Нейросеревые модели
Тема: Нейросеревые
модели
Оглавление
1. Введение
. Основы
из высшей математики
2.1
Векторные пространства
.2
Матрицы и линейные преобразования векторов
3. Биологический
нейрон и его кибернетическая модель
.1
Биологический нейрон
.2 Нейронные
сети
.3 Структура
простой рефлекторной нейронной сети
.4
Биологическая изменчивость и обучение нейронных сетей
.5 Формальный
нейрон
.6 Обучение
нейрона детектированию границы «черное - белое»
.7
Классификация нейронных сетей
. Персептрон
Розенблатта
.1 Теорема об
обучении персептрона
.2 Линейная
разделимость и персептронная представляемость
. Принцип
WTA в модели Липмана-Хемминга
. Карта
самоорганизации Кохонена
. Нейронная
сеть встречного распространения
. Когнитрон
и неокогнитрон Фукушимы
.1 Когнитрон
- самоорганизующаяся многослойная нейросеть
.2
Неокогнитрон
.3
Неокогнитрон и инвариантное распознавание образов
. Общее
понятие сетей АРТ
.1 Дилемма
стабильности-пластичности восприятия
.2 Принцип
адаптивного резонанса
.3 Обучение
сети АРТ
.4 Теоремы АРТ
. Сжатие
данных и ассоциативная память
. Распознавание
образов, классификация, категоризация
. Современность
нейросетевых технологий
.1 Черты
современных архитектур
.2
Программное обеспечение
.3
Многообразие применения
Вывод
Практическая
часть
Список литературы
1. Введение
Искусственные
нейронные сети (ИНС) - математические модели, а также их программные или
аппаратные реализации, построенные по принципу организации и функционирования
биологических нейронных сетей - сетей нервных клеток живого организма. Это
понятие возникло при изучении процессов, протекающих в мозге, и при попытке
смоделировать эти процессы.
К рубежу 80-х
годов были достигнуты значительные результаты в совсем молодой синергетике -
науке о самоорганизации в неравновесных системах; систематизированы факты и
проведены многочисленные новые эксперименты в нейрофизиологии, в частности,
подробно изучено строение и механизм действия отдельных нейронов; сформулирован
принцип работы и создана первая ЭВМ с параллельной архитектурой. Эти обстоятельства,
по-видимому, стимулировали начало интенсивных исследований нейронных сетей, как
моделей ассоциативной памяти.
Широкий
интерес к нейронным сетям был инициирован после появления работы Хопфилда
(Hopfield J.J., 1982), который показал, что задача с изинговскими нейронами
может быть сведена к обобщениям ряда моделей, разработанных к тому моменту в
физике неупорядоченных систем. Работа сети Хопфилда (наиболее подробно
обсуждаемая в физической литературе) состоит в релаксации начального
"спинового портрета" матрицы двоичных кодов к одному из стационарных
состояний, определяемых правилом обучения (правилом Хебба). Таким образом,
данная сеть может применяться для задач распознавания.
В 1986 году
появилась работа Румельхарта, Хинтона и Вильямса (Rumelhart D.E., Hinton G.E.,
Williams R.J., 1986), содержавшая ответ на вопрос, долгое время сдерживавший
развитие нейроинформатики - как обучаются иерархические слоистые нейронные
сети, для которых "классиками" еще в 40-50 х годах была доказана
универсальность для широкого класса задач. В последующие годы предложенный
Хинтоном алгоритм обратного распространения ошибок претерпел бесчисленное
множество вариаций и модификаций. Многообразие предлагаемых алгоритмов,
характеризующихся различной степенью детальности проработки, возможностями их
параллельной реализации, а также наличием аппаратной реализации, приводит к
особой актуальности исследования по сравнительным характеристикам различных
методик. "Подмигните компьютеру - он поймет". В начале 90-х под таким
заголовком в старейшей уважаемой газете Нью-Йорк Таймс появилась статья,
рассказывающая о современных достижениях и направлениях в области
интеллектуальных компьютерных систем. Среди магистральных путей развития данной
отрасли эксперты издания выделили:
· Компьютеры с высокой степенью параллелизма обработки
информации, которые могут разделить ту или иную задачу на части и обрабатывать
их одновременно, тем самым значительно сокращая общее время вычислений;
· Компьютеры, в которых вместо электронных сигналов для
передачи информации используется оптика. Оптические сигналы уже начали
использоваться для передачи данных между компьютерами;
· Компьютеры с нейронными сетями, представляющие собой машины,
работающие аналогично тому, как по нашим современным представлениям, функционирует
мозг.
Третье направление представляет наибольший интерес, так как нейронные
сети - мощный и на сегодня, пожалуй, наилучший метод для решения задач
распознавания образов в ситуациях, когда в экспериментальных данных отсутствуют
значительные фрагменты информации, а имеющаяся информация предельно зашумлена.
Высокая степень параллельности, допускаемая при реализации нейросистем,
обеспечивает обработку недоступных оператору объемов информации за времена,
меньшие или сравнимые с допустимыми временами измерений.
Свой вклад в становление нейронауки внесли биология и физиология высшей
нервной деятельности, психология восприятия, дискретная математика,
статистическая физика и синергетика, и, конечно, кибернетика и, конечно,
компьютерное моделирование. Нейронаука в современный момент переживает период
перехода от юного состояния к зрелости. Развитие в области теории и приложений
нейронных сетей идет в самых разных направлениях: идут поиски новых нелинейных
элементов, которые могли бы реализовывать сложное коллективное поведение в
ансамбле нейронов, предлагаются новые архитектуры нейронных сетей, идет поиск
областей приложения нейронных сетей в системах обработки изображений,
распознавания образов и речи, робототехники и др. Значительное место в данных
исследованиях традиционно занимает математическое моделирование.
2. Основы из высшей математики
Традиционно используемым для описания нейронных сетей математическим
языком является аппарат векторной и матричной алгебры, кроме них
дифференциальные уравнения, применяемые для анализа нейронных сетей в
непрерывном времени, а также для построения детальных моделей нейрона;
Фурье-анализ для описания поведения системы при кодировании в частотной
области; теория оптимизации как основа для разработки алгоритмов обучения; математическая
логика и булева алгебра - для описания двоичных сетей, и другие.
2.1 Векторные пространства
Основным структурным элементом в описании способов обработки информации
нейронной сетью является вектор - упорядоченный набор чисел, называемых
компонентами вектора.
В предлагаемом рассмотрении не будем делать разницы в понятиях вектор
(упорядоченная совокупность компонент) и образ (совокупность черт или признаков
образа). Способы выбора совокупности признаков и формирования информационного
вектора определяются конкретными приложениями.

Примеры
векторов: а) булев вектор с 25 компонентами, нумеруемыми по строкам, б)
действительный вектор из пространства R4.
Множество
векторов с действительными компонентами является частным случаем более общего
понятия, называемого линейным векторным пространством V, если для его элементов
определены операции векторного сложения "+" и умножения на
скаляр".", удовлетворяющие перечисленным ниже соотношениям
(здесь x, y, z - вектора из V, а a, b - скаляры из R):
1. x + y = y + x, результат принадлежит V (свойство коммутативности)
2. a . (x + y) = a . x + a . y, результат принадлежит V (свойством
дистрибутивности)
. (a + b) . x = a . x + b . x, результат
принадлежит V (свойством дистрибутивности)
. ( x + y) + z = x + (y + z), результат принадлежит V (свойством
ассоциативности введенных операций.)
. ( a .
b ) . x = a . ( b . x ), результат
принадлежит V
6. $ o из V: " x из V => o + x = x (существует нулевой элемент)
. для скаляров 0 и 1, " x из V имеем 0 . x = o, 1 . x = x
Для математического описания степени сходства векторное пространство
может быть снабжено скалярной метрикой - расстоянием d(x,y) между всякими двумя
векторами x и y. Пространства, с заданной метрикой называют метрическими. Для
метрики должны выполняться условия неотрицательности, симметричности, а также
неравенство треугольника:
. d ( x, y ) >= 0, причем d ( y, x ) = 0 <=> x = y
. d ( x, y ) = d ( y, x )
3. " y, d ( x, z ) <= d ( x, y ) + d ( y, z )
Далее будем использовать в основном две метрики - Евклидово расстояние и
метрика Хемминга. Евклидова метрика для прямоугольной системы координат
определяется формулой:
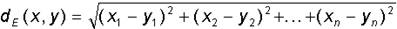
Хеммингово
расстояние dH используется обычно для булевых векторов (компоненты
которых равны 0 или 1), и равно числу различающихся в обоих векторах компонент.
Для
векторов вводится понятие нормы ||x|| - длины вектора x. Пространство в котором
определена норма векторов называется нормированным. Норма должна обладать
следующими свойствами:
1. ||x|| >= 0, причем ||x|| = 0 <=> x = o
. || a.x || = |a| ||x||
. ||x + y|| <= ||x|| + ||y||
Для образов, состоящих из действительных признаков мы будем в дальнейшем
иметь дело именно с Евклидовым пространством. В случае булевых векторов
размерности n рассматриваемое пространство представляет собой множество вершин
n-мерного гиперкуба с Хемминговой метрикой. Расстояние между двумя вершинами
определяется длиной кратчайшего соединяющего их пути, измеренной вдоль ребер.
Важным для нейросетевых приложений случаем является множество векторов,
компоненты которых являются действительными числами, принадлежащими отрезку
[0,1]. Множество таких векторов не является линейным векторным пространством,
так как их сумма может иметь компоненты вне рассматриваемого отрезка. Однако
для пары таких векторов сохраняются понятия скалярного произведения и
Евклидового расстояния. Вторым интересным примером, важным с практической точки
зрения, является множество векторов одинаковой длины (равной, например,
единице). Образно говоря, "кончики" этих векторов принадлежат
гиперсфере единичного радиуса в n-мерном пространстве. Гиперсфера также не
является линейным пространством (в частности, отсутствует нулевой элемент). Для
заданной совокупности признаков, определяющих пространство векторов, может быть
сформирован такой минимальный набор векторов, в разной степени обладающих этими
признаками, что на его основе, линейно комбинируя вектора из набора, можно
сформировать все возможные иные вектора. Такой набор называется базисом пространства.
2.2 Матрицы и линейные преобразования векторов
Равно тому, как был рассмотрен вектор - объект, определяемый одним
индексом (номером компоненты или признака), может быть введен и объект с двумя
индексами, матрица. Эти два индекса определяют компоненты матрицы Aij,
располагаемые по строкам и столбцам, причем первый индекс i определяет номер
строки, а второй j - номер столбца. Приведем некоторые тождества для операций
над матрицами. Для всяких A,B и C и единичной матрицы I имеет место:
. IA = AI = A
. (AB)C = A(BC)
. A(B+C) = AB + AC
. (AT)T = A
. (A+B)T = AT + BT
. (AB)T = BTAT
3. Биологический нейрон и его кибернетическая модель
Биологический фундамент при изучении функций, таких как распознавание
образов (зрительных, слуховых, сенсорных и других), память и устойчивое
управление движением тела является крайне важным, природное многообразие дает
исключительно богатый исходный материал для направленного создания
искусственных моделей.
Метод нейробиологии.
К предмету нейробиологии относится изучение нервной системы и ее главного
органа - мозга. Принципиальным вопросом для этой науки является выяснение
соотношения между строением нервной системы и ее функцией. При этом
рассмотрение проводится на нескольких уровнях: молекулярном, клеточном, на
уровне отдельного органа, организма в целом, и далее на уровне социальной
группы. Таким образом, классический нейробиологический подход состоит в
последовательном продвижении от элементарных форм в направлении их усложнения.
Начнем рассмотрение с клеточного уровня. По современным представлениям,
именно на нем совокупность элементарных молекулярных химико-биологических
процессов, протекающих в отдельной клетке, формирует ее как элементарных
процессор, способный к простейшей переработке информации.
3.1 Биологический нейрон
Элементом клеточной структуры мозга является нервная клетка - нейрон.
Нейрон в своем строении имеет много общих черт с другими клетками биоткани:
тело нейрона окружено плазматической мембраной, внутри которой находится
цитоплазма, ядро и другие составляющие клетки. Однако нервная клетка
существенно отличается от иных по своему функциональному назначению. Нейрон
выполняет прием, элементарное преобразование и дальнейшую передачу информации
другим нейронам. Информация переносится в виде импульсов нервной активности,
имеющих электрохимическую природу. Нейроны крайне разнообразны по форме,
которая зависит от их местонахождения в нервной системе и особенностей
функционирования. Тело клетки содержит множество ветвящихся отростков двух
типов. Отростки первого типа, называемые дендритами за их сходство с кроной
раскидистого дерева, служат в качестве входных каналов для нервных импульсов от
других нейронов. Эти импульсы поступают в сому или тело клетки размером от 3 до
100 микрон, вызывая ее специфическое возбуждение, которое затем
распространяется по выводному отростку второго типа - аксону. Длина аксонов
обычно заметно превосходит размеры дендритов, в отдельных случаях достигая
десятков сантиметров и даже метров. Тело нейрона, заполненное проводящим ионным
раствором, окружено мембраной толщиной около 75 ангстрем, обладающей низкой
проводимостью. Между внутренней поверхностью мембраны аксона и внешней средой
поддерживается разность электрических потенциалов. Это осуществляется при
помощи молекулярного механизма ионных насосов, создающих различную концентрацию
положительных ионов K+ и Na+ внутри и вне клетки.
Проницаемость мембраны нейрона селективна для этих ионов. Внутри аксона клетки,
находящейся в состоянии покоя, активный транспорт ионов стремится поддерживать
концентрацию ионов калия более высокой, чем ионов натрия, тогда как в жидкости,
окружающей аксон, выше оказывается концентрация ионов Na+. Пассивная
диффузия более подвижных ионов калия приводит к их интенсивному выходу из
клетки, что обуславливает ее общий отрицательный относительно внешней среды
потенциал покоя, составляющий около -65 милливольт.
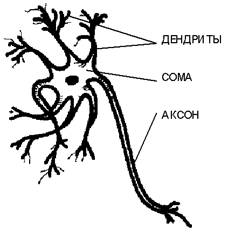
Общая
схема строения биологического нейрона.
