Реализация различных методов доступа к данным в таблицах по имени
Федеральное
Агентство по образованию
Российской
Федерации
Бийский
технологический институт (филиал)
Государственного
образовательного учреждения высшего
профессионального
образования
«Алтайский
государственный технический университет
Им. И. И.
Ползунова»
(БТИ АлтГТУ)
Факультет
информационных технологий,
автоматизации
и управления
Кафедра МСИА
Пояснительная
записка к курсовой работе
КР
200106.11.000 ПЗ
«Реализация различных методов доступа
к данным в таблицах по имени»
Выполнила:
студентка группы ИИТТ-72
Пахомова М.
И.
Руководитель:
доцент
Заборовский
А. Н.
2010
РЕФЕРАТ
Пахомова Мария Ивановна
Реализация различных методов доступа к данным в таблицах по
имени
Целью данной курсовой работы является написание программы реализации различных методов доступа
к данным в таблицах по имени.
Курсовая работа содержит пояснительную записку, программу, презентацию.
Пояснительная записка: 25 страниц, 6 рисунков, 4 источника.
СОДЕРЖАНИЕ
Введение 4
Теоретическая часть 5
Организация доступа по имени 5
Понятие таблицы 5
Анализ способов организации
таблиц. 6
. Просматриваемые таблицы 7
. Упорядоченные таблицы 7
. Таблицы с вычисляемыми
адресами 8
Хеширование данных 10
Практическая часть 13
Связывание 13
Преимущества и недостатки
связывания 16
Бинарный (двоичный) поиск 17
Интерфейс программы 21
Заключение 24
Литература 25
ВВЕДЕНИЕ
программа таблица хеширование бинарный
Таблицы являются одними из наиболее распространенных структур данных,
используемых при создании системного и прикладного математического обеспечения.
Таблицы широко применяются в трансляторах (таблицы идентификаторов) и
операционных системах, могут рассматриваться как программная реализация схемы
ассоциативной памяти и т.п.
Выполнение курсовой работы ориентировано на достижение следующих
учебно-методических целей:
· знакомство с проблематикой и методами организации доступа по имени;
· развитие практических навыков по созданию структур хранения
для динамических структур данных (на примере таблиц);
· изучение и практическое освоение методов поиска в таблицах с
различными типами организации данных.
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Организация
доступа по имени
Существование отношения "иметь имя" является обязательным в
большинстве разрабатываемых программистами структур данных; доступ по имени в
этих структурах служит для получения соответствия между адресным принципом
указания элементов памяти ЭВМ и общепринятым (более удобным для человека)
способом указания объектов по их именам.
Зачастую ставится задача создания программных средств, поддерживающих
табличные динамические структуры данных (таблицы) и базовые операции над ними:
· поиск элемента;
· вставка элемента (без дублирования);
· удаление элемента.
Выполнение операций над таблицами может осуществляться с различной
степенью эффективности в зависимости от способа организации таблицы:
· просмотровые (неупорядоченные);
· упорядоченные (сортированные);
· перемешанные (с вычисляемыми адресами).
Понятие
таблицы
Под таблицей следует понимать динамическую структуру данных, которая в
каждый момент выполнения вычислений состоит из конечного набора элементов
(записей); записи таблицы могут подразделяться на несколько полей; при этом
количество и тип полей является одинаковыми для всех записей таблицы. Первое
поле всех записей таблицы обычно называют ключом, поля записи без ключевого
поля образуют тело записи. Например, задавая соответствие между
идентификаторами переменных (именами) и их адресами в памяти ЭВМ, мы можем
построить простейшую таблицу вида
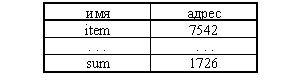
Пример таблицы для организации доступа по имени, в которой каждая
строка-запись состоит из двух полей: поля ключа (имени) и поля тела записи
(адреса).
Основные операции, выполняемые над таблицами, определяются следующим
набором операций:
· поиск записи (по одному или нескольким ключам);
· вставки записи (с контролем возможных повторений);
· удаления записи.
Операции вставки и удаления записей служат для формирования требуемого
набора записей; операция поиска записи по ключу обеспечивает доступ по имени
(ключу) к записям таблицы.
