Определение параметров регрессионной зависимости выполнения плана по затратам на 1 рубль выпущенной продукции от выполнения плана по хлебопечению
МИНИСТЕРСТВО
ОБРАЗОВАНИЯ РЕСПУБЛИКИ БЕЛАРУСЬ
Учреждение
образования
«Гомельский
государственный технический университет
имени
П.О.Сухого»
Факультет
автоматизированных и информационных систем
Кафедра
«Информационные технологии»
направление
специальности 1-40 01 02-01 «Информационные системы и
технологии в
проектировании и производстве»
ПОЯСНИТЕЛЬНАЯ
ЗАПИСКА
к курсовой
работе
по
дисциплине «Основы алгоритмизации и программирования»
на тему:
«Определение параметров регрессионной зависимости выполнения плана по затратам
на 1 рубль выпущенной продукции от выполнения плана по хлебопечению»
Исполнитель:
студент гр. ИТ-12
Бажкова
А.С.
Руководитель:
доцент
Кравченко
О.А
Гомель 2013
СОДЕРЖАНИЕ
Введение
. Постановка задач и исходные
данные
. Описание структуры
программы
. Графическая схема алгоритма
решения задачи
.1 Детализация блока А-B
.2 Детализация блока B-C
.3 Детализация блока C-D
.4 Детализация блока E-F
.5 Детализация блока G-H
.6 Детализация блока H-I
. Расчет параметров
регрессионных зависимостей с помощью надстройки анализа MS Excel
.1 Расчет параметров
регрессионных зависимостей
.2 График с исходными данными и
регрессионными зависимостями
. Описание функциональности
системы программирования
. Среда программирования
Dev-C
Список используемой литературы
Приложение A
Приложение Б
ВВЕДЕНИЕ
Регрессионный анализ - статистический метод
исследования влияния одной или нескольких независимых переменных 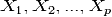 на
зависимую переменную
на
зависимую переменную 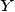 . Независимые
переменные иначе называют регрессорами или предикторами, а зависимые переменные
- критериальными. Терминология зависимых и независимых переменных отражает лишь
математическую зависимость переменных, а не причинно-следственные отношения.
. Независимые
переменные иначе называют регрессорами или предикторами, а зависимые переменные
- критериальными. Терминология зависимых и независимых переменных отражает лишь
математическую зависимость переменных, а не причинно-следственные отношения.
Целью регрессионного анализа является :
· Определение степени
детерминированности вариации зависимой переменной независимыми переменными.
· Нахождение значения зависимой
переменной с помощью независимой(-ых).
· Определение вклада отдельных
независимых переменных в вариацию зависимой.
Регрессионный анализ нельзя использовать для
определения наличия связи между переменными, поскольку наличие такой связи и
есть предпосылка для применения анализа.
Регрессионный анализ - один из наиболее
разработанных методов математической статистики. Для реализации регрессионного
анализа необходимо выполнение ряда специальных . В реальной жизни строгое
соответствие требованиям регрессионного и корреляционного анализа встречается
очень редко, однако оба эти метода весьма распространены в экономических
исследованиях. Зависимости в экономике могут быть не только прямыми, но и
обратными и нелинейными. [1]
В ходе регрессионного анализа решаются две
основные задачи:
· Построение уравнения регрессии, т.е.
нахождение вида зависимости между результатным показателем и независимыми
факторами x1, x2, ..., xn.
· Оценка значимости полученного
уравнения, т.е. определение того, насколько выбранные факторные признаки
объясняют вариацию признака у.
Необходимо отметить, что в экономических
исследованиях корреляционный и регрессионный анализы нередко объединяются в
один - корреляционно-регрессионный анализ. Подразумевается, что в результате
такого анализа будет построена регрессионная зависимость (т.е. проведен регрессионный
анализ) и рассчитаны коэффициенты ее тесноты и значимости (т.е. проведен
корреляционный анализ).
Пользуясь методами корреляционно-регрессионного
анализа, аналитики измеряют тесноту связей показателей с помощью коэффициента
корреляции. При этом обнаруживаются связи, различные по силе (сильные, слабые,
умеренные и др.) и различные по направлению (прямые, обратные). Если связи
окажутся существенными, то целесообразно будет найти их математическое
выражение в виде регрессионной модели и оценить статистическую значимость
модели.
Корреляционно-регрессионный анализ считается
одним из главных методов в маркетинге, наряду с оптимизационными расчетами, а
также математическим и графическим моделированием трендов (тенденций). Широко
применяются как однофакторные, так и множественные регрессионные модели.
Корреляционный анализ - метод установления связи
и измерения ее тесноты между наблюдениями, которые можно считать случайными и
выбранными из совокупности, распределенной по многомерному нормальному закону.
Корреляционной связью называется такая
статистическая связь, при которой различным значениям одной переменной
соответствуют разные средние значения другой. Возникать корреляционная связь
может несколькими путями. Важнейший из них - причинная зависимость вариации результативного
признака от изменения факторного. Кроме того, такой вид связи может наблюдаться
между двумя следствиями одной причины. Основной особенностью корреляционного
анализа следует признать то, что он устанавливает лишь факт наличия связи и
степень ее тесноты, не вскрывая ее причин.[2]
Корреля́ция
(от лат. correlatio - соотношение, взаимосвязь) - статистическая взаимосвязь
двух или нескольких случайных величин (либо величин, которые можно с некоторой
допустимой степенью точности считать таковыми). При этом изменения значений
одной или нескольких из этих величин сопутствуют систематическому изменению
значений другой или других величин. Математической мерой корреляции двух
случайных величин служит корреляционное отношение , либо коэффициент корреляции
. В случае, если изменение одной случайной величины не ведёт к закономерному
изменению другой случайной величины, но приводит к изменению другой
статистической характеристики данной случайной величины, то подобная связь не
считается корреляционной, хотя и является статистической.
Частная корреляция - зависимость между
результативным и одним факторным признаками при фиксированном значении других
факторных признаков. Множественная корреляция - зависимость результативного и
двух или более факторных признаков, включенных в исследование.
