Модуль поддержки принятия управленческих решений на медицинском предприятии
Содержание
Введение
1. Теоретическая часть
1.1 Определение DSS (СППР)
1.2 Общая схема принятия решений
1.3 Классификация СППР
Классификация на уровне пользователя
Классификация по функциональному наполнению интерфейса системы
Классификация на концептуальном уровне
Классификация по архитектуре
Классификация в зависимости от вида данных, с которыми работают
СППР
Классификация СППР по уровням
Классификация СППР по функциональным возможностям
Классификация СППР по уровню распределенности
1.4 Перспективы развития систем поддержки принятия решений
1.5 Аналитические методы в средствах разведки данных (DataMining)
1.6 Анализ данных в медицинских информационных системах и СППР
Выводы по разделу 1
2. Аналитическая часть
2.1 Ассоциативные правила (AssociationRules)
Численные ассоциативные правила (QuantitativeAssociationRules)
2.2 Apriori - масштабируемый алгоритм поиска ассоциативных правил
Свойство анти-монотонности
Алгоритм Apriori
2.3 FPG - альтернативный алгоритм поиска ассоциативных правил
Алгоритм Frequent Pattern-Growth Strategy (FPG)
Извлечение частых предметных наборов из FP-дерева
Выводы по разделу 3
4. Эффективность применения модуля поддержки принятия
управленческих решений и полученные с его помощью результаты
4.1 Эффективность модуля ППУР
Эффективность поиска ассоциативных правил
Эффективность графиков приобретения услуг
Эффективность оценки загруженности персонала
4.2 Полученные результаты
Результаты поиска ассоциативных правил
Результаты построения графиков приобретенных услуг
Результаты оценки загруженности персонала
Выводы по разделу 4
Сноски
Введение
Актуальность темы обусловлена тем, что современные
медицинские предприятия оснащены передовыми технологиями: медицинское
оборудование, информационные системы управления данными, лаборатории, что
порождает необходимость в автоматизированном анализе данных с помощью
встроенного модуля поддержки принятия решений.
Медицинский учет, медицинская отчетность и их анализ являются
последовательными и взаимно связанными звеньями. Взаимная связь этих звеньев
заключается в следующем: правильно организованный медицинский учет способствует
рациональной организации труда медицинского персонала для улучшения
медицинского обслуживания и создает возможность последовательно накапливать
данные о деятельности учреждения.
Медицинская документация представляет собой набор документов,
предназначенных для записи данных о состоянии здоровья населения и отдельных
лиц, отражающих характер, объем и качество оказываемой медицинской помощи, для
ее организации и управления службами здравоохранения.
Система поддержки принятия решений позволяет использовать
полученные данные, на основе которых помогает менеджеру в принятии решения, а
также обеспечивают поддержку принимаемого решения менеджером. Важнейшей целью
этих СППР является поиск наиболее рациональных вариантов развития бизнеса
компании с учетом влияния различных факторов, таких как конъюнктура целевых для
компании рынков, изменения финансовых рынков и рынков капиталов, изменения в
законодательстве и сезонные вспышки заболеваний, посещаемость,
распространенность вида заболевания, количество операций, занятость
медицинского персонала и др.
По сути, они представляют собой конечные наборы отчетов,
построенные на основании данных из транзакционной информационной системы
предприятия, в идеале адекватно отражающей в режиме реального времени основные
аспекты производственной и финансовой деятельности.
СППР в медицинских информационных системах используются для
помощи менеджерам и руководителям в принятии решений на основе анализа большого
количества статистической информации. Например, помощь с составлением рабочего
графика, выявление перспективных путей развития предприятия или предупреждение
о возможной нехватке врача-специалиста, в связи с большой проходимостью
пациентов или сезонными вспышками заболеваний
Предметами данного исследования являются системы
автоматизированной обработки информации.
Объектом исследования является - программное обеспечение
систем автоматизированной обработки информации.
Цель работы: разработать и внедрить программный модуль
поддержки принятия управленческих решений для информационной системы
медицинского предприятия ООО "Центр Эндохирургических Технологий".
Исходя из цели работы были поставлены следующие задачи:
- Рассмотреть существующие методы
информационной поддержки принятия решения.
- Рассмотреть различные методы и алгоритмы DataMining в задачах поддержки
принятия решений
- Разработать модуль поддержки принятие
управленческих решений с использованием методов DataMining (метод ассоциативных
правил, секвенциальный анализ, и т.д.)
- Интегрировать программный модуль поддержки
принятия управленческих решений с информационной системой предприятия.
1.
Теоретическая часть
Одной из возможных технологий организации подобного
взаимодействия, является технология систем поддержки принятия решений (СППР).
Современные системы поддержки принятия решения представляют собой системы,
максимально приспособленные к решению задач повседневной управленческой
деятельности, являются инструментом, призванным оказать помощь лицам, принимающим
решения (ЛПР). С помощью СППР может производиться выбор решений некоторых
неструктурированных и слабоструктурированных задач, в том числе и
многокритериальных.
.1
Определение DSS (СППР)
Для функционирования ИС необходимо обеспечить как наличие
средств генерации данных так и средства их анализа. Имеющиеся в ИС средства
построения запросов и различные механизмы поиска хотя и облегчают извлечение
нужной информации, но все же не способны дать достаточно интеллектуальную ее
оценку, т.е. сделать обобщение, группирование, удаление избыточных данных и
повысить достоверность за счет исключения ошибок и обработки нескольких
независимых источников информации (не только корпоративных БД, но и внешних).
Проблема эта становится чрезвычайно важной в связи с лавинообразным
возрастанием объема информации и увеличением требований к инфосистемам по
производительности - сегодня успех в управлении предприятием во многом
определяется оперативностью принятия решений, данные для которых и
предоставляет ИС.
СППР представляют собой системы, разработанные для поддержки
процессов принятия решений в сложных мало структурированных ситуациях,
связанных с разработкой и принятием решений. Главной особенностью
информационной технологии поддержки принятия решений является качественно новый
метод организации взаимодействия человека и компьютера. Выработка решения, что
является основной целью этой технологии, происходит в результате итерационного
процесса, изображенного на рисунке 1, в котором участвуют:
- система поддержки
принятия решений в роли вычислительного звена и объекта управления;
- человек как управляющее
звено, задающее входные данные и оценивающее полученный результат вычислений на
компьютере.
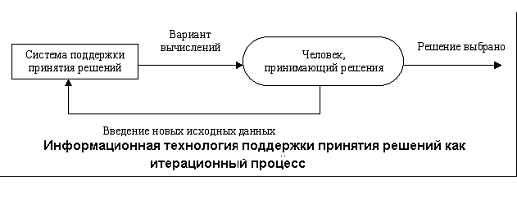
Рисунок 1 - Информационная технология поддержки принятия решений
как итерационный процесс
Окончание итерационного процесса происходит по воле человека. В
этом случае можно говорить о способности информационной системы совместно с
пользователем создавать новую информацию для принятия решений.
СППР могут включать в себя ситуационные центры, средства
многомерного анализа данных и прочие инструменты аналитической, позволяют
моделировать правила и стратегии бизнеса и иметь интеллектуальный доступ к
неструктурированной информации. Используемые на этом уровне специальные
математические методы позволяют прогнозировать динамику различных показателей,
анализировать затраты по разным видам деятельности, уяснять их детальную
структуру, формировать подробные бюджеты по разным схемам.
До сих пор нет единого определения СППР, в качестве примера можно
привести следующие:
- это наиболее мощный
представитель класса аналитических систем ориентированный на:
- анализ больших массивов
данных,
- на выполнение более
сложных запросов,
- моделирование процессов
предметной области,
- прогнозирование,
- нахождение зависимостей
между данными
- это интерактивная
прикладная система, которая обеспечивает конечным пользователям, принимающим
решение, легкий и удобный доступ к данным и моделям с целью принятия решений в
слабоструктурированных и неструктурированных ситуациях в разных областях
человеческой деятельности
- это такие системы,
которые основываются на использовании моделей и процедур обработки данных и
мыслей, которые помогают принимать решение
- это интерактивные
автоматизированные системы, которые помогают лицам, принимающим решение,
использовать данные и модели для решения неструктурированных и
слабоструктурированных проблем
- это компьютерная
информационная система, используемая для поддержки разных видов деятельности во
время принятия решений в ситуациях, когда невозможно или нежелательно иметь
автоматическую систему, полностью выполняющую весь процесс решений
- это многоуровневая
многофункциональная автоматизированная система выработки и реализации решений,
которая формируется на основе:
· синтеза функциональных и структурных схем
отдельных звеньев объекта;
модуль поддержка принятие решение
· сквозных моделей и задач по стадиям
жизненного цикла изделия и самого объекта;
· объединения разрозненных локальных
подсистем в единую систему управления;
· создания взаимосвязанных контуров
управления и усиления роли оперативного управления (для изучения логики и
диагностики их течения);
· углубления системного и
программно-целевого подхода к планированию и автоматического анализа работы
объекта;
· развития единых сквозных норм и
нормативов;
· создания разветвленной АРМ (как
интеллектуальных терминалов), обеспечения программных взаимосвязей,
согласования информации и диалога.
