|
Потомок 1
|
116
|
4
|
7
|
|
Потомок 2
|
12
|
4
|
7
|
Дискретная рекомбинация применима для любого типа генов (двоичные,
вещественные и символьные).
Промежуточная рекомбинация (Intermediate recombination) применима только
к вещественным переменным, но не к бинарным. В данном методе предварительно
определяется числовой интервал значений генов потомков, который должен
содержать значения генов родителей. Потомки создаются по следующему правилу:
где
множитель 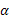 -
случайное число на отрезке [-d, 1 + d], d
-
случайное число на отрезке [-d, 1 + d], d 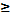 0. Как
отмечают сторонники этого метода, наиболее оптимальное воспроизведение
получается при d = 0,25. Для каждого гена создаваемого потомка выбирается
отдельный множитель .
0. Как
отмечают сторонники этого метода, наиболее оптимальное воспроизведение
получается при d = 0,25. Для каждого гена создаваемого потомка выбирается
отдельный множитель .
При
промежуточной рекомбинации возникают значения генов, отличные от значения генов
особей-родителей. Это приводит к возникновению новых особей, пригодность
которых может быть лучше, чем пригодность родителей. Иногда такой оператор
рекомбинации называется дифференциальным скрещиванием.
Линейная
рекомбинация (Line recombination) отличается от промежуточной тем, что
множитель  выбирается
для каждого потомка один раз. Если рассматривать особи популяции как точки в k-мерном
пространстве, где k - количество генов в одной особи, то можно сказать,
что при линейной рекомбинации генерируемые точки потомков лежат на прямой,
заданной двумя точками - родителями.
выбирается
для каждого потомка один раз. Если рассматривать особи популяции как точки в k-мерном
пространстве, где k - количество генов в одной особи, то можно сказать,
что при линейной рекомбинации генерируемые точки потомков лежат на прямой,
заданной двумя точками - родителями.
Кроссинговер
(бинарная рекомбинация)
Рекомбинацию
бинарных строк принято называть кроссинговером (кроссовером) или скрещиванием.
Одноточечный
кроссинговер (Single-point crossover) моделируется следующим образом. Пусть
имеются две родительские особи с хромосомами XXXXXX и YYYYYY.
Случайным образом определяется точка внутри хромосомы (точка разрыва), в
которой обе хромосомы делятся на две части и обмениваются ими:
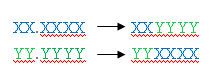
Такой
тип кроссинговера называется одноточечным, так как при нем родительские
хромосомы разделяются только в одной случайной точке.
Также
применяется двух- и N-точечный кроссинговер.
В
двухточечном кроссинговере (и многоточечном кроссинговере вообще) хромосомы
рассматриваются как циклы, которые формируются соединением концов линейной
хромосомы вместе. Для замены сегмента одного цикла сегментом другого цикла
требуется выбор двух точек разреза. В этом представлении, одноточечный
кроссинговер может быть рассмотрен как кроссинговер с двумя точками, но с одной
точкой разреза, зафиксированной в начале строки. Следовательно, двухточечный
кроссинговер решает ту же самую задачу, что и одноточечный, но более полно.
Для
многоточечного кроссинговера (Multi-point crossover) точки разреза выбираются
случайно без повторений и сортируются в порядке возрастания. При кроссинговере
происходит обмен участками хромосом, ограниченными точками разреза и таким
образом получают двух потомков. Участок особи с первым геном до первой точки
разреза в обмене не участвует. Применение многоточечного кроссинговера требует
введения нескольких переменных (точек разреза), и для воспроизведения
выбираются особи с наибольшей приспособленностью.
