Реляционные базы данных
Введение
Темой данной работы является реляционная база данных.
Основными идеями современных информационных технологий является концепция
о том, что все данные должны быть организованы в базы данных. Это делается для
того, чтобы была возможность адекватно отображать изменяющийся реальный мир и в
полном объеме удовлетворить информационные потребности пользователей. Создание
и функционирование таких баз данных управляются специальными программными
комплексами - системами управления базами данных (СУБД).
Причиной широкого распространения удобных и простых для восприятия
реляционных (табличных) СУБД послужило увеличение объема и структурной
сложности хранимых данных, расширение круга пользователей информационных
систем. Чтобы обеспечить одновременный доступ к данным различным пользователям,
находящимся на значительном расстоянии друг от друга и от места хранения баз
данных, были созданы сетевые мультипользовательские версии БД основанных на
реляционной структуре. Их основной задачей является решение специфических
проблем параллельных процессов, целостности (правильности) и безопасности
данных, а также санкционирование доступа.
Объектом проводимого исследования является реляционная структура данных.
Предметом проводимого исследования является реляционная база данных.
Целью данной работы является анализ реляционных баз данных и способов
манипулирования ими.
Для реализации поставленной цели предполагается решение следующих задач:
- дать основные понятия баз данных, описать архитектуру СУБД, модели
данных;
- раскрыть модель сущность-связь, описать характеристику связей,
классификацию сущностей, структуру первичных и внешних ключей, определить
понятие целостности данных;
описать реляционную структуру данных, реляционные базы данных и
способы манипулирования ими.
База данных - это организованное собрание данных, в которой данные
хранятся с некоторым назначением. Реляционная база данных создана была для
организации данных в таблицы и обеспечения операций извлечения, генерирующих
новые таблицы из уже имеющихся. Основной областью, в которой произошло наиболее
быстрое развитие баз данных, явились разработки приложений для Интернет. База
данных сервера поддерживает многие важные функции в Интернете. Фактически,
любое содержание веб - страниц может управляться базой данных.
1. Основные понятия БД и СУБД
реляционная
база данные
Восприятие реального мира строится как последовательность разных, иногда
и взаимосвязанных, явлений. Еще в древности люди различными способами описывали
эти явления, часто даже не понимая их сущности. Сегодня это описание называется
данными. К данным относятся: факты, явления, события, идеи или предметы.
Фиксация данных традиционно происходит через конкретные средства общения
- естественного языка или изображений, на конкретном носителе: камне или бумаге.
Учитывая тот факт, что естественный язык обладает достаточной гибкостью, данные
и их интерпретация (семантика) фиксируются совместно. Например, рассмотрим
утверждение "Стоимость билета на электричку 147". Здесь
"147" - данное, а "Стоимость билета на электричку" - его
семантика.
Очень часто данные и интерпретация разделяются. Например,
"Расписание движения поездов" представляется в виде таблицы, в
которой в верхней части отдельно от данных будет приведена их интерпретация, а
это затрудняет работу с данными и приводит к сложности получения сведения из
нижней части таблицы.
Разделение данных и интерпретации становиться еще более ощутимым, когда
ЭВМ применяется для ввода и обработки данных. Это происходит потому, ЭВМ может
иметь дело только с данными. Большая часть интерпретирующей информации не
фиксируются в явной форме (ЭВМ не "понимает", является ли
"22.50" стоимостью авиабилета или временем вылета). Почему так
происходит?
Существуют как минимум две исторические причины, способствующие тому, что
активное использование ЭВМ способствовало тому, что произошло разделение данных
и интерпретации:
- ЭВМ не имело достаточных возможностей, чтобы обрабатывать тексты на
естественном языке - основном языке интерпретации данных;
высокая стоимость памяти ЭВМ.
Память использовали для того, чтобы хранить сами данные, а интерпретацией
занимались непосредственно пользователи. Процесс выглядел следующим образом,
интерпретацию данных закладывали в программу, которая "понимала",
например, что пятое вводимое значение связано с временем прибытия поезда, а
пятое - с временем его убытия. Такая последовательность действий делала
программу незаменимой, потому что без интерпретации данные всего лишь
совокупность битов на запоминающем устройстве.