Некоторые виды коэффициентов корреляции могут
быть положительными или отрицательными. В первом случае предполагается, что мы
можем определить только наличие или отсутствие связи, а во втором - также и её
направление. Если предполагается, что на значениях переменных задано отношение
строгого порядка, то отрицательная корреляция - корреляция, при которой
увеличение одной переменной связано с уменьшением другой. При этом коэффициент
корреляции будет отрицательным. Положительная корреляция в таких условиях - это
такая связь, при которой увеличение одной переменной связано с увеличением
другой переменной. Возможна также ситуация отсутствия статистической
взаимосвязи - например, для независимых случайных величин.[3]
1.
ПОСТАНОВКА ЗАДАЧ И ИСХОДНЫЕ ДАННЫЕ
Исходными данными задачи являются:
1. набор значений фактора 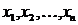 и набор
значений результата
и набор
значений результата 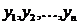 , указанных
в таблице 1.1 , где n - количество значений;
, указанных
в таблице 1.1 , где n - количество значений;
. две функции 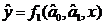 и
и  , которые
будут использоваться как регрессионные зависимости;
, которые
будут использоваться как регрессионные зависимости;
. указываются формулы, с
помощью которых можно рассчитать значения параметров 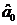 и
и 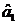 таких, что
зависимость наилучшим
образом приближает исходные наборы фактора и результата , а также
указываются аналогичные формулы для расчета параметров
таких, что
зависимость наилучшим
образом приближает исходные наборы фактора и результата , а также
указываются аналогичные формулы для расчета параметров 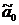 и
и 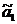 ;
;
. название функциональности
системы программирования, описание которой требуется найти в литературе.
В таблице 1.1 представлены исходные данные,
которые будут использованы в дальнейших вычислениях.
Таблица 1.1
|
Количество
значений
|
Значения
фактора
|
Значения
результата
|
|
1
|
100,0
|
85,5
|
|
2
|
97,8
|
98,3
|
|
3
|
0,0
|
72,5
|
|
4
|
0,0
|
84,9
|
|
5
|
88,1
|
92,9
|
|
6
|
98,7
|
100,8
|
|
7
|
94,0
|
98,8
|
|
8
|
92,5
|
93,5
|
|
9
|
90,7
|
93,1
|
|
10
|
91,4
|
98,5
|
|
11
|
94,3
|
94,3
|
|
12
|
96,2
|
91,8
|
|
13
|
91,2
|
93,5
|
|
14
|
94,4
|
97,0
|
|
15
|
94,7
|
98,5
|
|
16
|
0,0
|
96,3
|
Регрессионные зависимости:
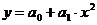 ,
,
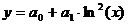 ;
;
На основе указанных исходных данных требуется
выполнить следующее:
1. Вычислить средние
значения этих наборов:
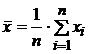 , (1.1)
, (1.1)
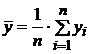 ; (1.2)
; (1.2)
2. Вычислить дисперсии:
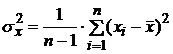 , (1.3)
, (1.3)
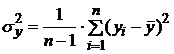 ; (1.4)
; (1.4)
3. Вычислить
среднеквадратические отклонения:
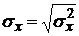 , (1.5)
, (1.5)
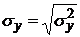 ; (1.6)
; (1.6)
4.
Вычислить коэффициент парной корреляции:
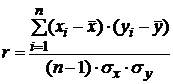 ; (1.7)
; (1.7)
Если |r|>0.5, тогда нужно
вычислить характеристики регрессионных зависимостей:
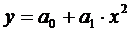 и
и 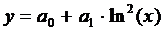 ;
;
5. Для первой
регрессии:
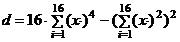 , (1.8)
, (1.8)
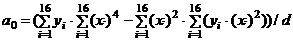 , (1.9)
, (1.9)
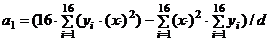 ;
(1.10)
;
(1.10)
6. Для второй
регрессии:
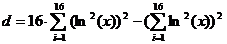 , (1.11)
, (1.11)
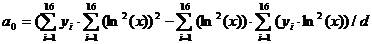 ,
(1.12)
,
(1.12)
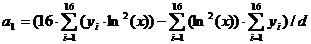 ;
(1.13)
;
(1.13)
7. Вычислить значения результата по
регрессионным зависимостям:
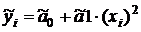 , (1.14)
, (1.14)
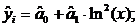 (1.15)
(1.15)
8. Вычислить остаточные дисперсии:
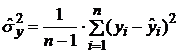 , (1.16)
, (1.16)
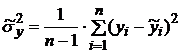 ; (1.17)
; (1.17)
9. Вычислить коэффициенты Фишера:
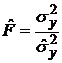 , (1.18)
, (1.18)
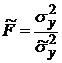 ; (1.19)
; (1.19)
10. Следующим этапом работы является
подготовка данных для отладки составленной программы. Подготовка данных
выполняется с помощью надстройки MSExcel
Пакет анализа;
2.
ОПИСАНИЕ СТРУКТУРЫ ПРОГРАММЫ
В таблице 2.1 приведены идентификаторы и типы
данных, которые были использованы при разработке алгоритма программ.
