Использование специализированных микропроцессоров
Задание
Тема курсовой работы: «Использование
специализированных микропроцессоров»
Разработать микропроцессорную систему для
реализации определённой математической задачи программным путём.
Параметры:
микропроцессор фирмы Analog Device;
диапазон входных сигналов 100 Гц до 10000 Гц;
точность представления информации 0,01%;
количество входных каналов- 4
количество процессоров ЦОС - 2;
использование внешней памяти - нет;
реализация последовательного канала связи - RS
485;
программа - БПФ 1024.
Состав курсовой работы:
пояснительная записка;
графическая часть: 1) схема электрическая
функциональная устройства;
) текст программы.
Этапы проектирования:
выбор процессора, описание архитектуры и системы
команд ;
разработка структурная схема устройства и выбор
элементной базы;
разработка функциональная схема и алгоритм
функционирования;
разработка программного обеспечения
защита.
Примечание: работа, оформленная с отступлениями
от ЕСКД (ГОСТ 2.105-95), до защиты не допускается.
Содержание
Введение
1
Выбор процессора ЦОС
2
Описание архитектуры процессоров ЦОС семейства ADSP-219x
2.1
Архитектура ядра
2.2
Описание процессора ADSP-2192
2.3
Периферия процессора ЦОС ADSP-2192
2.4
Архитектура памяти
2.5
Особенности системы команд процессора ЦОС ADSP-2192
3
Выбор элементной базы
.1
Выбор АЦП
.2
Кодек AD73322
.3
Реализация последовательного канала связи (RS-485)
.4
Выбор микроконтроллера
4
Разработка структурной схемы устройства
5
Разработка функциональной схемы устройства
6
Описание особенностей схемы
6.1
Несколько слов о шине PCI
7
Разработка и описание программы. Особенности ввода/вывода
Заключение
Список
литературы
Приложение
1. Алгоритм программы быстрого преобразования Фурье
Приложение
2. Функциональная схема устройства
Введение
Рассмотрим преимущества цифровой обработки
сигналов (ЦОС) на сравнении аналоговых и цифровых фильтров. Цифровые фильтры
всё чаще находят своё применение в модемах, радарах, анализаторах спектра,
оборудовании обработки речи и изображений (образов), и этому есть причины: в
сравнении с аналоговыми фильтрами, цифровые схемы обеспечивают более резкие
спады, не требуют калибровки и имеют несоизмеримо лучшую стабильность по
времени, температуре, и нестабильности питания. Простые изменения программного
обеспечения могут изменить характеристику фильтра в реальном времени, создавая
так называемые «адаптивные фильтры», в то время как аналоговые фильтры обычно
требуют аппаратных изменений.
Но цифровые фильтры хороши не в каждом
приложении. Аналоговая техника имеет лучшее соотношение цена/качество в схемах со
спадом до 24 дБ/октава. Если же требования к спаду характеристики превышают 24
- 36 дБ/октава, то цифровые фильтры начинают приобретать актуальность.
Фактически, в приложениях, требующих таких крутых спадов, многие разработчики
находят цифровые фильтры существенно более лёгкими в разработке. Прототипы
могут быть легко изменены заменой программ. И ещё, компьютерная симуляция
цифрового фильтра даёт точное исполнение фильтра, в то время как компьютерная
симуляция аналогового фильтра может только аппроксимировать реальное исполнение
фильтра, потому что аналоговые фильтры чувствительны к значениям компонентов,
которые изначально неточны и могут существенно изменяться.
Микроконтроллеры, микропроцессоры и процессоры
цифровой обработки сигналов.
Традиционные компьютеры особенно хороши для
применения в двух областях деятельности: (1) манипуляция данными, например,
подготовка текстов и управление базами данных; и (2) математические вычисления,
используемые в науке, технике и цифровой обработке сигналов. Однако, большинство
компьютеров не могут одинаково хорошо работать в обеих сферах. В компьютерных
приложениях, таких как, например, подготовка текстов, данные запоминаются,
сортируются, сравниваются, перемещаются и т.д., и время на выполнение этих
операций не имеет большого значения до тех пор, пока оно удовлетворяет
конечного пользователя. В приложениях, работающих с базами данных, периодически
возникает необходимость реализации математических операций, но скорость их
выполнения не является главным фактором. В большинстве случаев при
проектировании приложений общего назначения компании производители не
концентрируют внимания на создании более эффективных программ. Прикладные
программы оказываются перегруженными различными дополнительными возможностями,
для каждого обновления которых требуется все больше памяти и нужны все более
быстрые процессоры.
С другой стороны, для цифровой обработки
сигналов важно, чтобы математические операции выполнялись быстро, и время,
требуемое на выполнение команд, должно быть известно точно и заранее. Для этого
и программа, и аппаратура должны быть очень эффективными. Быстрое выполнение
операции умножения с последующим суммированием очень важно для реализации
быстрого преобразования Фурье, цифровых фильтров реального времени, умножения
матриц, манипуляции с графическими изображениями и т.д.
Проведенное предварительное обсуждение
требований, предъявляемых к цифровым сигнальным процессорам, важно для
понимания различий между микроконтроллерами, микропроцессорами и цифровыми
сигнальными процессорами. Хотя микроконтроллеры при использовании в
промышленных устройствах управления процессами могут выполнять такие функции
как умножение, сложение, деление, они лучше подходят для приложений, где
возможности процессора по реализации ввода-вывода и управления важнее, чем
скорость. Микроконтроллеры, например семейства 8051, обычно содержат ЦП, ПЗУ,
ОЗУ, последовательный и параллельный интерфейсы, счетчики и схемы прерываний.
Микроконвертеры MicroConverter™ компании Analog Devices Inc. содержат не только
ядро, построенное по архитектуре 8051, но также высококачественные ЦАП, АЦП и
блок энергонезависимой памяти, реализованной по технологии FLASH.
Процессоры ЦОС находят применение везде, где
нужны математические вычисления в реальном масштабе времени - это коммуникации,
обработка речи, обработка изображений, обработка звука, медицина, инструменты,
анализаторы спектра, системы управления в индустрии, военная техника, системы
АBS и EPS в автомобилях, и т.д.
В настоящее время на рынок процессоров ЦОС свои
продукты предлагают несколько очень крупных фирм, таких как Lucent, Analog
Devices Inc., Motorola, Texas Instruments. Каждая из компаний выпускает
несколько семейств, среди них процессоры с фиксированной точкой, плавающей
точкой и специальные процессоры для конкретных приложений. Кроме готовых
процессоров некоторые фирмы предлагают ядра ЦОС, среди этих фирм - Analog
Devices Inc., Infineon technologies, DSP Group. Все фирмы продают процессоры
одного класса в одной ценовой категории, и если один процессор дешевле другого,
то он обычно в чём-то уступает, например, в разрядности обрабатываемых данных.
Модельный ряд фирмы Analog Devices Inc., сегодня
представлен 16-ти разрядными процессорами с фиксированной запятой семейств
ADSP-21xx и Blackfin™, 32-х разрядные процессоры с плавающей запятой SHARC®, и
процессоры, способные обрабатывать данные в различных форматах TigerSHARC®.
Кроме отдельных процессоров фирма Analog Devices Inc. Выпускает встроенные
процессоры, объединённые с кодеками.
1. Выбор процессора ЦОС
Согласно заданию нужно реализовать быстрое
преобразование Фурье на 1024 точки, это накладывает определённые требования на
размер памяти. В общих словах, требования, предъявляемые к памяти для
N-точечного преобразования Фурье это N слов для вещественных входных данных, N
слов для мнимых данных, N слов для отсчётов синусоиды, часто называемых
коэффициентами БПФ или поворачивающими множителями и N слов для вещественных
преобразованных данных. Итого для преобразования на 1024 точки требуется память
в 4Кб слов. Кроме того, процессор должен выполнить вычисление за время, меньшее
длительности окна. Согласно теореме Котельникова частота дискретизации должна
быть не меньше удвоенной верхней частоты спектра сигнала. В нашем случае
верхняя частота сигнала составляет 10кГц, следовательно частота дискретизации
не может быть меньше 20кГц, мы выберем частоту дискретизации в 44,1 кГц -
стандартная частота формата CD. Длительность окна можно вычислить следующим
образом:
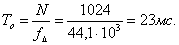
где Tо - длительность окна, - количество точек
преобразования,
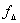 - частота
дискретизации.
- частота
дискретизации.
Требования к процессору таковы:
Размер памяти не меньше 4Кб слов;
Выполнение преобразования Фурье на 1024 точки
менее, чем за 23 миллисекунды.
Сравнение процессоров ЦОС ADSP2192, TMS320C5x,
DSP56000.
В задании определено использование двух
процессоров, поэтому целесообразно использование двух ядерного ЦОС ADSP2192,
имеющему два независимых ПЦОС. Хотя, если проанализировать требования к
процессору, окажется, что ресурсы ADSP2192 излишни, но если учесть, что при его
использовании нет необходимости организовывать интерфейс с устройствами
ввода/вывода, хост процессором (достаточно лишь подключить их по USB или PCI
шине), организовывать протокол арбитража многопроцессорной системы и
организовывать двухпортовую память, то чаша весов склонится в его сторону. В
таблице 1 дан сравнительный анализ однотипных процессоров различных фирм. Из
него видно, что процессор фирмы Analog Devices Inc. отвечает требованиям
технического задания. Кроме того, дополнительные ресурсы не будут лишними при
организации многоканального устройства - к процессору ADSP2192 можно подключить
три кодека (или трёхканальный кодек) AC’97 без дополнительных внешних
устройств. Избыточность ресурсов делает схему более гибкой - изменением
программного кода можно изменить алгоритм работы устройства или режимы его
работы.