DSS (СППР) - это человеко-машинный вычислительный комплекс,
ориентированный на анализ данных и обеспечивающий получение информации,
необходимой для принятия решений в сфере управления. Такое разнообразие
определений отображает широкий диапазон разных типов СППР. Но практически все
виды этих компьютерных систем характеризуются четкой структурой, которая
содержит три главных компонента, которые составляют основу классической
структуры СППР, отличающей ее от других типов ИС:
Три компонента - основа классической структуры СППР:
· интерфейс пользователя, который дает
возможность лицу, которое имеет право принимать решения, проводить диалог с
системой, используя разные программы ввода, форматы и технологии вывода;
· подсистема, предназначенная для
сохранения, управления, выбора, отображения и анализа данных;
подсистема, которая содержит набор моделей для обеспечения
ответов на множество запросов пользователей, для аналитических задач.
1.2 Структура
СППР
В состав системы поддержки принятия решений входят три
главных компонента: база данных, база моделей и программная подсистема, которая
состоит из трех подсистем: системы управления базой данных (СУБД), системы
управления базой моделей (СУБМ) и системы управления интерфейсом между
пользователем и компьютером. Структура СППР, а также функции составляющих ее
блоков, определяющих основные технологические операции, представлены на
рисунке.
Любая система поддержки принятия решений содержит подсистему
данных, которая состоит из двух основных частей: БД и системы управления базой
данных (СУБД) (Рисунок 2). БД играет в информационной технологии поддержки
принятия решений важную роль. Данные могут использоваться непосредственно
пользователем для расчетов при помощи математических моделей. СППР получают
информацию из управленческих и операционных ИС.
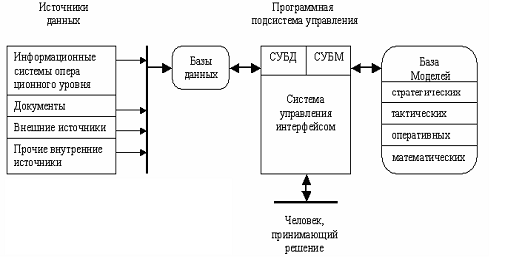
Рисунок 2-Основные компоненты информационной технологии поддержки
принятия решений
Источники данных и их особенности
- часть данных поступает от
информационной системы операционного уровня. Эффективность их использования
определяется предварительно обработкой:
- системой управления базой
данных, входящую в состав системы поддержки принятия решений;
- за пределами системы
поддержки принятия решений, создав для этого специальную базу данных. Этот
вариант более предпочтителен для предприятий, производящих большое количество
операций. Обработанные данные об операциях образуют файлы, которые для
повышения надежности и быстроты доступа хранятся за пределами системы поддержки
принятия решений.
- внутренние данные,
например данные о движении персонала, инженерные данные и т.п., которые должны
быть своевременно собраны, введены и поддержаны
- данные из внешних
источников. В числе необходимых внешних данных следует указать данные о
конкурентах, национальной и мировой экономике. В отличие от внутренних данных
внешние данные обычно приобретаются у специализирующихся на их сборе
организации.
- документы, включающих в
себя записи, письма, контракты, приказы и т.п. Если содержание этих документов
будет записано в памяти и затем обработано по некоторым ключевым
характеристикам (поставщикам, потребителям, датам, видам услуг и др.), то
система получит новый мощный источник информации.
Присущий технологии СППР акцент на обработку
неструктурированных и слабоструктурированных задач предопределяет некоторые
специфические требования к этим элементам компьютерной системы. Прежде всего,
речь идет о необходимости выполнять значительный объем операций
переструктурирования данных. Нужно предусмотреть возможность загрузки и следующей
обработки данных из внешних источников; функционирования СУБД в среде СППР в
отличие от обычной обработки информации в управленческих информационных
системах требует более широкого набора функций. Это касается также и БД.
Вообще базу данных можно определить как совокупность
элементов, организованных в соответствии с определенными правилами, которые
предусматривают общие принципы описания, сохранения и манипулирования данными
независимо от прикладных программ.
Связь конечных пользователей (прикладных программ) с базой
данных происходит с помощью СУБД. Последняя представляет собой систему
программного обеспечения, которая содержит средства обработки языками БД и
обеспечивает создания БД и ее целостность, поддерживает ее в актуальном
состоянии, дает возможность манипулировать данными и обрабатывать обращение к
БД, которые поступают от прикладных программ и (или) конечных пользователей при
условиях применяемой технологии обработки информации. В состав будто БД,
которые используются для изучения и обращение к данных, належит язык описания
данных (ЯОД) и язык манипулирования данными (ЯМД).
Язык описания данных предназначенный для определения
структуры БД. Описание данных заданной проблемной области может выполняться на
нескольких уровнях абстрагирования, причем на каждом уровне используется свое
ЯОД. Описание на любом уровне называется схемой. Чаще всего используется
трехуровневая система: концептуальный, логический и физический уровни. На
концептуальном уровне описываются взаимосвязи между системами данных, которые
отвечают реально действующим зависимостям между факторами и параметрами
проблемной среды. Структура данных на концептуальном уровне называется
концептуальной схемой. На логическому равные выбранные взаимосвязи отбиваются в
структуре записей БД. На физическом уровне решаются вопрос организации
размещения структуры записи на физических носителях информации.
Язык манипулирования данными обеспечивает доступ к данным и
содержит средства для сохранения, поиска, обновления и стирания записей. Языка
манипулирования данными, которые могут использоваться конечными пользователями
в диалоговом режиме, часто называют языками запросов.
СУБД должна обладать следующими возможностями.
- составление комбинаций
данных, получаемых из различных источников, посредством использования процедур
агрегирования и фильтрации;
- быстрое прибавление или
исключение того или иного источника данных;
- построение логической
структуры данных в терминах пользователя;
- использование и
манипулирование неофициальными данными для экспериментальной проверки рабочих
альтернатив пользователя;
- обеспечение полной
логической независимости этой БД от других операционных БД, функционирующих в
рамках фирмы.
БД и СУБД используются в любых компьютерных системах. Тем не
менее, сравнительно с обычными подходами к реализации БД для решения некоторых
задач к функциям и инструментам БД и СУБД в контексте системы поддержки
принятия решений выдвигается ряд дополнительных и специализированных
требований.
Компьютерная система поддержки принятия решений
Опыт применения компьютеров в задачах организационного
управления и принятия решений показал, что при решении конкретных проблем люди
предпочитают использовать упрощенные подходы, не требующие большого
разнообразия данных и изощренных моделей. В реальных ситуациях рассматриваемая
проблема описывается разнохарактерной информацией, в ней сочетаются
количественные и качественные факторы, наряду с объективными данными приходится
учитывать субъективные суждения руководителей, знания экспертов. Однако
описание проблемы почти никогда не является полным, так как бывает достаточно
трудно получить всю информацию, необходимую для анализа проблемы. И, наконец,
при подготовке и принятии решений необходимо учитывать особенности и пределы
человеческой системы переработки информации и специальным образом
подготавливать информацию, используемую людьми. Цель исследований по экспертным
системам состоит в разработке программ (устройств), которые при решении задач,
трудных для эксперта-человека, получают результаты, не уступающие по качеству и
эффективности решениям, получаемым экспертом. В большинстве случаев экспертные
системы решают трудно формализуемые задачи или задачи, не имеющие
алгоритмического решения. В настоящее время экспертные системы нашли применение
в разнообразных предметных областях (медицина, вычислительная техника,
геология, математика, сельское хозяйство, управление, электроника,
юриспруденция и др.).
Наиболее типичны для СППР многокритериальные задачи принятия
решений с объективными моделями и большими массивами количественных данных.