Таблица 2.1
|
Название
переменной в программе
|
Тип
|
Комментарий
|
|
fn
|
char[]
|
Имя
файла для открытия
|
|
i
|
int
|
Переменная
циклов
|
|
n
|
int
|
Количество
записей (райпо)
|
|
s
|
char[]
|
Промежуточная
переменная для вывода заголовка текстового файла
|
|
name
|
char[][]
|
Названия
райпо
|
|
z
|
char
|
Выбранный
пункт загрузки данных (из файла или вручную)
|
|
x
|
float[]
|
Массив
значений x
|
|
y
|
float[]
|
Массив
значений y
|
|
f
|
FILE*
|
Переменная-указатель
на открытый файл с данными
|
|
srx
|
float
|
Среднее
арифметическое по x
|
|
sry
|
float
|
Среднее
арифметическое по y
|
|
sxk
|
float
|
Дисперсия
по x
|
|
syk
|
float
|
Дисперсия
по y
|
|
sx
|
float
|
Среднеквадратичное
отклонение по x
|
|
sy
|
float
|
Среднеквадратичное
отклонение по y
|
|
r
|
float
|
Коэффициент
парной корреляции
|
|
a01
|
float
|
Коэффициент
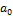 для
первой регрессии для
первой регрессии
|
|
a11
|
float
|
Коэффициент
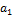 для
первой регрессии для
первой регрессии
|
|
a02
|
float
|
Коэффициент
для
второй регрессии
|
|
a12
|
float
|
Коэффициент
для
второй регрессии
|
|
y1
|
float*
|
Указатель
на массив значений первой регрессии
|
|
y2
|
float*
|
Указатель
на массив значений второй регрессии
|
|
ost_dy1
|
float
|
Остаточная
дисперсия для первой регрессии
|
|
ost_dy2
|
float
|
Остаточная
дисперсия для второй регрессии
|
|
fisher1
|
float
|
Коэффициент
Фишера для первой регрессии
|
|
fisher2
|
float
|
Коэффициент
Фишера для второй регрессии
|
. ГРАФИЧЕСКАЯ СХЕМА АЛГОРИТМА РЕШЕНИЯ ЗАДАЧИ
На рисунке 3.1 изображена графическая схема
основного алгоритма программы.
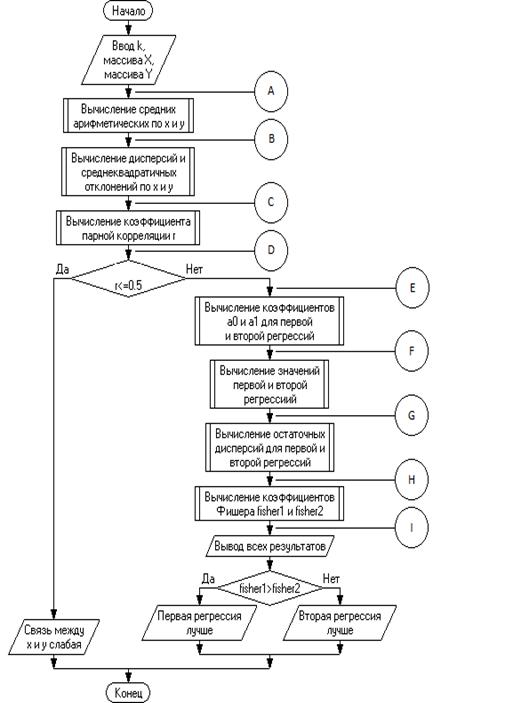
Рисунок 3.1 - Графическая схема основного
алгоритма
3.1 Детализация блока
А-B
На рисунке 3.2 представлена графическая схема
вычисления средних значений x
и y.
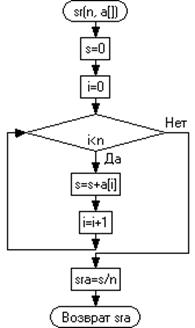
Рисунок 3.2 - Графическая схема вычисления
среднего значения х и у
3.2 Детализация блока B-C
На рисунке 3.3 представлена графическая схема
алгоритма вычисления дисперсии , среднеквадратичных отклонений по х и у.
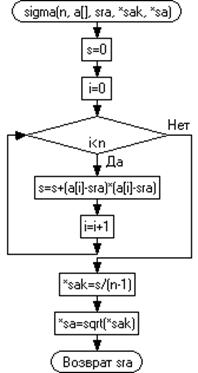
Рисунок 3.3 - Графическая схема вычисления
дисперсии и среднеквадратичного отклонения
3.3 Детализация блока C-D
На рисунке 3.4 представлена графическая схема
вычисления парной. Из подпрограммы передается вычисление коэффициентов парной
корреляции.
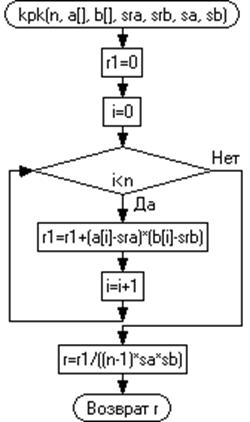
Рисунок 3.4 - Графическая схема вычисления
коэффициента парной корреляции
3.4 Детализация блока E-F
На рисунке 3.5 представлена графическая схема
для вычисления a0 и а1 для
регрессионных зависимостей.
.5.1 - первая функция регрессионной зависимости.
.5.2 - вторая функция регрессионной зависимости.
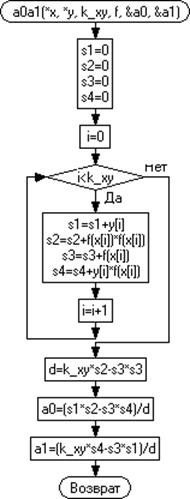
Рисунок 3.5 - Графическая схема вычисления а0 и
а1
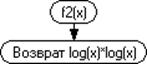
Рисунок 3.5.1 - Графическая схема подпрограммы f1
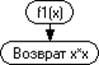
Рисунок 3.5.2 - Графическая схема подпрограммы f2
3.5 Детализация блока G-H
На рисунке 3.6 представлена графическая схема
вычисления остаточной дисперсии для первой и второй регрессии. Из подпрограммы
передается вычисленные остаточные дисперсии для регрессионных зависимостей.
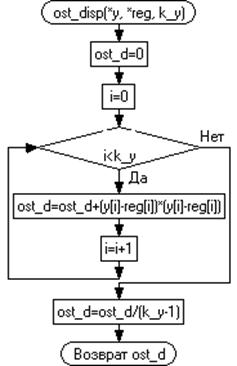
Рисунок 3.6 - Графическая схема вычисления
остаточной дисперсии для первой и второй регрессии
3.6 Детализация блока H-I
На рисунке 3.7 представлена графическая схема
вычисления коэффициентов Фишера для первой и второй регрессионной зависимости.
Из подпрограммы передаются вычисления коэффициенты Фишера для первой и второй
регрессии.