Одноточечный
и многоточечный кроссинговер определяют точки разреза, которые разделяют особи
на части. В отличие от них однородный кроссинговер (Uniform crossover) создает
маску (схему) особи, в каждом локусе которой находится потенциальная точка
кроссинговера. Маска кроссинговера имеет ту же длину, что и скрещивающиеся
особи. Создать маску можно следующим образом: введем некоторую величину 0 < p0 < 1, и если случайное число больше p0, то на n-ю позицию маски ставим 0, иначе - 1. Таким
образом, гены маски представляют собой случайные двоичные числа (0 или 1).
Согласно этим значениям, геном потомка становится первая (если ген маски = 0)
или вторая (если ген маски = 1) особь-родитель.
Триадный
кроссинговер (Triadic crossover). Данная разновидность кроссинговера отличается
от однородного тем, что после отбора пары родителей из остальных членов
популяции случайным образом выбирается особь, которая в дальнейшем используется
в качестве маски. Далее 10 % генов маски мутируют. Затем гены первого родителя
сравниваются с генами маски: если гены одинаковы, то они передаются первому
потомку, в противном случае на соответствующие позиции хромосомы потомка
переходят гены второго родителя. Генотип второго потомка отличается от генотипа
первого тем, что на тех позициях, где у первого потомка стоят гены первого
родителя, у второго потомка стоят гены второго родителя и наоборот.
Перетасовочный
кроссинговер (Shuffler crossover). В данном алгоритме особи, отобранные для
кроссинговера, случайным образом обмениваются генами. Затем выбирают точку для
одноточечного кроссинговера и проводят обмен частями хромосом. После
скрещивания созданные потомки вновь тасуются. Таким образом, при каждом
кроссинговере создаются не только новые потомки, но и модифицируются родители
(старые родители удаляются), что позволяет сократить число операций по
сравнению с однородным кроссинговером.
Кроссинговер
с уменьшением замены (Crossover with reduced surrogate). Оператор уменьшения
замены ограничивает кроссинговер, чтобы всегда, когда это возможно, создавать
новые особи. Это осуществляется за счет ограничения на выбор точки разреза:
точки разреза должны появляться только там, где гены различаются.
Как
было показано выше, кроссинговер генерирует новое решение (в виде
особи-потомка) на основе двух имеющихся, комбинируя их части. Поэтому число
различных решений, которые могут быть получены кроссинговером при использовании
одной и той же пары готовых решений, ограничено. Соответственно, пространство,
которое ГА может покрыть, используя лишь кроссинговер, жестко зависит от генофонда
популяции. Чем разнообразнее генотипы решений популяции, тем больше
пространство покрытия. При обнаружении локального оптимума соответствующий ему
генотип будет стремиться занять все позиции в популяции, и алгоритм может
сойтись к ложному оптимуму. Поэтому в генетическом алгоритме важную роль играют
мутации.
3.3 Мутация
После процесса воспроизводства происходят мутации (mutation). Данный
оператор необходим для «выбивания» популяции из локального экстремума и
препятствует преждевременной сходимости. Это достигается за счет того, что
изменяется случайно выбранный ген в хромосоме.
Так же как и кроссинговер, мутации могут проводиться не только по одной
случайной точке. Можно выбирать для изменения несколько точек в хромосоме,
причем их число также может быть случайным. Используют и мутации с изменением
сразу некоторой группы подряд идущих точек.
Вероятность мутации pm (как правило, pm << 1) может являться или фиксированным случайным числом на отрезке
[0;1], или функцией от какой-либо характеристики решаемой задачи. Например,
можно положить вероятность мутирования генов, обратно пропорциональную числу
всех генов в особи (размерности).
Мутация для вещественных особей (Real valued mutation).
Для мутации особей с вещественными числами необходимо определить величину
шага мутации - число, на которое изменится значение гена при мутировании.
Обычно определение шага мутации представляет некоторую трудность.
Оптимальный размер шага должен меняться в течение всего процесса поиска.
