>::= 6,8,10,18,21,23,25,1,4,12,14 30 38
Построим таблицу для LR(1)-анализатора:
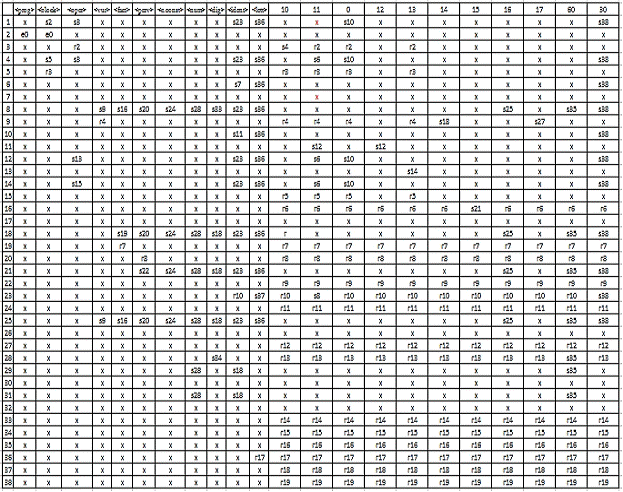
2.3
Формирование ПОЛИЗа
ПОЛИЗ - форма записи математических выражений, в которой операнды
расположены перед знаками операций. Также именуется как обратная польская
запись.
Приведем
таблицу приоритетов:
|
Операция
|
Приоритет
|
|
IF
|
0
|
|
?
|
1
|
|
:
|
1
|
|
+
|
7
|
|
-
|
7
|
|
&
|
8
|
|
#
|
8
|
|
:=
|
1
|
|
(
|
0
|
|
)
|
1
|
Преобразование в ПОЛИЗ логических выражений будем производить по
следующим правилам:
) Входная строка рассматривается слева направо. Операнды переписываются
в выходную строку, а знаки операций помещаются вначале в стек операций.
2) Если приоритет входного знака равен нулю или больше приоритета
знака, находящегося в вершине стека, то новый знак добавляется к вершине стека.
В противном случае из стека "выталкивается" и переписывается в
выходную строку знак, находящийся в вершине, а также следующие за ним знаки с
приоритетами большими или равными приоритету входного знака. После этого
входной знак добавляется к вершине стека.
.4
Формирование триад
Триады представляют собой запись операций в форме из трех составляющих: <операция>,
<операнд1> и <операнд2>, при этом один или оба операнда
могут быть ссылками на другую триаду в том случае, если в качестве операнда
данной триады выступает результат выполнения другой триады.
Триады при записи будем последовательно номеровать для удобства указания
ссылок одних триад на другие.
Рассмотрим алгоритм формирования триад:
1) просматривается строка ПОЛИЗа, начиная с первого символа;
2) если встретилась переменная или число, то увеличение счетчика;
) если встретилась операция, то формирование новой триады с
соответствующим кодом; в качестве операндов берутся один или два (в зависимости
от вида операции) предыдущих символа ПОЛИЗа, добавление их в качестве операндов
триады и удаление из ПОЛИЗа; в ПОЛИЗ записывается ссылка на эту триаду;
) если встречается метка, то запоминается в таблице меток номер
следующей триады, соответствующей данному номеру метки.
После прохождения всей цепочки ПОЛИЗа просматривается список триад, и
ссылки на метки заменяются ссылками на триады с соответствующими номерами.
.5
Оптимизация списка триад
В качестве метода оптимизации выбран метод удаления общих подвыражений.
Суть выбранного метода заключается в следующем:
1) выявление одинаковых триад;
) удаление одинаковых триад, кроме первой, путем модификации
прямого указателя (ПУ) и обратного указателя (ОУ). Прямой указатель триады,
предшествующей удаляемой, равен ПУ удаляемой, а ОУ следующей за удаляемой,
равен ОУ удаляемой;
) все ссылки на удаляемую триаду заменяются ссылками на первую из
равных триад. Процесс повторяется, начиная с п.1 до тех пор, пока появляются
одинаковые триады.
2.6
Интерпретация программы
Интерпретация - анализ, обработка и тут же выполнение исходной программы
или запроса (в отличие от компиляции, при которой программа транслируется без
её выполнения). Интерпретация будет происходить по списку оптимизированных
триад. Ниже представлен алгоритм трансляции:
Алгоритм интерпретации:
1. Индекс текущей триады=0
2. Если индекс триады превышает размер списка триад, то к п. 6.
