Распознавание мелодии с помощью нечеткого поиска
Курсовая работа
на тему:
"Распознавание мелодии с помощью нечеткого поиска"
Введение
Моя курсовая работа
посвящена исследованию проблемы сравнения звуковых файлов и определения степени
их схожести. Существует множество форматов для хранения аудиофайлов:
· Midi.
· mp3.
· ogg.
· wav и т.д.
Заметим, что
музыкальные произведения различаются жанрами, исполнителями и другими
характеристиками.
Задача сравнения
звука на данный момент является достаточно сложной и интересной, ее решение
может найти применение во многих областях, например, его можно использовать при
поиске определенных данных о мелодии, если мы знаем только то, как она звучит.
С развитием технологий задача сравнения файлов, в том числе и звуковых,
становится проще, в настоящее время имеются программные продукты, которые
позволяют осуществлять сравнение звуковых файлов (например, Audio Comparer позволяет сравнивать
форматы MP3, MP2, MP1, WMA, AIF, WAV, OGG), но не существует свободно
распространяемых приложений или сервисов свободного доступа, которые бы
позволяли получить информацию о степени схожести двух мелодий.
Несмотря на то, что
наиболее распространенным музыкальным форматом является mp3, особое внимание и
интерес хотелось бы уделить звуковым файлам в MIDI-формате. Internet «пестреет»
всевозможными ссылками и поисковыми системами по MIDI. Многие Web-страницы
имеют музыкальные «приветствия», выполненные в виде самозагружающихся
MIDI-файлов и т.д. Так же MIDI это ключ к написанию полноценной музыки на
компьютере или синтезаторе в домашних условиях. Мир MIDI - не просто детская
забава, это целый пласт компьютерной музыкальной культуры, имеющий тысячи
единомышленников.
Данный формат имеет
ряд плюсов:
· занимает
малое количество памяти на диске (хотя объемы жестких дисков становятся все
больше, но и количество хранимой информации все возрастает)
· структура
(она содержит в себе особым образом закодированную информацию о сыгранных
нотах)
· нет
зависимости от тембра (колористическая (обертоновая) окраска звука), то есть не
важно, на каком инструменте сыграна мелодия, на размер файла это никак не
повлияет
· большинство
программ звукозаписи сохраняют мелодию именно в этом формате.
В отличие от других
форматов это не оцифрованный звук, а наборы команд (проигрываемые ноты, ссылки
на проигрываемые инструменты, значения изменяемых параметров звука), которые
могут воспроизводиться по-разному в зависимости от устройства воспроизведения,
поэтому шумов и прочих помех, так например, белого шума в MP3 мелодиях здесь априори
быть не может. MIDI-файлы представляют произведения в символьном виде.
Удобство формата
MIDI как формата представления данных позволяет реализовывать устройства,
производящие автоматическую аранжировку по заданным аккордам, а также
приложения 3D-визуализации звука. Кроме того, такие файлы, как правило, имеют
на несколько порядков меньший размер, чем оцифрованный звук сравнимого
качества.
Реализация
сравнения файлов даёт возможность сообщить информацию об известном файле при их
совпадении, поиска похожих среди имеющихся файлов.
Для сравнения
файлов используется метод нечеткого поиска, основанный на метрике (расстоянии)
Левенштейна.
Расстояние
Левенштейна и его обобщения активно применяется:
· для
исправления ошибок в слове (в поисковых системах, базах данных, при вводе
текста, при автоматическом распознавании отсканированного текста или речи)
· для
сравнения текстовых файлов специализированными утилитами. В данном случае роль
«символов» играют строки, а роль «строк» файлы из которых происходит построчное
считывание.
· в
биоинформатике для сравнения генов, хромосом, белков.
В связи со
структурой данных MIDI-файла и использования метода нечеткого поиска, основанного на
расстоянии Левенштейна, задача сравнения рассматривается с совершенно иной
стороны, чем для цифровых форматов, это показывает новизну рассматриваемого
вопроса, с этим связана его актуальность.
Цель работы
заключается в подведении теоретической базы для распознавания и сравнения MIDI-файлов и
непосредственно реализация алгоритмов считывания из файлов .mid необходимых данных,
реализации алгоритма нечеткого поиска с использованием расстояния Левенштейна.
Происходит считывание данных из файлов в матричное представление, проведение на
основе полученной информации анализа, вычисление расстояния между двумя
мелодиями, анализ результата сравнения и предоставление решения об их схожести
(совпадении).
В работе
рассматривается:
· считывание
данных о MIDI-файле
· анализ
считываемой информации
· представление
данных в удобной для сравнения форме
· механизм
сравнения двух звуковых файлов.
Для реализации
необходимых процедур используются программные средства, созданные с помощью
платформы. Net, а именно, Microsoft Visual Studio 2010, язык разработки C#.
Из самых очевидных
плюсов C# можно выделить:
- Высокая
скорость разработки (благодаря Фреймворку)
- Неплохое
быстродействие, для подобных языков (например, в отличие от той же Java он
пред-компилируемый, а не полностью интерпретируемый)
- Одно
из основных применений - приложения не критичные к производительности.# больше
подходит для прикладного программирования под платформу Windows.
Как модель
программирования, С#/.NET предусматривает универсальный средний уровень,
который уже потом переводит прямо по ходу дела в микрокод конкретного
аппаратного обеспечения с нужными оптимизациями. В самом языке реализовано все
лучшее, что есть на нынешний момент в императивных языках.
мелодия сравнение
файл левенштейн
1.
Постановка задачи
Пусть в качестве
входных данных имеется два MIDI-файла. Необходимо реализовать сравнение данных файлов и выдачу, в
качестве выходного параметра, соответствующего результата пользователю. Для
достижения этой цели в первую очередь необходимо реализовать алгоритм
корректного считывания данных из файла, затем произвести сравнение данных из
двух MIDI-файлов и выдать результат сравнения.
Приложение должно
предусматривать дружественный и интуитивно понятный интерфейс.
Алгоритм работы
приложения должен включать следующие этапы:
. Выбор
сравниваемых файлов MIDI.
. Считывание
данных из MIDI-файла в удобное для сравнения представление (например, массив).
. Определение
похожести двух массивов MIDI-файлов и вычисление коэффициента похожести.
. На основе
значений коэффициента совершение вывода результата о совпадении данных файлов и
сообщении степени похожести.
