Разработка и реализация методов потокового анализа распараллеливаемых программ в Преобразователе программ СБкЗ_ПП
Разработка и реализация методов
потокового анализа распараллеливаемых программ в Преобразователе программ
СБкЗ_ПП
Оглавление
Введение
. Обзор литературы по теме
«потоковый анализ программ в распараллеливающих и оптимизирующих компиляторах»
.1 Распараллеливающие
компиляторы
.2 Представление программ
.3 Задачи потокового анализа
.4 Методы потокового анализа
.5 Теоретические свойства
методов
.6 Опыт реального применения
распараллеливающего компилятора
.7 Средства реализации
распараллеливающего компилятора
.8 Компиляция с переменным
набором оптимизирующих преобразований
.9 .Выводы из обзора
. Описание предметной
области, решаемых задач и методов их решения
.1 Описание предметной
области
.1.1 Граф алгоритма
.1.2 Графы зависимостей и
минимальные графы
.1.3 Циклы ParDo и избыточные
вычисления
.1.4 Эквивалентные по
вычислениям преобразования программ
.2 Модель структурных
программ
.2.1 Термины объекта
оптимизации
.2.2 Описание терминов
потокового анализа МСП
.3 Постановка задач и методы
их решения
.3.1 Алгоритм добавления
атрибутов ParDo
.4 Представление методов
потокового анализа программ
.4.1 Абстрактный синтаксис
языка методов потокового анализа программ
.4.2 Операционная семантика
языка методов потокового анализа программ
.4.3 Расширение базы методов
потокового анализа программ
. Техническая часть
.1 Назначение программного
средства (ПС)
.2 Архитектурно-контекстная
диаграмма СБкЗ_ПП
.2.1 Подсистема потокового
анализа
.3 Архитектурно-контекстная
диаграмма ПС
.4 Требования к программному
средству
.4.1 Общие функциональные
требования
.4.2 Конкретные
функциональные требования
.4.3 Требования к
программному обеспечению
.4.4 Требования к надежности
.4.5 Профиль пользователя
.4.6 Жизненный цикл
программного средства
.4.7 Требования к интерфейсу
.5 Проектная документация
.5.1 Архитектура программного
средства
.5.2 Спецификации функций
.5.3 Описание реализации
программного средства
.5.4 Описание использования
программного средства
. Тестирование
.1 Тестовые ситуации
.2 Тесты
. Экспериментальное изучение
свойств программного средства
.1 Цель экспериментов
.2 Описание среды
.3 План экспериментов
Эксперимент №1
Эксперимент №2
Эксперимент №3
.4 Результаты экспериментов
. Доказательство того, что
цели, сформулированные в задании, достигнуты. Обсуждение результатов дипломной
работы
Заключение
Список литературы
Приложение 1. Каталог
реструктурирующих преобразований программ
Вариант 1
Вариант 2
Приложение 2. Таблица
соответствий понятий
Приложение 3. Синтаксис языка
методов потокового анализа (расширенная БНФ)
Введение
Идея параллельных архитектур и ее техническое воплощение появились
практически сразу после создания вычислительных машин фон-неймановской
архитектуры. В основе лежит разумная идея повышения эффективности
(производительности) за счет распределения нагрузки на вычислительные
компоненты. На начальном этапе развития компьютерной техники вычислительные
блоки были маломощными, поэтому идея была хорошо воспринята и получила широкое
распространение. Однако с появлением персональных компьютеров и их лавинообразным
распространением, а также ростом технологий, внимание стало уделяться
последовательным вычислительным архитектурам, а параллельные системы заняли
свою узкую нишу в суперкомпьютерах и мэйнфреймах.
Тем не менее, сегодня ситуация меняется. Прирост производительности
дается все с большим трудом, существующие массовые технологии производства
нуждаются в существенной переработке и изысканиях. Поэтому ведущие
производители пошли по интенсивному пути развития и объявили о возврате
параллельных архитектур. Уже выпускаются двухядерные процессоры для настольных
решений, однако тенденция прослеживается четко. В связи с этим существенно
возрастает роль средств разработки программного обеспечения для параллельных
архитектур и немаловажную роль играют распараллеливающие компиляторы.
Потребность в распараллеливающих компиляторах появилась практически сразу
с началом работы над параллельными архитектурами, поскольку появилась
необходимость в адаптации накопленного багажа последовательных алгоритмов к
параллельным архитектурам. Такая потребность существует сейчас и вполне
закономерно будет существовать и в будущем (человек принципиально эффективнее
генерирует последовательные алгоритмы).
Основной задачей распараллеливающего компилятора является выявление
скрытого (как правило) или явного (что редко) параллелизма. Такой анализ
проводится не по самому тексту программы, а по ее модели.
В мире предложено уже много различных схем для последовательных программ,
оптимизирующие преобразования описываются в терминах различных схем программ,
что затрудняет объединение преобразований в рамках одного транслятора. Поэтому
возникает проблема стандартизации системы понятий для описания схемы программы,
в терминах которой можно было бы описывать все возможные оптимизирующие
преобразования, направленные на улучшение параллельности.
Задача выявления параллелизма в большинстве случаев сводится к задаче
определения различных типов зависимости между участками программы и итерациями
циклов.
Основной проблемой в сфере науки о преобразованиях программ является
невозможность своевременно выполнять компьютерные эксперименты. Цель таких
экспериментов - определить, насколько часто в реальных программах применимы те
или иные преобразования и какой эффект дает их применение. Единственным
средством проведения подобных экспериментов являются оптимизирующие
компиляторы, например, GCC [14, 23], распространяемый бесплатно (по лицензии
GPL), а из коммерческих разработок - компиляторы Intel C++ и Fortran [10].
Однако период времени, который обычно проходит от момента публикации описания
нового преобразования до момента окончания реализации оптимизирующего
компилятора, содержащего в своем наборе данное преобразование, настолько велик,
что результаты компьютерных экспериментов с этим преобразованием оказываются
мало актуальными. Кроме того, оптимизирующий компилятор обычно содержит большой
набор преобразований и встроенную стратегию их применения. Поэтому получить
результаты компьютерных экспериментов, относящихся к отдельному преобразованию
(а не ко всему набору), весьма проблематично.
Результаты потокового анализа по выявлению параллелизма используются для
применения оптимизирующих преобразований из класса реструктурирующих. В общем
случае этот класс направлен на эквивалентное преобразование программы,
позволяющее впоследствии ее распараллелить. Наиболее часто в трансляторах
используются следующие преобразования: перестановка циклов, слияние циклов,
разбиение цикла, распределение циклов. Множество используемых на практике
преобразований постоянно расширяется. Этому процессу в немалой степени
способствует появление компьютеров новой архитектуры.
Несмотря на то, что проблема оптимизации программ для компьютеров с
параллельной архитектурой существует уже более 20 лет, ее решение до сих пор
нельзя считать удовлетворительным. Было предложено много различных подходов к
оптимизации, но ни один из них не предполагает комплексного решения всего
множества возникающих проблем. Более того, как показали недавние исследования
Иллинойского университета, большинство методов потокового анализа распознают
лишь 15% из всех пар зависимостей. На этом фоне успешной выглядит система V-Ray
[15], практическое экспериментальное исследование которой показало
превосходство (порой весьма значительное) над другими системами оптимизации.
Однако V-Ray является лишь инструментом для выявления параллелизма, а анализ
результатов, выбор и применение ОП и производятся вручную и неинтерактивно, как
и постановка экспериментов. Существуют интерактивные системы, как, например,
Acovea [18] для компилятора GCC, позволяющие в диалоговом режиме управлять
стратегией оптимизации, то есть выбирать оптимизирующие преобразования. Однако
расширение множества целевых языков или преобразований потребует серьезной
модификации программы. Разрабатывается система, в которой библиотека
преобразований выделяется в отдельную самостоятельную часть - открытая
распараллеливающая система (ОРС) [17]. Система предназначена для
автоматического распараллеливания программ с процедурных языков
программирования (Фортран, Паскаль, Си) на параллельные компьютеры,
ориентированные на математические вычисления.
Помимо этого предложен новый подход - управляемый пакет оптимизаций [5].
Это пара <P,M>, где Р - пакет оптимизаций, а М - менеджер пакета
оптимизаций. Пакет оптимизаций представляет собой набор оптимизаций с одним и
тем же объектом применения. Менеджер оптимизаций определяет порядок запуска
оптимизаций пакета. Но данный проект пока не реализован до конца.
С целью решения упомянутых выше проблем в области разработки и применения
оптимизирующих компиляторов в отделе интеллектуальных систем ИАПУ ДВО РАН
предлагается концепция управления информацией о преобразованиях программ в
рамках Специализированного банка знаний о преобразованиях программ (СБкЗ_ПП).
СБкЗ_ПП состоит из информационного наполнения (ИН), оболочки ИН, программного
наполнения (ПН) и блока администрирования (БА). Одной из компонент ПН является
блок потокового анализа.
Целью данной дипломной работы является разработка и реализация подсистемы
потокового анализа, управляемого знаниями, для распараллеливаемых программ в
МСП как части СБкЗ_ПП.
Задачи дипломной работы:
· Разработка представления методов потокового анализа программ.
· Разработка требований к системе потокового анализа
распараллеливаемых программ, управляемой базой знаний.
· Разработка проекта верхнего и нижнего уровней для системы
потокового анализа распараллеливаемых программ, управляемой базой знаний.
· Реализация системы потокового анализа распараллеливаемых
программ, управляемой базой знаний.
Работа содержит следующие разделы:
· Глава 1 - обзор литературы, в котором проанализированы существующие
системы распараллеливания с акцентом на подсистему ПА, рассмотрены методы и
задачи ПА и различные внутренние представления программ.
· Глава 2 - постановку задачи и математическую модель;
· Глава 3 - техническую документацию программного средства;
· Глава 4 - описание тестирования программного средства;
· Глава 5 - Экспериментальное изучение свойств программного
средства.
· Глава 6 - доказательство того, что цели дипломной работы, сформулированные
в задании, достигнуты. Обсуждение результатов работы.
1.
Обзор литературы по теме «потоковый анализ программ в распараллеливающих и
оптимизирующих компиляторах»
.1
Распараллеливающие компиляторы
В данном разделе рассматриваются распараллеливающие компиляторы с точки
зрения их функциональности.
Открытая распараллеливающая система (ОРС) [13] предназначена для
автоматического распараллеливания программ с процедурных языков
программирования (Фортран, Паскаль, Си) на параллельные компьютеры, ориентированные
на математические вычисления.
В работе [10] рассматривается компилятор Intel.
Характеристики компиляторов Intel
· Значительная оптимизацияоптимизация кода еще на высоком уровне, т.е.
прежде всего, различные преобразования циклов
· Оптимизация вычислений с плавающей точкоймаксимальное
использование команд, реализованных на аппаратном уровне
· Межпроцедурные оптимизацииглобальная оптимизация всей
программы, в отличие от обычной оптимизации, которая затрагивает только код
конкретных функций
· Оптимизация на базе профилейвозможность запустить программу в
тестовом режиме, собрать данные о времени прохождения фрагментов кода внутри
часто используемых функций, а затем использовать эти данные для оптимизации
· Поддержка системы команд SSE в процессорах Pentium III
· Автоматическая векторизацияиспользование команд SSE и SSE2,
вставляемых автоматически компилятором
· Поддержка OpenMP для программирования на SMP-системахна
кластере рекомендуется преимущественно пользоваться интерфейсом MPI; имеет
смысл пользоваться библиотеками, распараллеленными для общей памяти.
· Предвыборка данныхиспользование команд предварительной
загрузки из памяти в кэш данных, которые понадобятся через некоторое время
· "Диспетчеризация" кода для различных
процессороввозможность генерации кода для различных процессоров в одном
исполняемом файле, что позволяет использовать преимущества новейших процессоров
для достижения на них наибольшей производительности, при сохранении двоичной
совместимости программ с более ранними процессорами; на нашем кластере это пока
не актуально, т.к. используются только процессоры Pentium III, а также не
предполагается передача и запуск на других машинах программ, откомпилированных
на кластере.
Основной целью проекта V-Ray [15] является развитие
математической технологии и программных средств, обеспечивающих достижение двух
основных свойств параллельных приложений: эффективности и переносимости. Это
включает в себя:
· разработку системы V-Ray - средства анализа и преобразования программ;
· разработку новых технологий, обеспечивающих развитие
переносимых параллельных приложений:
· разработку математических технологий оптимизации программ для
широкого спектра компьютеров.
Программные средства
Основным программным средством является V-Ray system. Она позволяет не только
оптимизировать существующие программы, но и получить эффективные реализации
программ для различных аппаратных платформ путем анализа лежащего в основе
программ алгоритмического подхода.
Анализ программ при помощи V-Ray system осуществляется за несколько этапов. На первом этапе
система определяет основные машинно-независимые свойства программ, а именно,
потенциал параллелизма и локальность использования данных. Она позволяет
определить влияние на качество программ четырех основных черт архитектуры компьютеров:
· параллельной обработки;
· векторной обработки;
· распределенной памяти;
· кеш-памяти.
На основе этой информации система предлагает возможные преобразования
программ, затем пользователь или система выбирает те из них, которые наиболее
подходят к архитектуре конкретного компьютера, и только после этого
производятся необходимые преобразования.
Лежащая в основе системы V-Ray математическая технология
гарантирует точность анализа для широкого класса программ. Это в частности
означает, что если система не помечает некоторый цикл как параллельный, то
действительно существует зависимость между итерациями цикла, и никакие другие
средства (препроцессоры, анализаторы и т.д.) не смогут доказать ее отсутствие.
Все изменения исходного кода делаются на основе эквивалентных
преобразований, которые гарантируют не только корректность исполнения
полученной программы, но и не влекут за собой изменения ошибок округления.
Информация со всех основных этапов выдается пользователю или на экране,
или через преобразования исходного кода.
Основным понятием V-Ray технологии является граф алгоритма -
ациклический ориентированный граф, вершины которого соответствуют отдельным
срабатываниям операторов программы. Две вершины графа соединяются направленной
дугой, если результат операции, соответствующей начальной вершине, используется
в качестве аргумента операции, соответствующей конечной вершине. Таким образом,
понятие графа алгоритма опирается на два основных понятия: отдельные
срабатывания операторов программы и точное описание информационных зависимостей
между ними.
Микроанализ
Иерархический граф управления. Система предоставляет возможность
посмотреть структуру отдельных процедур, составляющих проект с разным уровнем
детализации. На данном рисунке представлен иерархический граф управления одной
из процедур. Вершины этого графа соответствуют либо линейным участкам, либо
циклическим конструкциям. Дуги соответствуют передаче управления. На вершинах,
обозначающих циклы, выводятся цифры, которые соответствуют количеству вложенных
циклов.циклы. Можно определить, какие циклы являются параллельными (pardo).
Хождение по иерархии. Структура каждой циклической вершины может быть
изображена с помощью аналогичного графа.
Связь с исходным текстом. Есть возможность посмотреть текст исходной программы,
соответствующий каждой вершине графа.
Разные термины представления. Граф может быть построен с точностью до
линейных участков, где каждая вершина соответствует линейному участку
изображаемой программной единицы или циклической конструкции, или с точностью
до операторов, где каждая вершина - один оператор фортрана. В графе управления
можно оставить только вызовы процедур и таким образом получить структуру
вызовов.
Разные типы зависимостей. Система позволяет также построить граф
зависимости по данным по всем 4 типам зависимостей или их комбинациям. Граф
может быть построен с использованием графа алгоритма, построенного с помощью
V-Ray технологии или без его использования, так как не всегда возможно
построение графа алгоритма.
Макроанализ
Граф вызовов. Для анализа больших проектов важно знать структуру самого
проекта. Визуальное представление взаимодействия процедур можно получить с
помощью графа вызовов, который показывает порядок вызова процедур проекта.
Графические обозначения главной программы, подпрограмм и функций отличаются
Вложенность циклов. Для нахождения параллелизма важно знать циклическую
структуру процедур. Данный граф предоставляет возможность оценить максимальную
вложенность циклов в каждой процедуре
Операции: рост, из, в. Есть возможность построить граф вызовов шаг за
шагом. На первом этапе показываются только те процедуры, которые вызываются
непосредственно из главной программы. Дальше - те, которые удалены от главной
программы не более (или не менее) чем на два шага и т.д. Можно построить
подграф, отображающий только те процедуры, которые вызывают выбранную процедуру
(учитывая весь путь вызова) или которые вызываются из выбранной процедуры.
Циклический профиль, который для каждого вызова процедуры показывает
сумму объемлющих оператор вызова циклов и максимального уровня вложенных циклов
вызываемой процедуры. Выбирая строчку в списке, на графе выделяется
соответствующий путь.
Граф использования общей памяти. Данный граф отображает использование
общей памяти (COMMON-блоков) - какие блоки в каких процедурах используются
Одной из ключевых компонент кластерного уровня суперкомпьютеров программы
«СКИФ» является система автоматического распараллеливания вычислений - «Т-система»
[1]. За годы выполнения программы «СКИФ» была реализована большая часть идей,
заложенных основателями разработки Т-системы ещё в начале 80-х годов. Созданная
версия Т-системы обладает открытой и расширяемой архитектурой, легко
адаптируемой к стремительно меняющимся аппаратным платформам современных
суперкомпьютеров; Т-приложения - приложения, написанные на входном языке
программирования Т-системы Т++ - могут быть запущены на широком наборе
программно-аппаратных конфигураций, в том числе, на различных мета-кластерных
системах.
Т-система основывается на парадигме функционального программирования для
обеспечения динамического распараллеливания программ. При этом в Т-системе
найдены и реализованы весьма эффективные формы как для собственно организации
параллельного счета (синхронизация, распределение нагрузки), так и для сочетания
функционального стиля с императивными языками программирования (в Т-системе
используется гладкие расширение привычных для большинства программистов языков
C, C++, Fortran).
Работа выполнена в рамках программы «СКИФ» Союзного государства и при
поддержке программы фундаментальных научных исследований ОИТВС РАН
"Высокопроизводительные вычислительные системы, основанные на
принципиально новых методах организации вычислительных процессов" и
программы фундаментальных исследований Президиума РАН "Разработка фундаментальных
основ создания научной распределенной информационно-вычислительной среды на
основе технологий GRID"
За последние два года Т-система была существенно доработана с учетом
опыта её внедрения и эксплуатации в ходе первых трёх лет программы «СКИФ».
Современная версия Т-системы имеет ряд ярких отличительных черт, прежде всего,
к ним относятся:
Минимальные отличия диалекта языка программирования Т++ - входного языка
Т-системы - от базового языка С++. Различия так невелики, что поддерживается
режим компиляции Т-программ без использования Т-системы - с генерацией
последовательно исполняемого кода.
Микроядерная архитектура среды исполнения параллельных программ с
возможностью динамического расширения.
Динамическое связывание Т-приложений с используемой средой коммуникаций.
Поддерживается пересылка данных по семи различным реализациям MPI и PVM.
Поскольку для большинства Т-приложений производительность вычислений
является критическим фактором, разработаны две технологии компиляции
Т-программ:
· Конвертирование программ на Т++ в код на С++ с последующей компиляцией
оптимизирующим компилятором, наилучшим для целевой платформы.
· Компиляции на основе фронт-енда компилятора GNU,
обеспечивающую наиболее полную поддержку входного языка Т++ и ряда часто
используемых расширений С++.
Архитектура среды исполнения Т-системы
Архитектура системы OpenTS построена по “микроядерному” принципу: так
называемая исполняемая спецификация содержит в себе определение всех
необходимых базовых сущностей (классов и шаблонов классов в терминологии C++),
а также реализацию методов классов по-умолчанию. Глубокая проработка отдельных
аспектов (реализуемая зачастую как переопределение методов) выполняется в
отдельных модулях - расширениях Т-системы, которые, как и пользовательская
программа, взаимодействуют с исполняемой спецификацией - микроядром.
Микроядро системы, называемое «Т-Суперструктурой», или
функционально-ориентированная супервычислительная надстройка, структурно
организована как три программных уровня S, M и Т:уровень
Назначение S-уровня:
· Создать высокопроизводительную надстройку над стандартными средствами
управления памятью (кэширующий аллокатор, механизмы подсчета ссылок) и потоками
исполнения (кэширование тредов).
· Ввести абстракцию данных и обеспечить высокоэффективый разноприоритетный
транспорт для их доставки в виде активных сообщений.
· Поддержать “суперпамять”, или распределенную,
программно-управляемую память, доступную для всех существующих в распределенной
супервычислительной среде потоков.
S-уровень может быть по-разному реализован для разных архитектур.уровень
Назначение M-уровня:
· Поддержать мобильные потоки исполнения, объекты и ссылки
· Поддержать “копирование по необходимости” (Copy-On-Write) для
данных суперпамяти.
· Поддержать операцию блокирования и освобождения мобильных
объектов.
· Поддержать иерархию досок объявлений с информацией о
нераспределенных задачах и незадействованных процессорных и прочих ресурсов.
T-уровень
Назначение T-уровня:
· Реализовать понятия неготового значения и ссылки на неготовое значение
· Реализовать понятие Т-функции - мобильной функции, являющейся
гранулой параллелизма.
В качестве базового уровня поддержки сущностей Т-системы была создана и
реализована концепция «суперпамяти» - специализированной общей памяти для
организации обменов данными между Т-функциями. Для Т-величин, хранящихся с
ячейках «суперпамяти» реализован подсчёт ссылок и распределённая сборка мусора.
С целью устойчивой работы сборщика мусора в условиях сетевых коммуникаций,
реализован нетривиальный подсчёт ссылок на объекты.
Приложения и пользовательские библиотеки
К настоящему времени, с использованием современной версии Т-системы
созданы и создаются ряд приложений, в том числе в ходе работ по мероприятиям
программы «СКИФ». Вот некоторые из них:
· Инструментальное средство построения динамических интеллектуальных систем
«Миракл» - в рамках выполнения мероприятия 20 программы «СКИФ»
· Система «MultiGen» - оценка биологической активности веществ
· Программа численного моделирования разрушения кильватерной
волны
· Программа для численной оценки скорости приближения к
глобальному аттрактору уравнений Навье-Стокса в задаче о двумерной каверне
· Программа моделирования фолдинга белков
· Программа синтеза радиолокационного изображения из голограммы
РЛС космического базирования - в рамках выполнения работ по мероприятию 13
программы «СКИФ».
OpenTS и GRID-вычисления
Разработка вычислительных приложений для распределённых вычислительных
сред и , в частности, для GRID, является достаточно непростой задачей в первую
очередь из-за сложности балансировки нагрузки в гетерогенной среде. Т-система,
в силу обеспечения динамического распараллеливания, предоставляет программисту
возможности прозрачного использования гетерогенных конфигураций: сложность
выравнивания нагрузки «скрыта» от него в планировщике Т-системы,
распределяющего нагрузку между процессорами в кластере или мета-кластере.
Т-система предоставляет следующие возможности для обеспечения распределённых
вычислений:
Поддержка мета-кластерных реализаций MPI: MPICH-G2, IMPI, PACX-MPI
Обеспечение возможности пользовательского расширения стандартного
алгоритма планирования - через механизмы расширения Т-системы.
Информационная система ТРАНСФОРМ (ИС ТРАНСФОРМ) [11] по
преобразованиям программ создается для нужд лаборатории конструирования и
оптимизации программ ИСИ СО РАН. Система предназначена для накопления и
систематизации информации по преобразованиям программ и интеграции работы
сотрудников лаборатории. Предполагается при помощи ИС ТРАНСФОРМ выпускать
аналитические обзоры, обучать специалистов и внедрять преобразования программ в
повседневную практику программирования.
· Гибкость создаваемой системы приобретает первостепенное значение, для
достижения которой необходимо добиться наиболее точного отражения характерных
черт предметной области (ПрО). Поскольку база данных является основой ИС, то
требуемые возможности должны быть заложены в схему базы данных, что позволит в
дальнейшем корректировать режимы использования ИС. Для ее решения как первый
этап предлагается инфологическая схема, дающая представление об области
преобразований программ (не учитывая ограничений, накладываемых конкретной
СУБД) и призванная представить ясное, общедоступное описание БД для уточнения
требований и облегчения взаимодействия с пользователями системы. В работе
используется модель, называемая "объекты-связи". Она определяется в
терминах: атрибут, объект, структурная связь, запросная связь. Под атрибутом
понимается логически неделимый элемент структуры информации, характеризуемый
множеством атомарных значений. Каждый атрибут идентифицируется именем. Объект
инфологической схемы соответствует некоторой сущности реального мира,
представляющей интерес для ПрО. Под Структурной связью понимается иерархическое
отношение между объектами двух типов: владельцем и подчиненным. Для изображения
информационных структур используются диаграммы. Запросная связь - pro некоторая
операция, предусматривающая в алгоритме процесса переход от экземпляров одних
объектов, называемых исходными, к множеству экземпляров объекта, называемого конечным
в запросной связи.
В работе [6] рассматривается проект системы Прогресс.
Исходя из перспективности параллельных архитектур, разработчики считают
целесообразным разработку системы, ориентированной:
· на исследование эффективности применения различных систем преобразований
в процессе трансляции с императивных и функциональных языков для разных классов
программ и ЭВМ (включая ее зависимость от форм промежуточного представления
программ, наборов трансформаций, выбора контекстных условий и стратегий применения
преобразований);
· на быстрое прототипирование оптимизирующих компиляторов для
целевых архитектур (VLIW- и суперскалярные, мультипроцессоры с распределенной
памятью и т.д);
· на инструментальную поддержку обучения студентов методам
программирования и оптимизирующей трансляции для параллельных машин.
В качестве входных языков предполагается использовать Фортран-77,
Модула-2, Си++, а также язык функционального программирования SISAL (версии 2.0
или SISAL-90). Предполагается, что языки расширены за счет средств
аннотирования программ формализованными комментариями. Эти средства должны
позволять пользователю управлять процессом преобразования программы (например,
заданием дополнительной информации о свойствах программы), а системе -
комментировать результирующую программу информацией о процессе преобразования
программы. Предусматривается возможность реализации в рамках расширенного языка
преобразования последовательных программ в параллельные для параллельных версий
входного языка (например, перевод программы на языке Фортран 77 в программу на
языке Фортран 90).
Совокупности преобразований, поддерживаемые системой ПРОГРЕСС, должны
базироваться на богатой библиотеке преобразований, содержащей базовые
преобразования для разных промежуточных представлений программ, и развитых
средствах конструирования систем преобразований. Библиотека преобразований
включает наряду с универсальными (машинно-независимыми) и машинно-зависимые
преобразования, как правило, ориентированные на те или иные классы целевых
архитектур. Средства конструирования систем преобразований содержат встроенные
проверки контекстных условий и стратегии применения наборов преобразований, а
также поддерживают возможность их расширения (в частности, путем композиции
новых преобразований из существующих или заданием новых средствами,
аналогичными имеющимся в системах компьютерной алгебры) и задания новых
стратегий применения преобразований.
Система должна уметь осуществлять сравнение версий преобразуемой
программы по их сложности, в частности по структурной сложности, и по
результатам испытаний на тестовых наборах.
Считается целесообразным исследование таких форм промежуточного
представления программ, как абстрактное синтаксическое дерево, управляющий
граф, SSA-форма, граф программных зависимостей, иерархический граф заданий,
идеограф, сеть программных зависимостей, граф потока зависимостей, а также
представления IF1 и IF2, применяемые в компиляторах языка SISAL.
С функциональной точки зрения выделяются следующие компоненты
разрабатываемой системы:
Транслирующая подсистема - переводит входную программу, представленную в
текстовом виде, в основное промежуточное представление, ядром которого является
абстрактное синтаксическое дерево - АСД. Основное промежуточное представление
доступно во время работы любой подсистемы.
Подсистема промежуточных представлений - осуществляет переход от основного
к другим промежуточным представлениям (управляющий граф, граф программных
зависимостей, SSA-форма, иерархический граф заданий, временная сеть Петри и
др.), а также переводы программы из одного промежуточного представления в
другое (если такой перевод возможен). Подсистема поддерживает также набор
базовых операций, в частности, позволяющих осуществлять доступ к любым
конструкциям соответствующих представлений, генерацию элементов промежуточных
представлений и их модификацию (удаление оператора или переключение дуги в
управляющем графе и т.д.).
Подсистема преобразований - обеспечивает возможность задания и применения
различных систем преобразований к аннотированной программе (или отдельному ее
фрагменту) в заданном промежуточном представлении. При этом предполагается
возможность пополнения библиотеки преобразований, задания стратегий применения
наборов преобразований, использования различных режимов при выполнении систем
преобразований (например, со сбором статистической информации о процессе
выполнения системы преобразований, его визуализацией или документированием).
Подсистема оценки и моделирования - позволяет оценивать качество
результирующей программы с помощью статического анализа программы и
моделирования прогона программы на аппаратуре, а также собирать требуемую
информацию о процессах выполнения программы.
Ретранслирующая подсистема - позволяет получать текстовое представление
заданного фрагмента программы по ее промежуточному представлению.
Подсистема визуализации - обеспечивает возможность наглядного изображения
на экране процесса обработки программы.
Архивная подсистема (база данных) - обеспечивает хранение информации о
результатах применений систем преобразований.
Монитор - обеспечивает диалог с пользователем и взаимодействие
подсистем между собой.
Каждая из подсистем реализуется как абстрактный тип данных - через набор
операций, поддерживаемых данной подсистемой. Взаимодействие различных подсистем
осуществляется с помощью специальных интерфейсных подсистем.
В работе [7] был проведен обзор распараллеливающих систем. Некоторые из
них:
Система РТОРР служит поддержкой достаточно прямолинейного подхода
к оптимизации программ, при котором вначале определяются те части программы,
которые потребляют много времени, а затем эти части последовательно улучшаются.
Система состоит из ряда ИС, рассчитанных на программистов-профессионалов с
хорошим пониманием Unix и Fortran. Предполагается, что пользователь свободно
владеет понятиями параллельных архитектур и типов преобразований, полезных для
программ для этих архитектур. Развитие этой системы направлено на
удовлетворение потребностей широкого круга пользователей - от прикладных
программистов, которые не имеют возможности тратить время на оптимизацию
параллельных программ, до экспертов-программистов, которые хотят
эксплуатировать все особенности параллельных машин.
В качестве первого интерактивного интерфейса был выбран Emacs, который
предлагает полноценный текстовый редактор, средства управления файлами,
интерактивную подсказку (help) и хорошо известный язык Elisp, на котором можно
программировать. Замена Emacs на альтернативную систему управления файлами с
аналогичными возможностями производится непосредственно.
Большей частью анализ проводится на базе изучения циклов. С этой целью
осуществляется инструментовка всех гнезд циклов в последовательном входном
коде. Все варианты оптимизированной программы порождаются из инструментованного
входного кода.
РТОРР обеспечивает такие средства, что инструментовка программы может
быть произведена неявно с помощью команды cfmake в сочетании с командой instrument или с помощью редактора,
просматривающего входной код.
За шагом инструментовки программы следует генерация и исполнение
многочисленных вариантов программы. Примерами вариантов программ, интересных в
исследовании эффективности программы, служат последовательные, векторизованные
и векторно-параллельные программы.
Для того чтобы найти преобразования программ, которые могли бы улучшить
производительность, данные о результирующей программе собираются и
анализируются относительно некоторого числа оптимизационных факторов. Последние
обеспечивают информацию о производительности программы на основе знания
структуры циклов и делают намеки для оптимизирующих преобразований. Примерами
таких факторов могут служить ускорение цикла (loop speedup) и штраф за глобализацию (globalization penalty) (т.е. производительность уменьшается, когда данные
помещаются не в локальную, а в глобальную память).
Редактирование преобразований - достаточно простая задача, хотя некоторые
из них требуют аккуратного межпроцедурного анализа программ. Примерами таких
преобразований могут служить приватизация массивов и превращение цикла в
параллельный цикл. Редактирующее действие приватизации массивов состоит в
перемещении объявлений данных из исходной позиции в заголовок цикла и создании
параллельного цикла заменой DO на DOALL. Однако анализ приватизируемых массивов
требует внимательного определения связей def-use, а превращение цикла в
полностью параллельный цикл требует анализа зависимостей по данным.
Другие преобразования легче анализируются, но более утомительны для
редактирования. Они могут быть кандидатами на поддержку со стороны ИС.
Примерами служат преобразования сегментирование (strip mining) и сжатие цикла (loop coalescing).
Polaris разработан в Иллинойском университете. Большая часть фаз Роlaris'a
интрапроцедуральны и требуют подстановки тел вызываемых подпрограмм для
эффективного распараллеливания циклов. В системе поддерживается автоматическая
подстановка, а некоторые межпроцедурные фазы, такие как протягивание констант,
либо реализованы, либо такая реализация планируется (например, анализ массивных
областей, основанный на списках дескрипторов регулярных секций).
Система PTOOL разработана в университете Райе по заказу фирмы IBM
и представляет собой шаг в направлении создания развитых диалоговых систем
программирования, основанных на анализе зависимостей. Разработка и отладка
программ выполняется обычными методами на модели последовательной машины, а
потом пользователь ведет диалог с PTOOL по поводу распараллеливания итеративных
циклов.позволяет пользователю выбрать цикл в последовательной Фортран-программе
и спросить, могут ли его итерации исполняться параллельно. Если ответ - "нет",
то PTOOL отображает все зависимости, препятствующие распараллеливанию. При
обработке цикла PTOOL определяет множество переменных, которые могут быть
объявлены частными (private) для
каждой итерации. Это - ключевая особенность в уменьшении числа зависимостей,
показываемых пользователю, так как именно переменные, не относящиеся к частным,
могут порождать зависимости. Кроме того, PTOOL может работать с вызовами внутри
циклов.состоит из двух основных частей: анализатора PSERVE, выполняющего
построение графа зависимостей и межпроцедурный анализ, и диалогового блока
PQUERY, использующего построенный граф в процессе диалога с пользователем в
терминах исходной программы. При помощи графа зависимостей PTOOL обнаруживает
потенциальные ошибки организации доступа к данным и предупреждает о них
пользователя, но не обнаруживает ошибок синхронизации.
Анализатор PSERVE - это модифицированная версия предыдущей
распараллеливающей системы PFC. В PFC перед построением графа зависимостей
делаются предварительные преобразования (нормализация цикла, устранение
индуктивных переменных), которые могут существенно изменить структуру
программы. Поскольку целью PTOOL является точное отображение зависимостей,
существующих в исходном тексте, в ней эти предварительные преобразования исключаются.
Например, PTOOL не удаляет индуктивные переменные, но соответствующие дуги
графа зависимостей помечаются как избыточные. Построение избыточных дуг требует
дополнительных просмотров текста.
В процессе межпроцедурного анализа PTOOL, как и PFC, анализирует граф
вызова процедур на предмет выявления побочных эффектов. Помимо того, что
межпроцедурный анализ позволяет векторизовать некоторые циклы, содержащие
обращения к внешним процедурам, он уменьшает количество дуг в графе
зависимостей.- диалоговый компонент PTOOL - выдает текст исходной программы,
отмечая прямо на экране те переменные, которые образуют зависимости. Как
побочный эффект возможно обнаружение некоторых семантических ошибок, вносимых
при распараллеливании.
Опыт эксплуатации PTOOL сразу после ее создания позволил выделить три
категории недостатков.не полностью интерактивен,не может использоваться как
отладчик.отображает слишком много ложных зависимостей.
Существенным недостатком системы PTOOL является ее неспособность
поддерживать все фазы разработки программ. После внесения изменений в программу
необходимо повторить ее анализ с самого начала. PTOOL не поддерживает ни фазу
редактирования, ни фазу трансляции, ни фазу выполнения программы. Для решения
задач такого рода служит интегрированная среда программирования Rn,
также разработанная в университете Раиса.
Исходной целью создания Rn было обеспечение процесса разработки и
сопровождения опытными программистами больших программных систем, написанных на
Фортране (не обязательно для суперЭВМ), поэтому система поддерживает
межпроцедурный анализ и оптимизацию, сохраняя в то же время удобства
независимой трансляции.
Транслятор и редактор, входящие в состав Rn, подразделяются каждый на две
части: композиционную и модульную. Композиционные части обрабатывают целиком
текст программы, состоящий из модулей. Модульные части обрабатывают каждый
модуль отдельно, но при этом используют информацию, созданную композиционной
частью.
Все модули представлены в виде абстрактных синтаксических деревьев и
хранятся в базе данных RJ1. Деревья порождаются в процессе редактирования
модулей. Поэтому и сам редактор является структурным, т.е. процесс ввода и
изменения программ состоит в использовании заготовок (шаблонов) языковых
конструкций, в которые пользователь вставляет необходимые выражения, метки и
т.д. Синтаксический разбор выполняется сразу же при вводе каждой конструкции, и
обычный синтаксический анализатор всей программы применяется только для «чужих»
программ, поступающих в Rn извне.
Среда ParaScope [20] предназначена для поддержки процесса
разработки, анализа, трансляции и отладки больших параллельных программ
научного характера, написанных на языке Фортран. При разработке этой системы
предполагалось, что ParaScope будет включать следующие новые возможности:
· специальный редактор, объединяющий функции PTOOL и Rn и способный дать
программисту советы о том, как следует преобразовать программу для повышения
степени ее параллелизма; в частности, он должен уметь пошагово реконструировать
зависимости после любого вида редакторской правки и быть в состоянии
анализировать общие параллельные конструкции;
· глобальный анализ программы на предмет увеличения
параллелизма за счет открытой подстановки процедур; программный компилятор Rn
должен быть расширен для осуществления более мощных форм межпроцедурного
анализа и оптимизации;
· отладка программ с использованием результатов статического
анализа, подобно выполняемому в PFC и PTOOL. Отладчик должен помогать
программисту искать ошибки, возникающие в оптимизированной программе при
доступе к разделяемым данным.