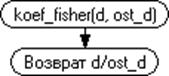
Рисунок 3.7 - Графическая схема вычисления
коэффициента Фишера
. РАСЧЕТ ПАРАМЕТРОВ РЕГРЕССИОНЫХ ЗАВИСИМОСТЕЙ С
ПОМОЩЬЮ НАДСТРОЙКИ ПАКЕТ АНАЛИЗА MS EXCEL
4.1 Расчет параметров
регрессионных зависимостей
На рисунке 4.1 отображены исходные данные:
факторы и результаты.
|
Исходные
данные
|
Райпо
|
Выполнение
плана по хлебопечению, %
|
Выполнение
плана по затратам на 1 рубль выпущенной продукции в 2005 г., %
|
|
Брестское
райпо
|
50,0
|
72,5
|
|
Ганцевичское
райпо
|
60,0
|
84,9
|
|
Столинское
райпо
|
70,0
|
96,3
|
|
Дрогичинское
райпо
|
88,1
|
92,9
|
|
Каменецкое
райпо
|
90,7
|
93,1
|
|
Малоритское
райпо
|
91,2
|
93,5
|
|
Кобринское
райпо
|
91,4
|
98,5
|
|
Ивацевичское
райпо
|
92,5
|
93,5
|
|
Ивановское
райпо
|
94,0
|
98,8
|
|
Лунинецкое
райпо
|
94,3
|
94,3
|
|
Пинское
райпо
|
94,4
|
97,0
|
|
Пружанское
райпо
|
94,7
|
98,5
|
|
Ляховичское
райпо
|
96,2
|
91,8
|
|
Березовское
райпо
|
97,8
|
98,3
|
|
Жабинковское
райпо
|
98,7
|
100,8
|
|
Барановичское
райпо
|
100,0
|
85,5
|
Рисунок 4.1 - Факторы и результаты
На рисунке 4.2 изображена таблица c
вычисленными данными, значениями первой и второй регрессии.
|
Значения
регрессий
|
Значение
первой регрессии
|
x^2
|
Значение
второй регрессии
|
ln(x)^2
|
|
81,3820268
|
2500,0
|
78,81669042
|
15,30392399
|
|
83,77708546
|
3600,0
|
83,35305698
|
16,76365739
|
|
86,60760934
|
4900,0
|
87,34968698
|
18,04971182
|
|
92,83826736
|
7761,6
|
93,58679007
|
20,05671623
|
|
93,8504627
|
8226,5
|
94,39900112
|
20,31807333
|
|
94,0484905
|
94,55311403
|
20,3676645
|
|
94,12800645
|
8354,0
|
94,61457508
|
20,38744173
|
|
94,56845774
|
8556,3
|
94,95075134
|
20,49561811
|
|
95,1775647
|
8836,0
|
95,40418919
|
20,64152748
|
|
95,30056185
|
8892,5
|
95,49419884
|
20,67049121
|
|
95,34164799
|
8911,4
|
95,52415242
|
20,68012981
|
|
95,4651677
|
8968,1
|
95,61386489
|
20,70899791
|
|
96,08864502
|
9254,4
|
96,05912895
|
20,85227708
|
|
96,76448703
|
9564,8
|
96,52814005
|
21,00319768
|
|
97,14954714
|
9741,7
|
96,78932858
|
21,08724416
|
|
97,71197223
|
10000,0
|
97,16333108
|
21,20759244
|
Рисунок 4.2
На рисунке 4.3 изображена таблица c
вычисленными данными, значениями первой и второй регрессии в формульном виде.
|
Значения
регрессий
|
Значение
первой регрессии
|
x^2
|
Значение
второй регрессии
|
ln(x)^2
|
|
=$C$21+$C$22*G2
|
=C2^2
|
=$C$27+$C$28*I2
|
=(LN(C2))^2
|
|
=$C$21+$C$22*G3
|
=C3^2
|
=$C$27+$C$28*I3
|
=(LN(C3))^2
|
|
=$C$21+$C$22*G4
|
=C4^2
|
=$C$27+$C$28*I4
|
=(LN(C4))^2
|
|
=$C$21+$C$22*G5
|
=C5^2
|
=$C$27+$C$28*I5
|
=(LN(C5))^2
|
|
=$C$21+$C$22*G6
|
=C6^2
|
=$C$27+$C$28*I6
|
=(LN(C6))^2
|
|
=$C$21+$C$22*G7
|
=C7^2
|
=$C$27+$C$28*I7
|
=(LN(C7))^2
|
|
=$C$21+$C$22*G8
|
=C8^2
|
=$C$27+$C$28*I8
|
=(LN(C8))^2
|
|
=$C$21+$C$22*G9
|
=C9^2
|
=$C$27+$C$28*I9
|
=(LN(C9))^2
|
|
=$C$21+$C$22*G10
|
=C10^2
|
=$C$27+$C$28*I10
|
=(LN(C10))^2
|
|
=$C$21+$C$22*G11
|
=C11^2
|
=$C$27+$C$28*I11
|
=(LN(C11))^2
|
|
=$C$21+$C$22*G12
|
=C12^2
|
=$C$27+$C$28*I12
|
=(LN(C12))^2
|
|
=$C$21+$C$22*G13
|
=C13^2
|
=$C$27+$C$28*I13
|
=(LN(C13))^2
|
|
=$C$21+$C$22*G14
|
=C14^2
|
=$C$27+$C$28*I14
|
=(LN(C14))^2
|
|
=$C$21+$C$22*G15
|
=C15^2
|
=$C$27+$C$28*I15
|
=(LN(C15))^2
|
|
=$C$21+$C$22*G16
|
=C16^2
|
=$C$27+$C$28*I16
|
=(LN(C16))^2
|
|
=$C$21+$C$22*G17
|
=C17^2
|
=$C$27+$C$28*I17
|
=(LN(C17))^2
|
Рисунок 4.3
На рисунке 4.4 изображены значения a0
и a1
для первой и второй регрессий.
|
Данные
по регрессиям
|
Первая
|
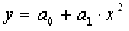
|
|
a0
|
75,93871165
|
|
a1
|
0,002177326
|
|
|
|
Вторая
|
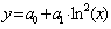
|
|
a0
|
31,25717775
|
|
a1
|
3,107667856
|
Рисунок 4.4
На рисунке 4.5 представлены результаты работы
функциональности для первой регрессии

Рисунок 4.5 - Результаты работы функциональности
для первой регрессии
На рисунке 4.6 представлены результаты работы
функциональности для второй регрессии.

