|
Этапы работ
|
Трудоемкость, часов
|
|
Техническое задание
|
70
|
|
Эскизный проект
|
90
|
|
Технический проект
|
140
|
|
Рабочий проект
|
170
|
|
Внедрение
|
50
|
|
Итого:
|
520
|
Расчет затрат компьютерного времени выполним по формуле 3.5:
З2 = Ск ·F0 , (3.5)
где Ск - стоимость компьютерного часа, грн.;0 -
затраты компьютерного времени на разработку программы, час.
Стоимость компьютерного часа вычисляется по формуле 3.6:
СК= СА + СЭ + СТО , (3.6)
где СА - амортизационные отчисления, грн.;
СЭ - энергозатраты, грн.;
СТО - затраты на техобслуживание, грн.
Амортизационные отчисления найдем по формуле 3.7:
СА= Сi· NАi / Fгодi, (3.7)
где Сi = 5000 - балансовая стоимость i-го оборудования,
которое использовалось для создания ПМК, грн.А - годовая норма
амортизации i-го оборудования, доли.год - годовой фонд времени
работы i-го оборудования, час.
Принимаем:А= 0,18; Fгод = 1920 часов.
Из формулы 3.7 получим: СА= 5000*0,18/1920 = 0,47 грн.
Энергозатраты найдем по формуле 3.8:
СЭ = РЭ · СкВт, (3.8)
где РЭ = 0,3- расход электроэнергии, потребляемой компьютером,
кВт/ч;
СкВт = 0, 2436 - стоимость 1 кВт/ч электроэнергии, грн.
Тогда получим: СЭ = 0,3*0, 2436 = 0,07 грн.
Затраты на техобслуживание найдем по формуле 3.9:
СТО= rТО* l, (3.9)
где rТО - часовая зарплата работника обслуживающего
оборудование, грн;
l - периодичность обслуживания (формула 3.10).
Принимаем часовую зарплату работника, обслуживающего оборудование:ТО
= 2100/160 = 13,125 грн/час.
l = Nто / Fмес, (3.10)
где Nто - количество обслуживаний оборудования в месяц;мес
- месячный фонд времени работы оборудования, час.
Принимаем Nто= 1; Fмес= 160 часов.
Тогда (формула 3.10): l=1/160 = 0,0062.
Применяя формулу 3.9, получим: СТО =13.125*0,0062 = 0,0813
грн.
Тогда стоимость компьютерного часа равна:
СК= 0,47 + 0,07 + 0,0813 = 0,6213 грн/час.
Таким образом, затраты компьютерного времени составят:
З2 = 0,6213*520 = 323,1 грн.
Косвенные расходы З3 определяются по формуле 3.11:
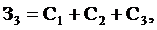 (3.11)
(3.11)
где
С1 - расходы на содержание помещений, грн.
С2
- расходы на освещение, отопление, охрану и уборку помещения, грн.3 - прочие расходы (стоимость различных материалов,
используемых при разработке проекта,услуги
сторонних организаций и т.п.), грн.
Площадь
помещения составляет 15 м2. Принимаем стоимость 1м2 помещения
- 200 грн. Следовательно, стоимость помещения составляет: 17*410= 3000 грн.
С1
= 3000*0,02 = 60 грн - затраты на содержание помещений составляют 2% от
стоимости здания;
С2
=3000*0,003 = 9 грн - расходы на освещение, отопление охрану и уборку помещений
составляют 0,03% от стоимости здания.3 = 1500*1 = 1500 - прочие
расходы (стоимость различных материалов, используемых при разработке проекта,
услуги сторонних организаций и т.п.) составляют 50% от стоимости вычислительной
техники.
Тогда,
используя формулу 3.11, получим: З3 = 60+9+1500 = 1569 грн.
Таким
образом, по формуле 3.2 рассчитаем затраты на создание ПМК:
К3
= 9145,5 + 323,1 + 1569 = 11037,5 грн.
Капитальные
затраты на выполнение и реализацию ПМК составят:
К
= 3000 + 3600 + 11037,5 = 17637,5 грн.
3.2 Расчёт годовой экономии от автоматизации работы аналитика
Годовая экономия от автоматизации работы аналитика рассчитывается по
формуле 3.12:
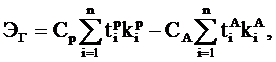 (3.12)
(3.12)
где
tip, tia - трудоёмкость выполнения i-й операции
соответственно в ручном и автоматизированном варианте, час;
kip, kia - повторяемость выполнения i-й операции в
ручном и автоматизированном вариантах в течении года, шт.;
Cp, Ca - часовая себестоимость выполнения операций в ручном и
автоматизированном вариантах, грн.;
n - количество
различных операций, выполнение которых автоматизируется.
Себестоимость
выполнения операций аналитика в ручном варианте определяется по формуле 3.13:
Cp = C1p + C2p, (3.13)
где C1p - затраты на оплату труда персонала, грн.;
C2p - косвенные расходы, грн.
Затраты на оплату труда персонала найдем по формуле 3.14.
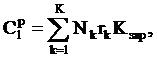 (3.14)
(3.14)
где
Nk -
количество работников k-й профессии, выполнявших работу до автоматизации,
чел.;
rk - часовая
зарплата одного работника k-й профессии, грн.;
Kзар - коэффициент начислений на фонд заработной платы,
доли;
k - число
различных профессий, используемых в ручном варианте.
Часовая
зарплата работника k-й профессии рассчитывается по формуле 3.15:
rk = Mk/Fkмес , (3.15)
где
Mk - месячный оклад работника, грн.;kмес -
месячный фонд времени работ работника, час.
Принимаем
Fkмес = 160
часов.
До
автоматизации работу выполняли 2 человека, т.е. N k=
2чел.
Месячный
оклад работника составляет: Mk=800 грн.
Часовая
зарплата составляет: rk = 800/160 = 5 грн/час.
Затраты
на оплату труда персонала составляют: C1p
= 2 * 5*1.3=13 грн.
Косвенные
расходы рассчитываются по формуле 3.16:
C2p
= C1 + C2 + C3 (3.16)
где С1 - затраты на содержание помещений, грн.;
С2 - расходы на освещение,отопление охрану и уборку помещений, грн.;3 - прочие расходы.