Наиболее пригодны маленькие шаги, но иногда большие шаги могут привести к
ускорению процесса. Гены могут мутировать согласно следующему правилу:
новая
переменная = старая переменная ± 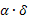 ,
,
где
знаки + или 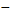 выбираются
с равной вероятностью, = 0,5
выбираются
с равной вероятностью, = 0,5 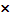 поисковое
пространство (интервал изменения данной переменной),
поисковое
пространство (интервал изменения данной переменной),
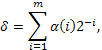
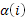 = 1 с
вероятностью
= 1 с
вероятностью 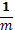 , в
противном случае = 0, m -
параметр.
, в
противном случае = 0, m -
параметр.
Новая
особь, получившаяся при такой мутации, не намного отличается от старой. Это
связано с тем, что вероятность маленького шага мутации выше, чем вероятность
большого шага. При m = 20, данный алгоритм мутации пригоден для
локализации оптимума с точностью 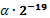 .
.
Плотность
мутации (Density mutation). Стратегия мутации с использованием понятия
плотности заключается в мутировании каждого гена потомка с заданной
вероятностью. Таким образом, кроме вероятности применения мутации к самому
потомку используется еще вероятность применения мутации к каждому его гену,
величину которой выбирают с таким расчетом, чтобы в среднем мутировало от 1 до
10 % генов.
3.4 Операторы отбора особей в новую популяцию
Для создания новой популяции можно использовать различные методы отбора
особей.
Отбор
усечением (Truncation selection). При отборе усечением используют популяцию,
состоящую как из особей-родителей, так и особей-потомков, отсортированную по
возрастанию значений функции пригодности особей. Число особей для скрещивания
выбирается в соответствии с порогом Т 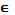 [0;1].
Порог определяет, какая доля особей, начиная с самой первой (самой пригодной),
будет принимать участие в отборе. Порог можно задать и числом больше 1, тогда
он будет просто равен числу особей из текущей популяции, допущенных к отбору.
Среди особей, попавших «под порог», случайным образом выбирается одна и
записывается в новую популяцию. Процесс повторяется N раз, пока размер новой
популяции не станет равен размеру исходной популяции. Новая популяция состоит
только из особей с высокой пригодностью, причем одна и та же особь может
встречаться несколько раз, а некоторые особи, имеющие пригодность выше
пороговой, могут не попасть в новую популяцию.
[0;1].
Порог определяет, какая доля особей, начиная с самой первой (самой пригодной),
будет принимать участие в отборе. Порог можно задать и числом больше 1, тогда
он будет просто равен числу особей из текущей популяции, допущенных к отбору.
Среди особей, попавших «под порог», случайным образом выбирается одна и
записывается в новую популяцию. Процесс повторяется N раз, пока размер новой
популяции не станет равен размеру исходной популяции. Новая популяция состоит
только из особей с высокой пригодностью, причем одна и та же особь может
встречаться несколько раз, а некоторые особи, имеющие пригодность выше
пороговой, могут не попасть в новую популяцию.
Из-за
того, что в этой стратегии используется отсортированная популяция, время ее
работы может быть большим для популяции большого размера и зависеть также от
алгоритма сортировки.
Элитарный
отбор (Elite selection). Создается промежуточная популяция, которая включает в
себя как родителей, так и их потомков. Члены этой популяции оцениваются, а за
тем из них выбираются N самых лучших (пригодных), которые и войдут в следующее
поколение. Зачастую данный метод комбинируют с другими - выбирают в новую
популяцию, например, 10 % «элитных» особей, а остальные 90 % - одним из
традиционных методов селекции. Иногда эти 90 % особей создают случайно, как при
создании начальной популяции перед запуском работы генетического алгоритма.
Использование стратегии элитизма оказывается весьма полезным для эффективности
ГА, так как не допускает потерю лучших решений. К примеру, если популяция
сошлась в локальном максимуме, а мутация вывела одну из строк в область
глобального, то при предыдущей стратегии весьма вероятно, что эта особь в
результате скрещивания будет потеряна, и решение задачи не будет получено. Если
же используется элитизм, то полученное хорошее решение будет оставаться в
популяции до тех пор, пока не будет найдено еще лучшее.