Анализ
способов организации таблиц
Способ построения таблицы должен приводить к быстрому выполнению
табличных операций. В зависимости от способов размещения записей в таблице
возможно использование различных методов выполнения операций обработки таблиц.
Эффективность применяемых способов организации может быть оценена, например, в
количестве просматриваемых записей таблицы при выполнении операций поиска,
вставки и удаления.
Далее следует характеристика основных способов построения таблиц.
Рассматриваемые способы имеют разные показатели по эффективности; для всех
перечисленных способов могут быть выделены области приложений, в которых
рекомендуемые способы являются наиболее целесообразными.
. Просматриваемые таблицы
Простейшим способом отыскания нужного элемента является метод полного
просмотра (сканирования), когда искомый ключ сравнивается по очереди со всеми
ключами таблицы, начиная с первого, вплоть до отыскания совпадающего элемента
или до исчерпания записей. Если ключи в таблице расположены в произвольном
порядке (неупорядоченная таблица), этот способ является единственно возможным.
Операция вставки в неупорядоченную таблицу может быть выполнена путем
добавления новой записи в конец таблицы с корректировкой номера последней
занятой строки. Операция удаления строки может быть реализована при помощи
переписывания последней записи таблицы на место удаляемой и соответствующей
корректировки номера последней строки.
= pN/2 + (1-p)N, (1)
где вероятность того, что искомая запись имеется в таблице; количество
записей в таблице.
. Упорядоченные таблицы
При большом количестве записей в таблице (N>>1) затраты на
выполнение полного просмотра становятся значительными. Эффективность процедуры
поиска можно повысить при размещении записей в таблице в порядке возрастания
(или убывания) ключей (упорядоченная, или сортированная таблица). Для поиска
нужной записи в таких таблицах может быть использован быстрый метод бинарного
(двоичного) поиска. Вместе с тем, в упорядоченных таблицах усложняется
реализация операций вставки и удаления записей, при выполнении которых для
сохранения упорядоченности становится необходимой перепаковка записей таблицы.
Среднее количество просматриваемых записей таблицы при использовании
бинарного поиска определяется как
= log2N. (2)
. Таблицы с вычисляемыми адресами
Иной возможный способ построения таблиц при большом количестве записей
состоит в предварительном (перед непосредственным поиском по таблице)
вычислении возможного месторасположения искомой записи. Данный метод
предполагает наличие некоторой простой функции h(key), которая отображает
множество имен на множество номеров строк таблицы. Эта функция называется
функцией хеширования или расстановки; таблицы, получаемые при таком способе
построения, называются таблицами с вычисляемыми адресами или перемешиваемыми
таблицами.
Функции расстановки могут быть построены разными способами. Например,
можно в качестве номера строки, в которой хранится или будет храниться при
вставке некоторый ключ, взять код первого символа имени, либо сумму всех кодов
символов ключа по модулю числа M, где M - длина таблицы (размер массива,
отведенного для ее хранения).
При использовании таблиц с вычисляемыми адресами может возникнуть ряд
дополнительных проблем. Так, например, при вставке новой записи функция
расстановки может выдать номер занятой строки массива (функция расстановки
может определять одни и те же значения для нескольких разных ключей). Такая
ситуация при вставке записи называется относительным переполнением таблицы или
коллизией. При возникновении коллизий возможны разные методы их разрешения:
· метод открытого перемешивания состоит в добавлении к вычисленному
занятому номеру некоторого фиксированного смещения (повторное перемешивание)
' = (k + p) mod N ; (3)
если новый адрес k'также является занятым, следует повторить процедуру
повторного перемешивания до тех пор, пока не обнаружится свободная строка, либо
таблица не будет исчерпана (если значения p и N являются взаимно-простыми,
открытое перемешивание обеспечивает нахождение свободной строки массива);
· метод цепочек при возникновении коллизий формирует линейные списки
(цепочки), в каждом из которых располагаются записи с одинаковым значением
функции расстановки (в этом случае в строках массива для размещения записей
следует добавить еще одно поле для ссылки на следующее звено списка).
Среднее количество просматриваемых записей при поиске записи в
перемешиваемых таблицах при предположении равной вероятности использования
ключей и при использовании функции расстановки с равномерным рассеиванием
ключей по строкам массива определяется следующим соотношением (разрешение коллизий
по методу открытого перемешивания)
= (1-? /2)/(1-? ) (4)
где
? - коэффициент заполненности таблицы (? = N/M); количество строк в
массиве для хранения записей; количество записей в таблице.
