Отказоустойчивые системы реального времени
Оглавление
Введение
1. Системы
реального времени
1.1 Основные
характеристики
1.1.1 Требования к
СРВ
1.1.2 Параметры
ОСРВ
1.2 Архитектура
ОСРВ
1.3 Механизмы
реального времени
2. Понятие
отказоустойчивости
2.1 Причины
сбоев
2.2 Элементы
отказоустойчивости
2.3 Способы
обеспечения отказоустойчивости
3. Отказоустойчивость
в существующих системах реального времени
3.1 QNX Neutrino
VxWorks
AE
Заключение
Список
литературы
Введение
При проектировании различной сложности систем
требуется выполнять различные условия, диктуемые поставленной задачей. При
этом, как правило, всегда есть стремление сделать систему с максимальным
коэффициентом полезного действия. Конечно, широко известно, что невозможно
сделать абсолютно все параметры системы максимально оптимальными. В любом
случае приходится выделять те или иные параметры, как более важные, а каким-то
назначать более низкий приоритет.
Особое место среди различного вида задач имеют
задачи реального времени. Все дело в том, что для их решения требуется
соблюдение множества условий, причем нельзя сказать, что определенным условием
можно пренебречь. У некоторых людей существует мнение, что задачи реального
времени можно решать с помощью операционных систем общего назначения [1] и
хорошего владения языками программирования, однако это неверно.
Неспециализированные ОС не имеют той особой структуры, позволяющей решать
поставленные задачи с максимальным качеством.
Как правило, системы реального времени создаются
для решения определенного класса задач, чаще - определенной группы задач. Но у
всех подобных систем есть ряд общих требований и качеств, которыми они
характеризуются. Это позволяет проводить соответствующие исследования и искать
новые пути решения проблем, общих для систем реального времени.
Одним из самых важных качеств является
отказоустойчивость системы. Этот параметр важен для любых систем, но в случае
реального времени - особенно. Данная работа предполагает исследование возможных
путей обеспечения отказоустойчивости для систем, а также рассмотрение реально
существующих подобных.
1. Системы
реального времени
1.1 Основные
характеристики
1.1.1 Требования к СРВ
Системы реального времени (СРВ) - структура,
состоящая из множества связанных между собой элементов [2], выполняющая
определенные функции, которая реагирует в течение определенного временного
промежутка на любое входное воздействие [3].
Это определение дает представление о
требованиях, предоставляемых к системам данного рода. Данные требования можно
свести к трем понятиям, названия которых перекочевали в русский язык с
английского:
Дедлайн (deadline) - директивный срок задачи
[4]. Это понятие сводится к тому, что выполнение любой обработки сигнала должно
происходить не более, чем за строго определенный временной период, и
закончиться к определенному моменту времени, который как раз и называется
дедлайном.
Джиттер (jitter) - разброс в значениях [4]. В
данном случае речь идет о времени отклика, т.е. времени обработки сигнала. При
этом в среднем, независимо от пришедшего на систему сигнала, значения должны
быть одинаковыми. Это означает, что в СРВ джиттер должен быть максимально
минимизирован.
Латентность (latency) - задержка реакции системы
[4]. Так как определено понятие дедлайна, естественным становится минимизация
задержки реакции системы на прерывание, т.е. минимизация латентности. При этом
значение латентности всегда меньше значения времени обработки рассматриваемого
сигнала, так как иначе наблюдается нарушение дедлайна.
Таким образом:
СРВ должна реагировать на любое входное
воздействие в течение определенного времени [5], заданного при проектировании
систем (понятие дедлайна). При этом для различных типов сигналов время реакции
системы может быть различно (с учетом минимизации значения джиттера), но
обязательно строго регламентировано в рамках разработанной системы.
СРВ должна реагировать на несколько одновременно
поступающих на вход сигналов [5], при этом ни один из сигналов не должен
обрабатываться дольше заданного для него времени (требуется соблюдение понятия
дедлайна).
Также СРВ можно разделить на два типа, в
зависимости от отношения к временным задержкам:
Системы жесткого реального времени, когда
задержки строго запрещены, при этом любая из них приводит к непригодности
системы.
Системы мягкого реального времени, когда
задержки запрещены, но допускаются, при этом характеристики системы ухудшаются:
производительность снижается [6].
.1.2 Параметры ОСРВ
Операционные системы реального времени (ОСРВ) -
операционные системы, обеспечивающие интерфейс для работы с СРВ. В отличие от
требований к СРВ, требований к ОСРВ больше, так как речь идет не о теории, а о
практике, т.е. о возможности реализовать заданную систему на самом деле.
В свое время, Мартин Тиммерман, исследователь в
области операционных систем реального времени, сформулировал свод требований,
необходимых для любой операционной системы, претендующей на звание системы
реального времени [7]:
ОС должна быть мультипрограммной и
мультизадачной.