Рисунок 4.6 - Результаты работы функциональности
для второй регрессии
На рисунке 4.7 и 4.8 изображены таблицы с
вычисленными данными.
|
Необходимые
вычисления
|
Среднее
значение x
|
87,8
|
|
Среднее
значение y
|
93,1
|
|
Дисперсия
по x
|
212,244
|
|
Дисперсия
по y
|
50,3611667
|
|
Среднеквадратичное
отклонение по x
|
14,5685964
|
|
Среднеквадратичное
отклонение по y
|
7,0965602
|
|
Коэффициент
парной корреляции r
|
0,71624791
|
|
Существует
ли связь между x и y?
|
Да
|
Рисунок 4.7
|
Остаточная
дисперсия первой регрессии
|
26,96729
|
|
Остаточная
дисперсия второй регрессии
|
22,649
|
|
Коэффициент
Фишера для первой регрессии
|
1,867491
|
|
Коэффициент
Фишера для второй регрессии
|
2,223549
|
Рисунок 4.8
4.2 График с исходными
данными и регрессионными зависимостями
На рисунке 4.9 изображен график зависимости
выполнение плана выпущенной продукции, значение первой и второй регрессий.
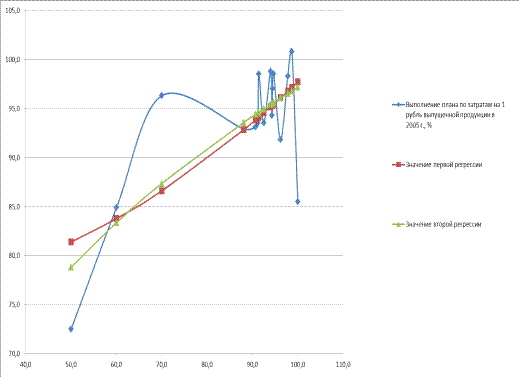
Рисунок 4.9 - График с исходными данными и
регрессионными зависимостями
. ОПИСАНИЕ ФУНКЦИОНИРОВАНИЯ ПРОГРАММНОГО
КОМПЛЕКСА
При запуске программы появляется диалоговое окно
с титульным листом. (рис. 5.1)

Рисунок 5.1 - Титульный лист
Далее пользователь должен нажать любую клавишу,
после нажатия любой клавиши пользователю предлагается выбор (рис. 5.2) :
"k" - ввод вручную с клавиатуры (рис. 5.3), "f" - ввод с
файла(рис. 5.4).
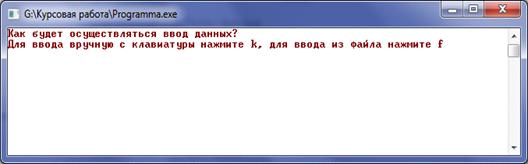
Рисунок 5.2 - Выбор ввода
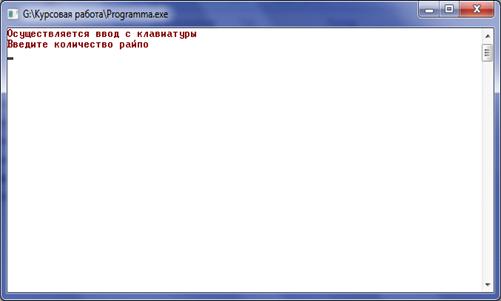
Рисунок 5.3 - Ввод данных с клавиатуры
Рисунок 5.4 - Ввод с файла
Если пользователь нажал "k", то
происходит запрос, какое количества записей будет вводиться. Если же
пользователь нажал "f", то программа просит ввести имя файла, в
котором находятся исходные данные.
Если пользователь ввел неправильное имя файла
или такой файл не существует, то программа выводит сообщение об ошибке.(рис.
5.5)

Рисунок 5.5 - Ошибка, файл не был найден
На рисунке 5.6 изображен файл с которого
считываются данные в программу. (789.txt)

Рисунок 5.6 - Файл, с которого считываются
данные для решения задачи, предусмотренной в курсовой работе
Если же название введено правильно или файл
существует, то программа производит вычисления и выводит в диалоговом окне.(рис.
5.7 и 5.8)
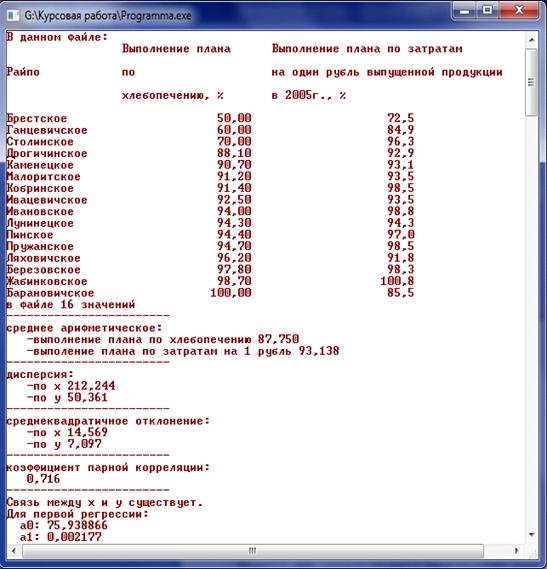
Рисунок 5.7 - Вывод вычисленных данных

Рисунок 5.8 - Вывод вычисленных данных
В конце программы данные сохраняются в файл rz.txt
(рис. 5.9)
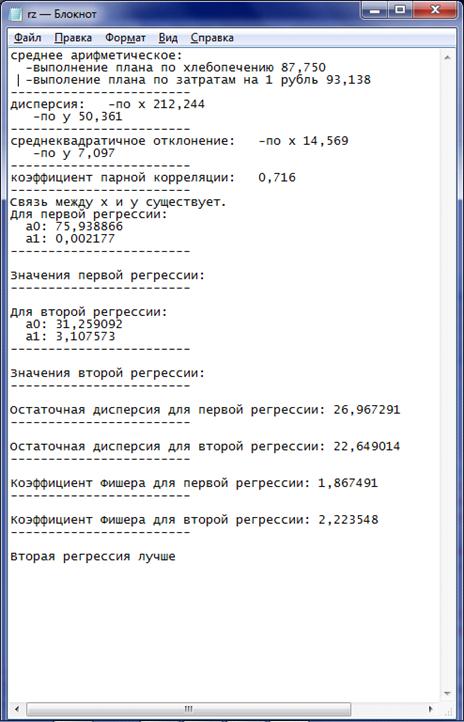
Рисунок 5.9 - Файл с сохраненными данными
регрессионный зависимость
программирование алгоритм
Выход из программы осуществляется нажатием любой
клавиши.