Следует отметить, что количество сравнений при поиске в перемешиваемых
таблицах согласно (4) зависит не от количества записей в таблице, а от
заполненности памяти, отведенной для размещения записей. Для примера, при
заполненности массива на 75% (? = 0.75) количество сравнений равно 2.5. Общая
схема системы поддержки таблиц
Хеширование
данных
Предположим, что нужно сохранить несколько записей, которые имеют
уникальные ключи со значениями от 1 до 100. Можно создать массив записей со 100
элементами и установить ключи каждой записи в 0. Чтобы добавить новую запись,
просто копируются ее данные в соответствующую позицию. Для вставки записи с
ключевым значением 37 следует скопировать запись в 37-ю позицию массива. Чтобы
найти запись с конкретным значением ключа, программа исследует соответствующую
запись массива. Для удаления записи нужно просто установить ее ключевое
значение в 0. Используя такую схему, вы можете добавлять, находить и удалять
элементы массива всего за один шаг.
К сожалению, в реальных приложениях ключевые значения не всегда
располагаются в диапазонах от 1 до 100. Возможные ключевые значения обычно
охватывают очень широкий диапазон. В качестве ключа база данных, содержащая
записи о сотрудниках, может использовать номер социального страхования.
Существует 1 млрд возможных комбинаций девятизначных чисел подобно номеру
социального страхования. Теоретически можно создать массив с одной записью для
каждого возможного девятизначного номера, но на практике для этого не хватит
памяти и дискового пространства. При том, что каждая запись занимает 1 Кбайт
памяти, для массива потребовалось бы 1 Тбайт (1 млн мегабайт) памяти. Даже если
бы компьютер и выделил такой объем памяти, эта схема оказалась бы очень
неэкономной.
Если в штате компании меньше 10 млн служащих, массив на 99% всегда будет
пуст.
Для решения подобных задач схемы хеширования отображают потенциально
большое количество возможных ключей в относительно компактной хеш-таблице. Если
в вашей компании работает 700 рабочих, вы можете объявить хеш-таблицу с 1000
записями.
Схема хеширования устанавливает соответствие между 700 записями о
служащих и 1000 позициями таблицы. Хеш-функция может заносить записи в ячейки
таблицы rfo первым трем цифрам номера социального страхования. Запись о
сотруднике с номером социального страхования 123-45-6789 будет находиться в позиции
123.
Конечно, если возможных ключевых значений больше, чем ячеек таблицы,
некоторые ключевые значения должны отобразиться в одну и ту же позицию в
хеш-таблице. Например, значения 123-45-6789 и 123-99-9999 отображаются в
таблице в позицию 123. Если есть 1 млрд возможных номеров социального
страхования, а в таблице всего 1000 позиций, в среднем каждую позицию будет
занимать 1 млн записей.
Во избежание подобной проблемы схема хеширования должна включать алгоритм
разрешения конфликтов (collision resolution policy), определяющий порядок
действий, если ключ отображается на занятую другой записью позицию.
Данные методы используют сходные способы разрешения конфликтных ситуаций.
Сначала ключ записи отображается на позицию хеш-таблицы. Если позиция уже
занята, то ключ заносится в новую позицию. Эта операция повторяется многократно
до тех пор, пока алгоритм, наконец, не найдет пустую позицию в таблице.
Последовательность действий при нахождении или добавлении элемента в
хеш-таблицу называется последовательностью проверки (probe sequence).
Для реализации хеширования необходимы три вещи:
· структура данных, называемая хеш-таблицей, для хранения данных;
· хеш-функция для отображения ключевых значений на ячейки
таблицы;
· алгоритм разрешения конфликтных ситуаций, который определяет
порядок действий в ситуации, если ключи отображаются на одну и ту же позицию.
ПРАКТИЧЕСКАЯ
ЧАСТЬ
Связывание
Один из методов разрешения конфликтов состоит в том, чтобы сохранять
записи, отображаемые на одну позицию таблицы, в связанных списках. Для вставки
новой записи с помощью хеш-функции выбирается связанный список, в котором будет
находиться эта запись. Затем запись добавляется в этот список.
