Создание программы-интерпретатора для обработки исходных текстов программ, выполняющих действия над комплексными числами
Введение
В настоящее время языки высокого уровня стали
основным средством разработки программ. Поэтому компиляторы составляют
существенную часть системного программного обеспечения ЭВМ. Сегодня только
очень малая часть программного обеспечения, требующая особой эффективности,
разрабатывается с помощью ассемблеров. В настоящее время имеет применение
довольно большое количество языков программирования. Наряду с традиционными
языками, такими, например, как Фортран, широкое распространение получили так
называемые «универсальные» языки (Паскаль, Си, Модула-2, Ада) и др., а также
некоторые специализированные (например, язык обработки списочных структур
Лисп). Кроме того, большое распространение получили языки, связанные с узкими
предметными областями, такие, как входные языки пакетов прикладных программ.
Для ряда названных языков имеется довольно много
реализаций для различных операционных систем и архитектур ЭВМ.
В рамках традиционных последовательных машин
развивается большое число различных направлений архитектур. Примерами могут
служить архитектуры CISC,
RISC. Такие ведущие
фирмы, как Intel, Motorola,
Sun, начинают
переходить на выпуск машин с RISC-архитектурами.
Естественно, для каждой новой системы команд требуется полный набор новых
компиляторов с распространенных языков.
Поэтому важную роль компиляторов в современном
системном ПО для ЭВМ невозможно переоценить.
В данной курсовой работе делается попытка
создания простого интерпретатора с целью изучения принципов строения и работы
этого вида системного ПО.
1. Техническое задание
В данной курсовой работе требуется:
Создать программу-интерпретатор, способную
получать на входе текстовый файл (в формате ASCII
или ANSI) с текстом
программы. На выходе - выводит на экран результаты вычислений, определяемых
программистом. Если входная программа содержит ошибку - сообщение о типе
ошибки.
Интерпретатор должен воспринимать и обрабатывать
следующие инструкции:
а) объявление переменной с одновременным
присвоением ей начального значения
Имя Переменной = значение или
Имя Переменной = выражение
Значение переменной задается вещественным числом
в десятичной системе счисления. Например, X=0.06
Выражения записываются по правилам, Например, F=-X/0.01
б) вывод результатов на экран
PRINT
(Имя Переменной) или PRINT
(выражение)
Например, PRINT(X)
и PRINT(X+F)
в) Операндами выражения могут быть вещественные
числа и имена объявленных ранее переменных. В выражении допускаются следующие
операторы:
+ сумма;
разность, унарный минус;
* произведение;
/ частное;
ABS(…) модуль
числа;
^ возведение в степень (степень выражается целым
числом ³0);
SQRT(…)
квадратный корень;
EXP(…)
экспонента;
LN(…)
натуральный логарифм.
Порядок выполнения операций может регулироваться
скобками ().
Инструкции в тексте программы разделяются точкой
с запятой, либо каждая инструкция - с новой строки.
2. Разработка грамматики
Список допустимых лексем (слов
языка).
Допустимыми являются:
имя переменной <имя переменной> = L<C>;
(L - буква, C
- цифра)
зарезервированные слова <зарезервированные
слова> = <'print',
'abs', 'sqrt',
'exp', 'ln'>
используемые символы <символы> = <'+',
'-', '/', '*', '(', ')', '.', '^'>
Все буквы - маленькие латинские.
Программа состоит из двух основных блоков,
парсера и лексера.
Парсер отвечает за разбиение на токены, а лексер
анализирует токены, и в зависимости от содержимого выполняет над ними действия.
3. Описание программы
Программа-интерпретатор выполнена с
использованием среды разработки Borland
С++ 6.0 и представляет собой интерактивную оболочку, позволяющую загружать
исходный ASCII-текст,
содержащий программу, написанную в соответствии с синтаксисом входного языка.
интерпретатор текстовый файл лексема
3.1 Интерфейс программы
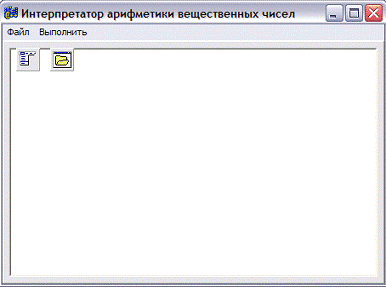
Интерфейс программы состоит из формы (Form1),
также ее можно считать диалоговым окном между пользователем и программой
выполняющей вычисление по заданному алгоритму.
На форме также расположены Panel1,
RichEdit1, MainMenu1
и OpenDialog1.
Свойства для компонентов
Panel1:
- Высота (Height)
= 289
Ширина (Width)
= 449
Form1:
- AutoSize
= true
Caption
= Интерпретатор арифметики вещественных чисел
MainMenu1:
Состоит из следующих пунктов
Файл
Открыть
Выход
Выполнить
Для пунктов меню Открыть, Выход и Выполнить
предусмотрены комбинации кнопок, для более быстрого выполнения задач.
Открыть Ctrl+O
Выход Ctrl+X
Выполнить F9
Структура меню
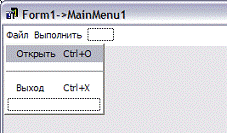
Для того чтобы задать каждому пункту меню
определенную комбинацию быстрых клавиш необходимо в окне Object
Inspector компонента MainMenu1
выбрать необходимый пункт меню и в поле ShortCut
выбрать необходимую комбинацию.
Из за того что мы используем RichEdit1
наше приложение будет интерактивным а именно, после того как код программы
будет загружен в окне нашего приложения в него можно будет вносить изменения и
дополнять его.
OpenDialog1:
Для того чтобы во время открытии текстового (txt)
файла нам не мешались файлы с другими расширениями, нам необходимо установить
фильтр для данного компонента OpenDialog1.
В окне Object
Inspector для OpenDialog1
в пункте Filter нажимаем на
кнопку  и
устанавливаем необходимые фильтры.
и
устанавливаем необходимые фильтры.

*.txt
- Отображать файлы с расширением TXT
*.* - Отображать все файлы
Результатом обработки текста программы является
вывод в окне интерпретатора результата вычисления, либо сообщения об ошибке.
