|
1
В двоичной системе счисления наиболее распространены следующие способы
выполнения операции умножения:
. Умножение младшими разрядами вперед со сдвигом множимого влево (аналог
«классического» варианта умножения в столбик)
. Умножение младшими разрядами вперед со сдвигом накапливаемой суммы
частичных произведений вправо.
. Умножение старшими разрядами вперед со сдвигом множимого вправо
. Умножение старшими разрядами вперед со сдвигом накапливаемой суммы
частичных произведений влево.
Все эти способы очень похожи по своей сути. Операция умножения состоит из
ряда последовательных операций сложения частичных произведений и сдвига числа.
Длительность процесса умножения при любом из этих способов составляет n шагов, где n - число разрядов числа.
Ту=n*tш,
где Ту - общее время умножения, tш - длительность одного шага умножения.
Один шаг умножения в общем случае состоит из двух микроопераций: сложения
и сдвига кодов, имеющих длительность tсл и tсд соответственно. Однако длительность
этих шагов неодинакова для рассмотренных выше способов умножения. Кроме того,
аппаратные затраты, связанные с реализацией того или иного способа различаются.
Поэтому при проектировании блока умножения, работающего по такому принципу,
конкретный способ реализации выбирается исходя из технических данных элементов,
используемых при построении и общей стоимости схемы.
В большинстве реальных задач большая часть арифметических операций - это
операции умножения и любое ускорение процесса умножения чисел существенно
увеличит общее быстродействие системы. Описанные выше способы имеют
длительность процесса умножения Tу=n*tш. При росте размерности операндов
значительно возрастает общее время умножения.
Для ускорения операции умножения применяют аппаратные и логические
методы. Логические методы - это методы, обеспечивающие ускорение процесса
умножения за счет устранения фиктивных операций сложения и объединения
многократных одноразрядных сдвигов одних и тех же кодовых комбинаций в единые
многоразрядные сдвиги. Аппаратные методы - это методы, обеспечивающие ускорение
процесса умножения за счет укрупнения блоков обрабатываемой информации и
уменьшении числа этих блоков.
Рассмотрим один из вариантов ускорения процесса умножения - матричный
метод умножения чисел Уоллеса на примере пятиразрядных чисел.
Этот метод основан на суммировании групп частных произведений с
последующим объединением сумм вместе с переносами для получения произведения.
Такая раздельная обработка промежуточных сумм и переносов требует так
называемого «дерева сумматоров». Схема умножительного устройства с запоминанием
переносов приведена на рисунке 2.2
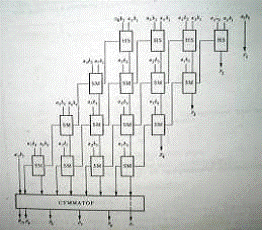
Рис 2.2. Схема умножительного устройства с запоминанием переносов.
Матричные методы выполнения операции умножения требуют больших аппаратных
затрат, однако дают большой выигрыш по времени.
По условию технического задания перемножаются 16-разрядные мантиссы. Если
организовывать процесс умножения не по матричной схеме, то общее время работы
схемы будет равно
Ту=16tш
tш=tИ+tSM+tСД, где
tИ - время задержки логического
элемента И
tSM - время работы полного одноразрядного сумматора
tСД - время работы сдвигового регистра.
При использовании сумматора, логического элемента и сдвигающего регистра
серии КР1533, время работы каждого шага будет не менее 70 нс. А поскольку
регистры и сумматоры должны быть 16-разрядные, а в данной серии таких регистров
и сумматоров нет, то придется ставить последовательно как минимум 2 регистра и
сумматора, что еще более увеличит время работы схемы. Таким образом, мы не
уложимся в требуемое время (2мкс), если будем использовать такой способ выполнения
операции умножения. Для того, чтобы схема работала быстрее, необходимо
использовать матричные методы умножения. В серии 1802 есть матричный умножитель
16-разрядных чисел 1802ВР5, который выполняет операцию умножения за 175нс.