Отбор
вытеснением (Exclusion selection). В данном отборе выбор особи в новую
популяцию зависит не только от величины ее пригодности, но и от того, есть ли
уже в формируемой популяции особь с аналогичным хромосомным набором. Отбор
проводится из числа родителей и их потомков. Из всех особей с одинаковой
приспособленностью предпочтение сначала отдается особям с разными генотипами.
Таким образом, достигаются две цели: во-первых, не теряются лучшие найденные
решения, обладающие различными хромосомными наборами, во-вторых, в популяции
постоянно поддерживается генетическое разнообразие. Вытеснение в данном случае
формирует новую популяцию скорее из удаленных особей, вместо особей,
группирующихся около текущего найденного решения. Данный метод наиболее пригоден
для многоэкстремальных задач, при этом помимо определения глобальных
экстремумов появляется возможность выделить и те локальные максимумы, значения
которых близки к глобальным.
4. Разнообразие генетических алгоритмов
Следует отметить, что в настоящее время ГА - это целый класс алгоритмов,
направленный на решение разнообразных задач.
Канонический ГА. Данная модель алгоритма является классической. Она была
предложена Джоном Холландом. Согласно ей, популяция состоит из N хромосом с
фиксированной разрядностью генов. С помощью пропорционального отбора
формируется промежуточный массив, из которого случайным образом выбираются два
родителя. Далее производится одноточечный кроссинговер, и созданные два потомка
мутируют (одноточечная мутация) с заданной вероятностью. Мутировавшие потомки
занимают места своих родителей. Процесс продолжается до тех пор, пока не будет
достигнут критерий окончания алгоритма.
Генитор. В модели генитор (Genitor) используется специфичный способ
отбора. Вначале, как и полагается, популяция инициализируется, и ее особи
оцениваются. Затем выбираются случайным образом две особи, скрещиваются, причем
получается только один потомок, который оценивается и занимает место менее
приспособленной особи в популяции (а не одного из родителей). После этого снова
случайным образом выбираются две особи, и их потомок занимает место
родительской особи с самой низкой приспособленностью. Таким образом, на каждом
шаге в популяции обновляется лишь одна особь. Процесс продолжается до тех пор,
пока пригодности хромосом не станут одинаковыми. В данный алгоритм можно
добавить мутацию потомка после его создания. Критерий окончания процесса, как и
вид кроссинговера и мутации, можно выбирать разными способами.
Метод прерывистого равновесия. Данный метод основан на палеонтологической
теории прерывистого равновесия, которая описывает быструю эволюцию за счет
вулканических и других изменений земной коры. Для применения данного метода в
технических задачах предлагается после каждой генерации промежуточного
поколения случайным образом перемешивать особи в популяции, а затем применять
основной ГА. В данной модели для отбора родительских пар используется
панмиксия. Получившиеся в результате кроссинговера потомки и наиболее пригодные
родители случайным образом смешиваются. Из общей массы в новое поколения
попадут лишь те особи, пригодность которых выше средней. Тем самым достигается
управление размером популяции в зависимости от наличия лучших особей. Такая
модификация метода прерывистого равновесия может позволить сократить неперспективные
популяции и расширить популяции, в которых находятся лучшие индивидуальности.
Данный метод используется для эффективного выхода из локальных ям.
Гибридный алгоритм. Идея гибридных алгоритмов (Hybrid algorithms)
заключается в сочетании генетического алгоритма с некоторым другим классическим
методом поиска, подходящим в данной задаче. В каждом поколении все
сгенерированные потомки оптимизируются выбранным методом и затем заносятся в
новую популяцию. Тем самым получается, что каждая особь в популяции достигает
локального оптимума, вблизи которого она находится. Далее производятся обычные
для ГА действия: отбор родительских пар, кроссинговер и мутации. На практике
гибридные алгоритмы оказываются очень удачными. Это связано с тем, что
вероятность попадания одной из особей в область глобального максимума обычно
велика. После оптимизации такая особь будет являться решением задачи.