3.2 Листинг программы
Unit1.cpp
#include
<vcl.h>
#pragma hdrstop
#include "Unit1.h"
//---------------------------------------------------------------------------
#pragma package(smart_init)
#pragma resource
"*.dfm"*Form1;
//---------------------------------------------------------------------------
__fastcall
TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{
}
//---------------------------------------------------------------------------__fastcall
TForm1::Open1Click(TObject *Sender)
{->Options.Clear();->Options
<< ofAllowMultiSelect <<
ofFileMustExist;(OpenDialog1->Execute())->Lines->LoadFromFile(OpenDialog1->FileName);
}
//---------------------------------------------------------------------------__fastcall
TForm1::Calculate1Click(TObject *Sender)
{*code;buffer[1024];=
RichEdit1->Lines->GetText();*cb = parser_codebuffer_new(code);
/* Вычислить
выражения
*/v1 = parser_evaluate(cb);
/* Напечатать результат выполнения операции
*/->Lines->Add((v1.error));
/* Важно: Обязательно освободить массив значений
v1 */_value_free(&v1);
/* Освободить буфер кода и список переменных */
parser_codebuffer_destroy(cb);
/* И
освободить
cb */(cb);
}__fastcall
TForm1::Variable_print_all(ParserVariable *variables[])
{(!variables) return;_t
i;buffer[1024];(i=0; i< MAX_VARIABLE_LIST_LEN; i++)
{(!variables[i]) continue;*var =
variables[i];(var->val.type)
{TOK_NUMERIC:(buffer,"%s=%s\n",var->name,
parser_value_show_as_string(&var->val));->Lines->Add
(buffer);;TOK_STRING:(buffer,"%s=%s\n",var->name,
var->val.s);->Lines->Add (buffer);;:(buffer, "%s Имеет
неизвестный
тип
переменной%d.\n",
var->name, var->val.type);->Lines->Add (buffer);;
}
}
}
//---------------------------------------------------------------------------__fastcall
TForm1::Exit1Click(TObject *Sender)
{();
}
Parser.cpp
#include "lexer.h"
#include "parser.h"
#include "Unit1.h"
#ifndef M_PI
#define M_PI 3.14159265358979323
#endifparser_statements(CodeBuffer
*cb);parser_assign(CodeBuffer *cb);do_sqrt(ParserVal *a, int
b);do_abs(ParserVal *, int);do_exp(ParserVal *, int);do_ln(ParserVal *,
int);do_pow(ParserVal *, int);do_integer(ParserVal *, int);do_round(ParserVal
*, int);do_fraction(ParserVal *, int);do_boolean_str(int oper, ParserVal *v1,
ParserVal *v2);do_boolean(int oper, ParserVal *v1, ParserVal *v2);do_math(int
oper, ParserVal *v1, ParserVal *v2);do_unary(int oper, ParserVal
*v1);do_power(ParserVal *v1, ParserVal *v2);parser_do_print(ParserVal *,
int);g_function_table[] = {
/* Массив
внутренних
функций
*/
{"sqrt", 1, do_sqrt},
{"abs", 1, do_abs},
{"exp", 1, do_exp},
{"ln", 1, do_ln},
{"pow", 2, do_pow},
{"print", 1,
parser_do_print},
{"int", 1, do_integer},
{"modf", 1, do_fraction}
};*lookup_builtin_function(char
*name);*builtin_function_arg_text(BuiltinFunction *func);_t parser_strlen(char
*s);execute_builtin_function(CodeBuffer *cb, BuiltinFunction
*func);parser_bool_or(CodeBuffer *cb);parser_bool_and(CodeBuffer
*cb);parser_bool1(CodeBuffer *cb);parser_bool2(CodeBuffer
*cb);parser_bool3(CodeBuffer *cb);parser_level1(CodeBuffer
*cb);parser_level2(CodeBuffer *cb);parser_level3(CodeBuffer
*cb);parser_level4(CodeBuffer *cb);parser_level5(CodeBuffer
*cb);parser_error(CodeBuffer *cb, char *msg, int
opt);parser_convert_to_numeric(ParserVal *v);parser_convert_to_string(ParserVal
*v);is_numeric(ParserVal *v);is_string(ParserVal *v);str_icmp(char *s1, char
*s2);parser_add_strings(ParserVal *v1, ParserVal *v2);get_int_part(double
x);round_num(double d, unsigned int dec_places);
/* Хранение глобальных tokenов для функций
которые не анализируют их */
TokenRec
currToken;parser_evaluate(CodeBuffer *cb)
{
/* Начало
parsingа
для
col 0, line 1 */>curr_pos = 0;>line_num = 1;(cb->char_backbuf, '\0',
MAX_CHAR_BACKBUF_LEN);>tok_backbuf_count =
0;_variable_add_standard_constants(cb);v1 = parser_statements(cb);
/* Необходимо освободить v1 после использования.
Вызов parser_value_free(&v1); */v1;
}parser_do_print(ParserVal *v, int
arg_count){buffer[1024];_convert_to_numeric(v);>s =
parser_format_string("Результат:%g",
v->d);->RichEdit1->Lines->Add(v->s);;
}parser_statements(CodeBuffer *cb)
{v1;_value_init_to_numeric(&v1,
0.0);_get_token(cb, &currToken);(currToken.type != TOK_EOF)
{= parser_assign(cb);(v1.error)
{_error(cb, v1.error, TRUE);v1;
}(v1.type)
{TOK_STRING:;TOK_NUMERIC:
break;'\n':
/* Пустая инструкция */;
}
}
/* Необходимо освободить V1 после использования.