Основной текст программы предоставлен в
приложении А , текст алгоритмов библиотечного файла расположен в приложении Б.
. СРЕДА ПРОГРАММИРОВАНИЯ DEV
- C++
-C++
- это интегрированная среда для программирования на языках С и C++,
работающая под управлением операционной системы Windows.
Среда Dev-C++
распространяется свободно с исходными кодами (на Delphi)
по лицензии GPL.
Достоинства оболочки Dev-C++:
поддержка компилятора GCC
интегрированная отладка (используется GDB)
менеджер проекта
настраиваемый редактор кода с подсветкой
синтаксиса
просмотрщик классов
автозавершение кода
список функций
поддержка профилей
быстрое создание Windows-приложений, консольных
программ, статичных библиотек и DLL (шаблоны)
поддержка шаблонов, позволяющих создавать свои
собственные типы проектов
создание makefile'а
редактирование и компиляция файлов ресурсов
менеджер инструментов
поддержка печати
средства поиска/замены (забавно было бы их не
обнаружить :-))
поддержка CVS
Основатель проекта Колин Лаплас, компания
Bloodshed Software. На настоящий момент не разрабатывается, вместо него активно
разрабатывается порт интерфейса Dev-C++ на wxWidgets - wxDev-C++.[4]
Интегрированные среды разработки были созданы
для того, чтобы максимизировать производительность программиста благодаря тесно
связанным компонентам с простыми пользовательскими интерфейсами. Это позволяет
разработчику сделать меньше действий для переключения различных режимов, в
отличие от дискретных программ разработки. Однако, так как ИСР является сложным
программным комплексом, то лишь после долгого процесса обучения среда
разработки сможет качественно ускорить процесс разработки ПО. Для уменьшения
барьера вхождения многие доcтаточно
интерактивны, а для облегчения перехода с одной на другую интерфейс у одного
производителя максимально близок, вплоть до использования одной ИСР.
ИСР, обычно, представляет собой единственную
программу, в которой проводилась вся разработка. Она, обычно, содержит много
функций для создания, изменения, компилирования, развертывания и отладки
программного обеспечения. Цель среды разработки заключается в том, чтобы
абстрагировать конфигурацию, необходимую, чтобы объединить утилиты командной
строки в одном модуле, который позволит уменьшить время, чтобы изучить язык, и
повысить производительность разработчика. Также считается, что трудная
интеграция задач разработки может далее повысить производительность. Например,
ИСР позволяет проанализировать код и тем самым обеспечить мгновенную обратную
связь и уведомить о синтаксических ошибках. В то время, как большинство
современных ИСР являются графическими, они использовались ещё до того, как
появились системы управления окнами (которые реализованы в Microsoft Windows
или X11 для *nix-систем). Они были основаны на тексте, используя функциональные
клавиши или горячие клавиши, чтобы выполнить различные задачи (например, Turbo
Pascal). Использование ИСР для разработки программного обеспечения является
прямой противоположностью способа, в котором используются несвязанные
инструменты, такие как vi (текстовый редактор), GCC (компилятор), и т. п.[5]
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1.http://ru.wikipedia.org/wiki/%D0%E5%E3%F0%E5%F1%F1%E8%EE%ED%ED%FB%E9_%E0%ED%E0%EB%E8%E7
.
http://ias.iot.ru/mod11.php#3
.http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D1%80%D1%80%D0%B5%D0%BB%D1%8F%D1%86%D0%B8%D1%8F
.
http://ru.wikipedia.org/wiki/Dev-C++
.http://ru.wikipedia.org/wiki/%D0%A1%D1%80%D0%B5%D0%B4%D0%B0_%D1%80%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B8_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D0%BE%D0%B3%D0%BE_%D0%BE%D0%B1%D0%B5%D1%81%D0%BF%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D1%8F
ПРИЛОЖЕНИЕ А
(обязательное)
Основной текст программы
#include <stdio.h>
#include <conio.h>
#include <iostream>
#include <windows.h>
#include "funkcii.h"
/*typedef float
(*func)(float);f1(float x);f2(float x);out_data(float *X, float *Y, int
k);sr(int n, float a[]); //функция
1sigma (int n, float a[], float sra, float *sak, float *sa); //функция
2kpk(int n, float a[], float b[], float sra, float srb, float sa, float
sb);a0a1(float *x, float *y, int k_xy, func f, float &a0, float &a1);*
regr(float a0, float a1, float *x, int k_x, func f);ost_disp(float *y, float
*reg, int k_y);koef_fisher(float d, float ost_d);*/()
{(LC_ALL, "rus");
system("color f4");// Цвет экрана и
шрифта (7 - белый фон, 4 - красный шрифт)("\t МИНИСТЕРСТВО ОБРАЗОВАНИЯ
РЕСПУБЛИКИ БЕЛАРУСЬ");("\t УЧРЕЖДЕНИЕ ОБРАЗОВАНИЯ <<ГОМЕЛЬСКИЙ
ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ");("\t УНИВЕРСИТЕТ ИМ. П. О.