Реализация этих возможностей привела к созданию входного редактора,
компилирующей системы и системы отладки. Рассмотрим их подробнее.
Редактор PED. Редактор в ParaScope включает новую версию входного
компилятора Rn, который объединяет все возможности
PTOOL, устраняя его слабые места - он может, в частности, пошагово
реконструировать зависимости после любой редакторской правки и анализировать
общие параллельные конструкции.
Ключевой системой, автоматически выявляющей параллелизм, является граф
зависимостей. Чтобы достичь поставленных целей, PED должен быть способен быстро
перестраивать граф зависимостей в ответ на редактирующие изменения и применение
предварительных преобразований, что реализуется в виде пошагового анализатора зависимостей.
В этом анализаторе имеются три принципиальных компонента: пошаговый анализатор
потока данных, эффективная реализация одного или более стандартных тестов на
зависимость и эффективный механизм оповещений, который позволяет каждому
компоненту, включенному в анализ, информировать других об имеющихся изменениях.
Для понимания этой организации следует смотреть на проверку зависимостей как на
двухфазный процесс. Первая фаза выявляет, какие определяющие точки в программе
могут воздействовать на каждое использование или определение в программе
(достигающие определения в анализе потока данных). На второй фазе применяется
тест на зависимость между определением и каждым использованием или
определением, которые достигаются им.
Кроме того, планируется поддерживать в PED богатый набор преобразований,
включая перестановку, разбиение и слияние циклов, расширение скаляров и др.
Каждое преобразование будет реализовываться как опция меню. При выборе
конкретного преобразования PED будет сообщать пользователю, можно ли установить
корректность преобразования, и будет оценивать его полезность. Если
пользователь решит продолжать, то PED будет применять преобразование и
перестраивать граф зависимостей.
Компилирующая система. Программный компилятор есть устройство, предназначенное
для оптимизации программ на глобальном уровне. Кроме того, он должен явно
управлять всеми межпроцедурными оптимизациями.
Программный компилятор в Rn первоначально был сконструирован как
поддержка оптимизации скалярных операций. Проблема компиляции для параллельных
машин значительно более сложная и требует более сложных инструментов. Поэтому
программный компилятор нуждается в доработке по следующим трем направлениям.
Во-первых, требуется увеличение точности межпроцедурного анализа для
обеспечения более строгого анализа в PED. Во-вторых, нужно расширить
номенклатуру оптимизаций программы в целом, особенно для помощи в управлении
иерархической памятью. В-третьих, требуется повысить статус модульного
компилятора до генератора кода хотя бы для одной целевой машины.
Parascope и система D, разработанные в университете Раиса, используют для
межпроцедурного анализа систему FIAT так же, как это сделано в FIAT/SUIF.
Parascope обеспечивает проведение некоторых видов межпроцедурного анализа,
таких как MOD/REF анализ, анализ массивных областей, основанный на дескрипторах
регулярных секций, анализ смешивания, протягивание констант и анализ символьных
величин. Система D построена в контексте Parascope и имеет целью трансляцию
Фортран-Б-программ. Фортран D - диалект Фортрана, подобный HPF - требует
проведения специальных видов анализа, таких как достигающая декомпозиция и
перекрытие.
Система SUIF [25] (Stanford University Intermediate Format), разработанная в Стэнфордском университете,
представляет собой инфраструктуру для исследований в области распараллеливающих
и оптимизирующих компиляторов.была разработана как платформа для исследования
методов компиляции для высокопроизводительных машин. Эта мощная, модульная,
гибкая, ясно документированная и достаточно паяная для компиляции больших
тестовых задач система была успешно использована для проведения исследований в
таких областях, как скалярная оптимизация, анализ зависимостей в массивах
данных, преобразования циклов с точки зрения локальности и параллелизма,
программное считывание с упреждением, планирование команд. Исследовательские
проекты, использующие SUIF, включают в себя декомпозицию глобальных данных и
вычислений как для машин с общей, так и с распределенной памятью, приватизацию
массивов, межпроцедурное распараллеливание, эффективный анализ указателей.
Исходя из целей создания, структура системы представляет собой небольшое
ядро (kernel) плюс инструментарий (toolkit), состоящий из различных
компиляторных анализов и оптимизаций. Ядро определяет промежуточное представление
и интерфейс между проходами компилятора. Этот интерфейс всегда один и тот же,
так что проходы в инструментарии могут быть легко включены, заменены и
переупорядочены.
Вся информация о программах, необходимая для реализации скалярных и
параллельных компиляторных оптимизаций, легко доступна из ядра SUIF.
Промежуточное представление охраняет почти всю информацию высокого уровня из
исходного кода. Доступ к структурам данных и манипулирование ими прямолинейны
благодаря модульной конструкции ядра.
Инструментарий SUIF содержит большое число проходов. Препроцессоры для
Фортрана и ANSI Си доступны для трансляции исходных программ в SUIF, который
включает параллелизатор, способный автоматически находить параллельные циклы и
порождать распараллеливаемый код. SUIF-toC-транслятор позволяет компоновать
распараллеливаемый код на любой платформе, на которую перенесена параллельная
библиотека времени исполнения. Система SUIF обеспечивает много возможностей для
поддержки распараллеливания: анализ зависимостей по данным, распознавание
редукции, множество символьных приемов для улучшения выявления параллелизма и
унимодулярные преобразования для увеличения параллелизма и локальности.
Включены также такие скалярные оптимизации, как частичное устранение
избыточности и распределение регистров.
Строение и функции ядра. Ядро системы SUIF реализует три главные функции:
· определяет промежуточное представление программ, поддерживающее как
реструктурирующие преобразования программ высокого уровня, так и анализ
программ и оптимизацию низкого уровня;
· обеспечивает функции для доступа и манипулирования с
промежуточным представлением;
· структурирует интерфейс между проходами компилятора.
Проходы в SUIF - это отдельные программы, которые осуществляют связь
через файлы. Формат этих файлов - один и тот же для всех стадий компиляции.
Система поддерживает эксперименты, допуская в аннотациях определенные
пользователями данные.
Программный промежуточный формат. Уровень представления программ в
распараллеливающем компиляторе есть критический элемент конструкции
компилятора. Используемый промежуточный формат - представление смешанного
уровня. Кроме условных операций нижнего уровня он включает в себя три
конструкции высокого уровня: циклы, условные операторы и доступы к массивам.
Циклические и условные представления аналогичны абстрактным синтаксическим
деревьям, но в отличие от них языковонезависимы. Эти конструкты накапливают всю
высокоуровневую информацию, необходимую для распараллеливания.
Параллелизатор исполняет анализ зависимостей по данным, используя
SUIF-библиотеку зависимостей. Анализатор зависимостей базируется на алгоритме
Майдана и состоит из серии быстрых точных тестов, каждый из которых применим в
ограниченной области. Его последний тест - алгоритм исключения Моцкина - Фурье,
расширенного для решения целочисленных задач. Анализатор также способен
обрабатывать некоторые простые нелинейные доступы к массивам.
Преобразователь циклов основан на алгоритме Вульфа - Лэм. Он работает с
циклами на базе векторов расстояний или векторов направлений. Механизмы
реализации преобразований циклов запасаются в библиотеке, которую могут
использовать другие пользователи для реализации различных стратегий
преобразования циклов.
Для того чтобы система SUIF могла распараллеливать циклы, содержащие
вызовы процедур, она дополняется системой FIAT, ориентированной на
межпроцедурный анализ. Более точно, FIAT представляет собой инструмент для
построения компиляторов, дающий возможность быстро прототипировать
межпроцедурный анализ и компилирующие системы. Первоначально FIAT был
интегрирован в систему ParaScope. При работе с FIAT программист должен только
обеспечить функции инициализации, оператор объединения, функцию передачи и
направление анализа. FIAT - система, управляемая спросом: программист не должен
беспокоиться о порядке межпроцедурного анализа. В FIAT/SUIF доступны несколько
видов межпроцедурного анализа. Вначале обратный анализ вычисляет передаточную
функцию, затем некоторые виды предусловий, которые дают каждое значение
переменной в терминах инвариантов цикла и индексов вложенных циклов.
Дополнительная фаза протягивает ограничения в виде неравенств из тестовых
условий. Наконец, реализуются некоторые виды обратного межпроцедурного анализа
массивов.
1.2
Представление программ
Основа распараллеливающего компилятора состоит в преобразованиях
программ. Эти преобразования можно было бы проводить на уровне исходного
текста, но пришлось бы многократно делать разбор этого текста (что требует
больших затрат времени). Поэтому целесообразно программу один раз разобрать,
записать результат разбора в специальном виде - внутреннем представлении - и
затем работать с этим внутренним представлением.
Внутреннее представление программы в компиляторе - это специальная
структура, в форме которой хранится информация о преобразуемой (компилируемой,
оптимизируемой, конвертируемой) программе. Внутреннее представление должно быть
удобно для преобразований программ. В это внутреннее представление должны
преобразовываться программы на языках ФОРТРАН, ПАСКАЛЬ, Си. Поскольку
большинство описанных в статьях преобразований программ ориентированы на
ФОРТРАН, внутреннее представление также ближе к ФОРТРАНу.
Главная часть внутреннего представления программ - это база данных,
состоящая из записей вида: (идентификатор, метка, указатель на оператор).
В таком виде представляются данные об исполнимой части программы - о ее
операторах. Описания данных и связи между подпрограммами хранятся отдельно в
виде таблиц.
Если бы все операторы программы были однотипные (например, присваивания),
то вместо указателя на оператор можно было бы хранить сам оператор (в
разобранном виде). Но поскольку для различных типов операторов необходима
разная информация, эта информация будет храниться отдельно, а в основной базе
будет только указатель на нее. Например, об операторе цикла со счетчиком должна
быть следующая информация:
· Указатель на запись в основной базе
· Имя счетчика цикла
· Левая граница
· Правая граница
· Шаг
· Метка последнего оператора тела цикла
· Идентификатор последнего оператора тела цикла
· Список счетчиков циклов, содержащих данный
· Канонизирован ли этот цикл
· Содержит ли этот цикл внутри себя другие циклы
· Распараллеливается ли этот цикл
Канонический вид операторов и выражений
Для упрощения преобразований операторы программы следует привести к
специальному унифицированному виду.
Всякий цикл с параметром (фортрановский DO, паскалевский FOR) может быть
приведен к виду, в котором левая граница счетчика- 1 и шаг- 1.
Любые условные операторы могут быть сведены к блочному условному
оператору «IF THEN ELSE ENDIF». При этом ELSE во внутреннем представлении
удобно тоже считать оператором.
Для некоторых преобразований важно, чтобы выражения программы были
приведены к некоторому стандартному виду. Особенно это необходимо при
построении графа информационных связей. Без такого стандарта трудно, например,
понять, что вхождения Х(2*I +1), Х(1 + I*2), Х(2*I + 2 - 1) и Х(I + 1 + I)
информационно зависимы. В данной работе предлагаются следующие стандартные
требования к записи выражений:
Аргументы коммутативной бинарной операции должны следовать в алфавитном
порядке. Например, P*Q а не Q*P.
Если в выражении некоторая одновременно и коммутативная и ассоциативная
операция должна выполняться несколько раз подряд, то все аргументы должны быть
отсортированы по алфавиту. Например, А + В - X (вычитание в этой записи следует
понимать как сложение с переменной с унарным минусом А + В + (-X)).
Сумма двух одинаковых выражений с может быть, разными числовыми
множителями заменяется таким выражением с множителем, который равен сумме исходных.
3*I - I > 2*I.
Можно выносить общий множитель-переменную, пользуясь законом
дистрибутивности. Но при вызове такой процедуры следует указывать, какие
множители следует выносить. Такая процедура может выполняться благополучно лишь
тогда, когда исходное выражение линейно зависит от совокупности указанных
переменных (если их несколько). Например, А*В + А*С + В*С >> А*В + (А +
В)*С, если выражение надо приводить относительно переменной С. Заметим, что в
этом примере невозможно привести исходное выражение относительно переменных А и
В одновременно, поскольку выражение нелинейно зависит от их совокупности. Если
выносимый множитель является не константой, а переменной или подвыражением, то
он пишется слева или справа в зависимости от алфавитного порядка с переменной,
относительно которой множитель выносится.
При записи отношений будем использовать «<» вместо «>» и «<=»
вместо «>=». (х + 2) < О вместо 0 > (х + 2).
Булевы выражения следует приводить к ДНФ (дизъюнктивной нормальной
форме), в которой аргументы конъюнкций и дизъюнкций расположены в алфавитном
порядке. При этом, выражение без отрицания должно записываться раньше такого же
выражения с отрицанием. Например, Not(A) and В and Z
or В and Y or not(B) and C.
Арифметические подвыражения над константами следует заменять их числовыми
значениями. Например, числом -5 можно заменить выражение (3 - 4*2).
Унарный «-» можно выносить, как множитель, если это особо оговорено в
параметрах процедуры.
Пример.
Х(I)*2 - 2*Х(I - 1) > 2*Х(I) - 2*Х(I - 1)
-2*Х(I) > (А(I) - 2))* Х(I)
*X(I) > X(I) *(Y(I) - 2))
Для реализации пункта 4 требований к стандартному виду выражения может
быть полезным предварительное раскрытие скобок по закону дистрибутивности.
Пример.
*(X-Y) + (A + 1)*(X + Y) > 5*X-5*Y+(A+ 1)*X + (A+ 1)*Y>
> (5 + (А +
1))*Х + (-5 + (А + l))*Y > (А + 6)*Х + (А - 4)*Y.
В арифметических выражениях, особенно в индексных, могут быть «приведены
подобные». Последние два слова взяты в кавычки, поскольку это понятие четко не
определено, хотя и знакомо всем со школьных лет. В данной системе под
приведением подобных понимается функция, у которой на входе арифметическое
выражение F и список переменных {Al, A2, ..., As}. На выходе - равносильное
выражение А 1*F1 + A2*F2 +...+ As*Fs + F(s + 1) (здесь Fl, F2, ..., F(s + 1) -
некоторые арифметические выражения, не зависящие от Al, A2, ..., As) или
сообщение о невозможности такого представления. Такое приведение необходимо, в
первую очередь, в индексных выражениях. Только после этого может строиться
какой-либо информационный граф. Оно может быть также использовано для
приведения рекуррентных циклов к виду
DO 99 I = 1, N 99 X(I)=F1*X(i-1)+...+Fs*X(I-s)+F(s+1)
Исключение индуктивных и охватывающих переменных упрощает анализ
программы, хотя может привести к ухудшению кода.
Анализ информационных зависимостей в программе
Для контроля над эквивалентностью преобразований необходим анализ
информационных зависимостей в программе. Для этих целей придуманы различные
средства: граф информационных связей, граф направлений зависимости, Омега-тест,
тест Банерджи, решетчатый граф программы и др.
Эквивалентность перестановки операторов присваивания может быть описана с
помощью графа информационных связей Лампорта, а эквивалентность перестановки
циклов - с помощью направлений зависимости. Из-за того, что вхождение
переменной в текст программы может многократно обращаться к памяти, граф
информационных связей Лампорта теряет некоторую информацию об информационных
зависимостях. Направление зависимости тоньше в том смысле, что оно отражает
последовательность обращений к памяти различных циклов гнезда, содержащего
данное вхождение. Направление зависимости часто рассматривается между
операторами, а не вхождениями - это более грубое допущение, чем в графе
Лампорта. Самый тонкий анализ зависимости дает решетчатый граф, активно
исследуемый в работах В.В. Воеводина и P. Feautrier (следует отметить, что этот
граф концептуально рассматривался и ранее, начиная с работы Лампорта о «методе
гиперплоскостей»). Но анализ эквивалентности преобразований программ на основе
этого фа-фа пока недостаточно разработан. Омега-тест и тест Банерджи - это
средства для построения дуг графа информационных связей или направлений
зависимости. Тест Банерджи более быстрый, а Омега-тест - более тонкий.[17]
В Открытой распараллеливающей системе используются абстрактные
синтаксические деревья.
Абстрактные синтаксические деревья
Листья - терминалы, остальные узлы - нетерминалы грамматики языка.
Корень AST - стартовый символ грамматики.
Дуги AST - правила вывода грамматики.
Из AST обычно исключается «синтаксический сахар», т.е. разделители и
другие грамматические символы, не несущие семантической информации.
Листья и узлы AST помечаются атрибутами, характеризующими их
свойства.точно отражает синтаксическую структуру исходного текста программы и
поэтому удобно для проведения высокоуровневых преобразований.
Язык описания преобразований
Всякое «механическое» преобразование можно представить как совокупность
элементарных операций над деревом программы:
· вставить поддерево/узел,
· удалить поддерево/узел,
· изменить поддерево/узел,
· скопировать поддерево/узел,
· изменить его атрибуты поддерева/узла, …
Такое представление может помочь избежать синтаксических ошибок при
проведении преобразований.
Язык описания преобразований должен оперировать поддеревьями AST или аналогичным древовидным
представлением.
Язык должен быть близким к предметной области, чтобы максимально
облегчить использование разработчиками преобразований.
Этот язык должен поддерживать возможность обработки «особых случаев» в
потенциально опасных конструкциях преобразований.
Язык описания преобразований ASTOL
Язык ASTOL (AST Operating Language - язык оперирования AST) разрабатывается в настоящее время.
Язык является императивным;
Язык содержит операторы, модифицирующие поддеревья AST программы (элементарные
преобразования), а также операторы модификации атрибутов отдельных узлов;
Язык позволяет описывать структуру дерева AST конкретного языка;
Для программ на языке ASTOL
разрабатывается конвертор, переводящий код с ASTOL в классы языка Си++.
ASTOL: раскрутка цикла
unroll(for_stmt src)
{
// блок операторов, который заменит собой цикл
declvar block_stmt block = createBlock();
/* создаем переменную с именем и типом, совпадающим со счетчиком цикла src */
createVarDeclaration(block, src[counter][type],
src[counter][name], src[min]);
rcopy(block.last_stmt, src.increment_stmt);
// в цикле по всем итерациям исходного цикла…
for(int index=src[min], src[max], src[step])
{
// копируем в конец блока тело исходного цикла…
rcopy(block.last_stmt, src.body);
// затем копируем оператор, инкрементирующий счетчик(block.last_stmt, src.increment_stmt);
}
// заменяем исходный for на
созданное поддерево…(src, block);
}
ASTOL
В примере элементарными преобразованиями являются:
· createBlock (создание составного оператора),
· createVarDeclaration (создание описания переменной),
· rcopy (рекурсивное копирование узла и всех потомков),
· rreplace (рекурсивная замена узла и всех потомков).
Для анализа преобразования на сохранение им статической семантической
корректности достаточно составления списка элементарных операций.
Логические спецификации для описания статической семантики
· Правила статической семантики задаются логическими предикатами и
функциями.
· Правила могут быть двух видов - правила-определения и
правила-ограничения.
· Правила-определения порождают совокупность фактов о
программе, а правила-ограничения контролируют, чтобы эти факты удовлетворяли
задаваемым условиям.
Правила-определения
Правила-определения на основе значений атрибутов узлов AST, его структуры
и других правил-определений порождают новые факты о разбираемой программе.
· Правила-определения выглядят как определения значений атрибутов, возможно
рекурсивные.
· Например, для дерева-выражения правило-определение может
рекурсивно вычислять тип выражения, основываясь на типах поддеревьев:
Правила-ограничения
Правила-ограничения собственно и задают статическую семантику.
· Правила-ограничения накладывают условия на значения атрибутов узлов
дерева разбора и на взаимные расположения этих узлов относительно друг друга.
Пример правила-ограничения: все переменные одной области видимости должны
иметь различающиеся имена.
Если для данной программы удается построить логическую модель, в которой
все факты, порожденные правилами-определениями, не противоречат
правилам-ограничениям, то программа считается корректной с точки зрения
статической семантики.
Если не удаётся, то программа считается некорректной. Причем нарушившееся
правило и определяет причину ошибки.
Априорная проверка корректности преобразований
Анализ показал, что правила-ограничения статической семантики многих
распространенных процедурных языков можно отнести к небольшому числу типов.
Эта классификация основана на способах связи узлов дерева программы.
Априорная проверка корректности преобразований
Основная идея:
· Если программа изначально семантически корректна, то после применения
преобразования она может стать некорректной, т.е. нарушится одно или более
правил-ограничений.
· Преобразование состоит из последовательности элементарных
преобразований.
· Необходимо определить, какие элементарные преобразования
могут привести к нарушению какого типа правила.
· Каждое ограничение статической семантики принадлежит одному
из 5 типов.
· Для каждого элементарного преобразования можно автоматически
определить правила какого типа оно может нарушить.
· Для реализации такого автоматического определения можно
построить отрицания каждого из типов правил. Эти отрицания покажут, какие
элементарные преобразования могут нарушить какие типы правил.
Например, удаление узла может нарушить правила о необходимости его
существования и т.д.
Пусть рассматриваемое правило принадлежит типу «многие-к-одному»:
Отрицание правила имеет вид:
$ A | " B ØP(A, B)
Условие P(A, B) будет нарушено,
если требуемый узел B не существует хотя бы для одного узла A.
Т.к. изначально программа была корректной, то это означает, что:
· какой-то узел (узлы) B был удален;
· были изменены атрибуты узлов, используемые для вычисления
предиката P;
· был добавлен новый узел A;
· изменены атрибуты существующего узла, участвующие в
вычислении P.
Следовательно, для данного типа правил потенциально опасными с точки
зрения статической семантики будут элементарные операции удаления узлов типа B
и вставки узлов типа A, а также операции изменения атрибутов, применяемые к
грамматическим символам этих типов.
Условия нарушения типов правил
· Программа-преобразование состоит из композиции элементарных
преобразований.
· Автоматически проверяем каждое его элементарное преобразование
и делаем вывод об ошибках во всем преобразовании.
· Разработчик преобразования должен проанализировать
предупреждения системы о нарушениях его преобразованием правил статической
семантики и сделать необходимые исправления в программе-преобразовании.
Автоматический перевод программы-преобразования в С++/Java
Программы, записанные на языке описания преобразования ASTOL, можно при
необходимости перевести в код на языке С++ или Java.
При этом потребуется поддержка со стороны системы, ориентированной на
использование древовидного внутреннего представления, например Открытой
распараллеливающей системы. [13], [17]
Знаменитый компилятор GNU GCC
использует следующее внутреннее представление программ [14]:
Большая часть работы компилятора GCC осуществляется над промежуточным
представлением называемым Register Transfer Language (RTL).

Рисунок 1
Transfer Language используется для представления инструкций.При этом
инструкции подробно описываются в духе списка LISP.оперирует пятью типами
объектов:
· Выражения (expressions)
· Целые числа (integers)
· Длинное целое (wide integers)
· Строки (strings)
· Вектора (vectors)
RTL формат
Каждый элемент RTL имеет:
· GET_CODE: код операции
o GET_RTX_CLASS: тип RTL
o GET_RTX_FORMAT: строка с типом каждого параметра
o GET_RTX_LENGTH: количество операндов
· GET_MODE: режим
o SImode: 4-х байтное целое
o QImode: 1 байтное целое
o SFmode: 4-х байтное с плавающей точкой
· Список операндов
· Флаги

Пример RTL
· Суммирует два операнда (plus: SI (<операнд 1>) (<операнд 2>))
o Операнды рассматриваются как четырехбайтные целые (plus: SI…)
· Первый операнд - это регистр (reg: SI 8)
o Регистр хранит 4-х байтное целое (reg : SI 8)
o Номер регистра - 8 (reg: SI 8)
· Второй операнд - целое число (const_int 128)
o Значение - число ‘128’ (const_int 128)
o Режим VOIDmode (не указан)
Представление констант в RTL
(const_int i) Этот тип выражения представляет целочисленное значение i.
Пример: (const_int 128)
(const_vector:m [x0 x1 …]) Представляет вектор констант. В квадратных скобках
указаны значения, хранящиеся в векторе. M собственно указывает тип значений
Представление регистров и памяти в RTL
(reg:m n) Для малых значений n (меньших константы FIRST_PSEUDO_REGISTER)
эта запись будет означать ссылку на конкретный аппаратный регистр. Для больших
значений n это будет означать временное значение или псевдорегистр.
(mem:m addr alias) Означает ссылку на основную память по адресу addr. M
означает тип объекта к которому ведется обращение (размер). Alias означает имя
переменной.
Представление арифметических выражений в RTL
(plus:m x y) Представляет сумму значений представленных x и y для типа
m.
(compare:m x y) Представляет результат вычитания y из x с целью
сравнения.форма в GCC
Static Single Assignment Form (SSA Form)
- форма представления программы в которой любой переменной значение
присваивается не более одного раза.форма и граф управления потоком были
предложены для представления потока данных и потока управления в программе.
Каждая из этих ранее независимых технологий использовалась в классе
оптимизаций. Большое число современных алгоритмов оптимизации программ основаны
на совместном использовании графа управления и SSA-формы.
Минусы представления RTL и дерева, используемого front end, как промежуточных представлений при работе
оптимизатора
Большинство проходов работают с RTL представлением.

Рисунок 2
Почему ни RTL представление, ни дерево в Front end не подходит для современных методов
оптимизации.обладает рядом минусов. Основные из них:
· Не подходит для высокоуровневых преобразований
· Потеряна оригинальная структура программы
Можно попробовать проводить оптимизацию на деревьях Front end. Ряд алгоритмов
так и делают. Особенно, если оптимизация зависит от языка программирования.
Деревья:
· Отражают структуру исходной программы
· Поддерживают высокоуровневые (близкие к исходному коду)
преобразования
НО:
Каждый front end использует свой диалект дерева.
Представление Tree SSA
Tree
SSA - это новая система оптимизации основанная на SSA представлении и
действующая на GCC Tree
представлении. Идея заключается в использовании специального представление в
целом очень похожего на дерево, используемое в Front end, но унифицированное для всех поддерживаемых языков.
Разработчики обещают внедрить данное представление в ближайших версиях GCC. Мы
рассмотрим корни этой идеи: SSA-представление и управляющий граф.- это форма
программы в которой значение каждой переменной присваивается только один раз,
но может читаться сколько угодно раз.
Ниже показаны типичные примеры преобразования в SSA форму.
If P then V ß 4 else V ß 6 /* используем далее V*/P then V1 ß 4 else V2 ß 6
V3 ß Ф(V1,
V2) /* используем далее V3*/
В местах соединения добавляем специальное присваивание.
ß 4
ß V + 5ß 6
ß V + 7ß 4
ß V1 + 5ß 6
ß V2 + 7
Каждое присваивание значения переменной дает ей новое уникальное имя.
Управляющий граф
Предложения программы организуются в базовые блоки (не обязательно максимальные).
Базовым блоком может быть любой фрагмент кода не содержащий переходов.
Программа входит в первое предложение такого блока и выходит из последнего.
Управляющий граф (control flow graph) - это направленный граф, в вершинах
которого расположены базовые блоки, а дуги соответствуют переходам.
Преобразование в SSA
Пусть программа представлена в виде control flow graph.
Каждое предложение внутреннего представления вычисляет некоторое
выражение и использует результат для присваивания или перехода.
Преобразование программы в SSA форму - двухэтапный процесс:
На первом этапе добавляются тривиальные Ф-функции в некоторые вершины
графа управляющей логики.
На втором этапе генерируются новые переменные (находятся зависимости,
переменные получают «версии»).
Массивы
«Хитрость» работы с массивами заключается в том, что все обращения к
элементам массивом оборачиваются специальными функциями.
Исключение составляет тот случай, если язык поддерживает операции с
массивами как со скалярами (поэлементное копирование и пр.). В этом случае
переменная массива обрабатывается как обычный скаляр.
Рассмотрим случай обращения к элементу массива.
Исходный код, использующий массивы:
ß A(i)(j)ß A(i)
ß A(k) + 2
Эквивалентный код, в котором использованы специальные операторы доступа:
ß Access(A, i)(j)ß Update(A, j, V)ß Access(A, k)
ß T + 2форма:
ß Access(A8, i7)(j)ß Update(A8, j6, V5)ß Access(A9, k4)
ß T1 + 2
Применение SSA
· Продвижение констант
· Удаление «мертвого кода»
· SSA представление также используется для определения эквивалентности
программ.
Fortran-DVM
[9] использует следующее описание:
Дерево разбора
Таблица символов и Таблица типов
Элементы Таблицы символов и Таблицы типов
|
признак
|
|
идентификационный номер
|
|
индекс
|
|
глобальный номер строки
|
|
локальный номер строки
|
|
спецификатор
|
|
указатель на метку
|
|
указатель на следующий оператор
|
|
указатель на имя файла
|
|
указатель на родителя по управлению
|
|
список свойств
|
|
список вершин(список процедур)
|
|
указатель на комментарий
|
|
указатель на Таблицу символов
|
|
L-дерево выражения
|
|
R-дерево выражения
|
|
запасное поле для выражения
|
|
do-метка (используется для do)
|
|
список-по-управлению-1
|
|
список-по-управлению-2 (для if)
|
|
запасное поле
|
Вершина дерева разбора, представляющая оператор (bif node)
|
признак
|
|
идентификационный номер
|
|
указатель на следующую вершину
|
|
указатель на элемент Таблицы типов
|
|
значение костанты
|
|
указатель на элемент Таблицы символов
|
|
L-дерево выражения
|
|
R-дерево выражения
|
Вершина дерева разбора, представляющая выражение (ll -node)
|
Признак
|
признак
|
|
идентификационный номер
|
идентификационный номер
|
|
длина
|
идентификатор
|
|
запасное поле
|
ссылка на Хэш-таблицу
|
|
запасное поле
|
специальный список
|
|
список использование-определение
|
специальный список
|
|
ссылка на базовый тип(для массива)
|
специальный список
|
|
границы измерений(для массива)
|
ссылка на следующий символ
|
|
ссылка на Таблицу типов
|
|
область действия
|
|
список использование-определение
|
|
атрибуты (маска)
|
|
флаг do-переменной
|
|
используется синт.анализатором
|
|
ссылка на значение(для констант)
|
|
специальные поля
|
Элементы Таблицы типов и Таблицы символов
1.3 Задачи
потокового анализа
Анализ потоков данных предложен в работах [8], [16].
Задача:
· определение глобальных свойств программы
· проверка контекстных условий оптимизирующих преобразований
Идея:
· определение свойств исполнения программы для каждого пути в графе
управления
· выделение общей части
Способ:
· итеративный алгоритм анализа потоков данных
Под анализом потоков данных понимают совокупность задач, нацеленных на
выяснение некоторых глобальных свойств программы, то есть извлечение информации
о поведении тех или иных конструкций в некотором контексте. Такая постановка
задачи возможна по той причине, что язык программирования и вычислительная
среда определяют некоторую общую, "безопасную" семантику конструкций,
которая годится "на все случаи жизни". Учет же контекстных условий
позволяет делать более конкретные, частные заключения о поведении той или иной
конструкции; при этом такие заключения, вообще говоря, перестают быть верными в
другом контексте. Например, общая семантика присваивания заключается в
вычислении выражения, стоящего в правой части, и присваивании полученного
значения в переменную, стоящую в левой части. Однако в случае, когда выражение
в правой части не имеет побочных эффектов, а переменная в левой части более
нигде не используется, данный оператор становится эквивалентен пустому.
Для того чтобы описать понятие контекста, снова обратимся к графу потока
управления. Понятно, что на смысл каждой конструкции может оказывать влияние
любая конструкция, из которой в этом графе достижима данная. Отсюда следует,
что для правильного учета контекста необходимо учесть влияние всех путей до
данной вершины, сначала определив влияние каждого пути, а затем выделив общую
часть. Задача осложняется тем, что при наличии контуров множество всех путей в
графе управления становится бесконечным.
Далее будет рассмотрен общепринятый итеративный подход, который позволяет
получить приближенное решение задач анализа потоков данных, а при определенных
условиях это решение становится точным
Пример:
struct S {int a; int b};
int F (int n, struct S * v)
{
int i, s = 0;
for (i=0; i<n; i++)
{q = (v+i)->a - (v+i)->b;(q < 0) s += (v+i)->a +
(v+i)->b;(v+i)->b = q;
(v+i)->a = (v+i)->b;
}
return s;
}
Выше приведен фрагмент программы. Вхождения одного и того же выражения
(v+i)->b, обведенные сплошной линией, являются эквивалентными. В то же время
вхождение того же самого выражения, обозначенное пунктирной линией, не
эквивалентно первым двум, поскольку else-часть условного оператора содержит
разрушающее присваивание.
Понятно, что для выяснения эквивалентности данных выражений необходимо
перебрать все пути и убедиться, что ни в одном из них значения переменных,
входящих в выражения, не меняются.
Достижимые определения
struct S {int a; int b};
int F (int n, struct S * v)
{
int i, s = 0;
for (i=0; i<n; i++)
{q = (v+i)->a - (v+i)->b;(q < 0) s += (v+i)->a +
(v+i)->b;(v+i)->b = q;
(v+i)->a = (v+i)->b;
}
return s;
}
Достижимые определения являются одной из классических задач анализа потоков данных.
Эту задачу можно сформулировать следующим образом:
для каждого вхождения переменной требуется определить множество
присваиваний, такое, что для каждого из них существует путь, в котором между
ним и данным вхождением отсутствуют другие присваивания той же переменной.
Неформально говоря, задача достижимых определений заключается в
выяснении, где именно устанавливаются значения того или иного вхождения данной
переменной.
На слайде показан пример программы, в котором выделены вхождения
некоторых переменных и некоторые присваивания. Стрелки ведут от определений
(присваиваний) к вхождениям переменных.
Видно, что решения этой задачи достаточно для построения представления
программы с использованием def-use chains, которое необходимо для проведения
многих оптимизаций.
Живые переменные:
S {int a; int b};F (int n, struct S * v)
{i, s = 0; {n, v}(i=0; i<n; i++) {i, s, n, v}
{q = (v+i)->a - (v+i)->b; {i, s, n, v}(q < 0) s +=
(v+i)->a + (v+i)->b; {i, s, n, v, q}(v+i)->b = q;
(v+i)->a = (v+i)->b;{i, s, n, v, q}
}s;
}
Живые переменные также являются классической задачей анализа потоков данных.
В ней требуется для каждой вершины графа потока управления построить множество
переменных, обладающих следующим свойством:
существует путь через данную вершину, начинающийся присваиванием данной
переменной и кончающийся ее использованием, не содержащий иных присваиваний той
же переменной.
Пример решения данной задачи для конкретной программы показан на слайде.
В общем случае, решение данной задачи играет важную роль в распределении
регистров.
Логически процесс решения задачи анализа потоков данных состоит из двух
стадий, выполняемых одновременно.
Локальная стадия заключается в учете влияния отдельного оператора (группы
операторов в вершине графа управления) в предположении, что уже имеется решение
задачи анализа потоков данных перед этим оператором.
На глобальной стадии происходит решение задачи анализа для каждого пути,
ведущего в данную вершину и затем выделение общей части всех таких решений.
Разметки и потоковые функции:
(X, <) - множество «фактов» с отношением
частичного порядка
G = (V, E, start, stop) - граф потока управления
m : V ® X - разметка
Отношения на разметках:
m1= m2 Û "vÎV m1(v)=m2(v)
m1< m2 Û "vÎV m1(v)<m2(v)
m1 £ m2 Û "vÎV m1(v)<m2(v) или m1(v)=m2(v)
F: (V ® X) ® (V ® X) - функция перехода
ms - неподвижная точка F Û F(ms)= ms
Шаги, необходимые для решения задачи анализа потока данных с помощью
итеративного подхода:
· формализовать решение задачи с помощью подходящей полурешетки
· описать преобразование потоков данных при проходе через вершину
графа управления с помощью монотонной, а лучше дистрибутивной функции
· применить итеративный алгоритм.
1.4 Методы
потокового анализа
В работе [16] предложен следующий подход:
Фиксируется некоторое частично упорядоченное множество "фактов"
(утверждений о свойствах программы) X. Отображение m, сопоставляющее вершинам графа
управления элементы X, назовем разметкой. Поточечное распространение отношений
равенства и порядка вводит аналогичные отношения на множестве разметок.
Функцией перехода называется отображение F, которое переводит одну
разметку в другую. Разметка ms называется неподвижной точкой отображения F тогда и только тогда, когда
F(ms)=ms.
Неформально говоря, разметка представляет собой некоторый набор потоковых
утверждений (т.е. утверждений о свойствах потоков данных) для каждой вершины
графа. Решение задачи в этом случае также может быть представлено с помощью
такой разметки, а процесс решения задачи анализа потоков данных может быть
описан как последовательное уточнение разметки, отталкиваясь от некоторой
начальной.
Итеративный алгоритм
(X, <) - множество конечной высоты
N:
"{x1, x2, ....}, xiÎX, xi<xi+1 "k, l (k>N)&(l>N) Þ xk=xl
F -
функция перехода:
" m F(m) ³ m
Итеративный алгоритм:
m0 - начальная разметка
mc=m0
while
(F(mc)¹ mc) do mc =F(mc);
Основной проблемой описанного выше подхода является проблема остановки
алгоритма. Процесс уточнения разметки должен прекратиться, в тот момент, когда
получено решение задачи анализа потоков данных. Однако поскольку решение задачи
неизвестно, то и воспользоваться этим наблюдением напрямую оказывается
невозможным. Поэтому для определения завершаемости алгоритма используется
другой принцип - принцип достижения неподвижной точки.
