Исследование эффективности пространственно-временной обработки изображений с использованием статистик среднего ранга при наличии импульсных помех
Введение
Характерной тенденцией развития современных систем обработки
изображений вне зависимости от их целевого назначения, является повышение
требований к эффективности и качеству мониторинга территории Земли, а также
объектов и явлений космического и воздушного пространства при наличии шумов и
помех.
Решение этих задач диктует необходимость совершенствования
математических и программных средств пространственно-временной фильтрации
изображений.
Пространственно-временная фильтрация изображений - совокупность
операций по преобразованию изображения, позволяющая осуществить выделение
искомого объекта среди других мешающих. С более общей точки зрения,
пространственная фильтрация изображений представляет собой важнейшую
подготовительную операцию максимизации отношения сигнал / помеха при
распознавании объекта, облегчающую принятие решении о наличии и положении
искомого объекта в поле изображения.
Основу современных методов пространственно-временной
фильтрации изображений составляют высококачественные средства ввода изображений
и эффективные численные алгоритмы пространственно-временной фильтрации
изображений при наличии помех и шумов.
С точки же зрения подготовки специалистов, основой
закрепления теоретического курса «Проектирования РЭС» является лабораторный практикум.
Поэтому разработка лабораторного программного комплекса для исследования
эффективности пространственно-временной обработки изображений является важной и
актуальной задачей.
Данный дипломный проект посвящен разработке лабораторной
работы №1 по дисциплине «Проектирование РЭС», целью которой служит исследование
эффективности весовой пространственно-временной обработки изображений с
использованием статистик среднего ранга при наличии белого шума и импульсных
помех.
1.
Технико-экономическое обоснование
Традиционно в вузовском образовании лабораторный практикум
основывался на аппаратной технологии, позволяющей проводить исследования
изучаемых процессов, принципов и закономерностей, устройств и систем на базе
лабораторных макетов и измерительных приборов.
Постановка новых работ с использованием лабораторных стендов
и макетов требует значительных затрат на разработку и изготовление самих
стендов, комплектацию рабочих мест контрольно-измерительным оборудованием и
тому подобное. В связи с этим перспективным является внедрение в лабораторный
практикум элементов программного моделирования.
Программа цикла лабораторных работ по курсу «Проектирование
РЭС» рассчитана на работу в лаборатории, которая укомплектована рабочими
местами, оснащенными ПЭВМ. Эти ПЭВМ, в свою очередь, объединены в локальную
сеть для облегчения установки программного обеспечения на рабочие места.
Разработанный в данном дипломном проекте программные блок позволит заменить
дорогостоящие лабораторные установки, следовательно, для введения нового цикла
лабораторных работ не потребуется закупка дополнительного оборудования. Таким
образом, затраты на введение курса лабораторных работ сводятся к затратам на
проектирование курса и обслуживание лаборатории.
Применение персональных ЭВМ (электронных вычислительных
машин) в лабораторном практикуме для исследования систем автоматического
управления дает возможность выполнить:
·
анализ
функционирования системы в различных режимах с учетом разброса параметров
элементов и наличия дестабилизирующих факторов;
·
синтез
структуры и принципиальной схемы устройств;
·
параметрическую
оптимизацию, при этом удается избежать трудоемкого и дорогостоящего этапа
макетирования.
Опыт совместного проведения работ по типовой и компьютерной
методикам подтвердил высокую эффективность данной технологии, помогающей
студентам быстрее и лучше осваивать изучаемые разделы программы.
2.
Теоретическая часть
2.1 Задача пространственно-временной обработки
изображений при наличии шумов и помех
Пространственная модель изображения
Пространственная модель изображения размера 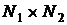 представляет собой двумерную дискретную
функцию
представляет собой двумерную дискретную
функцию  , координаты которой
, координаты которой 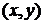 принимают дискретные значения:
принимают дискретные значения: 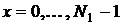 ,
, 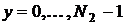 . При этом за начало координат принимается левый верхний угол
изображения. Каждое дискретное значение
. При этом за начало координат принимается левый верхний угол
изображения. Каждое дискретное значение 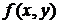 называется элементом изображения или пикселем.
называется элементом изображения или пикселем.
Изображения в процессе формирования и передачи по каналам связи
обычно подвергаются воздействию различных помех и шумов. Для описания случайных
воздействий используют модели аддитивного белого и импульсного шумов.
Наиболее распространенным видом помех является аддитивный белый
шум, статистически независимый от видеосигнала.
Если действие шума сказывается не по всей протяженности поля
изображения, а только в случайно расположенных точках, в которых значение
функции яркости заменяются случайными величинами, то шум называют импульсным
[25]. Можно считать, что в этом случае искаженные точки равномерно распределены
по всему полю изображения.
Таким образом, линейная модель наблюдения изображения в условиях
помех принимает вид [25]:
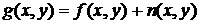 ,
,
где 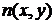 - аддитивный шум.
- аддитивный шум.
Виды фильтров пространственной обработки изображений
В общем случае схему искажения и восстановления (фильтрации)
изображений можно представить в виде, изображенном на рисунке 2.1.
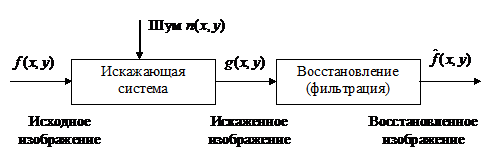
Рисунок 2.1 - Схема искажения и восстановления изображений
Целью восстановления искаженного изображения 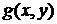 является получение из него при помощи
некоторой обработки изображения
является получение из него при помощи
некоторой обработки изображения 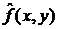 , которое было бы близко к исходному изображению по заданному критерию. Получающееся в
результате обработки изображение называется оценкой исходного (идеального) изображения .
, которое было бы близко к исходному изображению по заданному критерию. Получающееся в
результате обработки изображение называется оценкой исходного (идеального) изображения .
Тогда ошибка оценивания в каждой точке изображения определяется
выражением:
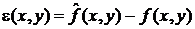 ,
,
а средняя квадратичная ошибка (СКО) - через ее квадрат, то
есть дисперсию ошибки:
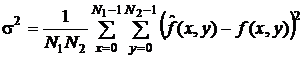 .
.
Критерий минимума квадрата СКО (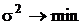 ) является наиболее универсальным и распространенным на практике
критерием качества восстановления при проектировании алгоритмов фильтрации
изображений. Однако, этот критерий имеет недостаток, заключающийся в том, что
он не всегда согласуется с субъективным критерием качества.
) является наиболее универсальным и распространенным на практике
критерием качества восстановления при проектировании алгоритмов фильтрации
изображений. Однако, этот критерий имеет недостаток, заключающийся в том, что
он не всегда согласуется с субъективным критерием качества.
Указанный критерий является конструктивным и позволяет
теоретически рассчитывать оптимальные (дающие минимум квадрата СКО) алгоритмы
фильтрации при рассмотренной модели наблюдения изображения . Однако оптимальные алгоритмы оказываются
сложными для расчета и реализации. Поэтому в автоматизированных системах
обработки изображений предпочтение отдается так называемым квазиоптимальным
алгоритмам, которые дают минимум квадрата СКО в некотором классе алгоритмов с
заданной структурой и незначительно отличаются от оптимальных по этому
критерию.
Еще одним широко распространенным на практике критерием
эффективности обработки изображений является связанный с рассмотренным критерий
максимума пикового отношения сигнал-шум (ПОСШ) [25]:
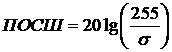 .
.
Фильтры, основанные на порядковых статистиках
Фильтры, основанные на порядковых статистиках, относятся к
классу нелинейных пространственных фильтров. Отклик такого фильтра определяется
предварительным упорядочиванием (ранжированием) значений пикселей, покрываемых
маской фильтра, и последующим выбором значения, находящегося на определенной
позиции упорядоченной последовательности (то есть имеющего определенный ранг).
Собственно фильтрация сводится к замещению исходного значения пикселя (в центре
маски) на полученное значение отклика фильтра. Наиболее известен медианный
фильтр, который, как следует из названия, заменяет значение пикселя на значение
медианы распределения яркостей всех пикселей в окрестности (включая и исходный)
[22].
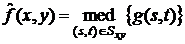 .
.
Чтобы выполнить медианную фильтрацию для элемента изображения,
необходимо сначала упорядочить по возрастанию значения пикселей внутри
окрестности, затем найти значение медианы, и, наконец, присвоить полученное
значение обрабатываемому элементу. Так, для окрестности 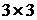 элементов медианой будет пятое значение
по величине, для окрестности
элементов медианой будет пятое значение
по величине, для окрестности 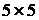 - тринадцатое значение, и так далее. Если несколько элементов в
окрестности имеют одинаковые значения, эти значения будут сгруппированы.
- тринадцатое значение, и так далее. Если несколько элементов в
окрестности имеют одинаковые значения, эти значения будут сгруппированы.
Необходимо отметить, что дисперсия медианы белого шума на выходе
медианного фильтра определяется выражением [24]:
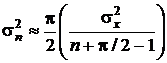
где 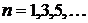 - размер апертуры.
- размер апертуры.
Равенство (2.1-6) показывает также, что для нормального белого
шума дисперсия медианы приблизительно на 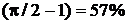 больше, чем дисперсия для среднего. Следовательно, скользящее
усреднение подавляет нормальный белый шум несколько лучше, чем медианный фильтр
с такой же апертурой. Иначе говоря, чтобы медианный фильтр давал ту же
дисперсию шума, что и скользящее усреднение в его апертуре должно быть на 57%
больше точек [22].
больше, чем дисперсия для среднего. Следовательно, скользящее
усреднение подавляет нормальный белый шум несколько лучше, чем медианный фильтр
с такой же апертурой. Иначе говоря, чтобы медианный фильтр давал ту же
дисперсию шума, что и скользящее усреднение в его апертуре должно быть на 57%
больше точек [22].
Характерной особенностью медианного фильтра, отличающей его от
рассмотренных выше фильтров, является сохранение перепадов яркости (контуров)
без искажений. При этом если перепады яркости велики по сравнению с дисперсией
аддитивного белого шума, то медианный фильтр дает меньшее значение СКО по
сравнению с оптимальным линейным фильтром [22].
Особенно эффективны медианные фильтры при фильтрации импульсных
шумов, которые выглядят как наложение на изображение случайных черных и белых
точек (с соответствующими вероятностями 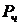 и
и 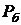 ) [22].
) [22].
Можно сказать, что основная функция медианного фильтра заключается
в замене отличающегося от фона значения пикселя на другое, более близкое его
соседям. На самом деле, изолированные темные или светлые (по сравнению с
окружающим фоном) кластеры, имеющие площадь не более чем 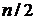 (половина площади маски фильтра), будут
удалены медианным фильтром с маской размерами
(половина площади маски фильтра), будут
удалены медианным фильтром с маской размерами 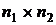 . В данном случае «удалены» означает, что значения пикселей в
соответствующих точках будут заменены на значения медиан по окрестностям.
Кластеры больших размеров искажаются значительно меньше [22].
. В данном случае «удалены» означает, что значения пикселей в
соответствующих точках будут заменены на значения медиан по окрестностям.
Кластеры больших размеров искажаются значительно меньше [22].
Хотя медианный фильтр значительно более распространен в
обработке изображений, чем остальные виды фильтров, основанные на порядковых
статистиках, тем не менее, он не является единственным. Медиана представляет
собой 50-й процентиль упорядоченного набора чисел, но, как следует из основ
статистики, упорядочивание предоставляет много других возможностей. Например,
использование 100-го процентиля приводит к так называемому фильтру максимума,
который полезен при поиске на изображении наиболее ярких точек по отношению
к окружающему фону. Процентиль 0 является фильтром минимума, используемым
для поиска противоположных значений [22].
В работе [24] был предложен псевдомедианный фильтр, который
обладает многими свойствами медианного фильтра, но требует меньших
вычислительных затрат с увеличением размера апертуры.
 ,
,
где 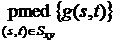 - оператор псевдомедианной фильтрации,
действующий следующим образом. Пусть
- оператор псевдомедианной фильтрации,
действующий следующим образом. Пусть 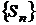 - последовательность элементов
- последовательность элементов 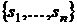 , тогда псевдомедиана такой последовательности определяется так:
, тогда псевдомедиана такой последовательности определяется так:
 ,
,
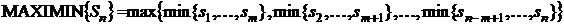 ,
,
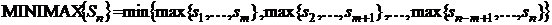 ,
,
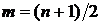 .
.
Медианные фильтры хорошо работают до тех пор, пока
пространственная плотность импульсного шума невелика (эмпирическое правило -  и
и 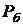 не превышают 0.2). Модифицированная
медианная фильтрация [22] помогает справиться с импульсным шумом, вероятности
которого превышают указанные значения. Дополнительное преимущество такого
модифицированного медианного фильтра состоит в том, что такой фильтр «старается
сохранить детали» в областях, искаженных не импульсным шумом. Обычный медианный
фильтр таким свойством не обладает.
не превышают 0.2). Модифицированная
медианная фильтрация [22] помогает справиться с импульсным шумом, вероятности
которого превышают указанные значения. Дополнительное преимущество такого
модифицированного медианного фильтра состоит в том, что такой фильтр «старается
сохранить детали» в областях, искаженных не импульсным шумом. Обычный медианный
фильтр таким свойством не обладает.
Подобно всем рассмотренным до сих пор фильтрам, модифицированный
медианный фильтр осуществляет обработку в прямоугольной окрестности 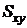 [22] в соответствии с приведенными ниже
условиями.
[22] в соответствии с приведенными ниже
условиями.
Алгоритм модифицированной медианной фильтрации состоит из двух
ветвей, обозначенных ниже как ветвь А и ветвь Б, и его действие заключается в
следующем.
Ветвь А: если 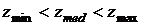 , перейти к ветви Б;
, перейти к ветви Б;
иначе результат равен 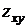 .
.
Ветвь Б: если 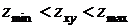 , результат равен ;
, результат равен ;
иначе результат равен 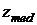 ,
,
где  - минимальное значение яркости в ,
- минимальное значение яркости в ,  - максимальное значение яркости в , - медиана значений яркости в , - значение яркости в точке
- максимальное значение яркости в , - медиана значений яркости в , - значение яркости в точке 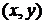 .
.
Значения и воспринимаются алгоритмом статистически как значения «импульсных»
составляющих шума, даже если они не равны наименьшему и наибольшему возможным
значениям яркости на изображении [25].
С учетом этого, ветвь А алгоритма преследует цель определить,
является ли медиана 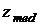 импульсом («черным» или «белым») или нет.
Если условие выполнено
импульсом («черным» или «белым») или нет.
Если условие выполнено 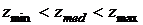 , то в силу указанных в предыдущем абзаце
причин не может быть импульсом. В этом случае
осуществляется переход к ветви Б и проверяется, является ли импульсом значение в той точке, которая отвечает
центру апертуры (отклик фильтра строится в этой точке). Если условие
, то в силу указанных в предыдущем абзаце
причин не может быть импульсом. В этом случае
осуществляется переход к ветви Б и проверяется, является ли импульсом значение в той точке, которая отвечает
центру апертуры (отклик фильтра строится в этой точке). Если условие 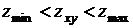 выполнено, то значение не является импульсом по тем же причинам,
что и выше. В этом случае алгоритм дает на выходе неизмененное значение .
выполнено, то значение не является импульсом по тем же причинам,
что и выше. В этом случае алгоритм дает на выходе неизмененное значение .
Сохранение значений в таких точках «промежуточного уровня» яркости
минимизирует искажения, вносимые обработкой изображения. Если условие нарушено, то либо 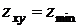 , либо
, либо 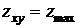 . В обоих случаях значение является экстремальным, и алгоритм дает
на выходе значение медианы которое, как следует из результатов работы ветви А, не является
значением импульсного шума. Последняя операция соответствует действию обычного
медианного фильтра. Отличие заключается в том, что обычный медианный фильтр
заменяет значение в каждой точке на значение медианы по соответствующей
окрестности. Это приводит к излишним искажениям деталей на изображении [25].
. В обоих случаях значение является экстремальным, и алгоритм дает
на выходе значение медианы которое, как следует из результатов работы ветви А, не является
значением импульсного шума. Последняя операция соответствует действию обычного
медианного фильтра. Отличие заключается в том, что обычный медианный фильтр
заменяет значение в каждой точке на значение медианы по соответствующей
окрестности. Это приводит к излишним искажениям деталей на изображении [25].
После получения значения обрабатываемого элемента изображения,
центр окрестности смещается в позицию следующего элемента. Алгоритм
инициализируется вновь и применяется к пикселям внутри окрестности , находящейся в новом положении.
· Фильтры, основанные на выборе
максимального и минимального
значений.
Хотя медианные фильтры, безусловно, принадлежат к числу
наиболее используемых в обработке изображений фильтров, основанных на
порядковых статистиках, это отнюдь не единственный пример таких фильтров.
Медиана представляет собой 50-ый процентиль упорядоченного набора чисел, однако
использование иных статистических характеристик представляет много других
возможностей. Например, использование 0-го процентиля приводит к фильтру,
основанному на выборе минимального значения (минимальному фильтру), который
задается выражением:
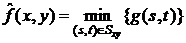 .
.
Такой фильтр полезен при обнаружении наиболее темных точек на
изображении. Кроме того, применение этого фильтра приводит к уменьшению
униполярного «белого» импульсного шума вследствии операции выбора минимума.