. Выдача
результатов пользователю.
Сама задача в свою
очередь состоит только из считывания данных, представления в удобном для работы
виде, определения сходства, то есть сравнения, и вычисления числового
результата. Причем считывание данных из MIDI-файла и определение
похожести двух массивов данных из MIDI-файлов и вычисление коэффициента похожести в свою очередь
являются подзадачами.
Для решения первой
подзадачи необходимо изучить спецификацию MIDI-файлов, понять, как
устроен файл, в какой последовательности хранятся данные, а определение похожести
двух массивов и вычисление коэффициента похожести в свою очередь является
подзадачей, которую в общем виде можно сформулировать следующим образом:
«По заданному
«слову» найти в тексте или словаре размера n все «слова», совпадающие с
этим словом (или начинающиеся с этого слова) с учетом k возможных
различий».
В данной работе, с
учетом специфики, рассматривается только частный случай данной задачи:
«По заданному
«слову» определить совпадение со «словом» (или начинающиеся с этого слова) из
словаря с учетом k возможных различий».
Такая задача имеет
свое название «задача нечеткого поиска».
При решении
необходимо учесть, что длительность мелодий (длина «слов») может быть
различной, они могут проигрываться в разных тональностях.
Данные приложение
получает от пользователя посредством диалоговых окон, поэтому необходимо учесть
и пользовательские ошибки, и их корректную обработку приложением. Пользователь
может ввести неверные данные, в этом случае программа должна среагировать и
предоставить второй шанс.
2. Анализ
задачи
Для считывания
данных из MIDI-файла, например, в Matlab’е уже написана специальная библиотека (более подробно это
рассматривалось в предыдущей курсовой работе), но после считывания получаются
избыточные данные, которые в рамках поставленной задачи не представляют
ценности, кроме того, Matlab энерго- и ресурсозатратен. Поэтому надежнее написать собственную
реализацию, предварительно изучив формат MIDI.
Вначале рассмотрим
основные понятия и определения.
MIDI (англ. Musical Instrument Digital Interface - цифровой интерфейс музыкальных инструментов) - стандарт
цифровой звукозаписи на формат обмена данными между электронными музыкальными
инструментами.
Стандартный
MIDI файл (.mid) - в отличие от других
форматов это не оцифрованный звук, а наборы команд (проигрываемые ноты, ссылки
на проигрываемые инструменты, значения изменяемых параметров звука), которые
могут воспроизводиться по-разному в зависимости от устройства воспроизведения.
Удобство формата MIDI как формата представления данных позволяет реализовывать
устройства, производящие автоматическую аранжировку по заданным аккордам, а
также приложения 3D-визуализации звука. Кроме того, такие файлы, как правило,
имеют на несколько порядков меньший размер, чем оцифрованный звук сравнимого
качества. Данные MIDI-файла хранятся в символьном виде (в виде записей).
Запись - это по своей сути набор взаимосвязанных байтов. В одном
MIDI-файле могут сосуществовать несколько различных записей. Каждая запись
может иметь свой собственный размер, то есть количество байтов в различных
записях может быть различно. Данные, хранящиеся в одной записи, связаны друг с
другом определенным образом.
Тогда общий подход
к решению задачи сформируется следующим образом:
· Считывание
содержимого файлов для сравнения в соответствующие массивы байтов.
· Проведение
процесса сравнения (посредством алгоритма) и вывода результата
Обработка данных,
посредством сравнения полученных результатов.
Файл цифрового
звука хранит в себе запись звука, файл MIDI хранит в себе запись действий
музыканта. Стандартный MIDI файл (SMF и Standard MIDI FIle) - это специально
разработанный формат файлов, предназначенный для хранения данных, записываемых
и / или исполняемых секвенсором, секвенсор может быть как программой для
компьютера, так и аппаратно выполненным модулем. В этом формате хранятся
стандартные MIDI сообщения (т.е. статус-байты и соответствующие им байты
данных), а также временные метки или маркеры для каждого сообщения (т.е.
последовательности байтов, указывающие, какое количество условных единиц
времени (импульсов, тиков) необходимо подождать перед тем, как исполнить
следующее событие MIDI). Этот формат позволяет сохранять информацию о темпе,
временном разрешении, выраженном в количестве тиков на одну четвертную
длительность (или во временных единицах, приходящихся на одну секунду, в
формате SMPTE. Формат времени SMPTE - часы: минуты: секунды: кадры.), обозначения размера, информацию
о музыкальных ключах, а также хранить названия треков и паттернов. Формат
предусматривает возможность сохранения в одном файле нескольких паттернов и
треков таким образом, что программы-приложения могут выбирать из всего набора
хранимой информации ту, которая будет понятна данному приложению.
Данные всегда
хранятся в виде записей. В одном MIDI-файле могут сосуществовать несколько
различных записей. Каждая запись может иметь свой собственный размер, т.е.
количество байтов в различных записях может быть различно. Данные, хранящиеся в
одной записи, связаны друг с другом определенным образом. Каждая запись
начинается с указания ее идентификатора, который состоит из четырех букв, т.е.
из четырех ASCII байтов. Этот идентификатор указывает, какой тип записи
представлен в содержащихся в записи байтах данных. Последующие за
идентификатором четыре байта (каждый из которых состоит из 8 бит) образуют
32-битное значение, указывающее длину (или размер) данной записи. Все записи
должны начинаться с этих двух полей: идентификатора записи и размера записи.
Эти два поля, занимающие всего 8 байт, образуют заголовок записи.
Стандартные MIDI-файлы
подразделяются на три разновидности или формата: 0, 1 и 2.
Рассмотрим их
подробнее:
· Файл
формата 1 содержит отдельный трек для каждого MIDI-канала, что отражает
привычную структуру аранжировки в секвенсоре.
· Файл
формата 2 содержит в себе несколько независимых произведений (или законченных
паттернов), каждый паттерн состоит из одного трека, содержащего сообщения по
всем 16-ти каналам. Этот формат предполагалось использовать в тех секвенсорах,
которые могут работать с независимыми паттернами, исполняемыми несколькими
инструментами одновременно. Однако формат 2 был повсеместно проигнорирован и в
настоящее время рассматривается в спецификации как «не предназначенный для
секвенсоров».