ОС должна использовать прерывания для
диспетчеризации, т.е. допускать вытеснение одной обрабатываемой программы
другой. Это требование приводит к следующему:
ОС должна обладать развитой системой
приоритетов.
ОС должна иметь систему наследования
приоритетов, т.е. повышение уровня приоритета потока до уровня потока, который
его вызывает, для исключения явления инверсии (когда завершение обработки
задачи с более высоким приоритетом зависит от обработки задачи с меньшим
приоритетом). Для описания этого требования можно привести следующий условный
пример: задача с приоритетом 3 вызывает подзадачу с приоритетом 9. Во время работы
подзадачи, в систему поступает задача с приоритетом 6. Из-за этого процесс с
приоритетом 9 прервется, и даст возможность работе только что поступившего
процесса. Однако это неверно, так как подзадача была лишь промежуточным этапом
в работе процесса с приоритетом 3, который важнее, чем вновь поступивший
процесс, а, следовательно, должен быть завершен раньше.
ОС должна обеспечивать механизмы синхронизации
задач.
Поведение ОС должно быть хорошо прогнозируемо,
говоря более точно - поведение системы должно быть строго детерминировано.
Рассмотрев требования к ОСРВ, можно сделать
вывод о параметрах, важных для разработки систем. К ним относятся [1]:
Время реакции системы на прерывание
(рассмотренное выше при перечислении требований к СРВ).
Время переключения контекста (время переключения
от одного процесса к другому).
Размер системы управления (фактически, речь идет
о размере ядра). При этом следует отметить, что со временем этот параметр
становится все менее важным. Все большие объемы памяти становятся доступными
для использования в любых ситуациях.
Возможность исполнения системы из ПЗУ, что
означает возможность создания компактных встроенных СРВ повышенной надёжности,
с ограниченным энергопотреблением, без внешних накопителей.
.2 Архитектура ОСРВ
Для выполнения соответствующих функций требуется
определенная архитектура операционной системы. В процессе исследований были
выделены 3 вида ОС, при этом у каждого вида архитектуры есть свои недостатки.
Рассмотрим их:
Монолитная архитектура.

Достоинство: повышенное быстродействие системы,
так как ядро совпадает с системой.
Недостаток: как ни странно, но наличие множества
модулей обеспечивает сложность системы [7], что приводит к непредсказуемости
поведения системы [6] в процессе эксплуатации в некоторых системах (очень
сложно предусмотреть все возможные реакции системы на те или иные входные
потоки данных).
Многослойная архитектура.

Достоинства: возможность обращения к аппаратуре
непосредственно, минуя сервисы системы, обеспечивает снижение времени отклика и
увеличивает предсказуемость реакции системы [7] (проще отследить, какая часть
дает сбой, в случае ошибки).
Недостаток: отсутствие многозадачности [6]
«Клиент-сервер» архитектура.

Достоинства: повышается надежность системы и её
отказоустойчивость, так как система фактически состоит из множества сервисов,
отказы которых легко прослеживаются и не критичны для работы системы в целом
(возможна перезагрузка сервиса без перезагрузки системы). Также подобная
архитектура улучшает масштабируемость системы [7], так как можно удалять
ненужные сервисы и легко добавлять дополнительные компоненты.
Недостаток: введение защиты памяти повышает
время переключения с одного процесса на другой (время переключения контекста),
что увеличивает время работы системы [7].
.3 Механизмы реального времени
Самым важным критерием оценки работы системы
реального времени является время, поэтому для разработчиков особенно важно
уметь управлять процессами так, чтобы временные ограничения выполнялись. В
теории [1] существует система, которая управляется путем описания возможных
событий на объекте. Для каждого события указывается лишь адрес выполняемой
команды и дедлайн. Однако в реальности таких систем нет, и разработчикам
приходится рассматривать все параметры систем реального времени для составления
сценария работы ОСРВ. Для этого программисты используют специальные механизмы
реального времени [1].
Система приоритетов процессов (задач) и
алгоритмы диспетчеризации (планирования).
В разработке эффективного планирования
используются два подхода: статические и динамические алгоритмы диспетчеризации.
В первом случае приоритеты присваиваются задачам до начала их выполнения, во
втором же приоритеты назначаются динамически, учитывая дедлайн задач. При этом,
как правило, планировщики ОСРВ учитывают возможность вытеснения задач в случае
необходимости.
Механизмы взаимодействия между задачами и
распределения ресурсов.
К таким механизмам относятся: семафоры,
мьютексы, события, сигналы, средства для работы с разделяемой памятью, каналы
данных (pipes), очереди сообщений. При этом важным остается скорость выделения
того или иного ресурса, а также время, на которое он блокируется используемым
процессом.