Значительно слабее освоена область задач с субъективными моделями, особенно
когда в них используются качественные данные. Еще менее разработанным является
применение ЭВМ на этапе предварительного анализа и структуризации
рассматриваемой проблемы - одного из принципиально важных этапов подготовки и
принятия решения. Основные трудности связаны здесь, во-первых, с тем, что
анализ проблемы представляет собой творческий процесс, плохо поддающийся
формализации. Во-вторых, пока еще крайне недостаточен арсенал средств, которые
могли бы использоваться при структуризации проблемы.
Степень структуризации проблемы - центральный момент для
СППР. Если проблема может быть полностью структурирована и окажется возможным
составить алгоритм ее решения, который удовлетворит пользователя, то поддержка
решения не нужна, так как этот алгоритм может заменить человека. В случае если
проблема не имеет структуры, и нет никаких требований к данным, то поддержка
решения невозможна, поскольку трудно определить стадии решения проблемы. Между
этими двумя полюсами лежит область применения СППР. Наибольший эффект СППР
могут дать при решении проблем, обладающих структурой, достаточной для
использования объективных моделей и применения вычислений, но где в то же время
существенными являются суждения и предпочтения человека. К подобным проблемам
можно отнести и лазерные процессы обработки материалов, которые наряду с
другими современными технологиями базируются как на разнообразных теоретических
моделях, так и на многочисленных экспериментальных данных и практическом опыте
работы квалифицированных специалистов-технологов.
Информационная технология поддержки принятия
решений
Главной особенностью информационной технологии поддержки
принятия решений является качественно новый метод организации взаимодействия
человека и компьютера. Выработка решения, что является основной целью этой
технологии, происходит в результате итерационного процесса, в котором
участвуют:
- система поддержки принятия решений в роли
вычислительного звена и объекта управления;
- человек как управляющее звено, задающее
входные данные и оценивающее полученный результат вычислений на компьютере.
Окончание итерационного процесса происходит по воле человека.
В этом случае можно говорить о способности информационной системы совместно с
пользователем создавать новую информацию для принятия решений.
Дополнительно к этой особенности информационной технологии
поддержки принятия решений можно указать еще ряд ее отличительных
характеристик:
- ориентация на решение плохо структурированных
задач;
- сочетание традиционных методов доступа и
обработки компьютерных данных с возможностями математических моделей и методами
решения задач на их основе;
- направленность на непрофессионального
пользователя;
- высокая адаптивность, обеспечивающая
возможность приспосабливаться к особенностям имеющегося технического и
программного обеспечения, а также требованиям пользователя.
Информационная технология поддержки принятия решений может
использоваться на любом уровне управления. Кроме того, решения, принимаемые на
различных уровнях управления, часто должны координироваться. Поэтому важной
функцией и систем, и технологий является координация лиц, принимающих решения,
как на разных уровнях управления, так и на одном уровне.
В отличие от традиционных технологий есть несколько важных
моментов, которые учитываются при создании СППР.
Первый, самый важный момент заключается в том, что
информация, которая нужна для принятия решений - это не просто факты, которые
надо выдавать человеку, принимающему решения, а факты, интерпретированные по
цели деятельности этого человека. То есть один и тот же факт, разный для людей,
имеющих разную целевую деятельность, интерпретируется по-разному. Поэтому в
рассматриваемой системе все факты должны интерпретироваться по сферам
деятельности.
Второй важный момент состоит в том, что в современных
условиях эффективное управление представляет собой ценный ресурс организации,
наряду с финансовыми, материальными, человеческими и другими ресурсами.
Следовательно, повышение эффективности управленческой деятельности становится
одним из направлений совершенствования деятельности предприятия в целом.
Трудности, возникающие при решении задачи автоматизированной
поддержки управленческого труда, связаны с его спецификой. Управленческий труд
отличается сложностью и многообразием, наличием большого числа форм и видов,
многосторонними связями с различными явлениями и процессами. Это, прежде всего,
труд творческий и интеллектуальный. На первый взгляд, большая его часть вообще
не поддается какой-либо формализации. Поэтому автоматизация управленческой
деятельности изначально связывалась только с автоматизацией некоторых
вспомогательных, рутинных операций. Но современное состояние информационных
компьютерных технологий, совершенствование технической платформы и появление
принципиально новых классов программных продуктов привело в наши дни к
изменению подходов к автоматизации управления производством.
При создании СППР учитывается ряд принципов:
. Машина должна вычислять, рассчитывать варианты, а
человек принимать решение.
2. Принцип Шоу: система должна быть такой, чтобы с ней
мог работать даже неподготовленный пользователь.
. Принцип "бюрократичности". Этот принцип
связан с уменьшением потока информации, который должен доставляться человеку
для принятия решения.
. Принцип объектно-ориентированного моделирования при
построении картины предметной области.
. Принцип динамической структуры.
. Принцип полноты информационного пространства.
. Принцип интеграции информационного пространства.
. Принцип децентрализации информационного хранилища.
. И, наконец, принцип компонентной сборки прикладных
режимов.
1.3 Общая
схема принятия решений
Общая схема процесса принятия решения включает следующие
этапы:
Предварительный
анализ проблемы
На этом этапе определяются:
- главные цели;
- уровни рассмотрения, элементы и структура
процесса;
- подсистемы и используемые ими основные
ресурсы, критерии качества функционирования подсистем;
- основные противоречия, узкие места и
ограничения.
Основная задача этого этапа заключается в определении целей,
которых необходимо достичь в процессе управления. Непосредственное участие в
процессе формирования этих целей должен принимать руководитель. Цели должны
быть конкретными и выражаться измеримыми значениями, тем самым задаются
показатели, которые будут впоследствии использоваться для выбора варианта
управленческого решения и контроля реализации управляющих воздействий.
Под воздействием внутренних или внешних факторов или при
получении дополнительной информации цели могут изменяться во времени. Таким
образом, при формулировке целей управления важно учитывать как факторы
взаимодействия (внутренние и внешние), так и временной аспект.
Для того, чтобы определить уровни рассмотрения, элементы и
структуру процесса может быть использован, в частности, подход,
предусматривающий декомпозицию главной цели до того уровня детализации, когда
для нижнего уровня иерархии целей можно сформулировать критерии, позволяющие
адекватно описать степень достижения целей при принятии той или иной
альтернативы (Рис.3.1).
Например, главная цель фирмы − выбор варианта внедрения
СППР с целью повышения рентабельности фирмы.

Рис. 3.1 Декомпозиция целей
Критериями оценки вариантов могут выступать, например,
затраты на внедрение, способность поддерживать решения, возможность адаптации к
другим видам деятельности фирмы, возможность защиты информации, время реакции
на запрос, надежность оборудования и пр. Наборы значений этих критериев
используются для описания исходов альтернативных вариантов решений (в
дальнейшем, "альтернатив"). Для решения таких сложных проблем следует
привлекать многих специалистов в разных областях знаний, что при использовании
такого подхода весьма затруднительно.
Цели управления должны учитывать всю накопленную объективную
и субъективную информацию, а также согласовываться с имеющимися возможностями и
ресурсами. В качестве технологий на этом этапе могут использоваться методики
SWOT-анализа (strength sand weaknesses, opportunities and threats −
достоинства и недостатки, возможности и угрозы), сегментного анализа и т.д.
В случае если поставленные цели не согласуются с имеющимися
ресурсами и возможностями, они могут оказаться недостижимыми. Это может
выявиться на последующих этапах процесса поддержки принятия решения, что
приведет к возврату на первый этап и уточнению и корректировке ранее
поставленных целей и показателей.
Постановка
задачи
Постановка конкретной задачи принятия решений (ЗПР) включает:
- формулировку задачи;
- определение типа задачи;
- выбор метода решения ЗПР;
- определение множества альтернатив и
основных критериев для выбора из них наилучшей, согласование критериев.
.3
Классификация СППР
Компьютерная поддержка процесса принятия решений основана на
формализации методов получения исходных и промежуточных оценок, даваемых ЛПР, и
алгоритмизации самого процесса выработки решения и представляет собой
итеративный процесс взаимодействия управленца и компьютера.
Программно компоненты структуры СППР в зависимости от
сложности поставленных задач реализованы по-разному, поэтому на рынке
программных продуктов предлагаются различные СППР. Все эти СППР можно
классифицировать по различным признакам.
Классификация
на уровне пользователя
На уровне пользователя Haettenschwiler (1999) делит СППР на:
Пассивной СППР называется система, которая помогает ЛПР в
принятии решения, но не может вынести предложение, какое решение принять.
