Применение кластерного анализа для выделения сегмента ключевых клиентов фитнес-клуба
ФГАОУВПО
«Казанский (Приволжский) федеральный университет»
ДОКЛАД
на
тему:
«ПРИМЕНЕНИЕ
КЛАСТЕРНОГО АНАЛИЗА ДЛЯ ВЫДЕЛЕНИЯ СЕГМЕНТА КЛЮЧЕВЫХ КЛИЕНТОВ ФИТНЕС-КЛУБА»
Выполнил:
Студент группы 901п
Газимов
Наиль Раилевич
Проверил:
Евстафьев Николай Васильевич
Казань 2012
Кластерный анализ - метод
классификации объектов по заданным признакам. Задача кластерного анализа
состоит в формировании групп:
– однородных внутри (условие
внутренней гомогенности);
– четко отличных друг от друга
(условие внешней гетерогенности).
Целью кластерного анализа в
маркетинге является определение целевых групп потребителей, для которых было бы
целесообразно разработать специальное торговое предложение, то есть уникальную
комбинацию инструментов маркетинга.
Элементы, включаемые в один и тот же
кластер, имеют разную степень схожести (уровень отличия друг от друга). Техника
кластерного анализа заключается в выявлении уровня схожести всех исследуемых
элементов и последовательном объединении элементов в порядке возрастания уровня
различия между ними. Число выявленных кластеров зависит от заданного уровня
схожести (различия) элементов, включаемых в один кластер.
Рассмотрим применение кластерного
анализа для выделения сегмента ключевых клиентов фитнес-клуба «DYNAMITE-GYM».
Из всей совокупности клиентов, занимающихся фитнесом в фитнес-клубе,
Dynamite-Gym
требуется выделить группы, однородные по возрасту и интересам (мотивам занятий
в фитнес-клубе). Для анализа используется выборка в размере 20 человек.
Следовательно, в проведении кластерного анализа участвуют 20 объектов и две
переменные, по которым будет производиться разделение объектов на однородные
группы (кластеры): возраст и интересы (мотивы занятий в фитнес-клубе) клиентов
(таблица 1).
В ходе проведенного анкетирования были выделены
4 группы интересов (4 мотива поведения) клиентов: «Внешний вид», «Здоровье»,
«Отдых» и «Престиж».
Каждая из перечисленных групп интересов
представлена в базе данных как самостоятельная переменная. Это означает, что
каждый клиент фитнес-клуба руководствуется не каким-то одним из четырех мотивов
поведения, а всеми сразу. Различия между клиентами состоят лишь в том, что
перечисленные интересы (мотивы поведения) важны для каждого в разной степени.
Следовательно, в ходе кластерного анализа следует выделить группы клиентов,
однородные по возрасту и по структуре их интересов.
кластерный анализ
маркетинг клиент
Таблица 1
Исходный массив данных для проведения
кластерного анализа
|
№
п/п
|
Объекты
исследования (клиенты)
|
Характеристики
объектов (переменные, по которым производится разделение на кластеры)
|
|
|
Возраст
|
Интересы
(мотивы поведения)
|
|
1
2 ... 30
|
Клиент
№ 1 Клиент № 2 ... Клиент № 30
|
|
|
Поскольку характеристика «интересы клиентов»
является множественной переменной, то есть в базе данных она представлена в
виде 4 переменных, то исходный массив данных (таблица 1) является трехмерным.
Метод кластерного анализа позволяет обрабатывать лишь двухмерные массивы данных
(объекты и их характеристики). Для того чтобы проведение кластерного анализа
стало возможным, необходимо преобразовать структуру исходного массива данных,
как представлено в таблице 2.
Таблица 2
Преобразованная структура исходного массива
данных для проведения кластерного анализа
|
№
п/п
|
Объекты
исследования (возрастные группы клиентов)
|
Интересы
клиентов (переменные, по которым производится разделение на кластеры)
|
|
|
Внешний
вид
|
Здоровье
|
Отдых
|
Престиж
|
|
1
|
18-25
лет
|
|
|
|
|
|
2
|
26-35
лет
|
|
|
|
|
|
3
|
36-45
лет
|
|
|
|
|
|
4
|
46-55
лет
|
|
|
|
|
|
5
|
55-65
лет
|
|
|
|
|
В таблицу 2 вносятся оценки клиентами степени, в
какой они руководствуются теми или иными интересами при проведении времени на
отдыхе. Данные оценки являются средними по каждой возрастной группе.