Использование же 100-го процентиля приводит к фильтру,
основанному на выборе максимального значения (максимальному фильтру):
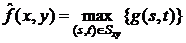 .
.
Такой фильтр полезен при обнаружении наиболее ярких точек на
изображении. Кроме того, поскольку униполярный «черный» импульсный шум
принимает минимальные значения, применение этого фильтра приводит к уменьшению
этого шума, так как в процессе фильтрации из окрестности  выбирается максимальное значение.
выбирается максимальное значение.
Весовая пространственная фильтрация
Пространственные методы фильтрации, рассмотренные ранее, в
общем случае описываются выражением вида [22]:
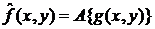 ,
,
где - искаженное изображение на входе
фильтра, - восстановленное изображение на выходе
фильтра, а 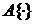 - оператор фильтрации, определенный в
некоторой окрестности , точки
- оператор фильтрации, определенный в
некоторой окрестности , точки 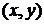 [22].
[22].
Главный подход в определении окрестности вокруг точки заключается в использовании квадратной
или прямоугольной области - подмножества изображения, центрированного в точке . Процесс фильтрации заключается в том,
что центр окрестности передвигается от пикселя к пикселю, начиная
с верхнего левого угла. Оператор выполняется в каждой точке , давая в результате выходное значение для данной точки - отклик фильтра [22].
С целью повышения эффективности фильтрации, то есть для уменьшения
квадрата СКО вида (2.1-3), используется весовая пространственная
фильтрация.
Пространственная фильтрация изображения с помощью весового фильтра задается
выражением общего вида:
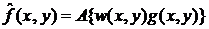 ,
,
где 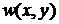 - весовая функция или функция
окна, однозначно определенная в окрестности .
- весовая функция или функция
окна, однозначно определенная в окрестности .
Согласно выражению (2.1-12) каждому элементу апертуры фильтра
соответствует определенное число, называемое весовым коэффициентом или
просто весом. Совокупность всех весовых коэффициентов составляет весовую
функцию . При этом апертура фильтра вместе с
заданной на ней весовой функцией называется маской.
Весовая пространственная фильтрация осуществляется перемещением маски
по изображению. В каждом положении маски весовая функция поэлементно умножается на значения
соответствующих пикселей фильтруемого изображения . Полученные произведения подвергаются
затем действию оператора фильтрации , который и определяет отклик фильтра для данной точки. При этом весовая
функция в процессе перемещения маски остается неизменной.
Временная фильтрация
При временной фильтрации изображений рассматривается
последовательность кадров изображения 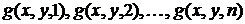 , полученных в дискретные моменты времени (рисунок 2.2). Апертура
, полученных в дискретные моменты времени (рисунок 2.2). Апертура 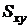 , в этом случае, принимает временной
характер, то есть включает в себя соответственные пиксели всех
, в этом случае, принимает временной
характер, то есть включает в себя соответственные пиксели всех 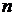 кадров (заштрихованные пиксели на рисунке
2.2).
кадров (заштрихованные пиксели на рисунке
2.2).

Рисунок 2.2 - Схема временной фильтрации изображений
Процесс временной фильтрации состоит в том, что апертура передвигается от пикселя к пикселю,
начиная с верхнего левого угла, при этом в каждой точке выполняется оператор фильтрации , давая отклик фильтра:
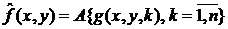 .
.
С учетом этого соответствующие выражения для фильтров,
определяемых соотношениями (2.1-5) - (2.1-10), при временной фильтрации
принимают следующий вид:
- среднеарифметический фильтр: 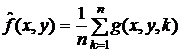 ;
;
- среднегеометрический фильтр: 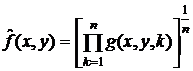 ;
;
- среднегармонический фильтр: 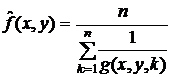 ;
;
- среднеконтргармонический фильтр: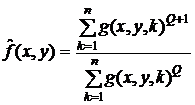 ;
;
- медианный фильтр: 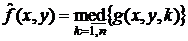 ;
;
- псевдомедианный фильтр: 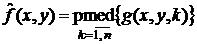 ;
;
- минимальный фильтр: 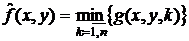 ;
;
- максимальный фильтр: 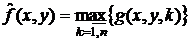 .
.
Необходимо отметить, что, как и в случае пространственной
фильтрации, для повышения эффективности временной фильтрации, то есть для
уменьшения квадрата СКО вида (2.1-3), используется весовая временная
фильтрация, которая задается выражением вида:
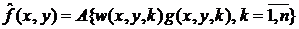 ,
,
где 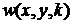 - весовая функция, которая вместе с
апертурой формирует маску.
- весовая функция, которая вместе с
апертурой формирует маску.
Весовая временная фильтрация осуществляется таким же способом, что
и пространственная.
При движении маски по полю кадров, в каждом ее положении весовая
функция поэлементно умножается на значения
соответствующих пикселей кадров 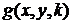 ,
, 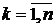 . Полученные произведения подвергаются
затем действию оператора фильтрации , который и определяет отклик фильтра для данной точки. При этом весовая функция
в процессе перемещения маски остается неизменной.
. Полученные произведения подвергаются
затем действию оператора фильтрации , который и определяет отклик фильтра для данной точки. При этом весовая функция
в процессе перемещения маски остается неизменной.
2.2 Методы оптимизации при
пространственно-временной обработке изображений
Задача весовой пространственно-временной
фильтрации как нелинейная задача оптимизации
В общем случае при весовой пространственно-временной фильтрации
выражение квадрата СКО ошибки приближения восстановленного и исходного изображений принимает вид:
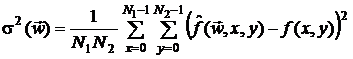 ,
,
где 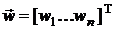 - -мерный вектор весовых коэффициентов маски, от выбора которого в
общем случае зависит восстановленное изображение
- -мерный вектор весовых коэффициентов маски, от выбора которого в
общем случае зависит восстановленное изображение 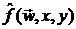 и величина квадрата СКО ошибки
и величина квадрата СКО ошибки 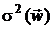 . При этом квадрат СКО ошибки является нелинейной функцией от
. При этом квадрат СКО ошибки является нелинейной функцией от 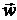 :
: 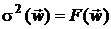 .
.
Таким образом, при весовой пространственно-временной фильтрации
изображений возникает задача нахождения такого оптимального вектора весовых
коэффициентов 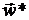 , который обеспечивал бы минимум квадрата
СКО (2.2-1), то есть минимум нелинейной функции
, который обеспечивал бы минимум квадрата
СКО (2.2-1), то есть минимум нелинейной функции 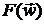 :
:
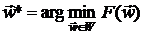 ,
,
на ограниченном замкнутом множестве допустимых весовых
коэффициентов 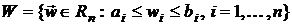 , где
, где 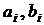 - значения i-й
компоненты вектора весовых коэффициентов, характеризующие область ее возможных
значений. В общем случае это нелинейная задача условной оптимизации (NCP-задача) [12].
- значения i-й
компоненты вектора весовых коэффициентов, характеризующие область ее возможных
значений. В общем случае это нелинейная задача условной оптимизации (NCP-задача) [12].
Двухэтапный алгоритм весовой фильтрации
Трудность разработки и применения наиболее эффективных
методов минимизации при весовой фильтрации обусловлена невозможностью оценить
свойства минимизируемой функции. Как правило, минимизируемая функция является
многоэкстремальной, что создает трудности в применении методов локального
спуска, так как это требует знания хорошего начального приближения, тяготеющего
к достаточно глубокому локальному (в наилучшем варианте - глобальному)
минимуму. Поэтому поиск хороших начальных приближений для методов локального спуска
в задачах весовой фильтрации является важной самостоятельной проблемой, от
решения которой зависит окончательный результат.
Другая трудность решения задачи (2.2-2) связана с учетом
ограничений на вектор . В регулярных методах спуска, особенно
основанных на градиентной информации, наличие ограничений изменяет либо схему
метода, либо минимизируемую функцию (метод штрафных функций), вводя в него
информацию о расстоянии текущей точки спуска до границы допустимой области. И в
том, и в другом случае схема оптимизации значительно усложняется [5].
Необходимо отметить еще одну трудность, сопутствующую задаче вида
(2.2-2). Имеется в виду разнородность компонент вектора весовых коэффициентов.
Это может привести к появлению многомерных «оврагов» у целевой функции, что
препятствует высокой скорости сходимости методов спуска при оптимизации в
совокупном пространстве 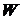 . Сходимость процесса повышается при
циклическом переборе спусков в пространстве однородных весовых коэффициентов.
. Сходимость процесса повышается при
циклическом переборе спусков в пространстве однородных весовых коэффициентов.
В связи с особенностями целевой функции (многоэкстремальность, не
выпуклость, неаналитичность, плохая обусловленность) при решении задачи (2.2-2)
необходимо использовать алгоритм, состоящий из двух этапов - глобального и
локального [19,20]. На первом этапе с использованием одного из методов
глобальной оптимизации находится грубое приближение оптимального вектора
весовых коэффициентов (область глобального экстремума). А на
втором этапе компоненты вектора определяются с заданной точностью одним из локальных методов.
Очевидно, что время поиска и точность решения целиком определяются
эффективностью используемых алгоритмов оптимизации.
Глобальный случайный поиск
Исторически первым и довольно долгое время единственным
широко используемым методом поиска глобального экстремума являлся метод,
названный впоследствии «мультистарт». Этот метод состоит в многократном
(последовательном или параллельном) отыскании локальных минимумов из различных
начальных точек, чаще всего случайных (такой вид алгоритма носит название
«случайный мультистарт») [8].
Использование случайного выбора при построении алгоритмов
глобальной оптимизации приводит к алгоритмам глобального случайного поиска
[17]. Основными причинами популярности методов случайного поиска среди
пользователей являются следующие. Структура алгоритмов довольно проста, и их
можно легко реализовать в виде программ ЭВМ. Алгоритмы робастны, то есть
малочувствительны к нерегулярностям поведения целевой функции, структуры
множества оптимизации, наличию случайных ошибок при вычислении функции; кроме
того, они малочувствительны к росту размерности множества оптимизации. Наконец,
в рамках известных схем случайного поиска легко строятся новые алгоритмы,
реализующие различные эвристические процедуры адаптации.
Разработано большое разнообразие методов глобального
случайного поиска [17]. В основе построение этих алгоритмов лежит следующая
общая схема:
Выбирается некоторое распределение вероятностей 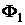 на W и полагается
на W и полагается 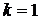 .
.
Моделируется некоторое число раз 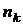 распределение
распределение 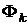 , при этом получаются точки
, при этом получаются точки 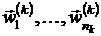 . В этих точках вычисляются значения функции
. В этих точках вычисляются значения функции 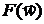 и полагается
и полагается 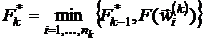 . В качестве приближения к точке
. В качестве приближения к точке 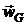 выбирается такая точка
выбирается такая точка 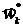 , в которой
, в которой 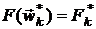 .
.
Согласно определенному правилу конструируется распределение
вероятностей 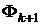 на W.
на W.
Проверяется условие останова, и если оно не выполняется, то
осуществляется переход к шагу 2 с заменой 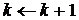 .
.
Таким образом, любой алгоритм глобального случайного поиска
состоит из некоторого числа итераций, на каждой из которых моделируется
специальным образом сконструированные распределения.
К сожалению, для алгоритмов глобального случайного поиска нет
повода испытывать оптимизм. Причины для этого следующие [17].
Во-первых, хотя большинство методов обладает теоретическим
свойством сходимости, оценки этой скорости сходимости показывают, что она
крайне медленная.
Во-вторых, методы случайного поиска, обладающие наибольшей
практической эффективностью, содержат в себе элементы эвристики и поэтому
обладают недостатком, присущим эвристическим методам: нечетко определен класс
задач, для которых методы эффективны; отсутствуют четкие рекомендации о выборе
параметров методов, а эти параметры в значительной степени влияют на
эффективность.
В-третьих, как показывают численные и теоретические
результаты, только за счет усложнения алгоритма и уменьшения доли случайности
можно повысить его эффективность.
Следовательно, применение алгоритмов глобального случайного
поиска при решении задачи весовой фильтрации наиболее рационально для
минимизации функций, вычисление которых не требует значительных затрат
машинного времени.
Классификация методов глобальной оптимизации
Использование двухэтапного алгоритма весовой фильтрации
предполагает на первом этапе применение процедуры, обеспечивающей поиск точки
(области) глобального экстремума - . Математическая формулировка этого факта имеет следующую форму
[8]:
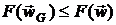 при всех
при всех 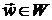 .
.
Последнее неравенство устанавливает интересный парадокс [8]: если
глобальный минимум и можно было бы случайно найти, то этот
факт невозможно проверить. Поэтому построение эффективного
неспециализированного алгоритма глобальной оптимизации возможно лишь для
определенного класса функций (гладких, с ограниченной скоростью изменения,
дифференцируемых конечное число раз и так далее).
Для того чтобы использовать полученную о целевой функции
информацию и рационально планировать процесс поиска, в глобальной оптимизации
используется термин «модель многоэкстремальной целевой функции» [11,13]. При
этом с одной стороны, желательно иметь достаточно общую модель, охватывающую
возможно большее число возникающих на практике задач. С другой стороны, модель
должна быть достаточно определенной, чтобы обеспечить эффективность построенных
на ее основе алгоритмов.
Ряд алгоритмов глобальной оптимизации обобщают известные локальные
методы. В этом случае в качестве модели принимается класс дифференцируемых или
дважды дифференцируемых функций [8]. Применение алгоритмов, основанных на этой
модели, к решению практических задач синтеза сталкивается с трудно решаемой
проблемой оценки границ производных [12]. Если оценка завышена, то для
получения приемлемой оценки глобального минимума может потребоваться огромное
количество вычислений целевой функции. Если же оценка занижена, то из
рассмотрения может быть исключена подобласть, фактически содержащая глобальный
минимум. При этом большинство методов этого класса строятся согласно принципу
минимакса [8].
Алгоритм глобальной оптимизации считается оптимальным в
минимаксном смысле, если он позволяет максимально быстро отыскивать минимум
наихудшей функции. Но пользователи алгоритмов оптимизации часто стремятся к
эффективности в среднем, для их типичной задачи, а не для какого-то редко
встречаемого на практике случая.
Стремление сформулировать математическую задачу глобальной
оптимизации, соответствующей практической ситуации, привело к введению
статистической модели многоэкстремальных функций [17]. В рамках статистической
модели алгоритмы глобальной оптимизации строятся по критерию средней
эффективности. Согласно этому критерию алгоритм считается оптимальным, если он
позволяет максимально быстро отыскивать минимум типичного (среднего)
представителя рассматриваемого класса функций.
Алгоритмы глобальной оптимизации в настоящее время принято
разделять на два класса [11,13,17]: использующие модель глобального поведения
функции (рациональные) и не использующие таковой (эвристические).
Наиболее яркими представителями рациональных алгоритмов являются
минимаксные и оптимальные в среднем алгоритмы. К первым относятся алгоритмы
минимизации функций с ограниченной скоростью изменения. Другой подход к
принятию рациональных решений в условиях неопределенности основан на применении
статистических моделей. Сюда же можно отнести и декомпозиционные методы,
использующие как идеи минимаксных алгоритмов, так и критерий средней
рациональности. Общим для рациональных алгоритмов является сложность
вспомогательных вычислений [8].
Наиболее яркими представителями эвристических алгоритмов являются
глобальные обобщения локальных (многократный локальный спуск из случайных точек
или чередование спуска в локальный минимум с подъемом в седловую точку). Кроме
этого, многие эвристические алгоритмы используют случайный поиск, то есть точки
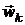 генерируются случайно (метод
Монте-Карло). Но, для того чтобы вероятность нахождения глобального минимума
сделать близкой к единице, количество точек должно быть очень большим.
генерируются случайно (метод
Монте-Карло). Но, для того чтобы вероятность нахождения глобального минимума
сделать близкой к единице, количество точек должно быть очень большим.
Основные идеи построения рациональных и эвристических алгоритмов
определяют следующую классификацию [11,17]:
1. Методы поиска глобального
экстремума, основанные на использовании алгоритмов локальной оптимизации.
2. Алгоритмы минимизации
функций с ограниченной скоростью изменения.
3. Методы, основанные на
использовании статистических моделей целевых функций.
4. Глобальный случайный
поиск.
5. Методы декомпозиции.
Анализ большого количества работ [8,11,17], посвященных
методам глобальной оптимизации показывает, что с точки зрения объема
вычислительных затрат, точности нахождения глобального экстремума и возможности
программной реализации наиболее предпочтительными являются алгоритмы
глобального случайного поиска и методы декомпозиции.
Метод динамического программирования
Еще один подход к решению задач глобальной оптимизации
основан на использовании динамического программирования. Этот метод относится к
классу методов декомпозиции - так называются методы, позволяющие задачи большой
размерности свести к последовательному решению ряда задач меньшей размерности.
Если эти вспомогательные задачи решены с достаточно хорошей точностью, то тем
самым и в исходной задаче глобальный минимум будет найден с высокой точностью
[8].
