Имитационное моделирование системы ипотечного кредитования
Содержание
Введение
Раздел 1. Теоретический анализ методов и алгоритмов
имитационного моделирования
.1 Анализ предметной области
.2 Равномерное распределение случайной величины
.3 Мультипликативный конгруэнтный метод
.4 Моделирование непрерывных случайных величин
.5 Моделирование дискретных распределений
.6 Нормальный закон распределения случайной величины
.7 Достоинства и недостатки метода имитационного
моделирования
.8 Этапы имитационного моделирования
Раздел 2. Описание практической части проведенного исследования
.1 Постановка задачи
.2 Разработка модели
.3 Алгоритм имитационного моделирования
.4 Моделирующий алгоритм
.5 Разработка программной реализации имитационной модели
Раздел 3. Проведение машинного эксперимента и оценка
полученных результатов
.1 Выбор языка программирования
.2 Машинный эксперимент с результатами моделирования
.3 Анализ данных
Заключение
Список использованной литературы
Приложение
Введение
В общем, моделирование можно считать универсальным методом описания
физических, технических, организационных и других систем. До появления
вычислительной техники в основном исследовались и применялись аналитические
модели. Любой закон описывающий поведение некоторой системы, связывающий
характеризующие ее величины, должен рассматриваться как модель этой системы.
Например, закон Ома описывающий величины физических процессов в электрической
цепи является моделью. Эта модель абстрагируется от частных характеристик
конкретного процесса и определяется соотношение существующих его параметров.
Таким образом характеризующей чертой любой модели является абстрагирование.
Указанная простейшая модель может быть отнесена к классу аналитических моделей,
поскольку является аналитическим соотношением, допускающим непосредственное
получение числовых результатов после постанови известных числовых параметров в
соответствующее выражение. Такими же моделями независимо от уровня их сложности
являются математические соотношения, описывающие связь параметров различных
физических и технических систем. Например, система дифференциальных уравнений
описывающие потоки жидкостей движения тел в различных средах, системы уравнений
описывающие связь электронных характеристик, сложных радиоэлектронных
устройств, системы уравнений для расчетно-сложных механических конструкций и
т.д.
Однако с усложнением системы в построении моделей, в которых мы
нуждаемся, их точное аналитическое описание становится все более
проблематичными. Кроме того есть необходимость в изучении поведения системы в
условиях изменяющихся случайным образом внешних воздействий. Эти два фактора
усложнение и случайный характер воздействий приводит к необходимости создания
другого класса моделей так называемых имитационных.
Моментом появления имитационного моделирования экономических процессов
как отдельного подхода к исследованию сложных систем обычно считают 1949г. -
год выхода статьи известных американских физиков Джона Неймона и Улома. Они то
время работали и занимались разработкой ядерного оружия в Лос Аламской
лаборатории. Сложность исследуемых ими процессов была столь велика, что задача
не поддавалась решению обычными аналитическими методами. Ученым пришла в голову
счастливая мысль применить статистические законы теории вероятности для решения
задач. Точность полученного решения оказалась удовлетворительным и с тех пор
указанный подход называемый методом статистических испытаний или иначе методом
Монте-Карло интенсивно исследовался и развивался.
Данный метод называется методом Монте-Карло, потому что в этом методе
существенным образом используется набор случайных чисел.
Программные средства имитационного моделирования начали широко
развиваться в 70-е гг. наиболее известными предметами программных продуктов
является компилятор языка стимула и система GPSS. Современный объектно-ориентированный подход впервые
появился на языке стимула. Поскольку язык был ориентирован на моделирование
систем, в нем реализована возможность инкапсуляции методов обработки для
элементов данных вместе с этими данными и возможность наследования свойств
объектов и их описаний.
Построение имитационной модели проходит следующие этапы:
 При
построение модели должен быть проведен анализ предметной области в которой
функционирует исследуемая система.
При
построение модели должен быть проведен анализ предметной области в которой
функционирует исследуемая система.
Формализация структуры взаимосвязи информационных и
других потоков циркулирующих в системе.
Определение статистических характеристик внешних воздействий,
установление видов законов распределения характеризующих эти воздействия и их
параметры.
Завершается
формализация описанием модели с помощью языка выбранной системы выполнения
имитационной модели.
Методом имитационного моделирования мы можем решать два класса задач в
некотором смысле противоположным друг другу. Это задачи синтеза и анализа.
Синтез системы производится многоэтапным уточнением структуры по
результатам имитационного эксперимента
Задача анализа в чистом виде для существующей системы с известной
структурой для уточнения и оптимизации параметров ее функционирования. При этом
оценивается степень загруженности отдельных звеньев системы, выявляются узкие
зрения, работа которых определяет в значительной мере общую производительность
системы.
Цель курсовой работы по дисциплине «Имитационное моделирование экономических
процессов» - ознакомление с современными концепциями построения моделирующих
систем, с основными приемами имитационного моделирования, встраиваемыми в общую
процедуру преобразования информации от структурирования и формализации
составляющих предметных областей до интерпретации обработанных данных и
приобретенных знаний, связанных с описанием экономических процессов. Данная
работа представляет собой работу по созданию и реализации математической модели
системы массового обслуживания для получения необходимых нам результатов на
основании исходных данных и известных математических зависимостей. Целью данной
курсовой работы является анализ работы коммерческого банка по выдаче кредитов;
моделирование работы кредитной системы коммерческого банка созданием программы
на языке С++, имитирующую работу кредитной системы коммерческого банка;
сравнение полученных результатов моделирующей программы с результатами работы
реального объекта.
Раздел 1. Теоретический анализ методов и алгоритмов имитационного
моделирования
1.1 Достоинства и недостатки метода имитационного
моделирования
В нашей курсовой работе мы использовали метод
имитационного моделирования. У данного метода моделирования можно выделить
некоторые достоинства и недостатки.
Основные достоинства метода имитационного
моделирования:
1. Имитационная модель позволяет описать
моделируемый процесс с большой адекватностью, чем другие.
2. Имитационная модель обладает гибкостью
варьирования, структуры алгоритмов и параметров системы.
. Применение ЭВМ существенно сокращает
продолжительность испытаний по сравнению с натуральным экспериментом, если он
возможен, а также их стоимость.
. Имитационная модель позволяет описать
моделируемый процесс с большой адекватностью, чем другие.
. Имитационная модель обладает гибкостью
варьирования, структуры алгоритмов и параметров системы.
. Применение ЭВМ существенно сокращает
продолжительность испытаний по сравнению с натуральным экспериментом, если он
возможен, а также их стоимость.
Основные недостатки метода имитационного моделирования:
1. Решение, полученное на имитационной модели,
всегда носит частный характер, т.к. оно соответствует фиксированным элементам
структуры, алгоритмам поведения и значениям параметров системы.
2. Большие трудозатраты на создание модели и
проведение экспериментов, а также обработку их результатов. Если использование
системы предполагает участие людей при проведении машинного эксперимента на
результаты может оказать влияние так называемый «Хауторнский эффект»,
заключающийся в том, что люди зная, что за ним наблюдают, могут изменить свое
обычное положение. Таким образом, использование термина имитационное
моделирование предполагает работу с такими математическими моделями, с помощью
которых результаты исследуемой операции нельзя заранее вычислить или предсказать.
Поэтому необходим эксперимент имитации на модели при заданных исходных данных.
Сущность машинной имитации заключается в реализации численного метода
проведения на ЭВМ экспериментов с математическими моделями, описывающими
поведение сложной системы в течении заданного или формируемого периода времени.
1.2 Этапы имитационного моделирования
Процесс последовательной разработки имитационной
модели наминается с создания простой модели, которая затем постепенно
усложняется в соответствии с требованиями, предъявляемыми решаемой проблемой. В
процессе имитационного моделирования можно выделить следующие основные этапы:
1. Формулирование проблемы: описание исследуемой
проблемы и определение целей исследования.
2. Разработка модели: логико-математическое описание
моделируемой системы в соответствии с формулировкой проблемы.
. Подготовка данных: идентификация,
спецификация и сбор данных.
. Трансляция модели: перевод модели на язык,
приемлемый для используемой ЭВМ
. Верификация: установление правильности машинных
программ.
. Валидация: оценка требуемой точности и
соответствия имитационной модели реальной системе.