.2 Алгоритм выполнения операции умножения для чисел с плавающей запятой
1. Вычисление порядка результата. D[16-23]=A[16-23]+B[16-23], где D[16-23] - разряды порядка результата умножения, A[16-23],B[16-23] - порядки сомножителей.
2. Если есть переполнение (флаг of=1), то выдать ошибку.
. Вычисление мантиссы результата D[0-15]=A[0-15]*B[0-15]. Для получения мантиссы
результата используется матричный умножитель, округляющий результат до 16
старших разрядов. Поскольку каждая мантисса содержит один знаковый разряд, то у
результата умножения их будет 2. Это необходимо учесть при выполнении
нормализации мантиссы.
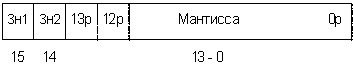
Рис
2.3 Вид мантиссы после операции умножения.
4. Нормализация мантиссы. Если D[13] не равно D[15] (то есть
знаковый разряд не равен старшему значащему разряду), то нормализация не
требуется и необходимо сдвинуть число, за исключением знакового разряда на 1
разряд влево, чтобы убрать лишний знаковый разряд (рис 2.4).
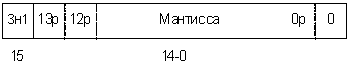
Рис
2.4. Нормализация мантиссы не требуется.
Если
же D[13] = D[15], то необходимо выполнить нормализацию: отнять 1
от порядка результата, поскольку производится сдвиг влево, что соответствует
умножению мантиссы на 2, после чего сдвинуть мантиссу на 2 разряда влево (рис
2.5). Если при вычитании 1 появилось переполнение, то необходимо выдать сигнал
ошибки.
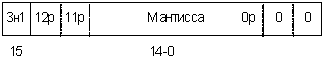
Рис
2.5. Необходима нормализация на 1 разряд.
2.4
Пример работы алгоритма умножения
Для
упрощения счета будем считать, что мантисса имеет 5 разрядов, включая знаковый,
а порядок - 4, включая знаковый.
Ma=0.1001Pa=0.011
Mb=0.1101Pb=1.110
Таким
образом, число A=(1/2+1/6)*23=0.5625*8=4.5
Число
B=(1/2+1/4+1/16)*2-2=0.8125/4=0.203125
1. Вычисление порядка результата
0.011+1.110=0.001
Проверка на переполнение: s1=0; s2=1; sr=0; p=1
of=((0 xor 1) xor 0 ) xor 1=0.
of=0,
значит, переполнения нет
2. Вычисление мантиссы результата
0.1001*0.1101=00.0111
3. Нормализация результата
Т.к знаковый разряд и старший значащий равны, то необходимо нормализовать
мантиссу.
Md=0.1110
Уменьшаем на 1 порядок:
.0001+1.111=0.000
Проверка на переполнение: s1=0; s2=1; sr=0; p=1
of=((0
xor 1) xor 0 ) xor
1=0.
of=0,
значит, переполнения нет
В результате умножения получилось следующее число: Md=0.1110, Pd=0.000
Для проверки, перемножим числа в десятичной системе счисления и сравним
результаты: 4.5*0.203125=0.9140625
Md=(1/2+1/4+1/8)*20=0.875
Результат укладывается в погрешность разрядной сетки, значит, алгоритм
работает верно.
3. Синтез структурной схемы
Упрощенно можно считать, что устройство состоит из трех основных блоков:
блок ввода, блок счета и блок вывода. В свою очередь, эти блоки можно разделить
на большее количество логически выделенных блоков:
· блок распознавания адреса и выдачи управляющих сигналов
· блок ввода чисел
· блок умножения мантисс
· блок сложения порядков
· блок нормализации мантиссы
· блок вывода результата
Блок распознавания адреса и выдачи управляющих сигналов.
Доступ к устройству осуществляется при появлении на шине адреса (ША)
16-ти разрядного адреса, 4 старшие разряды которого равны 0010 (адрес
устройства 2xxxh) и активном сигнале #AEN (здесь и далее будем считать, что
инверсный сигнал обозначается символом #). В зависимости от младшего разряда
адреса A0 и сигналов #IOW, #IOR на шине управления, на выход
выставляются различные управляющие сигналы на запись или чтение.