Активная СППР может сделать предложение, какое решение
следует выбрать.
Кооперативная СППР позволяет ЛПР изменять, пополнять или
улучшать решения, предлагаемые системой, посылая затем эти изменения в систему
для проверки. Система изменяет, пополняет или улучшает эти решения и посылает
их опять пользователю. Процесс продолжается до получения согласованного
решения.
Классификация
по функциональному наполнению интерфейса системы
В зависимости от функционального наполнения интерфейса
системы выделяют два основных типа СППР: EIS и DSS.(ExecutionInformationSystem)
− информационные системы руководства предприятия. Эти системы
ориентированы на неподготовленных пользователей, имеют упрощенный интерфейс,
базовый набор предлагаемых возможностей, фиксированные формы представления
информации. EIS-системы рисуют общую наглядную картину текущего состояния
бизнес-показателей работы компании и тенденции их развития, с возможностью
углубления рассматриваемой информации до уровня крупных объектов компании.
Реальная отдача EIS-системы та, которую видит руководство компании от внедрения
технологий СППР.
Для ИСР характерны следующие основные черты:
отчеты, как правило, базируются на стандартных для
организации запросах; число последних относительно невелико;
ИСР представляет отчеты в максимально удобном виде,
включающем, наряду с таблицами, деловую графику, мультимедийные возможности и
т.п.;
как правило, ИСР ориентированы на конкретный вертикальный
рынок, например финансы, маркетинг, управление
ресурсами.(DesicionSupportSystem) − полнофункциональные системы анализа и
исследования данных, рассчитанные на подготовленных пользователей, имеющих
знания как в части предметной области исследования, так и в части компьютерной
грамотности.
Технологии этого типа строятся на принципах многомерного
представления и анализа данных OLAP.
Такое деление систем на два типа не означает, что построение
СППР всегда предполагает реализацию только одного из этих типов. EIS и DSS
могут функционировать параллельно, разделяя общие данные и/или сервисы,
предоставляя свою функциональность как высшему руководству, так и специалистам
аналитических отделов компаний.
Классификация
на концептуальном уровне
На концептуальном уровне Power (2003) различает следующие
СППР, управляемые:
сообщениями (Communication-Driven DSS);
данными (Data-Driven DSS);
документами (Document-Driven DSS);
знаниями (Knowledge-Driven DSS);
моделями (Model-Driven DSS).
СППР, управляемые моделями, характеризуются в основном доступ
и манипуляции с математическими моделями.
Управляемая сообщениями СППР (Communication-Driven DSS)
(ранее групповая СППР - GDSS) поддерживает группу пользователей, работающих над
выполнением общей задачи.
СППР, управляемые данными (Data-Driven DSS) или СППР,
ориентированные на работу с данными (Data-oriented DSS), в основном
ориентируются на доступ и манипуляции с данными.
СППР, управляемые документами (Document-Driven DSS),
управляют, осуществляют поиск и манипулируют неструктурированной информацией,
заданной в различных форматах.
Наконец, СППР, управляемые знаниями (Knowledge-Driven DSS),
обеспечивают решение задач в виде фактов, правил, процедур.
На техническом уровне Power (1997) различает СППР всего
предприятия и настольную.
СППР всего предприятия подключена к большим хранилищам
информации и обслуживает многих менеджеров предприятия.
Настольная СППР - это малая система, обслуживающая лишь один
компьютер пользователя.
Классификация
по архитектуре
На сегодняшний день можно выделить четыре наиболее популярных
типа архитектур СППР:
Функциональная СППР.
Независимые витрины данных.
Двухуровневое хранилище данных.
Трехуровневое хранилище данных.
Классификация
в зависимости от вида данных, с которыми работают СППР
В зависимости от вида данных, с которыми эти системы
работают, СППР условно можно разделить на:
Оперативные СППР предназначены для немедленного реагирования
на изменения текущей ситуации в управлении финансово-хозяйственными процессами
компании. СППР этого типа получили название Информационных Систем Руководства
(Executive Information Systems, ИСР).
Для ИСР характерны следующие основные черты:
отчеты, как правило, базируются на стандартных для
организации запросах; число последних относительно невелико;
ИСР представляет отчеты в максимально удобном виде,
включающем, наряду с таблицами, деловую графику, мультимедийные возможности и
т.п.;
как правило, ИСР ориентированы на конкретный вертикальный
рынок, например финансы, маркетинг, управление ресурсами.
Стратегические СППР ориентированы на анализ значительных объемов
разнородной информации, поиск наиболее рациональных вариантов развития бизнеса
компании с учетом влияния различных факторов, предполагают глубокую проработку
данных. Неотъемлемым компонентом СППР этого уровня являются правила принятия
решений, которые на основе агрегированных данных дают возможность менеджерам
компании обосновывать свои решения, использовать факторы устойчивого роста
бизнеса компании и снижать риски. Технологии этого типа строятся на принципах
многомерного представления и анализа данных (OLAP
<#"607556.files/image004.gif">I. Каждая транзакция представляет собой
бинарный вектор, где t [k] =1, если ik элемент присутствует в
транзакции, иначе t [k] =0. Мы говорим, что транзакция T содержит X, некоторый
набор элементов из I, если X T. Ассоциативным правилом называется импликация X
T. Ассоциативным правилом называется импликация X Y, где XI, YI и X
Y, где XI, YI и X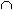 Y=
Y=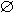 . Правило XY имеет поддержку s (support), если s% транзакций из D, содержат X
. Правило XY имеет поддержку s (support), если s% транзакций из D, содержат X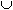 Y, supp (XY) = supp (XY). Достоверность правила показывает
какова вероятность того, что из X следует Y. Правило XY справедливо с достоверностью
(confidence) c, если c% транзакций из D, содержащих X, также содержат Y, conf
(XY) = supp (XY) /supp (X).
Y, supp (XY) = supp (XY). Достоверность правила показывает
какова вероятность того, что из X следует Y. Правило XY справедливо с достоверностью
(confidence) c, если c% транзакций из D, содержащих X, также содержат Y, conf
(XY) = supp (XY) /supp (X).
Другими словами, целью анализа является установление следующих
зависимостей: если в транзакции встретился некоторый набор элементов X, то на
основании этого можно сделать вывод о том, что другой набор элементов Y также
же должен появиться в этой транзакции. Установление таких зависимостей дает нам
возможность находить очень простые и интуитивно понятные правила.
Алгоритмы поиска ассоциативных правил предназначены для нахождения
всех правил X Y, причем поддержка и достоверность этих правил должны быть выше
некоторых наперед определенных порогов, называемых соответственно минимальной
поддержкой (minsupport) и минимальной достоверностью (minconfidence).
Задача нахождения ассоциативных правил разбивается на две
подзадачи:
1. Нахождение всех наборов элементов, которые удовлетворяют
порогу minsupport. Такие наборы элементов называются часто встречающимися.
2. Генерация правил из наборов элементов, найденных
согласно п.1. с достоверностью, удовлетворяющей порогу minconfidence.
Один из первых алгоритмов, эффективно решающих подобный класс
задач, - это алгоритм APriori [2]. Кроме этого алгоритма в последнее время был
разработан ряд других алгоритмов: DHP [5], Partition [6], DIC [7] и другие.
Значения для параметров минимальная поддержка и минимальная
достоверность выбираются таким образом, чтобы ограничить количество найденных
правил. Если поддержка имеет большое значение, то алгоритмы будут находить
правила, хорошо известные аналитикам или настолько очевидные, что нет никакого
смысла проводить такой анализ. С другой стороны, низкое значение поддержки
ведет к генерации огромного количества правил, что, конечно, требует
существенных вычислительных ресурсов. Тем не менее, большинство интересных
правил находится именно при низком значении порога поддержки. Хотя слишком
низкое значение поддержки ведет к генерации статистически необоснованных
правил.
Поиск ассоциативных правил совсем не тривиальная задача, как
может показаться на первый взгляд. Одна из проблем - алгоритмическая сложность
при нахождении часто встречающих наборов элементов, т.к. с ростом числа
элементов в I (| I |) экспоненциально растет число потенциальных наборов
элементов.
