|
Имя
|
Авторы
|
Отличия
|
|
LZ77
|
Ziv
and Lempel [1977]
|
Указатели
и символы чередуются. Указатели адресуют подстроку среди предыдущих N
символов.
|
|
LZR
|
Roden
et al [1981]
|
Указатели
и символы чередуются. Указатели адресуют подстроку среди всех предыдущих
символов.
|
|
LZSS
|
Bell
[1986]
|
Указатели
и символы различаются флажком-битом. Указатели адресуют подстроку среди
предыдущих N символов.
|
|
LZB
|
Bell
[1987]
|
Аналогично
LZSS, но для указателей применяется разное кодирование.
|
|
LZH
|
Brent
[1987]
|
Аналогично
LZSS, но на втором шаге для указателей применяется кодирование Хаффмана.
|
|
LZ78
|
Ziv
and Lempel [1978]
|
Указатели
и символы чередуются. Указатели адресуют ранее разобранную подстроку.
|
|
LZW
|
Welch
[1984]
|
Вывод
содержит только указатели. Указатели адресуют ранее разобранную подстроку.
Указатели имеют фиксированную длину.
|
|
LZC
|
Thomas
et al [1985]
|
Вывод
содержит только указатели. Указатели адресуют ранее разобранную подстроку.
|
|
LZT
|
Tischer
[1987]
|
Аналогично
LZC, но фразы помещаются в LRU-список.
|
|
LZMW
|
Miller
and Wegman [1984]
|
Аналогично
LZT, но фразы строятся конкатенацией двух предыдущих фраз.
|
|
LZJ
|
Jakobsson
[1985]
|
Вывод
содержит только указатели. Указатели адресуют подстроку среди всех предыдущих
символов.
|
|
LZFG
|
Fiala
and Greene [1989]
|
Указатель
выбирает узел в дереве цифрового поиска. Строки в дереве берутся из
скользящего окна.
|
Термин "LZ-схемы" происходят от имен
их изобретателей. Обычно каждый следующий рассматриваемый вариант есть
улучшение более раннего.
Коммерческие реализации алгоритма LZW
сжатия используют различные дополнительные методы повышения скорости работы
алгоритма и увеличения степени сжатия данных. Это относится, в основном, к
сложной организации таблиц для уменьшения времени поиска в ней, а также,
возможно, к выполнению некоторых преобразований над данными перед тем или после
того, как они попадут в таблицу строк.
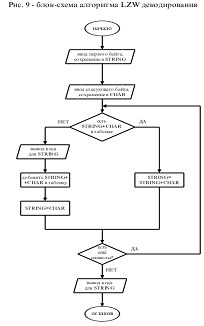
Блок-схема алгоритма LZW
декодирования.
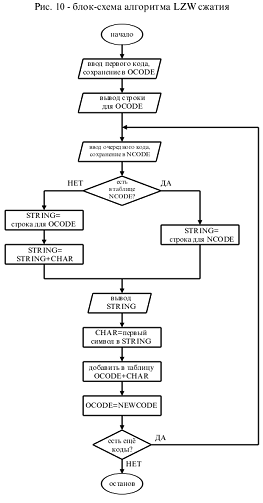
Блок-схема алгоритма LZW
сжатия.
1.4 Графический формат GIF
Сотрудник компании CompuServe Inc. Боб Берри
(Bob Berry), взял LZW в качестве основы для созданного им в 1987 году
принципиально нового графического формата GIF (Graphic Interchange Format).
Следует отметить, что созданная Терри Уэлчем компания Unisys, которой и
принадлежали авторские права на алгоритм LZW, взимала плату за его
использование только с производителей аппаратного обеспечения для компьютеров,
в котором применялся данный стандарт, например с изготовителей модемов.
Разработчики программного обеспечения "комиссионными сборами" не
облагались.
Однако зимой 1994 года компания Unisys, начавшая
испытывать финансовые проблемы, объявила LZW коммерческим стандартом,
потребовав оплаты за его использование. Это автоматически сделало GIF
единственным в мире "платным" графическим форматом, что вызвало волну
недовольства среди пользователей Интернета, поскольку практически на всех
современных web-сайтах, а также в 90% рекламных изображений так или иначе
применяются элементы GIF. Тем не менее GIF чрезвычайно широко используется в
Интернете и сейчас, причем пользователи не обязаны оплачивать кому бы то ни
было возможность опубликовать во Всемирной сети изображение в данном формате,
так как упомянутые выше финансовые претензии касаются в первую очередь,
производителей работающего с GIF программного обеспечения.
Благодаря возможностям алгоритма LZW стандарт
GIF позволяет значительно сокращать объем итогового графического файла по
сравнению с исходным изображением. Достигается это методом смешения сходных
оттенков в один. Если, например, в составе рисунка имеется участок, состоящий
из нескольких сходных полутонов, к примеру, голубого, светло-голубого и
темно-голубого цвета, они будут кодированы одним оттенком - голубым. Информация
об изображении в файле стандарта GIF записывается построчно, то есть представляет
собой массив описаний строк высотой в один пиксел. Именно это свойство GIF, а
также то, что данный формат оперирует фиксированной, так называемой
индексированной палитрой, причем число цветов в этой палитре не превышает 256,
сделало его наиболее популярным графическим форматом в современном Интернете.
Если готовится рисунок для сохранения в формате
GIF, необходимо избегать следующих художественных приемов: градиентных заливок,
размытий, постепенных цветовых переходов с множеством оттенков. Не следует также
пользоваться графическими фильтрами! Фильтру "блик" редактора Adobe
PhotoShop, для неравномерного смешения нескольких цветов на одном участке
изображения, например при создании эффектов изменения интенсивности освещения.