Частично-упорядоченное множество X называется множеством конечной высоты
N тогда и только тогда, когда длины всех строго возрастающих
последовательностей элементов X ограничены N. Это означает, что для
произвольной возрастающей последовательности начиная с некоторого места все
элементы становятся одинаковыми.
Функция перехода F, удовлетворяет соотношению F(m)³m для произвольной разметки m. При таком условии при итерировании F, начиная с
некоторого места, будет достигнута ее неподвижная точка. Множество X и функция
перехода F подбираются таким образом, чтобы эта неподвижная точка являлась
решением задачи анализа потоков данных.
Полурешетки
L -
множество c операцией Ù:
xÙx = x
· xÙy = yÙx
· x(ÙyÙz)=(xÙy)Ùz
Индуцированное отношение порядка:
x£y Û xÙy=x
Ограниченная полурешетка:
верхняя и нижняя грани:
^L: "xÎL ^L£ x
TL: "xÎL x£ TL
Монотонные функции:
f : L®L: x£y Þ f(x)£f(y)
Дистрибутивные функции:
f : L®L: f(xÙy) = f(x)Ùf(y)
Полурешеткой называется множество, снабженное идемпотентной,
коммутативной и ассоциативной операцией Ù (определение свойств этой операции приведено на
слайде). При наличии такой операции естественным образом индуцируется отношение
частичного порядка.
Полурешетка L называется ограниченной тогда и только тогда, когда в ней
существуют наибольший TL и наименьший ^L элементы.
Функция f называется монотонной, если она сохраняет отношение порядка и
дистрибутивной, если она является гомоморфизмом относительно полурешеточной
операции. Можно показать, что дистрибутивная функция всегда монотонна.
Неподвижные точки монотонной функции
L -
ограниченная полурешетка конечной высоты
f : L®L - монотонная функция Þ
· $xÎL : f(x)=x
Lf={xÎL : f(x)=x} - ограниченная полурешетка конечной
высоты=fn(^) - наименьшая
неподвижная точка, где
f0(x)=x(x)=f(fn-1(x))
Пусть L - ограниченная полурешетка конечной высоты, f - монотонная функция.
Можно показать тогда, что
· функция f обладает хотя бы одной неподвижной точкой
· множество всех неподвижных точек f является ограниченной
полурешеткой конечной высоты
· наименьшая неподвижная точка f может быть получена
итерированием функции f начиная с наименьшего элемента L
Пример
A={a, b, c, d, ..., z}
L=2A - ограниченная полурешетка конечной
высоты |A|
· xÙy=xÇy
· TL=A
· ^L=Æ
f(x)=xÈ{a} - монотонная функция
· TLf=A
· ^Lf={a}
Lf={x : aÎx}
В качестве примера ограниченной полурешетки конечной высоты
рассматривается множество всех подмножеств букв латинского алфавита с операцией
пересечения. Данная полурешетка является ограниченной - в качестве наибольшего
элемента выступает множество всех букв, в качестве наименьшего - пустое
множество. Так как множество всех букв конечно, то высота данной полурешетки
также будет конечной.
Функция, которая к своему аргументу добавляет букву a, является
монотонной. Наименьшей неподвижной точкой этой функции является множество,
состоящее из единственной буквы a, множество всех ее неподвижных точек есть
множество подмножеств букв, содержащих букву a.
Произведение полурешеток
L1, L2, ...., Lk - ограниченные полурешетки конечной высоты Þ
L=L1´L2´....´Lk={<x1, x2,
..., xk>, xiÎLi}
ограниченная полурешетка конечной высоты:
· <x1,x2,...,xk>Ù<y1,y2,...,yk>=<x1Ùy1,x2Ùy2,...,xkÙyk>
· <x1,x2,...,xk> £ <y1,y2,...,yk>Û(x1£y1)&(x2£y2)&...&(xk£yk)
· TL=<TL1,TL2,...,TLk>
· ^L=<^L1,^L2,...,^Lk>
f1,f2,...,fk - монотонные функции на L1, L2,
..., Lk Þ
f(<x1,x2,...,xk>)=<f(x1),f(x2),...,f(xk)> -
монотонная функция на L
Если L1,L2,...,Lk - ограниченные полурешетки конечной высоты, то такую же
структуру можно ввести и на декартовом произведении этих полурешеток, определяя
соответствующие понятия (операцию, наибольший и наименьший элементы)
покомпонентно.
Набор монотонных функций f1,f2,...,fk соответственно на полурешетках
L1,L2,...,Lk аналогичным образом индуцирует монотонную функцию на их декартовом
произведении.
Формализация задачи анализа потоков данных
граф потока управления G
ограниченная полурешетка конечной высоты L
"vÎV fv : L®L-
монотонная функция перехода
разметка before : V®L
разметка after : V®L
· наименьшее решение системы уравнений
/before(v)=ÙwÎpred(v)after(w) /
/after(v)=fv(before(v)) /(*)
Пусть есть ограниченная полурешетка конечной высоты L, граф потока
управления G и набор монотонных на L потоковых функций fv для каждой вершины v
графа G.
Тогда решением задачи анализа потоков данных называется пара наименьших
разметок before, after, являющихся решением системы уравнений (*), приведенной
на слайде.
Неформально говоря, полурешетка L представляет собой множество потоковых
фактов, разметка before описывает решение задачи анализа потоков данных до
исполнения операторов в данной вершине графа, а разметка after - после. Решеточная
операция описывает получение общей части нескольких решений. Систему уравнений
можно интерпретировать следующим образом: для каждой вершины решением задачи до
нее является общая часть решений всех предшественников данной вершины, а после
нее - применение к этой общей части потоковой функции, ассоциированной с данной
вершиной.
1.5
Теоретические свойства методов
Свойства итеративного подхода [16]:
· Нахождения точного решения задачи анализа потоков данных неразрешимо
Если все fv -
дистрибутивны, то наименьшая неподвижная точка F есть точное решение задачи анализа потоков данных
Может быть показано, что нахождение точного решения задачи анализа
потоков данных (т.е. наименьшего общего набора свойства при исполнении по всем
путям до данной вершины) неразрешимо. Таким образом, итеративный подход дает
только приближенное решение.
В случае, когда все потоковые функции не просто монотонны, но и
дистрибутивны, итеративное решение является точным.
Алгоритм с рабочим списком:
void Traverse (W: list<Vertex>) {
if (W is empty) return;
else {v = any of W;= W \ {v};= fv(ÙwÎpred(v)after(w));
if (after ¹ after (v)) {(v) = after;= W È succ(v);
}
}(W);
}
void DFA (G: CFG, L: Semilattice) {
for "vÎV do before(v)=after(v)=^L; ({start});
}
1.6 Опыт
реального применения распараллеливающего компилятора
Рассмотрим некоторые компиляторы.
Достижения компилятора Intel [10]:
Согласно результатам прогона тестов SPEC CPU2000, опубликованным на
сервере ixbt.com, компиляторы Intel версии 6.0 практически везде оказались
лучше по сравнению с компиляторами gcc версий 2.95.3, 2.96 и 3.1, и PGI версии
4.0.2. Эти тесты проводились в 2002 году на компьютере с процессором Pentium
4/1.7 ГГц и ОС RedHat Linux 7.3.
Согласно результатам тестов, проведенных компанией Polyhedron, компилятор
Intel Fortran версии 7.0 почти везде оказался лучше по сравнению с другими
компиляторами Fortran 77 для Linux (Absoft, GNU, Lahey, NAG, NAS, PGI). Только в некоторых
тестах компилятор Intel
незначительно проигрывает компиляторам Absoft, NAG и Lahey. Эти тесты были
проведены на компьютере с процессором Pentium 4/1.8 ГГц и ОС Mandrake Linux 8.1.
Поддержка стандартов
Компилятор Intel C++ Compiler 7.0 for Linux поддерживает стандарт языка Си ANSI/ISO (ISO/IEC
9899/1990). Возможно установка строгой совместимости со стандартом ANSI C
(-ansi) или расширенного диалекта ANSI C (-Xa). При использовании опции -c99
поддерживается некоторое подмножество стандарта C99: ключевое слова restrict,
массивы переменной длины, комплексные числа, объявления переменных в
произвольных местах кода, макро-определения с переменным числом аргументов,
inline-функции, булевский тип и др.
Поддерживается стандарт ISO/IEC 14882:1998 языка С++.
Компилятор Intel Fortran Compiler 7.0 for Linux поддерживает спецификацию ISO Fortran 95, а также совместим на уровне
исходных текстов с компилятором Compaq Visual Fortran 6.6.
Несомненно, в настоящее время среди свободно распространяемых открытых
компиляторов самым развитым является компилятор GCC [14]. Это
перенацеливаемый (как по входному языку, так и по целевой архитектуре)
компилятор доступный по лицензии GPL.
Отметим некоторые характерные черты данного компилятора:
· Поддерживает большое число языков и машинных архитектур:
o Языки: С, С++, Ada95 (GNAT), Fortran 77, Fortran
95, Pascal, Modula-2, Modula-3, Java, Cobol, Chill (Cygnus).
o Архитектуры: ARM, Alpha (DEC), Intel x86, Motorola 680x0, 68C11,
DSP56000, Hitachi SH и H8300, MIPS, IBM PowerPC,
HP PA-RISC, SUN SPARC, IA64, AMD x86-64.
· По качеству не уступает многим известным компиляторам (в том числе и
коммерческим). Так, на Alpha результаты работы GCC сравнимы с компилятором от
DEC.
· GCC является постоянно развивающимся проектом. Отметим
основные направления работы по развитию компилятора:
o реализация новых языков программирования;
o реализация новых алгоритмов оптимизации;
o улучшение библиотек времени исполнения;
o ускорение процесса отладки.
1.7
Средства реализации распараллеливающего компилятора
В качестве инструментального средства разработки компилятора Fortran-DVM [9] используется система Sage++.
Sage++ представляет собой объектно-ориентированную инструментальную
систему для построения систем преобразования программ на языках Фортран, Си и
Си++. Она является открытой библиотекой классов Си++, которая предоставляет
пользователю набор синтаксических анализаторов, дерево разбора, таблицы
символов и типов. Ядро системы составляет набор функций для реструктурирования
дерева разбора и механизм (называемый unparsing) для генерации нового кода по реструктурированному
внутреннему представлению.
Компилятор FDVM состоит из четырех компонент:
· Синтаксический анализ
· Преобразование дерева разбора
· Генерация кода на языке Фортран 77
· Генерация кода на языке HPF
Синтаксический анализ
Синтаксический анализатор системы Sage++ для Фортрана, который базируется на GNU Bison версии языка YACC, расширен средствами обработки директив DVM.
Синтаксический анализатор читает исходный файл, проверяет синтаксис, строит
дерево разбора и записывает его внутреннее представление.
Преобразование дерева разбора
Вторая фаза компиляции включает анализ и реструктурирование внутреннего
представления FDVM-программы. Директивы DVM заменяются последовательностями
вызовов функций системы поддержки Lib-DVM. Затем новый код генерируется по
модифицированному внутреннему представлению.
Программа “back-end” написана на языке C++ с использованием библиотеки
классов Sage++.
Библиотека Sage++
организуется как иерархия классов, которая обеспечивает доступ к дереву
разбора, Таблице символов и Таблице типов каждого файла из прикладного проекта.
В библиотеке имеется пять основных семейств классов: Project и Files,
Statements, Expressions, Symbols, Types.
Project
и Files соответствуют исходным файлам. Statements соответствуют операторам языка
Фортран и директивам DVM. Expressions - это выражения, содержащиеся в
операторах. Symbols являются объявленными пользователем
идентификаторами. Types представляют
типы, которые ассоциируются с каждым идентификатором и выражением.
Описания всех классов содержатся в файле libSage++.h.
Семь модулей составляют транслятор:
· dvm.cpp -
анализ и трансляция конструкций языка FDVM
· funcall.cpp -
генерация вызовов функций библиотеки Lib-DVM
· stmt.cpp -
реструктурирование дерева разбора
· io.cpp - трансляция
операторов ввода-вывода
· debug.cpp -
поддержка отладочного режима
· help.cpp -
вспомогательные подпрограммы
· hpf.cpp -
трансляция конструкций языка HPF-DVM
Генерация кода на языке Фортран 77
Генерация нового кода на языке Фортран 77 по модифицированному
внутреннему представлению осуществляется посредством функции unparse( ) класса File из библиотеки классов Sage++.
Генерация кода на языке HPF
Когда исходная FDVM-программа
конвертируется в программу на языке HPF, следующие подпрограммы и таблицы используются:
· unparse_hpf.c - подпрограммы генерации кода на
языке HPF
· low_hpf.c - подпрограммы нижнего уровня,
используемые для генерации
· unparse.hpf -
таблица, управляющая генерацией кода на языке HPF2
· unparse1.hpf -
таблица, управляющая генерацией кода на языке HPF1
1.8
Компиляция с переменным набором оптимизирующих преобразований
В компиляторе GCC оптимизация управляется с помощью флагов [23].
Перечисленные ниже опции управляют оптимизацией.
Если никакие опции оптимизации не используются, цель компилятора состоит
в том, чтобы сократить «стоимость» компиляции и получить ожидаемые результаты
от отладки. Операторы независимы: если вы остановите программу в точке
прерывания между операторами, то можете присвоить новое значение любой
переменной или изменить значение счетчика команд на адрес другого оператора в
функции и получить в точности те результаты, которых вы ожидаете.
При включенных флагах оптимизации компилятор пытается улучшить
производительность программы и/или уменьшить размер кода, жертвуя временем
компиляции и, может быть, возможностью отладки программы.
Компилятор производит оптимизацию, основываясь на том, что он знает о
программе. На уровнях оптимизации -O2 и выше, в частности, становится доступен
режим unit-at-a-time, позволяющий компилятору учитывать информацию о следующих
функциях файла при компиляции текущей. Компиляция нескольких исходных файлов в
один выходной в режиме unit-at-a-time позволяет компилятору использовать
информацию, собранную при компиляции каждого файла в отдельности.
Не все оптимизации контролируются флагами. Описаны только те, которым
соответствует какой-либо флаг.
Флаги
оптимизации -On (комбинации флагов -f флаг)
O1
Оптимизировать.
Оптимизирующая компиляция занимает немного больше времени и немного больше
памяти для больших функций. С флагом -O компилятор пытается уменьшить размер
кода и время исполнения, не используя оптимизации, отнимающие много времени.
O2
Оптимизировать
больше. GCC представляет почти все из доступных оптимизаций, которые не влияют
на размер кода. На включается развертка циклов. эта компиляция увеличвает время
компиляции и сгенерированный код.
O3
Больше
оптимизаций. -O3 включает все оптимизации -O2 а так же
-finline-functions,
funswitch-loops
fgcse-after-reload options.
-O0
Не
оптимизировать. По-умолчанию.
Os
Оптимизация
размера. -Os включает -O2 оптимизации, не увеличивающие размер исходного кода.
Так же включает другие оптимизации, уменьшающие размер кода.
Оптимизация
для архитектуры процессора
Так
же имеется возможность встраивать специальные оптимизации процессора или
архитектуры. Например, одна архитектура может иметь множество регистров. Это
может быть интеллектуально использовано в алгоритме перемещения регистра, для
хранения временных переменных между вычислениями. Данная оптимизация призвана
минимизировать количество доступов к кэшу и памяти, что позволяет обеспечивать
необходимое для процессороёмких операций быстродействие.
ACOVEA
[18] использует генетический алгоритм
для нахождения лучшего набора оптимизаций.
Генетический
алгоритм - это итеративный процесс, основанный свободно на биологической
эволюции через естественный отбор. Популяция «организмов» проверяется на
заданной проблеме и получает значение «здоровья», основанное на уровне успеха;
затем генерируется новое поколение организмов, причем более здоровые
«организмы» имеют большие шансы на размножение. У представителей нового
поколения могут появляться мутации. Затем процесс повторяется, пока не будет
получено определенное число поколений, или не будет достигнут ожидаемый
результат.
Код
на C++ к этой статье основан на последней версии библиотеки классов Evocosm.
Сам
генетический алгоритм AVOCEA прямой: начальная популяция состоит из случайных
наборов опций компилятора («организмов»), как предусмотрено объектом
компилятора. В AVOCEA 4.0.0 компилятор определятся XML-файлом.
В
каждом поколении, gccacovea компилирует исполняемый файл для каждого набора
опций. При выполнении, эталонные тесты замеряют время своих критических циклов
внутренне, используя clock_gettime, отправляя результата обратно gccacovea как
их «здоровье». Маленькое значение (меньшее время выполнения) означает большее
«здоровье» и большую вероятность воспроизведения; мутация и миграция между
популяциями вносит вариации для предотвращения стагнации популяции. В сущности,
нахождение лучшего набора опций для GCC - это классическая задача
минимизации.конфигурации компилятора
Файл
конфигурации - это XML-документ, устанавливающий опции и команды, по умолчанию
и эволюционирующие, для заданного компилятора и платформы. Например,
конфигурация gcc34_opteron.acovea предназначена для GCC версии 3.4, работающего
на 64-битной системе AMD Opteron.
Об
анализе
Так
как генетический алгоритм циклически проходит через поколения, то он отсеивает
лучший набор опций с помощью естественного отбора; опции, дающие быстрый код
будут появляться чаще, в то время как неблагоприятные опции будут иметь
тенденцию к исчезновению. Опции, не имеющие влияние на скорость кода, будут
появляться, вследствие случайности, примерно в 50% случаев. Нельзя просто
сказать, что «лучшие» опции те, что включены у лучшего «организма», потому что
среди них могут быть «нулевые» (не затрагивающие данный код) опции, не влияющие
на производительность.
Как
определить, какие опции действительно важны среди шума «нулевых» опций?
По
ходу выполнения, AVOCEA считает число раз, которое опция была включена у лучшей
хромосомы в каждом поколении каждой популяции. По умолчанию AVOCEA развивает
пять популяций из сорока представителей в течение двадцати поколений; если
опция включена каждым организмом в каждом поколении, счет будет 50 (?); чем
больший счет, чем большее число раз опция была включена, тем важнее опция для
получения быстрого кода на данном эталонном тесте. Наоборот, опция, которая
вредна, будет появляться очень редко (или вовсе не появится), в то время как
нейтральные опции (которые не оказывают влияния на скорость кода) должна
появляться среднее число раз (потому что не имеет значения, включена она или
нет).
Когда
AVOCEA завершит прогон тестов, она отобразит «полезные» и «вредные» опции,
набор предложенных решений и маленькую диаграмму сравнения производительности
этих предложенных решений на базовых тестах. Например, когда тестируется
компилятор, AVOCEA сравнивает результаты своих решений с результатами,
полученными при использовании параметров компилятора -O1, -O2 и -O3.
Генерируется изящно маленькая текстовая диаграмма, показывающая сравнительную
производительность. Будущая версия AVOCEA-GTK будет предоставлять наглядные
столбики.
Чтобы
различать «полезные» и «вредные» опции, берутся финальные суммы и вычисляется
«z-счет» для каждой опции. Z-счет измеряет разницу между значением и средним по
популяции в единицах среднеквадратичного отклонения. Если z-счет опции больше
единицы, считается, что она может быть полезна, когда z-счет меньше или равен
-1 - это указывает на то, что опция вредна. В общем, большее число прогонов
(большее число больших популяций развивается в течение большего числа
поколений) будет усиливать разницы между «хорошими» и «плохими» опциями, причем
некоторые достигнут z-счета равного 3 и более.
Управляемый
пакет оптимизаций [5] - это пара <P,M>,
где Р - пакет оптимизаций, а М - менеджер пакета оптимизаций. Пакет оптимизаций
представляет собой набор оптимизаций с одним и тем же объектом применения.
Менеджер оптимизаций определяет порядок запуска оптимизаций пакета. Он может
выполнять дополнительный анализ на применимость и эффективность оптимизаций,
входящих в пакет. Помимо этого, менеджер оптимизаций может сам выполнять ряд
преобразований промежуточного представления, имеющих тот же тип, что и элементы
пакета. Например, если объект оптимизации - операция, то менеджер пакета может
преобразовать узел управляющего графа, если - цикл, то преобразуется дерево
циклов. В этом случае у оптимизаций пакета есть возможность не выполнять
преобразования, а заказать композицию преобразований своему менеджеру.
Далее
приведем конкретные примеры управляемых пакетов оптимизаций, реализованных в
компиляторе.
Пакет
низкоуровневых оптимизаций на потоке данных.
Объектом
применения оптимизаций пакета является операция. Дадим краткое описание
оптимизаций, входящих в пакет.
· удаление мертвого кода. Удаляются операции, результаты которых далее
нигде не используются, а потому их присутствие не влияет на поведение программы
при исполнении.
· подстановка констант. Если удалось определить, что
результатом операции является константа, то операция удаляется, а константа
подставляется в места использования результата операции.
· сбор общих подвыражений. Если имеются две эквивалентные
операции, то одна из них удаляется, а во все места ее использования
подставляется результат второй. Если операции выполняются условно, то
оставшаяся операция рассматривается как предикат, равный логическому или
предикатов эквивалентных операций.
· эквивалентные преобразования выражений, состоящих из операций
представления. Например, х+0=х, х*1=х
· удаление избыточных записей в память. Обрабатываются два
случая. В первом записываемое значение является результатом чтения из памяти,
ранее выполненного по тому же адресу, и между этим чтением и записью нет
операций, модифицирующих ту же ячейку памяти. Здесь операция записи является
избыточной и потому удаляется. Во втором случае за первой операцией записи
следует другая запись (с не меньшим форматом) по тому же адресу, причем между
двумя этими операциями нет операции чтения из этой ячейки памяти. Здесь
удаляется первая операция записи.
· удаление избыточных операций чтения из памяти. Если операции
чтения можно поставить в соответствие предшествующую запись в память по тому же
адресу (с форматом, не меньшим, чем у этой операции чтения) и между этими
операциями нет других, записывающих по тому же адресу, то операция чтения
удаляется, а в местах ее использования подставляется записанное ранее значение.
Опишем менеджер пакета, включающего приведенные оптимизации. Минимальным
объектом его применения является узел управляющего графа, максимальным - вся
процедура. При обработке процедуры узлы управляющего графа обходятся в порядке,
который обеспечивает то свойство, что при переходе к следующему узлу, все его
предшественники в графе уже пройдены (при этом обратные дуги не учитываются).
Внутри узла операции обрабатываются в порядке их следования. Последовательность
операций узла можно упорядочить по некоторому правилу и использовать это
свойство при оптимизации. Далее для каждой операции запускается пакет
оптимизаций в том порядке, в котором они были представлены выше. Запуск пакета
для операции осуществляется в цикле, условием которого является неприменимость
ни одной из оптимизаций или удаление операции.
Оптимизации пакета не выполняют преобразования промежуточного
представления, а заказывают набор преобразований у менеджера пакета. Менеджер
пакета предоставляет следующие типы преобразования промежуточного представления:
· Подстановка вместо результата операции константы;
· Удаление операции по одному из правил;
· Замена результата операции на результат уже существующей
операции;
· Замена результата операции на результат дерева новых
операций, когда новые операции создаются по некоторому их формальному описанию.
Вынесение преобразований с уровня оптимизаций на уровень менеджера пакета
имеет много преимуществ. Во-первых, усиливается контроль над оптимизациями и
увеличивается гибкость пакета по отношению к изменениям промежуточного
представления. Зная тип преобразования, которое необходимо выполнить, менеджер
может в зависимости от контекста, в котором он вызывается, отменять ту или иную
оптимизацию, некорректную в этом контексте. Поскольку все преобразования
выполняет менеджер, при изменении свойства промежуточного представления
достаточно отразить это изменение только в нем. Во-вторых, многие потоковые
оптимизации существенно различаются только анализом и сильно пересекаются по
типам преобразований, применяющихся в низкоуровневых оптимизациях, и их
поддержка менеджером пакета избавляет от излишнего дублирования текстов и
существенно облегчает отладку компилятора.
Управляемый пакет оптимизаций имеет высокую эффективность при
сравнительно небольших затратах по времени. Большинство оптимизаций использует
одинаковые структуры данных, требующие инициализации. При объединении
оптимизаций в пакет инициализация дополнительных структур делается один раз.
Известно, что применение одних оптимизаций дает возможность применять другие.
Добиться эффективности, соизмеримой с эффективностью управляемого пакета, можно
многократными вызовами отдельных оптимизаций, но этот способ требует больших
временных ресурсов. В управляемом пакете управляемые вызовы осуществляются
только для тех операций, которые этого требуют. Для большинства операций
делается всего один проход по всем оптимизациям.
Пакет цикловых макрооптимизаций.
Объектом применения оптимизаций пакета является цикл. Перечислим
оптимизации, входящие в пакет.
· слияние внутреннего цикла с охватывающим циклом.
· перестановка циклов.
· полная раскрутка цикла.
· частичное повторение тела цикла (открутка).
· расщепление цикла по инвариантному условию. Для цикла
создается точная копия. Управление передается на цикл или его копию в
зависимости от предиката инвариантного условия. В цикле инвариантное условие
считается тождественной истиной, в копии - тождественной ложью.
· расщепление цикла по индексу. Если в цикле имеется условие,
ограничивающее изменение его индуктивной переменной, то он разбивается на два
цикла. В первом ограничение, заданное условием, берется в качестве верхней
границы, во втором - в качестве нижней. В обоих циклах убираются вычисления,
соответствующие условию выхода значения индуктивной переменной за ее границы.
· расщепление цикла по произвольному условию. В случае более
общего условия для некоторого условия класса циклов возможно расщепление одного
класса на три. Первый цикл не содержит альтернатив условия. Второй цикл
содержит первую альтернативу условия. Третий цикл вторую альтернативу условия.
Число итераций первого цикла равно числу итераций исходного цикла. Среднее
число итераций второго цикла равно среднему числу повторений первой
альтернативы. Среднее число итераций третьего цикла равно среднему числу
повторений второй альтернативы. Значения переменных исходного цикла,
используемых в альтернативах, запоминаются в массивы в первом цикле и
считываются во втором и третьем циклах.
· разрыв статически неразрешенных зависимостей по памяти. Во
многих случаях для пары операций чтения или записи, заданных в цикле,
невозможно статически определить, могут ли они обращаться к одной и той же
ячейке памяти во время исполнения. Иногда вне цикла можно сформировать цепочку
условий, выполнимость которых обеспечивает независимость по памяти некоторых
пар. В этом случае строится точная копия цикла, в которой указанные пары
операций считаются независимыми; на нее передается управление в случае
истинности цепочки условий.
Объектом применимости управляемого пакета является дерево циклов.
· Основные задачи:
· минимизировать время оптимизации цикловых участков.
· не допускать значительного роста кода, при этом эффективно
используя оптимизации, активно дублирующие циклы.
· разрешение конфликтов между оптимизациями.
Обработка дерева циклов происходит от листьев к корню.
В работе [10] рассматривается компилятор Intel:
Компилятор языка Си использует runtime-библиотеку, разработанную в рамках
проекта GNU (libc.a).
Вместе с компилятором Intel C++ поставляются следующие библиотеки:
· libcprts.a - runtime-библиотека языка С++ разработки Dinkumware.
· libcxa.a - дополнительная runtime-библиотека для С++
разработки Intel.
· libimf.a - библиотека математических функций разработки
Intel, в которую входят оптимизированные и высокоточные реализации
тригонометрических, гиперболических, экспоненциальных, специальных, комплексных
и других функций.
· libirc.a - runtime-поддержка профилировки (PGO) и
"диспетчеризации" кода в зависимости от процессора (см. выше).
· libguide.a - реализация OpenMP.
|
Уровни оптимизации
|
|
Опция
|
Описание
|
|
-O0
|
Отключает оптимизацию
|
|
-O1 или -O2
|
Базовая оптимизация на скорость работы. Отключается
инлайн-вставка библиотечных функций. Для компилятора С++ эти опции дают
одинаковую оптимизацию, для компилятора Фортрана опция -O2 предпочтительнее,
т.к. включает еще раскрутку циклов.
|
|
-O3
|
Более мощная оптимизация, включая преобразования циклов,
предвыборку данных, использование OpenMP. На некоторых программах может не
гарантироваться повышенная производительность по сравнению с -O2. Имеет смысл
использовать вместе с опциями векторизации -xK и -xW.
|
|
-unroll[n]
|
Включает раскрутку циклов до n раз.
|
|
Оптимизации под конкретный процессор
|
|
Опция
|
Описание
|
|
-tpp6
|
Оптимизация для процессоров Penitum Pro, Pentium II и
Pentium III
|
|
-tpp7
|
Оптимизация для процессоров Penitum 4 (эта опция включена
по умолчанию для компилятора на IA-32)
|
|
-xM
|
Генерация кода с использованием расширений MMX,
специфических для процессоров Pentium MMX, Pentium II и более поздних
|
|
-xK
|
Генерация кода с использованием расширений SSE, специфических
для процессоров Pentium III
|
|
-xW
|
Генерация кода с использованием расширений SSE2,
специфических для процессоров Pentium 4
|
|
Межпроцедурная оптимизация
|
|
-ip
|
Включается межпроцедурная оптимизация внутри одного файла.
Если при этом указать опцию -ip_no_inlining, то отключаются инлайн-вставки
функций.
|
|
-ipo
|
Включается межпроцедурная оптимизация между различными
файлами
|
|
Оптимизации с использованием профилей
|
|
-prof_gen
|
Генерируется "профилировочный" код, который будет
использован для профилировки, т.е. сбора данных о частоте прохождения тех или
иных мест в программе
|
|
-prof_use
|
Производится оптимизация на основе данных, полученных на
этапе профилировки. Имеет смысл использовать вместе с опцией межпроцедурной
оптимизации -ipo.
|
|
Распараллеливание для SMP-систем
|
|
-openmp
|
Включается поддержка стандарта OpenMP 2.0
|
|
-parallel
|
Включается автоматическое распараллеливание циклов
|
В этом списке перечислены статических библиотек, но для большинства из
них существуют также динамические, т.е. подключаемые во время запуска, варианты
(.so).
Вместе с компилятором Фортрана поставляются следующие библиотеки:
libCEPCF90.a, libIEPCF90.a, libintrins.a, libF90.a, также используется
библиотека математических функций libimf.a.
В ОРС [17] библиотека преобразований выделяется в отдельную
самостоятельную часть. Такая самостоятельность позволяет библиотеке уделять
больше внимания, преобразования классифицировать и группировать, сформировать
специальную архитектуру библиотеки, систему тестов для преобразований.
Преобразования программ образуют алгебраическую структуру в том смысле,
что последовательное выполнение двух преобразований опять является
преобразованием программ. Для некоторых преобразований программы существует
обратное (композиция исходного преобразования с обратным не меняет программы).
Всякое преобразование по форме представляет собой одну из редакторских
операций: вставить, удалить, найти, заменить, скопировать. Поэтому должны быть
процедуры, выполняющие такие преобразования над программой во внутреннем
представлении. Следует отметить, что такие операции нужны как над операторами,
так и над выражениями (подвыражениями).
Всякое преобразование должно сохранять синтаксическую и семантическую
корректность. Это означает, например, что нельзя менять местами в тексте
программы тело цикла и заголовок. Приведем пример и менее очевидной ошибки.
Если при развертке цикла копируется тело цикла, в котором есть операторы с
метками, то могут получиться два оператора с одной и той же меткой (чего не
допускает синтаксис ФОРТРАНа).
Программа, полученная после преобразования, должна быть эквивалентна
исходной (на одинаковых входных данных должны получаться одинаковые
результирующие данные). Эквивалентность преобразований отслеживается с помощью
какой-либо модели информационных зависимостей.
Преобразование должно быть целесообразным. Это означает, что после
преобразования качество программы должно повыситься. Бывают преобразования,
которые для одних архитектур компьютеров повышают быстродействие, а для других
- понижают. Например, та же развертка цикла эффективна для суперкомпьютеров с
VLIW-архитектурой, но может оказаться невыгодной для векторной.
Библиотека преобразований программ состоит из нескольких уровней.
Верхний уровень - оптимизирующие (распараллеливающие) преобразования. Эти
преобразования могут представлять собой композицию вспомогательных
преобразований. Например, вынос инварианта из цикла может быть получен в два
приема. Сначала выполняется разрезание цикла на два, в теле первого из
полученных циклов должен быть инвариантный оператор, а в теле другого -
остальные. Теперь у первого цикла следует удалить заголовок - и получится
искомое преобразование.
Нижний уровень - упомянутые выше редакторские преобразования.
Есть еще вспомогательные преобразования, вроде перестановки операторов
присваивания (такая перестановка сама по себе ценности не представляет, но
может быть полезна, например, при векторизации или при разрезании цикла).
Иногда одно оптимизирующее преобразование может играть роль вспомогательного
преобразования для другого.
Проверка эквивалентности обратного преобразования может сводиться к
проверке эквивалентности прямого (исходного). Например, для проверки
эквивалентности слияния циклов достаточно выполнить это слияние и проверить,
можно ли к нему применить разбиение цикла.
Самыми первыми должны выполняться канонизирующие преобразования,
приводящие элементы программы к стандартному виду.
Оптимизирующие (распараллеливающие) преобразования бывают локальными и
глобальными. В многочисленных публикациях описаны десятки таких преобразований.
Иногда на этапе компиляции трудно определить эквивалентность
преобразований. Это может быть, например, по той причине, что заранее не
определены значения внешних переменных или индексные выражения нелинейным
образом зависят от счетчиков объемлющих циклов. В этом случае могут быть
использованы методы динамической оптимизации.
При преобразованиях программ, как правило, текст программы разрастается.
Появляются новые операторы и выражения, которые, в свою очередь, могут
содержать новые переменные, метки, константы, функции. Поэтому разработан
генератор новых имен переменных, меток, констант и функций.
В распараллеливающем компиляторе множество преобразований ориентировано
на получение эффективного кода одного заранее заданного суперкомпьютера. В
распараллеливающей системе библиотека представляет собой самостоятельную
ценность. Это позволяет сосредоточиться на изящности архитектуры библиотеки,
что в конечном счете скажется на качестве.
Выводы из
обзора
Потребность в распараллеливающих компиляторах появилась практически сразу
с началом работы над параллельными архитектурами, поскольку появилась
необходимость в адаптации накопленного багажа последовательных алгоритмов к
параллельным архитектурам. Такая потребность существует сейчас и вполне
закономерно будет существовать и в будущем (человек принципиально эффективнее
генерирует последовательные алгоритмы).
Основной задачей распараллеливающего компилятора является выявление
скрытого (как правило) или явного (что редко) параллелизма. Такой анализ
проводится не по самому тексту программы, по ее модели.
В мире предложено уже много различных схем для последовательных,
оптимизирующие преобразования описываются в терминах различных схем программ,
что затрудняет объединение преобразований в рамках одного транслятора. Поэтому
возникает проблема стандартизации системы понятий для описания схемы программы,
в терминах которой можно было бы описывать все возможные оптимизирующие
преобразования, направленные на улучшение параллельности.
Задача выявления параллелизма в большинстве случаев сводится к задаче
определения различных типов зависимости между участками программы и итерациями
циклов.
Результаты потокового анализа по выявлению параллелизма используются для
применения оптимизирующих преобразований из класса реструктурирующих. В общем
случае этот класс направлен на эквивалентное преобразование программы,
позволяющее впоследствии ее распараллелить. Наиболее часто в трансляторах
используются следующие преобразования: перестановка циклов, слияние циклов,
разбиение цикла, распределение циклов. Множество используемых на практике
преобразований постоянно расширяется. Этому процессу в немалой степени
способствует появление компьютеров новой архитектуры.
Несмотря на то, что проблема оптимизации программ для компьютеров с
параллельной архитектурой существует уже более 20 лет, ее решение до сих пор
нельзя считать удовлетворительным. Было предложено много различных подходов к
оптимизации, но ни один из них не предполагает комплексного решения всего
множества возникающих проблем. Более того, как показали недавние исследования
Иллинойского университета, большинство методов потокового анализа распознают
лишь 15% из всех пар зависимостей. На этом фоне успешной выглядит система
V-Ray, практическое экспериментальное исследование которой показало превосходство
(порой весьма значительное) над другими системами оптимизации. Однако V-Ray
является лишь инструментом для выявления параллелизма, а анализ результатов,
выбор и применение ОП и производятся вручную и неинтерактивно, как и постановка
экспериментов.
2.
Описание предметной области, решаемых задач и методов их решения
.1
Описание предметной области
В данном параграфе описываются знания о преобразованиях и методах
потокового анализа распараллеливаемых программ.
.1.1 Граф
алгоритма
В процессе трансляции программа представляется в виде некоторой модели
программы или внутреннего представления. Такая модель не зависит от синтаксиса
входного языка и отражает только те семантические свойства реальных программ,
которые необходимы для оптимизации и трансляции. Это позволяет, во-первых, не
«привязывать» реализацию к одному конкретному входному языку, поскольку он
может быть модифицирован в процессе использования, во-вторых, представлять
программу в виде удобном для оптимизации, например в виде дерева и, в-третьих,
отображать только необходимые с точки зрения оптимизации и трансляции языковые
конструкции.
