Моделирование курса акций AAPL и IBM
Содержание
Введение
1. Теоретико-методологические подходы к моделированию временных
рядов
1.1 Временной ряд и его структура
1.2 Методы выделения тренда и трендовые модели
1.3 Оценка качества построенной модели
2. Исследование курса акций AAPL и IBM
2.1 Курсовая стоимость акции
2.2 Общая характеристика и историческое развитие компаний
2.3 Моделирование тенденции временного ряда акции AAPL
2.4 Моделирование тенденции временного ряда акции IBM при наличии
структурных изменений
2.4.1 Подбор трендовой модели
2.4.2 Тест Чоу для анализа структурных изменений
3. Прогнозирование курса акции aapl на основе адаптивных моделей
3.1 Построение модели ARMA (p,q)
3.2 Модель ARIMA (p,d,q)
3.3 Анализ моделей и прогнозирование
Заключение
Список использованных источников
Приложения
Введение
В каждой сфере экономики встречаются явления и процессы,
которые интересно и важно изучать в их развитии (например, цены, курсы валют,
режим протекания производственного процесса). Совокупность измерений подобного
рода показателей в течение некоторого периода времени и представляет собой
временной ряд. Если такую наблюдаемую совокупность определенным образом
обработать, при некоторых условиях возможно с большой точностью произвести
оценку будущего значения временного ряда, зная только предыдущие. Кроме того
можно попытаться выяснить механизм, лежащий в основе процесса. Для того чтобы
управлять им необходимо уметь освобождать временной ряд от компонент, которые
затемняют его динамику.
Целью дипломной работы является моделирование курса акций
AAPL и IBM и их прогнозирование на основе полученных моделей. Для достижения
поставленной цели необходимо решить следующие задачи:
) изучение теоретико-методологического подхода к
моделированию временных рядов;
2) построение полиномиальной модели тренда для курса
акции AAPL и ее корректирование с учетом автокорреляции остатков;
) построение модели для курса акции IBM с учетом
структурных изменений;
) построение адаптивных моделей для курса акции AAPL.
Объектом исследования являются ряды значений курса акций AAPL
и IBM за один торговый год по данным бирж NASDAQ и NYSE.
В процессе исследования применялся метод эконометрического
моделирования.
Методологическую основу исследования при написании дипломной
работы составили труды Суслова В. И, Лукашина Ю.П., Елисеевой И.И., Канторовича
Г.Г. и других специалистов.
Структура работы состоит из трех разделов, введения и
заключения.
В первом разделе раскрываются теоретико-методологические
подходы к моделированию временных рядов. Рассмотрены составляющие временного
ряда, проверка существования и методы выделения тренда, указан алгоритм оценки
качества построенной модели. Указаны особенности построения моделей при
нарушении условий Гаусса-Маркова.
Второй раздел посвящен исследованию курса акций AAPL и IBM,
построению и оценке качества трендовых моделей без учета и с учетом структурных
изменений. Предложено историческое развитие компаний.
В третьей части прогнозируется курс акции AAPL на основе
адаптивных моделей ARMA и ARIMA и модели тренда. Сравнение моделей
осуществляется по соответствующим критериям. По наилучшей модели построен
краткосрочный прогноз.
курс акция моделирование тренд
1.
Теоретико-методологические подходы к моделированию временных рядов
1.1 Временной
ряд и его структура
Временным рядом называют ряд наблюдаемых значений исследуемых
переменных, расположенных в хронологическом порядке или в порядке возрастания
времени, хотя возможно упорядочение и по какому-либо другому параметру.
Основной чертой, выделяющей анализ временных рядов среди других видов статистического
анализа, является существенность порядка, в котором производятся наблюдения
[6].
Различают два вида временных рядов. Пусть измерение некоторых
величин (температуры, напряжения и т.д.) производится непрерывно, по крайней
мере, теоретически. При этом наблюдения можно фиксировать в виде графика. Но
даже в том случае, когда изучаемые величины регистрируются непрерывно,
практически при их обработке используются только те значения, которые
соответствуют дискретному множеству моментов времени. Следовательно, если время
измеряется непрерывно, временной ряд называется непрерывным, если же время
фиксируется дискретно, т.е. через фиксированный интервал времени, то временной
ряд дискретен. В дипломной работе в дальнейшем мы будем иметь дело только с
дискретными временными рядами. Дискретные временные ряды получаются двумя
способами:
выборкой из непрерывных временных рядов через регулярные
промежутки времени, т.е. в определенный момент времени (например, численность
населения, величина собственного капитала фирмы, объем денежной массы, курс
акции), - такие временные ряды называются моментными;
накоплением переменной в течение некоторого периода времени,
т.е. за определенный момент времени (например, объем производства какого-либо
вида продукции, количество осадков, объем импорта), - в этом случае временные
ряды называются интервальными.
Также в теории и реже в практике рассматриваются производные
временные ряды, в которых наблюдаемые значения являются производными
величинами, т.е. средними или относительными показателями.
В эконометрии принято моделировать временной ряд как
случайный процесс, называемый также стохастическим процессом, под которым
понимается статистическое явление, развивающееся во времени согласно законам
теории вероятностей. Случайный процесс - это случайная последовательность.
Временной ряд - это лишь одна частная реализация такого теоретического
стохастического процесса:
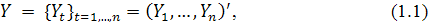
где 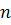 - длина временного ряда.
- длина временного ряда.
Временной ряд вида (1.1) также часто неформально называют
выборкой, хотя, по формальному определению, выборка должна состоять из
независимых, одинаково распределенных случайных величин.
Обычно стоит задача по данному ряду сделать какие-то заключения о
свойствах лежащего в его основе случайного процесса, оценить параметры, т.е.
исследовать характеристики структуры временного ряда, а также сделать прогнозы
на основе прошлых и настоящих значений временного ряда и т.п.
Возможные значения временного ряда в данный момент времени 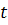 описываются с помощью случайной величины
описываются с помощью случайной величины 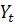 и связанного с ней распределения вероятностей
и связанного с ней распределения вероятностей 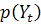 . Тогда наблюдаемое значение временного ряда в момент рассматривается как одно из множества значений, которые могла бы
принять случайная величина в этот момент времени. Следует отметить, однако, что, как
правило, наблюдения временного ряда взаимосвязаны, и для корректного его
описания следует рассматривать совместную вероятность
. Тогда наблюдаемое значение временного ряда в момент рассматривается как одно из множества значений, которые могла бы
принять случайная величина в этот момент времени. Следует отметить, однако, что, как
правило, наблюдения временного ряда взаимосвязаны, и для корректного его
описания следует рассматривать совместную вероятность 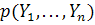 .
.
Для удобства можно провести классификацию случайных процессов и
соответствующих им временных рядов на детерминированные и случайные процессы
(временные ряды). Детерминированным называют процесс, который принимает
заданное значение с вероятностью единица. Например, его значения могут точно
определяться какой-либо математической функцией от момента времени . Обычно, когда идет речь о случайном процессе и случайном
временном ряде, то подразумевается, что он не является детерминированным.
Стохастические процессы подразделяются на стационарные и
нестационарные процессы. Стохастический процесс является стационарным, если он
находится в определенном смысле в статистическом равновесии, т.е. его свойства
с вероятностной точки зрения не зависят от времени. Процесс не стационарен,
если эти условия нарушаются.
Важное теоретическое значение имеют гауссовские процессы. Это
такие процессы, в которых любой набор наблюдений имеет совместное нормальное
распределение. Как правило, термин "временной ряд" сам по себе
подразумевает, что этот ряд является одномерным (скалярным).
При анализе экономических временных рядов традиционно различают
разные виды эволюции (динамики). Эти виды динамики могут, вообще говоря,
комбинироваться. Тем самым задается разложение временного ряда на составляющие
или компоненты, которые с экономической точки зрения несут разную
содержательную нагрузку. Различают два вида компонент: систематические (это
результат воздействия на временной ряд постоянно действующих факторов) и
случайные (это случайный шум или ошибка, нерегулярно воздействующие на ряд).
Перечислим наиболее важные компоненты. К систематическим относятся
следующие:
тенденция - соответствует медленному изменению, происходящему в
некотором направлении, которое сохраняется в течение значительного промежутка
времени. Тенденцию называют также трендом или долговременным движением;
циклические колебания - это более быстрая, чем тенденция,
квазипериодическая динамика, выходящая за рамки одного периода и в которой есть
фаза возрастания и фаза убывания. Промежуток времени между двумя вершинами или
впадинами считается длиною цикла. На циклические компоненты оказывают влияние
трудно идентифицируемые формальными методами факторы (изменение политической
ситуации, прирост или истощение ресурсов и др.). Наиболее часто цикл связан с
флуктуациями экономической активности;
сезонные колебания - соответствуют изменениям, которые происходят
регулярно в течение года, недели или суток, т.е. внутри одного выделенного
периода. Они связаны с сезонами и ритмами человеческой активности;
календарные эффекты - это отклонения, связанные с определенными
предсказуемыми календарными событиями, такими, как праздничные дни, количество
рабочих дней за месяц, високосный год и т.п.
Систематические компоненты могут одновременно все присутствовать
во временном ряде.
Случайные компоненты включают в себя следующие виды:
случайные флуктуации - беспорядочные движения относительно большой
частоты. Они порождаются влиянием разнородных событий на изучаемую величину
(несистематический или случайный эффект). Часто такую составляющую называют
шумом (этот термин пришел из технических приложений).
выбросы - это аномальные движения временного ряда, связанные с
редко происходящими событиями, которые резко, но лишь очень кратковременно
отклоняют ряд от общего закона, по которому он движется.
структурные сдвиги - это аномальные движения временного ряда,
связанные с редко происходящими событиями, имеющие скачкообразный характер и
меняющие тенденцию.
Некоторые экономические ряды можно считать представляющими те или
иные виды таких движений почти в чистом виде. Но большая часть их имеет очень
сложный вид. В них могут проявляться, например, как общая тенденция
возрастания, так и сезонные изменения, на которые могут накладываться случайные
флуктуации. Часто для анализа временных рядов оказывается полезным
изолированное рассмотрение отдельных компонент.
Для того чтобы можно было разложить конкретный ряд на эти
составляющие, требуется сделать какие-то допущения о том, какими свойствами они
должны обладать. Желательно построить сначала формальную статистическую модель,
которая бы включала в себя в каком-то виде эти составляющие, затем оценить ее,
а после этого на основании полученных оценок вычленить составляющие. Однако
построение формальной модели является сложной задачей. В частности, из
содержательного описания не всегда ясно, как моделировать те или иные
компоненты. Например, тренд может быть детерминированным или стохастическим.
Аналогично, сезонные колебания можно комбинировать с помощью детерминированных
переменных или с помощью стохастического процесса определенного вида.
Компоненты временного ряда могут входить в него аддитивно или мультипликативно,
либо в смешенном виде. Более того, далеко не все временные ряды имеют
достаточно простую структуру, чтобы можно было разложить их на указанные
составляющие. Существует два основных подхода к разложению временных рядов на
компоненты. Первый подход основан на использовании множественных регрессий с
факторами, являющимися функциями времени, второй основан на применении линейных
фильтров.
1.2 Методы
выделения тренда и трендовые модели
Существует три основных типа трендов.
Первым и самым очевидным типом тренда представляется тренд
среднего, когда временной ряд выглядит как колебания около медленно
возрастающей или убывающей величины.
Второй тип трендов - это тренд дисперсии. В этом случае во
времени меняется амплитуда колебаний переменной. Иными словами, процесс
гетероскедастичен. Часто в экономике различные процессы с возрастающим средним
имеют и возрастающую дисперсию.
Третий и более тонкий тип тренда, визуально не всегда
наблюдаемый, - изменение величины корреляции между текущим и предшествующим
значениями ряда, т.е. тренд автоковариации и автокорреляции [6].
Проводя разложение ряда на компоненты, как правило,
подразумевается под трендом изменение среднего уровня переменной, т.е. тренд
среднего. На практике часто необходимо оценить выборку на наличие тенденции.
Поскольку не всегда удается это сделать визуально, существует множество тестов
на определение наличия тренда. Приведем некоторые из них, которые являются
наиболее простыми и удобными в применении: метод Форстера-Стюарта.
Данный метод помимо возможности определения наличия тренда
позволяет обнаружить тренд дисперсии уровней ряда, что важно знать при анализе
и прогнозировании экономических явлений.
Метод предполагает выполнение следующих шагов:
1) каждый уровень ряда сравнивается со всеми предыдущими. На основании результатов
сравнения определяются вспомогательные величины
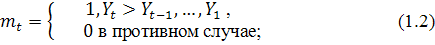
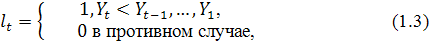
где 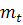 - индикатор событий, означающий, что все предыдущие уровни меньше
текущего,
- индикатор событий, означающий, что все предыдущие уровни меньше
текущего, 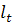 - индикатор событий, означающий, что все предыдущие уровни больше
текущего;
- индикатор событий, означающий, что все предыдущие уровни больше
текущего;
) рассчитываются 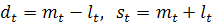 :
:
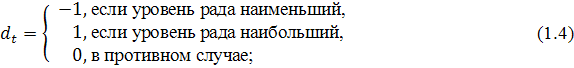
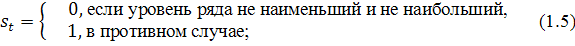
) рассчитываются величины

) проверяются гипотезы об отсутствии (наличии) тренда:
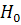 : тренд отсутствует при альтернативной гипотезе
: тренд отсутствует при альтернативной гипотезе 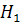 : тренд присутствует. Используется t-статистика
: тренд присутствует. Используется t-статистика
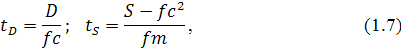
где 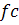 и
и 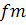 - постоянные метода, которые приводятся в специальных таблицах
для временных рядов в зависимости от объема выборки .
- постоянные метода, которые приводятся в специальных таблицах
для временных рядов в зависимости от объема выборки .
Если 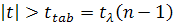 , то нулевая гипотеза отклоняется и тренд присутствует; тест Чоу.
, то нулевая гипотеза отклоняется и тренд присутствует; тест Чоу.
Данный тест используется для проверки гипотезы о стабильности
временного ряда, т.е. существовании стабильного тренда.
Рассмотрим алгоритм метода:
) предполагается, что временной ряд можно представить в
виде двух непересекающихся выборок до и после "переломного" момента.
По выборочным данным строиться общее уравнение регрессии для значений и частные уравнения для выделенных выборок;
) находится величина 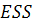 - сумма квадратов остатков общей модели регрессии. Также
находятся
- сумма квадратов остатков общей модели регрессии. Также
находятся 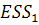 и
и 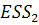 - суммы квадратов остатков частных моделей соответственно;
- суммы квадратов остатков частных моделей соответственно;
) проверяется гипотеза 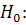 временной ряд не содержит стабильную тенденцию при альтернативной
гипотезе
временной ряд не содержит стабильную тенденцию при альтернативной
гипотезе 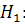 временной ряд содержит стабильную тенденцию.
временной ряд содержит стабильную тенденцию.
Используется F-статистика
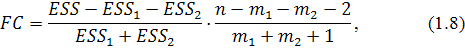
с распределением Фишера и степенями свободы 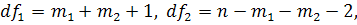 где
где 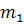 и
и 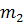 - число параметров уравнений не считая свободный член.
- число параметров уравнений не считая свободный член.
Если 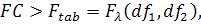 то временной ряд не содержит стабильной тенденции и необходимо
построение кусочно-непрерывной модели. При выполнении обратного условия:
то временной ряд не содержит стабильной тенденции и необходимо
построение кусочно-непрерывной модели. При выполнении обратного условия: 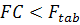 - временной ряд может быть описан с помощью общего уравнения.
- временной ряд может быть описан с помощью общего уравнения.