Это связано с тем, что алгоритм замещения схожих оттенков одним в формате GIF
далеко не всегда работает корректно. Поэтому участки с множеством различных
оттенков на небольшом фрагменте рисунка после сохранения изображения в
индексированной 256-цветовой палитре будут выглядеть смазанными и
"грязными". Этого можно избежать, применяя по возможности однотонные
и контрастные цвета. Одно из замечательных свойств стандарта GIF - его
уникальная особенность, названная разработчиками "interlace", или,
по-русски, "чересстрочность". Она позволяет загружать картинку с
сервера в клиентский браузер не целиком, а частями, причем процедура считывания
файла выглядит следующим образом: сначала на экране отображаются первая, пятая
и десятая строки, составляющие изображение, затем - вторая, шестая и одиннадцатая
и т. д. Таким образом, для пользователя создается иллюзия постепенной загрузки
графического элемента: картинка как бы медленно проявляется на странице, что не
только создаст красивый визуальный эффект, но и дает возможность пользователю
наблюдать за появлением графического изображения "в процессе", вмести
того чтобы несколько секунд любоваться на пустой участок экрана.
1.5 Формат TIFF
Растровый формат TIFF (Tagged Image File Format)
был создан для преодоления трудностей, которые возникают при переносе
графических файлов с IBM-совместимых ПЭВМ на ПЭВМ Macintosh и обратно.
Спецификация TIFF была выпущена Aldus
Corporation в 1986 году и представила данный формат в качестве стандартного
метода хранения черно-белых изображений, созданных сканерами и программными
пакетами верстки.
Широкое распространение получила разработанная в
апреле 1987 года модификация формата 4.0, которая могла поддерживать обработку
несжатых цветных RGB-изображений. TIFF модификации 5.0 (появившийся в августе
1988 года) позволял хранить цветные изображения с палитрой и поддерживать
алгоритм сжатия LZW. Выпущенный в июне 1992 года TIFF 6.0 расширил свои
функциональные возможности поддержкой цветных изображений моделей СМYK и YCbCr,
а также использовал метод сжатия JPEG.
TIFF сегодня - это стандартный файловый формат,
поддерживаемый большинством графических программ создания и обработки
изображений, а также программными пакетами верстки. Способность к расширению,
позволяющая записывать растровые изображения любой глубиной цвета, делает этот
формат весьма перспективным для хранения и обработки графической информации.
TIFF стал общим форматом для систем ввода
изображений со сканеров, используется в издательских системах и входит в состав
дистрибутивных приложений Windows.
Организация файла. Файлы TIFF состоят из трех
разделов: заголовка файла изображения (Image File Header - IFH), директории
файла изображений (Image File Directory - IFD) и растровых данных (Тэг). Из них
необходимыми являются только IFH и IFD. Следовательно, допускается возможность
существования файла TIFF, не содержащего растровых данных. Файл TIFF,
содержащий несколько изображений будет включать столько же директорий файла и
разделов растровых данных (по одному для каждого изображения). Структура
формата представлена на рисунке.
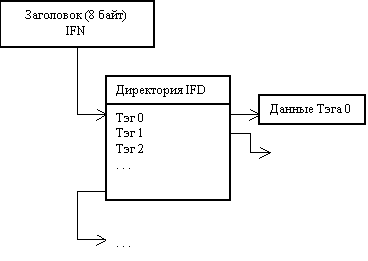
Рис. Обобщенная структура TIFF
- файла
В составе структуры TIFF - файла можно выделить:
. Заголовок, включающий:
идентификатор порядка байтов в файле (от старших
к младшим или наоборот);
номер версии;
указатель на первую директорию IFD;
. Директория (IFD) - содержит описание одного
изображения:
счетчик тэгов в директории;
последовательность тэгов;
. Тэг:
идентификатор поля;
тип поля (базовое, информационное, факсимильное
и поле запоминания и восстановления документов);
длина поля;
смещение в файле к данным.
Начальный заголовок содержит 8 байт. Вся
информация и параметры, имеющие отношение к изображению, хранятся в полях
признаков. Современные версии TIFF
включает 45 таких полей. Однако фактически есть два отдельных поля признака для
точного определения размеров изображения, а также поля для определения ПЭВМ,
программного обеспечения, даты создания файла и т. д. Несколько полей содержат
значения по умолчанию и, следовательно, не требуют уточнения. TIFF
снабжен полями, которые позволяют правильно отображать изображения с
нестандартной разрешающей способностьюявляется сложным форматом, поскольку
местоположение каждой директории и ее данных (включая растровые данные) может
изменяться. Единственной составной частью файла TIFF, которая имеет постоянное
место, является заголовок - он всегда располагается в первых 8 байтах каждого
файла TIFF. Все остальные данные файла создаются с использованием информации
IFD. Директория файла изображения и связанный с ней растр составляют субфайл
TIFF. Ограничений на количество субфайлов в файле TIFF не существует.
Каждая директория файла содержит одну или
несколько структур данных, называемых тегами. Каждый тег является 12-байтовой
записью, содержащей определенную информацию о растровых данных. Тег может
хранить данные любого типа, и спецификация TIFF определяет свыше 70 тегов,
которые применятся для представления заданной информации. Теги каждой
директории объединяются в непрерывные группы.
Теги, определенные спецификацией TIFF,
называются общедоступными и не могут изменяться в большей мере, чем это
предусмотрено спецификацией. Теги, определенные пользователем, называются
частными и предназначены для применения в пользовательских программах через
Developer’s Desk фирмы Aldus.
Файл TIFF может содержать любое количество
изображений (включая нулевое). Каждое изображение рассматривается как отдельный
растровый субфайл, данные которого описываются информацией IFD. Каждый субфайл
TIFF может быть записан в виде отдельного файла или вместе с другими субфайлами
объединен в один файл TIFF. Каждый растровый субфайл имеет свою директорию
файла изображения и может располагаться в любом месте (после заголовка).