Одним из главных
отличий формата 0 и 1 является способ размещения мета-событий. В формате 0
мета-события темпа и размера (так называемая карта темпа) перемешиваются с
другими MIDI-сообщениями. Кроме того, названия треков в этом формате не
сохраняются. В формате 1 первый трек в файле отводится исключительно под карту
темпа и другие мета-события, такие как Sequence/Track Name, Sequence Number,
Marker, SMPTE Offset (см. далее). В случае отсутствия в файле карты темпа, темп
принимается равным 120 BPM, а размер - 4/4.
Блок заголовка MThd
имеет идентификатор MThd и длину 6 байт (рис. 1). Фактически все MIDI файлы
начинаются с заголовка MThd, и именно этот факт является указанием на то, что
мы имеем дело со стандартным MIDI файлом. Данные заголовка представляют собой
три 16-битных слова. Первое слово (format) - формат SMF, может принимать одно
из трех значений - 0, 1 и 2. Второе слово (ntrks) - число блоков треков (то
есть самих треков) в файле. Для файла формата 0 оно будет всегда равно единице.
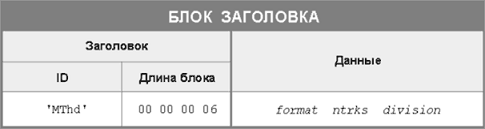
Рис. 1. Структура
блока MThd
Последнее слово
блока заголовка (division) задает способ измерения времени (timebase). Существуют два
способа: музыкальный (такты / доли) и абсолютный (time-code-based), основанный на
абсолютном времени. В любом случае дельта-время в файле измеряется тиками: при
музыкальном способе задается количество тиков, приходящихся на четверть (то
есть, PPQN (Pulse Per Quarter Note)), при абсолютном - количество тиков в одном SMPTE-кадре. Если старший
(15-й) бит поля division сброшен в ноль, то используется
музыкальный способ, а оставшиеся 15 бит содержат PPQN (до 32767)
Небольшое
отступление: на самом деле, внутри секвенсора никаких тиков нет. Есть
аппаратный таймер, который генерирует импульсы со строго постоянной частотой (например,
каждую микросекунду). Дельта-время - разница в тиках между данным событием и
предыдущим (либо началом песни). Подробнее о дельта-времени и его форме записи
будет описано далее.
За записью MThd
следует MTrk запись (рис. 2). Это единственный тип записи, отличающийся от MThd
записи, который определен для MIDI файлов в настоящее время. Если по какой-либо
причине в файле содержится идентификатор какой-либо записи другого типа, то,
вероятно, эта запись создана для какой-либо другой программы, и эта запись
должна быть проигнорирована в соответствии с указанной в ее заголовке длиной
данной записи.
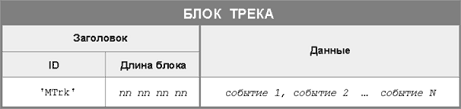
Рис. 2. Структура
блока MTrk
запись содержит в
себе MIDI данные и байты временных меток, а также необязательную информацию. Эти
данные относятся к одному треку. Очевидно, что количество MTrk записей в файле
должно совпадать со значением NumTraks, указанном в записи MThd. Заголовок
записи MTrk начинается с идентификатора записи, который представляет собой
четыре ASCII байта 'M', 'T', 'r', 'k', за которым следует значение длины
записи, т.е. число, равное количеству байтов в данной записи. Для различных
треков значения длин MTrk записей могут быть различны. (Например, трек,
содержащий партию скрипки из Концерта Баха, по всей видимости, будет содержать
больше данных, чем трек, содержащий басовую партию, в которой на один такт
приходится лишь две ноты.)
Трек в MIDI файле
аналогичен треку в MIDI секвенсоре. Трек секвенсора содержит последовательность
событий. Например, первым событием может быть взятие ноты «до» первой октавы.
Вторым событием может быть взятие ноты «ми» терцией выше. Эти два события могут
произойти в одно и то же время. Третьим событием может быть снятие ноты «до».
Это событие может произойти несколькими долями позже после первого события
(т.е. звук «до» будет снят спустя несколько долей после того, как он был взят).
В блоке трека
хранятся сами события, то есть MIDI-сообщения, снабженные меткой времени. В блоке должно
присутствовать хотя бы одно событие. Структура блока трека одинакова для MIDI-файлов любого формата
(0, 1, или 2).
Событие состоит из
дельта-времени и самого сообщения MIDI (рис. 3). Дельта-время хранится как величина переменной длины.

Рис. 3. Форма
записи MIDI-сообщения
Для каждого событие
указывается его время, именно в этот момент времени событие происходит, все
события организованы в пределах одной записи в памяти секвенсора в порядке их
появления во времени. В MIDI файле время события указывается перед байтами
данных, которые описывают само событие. Иными словами, временная метка события
предшествует описанию события. Например, если первое события происходит спустя
4 временных интервала (временной интервал устанавливается в MThd записи) после
начала воспроизведения, то соответствующее ему значение «дельта» и значение
промежутка времени v устанавливается равным 04. Если следующее событие
происходит одновременно с этим первым событием, то значение его времени дельта
равно 00.
Таким образом,
время дельта - это длительность, выраженная в элементарных временных
интервалах, между данным событием и ему предшествующим событием. Поскольку
предполагается, что все треки начинают воспроизводиться с момента времени
равного 0, то время дельта первого события становится равным 0. Однако
следующее событие может случиться и через полтора часа (то есть, через
несколько миллионов тиков). Как быть в этом случае? Ведь память нужно
экономить, а отводить под дельта-время фиксированное поле размеров в несколько
байт нежелательно. На помощь приходят так называемые величины переменной длины.
Они представляют удобный способ записи целых чисел - от самых малых до самых
больших, без необходимости отводить под число фиксированное количество байт.
Биты исходного числа упаковываются в один или более байтов: в каждый байт по
сеть бит (справа, биты с 0 по 6-ой). Старший бит в байте является служебным. В
зависимости от величины времени дельта, количество байтов может быть различным.
Для того чтобы отметить последний байт в последовательности этих байтов, необходимо
оставить 7-ой бит этого последнего байта чистым (старший бит равен 0).
Так, если время
дельта находится в пределах от 0 до 127, то оно может быть выражено одним
единственным байтом. Самое большое время дельта устанавливается в размере
0FFFFFFF (268 435 455 тиков, что при темпе в 500 ударов в минуту и разрешении
96 PPQN
составляет около четырех суток), для записи такого времени потребуется величина
переменной длины размером 4 байта. Время дельта соответствующая величина
переменной длины.
