Автоматизация процессов обработки потоков новостей в сети Интернет с целью интеграции контента
Дипломный
проект
Тема
Автоматизация
процессов обработки потоков новостей в сети Интернет с целью интеграции
контента
Студент
Стовпец А.А.
Руководитель
Егоров М.И.
Москва
2009г.
Введение
В настоящее время всё большее количество людей
получают доступ во всемирную паутину. Начинают делать заказы в интернет
магазинах, пользоваться интернет источниками информации, получать свежие
новости через интернет. По этому, залогом успешного заработка в сети, для
обладателей Интернет-ресурсов, является популярность, массовость и
привлекательность ресурсов.
В данном дипломном проекте автоматизируется одна
из функций подобного Интернет ресурса, сайта “zone-x.ru”. Этот сайт
специализируется на продаже товаров через Интернет. Магазин занимается
продажами в таких сферах как книги, кино, мультимедиа, косметика, парфюмерия,
аудио книги, музыка, ювелирные изделия. И одним из признаков успеха и
источником дополнительного заработка является высокая посещаемость ресурса. Чем
больше людей узнает о подобном магазине пользователей, тем больше у магазина
вероятных покупателей. Так же доход может идти и от показываемой рекламы на
этом сайте. И одним из инструментов повышения высокой посещаемости является
публикация свежих новостей из различных информационных агентств. Так как
пользователей больше привлекают ресурсы, с наибольшим разнообразием услуг. По
этому, в рамках данного дипломного проекта была рассмотрена и реализована
автоматизация сбора и обработки новостной информации.
При изучении данной предметной области было
выяснено, что работа с новостной информации идет на много медленнее чем она
может поступать. Да и точность обрабатываемой информации не очень высока. Это
происходит из-за того, что для поступающей информации используется ручная
обработка, которая к тому же является довольно дорогостоящей. Не полнота и не
точность новостной информации может привести к снижению числа посетителей
рассматриваемого ресурса.
Задачею данного дипломного проекта является
автоматизация обработки новостной информации, с целью повысить
производительность и точность обработки. Задачей автоматизированной обработки
является правильная интеграция поступающих новостей.
В рамках данного диплома было решено полностью
отказаться от ручной обработки поступающей новостной информации, что значительно
повысит производительность и точность обработки. Это в свою очередь повлияет на
повышение числа посетителей сайта zone-x.ru, и на повышение доходов от показа
рекламы на страницах сайта. Предполагается повысить привлекательность новостной
информации, с помощью вывода на страницы совместимых по тематическому
содержанию новостной. Например, в разделе книг о сети Интернет, целесообразно
выводить новости связанные с сетью интернет. Этот функционал так же будет
рассмотрен в рамках данного дипломного проекта.
1. Аналитическая часть
1.1
Технико-экономическая характеристика предметной области
.1.1 Характеристика предприятия
Предприятие Общество с ограниченной
ответственностью (ООО) "Зона ИКС" представляет собой организацию
занимающеюся распространением товаров культурной и развлекательной группы таких
как: Книги, Аудио/Видеозаписи и другие товары из сферы культурной составляющей
повседневной жизни граждан. Предприятие имеет магазин по продаже данных товаров
и интернет ресурс позволяющий предоставлять услуги по предварительному
ознакомлению и дальнейшему заказу товаров. Несмотря на то, что в настоящее
время на рынке аналогичных услуг выступает достаточно много организаций
предоставляющих подобные услуги таких как OZON.ru,
books.ru,
balero.ru,
предприятие ООО «Зона ИКС» имеет достаточно обширную аудиторию постоянных и
новых покупателей, а именно около пятидесяти тысяч человек ежедневно пользуются
услугами интернет магазина. В течение дня в среднем производится от ста до ста
пятидесяти покупок через интернет представительство, которые в дальнейшем
доставляются курьерской службой организации. В организации так же имеется
проект по интеграции новостного контента. Данный проект предполагает поиск и
связь новостей в сети интернет по смысловому содержанию и связи данных потоков
новостей с имеющимся каталогом книжной продукции по рубрикам. Основным
источником дохода от проекта является предоставление рекламных площадок для
рекламодателей на сайте проекта. В настоящий момент приблизительная
посещаемость проекта тридцать тысяч человек в день. Исходя из приблизительных
расчётов и статистики интернет магазина «Зона ИКС» основная часть посещений
новостного проекта производится пользователями интернет магазина.
Целью проекта является производство
интегрированного новостного контента позволяющего оценивать события с различных
точек зрения более чем из одного источника новостных интернет агентств и
осуществлять смысловые связи новостного контента с возможными периодическими
изданиями книжного магазина. Однако в настоящий момент в организации существует
трудоёмкий процесс по обработки и связи новостей по содержимому, данным
процессом занимаются сотрудник, производя связи полученных новостей вручную.
Организационная структура предприятия по
обслуживанию интернет представительства представляет собой последовательное
взаимодействие генерального директора с непосредственными исполнителями
отдельных видов деятельности организации. В отделах организации имеются
дополнительные связи между подчиненными и управляющими отдельными процессами, что
позволяет достигнуть дополнительной оперативности и полноты знаний необходимой
информации для принятия стратегических решений управляющим высшего эшелона, а
именно генеральному директору. Схема организационной структуры представлена на
рисунке № 1.1.
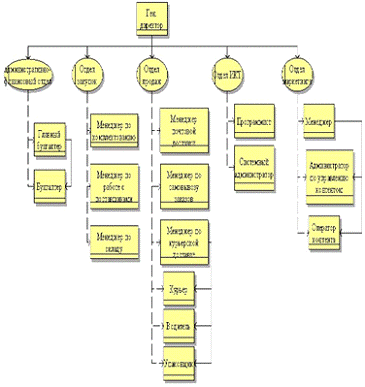
Рис. №1.1. Организационная структура предприятия
ООО Зона ИКС
Основные виды деятельности организации ООО «Зона
ИКС»:
· Закупка товаров у поставщиков;
· Комплектование товаров;
· Обработка почтовых заказов;
· Обработка заказов по само вывозу;
· Обработка курьерских доставок;
· Администрирование интернет
представительства;
· Автоматизирование систем интернет
представительства;
· Разработка маркетинговых решений;
· Обслуживание клиентов Интернет
представительства.
Среди основных видов деятельности организации
следует выделить вспомогательные процессы и виды деятельности, которые в
совокупности обеспечивают успешное функционирование организации. К таким видам
деятельности относится Автоматизирование систем интернет представительства.
В настоящий момент на предприятии функционируют
следующие средства информационного обеспечения:
· Сервер базы данных (БД) построен на основе MS
SQL Server.
Назначение - поддерживает бизнес процессы, сохраняет требуемую информацию в БД.
· Internet
Information Server (страницы
сайта,
скрипты,
CMS). Назначение
- поддерживает части бизнес-процессов, связанных с взаимодействием со
страницами сайта.
· Exchange
Server (почта).
Назначение - обеспечивает возможность обмена почтовыми сообщениями и почтовых
рассылок.
· Intranet
сайт «Зона ИКС» реализован через SharePoint,
где хранятся: описание структуры, общие концепции системы, банковские
реквизиты, инструкции для администраторов. Обеспечивает коммуникации между
сотрудниками, хранение документации;
· Индивидуальные разработки
предприятия, по облегчению ввода и выборке данных из существующих каталогов.
Назначение - облегчение ежедневных рутинных работ по дополнению информацией
каталога организации в интернет представительстве.
Для обеспечения работы информационных
составляющих предприятия в организации используется сервер, расположенный на
колокейшене в организации «Московская телекоммуникационная корпорация КОМКОР»
выполняющей партнерские программы по размещению серверов в специализированных
помещениях. Используется оборудование со следующими функциями:
· Сервер IBM System
x3850
o Процессор: Intel
Xeon Processor MP up to 3.66 GHz (single-core) and 3.30 GHz (dual-core)/667 MHz
front-side bus;
o L2 cache: 1MB
L2 per processor (single-core) and up to 2x2MB L2 (dual-core) and up to 16MB L3
(dual-core);
o Оперативная память: 4GB
PC2-3200 DDR
II SDRAM;
o Дисковые
отсеки:
6/6 2.5" Serial Attached SCSI (SAS);
o 440.4GB
Serial Attached SCSI;
o Сетевой интерфейс: Два порта Gigabit
Ethernet (GbE);
o Блок питания: 1300W;
o Поддержка
RAID: RAID-0, -1, -5 optional (ServeRAID™-8i);
o Операционная
система:
Microsoft® Windows® Server™ 2003 (Enterprise editions 64-bit).
1.1.2 Краткая характеристика
подразделения и видов его деятельности.
Подразделение предприятия подлежащее
рассмотрению это отдел Информационно Коммуникационных Технологий (Отдел ИКТ). В
задачи выполняемые подразделением входит обеспечение круглосуточной
работоспособности технических средств и их информационных составляющих в
качестве облуживания интернет представительства производятся работы по
добавлению и актуализации информации находящийся в каталоге предприятия. Отдел
состоит из следующих сотрудников выполняющих следующие функции:
· Программист
o Автоматизация процессов предприятия;
o Техническая поддержка
автоматизированных процессов.
· Системный администратор
o Поддержка работоспособности всей
системы;
o Подготовка и сохранение резервных
копий данных их периодическая проверка;
o Установка и конфигурирование
необходимых обновлений для операционных систем и используемых программ;
o Создание и поддержание в актуальном
состоянии пользовательских учётных записей;
o Поддержание информационной
безопасности в организации;
o Ведение отчётов по проделанной
работе;
o Устранение технических неполадок в
системе.
· Администратор по управлению контентом
o Просмотр и заполнение неполных
записей;
o Обновление информации из каталогов
издательств;
o Дополнение неполных записей.
· Оператор контента
o Сбор информации из RSS
каналов;
o Копирование информации в базу
данных;
o Рубрицирование информации;
o Сопоставление новостей по контенту.
Работа, выполняемая программистом, заключается в
обеспечении потребностей по автоматизации наиболее частых процессов по
обработки информации в отделе. Таким образом, под автоматизацией процессов
предприятия понимается получение информации от сотрудников отдела ИКТ запросов
на автоматизацию рутинных процессов. В настоящий момент, в отделе
автоматизирован процесс добавления информации из электронных каталогов
издательств о наличии товаров на складах их ценах и кратком описании товара.
В ходе работы Администратор по управлению
контентом выполняет обзор потенциально необходимых ресурсов для поиска и сбора
информации в сети интернет. Так как рассматриваемая организация является
небольшой, то по совместительству некоторые должностные обязанности нижестоящих
или равных по иерархии сотрудников могут передаваться, что позволяет
организации не прекращать свою деятельность в отсутствии некоторых сотрудников.
Необходимое техническое и информационное обеспечение для Администратора
управления контентом обеспечивает системный администратор и программист.