Площадь помещения составляет 15 м2. Принимаем стоимость 1м2
помещения - 200 грн. Следовательно, стоимость помещения составляет:
*200= 3000 грн.
С1 = 3000*2%/100% = 60 грн - затраты на содержание помещений
составляют 2% от стоимости здания;
Расходы на освещение,отопление охрану и уборку помещений С2 составляют
0,2-0,5 % от стоимости помещения: С2 = 3000*0,4%/100%= 9 грн.
Прочие расходы C3 составляют 100-120 % от фонда заработной
платы:3=13*100%/100% = 13 грн.
Из формулы 3.16 получим косвенные расходы:
C2p = 60 + 9 + 13 = 82 грн.
Себестоимость выполнения операций аналитика в ручном варианте по формуле
3.13 составит: СР = 13+ 82 = 95 грн.
Расчёт себестоимости выполнения операций аналитика в автоматизированном
варианте выполняется по формуле 3.17:
Са = C1a + C1a + C1a, (3.17)
где C1a - затраты на оплату труда персонала, грн.;
C2a - стоимость компьютерного времени,
грн.;
C3a - косвенные расходы, грн.
Затраты на оплату труда персонала найдем по формуле 3.18:
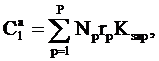 (3.18)
(3.18)
где
Np -
количество работников p-й профессии, выполнявших работу после автоматизации,
чел.;
rp - часовая
зарплата одного работника p-й профессии, грн.;
Kзар - коэффициент начислений на фонд заработной платы,
доли ;
p - число различных профессий, используемых в
автоматизированном варианте.
Принимаем:
Np =
2; Kзар = 1,3.
Количество
работников и их оклады не изменились, поэтому:
Са1
= Ср1 = 13 грн.
Стоимость
компьютерного времени найдем по формуле 3.19.
С2А=
СА + СЭ + СТО, (3.19)
где
СА= 0,3 - амортизационные отчисления, грн.;
СЭ
= 0,04 - энергозатраты, грн.;
СТО
= 0,0017 - затраты на техобслуживание, грн.
Таким
образом, С2А = 0,3 + 0,04 + 0,0017 = 0,3417 грн.
Косвенные
расходы С3А определяются по формуле 3.11:
С3А
= 60 + 9 + 1500 = 1569 грн
Тогда
по формуле 3.17: СА = 13 + 0,6213 + 1569= 1582,6 грн.
В
таблице 3.1 приведен перечень операций аналитика и их трудоемкость в ручном и
автоматизированном вариантах.
Таблица
3.1 - Трудоемкость операций аналитика при выполнении вручную и автоматически
|
№
|
Наименование операций
|
Трудоемкость Р (ч)
|
Трудоемкость А (ч)
|
Повторяемость (раз/год)
|
|
1
|
Сортировка результатов по
категориям
|
1
|
5/60
|
48
|
|
2
|
Анализ выборки с помощью
определенного алгоритма
|
4
|
10/60
|
48
|
|
3
|
Формирование графической модели
результатов анализа
|
4
|
10/60
|
48
|
|
4
|
Формирование отчета по
проделанной работе
|
8
|
5/60
|
6
|
Годовую экономию от внедрения программного комплекса получим по формуле
3.12:
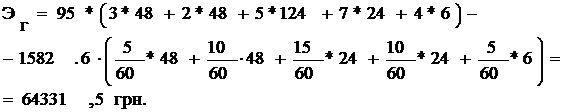
3.3 Расчет годового экономического эффекта
Экономический эффект определяется по формуле 3.20:
Эф = Эг - Ен · K, (3.20)
где Эг = 64331,5- годовая экономия текущих затрат, грн;
К = 17637,5- капитальные затраты на создание ПМК, грн.;
Ен
= 0,42 -
нормативный коэффициент экономической эффективности капиталовложений, доли.
Тогда Эф = 13156,7 - 0,42*17637,5= 5748,95 грн.
3.4 Расчет коэффициента экономической эффективности и срока
окупаемости капиталовложений
Коэффициент экономической эффективности капиталовложений найдем по
формуле:
Ep = Эг/К. (3.21)
ЕР = 13156,7/ 17637,5= 3,65.
Так как, ЕР =0,75 > Ен = 0,42, то внедрение
разработанного программного комплекса является экономически эффективным.
Срок окупаемости капиталовложений определим по формуле 3.22:
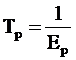 (3.22)
(3.22)
Тогда
подставив значение коэффициента экономической эффективности в формулу 3.22,
получим
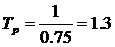 года.
года.
Так
как ТР =1,3 < Тн = 2,4 года (срок окупаемости
капиталовложений меньше нормативного), то можно утверждать, что
капиталовложения используются эффективно.
3.5 Выводы по разделу
Данный экономический расчет показывает, что разработка и использование
ПМК, разработанного в целях автоматизации работы аналитика, является
экономически оправданным и целесообразным. Об этом свидетельствуют следующие
данные:
– годовая экономия текущих затрат при внедрении программного комплекса
составит 13156,7 грн.;
– экономический эффект составит 5748,95 грн;
– срок окупаемости капиталовложений составит 1,3 года.
Вышеприведенные расчёты и сравнительная оценка эффективности работы
аналитика показали целесообразность создания автоматизированного рабочего
места. Основная экономия достигается за счет автоматизации труда, высвобождения
времени аналитика от выполнения рутинных операций. Автоматизация рабочего места
приведёт к уменьшению загруженности аналитика «бумажной» работой, что в свою
очередь, повысит эффективность работы, и снизит вероятность ошибок.
4. ОХРАНА ТРУДА
.1 Анализ опасных и вредных производственных факторов
На пользователя ПЭВМ воздействуют различные группы факторов трудовой
среды:
факторы производственной среды;
факторы трудового процесса (тяжесть и напряженность труда);
внутренние средства деятельности (производственный опыт человека, его
функциональное состояние);
внешние средства деятельности (рабочее место, пульт управления, СОИ,
основное и вспомогательное оборудование);
социально-психологические аспекты трудовых взаимоотношений.