Таблица 1
|
Процессор
ЦОС
|
ADSP2192
|
DSP56002
|
TMS320C50
|
TMS320C53
|
|
Два
процессора на кристалле
|
Да
|
Нет
|
Нет
|
Нет
|
|
Внутренняя
память
|
80К
слов на Р0 + 48К слов на Р1
|
1К
слов
|
9,5К
слов
|
3,5К
слов
|
|
Интерфейс
с внешней памятью и I/O устройствами без дополнительных аппаратных затрат
|
I/O-Да,
но отсутствует внешняя память
|
нет
|
нет
|
нет
|
|
Производительность
процессора
|
160MIPS
+ 160 MIPS
|
20MIPS
|
40MIPS
|
40MIPS
|
Прекрасно видно, что из представленных
процессоров только ADSP-2192 отвечает всем требованиям этих алгоритмов
(пространство ПП в каждом ядре составляет 16К слов). Кроме того, чтобы
процессоры работали при максимальных скоростях, им необходима быстрая память.
Внутренняя память как раз является оптимально быстрой. При скоростях процессора
в 25 MIPS и выше, чтобы избежать состояний ожидания (читай - потерь циклов при
каждом доступе к внешней памяти) необходима 15-ти наносекундная память или
более быстрая. Если для обеспечения интерфейса с памятью необходим дешифратор
адреса, то память должна быть ещё более быстрой, а быстрая память - это
довольно дорогое удовольствие. И ещё из перечисленных только ADSP-2192 и
TMS320C5x обладают возможностью ПДП, причём ADSP-2192 использует технологию
“cycle stealing”, позволяющей ядру выполнять любые действия, при доступе к
памяти устройств с ПДП, а процессор TMS320C5x вынужден простаивать, в
аналогичном случае.
В данном случае остановимся на самом мощном и
удобном, среди рассмотренных процессоров - на ПЦОС фирмы Analog Devices Inc.,
ADSP-2192.
2. Описание архитектуры процессоров ЦОС
семейства ADSP-219x
.1 Архитектура ядра
Семейство процессоров ADSP-219x - это
высокопроизводительные процессоры ЦОС для коммуникаций, инструментов,
управления в индустрии, обработке голоса/речи, медицине, военных применений и
т.д. Эти процессоры совместимы с предшествующими процессорами ЦОС семейства
ADSP-2100, но отличаются множеством дополнительных особенностей. Ядро ADSP-219x
совмещено с периферией на кристалле для возможности формирования завершённых
однокристальных систем (систем-на-кристалле). Внешняя для ядра (но
располагающаяся на том же кристалле) периферия содержит статическую оперативную
память (СОЗУ), интегрированную периферию ввода/вывода (I/0), таймер и
контроллер прерываний
Архитектура ADSP-219x совмещает
высокопроизводительное процессорное ядро с высокопроизводительными шинами (ПП,
ПД, ПДП). Ядро исполняет любую вычислительную команду за один цикл. Для
поддержания высокой скорости выполнения операций шины и КЭШ команд обеспечивают
быстрый, беспрепятственный поток данных к ядру.
На рисунке 1 показана детальная блок-диаграмма
процессора, иллюстрирующая следующие особенности архитектуры:
Вычислительные блоки - умножитель, АЛУ,
устройство сдвига и регистровый файл данных.
Программный секвенсер с КЭШем команд, таймер
интервалов и Генераторы Адреса Данных (ГАД1 и ГАД2).
Двухблоковая статическая оперативная память.
Внешние порты для организации интерфейса с
внешней памятью, периферией и хост-процессорами.
Процессор Ввода/Вывода (I/O) со встроенными
контроллерами ПДП, последовательными портами (SPORTы), порты последовательного
интерфейса с периферией (SPI) и порт UART.
Порт Доступа Тестирования JTAG для тестирования
и эмуляции (Порт внутрисхемного отладчика).
На рисунке 1 также показаны три шины ядра
ADSP-219x: шина Памяти Программ (ПП), шина Памяти Данных (ПД) и шина Прямого
Доступа к Памяти (ПДП). Шина ПП обеспечивает доступ и к инструкциям, и к
данным. В течение одного цикла, эти шины предоставляют процессору доступ к двум
операндам (один из ПП, и один из ПД) и одной команде (из КЭШа).
Шины соединяются с внешним портом ADSP-219x,
который обеспечивает интерфейс процессора с внешней памятью, устройствами с
отображением на память (I/O memory-mapped) и загрузочной памятью. Внешние порты
выполняют арбитраж шины и вырабатывают сигналы управления общей памяти,
глобальной памяти и устройствам ввода/вывода.

Далее показаны, современные требования к
процессорам ЦОС и на сколько ADSP-219x отвечает современным требованиям:
Быстрые, гибкие арифметические вычислительные
блоки
Быстрая, гибкая арифметика. Процессоры ЦОС
семейства ADSP-219x выполняют все вычислительные команды за один цикл. Они
обеспечивают как малый период цикла (высокая частота), так и полноценный набор
арифметических операций.
Беспрепятственный поток данных к вычислительным
блокам и от них
Беспрепятственный поток данных. Ядро ADSP-219x
имеет модифицированную Гарвардскую архитектуру, совмещённую с регистровым
файлом данных. В каждом цикле процессор ЦОС может:
Читать два значения из памяти или записать в
память одно значение
Совершить одно вычисление
Записать до трёх значений обратно в регистровый
файл
Увеличенная точность и динамический диапазон в
вычислительных блоках
Точность, увеличенная до 40 разрядов. Процессор
ЦОС оперирует с 16-ти разрядными целым и дробным форматами
(попарно-комплементарные числа со знаком или числа без знака). Процессоры
заносят числа с улучшенной точностью в регистры результата, уменьшая ошибки
промежуточных округлений.
Сдвоенные Генераторы Адреса с возможностью
организации циркулярного буфера
Сдвоенные Генераторы Адреса. В ядре есть два генератора
адреса данных (ГАДы), которые обеспечивают непосредственную или косвенную (с
пре- и пост-изменением) адресацию. Модульные и бит-реверсивные операции
поддерживают только размещение буфера данных в пределах страницы.
Эффективная организация последовательности
программ
Эффективная организация последовательности
программ. В дополнение к организации циклов с нулевым количеством
дополнительных тактов, ядро ЦОС поддерживает быстрые установку и выход для
циклов. Циклы могут быть вложенными (восемь уровней в аппаратном обеспечении),
и могут останавливаться прерываниями. Процессоры поддерживают как задержанные
ответвления, так и ветви без задержки.
Дадим краткое описание структурной схемы
процессора, представленной на рисунке 1.
Вычислительные блоки.
Вычислительные блоки процессора ЦОС -
арифметико-логическое устройство (АЛУ), умножитель/аккумулятор (умножитель) и
устройство сдвига выполняют численную обработку для алгоритмов ЦОС. Эти блоки
получают данные из регистров в регистровом файле данных. Команды для этих
блоков обеспечивают операции над числами в формате с фиксированной запятой.
Каждый из блоков выполняет команду за один цикл.
Вычислительные блоки выполняют различные типы
операций.
Арифметико-логические устройства.
АЛУ осуществляет арифметические и логические
операции над данными в формате с фиксированной точкой. Команды АЛУ с ФТ
оперируют с 16-ти разрядными данными в формате ФТ и выдают 16-ти разрядный
результаты с ФТ. Команды АЛУ включают:
Сложение и вычитание с ФТ
ФТ сложение с переносом, вычитание с займом,
инкремент, декремент
Логические команды И, ИЛИ, Исключающее ИЛИ, НЕ
Функции Abs, Pass, примитивы деления
Умножитель.
Умножитель выполняет ФТ-операции умножение и
умножение с накоплением. Умножение с накоплением возможно в вариантах умножения
с накопительным сложением 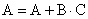 и умножения с
накопительным вычитанием
и умножения с
накопительным вычитанием 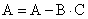 . Команды
умножителя с ФТ оперируют с 16-ти разрядными ФТ операндами и вырабатывает 40-ка
разрядные результаты. Входные данные обработаны как целые и как дробные числа,
как числа без знака или как попарно-комплементарные числа со знаком. Команды
умножителя включают:
. Команды
умножителя с ФТ оперируют с 16-ти разрядными ФТ операндами и вырабатывает 40-ка
разрядные результаты. Входные данные обработаны как целые и как дробные числа,
как числа без знака или как попарно-комплементарные числа со знаком. Команды
умножителя включают:
Умножение
Умножение с накоплением, дополнительно возможно
округление
Округление, насыщение или очистка регистра
результата
Устройство сдвига.
Устройство сдвига обеспечивает функции
поразрядного сдвига 16-ти разрядных входных данных, выдавая 40 разрядные числа
на выход. Эти функции включают:
Арифметический сдвиг (Ashift)
Логический сдвиг (Lshift)
Нормализацию (Norm)
Получение экспоненты (Exp)
Получение общей экспоненты для полного блока
чисел (Expadj)
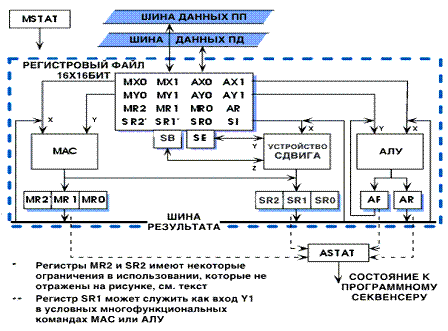

Рисунок 2 - Вычислительный блок
Пути для потока данных через вычислительные
блоки проходят параллельно (рисунок 2). Выход любого вычислительного блока
может служить входом для любого вычислительного блока в следующем цикле.
Пересылка данных в вычислительные блоки и из них производится через регистровый
файл данных. Регистровый файл состоит из 16 первичных и 16 второстепенных
регистров, первичные можно рассматривать как основные, а второстепенные - как
запасные. Регистровый файл соединяется с шинами данных ПП и ПД, обеспечивая
передачу данных между вычислительными блоками и памятью.
На рисунке 2 показано, что безусловные команды
умножителя, АЛУ и устройства сдвига, состоящие из одной операции, имеют
неограниченный
доступ
к регистрам данных в регистровом файле. Шина Результата позволяет
вычислительным блокам использовать любой регистр результата (MR2, MR1, MR0,
SR1, SR0 или AR) как операнд X для любой операции. Верхняя часть регистра
результата устройства сдвига (SR - Shifter Result), SR2, не может служить в
качестве обратной связи через шину результата.