Оператор контента в свою очередь производит
рассмотрение контента поступившего из каналов новостей, копирует необходимые
поля информации и производит сопоставление информации по смысловому содержанию,
затем рубрицирует информацию и выставляет соответствующие связи.
.2 Обоснование необходимости и цели
использования вычислительной техники для решения задачи
Рассматриваемый процесс и составляющие его
задачи представляют собой выполнение однотипных шагов по добавлению информации
из источников новостной информации если быть точным RSS-каналов,
в каталог предприятия с целью демонстрации данной собранной информации на сайте
интернет представительства. В качестве источников информации выступают ленты
новостей интернет представительств новостных организаций таких как: lenta.ru,
rian.ru
и другие. На основе поступившей информации из новостных организаций
производится ручная обработка данных, в ходе которой новости рубрицируются и
сопоставляются с уже имеющимися новостями из других агентств. После
рубрицирования и сопоставления данных, новостная информация поступает в каталог
базы данных как взаимосвязанные единицы информации, что позволяет предоставлять
консолидированный источник информации из различных областей на сайте интернет
представительства.
Из вышеописанного процесса обработки следует
отметить, что его выполнение является трудоёмким и отнимает большой промежуток
времени. Так же в результате ручной обработки информации возможны ошибочные
связи или же не полное покрытие связями всех имеющихся новостей. Целиком
пошагово весь процесс выглядит следующим образом:
· Просмотр списка RSS
каналов новостей;
· Сравнения списка поступивших
новостей;
· Добавление новостей в базу;
· Рубрицирование новости;
· Выставление связей между новостями;
Производительность труда одного оператора по
обработке контента приведена в таблице 1.1.
Таблица 1.1 Производительность труда без
автоматизации
|
Временные
отрезки в часах
|
1
|
8
(рабочий день)
|
40
(рабочая неделя)
|
160
(рабочий месяц)
|
1987
(рабочий год)
|
|
Количество
обработанных записей в штуках
|
7
|
56
|
280
|
1120
|
13909
|
|
Стоимость
обработки записи в рублях
|
42
|
336
|
1680
|
6720
|
83454
|
|
Общее
количество записей
|
~60
|
~480
|
~2400
|
~9600
|
~119220
|
Из приведенных данных в таблице 1.1. следует
отметить, что обработка вручную является дорогостоящей. По принятым договорным
и организационным нормам оператор получает по 6 рублей за одну дополненную
запись. В настоящий момент в организации имеется три оператора по обработки
информации, которые работают на сдельной основе. К основным недостаткам
обработки данных можно отнести такие как:
· Малое количество обрабатываемых записей;
· Возможность занесения ошибочной
информации;
· Дублирование записей;
· Возможность не найти необходимую
информацию;
· Низкая точность обработки
информации.
Структурно-функциональная диаграмма процесса
обработки новостной информации первого уровне, представлена на Рисунке 1.2.
Уровень A-0 представлен на
рисунке 1.3. На этой схеме продемонстрированы процессы системы обработки
новостной информации и потоки информации между ними, до автоматизации.
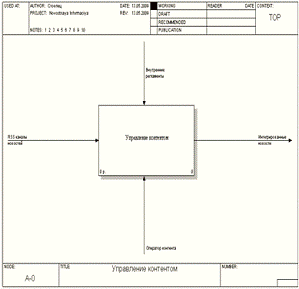
Рис. №1.2. Структурно-функциональная диаграмма
процесса обработка новостной информации верхнего уровня
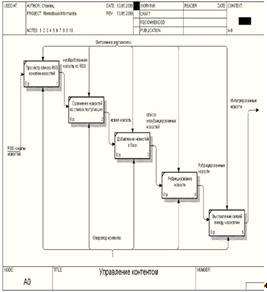
Рис. №1.3. Структурно-функциональная диаграмма
процесса обработка новостной информации уровень А-0
В ходе выполнения проекта предполагается
устранить такие недостатки как:
· Низкая производительность труда;
· Простой оборудования;
· Низкая достоверность результатов
из-за дублирования источников информации;
· Высокая трудоемкость обработки
информации (объемы работы были приведены в таблице 1.1.);
· Несовершенство процесса сбора и
обработки исходной информации.
.3 Постановка задачи
.3.1 Цели и назначение
автоматизированного варианта решения задачи
Цели и назначение
автоматизированного варианта решения задачи
С точки зрения достижения прямого экономического
эффекта проектируемая система предполагает увеличить количество обрабатываемых
и сопоставляемых новостей на определённый период времени. Так же проектируемая
система позволит сократить появление новостей без связей. Машинная обработка
поступающей информации позволит уменьшить затраты времени и соответственно
уменьшит себестоимость обработки поступающей информации.
С точки зрения достижения косвенного эффекта
проектируемая система позволит уменьшить число простоев оборудования.
Количество обрабатываемой информации возрастёт многократно, что позволит
покрывать все источники первичной информации. Увеличение объемов обслуживаемой
информации позволит предоставлять более полную информацию потенциальным
клиентам, что сделает данный ресурс наиболее привлекательным для посетителей
интернет сайта.
При внедрении проекта, предполагается
автоматизировать следующие операции обработки данных:
· Просмотр списка RSS
каналов новостей;
· Сравнения списка поступивших
новостей;
· Добавление новостей в базу;
· Рубрицирование новости;
· Выставление связей между новостями;
.3.2 Общая характеристика организации решения
задачи на ЭВМ
Для решения поставленных задач предполагается
использовать аппаратную архитектуру клиент-сервер. В качестве аппаратного
обеспечения для проектируемой системы предполагается использовать следующие
средства:
· Процессор AMD
Athlon X2
5600 2.8GHz;
· Оперативная память 4 гигабайта DDR2
SDRAM;
· Сетевое соединение минимум 100Mbit/sec
Ethernet 802.3ab;
· Память RAID
массив первого уровня не менее 400 гигабайт
· Форм-фактор предполагаемого
оборудования должен быть стандартным для размещения в охладительную стойку.
В подразделении отдела ИКТ предполагается
внесение изменений относительно всего процесса обработки новостной информации.
После автоматизации предполагается, что сбор информации из новостных агентств,
будит полностью автоматизирован, это позволит полностью охватывать объемы
информации поступающей от новостных агентств. Так же полной автоматизации
подлежит обработка информации, данное изменение позволит увеличить точность
связывания новостей поступающих из имеющихся источников информации.
Периодичность поступления оперативной и условно-постоянной информации
обуславливается обновлением вносимыми новостными агентствами в новостные
каналы, из которых поступает информация для обработки в проектируемой системе.
Этапы решения задачи для автоматизированного
варианта предполагают следующую последовательность:
· Анализ источников информации;
· Создание структуры базы данных;
· Разработка алгоритмов обработки
информации;
· Тестирование разработанных алгоритмов
обработки;
· Накопление базы данных с новостями;
· Формирование RSS
и HTML потоков с выдачей
сюжетов новостей;
Анализ источников информации - на этом этапе
производится обзор информации из- предполагаемых источников для дальнейшего
определения структуры сбора информации и выявления закономерностей в обработке.
Данный этап занимает приблизительно от двух до четырех дней.
Создание структуры базы данных - на этом этапе
производятся работы по созданию базы данных и определения её структуры. Данный
этап обработки занимает от двух до трёх дней.
Разработка алгоритмов обработки информации -
данный этап предполагает разработку и написание алгоритмов автоматизированной
обработки информации из источников. Данный этап обработки занимает от недели до
двух недель.
Тестирование разработанных алгоритмов - на
данном тапе обработки предполагается, что алгоритмы разработанные ранее будут
подвергнуты тестированию ограниченным набором тестовой информации которая
позволит оценить эффективность разработанных алгоритмов.
Сбор и накопление базы данных - данный этап
обработки данных предполагает последовательное накопление информации для
дальнейшего рубрицирования и интегрирования собранной информации.
Долговременность этапа обуславливается особенностью функционирования системы, предполагается,
что система функционирует непрерывно собирая информацию в базу и сохраняя её до
востребования.
Формирование RSS
и HTML потоков с выдачей
сюжетов новостей - на данном этапе предполагается обращение к базе данных для
получения последних тридцати сюжетов в базе данных и выдачи данных сюжетов
клиенту в RSS формате.
Порядок ввода первичной информации. В качестве
первичной информации используются файлы формата RSS. Используя базу источников
новостей по RSS каналам, автоматизированная система обработки с периодичностью
в десять минут скачивает с информационных агентств файлы в формате RSS. Эти
файлы имеют идентичную структуру, поэтому обрабатываются одним и тем же
алгоритмом. Этот алгоритм собирает данные о новостях которые имеют следующие
поля: заголовок, текст новости, категория, время публикации.
Так как названия каталогов значительно различны
и достигают количества до пятисот штук, обработчик приводит их к 19 общим
каталогам.
Краткая характеристика результатов. Результатом
обработки являются сюжеты новостей, содержащие все новости из различных
источников по общей теме. Данные сюжеты распространяются в виде HTML и RSS
файлов в сети интернет по протоколу HTTP в любом браузере через сеть Интернет.
Краткая характеристика системы ведения файлов в
базе данных. В базе данных новости хранятся в таблице новостей. так как нельзя
в полной мере классифицировать новость по её названию и содержанию, наиболее
уникальным элементом выбрана гиперссылка ведущая на полное раскрытие новостной
информации.
Для классификации в базе, данная гиперссылка
кодируется в формат с контрольными суммами crc32 плюс два первых символа md5.
Такой алгоритм кодирования используется из-за технических особенностей
кодирования по алгоритму crc32. Дело в том, что исходя из особенностей кодирования
на основе алгоритма crc32,
почти одинаковые записи могут иметь один и тот же вид в закодированном виде,
для избегания возможных потерь данных был разработан описанный выше алгоритм
кодирования.
Все новости связываются сюжет в отдельной
таблице в базе, с названием «тело новости», которое имеет два поля, ключ тела,
и время его создания, в качестве ключа тела используется ключ первой новости в
данном «теле новости». Далее каждой новой новости программно добавляется ключ
тела новости. С течением времени тело новости может получать всё больше связных
новостей.
Ограничение целостности организованно
программно, так как выбранный тип базы не позволяет внедрить такую функция
непосредственно в СУБД. Сам тип базы выбирался исходя из проанализированных
требований. По этому, выбранный тип БД в СУБД хоть и не поддерживает
собственные механизмы ограничения целостность, но при этом размеры базы, и
скорость работы с ней значительно выше, нежели другие типы БД.
Сама задача требует дельного анализа
автоматизированной области. И для её решения необходимо использовать
комплексный подход. При этом уже существующее программное обеспечение не может
в полной мере покрыть все требования. По этому, был выбран смешанный режим
решения задачи. Что позволяет разрабатывать собственное программное обеспечение
с использованием уже существующих библиотек.