· A0=1, #IOW=0 - запись числа В с шины данных во
внутренние регистры.
· A0=0, #IOR=0 - чтение результата умножения с шины данных.
· A0=1, #IOR=0 - чтение флагов с шины данных.
Блок ввода чисел
После получения сигнала на запись числа от блока распознавания адреса и
выдачи управляющих сигналов, происходит перенос значения, выставленного на шине
данных во внутренние регистры схемы.
Блок умножения мантисс
После записи операндов в соответствующие регистры начинается процесс
умножения мантисс. 16-разрядный результат на выходе выставляется по сигналу
выдачи результата на внутреннюю шину данных.
Блок сложения порядков
Начинает работу после записи операндов во внутренние регистры порядков.
Складывает порядки перемножаемых чисел. Если в результате сложения произошло
переполнение, то формирует соответствующий сигнал ошибки.
Блок нормализации мантиссы
На вход приходят мантисса с выходов блока умножения и порядок с блока
сложения порядков. Если мантисса не нормализована, происходит ее нормализация.
Если в процессе нормализации произошло переполнение порядка, формируется сигнал
об ошибке.
Блок вывода чисел
На вход подаются 24 разрядный результат, сигналы об ошибках, и
управляющие сигналы. В зависимости от управляющих сигналов, на шину подается
либо результат умножения двух чисел, либо флаги ошибок.
4. Синтез функциональной схемы
Для реализации возможности работы схемы в различных адресных
пространствах, используются переключатели и инверторы (2..9), с помощью которых
можно выбрать, прямой или инверсных сигнал старших линий адреса будет
подаваться на элементы, распознающие адрес.
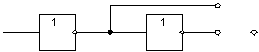
Рис
4.1 Выбор сигнала адресной линии
Для
распознавания адреса используется логический элемент И-НЕ, микросхема 10, на
входы которого подаются 4 старшие разряда адреса (для адресного пространства
2хххh это будут 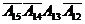 ), а
также инверсия сигнала #AEN. При активном #AEN и совпадении
адреса, на выходе появится сигнал подтверждения распознавания (#CS). ), а
также инверсия сигнала #AEN. При активном #AEN и совпадении
адреса, на выходе появится сигнал подтверждения распознавания (#CS).
Для
формирования управляющих сигналов используется сдвоенный дешифратор 1*2
(микросхема 11) с двумя управляющими входами для каждой части и общим
информационным входом. На информационный вход подается A0,на управляющие входы 1 части - сигналы #CS и
#IOW, для 2 части - #CS и #IOR.
С выхода дешифратора снимаются прямые значения для записи в регистры 1,12 , т.к
необходим передний фронт синхросигнала. Для чтения информации из выходных
регистров 22,23 необходим низкий уровень сигнала, поэтому выходы второй части
дешифратора инверсные.
В
результате на выходе дешифратора получим следующие управляющие сигналы:
· A0=0, #IOW=0,
#CS=0=>WRA(CLKX) - запись числа A
· A0=1, #IOW=0,
#CS=0=>WRB(CLKY) - запись числа B
· A0=0, #IOR=0,
#CS=0=>#RDD - чтение результата
· A0=1, #IOR=0,
#CS=0=>#RDF - чтение флагов
Одновременная подача активного уровня на IOR и IOW
считается запрещенной комбинацией.
Сигнал WRA(WRB) подается на синхровход регистров, соответствующих
числу A (B), и происходит запись числа с шины данных в соответствующие
регистры.