Впервые возможность применения метода динамического
программирования в задачах синтеза антенных решеток была показана в работе
[18]. В основе алгоритма, предложенного в ней, лежит итерационный процесс, на
каждом шаге которого находится вектор 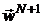 путем решения (
путем решения (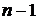 ) - шаговой задачи динамического программирования. Так, на
) - шаговой задачи динамического программирования. Так, на
k-м шаге решения для всех 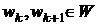 и фиксированных значений
и фиксированных значений 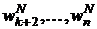 параметрического вектора
параметрического вектора 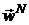 (вектора, полученного на предыдущем этапе) рассчитывается
функция:
(вектора, полученного на предыдущем этапе) рассчитывается
функция:
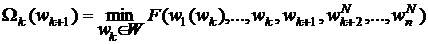 ,
,
где 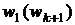 ,…,
,…,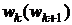 - так называемые функции оптимального соответствия, построенные
на (
- так называемые функции оптимального соответствия, построенные
на (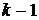 ) - м шаге.
) - м шаге.
Таким образом, на каждом шаге оптимизации рассматриваются все
комбинации лишь двух переменных 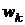 и
и 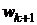 , поскольку считается, что оптимальные
значения k-1, k-2 и так далее переменных были определены на
предшествующих шагах расчета.
, поскольку считается, что оптимальные
значения k-1, k-2 и так далее переменных были определены на
предшествующих шагах расчета.
Соотношения 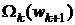 ,
, 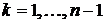 используются как рекуррентные для определения систем функций
оптимального соответствия
используются как рекуррентные для определения систем функций
оптимального соответствия 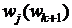 ,
, 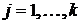 . На последнем, () - м шаге решения задачи динамического программирования, с
помощью построенной системы функций оптимального соответствия
. На последнем, () - м шаге решения задачи динамического программирования, с
помощью построенной системы функций оптимального соответствия 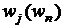 ,
, 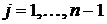 , определяется вектор
, определяется вектор 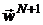 , такой, что
, такой, что 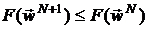 .
.
Таким образом, в результате (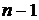 ) - шаговой процедуры оптимизации получен вектор
) - шаговой процедуры оптимизации получен вектор 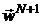 , для которого значения целевой функции не
больше, чем для . Вектор используется в качестве исходного для следующего этапа
итерационного процесса.
, для которого значения целевой функции не
больше, чем для . Вектор используется в качестве исходного для следующего этапа
итерационного процесса.
Поскольку при построении семейства функций оптимального соответствия
, 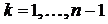 для всех
для всех 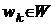 необходимо решать одномерную задачу
глобальной оптимизации, то практическая реализация данного алгоритма возможна
лишь на дискретном множестве, то есть когда каждая из переменных может принимать
необходимо решать одномерную задачу
глобальной оптимизации, то практическая реализация данного алгоритма возможна
лишь на дискретном множестве, то есть когда каждая из переменных может принимать 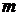 задаваемых на сетке значений. Если
итерационный процесс имеет
задаваемых на сетке значений. Если
итерационный процесс имеет 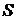 шагов, то необходимое число вычислений целевой функции можно определить по следующей формуле
шагов, то необходимое число вычислений целевой функции можно определить по следующей формуле 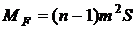 .
.
Практика решения многоэкстремальных задач синтеза и многочисленных
тестовых задач [19,20] показывает, что метод динамического программирования
эффективно использовать на первой стадии двухэтапного алгоритма с целью выхода
в область глобального экстремума. При этом надежное решение этих задач
достигается при числе сеточных узлов 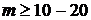 . Это приводит к увеличению вычислительных затрат особенно с
ростом размерности решаемых задач.
. Это приводит к увеличению вычислительных затрат особенно с
ростом размерности решаемых задач.
Поэтому в работе [20] была проведена модификация данного алгоритма
с целью повышения его эффективности при малом числе сеточных узлов 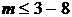 . Основу проведенной модификации составляет:
. Основу проведенной модификации составляет:
·
применение
интерполяции с использованием полинома Лагранжа при нахождении глобального
экстремума функции оптимального соответствия;
·
использование
процедуры адаптивного сдвига сеточных узлов на каждой итерации поиска.
Результаты численного моделирования, показывают высокую
эффективность проведенной модификации с точки зрения повышения точности выхода
в область нелокального экстремума при малом значении числа сеточных узлов .
Поскольку с увеличением размерности решаемых задач применение
регулярной сетки приводит к хорошо известному в теории сеток эффекту
«затенения» [8], в работе [20] предложен и исследован вариант метода
динамического программирования с использованием квазислучайной сетки.
Результаты исследований показали, что предложенный метод оказался значительно
эффективнее классического, практически не уступая модифицированному.
Таким образом, высокая эффективность методов динамического
программирования и определяет их применение для поиска области глобального
экстремума на первом этапе двухэтапного алгоритма весовой фильтрации. А на
втором этапе для определения точного местоположения глобального экстремума
необходимо использовать эффективные (численно устойчивые, обеспечивающие
высокую скорость сходимости и требующие минимального числа вычислительных
затрат) алгоритмы локальной оптимизации.
Классификация методов локальной оптимизации
Методы поиска локального экстремума принято ранжировать
следующим образом [12-18]:
1. Метод Ньютона и его модификации.
2. Квазиньютоновские методы.
. Градиентные методы.
. Методы прямого поиска.
Согласно этой классификации первенство держат ньютоновские
методы, поскольку использование информации второго порядка обеспечивает им
высокие скорости сходимости и позволяет делать качественные выводы относительно
найденного численного решения. Когда получение аналитических выражений первых и
вторых производных затруднено, лучшим будет использование квазиньютоновских
методов с конечно-разностной аппроксимацией производных. Градиентные методы
значительно уступают по своей эффективности ньютоновским и квазиньютоновским
вследствие низких скоростей сходимости, но наиболее широко используются из-за
простоты реализации. Методы прямого поиска при минимизации используют только
значения целевой функции, поэтому они гораздо менее эффективны, чем
градиентные, в тех случаях, когда последние применимы. Таким образом, чем
больше информации о производных, которую можно получить ценой приемлемых
затрат, будет использовано при решении задачи, тем лучше.
Большинство методов минимизации являются итерационными по своей
природе. Это означает, что, начиная с заданной точки 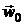 , называемой начальным приближением, в
дальнейшем получается последовательность точек
, называемой начальным приближением, в
дальнейшем получается последовательность точек 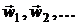 , которая, в принципе, должна сходится к точке
, которая, в принципе, должна сходится к точке 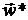 минимума целевой функции . Вычисление
минимума целевой функции . Вычисление 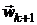 называется k-й итерацией, а точка - k-м приближением. В результате основное
уравнение для k-й итерации записывается в виде:
называется k-й итерацией, а точка - k-м приближением. В результате основное
уравнение для k-й итерации записывается в виде:
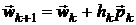 ,
, 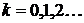 ,
,
где 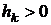 - скалярная величина (длина шага),
обеспечивающая неравенство
- скалярная величина (длина шага),
обеспечивающая неравенство 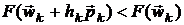 ,
, 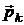 - направление поиска, правила вычисления
которого «определяют лицо алгоритма» минимизации и его эффективность.
- направление поиска, правила вычисления
которого «определяют лицо алгоритма» минимизации и его эффективность.
Так, в методе Ньютона направление поиска определяется системой
линейных алгебраических уравнений:
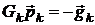 ,
,
где 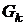 - матрица Гессе, матрица вторых частных
производных, а
- матрица Гессе, матрица вторых частных
производных, а  - вектор градиента функции .
- вектор градиента функции .
Необходимо заметить, что численное определение матрицы Гессе
на каждой итерации существенно снижает скорость сходимости (из-за наличия
ошибок округления), а также значительно увеличивает объем вычислительных
затрат.
В квазиньютоновских методах направление поиска вычисляется по формуле [14,17]:
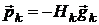 ,
,
где 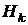 - приближение обратной матрицы Гессе.
Матрица
- приближение обратной матрицы Гессе.
Матрица 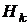 на первой итерации является единичной и
преобразуется от итерации к итерации в соответствии со следующей формулой
пересчета:
на первой итерации является единичной и
преобразуется от итерации к итерации в соответствии со следующей формулой
пересчета:
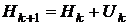 ,
,
где 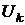 - поправочная матрица различных рангов.
Существуют различные формулы пересчета приближений обращенной матрицы Гессе,
использующие поправки разных рангов [14, 17]:
- поправочная матрица различных рангов.
Существуют различные формулы пересчета приближений обращенной матрицы Гессе,
использующие поправки разных рангов [14, 17]:
1.
Симметричная
формула ранга один (SR1-формула):
 ,
,
где 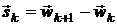 , а
, а 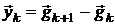 - соответствующее приращение градиента.
- соответствующее приращение градиента.
1.
Формула
Бройдена-Флетчера-Гольдфарба-Шанно (BFGS-формула):
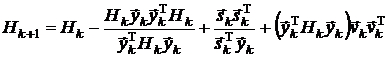 ,
,
где 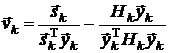 .
.
1.
Формула
Дэвидона-Флетчера-Пауэлла (DFP-формула):
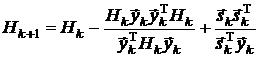 .
.
В последнее время в литературе, посвященной квазиньютоновским
методам, был предложен ряд алгоритмов, использующих иную схему безусловной
минимизации [14, 18]. Она отличается от классической квазиньютоновской схемы
тем, что предполагает непосредственную оценку 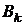 прямой матрицы Гессе , а не обратной к ней. В этом случае направление спуска
определяется из уравнения:
прямой матрицы Гессе , а не обратной к ней. В этом случае направление спуска
определяется из уравнения:
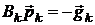 ,
,
которое решается с использованием разложения матрицы по методу
Холесского 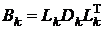 .
.
Каждой квазиньютоновской формуле для пересчета оценки обратной
матрицы Гессе , соответствует (в том смысле, что из 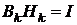 следует
следует 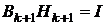 , где
, где 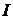 - единичная матрица) преобразованная
формула пересчета матрицы [14, 15, 18]:
- единичная матрица) преобразованная
формула пересчета матрицы [14, 15, 18]:
1.
Преобразованная
симметричная формула ранга один (SR1-формула):
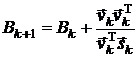 ,
,
где 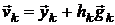 .
.
1.
Преобразованная
BFGS-формула:
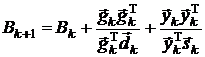 .
.
1.
Преобразованная
DFP-формула:
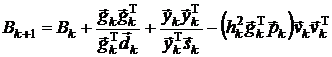 ,
,
где 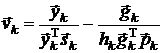 .
.
Следует отметить, что преобразованные формулы не содержат
операции умножения матрицы на вектор.
Имея разложение Холесского матриц , можно получать оценки их чисел обусловленности. Так справедливо
неравенство [14] 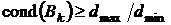 , где
, где 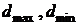 - максимальный и минимальный диагональные элементы фактора
- максимальный и минимальный диагональные элементы фактора 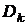 . На промежуточных операциях такие оценки
позволяют выявить ситуации, когда матрица обусловлена так плохо, что вычисляемый вектор из-за ошибок округления не будет
направлением спуска. При этом факторы разложения можно подправить так, что
обусловленность реализующей матрицы станет приемлемой [14, 15].
. На промежуточных операциях такие оценки
позволяют выявить ситуации, когда матрица обусловлена так плохо, что вычисляемый вектор из-за ошибок округления не будет
направлением спуска. При этом факторы разложения можно подправить так, что
обусловленность реализующей матрицы станет приемлемой [14, 15].
Помимо этого, использование факторизации Холесского позволяет
избежать потери положительной определенности матриц , что имеет место в обычных
квазиньютоновских методах из-за ошибок округления. Эта проблема возникает при
практической реализации алгоритма и, как правило, опускается в теории. Утрата
положительной определенности нежелательна, поскольку это приводит к внесению в
квазиньютоновскую аппроксимацию матриц () ошибочных поправок, уничтожающих
накопленную информацию о кривизне . Следствием этого является то, что вектор может указывать в сторону возрастания
минимизируемой функции. При этом по данным функционирования обычного (без
факторизации) квазиньютоновского алгоритма невозможно определить момент утраты
положительной определенности . Таким образом, при реализации квазиньютоновского метода
необходимо обеспечить численную положительную определенность приближений
матрицы Гессе (или обратной к ней).
Используя в квазиньютоновском поиске факторизацию Холесского,
легко обеспечить положительную определенность матрицы [14, 17]. Для этого на очередном шаге
вычислений коэффициентов множителей Холесского соответствующий диагональный
элемент матрицы 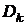 увеличивается настолько, чтобы
окончательное произведение
увеличивается настолько, чтобы
окончательное произведение 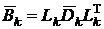 было положительно определенным и хорошо обусловленным. Когда этот
элемент выбран, очередной столбец множителя
было положительно определенным и хорошо обусловленным. Когда этот
элемент выбран, очередной столбец множителя 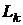 однозначно определяется требованием совпадения матриц и
однозначно определяется требованием совпадения матриц и 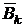 . Таким образом, в результате получается представление:
. Таким образом, в результате получается представление:
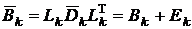 ,
,
где 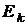 - неотрицательная диагональная матрица,
равная нулю, если матрица существенно положительно определена.
- неотрицательная диагональная матрица,
равная нулю, если матрица существенно положительно определена.
Методы сопряженных градиентов относятся к классу алгоритмов минимизации,
в которых вычисление направлений поиска не предполагает решения каких-либо
систем линейных уравнений. Это принципиально отличает их от методов Ньютона и
квазиньютоновских методов [12, 14].
ожно показать [12, 14], что направление 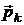 для очередной итерации в методе
сопряженных градиентов при минимизации квадратичных функций вычисляется как
линейная комбинация градиента в текущей точке
для очередной итерации в методе
сопряженных градиентов при минимизации квадратичных функций вычисляется как
линейная комбинация градиента в текущей точке 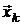 и
предыдущего направления
и
предыдущего направления 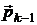 :
:
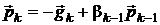 ,
,
где 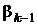 вычисляются по следующим теоретически
эквивалентным формулам [12]:
вычисляются по следующим теоретически
эквивалентным формулам [12]:
Формула Флетчера-Ривса: 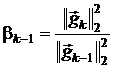 .
.
Формула Полака-Рибьера: 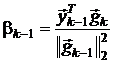 .
.
Теоретически этот метод конечен [12]: при точных вычислениях
он должен найти решение не более чем за n шагов.
Метод сопряженных градиентов легко обобщается на задачи
минимизации нелинейных функций общего вида. Для этого надо заменить
используемую в нем формулу расчета 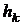 какой-нибудь процедурой одномерного поиска и уточнить, будет ли
направление всегда вычисляться по формуле (2.2-17)
или допускаются периодические отступления. Последние принято называть
рестартами или восстановлениями [11, 14]. Можно, например, принимая во
внимание n-шаговую теоретическую сходимость в
квадратичном случае, через каждые n шагов
отказываться от направления (15) и брать в качестве очередного антиградиент
какой-нибудь процедурой одномерного поиска и уточнить, будет ли
направление всегда вычисляться по формуле (2.2-17)
или допускаются периодические отступления. Последние принято называть
рестартами или восстановлениями [11, 14]. Можно, например, принимая во
внимание n-шаговую теоретическую сходимость в
квадратичном случае, через каждые n шагов
отказываться от направления (15) и брать в качестве очередного антиградиент 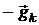 . Соответствующий метод называют
традиционным [11].
. Соответствующий метод называют
традиционным [11].
Традиционный метод сопряженных градиентов сходится в тех же
предположениях, что и метод наискорейшего спуска [11,15]. Для достаточно
широкого класса функций теоретическая скорость его сходимости при точной
одномерной минимизации оказывается n-шаговой
сверхлинейной. Однако, как показывает практический опыт, из-за ошибок
округления реальная скорость сходимости метода сопряженных градиентов почти
всегда линейна независимо от того, применяются рестарты или нет [11]. Поэтому
применение метода сопряженных градиентов следует считать успешным, когда
удовлетворительное решение удалось получить менее чем за 5n шагов.
В заключение следует отметить, что, хотя схема сопряженных
градиентов далека от идеала, на сегодня она является единственным разумным
универсальным средством решения задач безусловной минимизации с очень большим
числом переменных.
Конечно-разностная аппроксимация производных
При весовой пространственно-временной фильтрации решаются
задачи минимизации таких функций, которые хотя и являются гладкими, но
настолько сложными, что оказывается трудным или невозможным организовать
вычисление аналитических значений даже первых производных. В этом случае
наиболее эффективными и успешно применяемыми являются методы спуска, в которых
вектор градиента аппроксимируется конечными разностями [6,11]. При этом успех
применения метода во многом зависит от точности аппроксимации градиента.
Простейшая конечно-разностная аппроксимация градиента получается
на основе разложения функции в ряд Тейлора [8,11]:
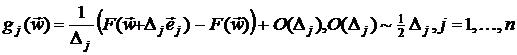 ,
,
где 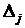 - интервал конечной разности, связанный с
j-й компонентой аргумента ;
- интервал конечной разности, связанный с
j-й компонентой аргумента ; 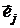 - единичный вектор, j-я
компонента которого равна единице;
- единичный вектор, j-я
компонента которого равна единице; 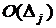 - ошибка порядка , связанная с отбрасываемыми членами ряда Тейлора и называемая
ошибкой отбрасывания. Выражение (2.2-20) называется односторонней
конечно-разностной аппроксимацией.
- ошибка порядка , связанная с отбрасываемыми членами ряда Тейлора и называемая
ошибкой отбрасывания. Выражение (2.2-20) называется односторонней
конечно-разностной аппроксимацией.