В форме величин
переменной длины указывается не только дельта-время, но и длина некоторых
событий.
Так могут выглядеть
величины переменной длины для разных значений времен дельта (время дельта
выражено в виде 32-битного значения):

Рис. 4. Примеры
чисел в различных формах записи
Первые байты (байт
1 или байты с 1 по 4) записи MTrk задают значение времени дельта для первого
события в формате величины переменной длины. Следующий за этой величиной байт
данных представляет собой первый байт события MIDI. Это байт носит название
байта статуса события или байта текущего MIDI статуса. Для MIDI событий он
представляет собой статус байт данного события. Первое событие в блоке трека
должно всегда начинаться со статус-байта. MIDI события представляют
собой обычные сообщения канала. Она могут быть сохранены (так же, как и при
передача) методом Running Status. Суть его проста - если передается серия сообщений с одним и тем
же статус-байтом, то достаточно передать только первый статус-байт, а остальные
опустить. Такой режим обеспечивает около 30% сжатия. Режим применяется только
при передаче голосовых сообщений и сообщений режима канала. Он очень хорошо
справляется с потоком сообщений непрерывных контроллеров, таких как колесо
модуляции и послекасание.
После статус байта
следуют один или два байта данных, в зависимости от типа события. После этих
байтов данных находится следующее значение времени дельта (в виде величины
переменной длины), и начинается процесс прочтения следующего события.
Особый случай
представляют собой сообщения SYSEX, имеющие статус байт, равный F0. События
SYSEX могут иметь любую длину. После статус байта F0 следует последовательность
значений переменной длины. Можем получить 32-битовое значение, которое равно
количеству следующих далее байтов, образующих SYSEX событие. Эта длина не
включает в себя статус байт (F0).
Конец трека - FF 2F
00. Это событие является обязательным. Оно обязано быть последним событием
каждой MTrk записи. Оно представляет собой явное обозначение конца MTrk записи.
Допускается использование единственного мета-события «Конец трека» для каждой
MTrk записи. Должно быть последним событием внутри блока трека. Точный момент
окончания трека необходим секвенсорам для возможности воспроизведения трека в
цикле или стыковки его с другим треком.
Темп FF 51 03 tt tt tt. Это
мета-событие указывает на изменения в темпе. Три байта данных tt tt tt
представляют собой величину темпа в терминах продолжительности одной четвертной
длительности в микросекундах. Иными словами, величина tt tt tt сообщает
секвенсору, что каждая четвертная длительность имеет продолжительность tt tt tt
микросекунд.
Например, если мы
указываем следующие 3 байта 07 A1 20, то каждая четверть должна составлять
0x07A120 (или 500000) микросекунд.
Таким образом, в
MIDI-файле темп указывается в терминах количества времени (т.е. количества
микросекунд), приходящегося на четвертную длительность.
Время PPQN. PPQN -
количество тиков, приходящихся на одну четвертную длительность, значение,
устанавливаемое для паттерна в MIDI-файле. Секвенсор, как правило, использует
внутренний счетчик времени, расположенный в аппаратной части оборудования, и на
основе получаемого от него времени вычисляет значение PPQN, которое
используется в качестве базовой единицы времени (один тик=v неделимая единица
времени в файле MIDI). Для определения длительности музыкального события удобно
использовать следующий формат времени: количество тактов: количество долей:
количество тиков.
Такое представление
оказывается гораздо более удобным и наглядным, чем указание количества
микросекунд, истекших от начала до конца фрагмента. К тому же это привычный для
музыкантов метод исчисления музыкального времени. Темп в терминах микросекунд
указывает количество микросекунд, приходящихся на одну четвертную длительность.
Из этого можно легко установить, что продолжительность одного тика будет равна
темпу, выраженному числом микросекунд в четвертной длительности, деленном на
величину PPQN. Так, если в MIDI-файле установлена величина PPQN в 96 единиц, то
это значит, что продолжительность одного тика при заданном темпе в 500000
микросекунд на четверть составит 500,000 / 96 (или 5,208.3) микросекунд. Иными
словами, между соседними MIDI-тиками должно вмещаться 5,208.3 микросекунд, если
установлен темп 120 BPM и значение количества тиков в одной четвертной PPQN =
96. При этом в каждой четвертной длительности будет укладываться 96 тиков, в
восьмой длительности - 48 тиков, в шестнадцатой - 24 тика и т.д. Отметим, что
для любого значения темпа может быть выбрано любое значение временного
разрешения, т.е. любое значение PPQN. Например, при темпе в 100 BPM можно
установить временное разрешение PPQN = 96 или PPQN = 192, или для временного
разрешения PPQN = 96 можно установить темп BPM = 100 или BPM = 120.
Временное
разрешение и темп - это две совершенно не зависимые друг от друга величины. Обе
эти величины необходимы, чтобы определить параметры вашего секвенсора или
внешней MIDI-аппаратуры.
MIDI-часы (MIDI Clock). Временные байты MIDI-часов используются при передаче
MIDI-сообщений для того, чтобы синхронизировать воспроизведение на двух
устройствах. Первое устройство генерирует импульсы MIDI-часов в соответствии со
своим темпом, а второе устройство подстраивается под них, синхронизируя
воспроизведение. MIDI-часы связаны с текущим музыкальным темпом пьесы.
Поскольку на каждую четвертную длительность приходится 24 импульса MIDI-часов,
то продолжительность одного промежутка времени MIDI-часов составит величину
равную темпу, выраженному в микросекундах, деленному на 24. Именно через такое
количество микросекунд посылается очередное сообщение MIDI-часов. В
вышеприведенном примере промежуток MIDI-часов составляет 500000/24, т.е.
20833.3 микросекунды. Легко посчитать, сколько приходится PPQN-тиков на один
интервал MIDI-часов.
Если установлена
величина PPQN = 96, то в одном промежутке MIDI-часов содержится 96/24 = 4 тика.
Временной отступ в
терминах: SMPTE - SMPTE Offset FF 54 05 hr mn se fr ff. Это мета-событие устанавливает время начала воспроизведения
данной MTrk-записи. Событие должно находиться в начале MTrk-записи. В файлах
формата 1 временной отступ должен храниться там же, где указание темпа, т.е. в
первой MTrk-записи. Здесь величина ff всегда обозначает количество сотых долей
кадра (фрейма).