. Берем триады по индексу текущей триады
. Берем триаду, которую необходимо выполнить
4.1. Берем первый операнд
4.2. Если этот операнд - ссылка на другую триаду, то рекурсивно
рассчитываем значение первого операнда
.3. Иначе берем второй операнд и проделываем над ним все те же
действия, которые произвели над первым
.4. Исходя из кода операции выполняем триаду
5. Рассчитываем индекс следующей выполняемой триады, переходим к п.
2
6. Конец
3. Описание
программы
Процесс трансляции разбивается на следующие основные блоки:
1. Лексический анализ - выделение из входного текста программы
лексем и их кодов. При наличии ошибок доступ к выполнению последующих блоков
закрыт;
2. Синтаксический анализ - проверка полученной цепочки лексем на
принадлежность правилам исходной грамматики. При наличии ошибок доступ к
выполнению следующих этапов закрыт;
. Формирование ПОЛИЗа - формирование такой цепочки лексем и
операндов, в которой операции встречаются в порядке их выполнения;
. Формирование триад - формирование некоторого промежуточного
кода, позволяющего в дальнейшем упростить перевод на машинный язык;
. Оптимизация триад - выявление неоптимальных участков кода в
списке триад с целью уменьшения их количества, и, соответственно, времени
выполнения полученного кода.
. Интерпретация программы - выполнение программы по триадам
Логическую структуру программы представим на рис.3.1.

Рисунок 3.1 - Логическая структура программы
Модуль интерфейса программы позволяет пользователю ввести текст программы
и последовательно выполнить все этапы трансляции. Переход на новый этап
происходит при отсутствии сообщений об ошибках на текущем этапе. Реализована
возможность загрузки текста программы из файла и сохранения текущего текста..
По окончании выполнения блока в автономном режиме пользователю отобразится
информация результате выполнения, в случае успеха выводятся логии работы
модуля.
4. Тестовые
примеры
.1
Тестирование лексического анализатора
анализатор триада транслятор интерпретатор
Пример №1. (Правильный пример)
Входные данные:
A:=5;
B:=0;:=1;C ? B:=2 : B:=3;:=B#A;
A:=C&B;:=B#A
Выходные данные:
Анализ программы:
Введенная программа::=5;
B:=0;:=1;C ? B:=2 : B:=3;:=B#A;:=C&B;:=B#A
Идентификатор: A
Ограничитель: :=
Идентификатор: 5
Ограничитель: ;
Идентификатор: B
Ограничитель: :=
Идентификатор: 0
Ограничитель: ;
Идентификатор: C
Ограничитель: :=
Идентификатор: 1
Ограничитель: ;
Ключевое слово: IF
Идентификатор: C
Ограничитель: ?
Идентификатор: B
Ограничитель: :=
Идентификатор: 2
Ограничитель: :
Идентификатор: B
Ограничитель: :=
Идентификатор: 3
Ограничитель: ;
Идентификатор: C
Ограничитель: :=
Идентификатор: B
Ограничитель: #
Идентификатор: A
Ограничитель: ;
Идентификатор: A
Ограничитель: :=
Идентификатор: C
Ограничитель: &
Идентификатор: B
Ограничитель: ;
Идентификатор: B
Ограничитель: :=
Идентификатор: B
Ограничитель: #
Идентификатор: A
В ходе анализа программы был получен список разбора:
[30, 11, 61, 10, 31, 11, 62, 10, 32, 11, 60, 10, 0, 32, 12, 31, 11, 63,
13, 31, 11, 64, 10, 32, 11, 31, 14, 30, 10, 30, 11, 32, 15, 31, 10, 31, 11, 31,
14, 30]
Таблица идентификаторов:
Код Идентификатор
A
B
C
Таблица констант:
Код Константа
1
5
0
2
3
Пример №2. (Неправильный пример)
Входные данные:
var a;b
begin
a=78;=78*9^8;
Выходные данные:
Время и дата запуска: Thu Apr 26 18:05:51 EEST 2012
Анализируемая программа:A;B BEGIN A=78; B=78*9^8; END $
По символу [ V ] переходим в состояние: S1
По символу [ A ] переходим в состояние: S2
По символу [ R ] переходим в состояние: S3
По символу [ ] переходим в состояние: H0
Обнаружено ключевое слово: VAR
