Аспекты задачи сокращения перебора при анализе сложных позиционных игр
Содержание
Введение
1. Подходы к реализации AI в логических играх
1.1 Понятие поиска
1.2 Позиционная игра
1.3 Подходы к решению задач выбора хода в позиционных играх
1.4 Особенности игры нарды
1.5 Правила игры в нарды
1.6 Оценочная функция
1.7 Самообучение
1.8 Нетранзитивность игр
1.9 Обзор литературы и существующих программ
1.10 Игровые деревья
1.11 Дерево игры в нарды
2. Построение эвристических оценочных функций
2.1 Выделение параметров
2.2 Определение более сильного игрока из двух
2.3 Настройка весовых коэффициентов
2.4 Линейная модель из 3-х параметров. Вид поверхности
2.5 Таблицы вероятностей
2.6 Снижение размерности. Гипергаммон
2.7 Разделение игрового процесса на фазы
3. Построение оценочных функций на основе нейронных сетей
3.1 Теория нейронных сетей
3.2 Использование нейронных сетей в качестве оценочной функции
3.3 Использование MatLab для обучения нейронных сетей
3.4 Экспериментальные данные
4. Реализация версии для мобильных устройств
4.1 Особенности программирования портативных устройств
4.1.1 Размер экрана
4.1.2 Быстрый отклик
4.1.3 Ввод данных
4.1.4 Питание
4.1.5 Память
4.1.6 Файловая система
4.2 Выбор средств разработки
4.3 Реализация игры
Заключение
Список литературы
Введение
В настоящее время мобильная связь имеет широкое
распространение в мире. При этом и без того немалое число пользователей
мобильных телефонов продолжает расти. Сами же мобильные телефоны больше не
являются просто средством связи. Благодаря поддержке сторонних приложений они
получают новые возможности. Соответственно возрастает спрос на софт для
мобильных телефонов. В том числе и на игры. Многие пользователи воспринимают
телефон как мобильный центр развлечений, поэтому игровые возможности устройства
являются для них наиболее приоритетными после его коммуникативных возможностей.
Еще несколько лет назад игровые возможности телефона
полностью определялись набором игр, "вшитых" в него производителем:
не существовало никакой возможности добавить новые игры. В настоящее же время
большинство телефонов работающих как под управлением операционных систем
(смартфоны), так и под управлением встроенного ПО (прошивки), поддерживают
технологию Java. Благодаря этой технологии, совместимой с любыми приложениями
созданными при помощи Java Micro Edition, появилась возможность написания любых
программ для мобильных устройств, в том числе и игр.
Человеческий мозг и вычислительная техника - различные
механизмы, каждый со своими собственными сильными и слабыми сторонами. Люди
способны к изучению, рассуждению по аналогии, обработке изображения. Вычислительные
машины же наоборот способны к большим числовым вычислениям и запоминанию
больших объемов информации. Выходит, что возможности человека и компьютера
дополняют друг друга: способность человека обрабатывать информацию - слабая
сторона деятельности компьютера, а преимущества компьютера являются
человеческими недостатками. Учитывая сложившуюся обстановку, правильным
решением будет использовать преимущества машины, а не ее слабости.
Исследования в области искусственного интеллекта внесли один
из самых глубоких вкладов 20-ого столетия в знания человечества. Изучений
привело к пониманию, что интеллект присущий только человеку, можно воссоздать,
используя вычислительную технику. Другими словами, появилась возможность
построения иллюзии человеческого разума, используя компьютерную
интеллектуальную систему. Эта возможность была ярко проиллюстрирована в истории
компьютерных игр. Применение искусственного интеллекта в логических играх дало
возможность решения трудных задач в реальном времени и с высокой эффективностью.
Построение высокоэффективных игровых программ стало одним из
главных триумфов искусственного интеллекта. Это произошло, частично, благодаря
успеху, достигнутому в таких логических играх, как нарды, шахматы, шашки,
реверси, и кости где компьютеры играют так же или лучше чем, лучшие
игроки-люди. Именно успех этих программ впервые показал обществу, что возможно
создать искусственный интеллект, который бы решал трудные задачи лучше людей.
Мобильная игра - игровая программа для мобильных устройств
<#"650802.files/image001.gif">
Рис. 1. Оценочная функция.
В качестве оценочной функции используются линейные модели
(линейная комбинация некоторых параметров).
В простейшей модели в качестве параметров можно взять просто
количество фишек на каждом поле, получив в сумме 26 параметров. Реально же
используют некоторые вычисляемые параметры, представляющие определенные
стратегические аспекты игры.
Одним из основных параметров является подсчет пипсов - это
число, которое нужно выбросить на игральных костях, чтобы вывести все свои
фишки. По этому параметру определяют лидерство и близость победы.
Число одинарных фишек также является важным параметром,
который стремятся сокращать все игроки, так как только одинарные фишки можно
побить в нардах, тем самым откинув противника в гонке за вывод фишек из доски.
Число полей с двумя и более фишками является
противоположностью предыдущему параметру, его стремятся максимизировать. Чем
больше таких полей, тем устойчивее позиция и тем сложнее через нее пройти.
Связанным параметром является построение блокад - несколько
смежных полей, занятых двойными или более фишками. С этим параметром можно
связать изменение стратегии - нужно проводить свои фишки вперед, если их
запирают.
Также считают число прямых возможностей взятия - это число
одинарных фишек на расстоянии 6 или меньше полей. Есть схожий с этим параметр -
число одинарных фишек на расстоянии меньшем 12. Схожим параметром является
вероятность взятия одинарной фишки, которая в большинстве случаев
рассчитывается по предварительно посчитанной таблице.
Равномерность распределения фишек по полям. Например, гораздо
выгоднее иметь три фишки на одном поле и еще три на другом, чем две и четыре на
тех же полях. В случае выпадения определенных костей может потребоваться сдвинуть
фишку с первого поля и тем самым сделать как минимум одну одинарную фишку.
Анализируя сыгранные партии можно заметить, что занятие
определенных позиций на доске способствует победе. Такими позициями является
4-я и 5-я клетки и соответственно 20-я и 21-я симметричные клетки. Таким
образом, в простейшем случае можно ввести факт занятия этих клеток в оценочную
функцию. В более общем случае, вводят весовые коэффициенты для всех полей
доски.
Также часто используется параметр коммуникации - нужно
стремиться располагать свои фишки на расстоянии не более 6 пипсов друг от
друга. Тем самым препятствовать разделению своих фишек.
При выводе своих фишек, нужно стремиться оставлять четное
число фишек на каждом поле, чтобы минимизировать шансы оставления одиночной
фишки после очередного хода.
Очень часто вводятся понятия контакта фишек - наличие хотя бы
одной вражеской фишки в направлении движения. Наличие факта контакта влияет на
используемую стратегию и может предполагать разные оценочные функции.
Эвристический метод, используемый для получения подобных
оценок, в общем, заключается во введении некоторой числовой функции на
множестве позиций, зависящей от ряда переменных, которую называют оценочной
функцией (evaluation function). Переменными, обычно служат разного рода элементарные
оценки позиции, такие как, например, материальный перевес, пешечные структуры,
угрозы фигурам. Функция должна быть легко вычисляема, поэтому её обычно строят
в виде линейной функции соответствующих переменных. Некоторые исследователи
ищут развитие этого метода в усложнении вида оценочной функции путем введения в
нее нелинейных элементов или использования булевых функций. Тем не менее,
сложность расчета такой функции имеет критическое значение, так как должна быть
оправдана отказом от исследования дальнейшего развития ситуации. Иными словами,
время, потраченное на вычисление слишком сложной оценочной функции, может быть
с гораздо большим успехом потрачено на просчет ходов из данной позиции, и
расчет более простой оценочной функции в полученных позициях.
Так или иначе, оценочная функция определяется набором
переменных, видом, и набором параметров. Выбор переменных производится путем
анализа экспертных знаний. На этом этапе иногда есть возможность обратиться к
литературе по теории данной игры, каковой в избытке можно найти по шахматам.
Кроме того, на практике часто очень полезны даже самые элементарные соображения
экспертов, имеющих опыт игры. Это очень важно в случае с играми, для которых не
создано такой внушительной теоретической базы. В некоторых, достаточно простых
играх хватает всего трех переменных, и такая функция делает игру программы
сносной; в шахматах их число обычно достигает нескольких сотен. Вид функции,
как уже говорилось, определяется сравнительной легкостью вычисления. Последним
этапом построения оценочной функции, а зачастую и всей программы, является
подбор параметров при переменных (нелинейных или булевых слагаемых), то есть
весов соответствующих критериев оценки позиции. Здесь анализа экспертных знаний
всегда недостаточно. Часто критерии кажутся несоотносимыми, хотя требуют
точнейшей сравнительной оценки. Большое количество переменных, а соответственно
и параметров, делает более-менее адекватный их априорный выбор просто
невозможным. Еще одна проблема при выборе параметров - их нестабильность в том
смысле, что в разных фазах игры, а иногда и в разных игровых ситуациях,
наиболее сильной игре соответствуют разные оценочные функции. Может появиться
необходимость в течение игры менять как параметры оценочной функции, так и её
структуру. В случае с фазами игры можно заранее предусмотреть такую замену, а в
случае с различными игровыми ситуациями (которых на практике может оказаться
больше, чем в теории) потребуется в процессе игры выбирать адекватную
программу. Причем существуют варианты: выбирать из готовых, и/или адаптировать
существующую программу, получая новую. Эта частная задача относится к классу
задач самообучения игровых программ, который подробнее рассматривается ниже.