На рис. 1 показан пример связывания хеш-таблицы, которая содержит 10
ячеек. Хеш-функция отображает ключ К на позицию массива К mod 10. Каждая
позиция массива содержит указатель на первый элемент связанного списка. Чтобы
вставить элемент в таблицу, вы добавляете его в соответствующий список.
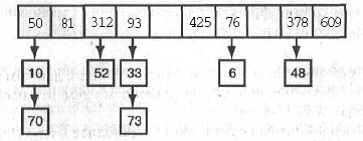
Рисунок 1- Связывание
Чтобы создать хеш-таблицу в Delphi, нужно объявить массив ячеек,
начинающийся с нуля. Этот массив и будет являться списком меток. Если
хеш-таблица будет содержать NumChains списков, объявите массив с границами от 0
до Num-Chains - 1. Установите каждое значение NextCell ячеек в nil.
Чтобы найти в хеш-таблице элемент с ключом К, необходимо вычислить К mod
NumChains. Таким образом вы получите индекс метки связанного списка, в котором
может содержаться элемент. Затем нужно просматривать список, пока не найдется
искомый элемент или не будет достигнут конец списка.
: PChainCell;
begin
// Определение цепи, содержащей значение.
cell := ListTci^ [value mod NumChains].NextCell;
while (cellonil) do
if (се!1Л.value = value) then break;:=
cellA.NextCell;;(cellonil) then
begin
// Какие-либо действия с ячейкой.
end;
Чтобы вставить в таблицу элемент с ключом К, сначала вычислим К mod
Num-Chains, определив таким образом, какой список должен содержать данное
значение. Затем, добавим элемент.
Insertltem(value : TTableData);, new_cell : PChainCell;
begin
.// Определение цепи, содержащей значение.
cell := OListTops"[value mod NumChains];
// Вставка элемента в начало цепи.
New(new_cell);
.Value := value;_cell*.NextCell := се!1л.NextCell,•
се!1л.NextCell := new_cell;
end;
Хеш-таблицы обычно содержат только одну запись с данным ключом. В этом
случае процедуре InsertIteih перед добавлением элемента необходимо проверить,
нет ли такого элемента в таблице.
Чтобы удалить элемент из хеш-таблицы, вычислите К mod NumChains,
определив содержащий его список. Затем элемент удаляется из списка.
Removeltem(value : TTableData);, nxt_cell : PChainCell;
begin
// Определение цепи, содержащей значение.
cell := @ListTops/4 [value mod NumChains];_cell := се!1Л.NextCell;
// Поиск элемента.
while (nxt_cellonil) do
if (nxt_cel!A.Value = value) then break;:=
nxt_cell;_cell := се!1л.NextCell;;(nxt_cellonil) then
// Ячейка найдена. Удаляем ее.
Се11л.NextCell :=
nxt_cellA.NextCell;(nxt_cell); ,;
end;
Удалить элемент из связанной таблицы также очень просто. Для этого
достаточно удалить ячейку элемента из соответствующего связанного списка, в то
время как в некоторых схемах хеширования удалить элемент трудно или даже
невозможно.
Один из недостатков связывания в том, что если число связанных списков
относительно невелико, то размер списков может стать огромным. Чтобы добавить
или найти элемент, придется исследовать большое число элементов списка. Если хеш-таблица
содержит 10 связанных списков и вы добавляете к таблице 10 000 элементов,
средняя длина связанного списка составит 1000. Всякий раз, когда вам нужно
будет найти элемент в таблице, потребуется исследовать 1000 или более ячеек.
Можно ускорить процесс поиска, отсортировав связанные списки. Это
позволяет прекратить поиск, если программа находит элемент со значением больше
искомого. В среднем потребуется проверить только половину списка, чтобы найти
элемент или определить, что его нет в списке.
cell : PChainCell;
begin
// Определение цепи, содержащей значение.
cell := ListTops* [value mod NumChains].NextCell;
// Поиск элемента.
while (cellonil) do(се11Л.Value >= value) then
break;:= се!1Л.NextCell;;(cellonil) then
if (cell.Value = value) then
begin
// Какие-либо действия с ячейкой.