Довольно часто возникает потребность в корректировке или
сглаживании исследуемого ряда значений. Сглаживание временного ряда выполняется
с помощью специальных функций, описывающих закономерности во времени
исследуемых экономических явлений. Целью сглаживания является устранение
случайных всплесков, т.е. построение плавных временных зависимостей для
выявления тренда. В теории обработки временных рядов существует множество
способов их сглаживания [9]: фильтрация с использованием преобразования Фурье,
кусочная аппроксимация многочленами, экспоненциальное и медианное сглаживание,
метод скользящего окна и др. Выбор той или иной функции в качестве тренда
является наиболее важным этапом анализа, т.к. ошибки приводят к погрешностям в
прогнозе. Основным инструментом, позволяющим отдать предпочтение той или иной
модели, являются приросты уровней (значений) ряда и их производные. Прирост
определяется как
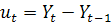 .
.
Темп роста:
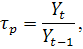
темп прироста:
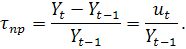
В рамках анализа тренда среднего выделяют следующие основные
способы аппроксимации временных рядов и соответствующие основные виды трендов
среднего [10]: полиномиальный тренд:
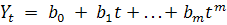 ,
,
где 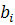 - параметры модели,
- параметры модели, 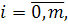 - независимая переменная.
- независимая переменная.
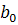 характеризует уровень ряда в момент времени
характеризует уровень ряда в момент времени 
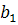 - скорость роста,
- скорость роста, 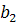 - ускорение роста,
- ускорение роста, 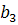 - изменение ускорения.
- изменение ускорения.
Частные случаи:
) 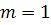 :
:
В данном случае имеет место линейный тренд:
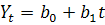 ,
,
Тогда
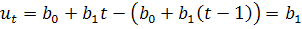 .
.
Используется для описания временных рядов, уровни которого
постоянно убывают или возрастают;
) 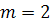 :
:
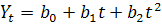 ,
,
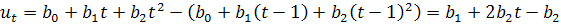 .
.
Т.е. 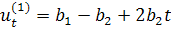 - приросты первого порядка имеют линейный вид,
- приросты первого порядка имеют линейный вид, 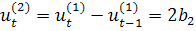 - приросты второго порядка являются константами. Используются,
когда приросты постоянно убывают или возрастают; экспоненциальный тренд:
- приросты второго порядка являются константами. Используются,
когда приросты постоянно убывают или возрастают; экспоненциальный тренд:
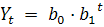 .
.
Используется для описания уровней временных рядов с постоянными
темпами роста и прироста.
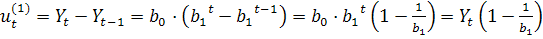 ,
,
т.е. зависит от самих уравнений.
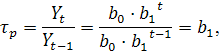
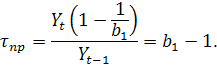
При 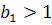 кривая растет во времени, при
кривая растет во времени, при 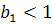 кривая убывает. Параметры и находятся по методу наименьших квадратов (МНК) линеаризованного
уравнения
кривая убывает. Параметры и находятся по методу наименьших квадратов (МНК) линеаризованного
уравнения
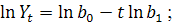
логарифмическая парабола:
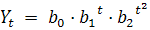 .
.
Темпы прироста являются линейной функцией от времени. Для его
изучения исходная модель преобразовывается в модель вида
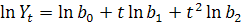 ,
,
тогда 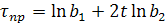 ; гармонический тренд:
; гармонический тренд:
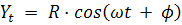 ,
,
где 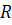 - амплитуда колебаний,
- амплитуда колебаний, 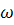 - угловая частота,
- угловая частота, 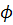 - фаза;образный тренд:
- фаза;образный тренд:
Подобного рода кривыми описываются демографические, страховые и
другие процессы. Различают:
1) кривую Гомперца:
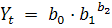 ,
,
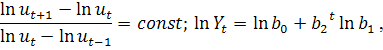
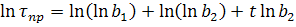 ;
;
2) кривую Перла-Рида:
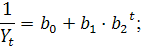
) логистическую кривую:
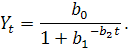
Оценивание параметров полиномиального и экспоненциального трендов
(после введения обозначения 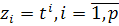 - в первом случае и логарифмирования функции во втором случае)
производится с помощью обычного МНК.
- в первом случае и логарифмирования функции во втором случае)
производится с помощью обычного МНК.
Гармонический тренд оправдан, когда в составе временного ряда
отчетливо прослеживаются периодические колебания. При этом если частота известна (или ее можно оценить), то функцию несложно представить в виде линейной комбинации синуса и
косинуса:
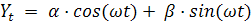
и, рассчитав значения векторов 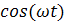 и
и 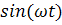 , также воспользоваться МНК для оценивания параметров
, также воспользоваться МНК для оценивания параметров 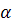 и
и 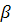 .
.
1.3 Оценка
качества построенной модели
Оценка качества модели подразумевает проверку ее
достоверности или адекватности. Эта проверка заключается в определении степени
соответствия модели некому реальному процессу. Адекватность модели проверяется
путем статистического тестирования.
Понятия достоверности и адекватности являются условными,
поскольку мы не можем рассчитывать на полное соответствие модели реальному
объекту, иначе это был бы сам объект, а не модель. Поэтому в процессе
моделирования следует учитывать адекватность не модели вообще, а именно тех ее
свойств, которые являются существенными с точки зрения проводимого
исследования.
В первую очередь оценивается значимость коэффициентов
построенной модели по выборочным данным, а также сама модель в целом. Для
этого, в частности, используются t-критерий Стьюдента и F-критерий Фишера [5]:
t-критерий Стьюдента:
Для коэффициента определяется фактическое значение t-критерия Стьюдента
определяется фактическое значение t-критерия Стьюдента

причем
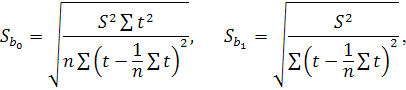
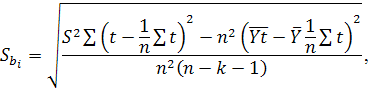
где

является остаточной дисперсией (стандартной ошибкой регрессии), - в данном случае независимая объясняющая переменная (фактор
времени).
Затем полученное фактическое значение сравнивается с табличным
значением 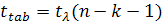 при заданном уровне значимости
при заданном уровне значимости 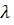 и при числе степеней свободы
и при числе степеней свободы 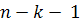 ( - длина выборки,
( - длина выборки, 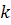 - порядок регрессии). Число степеней свободы показывает, сколько
независимых отклонений от возможных требуется для образования данной суммы квадратов. Если
выполняется неравенство
- порядок регрессии). Число степеней свободы показывает, сколько
независимых отклонений от возможных требуется для образования данной суммы квадратов. Если
выполняется неравенство 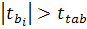 , то гипотеза о не значимости коэффициента отклоняется, т.е. коэффициент значим,
, то гипотеза о не значимости коэффициента отклоняется, т.е. коэффициент значим, 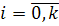 , где - количество регрессоров; F-критерий Фишера:
, где - количество регрессоров; F-критерий Фишера:
Формула для вычисления F-распределения со степенями свободы 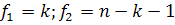 имеет вид:
имеет вид:
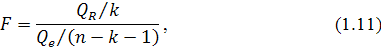
где - порядок регрессии, - длина ряда,
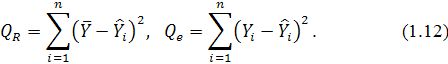
Затем полученное фактическое значение сравнивается с табличным
значением 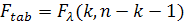 . Если выполняется неравенство
. Если выполняется неравенство 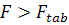 , то гипотеза о не значимости уравнения регрессии в целом
отклоняется, т.е. уравнение значимо.
, то гипотеза о не значимости уравнения регрессии в целом
отклоняется, т.е. уравнение значимо.
Следующим этапом в оценивании качества построенной модели может
служить разносторонний анализ значений остатков. Например, для подтверждения
предположения о нормальном законе распределения остатков используется критерий
Жака-Бера, который предполагает вычисление коэффициентов асимметрии

и эксцесса

Статистика Жака-Бера выражается следующей формулой:
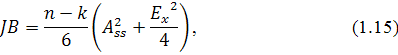
где - объем выборки, - порядок регрессии.
Статистика 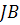 подчиняется распределению
подчиняется распределению 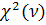 c
c 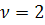 степенями свободы при справедливости гипотезы о нормальности
распределения.
степенями свободы при справедливости гипотезы о нормальности
распределения.
Если статистика принимает значение 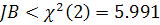 , то гипотеза о нормальном распределении остатков не отклоняется.
, то гипотеза о нормальном распределении остатков не отклоняется.
Для проверки остатков на случайность используется критерий
"поворотных точек" [7], который состоит в проверке следующего условия
при уровне значимости 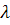 :
:
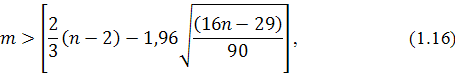
где - длина ряда, 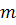 - число поворотных точек. Точка считается поворотной, если
сравниваемый остаток модели, рассматриваемый в качестве данной точки, больше
или меньше одновременно двух соседних элементов ряда остатков. Если неравенство
выполняется, то это свидетельствует о случайности остатков.
- число поворотных точек. Точка считается поворотной, если
сравниваемый остаток модели, рассматриваемый в качестве данной точки, больше
или меньше одновременно двух соседних элементов ряда остатков. Если неравенство
выполняется, то это свидетельствует о случайности остатков.
Для проверки наличия гетероскедастичности зачастую используется
ранговый коэффициент корреляции Спирмена, значение которого рассчитывается по
формуле:

где 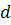 - абсолютная разность между рангами значений остатков
- абсолютная разность между рангами значений остатков 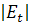 и
и 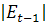 , - длина выборки.
, - длина выборки.
Далее оценивается статистическая значимость вычисленного 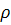 с помощью t-критерия:
с помощью t-критерия:

Если при уровне значимости выполняется неравенство 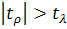 , то гипотеза об отсутствии гетероскедастичности остатков
отклоняется.
, то гипотеза об отсутствии гетероскедастичности остатков
отклоняется.
Для проверки автокорреляции используется критерий Дарбина-Уотсона,
значение которого рассчитывается формуле:
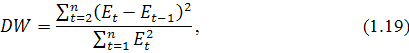
где 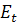 - остатки модели.
- остатки модели.
Полученное значение критерия 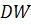 сравнивается с нижним и верхним критическими значениями
сравнивается с нижним и верхним критическими значениями 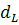 и
и 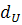 соответственно, определяемыми по статистическим таблицам.
Делается вывод об автокорреляции:
соответственно, определяемыми по статистическим таблицам.
Делается вывод об автокорреляции:
если 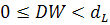 - положительная автокорреляция и гипотеза об отсутствии
автокорреляции отклоняется;
- положительная автокорреляция и гипотеза об отсутствии
автокорреляции отклоняется;
если 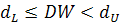 или
или 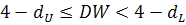 , то нельзя сделать определенный вывод об автокорреляции;
, то нельзя сделать определенный вывод об автокорреляции;
если 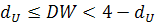 , то гипотеза об отсутствии автокорреляции не отклоняется;
, то гипотеза об отсутствии автокорреляции не отклоняется;
если 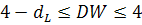 - отрицательная автокорреляция, гипотеза об отсутствии
автокорреляции отклоняется:
- отрицательная автокорреляция, гипотеза об отсутствии
автокорреляции отклоняется:
если 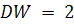 , то автокорреляция отсутствует.
, то автокорреляция отсутствует.
Широкое применение для проверки автокорреляции и проверки ряда на
"белый шум" получил Q-тест Льюинга-Бокса. Данная статистика может
быть определена следующим образом. Выдвигаются две конкурирующие гипотезы: : выборка представляет собой "белый шум" при
альтернативной : выборка не является "белым шумом".
Проводится статистическое испытание
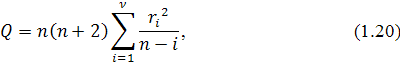
где - число наблюдений для рассматриваемой первой подвыборки, 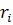 - автокорреляция - го порядка, и
- автокорреляция - го порядка, и 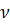 - число проверяемых лагов. Если
- число проверяемых лагов. Если 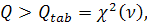 где
где  - квантили распределения
- квантили распределения 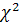 с степенями свободы, то нулевая гипотеза отклоняется и признается
наличие автокорреляции до - го порядка во временном ряду.
с степенями свободы, то нулевая гипотеза отклоняется и признается
наличие автокорреляции до - го порядка во временном ряду.
Имеет место интеграционный критерий Дарбина-Уотсона, который
используется для проверки ряда на стационарность. Значение статистики критерия
вычисляется по формуле:
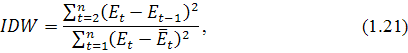
где 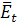 - выборочное среднее остатков модели.
- выборочное среднее остатков модели.
Выводы о стационарности или не стационарности делаются аналогично
выводам об отсутствии или наличии автокорреляции соответственно для обычного
критерия Дарбина-Уотсона.
Проверкой ряда на стационарность также является тест Дики-Фуллера,
для которого обычно оценивается модель авторегрессии [9] следующего вида:
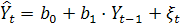 .
.
При заданном уровне значимости выдвигается гипотеза о значимости единичного корня : 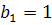 (временной ряд нестационарный) и альтернативная ей гипотеза :
(временной ряд нестационарный) и альтернативная ей гипотеза : 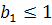 (временной ряд нестационарный). Для проверки гипотезы
используется t-статистика Дики-Фуллера:
(временной ряд нестационарный). Для проверки гипотезы
используется t-статистика Дики-Фуллера:

где - оценка коэффициента по выборочным данным;
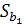 - стандартная ошибка коэффициента .
- стандартная ошибка коэффициента .
Различным вариантам моделей соответствуют различные критические
значения статистики 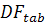 относительно . Если
относительно . Если 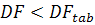 , то гипотеза не отклоняется и ряд является нестационарным.
, то гипотеза не отклоняется и ряд является нестационарным.
Практически всегда возникает ситуация, когда точная спецификация
модели для рассматриваемого процесса или явления неизвестна, причем построено несколько
моделей, оценка качества которых выявила их адекватность и хорошую
аппроксимацию к фактическим данным. Выходом из положения служат критерии,
позволяющие выбирать из некоторого множества моделей наилучшую. Наиболее
распространенными критериями являются информационные критерии Акаики и Шварца
[5].
Статистика Акаики находится по следующей формуле:
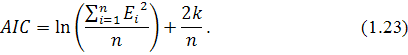
Статистика Шварца:
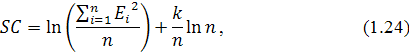
где 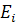 - остатки модели,
- остатки модели, 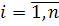 ,
,
- объем рассматриваемой выборки,
- число оцениваемых параметров или число ограничений на степени
свободы, т.е. значение в этом случае равно числу независимых переменных, включая
свободный член.
Первое слагаемое представляет собой штраф за большую дисперсию,
второе - штраф за использование дополнительных переменных. При сравнении двух
различных моделей предпочтение отдается той, которая имеет наименьшие значения
критериев.
2.
Исследование курса акций AAPL и IBM
Мировая практика анализа статистических данных показывает,
что меньше подвержены резким изменениям акции предприятий, производство которых
образовано на местном сырье и материалах. Конечно, существуют и непредвиденные
обстоятельства, катаклизмы, которые могут внести панику в биржевую жизнь, тем
самым повлияв на цену акции.
И все-таки динамика курса акций подчиняется определенным
правилам и тенденциям, которые можно и нужно принимать в расчет тем, кто
профессионально работает на рынке ценных бумаг.
Существенное влияние на изменение спроса на акции
определенных предприятий также оказывает сезонность. Банковские данные
акционерных обществ значительно меняют картину в зависимости от сезона.
Например, для сельхозпредприятий это связано с периодом выращивания, т.е.
затратным периодом реализации продукции, и сбора урожая, т.е. доходным.