Учитывая то, что прочие аспекты построения программ, играющих
в сложные позиционные игры (такие как порядок обхода дерева игры и построение
частичных оценок позиций), довольно тщательно изучены, и результаты
соответствующих исследований широко применяются, можно полагать, что решающую
роль в написании таких программ в настоящее время играет именно нахождение
наилучшей процедуры выбора оценочной функции. Данная работа рассматривает
некоторые проблемы связанные с задачей подбора параметров в оценочной функции
на этапе, когда её вид и набор переменных уже заданы (либо существует несколько
вариантов таковых).
1.7
Самообучение
Раньше можно было встретить следующее определение: процесс
изменения свойств системы, позволяющий ей достигнуть наилучшего или по крайней
мере приемлемого функционирования в изменяющихся условиях, называется
адаптацией. В то же время обучение определялось (там же) как передача знаний
или приемов решения задач от обучающего к обучаемому. Как видим, самообучением
в таком случае можно назвать получение системой информации, помогающей решать
задачи, из собственного опыта работы. Теперь, если в определении адаптации
изменить соответствующее условие на "в постоянных или изменяющихся
условиях", а как субъект процесса изменения свойств указать саму систему,
то полученное определение будет также подходить к понятию самообучения. Именно
в таком смысле применяется понятие самообучения в современных работах по
сложным позиционным играм.
Самообучением в этой области в наше время принято называть
выбор структуры или подбор параметров системы на основе исследования их
оптимальности путем непосредственной подстановки, оценки полученных
характеристик системы и соответствующей корректировки. Имеется в виду, что
система в процессе работы улучшает свои характеристики, изменяя параметры и
приближая их к идеальным, и таким образом "учится" на своем опыте. В
применении к сказанному выше можно сказать, что игровую программу можно
обучать, изменяя некоторые ее параметры, заставляя ее играть с экспертом или
другой программой и закрепляя благоприятные изменения. Наиболее подходящими (но
не единственными) параметрами для таких манипуляций являются параметры
оценочной функции, так как их изменение не подразумевает никаких изменений в
структурах данных или алгоритмах и, соответственно в тексте самой программы. В
то же время, эти параметры существенно влияют на качество игры программы.
Одним из самых распространенных подходов к проблеме обучения
в подобных ситуациях стал так называемый метод вскарабкивания на холм
(hillclimbing, описание программы играющей в короткие нарды и использующей этот
метод). Он заключается в следующем. За основу берется некоторый стартовый набор
параметров. Затем один из параметров изменяют. Программы с неизмененным и с
измененным параметром играют друг с другом. Дальнейшие действия производятся с
победившей программой и сводятся к повторению предыдущих шагов. Очевидно, что с
каждым шагом программа играет не хуже. Даже более того, в силу сказанного выше
о существенности параметров оценочной функции, на каком-то шаге программа
непременно должна начать играть лучше. Кроме того, если получено повышение
качества игры при изменении некоторого параметра, можно исследовать этот
параметр в направлении благоприятного изменения с достаточно маленьким шагом и
получить своего рода экстремум по этому параметру с соответствующей выбранному
шагу точностью. Вообще, если предположить, что качество игры можно численно
оценить то нашу задачу можно считать задачей поиска максимума этой оценки как
функции, зависящей от набора параметров оценочной функции как от переменных.
Теория экстремальных задач предлагает здесь метод покоординатного спуска,
возможность использования которого рассматривается далее.
Реально, нет никаких гарантий, что такая функция вообще
существует, но часто удобно предполагать её существование, так как у
исследуемого объекта иногда проявляются некоторые свойства функции. Главная
проблема в такой постановке задачи заключается в заведомом отсутствии градиента
и вообще каких бы то ни было частных производных этой функции. Точнее, частные
производные и градиент вероятно существуют, но нет никаких подходов к их
поиску. Таким образом, пойти в этом направлении дальше метода покоординатного
спуска не представляется возможным. С другой стороны, такая аналогия приводит к
выводу о том, что метод вскарабкивания на холм поможет нам найти лишь локальный
экстремум нашей гипотетической функции. Учитывая, что о характере этой функции
не известно практически ничего, можно предположить, что локальный экстремум в
данной ситуации может находиться сколь угодно далеко от глобального. Если так,
то мы найдем совсем не то, что искали. Предположим теперь, что рассматриваемая
игра относится к сложным, и её оценочная функция имеет не меньше десятка
параметров. Мы оптимизируем один из них, затем переходим к другому,
оптимизируем его.
Одна проблема здесь заключается в том, что следующий параметр
может не оптимизироваться при новом значении параметра, оптимизированного
первым. При этом не исключено, что его (этот следующий параметр) можно было
оптимизировать раньше, а результаты его оптимизации могли превосходить
полученные на деле. В результате обнаруживается возможность, выбрав не тот
параметр на каком-то шаге, вступить не на тот холм.
Другая проблема возникает уже при выборе третьего параметра
для оптимизации, так как совершенно не исключено, что наилучших результатов
можно достигнуть, выбрав параметр, уже подвергшийся изменению, вместо десятков
ещё не тронутых. Такие рассуждения приводят к выводу, что порядок, в котором
должны выбираться параметры для их изменения, может оказаться практически любым.
Исключение составляют только случаи, когда один параметр выбирается дважды
подряд, ввиду того, что мы договорились искать экстремум по выбранному
параметру. Но даже этот момент на деле может подвести. Возможно, дойдя до
экстремума по выбранному параметру, мы прошли мимо очень крутого подъема по
какому-то другому, и надо было остановиться на половине пути или пройти вдвое
дальше. Таким образом, долгое прохождение по значениям параметра для поиска
экстремума может быть не оправдано, по сравнению одним случайным, но удачным
шагом.
Итак, окончательный вывод выглядит так: при выборе очередного
параметра для изменения невозможно учитывать предыдущий порядок выбора
параметров. То есть каждый раз, выбирая очередной параметр, мы стоим на
распутье, где неоткуда получить никакой априорной информации, куда идти. Два
выхода из такой ситуации это: выбрать параметр случайно или попробовать все и
остановиться на том, который дает лучший результат. Второй выход сопряжен с
огромным расходом времени. Кроме того, что параметров много, неизвестно, на
сколько надо их менять. Таким образом, количество проб в таком случае
приблизительно равно произведению числа параметров на число предполагаемых
вариантов длины шага. Учитывая то, что каждая проба подразумевает состязание
двух программ, которое в свою очередь обычно заключается в проведении
нескольких партий, делаем вывод, что перебор всех вариантов - задача
трудновыполнимая. Кроме того, даже при таком подходе отнюдь не исключается
возможность пропустить верную дорогу, так как она может оказаться "за
поворотом", то есть необходимо исследовать все возможности на два шага
вперед, на три и т.д. Первый выход по крайней мере выполним. В таком методе
обучение программы отдаётся на волю случая. Этот подход называют также
эволюцией в популяции из двух особей. "Особями" здесь выступают
конкурирующие программы, из которых "выживает" сильнейшая, даёт
"потомство", которое "мутирует", то есть изменяет один из
параметров своей оценочной функции.
Преимуществом этого метода является сравнительная простота.
Процесс обучения можно запускать несколько раз из одной стартовой точки и если
программы забрались на разные холмы, то можно выбрать забравшуюся на
высочайший. Правда не решается проблема зависимости от стартовой оценочной
функции. Если стартовую точку и некий холм разделены "оврагом", то
программа никогда не заберется на него. Чтобы взобраться на холм, нужно по
крайней мере, чтобы стартовая оценочная функция попала на его склон. И даже это
не дает гарантии, что программа на него все-таки поднимется вообще и если
поднимется, то за конечное время. На практике использование подобных методов
нередко приводило, например, к бесконечному кружению по спирали по подножию
холма.