Все серьезные проблемы, которые возникают при введении данных, связаны с
тем, что между данными и использующими их программами существует очень жесткая
связь.
Как показывает практика, совместное использование одних и тех же данных,
приносит массу проблем. Например, очень часто бывает так, что при использовании
одной и той же ЭВМ пользователями создаются и используются в программах разные
наборы данных, содержащие сходную информацию. Это можно объяснить тем, что
пользователь просто не имеет информации о том, что сотрудник, который работает
рядом, давно ввел в ЭВМ нужные данные.
Очень удобно при использовании, когда разработчики прикладных программ,
размещают нужные им данные в файлах. Надо учитывать, что одинаковые данные в
разных приложениях отличаются организацией, то есть обладают разной последовательностью
размещения в записи, разные форматы одних и тех же полей и т.п. Поэтому
обобщить все данные очень сложно. Это связано с тем, что если один разработчик
производит изменение структуры записи файла, то и другой разработчик должен
произвести изменения в программах, использующих записи этого файла.
Архитектура СУБД
СУБД предназначено для предоставления доступа к данным различных
пользователей, причем, даже для тех, которые не имеют представления о том,
какими функциями обладают СУБД:
- физическое размещение в памяти данных и их описание;
- механизмы поиска запрашиваемых данных;
- проблемы, которые возникают, когда одновременно запрашиваются
одни и
- тех же данные многими пользователями (прикладными
программами);
- способы, которые обеспечивают защиту данных от некорректных
обновлений
- и (или) несанкционированного доступа;
- поддержание баз данных в актуальном состоянии и т. д.
Выполняя основные из перечисленных функций СУБД пользуется так же
различными описаниями данных. Каким образом создаются эти описания?
На первом этапе создания проекта базы данных анализируется предметная
область и выявляются основные требования к ней различных пользователей. Чаще
всего это сотрудники организации, для которой создается база данных. Отметим,
что за проектирование отвечает человек, которого называют администратором
данных (АБД). Это может быть какой-нибудь сотрудник данной организации или
будущий пользователь базы данных, который хорошо знаком с машинной обработкой
данных.
Вначале АБД проводит опрос и объединяет частные представления о
содержимом базы данных и свои представления о данных, которые могут
потребоваться в будущих приложениях. Затем он создает обобщенное неформальное
описание создаваемой базы данных. В описании используется естественный язык, математические
формулы, таблицы, графики и другие средства,
понятные всем людям, работающим над проектированием базы данных. Такое
описание называется инфологической моделью данных (см. Рисунок 1).
Эта модель ориентирована на человека и полностью независима от физических
параметров среды хранения данных. Примером такой среды может быть память
человека. Поэтому инфологическая модель должна оставаться неизменной до тех
пор, пока определенные изменения в реальном мире не потребуют изменения в ней
некоторого определения, чтобы эта модель продолжала отражать предметную
область.
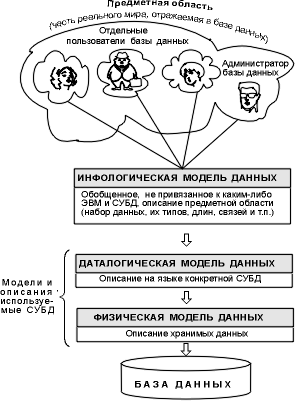
Рисунок 1 Уровни моделей данных
Остальные модели, приведенные на рис. 1 ориентированы на компьютер. С их
помощью осуществляется доступ программам и пользователям к хранимым данным
только по их именам. Физическое расположение этих данных не имеет значение.
Если необходимо отыскать данные, то СУБД это делает достаточно быстро по
физической модели данных.
Осуществление доступа происходит при помощи конкретной СУБД, поэтому
описание моделей должно происходить на языке описания данных этой СУБД2.
Это описание создается АБД по инфологической модели данных и называется
даталогической моделью данных.
Архитектура имеет три уровня: инфологический, даталогический и
физический, что позволяет обеспечить независимость хранимых данных от
использующих их программ. Если возникает необходимость, то АБД переписывает
хранимые данные на другие носители информации и (или) реорганизовывает их
физическую структуру, изменяя только физическую модель данных. При этом он
может подключить к системе любое число новых пользователей (новых приложений),
дополнив, если надо, даталогическую модель. Эти изменения как правило остаются
незамеченными уже существующими пользователями. Следовательно, возможность
развития системы баз данных без разрушения существующих приложений обеспечивает
определенная независимость данных.