При некоторых фиксированных входных данных программа описывает некоторый
алгоритм. Строится ориентированный граф. В качестве вершин берётся любое
множество, например, множество точек арифметического пространства, на которое
взаимнооднозначно отображается множество всех операций алгоритма. Берётся любая
пара вершин и, v. Допускают, что
согласно частичному порядку операция, соответствующая вершине u, должна поставлять аргумент
операции, соответствующей вершине v. Тогда проводится дуга из вершины и в вершину v. Если соответствующие операции могут выполняться независимо
друг от друга, дуга не проводится. В случае, когда аргументом операции является
начальное данное или результат операции нигде не используется, возможны
различные договоренности. Например, можно считать, что соответствующие дуги
отсутствуют. Построенный таким образом граф можно было бы назвать графом
информационной зависимости реализации алгоритма при фиксированных входных
данных. Однако такое название слишком громоздко. Поэтому его называют просто
графом алгоритма [4]. Независимо от способа построения ориентированного графа,
те его вершины, которые не имеют ни одной входящей или выходящей дуги, называют
соответственно входными или выходными вершинами графа.
Граф алгоритма почти всегда зависит от входных данных. Даже если в
программе отсутствуют условные операторы, он будет зависеть от размеров
массивов, т. к. они определяют общее число выполняемых операций и,
следовательно, общее число вершин графа. Так что в действительности граф
алгоритма почти всегда есть параметризованный граф. От значений параметров
зависит, конечно, не только число вершин, но и вся совокупность дуг. Если
программа не имеет условных операторов, то как ее саму, так и описанный ею
алгоритм называют детерминированными. В противном случае их называют
недетерминированными. Имеется одно принципиальное отличие графа
детерминированного алгоритма от графа недетерминированного алгоритма. Для детерминированного
алгоритма всегда существует взаимнооднозначное соответствие между всеми
операциями описывающей его программы и всеми вершинами графа алгоритма. Для
недетерминированного алгоритма взаимнооднозначного соответствия при всех
значениях параметров, т. е. входных данных, нет. Можно лишь утверждать, что в
этом случае при каждом наборе значений параметров существует взаимнооднозначное
соответствие между каким-то подмножеством всех операций программы и вершинами
графа. Разным значениям параметров могут соответствовать разные подмножества.
В дальнейшем, если не сделаны дополнительные оговорки, рассматриваются
детерминированные алгоритмы и программы. Причины введения этого ограничения
следующие:
· детерминированные алгоритмы и программы устроены проще и исследования
начинают именно с них;
· класс детерминированных алгоритмов и программ весьма широк
сам по себе;
· многие формально недетерминированные алгоритмы в
действительности являются почти детерминированными. Например, в том случае,
когда ветвления охватывают конечное число операций, не зависящее от значений
входных данных. Такие ветвления можно погрузить в более крупные операции,
имеющие, тем не менее, конечное число аргументов.
Если ветвления охватывают большие детерминированные фрагменты, то все
равно исследование графа алгоритма сводится к исследованию этих фрагментов.
Введенный в рассмотрение граф алгоритма есть ориентированный ациклический
мультиграф, Его ацикличность следует из того, что в любых программах
реализуются только явные вычисления и никакая величина не может определяться
через саму себя. Даже если в программе имеются рекурсивные выражения, то это
всего лишь удобная форма описания однотипных вычислений. При каждом обращении к
рекурсии на самом деле реализуются разные операции. В общем случае граф
алгоритма есть мультиграф, т. е. две вершины могут быть связаны несколькими
дугами. Это будет тогда, когда в качестве разных аргументов одной и той же
операции используется одна и та же величина. Для обозначения графа применяется
стандартная символика G = (V, Е), где V- множество вершин, Е- множество дуг графа G.
Истории реализаций программ называют графами алгоритмов. Формально между
понятиями истории реализации программы и графа алгоритма, описанного той же
программой, нет различий. Но название "граф алгоритма" лучше отражает
суть дела. Например, один и тот же алгоритм может быть описан на одном и том же
языке разными программами. Соответствующие истории формально также будут
разными, если для расположения вершин использовать один и тот же принцип.
Однако как графы все истории изоморфны между собой. Следовательно, они скорее
отражают не программы, а описываемый ими алгоритм. История реализации есть
графовая модель программы. Слово "граф" в названии "граф
алгоритма" подчеркивает это обстоятельство. Можно привести и другие
аргументы в пользу использования названия "граф алгоритма". По
определению, граф алгоритма существует для любой программы.
.1.2 Графы
зависимостей и минимальные графы
Прежде всего, необходимо точно описать множество вершин. Пусть задана
произвольная линейная программа. Перенумеруем подряд сверху вниз все операторы
циклов do, точнее, все параметры циклов. Обозначаются параметры через I1, ..., In . Считают, что из двух параметров младшим (старшим) является тот, у
которого номер меньше (больше). Перенумеруем также сверху вниз все операторы
присваивания и обозначим их через F1, ..., Fm.
С
каждым оператором присваивания свяжем тесно вложенное гнездо циклов. Его можно
получить, оставляя в программе только те циклы do, в тела которых входит рассматриваемый оператор. Такое
гнездо циклов называется опорным для данного оператора. Пусть опорное гнездо
оператора Fi описывается параметрами 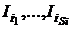 . Рассмотрим арифметическое пространство, координаты
точек которого совпадают со значениями этих параметров. Его размерность равна si. Такое пространство называется опорным. Если оператор не входит ни в
какое гнездо, то размерность опорного пространства будем считать равной 0. Не
ограничивая существенно общности, можно предполагать, что отдельный оператор
описывается гнездом циклов, у которых нижние и верхние границы изменения
каждого из параметров совпадают. Такое предположение позволяет приписать
какие-то параметры даже отдельным операторам.
. Рассмотрим арифметическое пространство, координаты
точек которого совпадают со значениями этих параметров. Его размерность равна si. Такое пространство называется опорным. Если оператор не входит ни в
какое гнездо, то размерность опорного пространства будем считать равной 0. Не
ограничивая существенно общности, можно предполагать, что отдельный оператор
описывается гнездом циклов, у которых нижние и верхние границы изменения
каждого из параметров совпадают. Такое предположение позволяет приписать
какие-то параметры даже отдельным операторам.
Границы
изменения параметров циклов опорного гнезда определяют в опорном пространстве
линейный многогранник. Его называют опорным для оператора Fi и обозначают Vi .
Ветвления, определяющие условия срабатывания оператора Fi,
вырезают из опорного многогранника некоторую область. Принимая во внимание
целочисленность параметров циклов, эту область можно описать конечным числом
замкнутых линейных многогранников. Ее также называют опорной и обозначают `Vi.
По определению `Vi Ì Vi.
Совокупность опорных областей `Vi для i = 1, 2, ..., т называется линейным пространством
итераций. Это есть многосвязная область, состоящая из линейных многогранников,
принадлежащих разным арифметическим пространствам. Факт, что некоторые или даже
все многогранники могут порождаться одними и теми же параметрами циклов, не
имеет сейчас никакого значения. Это будет отражаться лишь в том, что такие
многогранники будут в чем-то похожи по расположению в своих пространствах и
иметь какие-то размеры одинаковыми. По определению линейной программы каждый из
параметров пробегает некоторое множество целочисленных значений с шагом +1.
Точку линейного пространства итераций называют целочисленной, если все ее
координаты являются целыми числами. Совокупность всех целочисленных точек
линейного пространства итераций называется просто пространством итераций.
Границы
изменения параметров циклов и условия ветвления могут зависеть от внешних
переменных. Поэтому размеры всех многогранников и их конфигурации могут
зависеть от значений этих переменных. Как правило, с ростом значений переменных
размеры многогранников неограниченно увеличиваются. Это является характерной
чертой пространства итераций.
Каждому
срабатыванию оператора Fi при конкретных значениях параметров циклов ставится в соответствие точка пространства итераций
из области `Vi с теми же значениями координат . Тем
самым устанавливается взаимно однозначное соответствие между пространством
итераций и множеством всех срабатываний всех операторов программы. Принимая во
внимание структуру отдельных срабатываний, получается отображение на
пространство итераций множества всех исполняемых операций. Все точки одной
области `Vi и только
они соответствуют срабатываниям одного оператора Fi.
Строя
в дальнейшем какие-то графы на множестве операций программы всегда в качестве
множества вершин следует брать пространство итераций. Вершины называют точками
или векторами.
Каждая
линейная программа задает множество исполняемых операций. При реализации
программы операции выполняются в строго определенном порядке, который диктуется
самой программой. Этот порядок называется лексикографическим. Его обозначают
символом µ. Нестрогий лексикографический порядок будем
обозначать символом µ.
Утверждение
1
Пусть
точка J пространства итераций относится j-ому оператору программы и описывается
параметрами Ij1,..., Ij1j , точка I относится к i-ому оператору и описывается
параметрами Ii1,..., Ii1i. Пусть, например, j < i. Тогда:
•
если пересечение совокупностей номеров j1,…,jsj и i1,…,isi, пусто, то любой
параметр Ij1 младше любого параметра Iik;
•
если пересечение совокупностей номеров j1,…,jsj и i1,…,isi не пусто, то любой
параметр, номер которого входит в пересечение, младше любого параметра, номер
которого не входит в пересечение; любой параметр Ij1, номер которого не входит
в пересечение, младше любого параметра Iik номер которого также не входит в
пересечение [4].
Согласно
свойствам операторов do, области действия любых двух
таких операторов могут быть или вложенными одна в другую, или следующими одна
за другой. Поэтому, если в пересечении есть хотя бы один общий параметр, то это
означает, что у обоих опорных гнезд есть общий оператор цикла. В этом случае
любой оператор цикла, содержащий в своем теле рассматриваемый общий оператор и
присутствующий в одном из опорных гнезд, должен присутствовать и в другом
опорном гнезде. Новому общему оператору цикла соответствует младший параметр.
Это
утверждение позволяет ввести отношение порядка в линейном пространстве
итераций. Будем также называть его лексикографическим и обозначать тем же
символом µ. Рассмотрим любую пару различных точек I и J.
Пусть точка I описывается параметрами Ii1,..., Ii1i, точка J
описывается параметрами Ij1,..., Ij1j.
Будем
считать, что J µ I ,
если:
· либо пересечение совокупностей номеров пусто и j < i;
· либо пересечение совокупностей номеров не пусто, значения
всех одинаковых параметров попарно совпадают и j < i;
· либо пересечение совокупностей номеров не пусто, значения
каких-то младших одинаковых параметров могут попарно совпадать, но среди
одинаковых параметров, значения которых попарно не совпадают, самый младший
параметр точки j имеет меньшее значение, чем тот же параметр точки i.
Если рассматривать точки пространства итераций как точки линейного
пространства итераций, то лексикографический порядок в линейном пространстве
итераций автоматически порождает лексикографический порядок в пространстве
итераций. По построению он таков, что J µ I тогда и только тогда, когда при
последовательной реализации программы срабатывание оператора, соответствующее
точке J, будет осуществляться раньше
срабатывания оператора, соответствующего точке I.
Далее строятся ориентированные графы. Две точки пространства итераций
называются зависимыми, если при срабатываниях соответствующих им операторов
имеют место обращения к одной и той же переменной. Соединяются все или какие-то
пары зависимых точек дугами, направляя их от лексикографически младших точек к
лексикографически старшим. Тем самым получается ориентированный граф. Все графы
такого вида называются графами зависимостей. Они отличаются друг от друга как
типом обращения к переменной (использование ее значения или пересчет ее
значения), так и числом дуг. Не каждая пара зависимых точек обязательно будет
соединяться дугой. Но если пара зависимых точек соединяется дугой, то с данной
дугой однозначно связывается некоторая переменная. С ней сначала что-то
делается в операции, соответствующей начальной точке дуги, а затем с ней же
что-то делается в операции, соответствующей конечной точке дуги. Это
"что-то" в обеих точках может быть как одним и тем же, так и
различным.
Различают четыре типа зависимостей. Для всех начальных (конечных) точек
дуг одного типа имеет место один и тот же тип обращения к переменной,
определяющей зависимость. Именно, либо всюду значение переменной используется в
качестве аргумента при срабатывании оператора, либо всюду результат
срабатывания оператора используется для замены значения переменной. Использование
значения переменной в качестве аргумента обозначают символом "in", использование результата для
замены значения символом "out".
Парой in-out
(in-in, out-out, out-in) обозначают тип зависимости. Левый (правый) символ в паре относится к начальной (конечной)
точке дуги зависимости. Традиционно для типов зависимости используются
следующие названия:in - истинная или dataflow-зависимость;out -
антизависимость;out - зависимость по выходу;in - зависимость по входу.
Соответственно этому различают четыре типа графов зависимостей. Все дуги
любого графа имеют один и тот же тип зависимости.
.1.3 Циклы
ParDo и избыточные вычисления
Все графы зависимостей обладают общим свойством. Именно, для каждой дуги
конечная вершина лексикографически старше начальной. Такие графы называются
лексикографически правильными. Любой лексикографически правильный граф является
ациклическим.
Изучение параллельной структуры программ связано с изучением множеств
операций, которые можно выполнять независимо друг от друга. Дадим определения
соответствующих понятий. Пусть в пространстве итераций задан ориентированный
лексикографически правильный граф G. Это может быть какой-нибудь из минимальных графов зависимостей или
некоторый подграф любого из объединений минимальных графов или какой-либо другой
граф. Если программа зависит от внешних переменных, то от них будет зависеть и
граф G. Рассмотрим непересекающиеся
множества М1, ..., Mp вершин пространства итераций. Назовем эти множества
параллельными по графу G или
просто параллельными, если при любых фиксированных значениях внешних
переменных:
· любой путь графа G, связывающий две вершины одного множества, целиком
лежит в этом множестве;
· никакие две вершины из разных множеств не связаны путем графа
G.
Понятие параллельных множеств имеет очень прозрачный смысл. Допустим, что
граф G является объединением всех четырех
минимальных графов. Предположим, что выполнены все операции, которые
соответствуют начальным вершинам дуг, идущих в точки одного множества. Тогда
можно начинать выполнение операций этого множества независимо от того,
выполняются или не выполняются какие-либо другие операции, в том числе,
операции из других множеств. При этом гарантируется, что получаемые результаты
будут правильными.
Под параллельной структурой программы понимают совокупность сведений о
параллельных множествах в пространстве итераций. Сюда же будем относить и
сведения о тех преобразованиях, целью которых является либо выявление, либо
изменение параллельных множеств. Говоря о параллелизме в программах, обычно
обсуждают два его вида: макропараллелизм и микропараллелизм. Макропараллелизм
связан с ситуацией, когда все или хотя бы часть из параллельных множеств
содержат много точек. Микропараллелизм имеет дело с теми случаями, при которых
в каждом из параллельных множеств находится всего лишь несколько точек.
Типичным для микропараллелизма является ситуация, когда множества содержат
только по одной точке. В частности, параллельными будут те множества-точки
пространства итераций, которые не связаны дугой графа G.
Рассмотрим какой-нибудь цикл do произвольной программы из линейного
класса. Его также можно считать программой из линейного класса. Параметры
циклов, внешних по отношению к данному циклу do, играют в нем такую же роль, как и
внешние переменные программы. Их значения хотя и фиксированы к началу
выполнения цикла, но на момент исследования неизвестны. Можно лишь утверждать,
что вектор параметров внешних циклов является целочисленным и принадлежит
совокупности линейных многогранников. Рассмотрим далее пространство итераций цикла
do. Все его
точки можно разбить на непересекающиеся множества, если отнести к каждому
множеству те из них, которые соответствуют одной и той же итерации цикла.
Обозначают эти множества через М1, ..., Мp . Пусть в пространстве итераций цикла
введен ориентированный лексикографически правильный граф G. Будем говорить, что цикл имеет тип
ParDo no графу G, если множества М1, ..., Мр
параллельны по этому графу при любых допустимых, но фиксированных значениях
внешних переменных.
Заметим, что при любых значениях внешних переменных группы операций,
соответствующие множествам М1, ..., Мр , могут
выполняться последовательно друг за другом без выполнения каких-либо других
операций. Это означает, что если множества М1, ..., Мр
параллельны по графу G, то
несвязанность путем любой пары точек, принадлежащих различным множествам Mi, эквивалентна их несвязанности
дугами. Поэтому имеет место
Утверждение 4
Пусть в пространстве итераций цикла DO задан ориентированный лексикографически правильный граф G. Для того чтобы цикл DO был циклом ParDo по графу G, необходимо и достаточно, чтобы никакая пара точек пространства
итераций, соответствующих одним и тем же значениям параметров внешних циклов,
но различным значениям параметра рассматриваемого цикла, не была бы связана
дугой графа G.[4]
Теперь рассмотрим для цикла do его минимальные графы зависимостей
или какие-нибудь объединения этих графов.
Если цикл do имеет тип ParDo
по графу алгоритма, то никакие пары точек пространства итераций,
соответствующие разным итерациям цикла, не могут быть связаны дугами графа
алгоритма. Это означает, что при последовательном исполнении цикла результаты
реализации операций, относящихся к разным итерациям цикла, не влияют друг на
друга. Потенциально итерации цикла ParDo по графу алгоритма можно выполнять независимо друг от друга. Однако для
осуществления такой возможности нужно быть уверенным в правильности порядка
пересчета значений одних и тех же переменных на разных итерациях цикла.
Пусть цикл do имеет тип ParDo
по объединению графов алгоритма, антизависимостей и зависимостей по выходу. В
этом случае в цикле не существует ни одной пары операций, относящихся к разным
итерациям, в которых одна и та же переменная или пересчитывается, или
пересчитывается и используется. Однако могут существовать пары операций, в
которых используется одна и та же переменная. Итерации такого цикла можно
выполнять в любом порядке. При этом гарантируется правильность получаемых
результатов. Циклы подобного типа можно реализовывать на любых
многопроцессорных вычислительных системах. Но наиболее эффективно они
реализуются на системах с общей памятью. На системах с распределенной памятью
возможны большие временные потери из-за межпроцессорных обменов.
Предположим, что цикл do имеет тип ParDo по объединению всех четырех минимальных графов
зависимостей. Теперь любые пары операций из разных итераций циклов всегда имеют
дело с разными переменными. Поэтому такие циклы эффективно реализуются на любых
вычислительных системах, в том числе и на многопроцессорных системах с
распределенной памятью.
Таким образом, графы зависимостей цикла do играют исключительно важную роль в
распознавании параллельных свойств цикла. В силу этого необходимо иметь
эффективные критерии установления свойства ParDo по таким графам. Пусть граф G представлен покрывающими функциями вида х = Jy + j. Здесь J
числовая матрица, вектор j
линейно зависит от внешних переменных цикла, векторы х и у задают точки
пространства итераций цикла. Заметим, что параметру цикла соответствуют первые
координаты векторов х, у. Один из критериев таков.
Утверждение 5
Пусть граф G задан
покрывающими функциями вида х = Jy + j. Для того чтобы цикл имел тип ParDo по графу G, достаточно, чтобы граф G был пустым или для всех покрывающих функций первое равенство
в выражениях х = Jy + j имело вид x1 = у1. [4]
Почти всегда это условие на практике оказывается и необходимым. Например,
оно заведомо будет таким, если граф описывается покрывающими функциями точно и
покрывающие функции являются целочисленными.
.1.4
Эквивалентные по вычислениям преобразования программ
Чтобы использовать обнаруженный в программе параллелизм, его нужно,
прежде всего, каким-то образом записать. Обычно параллелизм описывают с помощью
специальных циклов. Чтобы параллелизм в программе описать циклами, программу
приходится преобразовывать.
Два арифметических выражения называют эквивалентными, если их записи
совпадают с точностью до обозначения переменных. Перенумеруем одинаковым
образом входные переменные эквивалентных выражений. Рассмотрим две линейные
программы. Предположим, что между их пространствами итераций установлено такое
взаимно однозначное соответствие, при котором соответствующие точки задают
срабатывания операторов с эквивалентными выражениями в правых частях. Подобные
пространства итераций называют эквивалентными, а указанное соответствие -
соответствием эквивалентности. Пусть фиксировано правило, по которому для
линейной программы однозначно строится какой-нибудь граф зависимостей. Возьмем
две программы с эквивалентными пространствами итераций и предположим, что соответствие
эквивалентности является изоморфным для графов. Кроме того, будем считать, что
сопоставляемые при изоморфизме дуги графов зависимостей относятся к входным
переменным с одними и теми же номерами. Такие программы будем называть
эквивалентными по графам зависимостей, а сами графы - графами эквивалентности.
Любое преобразование программы в эквивалентную ей программу будем называть
эквивалентным. Введенное понятие эквивалентности программ зависит от того,
какие графы мы хотим принять во внимание при преобразовании программ. Все
эквивалентные программы выполняют одно и то же множество операций, описанных
арифметическими выражениями. Однако при последовательной реализации программ
порядки выполнения операций могут различаться. В общем случае разные порядки могут
приводить к разным результатам. При специальном выборе графов эквивалентности
эквивалентные программы дают в одинаковых условиях реализации одни и те же
результаты, включая всю совокупность ошибок округления. Одинаковые условия
предполагают, в частности, что ошибка округления при выполнении любой операции
на конкретном компьютере определяется только входными данными операции. Этому
требованию удовлетворяют все используемые на практике компьютеры. Множества
используемых переменных в эквивалентных программах могут быть организованы в
массивы по-разному и могут различаться по их числу. В частности, по-разному
могут быть организованы переменные, через которые задаются входные данные и
которые формируют результаты. В реальных условиях приходится выполнять также
неэквивалентные преобразования. Типичным примером является замена одного
оператора последовательностью операторов, реализующих в точных вычислениях ту
же самую операцию. С формальной точки зрения преобразование не является
эквивалентным, т. к. меняется пространство итераций. В практическом отношении
такая замена из-за влияния ошибок округления чаще всего приводит к изменению
результатов вычислений, что также не дает основание считать подобное
преобразование эквивалентным.
Программы могут быть неэквивалентными даже в случае эквивалентности их
пространств итераций. Рассмотрим, например, суммирование элементов массива.
Пусть в одной из программ осуществляется последовательное суммирование, в
другой - принцип сдваивания. Допустим далее, что графами эквивалентности
являются графы алгоритма. Пространства итераций совпадают как по числу точек,
так и по содержанию соответствующих им операций. Тем не менее, программы не
эквивалентны, т. к. их графы алгоритмов не изоморфны. Заметим, что и в этом
случае при точных вычислениях программы будут давать одинаковые результаты,
если суммируются элементы одного и того же массива. Но в условиях влияния
ошибок округления результаты будут различными.
Сохранение результатов вычислений имеет безусловный приоритет при
преобразовании программ. Поэтому очень важно иметь критерий такого сохранения.
Уже отмечалась особая роль графа алгоритма среди минимальных графов. Посмотрим,
что объединяет программы, эквивалентные по этим графам.
Построим каноническую параллельную форму графа алгоритма одной из
программ. По построению начальная вершина любой дуги будет всегда находиться в
ярусе с меньшим номером, чем конечная вершина. В силу изоморфизма графов
эквивалентности каноническую параллельную форму другого графа можно взять такой
же, включая такое же расположение соответствующих вершин в ярусах. При этом
одинаково расположенным вершинам параллельных форм будут соответствовать одни и
те же операции. Одинаково расположенные дуги будут относиться к входным
переменным с одними и теми же номерами. Тогда все различия в последовательных
реализациях программ сводятся к различиям в переборах вершин параллельных форм
графов, определяемых лексикографическими порядками в пространствах итераций.
При любом порядке перебора вершин результаты выполнения операций,
соответствующих первым ярусам, зависят только от входных данных программ.
Поэтому для обеих программ они будут одинаковыми при одних и тех же входных
данных в операциях, соответствующих одинаково расположенным вершинам.
Предположим, что для обеих программ одинаковыми будут результаты выполнения
всех соответствующих операций из всех ярусов от 1-го до k-го, k ³ 1. Рассмотрим любую вершину J из (k +
1)-го яруса. Если в вершину J
входит дуга из вершины I, то
для каждой из программ I µ J по определению графа алгоритма. Вершина обязательно
находится в ярусе, номер которого не превосходит k. Следовательно, при любом допустимом переборе вершин наборы
значений аргументов для операции, соответствующей вершине J, будут одними и теми же. Это
означает, что и для (k +
1)-го яруса результаты выполнения соответствующих операций будут для обеих
программ одинаковыми. Заканчивая перебор всех ярусов, заключаем, что
справедливо
Утверждение 6
Пусть программы эквивалентны по графам алгоритма. Тогда при
последовательной реализации на одном и том же компьютере при одних и тех же
входных данных они будут давать одни и те же результаты, включая всю
совокупность ошибок округления.[4]
По существу программы, эквивалентные по графам алгоритма, представляют
различные записи одного и того же алгоритма. Единственное, чем они могут
принципиально отличаться друг от друга, - это объемом памяти, необходимым для
хранения результатов промежуточных вычислений, а также формой организации
переменных в массивы. Кроме этого, входные и выходные данные таких программ
могут отличаться друг от друга какой-либо их пересортировкой. Мы будем
предполагать, что при реализации эквивалентных программ необходимая
пересортировка делается. Эквивалентные программы обладают одним и тем же
параллелизмом. Однако записан он может быть по-разному. Например, в одной
программе какой-то параллелизм может быть описан явно в форме циклов ParDo. В другой программе этот же
параллелизм может оказаться неявно описанным в форме скошенного.
Основная цель преобразования программы заключается в приведении ее к
такому виду, в котором весь ее массовый параллелизм представлен явно в форме
циклов ParDo. Обязательным условием любого
преобразования является сохранение уровня точности получаемых результатов.
Запись преобразованной программы на алгоритмическом языке имеет большое
значение. Но в ближайших исследованиях мы не будем заниматься этим вопросом.
Под преобразованием программы понимается преобразование ее пространства
итераций с одновременным изменением используемых переменных. В этих условиях
реализация программы означает выполнение операций, соответствующих точкам
пространства итераций, в той последовательности, которая диктуется
лексикографическим порядком в данном пространстве.
Пусть выполняется преобразование программы. Чтобы показать, что исходная
и преобразованная программы дают одни и те же результаты, вроде бы нужно
построить для них графы алгоритмов и сравнить эти графы на изоморфизм. Однако
этот способ проверки эквивалентности программ не всегда возможно осуществить на
практике. Сравнение графов на изоморфизм является довольно трудоемкой задачей.
Кроме этого, очень часто принимать решение о том, какое преобразование нужно
делать, приходится по ходу построения самого преобразования. В этом случае мы
просто не можем получить граф алгоритма преобразованной программы. Поэтому
необходимо поступить иначе. Будем выполнять специальное преобразование. Оно
гарантирует в ряде случаев эквивалентность по графам алгоритма и позволяет
осуществлять промежуточный контроль. Это преобразование охватывает большую
группу конкретных преобразований, объединенных общим названием
переупорядочивание пространства итераций. Пусть для исходной программы построен
граф зависимостей. Специальное преобразование таково:
· выполняется эквивалентное преобразование пространства итераций;
· для новой программы выбираются такие переменные, чтобы при
преобразовании пространства итераций разные переменные переходили в разные,
одинаковые - в одинаковые;
· в новом пространстве итераций устанавливается
лексикографический порядок, при котором образ графа зависимостей будет
лексикографически правильным.
2.2 Модель
структурных программ
В данной части описывается представление программы в СБкЗ_ПП - модель
структурных программ (МСП). Формальное описание онтологии предметной области
«Классические оптимизирующие преобразования» представлено в работах [2, 3].
Первая часть содержит определение терминов для описания объекта оптимизации
преобразований. Вторая часть содержит термины для описания процесса
оптимизации.
.2.1
Термины объекта оптимизации
В работах [2] и [3] описана модель структурных программ (МСП).
Термины предметной области "Оптимизация программ (классические
оптимизирующие преобразования)" можно разбить на две группы: термины, при
помощи которых описываются программы (термины этой группы будем называть
терминами для описания объекта оптимизации), и термины, при помощи которых
описывается процесс оптимизации. Поэтому модель онтологии данной предметной
области также состоит из двух частей.
В работе [3] описана модель онтологии объекта оптимизации программ.
Сначала неформально описываются основные термины в данной предметной области, а
затем даётся их формальное определение. Кроме этого, приводится определение
языка описания МСП как примера обогащения модели онтологии. Описанная модель
онтологии оптимизации программ позволяет изменять модель языка, на котором
описываются оптимизируемые программы, что является важным при изучении свойств
ОП для различных языков программирования.
Объектом оптимизации является некоторая программа. Свойства программы
всегда формулируются в терминах математической модели этой программы.
Характеристикой любой программы является язык (множество программ), которому
эта программа принадлежит. Свойства языка также формулируются в терминах
математической модели этого языка. Тем самым, множество терминов для описания
объекта оптимизации может быть разбито на две группы: термины для описания
модели языка и термины для описания модели конкретной программы. Прежде чем
будет оптимизироваться конкретная программа, должен быть определен язык,
которому эта программа принадлежит. Следовательно, термины для описания модели
языка являются параметрами модели онтологии, а термины для описания модели
программы - неизвестными модели онтологии [3]. Тогда модель языка задается
указанием значений параметров, а модель конкретной программы - указанием
значений неизвестных.
Очевидно, что модель программы описывает не одну программу, а множество
программ, обладающих одинаковыми свойствами, а модель языка - множество языков,
обладающих одинаковыми свойствами. Поэтому к модели языка предъявляются
следующие требования:
· она должна позволять представлять основные конструкции императивных
языков программирования, существенные для описания последовательных ОП.
· она должна быть гибкой и расширяемой с тем, чтобы при
необходимости класс моделируемых программ мог быть легко расширен
· форма представления моделей программ должна быть удобна для
анализа как информационных потоков, так и потоков управления в программе.
Определение терминологии для описания объекта оптимизации
Онтология моделей программ описывается при помощи формализма,
предложенного в [21, 22]. Модель онтологии предметной области "Оптимизация
последовательных программ" состоит из двух модулей. Первый модуль содержит
определение терминов для описания объекта оптимизации, а второй - терминов для
описания процесса оптимизации. Первый модуль представляет собой необогащенную
систему логических соотношений с параметрами, записанную с использованием
предложений многосортного языка прикладной логики: при помощи предложений -
описаний значений имен в п.1.1 работы [3] определяются вспомогательные термины,
при помощи предложений - описаний сортов имен в п. 1.2. и 1.3. работы [3]
определяются параметры и неизвестные, при помощи предложений - ограничений на
интерпретацию имен в п.1.4 работы [3] определяются онтологические соглашения,
определяющие ограничения целостности модели языка, ограничения целостности
модели программы, а также взаимосвязь между моделью программы и моделью языка.
Для большей ясности изложения вначале описываются неизвестные и параметры
неформально.
Любая программа состоит из фрагментов, причем каждый фрагмент, в свою
очередь, также состоит из фрагментов, т.е. любая программа имеет синтаксическую
структуру, которую отражает математическая модель этой программы.
Каждый фрагмент, как элемент программы, обладает рядом свойств. Прежде
всего, у него есть адрес фрагмента - некоторая уникальная
характеристика, однозначно определяющая каждый фрагмент в программе.
Считают, что все фрагменты могут быть разбиты на три группы: операторы
описания, исполнимые операторы и элементы операторов. Каждый фрагмент
характеризуется своим классом, например, фрагмент может иметь класс оператор
присваивания, оператор цикла, оператор описания функций и т.д. Функция FragClass возвращает для указанного адреса
фрагмента класс этого фрагмента. Множество названий классов фрагментов (каждой
группы) в программе задают значения параметров Операторы описания,
Исполнимые операторы, Элементы операторов.
Синтаксическую структуру программы задают дуги управления. Каждая
дуга управления связывает два фрагмента программы. Каждая дуга управления имеет
метку, которая определяет тип связи между фрагментами. Для задания дуги
управления используется функция, имя которой совпадает с меткой дуги. Значение
параметра Имена дуг управления задает, какие метки могут иметь дуги
управления в программе. Для каждой дуги управления определена область действия
дуги управления. Эту область задает значение функционального параметра Область
действия дуг управления - функция, которая сопоставляет каждой метке дуги
пару, состоящую из двух множеств имен классов фрагментов: первое множество
определяет, фрагменты каких классов могут быть аргументами, а второе -
результатами дуги управления с данной меткой.
В программе всегда присутствует множество различных Идентификаторов. Идентификаторы
могут быть разных видов, например, идентификаторы переменных, функций, констант
и типов данных. Идентификаторы каждого вида образуют в программе множество,
название которого совпадает с названием вида. Значение параметра Виды
идентификаторов задает, идентификаторы каких видов могут быть в программе.
На множестве фрагментов и идентификаторов программы определены функции и
отношения, которые позволяют определить структуру программы и некоторые ее
свойства.
Функции, имеющие один аргумент (фрагмент или идентификатор) называются
атрибутами. Каждый атрибут имеет имя. Значение параметра Имена атрибутов задает,
какие атрибуты могут использоваться для описания свойств идентификаторов или
фрагментов в программе. Для каждого атрибута определяются область определения и
область значений атрибута. Эти области задаются значениями функциональных
параметров Область определения атрибута и Область значения атрибута.
Значение параметра Имена функций задает, какие функции, имеющие
два и более аргументов, могут использоваться при описании свойств фрагментов
или идентификаторов программы. Для каждой функции определяется область
определения и область значений. Эти области задаются значениями параметров Область
определения функции и Область значений функции.
Значение параметра Имена отношений задает, какие отношения могут
быть определены на множестве фрагментов и идентификаторов программы. Значения
параметров Определение отношения для каждого имени отношения задают
формулу определения истинности отношения между фрагментами и идентификаторами
программы.
Еще одним свойством фрагмента является его корректность. Значение
корректности задает предикат Корректность, который сопоставляет адресу
фрагмента истину, если у него имеются все дуги управления и атрибуты,
необходимые для этого фрагмента. Значение параметра Определение корректности
задает для каждого класса фрагмента, какие дуги управления и атрибуты
должны быть определены для фрагмента этого класса.
Значение параметра Элементарные типы задает для языка множество
идентификаторов типов данных, являющимися базовыми для всех остальных типов
данных этого языка.
Значение параметра Способы порождения задает множество названий
конструкторов типов данных в языке. Для каждого идентификатора типа данных в
программе определены значения таких свойств, как базовый тип и метод
конструирования типа из базового. Значение первого свойства задает функция BaseType, которая сопоставляет каждому идентификатору типа последовательность
идентификаторов типов, которые использованы при конструировании этого типа
данных. Значение второго свойства задает функция ConstructMethod, которая сопоставляет каждому идентификатору типа
название конструктора. Значением параметра Совместимость типов является
предикат, определяющий возможность неявного преобразования одного типа к
другому.
Значение параметра Зарезервированные имена задает множество имен
ролей, которые могут играть фрагменты или идентификаторы программы. Значение
параметра Область значения зарезервированного имени сопоставляет каждому
имени роли предикат, определяющий, какими свойствами должен обладать фрагмент
или идентификатор, играющий в программе эту роль.
Значение параметра Знаки операций задает множество символов, использующихся
в программе для обозначения каких-либо операций в выражениях (арифметических,
логических, преобразования и т.д.) программы. Функциональные параметры Число
аргументов и Приоритет, сопоставляют каждому символу операции количество
аргументов и приоритет.
.2.2
Описание терминов потокового анализа МСП
Для формального описания оптимизирующих преобразований в соответствии с
анализом зависимостей в циклах необходимо ввести вспомогательные термины в
существующую модель онтологии, описанную в работе [3].
Введём новое отношение: g - итерационная зависимость.
Сопоставляет двум операторам и циклу ложь, если между двумя операторами
отсутствует итерационная зависимость, и истину, если зависимость присутствует.
Введём новый атрибут
ParDo
Имена атрибутов º {Id, Def, Par, Left,
LeftExpr, Right, RightExpr, Image, IsArray, IsPointer, IsRec, IsFunc,
IsEffects, IsLValue, IsVar, Level, Op, Priority, Type, ByValue, FormRefParam,
FormValParam, RefParam, ChangeRefParam, ValParam, A, R, RR, RP, OwnerFunc,
Length, IsLine, Name, Result, TypeSet, LowBound, HighBound, ParentLevel, ParDo}
- ParDo
- сопоставляет фрагменту типа DFor
истину если он имеет тип ParDo,
и ложь в обратном случае.
Область определения атрибута º ( l(v: Имена атрибутов)
/ (v = ParDo =>
(l(v1: Адреса фрагментов È Идентификаторы) v1Î Адреса фрагментов & FragClass(v1) = {DFor})
Областью определения атрибута ParDo является множество фрагментов типа DFor.
Область значения атрибута = ( l(v: Имена атрибутов)
/ (v = ParDo =>
(l(v1:Значения атрибутов) v1 Î L))
Область значения атрибута ParDo
есть множество логических значений.
2.3
Постановка задач и методы их решения
Потоковый анализ является средством получения достоверной информации в
поведении программы без ее реального исполнения. Извлекаемые из текста программы
свойства - это глобальная информация о программе, которая не может быть
получена ни пробными запусками программы, ни изучением ее отдельных фрагментов.
В процессе потокового анализа происходит анализ определенных семантических
свойств программы.
После проведения потокового анализа над текстом программы можно ставить
эксперименты по модификации исходного кода программы, представленного в виде
дерева МСП, для его оптимизации. Методы потокового анализа для оптимизации
исходного кода описываются с помощью специального языка описания методов
(синтаксис языка см. «Приложение 3»). Для оптимизации исходного кода одним из
шагов является интерпретация нужных методов потокового анализа на дереве
исходного кода МСП.
Решение задачи интерпретации: Описать алгоритмы действий синтаксиса
методов потокового анализа.