1.8
Нетранзитивность игр
Одна из проблем метода вскарабкивания связана с транзитивностью
отношения "более сильный - более слабый" игровых программ. Если
программа A чаще всего выигрывает у программы B, а та в свою очередь чаще всего
выигрывает у программы C, то последняя может чаще всего выигрывать у программы
A. То есть транзитивность этого отношения стоит под вопросом. Программа,
играющая на среднем уровне, может в силу стечения обстоятельств иметь, скажем,
всего одну, но очень эффективную стратегию против гораздо более сильной
программы и постоянно её обыгрывать. При этом эта стратегия не действует против
других более сильных программ. Такие примеры существуют в жизни. Так,
величайшего шахматиста Александра Алёхина, очень часто обыгрывал шахматист
значительно менее высокого уровня Лайош Асталош. Известны и другие случаи
подобного "везения", в том числе и в командных играх, что говорит о
том, что это свойство нетранзитивности не является результатом каких-то
психологических феноменов, а присуще самим играм, в особенности сложным
позиционным.
1.9 Обзор
литературы и существующих программ
В последние годы в мире был опубликован ряд статей и
монографий, посвященных применению искусственного интеллекта (AI) в логических
играх, в частности в нардах.
В работе [13] G. Tesauro "TD-Gammon, a self-teaching backgammon program" отмечается, что
программа по игре в нарды (backgammon), реализованная с использованием нейронной сети,
добилась высоких результатов при игре с лучшими игроками-людьми, используя
параметры, полученные при игре сама с собой. Нейронная сеть использовалась для
оценки качества позиций. Программа оценивала все доступные за один ход позиции
и выбирала тот ход, который вел к наилучшей позиции. Параметры нейронной сети
модифицировались с помощью алгоритма TD.
В работе [14] J. Pollack & A. Blair "Co-Evolution in the successful learning of backgammon strategy” рассматривают
эволюционный подход к настройке весов нейронной сети, оценивающей позиции в
нардах. В работе предлагается использовать упрощенный вариант генетических
алгоритмов. Констатируется достижение достаточно высоких результатов несмотря
на некоторые огрехи в методике.
В работе [15] M. Buro "Efficient approximation of backgammon race equities” предлагается
использовать статистические методы и динамическое программирование для оценки
вероятности выигрыша позиции в нардах. В работе сообщается об обоснованности
применения данных методов.
Также в последнее время был выпущен ряд программ для PC и для мобильных
устройств.
В частности была выпущена программа GNUbackgammon для PC, распространяемая
бесплатно и использующая для оценки позиций нейронные сети. Предлагается
использовать несколько обученных сетей для разных фаз игры (начальная фаза,
активный контакт фишек, фаза вывода фишек с доски). Нужно отметить достаточно
высокий класс игры.
Также был выпущен ряд игр для телефонов, поддерживающих J2ME фирмами gameloft, ZingMagic. Их отличает
хорошая графика и приемлемый уровень игры.
1.10 Игровые
деревья
Для любой игры можно определить игровое дерево, узлы которого
суть игровые позиции, а дочерние узлы - позиции, достижимые из исходной за один
ход.
Также полагается, что дерево конечно, т.е. мы имеем дело с
игрой которая не длится вечно или имеет бесконечно много ходов из одной
позиции.
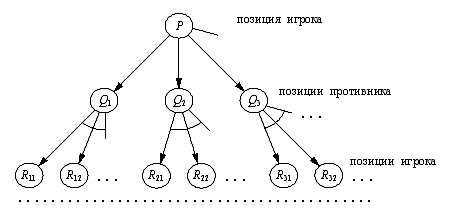
Рис. 2 Фрагмент игрового дерева
Многие сложные реальные задачи можно смоделировать с помощью
деревьев решений (decision trees). Каждый узел в дереве представляет собой один
шаг решения задачи. Ветвь в дереве соответствует решению, которое ведет к более
полному решению. Листы представляют собой окончательное решение. Цель состоит в
том, чтобы найти "наилучший" путь от корня до листа при выполнении
некоторых условий. Естественно, что условия и "наилучший" путь
зависят от сложности конкретной задачи.
На примере крестиков-ноликов показаны способы поиска в
деревьях игры наилучшего возможного хода. Последующие разделы описывают более
общие способы исследования деревьев решений. Для самых маленьких деревьев можно
использовать метод полного перебора (exhaustive searching) всех возможных
решений. Для работы с большими деревьями более подходит метод ветвей и границ
(brunch-and-bound technique), позволяющий отыскивать лучшее возможное решение
без поиска по всему дереву. Для огромных деревьев лучше использовать
эвристический метод (heuristic). При этом найденное решение может и не быть
наилучшим из возможных, но должно быть достаточно близким к нему.
1.11 Дерево
игры в нарды
Возможность игрока передвигать шашки определяется броском
двух кубиков. Существует 36 равновероятных комбинаций выпадения кубиков, из них
21 принципиально разная. В сети интернет можно найти большое количество
материалов по нескольким различным подходам к программированию игрока в нарды.
Некоторая систематизация этих материалов произведена авторами.
Игра описывается посредством дерева игры. Далее также по
аналогии определяются оценки позиций, применяется а,b - эвристика. Кроме того,
вводится такое новое понятие, как функция риска.
Так как нарды в большой степени отличаются от игр, подобных
шахматам, то некоторые подходы не применимы в отношении нард. Основным отличием
нард от шахмат является недетерминированность. Её привносит в нарды
стохастический фактор, обусловленный бросанием кубиков. Этот фактор значительно
усложняет исследование нард, но в то же время делает его более актуальным. Ведь
подавляющее большинство явлений и процессов в действительности так или иначе
связано с явлениями случайными, описываемыми вероятностно. В результате, дерево
игры в нарды - дерево недетерминированной игры. В связи с этим возникает
потребность дополнительном анализе дерева игры в нарды.
Учитывая то, что у нард очень большой коэффициент ветвления
дерева игровых позиций (достигает 200-300 доступных ходов из одной позиции) и
наличие случайности (броски костей) перебор в осложняется, вследствие
ограниченности вычислительных ресурсов. Для примера, в шахматах коэффициент
ветвления составляет порядка 40 ходов, а для шашек 8-15. Так например при
глубине поиска два существует 1,296 ходов, глубина 3 - 46,656 ходов. Поэтому
рассматриваются наиболее вероятные ходы, например выпадение дубля несколько раз
подряд маловероятно. При таком подходе число учитываемых ходов сокращается до
900 и 27,000 соответственно. Но даже такой подход не позволяет осуществлять
перебор ходов на большую глубину, т.к. их количество слишком велико, и время
работы существенно увеличивается. В следствие этого расчет ходов более чем на
глубину 2 не целесообразен. На рисунке 3. показана зависимость количества
вариантов ходов от глубины.
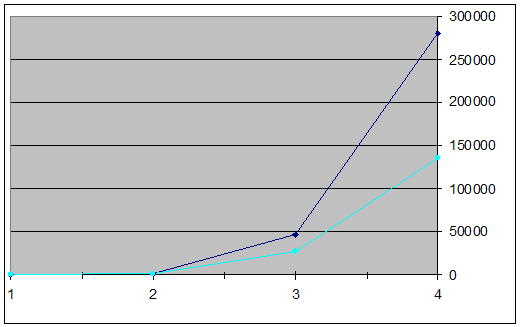
Рисунок 3. Зависимость количества вариантов ходов от глубины.
Поэтому необходима качественная оценочная функция, дающая
правдоподобную оценку вероятности победы игрока в данной позиции.
Что представляет из себя просмотр дерева игры и поиск в нем
ходов? При поиске ходов мы хотим создать в перспективе наиболее выгодную
ситуацию, желательно через как можно большее количество ходов, нас интересует
больше ситуация в будущем, а не в настоящем, поэтому и прибегают к дереву игры.
Причем, скорее всего выгодной ситуации в будущем будут предшествовать не самые
выгодные промежуточные ходы. Необходимо также учитывать наличие противника,
который предположительно будет ходить оптимально со своей точки зрения и
стараться ухудшить ситуацию для соперника.
Итак, строится дерево заданной глубины, в корне которого
текущая ситуация, а листья которого (на самой большой глубине) соответствуют
терминальным ситуациям, после которых улучшение невозможно. Фактически в
большинстве случаев оно возможно, но эта возможность скрыта от нас
ограниченностью дерева поиска.
Среди терминальных ситуаций требуется выделить лучшую с точки
зрения того игрока, для которого мы ищем ход и достижимую при условии наиболее
оптимального сопротивления второго игрока.
Качество хода определяется оценочной функцией, которая
применяется к конкретной позиции на доске. Оценочная функция может вычисляться
с точки зрения одного или другого игрока, например, количество белых или черных
фишек.
2. Построение
эвристических оценочных функций
2.1 Выделение
параметров
Реализованная программа игры за компьютер состоит из двух
частей. Первая часть генерирует все возможные ходы (при текущем броске костей)
доступные из текущей позиции. Вторая часть - оценочная функция, с помощью
которой выбирается наилучший ход. Учитывая то, что у нард очень большой
коэффициент ветвления дерева игровых позиций (достигает 200-300 доступных ходов
из одной позиции) и наличие случайности (броски костей) перебор в глубину не
представляется целесообразным, вследствие ограниченности вычислительных
ресурсов. Для примера, в шахматах коэффициент ветвления составляет порядка 40
ходов, а для шашек 8-15. Таким образом, применение "грубой силы"
("brute force”) для нард неэффективно.