Совершенно очевидно, что в период выращивания урожая трудно уверенно сказать,
какой будет финансовый результат деятельности. И конечно, на этот вопрос легко
ответить, когда продукция получена и реализуется.
Рассмотрим более детально формирование курса акции под
влиянием различных факторов.
2.1 Курсовая
стоимость акции
Акция - это ценная бумага, которая удостоверяет
право на участие в собственном капитале ее эмитента. Акции принадлежат к классу
паевых ценных бумаг и не имеют установленных сроков обращения, которое
необходимо учитывать во время исчисления их теоретической стоимости. Номинал
акции может быть разным, но в большинстве случаев эмитенты отдают предпочтение
выпуску акций небольшого номинала, который разрешает расширить рынок и повысить
их ликвидность. Как правило, номинал акции не отображает ее реальной стоимости,
а потому для анализа доходности акций используют курсовую, т.е. текущую
рыночную цену [4].
Курсовая цена акций зависит от разнообразных факторов:
величины и динамики дивидендов, общей конъюнктуры рынка, рыночной нормы
прибыли. На курс акций могут существенно повлиять управленческие решения
относительно реструктуризации компании-эмитента. Так, например, решение о
слиянии компаний большей частью повышают курсовую цену их акций.
Хотя внутреннюю стоимость акций можно определить разными
способами, но все они базируются на общем принципе, который заключается в
сопоставлении сгенерированных данной ценной бумагой доходов с рыночной нормой
прибыли. Показателем доходности может служить или уровень дивидендов, или величина
чистой прибыли в расчете на одну акцию. Второй показатель используют тогда,
когда дивиденды по какой-то причине не выплачиваются, а полученная прибыль
полностью реинвестируется, например, в процессе становления, расширение или
реорганизации акционерного предприятия. В последнее время инвесторы
предоставляют преимущество такому показателю, как чистый денежный поток в
расчете на одну акцию, считая его объективным.
Текущая внутренняя стоимость 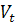 акции в общем виде в рамках фундаментального анализа может быть
рассчитана по формуле:
акции в общем виде в рамках фундаментального анализа может быть
рассчитана по формуле:
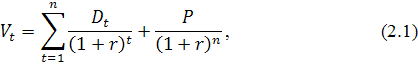
где 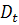 - дивиденд на акцию в момент времени ;
- дивиденд на акцию в момент времени ;
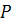 - цена продажи акции;
- цена продажи акции;
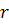 - норма доходности;
- норма доходности;
- горизонт прогнозирования,
т.е. дисконтированием денежного потока, генерируемого
анализируемой ценной бумагой.
Как видно из формулы (2.1), оценка теоретической стоимости акции
зависит от трех параметров: ожидаемые денежные поступления, которые состоят из
ожидаемых дивидендов и предполагаемой цены продажи , горизонта прогнозирования и норма доходности . Последний параметр оценивается достаточно просто, и для его
оценки существуют множество подходов. Второй параметр непосредственно зависит
от предполагаемого срока инвестирования. Первый вероятно наиболее существенен,
поскольку он непосредственно связан с активом и от точности его определения
зачастую зависит эффективность инвестиций на рынке акций.
Собственно практически все существующие на сегодняшний момент
модели оценки стоимости акций являются следствием из формулы (2.1), которая
видоизменяется в зависимости от целей инвестирования. Выделяют две основные
цели - получение доходов в виде дивидендов и получение дохода от прироста
курсовой стоимости ценной бумаги. Рассмотрение всех методов не представляется
целесообразным, поскольку их большое количество и тема данной работы не
предусматривает полное их рассмотрение. Приведем лишь некоторые, наиболее
употребляемые из них.
Допустим, что инвестор собирается купить акции некоторой компании
и владеть ими всегда. В этом случае для инвестора естественно определить цену
акции как текущее значение последовательности дивидендов, которые он надеется
получить. Таким образом, цена акции с точки зрения инвестора должна быть равна

где - дивиденд на акцию в момент времени ;
- норма доходности;
- горизонт прогнозирования.
Размер дивидендов может изменяться произвольно, но чаще это
изменение происходит систематически, т.е. дивиденды либо возрастают, либо
убывают, либо остаются постоянными. Ниже будут рассмотрены методы оценки акций
нулевого и постоянного роста.
Допустим, что дивиденды по обыкновенным акциям некоторой компании
по прогнозам останутся постоянными, т.е. 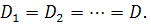 Тогда после подстановки
Тогда после подстановки 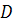 вместо значения в уравнение (2.2) оно преобразуется к виду
вместо значения в уравнение (2.2) оно преобразуется к виду
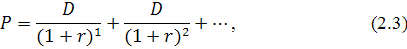
где - дивиденд на акцию;
- норма доходности,
т.е. цена акции нулевого роста равна текущему значению бессрочной
ренты с выплатами . Следовательно, уравнение (2.3) сводится к уравнению (2.4),
которое имеет вид

Наиболее частой практикой в западных компаниях является политика
стабильно растущих дивидендов, поскольку, таким образом, повышается
привлекательность акций, во-первых, с точки зрения защищенности будущих
дивидендов от инфляционного воздействия, а, во-вторых, стабильно растущие
дивиденды на протяжении длительного периода являются символом постоянного
развития компании. В данном случае стоимость обыкновенной акции, чаще всего,
оценивается при помощи формулы

где 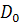 - дивиденд на акцию в момент времени t;
- дивиденд на акцию в момент времени t;
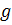 - предполагаемый темп роста дивидендов;
- предполагаемый темп роста дивидендов;
- норма доходности.
Если предприятие не выплачивает дивиденды, внутреннюю стоимость
акции можно оценить с использованием следующей факторной модели:
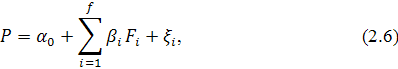
где 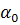 - свободный член;
- свободный член;
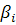 - чувствительность цены к - му фактору,
- чувствительность цены к - му фактору, 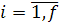 ;
;
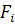 - предсказанное значение - го фактора;
- предсказанное значение - го фактора;
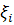 - случайная ошибка.
- случайная ошибка.
При использовании факторных моделей вида (2.6) возникает ряд
проблем. Во-первых, факторные модели строятся на анализе прошлой информации,
однако, не всегда те факторы, которые оказывали влияние на цену акции в
прошлом, будут аналогичным образом действовать и в будущем. Во-вторых, очень
трудно выделить именно те факторы, которые оказывали максимальное влияние на
цену акции. Также не стоит забывать, что значение случайной ошибки выбирается
случайным образом, она может достигать достаточно больших величин.
Тем не менее, факторная модель представляет собой попытку учесть
основные экономические силы, систематически воздействующие на курсовую
стоимость ценной бумаги.
2.2 Общая
характеристика и историческое развитие компаний
В данном разделе далее будут изложены основные этапы
исторического развития и направленность деятельности двух американских конкурирующих
компаний, акции которых взяты для исследования в дипломной работе.
Как известно, до середины 1980-х гг. компании IBM и Apple не
являлись прямыми конкурентами, поскольку IBM доминировала на рынке больших
электронных вычислительных машин, а Apple занималась созданием первых
персональных компьютеров. Затем в 1984 г. компания IBM, обеспокоенная
сокращением объемов продаж и данными о росте числа покупок различными клиентами
персональных компьютеров (ПК) у Apple, выпустила свой ПК. Прямое столкновение
лидеров резко усилило конкуренцию, что привело к уходу с рынка более слабых
соперников.(International Business Machines) - транснациональная корпорация со
штаб-квартирой в Армонке, штат Нью-Йорк (США), один из крупнейших в мире
производителей и поставщиков аппаратного и программного обеспечения, а также
IT-сервисов и консалтинговых услуг [15].
Компания, известная сейчас под именем IBM, была основана 16
июня 1911 года и называлась CTR (Computing Tabulating Recording). Она включила
в себя Computing Scale Company of America, Tabulating Machine Company (TMC -
бывшая компания Германа Холлерита) и International Time Recording Company.
Объединённая фирма выпускала широкий ассортимент электрического оборудования.
После компания начала специализироваться на создании больших табуляционных
машин. В 1924 году с выходом на канадский рынок и расширением ассортимента
продукции, CTR меняет название на International Business Machines или,
сокращённо, IBM.
В годы Второй мировой войны компания производила стрелковое
оружие (М1 Carbine и Browning Automatic Rifle).
В 1943 году началась история компьютеров IBM - был создан
"Марк I" весом около 4,5 тонн. Но уже в 1952 году появляется
"IBM 701", первый большой компьютер на лампах.
В 1959 году появились первые компьютеры IBM на транзисторах,
достигшие высокого уровня надёжности и быстродействия. Чуть раньше, в 1957
году, IBM ввела в обиход язык FORTRAN ("FORmula TRANslation"),
применявшийся для научных вычислений.
В 1964 году было представлено семейство IBM System/360,
являвшееся первыми универсальными компьютерами с байтовой адресацией памяти.
Совместимые с System/360 компьютеры IBM System Z выпускаются до сих пор, это
абсолютный рекорд совместимости.
В 1971 году компания представила гибкий диск, который стал
стандартом для хранения данных. В 1972 году был представлен обновлённый логотип
(буквы из синих полосок) компании, используемый до настоящего времени.
год прочно вошёл в историю человечества как год появления
персонального компьютера "IBM PC".64 килобайт оперативной памяти и
одного или двух флоппи-дисководов вполне хватало, чтобы исполнять операционную
систему DOS, предложенную небольшой компанией Microsoft, и некоторое количество
приложений.
Ориентировочно, в 1990 году была предпринята попытка
захватить рынок персональных компьютеров, выпустив компьютеры PS/2 с
операционной системой OS/2, несовместимые ни аппаратно, ни программно с PC и
DOS. В машинах были применены прогрессивные технологии, но, несмотря на
инновационность, рынок отверг данный продукт.
Последней попыткой восстановить контроль над рынком был
выпуск операционной системы OS/2 Warp V3.0, которая работала на обычных PC и
должна была конкурировать с проектом Microsoft Windows 95. Несмотря на
массированную рекламную компанию, и весьма хорошие характеристики, проект провалился.
В 2002 году компания приобрела консалтинговое подразделение
аудиторской компании PricewaterhouseCoopers за $3,5 млрд. В настоящее время
этот бизнес, влившийся в подразделение IBM Global Services, является самым
доходным в структуре IBM, приносящим больше половины дохода компании.
Рассмотрим компанию-конкурента IBM и ее основные этапы
развития.(Apple Incorporated) - американская корпорация, основанная Стивом
Джобсом и Стивом Возняком, являющаяся производителем персональных и планшетных
компьютеров, аудиоплееров, телефонов, программного обеспечения. Один из
пионеров в области персональных компьютеров и современных многозадачных
операционных систем с графическим интерфейсом. Штаб-квартира - в Купертино,
штат Калифорния [14].
Благодаря эстетичному дизайну и применению инновационных
технологий Apple создала уникальную репутацию в индустрии потребительской
электроники и имеет большую популярность, особенно в США. До 9 января 2007 года
официальным названием корпорации на протяжении более 30 лет было Apple
Computer. Отказ от слова "Computer" в названии демонстрирует смену
основного фокуса корпорации с традиционного для неё рынка компьютерной техники
на рынок бытовой электроники.
В середине 1970-х Джобс и Возняк собрали свой первый ПК на
базе процессора MOS Technology 6502. Продав несколько десятков таких
компьютеров, молодые предприниматели получили финансирование и официально
зарегистрировали фирму 1 апреля 1976 года.
"Apple I", выпущенный в 1976 году, был не первым
программируемым микрокомпьютером. Право первенства принадлежало компьютеру
"Альтаир 8800", который был создан любителем и распространялся через
каталоги в 1974 году. Однако, "Альтаир" не был технически
квалифицирован как ПК, поскольку не давал возможности накапливать и вызывать
данные при помощи программ пользования.
С 1977 по 1993 годы фирмой Apple выпускались различные модели
из линейки 8 (позднее 8/16) разрядных компьютеров "Apple II". В конце
1970-х и начале 1980-х годов "Apple II" и их клоны были самыми
распространёнными в мире персональными компьютерами. Было продано более 5 млн.
компьютеров "Apple II" по всему миру. Теперь принято считать, что
именно "Apple II" раз и навсегда открыл широкую дорогу перед новой
индустрией - производством персональных компьютеров. 1980 год в истории Apple
ознаменовался провальным по ряду причин проектом "Apple III". В марте
1981 года Возняк попал в авиакатастрофу и на время оставил работу. Проблемы с
продажами "Apple III" привели к тому, что Джобсу пришлось уволить 40
сотрудников. В прессе уже говорили о скором конце компании Apple. В 1984 году
фирма Apple впервые представила новый 32-разрядный компьютер
"Macintosh". В дальнейшем выпуск компьютеров этой серии стал основным
бизнесом компании. На протяжении двух десятилетий компания выпускала компьютеры
"Macintosh" на базе процессоров Motorola, оснащённые фирменной
операционной системой. Эта платформа выпускается только Apple. Apple -
публичная компания, её акции торгуются на бирже NASDAQ и Лондонской фондовой
бирже. Общее количество выпущенных акций на начало 2011 года составляло 921,28
млн. шт. По состоянию на 26 мая 2010 года рыночная стоимость компании Apple
превысила таковую у компании Microsoft. По состоянию на март 2011 года рыночная
капитализация компании оценивалась в $309,5 млрд.
2.3
Моделирование тенденции временного ряда акции AAPL
Рассматривается временной ряд, составленный из 252 значений
цены акции AAPL (приложение А), взятых за год, за период с 4 января 2010 г. по
31 декабря 2010 г. Значения являются ежедневными, в неделе 5 дней торгов.
В первую очередь приведем график исходных данных (значение
цены акции, приходящееся на определенную дату торгов), который имеет вид:
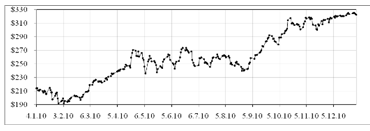
Рисунок 2.1 - График исходных данных для курса акции AAPL
Рассматриваемый ряд данных характеризуется возрастающей
тенденцией. Динамика представляет собой постепенное возрастание цены с
небольшими спадами в период с 29 января по 4 февраля и с 24 по 31 августа 2010
года. Наиболее экстремальные скачки в цене проявляются в период с 20 апреля по
2 июля.
После публикации финансовых результатов компании
Apple стало известно, что подобный результат явился следствием успешной продажи
новых моделей компьютеров Mac, телефонов и плееров IPhone и IPod, а также
планшетов IPad.
Кроме того ряд содержит большое количество мелких и более
крупных скачков, что свойственно курсам акций, которые являются достаточно
ликвидными и, благодаря своей высокой волатильности, привлекают инвесторов и
спекулянтов.
Вначале проверим ряд на наличие тренда методом Форстера-Стюарта.
На основании результатов сравнения каждого из уровней со всеми предыдущими по
формулам (1.2) и (1.3) получили две вспомогательные выборки и , которые были преобразованы в ряды вида (1.4) и (1.5). Рассчитав
величины и 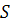 , а также t-статистику для каждой из них по формуле (1.7)
получили, что
, а также t-статистику для каждой из них по формуле (1.7)
получили, что 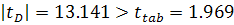 и
и 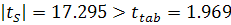 . Следовательно, нулевая гипотеза отклоняется и тренд присутствует. Теперь подберем его для данного
ряда.
. Следовательно, нулевая гипотеза отклоняется и тренд присутствует. Теперь подберем его для данного
ряда.
При добавлении линий тренда к графику исходных данных видно
(рисунок 2.2), что линейный тренд и полиномиальный тренд пятой степени наиболее
точно соответствуют тенденции исследуемого ряда.