Осуществляется с помощью создания программного средства, которое бы
выполняло шаги метода.
Такое программное средство разработано в рамках данной дипломной работы.
Требования и спецификации этого программного средства находятся в третьей главе
дипломной работы.
Также необходимо описать и добавить в базу методов потокового анализа
метод «ParDo».
.3.1
Алгоритм добавления атрибутов ParDo
Смыслом метода потокового анализа «ParDo» является добавление атрибутов ParDo.
Алгоритм записан на естественном языке и заключается в следующем:
Потоковый анализ проводится по тексту программы, Исходный текст программы
поступает на вход в виде МСП.
1. Если счетчик цикла DFor
(внут), являющегося телом другого DFor (внеш) не пересекается с объединением аргументных множеств начальной
границы цикла, конечной границы цикла и шага DFor (внеш), тогда
1.1 Если пересечение аргументного (а) и результатного (р) множеств
цикла (внут) - пустое множество, тогда (внеш) присваивается атрибут ParDo
1.2 Иначе
1.2.1 Для всех операторов присваивания Dass (присв) тела цикла (внут), начиная с первого
1.2.1.1 Если пересечение множеств (а), (р) и левой части оператора
присваивания (внут) не совпадает с пересечением (а), (р) и правой части
оператора присваивания (внут), то переход к 2.Иначе
.2.1.1.1 Если элементы пересечения - индексные переменные, иесли в
индексе (л) присутствуют переменные из условия цикла1, ииндекс (л) <>
(п), то переход к 2.
.2.2 (внеш) присваивается атрибут ParDo.
. Конец алгоритма.
Рассмотрим теперь подробный алгоритм потокового анализа с примером его
применения.
Пример работы алгоритма потокового анализа МСП
Поиск участка экономии «Гнездо циклов»
Нахождение участка экономии заключается в обходе МСП в ширину, начиная с
корня. Производится поиск участков вида (рисунок 2.1):
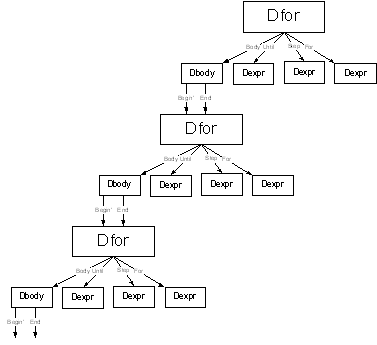
Рисунок
2.1 участок экономии
Для гнезд циклов вложенности n, где n - количество Dfor.
На найденном участке экономии нас интересуют счетчики циклов и границы их
изменения. Также необходимо выделить блоки присваивания (Dass), в которых происходит пересчет
переменных, то есть ветви LeftExpr и RightExpr содержат одну и ту же переменную.
Пусть найден участок экономии
DO i = 1, n
DO j = 1, nk = 1, nij = aij + bik
ckjDODODO
МСП которого выглядит так (рисунок 2.2):

Рисунок 2.2 МСП участка экономии
Из
этого фрагмента мы выделяем счетчики циклов:
i: (1, n)
j: (1, n)
k: (1,n)
проверяется,
что счетчик цикла DFor (внут), не пересекается с объединением аргументных
множеств начальной границы цикла, конечной границы цикла и шага DFor (внеш)
j не зависит от
цикла i
проверяется,
что аргументное и результатное множества не пересекаются
{a} Ç {a, b, c} ≠ Æ
проверяется,
что элементы пересечения - индексные переменные, ив индексе (л) присутствуют
переменные из условия цикла1, ииндекс (л) <> (п),
a - индексная
переменная
в
индексе (л) присутствуют переменные из условия циклов
i=i, j=j (рисунок 2.3)
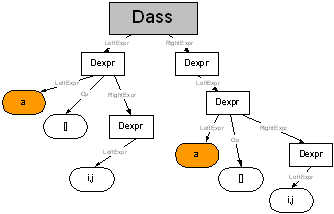
Рисунок
2.3
Циклу
i присваивается атрибут ParDo
Аналогично
оценивается цикл j. В результате ему тоже присваивается атрибут ParDo.
У
цикла K нет вложенных циклов, поэтому он не рассматривается.
Расширение
МСП терминами потокового анализа
Рисунок
2.4 МСП, расширенная терминами потокового анализа
2.4
Представление методов потокового анализа программ
Для представления методов потокового анализа программ в базе знаний
СБкЗ_ПП был разработан язык методов потокового анализа программ.
2.4.1
Абстрактный синтаксис языка методов потокового анализа программ
Абстрактный синтаксис языка методов потокового анализа описан в работе
[26].
.4.2
Операционная семантика языка методов потокового анализа программ
Метод потокового анализа = (метод потокового анализа:
Последовательность конструкций)
проц Метод_потокового_анализа(вершина: Вершина)
если вершина=«Фрагмент по дуге» то вызов Фрагмент_по_дуге()
если вершина=«Атрибут фрагмента» то вызов Атрибут_фрагмента()
если вершина=«Получить класс» то вызов Получить_класс()
если вершина=«Получить переменную выражения» то вызов
Получить_переменную_выражения()
если вершина=«Первый фрагмент по дуге из последовательности» то вызов
Первый_фрагмент_по_дуге_из_последовательности()
если вершина=«Следующий фрагмент по дуге из последовательности» то вызов
Следующий фрагмент по дуге из последовательности()
если вершина=«Пересечение множеств» то вызов Пересечение множеств()
если вершина=«Объединение множеств» то вызов Объединение множеств()
если вершина=«Равенство множеств» то вызов Равенство_множеств()
если вершина=«Логическая формула» то вызов Логическая_формула()
если вершина=«Составная логическая формула» то вызов
Составная_логическая_формула()
если вершина=«Терм логической формулы» то вызов Терм_логической_формулы()
если вершина=«Обход дерева программы» то вызов Обход_дерева_программ()
если вершина=«Обход дерева выражения» то вызов Обход_дерева_выражения()
если вершина=«Выбор» то вызов Выбор()
если вершина=«Цикл» то вызов Цикл()
если вершина=«Создание фрагмента» то вызов Создание_фрагмента()
если вершина=«Создание атрибута» то вызов Создание_атрибута()
если вершина=«Изменение атрибута» то вызов Изменение_атрибута()
если вершина=«Создание дуги» то вызов Создание_дуги()
если вершина=«Создание отношения» то вызов Создание_отношения()
если вершина=«Присваивание» то вызов Присваивание()
если вершина=«Выражение» то вызов Выражение()
если вершина=«Выражение в скобках» то вызов Выражение_в_скобках()
иначе вершина= Метод_потокового_анализа(вершина.дочерн[0])
Фрагмент по дуге = (аргумент-фрагмент, имя,
результат-фрагмент)
Описание: Фрагмент по дуге представляет собой функцию, которая
сопоставляет фрагменту Аргумент-фрагмент, фрагмент Результат-фрагмент, который
соединен с первым дугой с именем Имя дуги.
Семантика: Присвоить переменной Результат-фрагмент фрагмент, к которому
от Аргумент-фрагмента ведет дуга Имя дуги.
проц Фрагм_по_дуге (А_ф, имя_дуги, р_ф)
р_ф = а_ф.перейти_по_дуге(имя_дуги)
потоковый анализ распараллеливаемый программа
Атрибут фрагмента = (Аргумент-фрагмент, Имя атрибута,
Результат-атрибут)
Описание: Атрибут фрагмента есть функция, которая для фрагмента
Аргумент-фрагмент возвращает атрибут Результат-атрибут с именем Имя атрибута.
Семантика: Присвоить переменной Результат-атрибут атрибут фрагмента
Аргумент-фрагмент с именем Имя атрибута.
проц атрибут_фрагмента (А_ф, имя_атр, р_а)
р_а = а_ф.получить_атрибут(имя_атр)
Получить класс = (аргумент1 : переменная-фрагмент, результат
:
класс фрагмента)
Описание: Получить класс есть функция, которая для заданного фрагмента
Аргумент-фрагмент возвращает его класс.
Семантика: Присвоить Результату-классу фрагмента класс фрагмента
Аргумент-фрагмент.
проц Получить_класс (арг: вершина, рез: класс)
рез = арг.класс
Получить переменную выражения = ( Аргумент-фрагмент,
Результат-переменная)
Описание: функция, которая для заданного фрагмента Аргумент-фрагмента
класса Выражение возвращает переменную, если Аргумент-фрагмента является
терминальной вершиной бинарного дерева выражения МСП, либо пустое множество в противном
случае.
Семантика: Если Аргумент-фрагмента является терминальной вершиной
бинарного дерева выражения МСП, то присвоить Результату-переменной переменную,
которая является левой частью Выражения, в противном случае присвоить
Результату-переменной пустое множество.
Первый фрагмент по дуге из последовательности = (Аргумент-
фрагмент, Результат-фрагмент )
Описание: Функция Первый фрагмент по дуге из последовательности для
фрагмента Аргумент-фрагмент возвращает фрагмент Результат-фрагмент к которому ведет
первая дуга Оператор.
Семантика: Присвоить Результат-фрагменту фрагмент к которому от фрагмента
Аргумент-фрагмент ведет первая дуга Оператор.
проц Первый_фрагмент_по_дуге_из_последовательности (арг: вершина, рез:
вершина)
цикл i=1 по арг.количество_дочерн шаг 1
если арг.дочерн[i].тип
== оператор то
рез= арг.дочерн[i]
выход_из_цикла
Следующий фрагмент по дуге из последовательности =
(Аргумент-фрагмент, Аргумент-фрагмент2, Результат-фрагмент )
Описание: Функция Первый фрагмент по дуге из последовательности для
фрагмента Аргумент-фрагмент возвращает фрагмент Результат-фрагмент к которому
ведет дуга Оператор следующая за дугой, которая ведет к Аргумент-фрагменту2.
Семантика: Присвоить Результат-фрагменту фрагмент к которому от фрагмента
Аргумент-фрагмент ведет дуга Оператор следующая за дугой, которая ведет к
Аргумент-фрагменту2.
проц Следующий_фрагмент_по_дуге_из_последовательности (арг1:
вершина, арг2: вершина, рез: вершина)
i=1
пока арг1.дочерн[i] ≠
арг2 выполнять i=i+1
цикл j=i по арг.количество_дочерн шаг 1
если арг1.дочерн[i].тип
== оператор то
рез= арг1.дочерн[i]
выход_из_цикла
Пересечение множеств = (Аргумент-множество, Аргумент-
множество2, Результат-множество)
Описание: Пересечение множеств есть функция, которая для заданных
множеств Аргумент-множество и Аргумент-множество2 вычисляет
Результат-множество, равное их пересечению.
Семантика: Пересечь множества Аргумент-множество и Аргумент-множество2 и
присвоить полученное множество переменной Результат-множество.
проц Пересечение_множеств(арг1: множество, арг2: множество, рез:
множество)
объявить рез тип множество
цикл i=1 по арг1.количество шаг 1
цикл j=1 по арг2.количество шаг 1
если арг1[i] == арг2[j] то
объявить т тип двоичный
т=0
цикл k=1 по рез.количество шаг 1
если рез[k] == арг2[j] то т=1
если т ≠ 1 то рез.добавить(арг2[j])
выход_из_цикла
Объединение множеств = (Аргумент-множество, Аргумент-
множество2, Результат-множество)
Описание: Объединение множеств есть функция, которая для заданных
множеств Аргумент-множество и Аргумент-множество2 вычисляет
Результат-множество, равное их объединению.
Семантика: Объединить множества Аргумент-множество и Аргумент-множество2
и присвоить полученное множество переменной Результат-множество.
проц Объединение_множеств(арг1: множество, арг2: множество, рез:
множество)
объявить рез тип множество
объявить т тип двоичный
т=0
цикл i=1 по арг1.количество шаг 1
рез.добавить(арг1[i])
цикл j=1 по арг2.количество шаг 1
цикл k=1 по рез.количество шаг 1
если рез[k] == арг2[j] то т=1
если т ≠ 1 то рез.добавить(арг2[j])
выход_из_цикла
Равенство множеств = (Аргумент-множество, Аргумент-
множество2, Результат равенства)
Описание: Равенство множеств есть функция, которая для двух множеств
Аргумент-множество и Аргумент-множество2 возвращает истину, если оба множества
пусты, либо оба множества содержат одинаковые элементы и ложь в противном
случае.
Семантика: Если множества Аргумент-множество и Аргумент-множество2 пусты,
либо содержат одинаковые элементы присвоить Результату равенства значение
истина, в противном случае присвоить Результату равенства значение ложь.
проц Равенство_множеств(арг1: множество, арг2: множество, рез:
двоичный)
если арг1.количество == арг2.количество то
цикл i=1 по арг1.количество шаг 1
если арг1[i] ≠ арг2[i] то
рез=ложь
выход_из_цикла
иначе
рез=ложь
Логическая формула = (Терм логической формулы)
Описание: Логическая формула есть функция, область значения которой
Булево множество.
Семантика: Присвоить аргументу Булево множество истину или ложь в
зависимости от результата вычисления логической формулы, которая задается
Термом логической формулы
проц Логическая_формула(терм :
терм_логической_формулы):двоичный
если терм_логической_формулы(терм)==истина то
Логическая_формула= истина
иначе Логическая_формула=ложь
Составная логическая формула = объед (Терм логической
формулы, Знак логической операции, Терм логической формулы)
Описание: Терм логической формулы есть особого вида логическая формула.
Семантика: Для вычисления Составная логическая формула необходимо
вычислить первый аргумент Терм логической формулы, третий аргумент Терм
логической формулы, а после этого применить Знак логической операции к
полученным результатам.
проц Составная_логическая_формула (терм1:терм_логической_формулы,
зн:знак_логической_операции, терм2: терм_логической_формулы):двоичный
объявить т1 тип двоичный
т1=0
объявить т2 тип двоичный
т2=0
т1= терм_логической_формулы(терм1)
т2= терм_логической_формулы(терм2)
если зн == “<” и т1<т2 то Составная_логическая_формула = истина
если зн == “>” и т1>т2 то Составная_логическая_формула = истина
если зн == “=>” и т1=>т2 то Составная_логическая_формула = истина
если зн == “=<” и т1=<т2 то Составная_логическая_формула = истина
если зн == “<>” и т1<>т2 то Составная_логическая_формула =
истина
если зн == “==” и т1==т2 то Составная_логическая_формула = истина
если зн == “И” и т1 И т2 то Составная_логическая_формула = истина
если зн == “ИЛИ” и т1 ИЛИ т2 то Составная_логическая_формула = истина
если зн == “НЕ” и НЕ т1 то Составная_логическая_формула = истина
иначе Составная_логическая_формула = ложь
Обход дерева программы = (Начальный фрагмент, Текущий
фрагмент, Условие обхода, Тело обхода)
Описание: Обход дерева программы обозначает обход фрагментов дерева МСП
(кроме фрагментов класса Выражение) «сверху-вниз», «слева-направо» начиная с
фрагмента Начальный фрагмент, включая сам Начальный фрагмент. На каждой
итерации Текущий фрагмент является фрагментом МСП в соответствии с правилами
обхода. На каждой итерации проверяется Логическая формула, и если ее результат
истина, то выполняется последовательность Конструкций из Тела обхода. Обход
продолжается до тех пор, пока не будут пройдены все фрагменты поддерева МСП,
вершиной которого является Начальный фрагмент.
Семантика:
Выполнение Обход дерева программы представляет собой рекурсию:
Шаг 1 (база рекурсии):
Вызвать рекурсивную функцию Шаг2 Текущий фрагмент равен Начальный
фрагмент.
Шаг 2 (рекурсивная функция с параметром Текущий фрагмент):
Если класс переменной-фрагмента Текущий фрагмент равен
Описание_одной_функции, то:
выполнить Шаг 2 (Текущий фрагмент равен фрагменту Блок_описаний_функций,
к которому от текущего фрагмента ведет дуга Описание_функций);
выполнить Шаг 2 (Текущий фрагмент равен фрагменту
Блок_описаний_параметров, к которому от текущего фрагмента ведет дуга
Описание_параметров);
выполнить Шаг 2 (Текущий фрагмент равен фрагменту Блок_описаний_типов, к
которому от текущего фрагмента ведет дуга Описание_типов);
выполнить Шаг 2 (Текущий фрагмент равен фрагменту
Блок_описаний_переменных, к которому от текущего фрагмента ведет дуга Описание_переменных);
выполнить Шаг 2 (Текущий фрагмент равен фрагменту Программный_блок, к
которому от текущего фрагмента ведет дуга Тело).
Если класс текущего фрагмента Блок_описаний_функций, то последовательно
для каждого фрагмента Описание_одной_функции, к которому от текущего фрагмента
ведет дуга Оператор выполнить Шаг 2 (Текущий фрагмент равен фрагменту
Описание_одной_функции).
Если класс текущего фрагмента Блок_описаний_параметров, то
последовательно для каждого фрагмента Описание_одного_параметра, к которому от
текущего фрагмента ведет дуга Оператор выполнить Шаг2 (Текущий фрагмент равен
фрагменту Описание_одного_параметра).
Если класс текущего фрагмента Блок_описаний_типов, то последовательно для
каждого фрагмента Описание_одного_типа, к которому от текущего фрагмента ведет
дуга Оператор выполнить Шаг 2 (Текущий фрагмент равен фрагменту
Описание_одного_типа).
Если класс текущего фрагмента Блок_описаний_переменных, то
последовательно для каждого фрагмента Описание_одной_переменной, к которому от
текущего фрагмента ведет дуга Оператор выполнить Шаг 2 (Текущий фрагмент равен
фрагменту Описание_одной_переменной).
Если класс текущего фрагмента Программный_блок, то последовательно для
каждого фрагмента, к которому от Текущего фрагмента ведет дуга Оператор выполнить
Шаг 2 (Текущий фрагмент равен фрагменту к которому ведет дуга Оператор).
Если класс текущего фрагмента Условный_оператор, то:
выполнить Шаг 2 (Текущий фрагмент равен фрагменту Программный_блок, к
которому от текущего фрагмента ведет дуга То);
выполнить Шаг 2 (Текущий фрагмент равен фрагменту Программный_блок, к
которому от текущего фрагмента ведет дуга Иначе).
Если класс текущего фрагмента Цикл_for, то:
выполнить Шаг 2 (Текущий фрагмент равен фрагменту Программный_блок, к
которому от текущего фрагмента ведет дуга Тело).
Если класс текущего фрагмента Цикл_while, то:
выполнить Шаг2 (Текущий фрагмент равен фрагменту Программный_блок, к
которому от текущего фрагмента ведет дуга Тело).
Если класс текущего фрагмента Цикл_repeat, то:
выполнить Шаг 2 (Текущий фрагмент равен фрагменту Программный_блок, к
которому от текущего фрагмента ведет дуга Тело).
Если Условие обхода истинно, то поочередно выполнить Конструкции из Тела
обхода.
проц рекурсия(тек: вершина, усл: логическая_формула, тело: конструкция)
Если тек. Дуга (Выражение_справа).класс== Описание_одной_функции то
Рекурсия(тек.перейти_по_дуге(Описание_функций усл,тело)
Рекурсия(тек.перейти_по_дуге(Описание_параметров усл,тело)
Рекурсия(тек.перейти_по_дуге(Описание_типов усл,тело)
Рекурсия(тек.перейти_по_дуге(Описание_переменных усл,тело)
Рекурсия(тек.перейти_по_дуге(Тело усл,тело)
Если тек.дуга(Выражение_справа).класс== Блок_описаний_функций то
Для и=0 по тек.количество_дочерн
Рекурсия(тек.перейти_по_дуге(Описание_одной_функции и],усл,тело)
Если тек.дуга(Выражение_справа).класс== Блок_описаний_параметров то
Для и=0 по тек.количество_дочерн
Рекурсия(тек.перейти_по_дуге(Оператор [и]
,усл,тело)
Если тек.дуга(Выражение_справа).класс== Блок_описаний_типов то
Для и=0 по тек.количество_дочерн
Рекурсия(тек.перейти_по_дуге(Оператор [и]
,усл,тело)
Если тек. Дуга (Выражение_справа). класс== Блок_описаний_переменных то
Рекурсия (тек.перейти_по_дуге (Оператор [и]
,усл,тело)
Если тек. дуга (Выражение_справа).класс== Программный_блок то
Рекурсия (тек. перейти_по_дуге(Оператор усл,тело)
Если тек. дуга (Выражение_справа).класс== Условный_оператор то
Рекурсия (тек.перейти_по_дуге(То усл,тело)
Рекурсия(тек.перейти_по_дуге(Иначе усл,тело)
Если тек.дуга(Выражение_справа).класс== Цикл_for то
Рекурсия(тек.перейти_по_дуге(Тело усл,тело)
Если тек.дуга(Выражение_справа).класс== Цикл_while то
Рекурсия(тек.перейти_по_дуге(Тело усл,тело)
Если тек.дуга(Выражение_справа).класс== Цикл_repeat то
Рекурсия(тек.перейти_по_дуге(Тело усл,тело)
Если Условие обхода == Истина то
метод_потокового_анализа (Тело_обхода)
проц обход_дерева_программы(нач: вершина, тек: вершина,усл:
логическая_формула, тело: конструкция)
тек=нач
рекурсия(тек, усл, тело)
Обход дерева выражения = (Начальный фрагмент, Текущий
фрагмент, Тело обхода)
Описание: Обход дерева выражения есть обход бинарного дерева выражения
МСП по следующим правилам: обход бинарного дерева выражения МСП осуществляется
«снизу-вверх», «справа-налево» начиная с Начального фрагмента класса Выражение,
включая сам Начальный фрагмент. На каждой итерации Текущий фрагмент
соответствует фрагменту класса Выражение в соответствии с правилами обхода. На
каждой итерации выполняется последовательность Конструкций из Тела обхода.
Семантика:
Выполнение Обход дерева выражения представляет собой рекурсию:
Шаг 1 (база рекурсии): Вызвать рекурсивную функцию
Шаг 2 Текущий фрагмент равен Начальный фрагмент.
Шаг 2 (рекурсивная функция с параметром Текущий фрагмент):
Если у фрагмента Текущий фрагмент по дуге Выражение_справа находится
фрагмент класса Выражение, то
выполнить Шаг 2 (Текущий фрагмент равен фрагменту, к которому от текущего
фрагмента ведет дуга Выражение_справа).
Если у фрагмента Текущий фрагмент по дуге Выражение_слева находится
фрагмент класса “Выражение”, то
выполнить Шаг 2 (Текущий фрагмент равен фрагменту, к которому от текущего
фрагмента ведет дуга Выражение_слева).
Поочередно выполнить Конструкции из Тела обхода.
проц рек(тек: вершина, тело: конструкция)
Если тек.дуга(Выражение_справа).класс==выражение то
рек(тек.дуга(Выражение_справа), тело)
Если тек.дуга(Выражение_слева).класс==выражение то
Рек(тек.дуга(Выражение_слева), тело)
метод_потокового_анализа (тело)
проц обход_дерева_выражения(нач: вершина, тек: вершина, тело:
конструкция)
тек=нач
рек(нач, тело)
Выбор = (условие: Логическая формула, если истина: Последовательность
конструкций, [если ложь : Последовательность конструкций])
Описание: Выбор состоит из Условия, и двух последовательностей
Конструкций: Если истина и Если ложь.
Семантика: Если значение Условия есть истина, то выполнить
последовательность Конструкций Если истина, в противном случае выполнить
последовательность Конструкций Если ложь.
проц выбор(усл: Логическая_формула, ист: конструкция, ложь: конструкция)
объявить т тип булево
вызов логическая_формула(условие,т)
Если т==Истина то
метод_потокового_анализа (ист)
Иначе
метод_потокового_анализа (ложь)
Цикл = (Условие, Конструкция)
Описание: Цикл состоит из Условия, и последовательности Конструкций.
Семантика:
Выполнение Цикла есть выполнение следующих шагов:
Шаг1: Проверить Условие. Если значение Условия есть истина, выполнить
Шаг2.
Шаг2: Выполнить последовательность Конструкций, вернуться к Шаг1.
проц цикл(усл: условие, конст: вершина)
объявить т тип булево
пока логическая_формула(условие,т)== Истина
цикл и=1 по конст.количество шаг 1
метод_потокового_анализа(конст.дочерн[и])
Создание фрагмента = (Аргумент-фрагмент, Класс фрагмента,
Результат-фрагмент)
Описание: Создание фрагмента есть добавление к МСП нового фрагмента.
Семантика: Добавить к МСП новый фрагмент Результат-фрагмент. Класс нового
фрагмента - Класс фрагмента, а предок - Аргумент-фрагмент.
проц Создание_фрагмента(арг: вершина, класс: класс, рез: вершина)
рез = арг.создать_дочерн
рез.класс = класс
Создание атрибута = (Аргумент-фрагмент, Имя атрибута,
Значение атрибута)
Описание: Создание атрибута есть добавление к фрагменту МСП нового
атрибута.
Семантика: Добавить к фрагменту Аргумент-фрагмент новый атрибут с именем
Имя атрибута и значением Значение атрибута.
проц Создание_атрибута(арг: вершина, имя: строка, зн: переменная)
арг.создать_аттриб(имя, зн)
Изменение атрибута = (Переменная-атрибут, Значение атрибута)
Описание: Изменение атрибута есть изменение значения атрибута МСП.
Семантика: Изменить значение атрибута Переменная-атрибут на Значение
атрибута.
проц Изменение_атрибута(пер_атр:атрибут, знач: тип)
пер_атр.значение = знач
Создание дуги = (Аргумент-фрагмент, Имя дуги,
Аргумент-фрагмент2, Переменная-дуга)
Описание: Создание дуги есть добавление к МСП новой дуги.
Семантика: Добавить к МСП новую дугу Переменная-дуга от фрагмента
Аргумент-фрагмент к фрагменту Аргумент-фрагмент2 с именем Имя дуги.
проц Создание_дуги(арг: выражение, имя: строка, арг2: выражение, п_дуга:
переменная)
арг.создать_дугу(арг2, имя)
п_дуга = арг.дуга(имя)
Создание отношения = (Имя отношения, Аргумент-фрагмент,
Аргумент-фрагмент2, Аргумент-фрагмент3, Аргумент-фрагмент4,
Переменная-отношение)
Описание: Создание отношения есть добавление к МСП нового отношения.
Семантика: Добавить к МСП новое отношение Переменная-отношение с именем
Имя отношения, которое бы связывало фрагменты Аргумент-фрагмент,
Аргумент-фрагмент2, Аргумент-фрагмент3, Аргумент-фрагмент4.
проц Создание_отношения(имя_отн, а-ф, а-ф2, а-ф3, а-ф4, пер-отн)
объявить пер-отн тип отношение
пер-отн = создать_отношение(имя_отн, а-ф, а-ф2, а-ф3, а-ф4)
Создание переменной = (Значение переменной, тип переменной,
имя переменной)
Описание: Создание переменной есть добавление к МСП новой переменой.
Семантика: Добавить к МСП новую переменную с именем Имя переменной, типом
Тип переменной и значением Значение переменной.
проц Создание_переменной(зн_п, тип_п, имя_п)
объявить имя_п тип тип_п
имя_п = зн_п
Присваивание = (Левая часть присваивания, Правая часть
присваивания)
Семантика: Вычислить значение Правой части присваивания и присвоить его
Левой части присваивания.
Проц присваивание(л_ч: вершина, п_ч: вершина)
Если п_ч.тип == «Арифметическое выражение» то л_ч.значение =
арифметическое_выражение (п_ч.дочерн[1], п_ч.дочерн[2], п_ч.дочерн[3])
Если п_ч.тип ==л_ч.тип то л_ч.зачение = п_ч.значение
Арифметическое выражение = (Терм выражения, Знак операции,
Терм выражения)
Описание: Выражение есть последовательность арифметических операций.
Семантика: Для того, чтобы вычислить значение Выражения необходимо
вычислить значение Термов выражения и применить к ним Знак арифметической
операции.
проц Арифметическое_выражение(терм1: терм_выражения, зн: Знак_операции,
терм2: терм_выражения): тип
терм1 = (терм1.дочерн[0])
терм2 = (терм2.дочерн[0])
Если зн == «+» то Арифметическое_выражение = терм1.значение +
терм2.значение
Если зн == «-» то Арифметическое_выражение = терм1.значение -
терм2.значение
Если зн == «*» то Арифметическое_выражение = терм1.значение *
терм2.значение
Если зн == «/» то Арифметическое_выражение = терм1.значение /
терм2.значение
Если зн == «^» то Арифметическое_выражение = терм1.значение ^
терм2.значение
2.4.3
Расширение базы методов потокового анализа программ
При помощи редактора методов потокового анализа программ в базу методов
потокового анализа был занесен метод «ParDo». Представление этого метода в базе представлено ниже.
Метод потокового анализа
Название метода
ParDo
Конструкция -> Обход
Обход дерева программы
Начальный фрагмент -> Переменная-фрагмент «Функция_главная»
Текущий фрагмент -> Переменная-фрагмент «Цикл1»
Условие обхода
Переменная-фрагмент«Цикл1» == Класс_фрагмента «Цикл_Dfor»
Тело обхода
Обход дерева програмы
Начальный фрагмент -> Переменная-фрагмент «Цикл2»
Текущий фрагмент -> Переменная-фрагмент «Цикл1»
Условие обхода
Переменная-фрагмент «Цикл1» == Класс_фрагмента «Цикл_Dfor»
Тело обхода
Переменная-атрибут «Счетчик_Цикла1»
Переменная-фрагмент «Нач_гран_цикла2»
Атрибут_фрагмента( //Получили Сч_ц для внш «Цикл2»
«Цикл2»,
«Счетчик_цикла»,
«Счетчик_цикла1»)
Атрибут_фрагмента(//арг_множ от Нач_гр_ц (дуга For) «Цикл1»
Фрагмент_по_дуге(
«Цикл1»,
«Начальная_граница_цикла»,
«Нач_гран_цикла2»),
«Аргументное_множество»,
«Аргум_множ_1»)
Переменная-фрагмент «Кон_гран_цикла2»
Атрибут_фрагмента(//арг множ от Кон_гр_ц (дуга For) «Цикл1»
Фрагмент_по_дуге(
«Цикл1»,
«Конечная_граница_цикла»,
«Кон_гран_цикла2»),
«Аргументное_множество»,
«Арг_множ_2»)
Переменная-фрагмент «шаг»
Атрибут_фрагмента(//арг множ от шаг (дуга For) от «Цикл1»
Фрагмент_по_дуге(
«Цикл1»,
«шаг»,
«шаг1»),
«Аргументное_множество»,
«Арг_множ_3»)
Объединение_множеств(
Арг_множ_1,
Арг_множ_2,
«рез_об1»)
Объединение_множеств(
рез_об1,
Арг_множ_3,
«объед_множ2»)
Пересечение_множеств(
объед_множ2,
Счетчик_Цикла1,
«перес_множ1»)
Конструкция Выбор{//пункт 1
Условие -> равенство можеств
терм логической формулы -> перес_множ1
терм логической формулы -> пустое множество
Булево множество -> Истина
если истина// выполняем
Атрибут_фрагмента(//арг_множ от тело_ц (дуга For) «Цикл1»
Фрагмент_по_дуге(
«Цикл1»,
«тело_цикла»,
«тело_1»),
«Аргументное_множество»,
«Аргументное_1»)
Атрибут_фрагмента(//рез_множ от тело_ц (дуга For) «Цикл1»
Фрагмент_по_дуге( «Цикл1», «тело_цикла», «тело_1»),
«Результатное_множество»,
Пересечение_множеств(
Аргументное_1,
Результатное_2,
«перес_множ2») //
Конструкция Выбор//пункт 1
Условие -> равенство можеств
терм логической формулы -> перес_множ2
терм логической формулы -> пустое множество
Булево множество -> Истина
если истина// выполняем 1.1
Модификация программы
Создание атрибута(цикл2, «ParDo»,
«1»)
если ложь// выполняем 1.2
обход_дерева_программы («тело_1»,«текущий_DASS»,
«Класс_фрагмента(текущий_DASS)==
Оператор_присваивания» )// выполняем 1.2.1
{
аргумент-фрагмент «Левая_часть_DASS»
Атрибут_фрагмента(//для левой части выражения
Фрагмент_по_дуге(
«текущий_DASS»,
«левая часть»,
«л_ч»),
«Аргументное_множество»,
«левая_часть»)
аргумент-фрагмент «Правая_часть_DASS»
Атрибут_фрагмента(//для правой части выражения
Фрагмент_по_дуге(
«текущий_DASS»,
«правая часть»,
«п_ч»),
«результатное_множество»,
«правая_часть»)
пересечение множеств (
перес_множ2,
Левая_часть_DASS,
Перес_множ_л)
пересечение множеств (
перес_множ2,
Правая_часть_DASS,
Перес_множ_п)
Условие -> равенство множеств
терм логической формулы -> Перес_множ_п
терм логической формулы -> Перес_множ_л
Булево множество -> ложь
если истина// выполняем 2
«ошибка»=1
выход_из конструкции
если ложь// выполняем 1.2.1.1.1.
если
класс_фрагмента (
Фрагмент_по_дуге(
«текущий_DASS»,
«левая часть»,
«л_ч_2»)
==
«индекс»
значение_по_дуге(элем, индекс, «инд_л»)
Фрагмент_по_дуге(
«текущий_DASS»,
«правая часть»,
«п_ч_2»)
значение_по_дуге(элем, индекс, «инд_п»)
пересечение множеств(
Нач_гран_цикла2,
Инд_л,
«присут_л»)
пересечение множеств(
Нач_гран_цикла2,
Инд_п,
«присут_п»)
условие -> логическая формула
терм логической формулы -> инд_л
Знак логической операции -> <>
терм логической формулы -> инд_п
И
терм логической формулы -> присут_л
Булево множество -> истина
терм логической формулы -> пустое множество
И
терм логической формулы -> присут_п
Булево множество -> истина
терм логической формулы -> пустое множество
если истина// выполняем 2
«ошибка»=1
выход_из конструкции
)
Условие -> логическая формула
терм логической формулы -> ошибка
Знак логической операции -> =
терм логической формулы -> 0
если истина// выполняем 1.2.2
Модификация программы
Создание атрибута(цикл2, «ParDo»,
«1»)
3. Техническая
часть
В данной главе описан процесс проектирования программного средства,
приведены архитектурно-контекстная диаграмма, ее описание, сформулированы
требования к ПС, описан процесс кодирования ПС.
3.1
Назначение программного средства (ПС)
Программное средство, реализующее интерпретацию методов потокового
анализа, разработано для использования в системе СБкЗ_ПП. В рамках системы
программное средство обеспечивает функции потокового анализа МСП. Основное
предназначение - реализация методов потокового анализа преобразования МСП.
Программное средство реализовано в виде библиотеки, в котором содержатся
функции, интерпретирующие методы потокового анализа МСП. Такая архитектура
позволяет производить вызов подсистемы из других подсистем СБкЗ_ПП, если это необходимо.
Используя данную библиотеку, разработчик может выполнить интерпретацию методов
потокового анализа МСП, которая находится в специализированном банке знаний.
.2
Архитектурно-контекстная диаграмма СБкЗ_ПП
Рассмотрим архитектурно контекстную диаграмму системы управления СБкЗ_ПП.
Диаграмма отображает внешнее окружение Системы Управления (СУ) СБкЗ_ПП.
Здесь показано, что, работая с СБкЗ_ПП, пользователь может решать три основные
задачи: Задача 1 - работа со знаниями и данными, Задача 2 -
проведение экспериментов над преобразованием программ, Задача 3 -
построение макета оптимизирующего компилятора. Для решения задач в СБкЗ_ПП на
компьютере пользователя устанавливается интерфейсная часть (тонкий
клиент), который взаимодействует с СУ на стороне сервера.
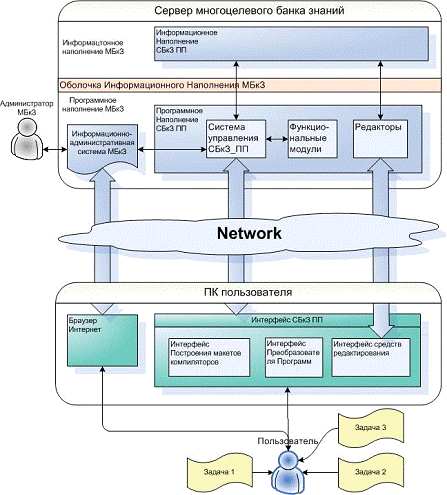
Рисунок 5. АКД СБкЗ_ПП
Клиентская часть, которая находится на компьютере пользователя,
включает в себя возможность трех режимов работы и соответственно три
интерфейса, для решения каждой задачи.
Интерфейс построения макетов компиляторов является графической клиентской
программой для макетирования оптимизирующих компиляторов.
Интерфейс Преобразователя Программ это графическая интерфейсная часть
для построения экспериментов по преобразованию программ. Интерфейс средств
редактирования - это универсальный графический интерфейс для всех структурных
редакторов знаний и данных по преобразованию программ.
Информационно административная система МБкЗ (ИАС) необходима для
регистрации прав и полномочий пользователя. С ней взаимодействия клиента
происходит через Браузер Интернет. После регистрации, при начале работы
с интерфейсной частью СБкЗ_ПП пользователю необходимо будет ввести Логин и
Пароль, присвоенный ему при регистрации. СУ сама взаимодействует с ИАС и
проверяет наличие данных пользователя и его права.