Модели данных
Рассмотрим инфологическую модель, отображающую законы реального мира в
различные концепции, доступные для понимания человеком. Они абсолютно
независимы от параметров среды хранения данных. На сегодняшний день, можно
назвать множество существующих подходов к построению таких моделей. Например,
графовые модели, семантические сети, модель "сущность-связь" и т.д.
Самой распространенной является модель "сущность-связь".
Ее суть в том, что инфологическую модель отображают в
компьютеро-ориентированную даталогическую модель, которая "понятна"
СУБД. СУБД, которые способны поддерживать различные даталогические модели
создавались в процессе интенсивного развития теории и практического
использования баз данных, в том числе и средств вычислительной.
Изначально, использовались иерархические даталогические модели, которые
были простыми в организации, имели заранее заданные связи между сущностями.
Достаточно высокую производительность иерархических СУБД на медленных ЭВМ с
весьма ограниченными объемами памяти обеспечивало сходство с физическими
моделями данных. При этом если данные не имели древовидной структуры возникало
много проблем.
Для мало ресурсных ЭВМ так же создавались сетевые модели. Они
представляют собой сложные структуры, которые в свою очередь состоят из
наборов" (поименованных двухуровневых деревьев), которые соединяются с
помощью "записей-связок", образуя цепочки и т.д. Чтобы увеличить
производительность СУБД при разработке сетевых моделей придумали множество
"маленьких хитростей". Но они существенно усложнили СУБД. Чтобы ими
успешно пользоваться программист должен знать массу терминов, изучить несколько
внутренних языков СУБД, детально представлять логическую структуру базы данных
для осуществления навигации среди различных экземпляров, наборов, записей и
т.п.
Это привело к необходимости поиска иных способов практического
использования иерархических и сетевых СУБД. Новые СУБД появились в конце 60-х
годов и отличались от предыдущих простотой организации и наличием весьма
удобных языков манипулирования данными. Главным недостатком этих СУБД стало
ограничение количества файлов для хранения данных, количества связей между
ними, длины записи и количества ее полей.
Эксплуатационные характеристики БД зависят от физической организации
данных, поэтому разработчики СУБД пытаются создать наиболее производительные
физические модели данных. Каждому пользователю предлагается тот или иной
инструментарий для поднастройки модели под конкретную БД. Так как на
сегодняшний день очень много разнообразных способов корректировки физических
моделей промышленных СУБД , что не позволяет рассмотреть их в этом разделе.
2. Реляционный подход
Еще в конце 60-х годов стали появляться работы, в которых обсуждались
возможности применения различных табличных даталогических моделей данных.
Особый интерес вызвала статья сотрудника фирмы IBM д-ра Э.Кодда (Codd E.F., A Relational
Model of Data for Large Shared Data Banks. CACM 13: 6, June 1970), в которой впервые был применен термин
"реляционная модель данных".
Так как Э. Кодд по образованию был математиком, он предложил для
обработки данных использовать аппарат теории множеств (объединение,
пересечение, разность, декартово произведение). Ему удалось показать, что любое
представление данных сводится к совокупности двумерных таблиц особого вида,
известного в математике как отношение - relation (англ.) [6,7].
Наименьшей единицей данных реляционной модели было принято отдельное
атомарное (неразложимое) для данной модели значение данных. Например, фамилия,
имя и отчество в одной предметной области могут рассматриваться как единое
значение, а в другой - как три различных значения.
Домен - это множество атомарных значений одного и того же типа. Их смысл
в следующем, например, если взять значения двух атрибутов из одного и того же
домена, то тогда необходимо производить сравнение, которое использует оба
атрибута, если же значения двух атрибутов берутся из различных доменов, то
смысла в их сравнении нет.
Рассмотрим конкретный пример для первого случая: при организации
транзитного рейса, целесообразно задать запрос: "Выдать рейсы, в которых
время вылета из Челябинска в Египет больше времени прибытия из Свердловска в
Стамбул".
