Исследование производительности мультипроцессорных систем с общей памятью
МИНИСТЕРСТВО
СЕЛЬСКОГО ХОЗЯЙСТВА РОССИЙСКОЙ ФЕДЕРАЦИИ
КУБАНСКИЙ
ГОСУДАРСТВЕННЫЙ АГРАРНЫЙ УНИВЕРСИТЕТ
Факультет
прикладной информатики
Кафедра
компьютерных технологий и систем
Курсовая
работа
по
дисциплине "Вычислительные системы,
сети и телекоммуникации"
Исследование
производительности мультипроцессорных систем с общей памятью
Руководитель: ассистент кафедры
КТС Богославский С.Н.
Краснодар
- 2006
Реферат
В данном курсовом проекте рассмотрена работа
многопроцессорной системы с общей памятью. Получены характеристики работы
системы при обработке 100 и 1000 заявок. Рассмотрена и проанализирована работа
многопроцессорной системы, имеющей 2, 5 и 10 процессоров. Полученные
результаты- характеристики работы системы занесены в таблицы, построены графики
и диаграммы. Программа, реализующая работу многопроцессорной системы, написана
на языке Turbo
Pascal, листинг программы
приведен в Приложении1.
Содержание
Введение
. Постановка задачи и метод исследования
. Краткая теория
2.1
Общие сведения об МПС с общей памятью
.2
Характеристики МПС с общей памятью
3. Результаты исследования
. Описание процедур и переменных, используемых в
программе
Заключение
Список литературы
Приложение
ВВЕДЕНИЕ
Начиная с 1980 года, идея того, что несколько
процессоров смогут разделять доступ к одной и той же памяти, подкрепленная
широким распространением микропроцессоров, стимулировала многих разработчиков
на создание мультипроцессоров, в которых несколько процессоров разделяют одну
физическую память, соединенную с ними с помощью разделяемой шины. Такие машины
стали исключительно эффективными по стоимости. Любая вычислительная система
достигает своей наивысшей производительности благодаря использованию
высокоскоростных элементов и параллельному выполнению большого числа операций.
Именно возможность параллельной работы различных устройств системы является
основой ускорения основных операций. Для увеличения производительности в состав
вычислительной системы вводится несколько процессоров, способных
функционировать параллельно во времени и независимо друг от друга и наряду с
тем взаимодействовать между собой и с другим оборудованием системы.
Многопроцессорные системы за годы развития
вычислительной техники претерпели ряд этапов своего развития. Исторически
первой стала осваиваться технология машины типа SIMD (Single
Instruction Multiple Data), состоящие из большого числа идентичных процессорных
элементов, имеющих собственную память. Все процессорные элементы в такой машине
выполняют одну и ту же программу. Однако в настоящее время наметился устойчивый
интерес к архитектурам MIMD (Multiple Instruction Multiple Data). Базовой
моделью вычислений на MIMD-мультипроцессоре является совокупность независимых
процессов, эпизодически обращающихся к разделяемым данным. Архитектура MIMD
может использовать все преимущества современной микропроцессорной технологии на
основе учета соотношения стоимость/производительность. При наличии у
процессоров кэш-памяти достаточного объема высокопроизводительная шина и общая
память могут удовлетворить обращения к памяти, поступающие от нескольких
процессоров. Поскольку имеется единственная память с одним и тем же временем
доступа, эти машины иногда называются UMA (Uniform Memory Access). Такой способ
организации со сравнительно небольшой разделяемой памятью в настоящее время
является очень эффективным и представляет собой популярный объект исследования.
Именно такая многопроцессорная система и будет являться объектом исследования
данного курсового проекта.
1. ПОСТАНОВКА ЗАДАЧИ
Для выполнения данной курсовой работы необходимо
написать программу, реализующую работу мультипроцессорной системы с общей
памятью, которая обрабатывает очереди заявок переменной длинны, поступающих
случайным образом.
В процессе работы программа должна обработать
очереди из 100 и 1000 заявок длинной 1-8 и 3-6; каждая очередь должна быть
обработана в системе, содержащей 2, 5 и 10 процессоров.