Регистры MR2 и SR2 отличаются от других
регистров результата. При использовании их в качестве регистров в составе
регистрового файла, регистры MR2 и SR2 являются 16-ти разрядными регистрами,
которые могут быть использованы как операнды Х или Y для команд умножителя, АЛУ
или устройства сдвига. При использовании в качестве регистров результата (как
часть MR или SR), только 8 младших разрядов регистров MR2 и SR2 содержат данные
(старшие 8 используются как расширение для знака). Эта разница (16 разрядов как
входной регистр, 8 разрядов - как выходной) влияет на то, как программный код
может использовать регистры MR2 и SR2. Расширение для знака показано на рисунке
3.

С помощью команд пересылки, регистры данных
могут загружать регистры Блока Устройства Сдвига (Shifter Block - SB) и
Экспоненты Устройства Сдвига (Shifter Exponent - SE) (или быть загруженными из
этих регистров), но регистры SB и SE не могут быть использованы как операнды X
и Y вычислительных устройств. Регистры SB и SE служат дополнительными входными
регистрами для устройства сдвига.
Вход регистра Состояния Режима (MSTAT)
устанавливает арифметические режимы для вычислительных блоков, а регистр
Состояния Арифметики записывает состояние/условия для результатов
вычислительных операций.
У вычислительных блоков процессора ЦОС имеется
регистровый файл данных - набор регистров данных, которые пересылают данные
между шинами данных и вычислительными устройствами. Программы ЦОС используют
эти регистры как локальное хранилище операндов и результатов.
Регистровый файл показан на рисунке 2.
Регистровый файл состоит из 16 главных и 16 второстепенных (альтернативных)
регистров. Все регистры данных 16-ти разрядные.
Доступ к данным памяти программ и к данным
памяти данных для чтения их из регистрового файла или записи данных в
регистровый файл происходит по шинам ПП и ПД, соответственно. Один доступ к
шине ПП и/или один доступ к шине ПД может быть осуществлён за один цикл. Между
регистрами в файле и шинами ПП и ПД могут пересылаться данные разрядностью до
16 бит по каждой шине.
Если операция указывает один и тот же регистр и
как входной, и как выходной, то чтение происходит в течение первой половины
цикла, а запись - во второй. При этом процессор использует старые данные как
операнд перед тем, как обновить значение регистра новым значением
(результатом). Если имеет место запись нескольких значений на одну позицию в
один цикл, записывается значение операции с высшим приоритетом. Процессор ЦОС
определяет приоритет на запись по типу операции; приоритеты от высшего к
низшему:
Операции пересылок: регистр-регистр,
регистр-память или память-регистр
Вычислительные операции: АЛУ, умножитель или
устройство сдвига
Программный секвенсер.
Программный секвенсер процессора ЦОС управляет
ходом программы, постоянно обеспечивая адрес следующей команды, которая будет
выполняться другими частями процессора ЦОС. В основном ход программы в процессоре
ЦОС линейный с последовательным выполнением команд процессором. Этот линейный
поток иногда изменяется, когда программа использует непоследовательные
программные структуры. Непоследовательные структуры направляют процессор ЦОС на
выполнение команды, которые находятся не по следующему адресу. Эти структуры
включают:
Циклы. Одна последовательность инструкций
выполняется несколько раз с близким к нулю количеством лишних циклов.
Подпрограммы. Процессор прерывает
последовательный ход, чтобы выполнить команды из другой части памяти программ.
Переходы. Ход программы перемещается в другую
часть памяти программ.
Прерывания. Подпрограммы, в которые события в
которые события переключают выполнение программы.
«Ленивый» режим. Команда, которая заставляет
процессор прекратить операции. Процессор находится в этом состоянии до
появления прерывания. Затем процессор обслуживает прерывание и продолжает
нормальное функционирование.
Секвенсер управляет выполнением этих программных
структур, путём выборки следующей команды. Как часть этих процессов секвенсер
выполняет следующие задания:
Инкрементирует адрес выборки
Обслуживает стеки
Оценивает условия
Декрементирует счётчик цикла
Вычисляет новый адрес
Обслуживает КЭШ команд
Управляет прерываниями
КЭШ команд.
Обычно секвенсер осуществляет выборку команды из
памяти в каждом цикле. Иногда, ограничения шины не позволяют некоторым данным и
командам быть выбранными в один цикл. Для уменьшения этих ограничений,
процессор ЦОС имеет КЭШ команд.
Когда процессор ЦОС выполняет команду, которая
требует доступа к данным по шине данных ПП, возникает конфликт, потому что
секвенсер использует шину данных ПП для выборки команд.
Когда пересылка данных по шине ПД нуждается в
доступе к тому же блоку памяти, из которого процессор ЦОС осуществляет выборку
команд, возникает конфликт блока, потому что только одна шина может получить
доступ к блоку в один момент времени.
Для избежания конфликтов шин и блоков процессор
ЦОС помещает эти команды в КЭШ, уменьшая тем самым задержки. Работа КЭШа не
требует вмешательств, за исключением случаев включения и отключения КЭШа.
В первый раз, когда процессор ЦОС встречается с
конфликтом выборки, процессор должен ждать, чтобы выбрать команду в следующем
цикле, что вызывает задержку. Процессор ЦОС автоматически записывает выбранную
команду в КЭШ, чтобы предотвратить такую задержку в будущем.
Секвенсер проверяет КЭШ команд при каждом
доступе к данным в ПП или конфликте блока. Если необходимая команда в КЭШе,
выборка из КЭШа производится параллельно с доступом к данным в памяти программ,
не вызывая никакой задержки.
Генераторы адреса данных.
Генераторы адреса данных (ГАДы) генерируют
адреса для пересылок данных в и из ПД и ПП. Генерируя адреса, ГАДы позволяют
программам обращаться к адресам косвенно, используя регистры ГАДа вместо
абсолютного адреса. Архитектура ГАДов поддерживает некоторые функции, которые
минимизируют количество дополнительных тактов в программах доступа к данным.
Эти функции:
Выдача адреса и пост-модификацию - обеспечивает
адрес в течение пересылки данных и автоматически изменяет хранившийся адрес для
следующей пересылки.
Выдача предизменённого адреса - обеспечивает
изменённый адрес в течение пересылки данных без изменения хранившегося адреса.
Изменение адреса - изменяет адрес без пересылки
данных.
Бит-реверсия адреса - обеспечивает
бит-реверсивный адрес в течение пересылки данных без реверсии хранившегося
адреса.
В ГАДах есть пять типов регистров. Эти регистры
хранят значения, которые ГАД использует для генерирования адресов. Ниже описаны
эти типы регистров:
Индексные регистры (I0-I3 для ГАД1 и I4-I7 для
ГАД2). Индексный регистр содержит адрес и действует как указатель на ячейку
памяти. Например, ГАД интерпретирует синтаксис DM(I0) и PM(I4) в команде как
адреса.
Регистры изменения (M0-M3 для ГАД1 и M4-M7 для
ГАД2). Регистр изменения обеспечивает инкремент или размер шага на который
пред- или пост-изменяется в течение пересылки. Например, команда dm(I0+=M1)
заставляет ГАД выдать адрес из регистра I0, затем изменить содержимое I0,
используя регистр M1.
Регистры длины и базовые регистры (L0-L3 и B0-B3
для ГАД1 и L4-L7 и B4-B7 для ГАД2). Регистры длины и базовые регистры
устанавливают диапазон адресов и начальный адрес для циклического буфера.
Регистры Страницы Памяти ГАДа (DMPG1 для ГАД1 и
DMPG2 для ГАД2). Регистры страниц устанавливают старшие 8 разрядов адреса для
доступа к памяти; 16-ти разрядные индексные и базовые регистры содержат младшие
16 разрядов.
Память.
Большинство микропроцессоров использует одну
шину адреса и данных для доступа к памяти. Этот тип архитектуры памяти
называется Фон Неймановской (Von Neumann) архитектурой. Но ЦОС требует большей
пропускной способности, чем может позволить Фон Неймановская архитектура,
поэтому множество процессоров ЦОС использует архитектуры памяти, в которых
имеются раздельные шины для хранения данных и программ. Две шины позволяют
процессору ЦОС получать слова данных и команд одновременно. Этот тип
архитектуры памяти назван Гарвардской (Harvard) архитектурой.
Семейство процессоров ADSP-219x делает шаг
вперёд, используя модифицированную Гарвардскую архитектуру. Эта архитектура
имеет шины программ и данных, но обеспечивает одно, унифицированное адресное
пространство для хранения программ и данных. Шина ПД несёт только данные, а
шина ПП может передавать и команды, и данные, позволяя получать двойной доступ
к данным.
Ядро ЦОС и периферия с возможностью ПДП
разделяют доступ к внутренней памяти. Каждый блок памяти может быть доступен
для ядра ЦОС и периферии с возможностью ПДП в каждом цикле, но передача ПДП
задерживается, если доступ к памяти осуществляется одновременно с ядром ЦОС.
Если процессор пытается получить два доступа к
одному блоку памяти в один цикл, может возникнуть конфликт доступа к памяти.
Когда возникает конфликт, возникает дополнительный цикл. Сначала завершается
доступ шины ПД, затем, в следующем (дополнительном) цикле завершается доступ
шины ПП.
В течение двойного доступа к данным за один
цикл, ядро процессора
использует независимые шины ПП и ПД для
одновременного доступа к данным из обоих блоков памяти. Хотя двойные доступы к
данным обеспечивает лучшую пропускную способность, существуют некоторые
ограничения на их использование. Ограничения на двойные доступы к данным за
один цикл:
Две части данных должны выбираться из разных
блоков памяти.
Если ядро пытается получить доступ к двум словам
в одном блоке памяти (по одной шине) в одной команде, нужен дополнительный
цикл.
Выполнение доступа к данным не может
конфликтовать с операцией выборки команды.
Если КЭШ содержит конфликтующую команду, доступ
к данным совершается за один цикл, а секвенсер использует «заКЭШированную»
команду. Если конфликтующая команда не в КЭШе, требуется дополнительный цикл
для совершения доступа к данным и помещения в КЭШ конфликтующей команды.