Так как планируется создание полностью
автоматизированной системы, без вмешательства сотрудников какого либо отдела,
поставленная задача решается однократно на этапе разработки проекта, и в
дальнейшем не требует дополнительных вмешательств, если того не требуют новые
задачи поставленные к проекту.
.3.3 Формализация расчётов подзадач
Основываясь на статистике за предыдущие отчётные
периоды, была выявлена закономерность количества средств получаемых за
демонстрацию рекламы от количества посетителей интернет сайта. Формализованное
описание входных показателей отображено в таблице 1.2.
Таблица 1.2. Формализованное описание входных
показателей
|
№
п/п
|
Наименование
входного показателя
|
Идентификатор
входного показателя
|
Количественная
оценка и расчёт
|
|
1
|
Количество
обрабатываемых записей в сутки
|
ZS
|
168
|
|
2
|
Стоимость
одной записи
|
PZ
|
6
|
|
3
|
Среднее
количество посетителей в день
|
KP
|
50000
|
|
4
|
Прибыль
за месяц
|
MP
|
51000
|
На основании полученных статистических показателей,
появляется возможность рассчитать следующие показатели дальнейшей эффективности
проекта. Формализованное описание результатных показателей представлено в
таблице 1.3.
Таблица №1.3 Формализованное описание
результатных показателей
|
№
п/п
|
Наименование
результатного показателя
|
Идентификатор
результатного показателя
|
Алгоритм
расчёта
|
Количественная
оценка и расчёт показателя
|
|
1
|
Затраты
на контент
|
ZK
|
ZK=ZS*30*PZ
|
168*30*6=30240
|
|
2
|
Чистая
прибыль
|
CHP
|
CHP=MP-ZK
|
51000-20760=20760
|
|
3
|
Количество
зависимых посетителей от количества записей
|
PMZ
|
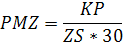
|
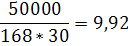
|
|
4
|
Показатель
месячной прибыли
|
MPP
|
MPP=(PMZ*ZS*30)-(KP-CHP)
|
(9,92*168*30)-(50000-20760)=20756
|
На основании этого можно полагать, что
автоматизация функции обработки информации увеличит количество посетителей,
следовательно, и доход с рекламы.
.4 Анализ существующих разработок, выбор и
обоснование стратегии автоматизации и способа приобретения ИС. Обоснование
выбора технологии проектирования
В настоящий момент в организации используется
программное средство «Opera
9.51» представляющее собой программу браузер которая позволяет просматривать
интернет страницы. Выбор данной программы был обоснован встроенным в неё
средством обработки новостных потоков RSS.
Встроенное средство обработки новостных потоков позволяет собирать потоки
новостей из каналов RSS
в объединённую форму вывода. Данное средство сбора потоков новостей работает в
диалоговом режиме обработки информации и имеет следующие возможности по обзору
и обработки пришедшей информации из RSS
канала новостей:
· Просмотр и расстановку в алфавитном порядке
поставщиков новостей;
· Просмотр и расстановку тематик
новостей в алфавитном порядке;
· Просмотр даты получения новостей;
· Просмотр объема новостной ленты в
килобайтах.
· Удаление новостных сообщений из
общей ленты новостей;
· Выставление пометок на определенные
новости;
При выборе определённой новости из общего объема
становятся доступны конкретные действия над выбранной новостью:
· Просмотр содержимого новости;
· Ссылка для перехода к новостному
агентству.
Данное программное средство было выбрано исходя
из нескольких параметров, которые позволяют сделать его наиболее приемлемым для
использования. К этим параметрам можно отнести, то, что данная программа
распространяется на основе бесплатной лицензии и не требует особых навыков для
общения с программой. Кроме того данная программа объединяет в себе функции
браузера и RSS клиента,
что позволяет не разделяя функциональности пользоваться одним программным
средством. Как уже упоминалось ранее, на предприятии существует технология
ручной обработки поступившей новостной информации её рубрицирования и
объединения в сюжеты данные поступившие из RSS
каналов обрабатываются во встроенном приложении браузера Opera
и копируются в ручную для дальнейшей обработки в MS
SQL Server.
В качестве технологии проектирования выбрана
концепция оригинального проектирования данная концепция позволит достичь
наиболее точного выполнения всех потребностей по обработки информации на всех
стадиях её обработки. К преимуществам данной концепции проектирования можно
отнести:
· Уникальность разрабатываемой системы;
· Индивидуальны параметры
функционирования;
· Точность в определенной заданной
области;
· Дешевое построение системы;
· Использование внутренних ресурсов.
К недостаткам данной концепции можно отнести
следующие:
· Узкая направленность системы;
· Несогласованность разработок;
· Привязанность к команде
разработчиков.
.5 Обоснование проектных решений по видам
обеспечения
.5.1 По техническому обеспечению (ТО)
Описание аппаратной составляющей серверной части
приведено ниже.
Для обеспечения высокоэффективной
работоспособности предполагаемой системы предполагается использовать ЭВМ
отвечающая требованиям оптимальной работоспособности системы. Учитывая, что для
работы предполагаемой системе требуется доступ в интернет, необходимо
использовать сетевое соединение с пропускной способностью не менее 100 Мб/сек.
В качестве стандарта соединения возможно использование Ethernet
802.3u или аналогичных.
Для сохранения объемов информации целесообразно использовать RAID-массив
первого уровня, данная архитектура показывает наиболее высокие скорости чтения
и записи информации и позволяет надежно хранить данные. Общий объем массива
должен составлять 800 гигабайт, так как исходя из особенности предметной
области, система должна накапливать данные и сохранять их до определенного
цикла очистки. Дисковые контролеры должны обладать высокой производительностью
при работе с дисковым массивом.
Так как при поиске и обработке информации
предполагается одновременные операции, то для обеспечения максимальной
эффективности необходимо использовать многоядерные процессоры или же системы
позволяющие объединить несколько многоядерных процессоров. Специфика
проектируемой системы предполагает многократное повторение операций, исходя из
этого, следует выбирать процессоры с высоким уровнем кэш-памяти.
Объем оперативной памяти является ключевым
фактором при работе с базой данных, объем оперативной памяти должен быть на
приемлемом уровне для обработки предполагаемого объема данных. Предположительно
объем памяти должен составлять 4 Гб для сервера базы данных.
Форм-фактор оборудования должен обладать
стандартными характеристиками для постановки в холодильную стойку.
К данным вышеперечисленным характеристиками
подходят все наиболее распространённые аппаратные решения для малого и среднего
бизнеса от таких производителей как Dell,
Intel, HP,
Sun, Acer.
Для обслуживания данного аппаратного обеспечения потребуется один человек.
.5.2 По информационному обеспечению (ИО)
Информационное обеспечение - это связь между
необходимой информацией и системами обработки и управления предприятием. Схема
типового информационного обеспечения представлена на рисунке 1.4.
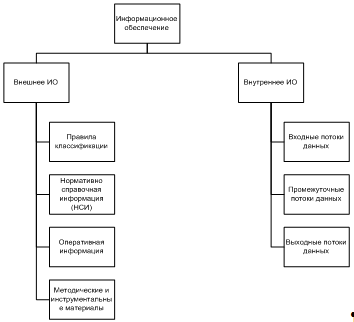
Рис.1.4 «Схема типового информационного
обеспечения»
При классификации в разрабатываемом проекте
будут использоваться собственные системы классификации. Выбранные при
разработке системы. Необходимость использования локальных классификаторов,
вызвана тем, что поступающая информация не может быть классифицирована по каким
либо уже имеющимся стандартам. Основным же требованием к кодированию объектов
является, организация ограничения дублирования информации.
Состав входных документов строго стандартизирован
информационными агентствами в формате RSS
без возможности, каких либо изменений для данного проекта. Состав и структура
выходных документов определён требованиями и договорённостями с разработчиками
автоматизированной системы. Наиболее подходящим форматом выходного документа
является XML файл.
Данный формат является электронным и не имеет бумажной формы, так как полностью
используется только автоматизированной системой.
Так как подразумевается разработка полностью
автоматизированной системы без участия сотрудников фирмы, в проекте отсутствуют
экранные формы.
В процессе работы системы не подразумевается
сохранять файлы на полное или временное хранение. Вся информация содержится в
отдельной от предприятия БД. Что позволяет снизить нагрузки на рабочую БД предприятия.
При поступлении из первичных документов вся информация обрабатывается и
сохраняется а БД, и при запросе автоматизированной системы из данных хранящихся
в БД генерируется выходной файл. Данный метод работы выбран по причине
повышенной текучести и обновления информации.
.5.3 Программному обеспечению
Программное обеспечение (ПО)- совокупность
программ системы обработки данных и программных документов, управляющих работой
компьютера или автоматизированной системы. ПО служит для улучшения
характеристик вычислительных систем: повышение производительности
обрабатываемой информации, повышение точности, повышение надёжности и
отказоустойчивости системы, появление автоматизированных рабочих мест.
На данный момент на рынке программных средств,
представлено большое число компаний и производителей операционных систем. Они
могут быть коммерческими или сводными, промышленными или ориентированными на
простых пользователей, серверные ОС. Из наиболее популярных ОС стоит выделить Windows
от Microsoft
Int, разнообразные
варианты Linux как платные
так и свободные версии, FreeBSD.
Все перечисленные ОС отвечают требованиям поставленным при разработке
автоматизированной системы. К таким требованиям относится:
· Производительность, данный показатель не
маловажен, так как предполагается работа с большими массивами данных.
· Отказоустойчивость, этот показатель
так же является наиболее важным, так как способность ОС оставаться
работоспособной в случае не предвиденных ситуаций добавляет плюсов в пользу ОС.
· Простота в обслуживании, важна так
же способность собственными силами конструировать архитектуру ОС не обращаясь
за помощью к сторонним организациям.
· Не дороговизна обслуживания, данный
показатель влияет прежде всего на экономическую эффективность разрабатываемой
автоматизированной системы.
· Защищённость.
После тщательного обзора была выбрана ОС Linux
Ubuntu 8.04 LTS
min. Данная ОС
распространяется по свободной лицензии и является совершенно бесплатной, её
обслуживание на столько просто, что не требуется помощи сторонних компаний. Так
же её платформа поддерживает работу всего ПО выбранного для данного проекта.
Для выбора среди множества операционных систем
были рассмотрены несколько кандидатов, наиболее удовлетворяющих требованиям
проекта:
· Debian 5.0 min
· openSuSE 11.1 min
· Ubuntu 8.04 LTS min
· CentOS 5.3 min
Данные операционные системы отвечают всем
требованиям к проекту. Они доступны, не требуют финансовых вложений, оставляют
за собой репутацию наиболее устойчивых систем. Все они поддерживаются и
обновляются в режиме реального времени, что сокращает риск взлома системы или
её выход из строя из-за системных ошибок. Так же данные операционные системы
имеют меньшее количество незадекларированных возможностей, что снижает риск
взлома системы.