Обозначение
размера: FF 58 04 nn dd cc bb. Обозначение размера представляется в виде набора четырех чисел.
Числа nn и dd представляют собой числитель и степень числа 2 знаменателя в
обозначении музыкального размера в том виде, в котором оно используется при
нотной записи. Знаменатель всегда представляет собой степень числа 2. Второй
степени соответствует четвертная длительность, третьей степени v восьмая. Число
bb выражает количество используемых 32-длительностей в четвертной ноте.
Обозначение
тональности: FF 59 02 sf mi. sf = -7, если используется 7 бемолей; -1, если
используется 1 бемоль, и т.д.; 0, если тональность до-мажор или ля-минор; 1,
если используется 1 диез; 2, если используется 2 диеза и т.д. mi = 0 и если
тональность мажорная, 1 и если тональность минорная.
В файлах формата 0
обозначения темпа и размера могут быть разбросаны по разным местам в пределах
одной MTrk-записи. В файлах формата 1 первая MTrk-запись должна состоять лишь
из событий темпа и размера. В файле формата 2 каждая MTrk-запись должна
начинаться с событий темпа и размера.
Замечание: Если в
миди-файле нет событий темпа и размера, то по умолчанию подразумевается
значение размера 4/4 и значение темпа 120 BPM.
Таким образом, мы
можем побайтно считать MIDI-файл, из его заголовка узнать всю необходимую информацию для
анализа (темп, такт, число тиков, приходящихся на один такт), считать музыку в
массив байтов и мы непосредственно перейдем к проблеме определения подобности
мелодий. Данная задача относится к задачам нечеткого поиска.
Алгоритмы нечеткого
поиска (также известного как поиск по сходству или fuzzy string
search) являются основой систем проверки орфографии и полноценных поисковых
систем вроде Google или Yandex. Например, такие алгоритмы используются для
функций наподобие «Возможно вы имели в виду…» в тех же поисковых системах.
Нечеткий поиск в большинстве своем используется для поиска строк в тексте,
подстроки в строке и т.д., но он подходит и для нашей задачи:
Для простоты
рассматривается сравнение двух мелодий, а не сравнение мелодии с набором
мелодий (то есть словарь из одного слова), то при сравнении без учета разбиения
на такты одна мелодия (наименьшая по количеству нот) будет словом. Размер слова
будет равен длине мелодии, а значением будет являться комбинация нот в мелодии.
При сравнении с
учетом разбиения на такты размер слова будет равен такту, а значением слова
будет являться кусочек мелодии из MIDI-файла. Словарем выступит мелодия, на сходство с которой и
определяется предоставленный образец.
Для простоты
изложения и понимания будем рассматривать нечеткий поиск применительно к
строкам.
Алгоритмы нечеткого
поиска характеризуются метрикой - функцией расстояния между двумя
словами, позволяющей оценить степень их сходства в данном контексте. Строгое
математическое определение метрики включает в себя необходимость соответствия
условию неравенства треугольника (X - множество слов, p - метрика):
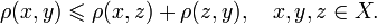
Между тем, в
большинстве случаев под метрикой подразумевается более общее понятие, не
требующее выполнения такого условия, это понятие можно также назвать расстоянием.
В числе наиболее
известных метрик - расстояния Хемминга, Левенштейна и Дамерау-Левенштейна.
Расстояние Хэмминга
- число позиций, в которых соответствующие символы двух слов одинаковой длины
различны. В более общем случае расстояние Хэмминга применяется для строк
одинаковой длины любых q-ичных алфавитов и служит метрикой различия
(функцией, определяющей расстояние в метрическом пространстве) объектов
одинаковой размерности.
Первоначально
метрика была сформулирована Ричардом Хэммингом во время его работы в Bell Labs для определения меры
различия между кодовыми комбинациями (двоичными векторами) в векторном
пространстве кодовых последовательностей, в этом случае расстоянием Хэмминга d
(x, y) между двумя двоичными последовательностями (векторами)
x и y длины n называется число позиций, в которых они
различны - в такой формулировке расстояние Хэмминга вошло в словарь алгоритмов
и структур данных национального института стандартов и технологий США (англ. NIST Dictionary of Algorithms and Data Structures). При этом
расстояние Хемминга является метрикой только на множестве слов одинаковой
длины, что сильно ограничивает область его применения. 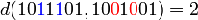
Впрочем, на
практике расстояние Хемминга оказывается практически бесполезным, уступая более
естественным с точки зрения человека метрикам. Одной из таких метрик является
расстояние Левенштейна (также редакционное расстояние или дистанция
редактирования). Расстояние Левенштейна - это минимальное количество операций
вставки одного символа, удаления одного символа и замены одного символа на
другой, необходимых для превращения одной строки в другую.
Впервые задачу
упомянул в 1965 году советский математик Владимир Иосифович Левенштейн при
изучении последовательностей 0 - 1. Впоследствии более общую задачу для
произвольного алфавита связали с его именем. Большой вклад в изучение вопроса
внёс Гасфилд.
Далее считается,
что элементы строк нумеруются с первого, как принято в математике, а не с
нулевого, как принято в языка программирования.
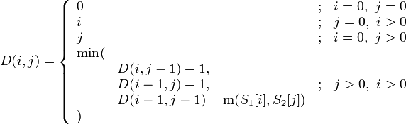
Шаг по i символизирует удаление из первой
строки, по j вставку в первую строку, а шаг по обоим индексам символизирует
замену символа или отсутствие изменений.
Весь процесс можно
представить следующей матрицей:
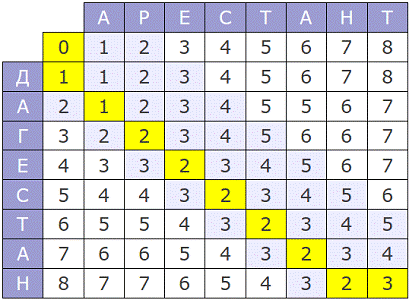
Рис. 5. Матрица
количества преобразований одного слова в другое
Как видно из
матрицы, из слова «арестант» получится слово «дагестан» всего за три операции
вставки, удаления, замещения.
Используя данные
метрики можно определить расстояние между частью мелодии предлагаемого образца
и частью мелодии из оригинала и на основе значения расстояния можно делать
вывод о степени похожести мелодий.
3.