Каждому изображению может соответствовать только одна директория.
Размер директории файла может изменяться,
поскольку она, как правило, содержит переменное количество записей данных,
тегов. Каждый тег, подобно полю заголовка, хранит уникальную информацию. Однако
между тегами существуют некоторые различия. Они могут добавляться в директорию
и удаляться из нее. Поля же обычного заголовка являются постоянными и
неперемещаемыми. Т.е., количество тегов в IFD может изменяться, а количество
полей обычного заголовка является постоянным.
Организация тегов TIFF. Тег можно сравнить с
полем данных заголовка файла. Правда, поле данных заголовка содержит только
данные постоянной длины и обычно имеет постоянную позицию в заголовке файла;
тег же может содержать или указывать данные, занимающие любое количество байтов
и расположенные в любом месте директории.
Такая универсальность тега возможна благодаря
его размеру. Поле заголовка, применяемое для хранения 1 байта данных, занимает
всего 1 байт. Тег, содержащий всего 1 байт информации, все равно занимает 12
байтов.
Тег формата TIFF имеет следующую структуру:
алгоритм сжатие
графический формат
Typedef struct _TifTag
{
Tagid; /* Идентификатор
тега */Datatype; /* Скалярный тип элементов данных */DataCount; /* Количество
элементов данных тега */DataOffset; /* Смещение элементов данных */
} TIFTAG;
Поле Tagid содержит числовое значение,
идентифицирующее тип информации, содержащейся в теге. Обычно в каждом файле
TIFF имеются сведения о высоте и ширине изображения, пиксельной глубине и схеме
кодирования Данных, примененной для сжатия растра. Обычно теги идентифицируются
по полю Tagid и всегда записываются в директории в порядке возрастания его
значений.
Данные изображения. Файлы TIFF хранят только
растровые данные, хотя, по мнению специалистов, в состав файла могут быть
добавлены несколько тегов, поддерживающих векторные изображения. Растровые
данные в файле TIFF не всегда расположены сразу после заголовка, как в
большинстве других форматов. Напротив, они могут находиться почти в любом месте
файла TIFF.
Изображения, записанные в формате TIFF 6.0,
могут быть организованы и в виде полос, и в виде фрагментов.
Полосы. Полоса представляет собой отдельный
набор из одной и более последовательно расположенных строк растровых данных
изображений. Разделение данных изображений на полосы значительно упрощает
буферирование, произвольный доступ и чередование. Подобный подход, называемый
также разделением на блоки или порции, существует и в некоторых других файловых
форматах. Однако разделение на полосы в формате TIFF имеет несколько
существенных отличий от других подобных концепций.
Для определения полосы растровых данных в файле
TIFF используются три тега: RowsPerStrip, StripOffsets и StripByteCounts.
Тег RowsPerStrip задает количество строк сжатых
растровых данных в каждой полосе. Значение по умолчанию тега RowsPerStrip,
равное 232-1, указывает максимально возможный размер изображения TIFF. Для всех
полос в субфайлах TIFF применяется однотипная схема сжатия, Все они имеют
одинаковые битовый и цветовой пол, пиксельную глубину и т.п. Чтобы определить
количество полос в субфайле изображения, отличного от YCbCr, используются теги
RowsPerStrip и ImageLenght.
Тег StripOffsets содержит массив смещений (по
одному на полосу), которые указывают позицию первого байта каждой полосы в
файле TIFF. Первый элемент массива указывает смещение первой полосы, второй -
смещение второй полосы и т.д. Если данные изображения разделены на плоскости
(PIanarConfiguration == 2), то тег StripOffsets располагает двухмерным массивом
значений - таблицей шириной SampIesPerPixeI. В таком случае сначала
записываются все колонки компонента цвета (плоскости) со значением 0, затем все
колонки компонента цвета (плоскости) со значением 1 и т.д. Полосы данных
изображения, организованные в виде плоскостей, могут записываться в файл TIFF в
любом порядке, но обычно записываются либо по плоскостям (RRRRGGGGBBBB), либо
по компонентам цвета (RGBRGBRGBRGB). Значения тега StripOffsets всегда
рассматриваются как показатели смещения от начала файла.
Тег StripByteCounts описывает массив значений,
указывающих размер каждой полосы в байтах. Подобно тегу StripOffsets он
содержит одномерный (в случае порций) или двухмерный (в случае плоскостей)
массив значений - по одному на полосу. Каждое из этих значений характеризует
количество байтов сжатых растровых данных, записанных в соответствующей полосе.
Целесообразность этого тега объясняется
следующим. В некоторых случаях полосы изображения занимают в файле различное
количество байтов, например из-за сжатия растровых данных изображения. Значение
тега StripByteCounts определяет размер полосы изображения после сжатия данных
изображения. Хотя несжатые строки изображения, как правило, занимают постоянное
количество байтов, размер сжатой строки зависит от типа содержащихся в ней
данных. Поскольку мы обычно записываем в полосу фиксированное количество строк
(а не байтов), то, очевидно, что большинство полос будут различаться по длине -
ведь каждая сжатая строка имеет свой размер. Если же растровые данные не
сжимались, то все полосы будут одинаковыми по размеру.
Программы записи TIFF обычно пытаются создавать
полосы таким образом, чтобы каждая из них включала в себя одинаковое количество
строк. Например, растр из 2200 строк может быть разделен на 22 полосы, каждая
из которых будет содержать 100 строк растровых данных. Но такое деление не
всегда возможно. Положим, растр состоит из 482 строк. Если его разделить на
полосы, содержащие по пять строк, то получим 97 полос, причем 96 из них будут
состоять из пяти строк данных, а 97-я - только из двух. В этом случае значение
пятого тега RowsPerStrip будет корректным для всех полос, кроме последней.