Специфика использования ПЭВМ состоит в том, что в процессе диалога
человека и машины пользователь воспринимает интеллектуальную машину как
равноправного собеседника. Поэтому возникает много совершенно новых
психологических и психофизиологических проблем, суть которых нужно учитывать
при проектировании трудового процесса. Другой особенностью является
значительная информационная нагрузка. Значительная нагрузка на центральную нервную
и зрительную системы вызывает повышение нервно-эмоционального напряжения, и,
как следствие, негативно влияет на сердечнососудистую систему. Важной стороной
функционирования организма пользователя является влияние на него комплекса
факторов трудовой среды, включающих действие электромагнитных волн разных
частотных диапазонов, статического электричества, шума, микроклиматических
факторов и др. Воздействие этого специфического комплекса может оказать на
здоровье человека отрицательное влияние. При работах с использованием
компьютеров возникает целый ряд эргономических проблем, решение которых может
значительно снизить нагрузку.
В этом случае имеются в виду только вопросы конструирования рабочего
места пользователя и не охватываются вопросы формирования рационально
построенных символов на экране и других, изменение которых возможно только при
конструировании новой техники. Работа пользователя ЭВМ чаще всего проходит при
активном взаимодействии с другими людьми. Поэтому возникают вопросы
межличностных взаимоотношений, включающие как психологические, так и
социально-психологические аспекты. Таким образом, на пользователя ЭВМ
воздействуют 4 группы факторов трудовой среды: физические, эргономические,
информационные и социально-психологические.
Все факторы производственной среды в соответствии с классификацией по
ГОСТ 12.0.003-74 «Опасные и вредные производственные факторы. Классификация»
подразделяют на опасные и вредные факторы. При работе на ПЭВМ существует
возможность воздействия следующих опасных производственных факторов:
возможность возникновения пожаров; воздействие электрического тока; возможность
механического травмирования (падения, ушибы и др.); ожоги в результате
случайного контакта с горячими поверхностями внутри лазерного принтера.
Вредные производственные факторы подразделяют на физические, химические,
биологические и психофизиологические производственные факторы. В процессе
работы на пользователя ПЭВМ оказывают действие следующие физические
производственные факторы:
повышенный уровень электромагнитного излучения;
повышенный уровень статического электричества;
повышенные уровни запыленности воздуха рабочей зоны;
повышенное содержание положительных и отрицательных ионов в воздухе
рабочей зоны;
пониженная или повышенная влажность воздуха рабочей зоны;
пониженная или повышенная подвижность воздуха рабочей зоны;
повышенный уровень шума;
повышенный или пониженный уровень освещенности;
нерациональная организация освещения рабочего места (повышенный уровень
прямой и отраженной блесткости, повышенный уровень ослепленности,
неравномерность распределения яркости в поле зрения, повышенная яркость
светового изображения, повышенный уровень пульсации светового потока).
Химические производственные факторы определяются характеристикой
соответствующего рабочего окружения. Контакт с веществами, специфичными для
рабочих мест с ПЭВМ (тонер, озон при работе лазерных принтеров) в правильно
проветриваемых помещениях ниже предельного уровня и не представляет опасности,
однако он может стать опасным в плохо вентилируемом помещении, содержащем
несколько лазерных принтеров и копировальных машин.
К психофизиологическим производственным факторам относятся: напряжение
зрения, напряжение внимания, интеллектуальные и эмоциональные нагрузки,
длительные статические нагрузки, монотонность труда, большие информационные
нагрузки, нерациональная организация рабочего места.
Вероятность воздействия биологических факторов (повышенное содержание в
воздухе рабочей зоны микроорганизмов) возрастает в переполненных и неправильно
вентилируемых помещениях.
Пользователи ПЭВМ в основном подвергаются воздействию физических и
психофизиологических производственных факторов.
Компьютер является источником электромагнитных полей (ЭМП) в диапазоне от
3 Гц до 300 МГц, которые могут быть разделены по их физическим свойствам на
электростатическое, переменное электрическое и переменное магнитное.
ПК является источником нескольких видов электромагнитных полей и
излучений: мягкого рентгеновского, ультрафиолетового, инфракрасного, видимого,
низкочастотного, сверхнизкочастотного и высокочастотного.
Работа на ПЭВМ связана с действием ряда стрессогенных факторов, которые
приводят к возникновению физиологических, психологических и поведенческих
изменений, расстройства здоровья. Психо-эмоциональный стресс способствует или
является причиной многих функциональных нарушений и заболеваний:
психосоматических (психозов, неврозов, нарушений сна);
сердечно-сосудистой системы (аритмии, гипертонической болезни, инфаркта
миокарда);
язвенно-дистрофических поражений желудочно-кишечного тракта;
снижение иммунитета, развития предрасположенности к вирусным и многим
инфекционным заболеваниям;
ревматических поражений и остеохондрозов;
онкологических заболеваний;
гормональных расстройств и нарушений половых функций и т.д.
Учет уровня и специфики действия негативных факторов на работоспособность
и здоровье пользователей компьютеров позволит конструировать рациональную
трудовую среду, в которой человек не только сохранит свое здоровье, но и сможет
производительно трудиться.
Элементы, которые формируют условия труда, являются отдельными
составляющими совокупности условий труды (шум, вибрация, температура и т.д.),
которые влияют на работников.
Элементы, которые определяют условия труда, можно сгруппировать в два
блока: санитарно-гигиенические; нервно-психологические.
От этих элементов зависит состояние здоровья работников и результат их
работы. Они обусловлены материально-производственной средой, возможностями
человека и машин (технологического процесса), социально-демографическим
составом работников. Специфика их заключается в том, что они кроме
непосредственного влияния на формирование условий труда, устанавливают
дополнительные мероприятия по развитию технологий, организации производства и
социального развития.
При работе в положении сидя большинство групп мышц находятся в постоянном
напряжении, которое приводит к быстрой утомляемости, содействует развитию
профессиональных патологических изгибов позвоночника. Неправильное расположение
дисплеев по высоте: очень низкое, под неправильным углом - является основной
причиной появления сутулости; очень высокое положение дисплея приводит к
длительному напряжению шейного отдела позвоночника, которое может привести к
развитию остеохондроза. Ненормальное состояние позвоночника (неправильная
осанка, разного рода искривления, сдвиг или деформация межпозвоночных дисков)
может стать причиной заболевания всего организма.