Эти средства обеспечивают непосредственную
работу со временем. Они позволяют задавать и измерять различные промежутки
времени, а также генерировать прерывания.
2. Понятие отказоустойчивости
2.1 Причины сбоев
Отказы по причине возникновения делятся на
конструкционные и эксплуатационные. Эксплуатационные возникают при неправильном
использовании системы, в то время как конструкционные происходят по вине
разработчиков, не предусмотревших все возможные реакции системы. В системах
реального времени возможно возникновение двух классов сбоев: программных и
аппаратных. При этом возникновение первых чаще всего означает нарушение
принципов реального времени, и фактически характеризует систему как систему
общего назначения (не применимую к задачам реального времени). Понятие
надёжности программного обеспечения неконструктивно, это означает, что на этапе
тестирования программы не были выявлены все ошибки, поэтому предполагается, что
они отсутствуют.
Обеспечить отказоустойчивость системы на
аппаратном уровне сложнее. При возникновении того или иного сбоя система должна
продолжать функционирование. Ясно, что в случае монолитной системы отказ любой
части приведет к отказу системы в целом. Рассматривая аппаратурные сбои [8],
можно выделить следующие основные классы отказов аппаратуры:
отказ процессора (некоего элементы системы);
отказ связи между элементами системы.
Идентификация отказа процессора какого-либо узла
сети классифицируется как отказ всего узла: он изолируется от остальной сети на
логическом уровне и при наличии соответствующей поддержки отключается на
аппаратном уровне (выключается питание). Идентификация отказа линии связи между
элементами приводит лишь к уменьшению степени связности узлов сети. Линия связи
изолируется на логическом уровне путем изменения маршрутов передачи сообщений
между узлами сети.
Основная особенность (и достоинство) сетевой
отказоустойчивой технологии - отсутствие какого-либо (даже самого
незначительного) единственного компонента (ресурса), выход из строя которого
приводит к фатальному отказу всей системы. Такая система не может содержать
какого-либо "центрального" (главного) узла, размещенного в одном из
процессорных элементов системы, она может состоять только из "равноправных"
частей, размещенных в каждом узле сети.
Предсказать и устранить все причины сбоев не
реально. С течением времени проявляются все новые источники опасности для
систем. В конце концов, задача разработчика - создать систему, для которой была
бы определена реакция на любое событие, даже ошибку. Таким образом, любой сбой
приведет к заранее определенному поведению, что должно обеспечить работу
системы фактически в любых условиях.
.2 Элементы отказоустойчивости
Изоляция приложений [9] - гарантия того, что ни
одна из программ не сможет разрушить ни другие приложения, ни базовую
операционную систему. Обычно эта задача решается путем использования блоков
управления памятью (диспетчеров памяти), для чего в операционной системе
имеется либо набор пользовательских API-интерфейсов (специально организованных
низкоуровневых методов, предоставляемых системой приложениям) для назначения
прав чтения/записи, либо, что встречается более часто, механизм создания
областей памяти с ограниченным доступом. При попытке обращения в запрещенную область
исполнение программы прекращается и запускается механизм восстановления после
сбоя. И что важнее всего, обработка исключительных ситуаций может быть
реализована в отдельном адресном пространстве приложения и никак не влиять на
остальные части системы.
Существует несколько весьма важных элементов
отказоустойчивости, гарантирующих высокую надежность системы
"Восстановление" ресурсов [9] - после
завершения работы прикладной программы (независимо по какой причине),
выделенные ей ресурсы должны быть возвращены в систему, если только они не
объявлены как резервные. При отсутствии этой возможности система с частыми
запусками/остановками приложений быстро приходит к состоянию неэффективной
работы в связи с недостатком требуемых ресурсов и необходимости её перезагрузки.
Учитывая потребность в таком качестве, как обслуживаемость, в этих случаях
нужна определенная гибкость, позволяющая контролировать живучесть объектов,
ответственных за поддержание уровней сервиса в процессе модернизации. Например,
серверная задача, извлекающая запросы из очереди сообщений, может быть заменена
без какого-либо уведомления клиентских программ, поскольку очередь продолжает
существовать независимо от замены и может накапливать запросы, пока обновленный
сервер не начнет работать. В состав операционной системы должны входить
средства переназначения прав владения, для того чтобы постоянно существующие
объекты не возвращались в систему во время восстановления ресурсов
"Пользовательский/супервизорный"
режимы [9] - если приложение исполняется в "системном", или
супервизорном режиме, то ему становятся доступными некоторые привилегированные
операции, которые могут привести к необратимым последствиям. Идеальная
операционная система должна обладать достаточной гибкостью, обеспечивая создание
привилегированных пользовательских "процессов", которые могут
исполняться в супервизорном режиме, но только после соответствующей
аутентификации
Защита от перерасхода ресурсов [9] - когда
пользовательские программы пишутся без контроля над использованием ими системных
ресурсов или содержат "размножающиеся" потоки исполнения, надежность
системы вследствие исполнения таких программ может серьезно снизиться. Защита
от перерасхода ресурсов, например, могла бы предусматривать ограничение уровней
приоритета пользовательских задач, контроль переполнения пользовательского
стека во избежание разрушения содержимого памяти других задач и т.д. Еще более
повысить отказоустойчивость системы можно путем определения "мягких"
(означающих выдачу предупреждающих сообщений) и "жестких" (сигнал об
исчерпании лимита пользования ресурсом) порогов, при нарушении которых
запускаются соответствующие действия по восстановлению.
