Система нахождения графических примитивов на изображении на основе преобразования Хафа
Система
нахождения графических примитивов на изображении на основе преобразования Хафа
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
. АНАЛИЗ СУЩЕСТВУЮЩИХ МЕТОДОВ
НАХОЖДЕНИЯ ГРАФИЧЕСКИХ ПРИМИТИВОВ И ПРОГРАММНЫХ РЕАЛИЗАЦИЙ
.1 Графические примитивы и методика
их отыскания
.2 Анализ и предварительная
обработка входных данных
.2.1 Фильтрация шумов
.2.2 Выделение границ
.3 Базовое преобразование Хафа
.3.1 Поиск прямых
.3.2 Выделение окружностей на
изображении
.3.3 Нахождение кривых высшего
порядка
.4 Модификации преобразования Хафа
.5 Нахождение точечных особенностей
изображения
.5.1 Детектор Харриса
.5.2 Масочный детектор
.6 Сравнительная характеристика
алгоритмов детекции
.7 Анализ существующих программных
решений
.8 Выводы по главе
. РАЗРАБОТКА ПРОГРАММНОГО ПРОДУКТА
.1 Структура программного продукта
.2 Руководство программиста
.3 Руководство пользователя
.4 Тестирование ПП
.5 Выводы по главе
ЗАКЛЮЧЕНИЕ
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
ВВЕДЕНИЕ
Системы компьютерного зрения и распознавания
образов широко входят в обыденную жизнь современного человека. Если изначально
такие системы, применялись исключительно в военных и медицинских целях, то
сейчас существует широкий спектр задач, где компьютерное зрение позволяет
эффективно решать задачи управления и оповещения.
Такие системы выполняют преобразование исходных
многомерных данных (цветных растровых изображений) в набор обобщенных выходных
данных (классов объектов, гипотез, функций принадлежности.). На начальных
этапах такого преобразования часто требуется найти графические примитивы -
окружности, эллипсы, прямоугольники, кривые, прямые и пр., - на сложном
зашумленном изображении и построить карту графических примитивов.
Преобразованная информация используется в
качестве входных данных для охранных систем, систем оптического распознавания
бумажных документов, картографических систем и систем моделирования трехмерных
сцен и объектов. На рынке существует ряд продуктов, выполняющих задачу сбора
данных по графическим примитивам. Однако алгоритмы и подходы, применяющиеся в
таких системах, не позволяют корректно проанализировать кадр, схему или
изображение, полученные в сложных условиях освещения. Программный продукт,
разрабатываемый на основе данного исследования, должен устранить этот пробел за
счет применения гибко настраиваемых фильтров и механизмов предварительной
обработки изображений, а также эффективных алгоритмов преобразования
изображения и поиска графических примитивов на основе данных, полученных на
предварительных этапах.
Целью данной работы является разработка программного
продукта, позволяющего проводить анализ изображения для нахождения и
классификации графических примитивов, формировать математическую модель и
осуществлять сбор информации о характеристиках графических примитивов (длина,
радиус, площадь и т.д.). Для достижения
заданной цели должны быть решены следующие задачи:
– Обзор существующих алгоритмов нахождения
геометрических объектов на изображении. Рассмотрение основных этапов
предварительной обработки изображения.
– Разработка классификации графических
примитивов.
– Разработка алгоритмов на основе базового
преобразования Хафа и его модификаций.
– Исследование механизмов нахождения
точечных особенностей изображения.
– Реализация программного продукта.
– Тестирование и отладка.
Первая глава выпускной квалификационной работы
посвящена проблемам классификации графических примитивов, а также существующим
подходам к их нахождению. Рассмотрен механизм обработки изображения, начиная с
исходного изображения, до получения информации о найденных объектах. Проведен
обзор шумоподавляющих фильтров, операторов детектирования краев изображения,
методов бинаризации. Рассмотрен базовый алгоритм преобразования Хафа и его
модификации. Проведен обзор алгоритмов нахождения точечных особенностей
изображения. Выполнена сравнительная характеристика методов на основе
преобразования Хафа.