Если в формуле (2.2-20) выполняется еще один шаг
тейлоровского разложения, то центральная конечно-разностная аппроксимация
градиента имеет вид:
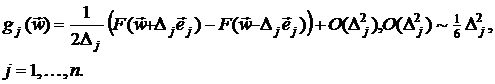
Соответствующая ошибка отбрасывания имеет уже порядок 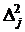 , однако для расчета каждой компоненты
градиента требуется вычисление двух значений функций, а не одного, как для односторонней
конечно-разностной аппроксимации.
, однако для расчета каждой компоненты
градиента требуется вычисление двух значений функций, а не одного, как для односторонней
конечно-разностной аппроксимации.
Тейлоровское разложение функции позволяет строить формулы аппроксимации конечными разностями ее
производных не только первого, но и более высоких порядков. В частности, приближением
первого порядка для элементов 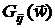 матрицы Гессе
матрицы Гессе 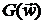 будет:
будет:
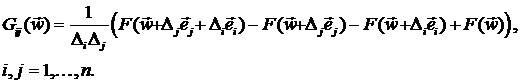
Эта формула есть результат аппроксимации j-го столбца матрицы вектором 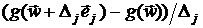 с последующей заменой компонент векторов
с последующей заменой компонент векторов 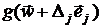 и
и 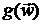 соответствующими разностями первого порядка.
соответствующими разностями первого порядка.
Неточность конечно-разностных аппроксимаций вида (2.2-20) -
(2.2-22) связана с ошибками трех типов [8,11,15]:
1. Ошибка отбрасывания. Эта
ошибка равняется остаточному члену тейлоровского разложения, отбрасываемому при
выводе формул аппроксимации.
Ошибка потери значащих цифр, связанная с разностью двух близких
значений функции . Если 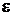 - относительная точность вычисления (в лучшем случае
- относительная точность вычисления (в лучшем случае 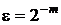 , где m - число двоичных цифр, с которыми ведутся вычисления). Абсолютная
ошибка вычисления имеет величину
, где m - число двоичных цифр, с которыми ведутся вычисления). Абсолютная
ошибка вычисления имеет величину 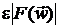 , тогда максимальная ошибка потери
значащих цифр для аппроксимаций вида (2.2-20) и (2.2-21) равна
, тогда максимальная ошибка потери
значащих цифр для аппроксимаций вида (2.2-20) и (2.2-21) равна 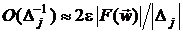 .
.
Ошибки округления. Вычисление оценки 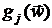 по заданным ,
по заданным , 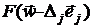 и
и 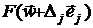 сопровождается ошибками округления,
неизбежными при машинном вычитании и делении. Они пренебрежимо малы в сравнении
с предыдущими.
сопровождается ошибками округления,
неизбежными при машинном вычитании и делении. Они пренебрежимо малы в сравнении
с предыдущими.
Таким образом, ошибка численного определения градиента в (2.2-20)
и (2.2-21) определяется ошибками отбрасывания и потери значащих цифр. Но если
первая из них пропорциональна конечно-разностному интервалу , то вторая - обратной ему величины.
Поэтому последствия варьирования для них противоположны. На практике конечно-разностный интервал
выбирается из соображений минимизации вычислимой оценки суммарной ошибки.
Результаты многочисленных исследований [8-11,14,15] показали
эффективность использования относительного конечно-разностного интервала 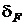 , одинакового для всех компонент . При этом оценка абсолютного
конечно-разностного интервала определяется выражением:
, одинакового для всех компонент . При этом оценка абсолютного
конечно-разностного интервала определяется выражением:
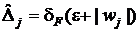 ,
, 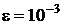 ,
,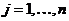 .
.
В настоящее время принята следующая стратегия вычисления
градиента. Сначала градиент надо вычислять по менее трудоемкой формуле
(2.2-20), а затем, когда последовательность точек попадает в область, где норма
градиента мала, надо переключиться на формулу (2.2-21). Переход осуществляется
тогда, когда на какой-либо итерации использование алгоритмом односторонней
конечно-разностной аппроксимации градиента не приводит к достаточному убыванию
функции, но критерии останова еще не выполняются. В этом случае алгоритм
продолжает свою работу с использованием центральной аппроксимации градиента до
тех пор, пока не выполнятся или критерии останова, или условие обратного
перехода. Условие перехода определяется следующим неравенством:
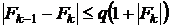 .
.
Величина q,
показывающая «существенность» убывания целевой функции от итерации к итерации,
является, по существу, порогом адаптивной процедуры переключения с одной схемы
численного дифференцирования на другую. Чем больше величина q, тем раньше происходит переход к
центральной аппроксимации, и, наоборот, при 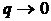 решение задачи происходит по односторонней схеме.
решение задачи происходит по односторонней схеме.
Методы условной оптимизации
В задачах весовой пространственно-временной фильтрации всегда
имеет место наличие ограничений, накладываемых на вектор весовых коэффициентов . Указанные ограничения можно записать в
общем виде:
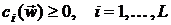 ,
,
где 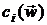 - непрерывно дифференцируемая функция.
При этом произвольная точка , удовлетворяющая таким ограничениям, считается допустимой.
Множество всех допустимых точек образует допустимую область:
- непрерывно дифференцируемая функция.
При этом произвольная точка , удовлетворяющая таким ограничениям, считается допустимой.
Множество всех допустимых точек образует допустимую область:
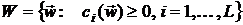 .
.
Ограничения значительно усложняют процесс оптимизации и приводят к
необходимости решения задач условной минимизации. Наличие эффективных алгоритмов
безусловной оптимизации дает возможность их применения в задачах с
ограничениями. В этом случае целевая функция должна быть модифицирована так,
чтобы она оставалась почти неизменной внутри допустимой области, но резко
возрастала при подходе к границам, задаваемым ограничениями. Последнего можно
добиться, если назначить штрафную функцию по каждому из ограничений. Тогда
вспомогательная функция будет иметь следующий вид [17]:
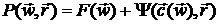 ,
,
где 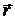 - вектор управляющих параметров,
- вектор управляющих параметров, 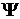 - «штрафная» функция, воздействие которой
регулируется вектором , а
- «штрафная» функция, воздействие которой
регулируется вектором , а 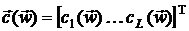 . Различные методы преобразования отличаются друг от друга выбором
и способом задания управлений,
позволяющим найти минимум функции при наличии ограничений посредством безусловной минимизации
. Различные методы преобразования отличаются друг от друга выбором
и способом задания управлений,
позволяющим найти минимум функции при наличии ограничений посредством безусловной минимизации 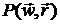 по . Если обозначить точку безусловного локального минимума функции через
по . Если обозначить точку безусловного локального минимума функции через 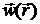 , то методы преобразования, в которых функция и последовательность
, то методы преобразования, в которых функция и последовательность 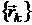 задаются так, что точки существуют, их можно отыскать (с любой
степенью точности) каким-нибудь из алгоритмов минимизации без ограничений и
задаются так, что точки существуют, их можно отыскать (с любой
степенью точности) каким-нибудь из алгоритмов минимизации без ограничений и 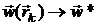 при
при 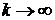 , называются методами последовательной безусловной минимизации или
просто последовательными методами [17]. Последовательные методы распадаются на
два класса. Первый - это методы штрафных функций (или, как они еще называются
методами внешней точки), использующие при поиске недопустимые точки. Второй
класс составляют методы барьерных функций (методы внутренней точки). Они
характеризуются тем, что поиск решения осуществляется, не выходя за пределы
допустимой области, что является определяющим при решении задач нелинейной
регрессии, для которых целевая функция вне W может быть
не определена. Поэтому целесообразно рассмотреть только методы барьерных
функций.
, называются методами последовательной безусловной минимизации или
просто последовательными методами [17]. Последовательные методы распадаются на
два класса. Первый - это методы штрафных функций (или, как они еще называются
методами внешней точки), использующие при поиске недопустимые точки. Второй
класс составляют методы барьерных функций (методы внутренней точки). Они
характеризуются тем, что поиск решения осуществляется, не выходя за пределы
допустимой области, что является определяющим при решении задач нелинейной
регрессии, для которых целевая функция вне W может быть
не определена. Поэтому целесообразно рассмотреть только методы барьерных
функций.
В методах барьерных функций подбирается так, чтобы на границе допустимой области «построить
барьер», препятствующий нарушению ограничений в процессе безусловной
минимизации функции , и чтобы точки с изменением 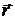 по некоторому правилу приближались к изнутри W. При этом барьерная функция определяется выражением [17]:
по некоторому правилу приближались к изнутри W. При этом барьерная функция определяется выражением [17]:
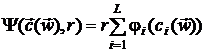 ,
,
где r - положительное число, а 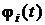 - непрерывные на интервале
- непрерывные на интервале 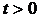 дифференцируемые функции, причем
дифференцируемые функции, причем 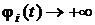 при
при 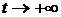 . Вспомогательная функция имеет вид:
. Вспомогательная функция имеет вид:
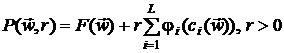 .
.
Она определена внутри W и
неограниченно возрастает, если 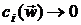 для какого-нибудь i.
Наиболее часто используются следующие барьерные функции [11,17]:
для какого-нибудь i.
Наиболее часто используются следующие барьерные функции [11,17]:
логарифмическая функция 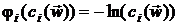 ;
;
обратная функция 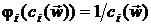 .
.
Чем меньше значение r,
тем меньше влияние второго слагаемого в выражении для 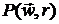 . Это обеспечивает сходимость при
. Это обеспечивает сходимость при 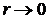 точек к и как следствие существенное убывание
значения и совпадение его в пределе с
точек к и как следствие существенное убывание
значения и совпадение его в пределе с 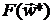 .
.
Модельная схема оптимизации в этом случае формулируется так [17]:
Выбирается монотонно убывающая сходящаяся к нулю
последовательность 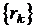 , например,
, например, 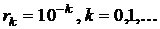 . Определяется начальное приближение
. Определяется начальное приближение 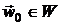 и полагается
и полагается 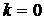 .
.
.
Начиная с точки , находится безусловный локальный минимум для 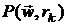 и принимается
и принимается 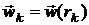 . Если критерий остановки не выполняется,
то возвращаются к шагу 2.
. Если критерий остановки не выполняется,
то возвращаются к шагу 2.
Доказано, что последовательность безусловных минимумов функции сходится к при условии непрерывности функции и существования ее локальных минимумов внутри допустимой области.
Однако сходимость может иметь место даже и тогда, когда эти условия полностью
не выполняются.
Непосредственное применение стандартных алгоритмов безусловной
минимизации функции встречает определенные трудности [17].
Так стандартные методы безусловной минимизации рассчитаны на то, что целевая
функция определена на всем пространстве. Но для функции это условие не выполняется, и, чем ближе 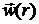 к границе множества W, тем реальнее возможность сделать шаг за
пределы допустимой области. Следовательно, в данном случае необходима
специальная процедура спуска по направлению, включающая проверку соблюдения
ограничений и эффективное правило сокращения недопустимого шага. Вполне
эффективным является следующий метод [17]. Если имеются точка , направление поиска метода и необходима следующая точка
к границе множества W, тем реальнее возможность сделать шаг за
пределы допустимой области. Следовательно, в данном случае необходима
специальная процедура спуска по направлению, включающая проверку соблюдения
ограничений и эффективное правило сокращения недопустимого шага. Вполне
эффективным является следующий метод [17]. Если имеются точка , направление поиска метода и необходима следующая точка 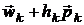 , то сначала выбирается значение шага
, то сначала выбирается значение шага 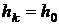 , проверяется выполнение ограничений
, проверяется выполнение ограничений 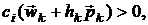
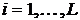 . Если они выполняются, то
. Если они выполняются, то 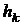 не меняется, иначе заменяется величиной
не меняется, иначе заменяется величиной 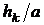 (где
(где 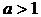 - коэффициент коррекции шага), находится
новая точка и вновь осуществляется проверка. В конце
концов, допустимая точка будет найдена.
- коэффициент коррекции шага), находится
новая точка и вновь осуществляется проверка. В конце
концов, допустимая точка будет найдена.
Таким образом, рассмотренные методы барьерных функций, построенные
на базе эффективных алгоритмов безусловной минимизации, являются наиболее
перспективными для решения задач весовой пространственно-временной фильтрации.
Критерии останова
Поскольку методы оптимизации носят итерационный характер, то
при их практической реализации возникает задача определения специальных правил
прерывания счета - критериев останова. Как правило, процесс оптимизации
прекращается, если:
1
достигнута
требуемая точность решения;
2
хорошее
приближение еще не найдено, но скорость движения к минимуму так упала, что не
имеет смысла продолжать счет;
3
метод
начал расходится или зациклился.
Этим условиям удовлетворяют следующие критерии останова,
используемые в работе [11,16,17]:
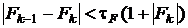 ,
,
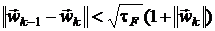 .
.
Приведенные неравенства отражают признаки близости
последовательностей 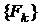 и
и 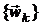 к своим пределам. Параметр
к своим пределам. Параметр 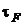 определяет число правильных разрядов
определяет число правильных разрядов 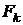 , которое хотелось бы получить. Например,
выбор
, которое хотелось бы получить. Например,
выбор 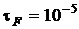 означает, что при
означает, что при 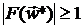 желательно, чтобы у и совпадали пять первых значащих цифр, а при
желательно, чтобы у и совпадали пять первых значащих цифр, а при 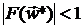 , чтобы и
, чтобы и 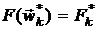 различались бы не более чем на
различались бы не более чем на 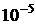 .
.
3.
Структура программы пространственно-временной обработки изображений
Результатом дипломного проекта стала рабочая версия программы
пространственно-временной обработки изображений STIP32, обобщённая
структурная схема которой приведена на рисунке 3.1. Программа состоит из трёх
частей. Разработанный доцентом кафедры РУС Смирновым А.А. графический интерфейс
пользователя (Graphical User Interface - GUI), в основу которого
положена система окон и стандартных средств ввода / вывода информации (меню,
таблицы, кнопки, радиокнопки, переключатели, строки ввода, списки и так далее),
осуществляет взаимодействие с блоком ввода / вывода информации.

Рисунок 3.1 - Обобщенная структурная схема программы
пространственно-временной обработки изображений
Главная программа включает в себя три основных блока: блок
ввода / вывода информации, блок фильтрации изображений и блок оптимизации,
взаимодействующий с библиотекой алгоритмов оптимизации. Все приведенные блоки
взаимосвязаны друг с другом и образуют единую полноценную систему обработки
изображений.
В блок ввода / вывода информации поступают соответствующие данные
от пользователя, который устанавливает необходимые параметры (вид фильтра и
фильтрации, размер апертуры, СКО белого шума, вероятности и появления импульсного шума, выбирает вид целевой функции, метод
оптимизации), используя интуитивно понятный графический интерфейс. Эти данные
поступают в блок фильтрации изображений и блок оптимизации.
Структурная схема блока фильтрации изображений приведена на
рисунке 3.2.

Рисунок 3.2 - Структурная схема блока фильтрации изображений
Библиотеки пространственных и временных фильтров включают в себя
следующие типы фильтров:
1.
Среднеарифметический.
2.
Среднегеометрический.
3.
Среднегармонический.
4.
Среднеконтргармонический.
5.
Медианный.
6.
Модифицированный
медианный.
7.
Минимальный.
8.
Максимальный.
9.
Псевдомедианный.
Блок статистического анализа позволяет произвести обработку
набора изображений с различными плотностями вероятности распределения яркости с
заданной величиной выборки каждого изображения из набора.
Библиотека алгоритмов оптимизации, связанная с блоком
оптимизации, что отражено на рисунке 3.2, взаимодействует с блоками
пространственной и временной фильтрации. Библиотека алгоритмов оптимизации
содержит методы локальной и глобальной оптимизации. В качестве локальных
методов выступают следующие методы многомерной оптимизации:
1.
Метод
Ньютона.
2.
Квазиньютоновский
метод с DFP-формулой пересчета.
3.
Квазиньютоновский
метод с преобразованной BFGS-формулой.
4.
Метод
сопряженных градиентов.
В качестве метода глобальной оптимизации используется метод
динамического программирования (ДП). В библиотеке алгоритмов оптимизации
представлено три метода ДП:
1.
Классический
метод ДП.
2.
Модифицированный
метод ДП.
3.
ДП со
случайной сеткой.
Таким образом, в блоке фильтрации изображений происходит формирование
целевой функции, находится ее минимум и соответствующий этому минимуму
оптимальный вектор весовых коэффициентов .
4.
Пользовательский интерфейс программы пространственно-временной обработки
изображений
Исследование обработки реальных изображений с различными
статистическими характеристиками проводится с использованием программного
комплекса Space-time image processing 32 (STIP32), структура модели которого рассмотрена в
предыдущем разделе.
Программа пространственно-временной обработки изображений
разработана на языке Си и имеет удобный графический интерфейс пользователя.
Табличный ввод данных, система окон и меню обеспечивают быстрое освоение
программы, не требующее специальной подготовки. В программе реализован контроль
информации, вводимой пользователем, при некорректных данных ему обеспечивается
соответствующая подсказка. Вводимая информация, результаты фильтрации, а также
весовые коэффициенты могут быть сохранены. Использование языка Си и Ассемблера
при разработке математического ядра и интерфейса приводит к уменьшению размера
исполняемого модуля и увеличению производительности базовых алгоритмов. Кроме
этого, исследование влияния оптимизирующих свойств современных Си-компиляторов
на производительность вычислительных программ показало, что наиболее компактный
и производительный код генерирует компилятор Watcom C++ 10.0, который и был
использован для создания данной программы. Программный комплекс работает на
компьютерах типа IBM PC с VGA адаптером под управлением MS-DOS версии 3.30 и
выше, занимает около 80K пространства на жестком диске.