Для перемножения мантисс используется матричный умножитель 16x16 с возможностью округления
результата до 16 разрядов (микросхема 13). На нем включен режим прозрачности
регистра результата, то есть этот регистр выключен и информация на выходах
схемы появляется сразу же по истечении времени задержки умножителя. На
8-разрядный комбинационный сумматор 15 подаются с выходов регистров 1 и 12
значения порядков двух перемножаемых чисел. По окончании сложения анализируется
переполнение путем вычисления следующей логической функции: O = S1 XOR S2 XOR SOUT XOR P на микросхеме 17, где S1 - знак 1-го операнда, S2 - знак 2-го операнда, SOUT - знаковый разряд результата, а P - перенос из знакового разряда. Если
значение функции O - истина,
проверяется, в какую сторону - положительную или отрицательную - произошло
переполнение. Это делается путем анализа знака любого из операндов, так как
сложение разнознаковых чисел к переполнению не приводит. Если упомянутый знак
положителен, формируется флаг ошибки на микросхеме 20, который по фронту
сигнала CLK записывается в регистр флагов. Если
же отрицательный - на первой секции микросхемы 19 формируется промежуточный
сигнал Z1, смысл которого будет объяснен
ниже.
По появлении результата на выходах умножителя, с помощью элемента
«ИСКЛЮЧАЮЩЕЕ ИЛИ» (14) проверяется, равны ли знаковый и старший значащий
разряд. Если равны, нужна нормализация мантиссы и уменьшение порядка на 1.
Последнее происходит посредством сумматора 16, в качестве первого операнда на
который подаются сигналы с выхода сумматора 15 (сумма порядков), а второго -
сигнал «Нормализация Нужна» с выхода микросхемы 14, размноженный на все 8
разрядов. Таким образом, при необходимости нормализации сумматор 16 сложит
порядок с «-1» в дополнительном коде, в противном случае - с нулем. По
окончании сложения производится проверка на переполнение, аналогичная уже описанной
для сумматора 15 на микросхеме 18. В качестве «флага нуля» на второй секции
микросхемы 19 формируется сигнал Z2.
Сигнал же переполнения в положительную сторону в данном случае не формируется,
так как при сложении с отрицательным числом не имеет смысла.
Затем элемент «ИЛИ» микросхемы 19 сигналы Z1 и Z2,
формирует на выходе итоговый флаг нуля, который и записывается во второй разряд
регистра флагов 23 по фронту CLK.
Итоговый порядок результата подается с выходов второго сумматора на входы
8-разрядного регистра порядка с 3 состояниями выходов (микросхема 22). Запись в
него происходит также по фронту CLK.
Для нормализации мантиссы используются 16 селекторов-мультиплексоров 2x1 с 3 состояниями выходов - по одному
на каждый ее разряд (микросхема 21). В случае, если нормализация не нужна, на
выходе установится значение M15
M13 … M1 M0
0, так как разряд M14 не является значащим, а образован в
результате перемножения двух знаковых 16-разрядных чисел.
Выходы мультиплексоров 21 и регистра порядка 22 включаются по сигналу #RDD, а регистра флагов - по сигналу #RDF.
5. Синтез принципиальной схемы
Для построения схемы используются в основном микросхемы серии 1533.
Микросхемы других серий использовались в случае отсутствия необходимых в данной
серии. Серия КР1533 - маломощные быстродействующие цифровые интегральные
микросхемы, предназначенные для организации высокоскоростного обмена и
обработки цифровой информации, временного и электрического согласования
сигналов в вычислительных системах. Микросхемы серии КР1533, по сравнению с
известными сериями логических элементов ТТЛ микросхем обладают минимальным
значением произведения быстродействия на рассеиваемую мощность. Зарубежный
аналог этой серии - SN74ALS***. При использовании микросхем
данной серии, время работы схемы в целом меньше требуемого в техническом
задании. Поэтому нет необходимости использовать другие более быстродействующие
серии микросхем.
Старшие разряды A12-15 подаются на инверторы DD2.1, получившиеся инверсии - на
инверторы DD4.1. Сигналы с выходов инверторов
подходят к переключателям, с помощью которых выбирается нужная комбинация
адреса схемы. Сигнал #AEN
инвертируется на DD2.2 и подается
вместе с сигналами от переключателей на микросхему DD5 8И-НЕ КР1533ЛА2. На выходе микросхемы имеем сигнал #CS (48 на схеме).