Вторая глава работы посвящена описанию
программной реализации рассмотренных методов детектирования объектов. Приведены
руководства пользователя и программиста, в которых изложены основные аспекты,
необходимые для работы и сопровождения данного программного продукта.
По данной тематике был сделан доклад на
научно-практической конференции студентов, аспирантов и молодых ученых
"Актуальные проблемы авиации и космонавтики" (Красноярск, 2011).
1.
АНАЛИЗ СУЩЕСТВУЮЩИХ МЕТОДОВ НАХОЖДЕНИЯ ГРАФИЧЕСКИХ ПРИМИТИВОВ И ПРОГРАММНЫХ
РЕАЛИЗАЦИЙ
.1 Графические примитивы и методика их отыскания
Под графическим примитивом понимается простейший
геометрический объект, отображаемый на экране дисплея. Основное назначение примитивов
- обеспечить программистов и пользователей удобным набором средств для
формирования геометрических объектов. Описание графического примитива обычно
содержит метрическую и атрибутивную части. Метрическая часть позволяет
сопоставить те величины, в которых задан графический примитив для отображения
его на дисплее и те величины, которые характеризуют его физическое или
логическое представление. Атрибутивная часть передает геометрические параметры,
характеризующие форму и расположение графического примитива.
В
основе построения любых графических элементов в современных графических
библиотеках лежат три основных примитива: точка, отрезок и треугольник. Нередко
в качестве примитива выступают прямоугольники, окружности, эллипсы, полигоны
произвольных форм и др. Классификация графических примитивов приведена в
таблице 1. В большинстве
задач, решаемых в рамках компьютерного зрения, особое значение имеют точки,
отрезки, треугольники, окружности и прямоугольники. Для обнаружения графических
примитивов на изображении используется ряд методов и алгоритмов. Сравнительный
анализ наиболее часто применяемых методов данного назначения приведен в таблице
2.
Таблица 1 - Классификация графических примитивов
|
Тип
примитива
|
Описание
|
|
Точка
|
Простейший
графический примитив, имеющий нулевую размерность. Точка характеризуется
только координатами своего местоположения.
|
|
Отрезок
|
Совокупность
точек, через которые проходит геометрический отрезок с заданными конечными
точками. Характеризуется начальной и конечной точками, или начальной точкой и
приращениями координат, или длиной и углом наклона.
|
|
Ломаная
|
Последовательности
отрезков, соединяющих заданные точки.
|
|
Полигон
|
Область,
ограниченная замкнутой ломанной.
|
|
Эллипс
|
Геометрическое
место точек плоскости, для которых сумма расстояний до двух данных точек
(фокусы) постоянна и больше расстояния между ними.
|
|
Окружность
|
Геометрическое
место точек плоскости, равноудаленных от заданной точки, называемой центром,
на заданное ненулевое расстояние, называемое ее радиусом.
|
|
Парабола
|
Геометрическое
место точек, равноудаленных от данной прямой (директриса параболы) и данной
точки (фокус параболы).
|
|
Гипербола
|
Геометрическое
место точек плоскости, для которых абсолютное значение разности расстояний до
двух выделенных точек (фокусы) постоянно.
|
|
Треугольник
|
Частный
случай полигона, ограниченный замкнутой ломанной, состоящей из трех отрезков.
|
|
Прямоугольник
|
Полигон,
ограниченный замкнутой ломанной в форме четырехугольника, все углы которого
прямые.
|
Таблица 2. Сравнительный анализ подходов к
обнаружению графических примитивов
|
Подход
|
Преимущества
|
|
Преобразование
Хафа
|
Полное
покрытие возможных состояний и положения объекта (за счет полного перебора в
стандартном алгоритме). Модифицируемость алгоритма, что позволяет сократить
время полного перебора без потери существенной информации.
|
Предназначен
лишь для поиска прямых и окружностей.
|
|
Преобразование
Радона
|
Инвариантность
по отношению к качеству изображения. Применяемый математический аппарат
позволяет легко переходить к другим видам преобразований (аффинным, Фурье).
