Создание веб-интерфейса для построения генеалогических деревьев
Введение
Темой данного дипломного проекта является создание
веб-сервиса для построения генеалогических деревьев, а именно разработка и
реализация серверной компоненты.
Развитие современных информационных технологий и
методов теории графов (см. [1]) повлекло за собой существенное продвижение в
различных областях знаний, в частности, в области генеалогии (см. [2]). В
результате этого началось активное развитие сервисов, пользующихся спросом как
у профессионалов, так и у любителей, желающих систематизировать всю известную
информацию о своих родственниках и наглядно представить эту информацию в виде
генеалогического дерева.
Существует большое количество разного рода средств,
предназначенных для построения генеалогических деревьев. Данные средства
подразделяются на два основных вида: локальные программы и веб-сервисы.
Применение локальных программ затрудняет обмен собранной информацией с другими
пользователями (родственниками). В веб-сервисах эта проблема исчезает, но
проявляется ряд других недостатков, таких как отсутствие импорта и экспорта
данных, отсутствие системы прав доступа к деревьям пользователя, ограничения
функциональности в бесплатном режиме и другие.
В этой связи становится необходимым создание
бесплатного веб-сервиса для построения генеалогических деревьев с возможностью
хранения и отображения различной пользовательской информации.
Целью дипломной работы является разработка и
реализация ключевых компонентов системы создаваемого веб-приложения, на которых
будет основана работа всего сервиса для построения генеалогических деревьев.
Стоит отметить, что данная цель является локальной
относительно цели создания всего веб-приложения, а работа является частью
комплексного проекта, выполняемого тремя студентами гр. 9208.
Цель дипломного проекта формирует следующий список
взаимосвязанных работ:
- исследование предметной области;
- поиск и рассмотрение существующих аналогов
разрабатываемого сервиса, выявление их достоинств и недостатков;
- составление общих и функциональных
требований;
- исследование и выбор оптимальных средств
разработки для решения поставленной задачи;
- изучение выбранных программных средств;
- разработка и реализация архитектуры
системы хранения данных;
- разработка и реализация интерфейса для
доступа к хранимым данным;
- разработка и реализация системы разграничения
прав доступа для разных групп пользователей;
- разработка и реализация вычисления
степеней родства между двумя персонами в генеалогическом дереве;
- отладка и тестирование разработанного
сервиса;
- анализ и оценка полученных результатов.
Для проведения работ решено использовать: операционную
систему Linux Ubuntu, систему контроля версий Git, язык программирования Python, фреймворк Django, объектно-реляционную
СУБД PostgreSQL, документо-ориентированную СУБД CouchDB, скриптовый язык
программирования JavaScript, инструмент управления проектами и отслеживания ошибок в
программном обеспечении Trac, текстовый редактор Jedit.
1. Постановка задачи
1.1 Общее
описание создаваемого сервиса
Создаваемый веб-сервис предназначается для пользователей сети интернет,
интересующихся историей своего рода, собирающих сведения о своих предках, и
желающих разобраться в родственных связях, а также привлечь к этому своих
близких.
Функции, выполняемые сервисом в интересах пользователя:
а) построение и печать родословных деревьев;
б) импорт и экспорт данных;
в) вычисление и отображение степеней родства между двумя
персонами в генеалогических деревьях;
г) хранение мультимедийных данных:
1) текст,
2) фотографии;
д) поиск и фильтрация данных;
е) статистика:
1) количество персон,
2) количество мужчин,
) количество женщин,
) число поколений,
) средняя продолжительность жизни,
) число детей.
Все эти функции доступны пользователю сервиса в личном
кабинете - разделе, который доступен только для зарегистрированных
пользователей. Личный кабинет позволяет авторизированным пользователям быстро и
удобно получать доступ к таким функциям, как работа с генеалогическими
деревьями, редактирование личной информации, обмен сообщениями с другими
пользователями, хранение мультимедиа-файлов и так далее.