.3 Способы
обеспечения отказоустойчивости
Для обеспечения надежного решения задач в
условиях отказов системы применяются два принципиально различающихся подхода
[10] - восстановление решения после отказа системы (или ее компонента) и
предотвращение отказа системы (отказоустойчивость). Системы, устойчивые к
отказам, либо маскируют отказы, либо ведут себя в случае отказа заранее
определенным образом.
По мере того как операционные системы реального
времени и встроенные компьютеры все чаще используются в критически важных
приложениях, разработчики создают новые ОС реального времени высокой готовности
[8]. Эти продукты включают в себя специальные программные компоненты, которые
инициируют предупреждения, запускают системную диагностику для того, чтобы
помочь выявить проблему, или автоматически переключаются на резервную систему.
Обеспечение отказоустойчивости предполагает
парирование действия константных отказов и маскирование сбоев (перемежающихся
отказов) [11], т.е. предотвращение распространения последствий сбоя на
продолжение выполнения системой своих функций. Парирование действия отказов
всегда связано с введением в систему того или иного вида избыточности.
Существует несколько способов обеспечения
отказоустойчивости работы систем. Один из них основан на фиксировании
константного отказа или сбоя системы в целом или в ее отдельных частях с
последующей реконфигурацией системы. Такой способ связан с прерыванием
функционирования системы, т.е. не обеспечивает отказоустойчивость в системах
реального времени.
Известен способ обеспечения отказоустойчивости,
позволяющий маскировать сбои и основанный на мажорировании, т.е. использовании
2n+1 каналов (в данном способе количество процессоров не играет роли, работа
может производиться и на одном, важно увеличение числа каналов) и схемы
голосования, отбирающей те выходные данные, которые представляют большинство.
Такой способ и используется для систем реального времени. Мажорирование может
быть осуществлено или аппаратно, или программно, или в комбинации этих
способов.
Недостатком таких способов является значительное
количество оборудования, даже в минимальном варианте при n=1 (троирование).
Другим недостатком способов мажорирования являются значительные потери
производительности. При аппаратной реализации потеря производительности связана
с необходимостью синхронизации процессов в резервированных каналах. При
программной реализации быстродействие системы снижается из-за затрат времени на
обмен информацией между каналами.
Причина такой неэффективности состоит в том, что
и при аппаратной, и при программной организации механизм маскирования сбоев,
т.е. голосование, определение неисправного канала, его блокирование и
последующее включение в нормальную работу, используется в каждом такте работы
системы вне зависимости от наличия или отсутствия сбоев. Эти временные потери
при практической реализации достигают 30-50%. К недостаткам мажорирования при
его реализации следует отнести также большое количество связей между каналами и
значительные трудности при проектировании.
Следует отметить, что при аппаратном
мажорировании нормальное функционирование при деградации системы до одного
канала обеспечивается лишь при дополнительных аппаратных и временных затратах.
При программном мажорировании в случае константных отказов реконфигурация до
одного исправного канала возможна без дополнительных аппаратных затрат. Но
увеличение кратности маскируемых сбоев в отличие от аппаратного мажорирования,
где это можно осуществить путем организации многократного голосования при
прохождении сигналов по системе или соответственно путем введения аппаратной
избыточности невозможно.
Сокращение аппаратной и временной избыточности и
расширение функциональных возможностей в некоторых случаях достигается тем, что
в способе, заключающемся в маскировании сбоев путем резервирования и включающем
определение наличия сбоев, идентификацию и блокировку неисправных каналов для
маскирования сбоев, используют независимую одновременную работу N каналов,
число которых на единицу больше кратности маскируемых сбоев, сигналы которых
подают на общий выход. По сигналам, полученным от детекторов сбоев, входящих в
состав каждого канала, производят блокировку прохождения сигналов от каналов, в
которых произошли сбои и пропускают на выход тот из сигналов от исправных
каналов, который приходит первым по времени.
При этом определение наличия сбоя, идентификация
и блокировка неисправных каналов производится либо после прохождения на выход
сигнала, пришедшего первым по времени, либо до его поступления.