Разделение возрастных групп на категории
(например, от 26 до 35 лет) было произведено в целях сокращения числа объектов
исследования. В проведении исследований участвовали клиенты в возрасте от 18 до
65 лет. Если бы в качестве объектов исследования были взяты возрастные группы,
объединяющие только клиентов определенного возраста (например, 18 лет, 25 лет...
45 лет и т.д.), то число объектов исследования составило бы 47 объектов (65 -
18). Большое число объектов исследования существенно затрудняет интерпретацию
результатов кластерного анализа. Разделение возрастных групп на категории
привело к сокращению числа объектов исследования (возрастных групп клиентов) с
47 до 5.
Для проведения кластерного анализа в
SPSS создается
новый файл данных (рисунки 1 и 2).
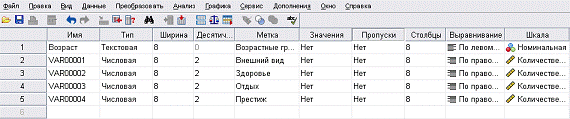
Рис. 1. Фрагмент вкладки «Переменные»
Четыре переменные с именами «VAR00001»,
«VAR00002», «VAR00003» и «VAR00004» являются компонентами факторной модели.
Значения этих переменных представляют собой усредненные балльные оценки
важности для клиентов каждой возрастной группы следующих интересов: «Внешний
вид», «Здоровье», «Отдых» и «Престиж» (рисунок 2).
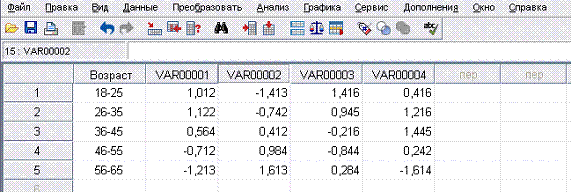
Рис. 2. Фрагмент вкладки «Переменные»
При проведении опроса респондентам предлагалось
оценить 4 мотива посещения фитнес-клуба по 5-балльной шкале («1» - «очень
важно» и «5» - «совсем не важно»). В результате проведения анализа средняя
оценка (3) была приравнена к нулю. Именно поэтому средние значения оценки
значения для клиентов четырех мотивов поведения, представленные на рисунке 2,
варьируют от -2 до 2. Чем больше отрицательное значение переменной, тем она
важнее; чем больше положительное значение переменной, тем она менее важна.
После того как сформирована база данных в
SPSS, следует перейти
непосредственно к заданию набора команд на выполнение кластерного анализа.
Кластерный анализ является одним из видов
классификационного анализа. Для задания команд на выполнение кластерного
анализа в SPSS
в меню различных видов анализа следует выбрать «Классификация».
«Классификация», в свою очередь,
имеет собственное меню, содержащее различные виды классификационного анализа, в
том числе три вида кластерного анализа. Используем иерархический кластерный
анализ, наиболее часто применяемый на практике.
Иерархический кластерный анализ отличается от
других видов кластерного анализа тем, что алгоритм его проведения является
многоступенчатым. Алгоритм иерархического кластерного анализа может быть
дивизионным или агломеративным.
В левом поле открывшегося диалогового окна
«Иерархический кластерный анализ» представлен список пяти переменных исходного
массива данных. Из них следует выбрать переменные, по которым будет
производиться формирование кластеров, и перенести их в правое поле. В
рассматриваемом примере - это переменные, характеризующие интересы (мотивы
поведения) клиентов: «Внешний вид», «Здоровье», «Отдых» и «Престиж».
Также из списка всех переменных исходной базы
данных следует выбрать переменную, значения которой являются объектами
исследования, и перенести ее в правое поле. В рассматриваемом примере это
переменная «возрастные группы».
В качестве кластеризации выберем «возрастные
ограничения», то есть в ходе кластерного анализа будут классифицироваться
(собираться в кластеры) возрастные группы клиентов, а не их интересы (мотивы
поведения). В качестве метода формирования кластеров выбран метод Варда.