. Стратегическое и тактическое планирование:
определение условий проведения машинного эксперимента с имитационной моделью.
. Экспериментирование: прогон имитационной
модели на ЭВМ для получения требуемой информации.
. Анализ результатов: изучение результатов
имитационного эксперимента для подготовки выводов и рекомендаций по решению
проблемы.
. Реализация и документирование: реализация
рекомендаций, полученных па основе имитации, и составление документации по
модели и ее использованию.
1.3 Проектирование алгоритма моделирования
Алгоритм имитационного моделирования процессов данного типа
структурируется вокруг следующих групп основных компонентов:
1. Организация цикла перебора отсчетов дискретного времени
моделирования, т.е. собственно организация процесса как последовательности
отдельных состояний системы в дискретном времени;
2. Наполнение этого цикла множеством независимых обработчиков
случайных событий происходящих в моделируемой системе.
Таким образом, мы имеем общий способ построения алгоритмов подобного
типа, который включает следующие основные компоненты:
1. Анализ событий в системе и проектирование структур данных
необходимых для хранения информации связанный с этими событиями;
2. Разработка отдельных алгоритмов обработки этих событий включающих
в общем случае модификацию параметров состояния системы и моделирование
следующего события того типа, обработка которого производится этим алгоритмом;
. Связывание отдельных разработанных выше алгоритмов и структур
данных в единой программе.
1.4 Выбор языка программирования
Структурное программирование - это технология создания программ,
позволяющая путем соблюдения определенных правил уменьшить время разработки и
количество ошибок, а также облегчить возможность модификации программы.
Разные типы процессоров имеют разный набор команд. Если язык
программирования ориентирован на конкретный тип процессора и учитывает его
особенности, то он называется языком программирования низкого уровня. Языком
самого низкого уровня является язык ассемблера, который просто представляет
каждую команду машинного кода в виде специальных символьных обозначений,
которые называются мнемониками. С помощью языков низкого уровня создаются очень
эффективные и компактные программы, т.к. разработчик получает доступ ко всем
возможностям процессора. Т.к. наборы инструкций для разных моделей процессоров
тоже разные, то каждой модели процессора соответствует свой язык ассемблера, и
написанная на нем программа может быть использована только в этой среде.
Подобные языки применяют для написания небольших системных приложений,
драйверов устройств и т. п..
С помощью языка программирования создается текст, описывающий ранее
составленный алгоритм. Чтобы получить работающую программу, надо этот текст
перевести в последовательность команд процессора, что выполняется при помощи
специальных программ, которые называются трансляторами. Трансляторы бывают двух
видов: компиляторы и интерпретаторы. Компилятор транслирует текст исходного
модуля в машинный код, который называется объектным модулем за один непрерывный
процесс. При этом сначала он просматривает исходный текст программы в поисках
синтаксических ошибок. Интерпретатор выполняет исходный модуль программы в
режиме оператор за оператором, по ходу работы, переводя каждый оператор на
машинный язык.
Языки программирования высокого уровня не учитывают особенности
конкретных компьютерных архитектур, поэтому создаваемые программы на уровне
исходных текстов легко переносятся на другие платформы, если для них созданы
соответствующие трансляторы. Разработка программ на языках высокого уровня
гораздо проще, чем на машинных языках.
Си - был создан в 70- е годы первоначально не рассматривался как массовый
язык программирования. Он планировался для замены ассемблера, чтобы иметь
возможность создавать такие же эффективные и короткие программы, но не зависеть
от конкретного процессора. Он во многом похож на Паскаль и имеет дополнительные
возможности для работы с памятью. На нем написано много прикладных и системных
программ, а также операционная система Unix.
Си++ - объектно-ориентированное расширение языка Си, созданное Бьярном
Страуструпом в 1980г.
В тексте на любом естественном языке можно выделить четыре основных элемента:
символы, слова, словосочетания и предложения. Алгоритмический язык также
содержит такие элементы, только слова называют лексемами (элементарными
конструкциями ), словосочетания - выражениями, предложения - операторами.
Лексемы образуются из символов, выражения из лексем и символов, операторы из
символов выражений и лексем.
Алфавит языка СИ++ включает
- прописные и строчные латинские буквы и знак подчеркивания;
- арабские цифры от 0 до 9;
специальные знаки “{},| []()+-/%*.\’:;&?<>=!#^
пробельные символы
Данные отображают в программе окружающий мир. Цель программы состоит в
обработке данных. Данные различных типов хранятся и обрабатываются по-разному.
Тип данных определяет:
1) внутреннее представление данных в памяти компьютера;
2) множество значений, которые могут принимать величины этого типа;
) операции и функции, которые можно применять к данным этого типа.
В зависимости от требований задания программист выбирает тип для объектов
программы. Типы Си++ можно разделить на простые и составные. К простым типам
относят типы, которые характеризуются одним значением. В Си++ определено 6
простых типов данных:
int
(целый)
char
(символьный)
wchar_t (расширенный символьный)
bool
(логический)
float(вещественный)
double
(вещественный с двойной точностью)
Существует 4 спецификатора типа, уточняющих внутреннее представление и
диапазон стандартных типов
short
(короткий)
long
(длинный)
signed
(знаковый)
unsigned (беззнаковый)
В языке Си++ нет встроенных средств ввода и вывода - он осуществляется с
помощью функций, типов и объектов, которые находятся в стандартных библиотеках.
Существует два основных способа: функции, унаследованные из Си и объекты Си++.
1.5 Метод Монте-Карло
В
конце 40-х годов американские физики применили для вычисления на ЭВМ сложных
квадратур метод, основанный на вероятностных законах. Этот метод был назван ими
методом Монте-Карло, имея в виду Монте-Карло как мировой центр игр, исход
которых определяется случаем. Суть метода станет ясной из следующего примера.
Предположим, что требуется определить площадь s под
некоторой кривой у =f(x)>о на отрезке [х1,х2], то
есть вычислить значение определённого интеграла 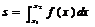 (1). Это
можно сделать следующим образом. Будем выбирать случайные точки в
прямоугольнике (х1,0), (x1,а), (х2,а), (х2,0), площадью
а(х2-х1) (см. рис.1) и считать число точек т, попавших
под кривую у = f(х). Тогда при общем числе п выбранных точек,
отношение т/n, очевидно, будет приближённо равным отношению искомой
площади s под кривой у = f(х) на отрезке
[х1,х2] к площади а(х2-х1)
прямоугольника. Откуда искомая площадь может быть вычислена по формуле
(1). Это
можно сделать следующим образом. Будем выбирать случайные точки в
прямоугольнике (х1,0), (x1,а), (х2,а), (х2,0), площадью
а(х2-х1) (см. рис.1) и считать число точек т, попавших
под кривую у = f(х). Тогда при общем числе п выбранных точек,
отношение т/n, очевидно, будет приближённо равным отношению искомой
площади s под кривой у = f(х) на отрезке
[х1,х2] к площади а(х2-х1)
прямоугольника. Откуда искомая площадь может быть вычислена по формуле 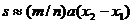 , причём вычисленное таким образом значение будет тем
ближе к точному значению интеграла (1), чем больше точек п взято и чем более
равномерно распределены точки внутри прямоугольника.
, причём вычисленное таким образом значение будет тем
ближе к точному значению интеграла (1), чем больше точек п взято и чем более
равномерно распределены точки внутри прямоугольника.
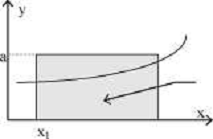
Рис.
1.
Проблема
состоит в том, чтобы получить на ЭВМ случайные числа с равномерным
распределением. Действительно, ЭВМ представляет собой детерминированное
устройство, которое при одних и тех же условиях всегда выдает один и тот же
результат. Одним из очевидно напрашивающихся представляется решение получить
случайную последовательность каким-либо из известных физических методов,
например с помощью рулетки, какие используются в казино, после чего записать
эти случайные числа во внешнюю память ЭВМ с целью последующего использования в
программе. Однако это потребовало бы значительных затрат времени для получения
достаточно длинной случайной последовательности, с одной стороны, и внешней
памяти для её сохранения, с другой. Следует отметить также тот факт, что в
момент появления метода ресурсы внешней памяти ЭВМ были весьма ограничены.