После запуска программы на экране появляется рабочее окно
программы. Окно содержит основные элементы интерфейса, отвечающие за ввод и
вывод информации.
Элементами ввода / вывода информации являются:
1. Раскрывающийся список, позволяющий сделать выбор
фильтра, используемого при выделении ТВ сигнала на фоне помех и шумов.
2. Выбор типа фильтрации:
. Загрузка обрабатываемого изображения.
При нажатии на кнопку [F3] «Загрузить» появляется диалоговое
окно «Обзор», в котором пользователю предоставляется возможность выбора
тестового изображения в формате *.pcx.
4. Выбор параметров параметрической оптимизации.
При вводе параметров оптимизации вызывается диалоговое окно
«Параметры оптимизации».
Для задания параметров оптимизации пользователю необходимо:
1) Выбрать в выпадающем списке метод первого (глобального)
этапа.
2) Выбрать в выпадающем списке метод второго
(локального) этапа.
) Выбрать в выпадающем списке вид барьерной функции.
) Задать параметры локальных методов оптимизации:
– относительное приращение аргумента;
·
штрафной
коэффициент;
·
пороговую
точность адаптации;
·
относительное
приращение градиента;
·
нижнюю
границу весовых коэффициентов;
·
верхнюю
границу весовых коэффициентов.
5) Задать параметры глобальных методов оптимизации:
– количество итераций;
– число точек на интервале.
6) Заполнить таблицу признаков оптимизации по следующему
правилу: если признак оптимизации равен 0, то соответствующий весовой
коэффициент не будет изменяться в ходе оптимизации, в противном случае (признак
оптимизации не равен 0) - будет.
5. Редактирование и просмотр весовых коэффициентов для
обработки изображений.
При нажатии клавиши F4 (кнопка «Веса»), у пользователя появляется
возможность, в раскрывшемся окне «Весовые коэффициенты», редактировать или
просмотреть весовые коэффициенты.
6. Загрузка ранее полученных весовых коэффициентов.
Нажатие клавиши F5 (кнопка «Загрузить веса») приводит к открытию
окна «Открыть» в котором можно указать путь к ранее сохраненным весовым
коэффициентам, записанным в файле с расширением *.txt, и открыть этот файл.
Указание пути к файлу с весовыми коэффициентами осуществляется посредством окон
«Папки» и «Диски», все найденные по указанному пути файлы с расширением *.txt будут отображены в окне
«Файлы». Для выбора необходимого файла, потребуется навести на его имя, в окне
«Файлы», курсор и нажать правую кнопку мыши, чтобы его подсветить, затем нажать
OK.
7. Запуск процесса параметрической оптимизации.
При условии заданных ранее параметрах оптимизации, нажатие
клавиши F9
(кнопка «Оптимизация») приводит к запуску процесса оптимизации.
8. Сохранение новых весовых коэффициентов.
В случае необходимости сохранения, полученных весовых
коэффициентов, нажатие клавиши F2 (кнопка «Сохранить веса») приводит к открытию окна
«Сохранить как».
Для сохранения коэффициентов в файле с расширением *.txt, необходимо ввести имя
файла в графу «Имя файла» и указать путь сохранения, используя для этого окна
«Папки» и «Диски». После этого нажать кнопку OK.
9. Установка параметров статистического анализа.
Нажатие клавиши F8 (кнопка «Параметры стат. анализа») активирует
окно «Параметры статистического анализа». В данном окне производятся выбор
серии изображений, по которым будет проводиться исследование, и установка
величины выборки каждого изображения в процессе статистического анализа. Помимо
этого, установка галочки у опции «Оптимизация», позволяет произвести
оптимизацию весовых коэффициентов по всему заданному набору изображений для
анализа.
10. Выбор дополнительных способов обработки
отфильтрованного ТВ изображения.
Нажатием клавиши F7 (кнопка «Доп. обработка»), открывается окно
«Дополнительная обработка отфильтрованного изображения».
Выбор требуемого вида обработки производится с путем
установки точки, слева от названия вида обработки.
11. Запуск статистического анализа.
Если предварительно были заданы параметры статистического
анализа, то нажатие комбинации клавиш Ctrl+F9 (кнопка «Стат. анализ») запускает процесс статистического
анализа, информация о ходе которого отображается в окне «Информация о ходе
статистического анализа».
12. Установка размера апертуры фильтра.
Размер апертуры устанавливается в пределах от 2 до 15.
13. Ввод значения вероятности появления белого 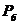 импульсного шума.
импульсного шума.
Возможные значения лежат в пределах от 0 до 0.5.
. Ввод значения СКО белого шума 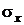 .
.
. Установка значения параметра Q для контргармонического фильтра.
. Индикаторы статистических характеристик:
1) СКО1 - СКО зашумленного изображения;
2) СКО2 - СКО отфильтрованного изображения;
3) 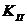 - коэффициент улучшения СКО на выходе
фильтра (дБ):
- коэффициент улучшения СКО на выходе
фильтра (дБ):
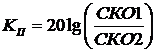 ;
;
4) ПОСШ1 - пиковое отношение сигнал-шум на входе фильтра
(дБ);
5) ПОСШ2 - пиковое отношение сигнал-шум на выходе
фильтра (дБ):
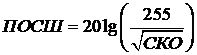 ;
;
6) Pч1 - вероятность появления черного импульсного шума
на зашумленном изображении;
7) Pч2 - вероятность появления черного импульсного
шума на отфильтрованном изображении (вероятность ложного воспроизведения);
8) Pб1 - вероятность появления белого импульсного шума
на зашумленном изображении;
9) Pб2 - вероятность появления белого импульсного шума
на отфильтрованном изображении (вероятность ложного воспроизведения);
10) Кп ср - средний коэффициент улучшения СКО на
выходе фильтра, рассчитанный путем статистического усреднения по набору
тестовых изображений (дБ);
11) ПОСШ1ср - среднее значение ПОСШ на входе
фильтра, рассчитанное путем статистического усреднения по набору тестовых
изображений (дБ);
12) ПОСШ2ср - среднее значение ПОСШ на выходе
фильтра, рассчитанное путем статистического усреднения по набору тестовых
изображений (дБ).
18. Аппроксимированные плотности вероятности
распределения яркости исходного не зашумленного изображения и отфильтрованного.
Таким образом, для выполнения весовой пространственной или
временной фильтрации, пользователю необходимо выполнить следующие действия:
1) Выбрать в главном окне программы нужное изображение.
Если же требуется произвести статистический анализ, то установить параметры
статистического анализа (F8);
2) Выбрать требуемый вид фильтра;
) Выбрать необходимый вид фильтрации;
) Установить требуемый размер апертуры, требуемые
значения СКО белого шума и вероятностей импульсного шума;
) Выбрать метод 1-го (глобального) этапа (нет, ДП
классический, ДП модифицированный или ДП со случайной сеткой);
) Выбрать метод 2-го (локального) этапа (Ньютона,
DFP, преобразованный BFGS или метод сопряженных градиентов);
) Выбрать вид барьерной функции (логарифмическая или
обратная);
) Установить параметры глобальных и локальных методов
и указать признаки;
) Запустить оптимизацию, нажав кнопку «Оптимизация»
(клавишу F9).
) После этого результаты выполнения программы можно
посмотреть на дисплее и при необходимости запустить оптимизацию повторно с
другими параметрами.
5.
Экспериментальная часть
В экспериментальной части дипломного проекта разработаны
методика проведения и порядок выполнения лабораторной работы №1 «Исследование
эффективности пространственно-временной обработки изображений с использованием
статистик среднего ранга при наличии импульсных помех».
5.1 Порядок выполнения лабораторной работы №1
пространственный изображение интерфейс программа
1. Выбрать по указанию преподавателя набор из 10
тестовых изображений.
2. Задать по указанию преподавателя тип фильтра
пространственно-временной обработки с использованием ранговых статистик среднего
ранга.
. Величину СКО белого шума задать равным 0.
. Установить режим пространственной фильтрации.
. Исследовать эффективность оптимальной весовой
пространственной фильтрации изображений при наличии импульсных помех по
следующей методике:
5.1. Задать размер апертуры равным 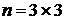 .
.
.2. Снять зависимости средних значений (усредненных по набору
из 10 тестовых изображений) коэффициента улучшения СКО на выходе фильтра  , ПОСШ на входе
, ПОСШ на входе  и выходе
и выходе 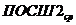 фильтра от вероятности появления белого импульсного шума . Величину менять в пределах от 0.1 до 0.4 с шагом 0.1.
фильтра от вероятности появления белого импульсного шума . Величину менять в пределах от 0.1 до 0.4 с шагом 0.1.
.3. Снять зависимости средних значений (усредненных по набору
из 10 тестовых изображений) коэффициента улучшения СКО на выходе фильтра и ПОСШ на выходе фильтра с использованием оптимальной весовой
пространственной фильтрации от вероятности появления белого импульсного шума . Величину менять в пределах от 0.1 до 0.4 с шагом 0.1.
.4. Полученные в п. 5.2. и п. 5.3. зависимости построить на
одном графике для 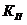 и для ПОСШ. Построить также зависимости
среднего выигрыша по коэффициенту улучшения СКО и ПОСШ на выходе фильтра,
полученного в результате оптимальной весовой обработки, от вероятности . Сделать выводы.
и для ПОСШ. Построить также зависимости
среднего выигрыша по коэффициенту улучшения СКО и ПОСШ на выходе фильтра,
полученного в результате оптимальной весовой обработки, от вероятности . Сделать выводы.
.5. Задать размер апертуры равным 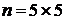 . Повторить п.п. 5.2 - 5.4.
. Повторить п.п. 5.2 - 5.4.
6. Установить режим временной фильтрации.
7. Исследовать эффективность оптимальной весовой
временной фильтрации изображений при наличии импульсных помех по следующей
методике:
7.1. Задать размер апертуры равным .
.2. Снять зависимости средних значений (усредненных по набору
из 10 тестовых изображений) коэффициента улучшения СКО на выходе фильтра , ПОСШ на входе и выходе фильтра от вероятности появления белого импульсного шума . Величину менять в пределах от 0.1 до 0.4 с шагом 0.1.
.3. Снять зависимости средних значений (усредненных по набору
из 10 тестовых изображений) коэффициента улучшения СКО на выходе фильтра и ПОСШ на выходе фильтра с использованием оптимальной весовой
временной фильтрации от вероятности появления белого импульсного шума . Величину менять в пределах от 0.1 до 0.4 с шагом 0.1.
.4. Полученные в п. 7.2. и п. 7.3. зависимости построить на
одном графике для и для ПОСШ. Построить также зависимости
среднего выигрыша по коэффициенту улучшения СКО и ПОСШ на выходе фильтра,
полученного в результате оптимальной весовой обработки, от вероятности . Сделать выводы.
.5. Задать размер апертуры равным 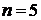 . Повторить п.п. 7.2 - 7.4.
. Повторить п.п. 7.2 - 7.4.
8. Сделать выводы об эффективности оптимальной весовой
обработки для выбранного типа фильтра.
5.2 Результаты выполнения лабораторной работы №1
Результаты выполнения лабораторной работы №1 с помощью
разработанного программного комплекса STIP32 приведены на рисунках 5.1-5.20. При выполнении
для примера был выбран вид фильтра с использованием статистик среднего ранга -
медианный фильтр.
Режим пространственной фильтрации изображений, размер апертуры .
Таблица 5.1 - Результаты пространственной фильтрации изображений с
апертурой
|
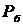 0,10,20,30,4 0,10,20,30,4
|
|
|
|
|
|
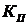 до оптимизации11,398,054,131,49 до оптимизации11,398,054,131,49
|
|
|
|
|
|
после оптимизации13,0913,4813,2112,16
|
|
|
|
|
|
Выигрыш 1,7005,4309,08010,67
|
|
|
|
|
|
 ПОСШ114,8111,8110,038,769 ПОСШ114,8111,8110,038,769
|
|
|
|
|
|
ПОСШ2 до
оптимизации
|
26,2
|
19,86
|
14,16
|
10,28
|
|
ПОСШ2 после
оптимизации
|
27,9
|
25,27
|
23,26
|
20,95
|
|
Выигрыш ПОСШ2
|
1,70
|
5,41
|
9,10
|
10,67
|
В результате проведённого эксперимента следует, что при увеличении
вероятности появления белого импульсного шума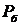 коэффициент улучшения СКО после использованием оптимальной
весовой пространственной фильтрацией существенно не изменяется на всем
диапазоне значений . В то время как коэффициент улучшения СКО
до оптимизации стремится к нулю.
коэффициент улучшения СКО после использованием оптимальной
весовой пространственной фильтрацией существенно не изменяется на всем
диапазоне значений . В то время как коэффициент улучшения СКО
до оптимизации стремится к нулю.
При увеличении вероятности появления белого импульсного шума
выигрыш коэффициента улучшения СКО возрастает. Например, при 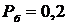 выигрыш коэффициента улучшения СКО с
оптимизацией примерно на 5 дБ больше, чем коэффициент улучшения без
оптимизации.
выигрыш коэффициента улучшения СКО с
оптимизацией примерно на 5 дБ больше, чем коэффициент улучшения без
оптимизации.
посш уменьшается с увеличением вероятности появления белого
импульсного шума . Но график, описывающий на выходе после использования оптимальной
весовой пространственной фильтрации, имеет значительно больше ПОСШ по сравнению
с ПОСШ на входе и выходе до оптимальной весовой обработки.
Средний выигрыш ПОСШ на выходе фильтра, полученного в результате
оптимальной весовой обработки, приблизительно на 5,2 дБ больше, чем до оптимизации при вероятности появления
белого импульсного шума 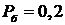 .
.
Режим пространственной фильтрации изображений, размер апертуры 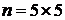 .
.
Таблица 5.2 - Результаты пространственной фильтрации изображений с
апертурой
|
0,10,20,30,4
|
|
|
|
|
|
до оптимизации10,0911,58,523,24
|
|
|
|
|
|
после оптимизации11,5813,9814,9115,04
|
|
|
|
|
|
Выигрыш 1,4902,4806,39011,800
|
|
|
|
|
|
ПОСШ114,8311,8210,058,78
|
|
|
|
|
|
ПОСШ2 до
оптимизации
|
24,92
|
23,32
|
18,57
|
12,03
|
|
ПОСШ2 после
оптимизации
|
26,4
|
25,79
|
24,96
|
23,83
|
|
Выигрыш ПОСШ2
|
1,48
|
2,47
|
6,39
|
11,80
|
При увеличении вероятности появления белого импульсного шума коэффициент улучшения СКО после
использования оптимальной весовой пространственной фильтрацией стремится к
постоянному значению, равному 15 дБ. В то время как коэффициент улучшения СКО
до оптимизации стремится к нулю.
При увеличении вероятности появления белого импульсного шума
выигрыш коэффициента улучшения СКО возрастает. При выигрыш коэффициента улучшения СКО с
оптимизацией примерно на 3 дБ больше, чем коэффициент улучшения без оптимизации.
ПОСШ уменьшается с увеличением вероятности появления белого
импульсного шума . Но график, описывающий на выходе после использования оптимальной
весовой пространственной фильтрации, имеет значительно больше ПОСШ при
увеличении вероятности появления белого импульсного шума по сравнению с ПОСШ на
входе и выходе до оптимальной весовой обработки.
Средний выигрыш ПОСШ на выходе фильтра, полученного в результате
оптимальной весовой обработки, приблизительно на 2,5 дБ больше, чем до
оптимизации при вероятности появления белого импульсного шума .
Режим временной фильтрации изображений, размер апертуры 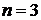 .
.
Таблица 5.3 - Результаты
временной фильтрации изображений с апертурой
|
0,10,20,30,4
|
|
|
|
|
|
до оптимизации5,512,8411,40,55
|
|
|
|
|
|
после оптимизации10,137,36,26,12
|
|
|
|
|
|
Выигрыш 4,6204,4594,8005,570
|
|
|
|
|
|
ПОСШ114,81411,810,0378,78
|
|
|
|
|
|
ПОСШ2 до
оптимизации
|
20,29
|
14,64
|
11,44
|
9,33
|
|
ПОСШ2 после
оптимизации
|
24,95
|
19,086
|
16,2
|
14,99
|
|
Выигрыш ПОСШ2
|
4,66
|
4,45
|
4,76
|
5,66
|
При увеличении вероятности появления белого импульсного шума коэффициент улучшения СКО до
использования оптимальной весовой временной фильтрации уменьшается во всем
диапазоне значений . В то время как коэффициент СКО после
использования оптимальной весовой временной фильтрации стабилизируется в районе
6 дБ. При этом выигрыш от использования весовой временной фильтрации составляет
5 дБ во всем диапазоне значений .
ПОСШ уменьшается с увеличением вероятности появления белого
импульсного шума . Но график, описывающий на выходе после использования оптимальной
весовой временной фильтрации, имеет больший выигрыш в ПОСШ по сравнению с ПОСШ
на входе и выходе до оптимальной весовой обработки.
Средний выигрыш ПОСШ на выходе фильтра, полученного в результате
оптимальной весовой обработки, приблизительно на 4,5 дБ больше, чем до оптимизации при вероятности появления
белого импульсного шума .
Режим временной фильтрации изображений, размер апертуры 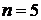 .
.