По символу [ ] переходим в состояние: H99
По символу [ A ] переходим в состояние: S19
По символу [ ; ] переходим в состояние: H20
Обнаружен идентификатор: A
По символу [ ; ] переходим в состояние: S21
По символу [ B ] переходим в состояние: H10
Обнаружен ограничитель: ;
По символу [ B ] переходим в состояние: S4
По символу [ ] переходим в состояние: H20
Обнаружен идентификатор: B
По символу [ ] переходим в состояние: H99
По символу [ B ] переходим в состояние: S4
По символу [ E ] переходим в состояние: S5
По символу [ G ] переходим в состояние: S6
По символу [ I ] переходим в состояние: S7
По символу [ N ] переходим в состояние: S8
По символу [ ] переходим в состояние: H1
Обнаружено ключевое слово: BEGIN
По символу [ ] переходим в состояние: H99
По символу [ A ] переходим в состояние: S19
По символу [ = ] переходим в состояние: H20
Обнаружен идентификатор: A
По символу [ = ] переходим в состояние: H-1
Обнаружен недопустимое выражение:
По символу [ 7 ] переходим в состояние: S20
По символу [ 8 ] переходим в состояние: S20
Обнаружена константа: 78
По символу [ ; ] переходим в состояние: S21
По символу [ ] переходим в состояние: H10
Обнаружен ограничитель: ;
По символу [ ] переходим в состояние: H99
По символу [ B ] переходим в состояние: S4
По символу [ = ] переходим в состояние: H20
Обнаружен идентификатор: B
По символу [ = ] переходим в состояние: H-1
Обнаружен недопустимое выражение:
По символу [ 7 ] переходим в состояние: S20
По символу [ 8 ] переходим в состояние: S20
Был найден недопустимый символ: [ * ]
По символу [ 9 ] переходим в состояние: S20
Был найден недопустимый символ: [ ^ ]
По символу [ 8 ] переходим в состояние: S20
По символу [ ; ] переходим в состояние: H50
Обнаружена константа: 8
По символу [ ; ] переходим в состояние: S21
По символу [ ] переходим в состояние: H10
Обнаружен ограничитель: ;
По символу [ ] переходим в состояние: H99
По символу [ E ] переходим в состояние: S9
По символу [ N ] переходим в состояние: S10
По символу [ D ] переходим в состояние: S11
По символу [ ] переходим в состояние: H2
Обнаружено ключевое слово: END
По символу [ ] переходим в состояние: H99
По символу [ $ ] переходим в состояние: K0
Лексический анализ закончился с ошибкой
4.2
Тестирование синтаксического анализатора
Пример №1. (Правильный пример)
Входные данные:
30 11 61 10 31 11 62 10 32 11 60 10 0 32 12 31 11 63 13 31 11 64 10 32 11
31 14 30 10 30 11 32 15 31 10 31 11 31 14 30
Выходные данные:
Начало синтаксического анализа:
Поданный список лексем:
[30, 11, 61, 10, 31, 11, 62, 10, 32, 11, 60, 10, 0, 32, 12, 31, 11, 63,
13, 31, 11, 64, 10, 32, 11, 31, 14, 30, 10, 30, 11, 32, 15, 31, 10, 31, 11, 31,
14, 30]
Таблица разбора:
Рабочий стек M(<A>,a) Входной символ Правило
<prog>,1 M (1 - 30) = S,38 30
---------------------------------------------------------------------------------------
30,38 M (38 - 11) = R,19 11
19
<prog>,1
---------------------------------------------------------------------------------------
<prog>,1 M (1 - <lett>) = S,36 <lett>
---------------------------------------------------------------------------------------
<lett>,36 M (36 - 11) = R,17 11 17
<prog>,1
--------------------------------------------------------------------------------------
<prog>,1 M (1 - <ident>) = S,23 <ident>
---------------------------------------------------------------------------------------
<block>,5 M (5 - <block>) = R,3 <block>
3 10,4
<oper>,3 <prog>,1
-------------------------------------------------------------------------------------------
<prog>,1 M (1 - <block>) = S,2 <block>
--------------------------------------------------------------------------------------------