Другим возможным решением было бы применить непосредственно какой-либо физический
метод генерации случайных чисел с помощью специально сконструированного для
этих целей подключаемого к ЭВМ аппаратного устройства и далее получать с его
помощью случайные числа непосредственно во время работы программы. В качестве
основы для такого устройства можно было бы использовать какой-либо электронный
прибор, например электронную лампу, вырабатывающие случайные уровни потенциала,
обусловленные тепловыми флуктуациями. Такие устройства могут быть
сконструированы, однако возникают проблемы с устойчивостью их работы во времени
и при изменении условий окружающей среды; существует также проблема
сертификации подобного устройства. В итоге исследователи остановились на более
простой и оказавшейся в дальнейшем продуктивной идее генерации вместо случайной
так называемой псевдослучайной, последовательности чисел с помощью специально
разработанного для этих целей алгоритма.
.6
Генерация псевдослучайных чисел на ЭВМ
Известно,
что многие широко используемые в математике алгоритмы приводят к числовым
последовательностям, элементы которых не поддаются детерминированному
определению в том смысле, что не известно закона, выражающегося математической
формулой и позволяющего определить значение элемента последовательности по его
номеру в ней без предварительного вычисления предшествующих элементов. Таковыми
являются, например, последовательность простых чисел и последовательность
десятичных цифр представления иррационального вещественного числа. Эти и
подобные им числовые последовательности могут, следовательно, рассматриваться
так, как если бы они были случайными, или, иначе говоря, - как псевдослучайные
последовательности.
Для
получения псевдослучайной последовательности Фон Нейманом был придуман простой
в вычислительном отношении алгоритм, известный как метод квадратов. Метод
состоит в многократном повторении процедуры, состоящей в возведении в квадрат
некоторого числового значения и взятия средних цифр полученного результата.
Пусть, например, мы выбрали в качестве исходного значения число wo=7654. Тогда и02 =76542 =58583716 и и1=5837,
и12 =58372 =34070569 и и2=0705, и
так далее. Однако, вскоре у метода обнаружился недостаток, заключающийся в
существенной неравномерности статистических частот различных числовых значений
элементов получаемой этим методом последовательности.
Были проведены широкие исследования для поиска
алгоритмов вычисления псевдослучайных чисел, обеспечивающих лучшую
равномерность. В результате был найден очень простой и эффективный в
вычислительном отношении, так называемый мультипликативный конгруэнтный метод,
свободный от указанного недостатка. Этот метод основан на рекуррентном
вычислении элементов псевдослучайной последовательности как результата
выполнения операции сравнения по некоторому заданному основанию. Переход к
следующему числу последовательности производится простым умножением результата
сравнения на некоторую заданную константу. На практике операции вычисления
произведения и взятия сравнения по заданному основанию совмещены. В качестве
основания сравнения используется величина 2m, где т - разрядность целочисленного регистра ЭВМ, в
котором хранится результат вычисления произведения. При целочисленном умножении
этого результата на заданную константу достаточно большой величины происходит
переполнение, вследствие чего в регистре результата сохраняются лишь т младших
разрядов произведения. Это число и будет фактически результатом операции
сравнения вычисленного произведения с числом 2т (напомним, что
операцией сравнения по некоторому основанию называется вычисление остатка от
деления первого операнда на это основание).
Формально схема вычисления может быть определена
следующим образом: uo=C, ui+1 =uic(mod2m),
где ui. - i-й член псевдослучайной
последовательности, с - некоторая константа, т -разрядность целочисленного
регистра ЭВМ. Качество полученной псевдослучайной последовательности зависит от
выбранного значения константы C.
Установлено, что хороший результат достигается при выборе её значения равным
максимальной нечётной степени числа 5, помещающегося в числовом регистре
фиксированной разрядности. Для 32-х разрядного регистра ЭВМ это будет число 513.
Ниже приведён исходный текст процедуры генерации указанным методом
псевдослучайной последовательности чисел, равномерно распределённых в интервале
[0,1], и гистограмма распределения, построенная по первой тысяче вычисленных с
помощью этой функции значений.
#define C (125*125*125*125*5)
//C=1220703125ulrand(void)
{unsigned long
u=C;=u*C;u/(float(0xFFFFFFFFul)+1);
}
1.7 Моделирование дискретной случайной величины
Предположим
вначале, что нам требуется смоделировать простейшую дискретную случайную
величину, принимающую два значения с равными вероятностями. Эта случайная
величина моделирует выбрасывание жребия или монеты. Если мы имеем в своём
распоряжении генератор псевдослучайных последовательностей, описанный в
предыдущем параграфе, то задача может быть решена следующим, достаточно
очевидным, способом. Поскольку псевдослучайное число, получаемое с помощью
функции rand(), распределено равномерно в интервале (0,1), то
одинаково вероятно, будет ли очередное полученное значение принадлежать левой
половине этого интервала [0,0.5) или правой [0.5,1]. По этой причине мы можем
одно из двух значений нашей случайной величины поставить в соответствие первому
из этих двух подинтервалов, а другое - второму, и далее выдавать значения в
зависимости от того к какому из этих двух подинтервалов будет принадлежать
очередное выпавшее значение генератора rand(). Эта
схема, очевидно, легко обобщается на дискретную случайную величину, принимающую
более двух значений. За каждым значением мы должны в этом случае
"закрепить" некоторый подинтервал значений функции rand()
с длиной, равной вероятности этого значения моделируемой дискретной случайной
величины, - причём так, чтобы интервалы, закрепленные за различными значениями
случайной величины не пересекались бы между собой. Поскольку сумма вероятностей
всех значений случайной величины равна единице, и таков же диапазон значений,
принимаемых псевдослучайной величиной, генерируемой функцией rand(),
то эти подинтервалы полностью покроют диапазон возможных значений, принимаемых
случайной величиной, генерируемой функцией rand(). Теперь
мы должны лишь всякий раз определять, к какому из множества выбранных указанным
выше образом подинтервалов принадлежит очередное выданное функцией rand()
значение, и выдавать соответствующее ему значение моделируемой дискретной
случайной величины. Формально этот метод может быть представлен в следующем
виде. Пусть у - случайная величина, равномерно распределённая на отрезке [0,1]
(в нашем случае - это результат очередного выполнения функции rand())
и ξ, - моделируемая дискретная случайная величина. Тогда
мы выдаем по получении очередного значения g случайной
величины γ
такое значение xi, дискретной
случайной величины ξ,, для которого верно двойное неравенство 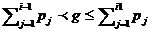 . Этим исчерпывается решение задачи моделирования
дискретной случайной величины с заданным распределением. Вышеприведённый
алгоритм легко реализуется программно, - например так, как в нижеприведённой
функции int discrete(float
p[]).
. Этим исчерпывается решение задачи моделирования
дискретной случайной величины с заданным распределением. Вышеприведённый
алгоритм легко реализуется программно, - например так, как в нижеприведённой
функции int discrete(float
p[]).
unsigned int discrete(float p[])
{,r; intk=0;=p [0]; r=rand();
(s<r){++;=s+p[k];} k;}
Функция принимает массив вероятностей моделируемой
дискретной случайной величины и выдаёт индекс очередного её сгенерированного
значения. Следует учесть, что поскольку индексация массивов в языке С
начинается с нуля, также с нуля индексируются значения разыгрываемой случайной
величины. То есть функция выдаёт значения в диапазоне от 0 до k-1 для дискретной случайной величины,
принимающей к значений.
1.8 Моделирование случайной величины, равномерно
распределённой в интервале (а,b)
Мы используем метод обратной функции для моделирования
равномерного и показательного распределений. Решаем уравнение
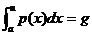 .
.
Для
этого, подставив выражение для плотности равномерного распределения на место
р(х), вначале вычислим интеграл в левой части уравнения,
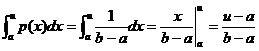 ,
,
а
затем для вычисления значений и равномерно распределённой в интервале (а,b)
случайной величины ξ, через значения g случайной
величины γ равномерно распределённой в интервале (0,1) просто
выразим переменную и через переменную g из уравнения
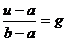 : u = g(b-a) + a.
: u = g(b-a) + a.