Интерфейсная часть взаимодействует с СУ через Интернет. После получения СУ данных
от пользователя, она организует последовательность работы Функциональных
Модулей (ФМ), находящихся в Программном наполнении СБкЗ_ПП.
Все знания и данные, необходимые для работы ФМ, СУ извлекает из Информационного
Наполнения СБкЗ_ПП, через оболочку МБкЗ.
Пользователь - пользователей можно разделить на три категории, каждая из
которых соответствует своей задаче:
.2.1
Подсистема потокового анализа
На рисунке представлена структура управления, с точки зрения
последовательности применения подсистем на ключевую внутреннюю структуру данных
МСП.
Рис.
6. Диаграмма потока данных
Выделенные
красным цветом элементы - интересующие нас участки.
На
этом этапе идет выбор оптимизирующих преобразований (реструктурирующие
преобразования см. Приложение 1), которые с помощью специального редактора
заносятся в базу знаний. Для выполнения оптимизаций необходимо выполнить
методы, используемые этими оптимизациями. Методы также заносятся в базу знаний
с помощью редактора методов потокового анализа программ. Выполнение методов
производится реализуемым ПС.
.3
Архитектурно-контекстная диаграмма ПС
Рассмотрим архитектуру и контекст подсистемы потокового анализа,
управляемого знаниями в рамках системы преобразований программ СБкЗ_ПП (рис.
7).
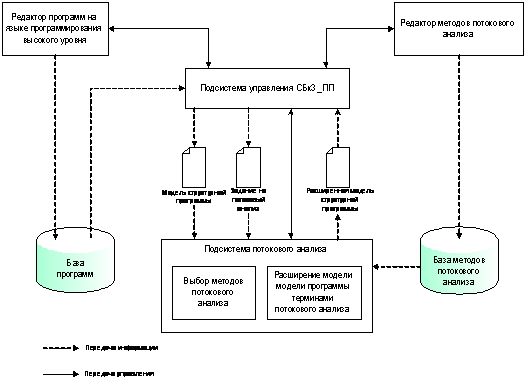
Рис. 7. Архитектурно-контекстная диаграмма подсистемы потокового анализа,
управляемого знаниями
Входной информацией подсистемы потокового анализа, управляемого знаниями
в системе преобразований программ, являются: модель структурной программы
(МСП), методы потокового анализа и задание на потоковый анализ программ.
Входная информация формируется подсистемой управления СБкЗ_ПП, которая
осуществляет взаимодействие с редакторами и передает управление подсистеме
потокового анализа. На выходе подсистемы формируется МСП, расширенная терминами
потокового анализа программ.
3.4
Требования к программному средству
Данный раздел содержит требования к программному средству. К ним
относятся общие функциональные требования, конкретные функциональные
требования, требования к надежности, к рабочим характеристикам, к среде.
.4.1 Общие
функциональные требования
Основной целью программного средства является расширение МСП термином
потокового анализа. Для достижения этой цели, необходимо, чтобы программное
средство обеспечивало:
1. Взаимодействие с банком знаний, в котором хранится МСП.
2. Взаимодействие с базой методов потокового анализа.
. Дополнительные функции, необходимые для интерпретации методов
потокового анализа (например: обход дерева МСП).
.4.2
Конкретные функциональные требования
Для соответствия функциональным требованиям, программное средство должно
содержать:
1. Функции взаимодействия с МБкЗ:
· подключение и открытие МБкЗ;
· закрытие соединения с МБкЗ.
2. Служебные функции:
· обход дерева метода потокового анализа;
· обход дерева МСП.
3. Функции интерпретации методов потокового анализа:.
· Изменение МСП в соответствии с указанными в методе изменениями.
.4.3
Требования к программному обеспечению
На компьютере должен быть установлен JDK версии 1.4 или выше.
.4.4
Требования к надежности
Возникновение внутренних ошибок, таких как, выход значения за пределы
диапазона или обращение по неверному адресу памяти, должно отслеживаться и
обрабатываться самим программным средством, не приводя к аварийному завершению
работы.
.4.5
Профиль пользователя
Пользователь должен обладать знаниями в области реструктурирующих
преобразований и владеть особенностями архитектуры программы и оболочки ИН
МБкЗ.
.4.6
Жизненный цикл программного средства
Описываемое программное средство реализует полный набор функций по
взаимодействию с окружением.
3.4.7
Требования к интерфейсу
Пользовательский интерфейс у программного средства отсутствует. Далее в
этой главе приводятся внутренние интерфейсы, при помощи которых программное
средство может взаимодействовать с другими программами.
3.5
Проектная документация
В данном разделе описывается проектная документация для программного
средства, которая включает в себя: описание данных, архитектуры, спецификаций
функций.
.5.1
Архитектура программного средства
Программное средство реализовано в виде класса Interpretator.
Класс имеет следующие функции:
LoadMethod(String method)
Функция, загружающая метод потокового анализа с именем method
changeMSP()
Функция, загружающая необходимое дерево МСП и запускающая обход дерева
методов
Mtd_tree(AST.Node cur)
Функция, вызывающая необходимое для заданной вершины дерева методов cur действие:
fragOnLink(cur)
Действия, выполняемые, если вершина cur - "Фрагмент по дуге"
FragAttr(cur)
Действия, выполняемые, если вершина cur - "Атрибут фрагмента"
GetClass(cur)
Действия, выполняемые, если вершина cur - "Получить класс"
GetPhraseVar(cur)
Действия, выполняемые, если вершина cur - "Получить переменную выражения"
FirstElem(cur)
Действия, выполняемые, если вершина cur - "Первый фрагмент по дуге из
последовательности"
NextElem(cur)
Действия, выполняемые, если вершина cur - "Следующий фрагмент по дуге из
последовательности"(cur)
Действия, выполняемые, если вершина cur - "Пересечение множеств"
ObyedMnoz(cur)
Действия, выполняемые, если вершина cur - "Объединение множеств"(cur)
Действия, выполняемые, если вершина cur - "Равенство множеств"
LogicFormula(cur)
Действия, выполняемые, если вершина cur - "Логическая формула"
ComplexLogicFormula (cur)
Действия, выполняемые, если вершина cur - "Составная логическая формула"
CreateFrag(cur)
Действия, выполняемые, если вершина cur - "Создание фрагмента"
CreateLink(cur)
Действия, выполняемые, если вершина cur - "Создание дуги"
CreateRel(cur)
Действия, выполняемые, если вершина cur - "Создание отношения"
ProgramTree(cur)
Действия, выполняемые, если вершина cur - "Обход дерева программы"
PartTree(cur)
Действия, выполняемые, если вершина cur - "Обход дерева выражения"
Choice(cur)
Действия, выполняемые, если вершина cur - "Выбор"
Cycle(cur)
Действия, выполняемые, если вершина cur - "Цикл"
CreateAttr(cur)
Действия, выполняемые, если вершина cur - "Создание атрибута"(cur)
Действия, выполняемые, если вершина cur - "Изменение атрибута"
CreateVar(cur)
Действия, выполняемые, если вершина cur - "Создание переменной"
Prisv(cur)
Действия, выполняемые, если вершина cur - "Присваивание"(cur)
Действия, выполняемые, если вершина cur - "Выражение"
3.5.2
Спецификации функций
LoadMethod(String method)
Входные параметры: строка method - имя загружаемого метода
Выходные параметры: целое vertex
- количество вершин дерева
Функция, загружающая метод потокового анализа с именем method:
Подключиться к банку.
Загрузить теорию «Методы потокового анализа программ» из банка "Банк
знаний о преобразованиях программ" в виде дерева типа AST.
Отключиться от банка.
changeMSP()
Входные параметры: нет
Выходные параметры: нет
Функция, загружающая необходимое дерево МСП и запускающая обход дерева
методов:
Mtd_tree(AST.Node cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - результат работы вызываемых процедур или
значение терминальной вершины, полученное рекурсивной работой функции.
Функция, вызывающая необходимое для заданной вершины дерева методов cur действие:
См. п.2.4. «Метод потокового анализа»
Более подробно о принципе работы следующих функций написано в п.2.4.
«Алгоритм решения задачи потокового анализа МСП».
fragOnLink(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-фрагмента
Действия, выполняемые, если вершина cur - "Фрагмент по дуге"
FragAttr(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-фрагмента
Действия, выполняемые, если вершина cur - "Атрибут фрагмента"
GetClass(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-класса фрагмента
Действия, выполняемые, если вершина cur - "Получить класс"
GetPhraseVar(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-переменной
Действия, выполняемые, если вершина cur - "Получить переменную выражения"
FirstElem(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-фрагмента
Действия, выполняемые, если вершина cur - "Первый фрагмент по дуге из
последовательности"
NextElem(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-фрагмента
Действия, выполняемые, если вершина cur - "Следующий фрагмент по дуге из
последовательности"(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-множества
Действия, выполняемые, если вершина cur - "Пересечение множеств"
ObyedMnoz(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-множества
Действия, выполняемые, если вершина cur - "Объединение множеств"(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата: «T» или «F»
Действия, выполняемые, если вершина cur - "Равенство множеств"
LogicFormula(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата: «T» или «F»
Действия, выполняемые, если вершина cur - "Логическая формула"
ComplexLogicFormula (cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата: «T» или «F»
Действия, выполняемые, если вершина cur - "Составная логическая формула"
CreateFrag(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-фрагмента
Действия, выполняемые, если вершина cur - "Создание фрагмента"
CreateLink(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-атрибута
Действия, выполняемые, если вершина cur - "Создание дуги"
CreateRel(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата
Действия, выполняемые, если вершина cur - "Создание отношения"
ProgramTree(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение «T» или «F»,
если обнаружена ошибка
Действия, выполняемые, если вершина cur - "Обход дерева программы"
PartTree(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение значение «T» или «F»,
если обнаружена ошибка
Действия, выполняемые, если вершина cur - "Обход дерева выражения"
Choice(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-фрагмента
Действия, выполняемые, если вершина cur - "Выбор"
Cycle(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение значение «T» или «F»,
если обнаружена ошибка
Действия, выполняемые, если вершина cur - "Цикл"
CreateAttr(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата-атрибута
Действия, выполняемые, если вершина cur - "Создание атрибута"(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата- атрибута
Действия, выполняемые, если вершина cur - "Изменение атрибута"
CreateVar(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение переменной
Действия, выполняемые, если вершина cur - "Создание переменной"
Prisv(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата
Действия, выполняемые, если вершина cur - "Присваивание"(cur)
Входные параметры: AST.Node cur - вершина дерева методов
Выходные параметры: строка - значение результата
Действия, выполняемые, если вершина cur - "Выражение"
3.5.3
Описание реализации программного средства
В данном разделе описывается реализация программного средства.
Среда реализации. Аппаратная часть среды: Intel Pentium-3 500 МГц, 256 Мб
ОЗУ. Программная составляющая: необходима установленная JDK версии 1.4 или
выше.
Описание реализации. Программное средство реализовано в виде библиотеки.
3.5.4 Описание
использования программного средства
Для того, чтобы запустить интерпретацию метода потокового анализа на
выполнение, необходимо импортировать библиотеку Interpretator и запустить процедуру LoadMethod(имя), где имя - название
необходимого метода потового анализа. Результатом работы интерпретатора методов
потокового анализа является измененная МСП.
4.
Тестирование
В данной главе описывается тестирование программного средства.
.1
Тестовые ситуации
. Указанного метода не найдено
. Указанный метод найден
.1 Метод использует "Фрагмент по дуге"
.2 Метод использует "Атрибут фрагмента"
.3 Метод использует "Получить класс"
.4 Метод использует "Получить переменную выражения"
.4.1 Аргумент-фрагмент - терминальная вершина
.4.2 Аргумент-фрагмент - нетерминальная вершина
.5 Метод использует "Первый фрагмент по дуге"
.6 Метод использует "Следующий фрагмент по дуге"
.7 Метод использует "Пересечение множеств"
.7.1 одно из множеств - пустое
.7.2 множества не пусты
.8 Метод использует "Объединение множеств"
.8.1 одно из множеств - пустое
.8.2 множества не пусты
.9 Метод использует "Равенство множеств"
.9.1множества равны
.9.2 множества не равны
.10 Метод использует "Логическая формула"
.11 Метод использует "Создание фрагмента"
.12 Метод использует "Создание дуги"
.13 Метод использует "Создание атрибута"
.14 Метод использует "Изменение атрибута"
.15 Метод использует "Создание переменной"
.16 Метод использует "Присваивание"
.16.1 типы левой и правой частей присваивания совместимы
.16.2 типы левой и правой частей присваивания несовместимы
.17 Метод использует "Выражение"
.18 Метод использует "Составная логическая формула"
.2 Тесты
По плану тестирование будет представлять собой тестирование всего
программного средства по методу «черного ящика».
|
№
|
№ тс
|
Вход
|
Ожидаемый результат
|
Выход
|
Успешность
|
|
1
|
1
|
Load method(“A”)
|
“”
|
“”
|
+
|
|
2
|
2
|
Load method(“ParDo”)
|
“T”
|
“T”
|
+
|
|
3
|
2.1
|
Арг = Фрагмент МСП (тип DIf) Имя_дуги =Если Результат
-фрагмент = рез
|
рез= фрагмент (тип DExpr, являющийся потомком Арг)
|
рез= фрагмент (тип DExpr, являющийся потомком Арг)
|
|
4
|
2.2
|
Арг = Фрагмент МСП (тип DAss) Имя_атрибута = Аргументное_множество Результат
-атрибут = рез
|
Рез={a, b, c}
|
Рез={a, b, c}
|
+
|
|
5
|
2.3
|
Арг = Фрагмент МСП (тип Dexpr) Результат-класс фрагмента = рез
|
Рез= «Выражение»
|
Рез= «Выражение»
|
+
|
|
6
|
2.4.1
|
Арг = Фрагмент МСП (тип Dexpr) Результат-переменная = рез
|
Рез= a
|
Рез= а
|
+
|
|
7
|
2.4.2
|
Арг = Фрагмент МСП (тип Dexpr) Результат-переменная = рез
|
Рез= Æ
|
Рез= Æ
|
+
|
|
8
|
2.5
|
Арг = Фрагмент МСП (тип Dbody) Результат -фрагмент = рез
|
рез= фрагмент (тип DIf, являющийся потомком Арг)
|
рез= фрагмент (тип DIf, являющийся потомком Арг)
|
+
|
|
9
|
2.6
|
Арг = Фрагмент МСП (тип Dbody) Результат -фрагмент = рез
|
рез= фрагмент (тип DExpr, являющийся потомком Арг)
|
рез= фрагмент (тип DExpr, являющийся потомком Арг)
|
+
|
|
10
|
2.7.1
|
Аргумент-множество1={a, b, c} Аргумент-множество2={} Результат-
множество=рез
|
Рез={ }
|
Рез={ }
|
+
|
|
10
|
2.7.2
|
Аргумент-множество1={a, b, c} Аргумент-множество2={a, c} Результат- множество=рез
|
Рез={a, c}
|
Рез={a, c}
|
+
|
|
11
|
2.8.1
|
Аргумент-множество1={a, b, c} Аргумент-множество2={} Результат-
множество=рез
|
Рез={a, b, c}
|
Рез={a, b, c}
|
+
|
|
12
|
2.8.2
|
Аргумент-множество1={a, b, c} Аргумент-множество2={a, c} Результат- множество=рез
|
Рез={a, b, c, a, c}
|
Рез={a, b, c, a, c }
|
+
|
|
13
|
2.9.1
|
Аргумент-множество1={a, b, c} Аргумент-множество2={} булево
=рез
|
Рез= "False"
|
Рез= "False"
|
+
|
|
14
|
2.9.2
|
Аргумент-множество1={a, b, c} Аргумент-множество2={a, b, c}
булево=рез
|
Рез= "True"
|
Рез= "True"
|
+
|
|
15
|
2.10
|
Логическая формула= составная логическая формула
Аргумент1=переменная арг1 Аргумент2= переменная арг2 Знак= «==»
|
"True"
|
"True"
|
+
|
|
16
|
2.11
|
Аргумент1=переменная арг1 Аргумент2= переменная переем_1
Знак= «==»
|
" False "
|
" False "
|
+
|
|
17
|
2.12
|
Арг = Фрагмент МСП (тип Dbody) класс =Условный Результат -фрагмент = рез
|
рез= фрагмент (тип DIf, являющийся потомком Арг)
|
рез= фрагмент (тип DIf, являющийся потомком Арг)
|
+
|
|
18
|
2.13
|
Арг = Фрагмент МСП (тип Dexpr) имя = Аргументное_множество значение = { a, b, c}
|
Создан аргумент от фрагмента арг Имя= Аргументное_множество
значение = {
a, b, c}
|
Создан аргумент от фрагмента арг Имя= Аргументное_множество
значение = {
a, b, c}
|
+
|
|
19
|
2.14
|
Арг = Фрагмент МСП (тип Dexpr) имя = Аргументное_множество значение = { b, c}
|
аргумент от фрагмента арг Имя= Аргументное_множество
значение = {b, c}
|
аргумент от фрагмента арг Имя= Аргументное_множество
значение = {b, c}
|
+
|
|
20
|
2.15
|
Имя переменной = пер1 Тип = вещественный
|
Создана переменная
|
Создана переменная
|
+
|
|
21
|
2.16.1
|
Левая часть = фрагм1 Правая часть = фрагм2
|
Фрагм1=фрагм2
|
Фрагм1=фрагм2
|
+
|
|
22
|
2.16.2
|
Левая часть = фрагм1 Правая часть = 34
|
F
|
F
|
+
|
|
23
|
2.17
|
Аргумент1=3 Аргумент2=5 Знак = "+"
|
8
|
8
|
+
|
|
24
|
2.18
|
(2+4)*5
|
30
|
30
|
+
|
5.
Экспериментальное изучение свойств программного средства
В данной главе приводятся результаты экспериментального исследования
свойств программного средства.
5.1 Цель экспериментов
1. Проверить совместимость с уже существующими компонентами новой версии
СБкЗ_ПП.
2. Оценить время работы программного средства в зависимости от
сложности исходных данных.
По окончании экспериментов необходимо сделать вывод о временных характеристиках
программного средства и его совместимости с уже реализованными компонентами
новой версии СБкЗ_ПП.
5.2
Описание среды
Схема применения компонентов СБкЗ_ПП, которая используется для проведения
экспериментов, выглядит следующим образом (цифрами обозначен порядок вызова):

Рис.
8. Схема применения компонентов СБкЗ_ПП для экспериментов
Рассмотрим
первый случай, когда необходимо проверить совместимость программного средства с
уже существующими компонентами новой версии СБкЗ_ПП.
На
данный момент представляется возможным экспериментально изучить совместимость с
МСП-генератором, осуществляющим перевод текста программы в терминах онтологии
ЯП «Pascal» в программу в терминах онтологии МСП и заполняющим полученную МСП в
специализированный банк знаний. Также возможно оценить совместимость с
«Редактором методов потокового анализа программ», который позволяет
просматривать, создавать и редактировать методы потокового анализа программ в
СБкЗ_ПП.
Данный
эксперимент позволит оценить, на сколько программное средство совместимо с уже
реализованными частями системы СБкЗ_ПП.
Для
второго случая, когда необходимо оценить время работы программного средства в
зависимости от сложности входных данных. Целесообразно разделить подсчет
времени для функций работы с Банком и функций, реализующих саму логику
программы. Для этого в исходный код были введены специальные счетчики для
функций и методов класса Interpretator, которые производят раздельный подсчет времени в
миллисекундах для указанных функций.
Входными
данными для ПС является дерево метода потокового анализа различной степени
сложности.
Также
на вход подается МСП различной сложности. Сложность МСП считается как сумма
сложностей входящих в нее операторов и операций. Сложность каждой отдельно
взято операции или оператора - это оценка сложности, построенная на основе
количества потомков соответствующего узла в МСП относительно количества
потомков унарной арифметической (или логической) операции в МСП. По этому
критерию была построена следующая таблица сложностей:
Таблица 1
Сложность операторов и операций
|
Операция
|
Сложность
|
|
Унарная арифметическая или логическая операция
|
1
|
|
Бинарная арифметическая или логическая операция
|
2
|
|
Операция взятия элемента массива
|
2
|
|
Оператор присваивания
|
4
|
|
Оператор объявления переменной
|
4
|
|
Условный оператор
|
5
|
|
Оператор цикла For
|
7
|
Другие операторы не рассматривались, поскольку указанного набора хватает
для оценки большинства программ.
Аппаратное обеспечение, используемое при проведении экспериментов: Intel Mobile 2.13 GHz, 1024 Мб ОЗУ. Программное
обеспечение, используемое при проведении экспериментов: ОС MS Windows XP.
Данные для проведения экспериментов описаны в приложении 1, набор тестовых
данных №1.
.3 План
экспериментов
Для достижения вышеуказанной цели необходимо придерживаться следующего
плана:
По схеме применения компонентов СБкЗ_ПП для экспериментов (рис. 9)
выполняется запуск соответствующих программных средств.
Для эксперимента использовались: дерево методов потокового анализа (694
вершины) и мсп:
Эксперимент
№1
В ходе эксперимента были выполнены следующие действия:
1. Запущена зарузка дерева методов потокового анализа.
2. Запущен МСП-генератор.
. На выходе МСП-генератора получена МСП, находящаяся в СБкЗ_ПП.
. Запущена программа, которая осуществляет интерпретирование
метода потокового анализа на дерево МСП.
. На выходе получена МСП, расширенная термином потокового анализа
и находящаяся в СБкЗ_ПП.
Рис
9. МСП для эксперимента
Результат: Все реализованные части системы СБкЗ_ПП отработали совместно
без возникновения ошибок. Время, за которое выполнились функции загрузки равно
144813 мсек. Время, за которое выполнились функции интерпретирования методов
равно 84 мсек.
Эксперимент
№2
В ходе эксперимента были выполнены следующие действия:
1. Запущена зарузка дерева методов потокового анализа (542 вершины).
2. МСП-генератор сгенерировал МСП, находящуюся в СБкЗ_ПП.
. Запущена программа, которая осуществляет интерпретирование
метода потокового анализа на дерево МСП.
. На выходе получена МСП, расширенная термином потокового анализа
и находящаяся в СБкЗ_ПП..
Результат: Время, за которое выполнились функции загрузки равно 65216
мсек. Время, за которое выполнились функции интерпретирования методов равно 52
мсек.
Эксперимент
№3
В ходе эксперимента были выполнены следующие действия:
1. Запущена зарузка дерева методов потокового анализа (128 вершин).
2. МСП-генератор сгенерировал МСП, находящуюся в СБкЗ_ПП.
. Запущена программа, которая осуществляет интерпретирование
метода потокового анализа на дерево МСП.
. На выходе получена МСП, расширенная термином потокового анализа
и находящаяся в СБкЗ_ПП.
Результат: Время, за которое выполнились функции загрузки равно 22217
мсек. Время, за которое выполнились функции интерпретирования методов равно 13
мсек.
5.4 Результаты
экспериментов
Сводная таблица времени выполнения приведена в таблице 2.
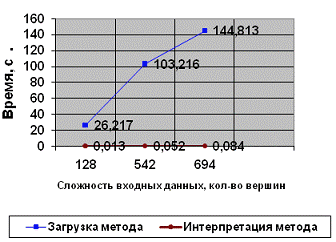
Таблица 2. Время выполнения экспериментов в мс (ось Y) и сложность входных данных (ось X)
Из вышеприведенных результатов экспериментов можно сделать следующие
выводы:
· Со всеми реализованными компонентами СБкЗ_ПП, программное средство
работало без сбоев, это позволяет сделать вывод, что оно совместимо с остальной
системой;
· Основываясь на результатах эксперимента можно заключить, что зависимость
времени выполнения от сложности является практически линейной. Стоит отметить,
что загрузка данных занимает значительно больше времени, чем их обработка, что
должно быть учтено при проектировании остальной системы СБкЗ_ПП и планировании
усилий на оптимизацию.
6.
Доказательство того, что цели, сформулированные в задании, достигнуты.
Обсуждение результатов дипломной работы
Целью дипломной работы является Разработка и реализация подсистемы
потокового анализа, управляемого знаниями, для распараллеливаемых программ в
МСП как части СБкЗ_ПП.
В ходе выполнения дипломной работы был проведен обзор литературы на тему
«потоковый анализ в распараллеливающих и оптимизирующих компиляторах», что
нашло свое отражение в Главе 1. В результате работы над литературой были
рассмотрены достижения в области распараллеливания программ: концепцию работы
компилятора, функциональность, эффективность, особенности реализации. Особое
внимание уделялось способам управления оптимизирующими преобразованиями, что
позволило, осуществить выбор наиболее эффективного и теоретически обоснованного
с целью реализации этого метода.
В результате работы была поставлена задача, занесен в базу знаний метод ParDO потокового анализа для
распараллеливаемых программ. Эта информация находится во второй главе данной
работы в разделе 2.4.3.
Было реализовано программное средство, интерпретирующее методы потокового
анализа, управляемого знаниями, для распараллеливаемых программ в МСП как части
СБкЗ_ПП. Программное средство было реализовано в среде IntelliJ Idea 6 на языке Java.
Для программного средства был разработан пакет документации, включающий в
себя требования к ПС, архитектурный проект, спецификация функций и отчет по
тестированию.
На основании этого можно считать, что цель дипломной работы достигнута.
Результатом работы является законченное программное средство, которое
успешно взаимодействует с программным и информационным наполнением СБкЗ_ПП и
выполняет возложенные на него функции.
Заключение
В ходе выполнения дипломной работы были получены следующие результаты:
· написан обзор литературы, по теме «потоковый анализ программ в
распараллеливающих и оптимизирующих компиляторах»;
· сформулированы требования к программному средству,
реализующему интерпретацию методов потокового анализа;
· создана техническая документация для программного средства;
· реализовано программное средство.
Список
литературы
1. Абрамов
С.М., Адамович А.И., Инюхин А.В., Московский А.А., Роганов А.В., Шевчук Ю.А.,
Шевчук Е.В. // Т-система с открытой архитектурой. ИПС РАН, г.
Переславль-Залесский.
#"551921.files/image015.gif">
$ v3: Dexpr & v3 <· Expr (X2) & OP(v3) = NULL & IsArray
(Type(Left(v3))) = true & isleft(v3)=isleft(v1) & A(Expr(X1)) \ Par(Y1)
\ Par(Y2) \ R(v3) = Æ
Неформальное описание трансформации
Меняем все нижние и верхние границы циклов, а также их шаги местами.
Также меняем местами счетчики циклов.
Формальное описание трансформации
$< Y1, Y2, E1, E2, E3, T1, T2, T3, B1, B2>
( »(E1Z,T1) & »(E2Z,T2) & »(E3Z,T3) & »(T1Z,E1) & »(T2Z,E2) & »(T3Z,E3), i1=Par(Y1) & i2=Par(Y2), E1ÞE1Z, E2ÞE2Z, E3ÞE3Z, T1ÞT1Z, T2ÞT2Z, T3ÞT3Z, Par(Y1)=i2, Par(Y2)=i1)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец / Обмен циклов /
. Распределение цикла
Бэкон 6.2.7 (23)
Воеводин 417
0.127 августа 2006
Описание
Распределение циклов (также называемое расщеплением циклов или
разделением циклов) разбивает гнездо циклов на несколько отдельных циклов.
Каждый из новых циклов имеет тоже итерационное пространство, что и исходный
цикл, но содержит подмножество операторов исходного цикла.
Это преобразование является обратным по отношению к преобразованию
слияния циклов. Пусть задан некоторый цикл. Построим для него граф
зависимостей. Допустим, что после переупорядочивания в теле цикла его можно
представить в виде двух подряд идущих фрагментов, и нет ни одной Дуги, идущей
из опорных пространств второго фрагмента в опорные пространства первого
фрагмента. Тогда цикл можно представить в виде двух Подряд идущих циклических
конструкций. Самые внешние циклы у них совпадают. Телом первого цикла является
первый фрагмент, телом второго - второй фрагмент. Если преобразуемый цикл имел
тип РаrDо, то тип ParDo будут иметь оба внешних цикла преобразованной
программы. Оба внешних цикла или один из них могут иметь тип РаrDо и в том
случае, когда таковым не является преобразуемый цикл.
Пример
было
do i = 1, nj = 1, m[i] = a[i] + c[j] = x[j] + x[j]*10dodo
стало
do all i = 1, n[i] = a[i] + cdoj = 1, m[j] = x[j] + x[j]*10do
В примере распределение уменьшает общее количество итераций и позволяет
распараллелить часть цикла. Распределение можно применять для любых циклов, но
все операторы, принадлежащие зависимой цепочке, должны размещаться в одном
цикле, и, если зависимость S1 Þ S2 имеет место в исходном цикле, то цикл, содержащий
оператор S1 должен предшествовать циклу, содержащему оператор S2.
Когда массивы, обрабатываемые в циклах, большие, распределение циклов
может улучшить использование памяти.
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из другого цикла For, тело которого, в свою очередь, состоит из двух
операторов.

Здесь Y1 - первый (внешний) цикл For, Y2 - второй (внутренний) цикл For.
У каждого цикла есть свои начальные границы - E1 и T1, свои конечные границы -
E3 и T3, свои шаги цикла E2 и T2 и свои тела циклов - B1 и B2. Причём Y2
является телом цикла Y1. D - представление тела внутреннего цикла Y2 в виде
последовательности двух операторов, X1 и X2 - первый и второй оператор.
Информационные условия:
результаты X2 не влияют на X1
результаты X1 не влияют на X2и X2 не имеют общих результатов
Аргументное множество X2 не содержит переменную цикла Y1
Аргументное множество X1 не содержит переменную цикла Y2
Оба цикла имеют тип ParDO
Формальное контекстное условие
$< Y1, Y2, E1, E2, E3, T1, T2, T3, B1, B2, D, X1, X2>(
FragClass(Y1)=Dfor
& FragClass(Y2)=Dfor
& FragClass(B1)=Dbody
& FragClass(B2)=Dbody
& FragClass(D)=Dsch & & FragClass(E1)=Dexpr
& FragClass(E2)=Dexpr
& FragClass(E3)=Dexpr
& FragClass(T1)=Dexpr
& FragClass(T2)=Dexpr
& FragClass(T3)=Dexpr
&FragClass(X1)=DASS
& FragClass(X2)=DASS
& B1=Body(Y1)
& Begin(B1)=Y2
& End(B1)=Y2
& B2=Body(Y2)
& D=Sch(B2)
& Begin(D)=Begin(X1) & End(D)=End(X2) & Left(E1)Î{Const} & Left(E2)Î{Const} & Left(E3)Î{Const} & Left(T1)Î{Const} & Left(T2)Î{Const} & Left(T3)Î{Const} &
R( X1) Ç R(X2) = Æ &( X1) Ç Par(Y2) = Æ &( X2) Ç Par(Y1) = Æ &
ParDO(Y1)=True & ParDO(Y2)=True &
g (X1, X2, Y1) = false & g (X2, X1, Y1) = false.
Неформальное описание трансформации
Гнездо из двух циклов разбиваем на два отдельных цикла
Формальное описание трансформации
$< Y1, Y2, E1, E2, E3, T1, T2, T3, B1, B2, X1, X2>
(FragClass(V1)={Dfor} & For(V1)=»(For(Y1)) & Until(V1)=
»(Until(Y1)) &
Step(V1)= »(Step(Y1))
& Par(V1)=Par(Y1) & Sch(Body(V1))=»(X1)) & & FragClass(V2)={Dfor} & For(V2)= »(For(Y2)) & Until(V2)=
»(Until(Y2)) &
Step(V2)= »(Step(Y2))
& Par(V2)=Par(Y2) & Sch(Body(V2))=»(X2) &FragClass(Z1)={Dsch} & Z1=V1||V2, Y1ÞZ1)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец / Распределение цикла /
. Объединение циклов
Бэкон 6.3.3 (27)
Воеводин 416
0.127 августа 2006
Описание
Объединением циклов называется преобразование, при котором тела двух
циклов объединяются, или сливаются, образуя один цикл. Это преобразование
используется для создания секционированного кода для векторных машин, а также
для уменьшения заголовка цикла при обычной оптимизации.
Объединение позволяет свернуть гнездо циклов в один цикл с оригинальными
индексными переменными, которые вычисляются с помощью другой индексной
переменной. Объединение может улучшить распределение цикла при параллельных
вычислениях и уменьшить итерационные переходы. Например, если n и m немного
больше, чем количество процессоров P (см. пример №6), то ни одна итерация,
равно как и внешний цикл не займет столько времени, с момента выполнения
последних n-P итераций, как первые P. Объединение двух циклов гарантирует, что
P итераций могут выполняться каждый раз за исключением последних (nm mod P)
итераций, как показано в примере
Пример
было
do all i=1, nall j=1, m[i,j] = a[i,j] +cdo alldo all
стало
do all T=1, n*m= ((T-1) / m)*m + 1= MOD(T-1, m) + 1[i,j] =
a[i,j] + cdo all
Неформальное контекстное условие
Участком экономии в данном случае является непрерывная последовательность
операторов, начинающаяся и заканчивающаяся циклом For. Между циклами могут
стоять и другие операторы. У циклов должны совпадать обе границы и шаг цикла,
переменные цикла могут иметь разные идентификаторы.
Схема
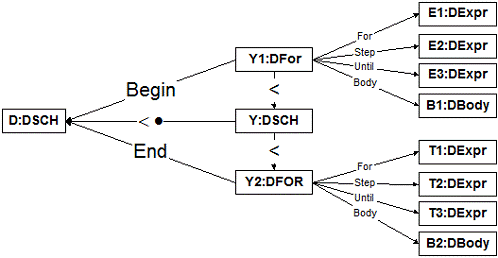
здесь D - последовательность операторов, Y1 и Y2 - два цикла For,
являющиеся ее началом и концом соответственно, Y - последовательность
операторов, возможно пустая, лежащая между ними. У каждого цикла есть свои
начальные границы - E1 и T1, свои конечные границы - E3 и T3, свои шаги цикла
E2 и Е2 и свои тела циклов - B1 и B2. Образы выражений E1 и Е1, E2 и T2, E3 и
T3 соответственно должны совпадать.
Информационные условия:
Результаты E1, E2, E3, B1, Y не должны влиять на T1, T2, T3 или B2
Результаты B2 не должны влиять на B1 и Y
Формальное контекстное условие
$<D, Y, Y1, Y2, E1, E2, E3, T1,T2,T3, B1,B2> (
FragClass(D)=Dsch & FragClass(Y1)=Dfor &(Y)=Dsch
& FragClass(Y2)=Dfor &(E1)=Dexpr & FragClass(E2)=Dexpr &
FragClass(E3)=Dexpr & FragClass(T1)=Dexpr & FragClass(T2)=Dexpr &
FragClass(T3)=Dexpr & FragClass(B1)=DBody & FragClass(B2)=DBody
&(D)=Y1 & End(D)= Y2 & Y2<>Y1 & <(Y1, Y) & <(Y,
Y2) & IsLine(D) & IsLine(Y) & B1=Body(Y1) & B2=Body(Y2)&
Image(E1)= Image(T1) & Image(E2)= Image(T2) & Image(E3)= Image(T3)
& ((R(E1) È R(E2) ÈR(E3) ÈR(B1) ÈR(Y)) Ç(A(T1) ÈA(T2) ÈA(T3) ÈA(B2)))= Æ & R(B2) Ç(A(B1) ÈA(Y))= Æ, ParDO(Y1)=True & ParDo(Y2)=True)
Неформальное описание трансформации
Тело цикла B1 заменяется на конкатенацию B1 и B2 c заменой в B2 всех
вхождений параметра цикла Y2 на параметр цикла B1
цикл Y2 заменяется на Null
Гнездо из двух циклов разбиваем на два отдельных цикла
Формальное описание трансформации
$<D, Y, Y1, Y2, E1, E2, E3, T1,T2,T3, B1,B2>(FragClass(B3)=Dsch
& B3=»(B1) || Zam(B2,
Par(Y2), Par(Y1)), B1ÞB3, Y2 Þ NULL)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец / Объединение циклов /
. Распределение цикла
Бэкон 6.2.3 (20)
Воеводин 418
0.127 августа 2006
Описание
Распределение циклов (также называемое расщеплением циклов или
разделением циклов) разбивает гнездо циклов на несколько отдельных циклов.
Каждый из новых циклов имеет тоже итерационное пространство, что и исходный
цикл, но содержит подмножество операторов исходного цикла.
Это преобразование является обратным по отношению к преобразованию
слияния циклов. Пусть задан некоторый цикл. Построим для него граф
зависимостей. Допустим, что после переупорядочивания в теле цикла его можно
представить в виде двух подряд идущих фрагментов, и нет ни одной Дуги, идущей
из опорных пространств второго фрагмента в опорные пространства первого
фрагмента. Тогда цикл можно представить в виде двух Подряд идущих циклических
конструкций. Самые внешние циклы у них совпадают. Телом первого цикла является
первый фрагмент, телом второго - второй фрагмент. Если преобразуемый цикл имел
тип РаrDо, то тип ParDo будут иметь оба внешних цикла преобразованной
программы. Оба внешних цикла или один из них могут иметь тип РаrDо и в том
случае, когда таковым не является преобразуемый цикл.
Пример
было
do i = 1, nj = 1, n[i,j] = a[i-1,j+1] + 1dodo
стало
do i = 1, nj = n, 1, -1[i,j] = a[i-1,j+1] + 1 do
end do
исходное гнездо циклов: дистанционный вектор (1, -1) - перестановка
недопустима
внутренний цикл инвертирован: вектор направлений (1, 1) - перестановка
допустима
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из последовательности операторов.- цикл. У цикла есть свои границы: Е1
- начальная граница, Е2 - конечная граница, Е3 - шаг цикла. B - тело цикла. E3
= 1. E1>0.