Программе чтения TIFF не обязательно знать количество строк в каждой полосе.
Достаточно прочесть последнее значение тега StripByteCounts, чтобы определить
количество байтов, которое следует прочесть для формирования последней полосы.
В организации растровых данных в виде полос есть
определенные преимущества. Например, в случае графических файлов большого
объема могут возникнуть ситуации, когда все изображение не помещается в
оперативной памяти ПЭВМ. В этом случае осуществляется считывание полосы, а
затем производится ее обработка. После обработки данных производится считывание
следующих полос. Если изображение помещается в памяти целиком, то сначала
читаются все полосы файла TIFF, а после этого происходит обработка данных.
Во-вторых, создав таблицу смешений полос, можно
значительно упростить произвольный доступ к растровым данным. Если необходимо
отобразить, например, последние 100 строк изображения, состоящего из 480 строк,
а растровые данные разделены на 48 полос по десять строк в каждой, то программа
чтения TIFF может пропустить первые 380 строк и обработать только те полосы,
смещения которых записаны в последних десяти элементах массива тега
StripOffsets. Если смещение не указано, то для определения начальной позиции
последних 100 строк необходимо читать все изображение с его начала.
Фрагменты. Полосы не являются единственно
возможным способом организации растровых данных. В TIFF 6.0 представлена
концепция разделения растровых данных на фрагменты. Полоса - это одномерный
объект, имеющий только длину, а фрагмент можно рассматривать как двухмерные
блоки (полосы), имеющие длину и ширину (подобно растру). Фактически каждый
фрагмент изображения можно рассматривать как сегмент растра. Таким образом,
изображение представляется в виде совокупности сегментов, называемых в
спецификациях TIFF
фрагментами, с учетом их местоположения в оригинале изображения.
Разделение изображения на прямоугольные
фрагменты имеет огромное преимущество (особенно в случае очень больших
изображений с высоким разрешением) по сравнению с разделением на горизонтальные
полосы.
Многие алгоритмы сжатия, и в частности JPEG, для
сжатия данных используют двухмерные фрагменты - блоки, а не одномерные полос.
Хранение сжатых данных в виде фрагментов способствует ускорению дешифровки
данных. Концепции разделения данных изображения на фрагменты (сегменты)
включены в спецификацию TIFF 6.0.
Если вместо полос применяются фрагменты, то три
тега, описывающие полосы (RowsPerStrip, StripByteCounts и StripOffsets),
заменяются тегами TileWidth, TileLenght, TileOffsets и TileByteCounts. Их
предназначение и способ применения фактически те же, что и у тегов, описывающих
полосы. Подобно полосам все фрагменты могут быть либо несжатыми, либо сжатыми
по одной схеме. Изображения TIFF могут быть разделены либо только на полосы,
либо только на фрагменты.
Теги TileWidth и TileLenght описывают размер
фрагментов данных изображения. Их значения должны быть кратными 16, а все
фрагменты субфайла должны иметь один размер. Это очень важно для некоторых
программ особенно в случае применения ориентированной на фрагменты схемы сжатия
JPEG. Спецификация TIFF 6.0 рекомендует, чтобы фрагменты были прямоугольной
форма и содержали (до сжатия) от 4 до 32 Кб данных изображения.
Значения тегов TileWidth и TileLenght могут
применяться для определения количества фрагментов субфайлов изображений,
отличных от YCbCr:
= (ImageWidth + (TileWidth - 1)) /
TileWidth;= (ImageLength + (TileLength - 1)) / TileLength;
= TilesAcross * TilesDown;
Если изображение разделено на плоскости
(PIanarConnguration = 2), то количество фрагментов можно вычислить следующим
образом:
== TilesAcross
* TilesDown * SamplesPerPixel;
Тег TileOnffets содержит массив смещений первых
байтов каждого фрагмента. Фрагменты записываются в субфайл в произвольном
порядке. Каждый фрагмент имеет собственное смещение и не зависит от других
фрагментов в субфайле. Смещения в этом теге указываются в направлении слева
направо и сверху вниз. Если данные изображения разделены на плоскости, то вначале
записываются все смещения для первой плоскости, затем все смещения для второй и
т.д. Количество смещений в этом теге равно количеству фрагментов изображения
(PIanarConnguration = 1) или количеству фрагментов, умноженному на значение
тега SamplesPerPixel (PIanarConnguration = 2). Смещения всегда указываются от
начала файла TIFF.
Последний тег - TileByteCounts - содержит данные
о количестве байтов в каждом сжатом фрагменте. Количество значений этого тега
также равно количеству фрагментов изображения, причем эти значения упорядочены
тем же способом, что и значения тега TileOffsets.
Обычно размер фрагмента выбирается таким, чтобы
точно разделить изображение. Изображение шириной 6400 пикселей и длиной 4800
пикселей можно точно разделить на 150 фрагментов шириной 640 пикселей и длиной
320 пикселей. Однако не все изображения имеют размеры, кратные 16. Изображение
шириной 2200 пикселей и длиной 2850 пикселей нельзя точно разделить на
фрагменты, размеры которых будут кратными 16. В этом случае решением может стать
выбор рациональных размеров фрагмента и дополнение изображения.
Под рациональными понимаются такие размеры
фрагмента, при которых размер изображения будет перекрываться минимально. При
указанном выше размере изображения можно применить разбиение на фрагменты
шириной 256 пикселей и длиной 320 пикселей, т.е. сохранить почти то же
соотношение ширины и высоты, что и у исходного изображения. Разбиение на
фрагменты таких размеров потребует применения по 104 дополнительных пикселя
набивки в каждой строке и 30 дополнительных строк. Размер данных изображения с
учетом набивки теперь составит 2304 пикселя в ширину и 2880 пикселей в длину,
что позволит точно разделить это изображение на 81 фрагмент размером 256 х 320
пикселей.