Интенсивная работа с клавиатурой вызывает болевые ощущения в локтевых
суставах, запястьях, в кистях и пальцах рук. Это может стать источником тяжелых
профессиональных заболеваний рук. Работа с клавиатурой является причиной 12 %
профессиональных заболеваний, вызванных повторяющимися движениями. Заболевания,
связанные с повторяющимися движениями, охватывают болезни нервов, мышц и
сухожилий рук.
Проведем расчет интегральной оценки условий труда и определения тяжести
труда. Определим категорию тяжести труда экономиста - оператор ЭВМ. Для этого
каждому фактору, который характеризует условия труда, необходимо присвоить
соответствующий балл. Данные представлены в таблице 4.1.
Таблица 4.1 - Оценка условий труда на рабочем месте
|
Факторы
|
Значение
|
Баллы
|
|
Температура воздуха на
рабочем месте, t °C
|
21
|
2
|
|
Относительная влажность
воздуха, ω %
|
50
|
1
|
|
Скорость движения воздуха,V
м\с
|
0,6
|
3
|
|
Освещенность, Е, лк
|
300
|
2
|
|
Шум (уровень звука), L, дБ
|
54
|
3
|
|
Длительность
сосредоточенного наблюдения, % от рабочего времени
|
80
|
4
|
Исходя из данных, приведенных в таблице, следует, что такие показатели,
как температура воздуха на рабочем месте, шум, точность зрительных работ,
длительность сосредоточенного наблюдения, длительность повторяющихся операций,
количество важных объектов наблюдения имеют бальную оценку выше 1. Данные
оценки будут использованы при дальнейших расчетах.
Для расчета интегральной бальной оценки тяжести труда используют следующую
формулу
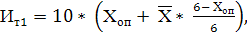 (4.1)
(4.1)
где Ит1 - интегральная бальная оценка тяжести труда;
Хоп - элемент условий труда, который получил наибольшую оценку;
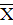 - средний балл всех активных элементов условий труда кроме
определяющего Хоп.
- средний балл всех активных элементов условий труда кроме
определяющего Хоп.
Расчет интегральной оценки тяжести работы требует предварительного
расчета среднего значения оценочных баллов Х (в расчет среднего балла не включается
высший балл).
Средний балл всех активных элементов условий труда, кроме определяющего
Хоп, рассчитывается по формуле:
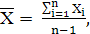 (4.2)
(4.2)
где 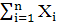 - сумма всех элементов кроме определяющего Хоп;
- сумма всех элементов кроме определяющего Хоп;
n -
количество учтенных элементов условий труда.
В соответствии с имеющимися данными, Хоп = 4, а количество учетных
элементов условий труда равняется 6.
Произведем расчеты по приведенным выше формулам.
Средний балл всех активных элементов условий труда, кроме определяющего
Хоп:
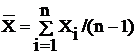 =(2+3+1+2+3)/(6-1)
=2,2 (балла),
=(2+3+1+2+3)/(6-1)
=2,2 (балла),
Интегральная
бальная оценка тяжести труда
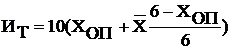
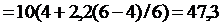 (балла)
(балла)
Интегральная оценка тяжести труда составляет 47,3, что
соответствует IV категории тяжести труда.
Интегральная бальная оценка тяжести труда позволяет
определить влияние условий труда на работоспособность человека. Степень
утомления определяется в условных единицах по формуле
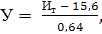 (4.3)
(4.3)
где У - степень утомления;
Ит - интегральная бальная оценка тяжести труда;
,6 и 0,64 - коэффициенты регрессии.
Степень утомления составит
Работоспособность человека определяется как величина
противоположная утомлению (в условных единицах):
R = 100 - У (4.4)
где R - работоспособность человека;
У - степень утомления.
Работоспособность составит:
R1
= 100 - 49,5 =
50,5.
К факторам, которые требуют проведения мероприятий по улучшению условий
труда, относятся факторы, которые имеют бальную оценку выше 2. Поэтому
необходимо разработать мероприятия для обеспечения безопасных и комфортных
условий труда, произвести расчеты вентиляции производственного помещения и
шума.
4.2 Разработка мероприятий для обеспечения безопасных и комфортных
условий труда
В соответствии с НПАОП 0.00-1.28-10 в рабочих помещениях и на рабочих
местах с ПЭВМ должны обеспечиваться оптимальные значения параметров
микроклимата.
Для обеспечения оптимальных микроклиматических условий в помещениях, в
которых размещены компьютеризованные рабочие места, они оборудованы системами
отопления и общеобменной вентиляции. При этом необходимо рассчитать минимальное
количество воздуха, подаваемое в помещение. Количество воздуха, удаляемого или
подаваемого общеобменной вентиляцией, определяется объемом помещения,
приходящегося на одного человека.
Расчет осуществляется в зависимости от количества работающих.
Определяем свободный объем одной комнаты помещения:
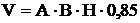 . (4.5)
. (4.5)
V=9 ∙ 4 ∙ 5,0 = 180,0 м3.
Определяем полный свободный объем помещения:
Vполн =2V. (4.5)
Vполн =2∙180,0 м3 = 360 м3.
Удельный свободный объем составляет:
V' = V / N. (4.6)
V' = 360 /9 = 40 м3 / чел.
Объем помещения на одного работающего составляет 40 м3 / чел.
При 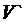 = 40 м3/чел требуется объем
вентиляционного воздуха >=20 м3/ч.
= 40 м3/чел требуется объем
вентиляционного воздуха >=20 м3/ч.
Таким образом, для наших условий работы требуется объем вентиляционного
воздуха >=20 м3/ч.
Для снижения скорости воздуха, дующего на работника, необходимо рабочее
место оградить перегородками. Также, рабочее место можно установить так, чтобы
оно не находилось на прямой линии между окном и дверью. Таким образом, мы
уберем работника со сквозняка.
В воздухе помещений всегда имеется в наличии повышенное количество заряженных
частиц. Ионный состав воздуха может значительно изменяться под воздействием
целой группы факторов.
НПАОП 0.03-3.06-80 «Санитарно-гигиенические нормы допустимых уровней
ионизации воздуха производственных и общественных помещений» регламентирует уровни
ионизации воздуха помещений при работе на ПЭВМ.