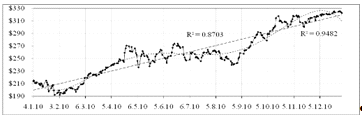
Рисунок 2.2 - График линейной и полиномиальной моделей для курса
AAPL
Модели имеют вид: линейный тренд
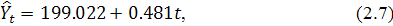
полиномиальный тренд 5-го порядка
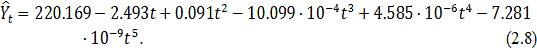
Коэффициенты детерминации для линейной и полиномиальной модели
равны соответственно 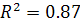 и
и 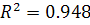 . Следовательно, построенная полиномиальная модель (2.8)
аппроксимирует исходные данные на 94.8%, остальные 5.2% приходятся на ошибки.
Т.е. полиномиальный тренд 5-го порядка очень хорошо описывает ряд, линейная
модель (2.7) - также хорошо, т.к.
. Следовательно, построенная полиномиальная модель (2.8)
аппроксимирует исходные данные на 94.8%, остальные 5.2% приходятся на ошибки.
Т.е. полиномиальный тренд 5-го порядка очень хорошо описывает ряд, линейная
модель (2.7) - также хорошо, т.к.  в обоих случаях. Будем рассматривать полиномиальную модель 5-го
порядка как более точную.
в обоих случаях. Будем рассматривать полиномиальную модель 5-го
порядка как более точную.
Используем критерий Стьюдента для проверки значимости
коэффициентов и критерий Фишера с уровнем значимости 0.05 для проверки
значимости уравнения полиномиальной регрессии в целом.
При уровне значимости 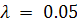 получили, что
получили, что 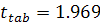 , в свою очередь фактические значения, вычисленные по (1.9) для
соответствующего коэффициента, равны:
, в свою очередь фактические значения, вычисленные по (1.9) для
соответствующего коэффициента, равны:
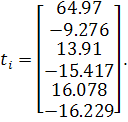
Видно, что 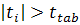 для любого
для любого 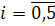 . Т.е. для модели (2.8) все коэффициенты уравнения регрессии
значимы.
. Т.е. для модели (2.8) все коэффициенты уравнения регрессии
значимы.
Значение критерия Фишера (1.11) 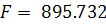 , что намного больше табличного значения
, что намного больше табличного значения 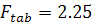 . Поскольку статистика , то можно сделать вывод о значимости уравнения регрессии по
данному критерию на заданном уровне значимости.
. Поскольку статистика , то можно сделать вывод о значимости уравнения регрессии по
данному критерию на заданном уровне значимости.
После построения модели необходимо проверить 5 предпосылок
Гаусса-Маркова: равенство нулю математического ожидания остатков; подчинение
остатков нормальному закону распределения; случайный характер остатков модели;
гомоскедастичность дисперсии остатков; отсутствие автокорреляционной
зависимости в остатках.
При выполнении всех пяти предпосылок оценки коэффициентов
регрессии будут обладать свойствами несмещенности, эффективности и
состоятельности. График остатков представлен на рисунке 2.3:
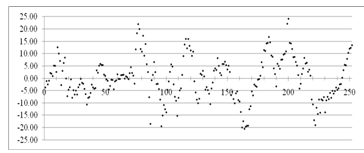
Рисунок 2.3 - График остатков полиномиальной модели для курса AAPL
. Математическое ожидание остатков имеет значение 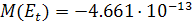 , которое очень близко к нулю. Отличие от нуля обусловлено
погрешностью вычислений.
, которое очень близко к нулю. Отличие от нуля обусловлено
погрешностью вычислений.
. Вычислим - стандартную ошибку регрессии, используя формулу (1.10).
Значение 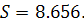
По правилу трех сигм при заданном уровне значимости можно считать, что случайная величина, распределенная по
нормальному закону, принадлежит интервалу 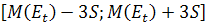 . Поскольку математическое ожидание близко к нулю, то остатки
принадлежат интервалу
. Поскольку математическое ожидание близко к нулю, то остатки
принадлежат интервалу 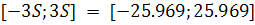 . Следовательно, на данном этапе нельзя отклонить гипотезу о
нормальном распределении остатков. Вычислим коэффициенты асимметрии и эксцесса
и воспользуемся статистикой Жака-Бера по формуле (1.15). Значение статистики
. Следовательно, на данном этапе нельзя отклонить гипотезу о
нормальном распределении остатков. Вычислим коэффициенты асимметрии и эксцесса
и воспользуемся статистикой Жака-Бера по формуле (1.15). Значение статистики 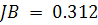 , что меньше квантили распределения
, что меньше квантили распределения 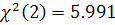 . Следовательно, гипотеза о нормальном распределении остатков не
отклоняется.
. Следовательно, гипотеза о нормальном распределении остатков не
отклоняется.
. Для проверки остатков на случайность используем критерий
"поворотных точек".помощью MS Excel вычисляем для ряда остатков:
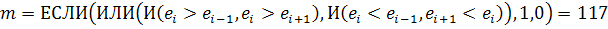
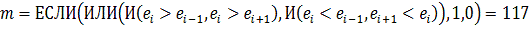 .
.
Правая часть неравенства (1.16) в свою очередь при уровне
значимости 0.05 принимает значение 166.373. Следовательно, выборка остатков
неслучайна.
. Для проверки наличия гетероскедастичности используем ранговый
коэффициент корреляции Спирмена.
Для рассматриваемого ряда остатков 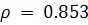 по формуле (1.17). Оценим статистическую значимость с помощью t-критерия по формуле (1.18):
по формуле (1.17). Оценим статистическую значимость с помощью t-критерия по формуле (1.18): 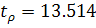 . Сравнив эту величину с табличной
. Сравнив эту величину с табличной 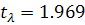 при уровне значимости , получили, что . Следовательно, гипотеза об отсутствии гетероскедастичности
остатков отклоняется.
при уровне значимости , получили, что . Следовательно, гипотеза об отсутствии гетероскедастичности
остатков отклоняется.
. Для проверки наличия автокорреляции в остатках воспользуемся
критерием Дарбина-Уотсона.
Используя формулу (1.19) получаем 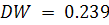 . Сравнивая рассчитанную величину с нижним значением критерия
. Сравнивая рассчитанную величину с нижним значением критерия 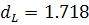 и принимая во внимание значение
и принимая во внимание значение 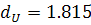 , делаем вывод - в остатках присутствует положительная
автокорреляция.
, делаем вывод - в остатках присутствует положительная
автокорреляция.
Подведем итоги анализа ряда остатков. Последние три предпосылки
Гаусса-Маркова: случайный характер остатков модели, гомоскедастичность
дисперсии остатков и отсутствие автокорреляционной зависимости в остатках -
оказались не соблюденными, что говорит о том, что построенные по МНК оценки
коэффициентов уравнения регрессии не являются состоятельными и эффективными.
Следовательно, данную модель необходимо корректировать.
Для того чтобы избавиться от автокорреляционной зависимости,
попробуем улучшить модель (2.8), построив для ряда остатков модель авторегрессии AR (p), где 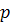 - параметр, определяющий порядок авторегрессии.
- параметр, определяющий порядок авторегрессии.
Порядок модели AR (p) определяется исходя из внешнего вида
графиков автокорреляционной (АКФ) и частной автокорреляционной (ЧАКФ) функций
ряда остатков.
Вычислим коэффициенты автокорреляции уровней ряда по формуле:
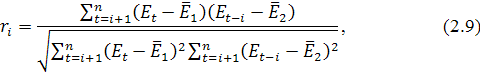
где - значения ряда остатков,
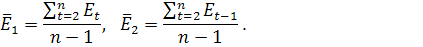
Вычислим коэффициенты частной автокорреляции по формулам:
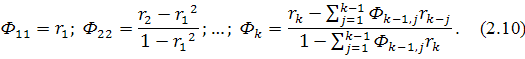
АКФ и ЧАКФ ряда представлены на рисунке 2.4 АКФ экспоненциально убывает и имеет
достаточно много положительных значений, величина которых вероятнее всего
обусловлена "распространением" автокорреляции при лаге 1, что
подтверждается графиком ЧАКФ, из которого видно, что значимым является лишь
значение ЧАКФ при лаге 1. Следовательно, для ряда будем строить модель AR (1) в виде:
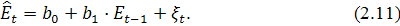
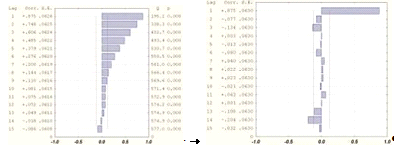
Рисунок 2.4 - АКФ и ЧАКФ ряда остатков модели (2.8)
Построение модели проводилось в программе Statistica 6.0 [2,13].
Оценка параметров проведена с помощью метода наименьших квадратов. Получена
следующая модель:
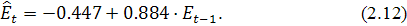
Теперь объединим модели (2.8) и (2.12) и построим график
получившейся модели (рисунок 2.5):
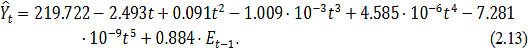
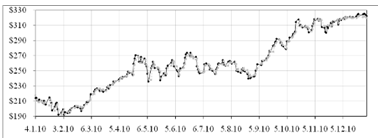
Рисунок 2.5 - График модели (2.13) и фактических значений акции
AAPL
Анализ остатков модели (2.13) показал, что ряд остатков
удовлетворяет всем пяти предпосылкам регрессионного анализа. В частности
статистика 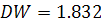 , что больше
, что больше 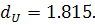 Следовательно, удалось избавиться от автокорреляции остатков. По
критерию поворотных точек получили
Следовательно, удалось избавиться от автокорреляции остатков. По
критерию поворотных точек получили 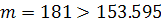 , что указывает на случайность остатков и, как следствие,
адекватность построенной трендовой модели. Также для рассматриваемого ряда
остатков скорректированной модели
, что указывает на случайность остатков и, как следствие,
адекватность построенной трендовой модели. Также для рассматриваемого ряда
остатков скорректированной модели 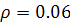 . Значит,
. Значит, 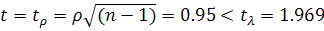 . Следовательно, удалось получить гомоскедастичные остатки.
. Следовательно, удалось получить гомоскедастичные остатки.
Проверим уравнение (2.13) на значимость по F-критерию Фишера.
Для модели (2.13) значение критерия Фишера (1.11) равно 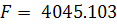 , что во много раз превышает табличное значение , следовательно, построенное уравнение (2.13) значимо.
, что во много раз превышает табличное значение , следовательно, построенное уравнение (2.13) значимо.
Коэффициент детерминации получившейся модели равен 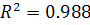 , что говорит о высокой точности приближения построенной модели к
исходному ряду данных, всего 1.2% приходится на ошибку.
, что говорит о высокой точности приближения построенной модели к
исходному ряду данных, всего 1.2% приходится на ошибку.
2.4
Моделирование тенденции временного ряда акции IBM при наличии структурных
изменений
Рассматривается временной ряд, составленный из 252 значений
цены акции IBM (приложение А), взятых за год, за период с 4 января 2010 г. по
31 декабря 2010 г. Значения являются ежедневными, в неделе 5 дней торгов.
В первую очередь приведем график исходных данных (зависимость
цены акции от даты торгов), он имеет вид:
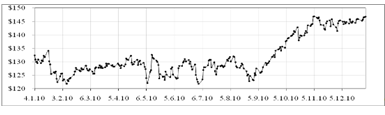
Рисунок 2.6 - График исходных данных для курса акции IBM
Рассматриваемый ряд данных характеризуется нестабильной
тенденцией. Ряд содержит значительное количество мелких скачков. Динамика
представляет собой три периода развития. В начальный период цена интенсивно
колеблется и имеет среднее значение около 127$, во втором периоде на протяжении
двух месяцев с 6 сентября по 5 ноября цена стремительно растет, несмотря на
один резкий скачок 18 октября. Цена становится достаточно стабильной без резких
"перепадов" (около 146$) только в третий период, приходящийся на
последний месяц.
Резкие "перепады", как правило, происходят в
результате воздействия на исследуемый ряд внешних факторов, в том числе
изменения в политике компании. Всплески зависят от экономических и политических
стратегий на финансовом рынке. К примеру, неожиданный всплеск произошел с 6
сентября по 5 ноября 2010 года.
После публикации финансовых результатов
корпорации IBM стало известно, что получить подобный результат удалось за счет
того, что бизнес-клиенты IBM по всему миру активно стали внедрять у себя
дорогое серверное оборудование в целом и дорогие мейнфреймы семейства System Z
в частности.
Метод Форстера-Стюарта, примененный к ряду курса акции IBM, выявил
наличие тренда, поскольку вычисленные по формуле (1.7) статистики 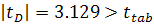 и
и 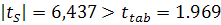 . Поэтому подберем тренд и построим модель, не принимая для начала
во внимания структурное изменение.
. Поэтому подберем тренд и построим модель, не принимая для начала
во внимания структурное изменение.
2.4.1 Подбор
трендовой модели
При подборе линий тренда к графику исходных данных было
выявлено (рисунок 2.7), что лишь полиномиальный тренд пятой степени наиболее
точно соответствуют тенденции исследуемого ряда.
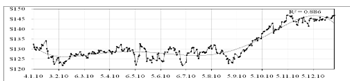
Рисунок 2.7 - График общей полиномиальной модели для курса
IBM
Модель имеет следующий вид:
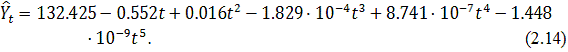
Коэффициенты детерминации 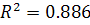 . Значит, построенная полиномиальная модель (2.14) аппроксимирует
исходные данные на 88.6%, остальные 11.4% приходятся на ошибки. Т.е.
полиномиальный тренд 5-го порядка достаточно хорошо описывает ряд. При
рассмотрении полиномов более высокого порядка можно заметить, что с увеличением
степени полинома, величина коэффициента детерминации практически не меняется:
для полиномиальной модели 6-й степеней коэффициент детерминации равен 0.887.
Таким образом, будем рассматривать полиномиальную модель 5-го порядка.
. Значит, построенная полиномиальная модель (2.14) аппроксимирует
исходные данные на 88.6%, остальные 11.4% приходятся на ошибки. Т.е.
полиномиальный тренд 5-го порядка достаточно хорошо описывает ряд. При
рассмотрении полиномов более высокого порядка можно заметить, что с увеличением
степени полинома, величина коэффициента детерминации практически не меняется:
для полиномиальной модели 6-й степеней коэффициент детерминации равен 0.887.
Таким образом, будем рассматривать полиномиальную модель 5-го порядка.
Используем критерий Стьюдента и критерий Фишера с уровнем
значимости 0.05 для проверки значимости коэффициентов и уравнения
полиномиальной регрессии в целом.
При уровне значимости 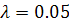 получили, что
получили, что 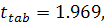 в свою очередь фактические значения принимают следующие значения:
в свою очередь фактические значения принимают следующие значения:
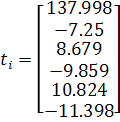
Видно, что для любого . Т.е. для модели (2.14) все коэффициенты регрессии значимы.
Значение критерия Фишера (1.11) 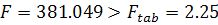 , что позволяет сделать вывод о значимости уравнения регрессии по
данному критерию на заданном уровне значимости.
, что позволяет сделать вывод о значимости уравнения регрессии по
данному критерию на заданном уровне значимости.
После построения модели необходимо проверить предпосылки
регрессионного анализа: случайный характер остатков модели, равенство нулю
математического ожидания остатков, отсутствие автокорреляционной зависимости в
остатках, гомоcкедастичность дисперсии остатков, подчинение остатков
нормальному закону распределения. График остатков представлен на рисунке 2.8:
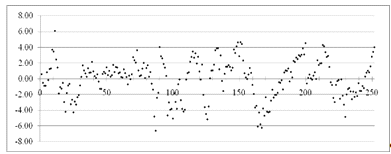
Рисунок 2.8 - График остатков полиномиальной модели для курса IBM
. Математическое ожидание остатков имеет значение 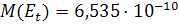 , которое близко к нулю. Отличие от нуля обусловлено погрешностью
вычислений.