<block>,2 M (2 - <block>) = E,0 <block>
--------------------------------------------------------------------------------------------
Разбор был успешно завершен
Пример №2. (Неправильный пример)
Входные данные:
0 20 10 21 10 22 1 20 11 51 1 11 13 20 14 21 2
Выходные данные:
Время и дата запуска: Thu Apr 26 18:18:37 EEST 2012
Список поданных закодированных лексем:
[0, 20, 10, 21, 10, 22, 1, 20, 11, 51, 1, 11, 13, 20, 14, 21, 2, 9]
<prog>-0 0 M(<prog>, 0) = 1
-0
---------------------------------------------------------
-1 0 M(0, 0) = -1
<obyav>-1
<block>-1
-0
---------------------------------------------------------
<obyav>-1 20 M(<obyav>,
20) = 2
<block>-1
-0
---------------------------------------------------------
<opis>-1 20 M(<opis>,
20) = 24
<obyav2>-1
<block>-1
-0
---------------------------------------------------------
<digit>-1 51 M(<digit>,
51) = 23
<num2>-1
<fact2>-1
<vur2>-1
<p.oper2>-1
-1
-0
---------------------------------------------------------
-1 51 M(50, 51) = -1
<num2>-1
<fact2>-1
<vur2>-1
<p.oper2>-1
-1
-0
---------------------------------------------------------
<num2>-1 1 M(<num2>, 1) = 0
<fact2>-1
<vur2>-1
<p.oper2>-1
-1
-0
Анализ был завершен, так как введенная программа не принадлежит
грамматике языка Logic3
4.3
Тестирование модуля формирования ПОЛИЗа
Пример №1. (Правильный пример)
Входные данные:
30 11 61 10 31 11 62 10 32 11 60 10 0 32 12 31 11 63 13 31 11 64 10 32 11
31 14 30 10 30 11 32 15 31 10 31 11 31 14 30
Выходные данные:
30 61 11 31
62 11 32 60 11 32 60 22 20 31 63 11 21 31 64 11 32 31 30 14 11 30 32 31 15 11
31 31 30 14 11
.4
Тестирование модуля формирования триад
Пример №1. (Правильный пример)
Входные данные:
30 61 11 31 62 11 32 60 11 32 60 22 20 31 63 11 21 31 64 11 32 31 30 14
11 30 32 31 15 11 31 31 30 14 11
Выходные данные:
0 11 30 61
11 31 62
11 32 60
22 32 60
20 83 87
11 31 63
21 89 0
11 31 64
14 31 30
11 32 88
15 32 31
11 30 90
14 31 30
11 31 92
.5 Тестирование модуля формирования триад
Пример №1. (Правильный пример)
Входные данные:
0 11 30 61
11 31 62
11 32 60
22 32 60
20 83 87
11 31 63
21 89 0
11 31 64
14 31 30
11 32 88
15 32 31
11 30 90
14 31 30
13 11 31 92
Выходные данные:
Оптимизация прошла успешно, удаленное количество триад: 1
11 30 61
11 31 62
11 32 60
22 32 60
20 83 87
11 31 63
21 89 0
11 31 64
14 31 30
11 32 88
15 32 31
11 30 90
11 31 88
4.6
Тестирование модуля интерпретации
Пример №1. (Правильный пример)
Входные данные:
0 11 30 61
11 31 62
11 32 60
22 32 60
20 83 87
11 31 63
21 89 0
11 31 64
14 31 30
11 32 88
15 32 31
11 30 90
11 31 88
Выходные данные:
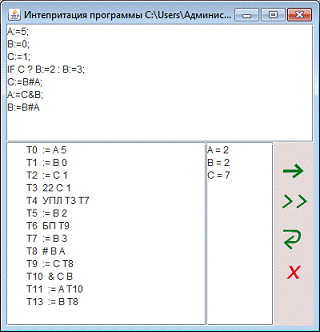
Заключение
В ходе работы над курсовым проектом была изучена методика построения
компилятора, прошло ознакомление с этапами интерпретации. Были получены
практические навыки по созданию модулей компилятора для подмножества грамматики
учебного языка Logic5. Проектирование проходило в несколько этапов:
проектирование блока лексического анализатора, проектирование блока
синтаксического анализатора, проектирование блока формирования ПОЛИЗа,
проектирование блоков построения и оптимизации списка триад, проектирование
блока интерпретации кода. При разработке лексического анализатора была
использована теория конечных автоматов и построена его автоматная модель,
позволяющая разбить исходный текст программы на лексемы. При разработке
синтаксического анализатора был использован метод LR(1). Построение ПОЛИЗа и триад осуществлялось на основе
цепочки лексем, получаемой с выхода лексического анализатора. Тестирование
программы показало, что программа работает корректно.