Однако выбор был сделан в пользу Ubuntu
8.04 LTS
min. Так как у этой
операционной системы, наибольшее количество готовых к установке программных
пакетов.
ОС Ubuntu
8.04 поставляется в различных комплектациях. Это может быть версия с полностью
предустановленными программными средствами, система с панелью
администрирования, позволяющая конфигурировать систему без определённых знаний
об linux системах. Так же
версия без предустановленных каких либо программных пакетов. Так как при
разработке система конфигурируется под проект, была выбрана версия без
программных пакетов.
В этом проекте к СУБД устанавливаются следующие
требования.
· Возможность использовать поля разных типов и
размеров.
· Возможность обеспечивать целостность
БД.
· Максимальный размер каждой таблицы
БД не менее 50 Гб.
· Возможность экспортировать и
импортировать данные в различных форматах.
· Работа со стандартным языком запроса
SQL
· Максимальный размер Базы данных, без
ограничения.
· Возможность взаимодействовать с
выбранным для проекта, языком программирования PHP.
· Надёжность.
· Устойчивость.
· Работоспособность в Unix среде, а
так же если потребуется, то и на платформе Windows
систем.
· Возможность, без потери данных
организовать кластер, если того потребует дальнейшее развитие системы.
· Полнотекстовая индексация и поиск с
использованием типа таблиц MyISAM
На платформе выбранной ОС целесообразней выбрать
подходящую СУБД. Из наиболее распространенных были рассмотрены такие СУБД как PosqtgreSQL
и MySQL.
MySQL и PosqtgreSQL
имеют как плюсы так и минусы при работе с ними. Рассмотрим характеристики обоих
систем в отдельности
PosqtgreSQL
с её последней версией на момент разработки (8.3.7) имеет следующие ограничения
представленные в таблице 1.4. Ограничения MySQL
представлены в таблице 1.5.
Таблица 1.4 Характеристика СУБД PosqtgreSQL
|
Максимальный
размер базы данных
|
Нет
ограничений
|
|
Максимальный
размер таблицы
|
32
ТБайт
|
|
Максимальный
размер записи
|
1,6
ТБайт
|
|
Максимальный
размер поля
|
1
ГБайт
|
|
Максимум
записей в таблице
|
Нет
ограничений
|
|
Максимум
полей в таблице
|
250-1600,
в зависимости от типов полей
|
|
Максимум
индексов в таблице
|
Нет
ограничений
|
Таблица 1.5 Характеристика
СУБД MySQL
|
Максимальный
размер базы данных
|
Нет
ограничений
|
|
Максимальный
размер таблицы
|
8
миллионов ТБайт
|
|
Максимум
записей в таблице
|
Нет
ограничений
|
|
Максимум
полей в таблице
|
Нет
ограничений
|
|
Максимум
индексов в таблице
|
Нет
ограничений
|
Про приведённым данным видно, что PosqtgreSQL
значительно уступает MySQL.
Так как MySQL отвечает
требованиям разрабатываемой системы и имеет наилучшие характеристики, было
решено в данном проекте использовать именно эту СУБД.
Так как в системе не предполагается сохранять
файлы отдельно на сервере, то вся нагрузка при хранении информации ложиться на
БД. Наиболее подходящим методом проектирования ПО является модульный. Данный
метод позволяет оптимизировать программный алгоритм, путём заключения частей
кода, которые используются многократно в отдельные функции(модули). Это
позволяет существенно повысить производительность. Так же было решено
использовать в проекте уже готовые классы (библиотеки) PEAR
для работы c данными и СУБД.
Такими классами являются:
· Класс работы с СУБД MySQL
· Класс работы с XML
и HTML
· Класс преобразования кодировок
· Весть проект создаётся в программном средстве
среды программирования PHP Expert Editor, а также на собственной среде
программирования портала farseer.ru.
· PHP Expert Editor позволяет работать
со скриптовым языком PHP
как локально, так и удалённо на сервере без нужды сохранять и переносить
скриптовые файлы на сервер. Данное ПО позволяет подключаться к серверу по
защищённому каналу и вносить изменения в коде скриптов в режиме реального
времени.
· Собственная среда программирования
портала farseer.ru.
Позволяет вносить изменения в код системы, без нужды использования стороннего
специализированного программного обеспечения, используя обычный браузер в любой
операционной системе. Данный вид редактирования работает в режиме реального
времени в любой точки доступа сети Интернет.
.5.4 Технологическому обеспечению
Так как вся входная
информация поступает в систему с интернет страниц, все действия по сбору данных
осуществляются по стандартному протоколу обмена данными в сети Интернет, HTTP без
возможности выбора других протоколов связи. Так же сбора данных RSS подразумевает
использовать только один метод сбора данных. С помощью метода GET-запросов к
серверам c RSS каналами. По этим запросам, сервера отдают файлы в
формате RSS. В качестве передачи информации используется тот же
протокол HTTP. B ответ на GET запросы, сервер отдаёт данные в структурированном виде в
формате XML или в другом удобном формате.
Информация с RSS поступает в
одном, заранее известном формате XML разметки. Для сбора данных с этих файлов используется
подключаемый класс работы XML файлами, который переводит данные в массив для их
дальнейшей обработки, рубрицированию и соединению по темам. Для соединения
новостей по темам используется собственный алгоритм, разработанный на портале farseer.ru. Изначально
для решения подобных задач использовался ручной труд операторов, который
требовал больших финансовых и временных затрат с минимальным коэффициентом
отдачи. Автоматизация данной функции на предприятии позволяет исключить
финансовые затраты на пополнение базы данных и значительно ускорить
скорость её заполнения.
. Проектная часть
.1 Информационное обеспечение задачи
.1.1 Информационная модель и её описание
Описание информационной модели в проекте
является одним из наиболее важных этапов, так как именно из информационной
модели можно определить схему движения входных, промежуточных и результатных
документов. Так же информационная модель позволяет определить на основании,
каких входных документов и нормативно-справочной информации (НСИ) производится
обработка и формирование выходных документов.
При описании информационной модели всю
информацию разделяют на исходную, обрабатываемую и исходящую. В
автоматизированной работе обработки и интеграции новостной информации,
исходящим документом будет являться, входная оперативная и
нормативно-справочная информации. На рисунке 2.1 представлена информационная
модель потоков данных.
В качестве входящей информации в процессе
обработки новостной информации выступают запросы на добавление RSS
канала, запрос на начало обработки информации и запрос на поиск релевантных
новостей по требуемому разделу. Это отражено как на структурно-фунциональной
модели рисунок 2.2 .
Запрос на добавление RSS
катала - в этом документе, на стадии разработки и сопровождения, разработчик
вводит следующую информацию об RSS
канале:
· Ссылка на источник RSS;
· Название информационного агентства;
· Ссылка на домашнюю страницу
информационного агентства;
· Периодичность сканирования;
· Шаблон сканирования.
Так как формат данных RSS
является одинаковым для всех источников новостной информации, каких либо
дополнительных изменений в коде системы не требуется, а для более тонкой
настройки сора данных используется шаблон сканирования.
Запрос на начало обработки информации - этот
документ составляется однократно при запуске системы. В нем прописывается
сценарий автоматизированной работы системы, без дальнейшего вмешательства
разработчика.
Запрос на поиск релевантных новостей по
требуемому разделу - в этом файле автоматизированная система отправляет запрос
на поиск соответствующих запросу новостей. В состав запроса входит: описание и
название книг, к которым требуется получить соответствующую новостную
информацию.
Из документов Запрос на добавление RSS
канала формируется база RSS
каналов, на основании которой а дальнейшем будет собираться новостная
информация. Из документа «Запрос на поиск релевантных новостей по требуемому
разделу» формируется запрос к базе новостей в виде SQL
запроса к базе данных.
Далее при автоматизированной работе системы, на
основании справочника каталогов новостей, сети Интернет и базы ссылок на RSS
каналы информационных агентств. Составляется база новостей. После обработки
базы новостей, составляется база сюжетов, которая состоит из одинаковый
новостей из различных информационных агентств.
Документ Запрос на поиск релевантных новостей по
требуемому разделу составляется автоматически на стороне интернет магазина. На
основании этого документа составляется SQL
запрос к базе сюжетов. После обработки запроса на выходе составляется файл с
релевантными новостями по требуемому каталогу. Этот файл отправляется как ответ
для автоматизированной системы получения новостей в формате XML.
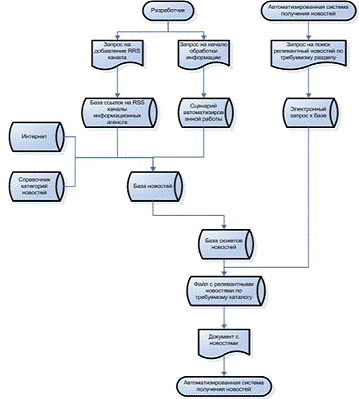
Рис. 2.1 Информационная модель
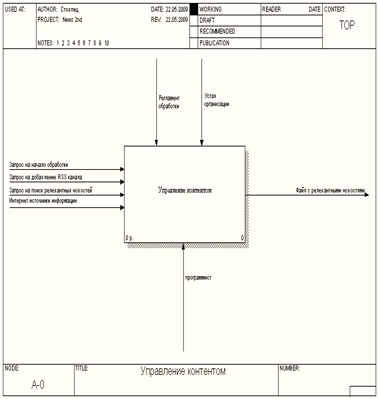
Рис. 2.2 Структурно-функциональная модель.
Диаграмма верхнего уровня
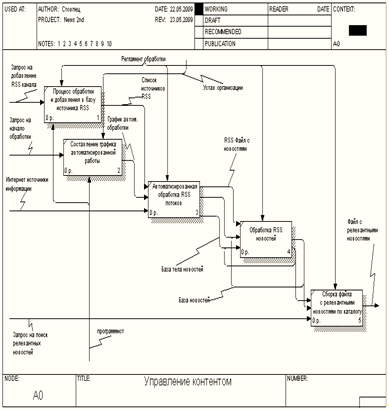
Рис. 2.3 Структурно-функциональная модель A-0
.1.2 Используемые классификаторы и системы
кодирования
В рассматриваемой задаче информационной модели
важнейшее место занимает сохранение целостности поступающей информации. Для
этого требуется упорядочить новостные потоки информации, с целью исключения
дублирующих данных, а затем формализовать (закодировать).
· Порядковый метод кодирования заключается в
последовательном присвоении регистрации объекта. При этом у метода отсутствуют
признаки классификации.
· Серийно-порядковый метод кодирования
заключается в последовательно регистрации объектов и использованием серии, для
обозначения объектов с одинаковыми признаками.
· Последовательный метод кодирования
заключается в регистрации объектов при которой знаки на каждой ступени деления
зависят от результатов разбиения на предыдущих ступенях.