|
Сложность
реализации. Огромное число операций.
|
|
Генетические
алгоритмы
|
В
некоторых случаях позволяют добиться большей производительности по сравнению
с преобразованиями Хафа и Радона. Адаптируемость к изменяющимся
характеристикам изображения.
|
Эвристический
алгоритм, не позволяет говорить о детерминированности проводимых
исследований.
|
В данной работе был выбран подход на основе
преобразования Хафа. Преобразование Хафа позволяет добиться приемлемых
результатов в рамках задач компьютерного зрения (например, в задачах
распознавания рукописного текста) без потерь производительности. Ограниченность
базового алгоритма в поиске прямых и окружностей исключается при использовании
модификаций преобразования Хафа, а также применением аппроксимационных методов
для нахождения более сложных графических примитивов (треугольников,
прямоугольников). Задача поиска точек на изображении решается с применением
угловых детекторов, основанных на схожих с преобразованием Хафа методиках
анализа пространства изображения.
.2 Анализ и предварительная обработка входных
данных
Входными данными для преобразования Хафа служат
монохромные изображения. Процесс получения геометрического описания
пространства изображения заключается в прохождении следующих этапов:
а) Ввод растрового цветного изображения.
б) Преобразование в полутоновое
изображение.
в) Сглаживающая фильтрация (для устранения
шумов).
г) Операторы выделения краев.
д) Бинаризация.
е) Преобразование Хафа (для нахождения
точек, прямых, окружностей, треугольников и прямоугольников) или применение
детектора Харриса и масочного детектора (для нахождения особых точек).
Рассмотренная последовательность действий не
является строго фиксированной и допускается изменение порядка следования
некоторых этапов, а также дополнение иными действиями по предварительной
обработке изображения (например, применение морфологических операций).
1.2.1 Фильтрация шумов
В процессе считывания и преобразования в
цифровой массив изображение подвергается различным искажениям и зашумлению, что
требует эффективных средств его улучшения и реставрации.
Идея применения сглаживающих фильтров достаточно
ясна. Заменой исходных значений элементов изображения на средние значения по
маске фильтра достигается уменьшение "резких" переходов уровней
яркости. Поскольку случайный шум как раз характеризуется резкими скачками
яркости, наиболее очевидным применениям сглаживания является подавление шума.
Однако контуры, которые обычно представляют интерес на изображении, также
характеризуются резкими перепадами яркостей, поэтому негативной стороной
применения сглаживающих фильтров является расфокусировка контуров. Другим
применением такой процедуры может быть сглаживание ложных контуров, которые
возникают при преобразовании с недостаточным числом уровней яркости. Главное
использование сглаживающих фильтров состоит в подавлении
"несущественных" деталей на изображении. Под
"несущественными" понимаются совокупности пикселей, которые малы по
сравнения с размерами маски фильтра [1].
Свертка с маской
Как правило, фильтрация осуществляется путем
свертки с маской, представляющей фильтр. Для высокочастотной и низкочастотной
фильтрации разработано много различных масок. Некоторые из них изображены на
рисунке 1.
|
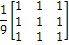
|
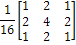
|
|
Рисунок
1 - Маски для низкочастотной фильтрации
|
Первая маска на рисунке 1 дает обычное среднее
значение. Заметим, что коэффициенты фильтра указаны как единицы, вместо 1/9.
Причина заключается в том, что такой вариант является более эффективным при
компьютерных вычислениях. Пространственный фильтр, все коэффициенты которого
одинаковы, иногда называют однородным усредняющим фильтром.
Вторая маска дает так называемое взвешенное
среднее. Этот термин применяется, чтобы показать, что значения элементов умножаются
на разные коэффициенты, что позволяет присвоить им разные веса по сравнению с
другими пикселями. Центр маски имеет самый большой вес при вычислении среднего.
Значения остальных коэффициентов в маске уменьшаются по мере удаления от центра
маски. Основная стратегия состоит в присвоении центральному пикселю наибольшего
веса, а остальным пикселям веса присваиваются обратно пропорционально их
расстоянию с целью уменьшение расфокусировки при сглаживании [1].