parser_value_free(&v1);
*/v1;
}parser_assign(CodeBuffer *cb)
{v1;**variables =
parser_variable_create_list();
/* Текущий token идентификатор а следующий token
знак '=' */
while (currToken.type == TOK_IDENT
&& lexer_lookahead(cb, '=', TRUE/*remove it*/))
{*var = (ParserVariable *)calloc(1,
sizeof(ParserVariable));>name = parser_format_string("%s",
currToken.str);_value_init_to_numeric(&var->val, 0.0);
/* Добавить
переменную
в
список
*/_variable_add_to_list(variables, var);_get_token(cb, &currToken);
}
/* Анализ и оценка значения */=
parser_bool1(cb);
if (!v1.error)
{_t i;(i = 0; i <
MAX_VARIABLE_LIST_LEN; i++)
{(!variables[i])
continue;_value_copy(&v1, &variables[i]->val);_variable_add_to_list(cb->variable_list,
variables[i]);
}
}(variables);v1;
}parser_bool1(CodeBuffer *cb)
{oper;v1 = parser_bool2(cb);
oper = currToken.type;
/* Логический оператор: '&&' Логическое
AND */
while (oper == TOK_AND)
{_PAR2("ОТЛАДКА
parser_bool1 (&&): Оператор=%c
Значение
v1=%s\n", oper, parser_value_show_as_string(&v1));_get_token(cb,
&currToken);v2 = parser_bool2(cb);_boolean(oper, &v1, &v2);
/* Free v2 */_value_free(&v2);=
currToken.type;(v1.error) break;
}v1;
}parser_bool2(CodeBuffer *cb)
{oper;v1 = parser_bool3(cb);
oper = currToken.type;
/* Логический оператор: '||' Логическое OR */
while (oper == TOK_OR)
{_PAR2("ОТЛАДКА
parser_bool2 (||): оператор=%c
Значение
v1=%s\n", oper, parser_value_show_as_string(&v1));_get_token(cb,
&currToken);v2 = parser_bool3(cb);_boolean(oper, &v1, &v2);
/* Free v2 */_value_free(&v2);=
currToken.type;(v1.error) break;
}v1;
}parser_bool3(CodeBuffer *cb)
{oper;v1 = parser_level1(cb);
oper = currToken.type;
/* Логический оператор: ==, >, >=, <,
<= */
while (oper == TOK_EQ || oper ==
TOK_GT || oper == TOK_LT || oper == TOK_LE || oper == TOK_GE)
{_PAR2("ОТЛАДКА
parser_bool3 (==, >, >=, <, <=): оператор=%c
Значение
v1=%s\n", oper, parser_value_show_as_string(&v1));_get_token(cb,
&currToken);v2 = parser_level1(cb);_boolean(oper, &v1, &v2);
/* Free v2 */_value_free(&v2);=
currToken.type;(v1.error) break;
}v1;
}parser_level1(CodeBuffer *cb)
{oper;v1 = parser_level2(cb);
oper = currToken.type;
/* Математические операторы: +, - */
while (oper == TOK_PLUS || oper ==
'-')
{_PAR2("ОТЛАДКА
parser_level1 (+/-): оператор=%c
Значение
v1=%s\n", oper, parser_value_show_as_string(&v1));_get_token(cb,
&currToken);v2 = parser_level2(cb);_math(oper, &v1, &v2);
/* Free v2 */_value_free(&v2);=
currToken.type;(v1.error) break;
}v1;
}parser_level2(CodeBuffer *cb)
{oper;v1 = parser_level3(cb);=
currToken.type;
// *, /(oper == TOK_MUL || oper ==
TOK_DIV)
{_PAR2("ОТЛАДКА
parser_level2: оператор=%c
Значение
v1=%s\n", oper, parser_value_show_as_string(&v1));_get_token(cb,
&currToken);v2 = parser_level3(cb);_math(oper, &v1, &v2);
/* Free v2 */_value_free(&v2);=
currToken.type;(v1.error) break;
}v1;
}parser_level3(CodeBuffer *cb)
{v1 = parser_level4(cb);
/* '^' Экспоненциальный:
2^3 = 8. */(currToken.type == TOK_EXP)
{_get_token(cb,
&currToken);("parser_level3: Оператор=%c
Значение
v1=%s\n", TOK_EXP, parser_value_show_as_string(&v1));_PAR2("ОТЛАДКА
parser_level3: Оператор=%c
Значение
v1=%s\n", TOK_EXP, parser_value_show_as_string(&v1));v2 =
parser_level3(cb); /* Recursively */_power(&v1, &v2);
/* Free v2 */_value_free(&v2);
}v1;
}parser_level4(CodeBuffer *cb)
{
int
oper;
oper = 0;
/* Унарный +/- пример. (+3)
+ -3. */(currToken.type == '-' || currToken.type == '+')
{= currToken.type;_get_token(cb,
&currToken);
}v1 = parser_level5(cb);(oper != 0)
{_PAR2("ОТЛАДКА
parser_level4 (унарный
+/-): Оператор=%c
Значение
v1=%s\n", oper, parser_value_show_as_string(&v1));_unary(oper,
&v1);
}v1;
}parser_level5(CodeBuffer *cb)
{val;v1; //= {.type=TOK_NUMERIC,
{.d=0.0},.error=NULL};.type=TOK_NUMERIC;.d=0.0;
v1.error=NULL;
/* Сохранение текущего типа tokenа */
val = currToken;(currToken.type)
{
/* '(' Выражение ')'.