· Параллельный метод кодирования
подразумевает независимую регистрацию объекта кодирования от остальных объектов
кодирования.
На основании приведённых методов было решено
использовать параллельной метод кодирования для всех видов объектов. Это
решение было принято на основании того, что кодированные объекты не имеют
определенно выдюженных признаков. При этом код объекта должен быть уникальным
для каждого объекта, с целью избежать дублирование объекта в базе.
В составе информационного обеспечения
рассматриваемого комплекса задач выделены следующие классификаторы:
· классификатор новостей;
· классификатор тела новости;
· классификатор категорий новостей;
· классификатор источников новостей.
Состав кодовых обозначений, представлен в
таблице2.1.
автоматизация входной оперативный информация
Таб. 2.1 Состав кодовых обозначений
|
Наименование
кодируемого множества объектов
|
Значность
кода
|
Система
кодирования
|
Система
классификации
|
Вид
классификатора
|
|
Код
новости
|
15
|
Параллельная
|
Отсутствует
|
Локальный.
|
|
Код
тела новости
|
15
|
Параллельная
|
Отсутствует
|
Локальный.
|
|
Номер
категории
|
15
|
Параллельная
|
Отсутствует
|
Локальный.
|
|
Код
источника новостей
|
15
|
Параллельная
|
Отсутствует
|
Локальный.
|
Для классификации новости используется
параллельное кодирование. Данный классификатор является локальным и состоит из
пятнадцати знаков. Код каждой новости получается контрольная сумма гиперссылки
новости, методом crc32.
Структурная формула классификатора новости приведена ниже.
Ф1 = [ХХХХХХХХХХХХХХХ]
Для классификации тела новости используется
параллельное кодирование. Данный классификатор является локальным и состоит из
семнадцати знаков. Структурная формула классификатора тела новости представлена
ниже.
Ф2 = [ХХХХХХХХХХХХХХХ]
Для классификации категории новости используется
порядковое кодирование. Данный классификатор является локальным и состоит из
трёх знаков. Код каждой категории получается контрольная сумма названия
категории, методом crc32.
Структурная формула классификатора категории новости приведена ниже.
Ф3 = [ХХХХХХХХХХХХХХХ]
Для классификации источника новости используется
порядковое кодирование. Данный классификатор является локальным и состоит из трёх
знаков. Код каждой категории получается контрольная сумма названия источника,
методом crc32.
Структурная формула классификатора источника новости приведена ниже.
Ф4 = [ХХХХХХХХХХХХХХХ]
2.1.3 Характеристика первичных документов с
нормативно-справочной и входной оперативной информацией
Особенностями дипломный проект подразумевает
тесная интеграция с источниками информации и системой, использующей выходную
информацию. Что исключает использование бумажных форм документов.
К входным документам с нормативно-справочоной
информацией относятся: запрос на добавление RSS
каналов и запрос на начало обработки информации. Хотя эти документы и не имеют
бумажной формы, но имеют структуру, и теоретически могут быть выведены на
экран, если бы это требовалось бы в разрабатываемой системе автоматизации.
В документе запрос на добавление RSS
канала, содержатся поля, содержащие всю требуемую информацию от RSS
каналах. Файл формирует разработчик один раз при старте системы. При этом
создаётся один документ, который имеет девятнадцать строк, по числу основных
информационных агентств отдающих новости по RSS
каналам. На основании этого документа строится справочник список источников RSS.
Структура документа описана в таблице 2.2.
Таблица. 2.2 Табличное представление документа
«запрос на добавление RSS
канала»
|
№
п/п
|
Наименование
поля
|
Длинна
поля
|
Тип
поля
|
|
1
|
Название
информационного агентства
|
200
|
Строковое
|
|
2
|
Хост
информационного агентства
|
150
|
Строковое
|
|
3
|
Гиперссылка
на источник
RSS
|
-
|
Текстовое
|
|
4
|
Время
точного сканировании RSS
|
11
|
Строковое
|
|
5
|
Интервал
сканирования
|
11
|
Числовое
|
В документе запрос на начало обработки
информации, содержаться поля, требуемые для автоматизированной работы системы.
Этот документ так же формируется один раз при старте системы. При этом
создаётся один документ, который имеет три записи. Электронная форма
редактирования данного документа представлена в приложении 1, рисунок 1.1.
Структура документа описана в таблице 2.3.
Таблица 2.3 Табличное представление документа
«запрос на начало обработки информации»
|
№
п/п
|
Наименование
поля
|
Длинна
поля
|
Тип
поля
|
|
1
|
Правило
автоматизации по минутам
|
-
|
Строковое
|
|
2
|
Правило
автоматизации по часам
|
-
|
Строковое
|
|
3
|
Правило
автоматизации по дням
|
-
|
Строковое
|
|
4
|
Правило
автоматизации по месяцам
|
-
|
Строковое
|
|
5
|
Правило
автоматизации по годам
|
-
|
Строковое
|
|
6
|
Команда
запуска автоматизированного процесса
|
-
|
Строковое
|
К входным документам с оперативной информацией
относится: Запрос на поиск релевантных новостей, Интернет источник информации.
Эти документы так же не имеют бумажных форм и теоретически могут быть
распечатаны, если бы были подобные требования.
В документе запрос на поиск релевантных новостей
содержатся поля для поиска релевантных новостей. Это документ создаются каждый
раз при обращении к системе с целью полевения релевантных новостей. Создаётся
один с одной записью. Структура документа описана в таблице 2.4.
Таблица 2.4 Табличное представление документа
«запрос на поиск релевантных новостей»
|
№
п/п
|
Наименование
поля
|
Длинна
поля
|
Тип
поля
|
|
1
|
Тексты
описания новости
|
-
|
Строковое
|
|
2
|
Категория
новостей
|
15
|
Строковое
|
|
3
|
Количество
новостей для вывода
|
3
|
Числовое
|
В документе Интернет источник информации
содержатся поля для записи их в базу данных. Этот документ создается один раз
каждые десять минут. Пир этом создаётся один документ количеством записей до
тридцати. Данный документ поступает от информационных агентств, и количество
записей в документе зависит от их внутренних регламентов. При этом создаётся
один документ. Этот документ имеет формат RSS.
Структура документа описана в таблице 2.5.
Таблица 2.5 Табличное представление «Интернет
источник информации»
|
№
п/п
|
Наименование
поля
|
Длинна
поля
|
Тип
поля
|
|
1
|
Источник
RSS
|
15
|
Справочник
источник RSS
|
|
2
|
Гиперссылка
новости
|
-
|
Строковое
|
|
3
|
Название
новости
|
-
|
Строковое
|
|
4
|
Текст
новости
|
-
|
Строковое
|
|
5
|
Категория
новости
|
-
|
Строковое
|
|
6
|
Дата
создания новости
|
25
|
Строковое
|
.1.4 Характеристика базы данных
Инфологическая модель или модель
(сущность-связь) строится для обеспечения наиболее удобного отображения той
информации которую предполагается хранить в создаваемой или проектируемой базе
данных. Данный вид модели строится специально на наиболее приближенном к
естественному языку понятиях, но зачастую, к сожалению данной реализации сложно
добиться так как в настоящее время нету возможности строить базы данных чисто
на естественном языке из-за его неоднозначности.
На рисунке 2.2 представлена схема инфологической
модели. На данной модели представлены сущности Тело новости, Новость, Категория
новости, Источник RSS
потока.
Объекты: «Новость», «Тело новости», «Категория
новости» имеют общую сущность «Новость RSS
потока из сети Интернет», На стадии создания система, объект «Категория
новости» Заполняется автоматизированной системой. Далее после анализа
всевозможных категорий новостей, они объединяются в двадцать категорий
новостей, которые охватывают все возможные темы новостей.
Объекты «Новость», «Тело новости» заполняются
данными из сущности «Новость RSS
потока из сети Интернет» на протяжении всего времени работы системы. При этом,
программными средствами реализовывается сохранение целостности Тела новости и
новости. Поле объекта «Тело новости» Код тела новости, заполняется Кодом
новости из объекта «Новости», если не удалось найти привязку новостей и записей
«Тела новости».
Объект «Источник RSS
новости» заполняется из сущности «Источник RSS
потока». И заполняется на стадии создания системы.
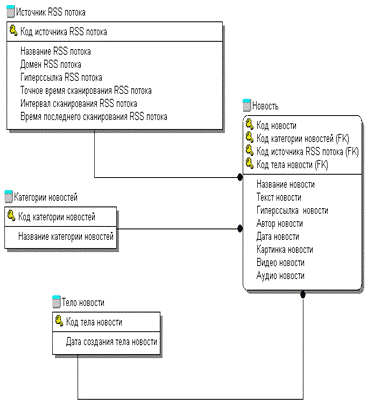
Рис. №2.4. Схема инфологической модели
Данная модель, отражающая взаимосвязи объектов,
отражает детальную картину проектируемых задач. На модели проиллюстрированы все
взаимосвязи объектов.
Детально рассмотрим представленную модель. На
данной модели сущности Тело новости и Новость имеют связь один ко многим,
процессе работы системы. Данная связь отражает, что у одного тела новости может
быть несколько новостей. При этом новости связываются с телом новости по
заранее разработанному алгоритму определения схожести новостей, что позволяет
сформировать сюжеты по одной теме. Таким образом, новости, связанные с телом
новости образуют новостной сюжет. Подобные новостные сюжеты впоследствии и
передаётся автоматизированной системе в качестве ответа на запрос.
Так же на модели имеется сущность категория
новости. Данная сущность отражает классификацию новостей по разным категориям.
Ответ автоматизированной системе составляется на основании выбранной категории.
Сами сущности связанны связью один ко многим. Что показывает, что у каждой
категории может быть несколько новостей.
Сущность источник новости также связан с
сущностью новость связью. Один ко многим, что отражает, что у каждого источника
может быть по несколько новостей. Данная связь помогает исключить попадание в
базу дубликатов новостей, а так же если в дальнейшем потребуется, вывод сюжетов
в зависимости от источников.
Даталогическая модель представляет собой
отображение инфологической модели в компьютеро-ориентированном виде, то есть в
виде понятным для СУБД. На основании инфологической модели рисунок 2.4 была
построена даталогическая модель. Структура даталогической модели представлена
на рисунке 2.5.
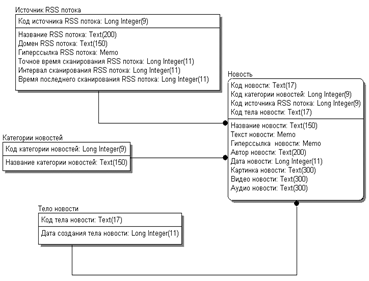
Рис. 2.5 Структура даталогической модели
Описание полей даталогической модели
представлены в таблице 2.6.
