Метод вылавливания ошибок
Метод
вылавливания ошибок
Метод является частным случаем перестановочного
декодирования. Предположим, что требуется исправить все векторы ошибок e = (e0, …, ev - 1) вес которых не
превосходит t при некотором фиксированном t £ [ (d - 1) /2]. Для выполнения
декодирования надо найти такое множество подстановок, чтобы код был инвариантен
относительно этого множества и чтобы для каждого вектора e, вес которого не
превосходит t, нашлась бы подстановка, передвигающая все ошибки из
информационных позиций в проверочные.
Метод перестановочного декодирования состоит в следующем.
Определим оператор подстановок pj По полученному вектору y вычисляются векторы
сдвигов pj {y} и их синдромы s (j), до тех пор, пока не
будет найден индекс j, для которого вес wt (s (j)) £ t. При этом все ошибки
будут сосредоточены в первых r = n - k позициях вектора pj {y} и задаются равенством [s (j)] T = (e0, …, er - 1). Следовательно,
принимаемый вектор декодируется как слово
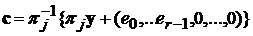 .
.
Метод вылавливания ошибок использует циклические постановки Dj. Метод позволяет исправлять все векторы
ошибок, содержащие круговую серию нулей длины не менее k.
Алгоритм.
1. Вычисляется синдром s (x) для принимаемого сигнала y (x), используя алгоритм деления на порождающий полином.
. Установка j: = 0
. Если wt (sj (x)) £ t, тогда полагаем e (x) = x j (sj, 0) и корректируем ошибку, вычисляя y (x) - e (x);
. Устанавливаем j: = j + 1;
. Если j = n, тогда алгоритм останавливается и ошибка
считается не выловленной;
. Если deg (sj - 1 (x) < n - k - 1, тогда
sj (x) = x sj - 1 (x); в противном случае - sj (x) = x sj - 1 (x) - g (x);
. Перейти к шагу 3.
Декодирование циклического кода путем вылавливания ошибок. Рассмотрим случай декодирования С кода с
параметрами (n,k), d=2t+1 и
проверочной матрицей H= [In-kA]. Передается кодовое слово с, а принимается вектор
y = c +E,
где E-вектор ошибки.
Синдром вектора y вычисляется
как
s = HyT = H (c + E)
T = H (E) T.
Образуем вектор E*= (sT, 0),
где 0 нулевой вектор, состоящий из k нулей. Нетрудно показать, что выполняется следующее соотношение
H (E*) T = s.
Вектора E и E* имеют один и тот же синдром и соответствуют одному и тому же
подмножеству кода C. Предположим, что вес синдрома wt (s) £ t. Тогда wt (E*) £ t и следовательно E = E* так
как соответствующее подмножество кода C может
содержать только один вектор заданного веса. Следовательно, вектор ошибки можно
записать через E = (sT,0). Теперь предположим, что структура вектор ошибки веса
не менее t может иметь в своем составе циклический
сдвиг пачки из k нулей. На определенном i - ом циклическом сдвиге в структуре вектора ошибки
отличные от нуля символы будут располагаться на первых (n-k) позициях. Для
этого значения i вес соответствующего синдрома wt (si (x)) £ t, где si (x) - синдром mod (xn-1). Если синдром si (x) вычислять как остаток от деления xiy (x) на порождающий полином g (x), тогда wt (si (x)) £ t для значений i соответствующих соотношению xiE (x) = (si, 0).
Таким образом, вектору ошибки E (x) соответствует циклический сдвиг E (x) = xi (si, 0).
Такое свойство синдрома позволяет построить следующий алгоритм
декодирования.
Алгоритм I.
1.
Вычисляется
синдром s
(x) для принимаемого
сигнала y
(x), используя алгоритм
деления на порождающий полином.
2.
Установка
i: = 0
3.
Если wt (si (x)) £ t, тогда полагаем E (x) = xi (si, 0) и
корректируем ошибку, вычисляя y (x) - E (x);
4.
Устанавливаем
i: = i+1;
5.
Если i = n, тогда алгоритм
останавливается и ошибка считается не выловленной;
6.