Формальное контекстное условие
$<Y,E1,E2,E3,B>(FragClass(Y)=Dfor & FragClass(B)=Dbody & FragClass(E1)=Dexpr
& FragClass(E1)=Dexpr
& FragClass(E2)=Dexpr
& FragClass(E3)=Dexpr
& ParDO(Y)=True & E1 = For(Y)
& E2 = Until(Y)
& E3 = Step(Y)
& B = Body(Y)
& Eval(E1, null, null) > 0 & Eval(E3, null, null) = 1 ).
Неформальное описание трансформации
Создаём Y'. Y' - это цикл For такой, что значения его начальной границы
совпадают со значениями конечной границы цикла Y, значение конечной границы со
значением начальной границы Y, а шаг цикла = -1.
Цикл Y переходит в цикл Y’.
Формальное описание трансформации
$<Y,E1,E2,E3,B,D> ( (c: Новые идентификаторы (Var, Int)) &
FragClass(Y')=Dfor & Par(Y’)=Par(Y) & Sch(Body(Y))=≈Sch(Body(Y’))&
For(Y’)=NewExp(C)& For(Y') =≈ (Until(Y))& Until(Y’)=NewExp(C)
& Until(Y') =≈ (For(Y)) & Eval(Step(Y')=1),Y=>Y’)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец /Распределение цикла /
. Разбиение цикла
Бэкон 6.2.6 (22)
0.127 августа 2006
Описание
Разбиение цикла является многомерным обобщением послойного разбора.
Разбиение цикла (также называемое блочным разбиением) в основном используется
для улучшения повторного использования кэша (Qc) и представляет собой деление
итерационного пространства на блоки и преобразования гнезда циклов для
проведения итераций над этими блоками. Однако оно может использоваться для
улучшения использования процессоров (на многопроцессорных машинах), регистров,
TLB (Translation Lookaside Buffer - используется для преобразования линейных
адресов в физические адреса), или размещения страниц памяти.
Ниже приведен пример №8 гнезда массивов, в котором матрице a присваивается транспонированная
матрица b. Во внутреннем цикле (с итерационной
переменной j) доступ к элементам массива b осуществляется максимальным шагом 1,
в то время, как доступ к элементам массива a - с максимальным шагом n. Перестановка циклов в данном случае не поможет, т.к.
после перестановки доступ к элементу массива b будет осуществляться с максимальным шагом n. Осуществляя дополнительные итерации
над прямоугольными подпространствами итерационного пространства, как показано в
примере №8, достигается полное использование кэша.
Пример
было
do i = 1, nj = 1, n[i,j] = b[j,i]dodo
стало
do TI = 1, n, 64TJ = 1, n, 64i = TI, min(TI+63,n)j = TJ,
min(TJ+63,n)[i,j] = b[j,i]dodododo
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из другого цикла For, тело которого, в свою очередь, состоит из
последовательности операторов. Здесь Y1 - первый (внешний) цикл For, Y2 -
второй (внутренний) цикл For. У каждого цикла есть свои начальные границы - O1
и O2, свои конечные границы - E1 и E2, свои шаги цикла S1 и S2 и свои тела
циклов - B1 и B2. Причём Y2 является телом цикла Y1. D - представление тела
внутреннего цикла Y2 в виде последовательности операторов
Формальное контекстное условие
< Y1, Y2, B1, B2, O1, O2, E1, E2, S1, S2, D > ( FragClass(Y1)=Dfor & FragClass(Y2)=Dfor &
FragClass(B1)=Dbody & FragClass(B2)=Dbody &
FragClass(D)=Dsch &(O1)=Dexpr & FragClass(E1)=Dexpr &
FragClass(S1)=Dexpr &(O2)=Dexpr & FragClass(E2)=Dexpr &
FragClass(S2)=Dexpr &=Body(Y1) & Begin(B1)=Y2 & End(B1)=Y2
&=Body(Y2) & D=Sch(B2) &
ParDO(Y1)=True
Неформальное описание трансформации
Создаём Y1'. Y1' - это цикл For такой, что значения его начальной и
конечной границы совпадают со значениями начальной и конечной границы цикла Y1
соответственно, а шаг цикла - увеличенный шаг цикла Y1. Создаём целочисленную
переменную - счётчик цикла Y1 - V1. Телом цикла Y1' является цикл Y2'. Y2' -
это цикл For такой, что значения его начальной и конечной границы совпадают со
значениями начальной и конечной границы цикла Y2 соответственно, а шаг цикла -
увеличенный шаг цикла Y2. Для него так же создаем целочисленную переменную,
которая будет являться счётчиком цикла - V2. Внутри цикла Y2 создаём цикл Y3 c
шагом 1, начальная граница которого совпадает с текущим значением V1, а
конечная - min(V1 + (значение(S1) - 1), E1). Y3 - является телом цикла Y2'.
Затем, уже внутри цикла Y3, создаём цикл Y4 так же c шагом 1. Начальная граница
Y4 совпадает с текущим значением V2, а конечная - min(V2 + (значение(S2) - 1),
E2). Y4 - является телом цикла Y3. Телом цикла Y4 - является последовательность
операторов - D
Формальное описание трансформации
< Y1, Y2, B1, B2, O1, O2,
E1, E2, S1, S2, D >
( (c: Новые идентификаторы (Var, Int)) &
FragClass(Y1')=Dfor & For(Y1')=≈(For(Y1)) &
Until(Y1')=≈(Until(Y1)) &(Y1')=Eval(Step(Y1),+,NewExpr(c)) &
V1=NewExpr(c) &(Y2')=Dfor &For(Y2')=≈(For(Y2)) & Until(Y2')=≈(Until(Y2))
&(Y2')=Eval(Step(Y2),+,NewExpr(c)) & V2=NewExpr(c) &(Y3)=Dfor &
Par(Y3)=≈(V1) & For (Y3)=Eval(V1) & Step (Y3)=Eval(1)
&(Y3)=MakeExpr(MakeExpr(MakeExpr(Step(Y1),-,1),+,V1),min,E1) &(Y4)=Dfor
& Par(Y4)=≈(V2) & For (Y4)=Eval(V2) & Step (Y4)=Eval(1)
&(Y4)=MakeExpr(MakeExpr(MakeExpr(Step(Y2),-,1),+,V2),min,E2)
&(Body(Y1'))=≈(Y2') & Sch(Body(Y2'))=≈(Y3) &
Sch(Body(Y3))=≈(Y4) &(Body(Y4))=≈(Y4) || =≈(Sch(Body(Y2))),
Y1 => Y1', Y2 => Y2' || Y3 | Y4 )
Характеристическая функция
Формула стратегии
Элементы потокового анализа Конец /Разбиение цикла/
. Развертка цикла
Бекон 6.3.1 (24)
0.127 августа 2006
Описание
Развёртка в точности копирует тело цикла некоторое количество раз,
называемое фактором разворачивания (unrolling factor) u. Каждая итерация после
этого будет состоять не из одного, а из u шагов. Выгода использования
разворачивания циклов была изучена на нескольких различных архитектурах.
Развёртка может улучшить производительность посредством:
· уменьшения количества итераций и соответственно количество условных
переходов;
· увеличения параллелизма инструкций;
Пример
было
do i=2, n-1[i] = a[i] + a[i - 1] * a[i + 1]do
стало
do i = 2, n-2, 2[i] = a[i] + a[i - 1] * a[i + 1][i + 1] = a[i
+ 1] + a[i] * a[i + 2]do(mod(n-2,2) = 1) then[n-1] = a[n-1] + a[n-2] * a[n]if
В примере №9 показаны все три варианта улучшений. Количество переходов
уменьшилось в два раза потому, что две итерации выполняются перед проверкой и
переходом в начало цикла. Параллелизм увеличен за счет того, что второе
присваивание может быть выполнено в то время, как выполняется первое и
обновлялись переменные цикла. Если элементы массива привязаны к регистрам, то
это увеличит эффективность, поскольку в теле цикла a[i] и a[i+1] используются
два раза. В этом случае данные будут загружены в регистры не три, а два раза за
итерацию. Если процессор содержит соответствующие инструкции, разворачивание
позволяет скомбинировать несколько операций по загрузке данных в регистры в
одну. Конструкция if в конце называется эпилогом цикла и должна быть
сгенерирована, когда неизвестно на этапе компиляции будет ли совпадать
количество итераций с фактором разворачивания u. Если u > 2, то эпилог цикла
- есть сам цикл.
Преимущество разворачивания циклов в том, что оно может применяться к
любому циклу и может быть выполнено как на высоком, так и на низком уровне.
Некоторые компиляторы выполняют, так называемое сворачивание циклов, перед
разворачиванием потому, что программы часто содержат циклы, которые были
развернуты вручную. Большинство компиляторов для высокопроизводительных
процессоров разворачивают как минимум самый внутренний цикл гнезда циклов.
Разворачивание внешнего цикла не настолько универсальная процедура потому, что
предполагает генерацию копий внутренних циклов. Иногда компилятор может
комбинировать эти копии, собирая их в ту же структуру, которая наблюдалась в
тексте исходного кода. Такое комбинирование называется развернуть-и-сжать
(unroll-and-jam).
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из последовательности операторов
Схема
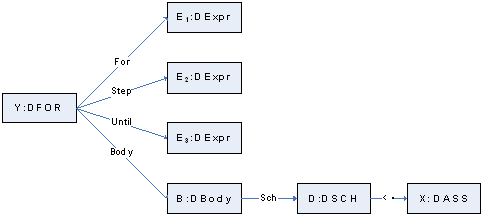
Здесь Y - цикл For. У него есть начальная граница - E1, конечная граница - E2, шаг E3 и тело - B. Причём D -
представление тела цикла Y в
виде последовательности операторов.
Информационные условия:
тело цикла B не содержит операторов, не зависимых от параметра цикла;
результаты X не влияют на параметр цикла;
фактор разворачивания u должен
быть меньше либо равен E2-1.
Формальное контекстное условие
$< Y, E1, E2, E3, B,D, U>(
FragClass(Y)=Dfor &(E1)=Dexpr &
FragClass(E2)=Dexpr &(E3)=Dexpr &
FragClass(U)=Dexpr &(B)=Dbody & FragClass(D)=Dsch &1=For(Y)
& E2=Until(Y) & E3=Step(Y) & B=Body(Y)
&=Sch(B) Ч X<·D Ч Not(Par(Y) Ç A(X) = Æ) &(U, null, null)
<= Eval(U, -, 1)
).
Неформальное описание трансформации
В зависимости от фактора разворачивания u:
. Копируем оператор X u раз c инкрементированным значением начальной границы E1 для каждой копии (iu=iu-1 + 1);
. Конечную границу E2 уменьшаем на u;
. Шаг цикла E3 увеличиваем на u;
. Если u
> 2, то создаём
после цикла Y условный оператор, условие которого
имеет вид mod(E2-u,
u) = 1, а ветка then состоит из оператора Х c декрементированным значением E1.
Формальное описание трансформации
Покрывает пункты 2, 3, 4 неформального описания трансформации.
$< Y, E1, E2, E3,
B,D, U>((Y1) = Dfor &(C1) = Dif &(X1)
= Dsch &(X2) = Dsch &= Новые идентификаторы (Var, Int) &11
= NewExpr(c) &(E11, ,) = Eval(Until(Y), -, U) &12
= NewExpr(c) &(E12) = Eval(Step(Y), +, U) &(Y1) =
≈ (For(Y)) &(Y1) = ≈ (E11) &(Y1)
= ≈ (E12) &(Y1) = Par(Y) &(C1) =
MakeExpr(MakeExpr(E2, -, U), mod, U), =, 1) &1 =
ZamFrag(X, Par(Y), Eval(Until(Y), -, 1)) &(Thcn(C1)) = ≈ (X1)
&(Eval(U, ,) > 2, X2 = Y1||С1, X2 = Y1), Y
=> X2).
Характеристическая функция
Формула стратегии
Элементы потокового анализа Конец /Развертка цикла/
. Шелушение, или разгрузка цикла
Бекон 6.3.5 (28)
0.127 августа 2006
Описание
Объединение двух циклов при совпадении верхней или нижней границ
итераций. Тело цикла с большим количеством итераций попадает в тело цикла с
меньшим количеством итераций. Оставшиеся итерации выполняются отдельно
Пример
было
Do i = 2, n
b[i] = b[i] + b[2]
end doall i = 3, n[i] = a[i] + cdo all
стало
if (2 <= n) then
b[2] = b[2] + b[2]ifall i=3, n[i] = b[i] + b[2][i] = a[i] + c do all
Неформальное контекстное условие
Данное ОП можно применить при выполнении следующих условий:
· если два цикла выполняются последовательно друг за другом;
· либо верхние границы заданы константами (значения констант
отличается на 1), а нижние переменными, причём совпадающими, либо наоборот;
· Шаги обоих циклов константы и совпадают;
· выполнение операторов одного цикла не влияет на результат
выполнения операторов другого цикла;
· аргументы тела одного из циклов не должны
пересекаться(совпадать) с результатами тела другого цикла;
результаты тел обоих циклов не должны пересекаться.
Формальное контекстное условие
$<Y1,Y2,E1,E2,O1,O2,B1,B2>(FragClass(Y1)=Dfor
& FragClass(Y2)=Dfor
& FragClass(O1)=Dexpr
& FragClass(O2)=Dexpr
& FragClass(E1)=Dexpr
& FragClass(E2)=Dexpr
& FragClass(S1)=Dexpr
& FragClass(S2)=Dexpr
& FragClass(B1)=Dbody
& FragClass(B2)=Dbody
&O1 = For(Y1)
& O2 = For(Y2)
& E1 = Until(Y1)
& E2 = Until(Y2)
& S1 = Step(S1)
& S2 = Step(S2)
& B1 = Body(Y1)
& B2 = Body(Y2)
&
<(Y1,Y2) & ((Left(O1) = Const & Left(O2) = Const
& Calc(O1, -, O2) = 1 & Left(E1) = Var & Left(E2) = Var &
LeftExpr(E1) = LeftExpr(E2)) Or (Left(E1) = Const & Left(E2) = Const &
Calc(E1, -, E2) = 1 & Left(O1) = Var & Left(O2) = Var &
LeftExpr(O1) = LeftExpr(O2))) & Left(S1) = Const & Left(S2) = Const
& Eval(S1) = Eval(S2) & (R(Y1) Ç R(Y2) = Æ) & (A(B1) Ç R(B2) = Æ) & (R(B1) Ç R(B2) = Æ) >)
Неформальное описание трансформации
Создаем условие IF для выноса одной итерации, если O1 и O2 - константы
тогда левая часть выражения минимум из O1 и O2, а правая часть выражения
максимум из O1 и O2. Тело IF есть тело цикла с минимальной начальной
константой.
Создаем цикл FOR такой что, если O1 и O2 - константы, O1 и O2 отличаются
на 1, E1 и E2 переменные, E1 = E2, S1 = S2 тогда FOR = объединение B1 и B2, O’
= максимум из O1 и O2, E’ = E1, S’ = S1.
Пояснения Y1 - DFOR - определение цикла, Y2 - DFOR - определение цикла,
O1 - DEXPR - начальное условие цикла Y1, O2 - DEXPR - начальное условие цикла
Y2, E1 - DEXPR - конечное условие цикла Y1, E2 - DEXPR - конечное условие цикла
Y2, B1 - DBODY - тело цикла Y1, B2 - DBODY - тело цикла Y2, IF1 - DIF - условие
If, FOR1 - DFOR - новый цикл.
Формальное описание трансформации
!<Y1,Y2,E1,E2,O1,O2,B1,B2>
(= iif( Type(Left(O1)) = Const & Type(Left(O1)) = Const,
true, false) &
(IF_EXPR) = DEXPR &(IF_EXPR) = '<=' &(IF_EXPR) =
iif(CASE1,(eval(O1)<eval(O2), Left(O1), Left(O2)),(eval(E1)<eval(E2),
Left(E1), Left(E2))) &(IF_EXPR) = iif(CASE1,(eval(O1)<eval(O2),
Left(O2), Left(O1)),(eval(E1)<eval(E2), Left(E2), Left(E1))) &(IF_THEN)
= DBODY &(IF_THEN) = iif(CASE1,(eval(O1) < eval(O2), SCH(B1),
SCH(B2)),(eval(E1) > eval(E2), SCH(B1), SCH(B2)))(IF1) = DIF &(IF1) = IF_EXPR
&(IF1) = IF_THEN &(FOR1) + DFOR &(FOR1) = iif(CASE1, iif(eval(B1)
> eval(B2), B1, B2), B1 )&(FOR1) = iif(CASE1, iif(eval(O1) <
eval(O2), O1, O2), O1 ) &(FOR1) = iif(CASE1, E1, iif(eval(E1) <
eval(E2), E1, E2) ) &(FOR1) = STEP(Y1) &(FOR1) = SCH(B1) || SCH(B2)
)
Характеристическая функция
Формула стратегии
Элементы потокового анализа Конец /Разгрузка цикла/
. Нормализация цикла
Бекон 6.3.6 (28)
0.127 августа 2006
Описание
Нормализация преобразует все циклы так, что индексная переменная
инициализируется единицей (или нулем) и увеличивается на 1 для каждой итерации.
Такое преобразование предоставляет возможность для слияния и упрощает анализ
зависимостей между циклами, как показано в примере №11 . Нормализация помогает
выявить, какие циклы являются кандидатами для расслаивания с последующим
слиянием. Наиболее важным использованием нормализации является разрешение
компьютеру применять тест для анализа индексов массивов, многие из которых
требуют нормализованных итерационных границ
Пример
было
do i = 1,n[i] = a[i] + cdoi = 2, n+1[i] = a[i-1] * b[i]do
стало
do i = 1, n[i] = a[i] +cdoi = 1, n[i+1] = a[i] * b[i+1]do
Возможны варианты реализации для подвыражений.
В постановке для операторов, просто.
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из последовательности операторов.- цикл. У цикла есть свои границы: Е1
- начальная граница, Е2 - конечная граница, Е3 - шаг цикла. B - тело цикла. E1
не равно 1
Формальное контекстное условие
$<Y,E1,E2,E3,B,D,X1,X2>(FragClass(Y)=Dfor & FragClass(B)=Dbody
& FragClass(E1)=Dexpr & FragClass(E1)=Dexpr & FragClass(E2)=Dexpr
& FragClass(E3)=Dexpr & ParDO(Y)=True & E1 = For(Y) & E2 =
Until(Y) & E3 = Step(Y) & B = Body(Y) & Eval(E1, null, null)
<> 1)
Неформальное описание трансформации
Значение верхней границы переходит в значение верхней границы+значение
нижней границы, значение нижней границы переходит в 1
Формальное описание трансформации
$<Y,E1,E2,E3,B,D,X1,X2>(Eval(Е2, null, null) = Eval(E2, +,
E1), E1=>1)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец /Нормализация цикла/
Вариант 2
1. обмен циклов
Бэкон 6.2.1 (16), Никитин _
0.115 октября 2006
Описание
Преобразование состоит в перестановке местами каких-либо двух циклов в
тесно вложенном гнезде циклов. В частности, всегда можно переставлять рядом
стоящие циклы, имеющие по всем зависимостям тип ParDo. После перестановки
свойство РаrDo сохраняется у обоих циклов. Если возможна перестановка 1-го
цикла с k-ым и 1-ый цикл имеет тип РаrDо, то после перестановки тип РаrDо будет
иметь k-ый цикл. Пусть самый внешний цикл имеет тип РаrDо по всем зависимостям.
Его всегда можно переставить со вторым циклом. Новый второй цикл будет также
иметь тип РаrDо по всем зависимостям. Поэтому его можно переставить с третьим
циклом и т. д. Это означает, что любой цикл РаrDо всегда можно поставить в
тесно вложенном гнезде на любое более глубокое место. При этом свойство РаrDо
сохраняется. В противоположность этому, в общем случае переставлять внутренний
цикл РаrDо "наружу" нельзя.
Перестановка является одним из самых сильных преобразований и может
значительно улучшить производительность.
Пример
было
Do i=1,nj=1,n[i]=total[i]+a[i,j]dodo
стало
Do j=1,ni=1,n[i]=total[i]+a[i,j] do
end do
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из другого цикла For, тело которого, в свою очередь, состоит из двух
операторов.
Здесь Y1 - первый (внешний) цикл For, Y2 - второй (внутренний) цикл For. У
каждого цикла есть свои начальные границы - E1 и T1, свои конечные границы - E3
и T3, свои шаги цикла E2 и T2 и свои тела циклов - B1 и B2. Причём Y2 является
телом цикла Y1. D - представление тела внутреннего цикла Y2 в виде
последовательности операторов, X1 и X2 - две части этой последовательности.
Информационные условия:
Любой цикл РаrDо всегда можно поставить в тесно вложенном гнезде на любое
более глубокое место.
Формальное контекстное условие
$< Y1, Y2, E1, E2, E3, T1, T2, T3, B1, B2, D, X1, X2>(
Класс_фрагмента (Y1)=
Цикл_с_шагом &
Класс_фрагмента (Y2)=
Цикл_с_шагом &
Класс_фрагмента (B1)=
Программный_блок &
Класс_фрагмента (B2)=
Программный_блок &
Класс_фрагмента (D)=
Последовательность_операторов &
Класс_фрагмента (E1)=
Выражение &
Класс_фрагмента (E2)=
Выражение &
Класс_фрагмента (E3)=
Выражение &
Класс_фрагмента (T1)=
Выражение &
Класс_фрагмента (T2)=
Выражение &
Класс_фрагмента (T3)=
Выражение &
Класс_фрагмента (X1)=
Присваивание &
Класс_фрагмента (X2)=
Присваивание &
B1=
Тело (Y1) & Первый_элемент_последовательности
(B1)=Y2 &
Последний_элемент_последовательности (B1)=Y2
& B2= Тело(Y2) &
D=
Дуга_последовательность_операторов (B2) & Первый_элемент_последовательности(D)= Первый_элемент_последовательности (X1) &
Последний_элемент_последовательности (D)= Последний_элемент_последовательности (X2) &
Тип_левой_части (E1)Î{Const} & Тип_левой_части (E2)Î{Const} &
Тип_левой_части (E3)Î{Const} & Тип_левой_части (T1)Î{Const} &
Тип_левой_части (T2)Î{Const} & Тип_левой_части (T3)Î{Const} &
Результатное множество (Выражение_справа (X1)) Ç Аргументное множество (Выражение_слева (X2)) = Æ &
Результатное множество (Выражение_слева (X1)) Ç Аргументное множество (Выражение_справа (X1)) = Æ &
Гнездо_циклов (Y1)=True &
g (X1, X2, Y1) = false & g (X2, X1, Y1) = false
&
$ v1: Выражение & v1 <· Выражение_слева (X1) & Символ_операции (v1) = NULL &
Результат_есть_массив (Тип (Тип_левой_части (v1))) = true & Аргументное
множество (Выражение_слева (X1)) \ Счетчик_цикла (Y1) \ Счетчик_цикла (Y2) \
Результатное множество (v1) = Æ

$ v3:
Выражение & v3 <· Выражение_справа (X2) & Символ_операции (v3) = NULL & Результат_есть_массив (Тип (Тип_левой_части (v3))) = true & Тип_левой_части (v3)= Тип_левой_части (v1) & Аргументное множество (Выражение_справа (X1)) \ Счетчик_цикла (Y1) \ Счетчик_цикла (Y2) \ Результатное множество (v3) = Æ
Неформальное описание трансформации
Меняем все нижние и верхние границы циклов, а также их шаги местами.
Также меняем местами счетчики циклов.
Формальное описание трансформации
$< Y1, Y2, E1, E2, E3, T1, T2, T3, B1, B2>
( »(E1Z,T1) & »(E2Z,T2) & »(E3Z,T3) & »(T1Z,E1) & »(T2Z,E2) & »(T3Z,E3), i1= Счетчик_цикла (Y1) & i2= Счетчик_цикла
(Y2), E1ÞE1Z, E2ÞE2Z, E3ÞE3Z, T1ÞT1Z, T2ÞT2Z, T3ÞT3Z, Счетчик_цикла (Y1)=i2, Счетчик_цикла (Y2)=i1)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Последовательность_операторов, Первый_элемент_последовательности,
Последний_элемент_последовательности, Дуга_последовательность_операторов,
Результатное множество,
Аргументное множество, Гнездо_циклов, g, Результат_есть_массив
Конец / Обмен циклов /
. Распределение цикла
Бэкон 6.2.7 (23)
Воеводин 417
0.127 августа 2006
Описание
Распределение циклов (также называемое расщеплением циклов или
разделением циклов) разбивает гнездо циклов на несколько отдельных циклов.
Каждый из новых циклов имеет тоже итерационное пространство, что и исходный
цикл, но содержит подмножество операторов исходного цикла.
Это преобразование является обратным по отношению к преобразованию слияния
циклов. Пусть задан некоторый цикл. Построим для него граф зависимостей.
Допустим, что после переупорядочивания в теле цикла его можно представить в
виде двух подряд идущих фрагментов, и нет ни одной Дуги, идущей из опорных
пространств второго фрагмента в опорные пространства первого фрагмента. Тогда
цикл можно представить в виде двух Подряд идущих циклических конструкций. Самые
внешние циклы у них совпадают. Телом первого цикла является первый фрагмент,
телом второго - второй фрагмент. Если преобразуемый цикл имел тип РаrDо, то тип
ParDo будут иметь оба внешних цикла преобразованной программы. Оба внешних
цикла или один из них могут иметь тип РаrDо и в том случае, когда таковым не
является преобразуемый цикл.
Пример
было
do i = 1, nj = 1, m[i] = a[i] + c[j] = x[j] + x[j]*10dodo
стало
do all i = 1, n[i] = a[i] + cdoj = 1, m[j] = x[j] + x[j]*10do
В примере распределение уменьшает общее количество итераций и позволяет
распараллелить часть цикла. Распределение можно применять для любых циклов, но
все операторы, принадлежащие зависимой цепочке, должны размещаться в одном
цикле, и, если зависимость S1 Þ S2 имеет место в исходном цикле, то цикл, содержащий
оператор S1 должен предшествовать циклу, содержащему оператор S2.
Когда массивы, обрабатываемые в циклах, большие, распределение циклов
может улучшить использование памяти.
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из другого цикла For, тело которого, в свою очередь, состоит из двух
операторов.

Здесь Y1 - первый (внешний) цикл For, Y2 - второй (внутренний) цикл For.
У каждого цикла есть свои начальные границы - E1 и T1, свои конечные границы -
E3 и T3, свои шаги цикла E2 и T2 и свои тела циклов - B1 и B2. Причём Y2
является телом цикла Y1. D - представление тела внутреннего цикла Y2 в виде
последовательности двух операторов, X1 и X2 - первый и второй оператор.
Информационные условия:
результаты X2 не влияют на X1
результаты X1 не влияют на X2и X2 не имеют общих результатов
Аргументное множество X2 не содержит переменную цикла Y1
Аргументное множество X1 не содержит переменную цикла Y2
Оба цикла имеют тип ParDO
Формальное контекстное условие
$< Y1, Y2, E1, E2, E3, T1, T2, T3, B1, B2, D, X1,
X2>(
Класс_фрагмента (Y1)=
Цикл_с_шагом &
Класс_фрагмента (Y2)=
Цикл_с_шагом &
Класс_фрагмента (B1)=
Программный_блок &
Класс_фрагмента (B2)=
Программный_блок &
Класс_фрагмента (D)=
Последовательность_операторов &
Класс_фрагмента (E1)=
Выражение &
Класс_фрагмента (E2)=
Выражение &
Класс_фрагмента (E3)=
Выражение &
Класс_фрагмента (T1)=
Выражение &
Класс_фрагмента (T2)=
Выражение &
Класс_фрагмента (T3)=
Выражение &
Класс_фрагмента (X1)=
Присваивание &
Класс_фрагмента (X2)=
Присваивание &
B1=
Тело (Y1) & Первый_элемент_последовательности
(B1)=Y2 &
Последний_элемент_последовательности (B1)=Y2
& B2= Тело (Y2) &
D=
Дуга_последовательность_операторов (B2) &
Первый_элемент_последовательности (D)=
Первый_элемент_последовательности (X1) &
Последний_элемент_последовательности (D)=
Последний_элемент_последовательности (X2) & Тип_левой_части
(E1)Î{Const} &
Тип_левой_части (E2)Î{Const} & Тип_левой_части (E3)Î{Const} &
Тип_левой_части (T1)Î{Const} & Тип_левой_части (T2)Î{Const} &
Тип_левой_части (T3)Î{Const} & Результатное множество ( X1) Ç
Результатное множество (X2) = Æ &
Аргументное множество ( X1) Ç Счетчик_цикла (Y2) = Æ &
Аргументное множество ( X2) Ç Счетчик_цикла (Y1) = Æ &
Гнездо циклов (Y1)=True & Гнездо циклов (Y2)=True &
g (X1, X2, Y1) = false & g (X2, X1, Y1) = false.
Неформальное описание трансформации
Гнездо из двух циклов разбиваем на два отдельных цикла
Формальное описание трансформации
$< Y1, Y2, E1, E2, E3, T1, T2, T3, B1, B2, X1, X2>
(Класс_фрагмента (V1)={
Цикл_с_шагом } & Начальная_граница_цикла (V1)=»(
Начальная_граница_цикла (Y1))
& Конечная_граница_цикла (V1)= »( Конечная_граница_цикла (Y1)) & Шаг (V1)= »( Шаг (Y1))
& Счетчик_цикла (V1)=
Счетчик_цикла (Y1) &
Дуга_последовательность_операторов (Тело (V1))=»(X1)) & & Класс_фрагмента (V2)={ Цикл_с_шагом } & Начальная_граница_цикла
(V2)= »( Начальная_граница_цикла (Y2)) & Конечная_граница_цикла (V2)= »(
Конечная_граница_цикла (Y2))
& Шаг (V2)= »( Шаг (Y2))
& Счетчик_цикла (V2)=
Счетчик_цикла (Y2) &
Дуга_последовательность_операторов (Тело (V2))=»(X2) &Класс_фрагмента (Z1)={ Последовательность_операторов }
& Z1=V1||V2, Y1ÞZ1)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец /Распределение цикла/
3. Объединение циклов
Бэкон 6.3.3 (27)
Воеводин 416
0.127 августа 2006
Описание
Объединением циклов называется преобразование, при котором тела двух
циклов объединяются, или сливаются, образуя один цикл. Это преобразование
используется для создания секционированного кода для векторных машин, а также
для уменьшения заголовка цикла при обычной оптимизации.
Объединение позволяет свернуть гнездо циклов в один цикл с оригинальными
индексными переменными, которые вычисляются с помощью другой индексной
переменной. Объединение может улучшить распределение цикла при параллельных
вычислениях и уменьшить итерационные переходы. Например, если n и m немного
больше, чем количество процессоров P (см. пример №6), то ни одна итерация,
равно как и внешний цикл не займет столько времени, с момента выполнения
последних n-P итераций, как первые P. Объединение двух циклов гарантирует, что
P итераций могут выполняться каждый раз за исключением последних (nm mod P)
итераций, как показано в примере
Пример
было
do all i=1, nall j=1, m[i,j] = a[i,j] +cdo alldo all
стало
do all T=1, n*m= ((T-1) / m)*m + 1= MOD(T-1, m) + 1[i,j] =
a[i,j] + c
end do all
Неформальное контекстное условие
Участком экономии в данном случае является непрерывная последовательность
операторов, начинающаяся и заканчивающаяся циклом For. Между циклами могут
стоять и другие операторы. У циклов должны совпадать обе границы и шаг цикла,
переменные цикла могут иметь разные идентификаторы.
Схема
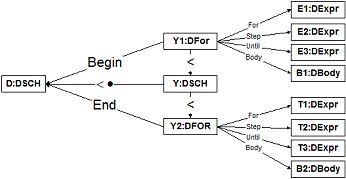
здесь D - последовательность операторов, Y1 и Y2 - два цикла For,
являющиеся ее началом и концом соответственно, Y - последовательность
операторов, возможно пустая, лежащая между ними. У каждого цикла есть свои
начальные границы - E1 и T1, свои конечные границы - E3 и T3, свои шаги цикла
E2 и Е2 и свои тела циклов - B1 и B2. Образы выражений E1 и Е1, E2 и T2, E3 и
T3 соответственно должны совпадать.
Информационные условия:
Результаты E1, E2, E3, B1, Y не должны влиять на T1, T2, T3 или B2
Результаты B2 не должны влиять на B1 и Y
Формальное контекстное условие
$<D, Y, Y1, Y2, E1, E2, E3, T1,T2,T3, B1,B2> (
Класс_фрагмента (D)= Последовательность_операторов &
Класс_фрагмента (Y1)= Цикл_с_шагом &
Класс_фрагмента (Y2)= Цикл_с_шагом &
Класс_фрагмента (Y)= Последовательность_операторов &
Класс_фрагмента (E1)= Выражение &
Класс_фрагмента (E2)= Выражение &
Класс_фрагмента (E3)= Выражение &
Класс_фрагмента (T1)= Выражение &
Класс_фрагмента (T2)= Выражение &
Класс_фрагмента (T3)= Выражение &
Класс_фрагмента (B1)= Программный_блок &
Класс_фрагмента (B2)= Программный_блок &
Первый_элемент_последовательности (D)=Y1 &
Последний_элемент_последовательности (D)= Y2 &<>Y1 &
<(Y1, Y) & <(Y, Y2) &
Непрерывная_последовательность (D) &
Непрерывная_последовательность (Y) &
B1=
Тело (Y1) &
B2=
Тело (Y2)&
Обратная_польская_запись (E1)=
Обратная_польская_запись (T1)
&
Обратная_польская_запись (E2)=
Обратная_польская_запись (T2)
&
Обратная_польская_запись (E3)=
Обратная_польская_запись (T3)
&
(
(Результатное множество (E1) È Результатное множество (E2) È Результатное множество (E3) È Результатное множество (B1) È Результатное множество (Y)) Ç
( Аргументное множество (T1) È Аргументное множество (T2) È Аргументное множество (T3) È Аргументное множество (B2)) )= Æ &
Результатное множество (B2) Ç(Аргументное множество (B1) È Аргументное множество (Y))= Æ,
Гнездо циклов (Y1)=True &
Гнездо циклов (Y2)=True )
Неформальное описание трансформации
Тело цикла B1 заменяется на конкатенацию B1 и B2 c заменой в B2 всех
вхождений параметра цикла Y2 на параметр цикла B1
цикл Y2 заменяется на Null
Гнездо из двух циклов разбиваем на два отдельных цикла
Формальное описание трансформации
$<D, Y, Y1, Y2, E1, E2, E3, T1,T2,T3, B1,B2>(
Класс_фрагмента (B3)=
Последовательность_операторов &
B3=» (B1) ||
Zam(B2, Счетчик_цикла (Y2), Счетчик_цикла (Y1) ),
B1ÞB3,
Y2 Þ NULL)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Последовательность_операторов, Первый_элемент_последовательности,
Последний_элемент_последовательности, Результатное множество, Аргументное
множество, Гнездо_циклов, Обратная_польская_запись,
Непрерывная_последовательность
Конец /Объединение циклов/
. Распределение цикла
Бэкон 6.2.3 (20)
Воеводин 418
0.127 августа 2006
Описание
Распределение циклов (также называемое расщеплением циклов или
разделением циклов) разбивает гнездо циклов на несколько отдельных циклов.
Каждый из новых циклов имеет тоже итерационное пространство, что и исходный
цикл, но содержит подмножество операторов исходного цикла.
Это преобразование является обратным по отношению к преобразованию
слияния циклов. Пусть задан некоторый цикл. Построим для него граф
зависимостей. Допустим, что после переупорядочивания в теле цикла его можно
представить в виде двух подряд идущих фрагментов, и нет ни одной Дуги, идущей
из опорных пространств второго фрагмента в опорные пространства первого
фрагмента. Тогда цикл можно представить в виде двух Подряд идущих циклических
конструкций. Самые внешние циклы у них совпадают. Телом первого цикла является
первый фрагмент, телом второго - второй фрагмент. Если преобразуемый цикл имел
тип РаrDо, то тип ParDo будут иметь оба внешних цикла преобразованной
программы. Оба внешних цикла или один из них могут иметь тип РаrDо и в том
случае, когда таковым не является преобразуемый цикл.
Пример
было
do i = 1, nj = 1, n[i,j] = a[i-1,j+1] + 1dodo
стало
do i = 1, nj = n, 1, -1[i,j] = a[i-1,j+1] + 1 do
end do
исходное гнездо циклов: дистанционный вектор (1, -1) - перестановка
недопустима
внутренний цикл инвертирован: вектор направлений (1, 1) - перестановка
допустима
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из последовательности операторов.
Y - цикл. У цикла есть свои границы: Е1 - начальная граница, Е2 -
конечная граница, Е3 - шаг цикла. B - тело цикла. E3 = 1. E1>0.