Медианный фильтр
Одномерный медианный фильтр представляет собой
скользящее окно, охватывающее нечетное число элементов изображения. Центральный
элемент заменяется медианой элементов изображения в окне. Медианой дискретной
последовательности N элементов
при нечетном N называют элемент,
для которого существует (N-1)/2
элементов меньших или равных ему по величине и (N-1)/2
элементов больших или равных ему по величине.
Медианный фильтр в одних случаях обеспечивает
подавление шума, а в других случаях вызывает нежелательное подавление сигнала.
Медианный фильтр не влияет на пилообразные и ступенчатые функции, что обычно
является полезным свойством, однако он подавляет импульсные сигналы,
длительность которых составляет менее половины ширины окна. Фильтр также
вызывает уплощение вершины треугольной функции.
Медианный фильтр более эффективно подавляет
разрозненные импульсные помехе, чем гладкие шумы. Медианную фильтрацию в целях
подавления шумов следует считать эвристическим методом. Следует проверять
получаемые результаты, чтобы убедиться в целесообразности медианной фильтрации
[3].
Фильтр Гаусса
Фильтр Гаусса (также известный как сглаживание
Гаусса) является результатом операции размытия изображения функцией Гаусса.
Данный подход широко применяется в графических редакторах, как правило, для
уменьшения зашумленности изображения и сглаживания резких краев. Также Гауссово
сглаживание используется в качестве оператора этапа предварительной обработки
во многих алгоритмах компьютерного зрения.
С точки зрения математики, применение фильтра
Гаусса равносильно свертке изображения с функцией Гаусса (также данный подход
известен как двумерное преобразование Вейерштрасса). Механизм работы фильтра
заключается в расчете функции Гаусса для каждого пикселя изображения. Уравнение
гауссовой функции для одного измерения имеет следующий вид:
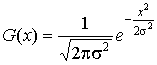
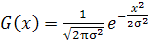 ,(1)
,(1)
где x -
координата объекта в одномерном пространстве;
s
- среднеквадратичное гауссово отклонение.
В двумерном случае дважды
осуществляется расчет функции Гаусса (1) для каждого из измерений:
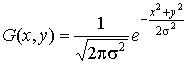
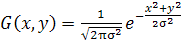 ,(2)
,(2)
где x,y -
координаты объекта в двумерном пространстве;
s
- среднеквадратичное гауссово отклонение.
Формула (2) дает поверхность,
ограниченную концентрическими окружностями, распределенными относительно
центральной точки по Гауссу. Значения, вычисляемые на основе этого
распределения, используются для построения конволюционной матрицы, которая
применяется к исходному изображению [5].
1.2.2 Выделение границ
Перепад - это связное множество пикселей,
лежащих на границе между двумя областями. Понятие перепада яркости является
"локальным", тогда как граница области, благодаря способу задания,
заключает в себе более глобальное представление. Чтобы с уверенностью классифицировать
точку как находящуюся на перепаде яркости, изменение яркости, ассоциированное с
данной точкой, должно быть существенно большим, чем допустимое изменение
яркости в точку фона. Поскольку мы имеем дело с локальными вычислениями, способ
определения того, какое значение является "существенным", а какое
нет, состоит в установлении порога. Мы определяем точку изображения как точку
перепада, если ее двумерная производная первого порядка превышает некоторый
порог. Связное множество таких точек есть перепад яркостей. Протяженный перепад
яркостей называют контуром. Термин "участок контура" обычно
используется, когда протяженность перепада мала по сравнению с размерами
изображения [16].
Операторы градиента
Вычисление первой производной цифрового
изображения основано на различных дискретных приближениях двумерного
градиента[6]. По определению, градиент изображения f(x,y)
в точке (x,y)
- это вектор вида:
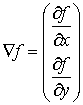
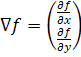 ,(3)
,(3)
где ¶f/¶x,
¶f/¶y
- частные производные по направлениям OX
и OY.