Численные
ассоциативные правила (QuantitativeAssociationRules)
При поиске ассоциативных правил задача была существенно
упрощена. По сути все сводилось к тому, присутствует в транзакции элемент или
нет. Т.е. если рассматривать случай рыночной корзины, то мы рассматривали два
состояния: куплен товар или нет, проигнорировав, например, информацию о том,
сколько было куплено, кто купил, характеристики покупателя и т.д. И можно
сказать, что рассматривали "булевские" ассоциативные правила. Если
взять любую базу данных, каждая транзакция состоит из различных типов данных:
числовых, категориальных и т.д. Для обработки таких записей и извлечения
численных ассоциативных правил был предложен алгоритм поиска [4].
Пример численного ассоциативного правила: [Возраст: 30-35] и
[Семейное положение: женат] [Месячный доход: 1000-1500 тугриков].
Помимо описанных выше ассоциативных правил существуют
косвенные ассоциативные правила, ассоциативные правила c отрицанием, временные
ассоциативные правила для событий связанных во времени и другие.
Алгоритм
Apriori
На первом шаге алгоритма подсчитываются 1-элементные часто
встречающиеся наборы. Для этого необходимо пройтись по всему набору данных и
подсчитать для них поддержку, т.е. сколько раз встречается в базе.
Следующие шаги будут состоять из двух частей: генерации
потенциально часто встречающихся наборов элементов (их называют кандидатами) и
подсчета поддержки для кандидатов.
Описанный выше алгоритм можно записать в виде следующего
псевдокода:
. F1 = (часто встречающиеся 1-элементные
наборы)
2. для (k=2; Fk-1<>; k++) (
. Ck = Apriorigen (Fk-1) // генерация
кандидатов
. для всех транзакций t 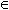 T (
T (
. Ct = subset (Ck, t) //
удаление избыточных правил
. для всех кандидатов c Ct
. c. count ++
. )
. Fk = ( c Ck | c. count>=
minsupport) // отбор кандидатов
. )
. Результат  Fk
Fk
Опишем функцию генерации кандидатов. На это раз нет никакой
необходимости вновь обращаться к базе данных. Для того, чтобы получить
k-элементные наборы, воспользуемся (k-1) - элементными наборами, которые были
определены на предыдущем шаге и являются часто встречающимися.
Вспомним, что наш исходный набор хранится в упорядоченном
виде. Генерация кандидатов также будет состоять из двух шагов.
. Объединение. Каждый кандидат Ck будет
формироваться путем расширения часто встречающегося набора размера (k-1)
добавлением элемента из другого (k-1) - элементного набора.
2. Приведем алгоритм этой функции Apriorigen в виде
небольшого SQL-подобного запроса.
. insertintoCk select p. item1,
p. item2, …, p. itemk-1, q. itemk-1 From Fk-1
p, Fk-1 q where p. item1= q. item1, p. item2
= q. item2, …, p. itemk-2 = q. itemk-2, p.
itemk-1< q. itemk-1
. Удаление избыточных правил. На основании свойства
анти-монотонности, следует удалить все наборы c Ck если хотя
бы одно из его (k-1) подмножеств не является часто встречающимся.
После генерации кандидатов следующей задачей является подсчет
поддержки для каждого кандидата. Очевидно, что количество кандидатов может быть
очень большим и нужен эффективный способ подсчета. Самый тривиальный способ -
сравнить каждую транзакцию с каждым кандидатом. Но это далеко не лучшее
решение. Гораздо быстрее и эффективнее использовать подход, основанный на
хранении кандидатов в хэш-дереве. Внутренние узлы дерева содержат хэш-таблицы с
указателями на потомков, а листья - на кандидатов. Это дерево нам пригодится
для быстрого подсчета поддержки для кандидатов.
Хэш-дерево строится каждый раз, когда формируются кандидаты.
Первоначально дерево состоит только из корня, который является листом, и не
содержит никаких кандидатов-наборов. Каждый раз когда формируется новый
кандидат, он заносится в корень дерева и так до тех пор, пока количество
кандидатов в корне-листе не превысит некоего порога. Как только количество
кандидатов становится больше порога, корень преобразуется в хэш-таблицу, т.е.
становится внутренним узлом, и для него создаются потомки-листья. И все примеры
распределяются по узлам-потомкам согласно хэш-значениям элементов, входящих в
набор, и т.д. Каждый новый кандидат хэшируется на внутренних узлах, пока он не
достигнет первого узла-листа, где он и будет храниться, пока количество наборов
опять же не превысит порога.
Хэш-дерево с кандидатами-наборами построено, теперь,
используя хэш-дерево, легко подсчитать поддержку для каждого кандидата. Для
этого нужно "пропустить" каждую транзакцию через дерево и увеличить
счетчики для тех кандидатов, чьи элементы также содержатся и в транзакции, т.е.
CkTi = Ck. На корневом уровне
хэш-функция применяется к каждому элементу из транзакции. Далее, на втором
уровне, хэш-функция применяется ко вторым элементам и т.д. На k-уровне
хэшируется k-элемент. И так до тех пор, пока не достигнем листа. Если кандидат,
хранящийся в листе, является подмножеством рассматриваемой транзакции, тогда
увеличиваем счетчик поддержки этого кандидата на единицу.
После того, как каждая транзакция из исходного набора данных
"пропущена" через дерево, можно проверить удовлетворяют ли значения
поддержки кандидатов минимальному порогу. Кандидаты, для которых это условие
выполняется, переносятся в разряд часто встречающихся. Кроме того, следует
запомнить и поддержку набора, она нам пригодится при извлечении правил. Эти же
действия применяются для нахождения (k+1) - элементных наборов и т.д.
После того как найдены все часто встречающиеся наборы
элементов, можно приступить непосредственно к генерации правил.
Извлечение правил - менее трудоемкая задача. Во-первых, для
подсчета достоверности правила достаточно знать поддержку самого набора и
множества, лежащего в условии правила. Например, имеется часто встречающийся
набор (A, B, C) и требуется подсчитать достоверность для правила AB C. Поддержка самого
набора нам известна, но и его множество (A, B), лежащее в условии правила,
также является часто встречающимся в силу свойства антимонотонности, и значит
его поддержка нам известна. Тогда мы легко сможем подсчитать достоверность. Это
избавляет нас от нежелательного просмотра базы транзакций, который потребовался
в том случае если бы это поддержка была неизвестна.
Чтобы извлечь правило из часто встречающегося набора F,
следует найти все его непустые подмножества. И для каждого подмножества s мы
сможем сформулировать правило s (F - s), если достоверность правила conf (s (F - s)) = supp (F)
/supp (s) не меньше порога minconf.
Заметим, что числитель остается постоянным. Тогда
достоверность имеет минимальное значение, если знаменатель имеет максимальное
значение, а это происходит в том случае, когда в условии правила имеется набор,
состоящий из одного элемента. Все супермножества данного множества имеют
меньшую или равную поддержку и, соответственно, большее значение достоверности.
Это свойство может быть использовано при извлечении правил. Если мы начнем
извлекать правила, рассматривая сначала только один элемент в условии правила,
и это правило имеет необходимую поддержку, тогда все правила, где в условии
стоят супермножества этого элемента, также имеют значение достоверности выше
заданного порога. Например, если правило A BCDE удовлетворяет
минимальному порогу достоверности minconf, тогда AB CDE также удовлетворяет.
Для того, чтобы извлечь все правила используется рекурсивная процедура. Важное
замечание: любое правило, составленное из часто встречающегося набора, должно
содержать все элементы набора. Например, если набор состоит из элементов (A, B,
C), то правило A B не должно рассматриваться.
2.3 FPG -
альтернативный алгоритм поиска ассоциативных правил
Узким местом в алгоритме a priori
<#"607556.files/image013.gif">
Рис.1. Построение FP-дерева на транзакции № 1
Сначала берем предмет с из транзакции №1. Поскольку он
является первым, то формируем для него узел и соединяем с родительским
(корневым) (рис.1, а). Затем берем следующий предмет b и
поскольку других узлов с тем же именем дерево пока не содержит, добавляем его в
виде нового узла, потомка узла с (рис 1, б). Таким же образом
формируем узлы для предметов d, e и a из транзакции № 1
(случаи в, г, и д на рис 1). На этом использование первой
транзакции для построения дерева закончено.
Для транзакции № 2, содержащей предметы c, b и a,
выбираем первый предмет, c. Поскольку дочерний узел с таким именем уже
существует, то в соответствии с правилом построения дерева новый узел не
создается, а добавляется к уже имеющемуся (рис.2, а). При добавлении
следующего предмета b используем то же правило: поскольку узел b является
дочерним по отношению к текущему (т.е. c), то мы также не создаем новый
узел, а увеличиваем индекс для имеющегося (рис.2, б). Для следующего
предмета из второй транзакции a в соответствии с правилом построения
FP-дерева придется создать новый узел, поскольку у узла b дочерние узлы
с именем a отсутствуют (рис.2, в).