Отношение на доменах D1, D2, ..., Dn (не обязательно, чтобы все они были
различны) состоит из заголовка и тела. На рис. 3 приведен пример отношения для
расписания движения самолетов.
Заголовок состоит из такого фиксированного множества атрибутов A1, A2,
..., An, что существует взаимно однозначное соответствие между этими атрибутами
Ai и определяющими их доменами Di (i=1,2,...,n).
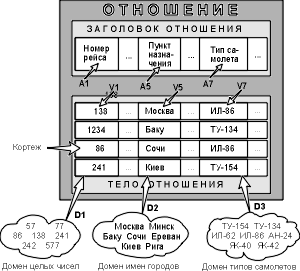
Рисунок 2. Отношение с математической точки
зрения (Ai - атрибуты, Vi - значения атрибутов)
Тело состоит из меняющегося во времени множества кортежей. В свою
очередь, каждый кортеж состоит из множества пар атрибут-значений (Ai:Vi),
(i=1,2,...,n), по одной такой паре для каждого атрибута Ai в заголовке. Для
любой заданной пары атрибут-значение (Ai:Vi) Vi является значением из
единственного домена Di, который связан с атрибутом Ai.
Степенью отношения называют число его атрибутов. Отношение степени один
называют унарным, степени два - бинарным, степени три - тернарным, ..., а
степени n - n-арным.
Кардинальным числом или мощность отношения называется число его кортежей.
Кардинальное число отношения всегда будет изменяться во времени в отличие от
его степени.
Поскольку отношение - это множество, а множества по определению не
содержат совпадающих элементов, то никакие два кортежа отношения не могут быть
дубликатами друг друга в любой произвольно-заданный момент времени. Пусть R -
отношение с атрибутами A1, A2, ..., An. Говорят, что множество атрибутов K=(Ai,
Aj, ..., Ak) отношения R является возможным ключом R тогда и только тогда,
когда происходит выполнение двух независимых от времени условий:
1. Уникальность: в произвольный заданный момент времени никакие два
различных кортежа R не имеют одного и того же значения для Ai, Aj, ..., Ak.
2. Минимальность: ни один из атрибутов Ai, Aj, ..., Ak не может быть
исключен из K без нарушения уникальности.
Каждому отношению соответствует хотя бы один возможный ключ. Это
происходит, потому что для всех его атрибутов выполняется условие уникальности.
За первичный ключ принимается один из возможных ключей (выбранный произвольным
образом). Остальные возможные ключи, если они есть, называются альтернативными
ключами.
Мы рассмотрели не все математические понятия, которые составили
теоретическую базу для создания сталиреляционных СУБД. Были разработаны
соответствующие языковые средства и программные системы, обеспечивающие их
высокую производительность, и созданы основы теории проектирования баз данных.
Массовым пользователем реляционных СУБД используются чаще всего неформальные
эквиваленты этих понятий:
Отношение - Таблица (иногда Файл), Кортеж - Строка (иногда Запись),
Атрибут - Столбец, Поле.
Индексы
Индекс представляет собой указатель на данные,
размещенные в реляционной таблице. Можно провести аналогию индекса таблицы базы
данных с указателем, обычно помещаемым в конце книги. Чтобы найти в книге
страницы, относящиеся к некоторой теме, проще всего обратиться к указателю, в
котором устанавливается соответствие между перечисленными в алфавитном порядке
темами и номерами страниц, и сразу определить страницы, которые следует
просмотреть. Чтобы без указателя найти все страницы, относящиеся к нужной теме,
пришлось бы просматривать всю книгу. Индекс базы данных предназначен для
аналогичных целей - чтобы ускорить поиск информации в таблице базы данных.
Индекс предоставляет информацию о точном физическом расположении данных в
таблице.
При создании индекса в нем сохраняется информация о
местонахождении записей, относящихся к индексируемому столбцу таблицы. При
добавлении в таблицу новых записей или удалении существующих индекс также
модифицируется.
При выполнении запроса к базе данных, в условие поиска
которого входит индексированный столбец, поиск значений производится в первую
очередь в индексе. Если этот поиск оказывается успешным, то в индексе
устанавливается точное местоположение искомых данных в таблице базы данных.
