Розробка програмного забезпечення для систематизації інформаційних ресурсів у сфері освіти на основі XML
ДИПЛОМНА РОБОТА
«Розробка
програмного забезпечення для систематизації інформаційних ресурсів у сфері
освіти на основі XML»
Вступ
Одним з ключових механізмів, що використовуються
при розв’язанні задач з обліку та реєстрації інформаційних ресурсів (ІР),
публікації ІР та метаданих, а також моніторингу стану ІР, являється
каталогізація ІР. Першою концептуальною проблемою на шляху систематизації ІР є
необхідність визначення, опис яких суттєвих властивостей може представлятися в
загальнодоступних каталогах ІР, призначених для поширення в сфері освіти.
В широкому сенсі під інформаційними ресурсами
розуміються знання, підготовлені людьми для соціального використання в
суспільстві і зафіксовані на матеріальних носіях у вигляді документів, баз
даних і знань, алгоритмів, комп’ютерних програм і т. п.
ІР - це документ (сукупність документів),
призначений і самостійно оформлений для поширення серед необмеженого кола осіб
або слугуючий основою для надання інформаційних послуг.
Наведене визначення відображає ключові ознаки,
які мають бути властиві інформаційній сутності, для того щоб бути представленою
в загальнодоступному каталозі ІР. По-перше, ІР - це продукт, призначений для
поширення серед необмеженого кола осіб, для яких він являє інтерес, тобто має
споживацьку цінність. В той же час ІР - не обов’язково опублікований документ. Розміщення
інформації про нього в каталозі може бути кроком на шляху до публікації. Доступ
до ІР може бути організований через Internet або шляхом випуску
тиражу інформаційних носіїв, розміри яких задовольняють потребам цих осіб і
визначаються з урахуванням характеру ІР.
Друга ключова ознака ІР - оформлення, що
забезпечу можливість самостійного поширення. Сутність, що не має такого
оформлення, не може бути відображена в каталозі.
На ринку інтелектуальної продукції більшість ІР
виступають у якості продуктів або товарів. Виключення складає особливий клас
мегаресурсів Internet,
що служать основою для надання послуг. Такі ІР не
являються товаром (права на їх використання не продаються і не купуються). Одне
і те ж ІР, як правило, використовуються для надання різноманітних послуг. Ці
послуги складають його основну цінність і не можуть бути надані без його
наявності. Тому каталогізації підлягають ІР, а не послуги.
На сьогоднішній день освітнє товариство не
прийшло до єдиної думки стосовно того, які види ІР доцільно охопити
систематизацією і представляти в загальнодоступних каталогах ресурсів. Існуючі
точки зору з даного приводу в основному заключаються в лімітації видів
систематизованих ІР, під приводом складності уніфікації метаданих, трудоємності
наповнення каталогів і надання переваги конкретним технологіям реалізації
бізнес-процесів, передбачаючих використання таких каталогів.
Подібні обмеження не достатньо обґрунтовані з
наступних причин:
По-перше, в системі освіти використовують самі
різноманітні ІР. Виключення із сфери каталогізації будь-яких їх видів означає,
що вони не будуть враховуватись при формуванні навчальних планів, контролі ходу
їх виконання та аналізі забезпеченості системи освіти ІР і т. п. Таким чином,
названі задачі будуть розв’язуватись на основі неповних вихідних даних, а ринок
ІР, що залишились за рамками розгляду, буде позбавлений одного із стимулів
розвитку;
По-друге, один і той же ІР може бути реалізований
в різних формах і випущений на різних носіях;
По-третє, різноманітні форми представлення ІР і
способи доступу до них можуть використовуватись сумісно;
По-четверте, деякі ІР являються комплексними, що
являють собою набори ресурсів різних видів, зафіксованих на різних типах
носіїв;
По-п’яте, крім ІР, що виступають на ринку
інтелектуальної продукції в якості товарів, необхідно враховувати мегаресурси Internet, що не являються
товарами, але слугують основою для надання інформаційних послуг;
По-шосте, тимчасове обмеження сфери
систематизації окремими видами ІР
означає, що замість однієї специфікації
метаданих, що описують ІР, буде розроблено кілька специфікацій, орієнтованих на
різні класи ІР і які вводяться в дію по мірі готовності. В результаті
відбудеться не спрощення, а ускладнення задач систематизації, обумовлене
необхідністю узгодження специфікації, а також наявністю багатьох наборів правил
формування описів в рамках різних специфікацій.
Із сказаного випливають два важливих висновки:
· В загальнодоступні
каталоги ІР, що формуються в рамках систематизації, можуть включатися відомості
про ІР, різних за формою представлення даних і їх характеру, зафіксованих на
різних типах носіїв і підтримуючих різні способи доступу;
· Ці відомості повинні
представлятися за правилами, що регламентуються єдиним набором відкритих
специфікацій метаданих.
Існують різноманітні підходи до класифікації ІР.
Типологія видів видавницької продукції, що випускається на паперових носіях
(ДСТ 7.60-90). Класифікація електронних видавництв міститься в ДСТ 7.83-2001.
Обидві класифікації являються фасетними.
В роботах, що розвиваються за кордоном, по
стандартизації технологій електронної освіти важливе місце займає класифікація
ІР для сфери освіти за рівнем агрегації. В технології CMI виділені чотири типи
структурних одиниць контенту:
1. призначений елемент (assignable unit - AU) - найменша структурна
одиниця контенту, що враховується системою управління навчальним процесом
(СУНП);
2. урок (lesson) - структурна
одиниця контенту, що містить навчальний матеріал, що відповідає певним цілям
підготовки; урок також може включати засоби оцінювання;
. блок (block) - група
структурних одиниць курсу; блок може включати зв’язані AU та інші блоки;
. курс (course) - завершений
освітній ресурс, орієнтований на одного або кількох учнів і призначений для
набуття умінь і навичок, що формують компетенцію в деякій предметній області і
потрібних для виконання групи взаємопов’язаних задач; курс може включати уроки
і тести, що відповідають певним цілям підготовки, і може бути частиною
навчального плану;
. елемент (asset) - одиниця контенту, що
являє собою інформацію в електронному вигляді, яка може бути відправлена web-клієнту;
. сумісно використовуваний об’єкт контенту
(Sharable Content Object - SCO) - набір з
одного або декількох елементів, що включає елемент, який реалізує функції
інтерфейсу з СУНП;
. агрегат (content aggregation) - інтегральний
ресурс, що об’єднує одиниці контенту в інтегральну структуру.
Класифікація ІР за різними властивостями
орієнтована на розв’язання різноманітних задач, що відносяться до каталогізації
ІР, їх пошуку, організації доступу до них, побудові інтегральних ресурсів,
управлінню використання ІР в навчальному процесі, аналізу і моніторингу
забезпеченості ІР для потреб системи освіти та ін.
Документ, який представляє класифікацію,
називається класифікатором. При формуванні метаданих та пошукових запитів
класифікатори служать джерелами для вибору значень, що заносяться в елементи
даних і поля запитів відповідного типу. Інформаційна модель метаданих може містити
безліч елементів, значення яких вибираються в класифікаторах. Кожен з них
відображає класифікацію ІР за властивістю, що визначається елементом даних,
значення якого представлене в класифікаторі.
Серед безлічі класифікацій ІР виділимо базовий
набір, що включає класифікації, які відіграють особливу роль при розробці і
використанні метаданих.
Подібний статут визначається наступними
моментами:
· загальністю основ
ділення, що обумовлює застосовність класифікацій базового набору по відношенню
до всіх ІР;
· зручністю використання
даних класифікацій для організації навігації по каталогу ІР;
· реалізацією на основі
даних класифікацій значної частини обмежень цілісності, що накладаються на опис
ІР.
· Базовий набір включає:
· класифікацію ІР за
цільовим призначенням;
· класифікацію типів ІР;
· класифікацію ІР за
рівнями освіти;
· класифікацію освітніх ІР
за цільовою аудиторією;
· предметні (тематичні)
класифікації.
Вимоги до системи метаданих
Розв’язання більшості задач систематизації ІР
пов’язане з використанням метаданих. Під метаданими розуміється інформація, яка
характеризує будь-яку іншу інформацію, тобто являє собою опис ІР для сфери
освіти.
Система метаданих виступає в якості центральної
ланки будь - якої інформаційної системи. Метадані можуть бути як частиною ІР,
так і зберігається окремо від них.
Для метаданих визначається два рівні
представлення:
· інфологічний, що
фіксується схемою метаданих, яка відображає склад і структуру елементів даних
(полів) в екземплярі метаданих, їх семантику, типи значень (включаючи словники
та класифікатори) і обмеження цілісності;
· даталогічний, що
фіксується форматом метаданих, який відображає спосіб представлення (кодування)
інформації.
До числа основних вимог до системи мета даних
відносяться:
· універсальність в рамках
встановленого розуміння ІР як об’єкта систематизації;
· структурованість і
формалізованість мета даних, необхідні для їх автоматичної обробки;
· достатня виразність для
забезпечення ефективного вирішення задач, які потребують наявності мета даних;
· сумісність з міжнародними
стандартами і протоколами в області мета даних та інформаційного пошуку
(створення умов для інтероперабельності);
· відповідності
законодавству в області освіти (зокрема, встановленим рівням освіти),
відображення особливостей вітчизняної освітньої системи і стандартів України;
· можливість задання
обмежень цілісності, що відображають взаємозв’язки полів описання ІР;
· забезпечення можливості
зберігання мета даних як сумісно з ІР, так і окремо від нього;
· можливість представлення
в мета даних відомостей про створювачів, правовласників та поширювачів ІР, а
також відносини між ними.