Пример. "((2
+ 5) * 6)"
*/TOK_PAROPEN:_get_token(cb,
&currToken);
v1 = parser_bool1(cb);
/* С правой скобкой ')' ? */(currToken.type
!= TOK_PARCLOSE)
{
/* Отсутствие правая скобка ')' */
v1.error
= parser_format_string("Отсутствует
правая скобка ')'.");
}_get_token(cb,
&currToken);;TOK_NUMERIC:.type = TOK_NUMERIC;.d =
currToken.val.d;_get_token(cb, &currToken);
break;TOK_IDENT:
{
/* Это встроенная функция? */*func
= lookup_builtin_function(currToken.str);
if (func)
{
/* Проверка открытия '(' */
if (!lexer_lookahead(cb,
'(',TRUE/*remove it*/))
{
/* Отсутствие
'(' */.error = parser_format_string("Отсутствует
левая
скобка
'(' у
функции%s.\n",
func->name);l_end_ident;
}_get_token(cb, &currToken);=
execute_builtin_function(cb, func);
/* С закрытием ')' ? */(currToken.type !=
TOK_PARCLOSE)
{
/* Отсутствие ')' */.error =
parser_format_string("Отсутствует правая скобка ')'. получен знак
'%s'.", currToken.str);
}
}
{ /* Это
переменная
*/i = parser_variable_find(cb->variable_list, currToken.str);(i > -1)
{*var =
cb->variable_list[i];_value_copy(&var->val, &v1);
}
{
/* Неизвестная переменная или идентификатор */
v1.error
= parser_format_string("Неизвестный
идентификатор '%s'.", currToken.str);
}
}_end_ident:_get_token(cb,
&currToken);
};TOK_STRING:
/* Строка
цитаты
" или
' */_value_set_to_string(&v1, currToken.str);_get_token(cb,
&currToken);;'\n':';':
/* Конец или пустой оператор */.type = '\n';
lexer_get_token(cb,
&currToken);;:.error = parser_format_string("Неизвестный
знак
'%s'", currToken.str);_get_token(cb, &currToken);
}_PAR2("ОТЛАДКА
parser_level5: type=%d Значение
v1=%s.\n", val.type, parser_value_show_as_string(&v1));v1;
}do_boolean_str(int oper, ParserVal
*v1, ParserVal *v2)
{_convert_to_string(v1);_convert_to_string(v2);ret
= strcmp(v1->s, v2->s);(oper)
{
/* v1 == v2
*/TOK_EQ:_value_set_to_numeric(v1, (double)(ret == 0));;
/* v1 > v2
*/TOK_GT:_value_set_to_numeric(v1, (double)(ret > 0));;
/* v1 >= v2
*/TOK_GE:_value_set_to_numeric(v1, (double)(ret > 0 || ret == 0));;
/* v1 < v2
*/TOK_LT:_value_set_to_numeric(v1, (double)(ret < 0));;
/* v1 <= v2
*/TOK_LE:_value_set_to_numeric(v1, (double)(ret < 0 || ret == 0));;
/* v1 && v2
*/TOK_AND:(!(parser_strlen(v1->s) && parser_strlen(v2->s)))
{
/* Set v1 to zero (FALSE)
*/_value_free(v1);
};
/* v1 || v2
*/TOK_OR:(!parser_strlen(v1->s))
{
/* Copy v2 to v1
*/_value_free(v1);_value_copy(v2, v1);
};
}
}do_boolean(int oper, ParserVal *v1,
ParserVal *v2)
{(is_string(v1) || is_string(v2))
{_boolean_str(oper, v1, v2);;
}_convert_to_numeric(v1);_convert_to_numeric(v2);(oper)
{
/* v1 == v2 */TOK_EQ:->d =
(v1->d == v2->d);;
/* v1 > v2 */TOK_GT:->d =
(v1->d > v2->d);;
/* v1 >= v2 */TOK_GE:->d =
(v1->d >= v2->d);;
/* v1 < v2 */TOK_LT:->d =
(v1->d < v2->d);;
/* v1 <= v2 */TOK_LE:->d =
(v1->d <= v2->d);;
/* v1 && v2
*/TOK_AND:(v1->d == 0.0 || v2->d == 0.0)
{
/* Set v1 to zero (FALSE) */->d =
0.0;
};
/* v1 || v2 */TOK_OR:(v1->d ==
0.0)
{
/* Copy v2 to v1 */->d =
v2->d;
};
}
}do_math(int oper, ParserVal *v1,
ParserVal *v2)
{(oper == '+')
{(is_string(v1) || is_string(v2))
{_add_strings(v1, v2);
}
{->d = v1->d + v2->d;
};
}((is_string(v1) || is_string(v2)))
{->error = parser_format_string("Строка
не может принять математический оператор '%c'.", oper);
return;
}_convert_to_numeric(v1);_convert_to_numeric(v2);(oper)
{'-':->d = v1->d -
v2->d;;'*':->d = v1->d * v2->d;;'/':(v2->d != 0.0)->d =
v1->d / v2->d;
{->error =
parser_format_string("Деление
на
ноль.");
};
}
}do_power(ParserVal *v1, ParserVal
*v2)
{_convert_to_numeric(v1);_convert_to_numeric(v2);(is_numeric(v1)
&& is_numeric(v2))
{d = v1->d;i;(i=1;
i<(long)v2->d; i++) v1->d *= d;
}
{->error = parser_format_string("Строка
не может принять экспоненциальный оператор '^'.");
}
}do_unary(int oper, ParserVal *v)
{_convert_to_numeric(v);(!is_numeric(v))
{>error =
parser_format_string("Строка
не
может
принять
унарный
'%c' оператор.",
oper);;
}>d = -v->d;
}is_numeric(ParserVal *v)
{v->type == TOK_NUMERIC;
}is_string(ParserVal *v)
{v->type == TOK_STRING;
}parser_convert_to_numeric(ParserVal
*v)
{(v->type == TOK_NUMERIC) return;
/* ATM we do not convert string to
numeric value */
}parser_convert_to_string(ParserVal
*v)
{
/* Преобразование числового значения в строку */
if (v->type == TOK_STRING)
return;
/* Value as string picture */*p =
parser_value_show_as_string(v);>s = (char*) calloc(MAX_NUMERIC_LEN,
sizeof(char));_t len = min(parser_strlen(p), MAX_NUMERIC_LEN-1);(len)(v->s,
p, len);
*(v->s + len) = '\0';>type =
TOK_STRING;
}*parser_value_show_as_string(ParserVal
*v)
{
/* Static char buffer, return
pointer to it */char buf[MAX_TOKEN_LEN];
/* Это
строка?
*/(v->type == TOK_STRING)
{_t len =
min(parser_strlen(v->s), MAX_TOKEN_LEN);(buf, v->s, len);
*(buf + len) = '\0';buf;
}
/* Это
числовое
*/ceil_diff = ceil(v->d) - v->d;floor_diff = v->d -
floor(v->d);diff, res;(ceil_diff < floor_diff)
{= ceil_diff;= ceil(v->d);
}
{= floor_diff;= floor(v->d);
}(diff < 0.0009)(buf,
"%ld", (long)res); /* Отобразить
как
целое
*/
else(buf, "%.3f", v->d); /*
Отобразить как действительное десятичное число */
return buf;
}parser_value_as_numeric(ParserVal
*v)
{(v->type ==
TOK_NUMERIC)v->d;0.0;
}*parser_value_as_string(ParserVal
*v)
{
/* Do not free the value.points to a
static char buffer.