Таб. 2.6 Описание полей даталогической модели
|
Сущность
|
Название
таблицы
|
Атрибут
|
Идентификация
поля
|
Тип
поля
|
|
Тело
новости
|
NEWSBODY
|
Код
тела новости
|
ID_NEWSBODY
|
VARCHAR
|
|
|
Название
категории новости
|
DATA_NEWSBODY
|
INTEGET
|
|
Новость
|
NEWS
|
Код
новости
|
ID_NEWS
|
VARCHAR
|
|
|
Код
категории новости
|
ID_CATALOG_NEWS
|
INTEGET
|
|
|
Код
источника RSS
потока
|
ID_RSSBOT
|
INTEGET
|
|
|
Код
тела новости
|
ID_NEWSBODY
|
VARCHAR
|
|
|
Название
новости
|
TITLE_NEWS
|
VARCHAR
|
|
|
Текст
новости
|
MINITEXT_NEWS
|
TEXT
|
|
|
Гиперссылка
новости
|
URL_NEWS
|
TEXT
|
|
|
Автор
новости
|
AUTOR_NEWS
|
VARCHAR
|
|
|
Дата
новости
|
DATE_NEWS
|
INTEGET
|
|
|
Картинка
новости
|
IMAGE_NEWS
|
VARCHAR
|
|
|
Видео
новости
|
VIDEO_NEWS
|
VARCHAR
|
|
|
Аудио
новости
|
AUDIO_NEWS
|
VARCHAR
|
|
Категория
новости
|
NEWS_CAT
|
Код
категории новости
|
ID_NEWS_CAT
|
INTEGET
|
|
|
Название
категории новости
|
NAME_NEWS_CAT
|
VARCHAR
|
|
Источник
RSS
потока
|
RSSBOT
|
Код
источника RSS потока
|
ID_RSSBOT
|
INTEGET
|
|
|
Название
RSS потока
|
NAME_RSSBOT
|
VARCHAR
|
|
|
Домен
RSS потока
|
URL_SITE_RSSBOT
|
VARCHAR
|
|
|
Гиперссылка
RSS потока
|
URL_RSSBOT
|
TEXT
|
|
|
Точное
время сканирования RSS потока
|
UPDATE_RSSBOT
|
INTEGET
|
|
|
Интервал
сканирования RSS потока
|
INTERVAL_RSSBOT
|
INTEGET
|
|
|
Время
последнего сканирования RSS потока
|
TIMEU_RSSBOT
|
INTEGET
|
|
|
|
|
|
|
|
В результате работы система, а именно при
обращении к ней автоматизированной системы получения релевантных новостей.
Составляется запрос к базе данных на получение наиболее релевантных новостей по
названию и описанию книг, в определённом каталоге, которые были получены от
автоматизированной системы. Результатом выполнения запроса, ответ от SQL
сервера в виде таблицы, которая не требует дальнейшего сохранения. Данная таблица
получается из нескольких таблиц в базе: Тело новости, новости, категория,
источник. Таблица имеет от нуля до пяти записей, и отсортирована по убыванию
степени релевантности. Для определения релевантности используется встроенные
возможности СУБД MySQL.
В частности SQL код MATCH
(название поля в таблице) AGAINST ('Текст для определения релевантности').
Пример таблицы с результатной информации представлен в таблице 2.7.
Таблица 2.7 Пример таблицы с результатной
информацией
|
№
|
Название
поля
|
Идентификатор
Поля
|
Тип
поля
|
Значность
Поля
|
|
1
|
Код
новости
|
ID_NEWS
|
Числовой
|
15
|
|
2
|
Код
тела новости
|
ID_NEWSBODY
|
Числовой
|
15
|
|
3
|
Код
источника новости
|
ID_NEWS_FROM
|
Числовой
|
15
|
|
4
|
Период
обновлений
|
PERIOD_OBN
|
Строковый
|
23
|
|
5
|
Название
новости
|
TITLE_NEWS
|
Строковый
|
150
|
|
6
|
Текст
новости
|
MINITEXT_NEWS
|
Строковый
|
500
|
|
7
|
Название
категории новости
|
CATALOG_NEWS
|
Строковый
|
200
|
|
8
|
Код
категории новости
|
ID_CATALOG_NEWS
|
Числовой
|
15
|
|
9
|
Гиперссылка
новости
|
URL_NEWS
|
Текстовый
|
-
|
|
10
|
Автор
новости
|
AUTOR_NEWS
|
Строковый
|
200
|
|
11
|
Дата
новости
|
DATE_NEWS
|
Числовой
|
11
|
|
12
|
Картинка
новости
|
IMAGE_NEWS
|
Строковый
|
300
|
|
13
|
Видео
новости
|
VIDEO_NEWS
|
Строковый
|
300
|
|
14
|
Аудио
новости
|
AUDIO_NEWS
|
Строковый
|
300
|
|
15
|
Показатель
релевантности
|
score
|
Числовой
|
7
|
Далее, на основании получаемой таблицы с данными
формируется исходящий файл, как ответ для автоматизированной системы. В этот
файл входят все поля кроме полей: Период обновления, и показателя
релевантности. Эти поля являются важными только для внутренней работы системы.
Из остальных полей, формируется файл ответа для автоматизированной системы. При
это поля: Картинка новости, Видео новости, Аудио новости и Автор новости могут
иметь пустые значения. Все остальные поля обязательны при составлении
результатного документа.
На основании результатной таблицы 2.7, составляется
результатный файл в формате XML,
который отправляется как ответ, автоматизированной системы получения новостей.
Электронный вид документа представлен в приложении 1 рисунок 1.2. На рисунке
видно, что документ имеет человекопонятный вид. Однако этот документ
предназначен для автоматизированной системы, которая в соответствии с
требованиями формирует на сайте сформированные сюжеты новостей, данные для
которых расположены в тегах ITEM
разметки XML. Данный
документ является весьма важным для предприятия. Так как он является частью
полезного ключевого контента для привлечения большего числа пользователей, а
следовательно, и увеличение заказов в Интернет-магазине.
Используя полученные данные из этого документа
можно строить различные варианты вывода информации, что продемонстрировано в
приложении 1 рисунки 1.8 и 1.9.
2.2 Программное обеспечение задачи
.2.1 Общие положения
Для разработки данного проекта принято решение
использовать скриптовая язык программирования PHP
версии 5. А в качестве среди разработки была использована программа PHP Expert
Editor. Данная программа
обладает множеством встроенных функций, удобной подсветкой кода, а так же
способностью подключаться по защищённому SSH2
каналу связи для редактирования программного кода на лету.
Все действия и манипуляции с автоматизированной
системой происходят через удалённый доступ по каналам связи сети Интернет и не
имеют пользовательского интерфейса. При этом если учесть то, что все функции
системы разделены на основные и служебные, можно изобразить структуру системы в
виде дерева функций. Учитывая все особенности системы, её удалённое
расположение на выделенном сервере, возможность доступа к ней по защищённому
каналу SSH2, при
использовании бесплатного встроенного функционала в Unix
системах или при использовании так же бесплатной программы Putty
в операционных системах Windows,
архитектура проектируемой системы представлена в виде дерева функций на рисунке
2.7.
Сценарий диалога позволяет детально определить
иерархию выполняемых операций в реализованном проекте. Схема сценария диалога
представлена на рисунке 2.6.
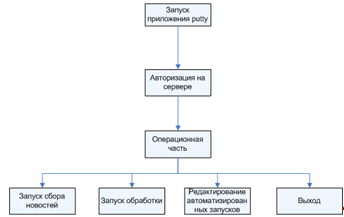
Рисунок 2.6. Сценарий диалога
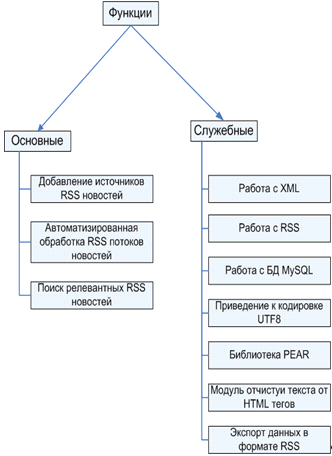
Рисунок 2.7. «Дерево функций»
.2.2 Структурная схема пакета
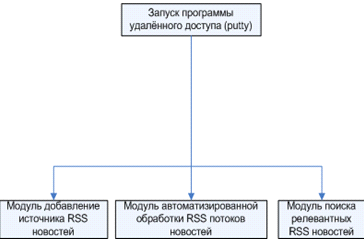
Основываясь на дереве функций, представленном на
рисунке 2.7 было построено дерев программных модулей, в состав которого вошли
все программные составляющие. На рисунке 2.8. представлено дерево программных
модулей.
.2.3 Описание программных модулей
В процессе разработки автоматизированной
средства на языке программирования PHP
был использован весь доступный функционал среды разработки PHP
Expert Editor,
а так же встроенной среды разработки портала farseer.ru,
которая также ориентирована на язык PHP.
Стало возможным, выделить основной функционал в отдельные модули, такие как:
· Добавление источника RSS
новостей.
· Автоматизированная обработка RSS
потоков новостей.
· Поиск релевантных RSS
новостей.
Все выделенные модули расположены на удалённом
сервере в сети интернет. Их запуск и автоматизированная работа осуществляется с
встроенного функционала связи по защищённому протоколу передачи данных SSH2,
Unix систем, либо с
использованием бесплатного продолжения putty
для Windows
систем.
Модуль «Добавление источника RSS
новостей» - процесс, позволяющий добавлять источники RSS
каналов непосредственно в базу. При этом в качестве информации выступаю:
название источника, домен источника гиперссылка источника, и временные правила
для организации расписания сканирования источника.
Модуль «Автоматизированная обработка RSS
новостей» - набор процессов связанных для выполнения общей поставленной задачи.
Среди таких процессов можно выделить:
· Процесс загрузки новостей из RSS
источника.
· Процесс обработки новой записи.
· Процесс рубрицирования записи.
Процесс загрузки новостей из RSS
источника отвечает за то, что по заранее сформированному временному сценарию,
обращается к RSS источникам
новостей, получает файл в формате RSS.
Использую служенную функцию для работы XML
и RSS, переводит
информацию в новостной массив данных.
Процесс обработки новой записи, получает данные
в виде новостного массива данных и начинает проверять каждую новость в
отдельности на то, что есть ли такая новость уже в базе или нет. Если новость
уже есть то процесс переходит к другой новости для обработки. Если же новости
нет то новость сохраняется в базу. При этом идёт проверка на релевантное
сходство обрабатываемой новости с имеющимися новостями в базе. Если сходство
обнаружено, то вновь добавленная новость связывается с телом похожей новости,
если нет, то обрабатываемая новость сама получает собственное тело новости.
Процесс рубрицирования записи, даны процесс
заключается в том, что все поступающие новости сводятся к 19 категорий
заложенных в базу при разработке. При этом если у новости нет категории, то она
получает категорию родительской новости.