Эффективное использование памяти основывается на
том, как программа и данные расположены в памяти и зависит от того, как
программа осуществляет доступ к данным.
Процессор Ввода/Вывода (Процессор I/O).
Процессор Ввода/Вывода управляет Прямым Доступом
к Памяти (ПДП) процессора ЦОС через внешний порт, хост порт, последовательный,
SPI и UART порты. Каждая ПДП операция передаёт полный блок данных. Управляя
ПДП, процессор Ввода/Вывода позволяет программе осуществлять пересылку данных,
как фоновую задачу, пока ядро процессора используется для других операций ЦОС.
Архитектура процессора Ввода/Вывода поддерживает некоторые операции ПДП. Эти
операции включают следующие типы передач:
Память ´ Память или
периферия с отображением на память
Память ´ Хост процессор
Память ´ Последовательный
порт Ввода/Вывода
Память ´
Serial Peripheral Interface (SPI) порт
Ввода/Вывода
Память ´ UART порт
Ввода/Вывода
Внешний Порт.
Внешний Порт процессора ЦОС расширяет шины
адреса и данных вне кристалла. Используя эти шины и внешние линии управления,
внешние системы могут осуществлять интерфейс процессора ЦОС с внешней памятью
или с периферией с отображением на память.
Хост Порт.
Интерфейс Хост Порта - это 8-ми или 16-ти
разрядное асинхронное ведомое устройство, соединённое с внешним хост
процессором.
Основной путь использования этого устройства -
обеспечение внешнего хост процессора прямым доступом к пространству памяти,
загрузочному пространству и пространству Ввода/Вывода процессоров ADSP-219Х.
Процессор ADSP-219Х действует как ведомый, поддерживающий и отвечающий на
доступы ведущих устройств, подключённых к хост порту. Ведущим хост процессором
может быть микроконтроллер, FGPA, или другой процессор ЦОС.
Последовательные порты.
Процессор ADSP-2191 имеет три независимых,
синхронных последовательных порта (SPORT0, SPORT1 и SPORT2), которые обеспечивают
интерфейс Ввода/Вывода к широкому спектру периферийных последовательных
устройств (SPORTы обеспечивают только синхронную последовательную передачу
данных; процессор ADSP-2191 обеспечивает асинхронную передачу по протоколу
RS-232 через UART). Каждый SPORT - это дуплексное устройство, способное к
одновременной передаче данных в обоих направлениях. Каждый SPORT имеет одну
группу выводов (данные, тактирование, синхронизация структуры) для передачи и
второй набор выводов для приёма. Функции приёма и передачи программируются
раздельно. SPORTы могут быть запрограммированы на определённую скорость
передачи, синхронизацию структуры и разрядность слова, путём записи в регистры
пространства ввода/вывода.
Все три SPORTа имеют одинаковые возможности и
программируются одинаковым способом. Каждый SPORT имеет собственный набор
регистров управления и буферов данных. SPORT2 разделяет выводы I/O с SPI
интерфейсом (SPI0 и SPI1); SPI интерфейс и последовательный порт SPORT2 не
могут быть включены одновременно.
Порты Serial
Peripheral Interface (SPI).
Процессор ЦОС имеет два независимых SPI порта -
SPI0 и SPI1, которые обеспечивают интерфейс Ввода/Вывода с широким спектром
SPI-совместимых устройств. Каждый SPI порт имеет собственный набор регистов
управления и буферов данных. SPI интерфейс разделяет выводы I/O с портом
SPORT2; SPI интерфейс и последовательный порт SPORT2 не могут быть включены
одновременно.
Порты SPI обеспечивают аппаратный интерфейс с
другими SPI-совместимыми устройствами без дополнительных внешних устройств. SPI
- это 4-х проводной интерфейс, состоящий из двух выводов для данных, вывод
выбора устройства и вывод тактирования. SPI - это дуплексный синхронный
последовательный интерфейс, поддерживающий режимы ведущего и ведомого устройств
и оборудование с несколькими ведущими устройствами..
Периферия UART - это дуплексный Универсальный
Асинхронный Приёмник/ Передатчик (Universal Asynchronous Receiver /
Transmitter), совместимый с индустриальным стандартом 16450. UART конвертирует
данные между последовательным и параллельным форматами. Последовательное
соединение влечёт использование асинхронного протокола, поддерживающего
различную длину слова, стоп-бит и возможность генерации паритета. Этот UART
содержит также управление модемом и аппаратное управление прерываниями, хотя
только TxD и RxD сигналы данных соединены с внешними выводами ADSP-2191.
Прерывания могут генерироваться из 12 уникальных событий.
Таймеры.
В процессоре ADSP-2191 есть три идентичных
32-разрядных таймера, каждый из которых может быть настроен независимо от
других на работу в одном из следующих режимов:
Режим ШИМ (PWMOUT)
Режим Счёта и Захвата (WDTH_CAP)
Режим ожидания внешних событий - Watchdog
(EXT_CLK)
У каждого таймера есть внешний вывод TMRx. Этот
вывод служит выходом в режиме PWMOUT, и входом в режимах WDTH_CAP и EXT_CLK.
Для обеспечения этих функций в каждом таймере имеется по семь 16-ти разрядных
регистров. Для улучшения диапазона и точности шесть из этих регистров могут
быть попарно объединены для получения 32-х разрядных значений.
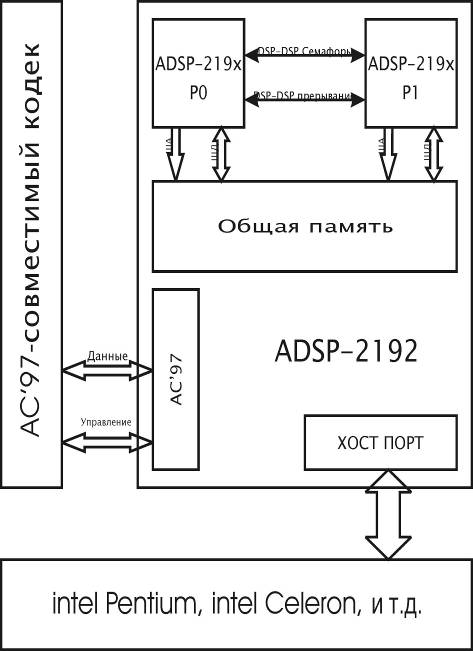
2.2 Описание процессора ADSP-2192
- однокристальный микрокомпьютер
оптимизированный для ЦОС и для других приложений высокоскоростной обработки
чисел, и он идеально вписывается в периферию персональных компьютеров.
совмещает на кристалле базовую архитектуру семейства ADSP-219x с двумя
процессорными ядрами ADSP-2192 (рисунок 4).включает в себя PCI-совместимый
порт, USB-совместимый порт, AC’97-совместимый порт, контроллер ПДП,
программируемый таймер, выводы программируемых флагов общего назначения,
расширенные возможности прерываний и интегрированные пространства памяти данных
и памяти программ.
В ADSP-2192m интегрировано 132К слов памяти,
настроенной, как 32К 24-разрядных слов оперативной памяти программ и 100К 16
разрядных слов оперативной памяти данных (ADSP-2192m - самый маломощный из
процессоров ADSP-2192); также включена схемотехника понижения потребляемой
мощности
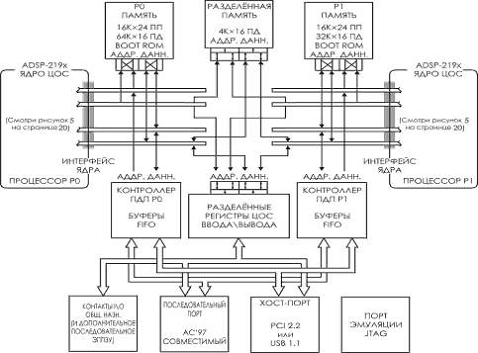
Рисунок 4 - Функциональная блок-диаграмма
процессора ADSP-2192
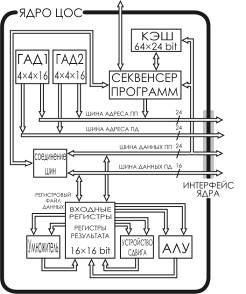

Рисунок 5 - Ядро ЦОС ADSP-219x.
Гибкая архитектура и разноплановая система
команд ADSP-2192 поддерживает параллельное выполнение нескольких операций.
Например, за один цикл, каждое из ядер ЦОС ADSP-2192 может, помимо стандартных
действий ядра ADSP-219х выполнять дополнительные операции.
Эти операции имеют место, пока процессор
продолжает:
Получать и/или передавать данные через Хост-порт
(PCI или USB интерфейсы)
Получать и/или передавать данные через AC’97
Функциональная блок-диаграмма на рисунке 4
иллюстрирует архитектуру ADSP-2192 процессора с двумя ядрами ЦОС, в то время
как блок-диаграмма на рисунке 5 показывает ядро ЦОС семейства ADSP-219x.
.3 Периферия процессора ЦОС ADSP-2192
Функциональная блок-диаграмма на рисунке 4
иллюстрирует внедрённую в кристалл периферию процессора ЦОС, которая включает
Хост-порт, порт AC’97, порт тестирования и эмуляции JTAG, флаги и контроллер
прерываний.
Процессор ADSP-2192 может отвечать на
прерывания, количество которых может достигать 13, в любой момент времени.
Порт кодека AC’97 на ADSP-2192 обеспечивает
полноценный синхронный, дуплексный интерфейс. Этот интерфейс поддерживает
стандарт AC’97.предоставляет до 9 контактов ввода/вывода общего назначения,
которые могут быть запрограммированы и как входы, и как выходы.
Программируемый таймер интервалов генерирует
периодические прерывания. 16-ти разрядный счётный регистр (TCOUNT) разрядного
декрементируется каждые n циклов, где n-1 - это значение масштаба, хранящееся в
16-ти разрядном регистре (TSCALE). Когда значение регистра счёта достигает
нуля, генерируется прерывание, и счётный регистр перезагружается из 16-ти
регистра периода (TPERIOD).