Формальное контекстное условие
$<Y,E1,E2,E3,B>(
Класс_фрагмента (Y)=
Цикл_с_шагом &
Класс_фрагмента (B)=
Программный_блок &
Класс_фрагмента (E1)=
Выражение &
Класс_фрагмента (E1)=
Выражение &
Класс_фрагмента (E2)=
Выражение &
Класс_фрагмента (E3)=
Выражение &
Гнездо циклов (Y)=True & E1 = Начальная_граница_цикла (Y) &
E2 =
Конечная_граница_цикла (Y)
& E3 = Шаг (Y) &
B =
Тело (Y) & Значение (E1, null, null)
> 0 &
Значение (E3, null, null) = 1 ).
Неформальное описание трансформации
Создаём Y'. Y' - это цикл For такой, что значения его начальной границы
совпадают со значениями конечной границы цикла Y, значение конечной границы со
значением начальной границы Y, а шаг цикла = -1.
Цикл Y переходит в цикл Y’.
Формальное описание трансформации
$<Y,E1,E2,E3,B,D> ( (c: Новые идентификаторы (Var, Int)) &
Класс_фрагмента (Y')=
Цикл_с_шагом & Счетчик_цикла (Y’)= Счетчик_цикла (Y)
& Дуга_последовательность_операторов (Тело (Y))=≈ Дуга_последовательность_операторов (Тело (Y’))& Начальная_граница_цикла (Y’)=NewExp(C)&
Начальная_граница_цикла (Y') =≈
(Конечная_граница_цикла (Y))&
Конечная_граница_цикла (Y’)=NewExp(C) & Конечная_граница_цикла (Y') =≈ (Начальная_граница_цикла (Y)) & Значение (Шаг (Y')=1),Y=>Y’)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец /Распределение цикла/
5. Разбиение цикла
Бэкон 6.2.6 (22)
0.127 августа 2006
Описание
Разбиение цикла является многомерным обобщением послойного разбора.
Разбиение цикла (также называемое блочным разбиением) в основном используется
для улучшения повторного использования кэша (Qc) и представляет собой деление
итерационного пространства на блоки и преобразования гнезда циклов для
проведения итераций над этими блоками. Однако оно может использоваться для
улучшения использования процессоров (на многопроцессорных машинах), регистров,
TLB (Translation Lookaside Buffer - используется для преобразования линейных
адресов в физические адреса), или размещения страниц памяти.
Ниже приведен пример №8 гнезда массивов, в котором матрице a присваивается транспонированная
матрица b. Во внутреннем цикле (с итерационной
переменной j) доступ к элементам массива b осуществляется максимальным шагом 1,
в то время, как доступ к элементам массива a - с максимальным шагом n. Перестановка циклов в данном случае не поможет, т.к.
после перестановки доступ к элементу массива b будет осуществляться с максимальным шагом n. Осуществляя дополнительные итерации
над прямоугольными подпространствами итерационного пространства, как показано в
примере, достигается полное использование кэша.
Пример
было
do i = 1, nj = 1, n[i,j] = b[j,i]dodo
стало
do TI = 1, n, 64TJ = 1, n, 64i = TI, min(TI+63,n)j = TJ,
min(TJ+63,n)[i,j] = b[j,i]dododo
end do
Неформальное контекстное условие
Участком экономии в данном случае является цикл For,
тело которого состоит из другого цикла For, тело которого, в свою очередь,
состоит из последовательности операторов. Здесь Y1 - первый (внешний) цикл For,
Y2 - второй (внутренний) цикл For. У каждого цикла есть свои начальные границы
- O1 и O2, свои конечные границы - E1 и E2, свои шаги цикла S1 и S2 и свои тела
циклов - B1 и B2. Причём Y2 является телом цикла Y1. D - представление тела
внутреннего цикла Y2 в виде последовательности операторов
Формальное контекстное условие
< Y1, Y2, B1, B2, O1, O2, E1, E2, S1, S2, D > (
Класс_фрагмента (Y1)=
Цикл_с_шагом &
Класс_фрагмента (Y2)=
Цикл_с_шагом &
Класс_фрагмента (B1)=
Программный_блок &
Класс_фрагмента (B2)=
Программный_блок &
Класс_фрагмента (D)=
Последовательность_операторов &
Класс_фрагмента (O1)=
Выражение &
Класс_фрагмента (E1)=
Выражение &
Класс_фрагмента (S1)=
Выражение &
Класс_фрагмента (O2)=
Выражение &
Класс_фрагмента (E2)=
Выражение &
Класс_фрагмента (S2)=
Выражение &
B1=
Тело (Y1) &
Первый_элемент_последовательности (B1)=Y2 &
Последний_элемент_последовательности (B1)=Y2
& B2= Тело (Y2) &
D=
Дуга_последовательность_операторов (B2) & Гнездо циклов (Y1)=True
Неформальное описание трансформации
Создаём Y1'. Y1' - это цикл For такой, что значения его начальной и
конечной границы совпадают со значениями начальной и конечной границы цикла Y1
соответственно, а шаг цикла - увеличенный шаг цикла Y1. Создаём целочисленную
переменную - счётчик цикла Y1 - V1. Телом цикла Y1' является цикл Y2'. Y2' -
это цикл For такой, что значения его начальной и конечной границы совпадают со
значениями начальной и конечной границы цикла Y2 соответственно, а шаг цикла -
увеличенный шаг цикла Y2. Для него так же создаем целочисленную переменную,
которая будет являться счётчиком цикла - V2. Внутри цикла Y2 создаём цикл Y3 c
шагом 1, начальная граница которого совпадает с текущим значением V1, а конечная
- min(V1 + (значение(S1) - 1), E1). Y3 - является телом цикла Y2'. Затем, уже
внутри цикла Y3, создаём цикл Y4 так же c шагом 1. Начальная граница Y4
совпадает с текущим значением V2, а конечная - min(V2 + (значение(S2) - 1),
E2). Y4 - является телом цикла Y3. Телом цикла Y4 - является последовательность
операторов - D
Формальное описание трансформации
< Y1, Y2, B1, B2, O1, O2,
E1, E2, S1, S2, D >
( (c: Новые идентификаторы (Var, Int)) &
Шаг (Y1')= Значение (Шаг (Y1),+,NewExpr(c))
& V1=NewExpr(c)
&
Класс_фрагмента (Y2')=
Цикл_с_шагом & Начальная_граница_цикла (Y2')=≈( Начальная_граница_цикла (Y2)) & Конечная_граница_цикла (Y2')=≈( Конечная_граница_цикла (Y2)) &
Шаг (Y2')= Значение (Шаг (Y2),+,NewExpr(c))
& V2=NewExpr(c)
&
Класс_фрагмента (Y3)=
Цикл_с_шагом & Счетчик_цикла (Y3)=≈(V1) &
Начальная_граница_цикла (Y3)=
Значение (V1) & Шаг (Y3)= Значение (1) &
Конечная_граница_цикла (Y3)=MakeExpr(MakeExpr(MakeExpr(Шаг (Y1),-,1),+,V1),min,E1) &
Класс_фрагмента (Y4)=
Цикл_с_шагом & Счетчик_цикла (Y4)=≈(V2) &
Начальная_граница_цикла (Y4)=
Значение (V2) & Шаг (Y4)= Значение (1) &
Конечная_граница_цикла (Y4)=MakeExpr(MakeExpr(MakeExpr(Шаг (Y2),-,1),+,V2),min,E2) &
Дуга_последовательность_операторов (Тело (Y1'))=≈(Y2')
& Дуга_последовательность_операторов (Тело (Y2'))=≈(Y3)
& Дуга_последовательность_операторов (Тело (Y3))=≈(Y4)
&
Дуга_последовательность_операторов (Тело (Y4))=≈(Y4) ||
=≈( Дуга_последовательность_операторов (Тело (Y2))), Y1
=> Y1', Y2 => Y2' ||
Y3 | Y4 )
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец /Разбиение цикла/
6. Развертка циклов
Бекон 6.3.1 (24)
0.127 августа 2006
Описание
Развёртка в точности копирует тело цикла некоторое количество раз,
называемое фактором разворачивания (unrolling factor) u. Каждая итерация после
этого будет состоять не из одного, а из u шагов. Выгода использования
разворачивания циклов была изучена на нескольких различных архитектурах.
Развёртка может улучшить производительность посредством:
· уменьшения количества итераций и соответственно количество условных
переходов;
· увеличения параллелизма инструкций;
улучшения использования регистров, кэша данных
Пример
было
do i=2, n-1[i] = a[i] + a[i - 1] * a[i + 1]do
стало
do i = 2, n-2, 2[i] = a[i] + a[i - 1] * a[i + 1][i + 1] = a[i
+ 1] + a[i] * a[i + 2]do(mod(n-2,2) = 1) then[n-1] = a[n-1] + a[n-2] * a[n]if
В примере №9 показаны все три варианта улучшений. Количество переходов
уменьшилось в два раза потому, что две итерации выполняются перед проверкой и
переходом в начало цикла. Параллелизм увеличен за счет того, что второе
присваивание может быть выполнено в то время, как выполняется первое и
обновлялись переменные цикла. Если элементы массива привязаны к регистрам, то
это увеличит эффективность, поскольку в теле цикла a[i] и a[i+1] используются
два раза. В этом случае данные будут загружены в регистры не три, а два раза за
итерацию. Если процессор содержит соответствующие инструкции, разворачивание
позволяет скомбинировать несколько операций по загрузке данных в регистры в
одну. Конструкция if в конце называется эпилогом цикла и должна быть
сгенерирована, когда неизвестно на этапе компиляции будет ли совпадать
количество итераций с фактором разворачивания u. Если u > 2, то эпилог цикла
- есть сам цикл.
Преимущество разворачивания циклов в том, что оно может применяться к
любому циклу и может быть выполнено как на высоком, так и на низком уровне.
Некоторые компиляторы выполняют, так называемое сворачивание циклов, перед
разворачиванием потому, что программы часто содержат циклы, которые были
развернуты вручную. Большинство компиляторов для высокопроизводительных
процессоров разворачивают как минимум самый внутренний цикл гнезда циклов.
Разворачивание внешнего цикла не настолько универсальная процедура потому, что
предполагает генерацию копий внутренних циклов. Иногда компилятор может
комбинировать эти копии, собирая их в ту же структуру, которая наблюдалась в
тексте исходного кода. Такое комбинирование называется развернуть-и-сжать
(unroll-and-jam).
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из последовательности операторов
Схема
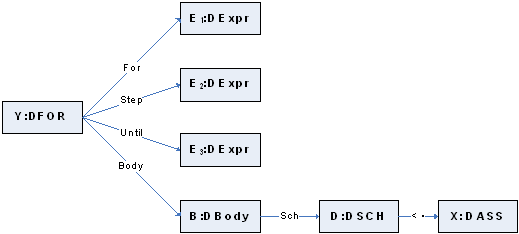
Здесь Y - цикл For. У него есть начальная граница - E1, конечная граница - E2, шаг E3 и тело - B. Причём D -
представление тела цикла Y в
виде последовательности операторов.
Информационные условия:
тело цикла B не содержит операторов, не зависимых от параметра цикла;
результаты X не влияют на параметр цикла;
фактор разворачивания u должен
быть меньше либо равен E2-1.
Формальное контекстное условие
$< Y, E1, E2, E3, B,D, U>(
Класс_фрагмента (Y)=
Цикл_с_шагом &
Класс_фрагмента (E1)= Выражение &
Класс_фрагмента (E2)= Выражение &
Класс_фрагмента (E3)= Выражение &
Класс_фрагмента (B)=
Программный_блок &
Класс_фрагмента (D)=
Последовательность_операторов &
Класс_фрагмента (U)=
Выражение &
E1= Начальная_граница_цикла (Y) &
E2= Конечная_граница_цикла (Y) &
E3= Шаг (Y) &
B=
Тело (Y) &
D=
Дуга_последовательность_операторов (B) Ч X<·D Ч Not(Счетчик_цикла (Y) Ç Аргументное множество (X) = Æ) &
Значение (U, null, null) <= Значение (U, -, 1)
)
Неформальное описание трансформации
В зависимости от фактора разворачивания u:
. Копируем оператор X u раз c инкрементированным значением начальной границы E1 для каждой копии (iu=iu-1 + 1);
. Конечную границу E2 уменьшаем на u;
. Шаг цикла E3 увеличиваем на u;
4. Если u
> 2, то создаём
после цикла Y условный оператор, условие которого
имеет вид mod(E2-u,
u) = 1, а ветка then состоит из оператора Х c декрементированным значением E1.
Формальное описание трансформации
Покрывает пункты 2, 3, 4 неформального описания трансформации.
$< Y, E1, E2, E3, B,D, U>(
Класс_фрагмента (Y1) = Цикл_с_шагом &
Класс_фрагмента (C1) = Условный_оператор &
Класс_фрагмента (X1) = Последовательность_операторов
&
Класс_фрагмента (X2) = Последовательность_операторов
&
c =
Новые идентификаторы (Var, Int) &
E11 = NewExpr(c)
&
Значение (E11, ,) = Значение
(Конечная_граница_цикла (Y), -,
U) &
E12 = NewExpr(c)
&
v(E12) = Значение (Шаг (Y), +, U) &
Начальная_граница_цикла (Y1) = ≈ (Начальная_граница_цикла
(Y)) &
Конечная_граница_цикла (Y1) = ≈ (E11) &
Шаг (Y1) = ≈ (E12) &
Счетчик_цикла (Y1) = Счетчик_цикла (Y) &
Если (C1)
= MakeExpr(MakeExpr(E2, -, U), mod, U), =, 1) &1 = ZamFrag(X, Счетчик_цикла (Y), Значение (Конечная_граница_цикла (Y), -, 1)) &
Дуга_последовательность_операторов (То (C1)) = ≈ (X1) &
Если (Значение (U, ,)
> 2, X2 = Y1||С1, X2 = Y1), Y => X2).
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец /Развертка циклов/
7. Шелушение, или разгрузка цикла
Бекон 6.3.5 (28)
0.127 августа 2006
Описание
Объединение двух циклов при совпадении верхней или нижней границ
итераций. Тело цикла с большим количеством итераций попадает в тело цикла с
меньшим количеством итераций. Оставшиеся итерации выполняются отдельно
Пример
было
Do i = 2, n
b[i] = b[i] + b[2]
end doall i = 3, n[i] = a[i] + cdo all
стало
if (2 <= n) then
b[2] = b[2] + b[2]ifall i=3, n[i] = b[i] + b[2][i] = a[i] + c
end do all
Неформальное контекстное условие
Данное ОП можно применить при выполнении следующих условий:
· если два цикла выполняются последовательно друг за другом;
· либо верхние границы заданы константами (значения констант
отличается на 1), а нижние переменными, причём совпадающими, либо наоборот;
· Шаги обоих циклов константы и совпадают;
· выполнение операторов одного цикла не влияет на результат
выполнения операторов другого цикла;
· аргументы тела одного из циклов не должны
пересекаться(совпадать) с результатами тела другого цикла;
результаты тел обоих циклов не должны пересекаться.
Формальное контекстное условие
$<Y1,Y2,E1,E2,O1,O2,B1,B2>( Класс_фрагмента (Y1)= Цикл_с_шагом &
Класс_фрагмента (Y2)=
Цикл_с_шагом &
Класс_фрагмента (O1)=
Выражение &
Класс_фрагмента (O2)=
Выражение &
Класс_фрагмента (E1)=
Выражение &
Класс_фрагмента (E2)=
Выражение &
Класс_фрагмента (S1)=
Выражение &
Класс_фрагмента (S2)=
Выражение &
Класс_фрагмента (B1)=
Программный_блок &
Класс_фрагмента (B2)=
Программный_блок &
O1
=Начальная_граница_цикла (Y1)
& O2=Начальная_граница_цикла (Y2)&
E1 =
Конечная_граница_цикла (Y1)
& E2 = Конечная_граница_цикла (Y2) &
S1 = Шаг (S1) & S2 = Шаг (S2) &1 = Тело (Y1) & B2 =
Тело (Y2) &
<(Y1,Y2) & ((Тип_левой_части (O1) = Const & Тип_левой_части
(O2) = Const & Calc(O1, -, O2) = 1 & Тип_левой_части (E1) = Var &
Тип_левой_части (E2) = Var & Левая_часть_выражения (E1) =
Левая_часть_выражения (E2)) Or (Тип_левой_части (E1) = Const &
Тип_левой_части (E2) = Const & Calc(E1, -, E2) = 1 & Тип_левой_части
(O1) = Var & Тип_левой_части (O2) = Var & Левая_часть_выражения (O1) =
Левая_часть_выражения (O2))) & Тип_левой_части (S1) = Const & Тип_левой_части
(S2) = Const & Значение (S1) = Значение (S2) & (Результатное множество
(Y1) Ç Результатное множество (Y2) = Æ) & (Аргументное множество (B1) Ç Результатное множество (B2) = Æ) & (Результатное множество (B1) Ç Результатное множество (B2) = Æ) >)
Неформальное описание трансформации
Создаем условие IF для выноса одной итерации, если O1 и O2 - константы
тогда левая часть выражения минимум из O1 и O2, а правая часть выражения
максимум из O1 и O2. Тело IF есть тело цикла с минимальной начальной
константой.
Создаем цикл FOR такой что, если O1 и O2 - константы, O1 и O2 отличаются
на 1, E1 и E2 переменные, E1 = E2, S1 = S2 тогда FOR = объединение B1 и B2, O’
= максимум из O1 и O2, E’ = E1, S’ = S1.
Формальное описание трансформации
!<Y1,Y2,E1,E2,O1,O2,B1,B2>
(= iif( Type(Тип_левой_части (O1)) = Const & Type(Тип_левой_части (O1)) = Const, true, false) &
Класс_фрагмента (IF_EXPR) = Выражение &
Op(IF_EXPR) = '<=' &
Тип_левой_части (IF_EXPR) = iif(CASE1,(Значение (O1)< Значение (O2),
Тип_левой_части (O1), Тип_левой_части (O2)),(Значение (E1)< Значение (E2),
Тип_левой_части (E1), Тип_левой_части (E2))) &
Right(IF_EXPR) = iif(CASE1,
iif(Значение (O1)< Значение (O2), Тип_левой_части (O2),
Тип_левой_части (O1)),(Значение (E1)< Значение (E2), Тип_левой_части (E2),
Тип_левой_части (E1))) &
Класс_фрагмента (IF_THEN) = Программный_блок &
Дуга_последовательность_операторов (IF_THEN) = iif(CASE1,(Значение (O1)
< Значение (O2), Дуга_последовательность_операторов (B1),
Дуга_последовательность_операторов (B2)),(Значение (E1) > Значение (E2), Дуга_последовательность_операторов
(B1), Дуга_последовательность_операторов (B2)))
Класс_фрагмента (IF1) = Условный_оператор &
Если
(IF1) = IF_EXPR &
То
(IF1) = IF_THEN &
Класс_фрагмента (FOR1) + Цикл_с_шагом &
Начальная_граница_цикла (FOR1) = iif(CASE1, iif(Значение (B1) >
Значение (B2), B1, B2), B1 )&
Первый_элемент_последовательности (FOR1) = iif(CASE1, iif(Значение (O1)
< Значение (O2), O1, O2), O1 ) &
Конечная_граница_цикла (FOR1) = iif(CASE1, E1,(Значение (E1) <
Значение (E2), E1, E2) ) &
Шаг (FOR1) = Шаг (Y1) &
Тело (FOR1) = Дуга_последовательность_операторов(B1) ||
Дуга_последовательность_операторов (B2)
)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец /Разгрузка цикла/
8. Нормализация цикла
Бекон 6.3.6 (28)
0.127 августа 2006
Описание
Нормализация преобразует все циклы так, что индексная переменная
инициализируется единицей (или нулем) и увеличивается на 1 для каждой итерации.
Такое преобразование предоставляет возможность для слияния и упрощает анализ
зависимостей между циклами, как показано в примере №11 . Нормализация помогает
выявить, какие циклы являются кандидатами для расслаивания с последующим
слиянием. Наиболее важным использованием нормализации является разрешение
компьютеру применять тест для анализа индексов массивов, многие из которых
требуют нормализованных итерационных границ
Пример
было
do i = 1,n[i] = a[i] + cdoi = 2, n+1[i] = a[i-1] * b[i]do
стало
do i = 1, n[i] = a[i] +cdoi = 1, n[i+1] = a[i] * b[i+1]do
Возможны варианты реализации для подвыражений.
В постановке для операторов, просто.
Неформальное контекстное условие
Участком экономии в данном случае является цикл For, тело которого
состоит из последовательности операторов.
Y - цикл. У цикла есть свои границы: Е1 - начальная граница, Е2 -
конечная граница, Е3 - шаг цикла. B - тело цикла. E1 не равно 1
Формальное контекстное условие
$<Y,E1,E2,E3,B,D,X1,X2>( Класс_фрагмента (Y)= Цикл_с_шагом &
Класс_фрагмента (B)= Программный_блок &
Класс_фрагмента (E1)= Выражение &
Класс_фрагмента (E1)= Выражение &
Класс_фрагмента (E2)= Выражение &
Класс_фрагмента (E3)= Выражение &
Гнездо циклов (Y)=True & E1 = Начальная_граница_цикла (Y) &=
Конечная_граница_цикла (Y) & E3 = Шаг (Y) &
B = Тело (Y) & Значение (E1, null, null) <> 1)
Неформальное описание трансформации
Значение верхней границы переходит в значение верхней границы+значение
нижней границы, значение нижней границы переходит в 1
Формальное описание трансформации
$<Y,E1,E2,E3,B,D,X1,X2>( Значение (Е2, null, null) = Значение (E2, +,
E1), E1=>1)
Характеристическая функция
Формула стратегии
Элементы потокового анализа
Конец / Нормализация цикла /
Приложение
2. Таблица соответствий понятий
С помощью данной таблицы каталог версии 1 из Приложения 1 можно
преобразовать в каталог версии 2, и наоборот.
|
Dfdef
|
Фрагмент
|
Описание_одной_функции
|
|
Dpdef
|
Фрагмент
|
Описание_одного_параметра
|
|
Dvdef
|
Фрагмент
|
Описание_одной_переменной
|
|
Dfdefbody(Dfdefsch)
|
Фрагмент
|
Блок_описаний_функций
|
|
Dpdefbody(Dpdefsch)
|
Фрагмент
|
Блок_описаний_параметров
|
|
Dvdefbody(Dvdefsch)
|
Фрагмент
|
Блок_описаний_переменных
|
|
Dass
|
Фрагмент
|
Присваивание
|
|
Dinput
|
Фрагмент
|
Ввод
|
|
Doutput
|
Фрагмент
|
Вывод
|
|
Dbody
|
Фрагмент
|
Программный_блок
|
|
Dif
|
Фрагмент
|
Условный_оператор
|
|
Dfor
|
Фрагмент
|
Цикл_с_шагом
|
|
Dwhile
|
Фрагмент
|
Цикл_с_предусловием
|
|
Drepeat
|
Фрагмент
|
Цикл_с_постусловием
|
|
Dcall
|
Фрагмент
|
Вызов_процедуры
|
|
Ddispose
|
Фрагмент
|
Уничтожение_динамической_переменной
|
|
Dsch
|
Фрагмент
|
Последовательность_операторов
|
|
Dexpr
|
Фрагмент
|
Выражение
|
|
FragClass
|
Функция
|
Класс_фрагмента
|
|
Isline
|
Атрибут
|
Непрерывная_последовательность_фрагментов
|
|
TypeSet
|
|
Фрагменты_члены_последовательности
|
|
Parent_Level
|
|
Количество_фрагментов_предков
|
|
Result
|
|
Переменная_результат_функций
|
|
Prefix
|
|
Конструирование_новых_типов
|
|
IsPsevdo
|
|
Псевдопеременная
|
|
Value
|
Атрибут
|
Зарезервированные_значения_констант (ссылка на область
памяти)
|
|
ParDo
|
|
Гнездо циклов
|
|
A
|
Атрибут
|
Аргументное множество
|
|
R
|
Атрибут
|
Результатное множество
|
|
RR
|
Атрибут
|
Сильно_результатное_множество
|
|
Begin
|
Атрибут
|
Первый_элемент_последовательности
|
|
End
|
Атрибут
|
Последний_элемент_последовательности
|
|
Sch
|
Дуга
|
Дуга_последовательность_операторов
|
|
Parent
|
Дуга
|
Фрагмент_предок
|
|
Image
|
Атрибут
|
Обратная_польская_запись
|
|
IsArray
|
Атрибут
|
Результат_есть_массив
|
|
IsPointer
|
Атрибут
|
Результат_есть_указатель
|
|
IsRec
|
Атрибут
|
Функция_прямо_рекурсивна
|
|
IsEffects
|
Атрибут
|
Побочный_эффект
|
|
IsLValue
|
Атрибут
|
Адресное_выражение
|
|
Level
|
|
Уровень_вложенности
|
|
Priority
|
|
Приоритет_операции
|
|
Type
|
Атрибут
|
Тип
|
|
FormRefParam
|
|
Параметры_по_ссылке
|
|
Form_Val_Param
|
|
Параметры_по_значению
|
|
RefParam
|
|
Фактические_параметры_по_ссылке
|
|
ChangeRefParam
|
|
Изменяемые_фактические_параметры_по_ссылке
|
|
ValParam
|
|
Фактические_параметры_по_значению
|
|
OwnerFunc
|
|
Оператор_описания_функции
|
|
If
|
|
Если
|
|
Then
|
|
То
|
|
Else
|
|
Иначе
|
|
Cond
|
|
Условие_цикла
|
|
For
|
|
Начальная_граница_цикла
|
|
Until
|
|
Конечная_граница_цикла
|
|
Step
|
|
Шаг
|
|
Body
|
|
Тело
|
|
FDefbody
|
Дуга
|
Описание_функций
|
|
PDefbody
|
|
Описание_параметров
|
|
TDefbody
|
|
Описание_типов
|
|
VDefbody
|
|
Описание_переменных
|
|
Expr
|
Дуга
|
Выражение_справа
|
|
LvalueExpr
|
Дуга
|
Выражение_слева
|
|
Next
|
|
Следующий_элемент_последовательности
|
|
Param
|
|
Список_параметров
|
|
Id
|
|
Def
|
|
Опеараторы_описания
|
|
Par
|
|
Счетчик_цикла
|
|
Left (IsLeft)
|
Атрибут
|
Тип_левой_части
|
|
LeftExpr
|
Атрибут
|
Левая_часть_выражения
|
|
Right (IsRight)
|
Атрибут
|
Тип_правой_части
|
|
RightExpr
|
Атрибут
|
Правая_часть_выражения
|
|
IsFunc
|
Атрибут
|
Является_функцией
|
|
IsVar
|
Атрибут
|
Переменная_не_параметр
|
|
Op
|
|
Символ_операции
|
|
ByValue
|
|
Передача_по_значению
|
|
Length
|
|
Количество_фрагментов
|
|
Name
|
|
Оригинальное_строковое_имя
|
|
LowBound
|
Атрибут
|
Нижняя_граница_массива
|
|
HighBound
|
Атрибут
|
Верхняя_граница_массива
|
|
Eval
|
Атрибут
|
Значение
|
|
Oper
|
Дуга
|
Оператор
|
|
El
|
Атрибут
|
Номер_элемента
|
|
Sim (»)
|
Отношение
|
Подобие
|
|
Prec (<)
|
Отношение
|
Непосредственное предшествование
|
|
PrecN (<<)
|
Отношение
|
Предшествование
|
|
Submodel (<•)
|
Отношение
|
Являться_частью
|
|
SubmodelN (<••)
|
Отношение
|
Являться_подмоделью
|
|
SubmodelPrec (<•<)
|
Отношение
|
Предшествование_подмоделей
|
|
PointerValues
|
Атрибут
|
Значения_указателя
|
|
Conc
|
Отношение
|
Объединенная_последовательность
|
|
Pred
|
Отношение
|
Предшествующая_последовательность
|
|
Posl
|
Отношение
|
Следующая_последовательность
|
|
Between
|
Отношение
|
Промежуточная_последовательность
|
|
Main
|
Зарезервированные имена
|
Имя главной функции
|
|
Global
|
Зарезервированные имена
|
Идентификатор глобальной перемнной
|
|
Expr
|
Зарезервированные имена
|
Возможное значение атрибута IsLeft (Тип_левой_части)
|
|
Num
|
Зарезервированные имена
|
Возможное значение атрибута IsLeft (Тип_левой_части)
|
|
Call
|
Зарезервированные имена
|
Возможное значение атрибута IsLeft (Тип_левой_части)
|
|
Var
|
Зарезервированные имена
|
Возможное значение атрибута IsLeft (Тип_левой_части)
|
|
Type
|
Зарезервированные имена
|
Возможное значение атрибута IsLeft (Тип_левой_части)
|
Приложение
3. Синтаксис языка методов потокового анализа (расширенная БНФ)
1. <Метод потокового анализа> ::= “Метод_потокового_анализа” “(“
<Название метода> “)” <Блок объявления переменных>
<Последовательность конструкций>
2. <Название метода> ::= <Строка>
. <Строка> ::= <Буква> | <Строка> <Буква>
| <Строка> <Цифра>
. <Буква> ::= А | ... | Я | a | ... | я| - | _ |
. <Цифра> ::= 0 | 1 … | 9
. <Последовательность конструкций> ::= “{”
[<Конструкция>] “}”
. <Блок объявления переменных> ::= [<Объявление
переменной>]
. <Объявление переменной> ::= <Тип переменной> “:”
(<Переменная-фрагмент> | <Переменная-атрибут> |
<Переменная-дуга> | <Переменная-отношение> | <Переменная>
[“,”] ) “;”
. <Тип переменной> ::= “Переменная-фрагмент” |
“Переменная-атрибут” | “ Переменная-дуга ” | “ Переменная-отношение ” | “Целое”
| “Вещественное”
. <Конструкция> ::= <Формула> | <Обход> |
<Выбор> | <Цикл> | <Присваивание> | <Модификация
программы>
. <Формула> ::= <Формула над фрагментом> | <Формула
над множеством> | <Логическая формула>
. <Обход> ::= <Обход дерева программы> | <Обход
дерева выражения>
. <Выбор> ::= “Если” “(” <Логическая формула> ”)” “То”
< Последовательность конструкций > [“Иначе” <Последовательность
конструкций>]
. <Цикл> ::= “Пока” <Условие> <Последовательность
конструкций>
. <Присваивание> ::= <Левая часть присваивания> “=”
<Правая часть присваивания>
. <Модификация программы> ::= <Создание фрагмента> |
<Создание атрибута> | <Изменение атрибута> | <Создание дуги>
| <Создание отношения> | <Создание переменной>
. <Формула над фрагментом> ::= <Фрагмент по дуге> |
<Атрибут фрагмента> | <Получить класс> | <Получить переменную
выражения> | <Первый фрагмент по дуге из последовательности> |
<Следующий фрагмент по дуге из последовательности>
. <Фрагмент по дуге> ::= “Фрагмент_по_дуге” “(”
<Переменная-фрагмент>, <Имя дуги>, <Переменная-фрагмент> “)”
. <Атрибут фрагмента> ::= “Атрибут_фрагмента” “(”
<Переменная-фрагмент>, <Имя атрибута>, <Переменная-атрибут>
“)”
. <Получить класс> ::= “Получить_класс” “(”
<Переменная-фрагмент>, <Класс фрагмента>“)”
. <Получить переменную выражения> ::=
“Получить_переменную_выражения” “(” <Переменная-фрагмент>,
<Переменная> “)”
. <Первый фрагмент по дуге из последовательности>
::= “Первый_фрагмент_по_дуге_из_последовательности” “(”
<Переменная-фрагмент>, <Переменная-фрагмент > “)”
. <Следующий фрагмент по дуге из последовательности>
::= “Следующий_фрагмент_по_дуге_из_последовательности” “(” < Переменная-фрагмент
>, < Переменная-фрагмент >, < Переменная-фрагмент > “)”
. <Формула над множеством> ::= <Пересечение множеств>
| <Объединение множеств> | <Равенство множеств>
. <Пересечение множеств> ::= “Пересечение_множеств” “(”
<Переменная-множество> <Переменная-множество>
<Переменная-множество> “)”
. <Объединение множеств> ::= “Объединение_множеств” “(”
<Переменная-множество> <Переменная-множество>
<Переменная-множество> “)”
. <Равенство множеств> ::= “Равенство_множеств” “(”
<Аргумент-множество> < Переменная-множество> <Булево
множество> “)”
. <Логическая формула> ::= <Терм логической формулы>
. <Составная логическая формула> ::= <Терм логической
формулы> <Знак логической операции> <Терм логической формулы>
. <Терм логической формулы> ::= <Составная логическая
формула> | <Булево множество> | <Равенство множеств> | <Класс
фрагмента> | <Имя дуги> | <Переменная-фрагмент> |
<Переменная-атрибут> | <Переменная-дуга> |
<Переменная-отношение> | <Имя атрибута> | <Имя отношения> |
<Переменная>
. <Знак логической операции> ::= “>” | “<” | “>=” |
“<=” | “<>” | “==” | “И” | “ИЛИ” | “НЕ”
. <Обход дерева программы> ::= “Обход_дерева_программы” “(“
<Переменная-фрагмент>, <Переменная-фрагмент>, <Логическая
формула> “)” <Последовательность конструкций>
. <Обход дерева выражения> ::= “Обход_дерева_выражения” “(“
<Переменная-фрагмент>, <Переменная-фрагмент> “)”
<Последовательность конструкций>
. <Модификация программы> ::= <Создание фрагмента> |
<Создание атрибута> | <Создание дуги> | <Создание отношения>
| <Создание переменной>
. <Создание фрагмента> ::= “Создать_фрагмент” “(“
<Переменная-фрагмент>, <Класс фрагмента> “;”
<Переменная-фрагмент> “)”
. <Создание атрибута> ::= “Создать_атрибут” “(“
<Переменная-фрагмент>, <Имя атрибута>, <Переменная-атрибут>
“)”
. <Создание дуги> ::= “Создать_дугу” “(“
<Переменная-фрагмент>, <Переменная-фрагмент>, <Имя дуги>,
<Переменная-дуга> “)”
. <Создание отношения> ::= “Создать_отношение” “(“
<Переменная-фрагмент>, <Переменная-фрагмент> [,
<Переменная-фрагмент> <Переменная-отношение> “)”
. <Значение> ::= <Целое> <Вещественное>
<булево множество>
. <Целое> ::= (<Цифра>)
. <Вещественное> ::= (<Цифра>)[,(<Цифра>)]
. <Присваивание> ::= <Левая часть присваивания> = <
Правая часть присваивания >
. <Левая часть присваивания> ::= <Переменная-фрагмент>
| <Переменная-атрибут> | <Переменная-дуга> | <
Переменная-отношение> | <Переменная>
. <Правая часть присваивания> ::=
<Переменная-фрагмент> | < Переменная-атрибут> |
<Переменная-дуга> | < Переменная-отношение> | <Переменная> |
<Значение> | <Арифметическое выражение>
. <Арифметическое выражение> ::= <Терм арифметического
выражения> <Знак арифметической операции> <Терм арифметического
выражения>
. <Знак арифметической операции> ::= “+” | “- ” | “* ” | “/
” | “^”
. <Класс фрагмента> ::= “Описание_переменной” |
“Описание_функции” | “Описание_параметра” | “Описание_переменных” |
“Описание_функций” | “Описание_параметров” | “Присваивание” | “Ввод” | “Вывод”
| “Программный_блок” | “Условный_оператор” | “Цикл_с_шагом” |
“Цикл_с_предусловием” | “Цикл_с_постусловием” | “Вызов_процедуры” |
“Уничтожение_динамической_переменной” | “Выражение” |
“Последовательность_операторов”
. <Имя атрибута> ::= “Обратная_польская_запись” |
“Результат_массив” | “Указатель” | “Функция_рекурсивна” | “Побочный_эффект” |
“Ссылка_на_область_памяти” | “Уровень_вложенности” | “Приоритет” | “Тип” |
“Параметры_по_ссылке” | “Параметры_по_значению” |
“Фактические_параметры_по_ссылке” |
“Изменяемые_фактические_параметры_по_ссылке” |
“Фактические_параметры_по_значению” | “Аргументное_множество” | “Результатное_множество”
| “Сильнорезультатное_множество” | “Оператор_описания_функции” |
“Непрерывная_последовательность_фрагментов” |
“Классы_фрагментов_последовательностей” | “Количество_фрагментов” |
“Идентификатор_результата” | “Псевдопеременная” | “Конструирование_новых_типов”
| “Леводопустимое выражение”
. <Имя дуги> ::= “Если” | “То” | “Иначе” | “Условие_цикла” |
“Для” | “До” | “Шаг” | “Тело_оператора” | “Блок_параметров” |
“Блок_локальных_параметров” | “Блок_вложенных _функций” | “Выражение_справа” |
“Выражение_слева” | “Первый_элемент_последовательности” |
“Последний_элемент_последовательности” | “Дуга_последовательность_операторов” |
“Сопоставляет_фрагменты” | “Следующий_фрагмент” | “Список_параметров”
. <Имя отношения> ::= “Непосредственное_предшествование” |
“Предшествование” | “Подобие” | “Являться_частью” | “Являться_подмоделью” |
“Предшествование_подмоделей” | “Объединенная_последовательность” |
“Промежуточная_последовательность” | “Предшествующая_последовательность” |
“Следующая_последовательность”
. <Булево множество> ::= “истина” | “ложь”
. <Переменная> ::= <Строка>
. <Переменная-множество> ::= <Строка>
. <Переменная-фрагмент> ::= <Строка>
. <Переменная-атрибут> ::= <Строка>
. <Переменная-дуга> ::= <Строка>
. <Переменная-отношение> ::= <Строка>