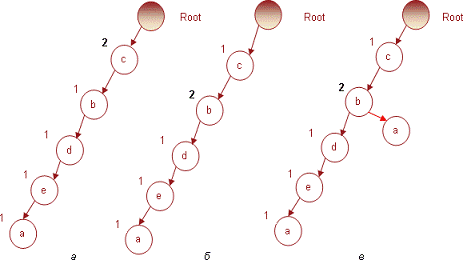
Рис.2. Построение FP-дерева на транзакции № 2
И, наконец, последняя транзакция № 7, содержащая предметный
набор (c d e), увеличит на 1 индексы соответствующих узлов. Получившееся
дерево, которое также является результирующим для всей БД транзакций,
представлено на рис.7.
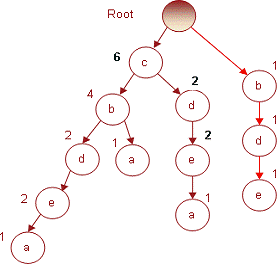
Рис.7. Результирующее дерево, построенное по всей БД
транзакций
Таким образом, после первого прохода базы данных и выполнения
соответствующих манипуляций с предметными наборами мы построили FP-дерево,
которое в компактном виде представляет информацию о частых предметных наборах и
позволяет производить их эффективное извлечение, что и делается на втором
сканировании БД.
Представление базы данных транзакций в виде FP-дерева
очевидно. Если в исходной базе данных каждый предмет повторяется многократно,
то в FP-дереве каждый предмет представляется в виде узла, а его индекс
указывает на то, сколько раз данный предмет появляется. Иными словами, если
предмет в исходной базе данных транзакций появляется 100 раз, то в дереве для
него достаточно создать узел и установить индекс 100.
Извлечение
частых предметных наборов из FP-дерева
Для каждого предмета в FP-дереве, а точнее, для связанных с
ними узлов, можно указать путь, т.е. последовательность узлов, которую надо
пройти от корневого узла до узла, связанного с данным предметом. Если предмет
представлен в нескольких ветвях дерева (что чаще всего и происходит), то таких
путей будет насколько. Например, для FP-дерева на рис.7 для предмета a можно
указать 3 пути: (cbdea, cba, cdea). Такой набор путей называется условным
базисом предмета (англ.: conditionalbase). Каждый путь в базисе состоит из двух
частей - префикса и суффикса. Префикс - это последовательность узлов, которые
проходит путь для того чтобы достичь узла, связанного с предметом. Суффикс -
это сам узел, к которому "прокладывается" путь. Таким образом, в
условном базисе все пути будут иметь различные префиксы и одинаковый суффикс.
Например, в пути cbdea префиксом будет cbde, а суффиксом - a.
Процесс извлечения из FP-дерева частых предметных наборов
будет заключаться в следующем.
. Выбираем предмет (например, a) и находим в дереве
все пути, которые ведут к узлам этого предмета Иными словами, для a это будет
набор (cbdea, cba, cdea). Затем для каждого пути подсчитываем, сколько раз данный
предмет встречается в нем, и записываем это в виде (cbdea, 1), (cba, 1) и
(cdea, 1).
2. Удалим сам предмет (суффикс набора) из ведущих к нему
путей, т.е. (cbdea, cba, cdea). После
это останутся только префиксы: (cbde, cb, cde).
. Подсчитаем, сколько раз каждый предмет появляется в
префиксах путей, полученных на предыдущем шаге, и упорядочим в порядке убывания
этих значений, получив новый набор транзакций.
. На его основе построим новое FP-дерево, которое
назовем условным FP-деревом (conditional FP-tree), поскольку оно связано
только с одним объектом (в нашем случае, a).
. В этом FP-дереве найдем все предметы (узлы), для
которых поддержка (количество появлений в дереве) равна 3 и больше, что
соответствует заданному уровню минимальной поддержки. Если предмет встречается
два или более раза, то его индексы, т.е. частоты появлений в условном базисе,
суммируются.
. Начиная с верхушки дерева, записываем пути, которые
ведут к каждому узлу, для которого поддержка/индекс больше или равны 3,
возвращаем назад предмет (суффикс шаблона), удаленный на шаге 2, и подсчитываем
индекс/поддержку, полученную в результате. Например, если предмет a
имеет индекс 3, то можно записать (c b a,3), что и будет являться
популярным предметным набором.
Префиксы путей, ведущих в условном дереве к узлам, связанным
с предметом e, будут: (c b d e,2) (c d e,2)
(b d e, 1). Подсчитав суммарную поддержку каждого предмета в
условном дереве и упорядочив предметы по ее убыванию, получим: (d,5), (c,4),
(b,3). Следовательно, популярными предметными наборами для предмета e
будут: (d, e,5), (d, c, e,4), (d,
b, e,3).
Таким образом, мы получили следующие популярные предметные
наборы: (c, a,3), (c, b,4), (c, d,4), (b, d,3), (d, e,5), (d, c, e,4), (d,
b, e,3).
Сравнительные исследования классического алгоритма a priori
<#"607556.files/image016.gif">
Рис. 12. Сравнение алгоритмов FPG и a priori
3 Модуль поддержки принятия управленческих решений
В данной главе рассматривается программная реализация FPG-алгоритма метода поиска
ассоциативных правил, построение графиков приобретения услуг и расчета
загруженности персонала.
Дается описание созданного информационного модуля, его
структуры и руководство пользователя и программиста.
Назначение и общие сведения о модуле ППУР
Модуль поддержки принятия управленческих решений на
медицинском предприятии предназначен для помощи и сокращения времени принятия
управленческих решений директором клиники.
Исходными данными для работы модуля являются данные из БД
информационной системы ОАО "Центр Эндохирургических технологий".
Функциональное назначение разработанного модуля состоит в
комплексной поддержке принятия управленческих решений.
Эксплуатационное назначение системы:
- обеспечение поддержки принятия решений для
директора медицинского предприятия;
Состав основных выполняемых функций:
- поиск ассоциативных правил в БД ОАО
"Центр Эндохирургических технологий";
- построение графиков приобретения услуг;
- расчет загруженности персонала
Техническое обеспечение.
Информационная система разработана в среде визуального
программирования Borland Developer Studio на языке Delphi. Минимальные требования
к аппаратному и программному обеспечению компьютера для надежной работы
программного модуля следующие:
- операционная система: WindowsXP, Vista, 7;
- процессор: Pentium - 4 и выше;
- оптимальный объем оперативной памяти:
512Mb;
- минимальный объем свободного дискового
пространства: 10Mb (не считая места, отводимого под данные).
Структура информационной системы
В структуре разработанной информационной системы выделяются
пять основные подсистем (рисунок 7):
- подсистема нормализации базы данных
- подсистема поиска ассоциативных правил
- подсистема расчета и построения графиков
приобретения услуг
- подсистема расчета коэффициента
загруженности персонала
- подсистема считывания базы данных.
Рисунок 9 - Структура модуля ППУР
Описание основных подсистем
Подсистема нормализации базы данных
Для корректной работы алгоритма поиска ассоциативных правил
требуется нормализация базы данных. Данная подсистема отвечает за корректную
конвертацию данных из исходной БД в формат, пригодный для работы алгоритма.
Таблица 5 - Пример участка исходной БД
|
Клиент
|
Услуга
|
Количество
|
Врач
|
|
1
|
3
|
3
|
1
|
|
1
|
2
|
1
|
2
|
Таблица 6 - Пример нормализованного участка исходной БД из
таблицы 5
|
Клиент
|
Услуга 1
|
Услуга 2
|
Услуга 3
|
Услуга.
|
|
1
|
0
|
1
|
3
|
.
|
Подсистема считывает данные из исходной БД с помощью
подсистемы считывания и осуществляет поиск транзакций с одним и тем же
идентификатором клиента. После прохождения всей БД формируется новая таблица
размерности n
на m, где n - число клиентов, m - число всех
предоставляемых услуг. Данная таблица хранится в создаваемом подсистемой файле
и используется подсистемой поиска ассоциативных правил.
Создание отдельного файла для хранения нормализованной БД
обусловлено необходимостью увеличения надежности процесса поиска ассоциативных
правил за счет разбиения всего процесса на две части: считывание БД и ее
нормализация и поиск ассоциативных правил. Данная необходимость возникает из-за
большого (~5-10c) времени считывания и нормализации БД и (~3-5с) времени поиска
ассоциативных правил.