Под
воздействием стимулирующих сигналов от других нейронов мембрана аксона динамически
изменяет свою проводимость. Мембрана на короткое время, составляющее около 2
миллисекунд, изменяет свою полярность (деполяризуется) и достигает потенциала
действия около +40 мв. В дальнейшем, по мере выхода ионов калия, положительный
заряд с внутренней стороны мембраны меняется на отрицательный, и наступает так
называемый период рефрактерности, длящийся около 200 мс. В течении этого
времени нейрон является полностью пассивным, практически неизменно сохраняя
потенциал внутри аксона на уровне около -70 мв. Импульс деполяризации клеточной
мембраны, называемый спайком, распространяется вдоль аксона практически без
затухания, поддерживаясь локальными ионными градиентами. Возбуждение нейрона в
виде спайка передается другим нейронам, которые таким образом объединены в
проводящую нервные импульсы сеть. Участки мембраны на аксоне, где размещаются
области контакта аксона данного нейрона с дендритами другими нейронов,
называются синапсами. В области синапса, имеющего сложное строение, происходит
обмен информацией о возбуждении между нейронами. Механизмы синаптической
передачи могут иметь химическую и электрическую природу. В химическом синапсе в
передаче импульсов участвуют специфические химические вещества -
нейромедиаторы, вызывающие изменения проницаемости локального участка мембраны.
В зависимости от типа вырабатываемого медиатора синапс может обладать
возбуждающим (эффективно проводящим возбуждение) или тормозящим действием.
Обычно на всех отростках одного нейрона вырабатывается один и тот же медиатор,
и поэтому нейрон в целом функционально является тормозящим или возбуждающим.
Это важное наблюдение о наличии нейронов различных типов существенно
используется при проектировании искусственных систем.
3.2 Нейронные сети
Взаимодействующие между собой посредством передачи через отростки
возбуждений нейроны формируют нейронные сети. Переход от рассмотрения
отдельного нейрона к изучению нейронных сетей является естественным шагом в
нейробиологической иерархии. Выделяют несколько (обычно три) основных типов
нейронных сетей, отличающихся структурой и назначением. Первый тип составляют
иерархические сети, часто встречающиеся в сенсорных и двигательных путях.
Информация в таких сетях передается в процессе последовательного перехода от
одного уровня иерархии к другому.
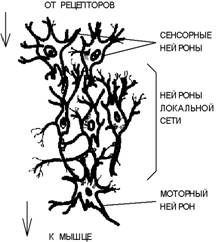
3.3 Структура простой рефлекторной нейронной сети
Нейроны образуют два характерных типа соединений - конвергентные, когда
большое число нейронов одного уровня контактирует с меньшим числом нейронов
следующего уровня, и дивергентные, в которых контакты устанавливаются со все
большим числом клеток последующих слоев иерархии. Сочетание конвергентных и
дивергентных соединений обеспечивает многократное дублирование информационных
путей, что является решающим фактором надежности нейронной сети. При гибели
части клеток, сохранившиеся нейроны оказываются в состоянии поддерживать
функционирование сети. Ко второму типу нейронных сетей относятся локальные
сети, формируемые нейронами с ограниченными сферами влияния. Нейроны локальных
сетей производят переработку информации в пределах одного уровня иерархии. При
этом функционально локальная сеть представляет собой относительно изолированную
тормозящую или возбуждающую структуру. Важную роль также играют так называемые
дивергентные сети с одним входом. Командный нейрон, находящийся в основании
такой сети может оказывать влияние сразу на множество нейронов, и поэтому сети
с одним входом выступают согласующим элементом в сложном сочетании нейросетевых
систем всех типов. Сигнал внешнего раздражителя воспринимается сенсорными
нейронами, связанными с чувствительными клетками-рецепторами. Сенсорные нейроны
формируют первый (нижний) уровень иерархии. Выработанные ими сигналы передаются
нейронам локальной сети, содержащим множество прямых и обратных связей с
сочетанием дивергентных и конвергентных соединений. Характер преобразованного в
локальных сетях сигнала определяет состояние возбуждения моторных нейронов. Эти
нейроны, составляющие верхний в рассматриваемой сети уровень иерархии, образно
говоря, "принимают решение", которое выражается в воздействии на
клетки мышечной ткани посредством нервно-мышечных соединений.
3.4 Биологическая изменчивость и обучение нейронных сетей
нейронный сеть кибернетический линейный вектор
Структура основных типов нейронных сетей генетически предопределена.
Однако детерминированные нейронные структуры демонстрируют свойства
изменчивости, обуславливающие их адаптацию к конкретным условиям
функционирования. Генетическая предопределенность имеет место также и в отношении
свойств отдельных нейронов, таких, например, как тип используемого
нейромедиатора, форма и размер клетки. Изменчивость на клеточном уровне
проявляется в пластичности синаптических контактов. Характер метаболической
активности нейрона и свойства проницаемости синаптической мембраны могут
меняться в ответ на длительную активизацию или торможение нейрона.
Синаптический контакт "тренируется" в ответ на условия
функционирования.
Специфическая изменчивость нейронных сетей и свойств отдельных нейронов
лежит в основе их способности к обучению - адаптации к условиям
функционирования - при неизменности в целом их морфологической структуры.
Следует заметить, однако, что рассмотрение изменчивости и обучаемости малых
групп нейронов не позволяет в целом ответить на вопросы об обучаемости на
уровне высших форм психической деятельности, связанных с интеллектом,
абстрактным мышлением, речью.
Основными действующими элементами нервной системы являются отдельные
клетки, называемые нейронами. Активность нейронов при передаче и обработке
нервных импульсов регулируется свойствами мембраны, которые могут меняться под
воздействием синаптических медиаторов. Биологические функции нейрона могут
меняться и адаптироваться к условиям функционирования. Нейроны объединяются в
нейронные сети, основные типы которых, а также схемы проводящих путей мозга
являются генетически запрограммированными. В процессе развития возможно
локальное видоизменение нейронных сетей с формированием новых соединений между
нейронами. Следует заметить, что нервная система содержит помимо нейронов
клетки других типов.
3.5 Формальный нейрон
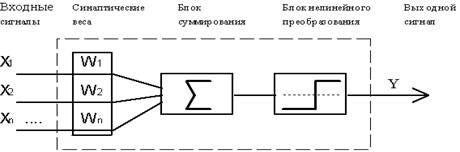
Функциональная
схема формального нейрона МакКалока и Пиитса.
С
современной точки зрения, формальный нейрон представляет собой математическую
модель простого процессора, имеющего несколько входов и один выход. Вектор
входных сигналов (поступающих через "дендриты") преобразуется
нейроном в выходной сигнал (распространяющийся по "аксону") с
использованием трех функциональных блоков: локальной памяти, блока суммирования
и блока нелинейного преобразования. Вектор локальной памяти содержит информацию
о весовых множителях, с которыми входные сигналы будут интерпретироваться
нейроном. Эти переменные веса являются аналогом чувствительности пластических синаптических
контактов. Выбором весов достигается та или иная интегральная функция нейрона.
В блоке суммирования происходит накопление общего входного сигнала (обычно
обозначаемого символом net), равного взвешенной сумме входов:
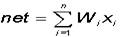
В
модели Маккалока и Питтса отсутствуют временные задержки входных сигналов,
поэтому значение net определяет полное внешнее возбуждение, воспринятое
нейроном. Отклик нейрон далее описывается по принципу "все или
ничего", т. е. переменная подвергается нелинейному пороговому
преобразованию, при котором выход (состояние активации нейрона) Y
устанавливается равным единице, если net > Q, и Y=0 в
обратном случае. Значение порога Q (часто полагаемое
равным нулю) также хранится в локальной памяти.
Важным
развитием теории формального нейрона является переход к аналоговым
(непрерывным) сигналам, а также к различным типам нелинейных переходных
функций. Опишем наиболее широко используемые типы переходных функций Y=f(net).
· Пороговая функция (рассмотренная Маккалоком и Питтсом):
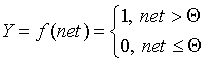
· Линейная функция, а также ее вариант - линейная функция с
погашением отрицательных сигналов:
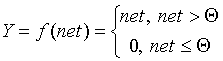
· Сигмоидальная функция:
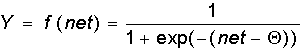
Сигмоидальная
функция обладает избирательной чувствительностью к сигналам разной
интенсивности, что соответствует биологическим данным. Наибольшая чувствительность
наблюдается вблизи порога, где малые изменения сигнала net приводят к ощутимым
изменениям выхода. Напротив, к вариациям сигнала в областях значительно выше
или ниже порогового уровня сигмоидальная функция не чувствительна, так как ее
производная при больших и малых аргументах стремится к нулю.
3.6 Обучение нейрона детектированию границы «черное-белое»
Способность формального нейрона к обучению проявляется в возможности
изменения значений вектора весов W, соответствующей пластичности синапсов биологических
нейронов. Пусть имеется образ, составленный из одномерной цепочки черных и
белых клеток. Зачерненные клетки соответствуют единичному сигналу, а белые
клетки - нулевому. Сигнал на входах формального нейрона устанавливается равным
значениям пар примыкающих клеток рассматриваемого образа. Нейрон обучается
всякий раз возбуждаться и выдавать единичный выходной сигнал, если его первый
вход соединен с белой клеткой, а второй (правый) - с черной. Таким образом,
нейрон должен служить детектором границы перехода от светлого к темному тону
образа.
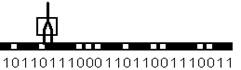
Формальный
нейрон с двумя входами, занятый обработкой образа в виде одномерной цепочки
черных и белых клеток. Функция, выполняемая нейроном, определяется следующей
таблицей:
|
Вход 1
|
Вход 2
|
Требуемый выход
|
|
1
|
1
|
0
|
|
1
|
0
|
0
|
|
0
|
1
|
1
|
|
0
|
0
|
0
|
3.7 Классификация нейронных сетей
.
по типу входной информации:
Аналоговые нейронные сети (используют информацию в форме действительных
чисел);
двоичные нейронные сети (оперируют с информацией, представленной в
двоичном виде).
II.
по характеру обучения:
Обучение с учителем - выходное пространство решений нейронной сети
известно;
Обучение без учителя - нейронная сеть формирует выходное пространство
решений только на основе входных воздействий. Такие сети называют
самоорганизующимися;
Обучение с подкреплением - система назначения штрафов и поощрений от
среды.
III.
по характеру настройки синапсов:
Сети с фиксированными связями (весовые коэффициенты нейронной сети
выбираются сразу, исходя из условий задачи, при этом: где W - весовые
коэффициенты сети);
сети с динамическими связями (для них в процессе обучения происходит
настройка синаптических связей, то есть, где W - весовые коэффициенты сети).
IV.
по времени передачи сигнала:
В ряде нейронных сетей активирующая функция может зависеть не только от
весовых коэффициентов связей wij, но и от времени передачи импульса (сигнала)
по каналам связи τij. По этому в общем виде активирующая (передающая)
функция связи cij от элемента ui к элементу uj имеет вид: . Тогда синхронной
сетью называют такую сеть, у которой время передачи τij
каждой связи равно либо
нулю, либо фиксированной постоянной τ. Асинхронной называют такую сеть у
которой время передачи τij для каждой связи между элементами ui и uj свое, но
тоже постоянное.
V.
по характеру связей:
сети прямого распространения (персептрон Розенблатта и т.д.);
рекуррентные нейронные сети(сеть Хопфилда, сеть Коско и т.д.)ý.
Другие известные типы связей: многослойный персептрон; сеть Джордана,
сеть Элмана, сеть Хэмминга, сеть Ворда, сеть Кохонена, нейронный газ,
когнитрон, неокогнитрон, хаотическая нейронная сеть, осцилляторная нейронная
сеть, сеть встречного распространения, RBF-сеть, сеть обобщенной регрессии,
вероятностная сеть, сиамская нейронная сеть, сети адаптивного резонанса.
4. Персептрон Розенблатта
Одной из первых искусственных сетей, способных к перцепции (восприятию) и
формированию реакции на воспринятый стимул, явился PERCEPTRON Розенблатта
(F.Rosenblatt, 1957). Персептрон рассматривался его автором не как конкретное
техническое вычислительное устройство, а как модель работы мозга.
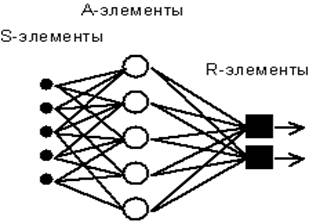
Элементарный
персептрон Розенблатта.
Простейший
классический персептрон содержит нейроподобные элементы трех типов, назначение
которых в целом соответствует нейронам рефлекторной нейронной сети,
рассмотренной в предыдущей лекции. S-элементы формируют сетчатку сенсорных
клеток, принимающих двоичные сигналы от внешнего мира. Далее сигналы поступают
в слой ассоциативных или A-элементов (для упрощения изображения часть связей от
входных S-клеток к A-клеткам не показана). Только ассоциативные элементы,
представляющие собой формальные нейроны, выполняют нелинейную обработку
информации и имеют изменяемые веса связей. R-элементы с фиксированными весами
формируют сигнал реакции персептрона на входной стимул. Представленная сеть
обычно называется однослойной, так как имеет только один слой нейропроцессорных
элементов. Однослойный персептрон характеризуется матрицей синаптических связей
W от S- к A-элементам. Элемент матрицы 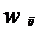 отвечает
связи, ведущей от i-го S-элемента к j-му A-элементу.
отвечает
связи, ведущей от i-го S-элемента к j-му A-элементу.
4.1 Теорема об обучении персептрона
Обучение сети состоит в подстройке весовых коэффициентов каждого нейрона.
Пусть имеется набор пар векторов (xa, ya), a =
1..p, называемый обучающей выборкой. Будем называть нейронную сеть обученной на
данной обучающей выборке, если при подаче на входы сети каждого вектора xa на выходах всякий раз получается
соответствующий вектор ya .
Алгоритм обучения включает несколько шагов:
|
Шаг 0.
|
Начальные значения весов
всех нейронов 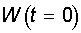 полагаются случайными. полагаются случайными.
|
|
Шаг 1.
|
Сети предъявляется входной
образ x, в результате формируется выходной образ 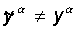
|
|
Шаг 2.
|
Вычисляется вектор ошибки 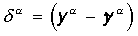 , делаемой сетью на выходе. Дальнейшая идея состоит
в том, что изменение вектора весовых коэффициентов в области малых ошибок
должно быть пропорционально ошибке на выходе, и равно нулю если ошибка равна
нулю. , делаемой сетью на выходе. Дальнейшая идея состоит
в том, что изменение вектора весовых коэффициентов в области малых ошибок
должно быть пропорционально ошибке на выходе, и равно нулю если ошибка равна
нулю.
|
|
Шаг 3.
|
Вектор весов модифицируется
по следующей формуле: 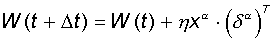 . Здесь . Здесь 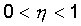 - темп
обучения. - темп
обучения.
|
|
Шаг 4.
|
Шаги 1-3 повторяются для
всех обучающих векторов. Один цикл последовательного предъявления всей
выборки называется эпохой. Обучение завершается по истечении нескольких эпох,
а) когда итерации сойдутся, т.е. вектор весов перестает изменяться, или б)
когда полная просуммированная по всем векторам абсолютная ошибка станет
меньше некоторого малого значения.
|
Используемая на шаге 3 формула учитывает следующие обстоятельства: а)
модифицируются только компоненты матрицы весов, отвечающие ненулевым значениям
входов; б) знак приращения веса соответствует знаку ошибки, т.е. положительная
ошибка (d > 0, значение выхода меньше
требуемого) проводит к усилению связи; в) обучение каждого нейрона происходит
независимо от обучения остальных нейронов, что соответствует важному с
биологической точки зрения, принципу локальности обучения.