1.2 Суть
задачи
сервис генеалогическое
дерево
Задача дипломного проекта - создать веб-сервис для построения
генеалогических деревьев. Поставленная задача разбивается на следующие
подзадачи:
- разработка и реализация серверной части сервиса;
- разработка и реализация клиентской части
сервиса, которая будет предоставлять пользователям возможность создания и
редактирования генеалогических деревьев;
- разработка и реализация возможностей
импорта и экспорта данных.
Комплексный проект создания веб-сервиса для построения генеалогических
деревьев инициирован группой студентов. Его окончательная формулировка и
формулировка конкретных задач проведена совместно с научным руководителем.
Задачей данной дипломной работы является разработка и
реализация ключевых компонентов системы создаваемого веб-сервиса, на которых
будет основана работа всего сервиса для построения генеалогических деревьев. В
эту задачу входят такие обширные подзадачи, как:
а) разработка и реализация базы данных для хранения всей
получаемой от пользователей информации и всех данных проекта. Для решения этой
подзадачи необходимо:
- исследовать существующие реляционные и
нереляционные базы данных, их характеристики и главные достоинства;
- выбрать наиболее оптимальные СУБД для
хранения данных проекта;
- разработать и реализовать архитектуру баз
данных;
- реализовать возможность взаимодействия
между выбранными базами данных.
б) разработка и реализация интерфейса для доступа к
хранимым данным. В интерфейсе необходимо предоставить стандартный набор
операций над данными:
- запись;
- чтение;
- редактирование;
- удаление.
в) авторизация зарегистрированных в сервисе пользователей;
г) разработка и реализация разграничения прав доступа
для разных групп пользователей;
д) вычисление и отображение степеней родства между
любыми двумя персонами в одном дереве.
1.3 Аналоги
В качестве аналогов рассмотрены такие существующие в
настоящее время веб-сервисы для построения генеалогических деревьев, как:
а) сервис «Genway - больше, чем семья!» (см. [3]);
б) сервис «Moederevo» (см. [4]);
в) сервис «MyHeritage» (см. [5]).
Далее проанализируем достоинства и недостатки перечисленных
аналогов.
1.3.1 Сервис «Genway - больше, чем семья!»
Сервис «Genway - больше, чем семья!» содержит графический
редактор для построения генеалогических деревьев, обладает приятным дизайном и
предоставляет возможность отметить местонахождение человека на карте.
В качестве недостатков сервиса можно отметить следующее:
- сложный интерфейс, неудобное расположение элементов управления;
- возможность строить некорректные деревья;
- отсутствие контроля приватности данных;
- отсутствие импорта и экспорта дерева.
1.3.2 Сервис «Moederevo»
Сервис «Moederevo», помимо графического редактора для
построения деревьев и интуитивно понятного интерфейса, предоставляет
возможность печати дерева. Но существенными недостатками являются отсутствие контроля приватности
данных и отсутствие возможности импорта и экспорта генеалогических деревьев.
- графический редактор для составления дерева;
- интуитивно понятный интерфейс;
- возможность печати дерева;
- разнообразие стилей и настроек вида дерева;
- приятный дизайн.
Существенным недостатком данного сервиса является отсутствие возможности импорта и
экспорта генеалогических деревьев.
В таблице 1 представлен сравнительный анализ перечисленных
выше веб-сервисов для построения генеалогических деревьев.
Таблица 1
Сравнительный анализ веб-сервисов для построения генеалогических
деревьев
|
«Genway -
больше, чем семья»
|
«Moederevo»
|
«MyHeritage»
|
|
Приятный дизайн
|
да
|
да
|
да
|
|
Интуитивно
понятный интерфейс
|
нет
|
да
|
да
|
|
Графический
редактор
|
да
|
да
|
да
|
|
Контроль
приватности данных
|
нет
|
нет
|
да
|
|
Возможность
импорта и экспорта данных
|
нет
|
нет
|
нет
|
|
Возможность
печати дерева
|
нет
|
да
|
да
|
Подводя итог проведенному анализу существующих в настоящее
время веб-сервисов для построения генеалогических деревьев можно сказать, что
одним из крупнейших в сети интернет генеалогическим ресурсом является сервис
«MyHeritage». Существенным недостатком данного сервиса является ограниченные
возможности в бесплатном режиме (ограниченное количество родственников в
дереве, ограниченное количество доступного места для хранения мультимедийных
данных). Ни один из рассмотренных ресурсов не поддерживает импорт и экспорт
данных, то есть не предоставляет пользователю возможности сохранить свои
наработки вне сервиса.
