Разработка программного продукта, исключающего коллизию
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
ГЛАВА 1. ТЕОРЕТИЧЕСКИЙ РАЗДЕЛ
.1 Актуальность
.2 Общие основы
ГЛАВА 2. ПРОЕКТНЫЙ РАЗДЕЛ
.1 Принцип построения хеш -
функций
.2 Применение хеширования
ГЛАВА 3. ПРОГРАММНАЯ
РЕАЛИЗАЦИЯ
.1 Организация структуры
данных
.2 Реализация функций
структуры
ГЛАВА 4. ЭКСПЕРИМЕНТАЛЬНЫЙ
РАЗДЕЛ
.1 Руководство пользователя
ЗАКЛЮЧЕНИЕ
СПИСОК ЛИТЕРАТУРЫ
ВВЕДЕНИЕ
С хешированием мы сталкиваемся едва ли не на каждом шагу: при работе с
браузером (список Web-ссылок), текстовым редактором и переводчиком (словарь),
языками скриптов (Perl, Python, PHP и др.), компилятором (таблица
символов). По словам Брайана Кернигана, это «одно из величайших изобретений
информатики». Заглядывая в адресную книгу, энциклопедию, алфавитный указатель,
мы даже не задумываемся, что упорядочение по алфавиту является не чем иным, как
хешированием.
Хеширование есть разбиение множества ключей (однозначно характеризующих
элементы хранения и представленных, как правило, в виде текстовых строк или
чисел) на непересекающиеся подмножества (наборы элементов), обладающие
определенным свойством. Это свойство описывается функцией хеширования, или
хеш-функцией, и называется хеш-адресом. Решение обратной задачи возложено на
хеш-структуры (хеш-таблицы): по хеш-адресу они обеспечивают быстрый доступ к
нужному элементу. В идеале для задач поиска хеш-адрес должен быть уникальным,
чтобы за одно обращение получить доступ к элементу, характеризуемому заданным
ключом (идеальная хеш-функция). Однако, на практике идеал приходится заменять
компромиссом и исходить из того, что получающиеся наборы с одинаковым
хеш-адресом содержат более одного элемента.
Целью данной работы, является реализация метода и разработка программного
продукта, исключающего коллизию.
ГЛАВА 1.
ТЕОРЕТИЧЕСКИЙ РАЗДЕЛ
1.1 Актуальность
Мир захлестнула волна информации. Главное при работе с ней - быстрый
поиск с последующей выборкой. Информация хранится в базах данных, и базы данных
стоят сейчас почти на каждом компьютере. Обычно базы состоят из таблиц.
Рассмотрим типичную структуру таблицы в реляционной базе данных. Все поля,
входящие в таблицу, можно разбить на три группы: системные поля, поля
наименования, и поля данных.
Системные поля - это ключи. В них входят первичный ключ (счетчик) для
связи с подчиненными таблицами и вторичные ключи для связи с главными таблицами
(если данная таблица является подчиненной).
Поля данных - в них хранятся данные об объекте. Это поля типа числовые,
денежные, дата/время, и т.д.
При работе с таблицей одна из главных задач - выборка, причем в
большинстве случаев выборка осуществляется по параметру (то есть из таблицы
выбираются только те записи, которые соответствуют некоторому условию).
Существуют два подхода к выборке: сверху, со стороны пользователей, и снизу, со
стороны аппаратного обеспечения («железа»).
При подходе сверху главный определяющий фактор - удобство пользователя.
Существует много способов доступа к данным в таблицах, но наибольшее
распространение получил язык SQL. Фактически SQL фактически стал индустриальным
стандартом для реляционных баз данных. Американский Институт Национальных
Стандартов (ANSI) в 1986 году объявил язык SQL стандартом для реляционных баз
данных. То же самое сделала и Международная Организация по стандартам (ISO).
Все основные реляционные системы управления баз данных поддерживают в том или
ином виде язык SQL, и большинство разработчиков реляционных систем управления
базами данных стремятся следовать стандарту ANSI. Конструкторы SQL встроены в
настольные СУБД (ACCESS, Delphi), серверные приложения работают в основном с
SQL (ORACLE, SQL server).
В команде SQL указывается сама команда (действие, которое надо
совершить), область выборки (таблицы, из которых необходимо произвести
выборку), данные, которые должны быть выданы (список полей), условия связи
между таблицами и условия отбора, то есть по команде SQL фактически
осуществляется ассоциативная выборка из базы данных.
При подходе снизу главный определяющий фактор - архитектура компьютера. В
настоящее время компьютеры имеют адресную структуру памяти и приспособлены для
операций «мало данных - много команд», а при работе с данными (при выборке)
чаще всего происходят операции типа «много данных - мало команд» Произошедшее
за последнее время бурное развитие компьютерной техники не только не решило, а
скорее усугубило эту проблему. Производительность процессоров увеличилось во
много раз, увеличилась емкость винчестеров и размер оперативной памяти. Но при
этом производительность канала память - процессор увеличилась сравнительно
медленно, и является в данный момент камнем преткновения. Применение аппаратных
средств ускорения (кэширования) тоже не очень эффективно из-за больших объемов
данных.
Для того чтобы получить доступ к нужной записи в таблице необходимо либо
перебирать все записи (для этого потребуется N циклов, N - число записей в
таблице), либо найти адрес записи (так как память компьютера имеет адресную
архитектуру). Для ускорения поиска прилагаются большие усилия: применяют
сортировки (то есть записи упорядочивают в определенном порядке),
индексирование, и хеширование (адрес записи - некоторая функция от значения
аргумента записи). Рассмотрим подробнее все эти способы.