3. Отказоустойчивость
в существующих системах реального времени
3.1 QNX Neutrino
отказоустойчивость
система реальное время
QNX - первая коммерческая ОС, построенная на
принципах микроядра и обмена сообщениями [12]. Система реализована в виде
совокупности независимых (но взаимодействующих через обмен сообщениями)
процессов различного уровня (менеджеры и драйверы), каждый из которых реализует
определенный вид сервиса. В процессе разработки системы в качестве её основного
применения рассматривались критические ситуации, при которых отказ приводил бы
к крупному материальному ущербу или даже к человеческим жертвам [13]. В связи с
этим в QNX Neutrino наряду с микроядерной архитектурой с полной изоляцией
модулей в ОЗУ предусмотрен ряд механизмов, обеспечивающих надежность
автоматизированных систем [13].
Микроядерная архитектура с полной изоляцией
модулей в ОЗУ
В подобной архитектуре [13] микроядро является
связывающим элементом, обеспечивающим связь элементов системы между собой, но
при этом не реализует большинство системных сервисов. Это позволяет
разработчику самому решить, какие сервисы нужны для решения его прикладной
задачи, позволяет самому написать необходимые системные приложения и подключить
их в систему, создавая по возможности ОС весьма небольшого размера и узкой
специализации.
Одновременно с этим микроядро отвечает за
реализацию всех механизмов поддержки жесткого реального времени:
фиксированные приоритеты потоков (256 уровней) и
функция-обработчик ISR (обработчик прерываний [16] - специальная процедура,
вызываемая по прерыванию для выполнения его обработки);
мгновенное вытеснение задачи с меньшим
приоритетом;
вытесняемые системные вызовы;
защита от инверсии приоритетов на базе протокола
наследования приоритетов;
исключение непредвиденных расходов ресурсов;
механизм трассировки ядра, позволяющий узнать
точное время каждой операции.
Механизм адаптивного квотирования ресурсов ЦПУ и
ОЗУ
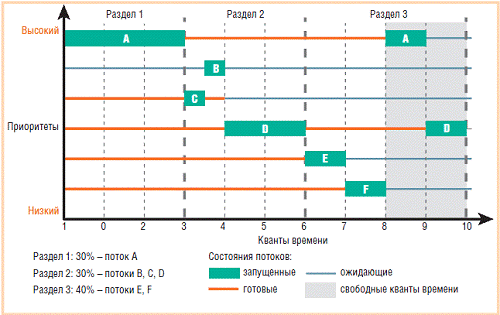
Проще всего рассмотреть механизм на примере
[13]. Имеется система и шесть выполняемых в ней потоков (A, B, C, D, E, F), у
каждого из который имеется свой приоритет (у А максимальный, у F -
минимальный). Для квотирования (разделения) ресурсов процессора созданы три
логических раздела по 30%, 40% и 40% от всего процессорного времени. При этом
поток A выполняется в разделе 1, потоки B, C и D - в разделе 2, а все остальные
- в третьем разделе. Если какие-то потоки не полностью используют свой раздел
(случай раздела №3), то процессорное время распределяется между готовыми к
исполнению потоками всех разделов в соответствии с их приоритетами (отсюда
приставка «адаптированные» в названии механизма).
Механизм обеспечения «горячей» замены сервисов
Существует два варианта использования механизма
«горячей» замены [13].
Первый вариант - запуск «теневого» сервера,
дублера, который в случае сбоя основного сервера начинает обработку его
запросов. Возможны варианты, при которых теневой сервер начинает работу до сбоя
основного, а также ситуации, в которых один сервер имеет множество дублеров.
Второй вариант - обновление сервера без перерыва
в обработке клиентских запросов. В случае запуска нового сервера обеспечивается
перенаправление запросов на него путем регистрации у него имени старого
сервера, в то время как он может закончить обработку старых запросов и
прекратить свою работу.
Технология быстрой активизации устройств
Этот механизм [13] позволяет еще до загрузки и
в процессе загрузки ОС обеспечивать отклик на внешние события. Речь идет о
возможности приступить к обработке критичных сигналов через десятки миллисекунд
после подачи питания на ЦПУ. Особенность технологии заключается в том, что
после окончания загрузки ОС обработку запросов может продолжить полноценный
драйвер без задержек времени или потерь данных.
Эта технология носит название технологии
мини-драйверов [15]. Технология мини-драйверов - это подход с применением
компактных, высокоэффективных драйверов устройств, которые начинают выполняться
до инициализации ядра ОС. Мини-драйвер, определенный в загрузочном файле
системы, может быстро и своевременно реагировать на сообщения, выдаваемые при
включении питания, обеспечивая прием всех без исключения сообщений во время
загрузки ОС. Производится опрос всех устройств, входящих в систему, при этом в
случае, если ответ не получен, делается вывод об отказе данного устройства.
После загрузки ОС мини-драйвер может продолжить свою работу или передать
управление полной версии драйвера, которая затем может обработать все
сообщения, буферизированные мини-драйвером.