Необходимые концентрации позитивных и негативных ионов в воздухе рабочих
зон обеспечиваются применением:
генераторов негативных ионов;
кондиционеров;
проветриванием, систем обще обменной вентиляции, устройств местной
вентиляции;
защитных экранов, которые заземлены;
влажной уборки
Таблица 4.2 - Уровни ионизации воздуха помещений при работе на
электронно-вычислительной машине
|
Уровни
|
Количество ионов в
|
1 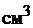 воздуха воздуха
|
|
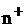 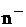
|
|
|
Минимально
необходимые
|
400
|
600
|
|
Оптимальные
|
1500-3000
|
3000-5000
|
|
Максимально
допустимые
|
50000
|
50000
|
Наиболее
опасной для здоровья является увеличенная концентрация озона - высокотоксичного
раздражающего газа. Согласно ГОСТ 12.1.005-88 содержание озона в воздухе
рабочей зоны не должно превышать 0,1мг/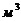 ;
содержание пыли - 4 мг/. Для избежания увеличенной концентрации озона
необходимо выключать ПЭВМ в случае, когда он не используется, а лазерный
принтер желательно размещать подальше от рабочего места оператора. Однако, это
дополнительные методы, основным же методом предотвращения негативного
воздействия озона и других вредных веществ на здоровье операторов есть
обеспечение функционирования приточно-вытяжной вентиляции. Для того, чтобы
вредные вещества не проникали из соседних помещений в помещениях с ПЭВМ,
необходимо создать некоторое избыточное давление.
;
содержание пыли - 4 мг/. Для избежания увеличенной концентрации озона
необходимо выключать ПЭВМ в случае, когда он не используется, а лазерный
принтер желательно размещать подальше от рабочего места оператора. Однако, это
дополнительные методы, основным же методом предотвращения негативного
воздействия озона и других вредных веществ на здоровье операторов есть
обеспечение функционирования приточно-вытяжной вентиляции. Для того, чтобы
вредные вещества не проникали из соседних помещений в помещениях с ПЭВМ,
необходимо создать некоторое избыточное давление.
Под производственным помещением понимают замкнутое пространство в
специально предназначенных зданиях и сооружениях, в которых постоянно (по
сменам) или периодически (на протяжении рабочего дня) осуществляется трудовая
деятельность людей.
Помещения для работы на ПЭВМ должны соответствовать требованиям СНиП
2.09.02-85 «Производственные здания», СНиП 2.01.02-85 «Противопожарные нормы
проектирования зданий и сооружений», НПАОП 0.00-1.31-99 «Правила охраны труда
при эксплуатации электронно вычислительных машин» и ДСанПіН 3.3.2-007-98
«Государственные санитарные правила и нормы работы с визуальными дисплейными
терминалами электронно-вычислительных машин».
Важнейшее значение имеет организация освещения. Освещение помещения
должно соответствовать требованиям СНиП II-4-79 «Естественное и искусственное
освещение» и НПАОП 0.00-1.31-99 «Правила охраны труда при эксплуатации
электронно-вычислительных машин». С учетом специфики зрительной работы с ПЭВМ
наиболее пригодными являются помещения с односторонним расположением окон,
причем желательно, чтобы площадь застекления не превышала 25-50%. Лучше всего,
если окна ориентированы на север или северо-восток. Это даст возможность
устранить нежелательное ослепляющее действие солнечных лучей. Окна оборудуют
регулирующими устройствами (жалюзи, занавески, внешние козырьки). Коэффициент
естественной освещенности не менее 1,5%. Для исключения попадания отраженных
отблесков в глаза пользователей поверхности в помещении должны иметь матовую
или полуматовую фактуру. Коэффициент отражения составляет: для потолка -
0,7-0,8; стен - 0,5-0,6; пола - 0,3-0,5; др. поверхностей - 0,4-0,5.
Искусственное освещение помещений - общее равномерное с применением
люминесцентных ламп, освещенность рабочих поверхностей составляет 300 - 500 лк.
Общее освещение выполнено в виде сплошных или прерывистых линий светильников,
размещаемых сбоку от рабочих мест (преимущественно слева). Допускается
применение светильников следующих классов светораспределения: светильники
прямого света, преимущественно прямого света и преимущественно отраженного
света. Применяются светильники с рассеивателями и зеркальными экранными сетками
или отражателями, укомплектованные высокочастотными пускорегулирующими
аппаратами. В качестве источника света предпочтительнее применять
люминесцентные лампы типа ЛБ. Коэффициент запаса для осветительной установки
следует принимать равным 1,4. Применение местного освещения разрешается только
при работе с двумя носителями (бумажным и электронным, при этом преобладает
работа с документами) или в случае невозможности обеспечения системой общего
освещения требуемого уровня освещенности. Светильники местного освещения (допускается
применение ламп накаливания) имеют полупрозрачный отражатель с защитным углом
не менее 40о.
Уровень шума на рабочих местах в соответствии с требованиями ГОСТ
12.1.003-89 «Шум. Общие требования безопасности», НПАОП 0.00-1.28-10 «Правила
охраны труда при эксплуатации электронно-вычислительных машин» и ДСанПіН
3.3.2-007-98 «Государственные санитарные правила и нормы работы с визуальными
дисплейными терминалами электронно-вычислительных машин» не превышает:
для программистов - 50 дБ·А;
помещения управления, рабочие комнаты - 60 дБ·А;
для операторов обработки информации на ПЭВМ и операторов компьютерного
набора - 65 дБ·А;
в помещениях для размещения шумных агрегатов ЭВМ -
75 дБ·А.
Для достижения требуемого уровня применяют рациональное размещение
рабочих мест в помещении и акустическую обработку помещения. В качестве средств
шумопоглощения применяются не горючие или трудно горючие специальные
перфорированные плиты, панели с максимальным коэффициентом звукопоглощения в
пределах частот 31,5 - 8000 Гц. Кроме того, применяются подвесные потолки с
аналогичными свойствами.
Аккустическая обработка помещения защищает работающих от внутренних и
внешних шумов(улица, смежные помещения) и является более универсальной.