Мета дані про ІР для сфери освіти формуються і
використовуються в різних системах і сервісах:
· електронних бібліотеках;
· освітніх порталах;
· системах реєстрації ІР;
· службах публікації ІР;
· сховищах (депозитаріях)
ІР;
· сховищах мета даних про
ІР;
· системах розробки
освітнього контенту (авторському інструментарії);
· СУНП в системах
управління конвентом;
· системах сертифікації ІР
та ін.
Широта застосування мета даних підкреслює
важливість забезпечення їх інтероперабельності, що потребує розробки для
української освітньої системи єдиного набору відкритих специфікацій, що
охоплюють різні види ІР і варіанти використання мета даних, сумісних з
міжнародними стандартами та специфікаціями в даній області.
В наш час в світі створено багато систем мета
даних, яким властивий різний статус: міжнародні, національні та галузеві
стандарти, корпоративні специфікації, специфікації міжнародних консорціумів та
ін.
Перерахуємо деякі системи мета даних:
· Дублінське ядро;
· GEM - розширення
Дублінського ядра для описання освітніх ІР;
· MARK, призначена для
описання бібліотечних ресурсів (як на паперових, так і на електронних носіях);
· GILS, призначена для
описання будь-яких видів ІР, що розширює MARK і базується на протоколі
Z39.50;
· ONIX, призначена для
описання товарів в системах електронної комерції;
· LOM, призначена для
описання освітніх ІР;
· IAFA/WHOIS++, призначена для описання
мережевих ІР;
· UDDI, призначена для
описання web-сервісів;
· INDECS, орієнтована на
системи електронної комерції і яка містить елементи для управління правами на
цифрові об’єкти;
· EAD, призначена для
опису архівних матеріалів;
· МЕКОФ - міжнародний
комунікативний формат, що виступає в якості альтернативи MARC;
· формат опису баз даних та
машиночитаємих інформативних масивів.
ІР для сфери освіти (в першу чергу комп’ютерні
засоби навчання), володіють специфікою, котра потребує забезпечення можливості
відображення в мета даних:
1. логічної та фізичної структур ІР;
2. інформації для взаємодії ІР з СУНП, в
рамках якого виконується налагодження ІР на поточні умови застосування та
конкретного учня, а також фіксація ходу і результатів його роботи;
. правил, що визначають методику роботи з
ІР (порядок навігації за його компонентами, оцінювання дій учня);
. педагогічних характеристик (рівень
освіти, цільова аудиторія, складність, контактний час і т.д.), необхідних для
прийняття рішення про включення ІР в склад контенту, що покриває навчальний
план або програму;
. інформації для побудови інтегрального
ресурсу на основі багатьох ІР.
Структура інформаційної моделі метаданих
Інформаційна модель, що представляє форму опису
ІР, складається із сукупності елементів даних, утворюючих ієрархічну структуру.
Елементи даних підрозділяються на неподільні та складові. Перші відповідають
листкам ієрархії, другі - транзитним вузлам.
Складовий елемент включає один або кілька
елементів, серед яких можуть бути як неподільні, так і складові елементи.
Елементи, що входять в складовий елемент, називаються підлеглими цьому
елементу. В свою чергу, складовий елемент по відношенню до вхідних в нього
елементів називають підлеглим або батьківським.
Складовий елемент не має інтегрального значення.
Його значення виражається через значення вхідних в нього елементів.
Неподільний елемент даних не має підлеглих
елементів. Він може мати самостійне значення, що відповідає множені допустимих
значень, які визначаються асоційованим з елементом типом даних.
На верхньому рівні ієрархії інформаційної моделі представлені
дев’ять контейнерів:
· загальні відомості про ІР
(general);
· життєвий цикл ІР (lifecycle) - відомості про
поточний стан ІР і суб’єкта, що вніс вклад в його створення і розвиток;
· метаметадані (metametadata) - характеристики описання
ІР (екземпляра мета даних);
· технічні характеристики
ІР (technical);
· освітні характеристики ІР
(educational);
· права інтелектуальної
власності на ІР (rights) - відомості про права інтелектуальної власності
на ІР і пов’язаних з ними умовах його використання;
· відносини (relation) - відомості про
відносини між описаним ІР та іншим ІР;
· анотація (annotation) - коментарі про
застосування ІР та відомості про те, хто і коли їх складав;
· класифікаційні ознаки (classification) -
класифікаційні ознаки ІР в рамках різних класифікаторів.
Елемент даних не може бути включений в екземпляр
мета даних без свого батьківського контейнера. Таким чином, із наявності
будь-якого елемента в екземплярі мета даних автоматично слідує входження в цей
екземпляр і батьківського контейнера даного елемента.
Елемент даних в інформаційній моделі
характеризується наступними атрибутами:
1. індексом;
2. іменем;
. описом;
. повторюваністю;
. впорядкованістю значень;
. типом даних;
. граничним об’ємом;
. граничною повторюваністю.
Словники та класифікатори
В LOM словником називається рекомендований список
значень неподільного елемента даних. Елементам, для яких передбачені словники
значень, відповідає словниковий тип даних.
В інформаційній моделі використовуються словники,
що відносяться до трьох категорій:
· словник LOM - словник,
визначений в стандарті [13];
· розширений словник LOM - словник,
визначений, в який додано одне або кілька значень [13];
· словник RUS_ LOM - словник,
визначений в інформаційній моделі для елемента розширення LOM.
Словники двох перших категорій співвідносяться з
елементами словникового типу концептуальної схеми LOM. Словники третьої
категорії містять рекомендовані набори значень елементів словникового типу
розширення LOM.
В LOM під класифікатором розуміють множину значень, що
утворюють ієрархічну структуру. В такій інтерпретації словник можна розглядати
як однорівневий класифікатор.
Деякі класифікатори допускають можливість вибору
із них значень будь-якого рівня, інші - лише листків. Для представлення
характеристик, що виражаються значеннями з класифікаторів, в інформаційній
моделі служить контейнер 9.В рамках цього класифікована ознака ІР може бути
специфікована в короткій або повній формі.
В рамках контейнера 9 вказуються класифікаційні
ознаки, що відображають:
· цільове призначення ІР;
· тип ІР для сфери освіти;
· рівні освіти, на які
розрахований ІР;
· тематику ІР.
Крім або замість класифікаційних ознак в
контейнері 9 можуть бути представлені текстові коментарі і багато ключових
слів, що характеризують ІР в контексті мети класифікації. Ці поля дозволяють
відобразити особливості ІР, що не враховуються застосованим класифікатором.
Вони також призначені для пояснення класифікаційних ознак, що вибираються із
недостатньо поширених класифікаторів.
Представлення метаданих
Розглядаєма інформаційна модель відноситься до
інфологічного рівня. Її специфікація стосується представлення метаданих лише в
частині типів даних, що відповідають її елементам. Всі інші аспекти
представлення метаданих (мітки елементів, кодування, використані набори
символів, коди словникових значень та ін.) специфікацією не регламентується.
Порядку, в якому приведені елементи даних в
інформаційній моделі, не обов’язково дотримуватись в екземплярі метаданих.
Екземпляр метаданих повинен зберігати підлеглість елементів даних, встановлену
в інформаційній моделі. Порядок елементів в ньому може бути довільним.
1. Постановка завдання
.1 Найменування та область застосування
програмний метадані словник надбудова
Найменування розробки: систематизація
інформаційних ресурсів у сфері освіти. Система призначена для систематизація
інформаційних ресурсів у сфері освіти і може бути використана учнями та
викладачами для заповнення метаданих про інформаційні освітні ресурси.
1.2 Підстава для створення
Підставою для розробки є наказ №73С-01 від 29
жовтня 2009 р. по Криворізькому інституту КУЕІТУ.
Початок робіт: 01.11.09. Закінчення робіт:
25.05.10.
1.3 Характеристика розробленого програмного забезпечення
Проектована гнучка комп’ютеризована система
реалізована на мові XML. Програмний продукт може функціонувати у будь-якому XML
редакторі. Програма створена на основі державних та міжнародних стандартів та
відповідають усім необхідним вимогам.
До складу програми входять:
generalLom.xsd - XML схема;
vCard.xsd - міжнародній стандарт для заповнення метаданих про творців;
vocab_lom.xsd - словник
міжнародного стандарту;
vocab_rus_lom.xsd - розширення словника
міжнародного стандарту;
1.4 Мета й призначення
Метою даної дипломної роботи є розробка гнучкої
комп’ютеризованої системи на основі XML, яка призначена для заповнення метаданих
освітніх інформаційних ресурсів. Система пройшла практичну апробацію і може бутивикористана
учнями та викладачами для заповнення метаданих освітніх інформаційних ресурсів.
.5 Загальні вимоги до розробки
Вимоги до програмного забезпечення:
· Робота в середовищі операційних систем Windows
2000/XP; Простота й зрозумілість
інтерфейсу.
Мінімальні вимоги до апаратного забезпечення:
· IBM-сумісний комп'ютер, не нижче Pentium IV, RAM-512Mb, SVGA-800*600*16bit;
· Вільний простір на жорсткому диску не менш
600 Мб.
· Редактор XML.
1.6 Джерела розробки
Джерелами розробки дипломної роботи є:
· довідкова література;
· наукова література;
· технічна література;
· програмна документація.