Создаваемый сервис разрабатывается с целью устранения
найденных недостатков, не забывая про имеющиеся достоинства перечисленных
сервисов.
1.4
Выбранные программные средства
Для реализации сервиса основным языком разработки выбран язык
Python (см. [6]).
Язык Python - это стабильный и распространённый
высокоуровневый язык программирования с акцентом на производительность
разработчика и читаемость кода; язык общего назначения с широким спектром
возможного применения, выразительным синтаксисом и приемлемой
производительностью. Недостаток языка - относительно невысокая скорость
выполнения программ - компенсируется уменьшением времени разработки
программы. В среднем, программа, написанная на Python, в 2-4 раза компактнее,
чем её аналог на C++ или Java.
В качестве каркаса приложения выбран фреймворк Django (см.
[7]). Django (Джанго) - свободный фреймворк для веб-приложений на языке
Python.
Для хранения данных проекта решено использовать два типа
СУБД: реляционную и нереляционную базы данных (см. [8]). Такой выбор основан на
необходимости хранения разнородных данных. Реляционная база данных хранит
данные, удобно представимые в табличном виде: данные о пользователях, данные о
географическом расположении пользователей, о правах доступа, о мультимедийных
данных. Для хранения данных о генеалогических деревьях используется
документо-ориентированная база данных.
1.4.1 Выбор
реляционной базы данных
В качестве реляционных баз данных рассматривались две
наиболее популярные реляционные базы данных с открытым исходным кодом: MySQL и
PostgreSQL.
Каждая база имеет свои особенности и отличия. Если необходимо
быстрое хранилище для простых запросов с минимальной настройкой, лучше выбирать
MySQL. Если необходимо надежное хранилище для большого объема данных с
возможностью расширения, репликации, полностью соответствующее современным
стандартам языка SQL (см. [9]), рекомендуется использовать PostgreSQL.хорошо
использовать для простых запросов с отключенными транзакциями, в то время как
PostgreSQL может поддерживать более серьезную нагрузку и сложные запросы
параллельно с записью в базу данных. Ниша, которую занимает PostgreSQL, более широкая,
и потенциал у PostgreSQL выше. Ниша MySQL скромнее, MySQL оправдывает себя как
хранилище для некритичных по нагрузке и производительности баз данных.
Основное преимущество PostgreSQL - безопасное и
защищённое хранилище данных. В качестве полнофункциональной, свободной
реляционной БД (RDBMS), PostgreSQL обладает многими характеристиками,
спроектированными для поддержки критически-важных приложений с большим потоком
транзакций.
В силу всего вышеперечисленного, в качестве реляционной базы
данных решено использовать PostgreSQL (см. [10]).
1.4.2
Выбор нереляционной базы данных
В качестве нереляционной базы данных выбрана база CouchDB
(см. [11]).
Основные характеристики этой базы:
- данные сохраняются не в строках и
колонках, а в виде JSON-подобных документов, моделью которых является не
таблицы, а деревья;
- целостность базы данных обеспечивается
исключительно на уровне отдельных записей (но не на уровне связей между ними);
- для построения индексов и выполнения
запросов используются функции представления;
- функции-валидаторы, функции-представления,
функции-фильтры сохраняются в текстовом виде в самой базе данных;
- каждой базе данных в системе CouchDB
соответствует единственное В-дерево; каждое B-дерево хранится в виде отдельного
файла на диске;
- поддерживается вертикальная
масштабируемость, что означает поддержку как огромных кластеров, так и
портативных устройств.