Средства реализации
Для реализации
решения поставленной задачи выбрана. Net платформа, среда разработки Microsoft Visual Studio 2010 и язык C#.
Основные
особенности.NET:
· Общеязыковая
система типов
· Проверка
типов параметров
· Отсутствие
возможности прямого управления памятью
· Сборка
мусора
· Компонентная
технология
· Отсутствие
традиционных проблем с утечкой памяти
· Продвинутая
система безопасности
· Многообразие
языков программирования
· Богатая
библиотека готовых компонентов
· Поддержка
различных платформ (Compact Framework, Micro Framework)
Из самых очевидных
плюсов C# можно выделить:
· Высокая
скорость разработки (благодаря Фреймворку)
· Неплохое
быстродействие, для подобных языков (например, в отличие от той же Java он
предкомпилируемый, а не полностью интерпретируемый)
· Одно
из основных применений - приложения не критичные к производительности.# больше
подходит для прикладного программирования под платформу Windows. Он унаследовал
много полезных возможностей от других языков программирования и напрямую связан
с двумя наиболее широко применяемыми в мире компьютерными языками - С и С++. C# разработан для создания
переносимого кода. В среде Visual Studio и в языке C# реализованы:
· Динамическая
поддержка
· Поддержка
эквивалентности типов
· Ковариация
(позволяет использовать более производный тип, чем это указано в универсальном
параметре)
· Контрвариация
(позволяет использовать менее производный тип)
Благодаря
ковариации и контрвариации можно осуществлять неявное преобразование классов,
реализующих вариантные интерфейсы и обеспечивать большую гибкость при сопоставлении
сигнатур методов с типами вариантных делегатов.
Как модель
программирования С#/.NET предусматривает универсальный средний уровень, который
уже потом переводит прямо по ходу дела в микрокод конкретного железа с нужными
оптимизациями. В самом языке реализовано все лучшее, что есть в императивных
языках.
4.
Интерфейс пользователя
Рассмотрим
диаграмму вариантов использования (рис. 6), для того чтобы понять основные
функциональные особенности разрабатываемого приложения. На основании доступных
пользователю функций необходимо реализовать дружественный интерфейс.
Мы получаем, что
пользователь должен иметь возможность выбора мелодий для сравнения (кнопки
«Обзор»), вызова сравнения мелодий (кнопка «Выполнить сравнение»), а так же
возможность просмотра информации о программе (кнопка «О программе»).
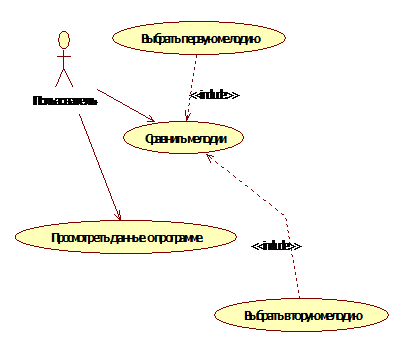
Рис. 6. Диаграмма
вариантов использования (UseCaseDiagram)
Выбор мелодий для
сравнения происходит на главном окне приложения, которое выглядит следующим
образом:
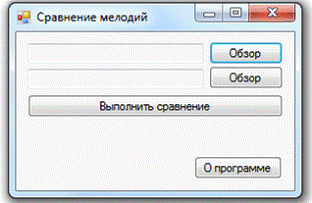
Рис. 7. Главное
окно приложения
Выбор мелодий для
сравнения производится с помощью диалогового окна, которое вызывается по
нажатию кнопки «Обзор». При выборе файла для сравнения происходит отображение
только папок для открытия и файлов, имеющих расширение *.mid. Данное ограничение
введено для контроля данных, вводимых пользователем. Оно достигается
фильтрацией отображаемых файлов по расширению.
Так же пользователю
не может самостоятельно ввести полный путь к файлу, это позволяет не делать
проверки типа выбранного файла, то есть гарантированно приложению будет передан
звуковой файл с расширением.mid.
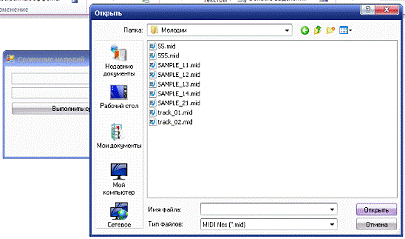
Рис. 8. Выбор файла
для сравнения
Для выполнения
сравнения мелодий необходимо выбрать соответствующее действие с помощью нажатия
на кнопку «Выполнить сравнение». При нажатии на кнопку происходит проверка на
ввод всех необходимых данных. Если хотя бы одна мелодия не была выбрана, то
будет выдано соответствующее сообщение пользователю.
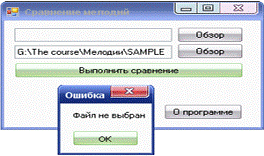
Рис. 9.
Некорректный ввод данных
В случае
корректного ввода выполняется сравнение входных файлов. Результат сравнения
отображается пользователю в окне сообщения.
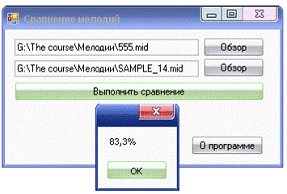
Рис. 10. Результат
работы программы
Информацию о
приложении пользователь может узнать из соответствующего сообщения, вызвав его
нажатием кнопки «О программе».
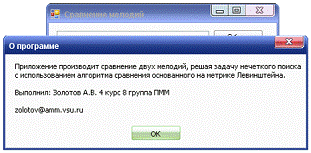
Рис. 11.
Отображение информации о приложении
5.
Реализация
Приложение написано
на объектно-ориентированном языке C#, что предполагает реализацию через классы. В приложение описано
три класса, далее мы рассмотрим их подробнее.