Для формирования управляющих сигналов используется дешифратор DD6 КР1533ИД4. На управляющие входы 1
части подаются сигналы #CS и
инверсия #IOW (инвертируется на DD2.2), т.к. вход V2 в первой части дешифратора не инверсный; для второй
части подаются сигналы #CS и #IOR. На информационный вход 1 подается
сигнал A0. Сигналы на запись 50,51, полученные на выходах
дешифратора имеют низкий активный уровень, а для записи в регистры необходим
фронт, поэтому они инвертируются на инверторах DD7.1, и получаются сигналы 54:WRA(CLKX)
, 55:WRB(CLKY).
Для выполнения операции умножения используется микросхема DD8 - КМ1802ВР5 - параллельный
умножитель 16*16 разрядов, предназначенный для построения быстродействующих
процессоров цифровой обработки сигналов, специализированных и универсальный
цифровых ЭВМ и т.д. Каждый из операндов может быть либо кодом (числом без
знака), либо числом со знаком. Так как на входную шину данных поступают числа в
дополнительном коде, необходимо подать логическую единицу на входы TCX и TCY, чтобы умножитель работал в режиме знаковых
операндов. На выходе умножителя вырабатывается произведение двойной точности
(32 разряда), которое может быть округлено до 16 разрядов посредством подачи
логической единицы на вход RND.
Умножитель может не использовать выходные регистры произведения, если подать на
его вход RS логическую единицу. Поскольку в
процессе работы не используется младшая часть произведения, ее выходной
буферный каскад следует перевести в третье состояние путем подачи на вход TRIL логической единицы. Вход TRIM управляет выходным каскадом старшей
части произведения, поэтому на него подается логический 0.
Поскольку в умножителе 1802ВР5 есть внутренние регистры для хранения
множителей, то нет необходимости выделять дополнительные регистры для хранения
мантисс чисел: их можно сразу записывать в умножитель. Для реализации этого
необходимо подавать сигнал записи одновременно и на регистр, хранящий порядок,
и на умножитель. При появлении фронта сигнала WRA(CLKX)
происходит запись порядка числа A в
регистр DD1 КР1533ИР23 и мантиссы в умножитель DD8 1802ВР5. При появлении переднего
фронта сигнала WRB(CLKY) происходит запись порядка числа B в регистр DD3 и мантиссы в умножитель.
Микросхемы DD10, DD11, DD12 и DD13 -
это 4-х разрядные параллельные комбинационные сумматоры с параллельным
переносом на микросхемах К155ИМ3. Младшие разряды порядков P10-3 и P20-3 подаются на сумматор DD10, а старшие P14-7 и P24-7 - на сумматор DD11. На вход начального переноса
сумматора DD10 подается логический 0, а выходной перенос
DD10 соединен со входным переносом на DD11.
Сигналы 8 и 16 со входной шины данных и сигналы 8 и 9 с шины блока
сложения порядков подаются на 3 последовательно соединенных элемента
«ИСКЛЮЧАЮЩЕЕ ИЛИ» на МС КМ555ЛП5 7486 DD9.2 для
определения факта переполнения. Затем результат на 1-ом элементе «И» в МС DD15 конъюнктируется со знаком
операнда, образуя сигнал Z1, а
на третьем элементе «И» результат конъюнктируется с проинвертированным знаком
первого операнда, образуя флаг переполнения E.
На второй паре сумматоров DD12 и
DD13 все происходит аналогично, за
исключением того, что в качестве второго операнда подается сигнал «Нормализация
нужна», формирующийся на МС DD9.1
и DD4.2 - «ИСКЛЮЧАЮЩЕМ ИЛИ» и инверторе
соответственно. Здесь необходимо отметить, что сигнал «Нормализация нужна» с
выхода инвертора DD4.2 подается в
общей сложности на 13 различных входов микросхем. DD12 (на 4 входа), DD13 (4), DD14 (1), DD19-DD22
(по одному). Поэтому необходимо убедиться, используя паспортные данные
микросхем, что в результате такого ветвления не произойдет перегрузки по току.