В результате выполнения программы должны быть
получены следующие показатели:
. Сумма длин всех заявок данной очереди;
. Время, необходимое для обработки данной
очереди заданий при наличии 2-х, 5-ти и 10-ти процессоров;
. Среднее время простоя процессоров;
. Среднее время выполнения 1 заявки.
Все полученные данные должны быть занесены в
таблицу.
2. КРАТКАЯ ТЕОРИЯ
.1 Общие сведения об МПС с общей
памятью
Вычислительная система, содержащая несколько
процессоров, связанных между собой и с общим для них комплектом внешних
устройств, называются мультипроцессорными системами (МПС).
Производительность МПС увеличивается по
сравнению с однопроцессорной системой за счет того, что мультипроцессорная
организация создает возможность для одновременной обработки нескольких задач
или параллельной обработки различных частей одной задачи. В мультипроцессорной
системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно
независимо от других процессорных элементов. Одной из отличительных
особенностей многопроцессорной вычислительной системы является сеть обмена, с
помощью которой процессоры соединяются друг с другом или с памятью. Модель
обмена настолько важна для многопроцессорной системы, что многие характеристики
производительности и другие оценки выражаются отношением времени обработки к
времени обмена, соответствующим решаемым задачам. По способу связи между
процессорами и памятью системы МПС разделяются на МПС с памятью общей
(полнодоступной) и индивидуальной (раздельной). В мультипроцессорах с общей
памятью имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ
связываются с помощью общей шины или сети обмена. Структура МПС с общей памятью
наиболее универсальна, любая информация, хранимая в памяти системы, в равной
степени доступна любому процессору и каналу ввода/вывода. Отрицательное
свойство МПС с общей памятью - большие затраты оборудования в коммутаторах.
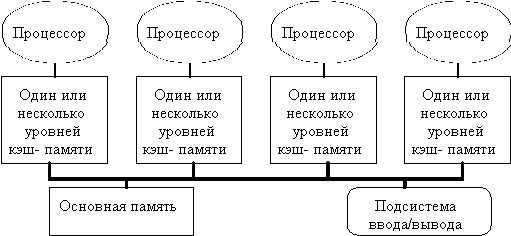
Рис. Типовая архитектура
мультипроцессорной системы с общей памятью.
В противоположность этому варианту в
слабосвязанных многопроцессорных системах (машинах с локальной памятью) вся
память делится между процессорными элементами и каждый блок памяти доступен
только связанному с ним процессору. Отрицательным последствием разделения
памяти между процессорами является потеря ресурсов быстродействия в процессе
обмена информацией между модулями памяти и общей памятью системы. Потери
возникают, во-первых, из-за возможных приостановок работы процессоров для
ожидания моментов окончания обмена данными с общей памятью и, во-вторых, из-за
дополнительной загрузки модулей памяти операциями обмена.
В МПС с общей памятью каждый из
процессоров имеет доступ к любому модулю памяти, которые могут функционировать
независимо друг от друга и в каждый момент времени может выполняться
одновременные обращения с целью записи или чтения слова информации, число
которых определяется числом модулей. Конфликтные ситуации (обращение к одному и
тому же модулю памяти) разрешаются коммутатором, начинающим обслуживать первым
устройство с наибольшим приоритетом, например, процессор с наименьшим номером.
Каждый из процессоров может инициировать работу любого канала ввода/вывода.
Пусть в МПС используются одинаковые
процессоры, т.е. МПС - однородная система. Наличие общей оперативной памяти, в
которой размещается вся необходимая информация, и однородность системы
позволяют выполнять любую программу на любом процессоре, т.е. любой процессор может
принять на обслуживание любую заявку. Режим работы МПС, при котором каждый из
процессоров может обслуживать любую заявку, называется режимом разделения
нагрузки. При этом режиме каждый из N процессоров принимает на обслуживание N-ю
часть заявок, т.е. N-ю часть общей нагрузки. Процесс обслуживания заявок в
режиме разделения нагрузки можно рассматривать как процесс функционирования
одной многоканальной системы массового обслуживания с интенсивностью l
входящего потока, общей очередью О, заявки из которой выбираются в порядке
поступления их в систему, и средней длительностью обслуживания заявки каждым из
процессоров Пр1,…, ПрN равной J.