Заметим,
что полученная формула очевидна. Действительно, для пересчёта равномерно
распределённой в интервале (0,1) случайной величины в случайную величину,
равномерно распределённую в интервале (а,b), мы должны
вначале "растянуть" диапазон значений единичной длины в диапазон
значений длины (b-а) умножая значение g на (b-а),
а затем переместить полученный результат из интервала (0,1) в интервал (а, b),
прибавив к нему значение а. Запись полученной формулы в виде функции языка С:
float uniform (float a, float b) {return rand () *
(b-a)+a;}
позволит
нам программно генерировать случайные величины с равномерным распределением в
любом заданном конечном интервале значений (а, b).
.9
Моделирование случайной величины с показательным распределением
Так
же как и в предыдущем параграфе для моделирования равномерного распределения,
решаем задачу методом обратной функции. Исходное уравнение имеет вид
 , где
, где 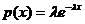 ,
,
Вначале
вычислим значение интеграла в левой части уравнения:
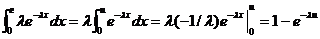
Теперь
выразим и через g из полученного уравнения 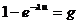 . Получим формулу
. Получим формулу 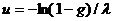 .
Поскольку случайная величина (1-γ) имеет такое же распределение, как и случайная величина γ, то для получения значения и случайной величины ξ с показательным распределением по значению g
случайной величины γ с равномерным распределением в интервале (0,1)
используем более простую формулу
.
Поскольку случайная величина (1-γ) имеет такое же распределение, как и случайная величина γ, то для получения значения и случайной величины ξ с показательным распределением по значению g
случайной величины γ с равномерным распределением в интервале (0,1)
используем более простую формулу
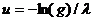 .
.
Функция
языка С для моделирования показательного распределения может быть реализована,
таким образом, в следующем виде:
float exponential (float lambda) { return -log (rand
())/lambda; }
Далее
в таблице приведены первые 100 значений псевдослучайной последовательности,
моделирующей случайную величину, имеющую показательное распределение с
параметром λ = 1, сгенерированные с помощью этой функции, а также
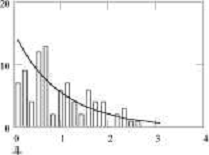
их среднее значение, оценка дисперсии и две гистограммы: первая, построенная по
первым 100 значениям из таблицы и вторая - по первой 1000 значений, также
сгенерированных с помощью приведённой выше функции.
Таблица.
|
1.6329
|
0.682062
|
0.003307
|
1.22792
|
0.036111
|
4.06966
|
2.26461
|
0.598209
|
0.475993
|
1.77939
|
|
0.627057
|
0.251593
|
0.333306
|
0.850373
|
0.693352
|
1.09183
|
0.197888
|
0.644725
|
0.977052
|
0.253682
|
|
0.609308
|
0.16996
|
1.79393
|
0.718406
|
5.95737
|
1.11292
|
0.90857
|
0.290526
|
2.47846
|
1.64329
|
|
0.303046
|
1.46484
|
3.50551
|
0.53748
|
0.621188
|
1.50169
|
4.25087
|
0.911306
|
0.210692
|
0.244696
|
|
1.25122
|
0.535883
|
1.68451
|
0.917857
|
0.225413
|
4.63928
|
0.57747
|
2.15182
|
0.018563
|
1.90741
|
|
1.57503
|
3.83291
|
2.32393
|
0.005425
|
0.985328
|
0.007985
|
0.714955
|
0.653691
|
0.605147
|
3.41126
|
|
1.81697
|
1.91627
|
0.76482
|
3.3194
|
1.16036
|
3.09068
|
0.633922
|
0.312492
|
0.475439
|
1.50114
|
|
0.377081
|
0.460445
|
0.148285
|
1.61427
|
2.35156
|
1.68769
|
2.24768
|
2.6736
|
1.45001
|
0.711622
|
|
0.59944
|
0.621646
|
0.915476
|
0.011233
|
1.11774
|
3.30505
|
0.260542
|
0.454106
|
1.1993
|
0.552846
|
|
0.52216
|
1.8368
|
0.487194
|
3.7079
|
5.49721
|
1.07459
|
1.2666
|
1.147
|
4.32023
|
1.25147
|
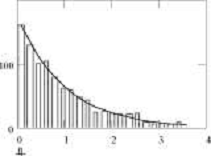
 value 1.00542
value 1.00542
Dispersion estimate 0.922283
С помощью программы для генерирования показательного
распределения можно моделировать простейший пуассоновский поток событий. Дело в
том, что для простейшего пуассоновского потока событий с интенсивностью λ интервалы времени между двумя
последовательными событиями потока распределены по показательному закону с
параметром λ.
.10 Моделирование нормального распределения
Функция
плотности нормального распределения 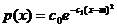 не
интегрируется в элементарных функциях. Поэтому метод обратной функции,
использовавшийся нами выше для моделирования равномерного и показательного
распределений здесь неприменим. Можно воспользоваться центральной предельной
теоремой и получать значения нормально распределённой последовательности как
сумму независимых равномерно распределённых случайных величин. Этот алгоритм
достаточно прост в реализации и поэтому часто используется. Однако мы выберем
иной, аналитический подход. Можно показать, что величины, вычисляемые по
формулам
не
интегрируется в элементарных функциях. Поэтому метод обратной функции,
использовавшийся нами выше для моделирования равномерного и показательного
распределений здесь неприменим. Можно воспользоваться центральной предельной
теоремой и получать значения нормально распределённой последовательности как
сумму независимых равномерно распределённых случайных величин. Этот алгоритм
достаточно прост в реализации и поэтому часто используется. Однако мы выберем
иной, аналитический подход. Можно показать, что величины, вычисляемые по
формулам 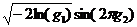 ,
, 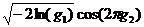 , где
, где 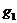 и
и 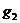 - две
независимые случайные величины с равномерным распределением в интервале (0,1),
имеют стандартное нормальное распределение. Поэтому нормальное распределение с
параметрами σ,
т можно реализовать вычислением величины
- две
независимые случайные величины с равномерным распределением в интервале (0,1),
имеют стандартное нормальное распределение. Поэтому нормальное распределение с
параметрами σ,
т можно реализовать вычислением величины 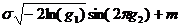 . Вот функция для генерации псевдослучайной
последовательности с нормальным распределением этим методом:
. Вот функция для генерации псевдослучайной
последовательности с нормальным распределением этим методом:
float gauss(float mean, float sigma)
{return
sqrt(-2*log(rand()))*sin(2*M_PI*rand())*sigma+mean;}
и гистограмма, построенная по первой тысяче значений,
выданных этой функцией в результате её вызова с параметрами т = 0, о = 1:
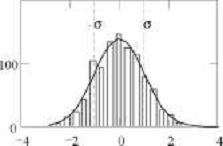
Histogram Normal distribution
.11 Моделирование СМО с N обрабатывающими устройствами
без очереди с отказами
Первый этап моделирования состоит в определении происходящих
в системе событий и логики их обработки. В нашей системе происходят события
двух типов. Первый - поступление в систему очередного требования. Второй -
завершение обслуживания требования устройством. Логическая последовательность
обработки событий этих двух типов следующая - сначала обрабатывается завершение
обслуживания требования устройством, затем - распределение очередного
поступившего в систему требования обрабатывающему устройству. Эта
последовательность диктуется логикой обслуживания требований в системе. Если в
какой-либо дискретный момент времени в систему поступает очередное требование и
одновременно с этим завершается обработка какого-либо из уже находящихся в
системе, то вначале необходимо обработать завершение обслуживания, и лишь затем
поступление нового требования в систему. Это диктуется тем, что вновь
поступившему требованию требуется свободное устройство, которое появится,
возможно, лишь в результате завершения обслуживания какого-либо из уже
обрабатывающихся системой требований. В самом общем виде завершение обработки
состоит в высвобождении занятого устройства и увеличении на единицу счётчика
числа обработанных требований. Точно так же, обработка поступления состоит в
выборе свободного устройства и передаче ему требования на обработку, или, в
случае отсутствия такового устройства, в отказе в обработке данного требования.