Механизм формирования распределенной
вычислительной среды
Являясь традиционным, механизм связывает в
единую сетевую инфраструктуру непосредственно ядра копий QNX Neutrino,
выполняющихся на разных ЭВМ сети [13]. С точки зрения приложений и системных
сервисов автоматизированной системы выполнение происходит на одной ЭВМ, при
этом возникает псевдоединая виртуальная суперЭВМ (приставка «псевдо»
используется, чтобы подчеркнуть независимость отдельных узлов сети).
Механизм поддержки резервирования физических
каналов связи в кластере
Для каждого логического соединения
процесса-клиента с процессом-сервером может быть определен один из трех
вариантов физического канала [13]:
С автоматической балансировкой нагрузки.
Данный вариант характерен тем, что протокол сети
Qnet самостоятельно принимает решение по какой из всех доступных линий связи
передавать пакеты (при этом анализируются различные параметры, как то время
отклика удаленного узла на запросы и т.д.).
С предпочтением.
Этот вариант отличается от предыдущего лишь тем,
что задается предпочтительный сетевой адаптер, который в случае отсутствия
заменяется по схеме первого варианта.
Эксклюзивный.
В данном случае строго задается определенный адаптер.
В случае его отказа данные не будут передаваться вовсе, даже если для передачи
доступны другие линии связи.
Что важно: изменение варианта не требует
перекомпиляции программ и может происходить на любом этапе жизненного цикла
системы. Таким образом, в работе системы используется не случайный канал, а
выбранный в ходе анализа определенных параметров при проектировании системы (с
предпочтением, эксклюзивный) или в ходе её работы, т.е. исключается любая
случайность, что повышает отказоустойчивость системы.
Механизм обеспечения балансировки нагрузки на
сервисы
В случае [13], когда вычислительных ресурсов
системы недостаточно, в сетевую автоматизированную систему могут быть добавлены
дополнительные ЭВМ, на которые возможно переложить решение части задач. Суть
механизма заключается в том, что при получении от клиента запроса на
установление соединения сервер может вместо возврата клиенту идентификатора
соединения перенаправить клиента к другому серверу.
Технология автоматического восстановления
процессов
В основе технологии [13] лежит монитор ключевых
процессов, основное назначение которого - максимально быстрое определение факта
сбоя серверного приложения и принятие мер для восстановления нормальной работы
сервиса. Для этого монитор в начале работы дублирует себя, а затем обменивается
с клоном информацией об обрабатываемых процессах. Как только один из мониторов
начинает сбоить, второй порождает своего дублера и так далее.
Технология автоматизации восстановления
логических соединений
Эта технология [13] предназначена для
сохранения логических соединений между клиентами и серверами в случаях
временных отказов физических линий связи. Для этого в клиентских программах
предусмотрена обработка кодов ошибок, возникающих при разрывах соединений, для
последующего восстановления связей.AE
ОС VxWorks AE (Advanced Edition) [14] - первая
коммерческая ОС реального времени, предназначенная для построения
высоконадежных отказоустойчивых систем.
В VxWorks АЕ [9] поддерживается автоматическое
восстановление регенерация ресурсов, предотвращающая "утечки"
ресурсов (которые в противном случае, так или иначе, происходят в любой
динамичной системе). Также в системе имеется встроенный распределенный механизм
обмена сообщениями, способствующий определенному повышению степени отказоустойчивости.
В отличие от обычной VxWorks, VxWorks AE построена по технологии
"Protection Domain", позволяющей изолировать ядро ОС от приложений и
приложения друг от друга. Данная технология требует более внимательного
рассмотрения.Domain (домены защиты) [9] - принцип структурирования ядра ОС, при
котором разработчик может изолировать процессы и ресурсы при помощи
специального контейнера ресурсов, в котором задаются параметры среды
исполнения. Существует два способа создания доменов защиты: статический (при
запуске ОС) и динамический (в ходе работы ОС). При этом каждый домен защиты
характеризуется собственным адресным пространством и имеет несколько видов
доступа к нему со стороны других доменов. Однако домены защиты, в которых
исполняется многозадачное приложение, в виртуальном адресном пространстве на
самом деле перекрываются. Но исполняющаяся в одном домене защиты прикладная
программа не «видит» другие домены. Таким образом, организуется изоляция
приложений и, соответственно, отказов, что приводит к повышению надежности.
Каждый домен защиты приложений имеет свою
собственную таблицу символов и собственный пул динамической памяти (heap) [9].