В качестве оценочной функции используются линейные модели
(линейная комбинация некоторых параметров) и нейронные сети (трехслойная
нейронная сеть).
В простейшей модели в качестве параметров можно взять просто
количество фишек на каждом поле, получив в сумме 26 параметров. Реально же
используют некоторые вычисляемые параметры, представляющие определенные
стратегические аспекты игры.
Одним из основных параметров является подсчет пипсов (pips) - это число, которое
нужно выбросить на игральных костях, чтобы вывести все свои фишки. По этому
параметру определяют лидерство и близость победы.
Число одинарных фишек (blots) также является важным
параметром, который стремятся сокращать все игроки, так как только одинарные
фишки можно побить в нардах, тем самым откинув противника в гонке за вывод
фишек из доски.
Число полей с двумя и более фишками (hold) является
противоположностью предыдущему параметру, его стремятся максимизировать. Чем
больше таких полей, тем устойчивее позиция и тем сложнее через нее пройти.
Связанным параметром является построение блокад - несколько
смежных полей, занятых двойными или более фишками. С этим параметром можно
связать изменение стратегии - нужно проводить свои фишки вперед, если их
запирают.
Также считают число прямых возможностей взятия (direct shot) - это число одинарных
фишек на расстоянии 6 или меньше полей. Есть схожий с этим параметр indirect shots - число одинарных фишек
на расстоянии меньшем 12. Схожим параметром является вероятность взятия
одинарной фишки, которая в большинстве случаев рассчитывается по предварительно
посчитанной таблице.
Равномерность распределения фишек по полям. Например, гораздо
выгоднее иметь три фишки на одном поле и еще три на другом, чем две и четыре на
тех же полях. В случае выпадения определенных костей может потребоваться
сдвинуть фишку с первого поля и тем самым сделать как минимум одну одинарную
фишку.
Анализируя сыгранные партии можно заметить, что занятие
определенных позиций (golden point) на доске способствует победе. Такими позициями
является 4-я и 5-я клетки и соответственно 20-я и 21-я симметричные клетки.
Таким образом, в простейшем случае можно ввести факт занятия этих клеток в
оценочную функцию. В более общем случае, вводят весовые коэффициенты для всех
полей доски.
Также часто используется параметр коммуникации - нужно
стремиться располагать свои фишки на расстоянии не более 6 пипсов друг от
друга. Тем самым препятствовать разделению своих фишек.
При выводе своих фишек, нужно стремиться оставлять четное
число фишек на каждом поле, чтобы минимизировать шансы оставления одиночной
фишки после очередного хода.
Очень часто вводятся понятия контакта фишек - наличие хотя
одной вражеской фишки в направлении движения. Наличие факта контакта влияет на
используемую стратегию и может предполагать разные оценочные функции.
В целом можно отметить, что с ростом числа параметров в
модели росло и время обучения, но также росло и качество оценки позиции.
2.2
Определение более сильного игрока из двух
В силу того, что и в игре присутствует элемент везения возможна
ситуация, когда слабый соперник может выиграть у более сильного, что ставит
вопрос об определении более сильного игрока из двух. В случае, когда один
соперник заведомо сильнее другого эффект везения практически не проявляется и
выбрать сильнейшего можно сыграв незначительное число партий. К тому же данная
ситуация случается не так часто. Когда же силы игроков примерно равны (такое
часто случается при подборе весов оценочной функции) выбирать сложнее.
Соответственно требуется оценить число партий, которые необходимо сыграть,
чтобы достоверно определить победителя. Можно доказать, что число побед одного
игрока над другим распределено по нормальному закону. В этом случае для
получения доверительного интервала для оценки математического ожидания
вероятности победы первого игрока можно воспользоваться следующим выражением:  , где
, где 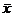 -выборочное среднее,
-выборочное среднее, 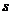 - "исправленное” среднее квадратическое отклонение,
- "исправленное” среднее квадратическое отклонение, 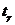 - коэффициент Стьюдента с надежностью
- коэффициент Стьюдента с надежностью 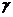 ,
, 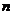 - объем выборки. Так как силы игроков примерно равны, можно
считать, что вероятности выпадения 1 (победа белых) или 0 (победа черных)
равны. Тогда задавшись
- объем выборки. Так как силы игроков примерно равны, можно
считать, что вероятности выпадения 1 (победа белых) или 0 (победа черных)
равны. Тогда задавшись 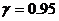 , получим доверительный интервал для
, получим доверительный интервал для 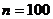 :
: 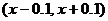 . А для
. А для 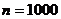 :
: 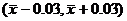 . Основываясь на полученных данных, сравнивать силу двух игроков,
примерно равных по силе, корректно только при числе сыгранных партий близком к
тысяче и более.
. Основываясь на полученных данных, сравнивать силу двух игроков,
примерно равных по силе, корректно только при числе сыгранных партий близком к
тысяче и более.
2.3 Настройка
весовых коэффициентов
Исходя из пункта 1.6 оценочная функция будет иметь вид:
f = - pip - one + group (x2 even if) + block +
pos;
где
pip - расстояние до конца
доски,
one - количество одиночных фишек,
group - вхождение в группу фишек (умножается на два,
если количество фишек в группе чётное),
block - если блокируется фишки противника,
pos - если занимается 4-я, 5-я, 20-я или 21-я
клетка.
2.4 Линейная
модель из 3-х параметров. Вид поверхности
При нынешнем уровне развития вычислительной техники, при
большом числе параметров модели (например, если в качестве параметров
использовать число фишек на каждом поле) перебрать все параметры для
определения подходящих величин не представляется возможным. Но получить
представление о виде поверхности количества побед модели над эталонным игроком,
на примере коротких нард, можно, сведя количество параметров до трех: pips (сумма чисел, которые
нужно выкинуть на кубиках, чтобы выиграть партию), blots (число одиночных фишек),
hold (число удерживаемых
позиций, т.е. с числом фишек больше двух). В результате были построены
зависимости количества побед над эталонным игроком (выбирающим ходы случайным
образом) от blots и hold при фиксированных значениях pips, выбранных равными +1, -
1, +5, - 5. Учитывается разница этих параметров для игроков, играющих белыми и
черными фишками. Перебор этих параметров осуществлялся в диапазоне от - 10 до 10.
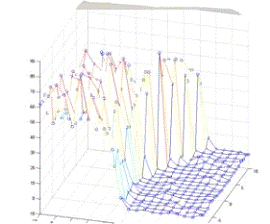
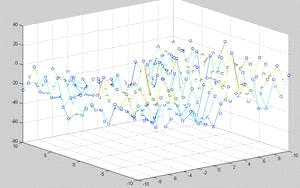
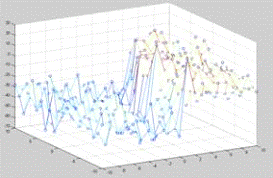
pips = 1 pips = - 1
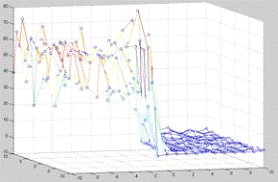
 = 5 pips = - 5
= 5 pips = - 5
Рис. 4. Поверхности количества побед линейной модели над
эталонным игроком от величины параметров.
Из графиков видно, что все три параметра в значительной мере
влияют на качество оценки позиций. Так параметр pips можно проассоциировать с
близостью победы, соответственно, следует максимизировать вес этого параметра.
Количество удерживаемых клеток (две и более фишек на одном поле) также
значительно влияет на количество побед так как его фишки сложнее побить и
соответственно, игрок, обращающий на это внимание выигрывает чаще. Количество blots игрок должен стремиться
минимизировать, так как это "откатывает” его назад. Наилучшие результаты
дало сочетание весов pips = 1, blots = - 8, hold = - 8.
В процессе проведения расчетов было отмечено, что чем ближе
игроки по силе (близость к 0 разницы количества побед игроков) тем дольше идет
партия. Также в ряде статей (например в [11]) отмечается увеличение длины
партий с ростом класса игрока. Данный эффект также был отмечен и в игре в
нарды.
2.5 Таблицы
вероятностей
Для усиления игры программы были опробованы таблицы
вероятностей. Для игры нарды можно построить два типа таких таблиц:
двусторонние и односторонние. Двусторонние таблицы содержат предварительно
просчитанные вероятности победы. Например для шести и менее фишек, находящихся
в доме есть 924 возможных позиции, всего 924*924 = 853,776 возможных позиций
для каждой из которых нужно хранить вероятность победы. Наибольшая проблема
таких таблиц - экспоненциальный рост размера с увеличением числа фишек и полей.
Так, для упомянутой таблицы объем занимаемой памяти можно оценить шестью
мегабайтами, что выходит за рамки ограничений мобильных устройств.