Указанные два обработчика событий включаются в основной цикл отсчёта дискретных
моментов времени периода моделирования, как показано ниже:
//инициализация:
//основной цикл: for (t=0; t<T; t++)
{
//обработка завершения обслуживания требования:
//обработка поступления нового требования в систему:
// завершение: {...}
В качестве параметров модели используем следующие
константы и макроопределения: • Т - время моделирования (в сек.);- число
обрабатывающих устройств в системе;
RIN - генератор случайного потока поступающих в систему
требований;
RON - генератор интервалов времени обработки требования
обрабатывающим устройством;
Программная реализация алгоритма и результат её
выполнения приведены ниже на рис. 1, 2. Исходный текст программы начинается с
определения параметров модели и прочих исходных данных. Все они определяются с
помощью директивы препроцессора "#define". Макросы RIN и RON
определяют вызовы функций, моделирующих распределение интервалов времени между
событиями входного потока требований и интервалов времени от начала до
завершения обслуживания требования обрабатывающим устройством, соответственно.
Сами функции моделирования случайных последовательностей, распределенных по
различным законам, определены в файле rand.cpp, текст которого подключается к
тексту модели процесса с помощью директивы препроцессора "#include" в первой строке текста
программной реализации модели. Полный текст модуля rand.cpp
приведён в приложении 1. Константа "Т" определяет длительность
периода моделирования в единицах дискретного времени моделирования. Константа
"N" задаёт число обрабатывающих
устройств. Константа "VACANCY"
определяет специальное значение для элемента массива ton[], означающее, что обрабатывающее устройство,
сопоставленное данному элементу массива свободно. Поскольку массив ton[] предназначен для хранения моментов
времени завершения обслуживания требования соответствующим устройством, которые
могут принимать лишь неотрицательные значения, то в качестве такого,
сигнализирующего о незанятости устройства значения, взято первое неиспользуемое
отрицательное число - "-1". Программа начинается с описания типов
следующих используемых переменных:
·
i,j,k - используются
для хранения вспомогательных индексных значений;
·
n - число обработанных требований;
·
m - число отказов в обслуживании;
·
t - дискретные отсчёты времени периода
моделирования;
·
tin - момент поступления в систему
следующего требования;
• ton[]
- моменты завершения обработки требований соответствующими элементам массива
обрабатывающими устройствами.
Все переменные определяются как беззнаковые длинные
целочисленные переменные. Это связано с тем, что диапазона значений простого
типа int - от -32768 до 32767 может быть недостаточно
для представления используемых значений данных модели. Далее следует собственно
моделирующий алгоритм: 1.Инициализация переменных:
1.1.Инициализация массива ton[] - все обрабатывающие устройства помечаются как
свободные присваиванием элементам массива метки "vacancy":
"for(i=o;i<N;i++)
ton[i]=VACANCY;";
2.
Инициализация
числа обработанных требований "n" и отказов "m" нулевыми значениями: "n=о; m=о;";
3.
Генерация момента
времени поступления в систему первого требования и сохранение его значения в
переменной tin:
"tin=RIN;"
. Цикл перебора дискретных отсчётов времени периода
моделирования:
.1. Определение числа итераций цикла перебора
дискретных отсчётов периода моделирования: "for(t=o;t<T;t++)" и вход в тело цикла
"{"; 2.1.1.Обработка завершения обслуживания требования:
.1.1.1.Определение числа итераций цикла перебора
устройств: "for (i=o,i<N;i++)" и вход в тело цикла
.1.1.2.Если текущий момент времени t совпадает с моментом, установленным
для завершения обслуживания требования i-м устройством ton[i]: "if (ton[i]= = t)", то
2.1.1.2.1. освобождение устройства:
"ton[i]=VACANCY;";
.1.1.2.2.увеличение на единицу числа обработанных
требований: "п++;";
.1.1.3.Конец цикла перебора устройств 2.1.1.1.:
"}".
.1.2 Обработка очередного поступающего в систему
требования:
.1.2.1.Поиск первого свободного обрабатывающего
устройства:
"i = 0; while (ton[i] != VACANCY
&& i<N)
2.1.2.2.Если свободное устройство найдено: "if (i<n) ", 2.1.2.2.1. то передача
требования на обработку этому устройству, которая в нашем случае заключается
просто в генерации момента времени завершения обслуживания этого требования
"t+RON" и сохранение его в соответствующем найденному
свободному устройству i-м
элементе массива ton[]:
"ton[i] = t+RON",
.1.2.2.2. иначе отказ в обслуживании требования;
обработка отказа здесь состоит просто в увеличении на
единицу счётчика числа отказов m: m++;
.1.2.3 Генерация момента поступления в систему нового
требования и сохранение его в переменной tin:
"tin=t+RIN;"
.2. Конец блока цикла 2.1.: "}" 3.
Завершение процесса моделирования:
.1. Вывод результатов моделирования - в данном случае
значений заданного числа обрабатывающих устройств N, числа обработанных требований n, и числа отказов m.
Раздел 2. Имитационное моделирование процесса
2.1 Постановка задачи (Вариант№21)
Провести имитационное моделирование кредитной системы коммерческого
банка. Период моделирования n лет.
Интервал времени между двумя последовательно выданными кредитами моделировать
случайной величиной τ1, имеющей показательное распределение с параметром λ1 дней-1. Максимальное число
одновременных выданных кредитов сmax. Сумма выданного кредита моделируется случайной величиной n1, равномерно распределенной в интервале [n1min,…,n1max]. Срок до дня погашения кредита моделировать случайной
величиной τ2 с распределением Р(τ2) (условно принять, что погашение всей суммы кредита
производится клиентом единовременно). Годовая процентная ставка по кредиту h процентов. Начисление процентов
ежедневное.
Рассчитать:
§ Количество выданных банком за период моделирования кредитов;
§ Общую сумму кредитов;
§ Среднюю дневную величину кредитованных банком средств;
§ Суммарную за период моделирования и среднемесячный доход банка от
выданных кредитов.
Параметры модели:
§ n = 5
§ h = 20
§ λ=1/7
§ Cmax=100
§ n1min=100000, n1max=10000000
§ 90 120 150 180 210 240 270 365
P(τ2)=0,05 0,1 0,2 0,2 0,2 0,05 0,05 0,15
(первая строка значения случайной величины в днях, вторая -
соответствующие вероятности)
Рассчитать параметры модели в условиях увеличения частоты выдачи кредитов
(λ=20),
уменьшения сумм кредитов
(нормальное распределение с параметрами m=30000 и σ=4), изменения сроков (нормальное
распределение с параметрами m=365
и σ=30)
и увеличения макс.
кол-ва одновременно выдаваемых кредитов (Cmax=10000).
Средство реализации модели - программа на языке С++.
2.2 Разработка модели
В данной курсовой работе применили экспоненциальное, дискретное
равномерное, нормальное распределения. Интервал времени между двумя
последовательно выданными кредитами имеет экспоненциальное распределение.
.3 Моделирующий алгоритм
Параметры модели:
· N - время моделирования (лет);
· Cmax - макс. количество одновременно выдаваемых кредитов;
· RIN - интервал
времени между двумя последовательными выдачами кредитов, моделирующийся
случайной величиной τ1, имеющей
показательное распределение с параметром λ1 дней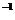 ;
;
· RON - время до
дня погашения кредита, моделирующееся случайной величиной τ2 с
распределением P(τ2);
· N1 - сумма
кредита, моделирующаяся случ. величиной n1, равномерно
распределенной в интервале от 10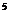 до 10
до 10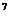 (руб.);
(руб.);
· H - годовая процентная ставка;
Переменные состояния
· tin - Время поступления очередного требования;
· ton - Массив моментов погашения кредита;
Параметры расчета
· Kred - Количество выданных кредитов:
· Otk - количество отказов;
· Sum_Kred -
общая сумма выданных кредитов;
· Sred_Vel -
средняя дневная величина выданных кредитов;
· Ob_Doxod - суммарный доход;
· Mec_Doxod - среднемесячный доход.
Далее следует собственно моделирующий алгоритм:
. Инициализация переменных:
1.1. Инициализация массива ton[] - все обрабатывающие устройства помечаются как
свободные присваиванием элементам массива “-1”
"for(i=0;i<Cmax;i++)ton[i]=-1;";
2.
Инициализация
числа заявок на кредит "Kred"
и отказов по кредитам "Otk"
нулевыми значениями: "Kred=о;
Otk=о;";
3.