*/parser_value_show_as_string(v);
}parser_value_as_boolean(ParserVal
*v)
{(v->type ==
TOK_NUMERIC)(int)v->d != 0;(str_icmp(v->s, "Истина"))TRUE;(str_icmp(v->s,
"1"))TRUE;(str_icmp(v->s, "Лож"))FALSE;(str_icmp(v->s,
"0"))FALSE;FALSE;
}parser_add_strings(ParserVal *v1,
ParserVal *v2)
{_convert_to_string(v1);_convert_to_string(v2);
size_t len1 =
min(parser_strlen(v1->s), MAX_TOKEN_LEN);_t len2 =
min(parser_strlen(v2->s), MAX_TOKEN_LEN);
*(p + len1 + len2) =
'\0';(v1->s);->s = p;
}
/* ************************** */
/* Numeric and string values */
/* **************************
*/parser_value_set_to_numeric(ParserVal *v, double d)
{_value_free(v);_value_init_to_numeric(v,
d);
}parser_value_set_to_string(ParserVal
*v, char *s)
{_value_free(v);_value_init_to_string(v,
s);
}parser_value_init_to_numeric(ParserVal
*v, double d)
{>d = d;>type =
TOK_NUMERIC;>error = NULL;
}parser_value_init_to_string(ParserVal
*v, char *s)
{_t len = min(parser_strlen(s),
MAX_TOKEN_LEN);>s = (char*)calloc(len + 1, sizeof(char));(len)(v->s, s,
len);
*(v->s + len) = '\0';>type =
TOK_STRING;>error = NULL;
}parser_value_free(ParserVal *v)
{_value_delete(v);
}parser_value_copy(ParserVal
*from_v, ParserVal *to_v)
{
*to_v = *from_v;(from_v->type !=
TOK_STRING) return;_t len = min(parser_strlen(from_v->s),
MAX_TOKEN_LEN);_v->s =(char*) calloc(len + 1, sizeof(char));(len)(to_v->s,
from_v->s, len);
*(to_v->s+len) = '\0';
}parser_value_delete(ParserVal *v)
{(v->type == TOK_STRING)
{
/* Free string value */(v->s)
free(v->s);>s = NULL;
}
/* Free error */(v->error)
free(v->error);>error = NULL;
/*it keep the type.
*/
}do_sqrt(ParserVal *v, int
arg_count)
{
/* Return sqrt(v[0]) in v[0] */[0].d
= sqrt(v[0].d);
}do_abs(ParserVal *v, int arg_count)
{
/* Return abs(v[0]) in v[0]. */[0].d
= fabs(v[0].d);
}do_exp(ParserVal *v, int arg_count)
{
/* Return exp(v[0]) in v[0]. */[0].d
= exp(v[0].d);
}do_ln(ParserVal *v, int arg_count)
{
/* Return log(v[0]) in v[0]. */[0].d
= log(v[0].d);
}do_pow(ParserVal *v, int arg_count)
{
/* Return pow(v[0], v[1]) in v[0].
*/[0].d = pow(v[0].d, v[1].d);
}do_integer(ParserVal *v, int
arg_count)
{
/* Return integer (whole part of)
v[0] in v[0]. */(v[0].d, &v[0].d/*int part*/);
}do_fraction(ParserVal *v, int
arg_count)
{
/* Return fraction (decimal part of)
v[0] in v[0]. */int_part;[0].d/*fraction*/ = modf(v[0].d, &int_part);
}do_round(ParserVal *v, int
arg_count)
{
/* Round v[0] to nearest n decimal.
n = {0...10}.[1] contains n. Returns the rounded value in v[0].
*/
/* TODO: Find a better way to do
this ! */char buf[MAX_NUMERIC_LEN];char format[MAX_NUMERIC_LEN];
sprintf(format, "%%.%df",
(int)v[1].d);(buf, format, v[0].d);
v[0].d = atof(buf);
}*lookup_builtin_function(char
*name)
{i;(i=0; i<
sizeof(g_function_table)/sizeof(g_function_table[0]); i++)
{(!strcmp(g_function_table[i].name,
name))&g_function_table[i];
}NULL;
}execute_builtin_function(CodeBuffer
*cb, BuiltinFunction *func)
{v[MAX_FUNC_ARGS];i;(i=0; i<
MAX_FUNC_ARGS; i++)_value_init_to_numeric(&v[i], 0.0);(!func) return
v[0];arg_count = 0;(func->num_args)
{[arg_count] =
parser_bool1(cb);_count++;(arg_count >= func->num_args || arg_count >=
MAX_FUNC_ARGS) break;(func->num_args == (int)'*')
{(currToken.type == ',')
{
/* Removed comma */
; /* ok */
}if (currToken.type == ')')
{;
}
{[0].error =
parser_format_string("Missing ',' or ')' at function%s.",
func->name);v[0];
}
}
{
/* Remove comma between expressions
*/(currToken.type != TOK_COMMA)
{*p =
builtin_function_arg_text(func);[0].error = parser_format_string("Missing
',' at function%s. Function%s takes%s arguments.", func->name,
func->name, p);(p);v[0];
}
}
/* Next token */_get_token(cb,
&currToken);
}(arg_count == 0)
{*p =
builtin_function_arg_text(func);[0].error = parser_format_string("Не
заданы
аргументы.
Функция%s
имеет%s
аргумент(ы).",
func->name, p);(p);v[0];
}>func(v, arg_count);v[0];
}*builtin_function_arg_text(BuiltinFunction
*func)
{*p;(func->num_args == '*')=
parser_format_string("До%d",
MAX_FUNC_ARGS);= parser_format_string("%d", func->num_args);
/* You should free() the value after
usage */p;
}*parser_copy_string(char *s)
{_t len = min(parser_strlen(s),
MAX_TOKEN_LEN);*tmp = (char*)calloc(len+1, sizeof(char));(len)(tmp, s, len);
*(tmp+len) = '\0';tmp;
}*parser_quote_string(char *s)
{_t len = min(parser_strlen(s),
MAX_TOKEN_LEN);*tmp;(len > 0 && (*s == '"' || *s == '\''))
{parser_copy_string(s);
}=(char*) calloc(len + 3/* " +
\0 + " */, sizeof(char));
*tmp = '"';(len)(tmp+1, s,
len);
*(tmp+len+1) = '"';
*(tmp+len+2) = '\0';tmp;
}_t parser_strlen(char *s)
{(!s) return (size_t)0;strlen(s);
}*parser_format_string(const char
*fmt,...)