Значительная экономия может быть достигнута при использовании
односторонних таблиц в которых хранятся вероятности вывода всех фишек в данной
позиции за n ходов - 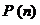 . Предположим, что для игроков A и B в текущей позиции нам известны
распределения
. Предположим, что для игроков A и B в текущей позиции нам известны
распределения 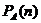 и
и 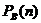 , тогда вероятность того что игрок A выведет все свои фишки первым будет рассчитываться по формуле:
, тогда вероятность того что игрок A выведет все свои фишки первым будет рассчитываться по формуле: 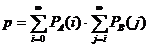 . Число позиций состоящих из 15 фишек на 6
полях равно 54,264 и такая таблица будет занимать в памяти примерно 1.4
мегабайта, что гораздо ближе к ограничениям для существующих мобильных
устройств.
. Число позиций состоящих из 15 фишек на 6
полях равно 54,264 и такая таблица будет занимать в памяти примерно 1.4
мегабайта, что гораздо ближе к ограничениям для существующих мобильных
устройств.
Как оказалось, прирост качества игры от использования такой
таблицы оказался незначительным, что может быть объяснено ее небольшим размером
и тем, что только порядка 1-2% позиций в игре оценивается по ней.
Но можно применить похожие принципы для генерации выборки для обучения
нейронной сети. Так, чтобы получить оценку вероятности выигрыша из данной
позиции можно сформировать некоторый набор позиций. И для каждой из этих
позиций провести по N партий, между двумя равными сильными
игроками. Причем, под числом побед белых над черными можно понимать оценку
данной позиции. На сгенерированной таким образом выборке можно обучить
нейронную сеть и получить оценочную функцию высокого класса. Можно повторять
этот процесс итеративно для улучшения качества оценки.
2.6 Снижение
размерности. Гипергаммон
Одним из способов изучения особенностей игры является
снижение размерности. Так, существует разновидность игры нарды - гипергаммон.
Гипергаммон - вариант нард в котором каждый игрок имеет по три фишки и игра
ведется на обычной доске. Дальнейшее упрощение - рассмотрение только одной
стороны, в котором рассматривается процесс вывода фишек без взятий.
2.7
Разделение игрового процесса на фазы
Игровой процесс в большинстве игр можно достаточно формально
разделить на фазы. Для нард можно выделить следующие фазы: позиции близкие к
начальной, фаза контакта (характеризуется большим числом взятий) и фаза разрыва
контакта (когда единственная цель - как можно быстрее вывести свои фишки). Для
каждой фазы характерна определенна стратегия, и соответственно для общего
повышения качества оценки позиции, можно предварительно классифицировать
оцениваемую позицию и применять разные оценочные функции.
Наиболее простой и наглядной для анализа представляется фаза
разрыва контакта для которой верно следующее утверждение: перед любой из своих
фишек нет фишек противника. Этот случай хорош тем, что можно рассматривать
процесс вывода фишек только одним из игроков - для другого полученные
результаты можно применять автоматически. Частным случаем этой фазы является стадия
непосредственного вывода фишек с последних шести полей.
Для исследования этой фазы игры удобно построить полную
таблицу позиций для небольшого числа фишек (пять - шесть фишек) и посчитать
математическое ожидание числа ходов, необходимых для вывода всех фишек из этой
позиции в случае игры наилучшим образом. В работе была построена такая таблица
методом динамического программирования. Полученные результаты хорошо обобщаются
и на большее число фишек.
Такая таблица занимает значительные объемы памяти (мегабайты)
поэтому ее хранение для оценивания позиций неэффективно. Также невозможно
использование таких данных для оценивания других позиций (контакта). Для этого
нужно аппроксимировать эти данные некоторой функцией. В работе использовалось
несколько видов функций: сумма расстояний до выхода плюс сумма квадратов
расстояний, формула с частным от деления тех же самых параметров, нейронная
сеть. Для настройки параметров этих функций использовался метод наименьших
квадратов
Для сравнения была построена точно такая же таблица на основе
эвристического алгоритма, двигающего дальнюю фишку (подробное описание этого
алгоритма). После сверки каждой позиции, выяснилось, что максимально различие в
числе ходов составляет не более 3%. Таким образом можно говорить, что такой алгоритм
может быть применен для оценки позиции для фазы разрыва контакта практически
без ущерба для качества игры по сравнению с оптимальным вариантом. Такой
вариант также хорош своей простотой, легкостью реализации и нетребовательностью
к аппаратным ресурсам.
3. Построение
оценочных функций на основе нейронных сетей
3.1 Теория
нейронных сетей
Искусственные нейронные сети появились в середине пятидесятых
годов в качестве математической модели нервной деятельности, в том числе
и деятельности головного мозга человека. Нейробиологические исследования с
использованием искусственных нейронных сетей интенсивно ведутся и сегодня.
Одним из важных направлений использования нейронных сетей
является аппроксимация функций. Показано, что нейронные сети с соответствующей
топологией и числом узлов образуют класс универсальных аппроксиматоров, т.е.
позволяет сколь угодно хорошо аппроксимировать функции.
Под искусственной нейронной сетью обычно понимают
ориентированный граф - сеть состоящий из вершин - нейронов соединенных ребрами
- связями. Каждый нейрон может принимать несколько, или бесконечно много,
состояний, характеризующихся потенциалом нейрона - некоторым действительным
числом. К нейрону подходят входные связи, по которым ему передается возбуждение
от других нейронов, и выходные связи при помощи которых нейрон передает
возбуждение другим нейронам. Состояние нейрона pi определяется как
некоторая нелинейная функция f от суммарного возбуждения переданного ему
другими нейронами:
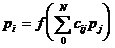 ,
,
где pj - потенциал возбуждающего нейрона, а cij - вес
соответствующей связи.
Первоначально в нейронной сети входные нейроны возбуждаются
подаваемым сигналом. Далее нейроны переходят в некоторые состояния в
соответствии с описанным правилом. После перехода всех нейронов сети в
финальное состояние с выходных нейронов снимаются потенциалы, по которым
определяется результат работы сети.
В процессе тренировки нейронной сети происходит подбор весов
связей, обеспечивающих наименьшую ошибку аппроксимации функции. В настоящее
время известно много алгоритмов тренировки нейронных сетей, но в данном случае
были употреблены генетические алгоритмы.
Типы нейронных сетей (многослойный перцептрон (MLP), сети построенные по адаптивной
резонансной теории (ART), двунаправленная ассоциативная память (BAM), самоорганизующиеся карты (SOM)) различаются топологией и методом
обучения. Под топологией сети понимается количеством входных и выходных
нейронов, число скрытых уровней и способ связи нейронов. Считается, что в
задачах аппроксимации функций наилучшие результаты достигаются при
использовании многослойного перцептрона (MLP).
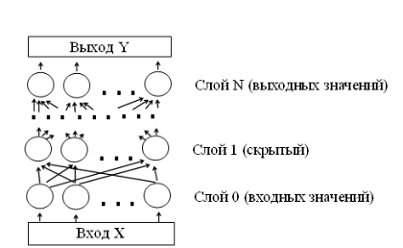
Рис 5. Схема топологии многослойного перцептрона.
При работе многослойного перцептрона, первоначально нейроны 0ого
возбуждаются входным вектором х, после чего последовательно вычисляются
состояния нейронов 1ого,2 ого и наконец последнего Nого
- выходного уровня.
При обучении сети необходимо определить число уровней,
количество нейронов на уровнях и веса связей cij, обеспечивающие
наилучшее представление зависимости выхода у от входа х.
Для правильного обучения сети важно выбрать нужное количество
нейронов (определить топологию сети). В ряде работ предлагается для этого
обучить несколько сетей с различной топологией и выбрать ту, где получился
наилучший результат.
Генетические алгоритмы.
Генетический алгоритм (Genetic algorithm) представляет собой
технику оптимизации, которая моделирует феномен естественной эволюции (впервые
открытый Чарльзом Дарвином). При естественной эволюции выживают и дают самое
многочисленное потомство особи, наиболее адаптированные к сложным условиям
окружающей среды. Степень адаптации, в свою очередь, зависит от набора хромосом
конкретной особи, полученным от родителей. Это основа выживания сильнейшего -
не только процесс выживания, но и участие в формировании следующего поколения.
Решение задачи кодируются в хромосому. Отдельные гены
хромосомы представляют собой уникальные переменные для изучаемой проблемы. При
отборе "здоровых” хромосом из популяции и использовании генетических
операторов (таких как рекомбинирование и мутация) в популяции остаются только
те хромосомы, которые лучше всех приспособлены к окружающей среде, то есть
наиболее полно отвечают задаче.
При рекомбинировании (Recombination) части хромосом
перемещаются, может быть, даже изменяются, а получившиеся новые хромосомы
возвращаются обратно в популяцию для формирования следующего поколения. Первая
группа хромосом обычно называется родителями, а вторая детьми. С одинаковой
вероятностью могут применяться один или несколько генетических операторов.