, которое близко к нулю. Отличие от нуля обусловлено погрешностью
вычислений.
. Стандартная ошибка регрессии 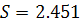 . Остатки принадлежат интервалу
. Остатки принадлежат интервалу 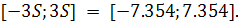 Следовательно, на данном этапе нельзя отклонить гипотезу о
нормальном распределении остатков. Вычислив коэффициенты асимметрии и эксцесса,
воспользуемся статистикой Жака-Бера. Статистика подчиняется распределению
Следовательно, на данном этапе нельзя отклонить гипотезу о
нормальном распределении остатков. Вычислив коэффициенты асимметрии и эксцесса,
воспользуемся статистикой Жака-Бера. Статистика подчиняется распределению 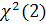 при справедливости гипотезы о нормальности распределения.
Значение статистики
при справедливости гипотезы о нормальности распределения.
Значение статистики 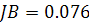 , что меньше квантили распределения равной 5.991. следовательно, принимаем гипотезу о нормальном
распределении остатков.
, что меньше квантили распределения равной 5.991. следовательно, принимаем гипотезу о нормальном
распределении остатков.
. Для проверки наличия гетероcкедастичности используем ранговый
коэффициент корреляции Спирмена.
Для рассматриваемого ряда остатков 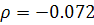 . Оценим статистическую значимость с помощью t-критерия:
. Оценим статистическую значимость с помощью t-критерия: 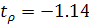 . Сравним эту величину с табличной
. Сравним эту величину с табличной 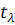 при уровне значимости . Получаем
при уровне значимости . Получаем 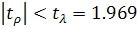 . Следовательно, гипотеза об отсутствии гетероскедастичности
остатков не отклоняется.
. Следовательно, гипотеза об отсутствии гетероскедастичности
остатков не отклоняется.
. Для проверки наличия автокорреляции в остатках воспользуемся
критерием Дарбина-Уотсона.
По формуле (1.19) получаем 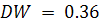 . Сравнивая рассчитанную величину с нижним значением критерия , делаем вывод - в остатках присутствует положительная
автокорреляция. Как и в случае оценки качества модели для акции AAPL, последние
три предпосылки Гаусса-Маркова не выполняются. Данную модель необходимо
скорректировать. Для того чтобы избавиться от автокорреляционной зависимости в
модели (2.14) построим для ряда остатков модель авторегрессии AR (p). Порядок
модели AR (p) определим исходя из внешнего вида графиков АКФ и ЧАКФ ряда остатков
, которые изображены на рисунке 2.9 Видно, что АКФ убывает, имеет
много положительных значений, ЧАКФ имеет значимое значение лишь при лаге 1.
Следовательно, для ряда остатков будем строить модель AR (1) вида (2.11).
. Сравнивая рассчитанную величину с нижним значением критерия , делаем вывод - в остатках присутствует положительная
автокорреляция. Как и в случае оценки качества модели для акции AAPL, последние
три предпосылки Гаусса-Маркова не выполняются. Данную модель необходимо
скорректировать. Для того чтобы избавиться от автокорреляционной зависимости в
модели (2.14) построим для ряда остатков модель авторегрессии AR (p). Порядок
модели AR (p) определим исходя из внешнего вида графиков АКФ и ЧАКФ ряда остатков
, которые изображены на рисунке 2.9 Видно, что АКФ убывает, имеет
много положительных значений, ЧАКФ имеет значимое значение лишь при лаге 1.
Следовательно, для ряда остатков будем строить модель AR (1) вида (2.11).
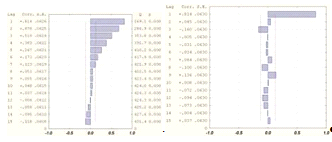
Рисунок 2.9 - АКФ и ЧАКФ ряда остатков модели (2.14)
Построение модели проводилось в программе Statistica 6.0. Получена
следующая модель:
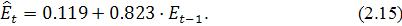
Теперь объединим модели (2.14) и (2.15) и построим график
получившейся модели, изображенный на рисунке 2.10:
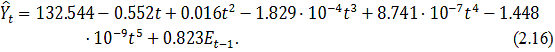
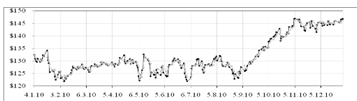
Рисунок 2.10 - График модели (2.16) и фактических значений акции
IBM
Анализ остатков модели (2.16) показал, что ряд остатков
удовлетворяет всем пяти предпосылкам регрессионного анализа.
Значение критерия Фишера (1.11) равно 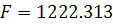 , что во много раз больше табличного значения , следовательно, построенное уравнение (2.16) значимо.
, что во много раз больше табличного значения , следовательно, построенное уравнение (2.16) значимо.
Коэффициент детерминации получившейся модели равен 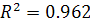 , что говорит о высокой точности приближения построенной модели к
исходному ряду данных, всего 3.8% приходится на ошибку.
, что говорит о высокой точности приближения построенной модели к
исходному ряду данных, всего 3.8% приходится на ошибку.
2.4.2 Тест
Чоу для анализа структурных изменений
Теперь необходимо выяснить значимо ли повлияло структурное
изменение на характер тенденции. Если влияние оказалось весомым, тогда
необходимо строить кусочно-непрерывную модель регрессии. В противном случае,
динамику данной акции можно описать с помощью единого уравнения регрессии.
Проверка данного предположения осуществляется при помощи статистического теста
Чоу, который позволяет определить, является ли тренд стабильным или нет.
При построении кусочно-непрерывной модели происходит
уменьшение суммы квадратов остатков по сравнению с единым уравнением тренда.
Тем не менее, разделение совокупности значений на части ведет к потере числа
наблюдений, а именно, к уменьшению числа свободы в каждом уравнении
кусочно-непрерывной модели [5].
Построим регрессионные модели для двух подвыборок значений акции
IBM. Модель для единой совокупности была построена в предыдущем пункте
"переломным" моментом 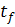 можно считать 7 сентября 2010, после которого начался
стремительный рост цены на данную акцию. В данном случае числовым эквивалентом
момента служит значение
можно считать 7 сентября 2010, после которого начался
стремительный рост цены на данную акцию. В данном случае числовым эквивалентом
момента служит значение 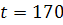 фактора времени. Значит, объем первой подвыборки
фактора времени. Значит, объем первой подвыборки 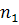 принимаем равным 170, соответственно объем второй -
принимаем равным 170, соответственно объем второй - 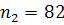 .
.
Тест Чоу показал, что 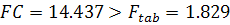 , т.е. временной ряд не содержит стабильной тенденции и необходимо
построение кусочно-непрерывной модели. Вначале рассмотрим первую подвыборку и построим
для нее модель, наилучшим образом аппроксимирующую полученные значения к
исходному ряду. Изобразим на графике данную подвыборку и построенную трендовую
модель, которая является полиномиальной моделью 5 степени (рисунок 2.11).
, т.е. временной ряд не содержит стабильной тенденции и необходимо
построение кусочно-непрерывной модели. Вначале рассмотрим первую подвыборку и построим
для нее модель, наилучшим образом аппроксимирующую полученные значения к
исходному ряду. Изобразим на графике данную подвыборку и построенную трендовую
модель, которая является полиномиальной моделью 5 степени (рисунок 2.11).
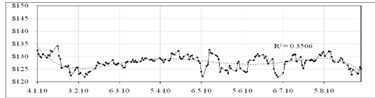
Рисунок 2.11 - График первой подвыборки значений курса акции IBM
Уравнение модели имеет вид:
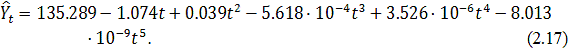
Коэффициент детерминации для полиномиальной модели 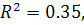 что говорит о плохом качестве и, очевидно, не точной
аппроксимации к исходным данным. Попробуем построить модель AR (p), подобрав
для нее параметр .
что говорит о плохом качестве и, очевидно, не точной
аппроксимации к исходным данным. Попробуем построить модель AR (p), подобрав
для нее параметр .
Изобразим графики АКФ и ЧАКФ данного ряда, которые представлены на
рисунке 2.12.
АКФ экспоненциально убывает. Значимым является лишь первый
коэффициент автокорреляции, что подтверждается графиком ЧАКФ. Поэтому выберем 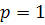 , т.е. построим модель AR (p) в виде:
, т.е. построим модель AR (p) в виде:

Построение модели проводилось в программе Statistica 6.0. В
результате была получена модель следующего вида:
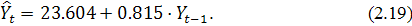
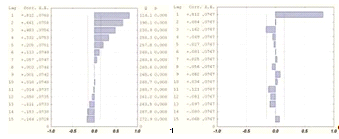
Рисунок 2.12 - График АКФ и ЧАКФ первой подвыборки
Применение критерия Стьюдента показало (1.9), что оба коэффициента
значимы:
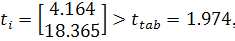
критерий Фишера (1.11) также позволяет сделать вывод о значимости
всего уравнения:
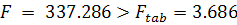 .
.
Проверим, соблюдаются ли предпосылки Гаусса-Маркова для данного
уравнения. Математическое ожидание имеет приближенное к нулю значение: 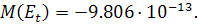 Стандартная ошибка регрессии
Стандартная ошибка регрессии 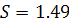 , некоторые значения остатков данной модели не принадлежат
интервалу
, некоторые значения остатков данной модели не принадлежат
интервалу 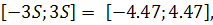 что позволяет отклонить гипотезу о нормальном распределении
остатков. Также статистика Жака-Бера оказалась равной
что позволяет отклонить гипотезу о нормальном распределении
остатков. Также статистика Жака-Бера оказалась равной 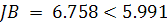 , что подтверждает отклонение гипотезы, т.е. остатки не имеют
нормального распределения. Критерий "поворотных точек" дал следующие
результаты:
, что подтверждает отклонение гипотезы, т.е. остатки не имеют
нормального распределения. Критерий "поворотных точек" дал следующие
результаты: 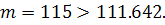 Значит, остатки случайны. Ранговый коэффициент Спирмана
Значит, остатки случайны. Ранговый коэффициент Спирмана 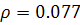 ,
, 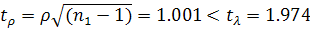 , следовательно, остатки гомоскедастичные. Критерий
Дарбина-Уотсона показал, что автокорреляция отсутствует, т.к.
, следовательно, остатки гомоскедастичные. Критерий
Дарбина-Уотсона показал, что автокорреляция отсутствует, т.к. 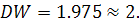 Анализируя полученные результаты, приходим к выводу, что лишь
одна предпосылка не соблюдена, а именно остатки не имеют нормального
распределения. Вообще говоря, для авторегрессионных моделей выполнение этого
условия не обязательно. Необходимым является то, чтобы полученный ряд остатков
построенной модели был "белым шумом", т.е. остатки должны быть
гомоскедастичны (с однородной дисперсией).
Анализируя полученные результаты, приходим к выводу, что лишь
одна предпосылка не соблюдена, а именно остатки не имеют нормального
распределения. Вообще говоря, для авторегрессионных моделей выполнение этого
условия не обязательно. Необходимым является то, чтобы полученный ряд остатков
построенной модели был "белым шумом", т.е. остатки должны быть
гомоскедастичны (с однородной дисперсией).
Для проверки данного факта протестируем выборочную автокорреляцию
с помощью Q-статистики Льюинга-Бокса (1.20). Вычислим значение статистики для
первых 15 лагов. Результаты приведены в таблице 2.1.
Таблица 2.1 - Вычисленные и табличные значения Q-статистики
Льюинга-Бокса
|
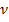
|
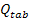
|
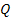
|
|
1
|
3.841
|
0.017
|
|
2
|
5.991
|
3.509
|
|
3
|
7.815
|
3.56
|
|
4
|
9.488
|
3.933
|
|
5
|
11.071
|
4.449
|
|
6
|
12.592
|
6.127
|
|
7
|
14.067
|
6.129
|
|
8
|
15.507
|
10.983
|
|
9
|
16.919
|
11.097
|
|
10
|
18.307
|
11.347
|
|
11
|
19.675
|
12.124
|
|
12
|
21.026
|
12.79
|
|
13
|
22.362
|
12.858
|
|
14
|
23.685
|
14.658
|
|
15
|
24.996
|
14.776
|
Из таблицы видно, что значения статистики не превосходят табличных
значений, т.е. 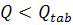 для любого
для любого 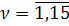 , поэтому нулевая гипотеза не отклоняется и выборка является
"белым шумом". Коэффициент детерминации имеет достаточно высокое
значение, , что говорит о том, что модель AR (1) на 87% точно описывает ряд.
Уравнение значимо в целом, поскольку
, поэтому нулевая гипотеза не отклоняется и выборка является
"белым шумом". Коэффициент детерминации имеет достаточно высокое
значение, , что говорит о том, что модель AR (1) на 87% точно описывает ряд.
Уравнение значимо в целом, поскольку 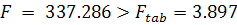 .
.
Теперь рассмотрим вторую подвыборку и попытаемся построить
для нее модель, наилучшим образом аппроксимирующую полученные значения к
исходному ряду. Изобразим на рисунке 2.13 данную подвыборку и построенную
трендовую модель, которая является полиномиальной моделью 3-й степени.
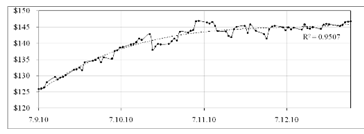
Рисунок 2.13 - График второй подвыборки значений курса акции
IBM
Коэффициенты детерминации для полиномиальных моделей более
высокого порядка не превосходят 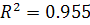 .
.
Значит, следуя принципу экономичности, который заключается в
выборе модели с наименьшим числом параметров среди других моделей, признанных
на одном и том же наборе данных также адекватными по некоторому признаку, будем
рассматривать полиномиальную модель 3-го порядка.
Уравнение модели имеет вид:
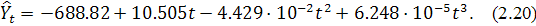
Применение критерия Стьюдента (1.9) показало, что все коэффициенты
значимы:
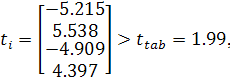
критерий Фишера (1.11) также позволяет сделать вывод о значимости
всего уравнения:
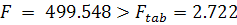 .
.
Проверим, соблюдаются ли предпосылки Гаусса-Маркова для данного
уравнения. Математическое ожидание имеет приближенное к нулю значение: 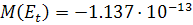 . Стандартная ошибка регрессии
. Стандартная ошибка регрессии 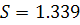 , остатки принадлежат интервалу
, остатки принадлежат интервалу 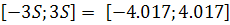 , следовательно, на данном этапе нельзя отклонить гипотезу о
нормальном распределении остатков. Вычислив коэффициенты асимметрии и эксцесса
и значение статистики Жака-Бера
, следовательно, на данном этапе нельзя отклонить гипотезу о
нормальном распределении остатков. Вычислив коэффициенты асимметрии и эксцесса
и значение статистики Жака-Бера 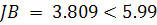 , получили, что гипотеза о нормальном распределении остатков не
отклоняется. Критерий поворотных точек дал следующие результаты:
, получили, что гипотеза о нормальном распределении остатков не
отклоняется. Критерий поворотных точек дал следующие результаты: 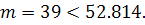 Значит, остатки не являются случайными. Ранговый коэффициент
корреляции Спирмана
Значит, остатки не являются случайными. Ранговый коэффициент
корреляции Спирмана 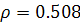 , t-статистика
, t-статистика 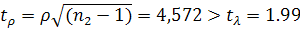 , следовательно, остатки гетероскедастичные. Используя статистику
Дарбина-Уотсона (1.19) получаем
, следовательно, остатки гетероскедастичные. Используя статистику
Дарбина-Уотсона (1.19) получаем 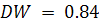 . Сравнивая рассчитанную величину с нижним значением критерия
. Сравнивая рассчитанную величину с нижним значением критерия 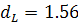 и принимая во внимание значение
и принимая во внимание значение 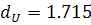 , делаем вывод - в остатках присутствует положительная
автокорреляция.