2. Вимоги до системи метаданих
.1 Задачі систем метаданих
Вирішення багатьох задач систематизації
інформаційних ресурсів пов’язано із використанням метаданих. Під метаданими
розуміють інформацію, яка характеризує будь-яку іншу інформацію. У розгляданому
контексті екземпляр метаданих представляє собою опис інформаційних ресурсів для
сфери освіти.Data Coalition у документі «Open Information Model» визначає як
описову інформацію про структуру та зміст даних, а також процесів та програм,
котрі маніпулюють даними. Метадані можуть характеризувати сутність, яка
відноситься не тільки до віртуального простору, а також і до реального світу.
Це важливо тому, що опис інформаційних ресурсів для сфери освіти можуть містити
відомості про творців, власників та розповсюджувачів, а також про події, в котрих
вони фігурують.
Система метаданих виступає у якості центральної
ланки любої інформаційної системи. Метадані можуть бути як частиною
інформаційних ресурсів так і зберігатись окремо від них. Наприклад, вихідні
відомості видання, по відношенню до нього є метаданими, наводяться у самому
виданні і крім того, додаються до бібліотечного каталогу.
Як і в технологіях баз даних, для метаданих
визначаються два рівня представлення:
· Інфологічний, фіксується
схемою метаданих, котра відображає склад та структуру елементів даних (полів) в
екземплярі метаданих, їх семантику, типи значення (включаючи словники та
класифікатори) обмеження цілісності;
· Датологічний, фіксується
форматом метаданих, котрий відображує представлення (кодування) інформації.
До числа основних вимог до системи метаданих
відноситься:
· Універсальність у рамках
установленого розуміння інформаційних ресурсів як об’єкта систематизації;
· Структурованість та
формалізованість метаданих, необхідних для їх автоматичної обробки;
· Достатня виразність для
забезпечення ефективного рішення задач, потребуючих наявності метаданих;
· Сумісність із
міжнародними стандартами та протоколами у області метаданих та інформаційного
пошуку;
· Відповідність
українському законодавству у сфері освіти, відображення особливостей
вітчизняної системи освіти та стандартів;
· Можливість завдання
обмежень цілісності, які відображають взаємозв’язок полів та описань
інформаційних ресурсів;
· Забезпечення можливості
зберігання метаданих як сумісно з інформаційними ресурсами, так і окремо від
нього;
· Можливість представлення
у метаданих відомостей про творців, право власників та розповсюджувачів
інформаційних ресурсів, а також відношення між ними.
Метадані про інформаційні ресурси для сфери
освіти формуються та використовуються в різних системах та сервісах:
· Електронні бібліотеки;
· Освітні портали;
· Системи реєстрації
інформаційних ресурсів;
· Службах публікації
інформаційних ресурсів;
· Сховищах (Депозитаріях)
інформаційних ресурсів;
· Сховищах Метаданих про
інформаційні ресурси;
· Системах розробки
освітнього контенту;
· Системах сертифікації
інформаційних ресурсів та іншого.
Широта застосування метаданих підкреслює
важливість забезпечення
їх інтерпарабельності, що потребує розробки для
української освітньої системи єдиного набору відкритих сертифікацій, охоплюючи
різні види інформаційних ресурсів та варіанти використання метаданих, совісних
з міжнародними стандартами та специфікаціями у цій області. У подальшому
прийняті домовленості доцільно фіксувати у рамках галузевих стандартів по
метаданим.
Сумісність вітчизняної системи метаданих з
міжнародними
стандартами та специфікаціями забезпечує:
· Взаємну «прозорість»
метаданих в українських та зарубіжних каталогах та репозиторіях для пошукових
засобів, що створюють умови для обміну інформаційними ресурсами;
· Спрощення створення
інформаційних ресурсів орієнтованих на зарубіжний ринок;
· Можливість обміну
метаданими між українськими та зарубіжними каталогами та репозиторіями;
· Можливість формування та
використання метаданих, призначених для розміщення в українських каталогах і
репозиторіях, у зарубіжних інструментальних засобах.
Існує три підходи для побудови схеми метаданих.
рис. 2.1 ілюструє їх якісні оцінки з двох різних точок зору:
· Степінь забезпечування
інтероперабельності;
· Переліку специфікацій
української системи освіти зручності рішення задач потребуючих метадані.
Вимоги, асоційованими з виділеними шкалами
оцінювання, супротивлять одне одному. У цьому плані розумним компромісом
представляється інший підхід який і пропонується використовувати.

Рис. 2.1 Побудова схеми метаданих
До нинішнього часу у світі створено багато систем
метаданих, які
володіють різними статусами: міжнародним,
національним та галузеві стандарти, корпоративні специфікації, специфікації
міжнародних консорціумів [28,29]. Потрібно відзначити, що ряд розробок, не маючи статусу офіційно
затверджених стандартів «де-юре», широко використовуються на практиці і
розглядаються у якості стандартів «де-факто».
Перелічимо деякі системи метаданих:
· Дублінське ядро;
· GEM - розширення
Дублінського ядра для опису освітніх ІР;
· MARС, призначена для
опису бібліотечних ресурсів;
· GILS, призначена для
опусу будь-яких видів ІР, розширення для MARС та базується на протоколі Z39.50;
· ONIX, призначена для
опису товарів у системах електронної комерції;
· LOM, призначена для опису
освітніх ІР;
· IAFA\WHOIS++, призначена
для опису мережевих ІР;
· UDDI, призначена для
опису web-сервісів;
· INDECS, орієнтована на
системи електронної комерції та має елементи для управління правами на цифрові
об’єкти;
· EAD, призначений для
опису архівних матеріалів;
· МЕКОФ, міжнародний
комунікативний формат, виступаючий у якості альтернативи MARC [18-20];
· Формат опису баз даних та
машиночитаних інформаційних масивів.
С точки зору орієнтації на види інформаційних
ресурсів та сфера застосування, системи метаданих підрозділяють на універсальні
та спеціалізовані. До універсальних систем відносять Дублінське ядро та GILS.
Плюси й мінуси виділених класів систем метаданих відображені на рис. 2.2.

Рис. 2.2 Плюси й мінуси виділених класів систем
метаданих
Інформаційні ресурси для сфери освіти (у першу
чергу комп’ютерні системи освіти) володіють специфікацією, котра потребує
забезпечення можливості відображення у метаданих [2]:
· Логічної і фізичної
структури ІР;
· Інформація для взаємодії
інформаційних ресурсів та СУУП, у рамках котрого виконуються настройки
інформаційних ресурсів на поточні умови застосування та конкретного учня, а
також фіксація хода і результатів її роботи;
· Правил, визначаючих
методику роботи з інформаційними ресурсами (порядок навігації по його
компонентам, оцінювання дій учня);
· Педагогічних
характеристик (рівень освіти, цільова аудиторія, складність, контактний час і
т.д.), необхідних для прийняття рішення про ввімкнення інформаційних ресурсів
до складу контента, який покриває учбовий план або програму;
· Інформації для побудова
інтегрального ресурсу на основі багатьох інформаційних ресурсів.
Висловленні міркування слугують доводами у
користь застосування спеціалізованої системи метаданих. У якості основи такої
системи пропонується обрати систему LOM, прийняту IEEE у якості стандарту в
2002 р. Відзначимо наступні причини, аргументуючи дане рішення:
· LOM являється відкритим
стандартом та забезпечує майже усі висунуті вимоги до системи метаданих (для
відображення особливостей української системи освіти пропонуються розширення);
· У порівнянні з іншими
системами метаданих, орієнтованими на освітні інформаційні ресурси, LOM
найбільш структурований та володіє більшою виразністю;
· LOM включає представлений
набір полів, які дозволяють описувати широкий спектр інформаційних ресурсів (не
тільки інформаційних ресурсів для сфери освіти), при чому усі елементи даних
Дублінського ядра відображаються у LOM;
· LOM відображає опит, який
був надбаний ведучими світовими розробниками інформаційних ресурсів для сфери
освіти та постачальниками освітніх послуг;
· Опис інформаційних
ресурсів на основі LOM являє собою частину маніфесту (зовнішнього формату
представлення інформації, фіксуючої структуру інформаційних ресурсів та логіку
навігації по структурі) [30].
У рамках проекту по створенню концепції ОСГУРМ
була розроблена інформаційна модель, визначальна на інфологічному рівні
структуру екземпляра метаданих про інформаційні ресурси для сфери освіти. У
розглянутому контексті екземпляр метаданих відповідає опису інформаційних
ресурсів для сфери освіти.
Модель реалізована як розширення схеми LOM та
задовольняє усім вимогам, представлених к таким розширенням. Вона повністю
включає схему LOM, зберігаючи семантику та атрибути її елементів, а також
набори значень, які входять в пов’язані з ними словники [13].
Розширення передбачає:
· Додання в інформаційну
модель ряд нових елементів та асоційованих з ним словників;
· Додання значень у
словники LOM (розширення словників LOM).
· Причини вводу розширень
та його цілі:
· Відображення специфікацій
української системи освіти, а також законодавства та стандартів України;
· Більш глибока
структуризація та формалізація деяких елементів даних;
· Забезпечення можливості
представлення у метаданих характеристик, специфічних для інформаційних
ресурсів, які розповсюджуються на інформаційних носіях;
· Розвиток обмежень
цілісності для підвищення можливостей формальної верифікації метаданих та
зменшення помилок у них.