Среди данных, выдаваемых
SPSS в качестве
результатов кластерного анализа, в первую очередь на экран выводится таблица,
содержащая результаты сравнения объектов исследования.
Таблица 3 Матрица близости
|
Наблюдение
|
Квадраты
Евклидовых Расстояний
|
|
1:18-25
|
2:26-35
|
3:36-45
|
4:46-55
|
5:56-65
|
|
1:
18-25
|
,000
|
1,324
|
7,254
|
13,856
|
19,510
|
|
2:
26-35
|
1,324
|
,000
|
3,043
|
10,492
|
19,444
|
|
3:
36-45
|
7,254
|
3,043
|
,000
|
3,797
|
14,208
|
|
4:
46-55
|
13,856
|
10,492
|
3,797
|
,000
|
5,364
|
|
5:
56-65
|
19,510
|
19,444
|
14,208
|
5,364
|
,000
|
|
Данные таблицы 3 показывают, в какой степени
схожи (различны) между собой разные возрастные категории клиентов по структуре
их интересов (мотивов посещения фитнес-клуба). Наиболее схожими относительно структуры
их интересов являются возрастные категории клиентов (18-25 лет) и (26-35 лет).
Квадрат евклидова расстояния между этими группами составляет всего 1,324 и
является минимальным из всех прочих значений этого показателя. Следовательно,
данные возрастные категории клиентов должны быть объединены в один кластер.
Для определения очередности последующего
объединения объектов исследования в кластеры необходимо заново определить
квадрат евклидова расстояния между вновь созданным кластером и прочими
кластерами.
Результаты расчета квадратов евклидова
расстояния для каждого этапа формирования кластеров не выводятся на экран
компьютера. Среди данных, выводимых на экран в качестве результатов кластерного
анализа, предоставляются лишь результаты сравнения кластеров на этапе, когда
каждый объект исследования рассматривается как кластер.
Данные таблицы 3 не предоставляют сведений об
очередности формирования кластеров. Она дает лишь общее представление о
сходстве (различии) объектов исследования. По данным этой таблицы можно сделать
лишь приблизительные выводы о том, какие из объектов исследования окажутся
объединенными в один кластер.
В качестве результатов проведения кластерного
анализа в SPSS
после таблицы с результатами сравнения объектов исследования на экран выводится
таблица «Шаги агломерации» (таблица 4).
Таблица 4
Шаги агломерации
|
Этап
|
Кластер
объединен с
|
Коэффициенты
|
Этап
первого появления кластера
|
Следующий
этап
|
|
Кластер
1
|
Кластер
2
|
|
Кластер
1
|
Кластер
2
|
|
|
1
|
1
|
,662
|
0
|
0
|
4
|
|
2
|
3
|
4
|
2,561
|
0
|
0
|
3
|
|
3
|
3
|
5
|
8,452
|
2
|
0
|
4
|
|
4
|
1
|
3
|
19,658
|
1
|
3
|
0
|
Таблица 4 описывает порядок построения
кластеров. Каждая строка представляет собой этап (шаг) процесса формирования
кластеров. Последняя строка таблицы описывает последний этап этого процесса,
когда все объекты исследования объединяются в один кластер.
Число строк в таблице «Шаги
агломерации» всегда на единицу меньше числа объектов исследования. В
рассматриваемом примере объектами исследования являются 5 возрастных категорий клиентов,
и число шагов их поэтапного объединения в один кластер составляет 4.
Основной принцип метода
Вард
заключается в том, что в первую очередь должны объединяться те кластеры,
объединение которых в наименьшей степени способствует увеличению гетерогенности
(разнородности) внутри формируемых кластеров.
В столбце «Коэффициент»
указываются значения коэффициента, характеризующего степень гетерогенности
(разнородности) формируемых кластеров. На начальном (нулевом) этапе
формирования кластеров, когда каждый объект исследования рассматривается как
кластер, все кластеры являются абсолютно гомогенными (однородными).
Коэффициент, характеризующий степень их гетерогенности, равен нулю.
Гетерогенность кластеров повышается по мере их
объединения в более крупные. На первом этапе при объединении кластеров 18-25
лет и 26-35 лет гетерогенность вновь созданного кластера характеризуется
значением коэффициента 0,662.