Генерация момента
времени поступления в систему первого требования и сохранение его значения в
переменной tin: "tin=RIN;"
2. Цикл перебора дискретных отсчётов времени периода
моделирования:
.1. Определение числа итераций цикла перебора
дискретных отсчётов (в днях) периода моделирования: "for(t=0;t<(N*365);t++)" и вход в тело цикла
"{"; 2.1.1.Обработка завершения обслуживания требования:
.1.1.1.Определение числа итераций цикла перебора
устройств: "for (i=0,i<Cmax;i++)" и вход в тело цикла
.1.1.2.Если текущий момент времени t совпадает с моментом, установленным
для погашения кредита: "if(ton[i]= = t)",
то
2.1.1.2.1. освобождение i-го устройства: "ton[i]=-1;";
2.1.1.2.2.увеличение на единицу числа выданных
кредитов: "Kred++;";
.1.1.3.Конец цикла перебора устройств 2.1.1.1.:
"}". 2.1.2.Обработка очередного поступающего в систему требования:
.1.2.1.Поиск первого свободного обрабатывающего устройства:
"i = 0; while (ton[i] != -1 && i<Cmax)
.1.2.2.Если свободное устройство найдено: "if (i< Cmax) ", 2.1.2.2.1. то выдача кредита
и подсчет времени, на которое он выдается, суммы выдаваемого кредита, обшей
суммы и общего дохода по уже выданным кредитам, что в нашем случае заключается
в выполнении следующих операторов:
T_Kred=RON;[i]=t+T_Kred;=N1;_Kred+=Sum;_Doxod+=Sum*T_Kred/365*H/100.0;
2.1.2.2.2. иначе отказ в выдаче кредита;
увеличении на единицу счётчика числа отказов Otk: ”Otk++;”
.1.2.3.Генерация момента поступления в систему нового
требования на получение кредита и сохранение его в
переменной tin: "tin=t+RIN;"
.2. Конец блока цикла 2.1.: "}"
. Завершение процесса моделирования:
3.1. Подсчет среднедневной величины кредитов, среднемесячного дохода
банка и вывод результатов моделирования кредитной системы - количество выданных
банком за период моделирования кредитов, общей суммы кредитов, средней дневной
величины кредитованных банком средств, суммарного за период моделирования и
среднемесячного дохода банка от выданных кредитов:
Mec_Doxod=Ob_Doxod/(N*12);<<'
'<<"Kolichestvo kreditov= "<<Kred<<endl;<<'
'<<"Kolichestvo otkazov= "<<Otk<<endl;<<'
'<<"Summa kreditov= "<<Sum_Kred/1000000<<"
mln.rub."<<endl;<<' '<<"Srednaya dnevnaya velichina
kredita= "<<Sred_Vel/1000000<<"
mln.rub."<<endl;<<' '<<"Summarniy dohod=
"<<Ob_Doxod/1000000<<"
mln.rub."<<endl;<<' '<<"Srednemesachniy dohod=
"<<Mec_Doxod/1000000<<" mln.rub."<<endl;
2.4 Программная реализация имитационной модели
. Инициализация параметров
int i, t, T_Kred, tin, ton[Cmax], Otk=0, Kred=0;Sum_Kred=0,
Sred_Vel, Mec_Doxod=0, Ob_Doxod=0, Sum;
2. Запуск программы
=RIN;
3. Основной цикл моделирования
(t=0;t<(N*365);t++)
. Обработка завершения
for(i=0;i<Cmax;i++)(ton[i]==t)
{[i]=-1;
Kred++;
}
5. Обработка очередного входящего события
(tin==t)
{=0;
while((ton[i]!=-1) && (i<Cmax)) i++;(i<Cmax)
{_Kred=RON;[i]=t+T_Kred;=N1;_Kred+=Sum;_Doxod+=Sum*T_Kred/365*H/100.0;
}Otk++;=t+RIN;
}
. Выводим результаты: количество кредитов, отказов, сумма выданных
кредитов, средняя дневная величина выданных кредитов, суммарный доход,
среднемесячный доход.
Sred_Vel=Sum_Kred/(N*365);_Doxod=Ob_Doxod/(N*12);<<'
'<<"Kolichestvo kreditov= "<<Kred<<endl;<<'
'<<"Kolichestvo otkazov= "<<Otk<<endl;<<'
'<<"Summa kreditov= "<<Sum_Kred/1000000<<"
mln.rub."<<endl;<<' '<<"Srednaya dnevnaya velichina
kredita= "<<Sred_Vel/1000000<<"
mln.rub."<<endl;<<' '<<"Summarniy dohod=
"<<Ob_Doxod/1000000<<"
mln.rub."<<endl;<<' '<<"Srednemesachniy dohod=
"<<Mec_Doxod/1000000<<" mln.rub."<<endl;
2.5 Машинный эксперимент с результатами моделирования
Запустив программу, написанную на языке С++ (см. приложение 1), мы
получили следующие результаты согласно исходным данным:
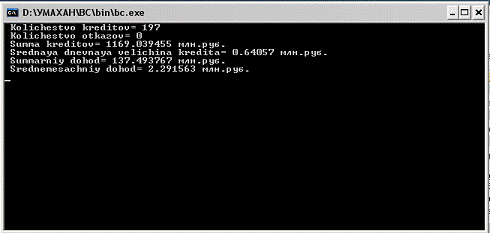
Рис.2. Результаты моделирования.
При данном кол-ве одновременно выдаваемых кредитов Cmax=100 было выдано 197 кредитов, общая
их сумма составила 1169,039455 млн. руб, суммарный доход составил 137,493767
млн. руб. Следовательно прибыльность кредитной системы ком. банка составляет
11,76%.
В результате машинного эксперимента с разработанной моделью мы получили
следующие данные, приведенные в таблице 1, которые меняются с изменением
параметра Cmax, который максимизирует число
одновременно выданных кредитов.
имитационный моделирование экспоненциальный программный
Таблица 1.
|
Cmax
|
10
|
20
|
30
|
40
|
50
|
60
|
70
|
80
|
90
|
100
|
|
кол. кред
|
80
|
72
|
184
|
197
|
197
|
197
|
197
|
197
|
197
|
197
|
|
отк
|
253
|
210
|
24
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
суммакред.
|
451,442113
|
825,718932
|
1068,96929
|
1169,039455
|
1169,039455
|
1169,039455
|
1169,039455
|
1169,039455
|
1169,039455
|
1169,039455
|
|
сред. вел.
|
0,247366
|
0,452449
|
0,585737
|
0,64057
|
0,64057
|
0,64057
|
0,64057
|
0,64057
|
0,64057
|
0,64057
|
|
об. доход
|
49,175248
|
95,872891
|
125,162964
|
137,493767
|
137,493767
|
137,493767
|
137,493767
|
137,493767
|
137,493767
|
137,493767
|
|
месс. доход
|
0,819587
|
1,597882
|
2,086049
|
2,291563
|
2,291563
|
2,291563
|
2,291563
|
2,291563
|
2,291563
|
2,291563
|
График 1.Зависимость числа выданных кредитов и числа отказов от макс.
числа одновременно выдаваемых кредитов
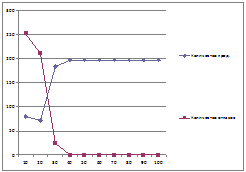
График 2.Зависимость суммы выданных кредитов и общего дохода от макс.
числа одновременно выдаваемых кредитов
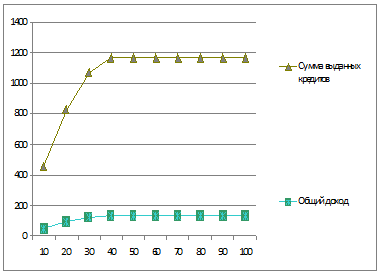
По данным таблицы и графиков мы видим, что максимальное число выданных кредитов
и макс. доход достигается при Cmax
равном 40. Также мы видим, что при количестве одновременно выдаваемых кредитов
большем чем 40, число выданных кредитов и доход у нас остается тот же. Это
объясняется тем, что в системе остаются вакансии на выдачу кредитов.