{*msg = (char*)calloc(MAX_TOKEN_LEN,
sizeof(char));_list args;_start(args, fmt);(msg, fmt, args);_end(args);msg;
}parser_error(CodeBuffer *cb, char
*msg, int opt)
{buffer[1024];(opt &&
cb)(buffer, "Ошибка парсера
в
строке%d:%s\n",
lexer_line_num(cb), msg);(buffer, "Ошибка
парсера%s\n",
msg);->RichEdit1->Lines->Add(buffer);
}
/* Переменные
*/parser_variable_add_value(CodeBuffer *cb, char *name, ParserVal *value)
{(value->type ==
TOK_STRING)_variable_add_string_var(cb, name, value->s, FALSE/*quoted*/);_variable_add_numeric_var(cb,
name, value->d);
}parser_variable_add_numeric_var(CodeBuffer
*cb, char *name, double val)
{(!(cb && name)) return;*var
= parser_variable_create_new(name);_value_init_to_numeric(&var->val,
val);_variable_add_to_list(cb->variable_list, var);
}parser_variable_add_string_var(CodeBuffer
*cb, char *name, char *val, int quoted)
{(!(cb && name)) return;*var
= parser_variable_create_new(name);
/* "Цитировать"
? */(quoted)
{*tmp =
parser_quote_string(val);_value_init_to_string(&var->val, tmp);(tmp);
}_value_init_to_string(&var->val,
val);_variable_add_to_list(cb->variable_list, var);
}parser_variable_add_standard_constants(CodeBuffer
*cb)
{(!cb) return;
}**parser_variable_create_list()
{
/* Создать пустой список переменных */**list;
list = (ParserVariable
**)calloc(MAX_VARIABLE_LIST_LEN, sizeof(ParserVariable));list;
}*parser_variable_create_new(char
*name)
{*var = (ParserVariable *)calloc(1,
sizeof(ParserVariable));>name = parser_format_string("%s", name);
/* Присвоить
0.0 (TOK_NUMERIC) */_value_init_to_numeric(&var->val, 0.0);var;
}parser_variable_add_to_list(ParserVariable
*variables[], ParserVariable *var)
{i;= parser_variable_find(variables,
var->name);
if (i > -1)
{ /* Обновление существующей переменной */
parser_variable_delete(variables[i]);[i]
= var;i;
}
/* Добавление
новой
переменной
*/(i = 0; i< MAX_VARIABLE_LIST_LEN; i++)
{(!variables[i])
{[i] = var;i;
}
}_error(NULL, "Список
переменных
переполнен.\n",
FALSE);-1;
}parser_variable_find(ParserVariable
*variables[], char *name)
{i;(i=0; i<
MAX_VARIABLE_LIST_LEN; i++)
{(!variables[i])
break;(!strcmp(name, variables[i]->name)) return i;
}-1;
}parser_variable_print_all(ParserVariable
*variables[])
{(!variables) return;_t i;(i=0;
i< MAX_VARIABLE_LIST_LEN; i++)
{(!variables[i]) continue;*var =
variables[i];(var->val.type)
{TOK_NUMERIC:("%s=%s
(numeric).\n", var->name, parser_value_show_as_string
(&var->val));;TOK_STRING:("%s=%s (string).\n", var->name,
var->val.s);;:("%s Неизвестный
тип
переменной%d.\n",
var->name, var->val.type);;
}
}
}*parser_variable_get_debug_text(ParserVariable
*variables[])
{
/* Return a long string (text) with
variable names and values.for inspection and debugging.
*/(!variables) return NULL;*text =
parser_format_string("Переменные:\n");_t
i;(i=0; i< MAX_VARIABLE_LIST_LEN; i++)
{(!variables[i]) continue;*var =
variables[i];*tmp;= NULL;(var->val.type)
{TOK_NUMERIC:=
parser_format_string("%s=%s (numeric).\n", var->name,
parser_value_show_as_string(&var->val));;TOK_STRING:=
parser_format_string("%s=%s (string).\n", var->name,
var->val.s);;:= parser_format_string("%s Неизвестный
тип
переменной%d.\n",
var->name, var->val.type);;
}(tmp)
{*tmp2 =
parser_format_string("%s%s", text, tmp);(text);= tmp2;
}(tmp);
}text;
}parser_variable_delete(ParserVariable
*var)
{(!var) return;_value_delete(&var->val);(var->name);>name
= NULL;
}parser_variable_delete_all(ParserVariable
*variables[])
{(!variables) return;_t i;(i=0;
i< MAX_VARIABLE_LIST_LEN; i++)
{_variable_delete(variables[i]);
}(variables);= NULL;
}str_icmp(char *s1, char *s2)
{strcmp(s1, s2);
}
Lexer.cpp
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <ctype.h>
#include "lexer.h"
#include
"parser.h"lexer_lookahead_token(CodeBuffer *cb, char *_token, int
_remove/*Удалить если
нашли?*/,
int _eat_nl/*Искать переводы
строки?
'\n' ?*/)
{tok;ret = FALSE;(1)
{_get_token(cb, &tok);(tok.type
== TOK_EOF) break;= (!strcmp(tok.str, _token));(!ret && (_eat_nl
&& tok.type == '\n')) continue;(!ret)
{_put_token_back(cb, &tok);
}
{(!_remove)_put_token_back(cb,
&tok);
};
}ret;
}lexer_put_token_back(CodeBuffer
*cb, TokenRec *_tokRec)
{(cb->tok_backbuf_count >=
MAX_TOKEN_BACKBUF_LEN-1)
{_error(cb, "Буфер
Tokenа
переполнен.\n");
}>tok_backbuf[cb->tok_backbuf_count]
= *_tokRec;>tok_backbuf_count++;
}lexer_get_token_from_backbuf(CodeBuffer
*cb, TokenRec *_tokRec)
{
/* Содержит
буфер
данные?