Таблица 5.4 - Результаты временной фильтрации изображений с
апертурой
|
0,10,20,30,4
|
|
|
|
|
|
до оптимизации10,725,42,621
|
|
|
|
|
|
после оптимизации20,5114,2410,848,81
|
|
|
|
|
|
Выигрыш 9,7908,8408,2207,810
|
|
|
|
|
|
ПОСШ114,7911,810,048,78
|
|
|
|
|
|
ПОСШ2 до
оптимизации
|
25,52
|
17,2
|
12,66
|
9,78
|
|
ПОСШ2 после
оптимизации
|
35,3
|
26,04
|
20,88
|
17,6
|
|
Выигрыш ПОСШ2
|
9,78
|
8,84
|
8,22
|
7,82
|
При увеличении вероятности появления белого импульсного шума коэффициент улучшения СКО до
использования оптимальной весовой временной фильтрации уменьшается во всем
диапазоне значений . В то время как коэффициент улучшения СКО
после использования оптимальной весовой временной фильтрации стабилизируется в
районе 9 дБ. При этом выигрыш от использования весовой временной фильтрации
составляет 8дБ во всем диапазоне значений .
ПОСШ уменьшается с увеличением вероятности появления белого
импульсного шума . Но график, описывающий на выходе после использования оптимальной
весовой временной фильтрации, имеет большее ПОСШ по сравнению с ПОСШ на входе и выходе до оптимальной весовой обработки.
Средний выигрыш ПОСШ на выходе фильтра, полученного в результате
оптимальной весовой обработки, приблизительно на 8 дБ больше, чем до оптимизации при вероятности появления
белого импульсного шума .
Выводы об эффективности оптимальной весовой
обработки для медианного фильтра
1. Отсутствие весовой обработки приводит к ухудшению
эффективности подавления с ростом вероятности .
. Применение двухэтапного метода оптимизации при весовой
пространственно-временной фильтрации изображений обеспечивает высокую
эффективность подавления во всем диапазоне вероятностей импульсного шума .
. С точки зрения вычислительных затрат и эффективности
подавления импульсных шумов наиболее эффективным является оптимальный весовой
временной медианный фильтр с апертурой, равной 5.
6.
Экономическая часть
6.1 Расчет ленточного графика
При проведении проектных работ для их реализации и
рациональной организации при ограничении на сроки разработки необходимо
предварительно спланировать проектные мероприятия. Целесообразно определить
перечень проектных работ, трудоемкость каждой из них и привести в соответствие
общую продолжительность проведения проектных мероприятий со сроками,
отпущенными на разработку[27].
Принцип построения ленточного графика осуществляется в
следующем порядке:
1. Определяются этапы и состав работ по подготовке
производства, технической документации с установлением количества чертежей
каждого формата.
2. Для каждого этапа разработки производства
устанавливается число исполнителей и продолжительность.
. Определяется трудоемкость выполнения каждого этапа.
Продолжительность каждой работы Тп будет
определяться по формуле:
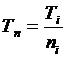 ,
,
где Ti - трудоемкость работ, человеко-дни, ni - численность
исполнителей, человек.
Перечень проводимых работ указан в таблице 6.1. Там же
приводятся исполнители и продолжительность выполнения работ.
Таблица 6.1 - Данные для построения ленточного графика
|
N
|
Наименование
этапов
|
Продолжительность,
дни
|
Исполнители
|
Численность
исполнителей, человек
|
Трудоемкость, Tn
|
|
1
|
Составление и
утверждение ТЗ
|
2
|
Р
|
1
|
2
|
|
2
|
Подбор литературы
|
2
|
И
|
1
|
2
|
|
3
|
Изучение обзора
литературы и информационных источников
|
3
|
И
|
1
|
3
|
|
4
|
Изучение
операндов и библиотеки языка Cи
|
23
|
И
|
1
|
23
|
|
5
|
Разработка
структуры программы
|
5
|
Р и И
|
2
|
2.5
|
|
6
|
Разработка
алгоритмов обработки изображений
|
7
|
И
|
1
|
7
|
|
7
|
Написание программы
по разработанному алгоритму
|
15
|
И
|
1
|
15
|
|
8
|
Согласование
алгоритма программы с руководителем
|
1
|
Р и И
|
2
|
0.5
|
|
9
|
Отладка
программы
|
5
|
И
|
1
|
5
|
|
10
|
Оформление
отчета по разработанному блоку для обработки изображений
|
7
|
И
|
1
|
7
|
|
11
|
Оформление
чертежей на основе результатов обработки изображений
|
3
|
И
|
1
|
3
|
|
12
|
Утверждение
отчета и чертежей
|
2
|
Р и И
|
2
|
1
|
|
13
|
Сдача проекта
|
1
|
И
|
1
|
1
|
|
Итого:
|
76
|
|
|
|
где Р - руководитель, И- исполнитель.
6.2 Расчет затрат на разработку
Составление сметы затрат на разработку
Смета затрат представляет собой стоимостную оценку
используемых в процессе производства продукции природных ресурсов, сырья,
материалов, топлива, энергии, основных фондов, трудовых ресурсов, а также
других затрат[28].
Определение затрат на разработку производится путём составления
калькуляции плановой себестоимости. Она составляется по следующим статьям
затрат.
1. Материальные затраты.
К этой статье относятся материалы, используемые при
проектировании. Перечень материалов, цена, стоимость без учета НДС приведена в
таблице 6.2.
Таблица 6.2 - Величина затрат на материалы
|
Наименование
материала
|
Количество,
штук
|
Цена за
единицу, руб.
|
Сумма, руб.
|
|
Программное
средство разработки
|
1
|
4500
|
4500
|
|
USB - флеш-карта, 4 ГБ
|
1
|
400
|
400
|
|
Картридж для
принтера
|
1
|
600
|
600
|
|
Комплект
канцелярских принадлежностей
|
1
|
150
|
150
|
|
Итого:
|
5650
|
В материальные затраты включаем расходы на электроэнергию:
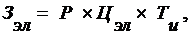
где Р - потребляемая мощность оборудования, кВт/ч, Цэл -
стоимость 1 кВт/ч, руб., Ти - время использования оборудования при
проведении работ, ч.
Для выполнения работы использовался
персональный компьютер потребляемой мощностью 360 Вт и принтер потребляемой
мощностью 350 Вт. Время работы ПЭВМ составляет 65 дней по 8 часов в день, а
принтера - 1 час.
Стоимость 1 кВт - 3,1 руб./кВт (на 2013
г.).
Получаем, что:
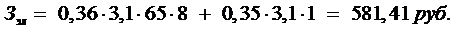
Следовательно, получаем, что материальные затраты составляют:
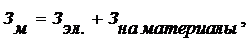
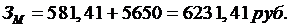
2. Затраты на оплату труда.
Затраты на оплату труда начисляются исходя из ставки
разработчика и времени затрачиваемого на выполнение работы.
Примем, что руководитель имеет ставку 20000 рублей,
исполнитель (инженер-конструктор 2 категории) имеет ставку 8000 рублей.
Таким образом, исходя из затрат времени на разработку
(руководитель - 10 дней, инженер-конструктор - 74 дня), заработная плата равна:
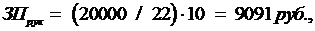
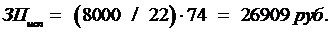
Фонд оплаты труда составит:
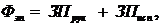
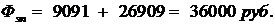
3. Амортизационные отчисления.
Амортизационные отчисления учитываются в сметной стоимости
научно-исследовательской работы и рассчитывается по следующей формуле:
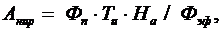
где Фп - балансовая стоимость
оборудования, Ти - время использования оборудования при
проведении работ, На - норма амортизации.
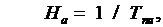
где Тпи - срок службы оборудования, лет, Фэф
- годовой эффективный фонд времени работы оборудования, для односменной работы
он составляет Фэф = 256 дней.
Время работы на ПЭВМ в данном примере
составляет 65 дней.
Срок службы компьютера - 2-3 года (на 2013
г.), тогда норма амортизации:
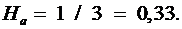
Амортизационные отчисления для компьютера
стоимостью в
рублей составят:
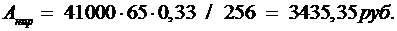
Общие прямые затраты составят следующую
сумму:
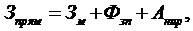
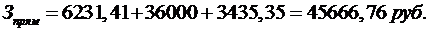
4. Прочие расходы.
- страховые взносы берутся в размере 30,2%
(в 2013 году) от величины фонда оплаты труда. В нашем примере они составят:
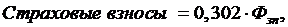
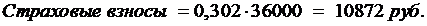
- величина остальных прочих расходов
берется от суммы прямых общих затрат в установленном размере. Для разработки
устройства они составят (20%):
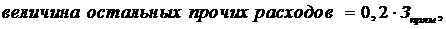
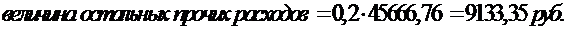
Прочие расходы составят:

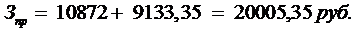

Общие затраты на разработку составят:
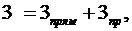
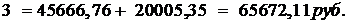
Необходимые расходы приведены в таблице
6.3.
Таблица 6.3 - Необходимые расходы на
разработку
|
Наименование
калькуляционных статей расходов
|
Сумма, руб.
|
Удельный вес, %
|
|
Материальные
затраты, Зм
|
6231,41
|
9,5
|
|
Затраты на заработную
плату, Фзп
|
36000
|
54,8
|
|
Амортизация
оборудования, Анир
|
5,23
|
|
Прочие расходы,
Зпр
|
20005,35
|
30,46
|
|
Общие затраты, З
|
65672,11
|
100
|
Расчет цены для НИР
Цена для НИР определяется как сумма затрат на разработку,
прибыли и НДС.
Прибыль составляет 40% от сметы затрат, то есть:
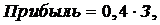
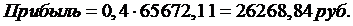
НДС составляет 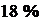 от суммы сметы затрат и прибыли, то есть:
от суммы сметы затрат и прибыли, то есть:
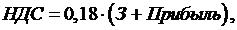
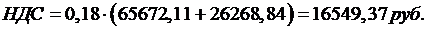
Отсюда цена для НИР составляет:
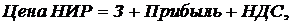
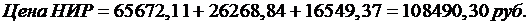
Цена НИР разработки блока пространственно-временной обработки
изображений составляет 108490,30 рублей.
6.3 Выводы по эффективности предложений
Экономическая эффективность использования разработанной
программной модели очевидна. Затраты на разработку программы составляют
65672,11 рублей, а общая цена НИР - 108490,30 рублей, в то время как цена
одного только осциллографа, необходимого для организации одного рабочего места
в случае использования лабораторного макета, более  рублей. А при стандартном оснащении, по
минимуму 10 рабочих мест, это будет стоить 500000 рублей. К тому же, разработка
и установка лабораторных макетов для организации подобной лабораторной работы
потребует не только на порядок больших финансовых вложений, но и времени,
затраченного на разработку, а также на обслуживание лабораторных макетов и
измерительных приборов. Но в связи с заменой лабораторного оборудования на
программный блок, установленный в ПК, осуществляется значительная экономия
средств университета при закупке лабораторных макетов и оборудования.
Дополнительных затрат на покупку новых ПЭВМ не потребуется, так как
разработанная программа не требует больших ресурсов и может использоваться на
имеющихся машинах.
рублей. А при стандартном оснащении, по
минимуму 10 рабочих мест, это будет стоить 500000 рублей. К тому же, разработка
и установка лабораторных макетов для организации подобной лабораторной работы
потребует не только на порядок больших финансовых вложений, но и времени,
затраченного на разработку, а также на обслуживание лабораторных макетов и
измерительных приборов. Но в связи с заменой лабораторного оборудования на
программный блок, установленный в ПК, осуществляется значительная экономия
средств университета при закупке лабораторных макетов и оборудования.
Дополнительных затрат на покупку новых ПЭВМ не потребуется, так как
разработанная программа не требует больших ресурсов и может использоваться на
имеющихся машинах.
С другой стороны, для аналогичных целей возможно приобретение
лицензионного программного обеспечения и адаптация его для решения поставленных
задач. При этом потребуется потратить значительное количество времени на
адаптацию и материальных средств на приобретение лицензионного пакета программ.
Так, цена лицензионного пакета MATLAB Individual составляет  , вместе с приложением Statistics Toolbox
Individual
, вместе с приложением Statistics Toolbox
Individual  стоимость в пересчете по курсу около
112200 руб.
стоимость в пересчете по курсу около
112200 руб.
Таким образом, разработка данного проекта экономически
целесообразна.
Заключение
Основные результаты дипломного проекта:
1.
Исследована
эффективность применения методов глобальной и локальной оптимизации в задачах
весовой пространственно-временной фильтрации изображений.
2.
Разработаны
методика проведения и порядок выполнения лабораторной работы №1 «Исследование
эффективности пространственно-временной обработки изображений с использованием
статистик среднего ранга при наличии импульсных помех».
3.
На
примерах обработки набора тестовых изображений показана высокая эффективность
применения оптимальной весовой пространственно-временной фильтрации изображений
с использованием статистик среднего ранга.
Библиографический
список
1. Батищев
Д.И. Поисковые методы оптимального проектирования. М.: Сов. радио, 1975.
2. Гемирштерн
В.И., Коган В.М. Методы оптимального проектирования. М.: Энергоиздат. 1980.
. Гуткин
Л.С. Оптимизация РЭУ. М.: Сов. радио. 1975.
. Рейклейтис
Г., Рейвиндран А., Рэгсдел К. Оптимизация в технике. В 2-х книгах. М.: Мир.
1986.
. Аоки
М. Введение в методы оптимизации. Основы и приложения нелинейного
программирования. М.: Наука. 1977.
. Базара
М., Шетти К. Нелинейное программирование. Теория и алгоритмы. М.: Мир. 1982.
. Бейко
И.В., Бублик Б.Н., Зинько П.Н. Методы и алгоритмы решения. Киев: Вища школа.
1983.
. Васильев
Ф.П. Численные методы решения экстремальных задач. М.: Наука. 1988.
. Гусин
С.Ю., Омельянов Г.А., Резников Г.А., Сироткин В.С. Минимизация в инженерных
расчетах на ЭВМ. М.: Машиностроение, 1981.
. Зангвилл
У.И. Нелинейное программирование. М.: Сов. радио. 1973.
. Моисеев
Н.Н., Иванилов Ю.П., Столярова Е.М. Методы оптимизации. М.: Наука. 1978.
. Гилл
Ф., Мюррей У., Райт М. Практическая оптимизация. М.: Мир. 1985.
. Пшеничный
Б.Н., Данилин Ю.М. Численные методы в экстремальных задачах. М.: Наука. 1975.
. Сухарев
А.Г., Тимохов А.В., Федоров В.В. Курс методов оптимизации. М.: Наука. 1986.
. Химмельблау
Д. Прикладное нелинейное программирование: Пер. с англ. М.: Мир, 1975.
. Фиакко
А., Мак-Кормик Г. Нелинейное программирование. Методы последовательной
безусловной минимизации. М.: Мир. 1972.
. Численные
методы условной оптимизации / Под ред. Ф. Гилла и У. Мюррея. М.: Мир. 1977.
. Поповкин
В.И., Маторин А.В. Синтез антенных решеток методом типа динамического
программирования // Радиотехника и электроника, 1974. Т.19. №10.
19. Маторин
А.В., Смирнов А.А. Двухэтапный численный метод решения задач синтеза
многоэлементных тонкопроволочных антенн и устройств сверхвысоких частот //
Радиотехника и электроника. 2001. Т. 46. №6.
20. Смирнов
А.А. Исследование и разработка алгоритмов параметрического синтеза устройств
СВЧ в радиотехнических системах: Автореферат дис. канд. техн. наук. Рязань:
РГРТА, 2000.
. Катковник
В.Я. Непараметрическая идентификация и сглаживание данных: методы локальной
аппроксимации. - М.: Наука, 1985. - 336 с.
. Гонсалес
Р., Вудс Р. Цифровая обработка изображений. М: Техносфера, 2005.
. Хуанг
Т.С. (ред.) Быстрые алгоритмы в цифровой обработке изображений. Преобразования
и медианные фильтры. М: Радио и связь, 1984.
. Прэтт
В.К. Цифровая обработка изображений. М: Мир, 1982.
. Ярославский
Л.П. Введение в цифровую обработку изображений. М: Советское радио, 1989.
. Рабинер
Л.Р., Голд Б. Теория и применение цифровой обработки сигналов. М: Мир, 1988.
. Под
ред. Гилла Ф., Мюррея У. Численные методы условной оптимизации. М.: Мир, 1977.
. Васина
Л.В., Евдокимова Е.Н., Рыжкова А.В. Выполнение экономической части дипломного
проекта: Методические указания. Рязань: РГРТУ, 2013.
. Зайцев
Ю.В. Безопасность и экологичность проекта. Рязань: РГРТУ, 2006.
. СанПиН
2.2.2/2.4.1340-03. Гигиенические требования к ПЭВМ и организации работы.
. ГОСТ
12.1.038-82. Электробезопасность. Предельно допустимые значения напряжений
прикосновения и токов.
. СНиП
23-05-95. Естественное и искусственное освещение.
. ГОСТ
12.1.004-91. Пожарная безопасность. Общие требования.
. НПБ
166-97. Нормы пожарной безопасности. Пожарная техника. Огнетушители. Требования
к эксплуатации.