Модуль «Поиск релевантных RSS
новостей» - набор процессов организующих релевантную выдачу по определённо
заданному запросу. В качестве запроса участвуют описания и название книг, по
заранее определённым разделам. Данный модуль также состоит из нескольких важных
процессов:
· Процесс преобразования запроса поиска
· Получения кода релевантных новостей
· Составление ответа
Процесс преобразования запроса поиска
заключается в том, что поступивший запрос от автоматизированной системы после
обработки преобразовывает в строку с SQL
запросом.
Процесс получения кода релевантных новостей,
получает сформированную строку SQL
запроса и выполняет её, для получения списка кодов наиболее релевантных
новостей.
Процесс составления отчёт заключается в том, что
по полученным спискам составляет ответ для автоматизированной системы в формате
XML
Подобное разделение модуля на отдельные процессы
позволяет распределить нагрузку между несколькими процессами, что значительно
повышает производительность.
.3 Технологическое обеспечение задачи
Технология сбора обработки и выдачи информации
наглядно продемонстрирована на рисунках 2.9, 2.10, 2.11. Сам технологический
процесс начинается с добавления в систему RSS
источников новостей. Это происходит путём введения данных об источниках, с
помощью использования файла запроса к процессу обработки. В котором содержится
информация об RSS источнике
новостей. Данная обработка, входящей информации, происходит на стадии запуска
автоматизированной системы. Это наглядно продемонстрировано на рисунке 2.9. В
результате система получает базу со всей информацией об источниках RSS
новостей.
Далее с использованием базы RSS
источников новостей, и расписания автоматизированной работы идёт обращение ко
всем источникам новостей. Вся новостная информация поступает в электронном виде
от источников новостей и имеет формат RSS.
Данная информация переводится из RSS
формата в массив данных, который временно хранится в оперативной памяти.
Дальнейшая цель системы, это поочерёдно обработать все вновь полученные
новости. В начале, идёт проверка на наличие новостей хотя бы одной новости в
массиве данных, который хранится в оперативной памяти. Если массив данных пуст,
то система заканчивает обработку. Если массив данных не пуст, то начинается
обработка массива. Каждая обработка заключается в поочерёдном обращении к
каждой записи в массиве данных. Каждая отдельная запись в данном массиве является
отдельной новостью. В начале, берётся запись, и базы новостей и тел новостей.
На этом этапе запись сравнивается с уже существующими новостями в базе. Если
удалось найти сходство новостей по заранее определённым параметрам в системе.
То запись становится новой новостью с прикреплением её к телу новости и
сохраняется в виде новости в базу новостей. Если не удалось найти сходство
обрабатываемой записи и новостей в базе, то запись записывается в базу тела
новости и в базу новостей с организацией связи между телом новости и самой
новостью. После операции по сравнению новостей идёт рубрицирование вновь
добавленной новости. При этом если в данных о новой новости есть привязка, к
какой-то рубрике, то она сводится к одной из 19 рубрик, заранее зафиксированных
в системе. Если таковой привязки нет, то новая новость получает туже привязку к
каталогу что и тело новости, к которой она относится. Далее процесс заключается
в том, что бы удалить из месива данных только что обработанную новость и
перейти к обработке всех новостей. После того как все вновь поступившие новости
обработаны. Система заканчивает работу. Схема технологического процесса
обработки информации представлена на рисунке 2.10.
Схема технологического процесса обработки и
выдачи результатной информации представлена на рисунке 2.11. На этой схеме
показано, что в начале идёт запрос от автоматизированной системы в виде данных
о запросе. В данном запросе содержится указание каталога новости, по которой
следует производить поиск новостей, и непосредственно текс, по которому будет
производиться поиск. В начале, идёт преобразование поступившего запроса в
строку с SQL кодом
обращение к базе данных новостей. Далее идёт обращение составленного запроса к
базе новостей для получения массива с кодами новостей, который временно
содержится в оперативной памяти. Следующей задачей является определить, найдены
новости или нет, поэтому следующим этапом идёт проверка массива в оперативной
памяти. Если в этом массиве есть хоть одна новость, то из базы данных
собирается информация о новостях код которых содержится в массиве котов. Все
полученные данные переводятся в электронный формат XML.
Если в массиве не найдено ни одной новости, то формируется электронный ответ об
этом так же в формате XML.
Сформированный XML
ответ отправляется в виде электронного файла для той системы, которая
отправляла запрос на поиск новостей.
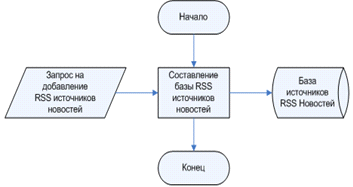
Рис. 2.9 Схема технологического процесса
«Добавление источников RSS
новостей»
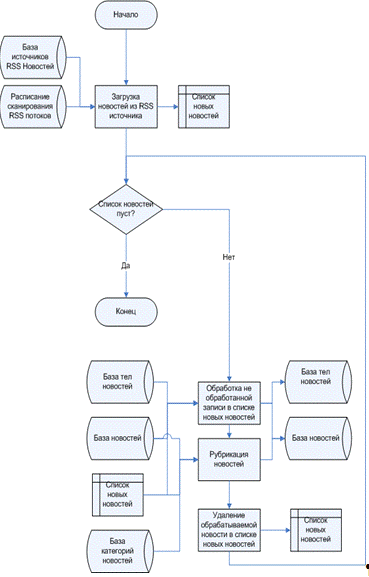
Рис. 2.10 Схема технологического процесса
«Автоматизированная обработка RSS
потоков новостей»
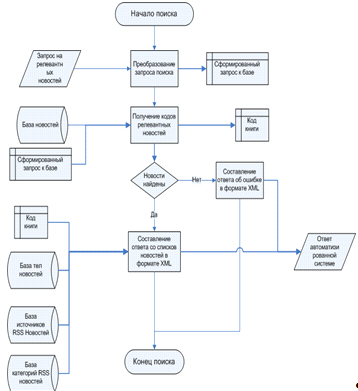
Рис. 2.11 Схема процесса поиск релевантных RSS
новостей»
.4 Описание контрольного примера реализации
проекта
В данном разделе будет описан контрольной пример
работы с системой. Это одна из важнейших частей данного дипломного проекта. Так
как здесь демонстрируется работоспособность всех разрабатываемых элементов
системы
В рамках данного проекта была разработана
полностью автоматизированная система, которая не требует наличие экранных форм
на этапе её эксплуатации. Однако на этапе запуска системы требуется внесение
начальных данных разработчиком. Данная функция реализована с использованием
удалённого подключение по защищённому каналу связи SSH2.
Для демонстрации подобного подключения используется программа putty
работающая в Windows
системах. При этом в unix
системах никаких дополнительных приложений не требуется, так как в них есть
встроенная утилита связи SSH.
Поскольку подключение удалённое, оно может
производиться с любого компьютера и из любого места. При этом встроенная система
защиты на удалённом сервере иллюстрирует в приложении 1 на рисунках 1.3 и 1.4.
В начале, разработчиком вводится сценарий
автоматизированной работы, который можно ввести при использовании команды crontable
-e. При этом
открывается консольный редактор, в котором можно задать сценарий
автоматизированной работы. Пример подобного задания сценария продемонстрирован
в приложении 1 на рисунке 1.1. После задания сценария, разработчик сохраняет
его, что является стартом для начала работы автоматизированной системы.
Ещё одно действие, которое выполняет
разработчик, это ввод в базу RSS
источников новостей. Разработчик может это сделать так же через приложение putty
но для большей наглядности пример заполненной базу продемонстрирован с подошью
возможностей сервера и скрипта работы с базами phpMyAdmin.
Представление базы представлено в приложении 1 рисунок 1.5.
Дальнейший функционал разработанной системы
полностью автоматизирован и не имеет экранных форм. Но для того что б
продемонстрировать работоспособность системы не мешать нормальному
функционированию сайта zone-x.ru,
были построены ряд демонстрационных примеров.
Для того что бы проиллюстрировать обращение
автоматизированной системы получение новостей, будет использован стандартный
браузер Mozilla Firefox 3. Самим обращением к разработанной системе будет,
является запрос в адресной строке. А ответом та информация которая выведется
окне браузера. Подобный вариант обращения к серверу для получения новостей
полностью идентичен обращению автоматизированной системы получения новостей.
В качестве ключевых параметров будет выступать
ключи cat и text.
Ключ cat
соответствует номеру категории. Ключ text
содержит текст, по которому требуется находить наиболее подходящие новости. В
данной демонстрации cat=
892345579 что соответствует разделу Интернет. Для параметра text
возьмём действующую страницу на сайте zone-x.ru,
а именно список книг в разделе Интернет, демонстрацию самой страницы можно
посмотреть в приложении 1 рисунок 1.6. В ответ получается файл в формате XML
с новостями. Подобный запрос продемонстрирован в приложении 1 рисунок 1.7.
С данными новостями в формате XML
возможны любые манипуляции. Например, выдача пользователям для чтения, показ
пред просмотр и расширенно на отдельной странице, трансляция в виде
дополнительного RSS
канала. Для демонстрации было создано пара макетов, которые можно просмотреть в
приложении 1 на рисунках 1.8 и 1.9. На данных рисунках продемонстрирована
возможность вывода новостных блоков, используя соответственно с оформлением
сайта zone-x.ru.
Вид и сложность таких новостных блоков очень разнообразна. А использование
системы в целом на много проще, функциональней и эффективнее.
3. Обоснование экономической эффективности
проекта
.1 Выбор и обоснование экономической
эффективности проекта
Экономическая эффективность - результативность
экономической системы, выражающаяся в отношении полезных конечных результатов
ее функционирования к затраченным ресурсам. Показатель экономической
эффективности складывается из производственных оценок процесса до внедрения
автоматизированной системы и после. При этом следует учитывать затраты,
требующиеся для автоматизации процесса. В конечном итоге экономическая
эффективность помогает определиться с тем, есть или нет необходимость во
внедрение автоматизированного варианта системы обработки информации.
В данном дипломном проекте базовым вариантом
является ручная система обработки новостной информации в ООО “Зона Икс”.
В качестве предлагаемой системы обработки
информации предлагается система, на базе технологий портала farseer.ru,
которыми предполагается заменить ручную обработку информации.
Экономическая эффективность проекта складывается
из двух составляющих: «косвенного эффекта», который характеризуется увеличением
объёмом обрабатываемой информации, повышением точности обрабатываемой
информации, снижением затрат на обработку; «прямого эффекта», который
характеризуется сокращением времени на обработку итоговых данных; сокращением
трудоемкости работы и стоимостных затрат обработки при обработке информации;
повышением достоверности и точности обработки информации.
Для расчета прямого эффекта необходимо
рассмотреть показатели трудовых и стоимостных затрат.