Доступные операторы включают мутацию и перекрестное скрещивание, которые
являются аналогами одноименных генетических процессов.
Оператор перекрестного скрещивания (Crossover) берет две хромосомы,
разделяет их в произвольной точке (для каждой хромосомы), а затем меняет
местами получившиеся "хвосты”. При этом образуется две новые хромосомы.
Разделение хромосомы в одной точке (получившее название перекрестного скрещивания
в одной точке) является не не единственной возможностью. Также возможно
использовать разделение в нескольких точках.
Оператор мутации (Mutation) вносит произвольное изменение в гены
хромосомы (иногда даже несколько изменений в зависимости от частоты применения).
Он позволяет создавать в популяции новый материал.
3.2
Использование нейронных сетей в качестве оценочной функции
Для применения нейронных сетей в качестве оценочной функции
нужно определить ее топологию, сформировать обучающую выборку и обучить.
Большинство авторов склоняется к использованию трехслойной
нейронной сети (MLP) как наиболее удобной в данном случае, такие сети были
использованы и в этой работе. Существует несколько подходов к определению числа
нейронов в каждом слое. Например, входные нейроны можно понимать как позицию на
доске, представленную в некотором виде (26 входов по числу полей на доске),
либо уже посчитанные параметры от эвристической оценочной функции, либо
совмещение этих вариантов.
В качестве данных для обучения могут быть применены: база
партий признанных игроков, выборка с позициями, оцененными эвристической
оценочной функцией, выборка с оценкой по числу выигранных партий одним из
игроков. Каждый из этих вариантов обладает своими преимуществами и
недостатками. Так, база партий признанных игроков может позволить получить
хорошие оценки качества позиций, но такие базы отсутствуют в свободном доступе,
либо имеют очень ограниченный объем или неопределенное происхождение. Нейронная
сеть, обученная по выборке с позициями, оцененными эвристической оценочной
функцией (ОФ), не может играть лучше чем исходная ОФ, но может вычисляться
быстрее. Наилучших результатов можно добиться используя выборки с оценкой по
числу выигранных партий одним из игроков. Для построения такой выборки проводится
N партий для некоторого
набора позиций (размер выборки), между двумя равными сильными игроками. Причем
под числом побед белых над черными можно понимать оценку данной позиции.
3.3
Использование MatLab для обучения нейронных сетей
Для обучения нейронной сети использовался инструмент nntool программного комплекса МаtLab 7.0. Использование MatLab для обучения нейронной
сети может быть объяснено повышенным удобством построения нейронных сетей с
помощью инструмента nntool, возможностью визуализации построенной нейронной сети,
возможностями значительных вариаций методов обучения нейронных сетей,
несколькими способами инициализации весов, наглядным представлением и
отсутствием необходимости разрабатывать и отлаживать код обучения НС, и тем
самым сокращение сроков разработки готовой программы.
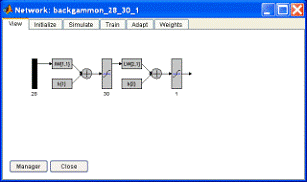
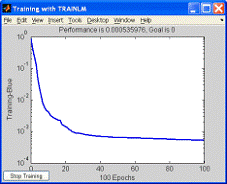
Рис. 6. Графическое представление одной из использовавшихся
нейронных сетей и график ошибки обучения сети в инструменте nntool.
В рамках этого подхода была написана программа-экспортер
позиций и их оценок из внутреннего представления программы в формат MatLab. Для получения данных
(весов нейронной сети) обратно была написана программа-импортер, которая
переводит веса обученной нейронной сети из MatLab во внутренний формат
программы.
Также была реализована функциональность нейронных сетей в
качестве оценочной функции (замена эвристической оценочной функции нейронной
сетью производится простой заменой классов в программе).
Для настройки весов нейронных сетей использовался алгоритм
обратного распространения ошибки. Суть метода состоит в измерении ошибки между
вектором выходных значений нейронов и желаемым выходом, с возвращением
получившейся ошибки к входному уровню с целью выбрать веса в связях минимизирующие
ошибки на выходном уровне, при помощи алгоритма дельта обучения. В комбинации с
этим методом также использовался стахостический метод, основанный на внесении
псевдослучайных изменений в величины весов, сохраняя те изменения, которые
ведут к улучшениям. Этот метод позволяет обойти такие проблемы как: локальные
минимумы и паралич сети. Брать наиболее сильные эвристические функции, для
получения правдоподобных оценок вероятности победы позиций, для работы с
большими, генерируется некоторое число позиций (в работе использовались выборки
размером 10 тыс.
3.4
Экспериментальные данные
Позиции для обучающей выборки брались из партий двух сильных
эвристических алгоритмов. Это позволяет получить репрезентативную выборку, в
отличие от метода случайной генерации позиций.
В качестве входов нейронной сети использовались количество
фишек на каждом поле (28 параметров) или параметры эвристической оценочной
функции (8-10 параметров). Из общих тенденций следует отметить, что время
обучения сети с более формализованными параметрами меньше, а качество игры
выше, что достигается предварительным просчетом параметров. Подход,
использующий параметры эвристической оценочной функции, позволяет достичь
лучших результатов, но требует больших вычислительных ресурсов, что не всегда
оправданно, особенно для портативных устройств.
Было опробовано несколько методик обучения нейронных сетей
(например, уже настроенная эвристическая функция для прямой оценки позиций в
выборке) и несколько топологий (число нейронов в каждом слое, наличие нейронных
смещений).
Наилучшие же результаты показал метод формирования обучающей
выборки, основанный на вычислении оценки по числу выигранных партий одним из
игроков. Так, для получения обучающей выборки генерируется некоторое число
позиций (в работе использовались выборки размером не более 10 тыс. позиций, для
работы с большими выборками инструменту nntool не хватает оперативной
памяти). Для оценки каждой из этих позиций проводится турнир из N партий между двумя
равными игроками, причем текущая позиция берется начальной для каждой партии.
Причем, под числом побед белых над черными можно понимать оценку данной
позиции. Число N в работе бралось не больше 10 тыс. партий (из-за большой
вычислительной сложности задачи). В качестве игроков следует брать наиболее
сильные эвристические функции, для получения правдоподобных оценок вероятности
победы из данной партии. Далее на полученной выборке обучается трехслойная
нейронная сеть и используется в программе в качестве оценочной функции.
В качестве сети использовалась трехслойная нейронная сеть с
28 нейронами во входном слое. В скрытом слое использовалось различное число
нейронов (1, 2, 5, 10, 20), но наилучший результат дала сеть с двумя нейронами,
что объясняется недостаточным объемом выборки и недостаточной точностью оценок.
Построенная нейронная сеть выигрывает около 55% партий у наилучшей
эвристической оценочной функции.
Для дальнейшего увеличения качества игры с применением
нейронных сетей, планируется увеличить объем обучающей выборки и точность
оценок, играя больше партий и используя более сложные ОФ. Увеличение выборок
повлечет за собой отказ от инструмента nntool и написание собственной
функции обучения сети, менее универсальной и менее требовательной к ресурсам.
Также предполагается построить несколько сетей, отвечающие за разные стадии
игры (отсутствие контакта фишек, вывод с доски). Также предполагается
построение итеративного процесса, в котором обученная сеть используется для
формирования следующей выборки, что должно позволить повысить качество игры.
4. Реализация
версии для мобильных устройств
4.1
Особенности программирования портативных устройств
В настоящее время все большую популярность приобретают
различного вида мобильные и портативные устройства, включая сотовые телефоны и
коммуникаторы, карманные персональные компьютеры (КПК) и системы навигации.
Хотя все они содержат в себе в том или ином виде универсальное вычислительное
устройство, архитектура их может существенно отличаться от архитектуры
персональных компьютеров (ПК).
Рассмотрим основные особенности программирования,
оборудования и пользовательского интерфейса портативных устройств.
4.1.1 Размер
экрана
Для портативных устройств существенной характеристикой
являются физические размеры и разрешение экрана. Из соображений эргономики
физические размеры экрана ограничены диагональю 3,5-4 дюйма, а типичное
разрешение составляет 160х160, 320х240 или 320х320 пикселей. Для сотовых
телефонов эти величины еще меньше и составляют порядка 1-2 дюймов и 128х128,
176х220 соответственно.
Такие ограничения естественным образом сказываются на
проектировании пользовательского интерфейса, который приобретает другие
свойства и приоритеты. Необходимо обеспечивать баланс между информационной
насыщенностью и уровнем заполнения экрана, но при этом в большинстве случаев
разрешение экрана может зависеть от конкретной модели и не известно заранее.
4.1.2 Быстрый
отклик
На ПК пользователи, как правило, работают с приложением
достаточно длительный период времени и время отклика, составляющее несколько
секунд, является приемлемым. На мобильных устройствах, таких как сотовые
телефоны, приложение может использоваться 15-20 раз по несколько минут в
течение дня. Таким образом, скорость приложений становится критическим
приоритетом при разработке.