Для манипуляций с данными используется JavaScript -
объектно-ориентированный скриптовый язык программирования (см. [12]).
2. Описание базы данных
2.1.
Реляционная база данных
Спроектирована реляционная база данных, состоящая из десяти
таблиц (см. [13]).
2.1.1 Концептуальная схема базы данных
Концептуальная схема базы данных, отображающая взаимосвязи
между таблицами, представлена на рис. 2.1.:
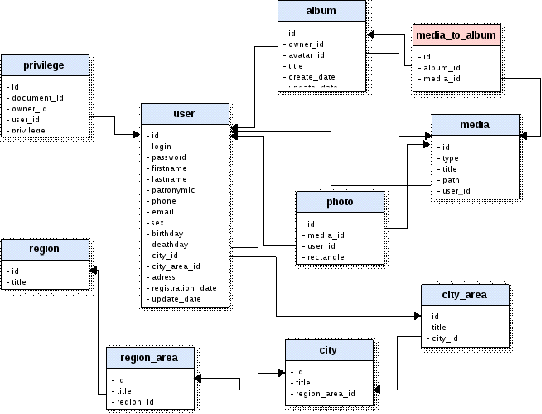
Рис. 2.1. Концептуальная схема базы данных
2.1.2 Описание назначения таблиц
Приведем описание таблиц:
- user - таблица хранит данные о
пользователях (табл. 2.1.);
- region - таблица с названиями
регионов (пример: Новосибирская область) (табл. 2.2.);
- region_area - таблица с названиями
районов региона, пример: Коченевский район (Новосибирская область, Коченевский
район) (табл. 2.3.);
- city - таблица с названиями
городов/сел/поселков, принадлежащих району региона, пример: с. Прокудское
(Новосибирская область, Коченевский район, с. Прокудское) (табл. 2.4.);
- city_area - таблица с названиями
районов города, пример: Ленинский (Новосибирск, Ленинский район) (табл. 2.5.);
- media - таблица для хранения
информации о мультимедийных данных (табл. 2.6.);
- photo - таблица для связи
пользователей и фотографий, на которых они отмечены (табл. 2.7.);
- privilege - таблица для хранения
информации о правах пользователей на генеалогические деревья других
пользователей (табл. 2.8.);
- media_to_album - таблица для
хранения связей между фотографиями и альбомами (табл. 2.10.).
С описанием структур перечисленных выше таблиц можно
ознакомиться в Приложении А.
2.2
Нереляционная база данных
2.2.1 Описание структуры документов
Нереляционная база данных будет хранить документы следующего
вида:
tree = {: [_0,
...,_N,
],: [_0,
...,_N,
],_id: int,_date: date,_date: date,: string,
},
где для упрощения представления вынесем отдельно описание FAMILY_K и PEOPLE_K:
- FAMILY_K =
{"id": int, "hasbent": int, "wife": int,
"children": list, "parent_families": list,
"child_families": list}
- PEOPLE_K =
{"id": int, "lastname": string, "name": string,
"patronymic": string, "sex": string, "birthday":
date, "deathdate": date, "parent_families": list,
"self_families": list}
2.2.2 Описание назначения полей
в документе
В документе будет храниться следующая информация о дереве:
- "owner_id": совпадает с id пользователя -
создателя дерева;
- "create_date": содержит информацию о дате
создания дерева;
- "update_date": содержит информацию о дате
последнего изменения дерева;
- "revision": хранит
идентификатор текущей ревизии;
- "families": коллекция семей, участвующих в
дереве;
- "peoples": коллекция персон, участвующих в
дереве.
Описание FAMILY_K:
- "id": хранит id семьи;
- "hasbent": хранит id персоны, которая
является мужем семьи;
- "wife": хранит id персоны, которая
является женой семьи;
- "children": хранит список, состоящий из id персон, являющихся
детьми семьи;
- "parent_families": хранит
список, состоящий из id семей, являющихся родительскими по отношению к
мужу и жене семьи;
- "child_families": хранит список,
состоящий из id семей, которые были образованы детьми семьи.