Данный метод обучения был назван “методом коррекции с обратной передачей
сигнала ошибки”. Позднее более широко стало известно название “d-правило”. Представленный алгоритм
относится к широкому классу алгоритмов обучения с учителем, поскольку известны
как входные вектора, так и требуемые значения выходных векторов (имеется
учитель, способный оценить правильность ответа ученика). Доказанная теорема
говорит о том, что персептрон способен обучится любому обучающему набору,
который он способен представить.
4.2 Линейная разделимость и персептронная представляемость
Каждый нейрон персептрона является формальным пороговым элементом,
принимающим единичные значения в случае, если суммарный взвешенный вход больше
некоторого порогового значения:
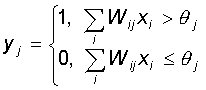
Таким
образом, при заданных значениях весов и порогов, нейрон имеет определенное
значение выходной активности для каждого возможного вектора входов. Множество
входных векторов, при которых нейрон активен (y=1), отделено от множества
векторов, на которых нейрон пассивен (y=0) гиперплоскостью, уравнение которой
есть, суть:
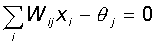
Следовательно,
нейрон способен отделить (иметь различный выход) только такие два множества
векторов входов, для которых имеется гиперплоскость, отсекающая одно множество
от другого. Такие множества называют линейно разделимыми. Рассмотрим пример.
Пусть имеется нейрон, для которого входной вектор содержит только две булевые
компоненты (Х1.Х2), определяющие плоскость. На данной плоскости
возможные значения векторов отвечают вершинам единичного квадрата. В каждой
вершине определено требуемое значение активности нейрона 0 (белая точка) или 1
(черная точка). Требуется определить, существует ли такое такой набор весов и порогов
нейрона, при котором этот нейрон сможет отделить точки разного цвета.
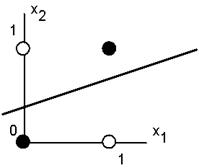
Белые
точки не могут быть отделены одной прямой от черных. Требуемая активность
нейрона для этого рисунка определяется таблицей, в которой не трудно узнать
задание логической функции “исключающее или”.
|
X1
|
X2
|
Y
|
|
0
|
0
|
0
|
|
1
|
0
|
1
|
|
0
|
1
|
1
|
|
1
|
1
|
0
|
Линейная неразделимость множеств аргументов, отвечающих различным
значениям функции означает, что функция “исключающее или”, столь широко
использующаяся в логических устройствах, не может быть представлена формальным
нейроном. При возрастании числа аргументов относительное число функций, которые
обладают свойством линейной разделимости резко уменьшается. А значит и резко
сужается класс функций, который может быть реализован персептроном (так
называемый класс функций, обладающий свойством персептронной представляемости).
Соответствующие данные приведены в следующей таблице:
|
Число переменных N
|
Полное число возможных
логических функций 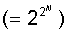 Из них линейно разделимых функций Из них линейно разделимых функций
|
|
|
1
|
4
|
4
|
|
2
|
16
|
14
|
|
3
|
256
|
104
|
|
4
|
65536
|
1882
|
|
5
|
> 1000000000
|
94572
|
Видно, что однослойный персептрон крайне ограничен в своих возможностях
для точного представления наперед заданной логической функции.
5. Принцип WTA в модели Липмана-Хемминга
WTA - winner take all (Победитель забирает все).
Рассмотрим
задачу о принадлежности образа x некоторому классу Xk,
определяемому заданными библиотечными образами xk. Каждый из
заданных образов обучающей выборки непосредственно определяет свой собственный
класс, и таким образом, задача сводится к поиску "ближайшего" образа.
В случае двух двоичных (0-1) образов расстояние между ними может быть
определено по Хеммингу, как число несовпадающих компонент. Теперь после вычисления
всех попарных расстояний 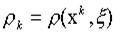 искомый класс определяется по наименьшему из них.
искомый класс определяется по наименьшему из них.
Нейросетевое
решение этой задачи может быть получено на основе архитектуры Липпмана-Хемминга
(Lippman R., 1987). Сеть имеет один слой одинаковых нейронов, число которых
равно количеству классов. Таким образом, каждый нейрон "отвечает" за
свой класс. Каждый нейрон связан с каждым из входов, число которых равно
размерности рассматриваемых библиотечных образов. Веса связей полагаются
равными нормированным библиотечным образам:

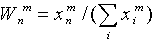
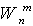 -
значение веса связи от n-го входа к m-му нейрону. Процесс поступления
информации о векторе x в нейронную сеть является безитерационным. При этом
входной вектор сначала нормируется:
-
значение веса связи от n-го входа к m-му нейрону. Процесс поступления
информации о векторе x в нейронную сеть является безитерационным. При этом
входной вектор сначала нормируется:
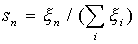 и нейроны
принимают начальные уровни активности:
и нейроны
принимают начальные уровни активности:
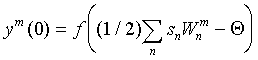
(x)
- переходная функция (функция активации) нейрона, которая выбирается равной
нулю при x<0, и f(x)=x при x>0. Пороги Q полагаются
обычно равными нулю.
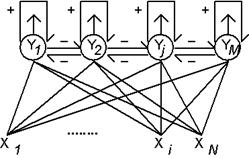
Нейронная
сеть Липпмана-Хемминга.
При поступлении входного вектора начальное возбуждение получают все
нейроны, скалярное произведение векторов памяти которых с входным вектором
превышает порог. В дальнейшем среди них предстоит выбрать один, для которого
оно максимально. Это достигается введением дополнительных обратных связей между
нейронами, устроенных по принципу "латерального торможения". Каждый
нейрон получает тормозящее (отрицательное) воздействие со стороны всех остальных
нейронов, пропорционально степени их возбуждения, и испытывает возбуждающее
(положительное) воздействие самого на себя.
Веса латеральных связей в нейронном слое нормируются таким образом, что
суммарный сигнал является возбуждающим только для нейрона с максимальной
исходной активностью. Остальные нейроны испытывают торможение:
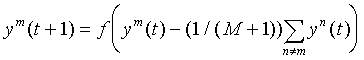
По выполнении некоторого числа итераций t для всех нейронов кроме одного
значение аргумента функции f(x) становится отрицательным, что обращает их
активность ym в нуль. Единственный, оставшийся активным, нейрон
является победителем. Он и указывает на тот класс, к которому принадлежит
введенный образ. Такой механизм получил название
"Победитель-Забирает-Все" (Winner Take All - WTA). Нейросетевая
парадигма Липпмана-Хемминга является моделью с прямой структурой памяти.
Информация, содержащаяся в библиотечных образах никак не обобщается, а
непосредственно запоминается в синаптических связях. Память здесь не является
распределенной, так как при выходе из строя одного нейрона полностью теряется
информация обо всем соответствующем ему образе памяти.
6. Карта самоорганизации Кохонена
Такие сети представляют собой соревновательную нейронную сеть с обучением
без учителя, выполняющую задачу визуализации и кластеризации. Является методом
проецирования многомерного пространства в пространство с более низкой
размерностью (чаще всего, двумерное), применяется также для решения задач
моделирования, прогнозирования и др. Является одной из версий нейронных сетей
Кохонена. Самоорганизующиеся карты Кохонена служат, в первую очередь, для
визуализации и первоначального («разведывательного») анализа данных.
Сигнал в сеть Кохонена поступает сразу на все нейроны, веса
соответствующих синапсов интерпретируются как координаты положения узла, и
выходной сигнал формируется по принципу «победитель забирает всё» - то есть
ненулевой выходной сигнал имеет нейрон, ближайший (в смысле весов синапсов) к
подаваемому на вход объекту. В процессе обучения веса синапсов настраиваются
таким образом, чтобы узлы решетки «располагались» в местах локальных сгущений
данных, то есть описывали кластерную структуру облака данных, с другой стороны,
связи между нейронами соответствуют отношениям соседства между соответствующими
кластерами в пространстве признаков.

Пример карты Кохонена. Размер каждого квадратика соответствует степени
возбуждения соответствующего нейрона.
Обучение
начинается с задания случайных значений матрице связей . В дальнейшем происходит процесс самоорганизации,
состоящий в модификации весов при предъявлении на вход векторов обучающей
выборки. Для каждого нейрона можно определить его расстояние до вектора входа:
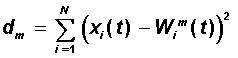
Далее выбирается нейрон m=m*, для которого это расстояние
минимально. На текущем шаге обучения t будут модифицироваться только веса
нейронов из окрестности нейрона m*:
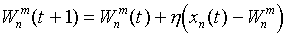
Первоначально в окрестности любого из нейронов находятся все нейроны
сети, в последствии эта окрестность сужается. В конце этапа обучения
подстраиваются только веса самого ближайшего нейрона. Нейронная сеть Кохонена
может обучаться и на искаженных версиях входных векторов, в процессе обучения
искажения, если они не носят систематический характер, сглаживаются.
Каждый нейрон несет информацию о кластере - сгустке в пространстве
входных образов, формируя для данной группы собирательный образ. Таким образом
НС Кохонена способна к обобщению.
7. Нейронная сеть встречного распространения
НС встречного распространения (ВР) обучается на выборке пар векторов
(X,Y)a задаче представления отображения X®Y. Замечательной особенностью этой
сети является способность обучению также и отображению совокупности XY в себя.
При этом, благодаря обобщению, появляется возможность восстановления пары (XY)
по одной известной компоненте (X или Y).
Сеть ВР состоит из двух слоев нейронов - слоя Кохонена и слоя Гроссберга.
В режиме функционирования (распознавания) нейроны слоя Кохонена работают по
принципу Победитель-Забирает-Все, определяя кластер, к которому принадлежит
входной образ. Затем выходная звезда слоя Гроссберга по сигналу
нейрона-победителя в слое Кохонена воспроизводит на выходах сети
соответствующий образ.
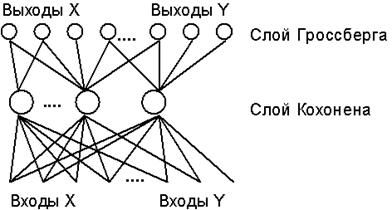
Архитектура
сети встречного распространения (для упрощения изображения показаны не все
связи).
Обучение весов слоя Кохонена выполняется без учителя на основе
самоорганизации (см. предыдущий пункт). Входной вектор (аналоговый) вначале нормируется,
сохраняя направление. После выполнения одной итерации обучения определяется
нейрон победитель, состояние его возбуждения устанавливается равным единице, и
теперь могут быть модифицированы веса соответствующей ему звезды Гроссберга.
Темпы обучения нейронов Кохонена и Гроссберга должны быть согласованы . В слое
Кохонена обучаются веса всех нейронов в окрестности победителя, которая
постепенно сужается до одного нейрона. НС производит линейную интерполяцию
между значениями выходных векторов, отвечающих нескольким кластерам.
8. Когнитрон и неокогнитрон Фукушимы
.1 Когнитрон - самоорганизующаяся многослойная нейросеть
Создание когнитрона (K.Fukushima, 1975) явилось плодом синтеза усилий
нейрофизиологов и психологов, а также специалистов в области нейрокибернетики,
совместно занятых изучением системы восприятия человека. Данная нейронная сеть
одновременно является как моделью процессов восприятия на микроуровне, так и
вычислительной системой, применяющейся для технических задач распознавания
образов.
Когнитрон состоит из иерархически связанных слоев нейронов двух типов -
тормозящих и возбуждающих. Состояние возбуждения каждого нейрона определяется
суммой его тормозящих и возбуждающих входов. Синаптические связи идут от
нейронов одного слоя (далее слоя 1) к следующему (слою 2). Относительно данной
синаптической связи соответствующий нейрон слоя 1 является пресинаптическим, а
нейрон второго слоя - постсинаптическим. Постсинаптические нейроны связаны не
со всеми нейронами 1-го слоя, а лишь с теми, которые принадлежат их локальной
области связей. Области связей близких друг к другу постсинаптических нейронов
перекрываются, поэтому активность данного пресинаптического нейрона будет
сказываться на все более расширяющейся области постсинаптических нейронов следующих
слоев иерархии.
Вход возбуждающего постсинаптического нейрона определяется отношением
суммы E его возбуждающих входов (a1, a2 и a3) к сумме I тормозящих входов (b1 и
вход от нейрона X):
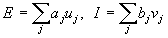
где u - возбуждающие входы с весами a, v-тормозящие входы с весами b. Все
веса имеют положительные значения. По значениям E и I вычисляется суммарное
воздействие на i-й нейрон: neti =((1+E)/(1+I))-1 . Его выходная
активность ui затем устанавливается равной neti, если neti
> 0. В противном случае выход устанавливается равным нулю.
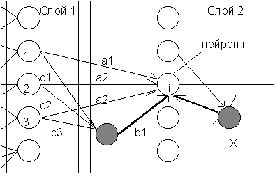
Постсинаптический
нейрон i слоя 2 связан с тремя нейронами в области связей (1,2 и 3) слоя 1 и
двумя тормозящими нейронами (показаны темным цветом). Тормозящий нейрон X
реализует латеральное торможение в области конкуренции нейрона i.В целом
КОГНИТРОН представляет собой иерархию слоев, последовательно связанных друг с
другом, как было рассмотрено выше для пары слой 1 - слой 2. При этом нейроны
слоя образуют не одномерную цепочку, а покрывают плоскость, аналогично
слоистому строению зрительной коры человека. Каждый слой реализует свой уровень
обобщения информации. Входные слои чувствительны к отдельным элементарным
структурам, например, линиям определенной ориентации или цвета. Последующие
слои реагируют уже на более сложные обобщенные образы. В самом верхнем уровне
иерархии активные нейроны определяют результат работы сети - узнавание
определенного образа. Для каждого в значительной степени нового образа картинка
активности выходного слоя будет уникальной. При этом она сохранится и при
предъявлении искаженной или зашумленной версии этого образа.
Таким
образом, обработка информации когнитроном происходит с формированием ассоциаций
и обобщений.
Автором
когнитрона - Фукушимой эта сеть применялась для оптического распознавания
символов - арабских цифр. Несмотря на успешные применения и многочисленные
достоинства, как соответствие нейроструктуры и механизмов обучения
биологическим моделям, параллельность и иерархичность обработки информации,
распределенность и ассоциативность памяти и др., КОГНИТРОН имеет и свои
недостатки. По-видимому, главным из них является неспособность этой сети
распознавать смещенные или повернутые относительно их исходного положения
образы.