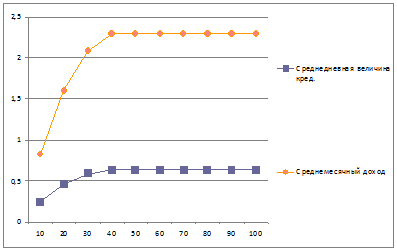
График 3. Зависимость среднедневной величины кредитов и среднемесячного
дохода от макс. числа одновременно выдаваемых кредитов
2.6 Машинный эксперимент с результатами моделирования при изменении
условий задачи
Модифицируя первоначальную программу в соответствии с новыми условиями
(переход банка на выдачу потребительских кредитов) (см. приложение 2) с целью
увеличения прибыльности мы получили следующие результаты:
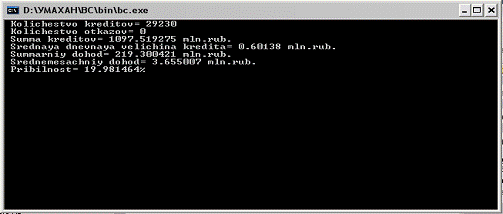

Рис.3. Результаты моделирования.
При данном кол-ве одновременно выдаваемых кредитов Cmax=10000 было выдано 29230 кредитов,
общая их сумма составила 1097,519275 млн. руб., суммарный доход составил
219,300421 млн. руб. Следовательно прибыльность кредитной системы ком. банка
увеличилась с 11,76 % до19,98 %.
В результате машинного эксперимента с разработанной моделью мы получили
следующие данные, приведенные в таблице 2, которые меняются с изменением
параметра Cmax, который максимизирует число
одновременно выданных кредитов.
Таблица 2.
|
Cmax
|
1000
|
2000
|
3000
|
4000
|
5000
|
6000
|
7000
|
8000
|
9000
|
10000
|
|
кол-кред
|
4360
|
8492
|
12528
|
16525
|
20527
|
24391
|
28142
|
29230
|
29230
|
29230
|
|
отк
|
30885
|
25876
|
21042
|
15648
|
10667
|
5837
|
1646
|
0
|
0
|
0
|
|
сумма_кред (млн. р.)
|
160,799926
|
314,730348
|
465,839634
|
615,749299
|
765,80943
|
911,669708
|
1053,178836
|
1097,519275
|
1097,519275
|
1097,519275
|
|
сред_днев_вел (млн. р.)
|
0,08811
|
0,172455
|
0,255255
|
0,337397
|
0,419622
|
0,499545
|
0,577084
|
0,60138
|
0,60138
|
0,60138
|
|
об_доход (млн. р.)
|
32,151756
|
62,88041
|
93,058489
|
122,963734
|
153,026166
|
182,097213
|
210,330468
|
219,300421
|
219,300421
|
219,300421
|
|
мес_доход (млн. р.)
|
0,535863
|
1,048007
|
1,550975
|
2,049396
|
2,550436
|
3,034954
|
3,505508
|
3,655007
|
3,655007
|
3,655007
|
График 4. Зависимость числа выданных кредитов и числа отказов от макс.
числа одновременно выдаваемых кредитов
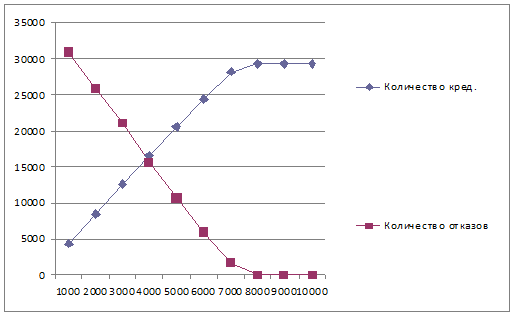
График 5.Зависимость суммы выданных кредитов и общего дохода от макс.
числа одновременно выдаваемых кредитов
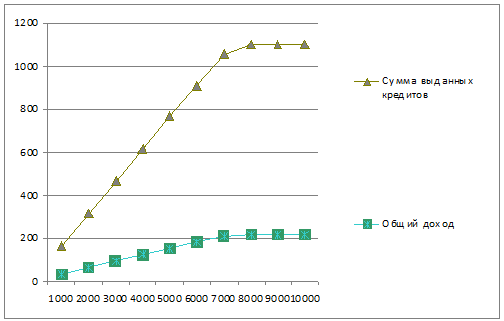
По данным таблицы и графиков мы видим, что максимальное число выданных
кредитов и макс. доход достигается при Cmax равном 8000. Также мы видим, что при количестве
одновременно выдаваемых кредитов большем чем 8000, число выданных кредитов и
доход у нас остается тот же. Это объясняется тем, что в системе остаются
вакансии на выдачу кредитов.
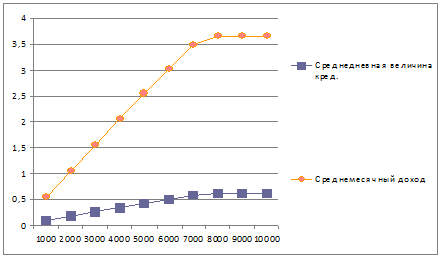
График 6.Зависимость среднедневной величины кредитов и среднемесячного
дохода от макс. числа одновременно выдаваемых кредитов
В результате машинного эксперимента с разработанной моделью мы получили
следующие данные, приведенные в таблице 3, которые меняются с изменением
параметра λ (частота выдачи кредитов).
Таблица 3.
|
λ
|
10
|
12
|
14
|
16
|
18
|
20
|
22
|
24
|
26
|
28
|
|
кол-кред
|
14553
|
17484
|
20445
|
23386
|
26344
|
29230
|
32146
|
35065
|
38016
|
40027
|
|
отк
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
сумма_кред (млн. р.)
|
546,329713
|
656,939314
|
768,299366
|
876,598928
|
986,549087
|
1097,519275
|
1206,599273
|
1315,949407
|
1428,148987
|
1498,680064
|
|
сред_днев_вел (млн. р.)
|
0,299359
|
0,359967
|
0,420986
|
0,480328
|
0,540575
|
0,60138
|
0,66115
|
0,721068
|
0,782547
|
0,821195
|
|
об_доход (млн. р.)
|
109,101558
|
131,221147
|
153,48588
|
175,14663
|
197,110766
|
219,300421
|
241,122764
|
262,932872
|
285,295565
|
299,284809
|
|
мес_доход (млн. р.)
|
1,818359
|
2,187019
|
2,558098
|
2,919111
|
3,285179
|
3,655007
|
4,018713
|
4,382215
|
4,754926
|
4,98808
|
|
прибыльность (%)
|
19,9699111
|
19,97462234
|
19,97735346
|
19,98024688
|
19,97982347
|
19,9814642
|
19,98366561
|
19,98046966
|
19,97659681
|
19,96989325
|
График 7. Зависимость числа выданных кредитов и числа отказов от макс.
числа одновременно выдаваемых кредитов
.7 Анализ данных
Анализ полученных результатов проводим построением математической модели
в MathCad. Используем полиномиальную регрессию
X-Y данных.
Вводим в матрицу X-Y данные, которые будут проанализированы (x-координата
в первой колонке, y-координата во второй):
Таблица 4

Вводим степень полинома наиболее подходящую исходя из формы кривой: 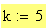
Получаем
следующие коэффициенты уравнения и коэф-т R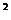 :
:
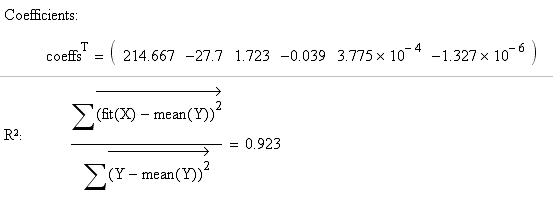
Степени свободы:

График полиномиальной регрессии Y от X:
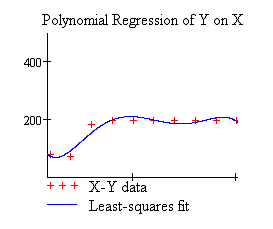
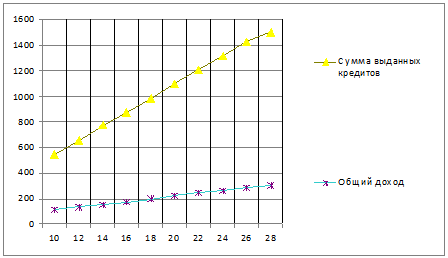
Рис.4. Результаты регрессии
- общая сумма выданных кредитов
X -
число одновременно выдаваемых кредитов
Y= 214,667-27,7x+1,723x-0,039x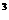 +0,0003775x
+0,0003775x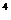 -0,000001327x
-0,000001327x
Проанализируем
данные полученные после модификации первоначальной программы.