Сортировки. При дихотомическом поиске в упорядоченном массиве количество
циклов поиска - log2N, где N - число записей в таблице. Но
сортировки производят только по одному полю. После совершения любого действия
над записями (добавления, изменения, удаления) приходится производить
упорядочивание (пересортировку) таблицы, а число перестановок возрастает в
геометрической прогрессии при увеличении количества записей.
Индексирование. Индексы - это специальные конструкции, которые позволяют
быстро найти адрес нужной записи и в настоящее время они широко применяются на
практике. На одну таблицу можно создавать несколько индексов. В качестве
примера можно рассмотреть рекомендации по применению индексов в ORACLE. Они
сводятся к следующему: рекомендуется использовать индексы для обеспечения
уникальности записей; для ускорения выборки данных; задавать индексы для тех
полей, выборку по которым производится чаще всего, и при этом рекомендуется
задавать на таблицу не более трех индексов, что очень мало. На практике
применяют индексы следующим образом: в системных полях таблиц используют один
или два индекса, и еще один индекс - на поля наименования. Область данных почти
никогда не индексируют, хотя отбор чаще всего происходит именно по этим полям.
Кроме того, на обновление индексов также требует времени, а сами индексы
занимают место на диске (а иногда размер индексов превышает размер основной
таблицы).
Поэтому индексация таблиц не очень помогает: индексы занимают место (а
иногда могут превышать размеры таблиц), а в случае отбора по неиндексированному
полю они не помогают.
Хеширование. При хешировании записей под таблицу сразу выделяют с запасом
некоторый объем памяти, и адрес записи в этом объеме - некоторая функция от
содержимого одного из полей записи (хеш-функция). Хеширование также проводят по
одному полю. Недостатки этого способа: необходимость в избыточном
резервировании памяти. Кроме этого, даже при достаточно большом выделенном
объеме памяти возможна ситуация, при котором на некоторое место претендуют
сразу две или более записей, то есть возникает коллизия.
1.2 Общие
основы
Хеширование
- преобразование входного массива данных произвольной длины в выходную битовую
строку фиксированной длины. Такие преобразования также называются хеш-функциями
или функциями свёртки, а их результаты называют хешем
<#"552424.files/image001.gif">
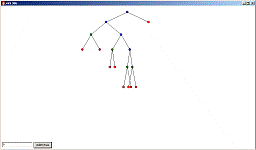
Программа представляет собой оконное приложение. В нижнем левом углу
располагается поле ввода и кнопка добавления введенных данных в дерево.
Основная область рабочего окна служит для прорисовки дерева.
При добавлении данных, на рабочей области отрисовывается построенное
дерево. Дерево может содержать до трех различных типов узлов, синие - не
содержащие данных, кроме указателей на потомков, зеленые - содержащие
пользовательские данные, и красные - NULL элементы.
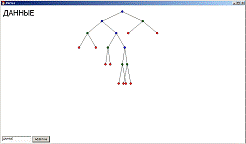
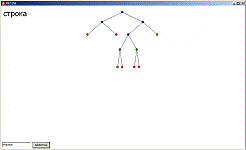
При непосредственном выборе узла с помощью мышки, происходит поиск и
вывод содержимого данного узла.
ЗАКЛЮЧЕНИЕ
Хеширование, которое родилось еще в середине прошлого века, активно
используется в наши дни везде, где требуется произвести быструю выборку данных.
Появились новые методы хеширования, новые модификации алгоритмов, написанных
ранее, что позволяет значительно ускорить и расширить возможности поиска
информации.
В своей работе я проанализировал современные подходы к организации
хранения и обработки данных, выявил преимущества использования hash - функций для достижения наилучшей
производительности поиска информации. Цель работы - создание программного
продукта, достигнута.
СПИСОК
ЛИТЕРАТУРЫ
1. Hellerman H., Digital Computer System Principles. McGraw-Hill, 1967.
3. Кнут Д., Искусство программирования,
т.3. М.: Вильямс, 2000.
4. Peterson W.W., Addressing for Random-Access Storage // IBM
Journal of Research and Development, 1957. V.1, N2. Р.130-146.
5. Morris R., Scatter Storage Techniques // Communications of
the ACM, 1968. V.11, N1. Р.38-44.
6. Buchholz W., IBM Systems J., 2 (1963), 86-111
7. Fundamenta Math. 46 (1958), 187-189
8. <http://www.ecst.csuchico.edu/~melody/courses/csci151_live/Dynamic_hash_notes.htm>
9. <http://planetmath.org/encyclopedia/Hashing.html>
10. <http://www.eptacom.net/pubblicazioni/pub_eng/mphash.html>
11. R. Cichelli, Minimal Perfect Hashing Made
Simple, Comm. ACM Vol. 23 No. 1, Jan. 1980.
12. T. Gunji, E. Goto, J. Information Proc., 3
(1980), 1-12
13. Чмора А., Современная прикладная криптография., М.:
Гелиос АРВ, 2001.
14. Litwin W., Proc. 6th International
Conf. on Very Large Databases (1980), 212-223
15. Кормен Т., Лейзерсон Ч., Ривест Р., Алгоритмы:
построение и анализ, М.: МЦНМО, 2001
16. Вирт Н., Алгоритмы + структуры данных = программы, М.:
Мир, 1985.
17. Керниган Б., Пайк Р., Практика программирования, СПб.:
Невский диалект, 2001.
18. Шень А, Программирование: теоремы и задачи. М.: МЦНМО,
1995.