Цвета изображения. Спецификация TIFF предлагает
концепцию основных типов изображений: двухуровневое, полутоновое, цветное с
палитрой и полноцветное. Для каждого основного типа изображений установлен
обязательный минимальный объем тегов.
TIFF
поддерживает два способа хранения цветовых данных. TIFF-P
подобен GIF и
использует цветовую палитру (карту) для изображения. Тогда сами данные об
изображении хранятся как коды в соответствии с цветовой картой. Этот метод
обеспечивает эффективность хранения, но ограничивает палитру 256 цветами.
Цветовая карта создает свои элементы из 48-битовой палитры (основная
структурная единица TIFF
- 2-байтовое слово, следовательно, по 16 цветов предоставлено каждой из
цветовых плоскостей аддитивной цветовой модели RGB:
красной, зеленой и синей). TIFF-R
используется для определения полных RGB-изображений.
Элемент растра представляется тремя 8-битовыми RGB-значениями,
что обеспечивает более 16 миллионов цветов.
Сжатие. TIFF
считается хорошо сжимающим форматом. Он поддерживает несколько схем сжатия,
специальные функции управления изображением и многие другие возможности. Кроме
того, он позволяет применять схему сжатия, заключающуюся в добавлении
необходимых тегов, определяемых пользователем. Формат TIFF 4.0 поддерживал лишь
групповое кодирование (RLE) и CCITT (T.4 и Т.6). Обычно эти схемы применяются
только для сжатия 8-битовых цветных и полутоновых, а также 1-битовых
черно-белых изображений соответственно. В TIFF 5.0 была добавлена схема сжатия
LZW, обычно используемая при работе с цветными изображениями, а в TIFF 6.0 - метод
JPEG, применяемый для сжатия многоградационных цветных и полутоновых
изображений. В TIFF применяется также схема сжатия PackBits RLE, используемая
инструментальными средствами Macintosh.
Еще одной особенностью TIFF
является спецификация разрешающей способности оборудования, например, IBM
PC, Macintosh
и т.д.
Формат TIFF
характеризуется большими объемами получаемых файлов (например, изображение
формата A4 в цветовой модели
CMYK с разрешением 300 dpi,
обычно применяемым для высококачественной печати, имеет объем порядка 40
Мбайт). Поэтому он используется преимущественно при вводе информации со
сканеров и в электронных версиях печатных изданий.
2. Возможности использования современных GPU
Появление современного GPU для вычисления общего
назначения обеспечило платформу, чтобы написать заявления, которые могут
управлять на сотнях маленьких ядер. CUDA (Вычисляют Объединенную Архитектуру
Устройства) является выполнением NVIDIA этой параллельной архитектуры на их GPU
и предоставляет ПЧЕЛУ программистам, чтобы разработать параллельные приложения,
используя язык программирования. CUDA обеспечивает абстракцию программного
обеспечения для аппаратных средств, названных блоками, которые являются группой
нити, которые могут разделить память. Эти блоки назначены на многие скалярные
процессоры, которым доступны аппаратные средства. Восемь скалярных процессоров
составляют мультипроцессор, и различные модели GPU содержат отличающееся
количество мультипроцессора.
Сжатие - важная и полезная техника, которая
может быть медленной на текущих центральных процессорах.
Первым алгоритмом сжатия, было сжатие
изображения JPEG. Большие файлы обычно будут требовать некоторые формы
вытекания данных и от GPU, JPEG требует только несколько копий памяти и от
устройств, уменьшая необходимую полосу пропускания памяти GPU и наверху.
Графический процессор (англ.
<http://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA>
Graphics processing unit, GPU) - отдельное устройство персонального компьютера
<http://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D1%81%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80>
или игровой приставки
<http://ru.wikipedia.org/wiki/%D0%98%D0%B3%D1%80%D0%BE%D0%B2%D0%B0%D1%8F_%D0%BF%D1%80%D0%B8%D1%81%D1%82%D0%B0%D0%B2%D0%BA%D0%B0>,
выполняющее графический рендеринг
<http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BD%D0%B4%D0%B5%D1%80%D0%B8%D0%BD%D0%B3>.
Современные графические процессоры очень эффективно обрабатывают и отображают
компьютерную графику
<http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D0%BA%D0%B0>,
благодаря специализированной конвейерной архитектуре они намного эффективнее в
обработке графической информации, чем типичный центральный процессор
<http://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BD%D1%82%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80>.
Графический процессор в современных
видеоадаптерах
<http://ru.wikipedia.org/wiki/%D0%92%D0%B8%D0%B4%D0%B5%D0%BE%D0%B0%D0%B4%D0%B0%D0%BF%D1%82%D0%B5%D1%80>
применяется в качестве ускорителя трёхмерной графики
<http://ru.wikipedia.org/wiki/%D0%A2%D1%80%D1%91%D1%85%D0%BC%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D0%BA%D0%B0>,
однако его можно использовать в некоторых случаях и для вычислений (GPGPU
<http://ru.wikipedia.org/wiki/GPGPU>). Отличительными особенностями по
сравнению с ЦП <http://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BD%D1%82%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80>
являются:
· архитектура, максимально нацеленная
на увеличение скорости расчёта текстур
<http://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BA%D1%81%D1%82%D1%83%D1%80%D0%B0_(%D1%82%D1%80%D1%91%D1%85%D0%BC%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D0%BA%D0%B0)>
и сложных графических объектов;
· ограниченный набор команд.