Понижение уровня шума за счет акустической обработки помещения определяется по
формуле
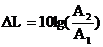 , (4.7)
, (4.7)
Где А1,А2 - звукопоглащение помещения до и после акустической обработки,
единицы поглощения.
Звукопоглащение помещения определяется по формуле:
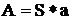 , (4.8)
, (4.8)
Где S - площадь поверхности;
а - коэффициент поглощения материала поверхности, единицы поглощения.
Уровень шума в помещении, размером 9х4х5 м, составляет 54 дбА.
Пол в помещении паркет, стены и потолок - обычная штукатурка. Вычислим
понижение уровня шума после акустической обработки стен и потолка
звукопоглощающим материалом(коэффициент поглощения 0,9)
А1 = 2*9*5*0,03 + 2*4*5*0,03 + 9*4*0,03 + 9*4*0,06 = 7,14 единиц
поглощения.
Вычислим звукопоглощение помещения после акустической обработки:
А2 = 2*9*5*0,9 + 2*4*5*0,9 + 9*4*0,9 + 9*4*0,06 = 151,56 единиц
поглощения.
Понижение уровня шума составляет:
DL = 10 lg (151,56/7,14) = 13,2 дБА.
Уровень шума в помещении после обработки (54 - 13,2 = 40,8 дбА ) отвечает
нормативным требованиям к помещению с ПЭВМ
Уровни вибрации в помещении не превышают требований ГОСТ 12.1.012-90
«Вибрационная безопасность. Общие требования». Для снижения вибрации
оборудование устанавливается на специальные амортизационные прокладки.
Параметры электромагнитного и электростатического полей на рабочих местах
соответствуют требованиям ГОСТ 12.1.006-84 «Электромагнитные поля радиочастот.
Допустимые уровни на рабочих местах и требования к проведению контроля», ГОСТ
12.1.005-88 «Общие санитарно-гигиенические требования к воздуху рабочей зоны»,
ГОСТ 12.1.045-84 «Электростатические поля. Допустимые уровни на рабочих местах
и требования к проведению контроля», НПАОП 0.00-1.28-10и ДСанПіН 3.3.2-007-98.
Электробезопасность обеспечивается выполнением требований ПУЭ, ПТЭ, ПТБ, НПАОП
0.00-1.31-99, ГОСТ 12.1.019-79 «Электробезопасность. Общие требования», ГОСТ
12.1.030-87 «Электробезопасность. Защитное заземление, зануление».
Оборудование, электропровода и кабели по исполнению и степени защиты
соответствуют классу зоны по ПУЭ, имеют аппаратуру защиты от тока короткого
замыкания и других аварийных режимов.
Требования к пожарной безопасности
Пожарная безопасность обеспечивается выполнением требований Правил
пожарной безопасности в Украине, НПАОП 0.00-1.31-99, ГОСТ 12.1.004-91 «Пожарная
безопасность. Общие требования». Здания и те их части, в которых располагаются
ПЭВМ, имеют степень огнестойкости не ниже II. Помещения для обслуживания,
ремонта и наладки относятся по пожаро-, взрывоопасности к категории В в
соответствии с ОНТП 24-86 «Определение категорий помещений и зданий по
взрывопожарной и пожарной опасности», а по классу помещения - к II - IIа
согласно ПУЭ. Помещения оснащены системой автоматической пожарной сигнализации с
дымовыми извещателями и переносными углекислотными огнетушителями из расчета 2
штуки на каждые 20 м2 площади помещения с учетом предельно
допустимых концентраций огнетушащего вещества. Недопустимо располагать
помещения с ПЭВМ в подвалах и цокольных этажах. Они не должны граничить с
помещениями, в которых уровни шума и вибрации превышают допустимые значения.
При помещениях с ПЭВМ оборудованы комнаты для отдыха во время работы,
приема пищи, психологической разгрузки и прочие бытовые помещения. Все эти
помещения отвечают СНиП 2.09.04-87 «Административные и бытовые здания».
НПАОП 0.00-1.28-10 регламентирует требования к организации рабочего места
пользователя ПЭВМ. Организация рабочего места предусматривает:
правильное размещение рабочего места в помещении;
выбор обоснованного с точки зрения эргономики рабочего положения,
производственной мебели с учетом антропометрических характеристик человека;
рациональную компоновку оснащения на рабочих местах;
учет характера и особенностей трудовой деятельности.
Требования к организации рабочего пространства
Организация рабочего места пользователя ПЭВМ обеспечивает соответствие
всех элементов рабочего места и их взаимного расположения эргономическим
требованиям ГОСТ 12.2.032-78 «Общие эргономические требования. Рабочее место при
выполнении работ сидя», характеру и особенностям трудовой деятельности.
Лучше всего размещать рабочие места с ПЭВМ рядами, причем относительно
окон они должны находиться так, чтобы естественный свет падал сбоку,
преимущественно слева. Это дает возможность исключить зеркальное отражение на
экране источников естественного света (окон) и попадания последних в поле
зрения пользователей.
При размещении рабочих мест придерживаются следующих требований:
рабочие места размещаются на расстоянии не меньше 1 м от стен со
световыми проемами;
расстояние между боковыми поверхностями мониторов не меньше 1,2 м;
расстояние между тыльной поверхностью одного монитора и экраном другого
не меньше 2,5 м;
При необходимости высокой концентрации внимания во время выполнения работ
с высоким уровнем напряженности рабочие места отделяются одно от другого
перегородками высотой 1,5 - 2 м.
Исходя из общих принципов организации рабочего места, систематизированы
факторы, которые оказывают влияние на конструкцию производственной мебели: рабочая
поза, поддержка веса тела, высота, глубина и ширина сидения, стабилизация
корпуса, спинка стула, форма и наклон поверхности сидения, подлокотники, высота
поверхности стола, расстояние от пола к нижней части крышки стола.
Конструкция рабочего стола отвечает современным требованиям эргономики и
обеспечивает оптимальное размещение на рабочей поверхности всего оснащения и
используемых приспособлений с учетом их размеров и конструктивных особенностей.
Высота рабочей поверхности стола находится в пределах 680 - 800 мм, а ширина и
глубина - обеспечивает возможность выполнения операций в зоне достижимости
моторного поля. Рекомендованные размеры стола: ширина 600 - 1400 мм, глубина
800 - 1000 мм. Рабочий стол имеет пространство для ног, может быть оборудован подставкой
для ног.