Рис. 12. Классы
приложения и их взаимосвязь
Класс-сущность,
который реализует хранение считанных данных, - это класс MIDI, так же он выполняет
считывание необходимых данных из указанного файла мелодии. В данном классе есть
две структуры:
· EventMidi - структура события
миди. Содержит данные дельта-времени, статус-байта, байты данных
· CompareData - структура, в которой
хранится нота - соответствующий номер такта
Класс так же
содержит поля и свойства, хранящие менее глобальные данные о мелодии:
· CompData - список нот с
соответствующим номером такта (List<CompareData>)
· _offsetMTrk - список номеров
позиций, с которых начинаются блоки MTrks (List<int>)
· _mTrks - список блоков MTrks, содержимое этих блоков
в виде массива байтов (List<byte[]>)
· Ppqn - количество тиков,
приходящихся на четверть - PPQN (Pulse Per Quarter Note) (int)
· MidiFormat - формат записи файла
миди (возможные значения 0, 1, 2) (int)
· TrackCount - количество блоков MTrk в файле (int)
· Nn - числитель размера
(значение по умолчанию 4)
· Dd - знаменатель размера
(значение по умолчанию 4)
· Tempo - темп мелодии
(значение по умолчанию 120ВРМ (beats per
minute)) (int)
· TickinShare - число тиков,
приходящихся на одну долю (int)
· TickinTakt - число тиков,
приходящихся на один такт (int)
Для считывания
данных из миди-файла в данном классе реализованы следующие методы:
· ReadMThd()
- осуществляет чтение блока MThd в миди файле, вычисляет значение Ppqn, TrackCount, MidiFormat, ничего не возвращает.
· FindOffsetMTrk() - вычисляет
позицию в миди-файле, с которой начинается очередной блок MTrk, данная информация
сохраняется в _offsetMTrk, ничего не возвращает
· CorrectReadMTrks() - анализирует
каждый блок MTrk и определяет сыгранные ноты и такт для нее, ничего не возвращает
· ReadMTrks (byte[] data) - определяет сыгранные
ноты и такт для нее, возвращает структуру CompareData, в которой хранится
список нот и номера тактов для соответствующей ноты
· Read() - производит
комплексный анализ файла, последовательно вызывая вышеописанные методы, ничего
не возвращает.
Класс, который
отвечает за отображение интерфейса пользователя - CompareMIDI. Содержит методы, в
которых описана реакция приложения на соответствующие действия пользователя, а
так же метод SelectFile(), в котором определяется выбранный для сравнения файл и
возвращается поток в файле, поддерживающий синхронные и асинхронные операции
чтения и записи.
И основной класс
приложение - управляющий класс Comparer, он отвечает за сравнение двух мелодий, которые переданы на вход
пользователем. В нем реализованы следующие методы:
· Compare() - производится
сравнение двух мелодий, определяется их процентное соответствие учитывая такт,
ничего не возвращает
· CompareMelody (MIDI. CompareData data1, MIDI. CompareData data2) - возвращает наименьше расстояние между двумя произведениями (int)
· InTaktCompare (IList<int> note1, IList<int> note2) - производится
сравнение двух наборов нот внутри такта с помощью метрики Левенштейна. (double)
· TaktCompare (MIDI. CompareData data1, MIDI. CompareData data2) - производится сравнение двух наборов нот, учитывая разбиение
по тактам. (double)
· GetValueOfStringTransform (String str1, String str2,
List<String> editorialRequirement) - вычисляет расстояние между
входными строками (int)
Рассмотрим алгоритм
работы приложения более подробно.
При нажатии «Обзор»
появляется диалоговое окно выбора файлов для сравнения. Основные действия
выполняются по нажатию кнопки «Выполнить сравнение».
Алгоритм сравнения
без учета тактов.
Для сравнения
мелодий без учета тактов, необходимо иметь список сыгранных нот (в алгоритме с
учетом такта, еще и номер такта, в котором играется нота). Так как ноты
уникальны, то им в соответствии ставится уникальный номер (от 0 до 127), а
каждому номеру можно поставить в соответствие символ из таблицы Unicode-8, то есть список
сыгранных нот - преобразовать в некую строку символов. Тогда алгоритм сравнения
без учета тактов будет выглядеть следующим образом. Берутся списки нот каждой
мелодии, осуществляется приведение к тональности одной из мелодий (линейный
сдвиг номеров нот на значение равное разности между начальными нотами мелодий,
с которых начинается сравнение, существенно, если мелодии имеют различное
количество сыгранных нот), числовые значения преобразовываются в строки, и вычисляется
расстояние Левенштейна. Если количество нот различно, n - количество нот в первой мелодии, m - количество нот во второй мелодии,
причем n>m, то количество значений расстояния Левенштейна будет равняться n-m+1 - количество возможных вариантов
сравнения. В этом случае будет выбираться минимум из расстояний Левенштейна.
Определяется процентное соотношение, вычисленное по формуле:
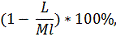
где L - минимум из возможных
расстояний Левенштейна, а Ml - наименьшее количество нот, выбранное из сравниваемых мелодий.
Алгоритм сравнения
с учетом тактов.
Для сравнения
мелодий с учетом тактов дополнительно потребуется знать, номер такта, в котором
сыграна конкретная нота. Берутся списки нот каждой мелодии, осуществляется
приведение к тональности одной из мелодий (линейный сдвиг номеров нот на
значение равное разности между начальными нотами мелодий, с которых начинается
сравнение, существенно, если мелодии имеют различное количество сыгранных нот).
Затем происходит разбиение списка нот на такты, и уже на основе каждого такта
осуществляется преобразование в отдельные строки (отдельный такт - отдельная
строка). Последовательно вычисляется расстояние Левенштейна между
соответствующими тактами, затем значения расстояния для каждого такта суммируются.
Возможных вариантов суммированного расстояния, так же как и при сравнении без
учета тактов равняется n-m+1. В этом случае выбирается минимум таких сумм. Определяется
процентное соотношение, вычисленное по формуле:
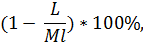
где L - минимум из возможных
расстояний Левенштейна, а Ml - наименьшее количество нот, выбранное из сравниваемых мелодий.
Пользователю
выдается наибольшее из процентных значений в виде отдельного сообщения. После
этого приложение готово осуществить сравнение следующих мелодий.
Физическое
размещение классов по файлам выглядит следующим образом:
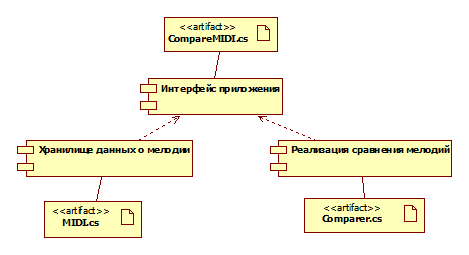
Рис. 13. Диаграмма
размещений (ImplementationDiagram)
6.
Тестирование
Сравнение мелодии и
ее части.
Рис. 14. Полное
совпадение
Сравнение коротких
мелодий с добавлением лишних нот.