*/(cb->tok_backbuf_count > 0)
{>tok_backbuf_count--;
*_tokRec =
cb->tok_backbuf[cb->tok_backbuf_count];
/* Взяли данные из буфера */TRUE;
}
{ /* Обнулить строку \0 */
*_tokRec->str = '\0';
_tokRec->type = TOK_EOF;
}
/* Буфер был пустой */
return FALSE;
}lexer_get_token(CodeBuffer *cb,
TokenRec *_tokRec)
{
/* Читаем следующий Token из буфера */
char ch;ch2 = 0;*cPtr;char
buf[MAX_TOKEN_LEN];
/* Очистить
буфер
tokenов
*/(_tokRec, sizeof(TokenRec), '\0');
*buf = *(buf+1) = *(buf+2) = '\0';
*(_tokRec->str) =
*(_tokRec->str+1) = *(_tokRec->str+2) = '\0';
_tokRec->type = TOK_EOF;
/* Проверка
буфера
tokenов
*/
if (lexer_get_token_from_backbuf(cb,
_tokRec))
{_tokRec->type;
}
/* Выбираем следующий символ, удаляем пробелы,
комментарии */
ch = lexer_get_charEx(cb);
/* Проверяем является ли символ оператором */
switch (ch)
{'=':
_tokRec->type = TOK_ASSIGN;
/* == */(lexer_lookahead(cb, '=',1))
_tokRec->type = TOK_EQ;;'+':
/* += */(lexer_lookahead(cb, '=',1))
_tokRec->type = TOK_ASPLUS;
/* ++ */if (lexer_lookahead(cb,
'+',1))
_tokRec->type = TOK_INCR;
/* + */
_tokRec->type = TOK_PLUS;;'-':
/* -= */(lexer_lookahead(cb, '=',1))
_tokRec->type = TOK_ASMINUS;
/* -- */if (lexer_lookahead(cb,
'-',1))
_tokRec->type = TOK_DECR;
/* - */
_tokRec->type = TOK_MINUS;;'*':
/* *= */(lexer_lookahead(cb, '=',1))
_tokRec->type = TOK_ASMUL;
/* * */
_tokRec->type = TOK_MUL;;'/':
/* /= */(lexer_lookahead(cb, '=',1))
_tokRec->type = TOK_ASDIV;
/* / */
_tokRec->type = TOK_DIV;;'^':
/* ^ */
_tokRec->type = TOK_EXP;;'%':
/*%= (modulus)
*/(lexer_lookahead(cb, '=',1))
_tokRec->type = TOK_ASMOD;
/*% */
_tokRec->type = TOK_MOD;
break;
}
/* Конец проверки. Это оператор? */(_tokRec->type
!= TOK_EOF)
{
*(_tokRec->str) = ch;
*(_tokRec->str+1) = '\0';
goto l_end;
}
/* Конец ввода данных? */(ch
== TOK_EOF)
{
_tokRec->type = ch;
goto l_end;
}
/* Новая строка или новый оператор? */(ch
== ';' || ch == '\n')
{
_tokRec->type = ch;
*(_tokRec->str) = ch;
goto l_end;
}(strchr("(),.{}", ch))
{
/* Знаки)
(;., } { */
_tokRec->type = ch;
*(_tokRec->str) = ch;l_end;
}
// Идентификатор=
tolower(ch);((ch2 >= 'a' && ch2 <= 'z') || strchr("_$",
ch))
{
*buf = ch;= buf +1;=
lexer_get_char(cb);((isalnum(ch) || strchr("_$", ch)) && ch
!= TOK_EOF)
{
*cPtr++ = ch;= lexer_get_char(cb);
}
*cPtr = '\0';
/* Возврат последнего символа в поток данных */
lexer_put_back(cb, ch);
_tokRec->type = TOK_IDENT;len =
min(strlen(buf), MAX_TOKEN_LEN);(_tokRec->str, buf, len);
*(_tokRec->str + len) = '\0';
}
/* Текстовая строка "xxx" или 'xxx' */
else if (ch == '"' || ch ==
'\'')
{chStart = ch;= buf;
ch2 = '\0'; // Поддержка кавычек внутри текста
".....\"...."
while (1)
{= lexer_get_char(cb);(ch ==
TOK_EOF) break;
// Проверка
\" и
\'(ch == chStart && ch2 != '\\')
{;
}
{= *cPtr;
*cPtr++ = ch;
}
}
*cPtr = '\0';len = min(strlen(buf),
MAX_TOKEN_LEN);
strncpy(_tokRec->str, buf, len);
*(_tokRec->str + len) = '\0';
_tokRec->type = TOK_STRING;
}
/* Это целое число или десятичное; 123, 0.51,.67,
-2.67, +89, -4e3, +2e-9*/
else if
(strchr("0123456789+-.", ch))
{hasDecimal = 0;hasExp =
0;hasExpSign = 0;= buf;
*cPtr++ = ch;(ch == '.') {
hasDecimal = 1; }
/* Принимаются следующие варианты записи:
.67, -2.67, +89, -4e3, +2e-9
*/
/* Также принимаются шестнадцатеричные числа в
виде 0x7FCD и 0XA. */is_hex = FALSE;(ch == '0')
{_hex = lexer_lookahead(cb, 'x', 1/*Истина*/);(!is_hex)_hex
= lexer_lookahead(cb, 'X', 1/*Истина*/);
}
/* Добавляем 'x' чтобы запись соответствовала
формату "0x" */
if (is_hex)
*cPtr++ = 'x';int count = 0;/*Сброс
индекса*/(1)
{= lexer_get_char(cb);(ch ==
TOK_EOF) break;(ch == '.' && !hasDecimal)
{
*cPtr++ = ch;= 1;
}if ((ch == 'e' || ch == 'E')
&& !hasExp)
{
*cPtr++ = ch;= 1;
}if (strchr("+-", ch)
&& hasExp && (!hasExpSign))
{
*cPtr++ = ch;= ch;
}if (strchr("0123456789",
ch))
{
*cPtr++ = ch;
}if (is_hex &&
strchr("ABCDEFabcdef", ch))
{
*cPtr++ = ch;
};(count++ > MAX_TOKEN_LEN)
break;
}
/* Возвращаем последний символ обратно в поток
*/
lexer_put_back(cb, ch);
*cPtr = '\0';d = atof(buf);
_tokRec->type = TOK_NUMERIC;
/* Возвращаем число в виде строки */
int len = min(strlen(buf),
MAX_TOKEN_LEN);
strncpy(_tokRec->str, buf, len);
*(_tokRec->str + len) =
'\0';(hasDecimal || hasExpSign == (int)'-')
{
_tokRec->val.d = d;
}
{
/* На самом деле целое */
_tokRec->val.d = (long)d;
}
} /* Конец проверки на число */
{
/* Неизвестный символ. Прекращаем дальнейший
ввод */
_tokRec->type = TOK_EOF;
}_end:
/* Заносим номер строки и возвращаем token
(*_tokRec) и его тип */
_tokRec->line_num = lexer_line_num(cb);_tokRec->type;
}lexer_line_num(CodeBuffer *cb)
{cb->line_num;
}lexer_put_back(CodeBuffer *cb, char
_ch)
{_t len =
strlen(cb->char_backbuf);(len < MAX_CHAR_BACKBUF_LEN - 1)
{
*(cb->char_backbuf + len) = _ch;
*(cb->char_backbuf + len+1) = '\0';
}
}
}lexer_remove_line(CodeBuffer *cb)
{ch = lexer_get_char(cb);(ch !=
TOK_EOF && ch != '\n')
{= lexer_get_char(cb);
}_put_back(cb, ch);
}lexer_get_charEx(CodeBuffer *cb)
{ch;ch2;move;=
lexer_get_char(cb);(ch != TOK_EOF)
{= 0;
/* Удаляем
пробелы
*/(isspace(ch))
{= lexer_get_char(cb);
}
/* Удаляем строки начинающиеся с '#' */
if (ch == '#')
{_remove_line(cb);=
lexer_get_char(cb);
}
/* Конец строки (оператора)? */(ch == '\n' || ch
== ';')
{ch;
}
/* Удаляем
пробелы
*/(isspace(ch))
{= lexer_get_char(cb);
}
/* Удаляем комментарии которые начинаются с '/
*' и заканчиваются */
if (ch == '/')
{= lexer_get_char(cb);
if (ch2 == '/')
{
/* Чтение до конца строки */
ch = lexer_get_char(cb);(ch !=
TOK_EOF && ch != '\n')
{= lexer_get_char(cb);
}= 1;
}if (ch2 == '*')
{count = 1; // Внутренний
счетчик
/* /* /*... */ */ */= lexer_get_char(cb);= 0;(ch != TOK_EOF)
{
// Комментарий закончился символом '*/'(ch ==
'/' && ch2 == '*')
{(--count <= 0)
{= 1;;
}
}
// Пропускаем все что внутри комментария /*
else if (ch == '*' && ch2 ==
'/')
{++;
}if (ch == '\n'|| ch == '\r')
{
;
}
/* Предыдущий
символ
*/= ch;= lexer_get_char(cb);
}(ch == TOK_EOF && count)
{_error(cb, "Многострочный комментарий не
закрыт /*... */ ");
}
}
{_put_back(cb, ch2);
}
}(move)= lexer_get_char(cb);;
}ch;
}lexer_lookahead(CodeBuffer *cb, int
_match_ch, int _remove)
{ret;ch = lexer_get_charEx(cb);(ch
== _match_ch)
{(!_remove) lexer_put_back(cb, ch);=
1;
}
{_put_back(cb, ch);= 0;
}ret;
}lexer_get_char(CodeBuffer *cb)
{ch = TOK_EOF;
/* Проверяем содержимое буфера */
if (cb->char_backbuf[0] != '\0')
{_t len =
strlen(cb->char_backbuf);= *(cb->char_backbuf + len - 1);
*(cb->char_backbuf + len-1) =
'\0';ch;
}(!cb->text)TOK_EOF;if
(*(cb->text + cb->curr_pos) == TOK_EOF)
{TOK_EOF;
}= *(cb->text +
cb->curr_pos);(ch == '\n')>line_num++;>curr_pos++;ch;
}lexer_error(CodeBuffer *cb, char
*_msg)
{(stderr, "Лексическая
ошибка:%s.%s\n",
(cb->name ? cb->name : ""), _msg);
}lexer_match(char *tok1, char *tok2)
{(!(tok1 && tok2)) return
FALSE;
size_t len1 = strlen(tok1);_t len2 =
strlen(tok2);(len2 < len1)
/* Соответствие
шаблона
в
части
tokenа,
например
lexer_match("abcd", "ab") => TRUE */
return !strncmp(tok1, tok2, len2);
else
/* Длинна Tokenа и шаблона должны совпадать */
return !strcmp(tok1, tok2);
}*lexer_codebuffer_new(char *code)
{*cb = (CodeBuffer *)calloc(1,
sizeof(CodeBuffer));
lexer_codebuffer_init(cb);
/* Выделить память для кода */
size_t len = min(strlen(code),
40960);
if (len)
{>text =(char*) calloc(len+1, sizeof(char));(cb->text,
code, len);
}cb;
}lexer_codebuffer_init(CodeBuffer
*cb)
{>text = cb->name =
NULL;>curr_pos = 0;>line_num = 1;(cb->char_backbuf, '\0',
MAX_CHAR_BACKBUF_LEN);
/* Счетчик
Tokenов
*/>tok_backbuf_count = 0;
/* Выделить память под переменные
(MAX_VARIABLE_LIST_LEN) */
cb->variable_list =
parser_variable_create_list();
}lexer_codebuffer_destroy(CodeBuffer
*cb)
{(!cb) return;
/* Очистить буфер кода */
free(cb->text);
free(cb->name);>curr_pos = 0;->line_num
= 1;
/* Удалить все переменные */
parser_variable_delete_all(cb->variable_list);>variable_list
= NULL;(cb->char_backbuf, '\0', MAX_CHAR_BACKBUF_LEN);
/* Обнулить
счетчик
Tokenов
*/>tok_backbuf_count = 0;
}
4. Описание тестового примера
Текст программы:
a=sqrt(36)=abs(-6)=2^2=exp(30)=ln(10)(a)(b)(c)(d)(e)=3.4+2.6(f)=a+b*c-d/e*f(g)
Результат
Результат:6
Результат:6
Результат:4
Результат:1.06865e+13
Результат:2.30259
Результат:6
Результат:-2.78465e+13
Заключение
В данной курсовой работе была выполнена задача
создания простой программы-интерпретатора для обработки исходных текстов
программ, выполняющих действия над комплексными числами.
Библиографический список
1. Серебряков
В.А., Галочкин М.П., Гончар Д.Р., Фуругян М.Г. Теория и реализация языков
программирования. М.: “МЗ-Пресс”, 2003.- 296 с.
2. Атакищев
О.И., Волков А.П., Титов В.С., Старков Ф.А. Формальные грамматики и их
применение в распознавании образов. - Курск, 2000. -115с.
. Бек
Л. Введение в системное программирование. - М.: Мир, 1988. - 448 с.
4. Молчанов
А.Ю. Системное программное обеспечение - СПб.: Питер, 2003 г.