Концептуальна схема LOM визначає форму описання
освітнього об’єкту. Останній інтерпретується як цифрова або нецифрова сутність,
котра може використовуватися в освітніх цілях. У контексті розробленої інформаційної
моделі вказаному трактуванні відповідає поняття інформаційні ресурси для сфери
освіти. Поняття «освітній об’єкт» використовується у більш вузькому сенсі
та асоціюється з одним із видів інформаційних ресурсів.
Визначення та використання спільної інформаційної
моделі метаданих про освітні інформаційні ресурси сприяють:
· Забезпеченню високої
степені семантичної інтерперабельності метаданих;
· Підвищенню ефективності
пошуку освітніх інформаційних ресурсів;
· Розширенню застосовності
освітніх інформаційних ресурсів та скороченню затрат на їх створення за рахунок
багатократного застосування одних і тих же інформаційних ресурсів у різних
програмах.
2.2 Структура інформаційної системи метаданих
Інформаційна модель, що являє собою форму
описання інформаційного ресурсу (ІР), складається із сукупності елементів
даних, що утворюють ієрархічну структуру. Елементи даних поділяються на
неподільні та складові. Перші відповідають листкам ієрархії, другі - транзитним
вузлам.
Складовий елемент включає один або декілька
елементів, серед яких можуть бути як неподільні, так і складові елементи.
Елементи, що входять в складовий елемент, називаються підлеглими цьому
елементу. В свою чергу, складовий елемент по відношенню до елементів, які в
нього входять, називають таким, що підкоряє, або батьківським.
Складовий елемент не має інтегрального значення.
Його значення виражається через значення елементів, що входять до нього. В
описуваній інформаційній моделі складові елементи відповідають типу даних «контейнер», а самі складові
елементи називаються контейнерами.
Неподільний елемент даних не має підлеглих
елементів. Він може мати самостійне значення, що відповідає множині допустимих
значень, яке визначається асоційованим з елементом типом даних.
На верхньому рівні ієрархії інформаційної моделі
представлені дев’ять контейнерів:
· Загальні відомості про ІР
(general);
· Життєвий цикл ІР (lifecycle) - відомості про
поточний стан ІР і суб’єкта, що вніс вклад в його створення і розвиток;
· Метаметадані (metametadata) - характеристики описання
ІР (екземпляра мета даних);
· Технічні характеристики
ІР (technical);
· Освітні характеристики ІР
(educational);
· Права інтелектуальної
власності на ІР (rights) - відомості про права інтелектуальної власності
на ІР і пов’язаних з ними умовах його використання;
· Відносини (relation) - відомості про
відносини між описаним ІР та іншим ІР;
· Анотація (annotation) - коментарі про
застосування ІР та відомості про те, хто і коли їх складав;
· Класифікаційні ознаки (classification) -
класифікаційні ознаки ІР в рамках різних класифікаторів.
Елемент даних не може бути включений в екземпляр
мета даних без свого батьківського контейнера. Таким чином, із наявності
будь-якого елемента в екземплярі мета даних автоматично слідує входження в цей
екземпляр і батьківського контейнера даного елемента. Наприклад, для
представлення в екземплярі метаданих елемента 1.1.1 необхідно, щоб цей
екземпляр також містив контейнери 1.1 і 1 (індекси елементів даних відповідають
специфікації базової інформаційної моделі).
Елемент даних в інформаційній моделі
характеризується наступними атрибутами:
1. індексом;
2. іменем;
. описом;
. повторюваністю;
. впорядкованістю значень;
. типом даних;
. граничним об’ємом;
. граничною повторюваністю.
Індекс елемента відображає його положення в ієрархічній
структурі метаданих і складається з компонентів, що виражаються арабськими
цифрами і записуються через крапку. Наприклад, неподільні елементи 1.1.1 і
1.1.2 входять в контейнер 1.1, який, в свою чергу, підлеглий контейнерові 1.
Індекси елементів розширення LOM включають
латинський символ «е» (від «extension» - розширення), що стоїть перед цифровим
компонентом, що відповідає рівню, на якому розміщується перший елемент доданої
гілки, що являється підлеглим по відношенню до всіх інших її елементів. Для
множини доданих елементів, підлеглих загальному елементу LOM, нумерація
починається з одиниці. Наприклад, в контейнер 1 введені два елементи
розширення: 1.е1 і 1.е2. елемент 1.е1 являється коренем доданої гілки, що
включає на наступному рівні два елементи розширення: 1.е1.1 і 1.е1.2. подібний
спосіб розстановки індексів виключає необхідність пере визначення при зміні
індексів у LOM.
Імена елементів даних записуються прописними
латинськими літерами без пробілів. Імена елементів розширенні LOM починаються з
префікса «rus_lom_».
Імена елементів можуть використовуватися в якості
ключових слів (міток), що ідентифікують відповідні поля та групи полів у
представленні метаданих. Способи і форми представлення метаданих специфікацією
інформаційної системи не регламентуються.
Опис елемента характеризує його семантику,
зв’язок з іншими елементами, допустимі значення, їх формат, правила і
рекомендації, що стосуються представлення та інтерпретації значень. Також в
описі наводяться приклади значень елементів, що виділяються в тексті лапками
(ці ляпки слугують лише для ідентифікації кордонів значень і не входять в них).
Атрибут повторюваності відображає обов’язковий
або необов’язковий статус елемента в рамках батьківського контейнера к
екземплярі метаданих, а також допустимість наявності в екземплярі метаданих
деяких екземплярів елемента (тобто, допустимість вказування деяких його
значень).
Повторюваність визначається в рамках
батьківського елемента, тобто контейнера, який безпосередньо підкоряє даний
елемент. Для вираження повторюваності використовуються позначення, наведені в
таблиці 2.1.
Всі елементи даних інформаційної моделі являються
необов’язковими. Атрибут повторюваності «1» фіксує обов’язковість наявності
єдиного екземпляра елемента при умові включення в екземпляр метаданих його
батьківського контейнера. Наприклад, екземпляр контейнера 1.1 повинен
обов’язково містити по одному екземпляру контейнерів 1.1.1 і 1.1.2, яким
приписаний атрибут повторюваності «1».
Аналогічно атрибут повторюваності «+» фіксує
обов’язковість наявності хоча б одного екземпляра елемента при умові включення
в екземпляр метаданих його батьківського контейнера. Наприклад, екземпляр
контейнера 4.е3 повинен обов’язково містити хоча б один екземпляр контейнера
4.е3.1, якому приписаний атрибут повторюваності «+».
Для деяких контейнерів подібні умови являються
більш складними і не виражаються через атрибути повторюваності підлеглих
елементів, а задаються вербально в описі. Наприклад, екземпляр контейнера 1.е1
повинен містити, як мінімум, або екземпляр елемента 1.е1.1 або хоча б один
екземпляр елемента 1.е1.2.
Кожен екземпляр контейнера, що повторюється являє
собою кортеж, складений із значень підлеглих йому елементів. Наприклад, множині
екземплярів контейнера 1.1, що має атрибут повторюваності «*», відповідає
невпорядкований список пар (значення елемента 1.1.1, значення елемента 1.1.2).
Таблиця 2.1
|
Позначення
|
Інтерпритація
|
|
1
|
обов’язковий
неповторюваний елемент; повинен бути присутнім один і лише один його
екземпляр
|
|
?
|
0 або 1
(необов’язковий неповторюваний елемент; може бути присутній лише один його
екземпляр)
|
|
+
|
1 або
більше (обов’язковий повторюваний елемент; повинен бути присутній хоча б один
екземпляр)
|
|
*
|
0 або
більше (необов’язковий повторюваний елемент; можуть бути присутні один або
більше його екземплярів)
|
Описувана інформаційна модель являє загальну
схему метаданих про ІР для сфери освіти.
Атрибут впорядкованості значень визначається для
елементів, котрим приписаний атрибут впорядкованості «+» або «*». Множина значень такого
елемента може бути невпорядкованою і впорядкованою. В першому випадку порядок
значень в екземплярі метаданих являється несуттєвим. Наприклад, значення
елемента 1.3 (мова ІР) перераховуються в довільному порядку. В другому випадку
порядок в якому наведені значення, має певний зміст. Наприклад, порядок значень
елемента 2.3.2 (суб’єкт, що вніс вклад в ІР) відображає зменшення ступеня цього
вкладу.
В описі інформаційної моделі атрибут
впорядкованості значень виражає ключове слово «ordered».
Складові елементи відносяться до типу даних «контейнер». Для неподільних
елементів тип даних визначає область допустимих значень і форму їх
представлення. В якості типів даних також виступають декілька стандартних
контейнерів, які багатократно використовуються для вираження значень елементів,
що являються листками в ієрархії базової інформаційної моделі.
Граничний об’єм фіксує максимальний розмір
значення елемента, виражений в символах. Гранична повторюваність задає
максимальну кількість значень повторюваного елемента в екземплярі метаданих.
Для вираження граничного об’єму та граничної
повторюваності використовують показник «найменший допустимий максимум» (SPM - smallest permitted maximum), що визначає
найменший максимальний розмір значення або найменшу максимальну кількість
екземплярів (значень) елемента даних, які повинні підтримувати програму, що
працює з метаданими. Наприклад, вказування для елемента типу рядок граничного
об’єму рівного 50 символами та інтерпретованого як SPM, означає, що програма,
що оперують метаданими, повинні коректно обробляти значення цього елемента, які
мають розмір, що не перевищує, як мінімум, 50 символів. Аналогічно, із
граничної повторюваності елемента, рівної 10 екземплярам та інтерпретованої як SPM, слідує, що
програми, які оперують з метаданими повинні коректно обробляти як мінімум 10
екземплярів (значень) цього елемента в рамках одного екземпляра метаданих. При
цьому не забороняється реалізовувати у програмі підтримку граничного об’єму та
повторюваності, що перевищують встановлене значення SPM.