Примером может служить чип R520
<http://ru.wikipedia.org/w/index.php?title=R520&action=edit&redlink=1>
от ATI <http://ru.wikipedia.org/wiki/ATI> или G70
<http://ru.wikipedia.org/w/index.php?title=G70&action=edit&redlink=1>
от nVidia <http://ru.wikipedia.org/wiki/NVidia>.
Современные графические процессоры
обладают значительно большей производительностью при вычислениях с плавающей
запятой, чем центральные процессоры. В наши дни графический процессор нашел
применение в самых различных областях высокопроизводительных вычислений,
включая компрессию, высококачественный рендеринг, трассировку лучей, машинное
зрение, биоинформатику, решение систем линейных уравнений, моделирование
физических эффектов и др. В то же время, перенос части (или всей)
вычислительной нагрузки с центрального процессора на графический может
обеспечить значительные преимущества не только при решении научных или
узкоспециализированных задач, но и повседневных пользовательских. В качестве
одной из таких задач, обеспечивающих значительную вычислительную нагрузку,
автором выбрано сжатие данных.
Методы: Решение поставленной задачи основано на
разработке специфических программ-шейдеров. Для эффективного использования
особенностей архитектуры графического процессора необходимо обеспечить
значительный параллелизм вычислений. В процессе выполнения проекта мы ориентируемся
на продукты компании NVIDIA: новые семейства графических процессоров - g80 и
g92; среду разработки CUDA SDK (www.nvidia.com). Используя фундаментальный
алгоритм сжатия данных и возможность его распараллеливания, можно разработать
новый алгоритм, более производительный и требующий меньшего количества ресурсов
для исполнения. В качестве базового алгоритма был выбран алгоритм сжатия данных
LZW (Lempel/Ziv/Welch). Последовательный характер этого алгоритма и структур
данных, использованных в нем, позволяет разбить входной поток данных на
несколько независимо друг от друга обрабатывающихся потоков. Результаты:
Предлагаемый подход имеет ряд преимуществ: 1) почти полная разгрузка
центрального процессора; 2) графический процессор является устройством изначально
ориентированным на сложные арифметические операции; 3) конвейерная обработка
данных, организованная в графическом процессоре, позволяет производить
параллельную обработку больших массивов данных. Слабым местом такого подхода
является интерфейс между центральным и графическим процессорами, так как
значительное время тратится на пересылку данных между этими устройствами.
Однако, этот недостаток носит условный характер, так как: 1) ведется разработка
и внедрение оборудования, имеющего большую пропускную способность интерфейса
графического процессора; 2) оптимизация шейдеров программистами может
практически свести на нет падение производительности при пересылке данных. В
отношении реализации алгоритма LZW на графическом процессоре следует отметить,
что незначительное увеличение результирующего файла по сравнению с классическим
алгоритмом LZW компенсируется гораздо большей скоростью вычислений и
практически полным освобождением центрального процессора от вычислительной
нагрузки. Преимущества данного подхода определяют перспективность разработки
алгоритмов сжатия для графических процессоров.
.1 Алгоритм
Шаги алгоритма должны быть выполнены в
последовательной манере, потому что операции в каждом блоке зависят от
продукции предыдущего блока. Сжатие начинается, загружая несжатое изображение в
форме 24-битового изображения битового массива с 8-битовой краснотой, зелёной и
синие ценности для каждого пиксела. Изображение загружено в главную память, и Jpeglib
выполняет операции на блоках из 8x8
пикселя под названием MCU
(минимальные закодированные единицы). Первый шаг после погрузки изображения
должен преобразовать ценности RGB
к YCC (luma,
синяя насыщенность цвета, красная насыщенность цвета). Это просто ряд линейных
операций на трех ценностях RGB
для каждого пиксела по изображению. Цель преобразование должна отделить яркость
(luma) изображения от
отдельных цветов.
.2 Исполнительные точки отсчёта
Ускорение выполнения
Центральный процессор только последовательная
версия 1.00
GPU Spectral Floor Calc & PCM
Window 0.23PCM Окно только
0.56PCM Окно
только,
memcpy удалил
1.17Spectral Floor Calc & PCM Windows &
MDCT для петель 0.79PCM Windows & MDCT для
петель 0.93PCM Windows & MDCT для петель, memcpy
удаленный 1.28
Исполнительные точки отсчета были взяты на
базируемой системе Windows, используя NVidia 8800 GTS 512, у которого была
полоса пропускания памяти между центральным процессором и пространством GPU 1.5
GB/s. От собранных данных могут быть сделаны несколько выводов. Первое и самое
очевидное заключение состоит в том, что спектральное вычисление пола, которое
требует верхнего из копирования трех множеств с плавающей запятой к GPU и
только вовлекает одно вычисление с плавающей запятой.
Заключение
Достаточно трудно охарактеризовать
результативность какой-либо техники сжатия данных. Степень сжатия определяется
различными факторами. LZW-сжатие выделяется среди прочих, когда встречается с
потоком данных, содержащим повторяющиеся строки любой структуры. По этой
причине он работает весьма эффективно, когда встречает английский текст.
Уровень сжатия может достигать 50% и выше. Соответственно, сжатие видеоформ и
копий экранов показывает еще большие результаты.
Трудности при сжатии файлов данных несколько
больше. В зависимости от данных, результат сжатия может быть как хорошим, так и
не очень удовлетворительным. В некоторых случаях "сжатый" файл может
превосходить по своим размерам исходный текст.
Одной из проблем является то, что приведенная
программа не адаптируется к различной длине файлов. Использование 14- или
15-битных кодов дает лучшую степень сжатия на больших файлах (это объясняется
тем, что для них строятся большие таблицы строк), но хуже работает с маленькими
файлами. Такие программы, как "ARC", решают эту проблему
использованием кодов переменной длины. Например, когда величина next_code
находится между 256 и 511, "ARC" читает и выводит 9-битные коды.