Важную роль при обнаружении контуров играет как
модуль вектора, так и его направление. Вычисление градиента изображения состоит
в получении величин частных производных для каждой точки. Одним из простейших способов
нахождения первых производных в точке состоит в применении перекрестного
градиентного оператора Робертса, который представляет собой маски, изображенные
на рисунке 2.
|
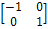
|
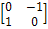
|
|
Рисунок
2 - Маски оператора Робертса
|
Реализация масок размерами 2´2
неудобна, так как у них нет четко выраженного центрального элемента. С этой
целью были разработан оператор Превитта, описываемый масками 3´3
на рисунке 3.
|
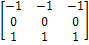
|
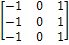
|
|
Рисунок
3 - Маски оператора Превитта
|
Небольшое видоизменение вышеуказанных масок
состоит в использовании весового коэффициента для средних элементов. Это
увеличенное значение используется для уменьшения эффекта сглаживания за счет
придания большего веса средним точкам. Данное видоизменение реализуется при
помощи оператора Собела, маски которого изображены на рисунке 4.
|
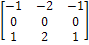
|
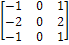
|
|
Рисунок
4 - Маски оператора Собела
|
На практике для вычисления дискретных градиентов
чаще всего используются операторы Превитта и Собела. Маски оператора Превитта
проще реализовать, чем маски оператора Собела, однако у последнего влияние шума
угловых элементов несколько меньше, что существенно при работе с производными
[7].
Лапласиан
Лапласиан двумерной функции f(x,y)
представляет собой производную второго порядка, определяемую выражением:
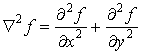
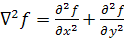 ,(4)
,(4)
где ¶2f/¶x2, ¶2f/¶y2- частные
производные второго порядка.
Для реализации производной второго
порядка в дискретном пространстве изображения применяются маски, изображенные
на рисунке 5.
Как правило, лапласиан напрямую не используется
для обнаружения контуров, что объясняется следующими причинами. Как производная
второго порядка, лапласиан является излишне чувствительным к шуму. Кроме того,
использование модуля лапласиана приводит к удвоению контуров, что дает
нежелательный эффект. Поэтому лапласиан обычно применяют в сочетании со
сглаживанием. При использовании функции сглаживания Гаусса выводится маска лапласиана
гауссиана [6].
Детектор Канни
Канни досконально исследовал проблему выделения
краев различной формы на полутоновом изображении и предложил три критерия,
определяющие эффективность детектора края [8]:
1. Хорошее обнаружение, т. е. минимальная вероятность
пропуска реального перепада яркости и минимальная вероятность ложного
определения перепада (максимизирование выходного отношения сигнал/шум).
2. Хорошая локализация (пиксели,
определенные как пиксели края, должны располагаться насколько возможно ближе к
центру истинного края).
. Только один отклик на один край.
Вышеперечисленные критерии были записаны в виде
уравнений, которые были решены численно, и был определен путем моделирования
вид оптимального (в смысле указанных выше критериев) оператора выделения края
определенной формы. На рисунке 6 показана свертка изображения с достаточно
большой маской, аппроксимирующей оператор [5].
|
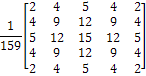
|
|
Рисунок
6 - Маска Канни
|
1.3 Базовое преобразование Хафа
Идея преобразования Хафа состоит в поиске
кривых, которые проходят через достаточное количество точек интереса [4].
Рассмотрим семейство кривых на плоскости, заданное параметрическим уравнением:
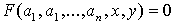
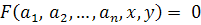 ,(5)
,(5)
где F(×) -
некоторая функция;
a1, a2, …, an- параметры
семейства кривых;
(x,y) -
координаты на плоскости.