.4 Архитектура памяти
Процессор ADSP-2192m предоставляет 132К слов
внутреннего статического ОЗУ. Эта память разделена на блоки Памяти Программ
(ПП) и Памяти Данных (ПД) в карте памяти каждого процессора ЦОС. В дополнение к
внутреннему пространству памяти, два ядра могут адресовать к двум
дополнительным отдельным адресным пространствам: пространству Ввода/Вывода и
пространству разделённой (общей) памяти,(рисунок 6).
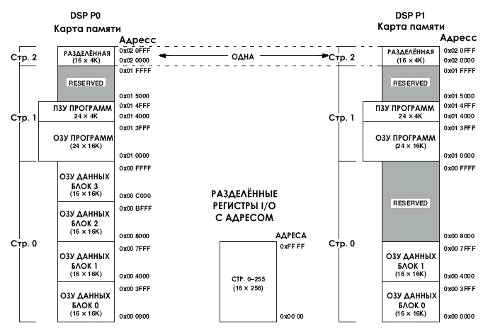

Два ядра процессора ЦОС ADSP-2192m могут
получить доступ к 80К и 48К ячейкам памяти, которые доступны через 24-х разрядные
шины - шины адреса ПП и ПД. У процессора ЦОС есть три функции, поддерживающие
доступ к полной карте памяти.
ГАДы генерируют 24 разрядные адреса для выборки
данных из полного диапазона адресов памяти процессора ЦОС. Ввиду того, что
индексные (адресные) регистры ГАДов 16 разрядные, и содержат только младшие
16-ти разрядов адресов, в каждом ГАДе есть собственный 8-ми разрядный
страничный регистр (DMPGx) для хранения 8-ми старших разрядов адреса. Перед
тем, как ГАД сгенерирует адрес, программа должна установить DMPGx ГАДа
соответственно странице памяти.
Программный Секвенсер генерирует адреса для
выборок команд. Для команд с относительной адресацией, программный секвенсер
базирует адреса для относительных переходов, вызовов и циклов на 24 разрядном
Счётчике Программ (СП). При прямой адресации (двухсловные команды) команда сама
обеспечивает непосредственно 24 разрядное значение адреса. Программный счётчик
допускает линейную адресацию в полном 24 разрядном диапазоне адресов.
Для косвенных переходов и вызовов, которые
используют 16-ти разрядный адресный регистр ГАДа как часть адреса, СП
полагается на регистр страницы косвенных переходов (IJPG), чтобы подгрузить 8
старших разрядов адреса. Перед выполнением межстраничного перехода или вызова
программа должна установить регистр IJPG программного секвенсера соответственно
странице памяти.
У каждого ядра ЦОС ADSP-219x есть собственная
внутренняя ПЗУ, которая содержит загрузочные подпрограммы (booting routines).
.5 Особенности системы команд процессора ЦОС
ADSP-2192
Особенностью является алгебраический синтаксис
языка ассемблера ADSP-219x, который был разработан для облегчения задачи
программирования и улучшения читабельности. Язык ассемблера, который использует
все преимущества уникальной архитектуры процессора, предлагая следующие выгоды:
синтаксис языка ассемблера ADSP-219x, это
надстройка языка ADSP-218x, и является с ним кодосовместимым (за исключением
двух регистров данных и основных регистров адресов ГАДа). Но возможно придётся
реструктурировать существующие программы для ADSP-218x, чтобы разделить
унифицированное пространство памяти ADSP-2192 и для соответствия его карте
векторов прерываний;
алгебраический синтаксис устраняет необходимость
запоминать шифрованные мнемокоды ассемблера. Например, типичная арифметическая
команда сложения, вроде AR=AX0+AY0, напоминает обыкновенное уравнение;
любая команда, за исключением двух,
ассемблируется в единственное 24 разрядное слово, которое может быть исполнено
за один цикл. Исключениями являются две двухсловные команды, одна из которых
записывает 16 или 24 бита непосредственных данных в память, а другая выполняет
переходы/вызовы на другие страницы памяти;
многофункциональные команды позволяют
параллельное выполнение арифметических,, команд сдвига с одной или двумя
выборками, или одной записью в область памяти процессора за один цикл;
поддержка более широкого набора условных и
безусловных переходов и вызовов, и больший набор условий, на котором базируется
выполнение условных команд.
3. Выбор элементной базы
.1 Выбор АЦП
Для выбора АЦП в ТЗ заданы ключевые параметры:
Разрешающая способность 0,01%, количество
каналов 4, диапазон входных сигналов от 100 Гц до 10000 Гц.
Соответственно, необходимо выбрать АЦП,
способный оцифровать сигнал.
Разрешающая способность (resoiution) - это
величина, максимальному числу кодовых комбинаций на входе АЦП. Разрешающая
способность выражается в процентах, разрядах или децибелах и характеризует
потенциальные возможности АЦП с точки зрения достижимой точности. Например,
12-разрядный АЦП имеет разрешающую способность 1/4096, или 0,0245% от полной
шкалы, или -72,2 дБ. В таблице 3 приведен ряд числовых соотношений между
количеством разрядов, разрешающей способностью и т.п.
Таблица 2
|
Разряды
(n)
|
|
Разрешение
|
дБ
|
%
|
|
2
|
2-2
|
¼
|
12
|
25
|
|
4
|
2-4
|
1/16
|
24,1
|
6,2
|
|
6
|
2-6
|
1/64
|
36,1
|
1,6
|
|
8
|
2-8
|
1/256
|
48,2
|
0,4
|
|
10
|
2-10
|
1/1024
|
60,2
|
0,1
|
|
12
|
2-12
|
1/4096
|
72,2
|
0,025
|
|
13
|
2-13
|
1/8192
|
78,2
|
0,006
|
|
14
|
2-14
|
1/16384
|
84,2
|
0,0016
|
|
15
|
2-15
|
1/32768
|
90,2
|
0,0004
|
|
16
|
2-16
|
1/65636
|
96,2
|
0,00001
|
Исходя из данных таблицы, для обеспечения точности
представления информации (разрешающей способности) 0,01% разрядность АЦП должна
составлять 13 разрядов.
.2 Кодек AD73322
Функциональная схема микросхемы AD73322 показана
на рисунке 7. Данный прибор представляет собой однокристальную микросхему с двумя
16-разрядными АЦП и двумя 16-разрядными ЦАП с возможностью работы с частотой
дискретизации 64 кГц. ИС AD73322 разработана для универсального применения,
включая обработку речи, телефонию с использованием сигма-дельта АЦП и
сигма-дельта ЦАП. Каждый канал обеспечивает отношение сигнал/шум на уровне 77
дБ.
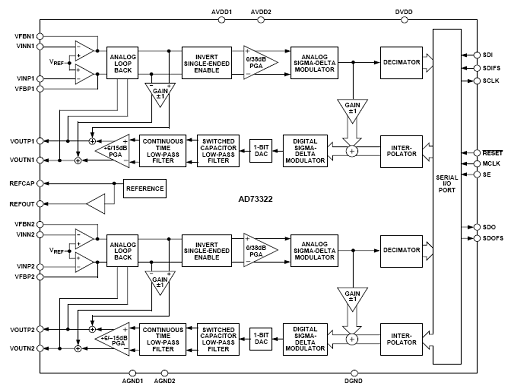
Рисунок 7 - Функциональная схема микросхемы
AD73322
Каналы АЦП и ЦАП имеют программируемые
коэффициенты усиления по входу и выходу с диапазонами до 38 дБ и 21 дБ соответственно.
Встроенный источник опорного напряжения допускает использование однополярного
питающего напряжения величиной +2.7-5.5 В. Его потребляемая мощность при
напряжении питания +3 В составляет 73 мВт.
Частота дискретизации кодека может быть
запрограммирована на одно из четырех фиксированных значений: 64 кГц, 32 кГц, 16
кГц и 8 кГц при частоте опорного задающего генератора 16.384 МГц.
Последовательный порт позволяет
легко
организовать интерфейс одного или нескольких кодеков, включенных каскадно, со
стандартными DSP-процессорами, имеющимися на рынке, например процессорами
семейства ADSP-21XX. Максимальное входное напряжение 3.156 в.
Таблица 3. Назначение контактов AD73322
|
VINP1
|
Аналоговый
позитивный вход «1»
|
|
VFBP1
|
Выход
обратной связи позитивного входа «1»
|
|
VINN1
|
Аналоговый
негативный вход «1»
|
|
VFBN1
|
Выход
обратной связи негативного входа «1»
|
|
AVDD2
|
Питание
аналоговой части «2»
|
|
AGND2
|
Земля
аналоговой части «2»
|
|
DGND
|
Цифровая
земля
|
Питание
цифровой части
|
|
SCLK
|
Сигнал
тактовой синхронизации
|
|
MCLK
|
Вход
мастер сигнала синхронизации
|
|
SDO
|
Выход
данных последовательного порта
|
|
SDOFS
|
Выход
сигнала кадровой синхронизации
|
|
SDIFS
|
Вход
кадровой синхронизации
|
|
SDI
|
Вход
данных последовательного порта
|
|
VOUTP2
|
Позитивный
аналоговый выход «2»
|
|
VOUTN2
|
негативный
аналоговый выход «2»
|

Рисунок 8 - Биты управляющего слова AD73322
Таблица 4. Описание битов управляющего слова
AD73322
|
15
|
Control/Data
|
Выбор
режима управления или работы с данными
|
|
14
|
Read/Write
|
Выбор
чтения или записи
|
|
13-11
|
Device
Address
|
Адрес
устройства
|
|
10-8
|
Register
Address
|
Адрес
управляющего регистра
|
|
7-0
|
Register
Data
|
Данные
регистра
|
Для нормальной работы кодека необходимо
установить следующие значения регистров управления:
В управляющем регистре В необходимо в 4,5,6
битах поставить 0.
В управляющем регистре В необходимо в 0,1,2,3
битах установить 1.
В управляющем регистре F необходимо в 5 бите
поставить 0.
В управляющем регистре С необходимо в 0-5,7 бите
поставить 1.
В управляющем регистре А необходимо будет выставлять
1 если идёт обмен данными.