,
end;;
Использование упорядоченных списков ускоряет поиск, но не устраняет саму
проблему переполнения таблиц. Лучшим решением будет создание хеш-таблицы
большего размера и повторное хеширование элементов в новой таблице так, чтобы
связанные списки в ней имели меньший размер. Но эта операция может занять много
времени, особенно в том случае, если списки сохранены на жестком диске или
каком-либо другом медленном устройстве, а не в оперативной памяти.
Бинарный
(двоичный) поиск
Пусть имеется N записей в виде линейного массива,
упорядоченных по ключам так, что k1 < k2 <...<
kN (ki =a[i].key). В дальнейшем будем вместо a[i].key
использовать обозначения ki и вместо x
- key.
Определить запись, имеющую ключ key, можно при помощи последовательного
поиска, но если учесть специфику массива, то поиск можно существенно сократить.
Для этого обратимся к середине массива и определим ключ ki. Если
ki = key, то нужная запись найдена. Если ki>key,
то key должен находиться в части массива, предшествующей ki,и
если ki < key, то во второй части. Теперь для
поиска нужного элемента достаточно рассматривать половину массива с ключами k1
,...., ki или ki ,...., kN.
Повторяя эту процедуру, после каждого неудачного сравнения key с
ki будем исключать приблизительно половину
непросмотренной части. Это и представляет суть двоичного (бинарного)
поиска, алгоритм которого можно записать следующим образом:
Algorithm BSEARCH [Бинарный поиск.]
Шаг B0. [ Инициализация. ] First:=1; Last:=N;
{ First, Last - указатели первого и последнего ключей. }
Шаг B1. [ Основной цикл. ] While Last³First do
Шаг B2. [Определение центрального ключа.]i:=(Fist+Last) div 2;
Шаг B3. [Проверка.]if key=ki then Stop;
Шаг B4. [Сравнение.]if key<ki then Last:=i-1 else
First:=i+1;
ШагB5. [Конец. ] End do (B1)
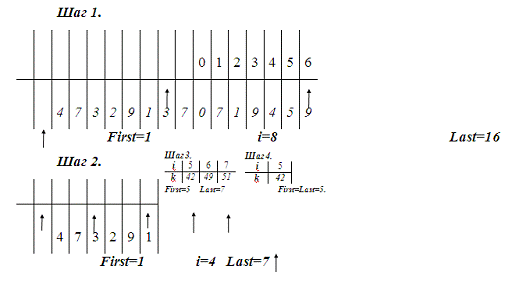
Блок схема алгоритма бинарного поиска приведена на рисунке 2.

На рисунке 3 приведен пример определения key=42.
Crt; {Реализация алгоритма бинарного поиска.}
Constn=1000; key=100;Arr=Array[1..n] of Integer;a:
Arr; key, i, n: Integer;BSEARCH(n,key: Integer; a: Arr; Var i: Integer); F, L:
Integer;Label LL;F:=1; L:=n;(L>=F) doi:=(F+L) div 2; If key=a[i] then Goto
LL;key<a[i] then L:=i-1 else F:=i+1;:END;{BSEARCH}ClrScr; {Начало.}i:=1 to n do a[i]:=i; {Ввод данных.}(n,key,a,i);{Сортировка.}(' Число элементов=',n:5,' Key=',key:4); {Вывод.}(‘a(i)=',a[i]:4;’ i=‘,i:4);
END.

Метод бинарного поиска можно применять для того, чтобы представить
упорядоченный массив в виде двоичного дерева. Значение ключа k(8)=53 является
корнем дерева. Интервалы ключей (1-7) и (9-16) помещаются
в память. Затем на втором шаге в первой и второй половинах определяются средние
элементы. Средние же элементы определяются в каждой четверти и т.д. Для данного
массива получим следующее бинарное дерево поиска (см. рисунок 4).
Пусть N=2k-1 -число записей в массиве
и двоичное дерево массива является полным, т.е. у каждой вершины есть как
левый, так и правый преемники. Дерево имеет высоту k-1, а число
вершин на уровне i равно 2 i (i=0,...,k-1).
Рассмотрим наихудший вариант работы алгоритма BSEARCH. Число
сравнений M, необходимых для отыскания заданного ключа, max(M)=k
{(k-1)- уровень вершины и k = log2 (N+1) Ü N=2 k -1}.