Полученный на втором элементе «И» DD15 сигнал Z2 заводится
вместе с Z1 на входы МС «ИЛИ» DD16 - КР1533ЛЛ1 7432. Результат - флаг нуля Z, который вместе с сигналами E (ошибка) и «Нормализация Нужна» перебрасывается
на шину управляющих сигналов под номерами 56, 57 и 58 соответственно.
Регистр порядка DD17 -
это МС КР1533ИР23
- 8-разрядный регистр с тремя состояниями выходов. На его информационные входы
заводятся сигналы с выходов сумматоров DD12 и DD13, на
вход C - сигнал CLK, а на вход E - #RDD. Выходы регистра подключены к
старшим 8 разрядам 24-разрядной выходной шины.
Для выдачи мантиссы на выход используются 4 счетверенных
селектора-мультиплексора 2x1 с
тремя состояниями выходов DD19-DD22 на МС КР1533КП11. На вход A0 DD19 подается 0,
так как «теряется» один разряд мантиссы M14, не являющийся значащим. На входы B0 и B1
DD19 подается 0, так как в этом случае
в результате сдвига на 1 разряд влево «теряются» уже 2 разряда мантиссы M14 и M13. Далее разряды мантиссы заводятся на мультиплексоры по
порядку, пропуская «потерянные» разряды. На адресный вход всех 4
мультиплексоров подается сигнал «Нормализация нужна» (номер 7). Если у этого
сигнала низкий уровень, на выходы селекторов попадает операнд A, иначе - B, при условии, что в этот момент у сигнала #RDD, который подается на входы E мультиплексоров, будет низкий
(активный) уровень. Выходы DD19-DD22 подаются на младшие 16 разрядов
выходной шины.
В качестве регистра флагов DD18
использован 4-разрядный сдвиговый регистр К533ИР16. Старшие 2 его разряда не
используются, на D0 подается флаг ошибки E, на D1 - флаг нуля Z. Для
того, чтобы регистр работал в режиме параллельной загрузки, на вход PE подается логическая единица. Режим
последовательного сдвига этого регистра не используется. Так как запись в
регистр происходит по заднему фронту сигнала на входе C, на него подается проинвертированный на инверторе DD7.2 сигнал CLK. Это имеет смысл лишь в случае, когда длительность
положительного импульса на синхровходе CLK превышает время задержки микросхемы инвертора DD7 (КР1531ЛН1 7404). В противном случае на вход C регистра следует просто подавать
сигнал CLK. В регистре DD18 вход E
неинверсный, поэтому на него подается проинвертированный на DD7.2 сигнал #RDF. Младшие 2 выхода регистра DD18 подаются на младшие 2 разряда выходной шины данных.
Оставшиеся 2 входа и 2 выхода регистра остаются свободными, так как не
используются.
6. Анализ временных задержек
Для проведения анализа временных задержек приведем основные временные характеристики
используемых микросхем
КР1533ИР23
Восьмиразрядный регистр на триггерах с защелкой с тремя состояниями на
выходе.
Время задержки распространения при включении по входу С - 16 нс
Время задержки распространения при выключении по входу С - 12 нс
Время задержки распространения при переходе в состояние высокого(низкого)
уровня из состояния «выключено» - 17 (18) нс
Время задержки распространения при переходе из состояния
высокого(низкого) уровня в состояния «выключено» - 40 нс
КР1533ЛН1
Шесть логических элементов «НЕ»
Время задержки распространения при переходе в состояние высокого(низкого)
уровня12(10) нс
КР1533ЛА2
Логический элемент 8И-НЕ.
Время задержки распространения при переходе в состояние высокого(низкого)
уровня - 12(10)нс
К155ИМ3
Полный двоичный четырехразрядный сумматор.
Время задержки распространения информации на выходах - 45нс
КМ555ЛП5
Четыре логических элемента «Исключающее ИЛИ».
Время задержки распространения при переходе в состояние высокого(низкого)
уровня - 30(22)нс
КР1533КП11
Четырехразрядный мультиплексор 2*1 с тремя устойчивыми состояниями.