При этом существенное влияние на общую эффективность
оказывает не только скорость выполнения кода, но и удобство взаимодействия
пользователя с интерфейсом приложения.
Для увеличения производительности следует минимизировать
количество перемещений между окнами, обрабатываемых диалогов и т.п. Раскладка
экрана приложения должна быть настолько простой, чтобы пользователь выполнил
свою задачу за минимальное время. Очень полезно разработать пользовательский
интерфейс в соответствии с интерфейсом других приложений.
4.1.3 Ввод
данных
Портативные устройства в силу своих габаритов не могут
обеспечить пользователя полноразмерными устройствами ввода - клавиатурой и
мышью. Как правило устройство оснащается упрощенной или виртуальной клавиатурой
и/или сенсорным экраном.
Учитывая, что эти средства не обеспечивают достаточного
удобства, следует минимизировать объем вводимой пользователем информации.
4.1.4 Питание
Портативные устройства обеспечиваются, как правило,
источником энергии существенно ограниченной емкости. Соответственно,
ресурсоемкие задачи, требующие большого объема вычислений, следует по
возможности выносить для решения сопутствующим ПО на стационарных ПК.
4.1.5 Память
Портативные устройства являются ограниченными по объему
доступной памяти, как для времени исполнения, так и для хранения данных.
Типичное значение доступной памяти для мобильных телефонов составляет от 128 Кб
до 2 Мб. Некоторые устройства поддерживают дополнительные карты памяти объемом
32-512 Мб, но только для хранения приложений и данных.
По этой причине существенной является оптимизация применяемых
алгоритмов и программ по следующим приоритетным направлениям (в порядке
убывания важности):
объем памяти, используемой при работе
скорость
объем кода
4.1.6
Файловая система
По причине ограниченного объема памяти для хранения данных
портативные устройства редко используют традиционные файловые системы.
Типичные свойства, обеспечиваемые ОС - доступ и установка
атрибутов отдельных записей, на не всех файлов для обеспечения частичной
синхронизации и работы с записями по месту, без предварительной загрузки и
последующей записи.
4.2 Выбор
средств разработки
Программа написана на языке Java с использованием
технологии Java Micro Edition. Язык Java - это объектно-ориентированный язык
программирования и программа разбита на части, называемые классами (или
объектами). Каждый класс описан в отдельном файле и компилируется также в
отдельный файл. Возможности объектно-ориентированного программирования
максимально использовались для того, чтобы отделить код интерфейса от кода
алгоритма, между которыми в сущности мало общего. Это позволяет с легкостью
модифицировать как интерфейс, так и алгоритм не затрагивая другие части
программы.
Рассмотрим вкратце архитектуру платформы Java 2 Platform,
Micro Edition (J2ME), которая использовалась при написании программы.
Для того, чтобы поддержать гибкость и настраиваемость
размещения, требуемые семейством ограниченных по ресурсам устройств, таких как
сотовые телефоны, архитектура J2ME спроектирована модульной и масштабируемой.
Эта модульность и масштабируемость определяется технологией J2ME в завершенной
прикладной модели времени исполнения, имеющей четыре программных уровня,
строящихся над операционной системой устройства.
На рисунке ниже показана схема архитектуры J2ME.
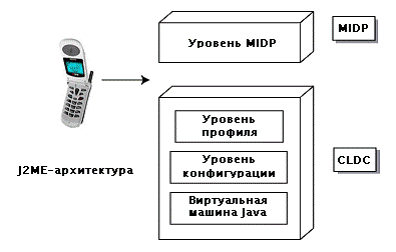
Уровень Java Virtual Machine (JVM). Этот уровень представляет собой реализацию
виртуальной машины Java, которая адаптирована под операционную систему
конкретного устройства и поддерживает конкретную конфигурацию J2ME.
Уровень конфигурации. Уровень конфигурации определяет минимальный
набор функций JVM и библиотек классов Java, доступных для определенной
категории устройств. В некоторой степени конфигурация определяет общие свойства
и особенности платформы Java и библиотек, которые в предположении разработчиков
должны быть доступны для всех устройств, принадлежащих конкретной категории.
Этот уровень менее видим для пользователей, но является очень важным для
разработчиков профилей.
Уровень профиля. Уровень профиля определяет минимальный набор API
(интерфейс программирования приложений), доступный для конкретного семейства
устройств. Профили создаются для конкретной конфигурации. Приложения создаются
для конкретного профиля и являются, таким образом, переносимыми на любое
устройство, поддерживающее этот профиль. Устройство может поддерживать
несколько профилей. Этот уровень является наиболее видимым для пользователей и
поставщиков приложений.
Уровень MIDP. Уровень Mobile Information Device Profile (MIDP)
представляет собой набор Java API, предназначенный для решения таких вопросов
как пользовательский интерфейс, постоянное хранение и сетевые функции.
Разработка игры нарды для мобильных телефонов проводилась с
применением Java 2 Micro Edition
Wireless Toolkit 2.2 (J2ME WTK 2.2).
Фазы разработки приложений с помощью Wireless Toolkit можно
представить в виде диаграмм:
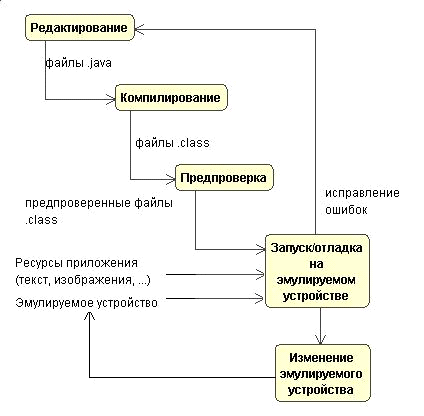
Схема 1 Фазы разработки приложений с помощью Wireless Toolkit
Достоинства и недостатки JAVA:
. Независимость от архитектуры ЭВМ
Самое большое преимущество Java - его
"нейтральность" по отношению к любой архитектуре. Программа,
полностью написанная на Java, будет исполняться везде, где есть Виртуальная
Java-машина, JVM (Java Virtual Machine).
. Безопасность
В популярной литературе наших дней, особенно если речь
заходит об Internet, стало модной темой обсуждение вопросов безопасности. Один
из ключевых принципов разработки языка Java заключался в обеспечении защиты от
несанкционированного доступа.
. Надежностьограничивает вас в нескольких ключевых областях и
таким образом способствует обнаружению ошибок на ранних стадиях разработки
программы. В то же время в ней отсутствуют многие источники ошибок,
свойственных другим языкам программирования (строгая типизация, например).
Большинство используемых сегодня программ "отказывают” в одной из двух
ситуаций: при выделении памяти, либо при возникновении исключительных ситуаций.
. Объектная ориентированность
Поскольку при разработке языка отсутствовала тяжелая
наследственность, для реализации объектов был избран удобный прагматичный
подход. Объектная модель в Java проста и легко расширяется, в то же время, ради
повышения производительности, числа и другие простые типы данных Java не
являются объектами.
. Простота и мощь
После освоения основных понятий объектно-ориентированного
программирования вы быстро научитесь программировать на Java. В наши дни
существует много систем программирования, гордящихся тем, что в них одной и той
же цели можно достичь десятком различных способов.
. Богатая объектная среда
Среда Java - это нечто гораздо большее, чем просто язык
программирования. В нее встроен набор ключевых классов, содержащих основные
абстракции реального мира, с которым придется иметь дело вашим программам.
Основой популярности Java являются встроенные классы-абстракции, сделавшие его
языком, действительно независимым от платформы.
. Производительность и предсказуемость
. Размер кода
В целом Java-система очень велика. Создаваемый код довольно
велик - Windows-станции для хорошей работы должны иметь хотя бы 20 Мб памяти.
Размер программы можно уменьшить, используя динамическую компоновку и
подключение классов только в необходимый момент.
. Требования к памяти
Требования к памяти очень тесно связаны с процессом
"сборки мусора”. Java нужно очень много дополнительной памяти, чтобы
чистка памяти не происходила в неподходящий момент.
4.3
Реализация игры
Итогом работы стала игровая программа нарды для мобильных
устройств с поддержкой технологии Java. Игра обладает богатой графикой и набором
особенностей, позволяющих выделить именно эту реализацию среди подобных игр
конкурентов. К этим особенностям можно отнести возможности игры с историческими
личностями, имеющими собственные стили игры, игры в турнирах, ведение
рейтингов. Скриншоты из игры представлены на рисунке 3.
Для управления игрой используются переменные: private byte gameState, private int currentColor, private int moveNumber.
moveNumber - это номер хода. currentColor - цвет игрока, выполняющего
ход (чёрный или белый). gameState может принимать значения:
byte GAMEOVER=1; // игра кончена
byte INPLAYERMOVE=3; // приложение ожидает выполнения хода игрока
byte INCOMPUTERMOVE=4; // приложение ожидает
выполнения хода компьютера
byte MOVECOMPLETED=5; // ход выполнен
Переменная gameState используется для управления событиями и
определения, какие процессы имеют место в данный момент. К примеру, если
пользователь хочет поставить фишку, он может это сделать только если сейчас его
очередь.