Рассмотрим пример индекса. На рис. 3 показан фрагмент
таблицы СТУДЕНТЫ и индекса, построенного по полю «Имя» данной таблицы. При
выполнении поиска по имени студента, просматривая индекс, можно сразу
определить порядковый номер записи, содержащей необходимую информацию, и затем
быстро найти в таблице сами данные. Если бы у таблицы отсутствовал индекс по
полю «Имя», то выполнение поиска по имени студента потребовало бы просмотра
всей таблицы. Таким образом, использование индексов снижает время выборки
данных.
Различают несколько типов индексов. Наиболее часто
выделяют три типа: простые; составные; уникальные.
Простые индексы представляют собой простейший и вместе
с тем наиболее распространенный тип индекса. Простой индекс строится на основе
только одного столбца реляционной таблицы (индекс, приведенный на Рисунке 3
является простым).
Составные индексы строятся по двум и более столбцам
реляционной таблицы. При создании составного индекса необходимо принимать во
внимание, что последовательность столбцов, по которым создается индекс, влияет
на скорость поиска данных.
Можно назвать два условия оптимальности следования
столбцов в составном индексе:
первым следует помещать столбец, содержащий наиболее
ограничивающее значение (то есть содержащий меньшее количество повторов);
первым следует помещать столбец, содержащий данные,
которые наиболее часто задаются в условиях поиска.
Сформулированные условия оптимальности часто являются
противоречивыми, так что между ними следует находить разумный компромисс.
Уникальные индексы не допускают введения в
таблицу дублирующих значений. Уникальные индексы используются не только с целью
повышения скорости поиска, но и для поддержания целостности данных. Уникальный
индекс может быть как простым, так и составным.
Реляционная база данных
По мере увеличения возможностей и уменьшения стоимости
вычислительных средств, получило развитие второе направление, связанное с
использованием средств вычислительной техники в автоматизированных информационных
системах. Здесь вычислительные возможности компьютеров отходят на второй план -
основные функции вычислительных средств в информационных системах состоят в
поддержке надежного хранения информации, выполнении специфических для данного
приложения преобразований информации и/или вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса.
Со временем именно второе направление, связанное с
хранением и обработкой данных, стало доминирующим, особенно после появления
персональных компьютеров. Использование персональных компьютеров для выполнения
сложных научных расчетов сейчас является скорее исключением. Интересно также
отметить, что современные персональные компьютеры, оборудованные процессорами с
громадными тактовыми частотами (на сегодняшний день рядовой дешевый процессор
работает на частоте 1800-2200 МГц), при решении сложных научных задач могут
даже уступать по вычислительным возможностям «большим» компьютерам 20-25-летней
давности.
Реляционной базой данных называется совокупность отношений,
которые
содержат всю информацию, хранящуюся в БД.
Пользователи воспринимают эту базу данных как совокупность таблиц.
Особенности таких таблиц:
. Таблица имеет уникальное имя и состоит из
однотипных строк.
. Существование фиксированного числа полей
(столбцов) и значений
(множественные поля и повторяющиеся группы
недопустимы). То есть, каждая позиция отличается от другой хотя бы единственным
значением.
. Возможность однозначной идентификации любой строки
таблицы.
. Присвоение столбцам таблицы однозначного имени,
причем в каждом из них размещаются однородные значения данных (даты, фамилии,
целые числа или денежные суммы).
. Полное информационное содержание базы данных
представляется в виде явных значений данных и такой метод представления
является единственным. В частности, не существует каких-либо специальных
"связей" или указателей, соединяющих одну таблицу с другой.
Так, связи между строкой с БЛ = 2 таблицы
"Блюда" на рис. 4 и строкой с ПР = 7 таблицы продукты (для
приготовления Харчо нужен Рис), представляется не с помощью указателей, а
благодаря существованию в таблице "Состав" строки, в которой номер
блюда равен 2, а номер продукта - 7.
. При выполнении операций с таблицей ее строки и
столбцы можно обрабатывать в любом порядке безотносительно к их информационному
содержанию. Этому способствует наличие имен таблиц и их столбцов, а также
возможность выделения любой их строки или любого набора строк с указанными
признаками.