Вводим в матрицу X-Y данные, которые будут проанализированы (x-координата
в первой колонке, y-координата во второй):
Таблица 5.
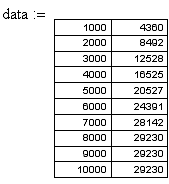
Вводим степень полинома наиболее подходящую исходя из формы кривой: 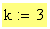
Получаем
следующие коэффициенты уравнения и коэф-т R:
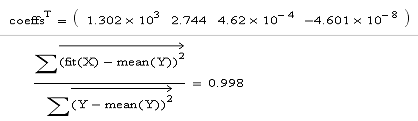
Степени свободы:

График полиномиальной регрессии Y от X:
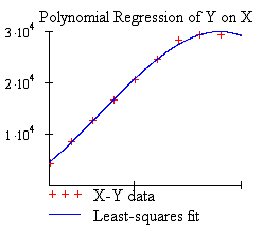
Рис.5. Результаты регрессии
- общая сумма выданных кредитов
X -
число одновременно выдаваемых кредитов
Y= 1302+2,744x+0,000462x-0,00000004601x
Заключение
Результатом данного курсового проекта является имитационная модель работы
кредитной системы коммерческого банка. Модель реализована на языке
программирования высокого уровня Си++.
Программа является рабочей. Выдает на экран вероятностные и
статистические характеристики работы процесса выдачи кредитов в соответствии с
постановкой задачи.
На основании проделанной работы, можно сделать следующие выводы:
1. Математическая модель системы массового обслуживания, созданная
нами, адекватна реальному объекту;
. Проведенные исследования показали эффективность нашей модели при
определении необходимых нам параметров по сравнению с ручным способом
моделирования и расчетов параметров;
3. Созданная модель имеет достаточную, для таких моделей, степень
универсальности, т.к. диапазон входных параметров системы можно легко и быстро
изменить.
Используя методы имитационного моделирования можно построить любую
необходимую нам модель и сделать некоторые выводы о её эффективности и других
характеристиках. Следовательно, принципы имитационного моделирования необходимы
в целях изучения и оценки эффективности какого-либо процесса или явления.
Список использованной литературы
1. Методические указания к выполнению курсового проекта по
дисциплине «Имитационное моделирование экономических процессов». - Махачкала,
ГОУ ВПО ДГТУ, 2008, 51 стр.
. Емельянов А.А. и др. - Имитационное моделирование
экономических процессов (2002)
. Советов Б.Я., Яковлев С.А. - Моделирование систем. (3-е
изд.)(М.,Высш.шк.2001.343с.)
4. Соболь И.М. «Численные методы Монте-Карло».-М.Наука,1973.
. Емельянов А.А., Власова Е.А., «Имитационное моделирование
экономических процессов» - М. Финансы и статистика,2002.
Приложение 1
#include <iostream.h>
#include <iomanip.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define C (125*125*125*125*5ul)
#define N 5
#define H 20.0
#define Cmax 100
#define RIN ceil(exponential(1.0/7.0))
#define RON discrete ()
#define N1 uniform (100000,10000000)
Rand(void)
{unsigned long int u=C;=u*C;u/float(0xfffffffful);
}
exponential(float lambda)
{-log(Rand())/lambda;
}
int discrete()
{i=0, A[8]={90, 120, 150, 180, 210, 240, 270, 365};x, k,
B[8]={0.05, 0.1, 0.2, 0.2, 0.2, 0.05, 0.05, 0.15};
=Rand();=B[0];
(k<x)
{++;+=B[i];
}A[i];
}
uniform (float a, float b)
{Rand()*(b-a)+a;
}
main()
{();
i, t, T_Kred, tin, ton[Cmax], Otk=0, Kred=0;Sum_Kred=0,
Sred_Vel, Mec_Doxod=0, Ob_Doxod=0, Sum;
(i=0;i<Cmax;i++) ton[i]=-1;
=RIN;
(t=0;t<(N*365);t++)
{(i=0;i<Cmax;i++)(ton[i]==t)
{[i]=-1;++;
}(tin==t)
{=0;((ton[i]!=-1) && (i<Cmax)) i++;(i<Cmax)
{_Kred=RON;[i]=t+T_Kred;=N1;_Kred+=Sum;_Doxod+=Sum*T_Kred/365*H/100.0;
}Otk++;=t+RIN;
}
}
_Vel=Sum_Kred/(N*365);_Doxod=Ob_Doxod/(N*12);
<<' '<<"Kolichestvo kreditov=
"<<Kred<<endl;<<' '<<"Kolichestvo otkazov=
"<<Otk<<endl;<<' '<<"Summa kreditov=
"<<Sum_Kred/1000000<<"
mln.rub."<<endl;<<' '<<"Srednaya dnevnaya velichina
kredita= "<<Sred_Vel/1000000<<"
mln.rub."<<endl;<<' '<<"Summarniy dohod=
"<<Ob_Doxod/1000000<<" mln.rub."<<endl;<<'
'<<"Srednemesachniy dohod=
"<<Mec_Doxod/1000000<<" mln.rub."<<endl;
();
}
Приложение 2
#include <iostream.h>
#include <iomanip.h>
#include <conio.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define C (125*125*125*125*5ul)
#define N 5
#define H 20.0
#define Cmax 10000
#define RIN exponential(20.0)
#define RON gauss(365,30)
#define N1 gauss(30000,4)
#define VACANCY (-1)
Rand(void)
{unsigned long int u=C;=u*C;u/float(0xfffffffful);
}
NextTime(float tv, float ta[], unsigned int size)
{t=tv;(unsigned int i=0;i<size;i++) if (ta[i]>=0
&& ta[i]<t)=ta[i];t;
}
exponential(float lambda)
{-log(Rand())/lambda;
}
int discrete()
{i=0, A[8]={90, 120, 150, 180, 210, 240, 270, 365};x, k,
B[8]={0.05, 0.1, 0.2, 0.2, 0.2, 0.05, 0.05, 0.15};
=Rand();=B[0];
(k<x)
{++;+=B[i];
}A[i];
}
uniform (float a, float b)
{Rand()*(b-a)+a;
}
gauss(float mean, float sigma)
{sqrt(-2*log(Rand()))*sin(2*M_PI*Rand())*sigma+mean;
}
main()
{();
long int i, T_Kred, Otk=0, Kred=0;t, tin,
ton[Cmax];Sum_Kred=0, Sred_Vel, Mec_Doxod=0, Ob_Doxod=0, Sum;
(i=0;i<Cmax;i++) ton[i]=VACANCY;
=RIN;
(t=tin;t<(N*365);t=NextTime(tin,ton,Cmax))
{(i=0;i<Cmax;i++)(ton[i]==t)
{[i]=VACANCY;++;
}(tin==t)
{=0;((ton[i]!=VACANCY) && (i<Cmax))
i++;(i<Cmax)
{_Kred=RON;[i]=t+T_Kred;=N1;_Kred+=Sum;_Doxod+=Sum*T_Kred/365*H/100.0;
}Otk++;=t+RIN;
}
}
_Vel=Sum_Kred/(N*365);_Doxod=Ob_Doxod/(N*12);
<<' '<<"Kolichestvo kreditov=
"<<Kred<<endl;<<' '<<"Kolichestvo otkazov=
"<<Otk<<endl;<<' '<<"Summa kreditov=
"<<Sum_Kred/1000000<<"
mln.rub."<<endl;<<' '<<"Srednaya dnevnaya velichina
kredita= "<<Sred_Vel/1000000<<"
mln.rub."<<endl;<<' '<<"Summarniy dohod=
"<<Ob_Doxod/1000000<<"
mln.rub."<<endl;<<' '<<"Srednemesachniy dohod=
"<<Mec_Doxod/1000000<<"
mln.rub."<<endl;<<' '<<"Pribilnost=
"<<(Ob_Doxod/Sum_Kred)*100<<"%"<<endl;
getch();
}