Параметры семейства кривых образуют
фазовое пространство, каждая точка которого (конкретные значения параметров a1, a2, …, an) соответствует
некоторой кривой. Ввиду дискретности машинного представления и входных данных
(изображения), требуется перевести непрерывное фазовое пространство в
дискретное пространство. Для этого в фазовом пространстве вводится сетка,
разбивающая его на ячейки, каждая из которых соответствует набору кривых с
близкими значениями параметров. Каждой ячейке фазового пространства можно
поставить в соответствие число (счетчик), указывающее количество точек интереса
на изображении, принадлежащих хотя бы одной из кривых, соответствующих данной
ячейке. Анализ счетчиков ячеек позволяет найти на изображении кривые, на
которых лежит наибольшее количество точек интереса [13].
Базовый алгоритм выделения кривых
состоит из следующих шагов:
1. Выбор сетки дискретизации. На этом этапе
выбирается шаг дискретизации для каждого параметра кривой. От этого выбора
будет зависеть сложность (~ скорость) и эффективность алгоритма.
. Заполнение аккумулятора (матрицы
счетчиков). Зачастую это самый долгий шаг алгоритма, поскольку заполнение
производится путем полного перебора.
. Анализ аккумулятора (поиск пиков). В
матрице аккумулятора ищется счетчик с максимальным значением.
. Выделение кривой. Каждая ячейка
аккумулятора есть значение фазового пространства, а значит, она задает
некоторую (искомую) кривую. Но поскольку значение на шаге 1 стало дискретным,
может потребоваться уточнение кривой каким-либо иным методом по уже найденным
точкам кривой.
. Вычитание из аккумулятора. Для точек
выделенной кривой считается временный аккумулятор и поточечно вычитается из
основного.
. Переход на шаг 3.
1.3.1 Поиск прямых
Прямую на плоскости можно задать следующим
образом:
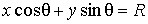
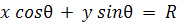 , (6)
, (6)
где R - длина
перпендикуляра опущенного на прямую из начала координат;
(x,y) -
координаты точки на прямой;
θ - угол между перпендикуляром
к прямой и осью OX (см. Рисунок 7).
|
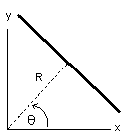
|
|
Рисунок
7 - Параметрическое представление прямой
|
Значение θ изменяется
в пределах от 0 до 2π, R ограничено
размерами входного изображения. Таким образом, функция, задающая семейство
прямых, имеет вид:
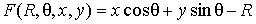
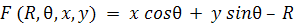 (7)
(7)
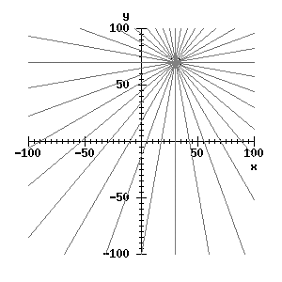
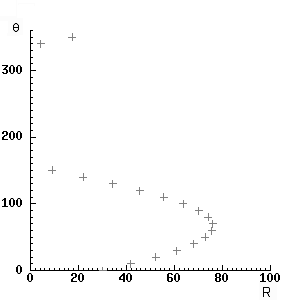
Через каждую точку (x,y)
изображения можно провести несколько прямых с разными значениями R и θ (см.
Рисунок 8), т. е. каждой точке (x,y)
изображения соответствует набор точек в фазовом пространстве (R,θ), образующий
синусоиду (см. Рисунок 9). В свою очередь каждой точке пространства (R,θ)
соответствует набор точек (x,y) на
изображении, образующий прямую [9].
|
|
|
Рисунок
8 - Задание семейства кривых на плоскости
|
|
|
|
Рисунок
9 - Фазовое пространство для семейства прямых, изображенных на рисунке 8
|
Каждой точке (R0,θ0)
пространства (R,θ)
можно поставить в соответствие счетчик, соответствующий количеству точек (x,y),
лежащих на прямой:
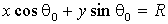 (8)
(8)
Ввиду дискретности машинного
представления входных данных, требуется перевести непрерывное фазовое
пространство в дискретное пространство. Введем сетку на пространстве (R,θ), одной
ячейке которой соответствует набор прямых с близкими значениями R и θ. Теперь
счетчик ставится в соответствие каждой ячейке сетки: ячейке [Ri,Ri+1]´[qi,qi+1] соответствует
число точек, удовлетворяющих уравнению:
, (9)
где 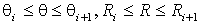
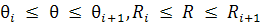 .