Манипулирование реляционными данными
Общеизвестен тот факт, что механизмы реляционной
алгебры и реляционного исчисления эквивалентны. Это означает, что для любого
допустимого выражения реляционной алгебры можно построить эквивалентную формулу
реляционного исчисления и наоборот. Как объяснить присутствие в реляционной
модели данных этих двух механизмов?
Ответ на этот вопрос в их различии уровнем
процедурности. На основе алгебраических операций строятся выражения реляционной
алгебры. Аналогично тому, как интерпретируются арифметические и логические
выражения, выражения реляционной алгебры имеют процедурную интерпретацию. То
есть, запрос, который представлен на языке реляционной алгебры, вычисляется на
основе вычислений элементарных алгебраических операций, при этом необходимо
учитывать их старшинство и возможное наличие скобок. Однозначной интерпретации
для формулы реляционного исчисления не существует. Формула призвана
устанавливать условия, которые должны удовлетворять кортежам результирующего
отношения. Именно поэтому языки реляционного исчисления являются более
непроцедурными или декларативными.
Учитывая эквивалентность механизмов реляционной
алгебры и реляционного исчисления, можно пользоваться любым из этих механизмов
для проверки степени реляционности некоторого языка БД.
Отметим, что хотя и редко алгебру или исчисление
принимаю в качестве полной основы какого-либо языка БД. Обычно (как, например,
в случае языка SQL) язык основывается на некоторой смеси алгебраических и
логических конструкций. Тем не менее, знание алгебраических и логических основ
языков баз данных часто бывает полезно на практике.
Различные проблемы при обновлении таблиц связаны,
прежде всего, со стремлением минимизировать число таблиц. Поэтому будут даны
рекомендации по разбиению некоторых больших таблиц на несколько маленьких.
Возникает вопрос: Как правильно сформировать требуемый ответ, если необходимые
данные хранятся в разных таблицах?
Э. Ф. Кодд предложил реляционную модель данных. Он
так же стал создателем инструмента для удобной работы с отношениями -
реляционной алгебры. Каждой операцией этой алгебры используется одна или
несколько таблиц (отношений) в качестве ее операндов и продуцирует в результате
новую таблицу, т.е. позволяет "разрезать" или "склеивать"
таблицы (Рисунок 3).

Рисунок 3. Некоторые операции реляционной алгебры
Для реализации всех операций реляционной алгебры и
почти всех их сочетаний были созданы языки манипулирования данными.Назовем
самые распространенные среди них:
. SQL: Structured Query Language - структуризованный
язык запросов;
2. QBE: Quere-By-Example - запросы по образцу.
Они относятся к языкам очень высокого уровня. Они
применяются для указания пользователем тех данных, которые необходимо получить,
но при этом процедура получения не уточняется.
Заключение
В настоящее время реляционные базы данных - наиболее распространенный тип
баз данных, что обусловлено относительной легкостью проектирования. Другим
решающим фактором превосходства РБД является поддержка производителей
программного обеспечения управления базами данных. Наиболее известные и широко
применяемые СУБД, такие как MS Access, SQL Server, MySQL
предназначены именно для работы с реляционными БД.
В реляционной базе данных данные хранятся в двумерных таблицах с
использованием простых доменов. Целостность реляционной базы данных
поддерживается с помощью правил целостности сущностей и ссылочной целостности.
Основное достоинство реляционных баз данных - это их совместимость с
самым распространенным языком запросов SQL. Только при единственном запросе на языке SQL, выполняется несколько операций:
соединение нескольких таблиц во временную таблицу и вырезание из таблицы
требуемых строк и столбцов, то есть, селекция и проекция. Табличная структура
реляционной базы данных проста в понимании для пользователя, как следствие и язык
SQL так же является достаточно простым
для изучения. Реляционная модель содержит достаточно большой теоретический
материал, на нем были основаны эволюционные преобразования и успешная
реализация реляционных баз данных. Именно популярность реляционных баз данных
сыграла решающую роль в том что язык SQL стал основным.