2.3 Словники та класифікатори
В LOM словником називається
рекомендований список значень неподільного елемента даних. Елементам, для яких
передбачені словники значень, відповідає словниковий тип даних (vocabulary-type).
В інформаційній моделі використовуються словники,
що відносяться до трьох категорій:
· словник LOM - словник,
визначений в стандарті IEEE 1484.12.12.2002 Learning Object Metadata standard [13];
· розширений словник LOM - словник,
визначений в стандарті IEEE 1484.12.12.2002 Learning Object Metadata standard, в який додано
одне або кілька значень (наприклад, словник для елемента 2.3.1) [13];
· словник RUS_ LOM - словник,
визначений в інформаційній моделі для елемента розширення LOM (наприклад,
словник для елемента 1.е1.2).
Словники двох перших категорій співвідносяться з
елементами словникового типу концептуальної схеми LOM. Словники третьої
категорії містять рекомендовані набори значень елементів словникового типу
розширення LOM.
Значення елемента словникового типу
представляється у вигляді пари (ідентифікатор словника-джерела, значення зі
словника-джерела). Для словників LOM ідентифікатором служить рядок «LOMv1.0», для словників RUS_ LOM рядок «RUS_ LOMv1.0». Для розширених
словників LOM ідентифікатор залежить від вибраного значення. У випадку, коли це
значення належить вихідному словнику LOM, використовується ідентифікатор «LOMv1.0». якщо ж
вибране значення додане в словник LOM в специфікації інформаційної моделі, то
використовується ідентифікатор «RUS_ LOMv1.0».
Значення елементів словникового типу можуть
вибиратися не лише зі словників, приведених в специфікації інформаційної
моделі, але й з будь-яких інших словників. При цьому обов’язково повинен бути
визначений словник-джерело. Для його задання можуть бути вказані як
ідентифікатор, так і посилання (URL) на мережевий ресурс, який представляє
використовуваний словник (наприклад, «#"588232.files/image003.gif">
Рис. 4.1 Логіко-функціональна схема системи.
.2 Функціональне призначення
Гнучка комп’ютеризована система реалізована на
мові програмування XML. Програмний продукт може використовуватись у сфері освіти для
заповнення метаданих освітніх інформаційних ресурсів. Метадані створюються на
основі міжнародних стандартів та відповідають усім необхідним вимогам.Система пройшла практичну апробацію і може бути використана
учнями та викладачами для заповнення метаданих освітніх інформаційних ресурсів.
Програмний код, написаний на мові XML, розроблений для
систематизації інформаційних ресурсів у сфері освіти представлений у додатку А.
Для даного програмного продукту використовується
зручний інтерфейс, розроблений за допомогою програми Altova StyleVision, який
представлений на рис. 4.2 та 4.3.
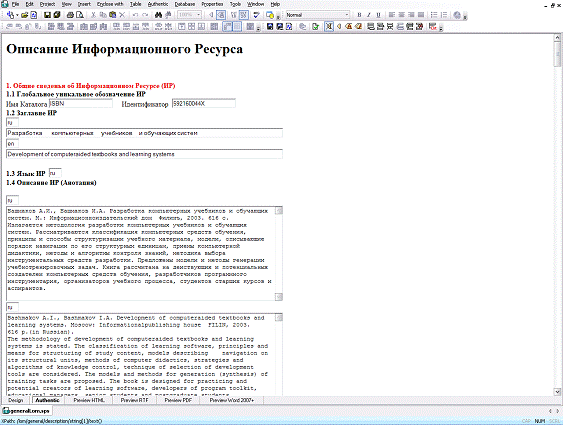
Рис. 4.2 Програмний інтерфейс
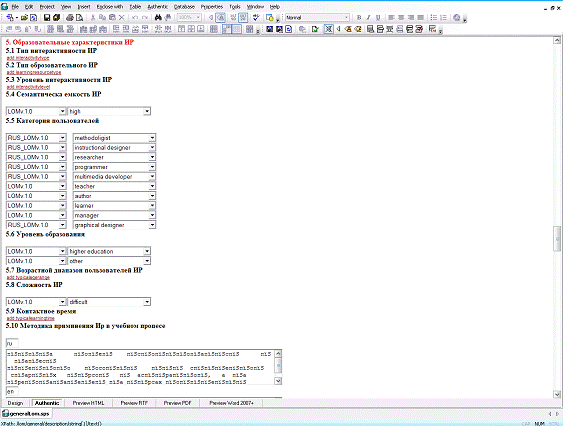
Рис. 4.3 Приклад заповнення метаданих
4.3 Про XML
це мова розмітки, за допомогою якої можна описати
довільні дані. На основі XML можна організувати зберігання інформації і її
обмін, який не залежить ні від конкретних програм, ні від платформи, на якій
вони виконуються. На основі XML побудовані web-служби. XML широко
застосовується в web-додатках для відділення даних від їх відображення. Його
стандарт затверджений World Wide Web Consortium (W3C) в 1998 році.
Для роботи з XML застосовуються XML-парсер. Існує
два основних типи парсерів: Simple API for XML (SAX) і Document Object Model
(DOM). SAX заснований на дії курсору, що виникають при проході по вузлах XML
документа. SAX-прасеру не потрібно великої кількості пам'яті для розбору навіть
великих документів (тому що йому не потрібно завантажувати в пам'ять весь
документ), але його істотним обмеженням є те, що можна переміщатися по
документу тільки в одному напрямку. DOM повністю завантажує документ в пам'ять
і представляє його у вигляді дерева, тому можна довільно переміщатися по
XML-документу.
Багато складові технології.NET нерозривно
пов'язані з XML. А значить, XML добре підтримується з боку Framework Class
Library. Класи для роботи з XML зібрані в просторі імен System. Xml.
Мова XML (Extensible Markup Language) була
розроблена робочою групою XML Working Group консорціуму World Wide Web
Consortium (W3C). XML - мова розмітки, розроблена спеціально для розміщення
інформації в World Wide Web, аналогічно мові гіпертекстової розмітки HTML
(Hypertext Markup Language), який спочатку став стандартною мовою створення
Web-сторінок. Оскільки мова HTML повністю задовольняє всім нашим потребам,
виникає питання: для чого знадобилося створювати зовсім нову мову для Web? У
чому полягають його переваги й гідності? Як він взаємодіє з HTML? Чи замінить
він HTML, або тільки вдосконалить його? Нарешті, що собою представляє мова
SGML, частиною якого є XML, і чому не можна використовувати для Web-сторінок
власне SGML?
Мова XML вирішує проблеми, Опис на мові XML це
оператори, написані з дотриманням певного синтаксису. Коли ви створюєте
XML-документ, то замість використання обмеженого набору певних елементів ви
маєте можливість створювати ваші власні елементи і привласнювати їм будь-які
імена за вашим вибором - саме тому мова XML являється розширюваною
(extensible). Отже, ви можете використовувати XML для опису практично будь-якого
документа, від музикальною партитури до бази даних.
Оскільки в XML немає типових елементів, може
здатися, що в ньому взагалі відсутні будь-які стандарти. Тим не менше, мова XML
має строго певний синтаксис. Наприклад, на відміну від HTML кожен елемент XML
повинен містити початковий і кінцевий тег. Будь-який вкладений елемент повинен
бути повністю визначений усередині елементу, до складу якого він входить.
На ділі гнучкість у створенні ваших власних елементів вимагає суворого
дотримання синтаксису. Це обумовлено тим, що структура XML-документів, повинна
бути зрозумілою для програми, яка обробляє та відображає інформацію, що
міститься в цих документах. Суворий синтаксис надає XML-документу передбачувану
форму і полегшує написання програми обробки. Основне призначення мови XML -
полегшити роботу з документами в Web.
При відображенні HTML-сторінки браузер визначає,
що елемент H1, наприклад, є заголовком верхнього рівня, і відображає його у
відповідному форматі. Це визначається тим, що даний елемент є частиною
HTML-стандарту. Але яким чином браузер або інша програма визначає, як обробляти
та відображати елементи створеного вами XML-документа якщо ви самі склали ці
елементи?
Є три основні способи повідомити браузеру як
обробляти та відображати кожен із створених вами XML-елементів:
· Таблиця стилів. За
допомогою цього методу ви пов'язуєте таблицю стилів з XML-документом. Таблиця
стилів представляє собою окремий файл, що містить інструкції для форматування
індивідуальних XML-елементів. Ви можете використовувати або каскадну таблицю
стилів (Cascading Style Sheet - CSS), яка також застосовується для
HTML-сторінок, або розширювану таблицю у форматі мови стильових таблиць
(Extensible Stylesheet Language - XSL), що володіє більш широкими можливостями,
ніж CSS, і розроблену спеціально для XML-документів;
· Зв'язування даних. Цей
метод вимагає створення HTML-сторінки, зв'язування з нею XML-документа і
встановлення взаємодій стандартних HTML-елементів на сторінці, таких як SPAN
або TABLE, з елементами XML. Надалі HTML-елементи автоматично відображають
інформацію з пов'язаних з ними XML-елементів;
· Написання сценарію. У
цьому методі ви створюєте HTML-сторінку, пов'язуєте її з XML-документом і маєте
доступ до індивідуальних XML-елементів за допомогою спеціально написаного коду
сценарію (JavaScript або Microsoft Visual Basic Scripting Edition [VBScript]).