СУХОГО>>");("\n\n\n\n\n");("\t Факультет
автоматизированных и информационных систем\n");("\t
Кафедра:<<Информационные технологии>>\n
");("\n\n\n\n\n");("\t КУРСОВАЯ РАБОТА\n");("\t
по дисциплине: <<Основы алгоритмизации и
программирования>>\n");("\t на тему :<<Определение
параметров регрессионной зависимости>>");
puts("\n\n\n\n\n\n\n\n");
puts("\t Выполнил:студент группы
ИТ-12");("\t Бажкова А.С.");("\t Принял преподователь:
");("\t доц.Кравченко О.А.");
puts("\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n");("\t
Гомель
2013");("\t\t\t\t\t\tНажмите
Enter для
продолжения
>>\n");
getch();//Задержка экрана до нажатия любой
клавиши
system("cls");//Очистка
экранаi,
n;s[80], fn[10], z, name[30][90];x[90], y[90];*rz;
puts ("Как будет осуществляться ввод
данных?\nДля ввода вручную с клавиатуры нажмите k, для ввода из файла нажмите
f");("%c", &z);("cls");//Очистка экрана
if (z=='f')
{*f;
puts ("Введите имя файла с раширением
.txt");
scanf ("%s",
&fn);=fopen (fn, "r");
if (f==NULL)
{("Файл не был найден");
getch ();0;
}
{("файл
%s открыт\n",
fn);
system("cls");//Очистка экрана("В
данном файле:");
fgets (s, 80, f);(s);(s, 80,
f);(s);(s, 80, f);(s);=0;(!feof(f))
{(f, "%s %f %f",
&name[i], &x[i], &y[i]);++;
}(f);=i;(i=0;i<n;i++)("%-15s
%20.2f %23.1f\n", name[i], x[i], y[i]);
}
}if(z=='k')
{("Осуществляется ввод с
клавиатуры");("Введите количество райпо");("%d",
&n);(i=0;i<n;i++)
{("Введите название райпо\n");
scanf ("%s",
&name[i]);(stdin);
printf ("Введите значение плана по
хлебопечению\n");
scanf ("%f",
&x[i]);(stdin);
printf ("Введите значение затрат на 1
рубль\n");
scanf ("%f",
&y[i]);(stdin);
}(i=0;i<n;i++)("%-10s %20.2f
%23.1f\n", name[i], x[i], y[i]);
}srx, sry; //объявление переменных для
вычисления среднего арифметического=sr(n, x); //вычисление ср. арифм. массива
x=sr(n, y); //вычисление ср. арифм. массива ysxk, syk, sx, sy; //объявление
переменных для вычисления дисперсии(n, x, srx, &sxk, &sx); //вызов
функции 2 для массива x(n, y, sry, &syk, &sy); //вызов функции 2 для
массива y
//рассчёт коэффициента парной корреляцииr;
r=kpk(n, x, y, srx, sry, sx, sy);
printf ("в файле %d значений\n",
n);("------------------------\n");("среднее
арифметическое:");(" -выполнение плана по хлебопечению %.3f \n",
srx);(" -выполение плана по затратам на 1 рубль %.3f\n", sry);("------------------------\n");("дисперсия:");("
-по x %.3f\n", sxk);
printf (" -по
y %.3f\n", syk);
printf
("------------------------\n");("среднеквадратичное
отклонение:");
printf (" -по
x %.3f\n", sx);(" -по
y %.3f\n", sy);
printf
("------------------------\n");("коэффициент парной корреляции:");
printf (" %.3f\n",
r);("------------------------\n");
if(fabs(r)<=0.5)("Связь между x и y
слабая / не существует.");
{("Связь между x и y существует.");
printf("\n");a01,
a11;a1(x, y, n, f1, a01, a11);("Для
первой
регрессии:\n
a0: %f\n a1: %f\n", a01,
a11);("------------------------\n");("\n");*y1 = regr(a01,
a11, x, n, f1);
printf("Значения первой
регрессии:\n");
out_data(x, y1,
n);("------------------------\n");("\n");a02, a12;a1(x, y,
n, f2, a02, a12);("Для второй
регрессии:\n
a0: %f\n a1: %f\n", a02,
a12);("------------------------\n");("\n");*y2 = regr(a02,
a12, x, n, f2);
printf("Значения второй
регрессии:\n");
out_data(x, y2,
n);("------------------------\n");("\n");ost_dy1 =
ost_disp(y, y1, n);
printf("Остаточная дисперсия для первой
регрессии: %f\n", ost_dy1);
printf
("------------------------\n");("\n");ost_dy2 = ost_disp(y,
y2, n);
printf("Остаточная дисперсия для второй
регрессии: %f\n", ost_dy2);
printf
("------------------------\n");("\n");fisher1 =
koef_fisher(syk, ost_dy1);
printf("Коэффициент Фишера для первой
регрессии: %f\n", fisher1);
printf
("------------------------\n");("\n");fisher2 =
koef_fisher(syk, ost_dy2);
printf("Коэффициент Фишера для второй
регрессии: %f\n", fisher2);
printf
("------------------------\n");("\n");(fisher1>fisher2)("Первая");("Вторая");("
регрессия
лучше\n");
}=fopen("rz.txt","w");
{(rz,"среднее
арифметическое:");(rz," -выполнение плана по хлебопечению %.3f
\n", srx);(rz," -выполение плана по затратам на 1 рубль %.3f\n",
sry);(rz,"------------------------\n");(rz,"дисперсия:");(rz,"
-по x %.3f\n", sxk);
fprintf (rz," -по
y %.3f\n", syk);
fprintf
(rz,"------------------------\n");(rz,"среднеквадратичное
отклонение:");
fprintf (rz," -по
x %.3f\n", sx);(rz," -по
y %.3f\n", sy);(rz,"------------------------\n");(rz,"коэффициент
парной
корреляции:");(rz,"