Время задержки распространения при переходе из состояния «выключено» в
состояние высокого(низкого) - 16 (18) нс
Время задержки распространения при переходе из состояния
высокого(низкого) уровня в состояние «выключено» - 40(25) нс
К533ИР16
Четырехразрядный универсальный регистр сдвига
Время задержки распространения при включении по входу С - 28 нс
КР1533ЛИ1
Четыре логических элемента И.
Время задержки распространения при переходе в состояние высокого(низкого)
уровня14(10) нс
КР1533ИД4
Сдвоенный дешифратор 2*4.
Время задержки распространения при включении(выключении) от
информационных входов до выходов32 нс
Время задержки распространения при включении(выключении) от управляющих
входов до выходов26 нс
КР1533ЛЛ1
Четыре логических элемента ИЛИ
Время задержки распространения при переходе в состояние высокого(низкого)
уровня14(12) нс
КР1802ВР5
Параллельный умножитель 16x16
разрядов
Время задержки распространения сигнала от входов CLKX, CLKY
до выходов P175 нс
При анализе временных задержек схемы будем руководствоваться не
максимально возможным уменьшением времени работы, так как ограничение в 10
тактов очень мягкое, а обеспечением гарантированного результата и простотой
использования схемы. Итак, проведем анализ временных задержек.
Время записи входных данных во внутренние регистры грубо определяется по
следующей формуле:
Tw = tDD2.1 + tDD4.1 + tDD5
+ tDD6 + tDD7.1 = 12 + 12 + 12 + 32 + 12 = 80 нс.
Это - заведомо больший результат, так как запись в регистры производится
по фронту, а дешифратор с инвертором может создавать фронты столь часто, сколь
это необходимо. Однако, сложность заключается в том, что нужно следить, чтобы
на шине данных в момент появления очередного фронта были выставлены данные для
записи, поэтому скорость записи во входные регистры схемы ограничивается
возможностью быстрой замены данных на входной шине. Следует также учитывать,
что до момента появления операндов на выходе внутреннего регистра также пройдет
время, равное 16 нс для регистра КР1533ИР23. Время записи во внутренние
регистры умножителя не учитывается, так как для него в паспортных данных
приведена общая задержка с учетом этого времени. Таким образом, задержка между
началом записи и появлением порядка на выходе регистров DD1 и DD3 равна 80 + 16 = 96 нс, а между началом записи и появлением
результата перемножения мантисс на выходах умножителя - 80 + 175 = 255 нс.
Поэтому будем исходить из того, что один цикл записи во внутренние
регистры длится 100 нс, что необычайно удобно, т.к. период сигнала CLK - 200нс.
Теперь проанализируем время, затрачиваемое на вычисление результата - с
момента появления на выходе умножителя результата до момента, когда
окончательные данные появятся на информационных входах микросхем DD17-DD22. Оно вычисляется по формуле:
Tp = tDD9.1 + tDD4.2 + tDD12 + tDD13 + 3*tDD14 + tDD15 + tDD16 = 30 + 12 + 45 + 45 + 3*30 + 14 + 14
= 250 нс.
Микросхемы DD10, DD11, DD9.2, DD4.3
и первые 2 элемента DD15 не
учитываются в этой формуле потому, что они никак не зависят от результата на
выходе умножителя и успевают отработать за те 175 - 16 = 159 нс, которые
работает умножитель. Действительно, Tf = tDD10 + tDD11 + 3*tDD9.2 + tDD4.3 + tDD15 = 45 + 45 + 3*30 + 12 + 14 = 206.
Казалось бы, Tf > 159нс, но не следует забывать,
что помимо сумматоров DD10 и
DD11, время работы которых 90нс <
159нс, Tp начинает зависеть от результатов
работы микросхем, входящих в Tf
только начиная с DD15, то есть по
прошествии tDD9.1 + tDD4.2 + tDD12 + tDD13 + 3*tDD14 = 30 + 12 + 45 + 45 + 3*30 = 222 нс
с момента начала своей работы. А поскольку 222 > 206, первоначально
вычисленное время Tp=250нс и
является максимальным временем работы вычислительной части схемы.