Однако, данная модель имеет ряд существенных недостатков:
создание дополнительных таблиц, которые учитывают индивидуальные
особенности элементов при помощи внешних ключей. Это связано с тем, что все
поля одной таблицы должны содержать постоянное число полей заранее определенных
типов. Происходит усложнение создания сложных взаимосвязей в базе данных;
- высокая трудоемкость манипулирования информацией и изменения
связей.
Разработка простых языков запросов, доступных для
изучения пользователями, не являющимися специалистами в этой области, стала
возможна благодаря реализации реляционных принципов в СУБД. А это в свою
очередь привело к тому. Что был расширен круг пользователей базами данных.
На сегодняшний день, благодаря широкому
распространению баз данных и достаточной их простоте в использовании, базы
данных можно рассматривать как стандарт СУБД для современных информационных
систем.
Глоссарий
|
№ п/п
|
Понятие
|
Определение
|
|
1
|
Аномалия
|
Проблема, проявляющаяся при
работе с отношениями, содержащими избыточные данные
|
|
2
|
База данных
|
Связанная между собой по
определенному признаку информация, организованная и хранимая особым образом
|
|
3
|
Детерминант функциональной
зависимости
|
Атрибут (или группа
атрибутов), находящийся в левой части выражения, которое представляет
функциональную зависимость
|
|
4
|
Избыточность данных
|
Ситуация, когда в
нескольких записях таблицы базы данных повторяется одна и та же информация
|
|
5
|
Индекс
|
Указатель на данные,
размещенные в реляционной таблице
|
|
6
|
Индекс
|
Указатель на данные,
размещенные в реляционной таблице
|
Многозначная зависимость
|
Зависимость между
атрибутами отношения (например, А, В и С), такая, что каждое значение А
представляет собой множество значений для А и множество значений для С.
Однако множества значений для В и С не зависят друг от друга.
|
|
8
|
Нормализация
|
Процесс реорганизации
данных путем ликвидации повторяющихся групп и иных противоречий с целью
приведения таблиц к виду, позволяющему осуществлять непротиворечивое и корректное
редактирование данных
|
|
9
|
Реляционная база данных
|
Хранилище данных,
содержащее набор двумерных связанных таблиц
|
|
10
|
Система управления базами
данных (СУБД)
|
Cистема, содержащая средства для управления базами
данных
|
|
11
|
Хранилище данных
|
Предметно-ориентированный,
интегрированный, привязанный ко времени и неизменяемый набор данных,
предназначенный для поддержки принятия решений
|
Список использованных источников:
1.
Бекаревич, Ю. Microsoft Access 2007 [Текст]. - М.: ВHV, 2007.- 720 с.- ISBN
978-5-9775-0097-5.
.
Гайдамакин, Н.А. Автоматизированные информационные системы, базы и банки данных
[Текст].- М.: Гелиос АРВ, 2008.- 648 с.- ISBN 5-85438-035-8.
.
Глушаков, С.В. Базы данных [Текст].- М.: Фолио, 2008.- 504.- ISBN
966-03-0992-9.
.
Голенищев, Э.П. Информационное обеспечение систем управления [Текст]. - Ростов
н/Д: «Феникс», 2010.-364 с.- ISBN 978-5-222-17051-9.
.
Дейт, К.Дж. Введение в системы баз данных [Текст], 8-е издание: Пер. с англ.-
М.: Вильяме, 2005.- 1328 с.- ISBN 0-321-19784-4.
.
Коннолли, Т. Базы данных. Проектирования, реализация и сопровождение [Текст].-
М.: Вильямс,2006.- 1440 с.- ISBN 0-201-70857-4.
.
Кузин, А.В. Базы данных [Текст].- М.: Академия, 2005.- 320 с.- ISBN:
5-7695-1796-4.
.
Кузнецов, С.Д. Основы баз данных: Учебное пособие [Текст]. - М.: Бином, 2007.-
328 с.- ISBN 978-5-7695-3772-1.
.
Роланд, Ф.Д. Основные концепции баз данных [Текст]: Пер. с англ.- М.:
Издательский дом "Вильяме", 2007.- 256 с.- ISBN 5-8459-0297-5.
.
Хомоненко, А. Базы данных [Текст].- СПб, Корона принт, 2010.- 736 с.- ISBN
978-5-7931-0838-6.