Теперь представляю вашему вниманию структурную схему игры:
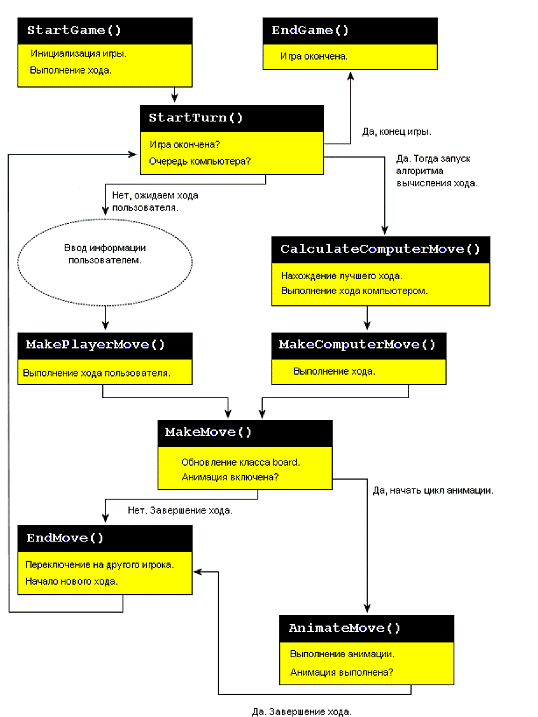
Схема 2. Структурная схема игры.
Функция StartTurn () вызывается в начале игры и после выполненного
хода любым из игроков. Она отвечает за определение игровой ситуации и
подготовку следующего хода.
Прежде всего она проверяет, имеет ли текущий игрок хоть одну
клетку для хода. Если нет, она переключает ход на другого игрока и проверяет,
имеет ли другой игрок клетки для хода. Когда ни один игрок не может делать ход,
значит, игра окончена.
В противном случае, функция организует выполнение хода для
текущего игрока. Если текущий игрок - пользователь, всё очень просто далее
вызывается MakePlayerMove (), которая выполняет некоторые служебные оерации и
вызывает MakeMove () для выполнения хода.
Если текущий игрок - компьютер, вызывается функция
CalculateComputerMove () для вычисления лучшего хода. Затем вызывается
MakeComputerMove () и MakeMove (). MakeMove () обновляет класс Board и помещает новую фишку в
нужную клетку.
Далее вызывается функция EndMove (), которая переключает
текущего игрока и вновь вызывает StartTurn ().
Функция CalculateComputerMove () содержит 6 вспомогательных
функций:
Первая функция генерирует все возможные ходы (с текущим
положением кубиков) и осуществляет выборку наиболее вероятных ходов.
Вторая функция осуществляет подсчёт пипсов. Количество пипсов
- это число, которое нужно выбросить на игральных костях, чтобы вывести все
свои фишки. По этому параметру определяют лидерство и близость победы.
Третья функция максимизации числа полей с двумя и более
фишками. Число полей с двумя и более фишками является противоположностью
предыдущему параметру, его стремятся максимизировать. Чем больше таких полей,
тем устойчивее позиция и тем сложнее через нее пройти.
Четвертая функция рассчитывает возможность блокад - несколько
смежных полей, занятых двойными или более фишками. С этим параметром можно
связать изменение стратегии - нужно проводить свои фишки вперед, если их
запирают.
Пятая функция анализирует число прямых возможностей взятий -
это число одинарных фишек на расстоянии 6 или меньше полей. Есть схожий с этим
параметр - число одинарных фишек на расстоянии меньшем 12. Схожим параметром
является вероятность взятия одинарной фишки, которая в большинстве случаев рассчитывается
по предварительно посчитанной таблице.
Шестая анализирует выгодную позицию. Анализируя сыгранные
партии можно заметить, что занятие определенных позиций на доске способствует
победе. Такими позициями является 4-я и 5-я клетки и соответственно 20-я и 21-я
симметричные клетки. Таким образом, в простейшем случае можно ввести факт
занятия этих клеток в оценочную функцию. В более общем случае, вводят весовые
коэффициенты для всех полей доски.
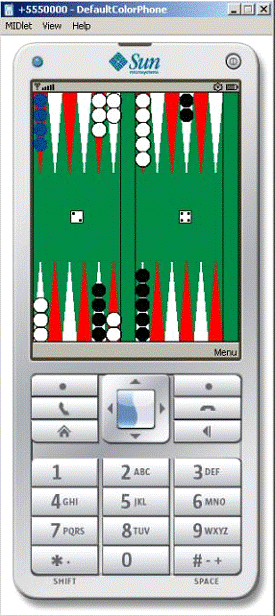

Рис. 6. Скриншоты игры.
Таблица 1. Используемые классы.
|
Наименование
класса
|
Назначение
класса
|
|
App
|
Унаследован
от класса Midlet. В нём создаются экземпляры имеющихся
классов, а также находится точка входа в программу. Класс отвечает за запуск
приложения и выход из него, а так же на всевозможные внешние реакции,
например звонок.
|
|
Board
|
Данный класс
представляет доску. Класс использует двумерный массив, который отвечает за
содержимое каждой клетки доски. Также этот класс содержит количество фишек
каждого игрока.
|
|
MyCanvas
|
Унаследован
от класса Canvas. В нем находится код, отвечающий за
управление процессом создания интерфейса пользователя, объявления набора
данных необходимых для работы всего приложения. В этом классе содержатся
объекты и методы, отвечающие за интерфейс, такие как меню, функция прорисовки
доски, реакция на нажатия клавиш. В классе содержится оценочная функция, а
так же алгоритм нахождения лучшего хода
|
Разработанная версия игры в короткие нарды основана на
линейной модели. Выбор в пользу линейной модели а не НС был сделан в виду
незначительного превосходства в качестве оценки позиций последней, но
значительно возросшем количестве вычислений, что критично для мобильных
устройств.
Заключение
В процессе работы были реализованы короткие нарды. Поскольку
в нардах присутствует элемент случайности (бросаются кости, которые определяют
количество ходов), алгоритмы, основанные на рекурсивном переборе позиций, не
позволяют добиться хороших результатов, необходимо было разработать хорошую
функцию оценки. Для решения этой задачи были построены линейные модели и
использовались нейронные сети с использованием игры с собой.
Для построения оценочной функции с использованием нейронных
сетей, использовалось несколько подходов. Так, в одном из самых перспективных
подходов для получения оценки вероятности выигрыша из данной позиции
формировался некоторый набор позиций. И для каждой из этих позиций проводилось
по N партий, между двумя
равными сильными игроками. Причем, под числом побед белых над черными можно
понимать оценку данной позиции. На сгенерированной таким образом выборке
обучалась нейронная сеть и полученная сеть использовалась как оценочная
функция. Можно повторять этот процесс итеративно для улучшения качества оценки.
К настоящему моменту был реализован прототип программы,
обладающий значительной частью функциональности и реализующий алгоритм игры.
Список
литературы
1. Ф.
Уоссермен, Нейрокомпьютерная техника: Теория и практика 1992г
2. Джонс
М.Т. Программирование искусственного интеллекта в приложениях /М. Тим Джонс;
Пер. с англ. - М.: ДМК Пресс 2004. - 312 с.: ил.
. Эккель
Б. Философия Java: Библиотека программиста Питер, 2001г
4. G.I.
Belchansky, N. V. Korobkov, "Neural network application for analysis of
satellite remote sensing data”, Research of the Earth form Space, 1998, N4, pp
111-120
. Imran
Ghory, Reinforcement learning in board games. 2004.
. J.
B. Pollack, A. D. Blair, Co-Evolution in the successful learning of backgammon
strategy.
. W.
Duch, R. Adamczak, Statistical methods for construction of neural networks.
. D.
Stoutamire, Machine learning, game play, and Go.
. W.
S. Sarle, Neural networks and statistical models, 1994.
. A.
Shapiro, G. Fuchs, R. Levinson, Learning a game strategy using pattern-weights
and self-play.
. J.
Baxter, A. Tridgell, L. Weaver, KnightCap: a chess program that learns by
combining TD with game-tree search.
. A.
Junghanns, J. Shaeffer, Search versus knowledge in game-playing programs
revisted.
. G.
Tesauro. TD-Gammon, a self-teaching backgammon program. Neural Computaion, 6:
215-219, 1994.
. J.
Pollack & A. Blair "Co-Evolution in the successful learning of
backgammon strategy.
. M.
Buro "Efficient approximation of backgammon race equities”.
16. Информационные
ресурсы сети Интернет (http://www.bkgm.com, http://www.gnubg.org).