Таким образом, с момента начала записи второго операнда до вычисления
результата проходит 255 + 250 = 505 нс, что весьма обидно, так как не хватило
всего 5 нс до значения 500нс, которое позволило бы сразу по пришествии
переднего фронта CLK записать результат
в регистры. Из этой ситуации можно выйти двумя путями:
1) смириться с потерей 95 нс и начинать запись второго операнда
по переднему фронту CLK, тогда
передний фронт CLK, который
придет через 600 нс после начала записи операнда инициирует запись результата в
регистр.
2) Начинать запись второго операнда за 5 нс до заднего фронта CLK.
Первый вариант значительно проще, поэтому при построении временной
диаграммы будем использовать его.
Теперь осталось проанализировать время между началом чтения по адресам
001000 - 001001 и появлением результата на выходной шине данных.
Tr = tDD2.1 + tDD4.1 + tDD5 + tDD6
+ max( tDD19, tDD17, tDD18+tDD7.2) = 12 + 12 + 12 + 32 + max(18, 18, 30 + 12) = 110 нс. Не
следует забывать, что это время является максимально возможным - в том случае,
если читается содержимое регистра флагов и если до начала чтения на шине адреса
был выставлен неверный адрес или же AEN имел неактивный единичный уровень. Во всех остальных случаях время
чтения оказывается менее 100 нс. Поэтому из данной ситуации также можно
наметить 2 выхода:
1) Сначала подавать запрос на чтение результата, а затем, не меняя 4
старших разрядов адреса и значения AEN, регистра флагов. В этом случае время чтения будет равно tDD6 + max( tDD19, tDD17, tDD18+tDD7.2) = 32 + max(18, 18, 30 + 12) = 74 нс
2) Подавать запрос на чтение регистра флагов за 10 нс до фронта CLK, чтобы данные появились на шине
вместе со следующим фронтом CLK.
При построении временной диаграммы лучше всего подавать все входные
сигналы по фронтам CLK, поэтому и в
этом случае выберем первый вариант.
Итак, максимальное время задержки распространения сигнала от входов D0-D23 до внутренних выходных регистров составляет 505нс + время
до первого переднего фронта CLK.
Максимальное время задержки распространения сигнала от входов A0-A5 до выходов D0-D23 составляет 110нс.
Максимальное время задержки распространения сигнала от входов D0-D23 до входных внутренних регистров составляет 100нс.
Суммарное время работы схемы при условии, что запись второго операнда
производится сразу же после записи первого по переднему фронту CLK и чтение результата производится
перед чтением регистра флагов, составляет 900нс. Этот случай проиллюстрирован
на временной диаграмме (рис. 6.1). Отметим, что это время никоим образом не
зависит от значений операндов, а зависит лишь от времени подачи и времени между
подачей их на входную шину данных, а также от порядка считывания значений
результата.

Рис
6.1 Временная диаграмма работы схемы.
Заключение
Из приведенных временных расчетов видно, что разработанный блок выполняет
операцию D=A*B за 900 нс,
работая на частоте 5 МГц, что меньше времени, установленного в техническом
задании. Полученные результаты в основном являются следствием использования
микросхем серий КР1533 и КР1802. В разделе 2.3 приведен пример работы алгоритма
умножения чисел, подтверждающий корректность функционирования схемы. Таким
образом, разработанное устройство полностью удовлетворяет техническому заданию.
Список использованной литературы
1. Пуховский В.Н. Лекции по курсу «Схемотехника»
2. Божич В.И. Лекции по курсу «Арифметические и
логические основы ЭВМ»
. Электронный справочник по цифровым и логическим
микросхемам.
. Шахнов В.А. «Микропроцессоры и микропроцессорные
интегральные микросхемы». Москва. «Радио и связь» 1988г.
. Юшин А.М. Цифровые микросхемы для электронных
устройств. Москва, «Высшая школа» 1993г.
. Савельев А.Я. «Арифметические и логические основы
цифровых автоматов».
. Лысиков Б.Г. «Арифметические и логические основы
цифровых автоматов».
Похожие работы на - Блок выполнения арифметической операции над числами A, B, D
|