Известно, что генетический алгоритм способен быстро найти во всей области
поиска хорошие решения, но он может испытывать трудности в получении из них
наилучших. Обычный оптимизационный метод может быстро достичь локального
максимума, но не может найти глобальный. Сочетание двух алгоритмов позволяет
использовать преимущества обоих.
СНС (Eshelman, 1991) расшифровывается как Cross-population selection, Heterogeneous recombination and Cataclysmic mutation. Данный алгоритм довольно быстро
сходится из-за того, что в нем нет мутаций, следующих за оператором
кроссинговера, используются популяции небольшого размера, и отбор особей в следующее
поколение ведется и между родительскими особями, и между их потомками. В данном
методе для кроссинговера выбирается случайная пара, но не допускается, чтобы
между родителями было маленькое хеммингово расстояние или мало расстояние между
крайними различающимися битами. Для скрещивания используется разновидность
однородного кроссовера HUX (Half Uniform Crossover), при котором потомку
переходит ровно половина битов каждого родителя. Для нового поколения
выбираются N лучших различных особей среди родителей и детей. При этом
дублирование строк не допускается. В модели СНС размер популяции относительно
мал - около 50 особей. Это оправдывает использование однородного кроссинговера
и позволяет алгоритму сойтись к решению. При получении более или менее одинаковых
строк СНС применяет cataclysmic mutation: все строки, кроме самой
приспособленной, подвергаются сильной мутации (изменяется около трети битов).
Таким образом, алгоритм перезапускается и далее продолжает работу, применяя
только кроссинговер.
В генетическом алгоритме с нефиксированным размером популяции (Genetic
Algorithm with Varying Population Size - GAVaPS) каждой особи приписывается
максимальный возраст, т.е. число поколений, по прошествии которых особь
погибает. Внедрение в алгоритм нового параметра - возраста - позволяет
исключить оператор отбора в новую популяцию. Возраст каждой особи индивидуален
и зависит от ее приспособленности. В каждом поколении t на этапе
воспроизведения обычным образом создается дополнительная популяция из потомков.
Размер дополнительной популяции (AuxPopsize(t)) пропорционален размеру основной
популяции (Popsize(t)) и равен:
AuxPopsize(t) = [Popsize(t) pc],
где pc - вероятность воспроизведения.
Для воспроизведения особи выбираются из основной популяции с равной
вероятностью независимо от их приспособленности. После применения мутации и
кроссинговера потомкам приписывается возраст согласно значению их
приспособленности. Возраст является константой на протяжении всей эволюции
особи (от рождения до гибели). Затем из основной популяции удаляются те особи,
срок жизни которых истек, и добавляются потомки из промежуточной популяции.
Таким образом, размер после одной итерации алгоритма вычисляется по формуле:
Popsize(t + 1) = Popsize(t) + AuxPopsize(t) - D(t),
где D(t) - число особей, которые умирают в поколении t.
5. Модели параллельных генетических алгоритмов
Генетические алгоритмы применяются и при параллельных вычислениях. При
этом формируется несколько живущих отдельно популяций. На этапе формирования
нового поколения по некоторому правилу отбираются особи из разных популяций.
Сгенерированная таким образом популяция в некоторых случаях заменяет все
остальные. Таким образом, происходит миграция особей одной популяции в другие
популяции. Поэтому параллельные ГА называют миграциями.
Простейший параллельный ГА.
Рассмотрим создание простейшего параллельного ГА из классической модели
Холланда. Для этого будем использовать турнирный отбор. Заведем N/2 процессов
(под процессом подразумевается некоторая машина, процессор, который может
работать независимо). Каждый из них будет выбирать случайно из популяции 4
особи, проводить 2 турнира, и победителей скрещивать. Полученные потомки будут
записываться в новое поколение. Таким образом, за один цикл работы одного
процесса будет сменяться целое поколение.