Когда величина next_code становится настолько большой, что необходимы 10-битные
коды, процедуры сжатия и распаковки увеличивают размер кода. Это значит, что
12- и 15-битные варианты программы работают хорошо и на маленьких файлах.
Другой проблемой больших файлов является то, что
с увеличением числа прочитанных байтов степень сжатия может начать ухудшаться.
Причина проста: так как размер таблицы строк фиксирован, после занесения
определенного числа строк их уже просто некуда добавить. Но построенная таблица
нужна только для той части файла, по которой она была построена. Оставшиеся
части файла могут иметь другие характеристики и в действительности нужна уже
несколько отличная таблица.
Обычным способом решения этой
проблемы является контроль степени сжатия. После того, как таблица строк
заполнена, упаковщик <http://www.pack-in.ru/> следит за поведением коэффициента
сжатия. После определенной степени его ухудшения таблица строк очищается и
начинает строиться заново.
Процедура распаковки определяет этот
момент тем, что упаковщик записывает в свой выходной поток специальный код.
Альтернативным способом является определение наиболее часто встречающихся строк
и чистка остальных. Адаптивная техника, подобная этой, может, однако, встретить
трудности реализации в программах разумного размера.
И, наконец, можно брать
вырабатываемые LZW-методом коды и пропускать их через адаптирующийся кодирующий
фильтр Хаффмана. Это дает несколько большую степень сжатия, но стоимость такой
работы более высока, также как и время обработки.
Приведенная программа была написана
и тестирована на MS-DOS машине и успешно скомпилирована и выполнена с
использованием обычного компилятора "C". Она должна работать на любой
машине, поддерживающей 16-битный целые и 32-битные длинные целые языка
"C".
Реализация компиляторов
"C" для MS-DOS обычно создает сложности при использовании массивов
больших, чем 64К байт, не позволяя использовать 15- или 16-битные коды в
программе. На машинах с другими процессорами, таких как VAX, эти сложности
преодолеваются, и облегчается использование кодов большей длины.
Отметим, что перевод этого кода на
язык ассемблера любой машины, поддерживающей 16- и 32-битную математику, не
встретит затруднений и позволит улучшить некоторые характеристики.
Различие между обычным LZW и LZW для GIF
заключаются в наличии двух дополнительных специальных кодов и переменном
размере сжатия.
Учитывая архитектуру сегодняшних систем,
возможно, продолжить повторно проектировать библиотеку Vorbis, чтобы взять
дальнейшее преимущество доступного GPU. Однако, осуществление перенесения,
вовлеченное в преобразование всех частей этот алгоритм в формат, который
является более способствующим векторной обработке, является трудоёмким,
утомительным, трудным к отладьте и вовлекает удаление многих интуитивных
элементов, достижимых арифметикой указателя.
Совместное управление алгоритмом между системным
центральным процессором и доступным GPU - эффективный метод для исполнительного
усовершенствования, когда соответствующие силы этих двух наборов микросхем
сохранены в памяти.
Список используемой литературы
1. Ватолин Д.С., Ратушняк А.,
Смирнов М., Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие
изображений и видео. - М.: ДИАЛОГ-МИФИ, 2002.
. Романов В.Ю. Популярные форматы
файлов для хранения графических изображений на IBM PC.- М.:Унитех, 1992.
. Семенюк В. В. Экономное
кодирование дискретной информации. - СПб.: СПбГИТМО (ТУ), 2001.
4.
<http://library.mephi.ru/data/scientific-sessions/2001/13/2146.html>
.
<http://algolist.manual.ru/compress/standard/lzw.php>
Приложение
/*Демонстрационная программа для LZW-алгоритма
сжатия/распаковки данных.*/
/* Mark R. Nelson*/
#include <stdio.h>
#define BITS 12 /* Установка длины кода равной
12, 13 */
#define HASHING_SHIFT BITS-8 /* или
14 битам.
*/
#define MAX_VALUE (1 << BITS) -1/*
Отметим, что на MS-DOS-машине при */
#define MAX_CODE MAX_VALUE - 1 /* длине кода 14
бит необходимо компилировать, используя large-модель. */
#if BITS == 14
#define TABLE_SIZE 18041 /* Размер таблицы строк
должен быть */
#endif /* простым числом, несколько большим, */
#if BITS == 13 /* чем
2**BITS. */
#define TABLE_SIZE 9029
#endif
#if BITS <= 12
#define TABLE_SIZE 5021
#endif*malloc();
/* Это массив для значений кодов */*code_value;
/* Этот массив содержит префиксы кодов */int
*prefix_code;
/* Этот массив содержит добавочные символы
*/char *append_character;
/* Этот массив содержит декодируемые строки
*/char decode_stack[4000];
/*Эта программа получает имя файла из командной
строки. Она упаковывает файл, посылая выходной поток в файл test.lzw. Затем
распаковывает test.lzw в test.out. Test.out должен быть точной копией исходного
файла.*/
main(int argc, char *argv[])
{*input_file;*output_file;*lzw_file;input_file_name[81];
/*Эти три буфера необходимы на стадии
упаковки.*/
code_value=malloc(TABLE_SIZE*sizeof(unsigned
int));_code=malloc(TABLE_SIZE*sizeof(unsigned int));_character=malloc(TABLE_SIZE*sizeof(unsigned
char));(code_value==NULL || prefix_code==NULL || append_character==NULL)
{("Fatal error allocating table
space!\n");
exit();
}
/*Получить имя файла, открыть его и открыть
выходной lzw-файл.*/
if
(argc>1)(input_file_name,argv[1]);
{("Input file name?