При такой настройке будет включено питание всех
аналоговых и цифровых частей, установлена частота дискретизации сигнала 44,1
кГц, питание осуществляется от 3 В.
.3 Реализация последовательного канала связи
(RS-485)
Протокол связи RS-485 является наиболее широко
используемым промышленным стандартом, использующим двунаправленную
сбалансированную линию передачи. Протокол поддерживает многоточечные
соединения, обеспечивая создание сетей с количеством узлов до 32 и передачу на
расстояние до 1200 м. Использование повторителей RS-485 позволяет увеличить
расстояние передачи еще на 1200 м или добавить еще 32 узла. Стандарт RS-485
поддерживает полудуплексную связь. Для передачи и приема данных достаточно
одной скрученной пары проводников.
Для реализации последовательного канала связи
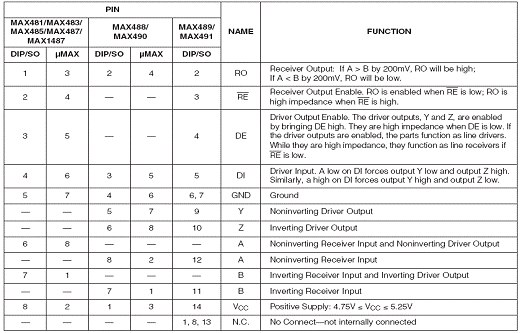
RS-485 мной использована микросхема MAX485, производства фирмы Maxim.
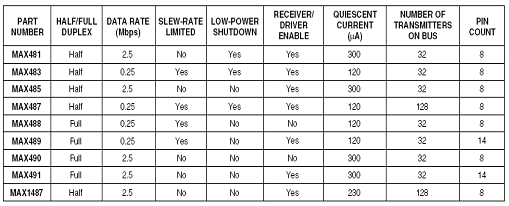
, MAX4S3, MAX4S5. МАХ487, МАХ481, и MAX1487 -
приемопередатчики с низким энергопотреблением для RS-485 и RS-422 связи. Каждая
часть содержит один драйвер и один получатель. MAX483, MAX487, MAX488, и МАХ48Э
показывают уменьшенные драйверы скорости просмотра файла изображения, которые
свертывают электромагнитные шумы и уменьшают отражения.
Эти приемопередатчики тянут {рисуют} между 120uA
и 500uA потока поставки когда разгружено или полностью загруженный
заблокированными драйверами. Дополнительно, MAX481, MAX483, и MAX487 имеют
низко-текущий режим завершения, в котором они потребляют только 0.1 uA. Все
части работают от единственного {отдельного} 5V источника.
Драйверы - ограниченный поток короткой схемы и
защищены против чрезмерного разложения мощности тепловой схемой завершения,
которая размещает выводы драйвера в состояние высокого импеданса. Ввод получателя
имеет отказобезопасность, которая гарантирует логически-высокий вывод, если
ввод - открытая схема.
МАХ485, MAX487, и MAX1487 разработаны для
полудуплексных приложений.
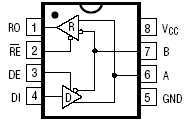
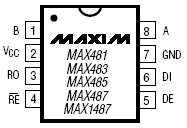
Рисунок 9 - Внешний вид и обозначение выводов
SN65ALS176
Таблица 6
3.4 Выбор микроконтроллера
Выбор микроконтроллеров в настоящее время очень
широк, лидирующее место по продаже микроконтроллеров занимает компания
Freescale, но в сегменте микроконтроллеров со встроенной Flash-памятью,
наиболее подходящих для новых разработок и переконфигурируемых устройств
лидирующую позицию занимает компания Atmel. Поэтому выбираем, в качестве
управляющего микроконтроллера типичный микроконтроллер типа 8051,производства
компании Atmel.
4. Разработка структурной схемы устройства

Кристалл ADSP-2192 содержит два ядра ЦОС и
внутреннюю память, доступ к которой в любой момент времени может получить любое
ядро. Часть адресного пространства доступна для обеих ядер. В случае попытки
одновременного доступа к памяти приоритет установлен следующим образом: P0, P1.
Таким образом, аппаратные устройства для согласования двух ядер разрабатывать
не нужно. Входные данные процессор будет получать через последовательный порт
от аналогово-цифрового преобразователя. АЦП должен быть многоканальным, чтобы
обеспечить выборку из восьми входных каналов и иметь достаточное количество разрядов
для обеспечения необходимой точности преобразования. Хост-порт процессора
поддерживает режим внешнего управления, поэтому необходимо предусмотреть шину
для подключения центрального процессора. Использовать внешнюю память не
требуется согласно технического задания, к тому же, объёма внутренней вполне
достаточно для решения поставленной задачи.
Выведение результатов обработки должно
происходить в стандарте RS-485, который представляет собой четырехпроводный
полный дуплексный канал связи. Нагрузкой данного порта является линия в виде
витой пары.
Полученная структурная схема представлена на
рисунок 10. Как показано на структурной схеме, ядра процессора соединяются друг
с другом с помощью специальных флагов, называемых семафорами (DSP-DSP
Semaphore0 и DSP-DSP Semaphore1). Обращение к считыванию входной информации
происходит поочередно двумя процессорами, поэтому чтобы не возникал конфликт
при обращении к одному блоку памяти одновремменно двух процессоров, мы и будем
использовать семафоры. Вывод результата вычисления также должен происходить
поочередно каждым из процессоров.
Фирма Analog Devices Inc. традиционно снабжает
свои процессоры портами, обеспечивающими соединение с периферийными
устройствами без дополнительных внешних устройств (дешифраторов адреса и т.д.),
так называемый glueless-интерфейс.
Питание процессора осуществляется от источника
постоянного напряжения. Дополнительную стабилизацию необходимо ввести для
питания АЦП, чтобы обеспечить заданную точность преобразования.
5. Разработка функциональной схемы устройства
Принципиальная схема будет немногим отличаться
от функциональной. Основные отличия будут в цепях питания: возле каждого вывода
питания, как можно ближе к микросхеме нужно установить пару конденсаторов -
один большой ёмкости и один - малой. Нужно обеспечить две «земли» - аналоговую
и цифровую.
Кроме того, нужно развязать на землю кварцевые
резонаторы. Для этого нужно соединить каждый вывод резонатора с конденсатором,
вторым выводом подключенным на землю.
Входы Jack Sense (JS0 и JS1) следует
сконфигурировать любым, удобным для пользователя способом. Если выключения
выходов не нужны, потому, то JS0 и JS1 можно оставить неподключенным (они
окажется соединённым с низким логическим уровнем через нагрузочный
подтягивающий к земле резистор), а в биты JSMT регистра Jack Sense/Audio
Interrupt/Status Register кодека AD73322a занести значение 000. В нашем
случае, для обеспечения большей
гибкости системы, есть смысл использовать эти выводы для переключения между
монофоническим и линейным стереофоническим выходом. Пример организации подобной
схемы с использованием трёхконтактного разъёма типа «джек» показан на рисунке
11. В этом случае, при подключении монофонического штекера JS1 окажется в
состоянии “IN” (на нём будет высокий логический уровень за счёт внутреннего
подтягивающего резистора), а JS0 в состоянии “OUT”. В этом состоянии должен
быть отключен стереофонический линейный выход. При подключении
стереофонического штекера оба вывода будут находиться в состоянии “IN”, и
должен быть отключён монофонический выход. Очевидно, что JS1 должен выключать
линейный выход, а JS0 - монофонический. Согласно соответствующей таблице
истинности (см. [8], Table I Jack Sense Mute Table - JSMT [2:0]) в биты
JSMT следует занести значение 101.
6. Описание особенностей схемы
Одной из особенностей схемы является
использование процессором с гарвардской архитектурой шины PCI, которая является
шиной систем, построенных на основе Фон-Неймановских машин. Ниже будет дано краткое
описание шины PCI.
Следующей особенностью является то,
что единственным видом внешней памяти, который можно подключить к процессору
является EEPROM - электрически перепрограммируемая энергонезависимая память,
которая может использоваться только для чтения. Но в данном случае это не
важно, т.к. начальная загрузка может производиться от хост-процессора, а в
нашем случае этот процессор может располагать огромными ресурсами, в т.ч. и
памятью.
К особенностям схемы следует отнести
обеспечение питания схемы от шины PCI. Шина расширения может обеспечить
напряжения питания в 3,3 или в 5 вольт, но одновременно оба напряжения питания
не получить, кроме того, напряжение питания цифровой части схемы составляет
3,3В, а напряжения питания аналоговой части составляет 5В. Поэтому для питания
цифровой части будут использоваться 3,3В от шины, а для питания аналоговой
части потребуется стабилизатор.
Ещё одной особенностью является
использование функции Jack Sense для переключения выходов кодека.
.1 Несколько слов о шине PCI
(Peripheral Component Interconnect)
local bus - шина соединения периферийных компонентов. Будучи локальной шиной
расширения, эта шина занимает особое место в современной архитектуре PC,
являясь мостом (mezzanine bus) между системной шиной процессора и шиной
ввода/вывода ISA/EISA или MCA. Шина является синхронной - фиксация всех
сигналов производится по фронту тактового импульса (CLK). Шина PCI все
транзакции трактует как пакетные: каждая транзакция начинается фазой адреса, за
которой может следовать одна или несколько фаз данных. Для адреса и данных
используются общие мультиплексированные линии AD. Четыре мультиплексированные
линии C/BE[3:0] используются для кодирования команд в фазе адреса и разрешения
байт в фазе данных. В начале транзакции инициирующее устройство (ИУ)
активизирует сигнал FRAME#, по шине AD передаёт целевой адрес, а по линиям
C/BE# - информацию о типе транзакции. Адресованное целевое устройство (ЦУ)
отзывается сигналом DEVSEL#, после чего ИУ может указать на свою готовность
сигналом IRDY#. Когда к обмену данными будет готово и ЦУ, оно установит сигнал
TRDY#. Данные по шине AD могут передаваться только при одновременном наличии
сигналов IRDY# и TRDY#. С помощью этих сигналов ИУ и ЦУ согласуют свои
скорости, вводя такты ожидания. На рисунке 12 приведена временная
диаграмма обмена, в которой и ИУ, и ЦУ вводят такты ожидания

Количество фаз (циклов) данных в пакете заранее
не определено, но перед последним циклом ИУ при введённом сигнале IRDY# снимает
сигнал FRAME#. После последней фазы данных ИУ снимает сигнал IRDY#, и шина
переходит в состояние покоя (PCI Idle) - оба сигнала IRDY# и FRAME# находятся в
пассивном состоянии (высокий логический уровень). ИУ завершает транзакцию одним
из следующих способов:
Нормальное завершение выполняется по окончании
обмена данными.