8.2 Неокогнитрон
О распознавании образов независимо от их положения, ориентации, а иногда
и размера и других деформации, говорят как об инвариантном относительно
соответствующих преобразований распознавании. Дальнейшие исследования группы
под руководством К. Фукушимы привели к развитию когнитрона и разработке новой
нейросетевой парадигмы - НЕОКОГНИТРОНА, который способен к инвариантному
распознаванию.
8.3 Неокогнитрон и инвариантное распознавание образов
Неокогнитрон состоит из иерархии нейронных слоев, каждый из которых
состоит из массива плоскостей. Каждый элемент массива состоит из пары
плоскостей нейронов. Первая плоскость состоит из так называемых простых
нейроклеток, которые получают сигналы от предыдущего слоя и выделяют
определенные образы. Эти образы далее обрабатываются сложными нейронами второй
плоскости, задачей которых является сделать выделенные образы менее зависимыми
от их положения.
Нейроны каждой пары плоскостей обучаются реагировать на определенный
образ, представленный в определенной ориентации. Для другого образа или для
нового угла поворота образа требуется новая пара плоскостей. Таким образом, при
больших объемах информации, неокогнитрон представляет собой огромную структуру
с большим числом плоскостей и слоев нейронов.
Простые нейроны чувствительны к небольшой области входного образа,
называемой рецептивной областью (или что тоже самое, областью связей). Простой
нейрон приходит в возбужденное состояние, если в его рецептивной области
возникает определенный образ. Рецептивные области простых клеток перекрываются
и покрывают все изображение. Сложные нейроны получают сигналы от простых
клеток, при этом для возбуждения сложного нейрона достаточно одного сигнала от
любого простого нейрона. Тем самым, сложная клетка регистрирует определенный
образ независимо от того, какой из простых нейронов выполнил детектирование, и,
значит, независимо от его расположения.
По мере распространения информации от слоя слою картинка нейронной
активности становится все менее чувствительной к ориентации и расположению
образа, и, в определенных пределах, к его размеру. Нейроны выходного слоя
выполняют окончательное инвариантное распознавание.
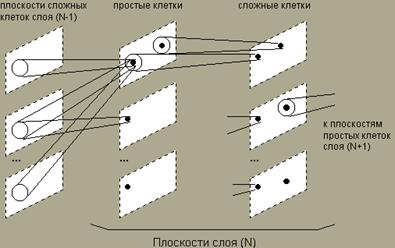
Общая
схема НЕОКОГНИТРОНА. Области связей показаны большими белыми кружками, а
области конкуренции - маленькими темными.
Неокогнитрон успешно проявил себя при распознавании символов. Нужно
отметить, что структура этой сети необычайно сложна, и объем вычислений очень
велик, поэтому компьютерные модели неокогнитрона будут слишком дорогими для
промышленных приложений.
9. Общее понятие сетей АРТ
.1 Дилемма стабильности-пластичности восприятия
Проблема стабильности-пластичности является одной из самых сложных и
трудно решаемых задач при построении искусственных систем, моделирующих
восприятие. Характер восприятия внешнего мира живыми организмами (и, прежде
всего, человеком) постоянно связан с решением дилеммы, является ли некоторый
образ "новой" информацией, и следовательно реакция на него должна
быть поисково-познавательной, с сохранением этого образа в памяти, либо этот
образ является вариантом "старой", уже знакомой картиной, и в этом
случае реакция организма должна соответствовать ранее накопленному опыту.
Специальное запоминание этого образа в последнем случае не требуется. Таким
образом, восприятие одновременно пластично, адаптированно к новой информации, и
при этом оно стабильно, то есть не разрушает память о старых образах.
9.2 Принцип адаптивного резонанса
Привлекательной особенностью нейронных сетей с адаптивным резонансом
является то, что они сохраняют пластичность при запоминании новых образов, и, в
то же время, предотвращают модификацию старой памяти. Нейросеть имеет
внутренний детектор новизны - тест на сравнение предъявленного образа с
содержимым памяти. При удачном поиске в памяти предъявленный образ
классифицируется с одновременной уточняющей модификацией синаптических весов
нейрона, выполнившего классификацию. О такой ситуации говорят, как о
возникновении адаптивного резонанса в сети в ответ на предъявление образа. Если
резонанс не возникает в пределах некоторого заданного порогового уровня, то
успешным считается тест новизны, и образ воспринимается сетью, как новый.
Модификация весов нейронов, не испытавших резонанса, при этом не производится.
Важным понятием в теории адаптивного резонанса является так называемый
шаблон критических черт (critical feature pattern) информации. Этот термин
показывает, что не все черты (детали), представленные в некотором образе,
являются существенными для системы восприятия. Результат распознавания определяется
присутствием специфичных критических особенностей в образе.
Отметим, что в общем случае одного лишь перечисления черт может оказаться
недостаточно для успешного функционирования искусственной нейронной системы,
критическими могут оказаться специфические связи между несколькими отдельными
чертами.
Вторым значительным выводом теории выступает необходимость самоадатации
алгоритма поиска образов в памяти. Нейронная сеть работает в постоянно
изменяющихся условиях, так что предопределенная схема поиска, отвечающая
некоторой структуре информации, может в дальнейшем оказаться неэффективной при
изменении этой структуры. В теории адаптивного резонанса это достигается
введением специализированной ориентирующей системы, которая самосогласованно
прекращает дальнейший поиск резонанса в памяти, и принимает решение о новизне
информации. Ориентирующая система также обучается в процессе работы.
В случае наличия резонанса теория АРТ предполагает возможность прямого
доступа к образу памяти, откликнувшемуся на резонанс. В этом случает шаблон
критических черт выступает ключом-прототипом для прямого доступа.
Обучение и функционирование сети АРТ происходит одновременно.
Нейрон-победитель определяет в пространстве входных векторов ближайший к
заданному входному образу вектор памяти, и если бы все черты исходного вектора
были критическими, это и было бы верной классификацией. Однако множество
критических черт стабилизируется лишь после относительно длительного обучения.
На данной фазе обучения лишь некоторые компоненты входного вектора принадлежат
актуальному множеству критических черт, поэтому может найтись другой
нейрон-классификатор, который на множестве критических черт окажется ближе к
исходному образу. Он и определяется в результате поиска.
9.3 Обучение сети АРТ
В начале функционирования все веса B и T нейронов, а также параметр
сходства получают начальные значения. Согласно теории АРТ, эти значения должны
удовлетворять условию
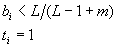
где
m - число компонент входного вектора X, значение L>1. Процесс обучения
происходит без учителя, на основе самоорганизации. Обучение производится для
весов нейрона-победителя в случае как успешной, так и неуспеншной
классификации. При этом веса вектора B стремятся к нормализованной величине
компонент вектора C:
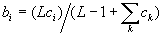
При
этом роль нормализации компонент крайне важна. Вектора с большим число единиц
приводят к небольшим значениям весов b, и наоборот. Таким образом, произведение
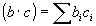
оказывается масштабированным. Масштабирование приводит к тому, что
возможно правильное различение векторов, даже если один является подмножеством
другого. Пусть нейрон X1 соответствует образу (100000), а нейрон X2 - образу
(111100). Эти образы являются, очевидно, различными. При обучении без
нормализации (т.е. bi ® ci) при поступлении в сеть первого образа, он
даст одинаковые скалярные произведения, равные 1, как с весами нейрона X1, так
и X2. Нейрон X2, в присутствии небольших шумовых отклонений в значениях весов,
может выиграть конкуренцию. При этом веса его вектора T установятся равными
(100000), и образ (111100) будет безвозвратно "забыт" сетью.
При применении нормализации исходные скалярные произведения будут равны
единице для нейрона X1, и значению 2/5 для нейрона X2 (при L=2). Тем самым,
нейрон X1 заслуженно и легко выиграет конкурентное соревнование.
Компоненты вектора T, как уже говорилось, при обучении устанавливаются
равными соответствующим значениям вектора C. Следует подчеркнуть, что это
процесс необратим. Если какая-то из компонент tj оказалась равной
нулю, то при дальнейшем обучении на фазах сравнения соответствующая компонента
cj никогда не получит подкрепления от tj=0 по правилу
2/3, и, следовательно, единичное значение tj не может быть
восстановлено. Обучение, таким образом, сопровождается обнулением все большего
числа компонент вектора T, оставшиеся ненулевыми компоненты определяют
множество критических черт данной категории.
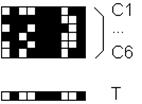
Обучающие
образы C и сформированный вектор критических черт T - минимальный набор общих
элементов категории.
9.4 Теоремы АРТ
1. По достижении стабильного состояния обучения предъявление одного из
обучающих векторов будет сразу приводить к правильной классификации без фазы
поиска, на основе прямого доступа. 2. Процесс поиска устойчив.3. Процесс
обучения устойчив. Обучение весов нейрона-победителя не приведет в дальнейшем к
переключению на другой нейрон.4. Процесс обучения конечен. Обученное состояние
для заданного набора образов будет достигнуто за конечное число итерации, при
этом дальнейшее предъявление этих образов не вызовет циклических изменений
значений весов.
Развитие теории АРТ продолжается. По высказыванию авторов теории, АРТ
представляет собой нечто существенно более конкретное, чем философское
построение, но намного менее конкретное, чем законченная программа для
компьютера. Однако уже в современном виде, опираясь на свою более чем 20-летнюю
историю, сети АРТ демонстрируют свои успешные применения в различных областях.
АРТ сделала также важный шаг в общей проблеме моделирования
пластично-стабильного восприятия.
10. Сжатие данных и ассоциативная память
Способность нейросетей к выявлению взаимосвязей между различными
параметрами дает возможность выразить данные большой размерности более компактно,
если данные тесно взаимосвязаны друг с другом. Обратный процесс -
восстановление исходного набора данных из части информации - называется
(авто)ассоциативной памятью. Ассоциативная память позволяет также
восстанавливать исходный сигнал (образ) из зашумленных (поврежденных) входных
данных. Решение задачи гетероассоциативной памяти позволяет реализовать память,
адресуемую по содержимому.
Этапы решения задач:
1) Сбор данных для обучения.
Выбор данных для обучения сети и их обработка является самым сложным
этапом решения задачи. Набор данных для обучения должен удовлетворять
нескольким критериям:
Репрезентативность - данные должны иллюстрировать истинное положение
вещей в предметной области;
Непротиворечивость - противоречивые данные в обучающей выборке приведут к
плохому качеству обучения сети;
Исходные данные преобразуются к виду, в котором их можно подать на входы
сети. Каждая запись в файле данных называется обучающей парой или обучающим
вектором. Обучающий вектор содержит по одному значению на каждый вход сети и, в
зависимости от типа обучения (с учителем или без), по одному значению для
каждого выхода сети. Обучение сети на «сыром» наборе, как правило, не даёт
качественных результатов. Существует ряд способов улучшить «восприятие» сети.
Нормировка выполняется, когда на различные входы подаются данные разной
размерности. Например, на первый вход сети подается величины со значениями от
нуля до единицы, а на второй - от ста до тысячи. При отсутствии нормировки
значения на втором входе будут всегда оказывать существенно большее влияние на
выход сети, чем значения на первом входе. При нормировке размерности всех
входных и выходных данных сводятся воедино;
Квантование выполняется над непрерывными величинами, для которых
выделяется конечный набор дискретных значений. Например, квантование используют
для задания частот звуковых сигналов при распознавании речи; фильтрация
выполняется для «зашумленных» данных.
Кроме того, большую роль играет само представление как входных, так и
выходных данных. Предположим, сеть обучается распознаванию букв на изображениях
и имеет один числовой выход - номер буквы в алфавите. В этом случае сеть
получит ложное представление о том, что буквы с номерами 1 и 2 более похожи,
чем буквы с номерами 1 и 3, что, в общем, неверно. Для того, чтобы избежать
такой ситуации, используют топологию сети с большим числом выходов, когда
каждый выход имеет свой смысл. Чем больше выходов в сети, тем большее
расстояние между классами и тем сложнее их спутать.
2) Подготовка и нормализация данных.
) Выбор топологии сети.
Выбирать тип сети следует исходя из постановки задачи и имеющихся данных
для обучения. Для обучения с учителем требуется наличие для каждого элемента
выборки «экспертной» оценки. Иногда получение такой оценки для большого массива
данных просто невозможно. В этих случаях естественным выбором является сеть,
обучающаяся без учителя, например, самоорганизующаяся карта Кохонена или
нейронная сеть Хопфилда. При решении других задач, таких как прогнозирование
временных рядов, экспертная оценка уже содержится в исходных данных и может
быть выделена при их обработке. В этом случае можно использовать многослойный
перцептрон или сеть Ворда.
4) Экспериментальный подбор характеристик сети.
После выбора общей структуры нужно экспериментально подобрать параметры
сети. Для сетей, подобных перцептрону, это будет число слоев, число блоков в
скрытых слоях (для сетей Ворда), наличие или отсутствие обходных соединений,
передаточные функции нейронов. При выборе количества слоев и нейронов в них
следует исходить из того, что способности сети к обобщению тем выше, чем больше
суммарное число связей между нейронами. С другой стороны, число связей
ограничено сверху количеством записей в обучающих данных.
5) Экспериментальный подбор параметров обучения.
После выбора конкретной топологии, необходимо выбрать параметры обучения
нейронной сети. Этот этап особенно важен для сетей, обучающихся с учителем. От
правильного выбора параметров зависит не только то, насколько быстро ответы
сети будут сходиться к правильным ответам. Например, выбор низкой скорости
обучения увеличит время схождения, однако иногда позволяет избежать паралича
сети. Увеличение момента обучения может привести как к увеличению, так и к
уменьшению времени сходимости, в зависимости от формы поверхности ошибки. Исходя
из такого противоречивого влияния параметров, можно сделать вывод, что их
значения нужно выбирать экспериментально, руководствуясь при этом критерием
завершения обучения (например, минимизация ошибки или ограничение по времени
обучения).
6) Собственно обучение.
В процессе обучения сеть в определенном порядке просматривает обучающую
выборку. Порядок просмотра может быть последовательным, случайным и т. д.