, делаем вывод - в остатках присутствует положительная
автокорреляция.
Следовательно, остатки не являются "белым шумом".
Возникает необходимость скорректировать ряд остатков. Построим для него модель
ARIMA (p,d,q), предварительно выбрав и обосновав полученные значения
параметров.(авторегрессия проинтегрированного скользящего среднего) -
методология, разработанная Боксом и Дженкинсом, достаточно популярная во многих
приложениях и научно-исследовательских разработках, и практика подтвердила его
мощность и гибкость. Однако, несмотря на прекрасные характеристики, ARIMA
является достаточно сложной моделью.
Общая модель включает в себя три типа параметров [3]: параметр
авторегрессии 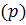 , порядок разности
, порядок разности 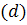 , параметр скользящего среднего
, параметр скользящего среднего 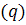 . В обозначениях модель записывается как ARIMA (p,d,q). В общем
виде уравнение модели выглядит следующим образом:
. В обозначениях модель записывается как ARIMA (p,d,q). В общем
виде уравнение модели выглядит следующим образом:
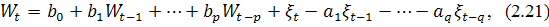
где 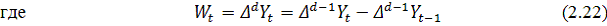
является разностью порядка между уровнями ряда;
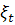 - случайный импульс или "белый шум".
- случайный импульс или "белый шум".
Как уже было установлено, ряд остатков не стационарен. Для приведения его к стационарному виду возьмем
первые разности, т.е. продифференцируем его, после чего останется подобрать
параметры и  при
при 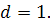 Взятие разностей подразумевает рассмотрение ряда
Взятие разностей подразумевает рассмотрение ряда 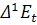 значений, полученных из исходного ряда по формуле (2.22):
значений, полученных из исходного ряда по формуле (2.22):
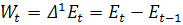 .
.
Данный ряд после преобразования является стационарным, поскольку
АКФ постепенно затухает, ЧАКФ также затухает и имеет наибольший выброс на
первом лаге. Видно, что АКФ и ЧАКФ продифференцированного ряда (рисунок 2.14)
имеют несколько выделяющихся значений на 1-м, 8-м, и 12-м лагах, а также на 6-м
лаге для ЧАКФ. Поэтому рассмотрим модели ARIMA (1,1,0), ARIMA (3,1,1), ARIMA
(6,1,1), ARIMA (6,1,3) и сравним их по информационным критериям Акаики и Шварца
(1.23,1.24), которые позволяют выбрать оптимальную модель и минимизировать
количество используемых в ней параметров.
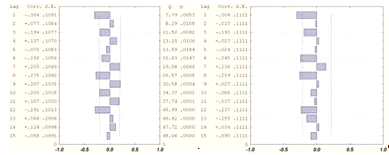
Рисунок 2.14 - График АКФ и ЧАКФ продифференцированного ряда
остатков
Построение моделей производим в программе Statistica 6.0, в
результате после исключения незначимых коэффициентов получены следующие уравнения:
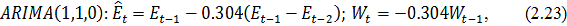
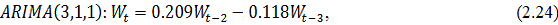
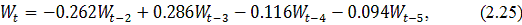
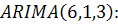
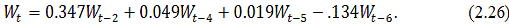
Остатки моделей удовлетворяют всем предпосылкам Гаусса-Маркова.
Сравнивая модели по информационному критерию Акаики
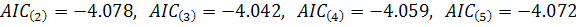
и Шварца
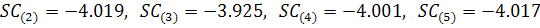
можно сделать вывод о том, что наилучшей для остатков является
модель (2.23). Объединив модель (2.20) и (2.23) получим следующее уравнение:
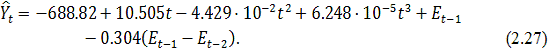
Оценим коэффициент детерминации и значение F-критерия Фишера
(1.11) для данной модели  ,
,  , что больше табличного значения , следовательно, модель на 98.3% точно описывает исходные данные
ряда и всего 1.7% приходится на ошибку. Построенная модель является адекватной.
, что больше табличного значения , следовательно, модель на 98.3% точно описывает исходные данные
ряда и всего 1.7% приходится на ошибку. Построенная модель является адекватной.
Подводя итоги, общий вид исправленной кусочно-непрерывной модели
можно записать в виде системы двух равенств:
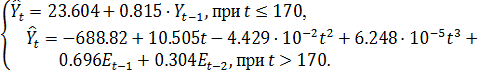
3.
Прогнозирование курса акции aapl на основе адаптивных моделей
3.1
Построение модели ARMA (p,q)
Построив для наглядности в приложении Statistica 6.0 графики
АКФ и ЧАКФ (рисунок 3.1) получили, что АКФ убывает, а ЧАКФ имеет резко выделяющееся
значения на 1-м лаге. ЧАКФ подтверждает, что значения АКФ. начиная со второго
лага, обусловлены корреляцией на 1-м лаге.
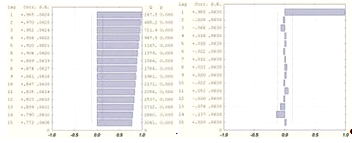
Рисунок 3.1 - АКФ и ЧАКФ для курса AAPL
Согласно свойствам АКФ и ЧАКФ можно предположить [4], что
курс акции AAPL описывается моделью ARMA (1,0). Будем строить данную модель в
виде:

По выборочным данным в приложении Statistica 6.0 получены
оценки коэффициентов модели. Аналитический вид может быть представлен следующим
уравнением:
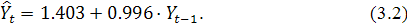
Несмотря на то, что по критерию Стьюдента на 5% -ом уровне
значимости свободный член оказался незначим: 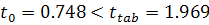 , но из экономических соображений его не будем удалять из
уравнения модели.
, но из экономических соображений его не будем удалять из
уравнения модели.
По критерию Фишера уравнение регрессии значимо, поскольку
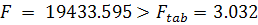 .
.
Коэффициент детерминации  , что говорит об очень хорошем качестве построенной модели. На
98.7% модель ARMA (1,0) аппроксимирует исходные данные временного ряда,
остальное приходится на ошибку.
, что говорит об очень хорошем качестве построенной модели. На
98.7% модель ARMA (1,0) аппроксимирует исходные данные временного ряда,
остальное приходится на ошибку.
На рисунке 3.2 приведем график остатков модели (3.2).
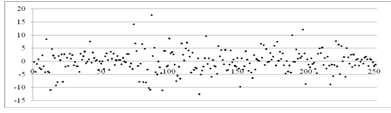
Рисунок 3.2 - График остатков модели (3.2)
Визуальный анализ дает возможность предположить, что ряд остатков
является стационарным, поскольку в нем отсутствует определенная направленность.
Проверим, выполняются ли для остатков условия Гаусса-Маркова.
. С учетом погрешности в вычислениях математическое ожидание
остатков имеет значение 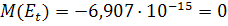 .
.
. Стандартная ошибка регрессии 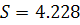 . Несколько значений остатков лежат вне интервала
. Несколько значений остатков лежат вне интервала 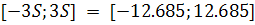 и являются своего рода выбросами, резко выделяющимися на фоне
общей картины остатков, что, возможно, вызвано неточностью в вычислениях.
Поэтому отклонить или принять гипотезу о нормальном распределении остатков затруднительно.
Применяя статистику Жака-Бера, предварительно вычислив коэффициенты асимметрии
и эксцесса, установили, что гипотеза о нормальном распределении остатков
отклоняется, поскольку значение статистики
и являются своего рода выбросами, резко выделяющимися на фоне
общей картины остатков, что, возможно, вызвано неточностью в вычислениях.
Поэтому отклонить или принять гипотезу о нормальном распределении остатков затруднительно.
Применяя статистику Жака-Бера, предварительно вычислив коэффициенты асимметрии
и эксцесса, установили, что гипотеза о нормальном распределении остатков
отклоняется, поскольку значение статистики 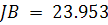 , что гораздо больше квантили распределения равной 5.991.
, что гораздо больше квантили распределения равной 5.991.
. Для проверки остатков на случайность используем критерий
"поворотных точек". Для данного ряда остатков получили 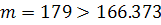 . Следовательно, выборка остатков случайна.
. Следовательно, выборка остатков случайна.
. Для рассматриваемого ряда остатков при проверке на наличие
гетероскедастичности ранговый коэффициент корреляции Спирмена оказался равным 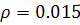 . Оценив статистическую значимость с помощью t-критерия:
. Оценив статистическую значимость с помощью t-критерия: 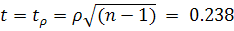 , и сравнив эту величину с табличной при уровне значимости , получили, что
, и сравнив эту величину с табличной при уровне значимости , получили, что 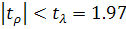 . Следовательно, гипотеза об отсутствии гетероскедастичности
остатков не отклоняется.
. Следовательно, гипотеза об отсутствии гетероскедастичности
остатков не отклоняется.
. Для проверки наличия автокорреляции в остатках воспользуемся
критерием Дарбина-Уотсона. Используя формулу (1.19) получаем 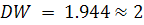 . Полученное значение статистики говорит об отсутствии
автокорреляции между соседними значениями остатков. Данный вывод также
подтверждает график АКФ остатков модели, изображенный на рисунке 3.3.
. Полученное значение статистики говорит об отсутствии
автокорреляции между соседними значениями остатков. Данный вывод также
подтверждает график АКФ остатков модели, изображенный на рисунке 3.3.
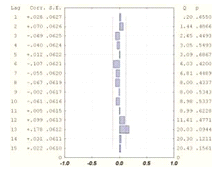
Рисунок 3.3 - График АКФ остатков модели (3.2)
Итак, проверка показала, что одно из условий, а именно,
предпосылка о нормальности распределения остатков, нарушается. Поскольку
необходимым является то, чтобы получившийся ряд остатков являлся "белым
шумом", для авторегрессионных моделей выполнение этой вышеуказанной
предпосылки не является обязательным [8]. Для того чтобы проверить остатки,
воспользуемся Q-статистикой Льюинга-Бокса, рассчитав ее для первых 15 значений
лагов автокорреляционной функции. Рассматриваемый ряд оказался "белым
шумом", поскольку значения статистики не превосходят табличных значений,
т.е. . Нулевая гипотеза не отклоняется и выборка является "белым
шумом". Ввиду полученных результатов можно сделать вывод об адекватности
построенной модели и о хорошей аппроксимации теоретических значений к
фактическим значениям временного ряда. Модель в дальнейшем пригодна к
использованию для построения прогноза.
3.2 Модель
ARIMA (p,d,q)
Основными инструментами идентификации порядка модели ARIMA
(p,d,q) являются графики АКФ и ЧАКФ [3]. Также при построении модели в первую
очередь необходимо проверить рассматриваемый ряд на стационарность. Признаками
не стационарности являются наличие тренда, гетероскедастичность, изменяющаяся
автокорреляция.
Проанализируем АКФ и ЧАКФ рассматриваемого ряда. Их графические
представления уже были приведены па рисунке 3.1 График АКФ позволяет
предположить, что исходный временной ряд может быть описан авторегрессионным
процессом с коэффициентом при лаговой переменной, близким к 1, т.е. это говорит о не
стационарности процесса, поскольку АКФ убывает очень медленно [12].
Подтверждением служит проверка ряда с помощью статистики
Дики-Фуллера (1.22), которая при уровне значимости выдает значение t-статистики 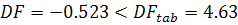 , что говорит о не стационарности ряда.
, что говорит о не стационарности ряда.
Одним из способов приведения ряда к стационарному виду является
дифференцирование ряда [3]. Рассмотрим ряд, полученный из исходного ряда
взятием разности 1-го порядка. Глядя на рисунок 3.4 можно заметить, что
полученный с помощью дифференцирования ряд уже больше похож на стационарный - в
нем отсутствует тренд.
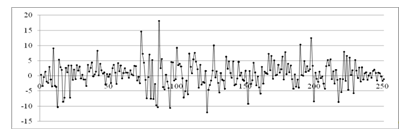
Рисунок 3.4 - Продифференцированный ряд значений цены акции AAPL
Проверку ряда на стационарность проведем теперь с помощью
интеграционной статистики Дарбина-Уотсона. Применняя формулу (1.21) для уровней
исходного ряда цен находим значение статистики
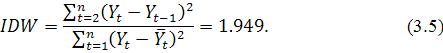
Рассчитанное значения статистики (3.5) очень близко к 2, что
позволяет принять гипотезу о стационарности ряда. Таким образом, исходный ряд
приведен к стационарному виду взятием разности первого порядка, следовательно, 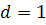 .
.
Внешний вид АКФ и ЧАКФ (рисунок 3.5) дают основание предположить,
что полученный дифференцированием ряд является "белым шумом".
Q-статистика Люинга-Бокса подтверждает выдвинутое предположение, т.к.
рассчитанные значения  не превосходят критических (табличных) значений статистики
не превосходят критических (табличных) значений статистики 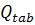 на 5% -ом уровне значимости. Следовательно, процесс является
"белым шумом".
на 5% -ом уровне значимости. Следовательно, процесс является
"белым шумом".
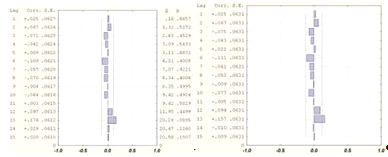
Рисунок 3.5 - АКФ и ЧАКФ продифференцированного ряда курса AAPL
Исходя из полученных результатов анализа, приходим к выводу, что
рассматриваемый ряд можно описать моделью ARIMA (p,1,q).
По внешнему виду графиков не всегда удается определить оптимальные
параметры модели [1], что характерно для нашей ситуации. Поэтому построим
модели ARIMA (1,1,0), ARIMA (0,1,1), ARIMA (2,1,2), ARIMA (3,1,2), ARIMA
(6,1,3) и сравним их по информационным критериям Акаики и Шварца (1.23,1.24).
Построение моделей производим в программе Statistica 6.0, в
результате после исключения незначимых коэффициентов получены следующие
уравнения:
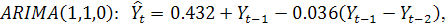
или, учитывая формулу (3.4), получим
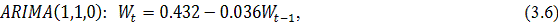
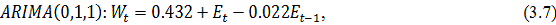
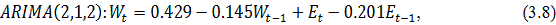
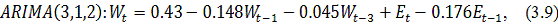
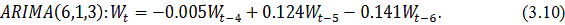
Сравним модели по информационному критерию Акаики и Шварца.
Результат сравнения приведены в таблице 3.1:
Таблица 3.1 - Значения критериев Акаики и Шварца для
построенных моделей
|
Модель
|
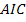
|
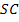
|
|
ARIMA (1,1,0)
|
-2.089
|
-2.076
|
|
ARIMA (0,1,1)
|
-2.113
|
-2.045
|
|
ARIMA (2,1,2)
|
-2.189
|
-2.097
|
|
ARIMA (3,1,2)
|
-2.219
|
-2.179
|
|
ARIMA (6,1,3)
|
-2.196
|
-2.144
|
Наилучшей моделью оказалась модель ARIMA (3,1,2), поскольку
она имеет наименьшие значения критериев. Остатки модели удовлетворяют всем
предпосылкам Гаусса-Маркова.
Оценим коэффициент детерминации и значение F-критерия Фишера
(1.11) для данной модели 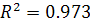 ,
, 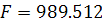 , что больше табличного значения , следовательно, модель на 97.3% точно описывает исходные данные
ряда и всего 2.7% приходится на ошибку. Итак, построенная модель является
адекватной. Она хорошо аппроксимирует значения акции AAPL. Следовательно,
данную модель можно использовать для построения краткосрочного точечного
прогноза.