Если deg (si-1 (x) < n-k-1, тогда si (x) = x si-1 (x); в противном случае - si (x) = x si-1 (x) - g (x);
7.
Перейти
к шагу 3.
Пример. Пусть g (x) = 1+x2+x3 генерирует бинарный циклический код (7,4,3),
позволяющий исправлять одну ошибки.
Предположим, что передается кодовое слово c (x) = 1+x+x5 = (1+x+x2) g (x), а принимается вектор y (x) = 1+x+x5+x6. Разделим вектор y (x) на порождающий полином g (x)
y (x) = (x3+1) g (x) + (x+x2), s (x) = (x+x2).
Такт как вес синдрома больше 1, то вычисляем синдром
циклического сдвига s1 (x) для xy (x). Поскольку степень синдрома s (x) равна 2 = n-k-1, то
s1 (x) = xs (x) mod g (x) = 1.
Вес синдрома равен единице и соответствует корректирующей
способности кода. Следовательно, вектор ошибки равен
E (x) = x7-1 (s1,0) = x6 (100 0000) = x6.
Пример. Пусть g (x) = 1+x4+x6+x7+x8 генерирует бинарный циклический код (15,7,5),
позволяющий исправлять две ошибки.
Любая ошибка веса два содержащая в своей структуре пачку из 7
нулей может быть выловлена.
Предположим, что принимается вектор y= (1100 1110 1100 010).
Вычислим синдром y (x) = (x +x2+x4+x5) g (x) + (1+x2+x5+x7). Далее, вычисляем синдромы si (x) для циклических сдвигов
xiy (x) до тех пор, пока вес
синдрома не станет не более двух wt (si (x)) £2.
Вычисления сведем в таблицу
|
i
|
Si
(x)
|
|
0
|
10100101
|
|
1
|
11011001
|
|
2
|
11100111
|
|
3
|
11111000
|
|
4
|
01111100
|
|
5
|
00111111
|
|
6
|
00011111
|
|
7
|
10000100
|
Ошибка представляется как
E = x15-7 (s7,0) = x8 (10000100 0000000) =
(0000 0000 1000 010),
Декодируем
кодовое слово как
c = y - E = (1100 1110 0100 000).
Пакеты ошибок
Характерной особенностью циклических кодов является
способность к распознаванию пакетов ошибок. Под пакетом ошибок понимается
группирование ошибок в одной ограниченной области кодового слова. Пакет ошибок
в полиномиальном виде можно представить как
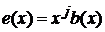
Например, задавая 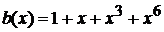 , пакет ошибок в векторном виде будет иметь вид
, пакет ошибок в векторном виде будет иметь вид
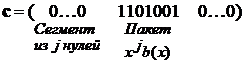 .
.
Пакет ошибок начинается и заканчивается отличным от нуля символом.
Если длина пакета не превосходит величины r = n - k, то степень полинома ошибок меньше r. В этом случае e (x) не делится на g (x) без остатка и синдром принятого слова всегда отличен от
нулевого. Пакет ошибок длиной равной или меньшей r всегда распознается. Распознается также любой циклический сдвиг
многочлена b (x) степени, меньшей r.
Для циклического (n, k) - кода доля не обнаруживаемых пакетов ошибок длины l > r + 1 равна 2 - r.
Граница Рейджера. Для любого линейного (n, k) - кода, исправляющего пачки ошибок
длиной b и меньше, должно выполняться следующее соотношение:
n - k ³ 2b.
Из теоремы следует, что если g1 (x) -
неприводимый многочлен с периодом n1, степень которого не меньше b, взаимно простой с полиномом (x2b - 1), тогда циклический код длиной (2b - 1) n1/ НОД (2b - 1, n1) с порождающим многочленом (x2b-1 - 1) g1 (x) исправляет пачки ошибок длиной b и менее. Такой код называется кодом Файра, он имеет более
чем 3b - 1 проверочных символов, что на b - 1 больше нижней границы Рейджера,
равной 2b.