Некоторые сети, обучающиеся без учителя, например, сети Хопфилда просматривают
выборку только один раз. Другие, например, сети Кохонена, а также сети,
обучающиеся с учителем, просматривают выборку множество раз, при этом один
полный проход по выборке называется эпохой обучения. При обучении с учителем
набор исходных данных делят на две части - собственно обучающую выборку и
тестовые данные; принцип разделения может быть произвольным. Обучающие данные
подаются сети для обучения, а проверочные используются для расчета ошибки сети
(проверочные данные никогда для обучения сети не применяются). Таким образом, если
на проверочных данных ошибка уменьшается, то сеть действительно выполняет
обобщение. Если ошибка на обучающих данных продолжает уменьшаться, а ошибка на
тестовых данных увеличивается, значит, сеть перестала выполнять обобщение и
просто «запоминает» обучающие данные. Это явление называется переобучением сети
или оверфиттингом. В таких случаях обучение обычно прекращают. В процессе
обучения могут проявиться другие проблемы, такие как паралич или попадание сети
в локальный минимум поверхности ошибок. Невозможно заранее предсказать
проявление той или иной проблемы, равно как и дать однозначные рекомендации к
их разрешению.
7) Проверка адекватности обучения.
Даже в случае успешного, на первый взгляд, обучения сеть не всегда
обучается именно тому, чего от неё хотел создатель. Известен случай, когда сеть
обучалась распознаванию изображений танков по фотографиям, однако позднее
выяснилось, что все танки были сфотографированы на одном и том же фоне. В
результате сеть «научилась» распознавать этот тип ландшафта, вместо того, чтобы
«научиться» распознавать танки. Таким образом, сеть «понимает» не то, что от
неё требовалось, а то, что проще всего обобщить.
8) Корректировка параметров, окончательное обучение.
) Вербализация сети с целью дальнейшего использования.
11. Распознавание образов, классификация, категоризация
В качестве образов могут выступать различные по своей природе объекты:
символы текста, изображения, образцы звуков и т. д. При обучении сети
предлагаются различные образцы образов с указанием того, к какому классу они
относятся. Образец, как правило, представляется как вектор значений признаков.
При этом совокупность всех признаков должна однозначно определять класс, к
которому относится образец. В случае, если признаков недостаточно, сеть может
соотнести один и тот же образец с несколькими классами, что неверно. По
окончании обучения сети ей можно предъявлять неизвестные ранее образы и
получать ответ о принадлежности к определённому классу.
Топология такой сети характеризуется тем, что количество нейронов в
выходном слое, как правило, равно количеству определяемых классов. Когда сети
предъявляется некий образ, на одном из её выходов должен появиться признак
того, что образ принадлежит этому классу. В то же время на других выходах
должен быть признак того, что образ данному классу не принадлежит. Если на двух
или более выходах есть признак принадлежности к классу, считается что сеть «не
уверена» в своём ответе.
Итак, задачей системы-классификатора является установление принадлежности
образа к одному из формально определенных классов. Примерами такой задачи
является задача классификации растений в ботанике, классификация химических
веществ по их свойствам и типам возможных реакций, в которые они вступают, и
другие. Формальные признаки могут быть определены посредством правил типа
“если..-то..”, а системы, оперирующие с такими правилами, получили название
экспертных систем.
Проблема категоризации находится на ступеньку выше по сложности в
сравнении с классификацией. Особенность ее заключается в том, что помимо
отнесения образа к какой-либо группе, требуется определить сами эти группы,
т.е. сформировать категории. В случае обучения с учителем формирование
категорий происходит методом проб и ошибок на основе примеров с известными
ответами, предоставляемыми экспертом. Учитель управляет обучением при помощи
изменения параметров связей и, реже, самой топологии сети.
Задачей системы-категоризатора является формирование обобщающих признаков
в совокупности примеров. При увеличении числа примеров несущественные, случайные
признаки сглаживаются, а часто встречающиеся - усиливаются, при этом происходит
постепенное уточнение границ категорий. Важно отметить различие в характере
неявных “знаний”, запомненных искусственной нейронной сетью, и явных,
формальных “знаний”, заложенных в экспертных системах.
Некоторые сходства и различия представлены в следующей таблице:
|
Экспертные системы (ЭС)
|
Нейросетевые системы (НС)
|
|
Источник знаний
|
Формализованный опыт
эксперта, выраженный в виде логических утверждений - правил и фактов, безусловно
принимаемых системой
|
Совокупный опыт
эксперта-учителя, отбирающего примеры для обучения + индивидуальный опыт
обучающейся на этих примерах нейронной сети
|
|
Характер знаний
|
Формально-логическое
“левополушарное” знание в виде правил
|
Ассоциативное “правополушарное”
знание в виде связей между нейронами сети
|
|
Развитие знаний
|
В форме расширения
совокупности правил и фактов (базы знаний)
|
В форме дообучения на
дополнительной последовательности примеров, с уточнением границ категорий и
формированием новых категорий
|
|
Роль эксперта
|
Задает на основе правил
полный объем знаний экспертной системы
|
Отбирает характерные
примеры, не формулируя специально обоснование своего выбора
|
|
Роль искусственной системы
|
Поиск цепочки фактов и
правил для доказательства суждения
|
Формирование
индивидуального опыта в форме категорий, получаемых на основе примеров и
категоризация образов
|
12. Современность нейросетевых технологий
.1 Черты современных архитектур
Классические исследования, выполненные в послевоенные годы и дальнейших
бурный прогресс в нейроинформатике в 80-е годы определили некоторые общие черты
перспективных архитектур и направления исследований.
. Плотное сопряжение теоретических исследований с поиском новых
физических принципов и физических сред для аппаратной реализации нейронных
сетей. Здесь прежде всего следует отметить оптические системы, как линейные,
так и нелинейные: фурье-оптика, голограммы, нелинейные фоторефрактивные
кристаллы, оптические волноводные волокна, электронно-оптические умножители и
другие. Перспективными также являются среды с естественными автоволновыми
свойствами (химические и биологические). Все эти среды реализуют важное
свойство массивной параллельности при обработке информации. Кроме того, они,
как правило, содержат механизмы "саморегулирования", позволяющие
организовывать обучение без учителя.
. Иерархичность архитектур и разделение функций нейронов. В
современных архитектурах используются слои или отдельные нейроны нескольких
различных типов: командные нейроны-переключатели, пороговые нейроны, нейронные
слои с латеральным торможением, работающие по принципу "победитель
забирает все". Априорное разделение функций нейронов значительно упрощает
обучение, так как сеть изначально структурно соответствует задаче.
. Преимущественное использование методов обучения без учителя, за
счет самоорганизации. Эти методы имеют глубокие биологические основания, они
обеспечивают локальный характер обучения. Это позволяет не применять глобальную
связность сети. С учителем обучаются только внешние, выходные слои нейронов,
причем роль учителя часто сводится только к общей экспертной оценке качества
работы сети.
. Ориентация исследований и архитектур непосредственно на
приложения. Модели общего характера, такие как сеть Хопфилда или многослойный
персептрон, в основном представляют научный интерес, так как допускают
относительно полное теоретическое исследование.
Этот список является далеко не полным.
12.2 Программное обеспечение
К настоящему времени сформировался обширный рынок нейросетевых продуктов.
Подавляющее большинство продуктов представлено в виде моделирующего
программного обеспечения. Ведущие фирмы разрабатывают также и
специализированные нейрочипы или нейроплаты в виде приставок к обычным ЭВМ (как
правило, персональным ЭВМ линии IBM PC AT). При этом программы могут работать
как без нейро-приставок, так и с ними. В последнем случае быстродействие
гибридной ЭВМ возрастает в сотни и тысячи раз. Некоторые наиболее извесные и
популярные нейросистемы: NeuralWorks Professional II Plus, ExploreNet 3000,
NeuroShell 2.0
12.3 Многообразие применения
Нейронные сети - универсальные аппроксимирующие устройства и могут с
любой точностью имитировать любой непрерывный автомат. Результаты работ М.
Доррера и др. дают подход к раскрытию механизма интуиции нейронных сетей,
проявляющейся при решении ими психодиагностических задач. Нейронные сети широко
используются в химических и биохимических исследованиях. Так же важна их роль
при прогнозировании динамики фондовых рынков и других экономических задач.
Возможно применение нейросетевых моделей в составе геоинформационных систем. И,
конечно, в решении различных математических и физических задач и т.д.
Вывод
С точки зрения машинного обучения, нейронная сеть представляет собой
частный случай методов распознавания образов, дискриминантного анализа, методов
кластеризации и т. п. С математической точки зрения, обучение нейронных сетей -
это многопараметрическая задача нелинейной оптимизации. С точки зрения
кибернетики, нейронная сеть используется в задачах адаптивного управления и как
алгоритмы для робототехники. С точки зрения развития вычислительной техники и
программирования, нейронная сеть - способ решения проблемы эффективного
параллелизма. А с точки зрения искусственного интеллекта, ИНС является основой
философского течения коннективизма и основным направлением в структурном
подходе по изучению возможности построения (моделирования) естественного
интеллекта с помощью компьютерных алгоритмов.
Нейронные сети не программируются в привычном смысле этого слова, они
обучаются. Возможность обучения - одно из главных преимуществ нейронных сетей
перед традиционными алгоритмами. Технически обучение заключается в нахождении
коэффициентов связей между нейронами. В процессе обучения нейронная сеть
способна выявлять сложные зависимости между входными данными и выходными, а
также выполнять обобщение. Это значит, что, в случае успешного обучения, сеть
сможет вернуть верный результат на основании данных, которые отсутствовали в
обучающей выборке, а также неполных и/или «зашумленных», частично искаженных
данных.
Следует отметить, что вычислительные системы, основанные на искусственных
нейронных сетях, обладают рядом качеств, которые присущи мозгу человека:
массовый параллелизм; распределённое представление информации и вычисления;
способность к обучению и обобщению; адаптивность; свойство контекстуальной
обработки информации; толерантность к ошибкам; низкое энергопотребление.
В заключение можно сказать, что в данной работе были рассмотрены
историческое формирование и развитие нейронауки, общие основы и введения в
область искусственных нейронных систем и нейросетевого моделирования, выделены
виды их реализации и самого процесса аппаратного «восприятия», а так же описаны
различные виды нейросетей и их особенности. Подчеркивается важность
нейросетевых технологий в современной науке и жизни, которая объясняется
многообразием их применения; уделяется внимание продолжающемуся развитию
искусственной нейроиндустрии.
Практическая часть
Лабораторная работа № 1
Искусственные нейронные сети
Цель работы: изучение архитектуры искусственных нейронных сетей,
способов их графического изображения в виде функциональных и структурных схем и
программного представления в виде объектов специального класса network,
включающих массив структур с атрибутами сети и набор необходимых методов для
создания, инициализации, обучения, моделирования и визуализации сети, а также
приобретение навыков построения сетей различной архитектуры с помощью
инструментального программного пакета Neural Network Toolbox системы MATLAB.
Теоретические сведения.
Отдельные нейроны способны после некоторой процедуры обучения решать ряд
задач искусственного интеллекта, все же эффективного решения сложных задач по
распознаванию образов, идентификации и классификации объектов, распознаванию и
синтезу речи, оптимальному управлению применяют достаточно большие группы
нейронов, образуя из них искусственные нейронные сети в виде связанных между
собой слоёв, напоминающие биологические нейронные (нервные) сети человека и
животных. Существует множество способов организации искусственных нейронных
сетей, которые могут содержать различное число слоёв нейронов. Нейроны могут
быть связаны между собой как внутри отдельных слоёв, так и между слоями. В
зависимости от направления передачи сигнала эти связи могут быть прямыми или
обратными. Слой нейронов, непосредственно принимающий информацию из внешней
среды, называется входным слоем, а слой, передающий ин- формацию во внешнею
среду, - выходным слоем. Остальные слои, если они имеются в сети, называются
промежуточными, или скрытыми. В ряде случаев такого функционального
распределения слоёв сети не производится, так что входы и выходы могут
присоединяться к любым слоям и иметь произвольное число компонент.
Структура, или архитектура сети искусственных нейронов зависит от той
конкретной задачи, которую должна решать сеть. Она может быть однослойной без
обратных связей или с обратными связями, двухслойной с прямыми связями,
трехслойной с обратными связями и т. д. Сети с обратными связями называют часто
рекуррентными. Описание архитектуры искусственной нейронной сети помимо
указания числа слоёв и связей между ними должно включать сведения о количестве
нейронов в каждом слое, виде функций активации в каждом слое, наличии смещений
для каждого слоя, наличии компонент входных, выходных и целевых векторов, а в
ряде случаев и характеристики топологии слоёв. Например, для аппроксимации
любой функции с конечным числом точек разрыва широко используется сеть с прямой
передачей сигналов. В этой сети имеется несколько слоёв с сигмоидальными
функциями активации. Выходной слой содержит нейроны с линейными функциями
активации. Данная сеть не имеет обратных связей, поэтому её называют сетью с
прямой передачей сигналов (FF-net).
Графически искусственная нейронная сеть изображается в виде
функциональной или структурой схемы. На функциональной схеме сети с помощью
геометрических фигур изображаются её функциональные блоки, а стрелками
показываются входы, выходы и связи. В блоках и на стрелках указываются
необходимые обозначения и параметры.
Структурная схема сети изображается с помощью типового набора блоков,
соединительных элементов и обозначений, принятых в инструментальном программном
пакете Neural Network Toolbox системы MATLAB и пакете имитационного
моделирования Simulink той же системы. Структурная схема сети может быть
укрупнённой или детальной, причём степень детализации определяется
пользователем.
Системы обозначений блоков, элементов и параметров сети является
векторно-матричной, принятой в системе MATLAB. Если в обозначении используется
два индекса, то, как правило, первый индекс (индекс строки) указывает адресата,
или пункт назначения, а второй индекс (индекс столбца) - источник структурной
схемы сети. Структурные схемы создаются системой автоматически с помощью
команды gensim. Если элементом вектора или матрицы на структурной схеме
является сложный объект, то используются соответственно ячейка и массив ячеек.
Программным представлением, или вычислительной моделью искусственной нейронный
сети, является объект специального класса network, который включает массив
структур с атрибутами сети и на- бор методов, необходимых для создания сети, а
также для её инициализации, обучения, моделирования и визуализации. Класс
Network имеет два общих конструктора, один из которых не имеет параметров и
обеспечивает создание массива структур с нулевыми значениями полей, а второй -
имеет минимальный набор параметров для создания модели нейронной сети,
достраиваемой затем до нужной конфигурации с помощью операторов присваивания.
Для создания нейронных сетей определённого вида используются специальные
конструкторы.
Практические задания.
Задание 1. Создать вычислительную модель нейронной сети с двумя
выходами, тремя слоями и одним целевым входом, используя общий конструктор сети
с параметрами
Net = network (numInputs, numLayers, biasConnect,
imputConnect,
layerConnect, outputConnect, tartegtConnect).
Связи между слоями должны быть только прямыми, входы необходимо соединить
с первым слоем, а выход - с последним. Выход должен быть целевым, первый слой
должен иметь смещения.