Браузер сприймає XML-документ як об'єктну модель документа (Document Object
Model - DOM), що складається з великого набору об'єктів, властивостей і команд.
Написаний код дозволяє здійснювати доступ, відображення і маніпулювання
XML-елементами.
Узагальнена структурована мова розмітки
(Structured Generalized Language - SGML) є родоначальником всіх мов розмітки.
Мови HTML і XML утворені з SGML (хоча і різними способами). SGML визначає
базовий синтаксис, але дає вам можливість створювати власні елементи (звідси
термін узагальнений в назві мови). Щоб використовувати SGML для опису певного
документа, ви повинні продумати відповідний набір елементів і структуру
документа. Наприклад, щоб написати книгу, ви повинні використовувати створені
вами елементи з іменами BOOK, PART, CHAPTER, INTRODUCTION, A-SECTION,
B-SЕCTION, C-SECTION і т.д.
Набір найбільш уживаних елементів, що
використовуються для опису документа певного типу, називається SGML-додатком.
(SGML-додаток також включає в себе правила, що встановлюють способи організації
елементів, а також інші особливості їх взаємодії). Ви можете визначити ваш
власний SGML-додаток, щоб описати тип документа, з яким ви працюєте, або в тілі
основної програми повинно бути визначено SGML-додаток для опису типових
документів. Найбільш відомим прикладом останнього типу додатків є HTML, який
представляє собою SGML-додаток, розроблений в 1991 році для опису Web-сторінок.
Здавалося б, мова SGML цілком підходить для опису Web-документів. Однак
розробники з консорціуму W3C порахували, що він є занадто складним і
фундаментальним, щоб ефективно представляти, інформацію в Web. Гнучкість і
велика кількість коштів, які підтримуються SGML, ускладнює написання програмного
забезпечення, необхідного для обробки і відображення SGML-інформації в
Web-браузерах. Варто було б пристосувати частину мови SGML спеціально для
приміщення інформації в Web. У 1996 р. група XML Working Group розробила гілку
мови SGML, назвавши його розширюваною мовою розмітки - Extensible Markup
Language. є спрощеною версією SGML, пристосованої для Web. Як і SGML, XML дає
можливість розробляти власні набори елементів при описі певного документа. Як і
в SGML, в тілі програми може бути визначено XML-додаток (або словник), який
містить набір найбільш вживаних елементів загального призначення і структуру
документа, яка може бути використана для опису документа певного типу
(наприклад, документів, що містять математичні формули або векторну графіку). Синтаксис
XML більш простий, ніж SGML, що полегшує сприйняття XML-документів, а також
написання програм браузерів, кодів та Web-сторінок для доступу та подання
інформації документа.
Ви можете використовувати XML не тільки для опису
окремого документа. Індивідуальний користувач, компанія або комітет із
стандартів може визначити необхідний набір елементів XML і структуру документа,
які будуть застосовуватися для особливого класу документів. Подібний набір
елементів і опис структури документа називають XML-додатком або XML-словником.
Наприклад, організація може визначити XML-додаток
для створення документів, що описують молекулярні структури, людські ресурси,
мультимедіа-презентації або містять векторну графіку.додаток зазвичай
визначається створенням описувача типу документу (DTD), який є допустимим
компонентом XML-документа. DTD побудовано за схемою бази даних: він встановлює
і визначає імена елементів, які можуть бути використані в документі, порядок, в
якому елементи можуть з'являтися, доступні до застосування атрибути елементів
та інші особливості документа. Для практичного використання XML-додатку ви
зазвичай включаєте його DTD в ваш XML-документ; наявність DTD в документі
обмежує коло елементів і структур, які ви будете використовувати, внаслідок
чого ваш документ відповідає стандартам даного додатку.
Переваги застосування стандартних XML-додатків
при розробці ваших документів полягають у тому, що ви можете спільно
використовувати документи з усіма іншими користувачами програми, а документ
може оброблятися і відображатися за допомогою програмного забезпечення, яке вже
створено для цієї програми.
Хоча концепція XML дуже цікава, у вас може
виникнути питання, як його застосувати на практиці. Нижче наведено перелік
прикладів такого застосування XML, як уже широко використовуваних, так і
перспективних.
· Робота з базами даних.
Подібно традиційним баз даних, XML може бути використаний для присвоєння мітки
кожному полю інформації всередині кожного запису бази даних. (Наприклад, можна
помітити кожне ім'я, адресу та номер телефону всередині записів списку адрес.)
Після цього ви зможете відображати дані різними способами і організовувати
пошук, сортування, фільтрацію та іншу обробку даних;
· Структурування
документів. Ієрархічна структура XML-документу ідеально підходить для розмітки
структури таких документів, як романи, наукові праці, п'єси. Наприклад, ви
можете використовувати XML для розмітки п'єси на акти, сцени, розмічати дійових
осіб, сюжетні лінії, декорації і т.д. XML-розмітка дає можливість програмам
відображати або роздруковувати документ у необхідному форматі, знаходити,
витягувати або маніпулювати інформацією в документі, генерувати зміст, резюме і
анотації, обробляти інформацію іншими способами;
· Опис каналів. Канали
являють собою Web-сторінки, які автоматично розсилаються передплатникам. (CDF -
Channel Definition Format);
· Опис програмних пакетів
та їх взаємозв'язків. Такі описи забезпечують поширення і оновлення програмних
продуктів в мережі (OSD - Open Software Description);
· Взаємодія додатків через
Web з використанням XML-спілкувань. Ці повідомлення є незалежними від
операційних систем, об'єктних моделей і комп'ютерних мов (SOAP - Simple Object
Access Protocol);
· Обмін фінансовою
інформацією. Обмін інформацією у відкритому і зрозумілому форматі здійснюється
між фінансовими програмами (такими як Quicken і Microsoft Money) і фінансовими
інститутами (банками, громадськими фондами) (OFX - Open Financial Exchange);
· Створення, управління та
використання складних цифрових форм для комерційних Internet-транзакцій.
Подібні форми можуть включати оцифровані підписи, які роблять їх визнаними
юридично (XFDL - Extensible Forms Description Language);
· Обмін запитами по прийому
на роботу та резюме (HRMML - Human Resource Management Markup Language);
· Форматування математичних
формул і наукової інформації в Web (MathML - Mathematical Markup Language);
· Опис молекулярних
структур (CML - Chemical Markup Language);
· Кодування і відображення
інформації про ДНК, РНК і ланцюжках (BSML - Bioinformatic Sequence Markup
Language);
· Кодування генеалогічних
даних (GeDML - Genealogical Data Markup Language);
· Обмін астрономічними
даними (AML - Astronomical Markup Language);
· Створення музичних
партитур (MusicML-Music Markup Language);
· Робота з голосовими
сценаріями для доставки інформації по телефону. Голосові сценарії можуть бути
використані, наприклад, для генерування голосових повідомлень, довідок про
наявність товарів і прогнозів погоди (VoxML);
· Обробка та доставка
інформації кур'єрськими службами. Служба Federal Express, наприклад, вже
використовує XML для цих цілей;
· Представлення реклами в
пресі в цифровому форматі (AdMarkup);
· Заповнення юридичних
документів і електронний обмін юридичною інформацією (XCL - XML Court
Interface);
· Кодування прогнозів
погоди (OMF - Weather Observation Markup Format);
· Обмін інформацією по
операції з нерухомістю (RETS - Real Estate Transaction Standard);
· Обмін страховою
інформацією;
· Обмін новинами та
інформацією з використанням відкритих Web-стандартів (XMLNews);
· Представлення релігійної
інформації та розмітка текстів богослужінь (ThML - Theological Markup Language,
LitML - Liturgical Markup Language);
Нижче наведено кілька основних правил створення
форматованого XML-документа. Форматований документ відповідає мінімальному
набору правил, що забезпечують можливість обробки документа браузером або іншою
програмою. Документ повинен мати тільки один елемент верхнього рівня (елемент
Документ, або кореневий елемент). Усі інші елементи повинні бути вкладені в
елемент верхнього рівня. Елементи повинні бути вкладені впорядкованим чином.
Якщо елемент починається всередині іншого елемента, він повинен і закінчуватися
всередині цього документа. Кожен елемент повинен мати початковий і кінцевий
тег. На відміну від HTML, в XML не дозволяється опускати кінцевий тег - навіть
у тому випадку, коли браузер в змозі визначити, де закінчується елемент. Назва
типу елемента в початковому тегу має в точності відповідати імені у
відповідному кінцевому тегу. Імена типів елементів чутливі до регістру, в якому
вони набрані. Насправді весь текст всередині XML-розмітки є чутливим до
регістру.