Таким образом, несколько копий одного и то же приложения может быть загружено и
запущено одновременно в нескольких доменах защиты. В каждом домене защиты может
исполняться любое количество задач, так что если в домене защиты есть
какой-либо реентерабельный код, то внутри этого домена может быть одновременно
запущено несколько экземпляров одной и той же программы путем порождения в этом
домене множества задач с одной и той же точкой входа. Кроме того, если в один и
тот же домен защиты загружается код для нескольких программ, то в этом домене
может быть порождено несколько задач с отдельными точками входа. Подобная
гибкость обеспечивает прикладному разработчику широкую свободу разбиения
системы на домены защиты по собственному усмотрению. Контроль переполнения
стека каждой задачи и возможность автоматически увеличивать размеры пула
динамической памяти (в определенных пределах) в случае переполнения
представляет собой одну из мер защиты от перерасхода ресурсов. Кроме того,
такая система позволяет ограничивать диапазон задачных приоритетов внутри
доменов защиты. Таким образом, предотвращается "неуправляемое размножение"
приложений и в любом случае устраняется их возможное влияние на исполнение
других прикладных задач. Глобальными объектами, обеспечивающими синхронизацию
исполнения приложений, по-прежнему являются механизмы межпроцессного
взаимодействия типа очередей, семафоров, каналов и конвейеров
В VxWorks АЕ [9] реализован новый масштабируемый
механизм обмена сообщениями, который расширяет возможности локальной системы
передачи сообщений (то есть очереди сообщений в "родной" среде) за
пределы одного процессора. ОС автоматически определяет, локальная или нет
данная очередь для процессора, и при необходимости пересылает сообщения в
удаленные очереди, пользуясь службой или реестром распределенных и резервных
имен. Высокая надежность обмена сообщениями гарантируется протоколом передачи
благодаря поддержке подтверждений приема сообщений и нумерации пакетов,
обеспечивающих целостность принимаемых сообщений.
Повышение отказоустойчивости распределенного
обмена сообщениями в VxWorks АЕ обеспечивается API-интерфейсами,
предоставляющими доступ к резервной базе данных сервера имен для удаленной маршрутизации
сообщений. В системе нет единичных точек отказа, и если какие-либо сервисные
функции (или весь узел), связанные с обслуживанием удаленных очередей,
становятся недоступными, очереди сообщений могут быть повторно созданы и
зарегистрированы в других узлах благодаря наличию соответствующих ссылок в базе
данных. Затем осуществляется обновление базы данных сервера имен, и "пункт
обслуживания" перемещается в исправный узел. Это чрезвычайно мощная
возможность, особенно при использовании резервного оборудования для повышения
доступности сервиса. Более того, как оказалось, система обмена сообщениями в
VxWorks АЕ обладает практически неограниченными возможностями масштабирования,
что было продемонстрировано на существующих VxWorks-системах с числом узлов до
512.
Важно, что операционная система VxWorks АЕ
является достаточно гибкой, чтобы поддерживать обмен сообщениями там, где это
действительно имеет смысл, и не применяет его для обмена информацией между
локальными процессами, где он приводит к излишним издержкам.
Архитектура высокой готовности Foundation HA
[9], разработанная в компании Wind River, обладает способностью отличать
базовые причины возникающих в системе сбойных ситуаций (отказы) и признаки,
появляющиеся как свидетельства этих причин. Единичный отказ (типа отказа
какого-либо программного или аппаратного компонента) может стать источником
множества признаков. В Foundation HA имеется стандартный API-интерфейс
оповещения, посредством которого усиленные программные компоненты передают
признаки на уровень оповещения Foundation HA
Назначение системы управления признаками AMS
(Alarm Management System) [9] - обеспечение единой инфраструктуры для кода
восстановления после отказов, организованного в виде набора обработчиков
признаков отказа. Обработчики регистрируются в AMS и указывают, от каких
источников они ожидают признаки. При их поступлении система AMS определяет,
какому обработчику передать тот или иной признак для дальнейшего обслуживания.
Если его причиной является отказ, то обработчиком является процедура
восстановления после отказа. Обработчик умеет сопоставлять признаки друг с
другом и группировать их в единый отказ и запускать соответствующую процедуру
восстановления для всех сразу. Назначение этой процедуры - ликвидировать
последствия отказов с минимальным нарушением нормального функционирования
системы.
Усиленные программные компоненты классифицируют
признаки отказов по степени их серьезности, при этом обработчики могут менять
степень серьезности признака, опираясь на собственные сведения о системе и
дополнительные условия, необходимые для корректной интерпретации степени
важности признака отказа. Необходимо отметить, что в системе могут
генерироваться определенные наборы параметров, которые на самом деле не
являются признаками отказов. В частности, модуль распределения памяти может
генерировать признак отказа при обнаружении нехватки памяти, но если подобная
ситуация была предусмотрена спецификацией данной системы, то она фактически
отказом не является.
Заключение
В данной работе были рассмотрены понятия
операционных систем реального времени и отказоустойчивости, а также механизмы
обеспечения отказоустойчивости. Помимо общих направлений были рассмотрены
реально существующие операционные системы и внутренние решения проблемы
отказоустойчивости компаний-разработчиков.