Модель миграции (Migration) представляет популяцию как множество
подпопуляций. Каждая подпопуляция обрабатывается отдельным процессором. Эти
подпопуляций развиваются независимо друг от друга в течение одинакового
количества поколений Т (время изоляции). По истечении времени изоляции
происходит обмен особями между подпопуляциями (миграция). Количество особей,
подвергшихся обмену (вероятность миграции), метод отбора особей для миграции и
схема миграции определяет частоту возникновения генетического многообразия в
подпопуляциях и обмен информацией между популяциями.
Отбор особей для миграции может происходить следующим образом:
• случайная однообразная выборка из числа особей;
• пропорциональный отбор: для миграции берутся наиболее пригодные особи.
Отдельные подпопуляции в параллельных ГА можно условно принять за вершины
некоторого графа. В связи с этим можно рассматривать топологию графа
миграционного ГА. Наиболее распространенной топологией миграции является полный
граф (см. схему 2), при которой особи из любой подпопуляций могут мигрировать в
любую другую подпопуляцию. Для каждой подпопуляций полное количество
потенциальных иммигрантов строится на основе всех подпопуляций. Мигрирующая
особь случайным образом выбирается из этого общего числа.
При использовании в неограниченной миграции пропорционального отбора
сначала формируется массив из наиболее пригодных особей, отобранных по всем
подпопуляциям. Случайным образом из этого массива выбирается особь, и ею
заменяют наименее пригодную особь в подпопуляции 1. Аналогичные действия
проделываем с остальными подпопуляциями. Возможно, что какая-то популяция
получит дубликат своей «хорошей» особи.
Другая основная миграционная схема - это топология кольца (см. схему 3).
Здесь особи передаются между соседними (по направлению обхода) подпопуляциями.
Таким образом, особи из одной подпопуляций могут мигрировать только в одну -
соседнюю подпопуляцию.
На схеме 4 представлена стратегия миграции, похожая на топологию кольца.
Как и при топологии кольца, миграция осуществляется только между ближайшими
соседями. Однако миграция в этой модели также возможна между «крайними»
подпопуляциями (тороидальные краевые миграции).
Глобальная модель «Рабочий и Хозяин».
Алгоритм «Рабочий и Хозяин» (Global model - worker/farmer) реализуется с применением нескольких одновременно
работающих компьютеров (см. схему 5). Среди всех компьютеров выделяют «Хозяина»
и «Рабочих». Компьютеры - «Рабочие» отвечают за процессы воспроизводства,
мутации и вычисления функции пригодности особей для их отбора в новое
поколение. Все созданные и оцененные «Рабочими» особи поступают к компьютеру -
«Хозяину», который затем проводит отбор особей согласно оценке их пригодности в
новую популяцию. Отобранные особи передаются «Хозяином» к компьютерам -
«Рабочим».
Модель диффузии, или островная модель ГА.
Островная модель является наиболее распространенной моделью параллельного
ГА. Ее суть заключается в том, что популяция, как правило состоящая из очень
большого числа особей, разбивается на одинаковые по размеру подпопуляции.
Каждая подпопуляция обрабатывается отдельным процессором с помощью одной из
разновидностей непараллельного ГА. Изредка, например, через пять поколений,
подпопуляции будут обмениваться несколькими особями. Такие миграции позволяют
подпопуляциям совместно использовать генетический материал.
Пусть выполняются 16 независимых генетических алгоритмов, используя
подпопуляции из 1000 особей на каждом процессоре. Если миграций нет, то
происходит 16 независимых поисков решения. Все поиски ведутся на различных
начальных популяциях и сходятся к определенным особям. Исследования
подтверждают, что генетический дрейф склонен приводить подпопуляции к различным
доминирующим особям. Это связано с тем, что, во-первых, количество островов,
принимающих доминирующих «эмигрантов» с острова, ограничено (2-5 островов).