Заявка, поступающая в систему,
содержащую N процессоров, при наличии хотя бы одного свободного процессора
немедленно принимается последним на обслуживание. Если все процессоры заняты
обслуживанием ранее поступивших заявок, поступающая заявка размещается в
очереди.
2.2 Характеристики МПС с общей
памятью
Пусть в МПС поступает М потоков с
интенсивностями l1,...,lM. Обслуживание заявок сводится к выполнению
соответствующих программ, средние трудоемкости которых равны Q1,…,QM операций в
расчете на один прогон программы. Примем, что обслуживание заявок выполняется
на основе дисциплины FIFO. В таком случае можно считать, что система
обслуживает однородный поток заявок, поступающих с интенсивностью
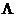 =
=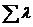 i
i
Для обслуживания любой заявки из
суммарного потока требуется в среднем процессорных операций 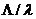 .На каждый
из процессоров поступает N-я доля заявок и, следовательно, отдельный процессор
обслуживает поток с интенсивностью
.На каждый
из процессоров поступает N-я доля заявок и, следовательно, отдельный процессор
обслуживает поток с интенсивностью 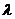 /N .
/N .
Среднее время простоя процессоров
можно получить, приняв ti за время
простоя i-того
процессора, тогда среднее время простоя 1 процессора вычисляется по формуле:
T=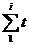 i /N,
i /N,
где N- количество
процессоров.
3. РЕЗУЛЬТАТЫ ИССЛЕДОВАНИЯ
Таблица 3.1 Результаты работы
многопроцессорных систем, обрабатывающих очередь из 100 заданий
|
Кол-во
процессоров
|
Длина
заявки 1-8
|
Длина
заявки 3-6
|
|
Сумма
длин заявок 487
|
Сумма
длин заявок 874
|
|
Время
работы системы
|
Среднее
время простоя
|
Среднее
время выполнения 1 заявки
|
Время
работы системы
|
Среднее
время простоя
|
Среднее
время выполнения 1 заявки
|
|
2
|
278
|
6,0
|
2,8
|
249
|
2,0
|
|
5
|
113
|
7,3
|
1,1
|
103
|
3,2
|
1,0
|
|
10
|
59
|
5,6
|
0,6
|
54
|
3,3
|
0,4
|
График 3.1
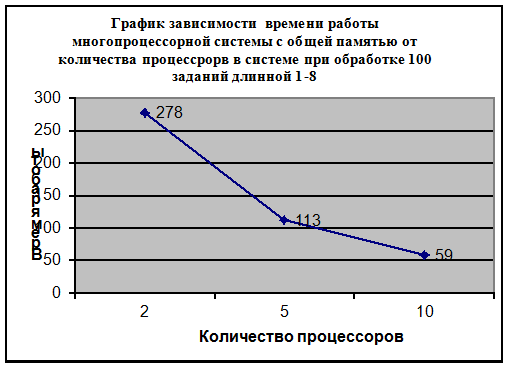
Диаграмма 3.1
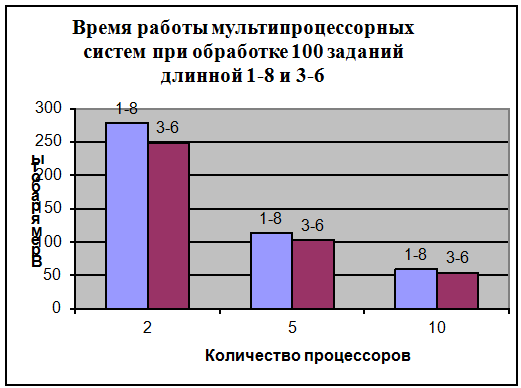
Таблица 3.2 Результаты работы
многопроцессорных систем, обрабатывающих очередь из 1000 заданий
|
Кол-во
процессоров
|
Длина
заявки 1-8
|
Длина
заявки 3-6
|
|
Сумма
длин заявок 4456
|
Сумма
длин заявок 8461
|
|
Время