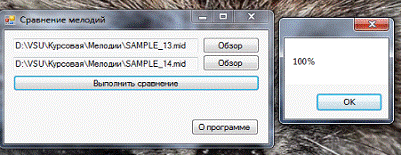
Рис. 15. Полное
совпадение
Сравнение длинных
мелодий с добавлением лишних нот.
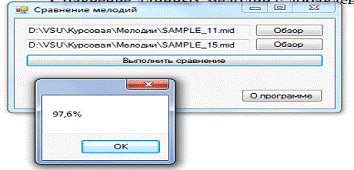
Рис. 16. Мелодии
похожи
Сравнение мелодий в
разной тональности.
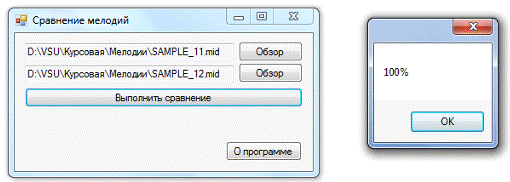
Рис. 17. Полное
совпадение
Сравнение различных
мелодий.
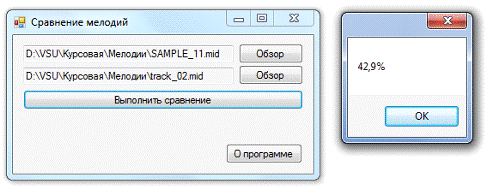
Рис. 18. Малый
процент совпадения
Заключение
В ходе работы была
подробно рассмотрена структура MIDI-файла. Были реализованы способы определения степени сходства
мелодий, путем разбиения всей мелодии на такты и сравнения с помощью
соответствующих метрик. На основе значения метрик делается вывод о степени
сходства двух мелодий.
Было изучено
применение расстояния Левенштейна в различных областях, предложена и реализована
идея использования данного расстояния для сравнения мелодий в формате MIDI. Отметим, что сравнение
мелодий проводилось двумя способами: с разбиением на такты и сравнение целых
мелодий. Было проведено тестирование приложения с различными входными данными и
изучено влияние отклонения нот от их истинного звучания на результаты
сравнения.
В тестах отражена
возможность сравнивать мелодии, сыгранные с ошибкой. Рассмотрены случаи
сравнения целой мелодии и ее отрывка (отрывок взят «чистый» и с ошибкой, количество
ошибок меняется).
Дальнейшей целью
исследования является разработка расширенного пользовательского сервиса,
который позволил бы осуществлять поиск по базе данных мелодии по ее фрагменту.
Также будет продолжено тестирование алгоритма, оптимизации выполнения.
Список
источников
1. Белобородов А.Ю. Система поиска
MIDI-файлов
по заданной мелодии / А.Ю. Белобородов // Тезисы докладов Международной
научно-практической конференции аспирантов и студентов «Инженерия программного
обеспечения 2009». - Киев: Национальный авиационный институт, 2009. - с. 38.
2. Грэхем Иан.
Объектно-ориентированные методы. Принципы и практика. 3-е издание. / Иан
Грэхем. - М.: Издательский дом «Вильямс», 2004. - 880 с.
. Юцевич Ю. Словарь
музыкальных терминов. / Ю. Юцевич. - Киев: Музычна Украина, 1988. - 262 с.
. Способин И.В. Элементарная
теория музыки. / И.В. Способин. - Москва: Музгиз, 1959. - 202 с.
. Золотов А.В. О
распознавании мелодии в формате MIDI при помощи методов нечеткого поиска / А.В. Золотов, М.К. Чернышов
// Материалы XII международной научно-методической конференции. «Информатика:
проблемы, методология, технология» (Воронеж, 9-10 февраля 2012 г.). - Воронеж:
Издательско-полиграфический центр Воронежского государственного университета,
2012. - с. 149-150.
. Нечеткий поиск в тексте и
словаре: [сайт]. - (URL: http://habrahabr.ru/post/114997/) (дата обращения: 12.10.2011).
. Расстояние Левенштейна:
[сайт]. - (URL: http://ru.wikipedia.org/wiki/%D0% A0% D0% B0% D1% 81% D1% 81%
D1% 82% D0% BE % D1% 8F % D0% BD % D0% B8% D0% B5_%D0% 9B % D0% B5% D0% B2% D0%
B5% D0% BD % D1% 88% D1% 82% D0% B5% D0% B9% D0% BD % D0% B0) (дата обращения
12.10.2011).
. Расстояние между строками:
миф или реальность?!: [сайт]. - (URL: http://coderlife.ru/progr/rasstoyanie-mezhdu-strokami-mif-ili-realnost.html)
(дата обращения: 20.02.2012).
. MIDI в деталях. Часть 1 -
Основы.: [сайт]. - (URL: http://www.muzoborudovanie.ru/articles/midi/midi1.php) (дата
обращения: 01.03.2011).
. MIDI в деталях. Часть 2 -
Сообщения канала.: [сайт]. - (URL: http://www.muzoborudovanie.ru/articles/midi/midi2.php) (дата
обращения: 01.03.2011).
. MIDI в деталях. Часть 3 -
Системные сообщения.: [сайт]. - (URL: http://www.muzoborudovanie.ru/articles/midi/midi3.php) (дата
обращения: 01.03.2011).
. MIDI в деталях. Часть 4 -
MIDI Time Code.: [сайт]. - (URL: http://www.muzoborudovanie.ru/articles/midi/midi4.php) (дата
обращения: 01.03.2011).
. MIDI в деталях. Часть 5 -
Стандартные MIDI-файлы.: [сайт]. - (URL: http://www.muzoborudovanie.ru/articles/midi/midi5.php) (дата
обращения: 01.03.2011).
. MIDI в деталях. Часть 6 -
Передача данных.: [сайт]. - (URL: http://www.muzoborudovanie.ru/articles/midi/midi6.php) (дата
обращения: 01.03.2011).
. MIDI в деталях. Часть 7.1 -
MIDI Show Control.: [сайт]. - (URL: http://www.muzoborudovanie.ru/articles/midi/midi71.php) (дата
обращения: 01.03.2011).
16. MIDI в деталях. Часть 7.2 - MIDI Show Control. Двухэтапное
подтверждение.: [сайт]. - (URL: http://www.muzoborudovanie.ru/articles/midi/midi72.php) (дата
обращения: 01.03.2011).