. СанПиН
2.2.2.548-96. Гигиенические требования к микроклимату производственных
помещений.
. СанПиН
2.2.4.1191-03 «Электромагнитные поля в производственных условиях»
. ГОСТ
Р 50948-2001. Средства отображения информации индивидуального пользования.
Общие эргономические требования и требования безопасности.
Приложение
Листинг программы пространственно-временной обработки
изображений
#define _Main_ /* Инициализация основных глобальных
переменных */
#define _RUS_ /* Использовать русский язык в основных
диалогах и кнопках */
#define _KEYS_ /* Включить определения основных клавиш на
клавиатуре */
/* Определения для использования основных «классов»
интерфейса */
#define Uses_ButtonBar
#define Uses_Cluster
#define Uses_ComboBox
#define Uses_Count
#define Uses_DTable
#define Uses_Graph
#define Uses_ImageBox
#define Uses_ListBox
#define Uses_FileList
#define Uses_StaticText
#define Uses_Table
/* Определение основных команд пользователя */
#define cmFileNew 100
#define cmFileOpen 101
#define cmFileSaveAs 102
#define cmFileView 103
#define cmResultsRun 110
#define cmResultsCalc 111
#define cmResultsSaveAs 112
#define cmHelpAbout 120
#define cmFilterWeights 130
#define cmFilterWeightsSave 131
#define cmOptParams 140
#define cmOptRun 150
#define ID_Inset1 200
#define ID_Inset2 300
#define SZI sizeof(int)
#define SZF sizeof(float)
#define MAX_POINTS 128
#define NIMAGE 9+2
#define IMAGE_W 360
#define IMAGE_H 240
#define PAL_SIZE 768
#include «font.h»
#include «win.h»
#include <conio.h>
#include <dos.h>
#include <fcntl.h>
#include <float.h>
#include <math.h>
#include <io.h>
#include <i86.h>
#include <stdio.h>
#include «histo.c»
#include «filters2.c»
/* использование «класса» ImageBox */
#if defined (Uses_ImageBox)void PASCAL
ImageBoxHandleEvent(LPList);void PASCAL ImageBoxRedraw(LPList);void PASCAL
ImageBoxItemRedraw (LPList, LPListItem);
#define HIMAGEBOX ImageBoxHandleEvent
#define ImageBoxNew ButtonNew
#endif
#include «imagebox.c»
aOf;*pImageBuff[NIMAGE],*pBuffer,*pImage;pProgName=
«Обработка изображений»;aWinMainTitle[80],[80],[67]= «IMAGES\\»,[67]=
«C:\\IMSS\\»,[13]= «test.pcx»;
*pImageLine,*pPDF[2],*pHisto[2],[6]={0,0,20,0,255,15},[6]={0,255,15,0,0,0},[6]={0,255,15,0,0,0},[4]={2,9,1,0},[4]={0,50,1,0},[4]={0,0.
5,0. 01,0},[4]={0,0. 5,0. 01,0},[4]={-100,100,0. 01,0},=3, Var=0, Pa=0,
Pb=0;float pQ,*pWF;*pWSigns;nNumPoints=33, nNP, nNumPoints2=33, nNP2,=0,
nFilterationType=0, aOptions[]={1,},, nH, nSize;FilteringError[2];
/* Внешние переменные, необходимые для
отображения результатов оптимизации
*/pImgItem[NIMAGE];pImg;pTable;
#include «opt2.c»
*fp;
LPSTR
/* Названия параметров */[] = {
«Апертура:»,
«СКО б.ш.:»,
«Pч:»,
«Pб:»,
«Параметр Q:»,
«Весовые коэффициенты»,
},
/* Виды фильтрации */[] = {
«Вид фильтрации:»,
«Пространственная»,
«Временная»,
},
/* Типы фильтров */[] = {
«Фильтр:»,
«Медианный»,
«Среднеарифметический»,
«Среднегеометрический»,
«Среднегармонический»,
«Среднеконтргармонический»,
«Модифицир. медианный»,
«Минимальный»,
«Максимальный»,
«Псевдомедианный»,
},
/* Ошибка фильтрации */[] = {
«СКО на входе:»,
«СКО на выходе:»,
};
#define MASK_FPU
(SW_INVALID|SW_ZERODIVIDE|SW_OVERFLOW|SW_UNDERFLOW)matherr (struct exception
*e) {return 1;}
/* LoadPCXFile - загружает файл в формате PCX */int
PASCAL(int hFile, int *nW, int *nH, int *nSize, Boolean IsPaletteLoad) {i, j, chr,
cnt;p1, p2, p3;
/* Узнаем размер файла, выделяем под него буфер
памяти
и читаем его туда */=(PCXHEADERPTR)
(pBuffer=malloc (j=filelength(hFile)));(read (hFile, pBuffer, j)==-1)
{(pBuffer);(hFile);False;
}(hFile);
/* Проверяем 256 цветное ли это изображение или
нет? */(pHDR->manuf!=10 || pHDR->encod!=1 || pHDR->bitpx!=8)
{(pBuffer);False;
}
/* Проверяем правильность размеров изображения
*/((i=(int) pHDR->bplin)!=IMAGE_W ||
(j=pHDR->y2-pHDR->y1+1)!=IMAGE_H)
{(pBuffer);False;
}
/* Декодируем изображение по алгоритму RLE */
*nSize=(aSrv0 [1]=*nW=i)*(*nH=j);
/* Распределяем память */(pImageLine==NULL)
{=malloc (*nSize*sizeof(float));(i=0; i<NIMAGE; i++)
pImageBuff[i]=malloc(*nSize);
}=pBuffer+sizeof(PCXHEADER);(j=0; j<*nSize;)
{=1;(((chr=*pImage++)&0xC0)==0xC0) {=chr&0x3F;=*pImage++;
}(chr==7 || chr==15) chr -;if (chr==8)
chr++;(i=0; i<cnt; i++) pImageBuff[0] [j++]=chr;
}
/* Декодируем и загружаем палитру,
исключая системные регистры 7,8,15
*/(IsPaletteLoad)(outp (0x3C8,0), i=1; i<PAL_SIZE+1; i+=3) {(i==22)
p1=p2=p3=0x30;if (i==25) p1=p2=p3=0x20;if (i==46)
p1=p2=p3=0xFF;{p1=pImage[i]>>2; p2=pImage [i+1]>>2; p3=pImage
[i+2]>>2;}(0x3C9, p1); outp (0x3C9, p2); outp (0x3C9, p3);
}
/* Освобождаем буфер памяти под тестовое
изображение */(pBuffer);True;
}
/* GetFilterWeights - просмотр и редактирование
весовых коэффициентов */int near PASCAL(void) {i, j, w=50, h=280,
x=(MaxX-w)>>1, y=(MaxY-h+40)>>1,
nNSS=SquareSize;**pWeights;*pNameWeights;p1;
/* Распределение памяти */=malloc (nNSS*sizeof
(float *));=malloc (nNSS*sizeof(LPSTR));(i=0; i<nNSS; w+=69, i++)
{[i]=malloc (nNSS*sizeof(float));[i]=calloc (nNSS, 4);(i+1, pNameWeights[i],
10);(j=0; j<nNSS; j++) pWeights[i] [j]=pWF [j*nNSS+i];
}=(MaxX-w)>>1;
/* Создание таблицы */=ListInit (TableNew(x+5,
y+25,22,20,9, nNSS),, isSelected,(«N/N», NULLSTR, 40,5, OUT|COUNT),);(i=0;
i<nNSS; i++)(p1, TableItemNew (pNameWeights[i], pWeights[i], 70,9,
IN|FLOAT));
(pIPName[5], x, y, w, h, p1,(ListNew(), HBUTTON,
isSelected,(HB_OK, x+w-141, y+h - 35,64,24, cmOk),(HB_CANCEL, x+w-69, y+h -
35,64,24, cmCancel),),);
(;) {(! getEvent()); WinHandleEvent();
(event.what) {Command:(event.p1==cmOk)(i=0;
i<nNSS; i++)(j=0; j<nNSS; j++) pWF [j*nNSS+i]=pWeights[i] [j];(Key, ESC,
event.p1);;Key:(event.p1==ESC) {
/* Освобождение памяти и выход */(i=0; i<nNSS;
i++) {(pWeights[i]);(pNameWeights[i]);
}(pWeights);(pNameWeights);event.p2;
}
}
}
}
#include <fcntl.h>
#include <io.h>
#ifdef _RUS_LPSTR Messages[]={
«Обзор», «Тестовые изображения:»,
};
#elseLPSTR Messages[]={
«Browse», «Image samples:»
};
#endif
/* BrowsePCXFile - просмотр и загрузка тестового изображения
*/
static int near PASCAL(LPOpenFileName pF)
{pFileName=pF->FileName, pBuffer,=malloc (IMAGE_W*IMAGE_H);w=550, h=380,
x=(MaxX-w)>>1, y=(MaxY-h)>>1,, j, chr, cnt, hFile, nCurrFile=-1,
bIsTrueFile=1;pFile, pImgItem;pButtons, pImg;
((LPSTR) Messages[0], x, y, w, h,(ListNew(),
HSTATIC, 0,(Messages[1], x+10, y+28),),(ListNew(), HLISTBOX,
isSelected,=ListBoxNew (pFileName, x+10, y+45,160,16,0, FAARC|FARO),),(pImg=ListNew(),
HIMAGEBOX, 0,=ImageBoxNew (pImageBuffer, x+180, y+45,
IMAGE_W, IMAGE_H, 0),),(pButtons=ListNew(),
HBUTTON, isSelected,(HB_OK, x+180, y+h - 37,64,24, cmOk),(HB_CANCEL, x+254, y+h
- 37,64,24, cmClose),),);
(putEvent(Nothing, 0,0);) {(! getEvent());
WinHandleEvent();
(nCurrFile!=pFile->p1+pFile->command
&& qe==qb) {=pFile->p1+pFile->command;(aImagesPath, «%s % s»,
aImagesDir,(pFileName,
(LPSTR)*((LPSTR *) pFile->name+nCurrFile)));
/* Открываем файл с тестовым изображением и
загружаем его */=FOpen (aImagesPath, O_RDONLY|O_BINARY);
/* Узнаем размер файла, выделяем под него буфер
памяти и
читаем его туда */
=(PCXHEADERPTR) (pBuffer=malloc
(j=filelength(hFile)));(hFile, pBuffer, j);(hFile);
/* Проверяем 256 цветное ли это изображение или нет,
а тажке правильность размеров изображения
*/(pHDR->manuf!=10 || pHDR->encod!=1 || pHDR->bitpx!=8
||>bplin!=IMAGE_W || (pHDR->y2-pHDR->y1+1)!=IMAGE_H)
{(bIsTrueFile=j=0; j<IMAGE_W*IMAGE_H; j++)
pImageBuffer[j]=15;
}
else {
/* Декодируем изображение по алгоритму RLE
*/(bIsTrueFile=1, pImage=pBuffer+sizeof(PCXHEADER),
j=0; j<IMAGE_W*IMAGE_H;)
{=1;(((chr=*pImage++)&0xC0)==0xC0) {=chr&0x3F;=*pImage++;
}(chr==7 || chr==15) chr -;if (chr==8)
chr++;(i=0; i<cnt; i++) pImageBuffer [j++]=chr;
}
}
/* Освобождаем буфер памяти под тестовое
изображение */(pBuffer);
/* Перерисовываем изображение */(pImg, pImgItem);
}
(event.what)
{cmFileListChanged:>curr=pButtons->first;(pButtons);;DOSCriticalError:(FatalError)
{(Messages[4], Messages[5], x+45, y+77,350,160);=0;
};Command: putEvent (Key, ESC,
event.p1);;Key:(event.p1==ESC) {((i=(event.p2==cmOk &&
bIsTrueFile)))(j=0; j<IMAGE_W*IMAGE_H; j++)
pImageBuff[0]
[j]=pImageBuffer[j];(pImageBuffer);i? cmOk: cmCancel;
}
}
}
}
/* ScreenToPCXFile - сохранение копии экрана в файле
формата PCX */
void(void) {int nCurrPCXFile;i, j, k, nTotal=0,
nScreenSize=MaxX*MaxY;this, last=*_pLFB, runCount=1;pBuff=calloc (nScreenSize,
1),=malloc (PAL_SIZE);aFileName[67];
/* Формирование заголовка PCX файла */=calloc
(sizeof(PCXHEADER), 1);>manuf=0x0A;>hard
=0x05;>encod=0x01;>bitpx=0x08;>x2 =MaxX-1;>y2 =MaxY-1;>hres
=0x00C8;>vres =0x00C8;>nplanes=0x01;>bplin=MaxX;>palinfo=0x01;
/* Сжатие содержимого экрана по алгоритму RLE
*/(i=0; i<MaxY; i++) {(last=_pLFB [k=i*MaxX], runCount=1, j=1; j<MaxX;
j++) {((this=_pLFB [k+j])==last) {(++runCount==63)
{[nTotal++]=runCount|0xC0;[nTotal++]=last;=0;
}
} else {(runCount) {(runCount==1 &&
(last&0xC0)!=0xC0)[nTotal++]=last;{[nTotal++]=runCount|0xC0;[nTotal++]=last;
}
}=this;=1;
}
}(runCount) {(runCount==1 && (last&0xC0)!=0xC0)
pBuff [nTotal++]=last;{[nTotal++]=runCount|0xC0;[nTotal++]=last;
}
}
}
/* Конец данных */[nTotal++]=0x0C;
/* Считывание палитры */(outp (0x3C7,0), i=0;
i<PAL_SIZE; i+=3) {[i]
=inp(0x3C9)<<2;[i+1]=inp(0x3C9)<<2;[i+2]=inp(0x3C9)<<2;
}
/* Открытие файла на запись */(aFileName, «%sSCR
% 05 d.pcx», aScreensDir,++nCurrPCXFile);=creat (aFileName, S_IWRITE|S_IREAD);
/* Запись заголовка PCX файла */(i, pHDR,
sizeof(PCXHEADER));
/* Запись сжатых данных */(i, pBuff, nTotal);
/* Запись палитры */(i, pPal, PAL_SIZE);
/* Закрытие файла */(i);
/* Освобождение памяти */(pBuff); free(pPal);
free(pHDR);
/* Звуковой сигнал */(1000); WaitSec();
nosound();
}
/* Главная функция */main (int
argc, char *argv[]) {i, j, k, l, m, n, x=-3, y=-3, w, h, chr, cnt, nMaxSS,
nNSS, nCurrLine;Rnd, Rnd1;pCount, pCluster, pComboBox, pGr[2];pComboBoxItem[2],
pImgCurr;aTemp[NIMAGE], aBuffText[128];
/* Устанавливаем требуемый VESA режим
*/(InitMode()!=VESA_OK) return;(argc>1) nCurrMode=atoi (argv[1]); else
LoadCurrMode (argv[0]);(nCurrMode);();
_control87 (MASK_FPU, MASK_FPU);
/*colbkg=15;*/
/* Распределяем память под весовые коэффициенты
фильтров */=malloc((nMaxSS=aBuff1 [1]*aBuff1 [1])*SZF);=malloc((nMaxSS=aBuff1
[1]*aBuff1 [1])*SZI);(i=0; i<nMaxSS; i++) {pWF[i]=1.0; pWSigns[i]=0;}
/* Открываем файл с тестовым изображением и
загружаем его */(aImagesPath, «%s % s», aImagesDir, aFileName);((i=open
(aImagesPath, O_RDONLY|O_BINARY))==-1 ||
! LoadPCXFile (i,&nW,&nH,&nSize,
True)) {(«Ошибка», «Невозможно открыть файл с изображением!»,
(MaxX-300)>>1,
(MaxY-150)>>1,300,150);exit;
}(k=(nH>>1)*nW, i=0; i<nW; i++)
pImageLine[i]=pImageBuff[0] [k+i];
/* Вводим белый шум и импульсный шум */(aBuff2
[3]=Var, i=0; i<nSize; i++)(j=1; j<NIMAGE; j++)
{((Rnd=PulseRand())>=0) chr=(char) Rnd;chr=pImageBuff[0] [i];+=(int)
(Var*NRand());(chr==7 || chr==15) chr -;if (chr==8) chr++;if (chr>255)
chr=255;if (chr<0) chr=0;[j] [i]=chr;
}
/* Фильтруем зашумленное изображение 2D фильтром
*/D[nFilterType] (pImageBuff[1], pImageBuff [NIMAGE-1], nW, nH,
nNSS=aBuff1 [3]=SquareSize);
/* Вычисляем СКО ошибок
*/(Rnd=Rnd1=0, k=0.5*SquareSize, n=k*nW, l=nW - (k<<1), m=nH -
(k<<1),=k; i<=m; i++, n+=nW)(j=k; j<=l; j++) {=((int) pImageBuff[0]
[n+j]) - ((int) pImageBuff[1] [n+j]);+=chr*chr;=((int) pImageBuff[0] [n+j]) -
((int) pImageBuff [NIMAGE-1] [n+j]);+=chr*chr;
}[0]=sqrt (Rnd/(l*m-1));[1]=sqrt (Rnd1/(l*m-1));
/* Оцениваем ФПВ одной строки */[1]=calloc
(nNumPoints2, SZF);[1]=calloc
(nNP2=(MAX_POINTS/(nNumPoints2-1))*(nNumPoints2-1)+1,
SZF);(pImageBuff[0], pPDF[1], pHisto[1], aSrv2,
nW, nNumPoints2,
nNP2);
=MaxX+6; h=MaxY+6;[3]=pQ;
/*
================================================================
*/(aWinMainTitle, x, y, w, h,
/* Надписи =========================
*/(ListNew(), HSTATIC, 0,(pFName[0], x+10, y+30),(pOptionsText[0], x+233,
y+30),(pIPName[0], x+10, y+55),(pIPName[1], x+118, y+55),(pIPName[2], x+223,
y+55),(pIPName[3], x+294, y+55),(pIPName[4], x+365, y+55),(«Тестовое
изображение:», x+10, y+75),(«Зашумленное изображение:», x+nW+65,
y+75),(«Отфильтрованное изображение:», x+10, y+95+nH),(«Сигнал выделенной
строки:», x+nW+65, y+90+nH),(«Гистограмма выделенной строки:»,
x+nW+65,+nH+228),),
/* Выпадающий список
============================== */(pComboBox=ListNew(), HCOMBOBOX, isSelected,[0]=ListBoxNew
(pFName+1, x+51, y+27,177,6,
sizeof(pFName)/sizeof(LPSTR) -
1,0),[1]=ListBoxNew (pOptionsText+1, x+323, y+27,127,2,
sizeof(pOptionsText)/sizeof(LPSTR) - 1,0),),
/* Счетчики
======================================== */(pCount=ListNew(), HCOUNT,
isSelected,(aBuff1, x+63, y+52,50),(aBuff2, x+168, y+52,50),(aBuff3, x+239,
y+52,50),(aBuff4, x+310, y+52,50),(aBuff5, x+430, y+52,60),),
/* Кнопки
========================================= */(ListNew(), HBUTTON,
isSelected,(«[F3] Загрузить…», x+453, y+27,104,22, cmFileOpen),(«[F4] Веса…»,
x+560, y+27,84,22, cmFilterWeights),(«[F6] Пар.опт…», x+492, y+50,90,22,
cmOptParams),(«[F9] Пуск», x+584, y+50,60,22, cmOptRun),),
/* Таблица СКО ошибок
===================================== */(pTable=TableNew (x+646,
y+27,0,23,2,2), HTABLE, isSelected,(NULLSTR, pErrorText, 90,0,
OUT|STRING),(NULLSTR, FilteringError, 62,8, OUT|FLOAT),),
/* Изображение
==================================== */(pImg=ListNew(), HIMAGEBOX,
isSelected,[0]=ImageBoxNew (pImageBuff[0], x+10, y+90, nW, nH,
nCurrLine=nH>>1),[1]=ImageBoxNew
(pImageBuff[1], x+nW+65, y+90, nW, nH,
nH>>1),[NIMAGE-1]=ImageBoxNew
(pImageBuff[NIMAGE-1], x+10,
y+110+nH, nW, nH, nH>>1),),
/* Графики
======================================== */(pGr[0]=ListNew(), HGRAPH, 0,(x+nW+65,
y+105+nH, nW, 110, nW, aSrv0,&pImageLine, 1),(x+nW+65, y+242+nH, nW, 108,
nNP2, aSrv2, pPDF+1,1),),);
WinSetTitle (aFileName, pProgName, aFileName);
/*
===============================================================
*/(pImgCurr=pImg->curr;) {/* Бесконечный цикл обработки команд */(!