Декодирование пачки ошибок методом вылавливания. Параметры корректирующего кода (n, k), исправляющего пачки ошибок длиной t, должны удовлетворять условию (n - k) ³ 2t. Предполагается, что структура вектора пачки ошибок длиной t имеет отрезок из (n - t) нулевых элементов. Если вектор e представляет собой пачку ошибок длиной t и ошибки располагаются на первых (n - k) позициях
вектора, тогда синдром H (eT) = s характеризует структуру пачки ошибок длины не более t. Если ошибки располагаются не первых (n - k) позициях вектора, то для вычисления оценки ошибки используется
свойство циклического сдвига синдрома, как и в рассмотренном выше случае,
только контролируется не вес используется его свойство (см. алгоритм I). Контролируется (n - k) первых
позиций синдрома. Если конфигурация синдрома sj (x) идентифицирует пачку ошибок длиной t или менее, то вектор ошибок e (x) = xn - j (si,0).
вылавливание ошибка циклический код
Декодирование пачки ошибок методом вылавливания. Параметры корректирующего
кода (n,k), исправляющего пачки
ошибок длиной t,
должны удовлетворять условию (n-k) ³ 2t. Предполагается, что структура вектора пачки ошибок длиной t имеет отрезок из (n-t) нулевых элементов. Если
вектор E представляет собой пачку ошибок длиной t и ошибки располагаются
на первых (n-k) позициях вектора, тогда
синдром H
(ET) = s характеризует структуру (нециклической) пачки
ошибок длины не более t. Если ошибки располагаются не первых (n-k) позициях вектора, то
для вычисления синдрома используется его свойство (см. алгоритм I).
Алгоритм II.
1.
Вычисляется
синдром s
(x) для y (x).
2.
Устанавливается
i: =0.
3.
Контролируется
(n-k) первых позиций
синдрома. Если конфигурация синдрома si (x) идентифицирует пачку
ошибок (нециклическую) длиной t или менее, то вектор ошибок E (x) = xn-i (si,0).
4.
Устанавливается
i: = i+1.
5.
Если i = n, то алгоритм
останавливается и считается, что ошибка не вылавливается.
6.
Вычисляется
синдром si (x) по аналогии с алгоритмом I.
7.
Переход
к шагу 3.
Пример. Пусть g (x) = 1+x+x2+x3+x6 генерирует бинарный циклический код (15,9), позволяющий
исправлять пачку ошибок длиной t = 3. Принимаемый вектор
y = (1110 1110 1100 000).
Вычислим синдром
y (x) = (x2+x3) g (x) + (1+x+x4+x5), s (x) = (1+x+x4+x5).
Конфигурация первых символов (n-k) =15 - 9 =6 синдрома не
соответствует пачки ошибки длиной 3. Вычисляем значения синдрома для других
циклических сдвигов принимаемого сигнала:
|
isi (x)
|
|
|
0
|
110011
|
|
1
|
100101
|
|
2
|
101110
|
|
3
|
010111
|
|
4
|
110111
|
|
5
|
100111
|
|
6
|
101111
|
|
7
|
101011
|
|
8
|
101001
|
|
9
|
101000 - пачка
ошибок t = 3
|
Вектор ошибок вычисляется как E (x) = xn-i (s9,0) = x6 (101000 000000000) =
(000000 101000000) mod (x15-1).
Переданное кодовое слово восстанавливается как
c (x) = y (x) - E (x) = (1110 1100 0100 000).
Заметим, что в рассматриваемом примере синдром s8 (x) имеет вес равный 3, но
конфигурация структуры не соответствует пачки ошибок длиной 3.
В таблице приводятся сведения о корректирующей способности
пачки ошибок некоторых циклических кодов
|
g (x)
|
(n,k)
|
Длина
исправляемой пачки ошибок t
|
|
1+x2+x3+x4
|
(7,3)
|
2
|
|
1+x2+x4+x5
|
(15,10)
|
2
|
|
1+x4+x5+x6
|
(31,25)
|
|
|
1+x3+x4+x5+x6
|
(15,9)
|
3
|
|
1+x+x2+x3+x6
|
(15,9)
|
3
|