работы системы
|
Среднее
время простоя
|
Среднее
время выполнения 1 заявки
|
Время
работы системы
|
Среднее
время простоя
|
Среднее
время выполнения 1 заявки
|
|
2
|
2736
|
6,2
|
2,7
|
2519
|
1,6
|
2,5
|
|
5
|
1098
|
5,5
|
1,1
|
1010
|
3,0
|
1,0
|
|
10
|
554
|
6,0
|
0,6
|
512
|
3,1
|
0,5
|
График 3.2
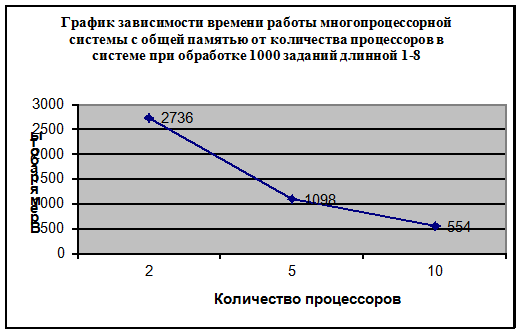
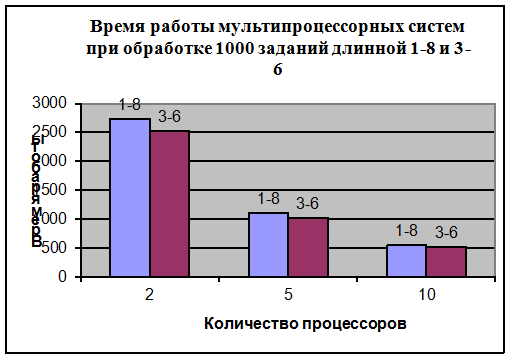
Диаграмма 3.2
4. ОПИСАНИЕ ПРОЦЕДУР, ИСПОЛЬЗУЕМЫХ В
ПРОГРАММЕ
Глобальные переменные
procc: array
[1..10] of
integer- массив
процессоров системы
c: integer
- переменная для подсчета количества простаивавших процессоров;
k: integer
- переменная для подсчета общего времени простоя процессоров;
cz: integer
- переменная для хранения текущего числа заданий(100 или 1000);
na: integer
- переменная для хранения суммы длин заданий;
max: integer
- переменная для хранения количества времени , которое проработает система
после того, как ей будет передано последнее задание на обработку; Процедуры
Procedure
mass (chzad:
integer; proc:
integer) - процедура,
имитирующая работу многопроцессорной системы с общей памятью, выполняет
обработку массива, состоящего из cz
заданий, в системе с pr
процессорами. В качестве параметров получает количество заданий chzad
и количество процессоров proc
в системе;
s:integer
- переменная для подсчета времени, в течении которого будут выполняться chzad
заданий;
f:Boolean
-
переменная для проверки передано ли очередное задание свободному процессору;
procedure
vizov - процедура
создает массив заданий длинной 1-8 и 3-6 и отправляет его на обработку 2-х,
5-ти и 10-ти процессорной системе при помощи вызова процедуры mass.
Процедура вызывается в основной программе для 100 и 1000 заданий отдельно;
pr:integer
- переменная для хранения количества процессоров системы;
мультипроцессорный память заявка архитектура
ЗАКЛЮЧЕНИЕ
Полученные данные показали прямую зависимость
общей производительности системы от количества процессоров, т.е. с ростом числа
процессоров в системе растет и общая производительность системы; эта
зависимость хорошо видна на Графике 3.1. Как видно из Таблицы 3.1 для обработки
одной и той же очереди заявок общей длинной 487 системе с 2-мя процессорами
требуется почти в 2,5 раза больше времени, чем системе с 5-ю процессорами и в
4,7 раза больше, чем системе с 10-тью процессорами.