%.3f\n", r);(rz,"------------------------\n");(fabs(r)<=0.5)
fprintf(rz,"Связь между x и y слабая / не
существует.");
{(rz,"Связь между x и y существует.");
fprintf(rz,"\n");a01,
a11;a1(x, y, n, f1, a01, a11);(rz,"Для
первой
регрессии:\n
a0: %f\n a1: %f\n", a01,
a11);(rz,"------------------------\n");(rz,"\n");*y1 =
regr(a01, a11, x, n, f1);
fprintf(rz,"Значения первой
регрессии:\n");
fprintf(rz,"------------------------\n");(rz,"\n");a02,
a12;a1(x, y, n, f2, a02, a12);(rz,"Для
второй
регрессии:\n
a0: %f\n a1: %f\n", a02,
a12);(rz,"------------------------\n");(rz,"\n");*y2 =
regr(a02, a12, x, n, f2);
fprintf(rz,"Значения второй
регрессии:\n");
fprintf(rz,"------------------------\n");(rz,"\n");ost_dy1
= ost_disp(y, y1, n);
fprintf(rz,"Остаточная дисперсия для первой
регрессии: %f\n", ost_dy1);
fprintf(rz,"------------------------\n");(rz,"\n");ost_dy2
= ost_disp(y, y2, n);
fprintf(rz,"Остаточная дисперсия для второй
регрессии: %f\n", ost_dy2);
fprintf(rz,"------------------------\n");(rz,"\n");fisher1
= koef_fisher(syk, ost_dy1);
fprintf(rz,"Коэффициент Фишера для первой
регрессии: %f\n", fisher1);
fprintf(rz,"------------------------\n");(rz,"\n");fisher2
= koef_fisher(syk, ost_dy2);
fprintf(rz,"Коэффициент Фишера для второй
регрессии: %f\n", fisher2);
fprintf(rz,"------------------------\n");(rz,"\n");(fisher1>fisher2)(rz,"Первая");(rz,"Вторая");(rz,"
регрессия
лучше\n");
}("\n");("Результаты выполнения
программы сохранены в файл");
fclose(rz);
}();0;
}
/*float f1(float x)
{(x*x);
}f2(float x)
{(pow(log(x), 2));
}out_data(float *X, float *Y, int k)
{ //вывод исходных данныхi;
for(i=0;i<k;i++)("%14.2f|%14.2f\n",
X[i], Y[i]);
}
//функция вычисления среднего арифметического
(1)sr(int n, float a[])
{i;s,
sra;=0;(i=0;i<n;i++)=s+a[i];=s/n;(sra);
}
//функция вычисления дисперсии и
среднеквадратичного отклонения (2)
void sigma (int n, float a[], float
sra, float *sak, float *sa)
{s;i;=0;(i=0;i<n;i++)=s+(a[i]-sra)*(a[i]-sra);
*sak=s/(n-1);
*sa=sqrt(*sak);
}kpk(int n, float a[], float b[],
float sra, float srb, float sa, float sb)
{i;r,
r1;=0;(i=0;i<n;i++)=r1+(a[i]-sra)*(b[i]-srb);=r1/((n-1)*sa*sb);(r);
}a0a1(float *x, float *y, int k_xy,
func f, float &a0, float &a1)
{ //функция нахождения коэффициентов a0 и a1
регрессий
float s1=0, s2=0, s3=0, s4=0,
d;i;(i=0;i<k_xy;i++)
{ //накопление сумм для вычислений=s1+y[i];
s2=s2+pow(f(x[i]),
2);=s3+f(x[i]);=s4+y[i]*f(x[i]);
}=k_xy*s2-pow(s3, 2); //вычисление коэффициента
d=(s1*s2 - s3*s4)/d; //коэффициента а0=(k_xy*s4
- s3*s1)/d; //и а1
}* regr(float a0, float a1, float
*x, int k_x, func f)
{
//функция нахождения значений регрессий*reg = new float[k_x];
int
i;(i=0;i<k_x;i++)[i]=a0+a1*f(x[i]);(reg);
}ost_disp(float *y, float *reg, int
k_y)
{
//функция нахождения остаточных дисперсийost_d=0;
int
i;(i=0;i<k_y;i++)_d+=pow(y[i]-reg[i], 2);_d/=k_y-1;(ost_d);
}koef_fisher(float d, float ost_d)
{
//функция нахождения коэффициентов Фишера(d/ost_d);
}*/
ПРИЛОЖЕНИЕ
Б
(обязательное)
Текст
библиотечного файла
#ifndef _funkcii_H_
#define _funkcii_H_s_
{(x*x);
}f2(float x)
{(pow(log(x), 2));
}out_data(float *X, float *Y, int k)
{
//вывод исходных данныхi;
for(i=0;i<k;i++)("%14.2f|%14.2f\n",
X[i], Y[i]);
}
//функция
вычисления среднего арифметического (1)sr(int n, float a[])
{i;s,
sra;=0;(i=0;i<n;i++)=s+a[i];=s/n;(sra);
}
//функция
вычисления дисперсии и среднеквадратичного отклонения (2)
void sigma (int n, float a[], float
sra, float *sak, float *sa)
{s;i;=0;(i=0;i<n;i++)=s+(a[i]-sra)*(a[i]-sra);
*sak=s/(n-1);
*sa=sqrt(*sak);
}kpk(int n, float a[], float b[],
float sra, float srb, float sa, float sb)
{i;r,
r1;=0;(i=0;i<n;i++)=r1+(a[i]-sra)*(b[i]-srb);=r1/((n-1)*sa*sb);(r);
}a0a1(float *x, float *y, int k_xy,
func f, float &a0, float &a1)
{
//функция нахождения коэффициентов a0 и a1 регрессий
float s1=0, s2=0, s3=0, s4=0,
d;i;(i=0;i<k_xy;i++)
{
//накопление сумм для вычислений=s1+y[i];
s2=s2+pow(f(x[i]),
2);=s3+f(x[i]);=s4+y[i]*f(x[i]);
}=k_xy*s2-pow(s3, 2); //вычисление коэффициента
d=(s1*s2 - s3*s4)/d; //коэффициента а0=(k_xy*s4
- s3*s1)/d; //и а1
}* regr(float a0, float a1, float
*x, int k_x, func f)
{
//функция нахождения значений регрессий*reg = new float[k_x];
int
i;(i=0;i<k_x;i++)[i]=a0+a1*f(x[i]);(reg);
}ost_disp(float *y, float *reg, int
k_y)
{
//функция нахождения остаточных дисперсийost_d=0;
int
i;(i=0;i<k_y;i++)_d+=pow(y[i]-reg[i], 2);_d/=k_y-1;(ost_d);
}koef_fisher(float d, float ost_d)
{
//функция нахождения коэффициентов Фишера(d/ost_d);
}
#endif