Смысл и значения параметров конструктора для создания модели сети
заданной архитектуры таковы:
numImputs=2 - количество входов сети;=3 - количество слоёв в
сети;=[1; 0; 0] - матрица связности для смещений размера numLayers * 1;=[1 1; 0
0; 0 0] - матрица связности для входов
размера numLayers * numImputs;=[0 0 0;1 0 0 0 ; 0 1 0] -
матрица связности для сло-
ёв размера numLayers * numLayers;=[0 0 1] - матрица связности
для выходов разме-
ра 1* numLayers;=[0 0 1] - матрица связности для целей
размера 1 *.
Порядок выполнения заданий следующий:
. Создать шаблон сети, выполнив команду
net = network (2, 3, [1; 0; 0], [1 1; 0 0 ; 0 0], …. ,
[0 0 0 ; 1 0 0 ; 0 1 0], [0 0 1])
2. Проверить значения полей вычислительной модели нейронной сети net и их
соответствие заданным значениям в списке параметров.
. Проверить значения вычисляемых полей модели, которые дополняют описание
архитектуры сети
numOutputs = 1 - количество выходов сети;= 1 - количество
целей сети;= 0 - максимальное значение задержки для
входов сети.= 0 - максимальное значение задержки для
слоёв сети.
Заметим, что каждый выход и каждая цель присоединяются к одному или
нескольким слоям при этом количество компонент выхода или цели равно количеству
нейронов в соответствующем слое. Для увеличения возможности модели в сеть
включают линии задержки либо на её входах, либо между слоями. Каждая линия
задерживает сигнал на один такт. Параметры numInputDelays и NumLayerDelays
определяют максимальное число линий для какого-либо входа или слоя
соответственно.
. Проанализировать структурную схему построенной сети, выполнив команду gensim(net)
и детализируя блоки с помощью двойного щелчка левой клавиши мыши по
рассматриваемому блоку. На структурных схемах искусственных нейронных сетей в
пакете NNT используются следующие обозначения:
а) Neural Network - искусственная нейронная сеть с обозначениями
входов p{1}, p{2}, … и выхода y{1};
б) входы Input1 , или p{1} и Input2 , или p{2};
в) дисплей y{1};
г) Layer 1, Layer 2, Layer 3, … слои нейронов с обозначениями
входов p{1}, p{2], a{1}, a{2}, … и выходов a{1}, a{2}, a{3}, … ,
y{1};
д) TDL - линии задержки (Time Delay) с именами Delays1,
Delays2, ..., которые обеспечивают задержку входных сигналов или сигналов
между слоями нейронов на 1, 2, 3, … такта;
е) Weights - весовая матрица для входных сигналов или сигналов
между слоями нейронов; размер матрицы весов для каждого вектора входа S×R, где S - число нейронов входного слоя, а R -
число компонент вектора входа, умноженное на число задержек; размер матрицы для
сигнлов от слоя j к слою i равен S×R, где S - число нейронов в слое i, а R -
число нейронов в слое j, умноженное на число задержек;
ж) dotprod - блок взвешивания входных сигналов и сигналов между
слоями, на выходе которого получается сумма взвешенных, т. е. умноженных на
соответствующие веса компонент сигнала;
з) mux - концентратор входных сигналов и сигналов между слоями,
преобразует набор скалярных сигналов в вектор, а набор векторов в один вектор
суммарной длины;
и) netsum - блок суммирования компонент для каждого нейрона слоя:
компонент от нескольких векторов входа с учётом задержек, смещения и т. п.;
к) hardlim, purelin и т. д. - блоки функций активации;
л) pd{1, 1}, pd{1, 2}, ad{2, 1}, ... - сигналы после линий
задержки (d - delay);
м) iz{1, 1}, iz{1, 2}, lz{2, 1}, lz{3, 2} - вектор-сигналы с
выхода концентратора;
н) bias - блок весов смещений для слоя нейронов;
о) IW - массив ячеек с матрицами весов входов: IW{i, j} -
матрицы для слоя i от входного вектора j;
п) LW - массив ячеек с матрицами весов для слоёв: LW{i, j} -
матрицы для слоя i от слоя j.
. Проанализировать все параметры каждого блока структурной схемы
рассматриваемой нейронной сети и в случае необходимости обратиться к справочной
системе пакета NNT.
. Задать нулевые последовательности сигналов для входов
P = [0 0 ; 0 0]
и произвести моделирование сети
A = sim(net, P).
7. Задать диапазоны входных сигналов и весовые матрицы с помощью
следующих присваиваний:
net.inputs{1}.range = [0 1];.inputs{2}.range = [0 1];
net.b{1} = - ¼;
net.IW{1, 1} = [0.5];.IW{1, 2} = [0.5];.LW{2, 1} =
[0.5];.LW{3, 2} = [0.5].
Исполнить команду gensim(net) и проверить параметры блока.
. Вывести на экран поля вычислительной модели и их содержимое, используя
функцию celldisp. Убедиться в правильности значений полей модели.
. Промоделировать созданную статическую сеть, т. е. сеть без линий
задержки, используя групповое и последовательное представление входных сигналов
PG = [0.5 1 ; 1 0.5];= {[0.5 1] [1 0.5]};= sim(net, PG);=
sim(net, PS).
Убедиться, что для статической сети групповое и последовательное
представления входных сигналов дают один и тот же результат.
. Дополнить архитектуру созданной нейронной сети линиями задержки для
входных сигналов и для сигналов между 2-м и 3-м слоями, превратив таким образом
статическую сеть в динамическую:
net.inputWeights{1, 1}.delays = [0 1];.inputWeights{1,
2}.delays = [0 1];.layerWeights{3, 2}.delays = [0 1 2].
Построить структурную схему динамической сети и выяснить смысл
используемых операторов присваивания.
. Скорректировать весовые матрицы:
net.IW{1, 1} = [0.5 0.5];.IW{1, 2} = [0.5 0.25];.LW{3, 2} =
[0.5 0.25 1].
12. Промоделировать динамическую сеть, используя групповое и
последовательное представление входных сигналов:
AG = sim(net, PG);= sim(net, PS).
Убедиться, что групповое представление входных сигналов иска- жает
результат, так как в этом случае работа одной сети заменяется параллельной
работой двух (по числу последовательностей) одинаковых сетей с нулевыми
начальными значениями сигналов на выходах линий задержки.
. Вывести на печать поля вычислительной модели и их содержимое, используя
функцию celldisp.
. Сохранить содержимое командного окна в М-файле для последующего
использования.
Задание 2. Создать точно такую же динамическую сеть asgnet,
используя конструктор класса network без параметров и задавая значения
соответствующих полей вычислительной модели с помощью операторов присваивания.
Убедиться в идентичности сетей net и asgnet.
Сравнить результаты работы полученных сетей.
Задание 3. Используя блоки имитационного моделирования инструментального
пакета Simulink системы MATLAB, построить модель динамической сети asgnet,
провести исследование модели, проверить адекватность её поведения поведению
модели net и оформить электронный отчёт с помощью генератора Report
Generator.
Задание 4. Используя конструктор класса network с параметрами и
операторы присваивания для полей и ячеек объектов этого класса, построить,
выдать на экран и промоделировать искусственные нейронные сети следующей
архитектуры:
а) однослойная сеть с тремя нейронами, тремя двухкомпонентными входами и
одним целевым выходом;
б) трёхслойная сеть с прямой передачей сигналов и с тремя нейронами в
каждом слое; количество входов - три с двумя, пятью и тремя
компонентами; для всех слоёв имеется смещение; выход -один;
в) трёхслойная сеть, в которой каждый слой соединён со всеми остальными;
вход - один и состоит из двух компонентов; количество нейронов в каждом
слое - три; слои имеют смещения;
г) трёхслойная динамическая сеть с тремя нейронами в каждом слое; число
входов - три, из них каждый состоит из трёх компонентов; имеются
смещения на всех слоях; линии задержки задерживают сигналы на один и два такта
и включены между всеми слоями, а также на входе;
д) квадратная сеть с десятью слоями и десятью нейронами в каждом слое;
десять векторов подключаются по одному к каждому слою; имеется десять выходов
от всех слоёв сети; смещения подключены к каждому слою.
Лабораторная работа № 2
Методы и алгоритмы обучения искусственных нейронных сетей
Цель работы: изучение и приобретение навыков практического применения
методов и алгоритмов инициализации и обучения искусственных нейронных сетей, а
также овладение способами их разработки.
Теоретические сведения.
После того как сформирована архитектура нейронной сети, должны быть
заданы начальные значения весов и смещений, или иными словами, сеть должна быть
инициализирована. Такая процедура выполняется с помощью метода init для
объектов класса network. Оператор вызова этого метода имеет вид:
net = init (net).
Перед вызовом этого метода в вычислительной модели сети необходимо задать
следующие свойства:
net.initFcn - для определения функций, которые будут использоваться для
задания начальных матриц весов и весов слоёв, а также начальных векторов смещений;
net.layers {i}. initFcn - для задания функции инициализации i-го слоя;
net.biases{i}.initFcn - для задания начального вектора смещения i-го слоя;
net.inputWeights{i,j}.initFcn - для задания функции вычисления
матрицы весов к слою i от входа j;
net.layerWeight{i,j}.initFcn - для задания функции вычисления
матрицы весов к слою i от входа j;
net.initParam - для задания параметров функций инициализации.
Способ инициализации сети определяется заданием свойств и net.initFcn
net.layers{i}.initFcn.
Для сетей с прямой передачей сигналов по умолчанию используется net.initFcn
= ‘initlay’, что разрешает для каждого слоя использовать собственные
функции инициализации, задаваемые свойством net.layers{i}.initFcn с
двумя возможными значениями: ‘initwb’ и ’initnw’.
Функция initwb позволяет использовать собственные функции
инициализации для каждой матрицы весов и для каждого вектора смещений, при этом
возможными значениями для свойств net.inputWeights{i,j}.initFcn и net.layerWeight{i,j}.initFcn
являются:
‘initzero’, ‘midpoint’, ’randnc’, ’rands’, а для свойства net.biases{i}.initFcn
- значения ‘initcon’, ‘initzero и ‘rands’.
Для сетей без обратных связей с линейными функциями активации веса обычно
инициализируются случайными значениями из интервала [-1 1].
Функция initnw реализуют алгоритм Nguyen-Widrow и
применяется для слоёв, использующих сигмоидальные функции активации.
Эта функция генерирует начальные веса и смещения для слоя так, чтобы
активные области нейронов были распределены равномерно относительно области
входов, что обеспечивает минимизацию числа нейронов сети и время обучения.
Другими возможными значениями свойства net.initFcn являются: ‘initcon’,
‘initnw’, ‘initwb’ и ‘initzero’.
Помимо функции initnw следующие функции производят
непосредственную инициализацию весов и смещений:
initzero присваивает матрицам весов и векторам смещений нулевые значения;
rands присваивает матрицам весов и векторам смещений случайные значения из
диапазона [-1 1];
randnr присваивает матрице весов случайные нормированные строки из диапазона [-1
1];
randnc присваивает матрице весов случайные нормированные столбцы из диапазона
[-1 1];
midpoint присваивает элементам вектора смещения начальные равные смещения,
зависящие от числа нейронов в слое, и используется вместе с функцией настройки learncon.
Таким образом, задание функций инициализации для вычисли тельной модели
нейронной сети является многоступенчатым и выполняется по следующему алгоритму:
. Выбрать для свойства net.initFcn одно из возможных значений: ‘initzero’,
‘initcon’, ‘initnw’, ‘initwb’ или ‘initlay’.
. Если выбраны значения ‘initzero’, ‘initcon’ или ‘initnw’,
то задание функций инициализации сети завершено.
. Если выбрано значение ‘initwb’, то переход к шагу 6.
. Если выбрано значение ‘initlay’, то переходим к слоям и для каждого
слоя i свойству net.layers{i}.initFcn необходимо задать одно из
возможных значений: ‘initnw’ или ‘initwb’.
. Если для i-го слоя выбрано значение ‘initnw’, то для этого слоя
задание функций инициализации завершено.
. Если для всех слоев сети или для какого-то слоя установлено свойство ‘initwb’,
то для этих слоёв необходимо задать свойства net.biases{i}.initFcn,
выбрав его из набора: ‘initzero’, ‘rands’ или ‘initcon’, а также
свойства net.layerWeights{i,j}.initFcn, используя следующие значения: ‘initzero’,
‘midpoint’, ‘randnc’, ‘randnr’ или ‘rands’.
Заметим, что с помощью оператора revert(net) можно возвратить
значения весов и смещений к ранее установленным значениям. После инициализации
нейронной сети её необходимо обучить решению конкретной прикладной задачи. Для
этих целей нужно собрать обучающий набор данных, содержащий интересующие
признаки изучаемого объекта, используя имеющийся опыт. Сначала следует включить
все признаки, которые, по мнению аналитиков и экспертов, являются
существенными; на последующих этапах это множество, вероятно, будет сокращено.
Обычно для этих целей используются эвристические правила, которые устанавливают
связь между количеством необходимых наблюдений и размером сети. Обычно
количество наблюдений на порядок больше числа связей в сети и возрастает по
нелинейному закону, так что уже при довольно небольшом числе признаков,
например 50, может потребоваться огромное число наблюдений.
Эта проблема носит название "проклятие размерности". Для
большинства реальных задач бывает достаточно нескольких сотен или тысяч
наблюдений.
После того как собран обучающий набор данных для проектируемой сети,
производится автоматическая настройка весов и смещений с помощью процедур
обучения, которые минимизируют разность между желаемым сигналом и полученным на
выходе в результате моделирования сети. Эта разность носит название
"ошибки обучения". Используя ошибки обучения для всех имеющихся
наблюдений, можно сформировать функцию ошибок или критерий качества обучения.
Чаще всего в качестве такого критерия используется сумма квадратов ошибок. Для
линейных сетей при этом удаётся найти абсолютный минимум критерия качества, для
других сетей достижение такого минимума не гарантируется. Это объясняется тем,
что для линейной сети критерий качества, как функция весов и смещения, является
параболоидом, а для других сетей - очень сложной поверхностью в N+1-мерном
пространстве, где N - число весовых коэффициентов и смещений.
С учётом специфики нейронных сетей для них разработаны специальные
алгоритмы обучения. Алгоритмы действуют итеративно, по шагам. Величина шага
определяет скорость обучения и регулируется параметром скорости настройки. При
большом шаге имеется большая вероятность пропуска абсолютного минимума, при
малом шаге может сильно возрасти время обучения. Шаги алгоритма принято
называть эпохами или циклами.