, что больше табличного значения , следовательно, модель на 97.3% точно описывает исходные данные
ряда и всего 2.7% приходится на ошибку. Итак, построенная модель является
адекватной. Она хорошо аппроксимирует значения акции AAPL. Следовательно,
данную модель можно использовать для построения краткосрочного точечного
прогноза.
3.3 Анализ
моделей и прогнозирование
Прогнозировать падение или увеличение курса акций с высокой
точностью практически невозможно. Действительно, попытки предугадать скачки по
изменению стоимости акций очень сложно. Эти трудности возникают главным образом
тогда, когда крупные финансовые компании умышленно играют на понижении или
повышении курса с целью спекулятивного выигрыша [1].
Поскольку одной из моделей, выбранных для прогнозирования,
является модель ARIMA, то необходимо отметить, что он вычисляется из
проинтегрированных рядов (интегрирование, более точно суммирование, в данном
случае означает просто операцию, обратную взятию разностей с соответствующими
лагами). Таким образом, проводя обратные преобразования, вы возвращаетесь к
исходному ряду, и прогноз соответствует исходным данным, что обеспечивает более
легкую интерпретацию результатов [11].
В предыдущей главе и в предыдущих пунктах были построены три
модели: смешанная модель (трендовая модель + AR (1) на остатках), модель ARMA
(1,0) и ARIMA (3,1,2). Теперь необходимо статистически сравнить эти модели
между собой и построить прогноз. Для сравнения моделей будем использовать
значения средних ошибок аппроксимации 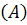 , которое вычисляется по формуле
, которое вычисляется по формуле
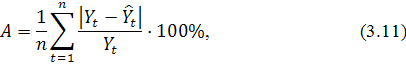
где - значения исходного ряда;
 - значение, полученное по построенной модели;
- значение, полученное по построенной модели;
- объем временного ряда.
Рассмотрим суммы квадратов остатков моделей  (1.12) и величины остаточных дисперсий
(1.12) и величины остаточных дисперсий 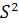 (1.10). Результаты сравнения приведены в таблице 3.2.
(1.10). Результаты сравнения приведены в таблице 3.2.
Таблица 3.2 - Статистическое сравнение моделей на основе
значений критериев
|
Модель
|
Значения критериев
|
|
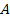
|
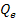
|
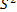
|
|
Трендовая модель + AR (1) на остатках
|
1.198%
|
4242.671
|
16.836
|
|
ARMA (1,0)
|
1.227%
|
4452.118
|
17.880
|
|
ARIMA (3,1,2)
|
1.204%
|
4369.652
|
17.313
|
Из таблицы видно, что наибольшее преимущество перед
остальными имеет смешанная модель, но также следует заметить, что полученное
значения средней относительной ошибки говорит о достаточно высоком уровне
точности построенных моделей (ошибка менее 5% свидетельствует об
удовлетворительном уровне точности; ошибка в 8-10 и более процентов считается
очень большой) [5].
Построенные модели эффективны только для краткосрочного
прогноза, поэтому будем строить прогноз на 5 дней (рисунки 3.6, 3.7, 3.8),
после чего сравним полученные результаты.
При прогнозировании существует подход [11], когда модель
проверяют на адекватность и точность на фактических данных, не использованных
при построении модели (приложение А).
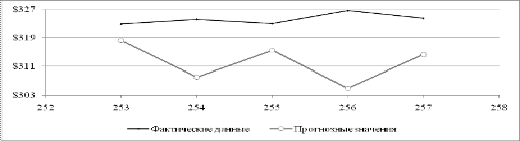
Рисунок 3.6 - Прогноз по смешанной модели
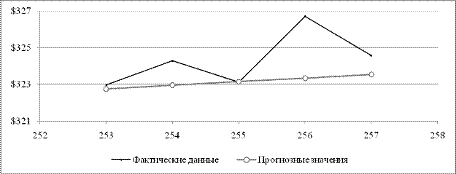
Рисунок 3.7 - Прогноз по модели ARMA (1,0)
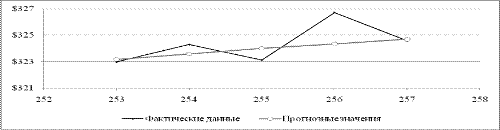
Рисунок 3.8 - Прогноз по модели ARIMA (3,1,2)
Расчет прогноза проведен по формулам для 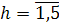 :
:
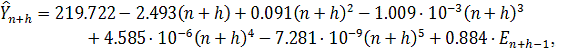
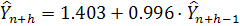 ,
,
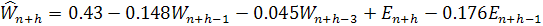 ,
,
для моделей (2.13), (3.2) и (3.9) соответственно.
Сравнивая полученные прогнозные значения с фактическими данными,
можно заметить, что прогноз по смешенной модели оказался слишком неточным,
поскольку модель не уловила возрастающую тенденцию ряда. Поэтому данную модель
не стоит использовать для прогноза. Также из рисунков видно, что прогнозные
значения достаточно сильно отличаются от фактических данных, поскольку
построенные модели, как было сказано выше, не являются эффективными для
долгосрочного прогноза курса валют. Скачки фактических значений на 3-м и 4-м
дне прогноза являются следствием влияния многих внешних экономических факторов
на курс акции.
Чтобы сделать окончательный выбор о том, какую модель лучше
использовать для прогнозирования, вычислим средние ошибки прогнозов по формуле
(3.11):
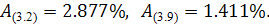
Таким образом, основываясь на полученных результатах (3.12),
лучший прогноз получен по модели (3.9). Несмотря на то, что при сравнении
моделей наиболее точно описывающей исходный ряд оказалась модель (2.13),
прогноз с ее использованием дал худший результат.
Учитывая то, что на данный момент информация о значениях курса
акций на каждый день является доступной, можно с достаточно высокой точностью
делать краткосрочный прогноз на 1-2 дня вперед по модели (3.9), и
корректировать дальнейшие прогнозные значения с получением новых значений курса
акции AAPL.
Заключение
Моделирование и прогнозирование курса акций очень важно для специалистов
в области рынка ценных бумаг. Особенно необходим краткосрочный прогноз.
В работе исследована динамика курса акций AAPL и IBM по
данным бирж NASDAQ и NYSE. В динамике акции AAPL прослеживается возрастающая
тенденция, в динамике акции IBM - резкое изменение тенденции на период с 5
сентября по 6 ноября, которое было вызвано увеличением спроса на продукцию
компании, следствием чего стало увеличение прибыли и курса акций. Были
построены полиномиальные модели тренда для обоих временных рядов значений курса
акций. Проверен исследуемый ряд IBM на структурную стабильность с помощью теста
Чоу. Построена кусочно-непрерывная модель. После корректирования остатков при
помощи адаптивных моделей получены смешанные модели, обладающие лучшей
аппроксимацией исходных данных.
С другой стороны, предполагая, что непосредственно уровни
временного ряда значений курса акции AAPL подвержены автокорреляционной
зависимости были рассмотрены адаптивные модели. Построены модели ARMA и ARIMA и
с помощью специального статистического сравнения выбраны наиболее лучшие
модели. На их основе построен краткосрочный прогноз.
Показано, что смешанная модель является наилучшей по
значениям таких показателей как сумма квадратов остатков, остаточная дисперсия
и стандартная ошибка аппроксимации. Однако адаптивные модели лучше уловили
поведение курса акции AAPL, поэтому построение прогноза желательно проводить по
модели ARIMA (3,1,2).
В общем случае построить модель, у которой прогноз совпадал
бы с фактическими данными, практически невозможно. Скорее всего, это связано с
тем, что на исследуемый показатель каждый день влияют многие внешние факторы,
учесть в совокупности которые не удается.
Список
использованных источников
1
Бокс, Дж. Анализ временных рядов, прогноз и управление [Текст]: в 2 т. / Дж.
Бокс, Г. Дженкинс. - М.: Мир, 1974.
Боровиков,
В П. Популярное введение в программу Statistica: пособие для студентов вуза /
В.П. Боровиков. - СПб.: Питер, 2003. - 239 с.
Буре,
В.М. Основы эконометрики [Текст]: учебное пособие для вузов / В.М. Буре, Е.А.
Евсеев. - СПб.: СПбГУ, 2004. - 256 с.
Дараган,
В.А. Игра на бирже [Текст]: пособие для трейдеров / В.А. Дараган. - М.: УРСС,
1998. - 211 с.
Елисеева,
И.И. Практикум по эконометрике [Текст]: учебное пособие / И.И. Елисеева. - М.:
Финансы и статистика, 2002. - 192 с.
Канторович,
Г.Г. Анализ временных рядов [Текст]: лекционные и методические материалы: курс
лекций / Г.Г. Канторович. - Экономический журнал ВШЭ: ГУ ВШЭ, 2003. - 129 с.
Кендэл,
М. Временные ряды [Текст]: практическое руководство / М. Кендэл. - М.: Финансы
и статистика, 1981. - 199 с.
Кремер,
Н.Ш. Эконометрика [Текст]: учебное пособие для вузов / Н.Ш. Кремер, Б.А. Путко.
- М.: ЮНИТИ-ДАНА, 2002. - 311 с.
Лукашин,
Ю.П. Анализ авторегрессии [Текст]: сборник статей / Ю.П. Лукашин. - М.:
Статистика, 1978. - 232 с.
Суслов,
В.И. Эконометрия [Текст]: учебное пособие / В.И. Суслов [и др.]; под общ.
ред.В.И. Суслова. - Новосибирск: СО РАН, 2005. - 744 с.
Халафян,
А.А. STATISTICА 6. Статистический анализ данных.3-е изд. [Текст]: учебник /
А.А. Халафян. - М.: Бином-Пресс, 2007. - 512 с.
Шелобаев,
С.И. Математические методы и модели в экономике, финансах, бизнесе [Текст]:
учебное пособие для вузов / С.И. Шелобаев. - М.: ЮНИТИ-ДАНА, 2001. - 367 с.
13 Электронный
учебник по статистике [Электронный ресурс] / М.: StatSoft. Режим доступа:
<http://www.statsoft.ru>
News and reviews
analytics [Электронный ресурс] / Режим доступа:
<http://onlineexplore.org/apple>
Wikipedia
[Электронный ресурс]: свободная энциклопедия / Режим доступа: http://ru.
wikipedia.org/wiki/IBM <http://ru.wikipedia.org/wiki/IBM>
Приложения
Приложение А
Исходные значения курса акции AAPL:
|
Дата
|
Цена, $
|
|
1/4/2010
|
214.01
|
|
1/5/2010
|
214.38
|
|
1/6/2010
|
210.97
|
|
1/7/2010
|
210.58
|
|
1/8/2010
|
211.98
|
|
1/11/2010
|
210.11
|
|
1/12/2010
|
207.72
|
|
1/13/2010
|
210.65
|
|
1/14/2010
|
209.43
|
|
1/15/2010
|
205.93
|
|
1/19/2010
|
215.04
|
|
1/20/2010
|
211.725
|
|
1/21/2010
|
208.072
|
|
1/22/2010
|
197.75
|
|
1/25/2010
|
203.075
|
|
1/26/2010
|
205.94
|
|
1/27/2010
|
207.884
|
|
1/28/2010
|
199.29
|
|
1/29/2010
|
192.063
|
|
2/1/2010
|
194.73
|
|
2/2/2010
|
195.86
|
|
2/3/2010
|
199.23
|
|
2/4/2010
|
192.05
|
|
2/5/2010
|
195.46
|
|
2/8/2010
|
194.12
|
|
2/9/2010
|
196.19
|
|
2/10/2010
|
195.116
|
|
2/11/2010
|
198.67
|
|
2/12/2010
|
200.38
|
|
2/16/2010
|
203.4
|
|
2/17/2010
|
202.55
|
|
2/18/2010
|
202.928
|
|
2/19/2010
|
201.67
|
|
2/22/2010
|
200.416
|
|
2/23/2010
|
197.059
|
|
2/24/2010
|
200.656
|
|
2/25/2010
|
202
|
|
2/26/2010
|
204.62
|
|
3/1/2010
|
208.99
|
|
3/2/2010
|
208.85
|
|
3/3/2010
|
209.33
|
|
3/4/2010
|
210.71
|
|
3/5/2010
|
218.95
|
|
3/8/2010
|
|
3/9/2010
|
223.02
|
|
3/10/2010
|
224.84
|
|
3/11/2010
|
225.5
|
|
3/12/2010
|
226.6
|
|
3/15/2010
|
223.84
|
|
3/16/2010
|
224.45
|
|
3/17/2010
|
224.12
|
|
3/18/2010
|
224.65
|
|
3/19/2010
|
222.2499
|
|
3/22/2010
|
224.75
|
|
3/23/2010
|
228.36
|
|
3/24/2010
|
229.37
|
|
3/25/2010
|
226.65
|
|
3/26/2010
|
230.9
|
|
3/29/2010
|
232.39
|
|
3/30/2010
|
235.845
|
|
3/31/2010
|
235
|
|
4/1/2010
|
235.97
|
|
4/5/2010
|
238.49
|
|
4/6/2010
|
239.54