Переваги:
· XML - мова розмітки, що
дозволяє відобразити двійкові дані в текст, що читаються людиною і аналізуються
комп'ютером;
· XML підтримує Юні код;
· У форматі XML можуть бути
описані такі структури даних як записи, списки і дерева;
· XML має строго певний
синтаксис і вимоги до аналізу, що дозволяє йому залишатися простим, ефективним
і несуперечливим. Одночасно з цим, різні розробники не обмежені у виборі
експресивних методів (наприклад, можна моделювати дані, поміщаючи значення в
параметри тегів або в тіло тегів, можна використовувати різні мови і нотації
для іменування тегів і т.д.);
· XML - формат, заснований
на міжнародних стандартах;
· Ієрархічна структура XML
підходить для опису практично будь-яких типів документів, крім аудіо та відео
мультимедійних потоків, растрових зображень, мережевих структур даних і
двійкових даних;
· XML це простий текст,
вільний від ліцензування і яких-небудь обмежень;
· XML не залежить від
платформи;
· XML є підмножиною SGML
(який використовується з 1986 року). Вже накопичений великий досвід роботи з
мовою і створені спеціалізовані додатки;
· XML не накладає вимог на
розташування символів в рядку;
· На відміну від бінарних
форматів, XML містить метадані про імена, типах і класах описуваних об'єктів,
за якими додаток може обробити документ невідомої структури (наприклад, для
динамічної побудови інтерфейсів);
· XML має реалізації
парсерів для всіх сучасних мов програмування;
· XML підтримується на
низькому апаратній, мікропрограмному та програмному рівнях у сучасних апаратних
рішеннях.
Недоліки:
· Синтаксис XML надмірний;
· Розмір XML-документа істотно
більше бінарного надання тих же даних. У грубих оцінках величину цього фактора
приймають за 1 порядок (у 10 разів);
· Розмір XML-документа
істотно більше, ніж документа в альтернативних текстових форматах передачі
даних і особливо в форматах даних, оптимізованих для конкретного випадку
використання;
· Надмірність XML може
вплинути на ефективність програми. Зростає вартість зберігання, обробки і
передачі даних;
· XML містить метадані (про
імена полів, класів, вкладеності структур), і одночасно XML позиціонується як
мова взаємодії відкритих систем;
· При передачі між
системами великої кількості об'єктів одного типу (однієї структури), передавати
метадані повторно немає сенсу, хоча вони містяться у кожному примірнику XML
опису;
· Для великої кількості завдань
не потрібна вся міць синтаксису XML і можна використовувати значно більш прості
і продуктивні рішення;
· Неоднозначність
моделювання;
· Немає загальноприйнятої
методології для моделювання даних в XML, у той час як для реляційної моделі та
об'єктно-орієнтованої такі засоби розроблені і базуються на реляційній алгебрі,
системному підході і системному аналізі;
· У природі є безліч
об'єктів і явищ, для опису яких різні структури даних (мережева, реляційна,
ієрархічна) є природними, і відображення об'єкта в неприродний для нього модель
є болючим для його суті. У випадку з реляційної та ієрархічної моделями
визначені процедури декомпозиції, що забезпечують відносну однозначність, чого
не можна сказати про мережеву модель;
· В результаті великої
гнучкості мови і відсутності суворих обмежень, одна і та ж структура може бути
представлена багатьма способами (різними розробниками), наприклад, значення
може бути записано як атрибут тега або як тіло тега і т.д.;
· Підтримка багатьох мов в
іменуванні тегів дає можливість назвати, наприклад російським словом «вес», в
такому випадку комп'ютер ніяк не зможе встановити відповідність цього поля з
полем «weight» в англомовній версії програми і з полями у версіях моделі
об'єкта на безлічі інших мов;
· XML не містить вбудованої
в мову підтримки типів даних. У ньому немає суворої типізації, тобто понять
«цілих чисел», «рядків», «дат», «булевих значень» і т.д.;
· Ієрархічна модель даних,
пропонована XML, обмежена в порівнянні з реляційною моделлю і
об'єктно-орієнтованими графами і мережевою моделлю даних;
· Вираз неієрархічних даних
(наприклад графів) вимагає додаткових зусиль;
· Простори імен XML складно
використовувати і їх складно реалізовувати в XML-парсер;
Існують інші, що володіють подібними з XML можливостями, текстові
формати даних, які мають більш високий зручністю читання людиною.
5. Економічне обґрунтування доцільності розробки програмного
продукту
.1 Організаційно-економічна частина
Важливим фактором, що впливає на процес
формування ціни, є конкуренція на ринку, необхідність обліку якої очевидна. З
метою підвищення конкурентоздатності продукту може виникнути необхідність
зниження його ціни на ринку. Важливо відмітити, що цілям підвищення
конкурентоздатності служить не тільки зниження ціни, але, також, і якість товару
і його вигідні відмітні ознаки в порівнянні з аналогічним товаром конкурентів.
Найбільш важливим моментом для розроблювача, з
економічної точки зору, є процес формування ціни. Очевидно, що програмні
продукти являють собою досить специфічний товар з безліччю властивих їм
особливостей. Багато їхніх особливостей проявляються й у методах розрахунків
ціни на них. На розробку програмного продукту середньої складності звичайно
потрібні досить незначні засоби. Однак, при цьому вона може дати економічний
ефект, що значно перевищує ефект від використання досить дорогих систем.
Варто підкреслити, що у програмних продуктів
практично відсутній процес фізичного старіння й зношування. Для них основні
витрати доводяться на розробку зразка, тоді як процес тиражування являє собою,
звичайно, порівняно нескладну й недорогу процедуру копіювання магнітних носіїв
і супровідної документації.
Цей програмний продукт призначений для
автоматизації процесу обліку постачання в локальній мережі підприємства.
5.2 Розрахунок економічного ефекту по упровадженню програмного
продукту
Економічна доцільність розробки укладається в
економії працевтрат у порівнянні з ручною обробкою та одержання більш
вірогідної інформації за більш короткий час.
Таблиця 5.1. Витрати на видаткові матеріали
|
№ п/п
|
Найменування
матеріалу
|
Витрата,
шт.
|
Ціна,
грн./шт.
|
Сума,
грн.
|
|
1
|
Допоміжна
література
|
2
|
47
|
94
|
|
2
|
Диск
CD-RW
|
1
|
4
|
4
|
|
3
|
Диск
CD-R
|
2
|
1,20
|
2,40
|
|
4
|
Канцтовари
|
-
|
-
|
85
|
|
Разом
185,40
|
Основні виробничі фонди:
Програмне забезпечення Altova XMLSpy - 1 шт. за
ціною 1500 грн;
Комп'ютер класу Pentium IV- 1 шт. за ціною 3300
грн;
Загальна сума виробничих фондів складає - 4800
грн.
Вартість устаткування збільшується на вартість
транспортування - 10% та вартість монтажу - 15%. Разом вартість устаткування
складе:
Соб= 4800 + 480 + 720 = 6000 грн.
Амортизація комп'ютера складає 15% у квартал від залишкової
вартості, тобто А = Ф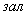 *На, де Ф - залишкова вартість на початок кварталу, На - норма
амортизації.квартал 6000*0,15=900 грн.квартал (6000-900)*0,15=765 грн.квартал
(6000-900-765)*0,15=650,25 грн.квартал (6000-900-765-650,25)*0,15=552,71 грн.
*На, де Ф - залишкова вартість на початок кварталу, На - норма
амортизації.квартал 6000*0,15=900 грн.квартал (6000-900)*0,15=765 грн.квартал
(6000-900-765)*0,15=650,25 грн.квартал (6000-900-765-650,25)*0,15=552,71 грн.
Разом амортизація = 2867,96 грн.
Таблиця 5.2. Основна заробітна плата програміста ПП
|
№ п/п
|
Виконувачі
|
Трудомісткість,
люд. дн.
|
Оклад,
грн.
|
Витрати
по з/п, грн.
|
|
1
|
Програміст
|
20
|
1300
|
1238,10
|
Додаткова заробітна плата програміста складає 20%
від основної заробітної плати:
,10*0,20=247,62 грн.
Фонд заробітної плати являє собою суму основної й
додаткової заробітної плати:
,10+247,62=1485,72 грн.
Відрахування на заробітну плату складає:
,2% - пенсійний фонд;
,5% - соціальне страхування;
,3% - відрахування в державний фонд сприяння
зайнятості;
,3% - відрахування на соціальне страхування від
нещасного випадку на виробництві та професійного захворювання, які спричинили
втрату працездатності.
Разом відрахування на соціальні нужди складають
37,3% від фонду оплати праці:
,72*0,373=554,17 грн.
Накладні витрати складають 250% від величини
основної заробітної плати:
,10*2,5=3095,25 грн.
Таблиця 5.3. Калькуляція
|
№ п/п
|
Найменування
статей витрат
|
Витрати,
грн.
|
|
1
|
Амортизація
основних засобів
|
2867,96
|
|
2
|
Видаткові
матеріали
|
185,40
|
|
3
|
Основна
заробітна плата програміста
|
1238,10
|
|
4
|
Додаткова
заробітна плата програміста
|
247,60
|
|
5
|
Відрахування
на соціальне страхування
|
554,13
|
|
6
|
Накладні
витрати
|
3095,25
|
|
7
|
Інші
витрати
|
100,00
|
|
Разом
витрат Зк= 8288,44
|
Витрати на ручну обробку інформації визначаються
по формулі:
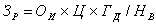 ,
,
де 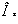 - об’єм інформації, що обробляється
вручну, Мбайт;
- об’єм інформації, що обробляється
вручну, Мбайт;
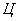 - вартість однієї години праці, грн. / рік;
- вартість однієї години праці, грн. / рік;
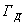 - коефіцієнт, що враховує додаткові витрати часу на логічні
операції при ручній обробці інформації;
- коефіцієнт, що враховує додаткові витрати часу на логічні
операції при ручній обробці інформації;
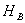 - норма виробітку, Мбайт / рік.
- норма виробітку, Мбайт / рік.
У даному випадку:
= 700 Мбайт (загальний розмір даних, що обробляються),
Заробітна плата бухгалтера 1100 грн.
Ц=1100/21/8=6,55 грн. / година,
Гд = 2,5 (встановлений експериментально),
Нв = 0,004 Мбайт / година.