На каждом цикле на вход сети последовательно подаются все обучающие
наблюдения, выходные значения сравниваются с целевыми значениями и вычисляется
функция критерия качества обучения - функция ошибки. Значения функции ошибки, а
также её градиента используются для корректировки весов и смещений, после чего
все действия повторяются. Процесс обучения прекращается по следующим трём
причинам, если:
а) реализовано заданное количество циклов;
б) ошибка достигла заданной величины;
в) ошибка достигла некоторого значения и перестала уменьшаться.
Во всех этих случаях сеть минимизировала ошибку на некотором ограниченном
обучающем множестве, а не на множестве реальных входных сигналов при работе
модели. Попытки усложнить модель и снизить ошибку на заданном обучающем
множестве могут привести к обратному эффекту, когда для реальных данных ошибка
становится ещё больше. Эта ситуация называется явлением переобучения нейронной
сети.
Для того чтобы выявить эффект переобучения нейронной сети, используется
механизм контрольной проверки. С этой целью часть обучающих наблюдений
резервируется как контрольные наблюдения и не используется при обучении сети.
По мере обучения контрольные наблюдения применяются для независимого контроля
результата. Если на некотором этапе ошибка на контрольном множестве перестала
убывать, обучение следует прекратить даже в том случае, когда ошибка на
обучающем множестве продолжает уменьшаться, чтобы избежать явления
переобучения. В этом случае следует уменьшить количество нейронов или слоёв,
так как сеть является слишком мощной для решения данной задачи. Если же,
наоборот, сеть имеет недостаточную мощность, чтобы воспроизвести зависимость,
то явление переобучения скорее всего наблюдаться не будет и обе ошибки - обучения
и контроля - не достигнут требуемого уровня.
Таким образом, для отыскания глобального минимума ошибки приходится
экспериментировать с большим числом сетей различной конфигурации, обучая каждую
из них несколько раз и сравнивая полученные результаты. Главным критерием
выбора в этих случаях является контрольная погрешность. При этом применяется
правило, согласно которому из двух нейронных сетей с приблизительно равными
контрольными погрешностями следует выбирать ту, которая проще.
Необходимость многократных экспериментов ведёт к тому, что контрольное
множество начинает играть ключевую роль в выборе нейронной сети, т. е.
участвует в процессе обучения. Тем самым его роль как независимого критерия
качества модели ослабляется, поскольку при большом числе экспериментов
возникает риск переобучения нейронной сети на контрольном множестве.
Для того, чтобы гарантировать надёжность выбираемой модели сети,
резервируют ещё тестовое множество наблюдений. Итоговая модель тестируется на
данных из этого множества, чтобы убедиться, что результаты, достигнутые на
обучающем и контрольном множествах, реальны. При этом тестовое множество должно
использоваться только один раз, иначе оно превратится в контрольное множество.
Итак, процедура построения нейронной сети состоит из следующих шагов:
. Выбрать начальную конфигурацию сети в виде одного слоя с числом
нейронов, равным половине общего количества входов и выходов.
. Обучить сеть и проверить ее на контрольном множестве, добавив в случае
необходимости дополнительные нейроны и промежуточные слои.
. Проверить, не переобучена ли сеть. Если имеет место эффект
переобучения, то произвести реконфигурацию сети.
Для того чтобы проектируемая сеть успешно решала задачу, необходимо
обеспечить представительность обучающего, контрольного и тестового множества.
По крайней мере, лучше всего постараться сделать так, чтобы наблюдения
различных типов были представлены равномерно. Хорошо спроектированная сеть
должна обладать свойством обобщения, когда она, будучи обученной на некотором
множестве данных, приобретает способность выдавать правильные результаты для
достаточно широкого класса данных, в том числе и непредставленных при обучении.
Другой подход к процедуре обучения сети можно сформулировать, если
рассматривать её как процесс, обратный моделированию.
В этом случае требуется подобрать такие значения весов и смещений,
которые обеспечивали бы нужное соответствие между входами и желаемыми
значениями на выходе. Такая процедура обучения носит название процедуры
адаптации и достаточно широко применяется для настройки параметров нейронных
сетей.
По умолчанию для сетей с прямой передачей сигналов в качестве критерия
обучения используется функционал, представляющий собой сумму квадратов ошибок
между выходами сети и их целевыми значениями:
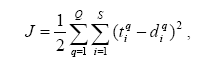
где Q - объём выборки; q - номер выборки; i - номер выхода;
Целью обучения сети является минимизация этого функционала с помощью изменения
весов и смещений.
В настоящее время разработано несколько методов минимизации функционала
ошибки на основе известных методов определения экстремумов функций нескольких
переменных. Все эти методы можно разделить на три класса:
а) методы нулевого порядка, в которых для нахождения минимума
используется только информация о значениях функционала в заданных точках;
б) методы первого порядка, в которых используется градиент функционала
ошибки по настраиваемым параметрам, использующий частные производные
функционала;
в) методы второго порядка, в которых используются вторые производные
функционала.
Для линейных сетей задача нахождения минимума функционала (параболоида)
сводится к решению системы линейных уравнений, включающих веса, смещения,
входные обучающие значения и целевые выходы и, таким образом, может быть решена
без использования итерационных методов. Во всех остальных случаях надо
использовать методы первого или второго порядка.
Если используется градиент функционала ошибки, то
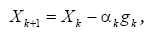
где X k и X k+1 - векторы параметров на k-й и k+1-й итерациях;
αk - параметр скорости
обучения; k g - градиент функционала, соответствующий k-й итерации.
Если используется сопряжённый градиент функционала, то на первой итерации
направление движения 0 p выбирают против градиента 0 g этой итерации:
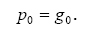
Для следующих итераций направление k p выбирают как линейную комбинацию
векторов k g и k −1 p:
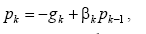
а вектор параметров рассчитывают по формуле:
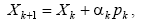
Для методов второго порядка расчет параметров на k-м шаге производят по
формуле (метод Ньютона):
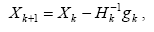
где Hk - матрица вторых частных производных целевой функции (матрица
Тессе); gk - вектор градиента на k-й итерации. Вычисление матрицы Тессе требует
больших затрат машинного времени, поэтому её заменяют приближенными выражениями
(квазиньютоновские алгоритмы).
Градиентными алгоритмами обучения являются:
GD - алгоритм градиентного спуска;
GDM - алгоритм градиентного спуска с возмущением;
GDA - алгоритм градиентного спуска с выбором параметра скорости настройки;
Rprop - пороговый алгоритм обратного распространения ошибки;
GDX - алгоритм градиентного спуска с возмущением и адаптацией параметра
скорости настройки.
Алгоритмами, основанными на использовании метода сопряженных градиентов,
являются:
CGF - алгоритм Флетчера-Ривса;
CGP - алгоритм Полака-Ребейры;
CGB - алгоритм Биеле-Пауэлла;
SCG - алгоритм Молера.
Квазиньютоновскими алгоритмами являются:
DFGS - алгоритм Бройдена, Флетчера, Гольдфарба и Шанно;
OSS - одношаговый алгоритм метода секущих плоскостей (алгоритм Баттини);
LM - алгоритм Левенберга-Марквардта;
BR - алгоритм Левенберга-Марквардта с регуляризацией по Байесу.
В процессе работы алгоритмов минимизации функционала ошибки часто
возникает задача одномерного поиска минимума вдоль заданного направления. Для
этих целей используется метод золотого сечения GOL, алгоритм Брента BRE,
метод половинного деления и кубической интерполяции HYB, алгоритм
Чараламбуса CHA и алгоритм перебора с возвратом BAC.
Практические задания.
Задание 1. Адаптировать параметры однослойной статической линейной сети
с двумя входами для аппроксимации линейной зависимости вида t = 2 p1 + p2 ,
выполнив следующие действия:
. С помощью конструктора линейного слоя
net = newlin(PR, s, id, lr),
где PR - массив размера Rx2 минимальных и максимальных значений
для R векторов входа; s - число нейронов в слое; id - описание
линий задержек на входе слоя; lr - параметр скорости настройки,
сформировать линейную сеть:
= newlin([-1 1; -1 1], 1, 0, 0).
. Подготовить обучающие последовательности в виде массивов ячеек,
используя зависимости 1 2 t = 2 p + p и четыре пары значений 1 p и 2 p
(произвольные):
P = {[-1; 1] [-1/3; 1/4] [1/2; 0] [1/6; 2/3]};= { -1 -5/12 1
1 }.
3. Для группировки представления обучающей последовательности
преобразовать массивы ячеек в массивы чисел:
= [P{:}], T1 = [T{:}].
. Выполнить команды net и gensim(net), проанализировать
поля вычислительной модели и структурную схему сети и записать в тетрадь
значения полей, определяющих процесс настройки параметров сети (весов и
смещений):
net.initFcn - функция для задания начальных матриц весов и векторов
смещений;
net.initParam - набор параметров для функции initFcn, которые можно
определить с помощью команды help(net.initFcn), где nitFcn -
заданная функция инициализации: initcon, initlay, initnw,
initnwb, initzero;.adaptFcn - функция адаптации нейронной сети,
используемая при вызове метода adapt класса network: adaptwb или trains;
net.adaptParam - параметры функции адаптации, определяемые с помощью команды
help(net.adaptFcn);
net.trainFcn - функция обучения нейронной сети, используемая при вызове
метода train класса network: trainb, trainbfg, traingbr, trainc,
traincgb, traincgt, traincgp, trainngd, traingda, traingdm, traingdx,
trainlm, trainoss, trainr, trainrp, trainscg;
net.trainParam - параметры функции обучения, определяемые с помощью команды help(net.trainFcn);
net.performFcn - функция оценки качества обучения, используемая при вызове
метода train: mae, mse, msereg, sse;
net.performParam - параметры функции оценки качества обучения, определяемые с
помощью команды help(net.performFcn);
net.layers{1}.initFcn - функция инициализации параметров слоя: initnw, initwb;
net.layers{1}.transferFcn - функция активации, которая для линейного слоя должна
быть purelin;
net.layers{1}.netInputFcn - функция накопления для слоя: netprod, netsum;
net.biases{1}.initFcn - функция инициализации вектора смещений: initcon,
initzero, rands;
net.biases{1}.lean - индикатор настройки: 0 - с помощью метода adapt, 1 -
с помощью метода train;
net.biases{1}.learnFcn - функция настройки вектора смещений: learncon,
learngd, learngdm, learnnp, learnwh;
net.biases{1}.learnParam - параметры функции настройки, определяемые с помощью
команды help.(net.biases{1}.learnFcn);
net.inputWeights{1, 1}.initFcn - функция инициализации весов входа: initzero,
midpoint, randnc, randnr, rands;
net.inputWeights{1,1}.learn - индикатор настройки: 0 - с
помощью метода adapt, 1 - с помощью метода train;
net.inputWeights{1,1}.learnFcn - функция настройки весов: learngd,
learngdm, learnhd, learnis, learnk, learnlv1, learnlv2, learnos,
learnnp, learnpn, learnsom, learnnwh;
net.inputWeights{1,1}.learnParam - параметры функции настройки,
определяемые с помощью команды help(net.inputWeights {1,1}.learnParam);
net.inputWeights{1,1}.weightFcn - функция для вычисления взвешенных
входов для слоя: dist, dotprod, mandist,negdist, normprod;
для многослойных сетей параметры net.inputWeights{i,j}, связанные
с обучением такие, как initFcn, learn, learnFcn, learnParam, weightFcn,
имеют тот же смысл и могут принимать такие же значения, что и
соответствующие параметры для net.inputWeights{1,1}.
. Выполнить один цикл адаптации сети с нулевым параметром скорости
настройки:
[net1, a, e,] = adapt(net, P, T,);.IW{1,1} % - матрица весов
после адаптации;% - четыре значения выхода;% - четыре значения ошибки.
6. Инициализировать нулями веса входов и смещений и задать параметры
скорости настройки для них соответственно 0.2 и 0:
net.IW{1} = [0 0];.b{1} = 0;.inputWeights{1,1}.learnParm.lr =
0.2;.biases{1}.learnParam.lr =0.
Нулевое значение параметра скорости настройки для смещения обусловлено
тем, что заданная зависимость 1 2 t = 2 p + p не имеет постоянной составляющей.
. Выполнить один цикл адаптации с заданным значением параметра скорости
адаптации:
[net1, a, e] = adapt (net, P, T);.IW{1,1} % - значения весов
в сети net1 изменились;% - четыре значения выхода сети net1;% - четыре значения
ошибки сети net1.
8. Выполнить адаптацию сети net с помощью 30 циклов:
for i = 1:30,
[net, a{i}, e{i}] = adapt(net, P, T);(i, :) =
net.IW{1,1};;mat(a{30}) % - значения выхода на последнем цикле;mat(e{30}) % -
значение ошибки на последнем цикле;(30, :) % - веса после 30
циклов;(cell2mat(e{30}) % - функция ошибок: 0.0017176.
Здесь cell2mat - функция преобразования массива числовых ячеек в
массив чисел, а mse - функция среднеквадратичной ошибки.
. Построить графики зависимости значений выходов сети и весовых
коэффициентов, а также среднеквадратичной ошибки от числа циклов, используя
функцию subplot для деления экрана на окна: subplot(3,1,1)
for i = 1:1:30, plot(i, cell2mat(a{i}), ′k′),on;(′′),
ylabel(′Выходы a(i)′)(3,1,2)(0:30, [[0 0]; W], ′k′)(′′),
ylabel(′Веса входов W(i) ′)(3,1,3)i = 1:30, E(i) = mse(e{i});
end(1:30, E, ′+k′)(′Циклы′), ylabel(′Ошибка′),
grid
10. Адаптировать рассматриваемую модель статической сети для
аппроксимации той же зависимости и с теми же требованиями к погрешности,
используя групповой способ представления обучающей последовательности:
P = [-1 -1/3 1/2 1/6; 1 1/4 0 2/3];= [-1 -5/12 1 1];=
newlin([-1 1; -1 1], 1, 0, 0, 0.2);= IW{1} = [0 0]; % - присваивание начальных
весов;.l{1} = 0; % - присваивание начального
смещения;.inputWeughts{1,1}.learnParam.lr = 0.2;= 10;= 1; % - для подсчета
количества циклов;EE > 0.0017176
[net, a{i}, e{i}, pf] = adapt(net, P, T);(i, :) = net
.IW{1,1};= mse(e{i});(i) = EE;= i + 1;;
11. Проанализировать результаты и сделать их сравнение с результатами для
последовательного представления обучающей последовательности:
W(63, :)mat(a{63})= mse(e{63})(e{1})
12. Для полученных результатов построить графики и сравнить их с
предыдущими:
subplot(3,1,1)i = 1:1:63, plot(i, cell2mat(a{i}), ′k′),on;(′′),
ylabel(′Выходы a(i′′), grid(3,1,2)(0:63, [[0 0]; W], ′k′)(′′),
ylabel(′Веса входов W(i)′), grid(3,1,3)(1:63, ee, ′+k′)(′Циклы′),
ylabel(′Ошибка′), grid
Задание 2. Адаптировать параметры однослойной динамической сети с одним
входом и одной линией задержки для аппроксимации рекуррентного соотношения y(t)
= 2 p(t) + p(t −1) , выполнив следующие действия:
. Так как для динамических сетей групповой способ представления
обучающего множества не используется, подготовить данные для последовательной
адаптации в виде массивов ячеек значений входа и цели:
P = {-1/2 1/3 1/5 1/4); % - значения входа p(t);= {-1 1/6
11/15 7/10}; % - значения цели y(t).