Подсистема поиска ассоциативных правил
Данная подсистема предназначена для поиска ассоциативных
правил на основе файла с нормализованной БД, полученного после работы
подсистемы нормализации БД.
Поиск ассоциативных правил осуществляется с помощью FPG-алгоритма.
Результатом работы данной подсистемы является таблица
ассоциативных правил.
Подсистема расчета и построения графиков приобретения услуг
Данная подсистема предназначена для представления информации
о продажах услуг за выбранный период времени в наглядной форме (в виде графиков).
Подсистема использует данные о транзакциях из корпоративной
БД (полученных с помощью модуля считывания), на основе которых производится
суммирование приобретенных услуг за выбранный период времени. Вывод результатов
осуществляется в графическом виде.
Подсистема расчета коэффициента загруженности персонала
Данная подсистема предназначена для расчета и отображения
информации о занятости персонала.
Входными данными для подсистемы являются данные из
корпоративной БД (полученные подсистемой считывания). Для каждого работника
рассчитывается коэффициент загруженности на основе транзакций с оказанными
услугами, длительности услуг и установленными рабочими часами для данного
работника. Результат предоставляется в виде таблицы с возможностью сортировки.
Подсистема считывания базы данных.
Данная подсистема предназначена для обеспечения корректного
считывания информации из базы данных, которое необходимо для работы остальных
подсистем модуля.
Руководство пользователя
Порядок работы с модулем ППУР
Для того, чтобы начать работу с модулем необходимо нажать на
соответствующую кнопку в главном меню корпоративной информационной системы.
После чего будет открыта основная форма модуля рисунок х.
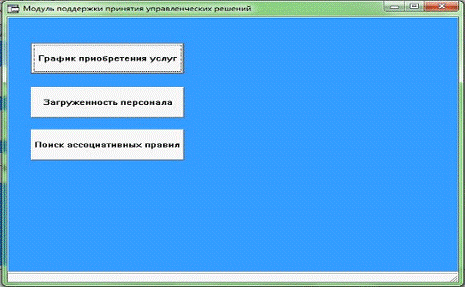
Рисунок 10. Основная форма модуля.
На этой форме пользователь может выбрать интересующую его
функцию или закрыть окно модуля.
Выбрав "График приобретенных услуг" пользователь
попадает на новую форму (Рисунок х2).
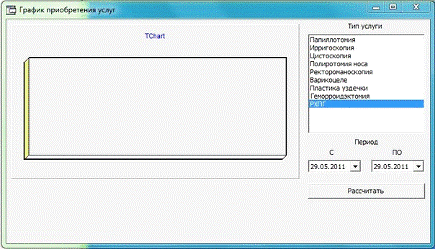
Рисунок 11 - График приобретения услуг
В поле справа находится список всех услуг, загружаемый из БД,
а также два поля даты, указывающие временной интервал построения. Пользователь
выбирает интересующую его услугу, затем вводит даты с и по и нажимает кнопку
рассчитать. После этого в левой части окна рисуется график зависимости
количества приобретенных услуг от времени.
Выбрав "Загруженность персонала" из главного окна
пользователь попадает на новую форму (рисунок х3).
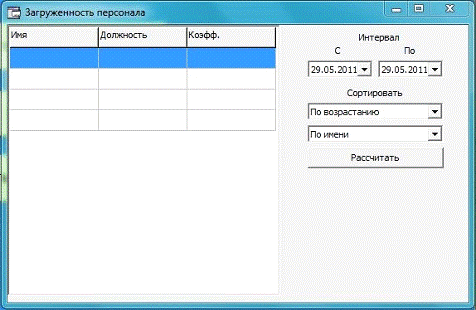
Рисунок 12 - Форма загруженности персонала.
В данной форме пользователь указывает временой интервал и
опции сортировки. Отсортировать результат можно по возрастанию или убыванию
коэффициента загруженности или по алфавиту. Для получения результата необходимо
нажать на кнопку "Рассчитать". Результат выдается в форме
отсортированной таблицы слева.
Выбрав "Поиск ассоциативных правил" пользователь
попадает на новую форму (Рисунок 13).
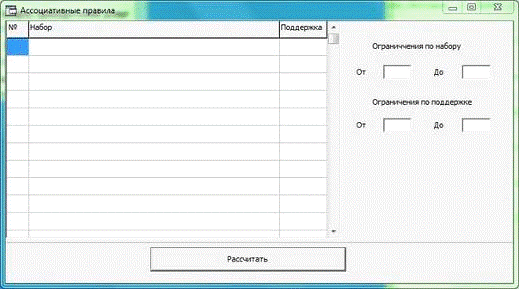
Рисунок 13 - Форма ассоциативных правил.
Здесь пользователю предлагается выбрать диапазон поддержки и
ограничение на размер наборов (по умолчанию ограничения нет). После нажатия на
кнопку "Рассчитать" в таблицу слева заносятся ассоциативные правила с
их поддержками. Таблица сортируется по убыванию поддержки.
Выход из модуля ППУР производится по закрытию окна главного
меню.
Возможные неисправности программного обеспечения
Во время работы программного обеспечения могут возникать
ошибки, которые можно подразделить на внутренние и внешние. Внешние ошибки
связаны с отказом операционной системы, в среде которой работает программное
обеспечение. Они могут быть вызваны сбоями аппаратного обеспечения, файловой
структуры операционной системы и так далее. Внутренние ошибки не связаны с
состоянием среды функционирования ПО, а обусловлены неисправностями самого
программного обеспечения. Основная причина возникновения внутренних ошибок -
недостатки в процессе проектирования ПО. Также вероятной причиной возникновения
внутренних ошибок может заключаться в некорректности исходных данных.
Программные средства представляет собой совокупность классов,
которые представлены на рисунке 17.
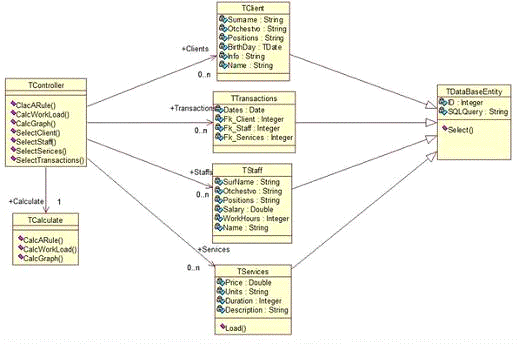
Рисунок 14 - Диаграмма классов
1. ТClient - класс работает с базой
данных, а именно с таблицей Clients (загружает и подготавливает информацию для
расчетов).
2. ТStaff - класс работает с базой
данных, а именно с таблицей Staff (загружает и подготавливает информацию для
расчетов).
3. ТServicesкласс работает с базой
данных, а именно с таблицей Services (загружает и подготавливает информацию для
расчетов).
4. Transaction - класс также работает с
базой данных, но загружает данные из всех таблиц в одну, формируя таблицу
транзакций, которая также используется для расчетов и отображения.
5. TDataBaseEntity - класс от которого наследуются
все классы сущности. Он содержит необходимые методы и поля для загрузки
информации из БД.
6. ТController - обеспечивает передачу
необходимых данных между всеми другими классами и слоями. (Например, передачу
данных от классов сущностей к калькулятору или от калькулятора на формы)
7. ТCalculate - содержит алгоритмы и
производит все математические расчеты
Выводы по
разделу 3
Программное обеспечение, описанное выше, обладает достаточным
функционалом для решения следующих задач: поиск ассоциативных правил в
корпоративной базе данных ОАО "Центр Эндохирургических технологий",
построение графиков приобретения услуг, расчет загруженности перснонала.
Данное программное обеспечение имеет удобный пользовательский
интерфейс, что обеспечивается простотой работы с модулем (небольшое число форм
и параметров для расчета), а также возможностью доработки за счет
предоставления исходного текста программного модуля и руководства программиста.
4.
Эффективность применения модуля поддержки принятия управленческих решений и
полученные с его помощью результаты
4.1
Эффективность модуля ППУР
Эффективность применения модуля ППУР можно оценить,
рассмотрев эффективность каждой из его функций в отдельности.
Эффективность
поиска ассоциативных правил
Эффективность поиска ассоциативных правил обуславливается
эффективностью применения данного подхода к корпоративной БД ОАО "Центр
Эндохирургических технологий" и эффективностью самого алгоритма.