Во-вторых, обмен особями односторонен. Поэтому в большой популяции появятся
группы островов с различными доминирующими особями. Если популяция небольшого
размера, то возможно быстрая миграция ложных доминирующих особей. Например,
истинное решение находится только на одном острове, а несколько ложных доминант
- на других островах. Тогда при миграции количество ложных особей на островах
возрастет (на каждый остров миграции происходят с не менее 2 островов),
генетическим алгоритмом верное решение будет разрушено. Тем самым в маленькой
популяции при генетическом дрейфе возможно появление ошибочных доминирующих
особей и схождение алгоритма к ложному оптимуму.
Введение миграций в островной модели позволяет находить различные
особи-доминанты в подпопуляциях, что способствует поддержанию многообразия в
популяции. Каждую подпопуляции можно принять за остров. Во время миграции
подпопуляции обмениваются своим доминирующим генетическим материалом. При
частой миграции большого количества особей происходит перемешивание
генетического материала. Тем самым устраняются локальные различия между
островами. Очень редкие миграции не позволяют предотвратить преждевременную
сходимость алгоритма в маленьких подпопуляциях. В рассматриваемой модели с
каждого острова миграции могут происходить лишь на определенное расстояние: 2-5
острова в зависимости от количества подпопуляции. Таким образом, каждый остров
оказывается почти изолированным. Количество островов, на которые могут
мигрировать особи одной подпопуляции, называют расстоянием изоляции. Следует
заметить, что взаимные миграции исключены (рис. 5).
Все приведенные варианты ГА можно моделировать, задавая разные значения
параметров ГА и типы операторов. Например, в островной модели ГА можно
моделировать различные комбинации способов отбора и формирования следующего
поколения или сделать так, что в разных популяциях будут использоваться разные
комбинации операторов ГА.
6. Модернизация генетических алгоритмов
Одной из серьезных проблем, возникающих при использовании генетических
алгоритмов, является преждевременная сходимость. Не рекомендуется использовать
классические ГА на маленьких популяциях, поскольку в популяциях с малым размером
гены распространяются слишком быстро: все особи становятся похожими (популяция
вырождается) еще до того, как найдено решение задачи. То есть новый генотип с
лучшей оценкой быстро вытесняет менее хорошие комбинации генов, исключая
возможность получения лучшего решения на их базе. Можно предложить три основных
пути устранения преждевременной сходимости: увеличение размера популяции,
применение самоадаптирующихся генетических операторов и создание «банка»
заменяемых особей.
В первом случае, увеличивая размер популяции, можно надеяться на
достижение многообразия генотипа в популяции. Но, с другой стороны, увеличение
числа особей ведет к увеличению занимаемой памяти и времени работы алгоритма.
Данный подход может быть эффективен или при параллельных вычислениях, или при
наличии достаточно простой целевой функции.
Второй, и самый распространенный способ, - использование
самоадаптирующихся алгоритмов. Самоадаптация заключается в применении
динамических мутаций. Динамические мутации в зависимости от скрещивающихся
особей меняют значение вероятности мутации, тем самым становится возможным
самоуправление алгоритма. В таких случаях выбирается малый размер популяции.
В третьем случае создается массив для сохранения особей, генотип которых
был утерян при формировании новых поколений, и временами эти особи добавляются
в популяцию.
Неоднородная мутация.
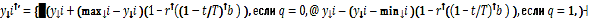
где
q случайным образом принимает значения 0 или 1; r -
случайное число, принимающее значение из диапазона [0; 1]; t - номер поколения;
Т - максимальное число поколений; b - некоторый параметр,
обусловленный природой задачи; и - верхняя и нижняя границы для величины 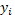 .
.
Инцест.