2. Выполнить адаптацию и построение графиков
net = newlin([-1 1], 1, [0 1], 0.5); % - help(newlin);= {0};
% - начальное условие для линии задержки;.IW{1} = [0 0]; % - веса для основного
и задержанного входов;.biasConnect = 0; % - значение смещения;= 10; i = 1;EE
> 0.0001
[net, a{i}, e{i}, pf] = adapt(net, P, T);(i, :) =
net.IW{1,1};= mse(e{i});(i) = EE;= i +1;(22, :){22}(3,1,1)i = 1:1:22, plot(i,
cell2mat(a{i}), ′k′)on;(′′), ylabel(′Выходы a(i)′),
grid(3,1,2)(0:22,[[0 0]; W], ′k′)(′′), ylabel(‘Веса
входов W(i)′), grid(3,1,3)(1:22, ee, ′+k′)(′Циклы ′),
ylabel(′Ошибка′)grid
Задание 3. Обучить нейронную сеть, для которой модель и зависимость
выхода от входов приведены в задании 1, выполнив команды и используя
последовательный и групповой способы представления обучающей
последовательности:
а) для последовательного способа:
net=newlin ([-1 1; -1 1], 1, 0, 0);.IW{1}= [0 0];.b{1} = 0;=
{[-1 1][-1/3; 1/4][1/2 0][1/6;2/3]};= {-1 -5/12 1 1}.inputWeights{1,
1}.learnParam.lr = 0.2;.biases{1}.learnParam.lr = 0;.trainParam.epochs =
30;=train (net,P,T);= net1.IW{1} % - параметры после обучения:= sim(net1,p)=
mse([Y{:}] - [T{:}]) % - ошибка 1.3817*e-003
б) для группового способа:
P = [-1 -1/3; 1/2 1/6; 1 1/4 0 2/3];= [-1 -5/12 1 1]=train
(net,P,T);= net1.IW{1} % - параметры после обучения:= sim(net1,P)= mse(y-T) % -
та же ошибка 1.3817*e-003
Задание 4. Обучить динамическую линейную сеть, рассмотренную во 2-м
задании и сравнить результаты, выполнив следующие команды:
net = newlin([-1 1] , 1,[0 1], 0.5)= {0} % - начальное
условие линии задержки;.IW{1} = [0 0] % - начальные веса входов;.biasConnect =
0; % - смещение отсутствует;.trainParam.epochs = 22;= {-1/2 1/3 1/5 1/4}; % -
вектор входа;= {-1 1/6 11/15 7/10}; % - вектор цели;= train(net, P, T, Pi); % -
обучение сети;= net1.IW{1} % - веса после обучения сети;= sim(net1, P); % -
моделирование новой сети;= mse( [Y{:}] - [T{:}] ) % - ошибка = 3.6514е-005.
Задание 5. Создать и инициализировать трёхслойную сеть с двумя входами
для последующего обучения сети методом обратного распространения ошибки,
выполнив следующие действия:
. Создать шаблон сети:
net5 = network(2, ... % - число входов;
, ... % - число слоёв сети;
[1; 1; 1], ... % - связь смещений;
[1 1 ; 0 0; 0 0], ... % - связь входов;
[ 0 0 0 ; 1 0 0 ; 0 1 0], ... % - связь слоёв;
[0 0 1], ... % - связь выходов;
[0 0 1] ); % - связь целей.
2. Настроить параметры сети для инициализации с помощью алгоритма Нгуена-Видроу
для обеспечения возможности использования метода обратного распространения:
net5.initFcn = ′initlay′; % - для
сети;.layers{1}.initFcn = ′initnw′; % - для 1-го
слоя;.layers{2}.initFcn = ′initnw′; % - для 2-го
слоя;.layers{3}.initFcn = ′initnw′; % - для 3-го слоя.
3. Проинициализировать сеть для её последующего обучения методом
обратного распространения ошибки:
net5 = init(net5);.IW{1, 1} % - матрица весов для 1-го
входа;.IW{1, 2} % - матрица весов для 2-го входа;.LW{2, 1} % - матрица весов
для 2-го слоя;.LW{3, 2} % - матрица весов для 3-го слоя;.b{1} % - матрица
смещения для 1-го слоя;.b{2} % - матрица смещения для 2-го слоя;.b{3} % -
матрица смещения для 3-го слоя.
4. Промоделировать сеть с начальными значениями весов и смещений:
P = [0.5 1 ; 1 0.5]; % - значения входных векторов;=
sim(net5) % - моделирование сети.
Задание 6. Создать и инициализировать трёхслойную сеть с двумя входами
для последующего обучения различными методами, выполнив следующие действия:
. Создать шаблон сети, воспользовавшись шаблоном net5:
net6 = net5; % - создание новой копии сети;= revert(net5); %
- возврат к настройке параметров по умолчанию.
2. Настроить параметры сети с помощью функции инициализации нулевых
значений весов и смещений initzero:
net6.initFcn = ′initlay′;.layers{1}.initFcn = ′initnw′;.layers{2}.initFcn
= ′initnw′;.layers{3}.initFcn = ′initnw′;.inputWeights{1
,1}.initFcn = ′initzero′;.inputWeights{1 ,2}.initFcn = ′initzero′;.layerWeights{2
,1}.initFcn = ′initzero′;.layerWeights{3 ,2}.initFcn = ′initzero′;.biases{1}.initFcn
= ′initzero′;.biases{2}.initFcn = ′initzero′;.biases{3}.initFcn
= ′initzero′;.init(net6); % - инициализация сети.
3. Выдать на экран матрицы весов и смещения, используя команды 3-го
пункта 5-го задания.
. Промоделировать сеть и возвратить её к исходным значениям весов и
смещений:
Ynet6 = sim(net6);= revert(net6).
Задание 7. Создать и инициализировать трёхслойную сеть с двумя входами,
используя следующие функции инициализации:
а) rands - для задания случайных весов и смещений.
б) randnc - для задания случайной матрицы с нормированными
столбцами;
в) randnv - для задания случайной матрицы с нормированными строками;
г) initcon - для задания равных смещений;
д) midpoint - для задания матрицы средних значений;
Для создания и инициализации сети использовать команды 6-го задания,
заменяя в них функцию initzero на рассматриваемые функции инициализации,
а сеть net6 - на сеть net7.
Задание 8. Создать двухслойную нейронную сеть с прямой передачей сигнала,
одним входом, двумя нейронами в первом слое и одним нейроном во втором слое,
настроить сеть для обучения с использованием алгоритма градиентного спуска GD,
обучить эту сеть и путём её моделирования оценить качество обучения. Порядок
выполнения задания следующий:
. Создать нейронную сеть с прямой передачей сигнала:
net8 = newff([0 5], …. % - диапазоны значений входа;
[2 1], ….. % - количество нейронов в слоях;
{′tansig′, % - функция активации для 1-го слоя;
′logsig′} % - функция активации для 2-го слоя;
′traingd′); % - имя функции обучения.
2. Убедиться, что веса и смещения каждого слоя инициализированы с помощью
алгоритма Нгуена-Видроу:
net8.initFcn % - должно быть ′initlay′;.layers{1}.initFcn
% - должно быть ′initnw′;.layers{2}.initFcn % - должно быть ′initnw′;.IW{1,1}
% - вес входа;.LW{2,1} % - веса для 2-го слоя..b{1}.b{2}
3. Задать обучающие последовательности входов и целей T:
P = [0 1 2 3 4 5]; % - вектор входа;= [0 0 0 1 1 1]; % -
вектор целей.
. Выдать на экран параметры обучающей функции traingd и их значений по
умолчанию:
info = traingd(′pdefaults′)= epochs: 100 % -
максимальное количество циклов
обучения;: 25 % - интервал вывода данных;: 0 % - предельное
значение критерия обучения;: Inf % - максимальное время обучения;_grad:
1.0e-006 % - максимальное значение градиента
критерия % качества;_fail: 5 % - максимально допустимый
уровень
% превышения ошибки контрольного
% подмножества по сравнению с обучающим.
Процедура обучения прекратится, когда будет выполнено одно из следующих
условий:
а) значение функции качества стало меньше предельного goal;
б) градиент критерия качества стал меньше значения min_grad;
в) достигнуто предельное значение циклов обучения epochs;
г) превышено максимальное время, отпущенное на обучение time;
д) ошибка контрольного подмножества превысила ошибку обучающего более чем
в max_fail раз.
Функция traingd предполагает, что функции взвешивания dotprod,
накопления netsum и активации transig или rogsig имеют
производные. Для вычисления производных критерия качества обу-
чения perf по переменным веса и смещения используется метод
обратного распространения. В соответствии с методом градиентного спуска вектор
настраиваемых переменных получает следующее приращение:= lr * dperf / dx ,
где tr - параметр скорости настройки, равный по умолчанию 0,01.
Функцией одновременного поиска минимума вдоль заданного направления в
данной сети является функция srchbac.
. Обучить рассматриваемую сеть: net8.trainParam.epochs =
500;.trainParam.90al = 0.01;
[net8, TR] = train(net8, P, T);% - характеристики процедуры
обучения.
6. Произвести моделирование сети и оценить качество ее обучения:
Ynet8 = sim(net8, P) % - целевые значения.
Задание 9. Повторить 8-е задание для следующих функций обучения: traingda,
traingdm, traingdx, trainrp, traincgf, traincgp, traincgb, trainscg,
trainbfg, trainoss, trainlm. Сравнить полученные результаты.
Задание 10. Создать и обучить сеть для аппроксимации синусоидальной
функции, зашумленной нормально распределенным шумом, выполнив следующие
действия:
. Задать обучающие последовательности:
P = [-1: .05: 1];= sin[2*pi*P] + 0.1*randn(size(P));
2. Сформировать сеть с прямой передачей сигнала:
net10 = newff([-1 1], [20 1], {′transig′, ′purelin′},
… ′trainbr′);
3. Настроить сеть:
net10.trainParam.epochs = 50;.trainParam.show = 10; % для
отображения.
4. Обучить сеть и построить график аппроксимируемой функции и график
выхода сети: net10 = train(net, P, T);
Y = sim(net, P);(P, Y, P, T, ‘+’) % - два графика.
5. Изменяя количество нейронов в первом слое, исследовать качество
аппроксимации.
Задание 11. Создать сеть и произвести ее последовательную адаптацию,
выполнив следующие команды:
net11 = newff([-1 2; 0 5], [3, 1], … {′tansig′, ′purelin′},
′traingd′);.inputWeights{1, 1}.learnFcn = ′learngd′;.layerWeights{2,
1}.learnFcn = ′learngd′;.biases{1}.learnFcn = ′learngd′;.biases{2}.learnFcn
= ′learngd′;.layerWeights{2, 1}.learnParam.lr = 0.2;= [-1 -1 2 2; 0
5 0 5];= [-1 -1 1 1];= num2cell(P,1);= num2cell(T,1);.adaptParam.passes = 50;
[net11, a, e] = adapt(net11, P,T);= sim(net11, P) % [-1.02]
[-0.99624] [1.0279] [1.0021];(e) % - должно быть 5,5909е-004.
Задание 12. Создать сеть и произвести ее последовательную адаптацию,
используя следующие функции настройки весов и смещений: learngdm, learnlv1,
learnlv2, learnk, learncon, learnis, learnos, learnsom, learnh, learnhd.
Сравнить алгоритм настройки для одной и той же обучающей
последовательности.
Задание 13. Создать, обучить и апробировать многослойную нейронную сеть
с прямой передачей сигнала для принятия решения о зачислении в высшее учебное
заведение абитуриентов, сдавших вступительные экзамены по математике, физике и
русскому языку.
Правила приема таковы:
. Проходной балл для абитуриентов, не имеющих льгот, должен быть равен
11;
. Удовлетворительные оценки по математике и физике для этой категории
абитуриентов недопустимы;
. Абитуриенты, имеющие льготы, зачисляются при любых положительных
оценках по всем трем предметам.
Для обучения сети следует использовать все изученные методы адаптации и
обучения и провести анализ их эффективности. Следует также определить
минимальное количество слоев и нейронов, обеспечивающее удовлетворительное
решение поставленной задачи. Для формирования обучающего, контрольного и
тестового множества построить дискретную имитационную модель, используя
инструментальный пакет Simulink.
Список литературы
1. Дьяконов,
В. Matlab 6: учебный курс [Текст] / В. Дьяконов. - СПб.: Питер, 2001. - 592 с.
. Медведев,
В. Г. Нейронные Сети Matlab 6 / В. Г. Медведев; под общ. ред. к.т.н. В. Г.
Потемкина. - М.: ДИАЛОГ-МИФИ, 2002. - 496 с. - (Пакеты прикладных программ;
Кн.4).
. Галушкин,
А. И. Теория нейронных сетей [Текст] / А. И. Галушкин. - М.: ИПРЖР, 2000. - 416
с.
. Галушкин,
А. И. Нейрокомпьютеры [Текст]. - М.: ИПРЖР, 2000. - 532 с.
.
Нейрокомпьютеры и интеллектуальные работы [Текст] / под ред. В. Г. Неелова. -
Киев: Пресса Украины, 1999. - 150 с.
.
Дунин-Барковский, В. П. Информационные процессы в нейронных структурах [Текст]
/ В. П. Дунин-Барковский. - М.: Наука, 1978.
. Сивохин, А.
В. Искусственные нейронные сети [Текст] /А. В. Сивохин; учеб. пособие / под
ред. профессора Б. Г. Хмелевского. - Пенза: Изд-во Пенз. гос. ун-та, 2002. - 70
с.
. Щербаков,
М. А. Искусственные нейронные сети: Конспект лекций [Текст] / М. А. Щербаков. -
Пенза: Изд-во Пенз. гос. тех. ун-та, 1996. - 44 с.
. Осовский,
С. Нейронные сети для обработки информации [Текст] / С. Осовский; пер. с
польского И. Д. Рудинского. - М.: Финансы и статистика, 2002. - 344 с.
. Дьяконов,
В. П. Matlab 6/6.1/6.5 + Simulink 4/5. Основы применения. [Текст]. Полное
руководство пользователя / В. П. Дьяконов. - М.: СОЛОН-Пресс, 2002. - 768 с.