|
|
4/7/2010
|
240.6
|
|
4/8/2010
|
239.95
|
|
4/9/2010
|
241.79
|
|
4/12/2010
|
242.29
|
|
4/13/2010
|
242.43
|
|
4/14/2010
|
245.69
|
|
4/15/2010
|
248.92
|
|
4/16/2010
|
247.4
|
|
4/19/2010
|
247.07
|
|
4/20/2010
|
244.59
|
|
4/21/2010
|
259.22
|
|
4/22/2010
|
266.4695
|
|
4/23/2010
|
270.83
|
|
4/26/2010
|
269.5
|
|
4/27/2010
|
262.04
|
|
4/28/2010
|
261.6
|
|
4/29/2010
|
268.64
|
|
4/30/2010
|
261.09
|
|
5/3/2010
|
266.35
|
|
5/4/2010
|
258.68
|
|
5/5/2010
|
255.985
|
|
5/6/2010
|
246.25
|
|
5/7/2010
|
235.86
|
|
5/10/2010
|
253.99
|
|
5/11/2010
|
256.52
|
|
5/12/2010
|
262.09
|
|
5/13/2010
|
258.36
|
|
5/14/2010
|
253.82
|
|
5/17/2010
|
254.22
|
|
5/18/2010
|
252.36
|
|
5/19/2010
|
248.34
|
|
5/20/2010
|
237.76
|
|
5/21/2010
|
242.32
|
|
5/24/2010
|
246.76
|
|
5/25/2010
|
245.22
|
|
5/26/2010
|
244.109
|
|
5/27/2010
|
253.35
|
|
5/28/2010
|
256.88
|
|
6/1/2010
|
260.83
|
|
6/2/2010
|
263.95
|
|
6/3/2010
|
263.12
|
|
6/4/2010
|
255.965
|
|
6/7/2010
|
250.94
|
|
6/8/2010
|
249.33
|
|
6/9/2010
|
243.2
|
|
6/10/2010
|
250.51
|
|
6/11/2010
|
253.51
|
|
6/14/2010
|
254.28
|
|
6/15/2010
|
259.69
|
|
6/16/2010
|
267.25
|
|
6/17/2010
|
271.87
|
|
6/18/2010
|
274.074
|
|
6/21/2010
|
270.17
|
|
6/22/2010
|
273.85
|
|
6/23/2010
|
270.97
|
|
6/24/2010
|
269
|
|
6/25/2010
|
266.7
|
|
6/28/2010
|
268.3
|
|
6/29/2010
|
256.17
|
|
6/30/2010
|
251.53
|
|
7/1/2010
|
248.48
|
|
7/2/2010
|
246.94
|
|
7/6/2010
|
248.63
|
|
7/7/2010
|
258.665
|
|
7/8/2010
|
258.09
|
|
7/9/2010
|
259.62
|
|
7/12/2010
|
257.285
|
|
7/13/2010
|
251.798
|
|
7/14/2010
|
252.727
|
|
7/15/2010
|
251.45
|
|
7/16/2010
|
249.9
|
|
7/19/2010
|
245.58
|
|
7/20/2010
|
251.89
|
|
7/21/2010
|
254.24
|
|
7/22/2010
|
259.024
|
|
7/23/2010
|
259.94
|
|
7/26/2010
|
259.28
|
|
7/27/2010
|
264.08
|
|
7/28/2010
|
260.96
|
|
7/29/2010
|
258.11
|
|
7/30/2010
|
257.25
|
|
8/2/2010
|
261.85
|
|
8/3/2010
|
261.93
|
|
8/4/2010
|
262.98
|
|
8/5/2010
|
261.7
|
|
8/6/2010
|
260.091
|
|
8/9/2010
|
261.75
|
|
8/10/2010
|
259.41
|
|
8/11/2010
|
250.19
|
|
8/12/2010
|
251.79
|
|
8/13/2010
|
249.1
|
|
8/16/2010
|
247.64
|
|
8/17/2010
|
251.97
|
|
8/18/2010
|
253.07
|
|
8/19/2010
|
249.88
|
|
8/20/2010
|
249.64
|
|
8/23/2010
|
245.8
|
|
8/24/2010
|
239.93
|
|
8/25/2010
|
242.89
|
|
8/26/2010
|
240.28
|
|
8/27/2010
|
241.62
|
|
8/30/2010
|
242.5
|
|
8/31/2010
|
243.1
|
|
9/1/2010
|
250.33
|
|
9/2/2010
|
252.17
|
|
9/3/2010
|
258.77
|
|
9/7/2010
|
257.81
|
|
9/8/2010
|
262.92
|
|
9/9/2010
|
263.07
|
|
9/10/2010
|
263.41
|
|
9/13/2010
|
267.04
|
|
9/14/2010
|
268.06
|
|
9/15/2010
|
270.22
|
|
9/16/2010
|
276.57
|
|
9/17/2010
|
275.37
|
|
9/20/2010
|
283.23
|
|
9/21/2010
|
283.77
|
|
9/22/2010
|
287.75
|
|
9/23/2010
|
288.92
|
|
9/24/2010
|
292.32
|
|
9/27/2010
|
291.164
|
|
9/28/2010
|
286.86
|
|
9/29/2010
|
287.37
|
|
9/30/2010
|
283.75
|
|
10/1/2010
|
282.52
|
|
10/4/2010
|
278.64
|
|
10/5/2010
|
288.94
|
|
10/6/2010
|
289.19
|
|
10/7/2010
|
289.22
|
|
10/8/2010
|
294.07
|
|
10/11/2010
|
295.36
|
|
10/12/2010
|
298.54
|
|
10/13/2010
|
300.14
|
|
10/14/2010
|
302.31
|
|
10/15/2010
|
314.74
|
|
10/18/2010
|
318
|
|
10/19/2010
|
309.49
|
|
10/20/2010
|
310.53
|
|
10/21/2010
|
309.52
|
|
10/22/2010
|
307.47
|
|
10/25/2010
|
308.84
|
|
10/26/2010
|
308.05
|
|
10/27/2010
|
307.83
|
|
10/28/2010
|
305.24
|
|
10/29/2010
|
300.98
|
|
11/1/2010
|
304.18
|
|
11/2/2010
|
309.36
|
|
11/3/2010
|
312.8
|
|
11/4/2010
|
318.27
|
|
11/5/2010
|
317.13
|
|
11/8/2010
|
318.62
|
|
11/9/2010
|
316.08
|
|
11/10/2010
|
318.03
|
|
11/11/2010
|
316.655
|
|
11/12/2010
|
308.03
|
307.035
|
|
11/16/2010
|
301.59
|
|
11/17/2010
|
300.5
|
|
11/18/2010
|
308.43
|
|
11/19/2010
|
306.73
|
|
11/22/2010
|
313.36
|
|
11/23/2010
|
308.73
|
|
11/24/2010
|
314.795
|
|
11/26/2010
|
315
|
|
11/29/2010
|
316.87
|
|
11/30/2010
|
311.15
|
|
12/1/2010
|
316.4
|
|
12/2/2010
|
318.15
|
|
12/3/2010
|
317.44
|
|
12/6/2010
|
320.15
|
|
12/7/2010
|
318.21
|
|
12/8/2010
|
321.01
|
|
12/9/2010
|
319.7575
|
|
12/10/2010
|
320.56
|
|
12/13/2010
|
321.67
|
|
12/14/2010
|
320.29
|
|
12/15/2010
|
320.36
|
|
12/16/2010
|
321.25
|
|
12/17/2010
|
320.61
|
|
12/20/2010
|
322.21
|
|
12/21/2010
|
324.205
|
|
12/22/2010
|
325.16
|
|
12/23/2010
|
323.6
|
|
12/27/2010
|
324.68
|
|
12/28/2010
|
325.47
|
|
12/29/2010
|
325.29
|
|
12/30/2010
|
323.66
|
|
12/31/2010
|
322.56
|
Исходные значения курса акции AAPL для прогноза:
|
Дата
|
Цена, $
|
|
1/3/2011
|
322.97
|
|
1/4/2011
|
324.29
|
|
1/5/2011
|
323.123
|
|
1/6/2011
|
326.73
|
|
1/7/2011
|
324.581
|
Исходные значения курса акции IBM:
|
Дата
|
Цена, $
|
|
1/4/2010
|
132.45
|
|
1/5/2010
|
130.85
|
|
1/6/2010
|
130
|
|
1/7/2010
|
129.55
|
|
1/8/2010
|
130.85
|
|
1/11/2010
|
129.48
|
|
1/12/2010
|
130.51
|
|
1/13/2010
|
130.23
|
|
1/14/2010
|
132.31
|
|
1/15/2010
|
131.78
|
|
1/19/2010
|
134.14
|
|
1/20/2010
|
130.25
|
|
1/21/2010
|
129
|
|
1/22/2010
|
125.5
|
|
1/25/2010
|
126.12
|
|
1/26/2010
|
125.75
|
|
1/27/2010
|
126.33
|
|
1/28/2010
|
123.75
|
|
1/29/2010
|
122.39
|
|
2/1/2010
|
124.67
|
|
2/2/2010
|
125.53
|
|
2/3/2010
|
125.66
|
|
2/4/2010
|
123
|
|
2/5/2010
|
123.52
|
|
2/8/2010
|
121.88
|
|
2/9/2010
|
123.21
|
|
2/10/2010
|
122.81
|
|
2/11/2010
|
123.73
|
|
2/12/2010
|
124
|
|
2/16/2010
|
125.23
|
|
2/17/2010
|
126.33
|
|
2/18/2010
|
127.81
|
|
2/19/2010
|
127.19
|
|
2/22/2010
|
126.85
|
|
2/23/2010
|
126.46
|
|
2/24/2010
|
127.59
|
|
2/25/2010
|
127.07
|
|
2/26/2010
|
127.16
|
|
3/1/2010
|
128.57
|
|
3/2/2010
|
127.42
|
|
3/3/2010
|
126.88
|
|
3/4/2010
|
126.72
|
|
3/5/2010
|
127.25
|
|
3/8/2010
|
126.41
|
|
3/9/2010
|
125.55
|
|
3/10/2010
|
125.62
|
|
3/11/2010
|
127.6
|
|
3/12/2010
|
127.94
|
|
3/15/2010
|
127.83
|
|
3/16/2010
|
128.67
|
|
3/17/2010
|
127.76
|
|
3/18/2010
|
128.38
|
|
3/19/2010
|
127.71
|
|
3/22/2010
|
127.98
|
|
3/23/2010
|
129.37
|
|
3/24/2010
|
128.53
|
|
3/25/2010
|
129.24
|
|
3/26/2010
|
129.26
|
|
3/29/2010
|
128.59
|
|
3/30/2010
|
128.77
|
|
3/31/2010
|
128.25
|
|
4/1/2010
|
128.25
|
|
4/5/2010
|
129.35
|
|
4/6/2010
|
128.93
|
|
4/7/2010
|
128.48
|
|
4/8/2010
|
127.61
|
|
4/9/2010
|
128.76
|
|
4/12/2010
|
128.36
|
|
4/13/2010
|
129.03
|
|
4/14/2010
|
131.25
|
|
4/15/2010
|
130.89
|
|
4/16/2010
|
130.63
|
|
4/19/2010
|
132.23
|
|
4/20/2010
|
129.69
|
|
4/21/2010
|
128.99
|
|
4/22/2010
|
129.13
|
|
4/23/2010
|
129.99
|
|
4/26/2010
|
130.73
|
|
4/27/2010
|
128.82
|
|
4/28/2010
|
130.1
|
|
4/29/2010
|
130.46
|
|
4/30/2010
|
129
|
|
5/3/2010
|
129.6
|
|
5/4/2010
|
128.12
|
|
5/5/2010
|
127.35
|
|
5/6/2010
|
123.92
|
|
5/7/2010
|
122.1
|
|
5/10/2010
|
126.27
|
|
5/11/2010
|
126.89
|
|
5/12/2010
|
132.68
|
|
5/13/2010
|
131.48
|
|
5/14/2010
|
131.19
|
|
5/17/2010
|
130.44
|
|
5/18/2010
|
129.95
|
|
5/19/2010
|
128.86
|
|
5/20/2010
|
123.8
|
|
5/21/2010
|
125.42
|
|
5/24/2010
|
124.45
|
|
5/25/2010
|
124.52
|
|
5/26/2010
|
123.23
|
|
5/27/2010
|
126.39
|
|
5/28/2010
|
125.26
|
|
6/1/2010
|
124.34
|
|
6/2/2010
|
127.41
|
|
6/3/2010
|
127.96
|
|
6/4/2010
|
125.28
|
|
6/7/2010
|
124.13
|
|
6/8/2010
|
123.72
|
|
6/9/2010
|
123.9
|
|
6/10/2010
|
127.68
|
|
6/11/2010
|
128.45
|
|
6/14/2010
|
128.5
|
|
6/15/2010
|
129.79
|
|
6/16/2010
|
130.35
|
|
6/17/2010
|
130.98
|
|
6/18/2010
|
130.15
|
|
6/21/2010
|
130.65
|
|
6/22/2010
|
129.3
|
|
6/23/2010
|
130.11
|
|
6/24/2010
|
128.19
|
|
6/25/2010
|
127.12
|
|
6/28/2010
|
128.98
|
|
6/29/2010
|
125.09
|
|
6/30/2010
|
123.48
|
|
7/1/2010
|
122.57
|
|
7/2/2010
|
121.86
|
|
7/6/2010
|
123.46
|
|
7/7/2010
|
127
|
|
7/8/2010
|
127.97
|
|
7/9/2010
|
127.96
|
|
7/12/2010
|
128.67
|
|
7/13/2010
|
130.48
|
|
7/14/2010
|
130.72
|
|
7/15/2010
|
130.72
|
|
7/16/2010
|
|
7/19/2010
|
129.79
|
|
7/20/2010
|
126.55
|
|
7/21/2010
|
125.27
|
|
7/22/2010
|
127.47
|
|
7/23/2010
|
128.38
|
|
7/26/2010
|
128.41
|
|
7/27/2010
|
128.63
|
|
7/28/2010
|
128.43
|
|
7/29/2010
|
128.02
|
|
7/30/2010
|
128.4
|
|
8/2/2010
|
130.76
|
|
8/3/2010
|
130.37
|
|
8/4/2010
|
131.27
|
|
8/5/2010
|
131.83
|
|
8/6/2010
|
130.14
|
|
8/9/2010
|
132
|
|
8/10/2010
|
131.84
|
|
8/11/2010
|
129.83
|
|
8/12/2010
|
128.3
|
|
8/13/2010
|
127.87
|
|
8/16/2010
|
127.77
|
|
8/17/2010
|
128.45
|
|
8/18/2010
|
129.3925
|
|
8/19/2010
|
128.9
|
|
8/20/2010
|
127.5
|
|
8/23/2010
|
126.47
|
|
8/24/2010
|
124.9
|
|
8/25/2010
|
125.27
|
|
8/26/2010
|
122.78
|
|
8/27/2010
|
124.73
|
|
8/30/2010
|
123.4
|
|
8/31/2010
|
123.13
|
|
9/1/2010
|
125.77
|
|
9/2/2010
|
125.04
|
|
9/3/2010
|
127.58
|
|
9/7/2010
|
125.95
|
|
9/8/2010
|
126.08
|
|
9/9/2010
|
126.36
|
|
9/10/2010
|
127.99
|
|
9/13/2010
|
129.61
|
|
9/14/2010
|
128.85
|
|
9/15/2010
|
129.43
|
|
9/16/2010
|
129.67
|
|
9/17/2010
|
130.19
|
|
9/20/2010
|
131.79
|
|
9/21/2010
|
131.98
|
|
9/22/2010
|
132.57
|
|
9/23/2010
|
131.67
|
|
9/24/2010
|
134.11
|
|
9/27/2010
|
134.65
|
|
9/28/2010
|
134.89
|
|
9/29/2010
|
135.48
|
|
9/30/2010
|
134.14
|
|
10/1/2010
|
135.64
|
|
10/4/2010
|
135.25
|
|
10/5/2010
|
137.66
|
|
10/6/2010
|
137.84
|
|
10/7/2010
|
138.72
|
|
10/8/2010
|
138.85
|
|
10/11/2010
|
139.66
|
|
10/12/2010
|
139.85
|
|
10/13/2010
|
140.37
|
|
10/14/2010
|
141.5
|
|
10/15/2010
|
141.06
|
|
10/18/2010
|
142.83
|
|
10/19/2010
|
138.03
|
|
10/20/2010
|
139.07
|
|
10/21/2010
|
139.83
|
|
10/22/2010
|
139.67
|
|
10/25/2010
|
139.84
|
|
10/26/2010
|
140.67
|
|
10/27/2010
|
141.43
|
|
10/28/2010
|
140.9
|
|
10/29/2010
|
143.6
|
|
11/1/2010
|
143.32
|
|
11/2/2010
|
143.84
|
|
11/3/2010
|
144.17
|
|
11/4/2010
|
146.79
|
|
11/5/2010
|
146.92
|
|
11/8/2010
|
146.46
|
|
11/9/2010
|
146.14
|
|
11/10/2010
|
146.55
|
|
11/11/2010
|
145.43
|
|
11/12/2010
|
143.74
|
|
11/15/2010
|
143.64
|
|
11/16/2010
|
142.24
|
|
11/17/2010
|
141.95
|
|
11/18/2010
|
144.36
|
|
11/19/2010
|
145.05
|
|
11/22/2010
|
145.39
|
|
11/23/2010
|
143.18
|
|
11/24/2010
|
145.81
|
|
11/26/2010
|
143.9
|
|
11/29/2010
|
142.89
|
|
11/30/2010
|
141.46
|
|
12/1/2010
|
144.41
|
|
12/2/2010
|
145.18
|
|
12/3/2010
|
145.38
|
|
12/6/2010
|
144.99
|
|
12/7/2010
|
144.02
|
|
12/8/2010
|
144.98
|
|
12/9/2010
|
144.3
|
|
12/10/2010
|
144.82
|
|
12/13/2010
|
144.28
|
|
12/14/2010
|
145.82
|
|
12/15/2010
|
144.72
|
|
12/16/2010
|
144.55
|
|
12/17/2010
|
145
|
|
12/20/2010
|
144.51
|
|
12/21/2010
|
145.74
|
|
12/22/2010
|
145.95
|
|
12/23/2010
|
145.89
|
|
12/27/2010
|
145.34
|
|
12/28/2010
|
145.71
|
|
12/29/2010
|
146.52
|
|
12/30/2010
|
146.67
|
|
12/31/2010
|
146.76
|