Стратегия
инцеста используется как механизм самоадаптации оператора мутации. Она
заключается в том, что «плотность мутации» (вероятность мутации каждого гена)
определяется для каждого потомка на основании генетической близости его
родителей. Например, это может быть отношение числа совпадающих генов родителей
к общему числу генов хромосомы. В результате инцеста на начальных этапах
алгоритма при высоком разнообразии генофонда популяции вероятность мутации
будет предельно мала, т.е. практически будет происходить лишь скрещивание. При
уменьшении разнообразия, возникающего в случае попадания алгоритма в локальный
оптимум, вероятность мутации возрастет. Очевидно, что при полном схождении
популяции алгоритм станет стохастическим, тем самым вероятность выхода
популяции из локального оптимума возрастет.
Заключение
На основании проведенной работы можно сделать выводы о том, что в
настоящее время генетические алгоритмы являются универсальным методом
оптимизации многопараметрических функций, и поэтому способны решать широкий
спектр задач.
Преимущества генетических алгоритмов:
· не требуют никакой информации о поведении функции (например,
дифференцируемости и непрерывности);
· относительно стойки к попаданию в локальные оптимумы;
· пригодны для решения крупномасштабных задач оптимизации за
счет эффективного распараллеливания;
· могут быть использованы для широкого класса задач;
· просты в реализации;
· могут быть использованы в задачах с изменяющейся средой.
В то же время существует ряд трудностей в практическом использовании
генетических алгоритмов, а именно:
· очень сложно найти точный глобальный оптимум;
· генетические алгоритмы неэффективно применять в случае
оптимизации функции, требующей большого времени на вычисление;
· сложно смоделировать для нахождения всех решений задачи;
· трудно применить для изолированных функций. Изолированность
(«поиск иголки в стоге сена») - проблема для любого метода оптимизации,
поскольку функция не предоставляет никакой информации, подсказывающей, в какой
области искать экстремум. Лишь случайное попадание особи в глобальный экстремум
может решить задачу (рис. 6);

Генетические алгоритмы предоставляют огромные материалы для исследований
за счет большого количества модификаций и параметров. Зачастую небольшое
изменение одного из них может привести к неожиданному улучшению результата.
В то же время следует помнить, что применение ГА полезно лишь в тех
случаях, когда для данной задачи нет подходящего специального алгоритма
решения. По сравнению со специальным алгоритмом, генетический будет работать не
только медленнее, но и менее эффективно (за исключением, возможно, гибридного
алгоритма).
Список литературы
. Батищев
Д.И. Генетические алгоритмы решения экстремальных задач /Д.И. Батищев/ - Нижний
Новгород: Нижегородский госуниверситет, 1995. - 62 с.
2. Дарвин
Ч. О происхождении видов путём естественного отбора или сохранении
благоприятствуемых пород в борьбе за жизнь /Ч. Дарвин/ - М.: АН СССР, 1939.
. Гладков
Л.А., Курейчик В.В., Курейчик В.М. Генетические алгоритмы /Л.А. Гладков, В.В.
Курейчик, В.М. Курейчик/ - М.: ФИЗМАТЛИТ, 2006. - 320 с.
. Панченко
Т.В. Генетические алгоритмы /Т.В. Панченко/ - Астрахань: издательский дом
«Астраханский университет», 2007. - 87 с.
. Санкт-Петербургский
государственный университет информационных технологий, механики и оптики.
Генетические алгоритмы. [Электронный ресурс]. Режим доступа:
http://rain.ifmo.ru/cat/. Загл. с экрана.
. Ю.
Цой. Авторский сайт. [Электронный ресурс]. Режим доступа:
http://www.qai.narod.ru/. Загл. с экрана.
. Исаев
С.А. Популярно о генетических алгоритмах. [Электронный ресурс]. Режим доступа: http://algolist.manual.ru/ai/ga/ga1.php. Загл. с экрана.