Эффективность FPG-алгоритма и его преимущества над алгоритмом Aprioriбыли рассмотрены во
второй части. И, хотя для такой небольшой корпоративной БД разница во времени
обработки результатов не так заметна, с расширением медицинского предприятия
преимущества выбранного алгоритма будут сказываться все сильнее.
Таким образом выбранный алгоритм можно считать эффективным и
оправданным.
Эффективность применения самого метода ассоциативных правил
для осуществления поддержки принятия управленческих решений на медицинском
предприятии не так очевидна в силу:
· высокой степени стандартизации процедур
оказания услуг
· небольшим вкладом свободы выбора
пользователя на наборы покупаемых им услуг
· относительно небольшим размером
медицинского учреждения
Результатами работы алгоритма становилось обнаружение
большого числа наборов с высокой степенью поддержки. Примерно 90% наборов
оказались очевидными, еще 5% неинформативными. Но оставшиеся 5% представляли
реальный интерес. Несмотря на очень хорошую осведомленность руководства о
процессе оказания услуг на предприятии был обнаружен ряд "интересных"
наборов, анализ которых привел к корректировки пакетов оказываемых клиникой
услуг и работы некоторых отделений медицинского предприятия. (подробнее в
разделе 4.2.1 Результаты поиска ассоциативных правил).
Поиск ассоциативных правил показал себя как эффективный
способ поддержки принятия управленческих решений несмотря на описанные выше
сложности. В перспективе внедрение данного метода в медицинские информационные
системы городского, краевого и федерального масштаба многократно увеличит его
эффективность и позволит обнаруживать не только популярные наборы приобретенных
услуг, но и случаи неправильного лечения, нецелевого использования
медикаментов, социальные тренды в области здравоохранения и много другое.
Эффективность
графиков приобретения услуг
Эффективность графического представления о приобретенных
пользователями услуг состоит в возможности быстро получить наглядную
информацию. Раньше за построения таких графиков на медицинском предприятии
отвечал секретарь, теперь же эту работу выполняет модуль ППУР, что экономит время
и в конечном счете средства предприятия.
Эффективность
оценки загруженности персонала
Эффективность данной функции заключается в возможности
сравнить загруженность различных специалистов и отделов медицинского
предприятия.
Хотя получаемый программой коэффициент в силу многих
субъективных причин не дает полного представления о загруженности того или
иного специалиста, получаемой информации достаточно для пересмотра графиков
работы персонала, принятия решений об увольнении или найме новых работников,
корректировке списка предоставляемых услуг (подробнее в разделе 4.2.3
Результаты оценки загруженности персонала).
4.2
Полученные результаты
В данном разделе представлены результаты работы модуля ППУР.
Результаты
поиска ассоциативных правил
Результатом работы алгоритма поиска ассоциативных правил
стало обнаружение огромного количества наборов разной размерности и разной
поддержки. В силу специфики работы медицинского предприятия полученные наборы
можно охарактеризовать:
· Высоким уровнем поддержки (для некоторых
троичных и четверных наборов более 100)
· Большой размерностью наборов (были
обнаружены наборы из четырех и пяти элементов)
Реализованная возможность фильтрации наборов ассоциативных
правил (возможность вводить ограничение на размер и поддержку) позволило в
значительной мере упростить анализ полученных результатов.
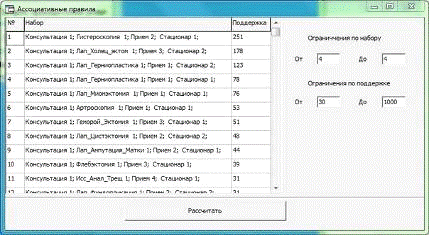
Рисунок 15 - Пример найденных ассоциативных правил.
В ходе анализа был выявлен ряд случаев, когда для одного и
того же типа лечения получались различные наборы. Так, например, для операции
лапороскопическаягерниопластика было выявлено два набора: Консультация 1;
Лап_Герниопластика 1; Прием 1; Стационар 2; и Консультация 1;
Лап_Герниопластика 1; Прием 1; Стационар 1; отличающиеся количеством дней в
стационаре. Пакет услуг предоставляемый клиникой на эту операцию предусматривал
один день стационара, в то время как в большинстве случаев (61%) клиент
оставался в стационаре на еще один дополнительный день, за который приходилось
платить отдельно. Это происходило в силу различного протекания реабилитации у
пациентов, а также из-за разного времени попадания в стационар. Итогом стал
пересмотр данного пакета услуг и включение дополнительного дня в стационаре.
Еще одним результатом работы алгоритма стало обнаружение наборов
с хорошей поддержкой, которые показывали что различные клиенты приобретали
несколько пакетов услуг, которые не были ранее связаны в один комплекс.
Например, был обнаружен набор Консультация 2; Гистероскопия 1; Лап_Миомэктомия
1; Прием 3; Стационар 2; с поддержкой 31. Этот результат привел руководство
клиники к решению о создании комплекса "Гистероскопия и Лапороскопическая
Миомэктомия", который предусматривал скидку на проведение второй операции,
которая должна была привлекать клиентов к повторному обращению в клинику для
продолжения лечения.
Благодаря данному алгоритму было также получено множество
закономерностей, которые могли бы быть "интересными" на большем
предприятии, но не представляющие интерес на малом в силу их очевидности.
Результаты
построения графиков приобретенных услуг
Результатами построения графиков приобретенных услуг стало
более точное представление руководства об объеме и временном распределении
оказываемых медицинским предприятием услуг в целом и о доле каждой услуги в
частности.
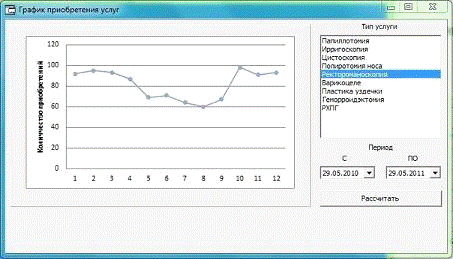
Рисунок 16 - Годовой график приобретения услуги
"Ректороманоскопия".
Благодаря продемонстрированной графиками динамики
приобретения клиентами услуг во времени, руководство смогло скорректировать
работу медицинского предприятия по сезонам. Например, помимо очевидного летнего
спада в приобретении услуг, был обнаружен пик спроса, приходящийся на сентябрь.
Итогами стало более грамотное распределение отпусков для персонала, а также
готовность по необходимости привлечь дополнительные кадры.
Результаты
оценки загруженности персонала
Результатом оценки загруженности персонала стало более
детальное понимание руководством степени загруженности специалистов. Например,
было обнаружено, что наиболее загруженным специалистом оказалась врач гинеколог
Кривонос Татьяна Александровна, что отражает реальное положение вещей. В итоге
была проведена консультация с этим специалистом и принято решение об увеличение
ее приемных часов и, соответственно, повышение зарплаты. Так же было проведено сравнение
загруженности специалистов одних направления и выявлена неравномерность в
распределении нагрузок.
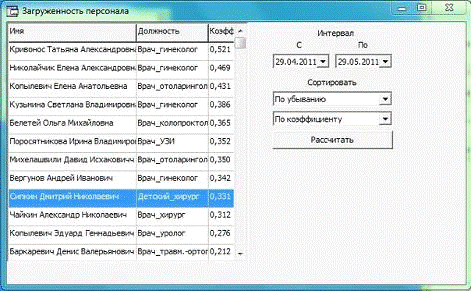
Рисунок 17 - Оценка загруженности персонала за месяц.
Выводы по
разделу 4
Модуль поддержки принятия управленческих решений на
медицинском предприятии, внедренный в информационную систему ОАО "Центр
Эндохирургических технологий" зарекомендовал себя как эффективное средство
поддержки принятия решений и доказал свою эффективность, показав реальные результаты
и позволив руководству клиники провести коррективы своей работы, основываясь на
полученных модулям результатах.
Сноски
Систе́ма подде́ржки приня́тия реше́ний (СППР) (англ.
<http://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA>Decision
Support System, DSS) - компьютерная
<http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80>
автоматизированная система
<http://ru.wikipedia.org/wiki/%D0%90%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82%D0%B8%D0%B7%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0>,
целью которой является помощь людям, принимающим решение в сложных условиях для
полного и объективного анализа предметной деятельности. СППР возникли в
результате слияния управленческих информационных систем
<http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0>
и систем управления базами данных
<http://ru.wikipedia.org/wiki/%D0%A1%D0%A3%D0%91%D0%94>. [1].