Завершение по тайм-ауту (Time-Out) происходит,
когда во время транзакции у ИУ отбирают право на управление шиной (снятием
сигнала GNT#) или когда истекает время, указанное в таймере MLT (медленное ЦУ
или слишком длинная транзакция).
Транзакция отвергается (Abort), когда в течение
заданного времени ИУ не получает ответа ЦУ (DEVSEL#).
Транзакция может быть прекращена и по инициативе
ЦУ, для этого оно может ввести сигнал STOP#. Возможны три типа прекращения:
Отключение (Disconnect) - сигнал STOP# вводится
во время активности TRDY#. В этом случае транзакция завершается после фазы
данных.
Отключение с повтором (Disconnect/Retry) -
сигнал STOP# вводится при пассивном состоянии TRDY#, и последняя фаза данных
отсутствует. Является указанием ИУ на необходимость повтора транзакции.
Отказ (Abort) - сигнал STOP# вводится
одновременно с сигналом DEVSEL# (в предыдущих случаях во время появления
сигнала STOP# сигнал DEVSEL# был активен). В этом случае последняя фаза данных
тоже отсутствует, но повтор не запрашивается.
Одной из особенностей шины PCI является
возможность обмена данными между процессором и памятью одновременно с обменом
между другими устройствами PCI - Concurrent PCI Transferring. Эта возможность
реализуется не всеми чипсетами (в описаниях она всегда специально
подчёркивается).
Таким образом, для реализации использования
внешней памяти по PCI нужна материнская плата с чипсетом, поддерживающим режим
Concurrent PCI Transferring.
Если реализовать схему для шины PCI с питанием
+5В Ключ будет находиться на месте контактов 50 и 51 (при питании +3,3В ключ
располагается на месте контактов 12 и 13).
-х разрядная шина PCI имеет два ряда по 62
контакта, которые располагаются на расстоянии 1,27мм друг от друга.
7. Разработка и описание программы. Особенности
ввода/вывода


В качестве основной программы
используется программа, предоставленная разработчиками фирмы Analog Devices,
Inc. (Проект вы можете найти в приложении
<../AppData/Local/Temp/AppData/Local/Temp/Temp1_allbest-r-00749956.zip/adsp-2191_complex_rad2_fft>
и на сайте Analog Devices www.analog.com
<../AppData/Local/Temp/AppData/Local/Temp/Temp1_allbest-r-00749956.zip/www.analog.com>).
Программа проверена на тест-драйве фирменного программного обеспечения
VISUALDSP++TM. На рисунке 13 показаны входные сигналы, подаваемые на
вход кодека - вещественные сигналы подаются по левому каналу, мнимые,
соответственно, по правому. Сигнал Inputreal - входной вещественный сигнал,
показанный на рисунке в двух различных масштабах, Inputimag - входной мнимый
сигнал, для реальных сигналов равный нулю. Результаты выполнения программы
должны выдать результаты, представленные на рисунке 14. На рисунке 15
изображены выходные сигналы: Refft - выходной вещественный сигнал, Inputreal -
выходной мнимый сигнал. Заметьте, что модель выходного сигнала на каждом
отсчёте - это модуль комплексного числа, представленного в каждый момент
времени выходными сигналами.

После того, как мы убедились в
работоспособности программы обработки можно приступить к разработке реализации
алгоритма многопроцессорной схемы. В качестве связи между процессорами будут
выступать прерывание DSP-to-DSP Interrupt, и семафоры DSP-DSP Semaphore0 и
DSP-DSP Semaphore1. Как видно из алгоритма, сначала происходит
инициализация, не отличающаяся от инициализации стандартной программы, затем
происходит очистка семафоров, её выполняет процессор P0:
/* Очиска флагов */= 0x0000;(0x34) =
ax0;
Поскольку программа будет управляться
прерываниями, то нужно их разрешить (эти строки должны присутствовать в обоих
процессорах):
/* Инициализация прерывания DSP-to-DSP Interrupt
*/
AY0=IMASK;=0x0100;= AY0 or AY1;
/* Демаскирование
DSP-DSP Interrupt */=AR;
/* Разрешение глобальных прерываний */INT;
Далее процессор P0 может выполнять любую
программу, в нашем случае он выполняет команду IDLE, которая заставляет его
делать «ничего», а процессор P1 прерывает его работу:
/* Ядро ЦОС P1 */
...=0x0004;(0x34)=ax0;
...
Чтобы процессор P1 слишком рано не прервал
работу процессора P0, нужно поставить достаточное число «пустых» операций NOP.
Следующим шагом процессор P1 входит в режим
IDLE, а процессор P0, проверив доступ к кодеку:
/* проверка Семафора0 в P0 */ChecK:
ay0 = 0x0001= reg(0x34);= ax0 AND
ay0EQ JUMP Get_InData;
JUMP Sema0Check;
...
выполняет набор окна данных, выставляет семафор
0
/* выставление Семафора0 */
...= 0x0001;(0x34) = ax0;
...
генерирует прерывание
...=0x0004;(0x34)=ax0;
...
и начинает обработку данных.
После того, как процессор P0 сгенерирует
прерывание, процессор P1 проверяет, с помощью семафоров, что ему делать:
/* проверка Семафора0 в P1 */ChecK:
ay0 = 0x0001= reg(0x34);= ax0 AND
ay0NE JUMP Get_InData;
JUMP Sema0Check;
...
очищает семафор0, и начинает обработку данных.
Аналогичным образом организуется и
вывод данных, только вместо семафора 0 процессоры оперируют семафором1.
Подробнее о межпроцессорной коммутации можно узнать из электронной книги [5].
К особенностям Ввода/Вывода можно
отнести использование адресных регистров Ввода/Вывода для коммутации с
хост-процессором и кодеком.
Передачи данных от AC’97 в память
процессора ЦОС выполняется использованием ПДП передач через буферы FIFO
процессора ЦОС. Каждое ядро ЦОС имеет четыре буфера FIFO, доступных для передач
к/от кодека AC’97. Регистры, которые контролируют ПДП передачи доступны только
из процессора ЦОС и определены, как часть пространства регистров ядра.
Несколько слов об архитектуре FIFO
данных.
Два FIFO из четырёх являются
входными буферами, принимающими данные в процессор. Два других - передающие,
посылают данные от процессора ЦОС к кодеку AC’97 или другому процессору ЦОС.
Каждый FIFO способен содержать восемь 16-ти разрядных слов. Когда получены
слова, или когда есть свободные места в буфере передачи могут генерироваться
прерывания.
Когда осуществляется коммутирование
с AC’97 интерфейсом, биты разрешения соединения Connection Enable в регистре
управления устанавливаются в значение 102. Бит 3 выбирает стерео или моно
передачи к и от AC’97 интерфейса. Биты 7-4 ассоциируют слот AC’97 с конкретным
FIFO. Когда выбрано стерео, оба, выбранный слот и следующий слот, ассоциируются
с FIFO. Обычно, стерео выбрано для данных левого и правого каналов, и оба -
левый и правый - должны быть ассоциированы с одним и тем же внешним AC’97
кодеком. В этом случае данные левого и правого каналов будут подаваться в один
FIFO, при этом данные левого канала подаются первыми.
Конфигурация для нашего случая:
AC’97, стерео, передача - слот 3,4; приём - слот 6,7.
/* маскирование AC’97 прерывания
*/=0x7FFF;
ax0=IMASK;=
ax0 AND ay0;
IMASK=ar;
/* Демаскирование FIFOTXI и TIMER
прерываний */
ay0=0x0240;=IMASK;=
ax0 OR ay0;
IMASK=ar;
/* Инициализация входн и выходных
буферов */
ay0=0x083A;(STCNTL0)=ay0;=0x0E3A;(SRCNTL0)=ax0;
…
Для получения и отправки данных
следует пользоваться следующими операциями:
…=REG(0x13);(0x12)=ax0;
…
Ввиду высокой скорости процессора
нужно регулировать скорость его обращения к кодеку для вывода данных:
/* Обработка FIFOTXI прерывания */
.section/codeIVfifo0tmitint;
TPERIOD=1;=0xE2E;=1;=1;TIMER;:=ax0
AND ay0;NE JUMP SelfLooping;;
/* Обработка
TIMER прерывания
*/
.section/codeIVtimerint;(DB);TIMER;=0;
Что касается шины PCI, то тут вполне
устраивают значения, устанавливаемые по сбросу.
Текст программы обработки сигнала
приведён в приложении.
Заключение
процессор сигнал
преобразование
В результате выполнения курсовой
работы было спроектировано устройство, способное выполнять быстрое
преобразование Фурье на 512 точек сигналов, частотой до 20 кГц в реальном
времени. Точность представления информации лучше 0,01%. Устройство состоит из
двухпроцессорного кристалла фирмы Analog Devices, Inc. и кодека той же фирмы. В
качестве хост-процессора выступает процессор устройства, имеющего шину PCI с
питанием 3,3В, и совместимую со стандартром PCI 2.2. К внешней памяти процессор
может обращаться по шине PCI, если данная функция поддерживается чипсетом.
В заключение хочется отметить, что
программа преобразования Фурье была проверена на тест-драйве фирменного ПО
фирмы Analog Devices, Inc. и была работоспособна. Симулирование выполнения
программы многопроцессорной системой не удалось по причине ограничений
тест-драйва, но проект содержащий ключевые моменты осуществления
межпроцессорной коммутации был отослан в центр технической поддержки (DSP.Europe@analog.com
<mailto:DSP.Europe@analog.com>), и разработчик Analog Devices
проверил работу этого проекта на реальном процессоре ADSP-219212MKST160 и
заверил, что программа работает правильно.