Как видно из таблиц 3.1 и 3.2 на
производительность многопроцессорной системы с общей памятью влияет и диапазон
длин заявок очереди. Для обработки очереди длинной 487, состоящей из 100
заявок, длина которых изменяется от 1 до 8, потребовалось почти столько же
времени, сколько и для обработки такой же очереди общей длинной 874(что почти в
2 раза больше предыдущей), заявки которой имеют длину 3-6. Это обусловлено тем,
при обработке первой очереди встречаются как очень короткие (длинной 1-4), так
и длинные заявки, на обработку которых требуется больше времени. В связи с этим
растет и среднее время простоя процессоров, т.к. некоторые процессоры могли
выполнить короткие заявки и завершить работу, в то время как остальные
продолжали выполнять длинные заявки. При обработке очереди длинной 3-6 разница
в длине заявки составляет 1-2, т.е. процессоры выполняют заявки практически
одновременно, таким образом, сокращается время простоя процессоров.
Среднее время выполнения одной заявки так же
находится в прямой зависимости от числа процессоров системы. Затраты времени на
выполнение одной заявки значительно сокращаются с ростом количества
процессоров, как видно из Таблиц 3.1 и 3.2 среднее время, необходимое на
выполнение одной заявки системе с двумя процессорами, составило 2,6. Системе с
пятью процессорами потребовалось примерно 1,1 системного времени, что в 2,4
раза больше, чем первой. Десятипроцессорная система выполняла дону заявку за
0,5, т.е. в 2 раза быстрее, чем предыдущая система.
Таким образом, можно сделать вывод, что
производительность многопроцессорной системы зависит, прежде всего, от
количества процессоров в системе, а так же от диапазона длин заявок очереди.
Полученные результаты показали, что наибольшей производительности система
достигает при наличии 10 процессоров и наименьшем диапазоне длин заявок очереди
( в данном случае 3-6).
Список
литературы
1. В.И.
Лойко; Вычислительные системы и сети”; г. Краснодар, изд. КГАУ, 2000 г.
. В.Л.
Бройдо; Вычислительные системы, сети и телекоммуникации”; Санкт-Петербург, 2002
г.
Приложение
Листинг программы
Program
df;
uses crt;: array [1..10] of
integer;:array[1..1000] of integer;,k,cz,na,max:integer;mass(chzad:integer;
proc:integer);
var,s,i:integer;:boolean;
j:=0;:=0;:=1;:=1;i<=chzad do
f:=false;
beginj:=1 to proc do
beginprocc[j]=0
then:=true;[j]:=zad[i];(i);(procc[j]);;;(s);;f=true;;:=0;j:=1 to proc
domax<procc[j] then max:=procc[j];
end;:=0;:=0;j:=1 to proc do
beginprocc[j]<max then
begin:=k+(max-procc[j]);
inc(c);;;:=s+max;c<> 0
then('TimeV=',s);('Prostoi ',k/c:3:3);(' Time1= ',s/chzad:3:3);('TimeV=',s);('Prostoi
',k,'');(' Time1= ',s/chzad:3:3);
end;;
procedure
vizov;pr,i:integer;:=0;i:=1 to cz
do[i]:=random(8)+1;:=na+zad[i];;('*******',cz,'ZADANII****');
writeln;('....Dlinna zayavki 1-8...'); writeln('== Dlinna ocheredi
',na,'====='); writeln;:=2;(pr, ' PROCC -> ');(cz,pr);:=5;( pr, ' PROCC
-> ');(cz,pr);:=10;(pr, ' PROCC -> ');(cz,pr);i:=1 to cz
do[i]:=3+random(3);:=na+zad[i];
end;
writeln;('Dlinna zayavki 3-6');
writeln('= Dlinna ocheredi ',na,'='); writeln;:=2;(pr, ' PROCC ->
');(cz,pr);:=5;( pr, ' PROCC -> ');(cz,pr);:=10;(pr, ' PROCC ->
');(cz,pr); writeln
readln;;;;:=100;;;:=1000;;
end.