Рабочий стул пользователя ПЭВМ имеет такие основные элементы: сидение,
спинку и стационарные или съемные подлокотники. Конструкция рабочего стула
обеспечивает поддержку рациональной рабочей позы во время выполнения основных
производственных операций, создает условия для изменения позы.
Ширина и глубина сиденья составляют не меньше 400 мм. Высота поверхности
сиденья регулируется в пределах 400-500 мм, а угол наклона поверхности - от 15°
вперед до 5° назад. Поверхность сиденья может быть плоской, передний край -
закруглен. Высота спинки сиденья составляет 300±20 мм, ширина - не меньше 380
мм, радиус кривизны в горизонтальной плоскости - 400 мм. Угол наклона спинки
регулируется в пределах 0-30° относительно вертикального положения. Расстояние
от спинки к переднему краю сиденья регулируется в пределах 260 - 400 мм.
Для снижения статического напряжения мышц рук применяются стационарные
или съемные подлокотники длиной не меньше 250 мм, шириной 70 мм, которые
регулируются по высоте над сидением в пределах 230±30 мм и по расстоянию между
подлокотниками в пределах 350 - 500 мм.
Расположение экрана монитора обеспечивает удобство зрительного наблюдения
в вертикальной плоскости под углом ± 30° от линии зрения пользователя.
Наилучшие зрительные условия и возможность распознавания знаков достигается
такой геометрией размещения, когда верхний край монитора находится на высоте
глаз, а взгляд направлен вниз, на центр экрана. Поскольку наиболее
благоприятным считается наклон головы вперед приблизительно на 20° от вертикали
(при таком положении головы мышцы шеи расслабляются), то экран также наклонен
назад на 20° от вертикали.
Экран монитора и клавиатура располагаются на оптимальном расстоянии от
глаз пользователя, но не ближе 600 мм, с учетом размера буквенно-цифровых
знаков и символов.
ПЭВМ, специальные периферийные устройства и другое оборудование отвечает
требованиям действующих в Украине стандартов, нормативов по охране труда и
НПАОП 0.00-1.31-99.
Допустимые значения электромагнитного излучения (НПАОП 0.00-1.31-99):
напряженность электромагнитного поля на расстоянии 50 см вокруг монитора
по электрической составляющей превышает: в диапазоне частот от 5 Гц до 2 кГц -
25 В/м; в диапазоне частот от 2 до 400 кГц - 2,5 В/м;
плотность магнитного потока не должна превышать: в диапазоне частот от 5
Гц до 2 кГц - 250 нТл; в диапазоне частот от 2 до 400 кГц - 25 нТл;
поверхностный электростатический потенциал не должен превышать 500 В;
мощность дозы рентгеновского излучения на расстоянии 5 см от экрана и
других поверхностей монитора не должна превышать 100 мкР/год.
Режим труда и отдыха - это распорядок, регламентирующий определенное
чередование времени работы и отдыха на протяжении смены, недели, месяца, года.
Режим труда и отдыха пользователей ПЭВМ определяется в зависимости от
выполняемой работы в соответствии с ДСанПіН 3.3.2-007-98 «Государственные
санитарные правила и нормы работы с визуальными дисплейными терминалами
электронно-вычислительных машин». Для сохранения здоровья, предупреждения
профессиональных заболеваний и обеспечения оптимальной работоспособности
предусматривают внутрисменные регламентированные перерывы для отдыха.
В случае невозможности предоставления регламентированных перерывов по
производственным обстоятельствам длительность непрерывной работы на ПЭВМ не
превышает 4 ч.
Во время регламентированных перерывов с целью снижения развивающегося у
пользователей нервно-эмоционального напряжения, утомление зрительного
анализатора, устранения негативного влияния гиподинамии, предотвращения
развития утомления выполняются комплексы специальных профилактических
упражнений.
С целью уменьшения негативного влияния монотонности работы применяют
изменение содержания и темпа работы. При высоком уровне напряженности работы на
ПЭВМ проводят психологическую разгрузку в специально оборудованных помещениях
во время регламентированных перерывов или в конце рабочего дня.
Исходя из осуществленной бальной оценки и произведенных расчетов, можем
сделать вывод о необходимости применения мероприятий по улучшению состояния
таких факторов, как вентиляция производственного помещения и уровень шума.
Улучшение условий микроклимата проводят за счет кондиционирования или
использования общеобменной вентиляции. Снижение уровня шума осуществляется за
счет акустической обработки помещений или установки перегородок.
4.3 Расчет эффективности мероприятий по охране труда
В результате проведенных мероприятий мы привели в соответствие параметры
освещенности и вентиляции, количественная оценка которых снизилась до 2 -х
баллов.
Произведем оценку соответствия факторов производственной среды, тяжести и
напряженности трудового процесса нормативным требованиям.
Произведем количественную и аналитическую оценку условий труда.
температура, х1=2 балла;
скорость движения воздуха, х2 = 2 балла;
влажность воздуха, х3 = 1 балл;
общее освещение, х4 = 2 балла;
продолжительность сосредоточенного наблюдения, х5 = 2 балла;
-
уровень шума,х6 = 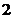 балла.
балла.
Определим
интегральную оценку тяжести труда определяют по формуле:
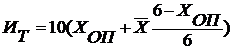 (4.13)
(4.13)
где
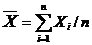 (4.14)
(4.14)
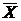 =
(2+2+1+2+2)/5 = 1,8 (балла).
=
(2+2+1+2+2)/5 = 1,8 (балла).
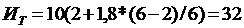 (балла).
(балла).
Интегральная балльная оценка тяжести труда в 32 балла отвечает 2
категории тяжести труда.
Определим степень утомления в условных единицах:
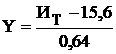 , (4.15)
, (4.15)
где 15,6 и 0,64 - коэффициенты регрессии.