Кроме того следует обратить
внимание, что ресурсы процессора используются неоптимально - очень большую
часть времени процессор простаивает - считывание и вывод данных занимают по
11,5мс, а выполнение БПФ - менее 70мкс. Другими словами, у процессора есть
более 11мс свободного времени, которое можно использовать для решения каких
либо задач. При включении в программу модулей аппроксимации квадратного корня
(имеется в одном из технических заданий на курсовую работу в группе Analog
Devices) и арктангенса на выход схемы можно было бы выдавать амплитудный и
фазовый спектр входного сигнала. Возможна обработка сигнала с помощью
преобразования его спектра и осуществление обратного преобразования Фурье, и т.
д.
Не следует делать вывод, что лучше
было бы использовать более медленный процессор, потому что в этом случае
экономического выигрыша не получится, потому что устаревшие процессоры стоят
дороже новых, а новые процессоры, отличающиеся по рабочей частоте на 10-20МГц
стоят абсолютно одинаково (www.eltech.spb.ru
<http://www.eltech.spb.ru>). Использование двух однопроцессорных
кристаллов также не принесёт особой выгоды, т.к. их ресурсы будут ещё менее
востребованы в данном приложении, но экономическую выгоду это принести может,
но ценой отсутствия интерфейсов AC’97, PCI и USB.
Список литературы
Баскаков
С.И. Радиотехнические цепи и сигналы: Учеб. для ВУЗов по спец. «Радиотехника» -
М.: Высш. шк., 1988.
Гук
М. Интерфейсы ПК: справочник - СПб: Питер Ком, 1999.
Руководство
пользователя по сигнальным микропроцессорам семейства ADSP-2100: Пер. с англ. -
СПб.: Санкт-Петербургский государственный электротехнический университет, 1997.
Хоровиц
П., Хилл У. Искусство схемотехники: в 3-х томах: Т.1. Пер. с англ. - М.: Мир,
1993.
ADSP-2192
INTERPROCESSOR COMMUNCATION - ©2001 Analog Devices, Inc. Printed in the
USA.x/2191 DSP Hardware Reference - ©2002 Analog Devices, Inc. Printed in the
USA.x DSP Instruction Set Reference - ©2002 Analog Devices, Inc. Printed in the
USA.Devices AC’97 SoundMAX® Codec AD-1981A - ©Analog Devices, Inc., 2002.
Printed in USA.Devices DSP Microcomputer ADSP-2192M - ©2002 Analog Devices,
Inc. Printed in USA.FOR PERFORMANCE ON THE ADSP-219x - ©2000, Analog Devices,
Inc.CMOS Fixed/Adjustable Output Step-Up Switching Regulators MAX631/632/633. -
©1990 Maxim Integrated Products, Printed USA.
Приложение
Текст программы преобразования Фурье.
/****************************************************************************x
Комплексное БПФ с прореживанием по времени
по алгоритму Radix-2
Выполняет БПФ с прореживанием по времени по
алгоритму radix-2 с длиной входных данных x(n) 64 или более.
Использование памятиДействительная часть
комплексных входных чисел находящихся в ПД в нормальном порядкеМнимая часть
комплексных входных чисел находящихся в ПП в нормальном порядкеДействительная
часть преобразованных данных, хранящихся в ПД/2Таблица Sin хранящася в
ПД/2Таблица Cos хранящася в ПД
Вызываемая информация:(twid_real[N/2])- таблица
sin(2pi*n/N) в бит-реверсивном порядке(twid_imag[N/2])- таблица cos(2pi*n/N) в
бит-реверсивном порядке
(Inputreal[N]) - действительная часть входного
массива, находится в ПД(Inputimag[N]) - мнимая часть входного массива,
находится в ПП
Результаты:(Refft[N]) - действительные
результаты БПФ в последовательном порядке(Inputreal[N]) - мнимые результаты БПФ
в последовательном порядке:
длина БПФ к-во циклов время, мкс 160МГц
--------------------------------------
1024 24160151
Использование памяти:
ПП код программы(24-bit) = 92 слова
ПП данные(24-bit) = N + 2 + N/2 слов
ПД данные(16-bit) = 2N + 4 + N + 1 слов
****************************************************************************/
/**********Константы, представленные ниже дожны
быть изменены для различных длин БПФ*******= количество точек БПФ, должно быть
2 в некоторой степени
log2N = log2(N)_Value = 2^(16-LOG2N)
Refft_Bitrev = Битреверсии адреса выходных
действитеьных чисел ПД_Bitrev = Битреверсии адреса выходных мнимых чисел ПД
******************************************************************************/
/* Установка констант для N-точечного БПФ */
#define N 512
#define Ndiv2 (N/2)
#define log2N 9
#defineMod_Value128
#defineRefft_Bitrev0x0001
#defineInputreal_Bitrev0x000
/* данные
ПД
*/
.section/data data1;
.VAR twid_imag [Ndiv2] =
"twid_sin.dat";
.VAR groups = 1;
.VAR node_space = Ndiv2;
/* данные
ПД
*/
.section/data seg_buf1;
.VAR Inputreal [N+2] =
"inreal.dat";
/* данные
ПД
*/
.section/data seg_buf2;
.VAR Refft[N+2];
/* данные ПП */
.section/pm data2;
.VAR/init24 twid_real [Ndiv2] =
"twid_cos.dat";
.VAR Inputimag [N+2] =
"inimag.dat";
/* код вектора прерываний ПП */
.section/pm IVreset;
JUMP start; NOP; NOP;
/* Код
программы
*/
.section/pm program;
start: = page(twid_real);/* Инициализация
страницы для данных ПП */= 0;= length(twid_imag);/* Инициализация циркулярного
буфера twid_imag*/= twid_imag;(b0) = AX1;/* Инициализация указателя на
twid_imag */= 1;= 0;/* Инициализация для модульной адрессации */= 0;=
length(twid_real); /* Инициализация циркулярного буфера twid_real*/=
twid_real;(b4) = AX1;/* Инициализация указателя на twid_real */= 1;= 0; /* Инициализация
для модульной адрессации */= -1;= 0;/* Инициализация для модульной адрессации
*/ = 0; = 0; = 0; = 8;/* Инициализация счётчика стадий */stage_loop UNTIL CE;/*
Вычисление всех стадий БПФ */
I0 = twid_imag;/* I0 --> (-S) W0
*/
I1 = Inputreal;/* I1 --> x1 в первой группе
данной стадии */= Inputreal;/* I2 --> x0 в первой группе данной стадии */
I4 = twid_real;/* I4 --> C W0 */
I5 = Inputimag;/* I5 --> y1 в первой группе
данной стадии */= Inputimag;/* I6 --> y0 в первой группе данной стадии */=
DM(groups);= SI;/* CNTR = # групп данной стадии */
SR = LSHIFT SI BY 1(LO);(groups) =
SR0;= DM(node_space);/* SI = изменению
node_space */
M2 =SI;=SI;(I1,M2);/* I1 --> x1 в первой
группе данной стадии */(I5,M7);/* I5 --> y1 в первой группе данной стадии */
DO group_loop UNTIL CE;= PM(I4,M5),
MX0 = DM(I1,M0);/* MY0=C, MX0=x1 */= MX0*MY0(SS), MX1 = PM(I5,M4);/*
MR=C*x1,MX1=y1 */= DM(I0,M1);/* MY1 = (-S) */= SI;/* CNTR = счётчик
бабочки
*/bfly_loop UNTIL CE;= MR-MX1*MY1(RND), AY0 = DM(I2,M0); /* MR=x1*C-y1*-S,
AY0=x0 */= MR1+AY0, AX1 = PM(I5,M5); /* AR=x0'=x0+(x1*C-y1*-S) */(I2,M1) = AR,
AR = AY0-MR1; /* DM=x0', AR=x1'=x0-(x1*C-y1*(-S)) */= MX0*MY1(SS), DM(I1,M1) =
AR; /* MR=x1*(-S), DM=x1' */= MR+MX1*MY0(RND), AY1 = PM(I6,M4), MX0 =
DM(I1,M0); /*MR=x1*(-S)+y1*C, AY1=y0, MX0= следующему
x1 */= MR1+AY1, MX1 = PM(I5,M6); /* AR=y0'=y0+(y1*C+x1*(-S)), MX1= следующему
y1 */(I6,M5) = AR, AR = AY1-MR1; /* PM=y0', AR=y1'=y0-(y1*C+x1*(-S)) */_loop:=
MX0*MY0(SS), PM(I5,M5) = AR; /* PM=y1' */= PM(I5,M7), MX0 = DM(I1,M2);
_loop:=PM(I6,M7), MX0=DM(I2,M2); =ASHIFT SI BY -1 (LO);_loop:(node_space)=SR0;
= twid_imag/* I0 --> (-S) */= Inputreal;/* I1 --> x1 */= Inputreal;/* I2
--> x0 */
M2 = 2; = Refft_Bitrev;/* Бит-реверсированное
Refft */= Mod_Value;/* Бит-реверсированное изменение */
I4 = twid_real;/* I4 --> C */ =
Inputimag;/* I5 --> y1 */= Inputimag;/* I6 --> y0 */= 2; (I1,M1);/* I1
-->x1 */(I5,M5);/* I5 -->y1 */= PM(I4,M5), MX0 = DM(I1,M2);/* MY0=C,
MX0=x1 */= MX0*MY0(SS), MX1 = PM(I5,M6);/* MR = C*x1, MX1 = y1 */= DM(I0,M1);/*
MY1 = (-S) */= Ndiv2;last_loop UNTIL CE;= MR-MX1*MY1(RND), AY0 = DM(I2,M2); /*
MR=x1*C-y1*(-S), AY0=x0 */= MR1+AY0, AY1 = PM(I6,M4); /*
AR=x0'=x0+(x1*C-y1*(-S)), AY1=y0 */
ENA BIT_REV;(I3,M3) = AR, AR = AY0-MR1;/* Чтение
действительных данных */= MX0*MY1(SS), DM(I3,M3) = AR;/*