getEvent()); WinHandleEvent();
(SquareSize!=aBuff1 [3]||(pQ!=aBuff5
[3]&&nFilterType==4))
goto Filtering;
(Var!=aBuff2 [3] || Pa!=aBuff3 [3] || Pb!=aBuff4
[3]) {
/* Вводим белый шум и импульсный шум */=aBuff2
[3]; Pa=aBuff3 [3]; Pb=aBuff4 [3];(CLOCK);(i=0; i<nSize; i++)(j=1;
j<NIMAGE; j++) {((Rnd=PulseRand())>=0) chr=(char) Rnd;chr=pImageBuff[0]
[i];+=(int) (Var*NRand());(chr==7 || chr==15) chr -;if (chr==8) chr++;if
(chr>255) chr=255;if (chr<0) chr=0;[j] [i]=chr;
}(pImg, pImgItem[1]);(ARROW);Filtering;
}
if (event.what==cmComboBoxChanged)
{(pComboBox->curr==pComboBoxItem[0]) nFilterType=event.p1;if
(pComboBox->curr==pComboBoxItem[1])
nFilterationType=event.p1;: /* Фильтруем
зашумленное изображение */=SquareSize=aBuff1 [3];=aBuff5 [3];(CLOCK);
/* Пространственная фильтрация */(!
nFilterationType) {D[nFilterType] (pImageBuff[1], pImageBuff [NIMAGE-1],
nW, nH, nNSS);
/* Вычисляем СКО ошибок */(Rnd=Rnd1=0,
k=0.5*SquareSize, n=k*nW, l=nW - (k<<1),
m=nH - (k<<1),=k; i<=m; i++, n+=nW)(j=k; j<=l; j++) {=((int)
pImageBuff[0] [n+j])-
((int) pImageBuff[1] [n+j]);+=chr*chr;=((int)
pImageBuff[0] [n+j])-
((int) pImageBuff [NIMAGE-1] [n+j]);+=chr*chr;
}[0]=sqrt (Rnd/(l*m-1));[1]=sqrt (Rnd1/(l*m-1));
}
/* Временная фильтрация */{(i=0; i<nSize;
i+=nW)(j=0; j<nW; j++) {(k=0; k<nNSS; k++) aTemp[k]=pImageBuff [k+1]
[i+j];[NIMAGE-1] [i+j]=
Filters1D[nFilterType] (aTemp, nNSS);
}
/* Вычисляем СКО ошибок
*/(Rnd=Rnd1=0, i=0; i<nSize; i++) {=((int) pImageBuff[0] [i]) - ((int)
pImageBuff[1] [i]);+=chr*chr;=((int) pImageBuff[0] [i]) - ((int) pImageBuff
[NIMAGE-1] [i]);+=chr*chr;
}[0]=sqrt (Rnd/(nSize-1));[1]=sqrt
(Rnd1/(nSize-1));
}
(pTable, pTable->first->prev);(pImg,
pImgItem [NIMAGE-1]);(pImgCurr==pImgItem [NIMAGE-1]) pImgCurr=NULL;(ARROW);
}(pImgCurr!=pImg->curr ||
nCurrLine!=pImgCurr->command) {(pImgCurr=pImg->curr, i=0; i<NIMAGE;
i++)
if (pImgCurr==pImgItem[i]) {l=i;
break;}(k=(nCurrLine=pImgCurr->command)*nW, j=0; j<nW;
j++)[j]=pImageBuff[l] [k+j];(pImageBuff[l]+k, pPDF[1], pHisto[1], aSrv2, nW,
nNumPoints2, nNP2);();(pGr[0]);
}
(event.what==Command) {(event.p1) {cmFileOpen:
/* Загружаем файл с тестовым изображением */(aOf.
FileName, «%s % s», aImagesDir, «*.pcx»);(BrowsePCXFile(&aOf)==cmOk) {
(aFileName, pProgName, aOf. FileName);
/* Вводим белый шум и импульсный шум
*/(CLOCK);(nCurrLine=-1, i=0; i<nSize; i++)(j=1; j<NIMAGE; j++)
{((Rnd=PulseRand())>=0) chr=(char) Rnd;chr=pImageBuff[0] [i];+=(int)
(Var*NRand());(chr==7 || chr==15) chr -;if (chr==8) chr++;if (chr>255)
chr=255;if (chr<0) chr=0;[j] [i]=chr;
}(pImg, pImgItem[0]);(pImg, pImgItem[1]);(ARROW);
/* Фильтруем зашумленное изображение 2D фильтром
*/Filtering;
};
/* Просмотр и редактирование весов
*/cmFilterWeights:(GetFilterWeights()==cmOk) goto Filtering;;
/* Ввод параметров оптимизации */
case cmOptParams: GetOptParams();;
/* Оптимизация весовых коэффициентов */cmOptRun:
/* Пространственная фильтрация */(!
nFilterationType) {
/* Вычисляем размерность вектора параметров X
*/(i=k=l=0; i<nNSS; i++, l+=nNSS)(j=0; j<nNSS; j++) if (pWSigns [l+j])
k++;
/* Если размерность задачи меньше двух, то выход
*/(k<2) break;
/* Перераспределяем память под вектор параметров
X */(k!=MX) {(X!=NULL) {free(X); free(Xl); free(Xh);}=malloc((MX=k)*SZF);=malloc
(MX*SZF);=malloc (MX*SZF);
}
/* Задаем начальное значение вектора параметров X
*/(i=k=l=0; i<nNSS; i++, l+=nNSS)(j=0; j<nNSS; j++)(pWSigns [l+j]) {
Xl[k]=XL; Xh[k]=XH; X [k++]=pWF [l+j];}
}
/* Временная фильтрация */{
/* Вычисляем размерность вектора параметров X
*/(i=k=0; i<nNSS; i++) if (pWSigns[i]) k++;
/* Если размерность задачи меньше двух, то выход
*/(k<2) break;
/* Перераспределяем память под вектор параметров
X */(k!=MX) {(X!=NULL) {free(X); free(Xl); free(Xh);}=malloc((MX=k)*SZF);=malloc
(MX*SZF);=malloc (MX*SZF);
}
/* Задаем начальное значение вектора параметров X
*/(i=k=0; i<nNSS; i++)(pWSigns[i]) {
Xl[k]=XL; Xh[k]=XH; X [k++]=pWF[i];}
}
/* Выбираем барьерную функцию
*/=BFuncs[nSelBFunc];
/* Запускаем оптимизацию */=nInterpolCounter=nItrCounter=n=0;
/* Метод 1-го этапа - глобальный
*/(nSelGlobalMethod)
n=GlobalMethods [nSelGlobalMethod-1]();
/* Метод 2-го этапа - локальный
*/[1]=rx;[nSelMethod]();=aBegData[1];
/* Получаем оптимальные веса из вектора
параметров X */(X);(0);
(aBuffText,
«Число вычислений\nцелевой функции:%d»,+n,
nFuncCounter);(«Статистика», aBuffText, (MaxX-280)>>1,
(MaxY-140)>>1,280,140);
;cmQuit: goto exit;
} /* switch */;
} /* if command */if (event.what==Key)
{=0;(event.p1) {F2: i=cmFilterWeightsSave;;F3: i=cmFileOpen;;F4:
i=cmFilterWeights;;F6: i=cmOptParams;;F9: i=cmOptRun;;F10:
/* Сохранение копии экрана в формате PCX */();;
}(i) {CountResetCursor(pCount); putEvent
(Command, i, 0);}
}
} /* for */
exit:
/* Освобождаем память */(i=0; i<NIMAGE; i++)
free (pImageBuff[i]);(pImageLine);(pHisto[0]); free (pPDF[0]);(pHisto[1]); free
(pPDF[1]);(pWF); free(pWSigns);(X!=NULL) {free(X); free(Xl); free(Xh);}
/* Восстанавливаем вектора прерываний и
видеорежим */();(argv[0]);();
}
/* файл opt2.c */
#include «opt2.h»
#define EPS_X 1e-8
/* Барьерные функции */
/* 1) Логарифмическая */float PASCAL(void) {i;x1,
x2, z=0;
(i=0; i<MX; i++) {((x1=(X[i] - Xl[i]))<0.0
|| (x2=(Xh[i] - X[i]))<0.0) return -1.0;+=-log (x1/(Xh[i] - Xl[i])+EPS_X) -
log (x2/(Xh[i] - Xl[i])+EPS_X);
}z;
}
/* 2) Обратная */float PASCAL(void) {i;x1, x2,
z=0;
(i=0; i<MX; i++) {((x1=(X[i] - Xl[i]))<0.0
|| (x2=(Xh[i] - X[i]))<0.0) return -1.0;+=(fabs (Xl[i])/(x1+EPS_X)+fabs
(Xh[i])/(x2+EPS_X));
}z;
}
/* Целевая функция */PASCAL(float *X) {i, j, k,
l, m, n, chr, nNSS=SquareSize;Var=0;aTemp[NIMAGE];
/* Фильтруем зашумленное изображение */
/* Пространственная фильтрация */(!
nFilterationType) {
/* Получаем новые веса из вектора параметров X
*/(i=k=l=0; i<nNSS; i++, l+=nNSS)(j=0; j<nNSS; j++) if (pWSigns [l+j])
pWF [l+j]=X [k++];
D[nFilterType] (pImageBuff[1], pImageBuff
[NIMAGE-1], nW, nH,);
/* Вычисляем СКО ошибок
*/(k=0.5*SquareSize, n=k*nW, l=nW - (k<<1), m=nH - (k<<1),=k;
i<=m; i++, n+=nW)(j=k; j<=l; j++) {=((int) pImageBuff[0] [n+j])-
((int) pImageBuff [NIMAGE-1] [n+j]);+=chr*chr;
}[1]=sqrt (Var/(l*m-1));
}
/* Временная фильтрация */{
/* Получаем новые веса из вектора параметров X
*/(i=k=0; i<nNSS; i++) if (pWSigns[i]) pWF[i]=X [k++];
(i=0; i<nSize; i+=nW)(j=0; j<nW; j++)
{(k=0; k<nNSS; k++) aTemp[k]=pImageBuff [k+1] [i+j];[NIMAGE-1]
[i+j]=Filters1D[nFilterType] (aTemp,
nNSS);
}
/* Вычисляем СКО ошибок */(i=0;
i<nSize; i++) {=((int) pImageBuff[0] [i]) - ((int) pImageBuff [NIMAGE-1]
[i]);+=chr*chr;
}[1]=sqrt (Var/(nSize-1));
}
++;
sqrt(Var);
}
/* Функция, отображающая текущие результаты
оптимизации */PASCAL(int nItrCounter) {();(pTable,
pTable->first->prev);(pImg, pImgItem [NIMAGE-1]);nItrCounter<100*MX;
}
/* Функция ввода параметров оптимизации */int
near PASCAL(void) {w=428, h=480, x=(MaxX-w)>>1, y=(MaxY-h)>>1, i,
j, nOff,
nNSS=SquareSize;*pTmp;tcb1, tcb2,
tcb3;pCombo=ListInit (ListNew(), HCOMBOBOX, isSelected,=ListBoxNew
(pOptText1+1, x+119, y+30,220,4,4,0),=ListBoxNew (pOptText2+1, x+119,
y+53,220,4,4,0),=ListBoxNew (pBFuncText+1, x+119,
y+76,220,2,2,0),);**pSigns;*pNameSigns;p1;
/* Распределение памяти */=malloc (nNSS*sizeof
(int *));=malloc (nNSS*sizeof(LPSTR));(i=0; i<nNSS; i++) {[i]=malloc
(nNSS*sizeof(int));[i]=calloc (nNSS, 4);(i+1, pNameSigns[i], 10);(j=0; j<nNSS;
j++) pSigns[i] [j]=pWSigns [j*nNSS+i];
}
/* Создание таблицы */=ListInit (DTableNew(x+10,
y+268, w - 37,20,20,9, nNSS, nNSS+1),, isSelected,(«N/N», NULLSTR, 40,0,
OUT|COUNT),);(i=0; i<nNSS; i++)(p1, DTableItemNew (pNameSigns[i], pSigns[i],
40,0,
IN|INT));->command=nSelGlobalMethod;->command=nSelMethod;->command=nSelBFunc;[0]=dx;
aBegData[1]=rx; aBegData[2]=qf; aBegData[3]=hg;[4]=nIterations;
aBegData[5]=N;[6]=XL; aBegData[7]=XH;
(«Параметры оптимизации», x, y, w, h,(ListNew(),
HSTATIC, 0,(pOptText1 [0], x+10, y+33),(pOptText2 [0], x+10,
y+56),(pBFuncText[0], x+10, y+79),(pBegDataText[8], x+10,
y+253),),,(TableNew(x+10, y+99,0,20,8,8), HTABLE, isSelected,(NULLSTR,
pBegDataText, 260,5, OUT|STRING),(NULLSTR, aBegData, 70,9, IN|FLOAT),),,(ListNew(),
HBUTTON, isSelected,(HB_OK, x+w-80, y+30,70,24, cmOk),(HB_CANCEL, x+w-80,
y+60,70,24, cmCancel),),);(;) {(! getEvent()); WinHandleEvent();(event.what)
{Command:(event.p1==cmOk) {(aBegData[0]<=0 || aBegData[1]<0 ||[2]<0 ||
aBegData[3]<=0 ||[4]<=0 || aBegData[5]<=1 ||[6] >= aBegData[7])
{(«Ошибка», «Некорректный ввод данных!»,
(MaxX-240)>>1,
(MaxY-120)>>1,240,120);;
}=aBegData[0]; rx=aBegData[1];=aBegData[2];
hg=aBegData[3];=aBegData[4]; N=aBegData[5];=aBegData[6];
XH=aBegData[7];=tcb1->command;=tcb2->command;=tcb3->command;(i=0;
i<nNSS; i++)(j=0; j<nNSS; j++)
pWSigns [j*nNSS+i]=pSigns[i] [j];
}(Key, ESC, event.p1);;Key:(event.p1==ESC) {
/* Освобождение памяти и выход */(i=0; i<nNSS;
i++) {(pSigns[i]);(pNameSigns[i]);
}(pSigns);(pNameSigns);event.p2;
}
}
}
}