На последнем (четвертом)
этапе при объединении всех объектов исследования в один кластер гетерогенность
созданного кластера характеризуется значением коэффициента 19,658.
Применение метода Вард
обеспечивает минимально возможное увеличение степени гетерогенности формируемых
кластеров в процессе объединения мелких кластеров в более крупные.
В таблице указывается
номер этапа формирования кластеров, когда новый кластер будет объединяться с
другими.
Например, на первом этапе при объединении
кластеров «18-25» и «26-35» создается новый кластер, ему
присваивается номер «1». Созданный кластер «1» будет объединяться с кластером «36-45»
на четвертом этапе формирования кластеров.
Таким образом, таблица достаточно подробно
описывает очередность формирования кластеров, начиная с нулевой стадии, когда
каждый объект исследования рассматривается как кластер, и заканчивая созданием
кластера, объединяющего все объекты исследования.
Отметим, что программа
SPSS не дает ответа на вопрос, какое число
формируемых кластеров является оптимальным.
При решении этой задачи учтем два аспекта:
1) В процессе формирования кластеров их число
становится все меньше, а количество объектов исследования, входящих в один
кластер, - все больше.
2) С увеличением числа объектов, объединяемых в
один кластер, растет гетерогенносгь формируемого кластера.
Оптимальным является такое число кластеров, при
котором сформированные кластеры:
– с одной стороны, объединяют в себе как можно
больше объектов исследования;
– с другой стороны, являются возможно
менее гетерогенными внутри.
Решение относительно оптимального числа
формируемых кластеров принимается на основании данных таблицы «Шаги
агломерации».
В результате проведения кластерного анализа
объекты исследования должны быть объединены в три кластера. Именно такое
решение обеспечит создание сравнительно однородных кластеров, объединяющих
достаточно большое число объектов исследования.
Результаты кластерного анализа нагляднее всего
представляются в виде дендограммы. Дендограмма является графическим
изображением таблицы «Шаги агломерации».
При построении дендограммы
SPSS нормирует значения
коэффициента, характеризующего степень гетерогенности формируемых кластеров, по
шкале от нуля до 25. Дендограмма иллюстрирует увеличение разнородности
кластеров по мере их укрупнения. Максимальное значение шкалы дендограммы 25
характеризует максимально возможную степень гетерогенности кластеров, когда все
объекты исследования объединены в один кластер.
H I E R A R C H I C A L C L U S T E
R A N A L Y S I S * using Ward MethodDistance Cluster CombineA S E 0
5
10
15
20
25Num
+---------+---------+---------+---------+---------+
-25 1 -+-----------------------------------------------+
-35 2 -+ |
-45 3 -----+-------------------+ |
-55 4 -----+
+-----------------------+
-65 5 -------------------------+
Рис. 3. Результат кластерного анализа:
дендограмма
В качестве оптимального числа формируемых
кластеров в рассматриваемом примере было определено число 3. Окончательным
результатом кластерного анализа является разделение 5 возрастных групп клиентов
на три кластера:
кластер 1: клиенты 18-35 лет;
кластер 2: клиенты 35-55 лет;
кластер 3: клиенты 56-65 лет.
Как видно из дендограммы, кластеры «1» и «2», то
есть возрастные группы клиентов «18-35 лет» и «36-55 лет», являются более
однородными по структуре интересов (мотивов проведения времени на отдыхе) по
сравнению с возрастной группой «56-65 лет».
После кластерного анализа можно проводить
дополнительные исследования, в ходе которых оцениваются особенности выделенных
кластеров. В нашем примере можно выяснить, какие именно интересы клиентов
(мотивы посещения фитнес-клуба) являются наиболее важными для каждого сформированного
кластера.
Также для выявления отличительных особенностей
сформированных кластеров можно провести впоследствии дискриминантный анализ. С
помощью дискриминантного анализа, например, можно выяснить, отличаются ли друг
от друга клиенты фитнес-клуба, оказавшиеся в разных кластерах, по каким-либо
социально-демографическим признакам (кроме возраста, поскольку эта переменная
лежит в основе формирования кластеров).