Описание PEOPLE_K:
- "id": хранит id персоны;
- "lastname": хранит фамилию
персоны;
- "name": хранит имя персоны;
- "patronymic": хранит отчество
персоны;
- "sex": хранит пол
персоны;
- "birthday": хранит дату рождения
персоны;
- "deathdate": хранит дату смерти
персоны;
- "parent_families": хранит
список, состоящий из id семей, являющихся родительскими по отношению к
персоне;
- "self_families ": хранит список,
состоящий из id семей, которые были образованы персоной.
3. Описание реализации работы с данными
3.1
Структура классов для манипуляции с данными
Для манипуляции с данными используются следующие классы:
а) class User (login, password,
firstname, lastname, patronymic, phone, email, sex, birthday, deathday,
city_id, city_area_id, address, registration_date, update_data, ip_info) - используется для записи данных в таблицу 'user';
б) class Region (title) - используется для записи
данных в таблицу 'region';
в) class RegionArea (title, region_id) - используется
для записи данных в таблицу 'region_area';
г) class City (title, region_area_id) - используется
для записи данных в таблицу 'city';
д) class CityArea (title, city_id) - используется
для записи данных в таблицу 'city_area';
е) class Media (type, title, path, owner_id) - используется
для записи данных в таблицу 'media';
ж) class Photo (media_id, user_id, rectangle) - используется
для записи данных в таблицу 'photo';
з) class Privilege (document_id, owner_id,
user_id, privilege) - используется для записи данных в таблицу 'privilege';
и) class Album (owner_id, avatar_id, title,
create_date, update_date) - используется для записи данных в таблицу 'album';
к) class MediaToAlbum (album_id, media_id)
- используется для записи данных в таблицу
'media_to_album';
л) class DatabaseConnection(address, user, password) - используется
для установки соединения с нереляционной базой данных;
м) DatabaseManager(connection, db_name) - используется
для создания запросов к нереляционной базе данных.
3.2.
Разграничение прав доступа к данным
Для решения задач проекта необходимо реализовать две системы
прав доступа. Первая система прав доступа будет отвечать за разграничение прав
доступа к ресурсам сервиса, а вторая - за разграничение доступа к
пользовательским данным.
3.2.1 Система прав доступа к
ресурсам сервиса
Существуют три роли пользователей:
а) незарегистрированные пользователи;
б) зарегистрированные пользователи;
в) администраторы.
Незарегистрированные пользователи имеют доступ к:
- главной странице,
- странице регистрации,
- страницам пользователей, разрешивших
полный доступ к своим данным.
Зарегистрированные пользователи имеют доступ к:
- главной странице,
- странице регистрации,
- страницам пользователей, разрешивших
полный доступ к своим данным,
- страницам пользователей, разрешивших
доступ к своим данным этому пользователю.
Администраторы имеют доступ как к вышеперечисленным данным,
так и к интерфейсу администратора.
3.2.2
Система
прав доступа к пользовательским данным
Система прав доступа к пользовательским данным базируется на
трех операциях:
а) отсутствие доступа;
б) доступ на чтение;
Права доступа могут быть назначены пользователю или группе
пользователей. При этом права, назначенные пользователю, имеют более высокий
приоритет.
3.3
Вычисление степеней родства
Степени родства между персонами в одном генеалогическом
дереве должны определяться в двух случаях:
а) определение кровности родства между двумя
персонами в одном генеалогическом дереве;
б) определение в дереве всех персон с заданным типом
родственной связи для некоторой выбранной персоны.
Задача определения кровного или некровного родства между
двумя персонами в дереве была решена поиском пути, в котором все родственники
между этими персонами являются кровными друг другу. Если такой путь существует,
то родственники являются кровными. Если такой путь отсутствует, родство
является некровным.
Определение в одном дереве всех персон с заданным типом
родственной связи для некоторой выбранной персоны реализуется по набору
существующих названий отношений между родственниками. Для этого разработан
набор терминов родственных связей, с которым можно ознакомиться в Приложении Б.