Y= 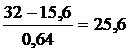
Работоспособность
человека определяется как величина противоположная утомлению (в условных
единицах):
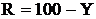 (4.16)
(4.16)
R= 100 - 25,6 = 74,4
Кроме того, можно определить каким образом изменение тяжести работы
влияет на работоспособность человека и его производительность:
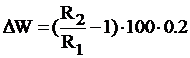 (4.17)
(4.17)
где
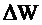 - рост производительности труда, %;и R2 -
работоспособность в условных единицах до и после внедрения мероприятий по
охране труда, которые снизили тяжесть труда;
- рост производительности труда, %;и R2 -
работоспособность в условных единицах до и после внедрения мероприятий по
охране труда, которые снизили тяжесть труда;
,2
- эмпирический коэффициент, который показывает влияние роста уровня работоспособности
на производительность труда.
Определяем
рост производительности труда по формуле (4.17):
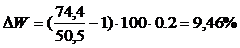
Для
оценки эффективности мероприятий по охране труда определяем также уменьшение
тяжести труда и степени утомления:
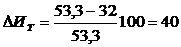 % (4.18)
% (4.18)
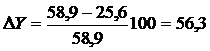 % (4.19)
% (4.19)
Таким образом, в результате разработки мероприятий по обеспечению
безопасных и комфортных условий труда, позволили повысить производительности
труда, уменьшить тяжесть труда и степень утомления.
ОБЩИЕ ВЫВОДЫ
В результате выполнения дипломного проекта, были проанализированы системы
анализа данных, создано техническое задание на создание программно методического
комплекса для анализа полученных из хранилища данных, спроектировано и
реализовано программное обеспечение для анализа данных и построения модели. При
проектировании структуры системы использовались SADT-диаграммы и диаграммы UML:
диаграмма классов, диаграмма последовательности. Разработана структура базы
данных.
На основе JAVA-технологий создан программный комплекс, который
позволяет удобно выбирать и редактировать данные до применение алгоритма
анализа, выполнять посторенние модели и сохранять её в общепринятых стандартах.
Был выполнен экономический анализ эффективности от внедрения программного
обеспечения. Были рассчитаны: годовая экономия текущих затрат при внедрении
программного комплекса, экономический эффект, срок окупаемости
капиталовложений.
Выполнен расчет условия труда, предложены мероприятия по их улучшению.
СПИСОК
ЛИТЕРАТУРЫ
1. Барсегян
А. А. Технологии анализа данных/А.А Барсегян, М. С. Куприянов, В. В.
Степаненко, И. И. Холод. - СПб.: Питер, 2004. - 331 с.
2. Дюк
В.А. Data Mining: учебный курс/ В.А Дюк, А.П. Самойленко. - СПб.: Питер, 2001.
- 250 с.
. Бусленко
Н.П. Моделирование сложных систем - М.: Наука, 2007- 400 с.
4. Архипенков С. Я
Хранилища данных /С. Я. Архипенков, Д. В. Голубев, О. Б. Максименко
<http://www.ozon.ru/detail.cfm/ent=2&ID=116727&partner=lissianski>.
- СПб.: Питер, 2002. - 275 с.
. Гаврилова Т.А.,
Хорошевский В.Ф. Базы знаний интеллектуальных систем. - СПб: Питер, 2001. -
384с.
. Бусленко Н.П.
Моделирование сложных систем - М.: Наука, 2007.- 400 с
. Советов Б.Я. Моделирование
систем. Учебник для ВУЗов/ Б.Я. Советов, Яковлев С.А.. - М.: Высшая школа,
2004. - 426 с.
. Математическое
моделирование: Методы, описания и исследования сложных систем / Под ред. А.А.
Самарского. - М.: Наука, 2003. - 614 с.
. Бендат Дж. Прикладной
анализ случайных данных/ Дж. Бендат, А. Пирсол. - М.: Мир, 1989. - 300 с.
. Елиферов В.Г.
Бизнес-процессы: Регламантация и управление: Учебник/ В.Г. Елиферов, В.В.
Репин. - М.: ИНФРА М, 2007. - 319 с.
. Краснощеков П.С.
Принципы построения моделей/ П.С. Краснощеков, А.А. Петров. - М., МГУ, 1983. -
165 с.
. Воеводин В.В.
Информационная структура алгоритмов. М.: Изд-во МГУ, 2002. - 235 с.
. Комков Н.И.
Организация систем планирования и управления прикладными исследованиями и
разработками / Н.И. Комков, Левин Б.И., Журдан Б.Е. - М.: Наука, 1986 - 233с.
. Гилуа М.М.
Множественная модель данных в информационных системах. - М.: Наука, 2004 - 114
с.
. Алгоритмы,
математическое обеспечение и архитектура многопроцессорных вычислительных
систем/Под ред. В.Е. Котова, И. Миклюшко. - М.: Наука 1982. - 336 с.
. Косенко Е.Ю. Методы
моделирования и проектирования распределенных информационно-управляющих систем.
/ Е.Ю. Косенко, Макаров С.С., Финаев В.И., Таганрог: Изд-во ТРТУ, 2004. - 198
с.
. Финаев В.И. Модели
принятия решений: Учебное пособие. - Таганрог: Изд-во ТРТУ, 2005. - 118 с.
. К. Арнольд. Язык
программирования Java. -М.:Вильямс, 1997. -304с.
19. Гама Э.
Прийоми Об’єктно-орієнтованого проектування. Паттерни
проектування / Э. Гама, Р. Хелм, Р.Джонсон, Дж. Влиссидес. - Спб. : Питер,
2011. - 368 с.
20. Косенко Е.Ю. Методы
моделирования и проектирования распределенных информационно-управляющих систем.
/ Е.Ю. Косенко, Макаров С.С., Финаев В.И., Таганрог: Изд-во ТРТУ, 2004. - 198
с.
. Методические
указания к выполнению экономической части дипломных проектов студентами
специальности “Компьютерные системы проектирования” / Сост. Скибина
А. В., Подгора Е. А. - Краматорск: ДГМА, 1998. - 22 с.
22. Демирчоглян
Г.Г. Компьютер и здоровье - М.: Лукоморье, 1997. - 256 с.
. Жидецький
В.Ц. Охорона праці користувачів комп’ютерів. - Львів: Афіша, 2000. - 176 с.
24. Навакатикян
А.О. Охрана труда пользователей компьютерных видеодисплейных терминалов / А.О.
Навакатикян, В.В. Кальниш, С.Н. Стрюков. - К.: Охрана труда, 1997. - 400 с.