К трудовым показателям затрат относятся
следующие:
Абсолютное снижение трудозатрат (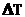 ) в часах за
год
) в часах за
год
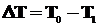 (1)
(1)
где T0 - трудовые затраты в часах за
год на обработку информации при существующем процессе,
T1 - трудовые
затраты в часах за год на обработку информации по предлагаемому варианту.
Относительное снижение трудовых
затрат (KT)
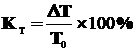 (2)
(2)
Индекс снижения трудозатрат (YT)
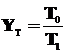 (3)
(3)
К стоимостным показателям относятся:
Абсолютное снижение стоимостных
затрат в рублях в год (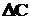 )
)
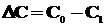 (4)
(4)
где C0 -
стоимостные затраты в рублях за год при существующем процессе,
С1 - стоимостные затраты в рублях за
год по предлагаемому варианту.
Относительное снижение стоимостных
затрат в рублях в год (KC)
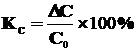 (5)
(5)
Индекс снижения стоимостных затрат (YC)
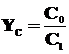 (6)
(6)
Период окупаемости проекта (TOK)
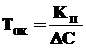 (7)
(7)
где КП - затраты в рублях на
создание и эксплуатацию проекта.
.2 Расчёт показателей экономической
эффективности
Для расчёта показателей
экономической эффективности были использованы следующие показатели из реального
процесса управления контентом.
· Стоимость
одной добавленной записи оператором составляет шесть рублей
· На
обработку и добавление одной записи оператором требуется примерно восемь с
половиной минут, что составляет 7 записей в час.
В качестве накладных
расходов для процесса обработки новостной информации выступает покупка и
обслуживание персональной рабочей станции для оператора, так, например
стоимость приобретения одной рабочей станции составляет пятнадцать тысяч
рублей. Так как вся работа заключается в обработке электронной информации,
дополнительных расходов на канцелярские товары не требуется. На основании
приведенной выше информации построим таблицы расчёта трудовых и стоимостных
затрат по базовому и проектному варианту. Расчёт стоимостных и трудовых затрат
по базовому варианту приведён в таблице 3.1. расчёт стоимостных и трудовых
затрат по проектному варианту приведён, в таблице 3.2.
Таблица 3.1. Расчет стоимостных и трудозатрат
базового процесса обработки новостной информации
|
№
п/п
|
Наименование
базовых операций
|
Оборудование
|
Ед.
измерения
|
Объем
работы в год
|
Норма
выработки (зап./час)
|
Трудоемкость
(гр.4 / гр.5)
|
Среднечасовая
з/п специалиста (руб.)
|
Часовая
стоимость накладных расходов (руб.)
|
Стоимостные
затраты для операций, вып. на ЭВМ ((гр.7+гр.8)*гр.6)
|
|
1
|
2
|
3
|
|
4
|
5
|
6
|
7
|
8
|
11
|
|
1
|
Обработка
новости
|
Компьютер;
|
запись
|
13909
|
7
|
1987
|
7
|
7,5
|
28811,5
|
|
|
Opera
|
|
|
|
|
|
|
|
|
Итого
|
|
|
|
|
1987
|
|
|
28811,5
|
Таблица 3.2. Расчет стоимостных и трудозатрат
внедрённой системы автоматизации обработки новостной информации.
|
№
п/п
|
Наименование
базовых операций
|
Оборудование
|
Ед.
измерения
|
Объем
работы в год
|
Норма
выработки (зап./час)
|
Трудоемкость
(гр.4 / гр.5)
|
Среднечасовая
з/п специалиста (руб.)
|
Часовая
стоимость накладных расходов (руб.)
|
Стоимостные
затраты для операций, вып. на ЭВМ ((гр.7+гр.8)*гр.6)
|
|
1
|
2
|
3
|
|
4
|
5
|
6
|
7
|
8
|
11
|
|
1
|
Поиск
и вывод записей
|
Сервер
|
запись
|
547500
|
400
|
1368,75
|
0
|
1,25
|
1710,9375
|
|
|
|
|
|
|
|
|
|
|
|
Итого
|
|
|
|
|
1368,75
|
|
|
1710,9375
|
Для автоматизированного варианта обработки
данных отсутствуют такие статьи расходов как оплата ручной обработки, так как
обработка производится полностью автоматизировано. Следовательно сокращается
стоимость затрат на оборудование так как не требуется содержать рабочее место и
обслуживать компьютер.
Для расчёта абсолютных показателей эффективности
проекта должны быть использованы показатели, рассчитанные в таблицах 3.1. и
3.2. Основываясь на данных показателях, построим таблицу 3.3. Показатели затрат
и таблицу 3.4. Показатели от внедрения автоматизированной системы обработки
новостной информации.
Таблица 3.3 Показатели затрат
|
Трудовые
затраты
|
Стоимостные
затраты
|
|
Базовый
вариант
|
T0=1987 часов
|
С0=28811,5+0=28811,5руб.
|
|
Проектный
вариант
|
T1=1369 часов
|
С1=0
руб.
|
Таблица 3.4. Показатели от внедрения
автоматизированной системы обработки новостной информации
|
Затраты
|
Абсолютное
изменение затрат
|
Относительное
изменение затрат
|
Индекс
изменения затрат
|
|
Базовый
вариант
|
Проектный
вариант
|
|
|
|
|
Трудоемкость
|
T0.(час)
|
T1.(час)
|
Рассчитывается
по формуле 1 DТ=Т0
-Т1,(час)
|
Рассчитывается
по формуле 2 КТ=DТ/T0*100%
|
Рассчитывается
по формуле 3 YT=T0/T1
|
|
1987
|
1368,75
|
618,25
|
31,11%
|
0,88
|
|
Стоимость
|
C0.(руб)
|
С1.(руб)
|
Рассчитывается
по формуле 4 DC=C0-C1,
(руб.)
|
Рассчитывается
по формуле 5 КC=DC/C0*100 %
|
Рассчитывается
по формуле 6 YC=C0/C1
|
|
28811,5
|
1710,9375
|
27100,5625
|
94%
|
0,07
|
Для более наглядной демонстрации результатов
расчётов экономической эффективности трудовых и стоимостных затрат на рисунке
3.1 и 3.2 приведены две круговые диаграммы, диаграмма трудовых затрат и
диаграмма стоимостных затрат соответствующе.
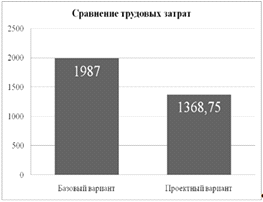
Рис. 3.1 диаграмма сравнения трудовых затрат
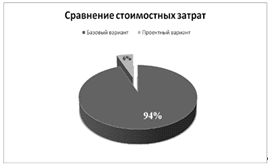
Рисунок 3.2 диаграмма сравнения стоимостных
затрат
Для оценки расходов на разработку и создание
автоматизированного варианта решения задачи необходимо выяснить следующие
показатели:
· Приобретение удалённого сервера
· Настройка удалённого сервера;
· Разработка и внедрение системы.
Так как в проекте используется сервер,
предоставляемый иностранным провайдером, цены на обслуживание оборудования во
многом зависят от колебаний стоимости валюты, но в среднем стоимость одного месяца
обслуживания оборудования составляет тысячу восемьсот рублей. Стоимость
настройки оборудования сервера рассчитывается исходя из стоимости часовой
оплаты сотрудника обладающего необходимыми навыками по настройки удалённого
доступа к серверу. В настоящий момент в организации есть программист, в
должностные обязанности которого входит настройка и обслуживание всего
оборудования. Оплата труда программиста составляет двести пятьдесят рублей в
час, время необходимое для настройки сервера составляет два часа. Для
разработки и внедрения проекта потребуется привлечение одного программиста
обладающего знаниями разработки приложений на языке PHP
в среде разработки PHP
Expert Edition,
знать принципы совместной работы СУБД MySQL
и PHP, основные знания
по пользованию и формированию формата XML.
Исходя из обзора рынка вакансий на настоящий момент, час работы подобного
специалиста стоит триста рублей. Основываясь на приведенных выше данных
рассчитаем затраты на разработку и внедрение автоматизированной системы. Затраты
на разработку и внедрение системы приведены в таблице 3.5.
Таб. 3.5 Затраты на разработку и внедрение
|
Наименование
работ
|
Трудовые
затраты (час.)
|
Стоимостные
затраты (руб.)
|
|
Проектирование
|
48
|
14000
|
|
Разработка
|
72
|
21000
|
|
Интеграция
|
4
|
1200
|
|
Тестирование
|
16
|
4000
|
|
Внедрение
|
2
|
600
|
|
Документирование
|
8
|
2000
|
|
Итого:
|
150
|
41000
|
Стоимость разработки системы складывается из
приведённых выше расходов на работу собственного программиста, наёмного
программиста и стоимости ежемесячной оплаты сервера.
КП=1800 + 500 + 41000 = 43300 рублей.
Период окупаемости для проекта рассчитывается по
формуле (7) раздела 3.1
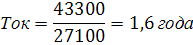
Заключение
В данном дипломном проекте была поставлена цель,
полностью автоматизировать обработку поступающей информации. Сократить издержки
на её обработку. Повысить количество обрабатываемой информации.
Из поставленных задач удалось полностью
автоматизировать функцию сбора и обработки новостной информации, тем самым
избавившись от дорогостоящего и не производительного ручного труда. Отказ от
ручной обработки значительно снижает, издержи и повышает количество
обрабатываемой информации.
Для достижения поставленных задач было изучено
множество новостных ресурсов, информационных агентств, а так же имеющихся на
рынке новостных интеграторов, таких как Рамблер Новости и Яндекс Новости. Так
же были проведении измерения схожести новостей, для из дальнейшей интеграции.
Так же было принято решение о выводе системы обработки новостной информации на
отдельный сервер. Это должно полностью исключить препятствие нормальной работе
Интернет-магазина. На удалённом сервере было разработано информационное и
программное обеспечение для автоматизированной обработки новостной информации.
А передача новостей реализована через xml
файлы данных.
После внедрения разработанной системы на
предприятии планируется её дальнейшее совершенствование и сопровождение. Так
как рассматриваемая, в данном дипломе сфера интернет деятельности, является
перспективной и имеет большой потенциал для развития.
Список литературы
1. Базы
данных. Описание системы управления реляционными базами данных. <#"606913.files/image030.gif">
Рисунок 1.1. Редактирование документа Запрос на
начало обработки информации

Рисунок 1.2 Пример результатного документа
Рисунок 1.3. Ввод логина пользователя
Рисунок 1.4 Успешная авторизация при вводе
логина и пароля
Рисунок 1.5 Иллюстрация базы RSS
источников новостей
Рисунок 1.6 Пример страницы с информацией
Рисунок 1.7 Пример запроса и ответа от
разработанной системы
Рисунок 1.8 Пример использования xml
выдачи новостей
Рисунок 1.9 Пример использования xml
выдачи новостей