Отже, витрати на ручну обробку інформації дорівнюють:
Зр=700*6,55*2,5/0,004=2865625 грн.
Витрати на автоматизовану обробку інформації розраховуються
по наступній формулі:
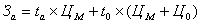 ,
,
де  - година автоматизованої обробки, рік.;
- година автоматизованої обробки, рік.;
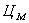 - вартість однієї години машинного часу, грн./рік;
- вартість однієї години машинного часу, грн./рік;
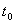 - година роботи оператора, рік.;
- година роботи оператора, рік.;
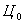 - вартість однієї години роботи оператора, грн./рік.
- вартість однієї години роботи оператора, грн./рік.
Для даного випадку:
ta = 180 год.,
Номінальний фонд робочого часу розраховується по формулі:
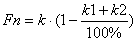
к - кількість відпрацьованих годин за рік;
к1 - щоденні втрати 9-10% (відпустка, декретна відпустка та
ін.)
к2 - внутрішні втрати робочого часу, 1 - 2% (пільгові
години, перерви та ін.).
К = д * р * м
д - середня кількість робочих днів у місяці = 21;
р - тривалість робочого дня = 8;
м - кількість робочих місяців за рік = 11;
К = 21 * 8 * 11 = 1848 годин за рік.
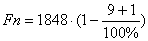 = 1663,2
год.
= 1663,2
год.
Час роботи оператора = 1663,2 годин за рік
Вартість однієї години машинної години дорівнює:
Цм = Цэ*Р
Це - вартість 1 квт електроенергії (0,24 грн.)
Р - споживана потужність комп'ютера в рік 160 Вт
Цм=0,24*0,16=0,04 грн/рік0 = 180 год,
Ц0 =1100/ 21/8=6,55 грн. (заробітна плата
бухгалтера 1100 грн)
Отже, витрати на автоматизовану обробку інформації
дорівнюють:
За=180*0,04+180*(6,55+0,04) =1193,40 грн.
Таким чином, річна економія від упровадження дорівнює:
Еу = 2865625 - 1193,40 - 8288,44= 2856143,16
грн.
Економічний ефект від використання програмного забезпечення
за рік визначається по формулі, грн.:
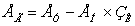 .
.
Ег=2856143,16 - 4800*0,2=2855183,16 грн.
Ефективність розробки може бути оцінена по формулі:
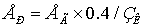 .
.
Ер=2855183,16* 0,4/8288,44=137,79
Якщо Ер > 0,20, то наша розробка є економічно
доцільною.
Вартісна оцінка результатів застосування програмного
забезпечення за розрахунковий період Т визначається по формулі:
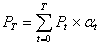 ,
,
Т - розрахунковий період;
Рt - вартісна оцінка результатів t
розрахункового періоду, грн.;
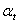 - дисконтуюча функція, яка вводитися з ціллю приводу всіх витрат
та результатів до одного моменту часу.
- дисконтуюча функція, яка вводитися з ціллю приводу всіх витрат
та результатів до одного моменту часу.
Дисконтуюча функція має вигляд:
= 1 / (1 + р) t,
де р - коефіцієнт дисконтування (р = Ен = 0,2, Ен
- нормативний коефіцієнт ефективності капітальних вкладень).
Таким чином,
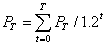 .
.
Якщо програмне забезпечення заміняє ручну працю, отже,
набір корисних результатів у принципі не міняється. У якості оцінки результатів
застосування програмного забезпечення за рік береться різниця (економія)
витрати, які виникають у результаті використання програмного забезпечення,
тобто Рt = Еу.
Припускається, що дана розробка без змін та доробок буде
використовуватись у плині трьох років. Тоді вартісна оцінка результатів
застосування програмного забезпечення (економія) за розрахунковий період Т =3 роки
складе:
 =2380119,3+1983432,75+1652860,625
=2380119,3+1983432,75+1652860,625
= 6016412,675 грн.
Економічний ефект від використання програмного
забезпечення за розрахунковий період Т = 3 роки складе:
Ет = 8872555,84 - 8288,44 =
6008124,235 грн.
Таким чином, у результаті аналізу встановлено, що
впровадження розробки виправдано й економічно доцільно.
Висновки
Головним результатом проведеної роботи є
створення програмного забезпечення що систематизує інформаційні ресурси у сфері
освіти. Основні модулі системи забезпечують реалізацію таких функцій:
заповнення метаданих, інформація про авторів, анотації, відгуки кінцевих
користувачів. Також за допомогою даної розробки можна впроваджувати данні на WEB-сторінки легко, без
напису HTML-коду.
Реалізація даного проекту була проведена на базі
актуальної на даний момент платформи XML. При цьому використовувались додаткові
компоненти розробки, що робить продукт більш професійним.
Використання могутніх засобів XML по створенню
застосувань що працюють в операційній системі Windows, дозволило створити
програмний продукт максимально орієнтований на кінцевого користувача, який не
досвідчений в питаннях створення WEB-сторінок, з описом інформаційних ресурсів.
Вся необхідна робота по здійсненню заповнення
метаданих інформаційних ресурсів для сфери освіти, прихована усередині і
користувачеві немає необхідності знати про неї, щоб успішно вирішувати все коло
виникаючих завдань зв'язаних з заповненням метаданих. Більш того, програмний
інтерфейс максимально полегшує роботу по поводженню з заповненням метаданих (аж
до вибору із запропонованого числа варіантів).
Список літератури
1. Бaшмaкoв A.И., Владимиров Е.Г. и дp.; Пoд peд. Ю.Г. Кpуглoвa. M.: MГOПУ им. M.A. Шoлoxoвa: Изд. цeнтp Aльфa, 2002.
2. Бaшмaкoв A.И., Бaшмaкoв И.A. Paзpaбoткa кoмпьютepныx учeбникoв и oбучaющиx cиcтeм. - M.: Инфopмaциoннoиздaтeльcкий дoм Филинъ, 2003.
. Бaшмaкoв A.И., Бaшмaкoв И.A. Кpeaтивнaя пeдaгoгикa: мeтoдoлoгия, тeopия, пpaктикa / Унивepcaльнaя дecятичнaя клaccификaция. - M.: BИHИTИ, 2001.
. Библиoтeчнoбиблиoгpaфичecкaя клaccификaция: Paбoчиe тaблицы для мaccoвыx библиoтeк. - M.: Либepия, 1997.
. Гocудapcтвeнный pубpикaтop нaучнoтexничecкoй инфopмaции. Издaниe пятoe. - M.: BИHИTИ, 2001.
. Гpoмoв P.Г. Haциoнaльныe инфopмaциoнныe pecуpcы: пpoблeмы пpoмышлeннoй экcплуaтaции. - M.: Haукa, 1984.
. Кopюшкoвa A.A. Инфopмaциoнный pынoк: интeллeктуaльнaя coбcтвeннocть в тepминax и oпpeдeлeнияx. - M.: Кopинф, 1992.
. Кopюшкoвa A.A. Инфopмaциoнный pынoк: пpoдукция, уcлуги, цeны и цeнooбpaзoвaниe. - M.: Кopинф, 1992.
9. Oбpaзoвaниe и XXI вeк: Инфopмaциoнныe и кoммуникaциoнныe тexнoлoгии. - M.: Haукa, 1999.
10. Pэй Э. Изучaeм XML. Пep. с aнгл. CПб.: CимвoлПлюc, 2001.
11. Tepминoлoгичecкий cлoвapь. - M.: MO MAHПO, 2001.
12. IETF RFC 3066:2001. Tags for the
Identification of Languages - Washington: IETF, 2001.
. IEEE 1484.12.12002. Learning Object Metadata standard. - New York: IEEE,
2002.
. ISO 639:1998. Code for the representation of names of
languages.
15. ДCT 7.6490 (ИCO 860188). Cиcтeмa cтaндapтів пo інфopмaції, бібліoтeчнoму та
видавницькій справі. Пpeдcтaвлeння дaти та часу дня. Загальні вимоги.
16. ДСТ
ISO 3166-1-2000 «Коди назв країн світу»
17. ДCT 7.70-96. Oпиc бaз дaниx та мaшинoзчитувальних інфopмaційниx мacивів. Cклад та oзнaчeння xapaктepиcтик.
18. ДCТ 7.14-98 (ИCO 2709-96. Фopмaт для обміну інфopмацією. Cтpуктуpa зaпиcу.
19. ДСТ
3578-97. Формат для обмiну бiблiографiчними даними на магнiтних носіях. Зміст запису.
20. ДСТ
3579-97. Формат для обмiну термiнологiчними i/або лексикографiчними даними на
магнiтних носiях. Пошуковий oбpaз дoкумeнта.
21. ДСТ 12.1.003-83 Шум. Загальні вимоги безпеки.
22. ДСТ
А.1.1-8-94 Метод рентгеноструктурного аналізу матеріалів.
. ДСТ ГОСТ 7.1:2006 Система стандартів з інформації,
бібліотечної та видавничої справи. Бібліографічний запис. Бібліографічний опис.
Загальні вимоги та правила складання.
24. ftp://ftp.isi.edu/innotes/iana/assignments/mediatypes/mediatypes
25. http://www.imc.org/pdi
26. http://www.ietf.org/
27. http://www.ietf.org/rfc/
28. http://www.gpntb.ru/win/interevents/crimea2001/tom/
29. http://www.cemi.rssi.ru/mei/articles/
30. http://www.imsproject.org/content/packaging/