Выбрав некоторую персону в генеалогическом дереве и тип родственной связи из
данного набора, можно получить всех персон в этом дереве, которые связаны с
выбранной персоной выбранным типом родственного отношения. Например, для любой
персоны дерева можно получить всех братьев или всех бабушек этой персоны.
Заключение
В результате проделанной работы полностью реализован
запланированный объём работы, включающий в себя реализацию системы хранения
данных проекта, реализацию системы разграничения прав доступа к ресурсам
сервиса и реализацию возможности определения родства между персонами
генеалогического дерева.
Разработанный сервис имеет практическую ценность для работы с
генеалогическими деревьями в веб-среде.
Для достижения поставленной цели проделаны следующие виды
работ:
- исследована предметная область;
- найдены и исследованы существующие
аналоги;
- составлены общие и функциональные
требования;
- исследованы возможные средства разработки
для решения поставленной задачи;
- выбраны и изучены средства разработки:
объектно-реляционная СУБД PostgreSQL, документо-ориентированная СУБД CouchDB, язык программирования Python, фреймворк Django, язык программирования JavaScript;
- разработана и реализована архитектура
реляционной базы данных;
- разработана и реализована архитектура
нереляционной базы данных;
- разработан и реализован интерфейс для
доступа к хранимым данным;
- разработана и реализована система
разграничения прав доступа для разных групп пользователей;
- разработано и реализовано вычисление
степеней родства между двумя персонами в генеалогическом дереве;
- проведена отладка и тестирование
разработанного сервиса.
Направлениями будущей деятельности являются разработка
методов для определения возможного родства между зарегистрированными
пользователями и определения названий родственных связей между любыми двумя
выбранными персонами в одном генеалогическом дереве, а также более углубленное
исследование вопроса безопасности данного сервиса с разработкой методов
обеспечения защищенности системы.
Литература:
. Ф. Харари. Теория графов = Graph Theory / пер. с англ. В. Козырев.
- М.: Либроком, 2009. - 302 с.;
2. Кочевых, Сергей Владимирович. Методическое пособие по проведению
генеалогических разысканий. Основы генеалогической культуры. - СПб.: 2006. - 80
с.;
3. Genway - больше, чем семья: [Электрон. Ресурс]. -
http://www.genway.ru [30.05.12];
4. Moederevo.com: [Электрон. Ресурс]. - http://moederevo.com
[30.05.12];
5. MyHeritage.com: [Электрон. Ресурс]. - http://www.myheritage.com
[30.05.12];
6. Дэвид М. Бизли. Python. Подробный справочник, 4-е издание. - пер. с
англ. А. Киселёв. - СПб.: Символ-Плюс, 2010. - 864 с.;
7. А. Головатый. Django. Подробное руководство = The Definitive Guide to Django / пер. с англ. А.
Киселев. - СПб.: Символ-Плюс, 2010. - 560 с.;
8. В.Ю. Пирогов. Информационные системы и базы данных. Организация и
проектирование. - СПб.: ХВ-Петербург, 2009. - 528 с.;
9. Кевин Е. Кляйн. SQL. Справочник = In a
Nutshell: A Desktop Quick Reference / пер. с англ. А. Слинкин, Е. Демьянов. - СПб.: Символ-Плюс, 2010. - 656 с.;
10. Gregory Smith. PostgreSQL 9.0 High Performance. - Packt
Publishing, 2010. - 468 с.;
11. J. Chris Anderson. CouchDB: The Definitive Guide . - O'Reilly
Media, 2010. - 250 c.;
12. Дэвид Флэнаган. JavaScript. Подробное руководство = JavaScript:
The Definitive Guide / пер. с
англ. А. Киселев. - 5-е изд. -
СПб.: Символ-Плюс, 2009. - 992 с.;
13. Джен Л. Харрингтон. Проектирование реляционных баз данных =
Relational Database Design / пер. с англ. И. Дранишников. - М.: Лори, 2006. -
230 с.