Само понятие систем реального времени основано
на том, что созданные системы должны быть способны не только гарантировать
решение поставленной задачи, но при этом должны соблюдать временные
ограничения. Отказоустойчивость систем реального времени является важным
параметром при их проектировании. Если пренебречь отказоустойчивостью, можно
попасть в ситуацию, при котором система перестает функционировать, при этом
задачи, требующие решения в данный момент времени, простаивают или вовсе
остаются нерешенными. В ряде технических приложений отказоустойчивость является
обязательным требованием, предъявляемым государственными надзорными органами к
техническим системам.
У всех способов обеспечения отказоустойчивости
есть сходная черта - дублирование. Только таким образом можно обеспечить
отказоустойчивость системы - в случае сбоя одного из её элементов моментально
заменить его. При этом каждая разрабатывающая компания в праве самостоятельно
определять способы обеспечения отказоустойчивости, разрабатывая для этого
определенные алгоритмы и специализированную аппаратуру.
Основой данной работы стало рассмотрение двух
операционных систем реального времени: QNX Neutrino и VxWorks AE. В каждой из
этих систем присутствуют разработанные специально для них способы обеспечения
отказоустойчивости. При этом в системе VxWorks AE разработка основана на
изолировании элементов системы, в то время как система QNX Neutrino
отталкивается от избыточности. Каждая ОС имеет множество механизмов обеспечения
отказоустойчивости, что позволяет использовать их в различных отраслях: в
банковском деле, в военной отрасли, добывающих отраслях, в химической
промышленности, энергетике и так далее.
Обеспечение отказоустойчивости является сложной
задачей, требующей исследований в этой области, и одновременно востребованной.
Это позволяет ожидать, что со временем появятся новые способы обеспечения
отказоустойчивости в системах реального времени.
Список литературы
Жданов
А.А. Операционные системы реального времени. - PCWeek, 8/1999 [электронная
версия] - <http://www.asutp.ru/?p=600591>
Древс
Ю.Г. Системы реального времени: технические и программные средства: Учебное
пособие. - М.: МИФИ, 2010. 320 с.
Системы
реального времени: Курсовая работа - 2010 [электронная версия] -
<http://otherreferats.allbest.ru/programming/00078575_0.html>
Реальное
время. - [электронный ресурс] -
<http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D0%B2%D1%80%D0%B5%D0%BC%D1%8F>
Конспект
лекций по учебной дисциплине «Операционные системы, среды и оболочки». -
[электронная версия] -
<http://rudocs.exdat.com/docs/index-78466.html?page=21>
Операционная
система реального времени. - [электронный ресурс] -
<http://ru.wikipedia.org/wiki/%CE%EF%E5%F0%E0%F6%E8%EE%ED%ED%E0%FF_%F1%E8%F1%F2%E5%EC%E0_%F0%E5%E0%EB%FC%ED%EE%E3%EE_%E2%F0%E5%EC%E5%ED%E8>
Конспект
лекций по дисциплине «Системы реального времени». - [электронная версия] -
<http://www.4stud.info/rtos/lecture1.html>
Разработка
отказоустойчивой операционной системы реального времени для вычислительных
систем с максимальным рангом отказоустойчивости. Реферат. - [электронная
версия] - <http://www.ref.by/refs/67/36799/1.html>
Фогелин
Д., Квинг Х. Реализация высокой готовности во встраиваемых системах. -
[электронная версия] - <http://www.asutp.ru/?p=600410>
Крюков
В.А. Распределенные ОС. Курс лекций. - [электронная версия] -
<http://www.parallel.ru/krukov/lec7.html>
Козлов
В.С., Листенгорт Ф.А., Меркулов В.А., Сиренко В.Г., Смаглий А.М., Щагин А.В.
Способ обеспечения отказоустойчивости вычислительных систем. Патент Российской
Федерации №2047899. - [электронная версия] -
<http://ru-patent.info/20/45-49/2047899.html>
Операционная
система реального времени QNX. Курсовая работа. - [электронная версия] -
<http://otherreferats.allbest.ru/programming/00162031_0.html>
Зыль
С. Штатные механизмы QNX Neutrino для обеспечения отказоустойчивости
вычислительных систем жёсткого реального времени. - СТА, 3/2009, 118 с. . -
[электронная версия] - <http://www.cta.ru/cms/f/389405.pdf>
Демьянов
А.В. VxWorks операционная система внутри Интернет. - [электронная версия] -
<http://www.asutp.ru/?p=600027>
Этьер
Ш., Мартин Р. Технология мгновенного запуска для автомобильных телематических и
информационно-развлекательных систем. - [электронная версия] -
<http://www.swd.ru/print.php3?pid=777>