");("%s",input_file_name);
}_file=fopen(input_file_name,"rb");_file=fopen("test.lzw","wb");(input_file==NULL
|| lzw_file==NULL)
{("Fatal error opening
files.\n");();
};
/*Сжатие
файла.*/(input_file,lzw_file);(input_file);(lzw_file);
free(code_value);
/*Сейчас открыть файлы для распаковки.*/
lzw_file=fopen("test.lzw","rb");_file=fopen("test.out","wb");(lzw_file==NULL
|| output_file==NULL)
{("Fatal error opening
files.\n");();
};
/*Распаковка
файла.*/(lzw_file,output_file);(lzw_file);(output_file);(prefix_code);(append_character);
}
/*Процедура
сжатия.*/(FILE
*input,FILE *output)
{int next_code;int character;int
string_code;int index;
int i;_code=256; /* Next_code - следующий
доступный код строки */(i=0;i<TABLE_SIZE;i++)/*Очистка таблицы строк перед
стартом */
code_value[i]=-1;=0;("Compressing...\n");_code=getc(input);
/* Get the first code*/
/*Основной цикл. Он выполняется до тех пор, пока
возможно чтение входного потока. Отметим, что он прекращает заполнение таблицы
строк после того, как все возможные коды были использованы.*/
while ((character=getc(input)) !=
(unsigned)EOF)
{(++i==1000) /* Печатает * через каждые 1000 */
{ /* чтений входных символов (для */=0; /*
умиротворения зрителя). */
printf("*");
}
index=find_match(string_code,character);(code_value[index]
!= -1) /* в таблице.
Если
есть, */_code=code_value[index];/* получает значение кода*//* Если нет,
добавляет ее */
{ /* в
таблицу.
*/(next_code <= MAX_CODE)
{_value[index]=next_code++;_code[index]=string_code;_character[index]=character;
}_code(output,string_code);/*Когда
обнаруживается,
что*/
string_code=character; /*строки нет в таблице,
*/
} /*выводится последняя строка*/
} /*перед
добавлением
новой
*/
/*
** End of the main loop.
*/_code(output,string_code); /* Вывод
последнего
кода
*/_code(output,MAX_VALUE); /* Вывод
признака
конца
потока
*/
output_code(output,0); /* Очистка буфера вывода
*/("\n");
}
/*Процедура хэширования. Она пытается найти
сопоставление для строки префикс+символ в таблице строк. Если найдено,
возвращается индекс. Если нет, то возвращается первый доступный индекс.*/
find_match(int hash_prefix,unsigned
int hash_character)
{index;offset;= (hash_character
<< HASHING_SHIFT) ^ hash_prefix;(index == 0)= 1;= TABLE_SIZE - index;(1)
{(code_value[index] ==
-1)(index);(prefix_code[index]==hash_prefix
&&append_character[index]==hash_character)(index);-=
offset;(index < 0)+= TABLE_SIZE;
}
}
/*Процедура
распаковки.
Она
читает файл LZW-формата и распаковывает его в выходной файл.*/
expand(FILE *input,FILE *output)
{int next_code;int new_code;int
old_code;character;counter;char *string;*decode_string(unsigned char
*buffer,unsigned int code);
next_code=256; /* Следующий доступный код. */=0;
/* Используется при выводе на экран.*/("Expanding...\n");_code=input_code(input);/*Читается
первый код, инициализируется*/=old_code; /* переменная character и посылается
первый */(old_code,output); /* код в выходной файл. */
/*Основной цикл распаковки. Читаются коды из
LZW-файла до тех пор, пока не встретится специальный код, указывающий на конец
данных.*/
while ((new_code=input_code(input))
!= (MAX_VALUE))
{(++counter==1000) { counter=0;
printf("*"); }
/*
** Проверка кода для специального случая
** STRING+CHARACTER+STRING+CHARACTER+
** STRING,
когда генерируется неопределенный код.
** Это заставляет его декодировать последний
код,
** добавив CHARACTER в конец декод. строки.
*/(new_code>=next_code)
{
*decode_stack=character;=decode_string(decode_stack+1,old_code);
}
/*Иначе
декодируется
новый
код.*/=decode_string(decode_stack,new_code);
/*Выводится декодируемая строка в обратном
порядке.*/
character=*string;(string >=
decode_stack)
putc(*string--,output);
/*Наконец, если возможно, добавляется новый код
в таблицу строк.*/
if (next_code <= MAX_CODE)
{_code[next_code]=old_code;_character[next_code]=character;_code++;
}_code=new_code;
}("\n");
}
/*Процедура простого декодирования строки из
таблицы строк, сохраняющая результат в буфер. Этот буфер потом может быть
выведен в обратном порядке программой распаковки.*/
char *decode_string(unsigned char
*buffer,unsigned int code)
{i;=0;(code > 255)
{
*buffer++ =
append_character[code];=prefix_code[code];(i++>=4094)
{("Fatal error during code
expansion.\n");();
}
}
*buffer=code;(buffer);
}
/*Следующие две процедуры управляют
вводом/выводом кодов переменной длины. Они для ясности написаны чрезвычайно
простыми и не очень эффективны.*/
input_code(FILE *input)
{int return_value;int
input_bit_count=0;unsigned long input_bit_buffer=0L;(input_bit_count <= 24)
{_bit_buffer|=(unsigned
long)getc(input)<<(24-input_bit_count);_bit_count += 8;
}_value=input_bit_buffer >>
(32-BITS);_bit_buffer <<= BITS;_bit_count -= BITS;(return_value);
}_code(FILE *output,unsigned int
code)
{int output_bit_count=0;unsigned
long output_bit_buffer=0L;_bit_buffer|=(unsigned
long)code<<(32-BITS-output_bit_count);_bit_count +=
BITS;(output_bit_count >= 8)
{(output_bit_buffer >>
24,output);_bit_buffer <<= 8;_bit_count -= 8;
}