Пусть все записи равновероятны и NCOMP (i) -1 уровень
ключа k i в двоичном дереве. Тогда NCOMP (i)
- есть число сравнений, необходимых для отыскания k i.
Среднее число сравнений теперь определяется при помощи выражения:
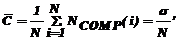 где
где 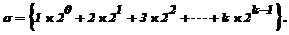
Рассмотрим
величину Sk - сумму членов геометрической прогрессии
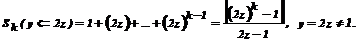
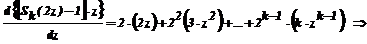
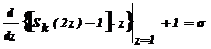 или
или 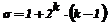 и
и
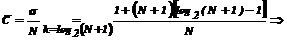
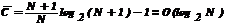
Интерфейс
программы
Программа состоит из двух частей или форм.
Первая часть - программа Chain формирует связанную хеш-таблицу. Введите
число создаваемых списков в поле Table Creation (Создание таблицы).
Отметьте опцию Sort Lists (Упорядоченные списки), если хотите, чтобы
программа использовала сортированные списки. Затем щелкните по кнопке Create
Table (Создать таблицу), и программа сформирует хеш-таблицу. Можно вводить
другие значения и неоднократно использовать кнопку Create Table, чтобы
создавать новые хеш-таблицы.
Хеш-таблицы, содержащие большое количество элементов, наиболее интересны,
поэтому программа Chain позволяет заполнять таблицу случайными элементами.
Введите число элементов и максимальное значение элементов в области Random
Items (Случайные элементы). Затем щелкните по кнопке Create Items (Создать
элементы), и программа добавит случайные элементы в хеш-таблицу.
И наконец, введите значение в поле Search Area (Поле поиска). При
щелчке по кнопке Add (Добавить) программа вставляет элемент в
хеш-таблицу, если такого элемента в таблице нет. Если вы нажимаете кнопку Find
(Найти), программа выполняет поиск элемента в таблице. При нажатии кнопки Remove
(Удалить) программа удаляет элемент.
После окончания операций вставки, поиска или удаления программа
отображает сводку о выполнении работы в нижней части формы, где сообщается,
успешно ли прошла операция, а также показывает число исследованных во время ее
выполнения элементов.
В данной строке также указывается текущая средняя длина успешной (если
элемент есть в таблице) и неудачной (если элемента в таблице нет) последовательностей
зондирования. Программа вычисляет это среднее значение, выполняя поиск для всех
чисел между единицей и наибольшим числом в хеш-таблице и подсчитывая затем
среднюю длину последовательности зондирования.
На рисунке 5 показано окно программы Chain после успешного поиска
элемента 777.

Рисунок 5 - Окно программы с методом доступа Хеширование данных.
Вторая часть программы реализует бинарное дерево с поиском и удаление
данных из него.
С помощью программы можно заполнить таблицу случайными числами. Затем
ввести в нижнее поле числовой элемент и добавить его в таблицу, либо удалить
его из таблицы с помощью кнопок с соответствующими названиями.
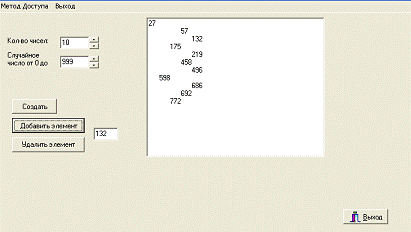
Рисунок 6 - Окно программы с реализацией бинарного дерева.
ЗАКЛЮЧЕНИЕ
Хеширование является самым быстродействующим из известных методов
программного поиска. Это его качество особенно проявляется при работе с
наборами данных большого размера. Адреса, получаемые из ключевых слов методом
хеширования, называются хеш-адресами. Таким образом, идея хеширования
заключается в том. чтобы взять некоторые характеристики ключа и использовать
полученную частичную информацию в качестве основы поиска.
ЛИТЕРАТУРА
1. Кнут Д. Искусство программирования. - М., 1977.
2. Налимов А.В. Основы алгоритмизации. - Барнаул, 2000.
. Род Стивенс Delphi готовые алгоритмы. - М., 2004.
. Фаронов В.В. Delphi программирование на языке высокого уровня. - М.,
2003.