.
Размер ячеек выбирается с учетом
следующих соображений. Если ячейки будут очень большими, то за
"прямую" может приниматься разрозненный набор точек. Если же
наоборот, ячейки будут слишком малы, есть вероятность, что ни одной прямой не
найдется - все счетчики будут иметь небольшое значение.
В общем случае алгоритм поиска
прямой на изображении при помощи преобразования Хафа выглядит так:
а) Обнулить счетчики всех ячеек.
б) Для каждой точки интереса.
в) Для каждой прямой, проходящей через
данную точку.
г) Увеличить соответствующий счетчик.
д) Выбрать ячейку с максимальным значением
счетчика.
е) Параметры прямой, проходящей через
максимальное число точек принять равным координатам центра выбранной ячейки в
фазовом пространстве.
Если прямых нужно найти несколько, можно
отсортировать счетчики по убыванию или рассматривать точки локальных максимумов
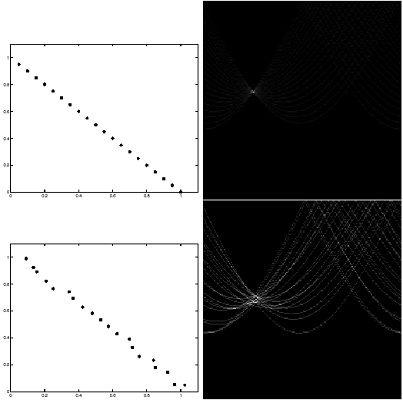
фазового пространства. На рисунке 10 изображены примеры исходных изображений и
соответствующих им фазовых пространств.
графический примитив
программный пользователь
|
|
|
Рисунок
10 - Пример работы преобразования Хафа: а) исходные изображения, б) фазовое
пространство (R, θ). Величина
счетчика в каждой точке фазового пространства обозначена оттенком серого (чем
больше счетчик, тем светлее точка)
|
.3.2 Выделение окружностей на изображении
Геометрическое место точек окружности можно
представить в виде формулы:
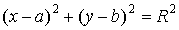
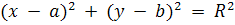 ,(10)
,(10)
где (a,b) -
координаты центра окружности;
(x,y) -
координаты точки на окружности;
R - ее
радиус.
Формула, задающая семейство
окружностей, имеет вид:
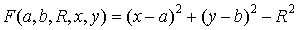
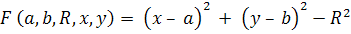 (11)
(11)
Если ставится задача найти окружность заранее
известного радиуса, то фазовым пространством будет плоскость параметров центра
окружности (a,b).
В таком случае, алгоритм выделения окружностей полностью аналогичен алгоритму
нахождения прямых.
Если радиус окружности заранее неизвестен, то
пространство параметров будет трехмерным - (a,b,R),
что существенно увеличивает вычислительную сложность решения задачи. Для
сведения задачи обратно к двумерному фазовому пространству в некоторых случаях
можно применить метод описанный в [4].
1.3.3 Нахождение кривых высшего порядка
Методика нахождения кривых высшего порядка
(эллипсы, параболы и т.д.) отличается от предыдущих подходов размерностью
фазового пространства.
Рассмотрим эту особенность на примере
детектирования эллипсов. Уравнение, задающее геометрическое место точек эллипса
в полярных координатах, принимает вид:
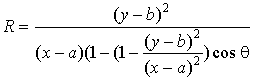
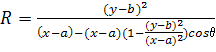 (12)
(12)
где (a,b) -
координаты центра эллипса;
R, θ - полярные
координаты эллипса.
Формула, задающая семейство
эллипсов, имеет вид:
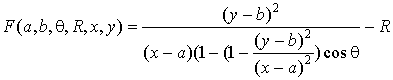
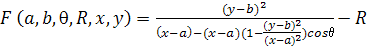 , (13)
, (13)
Для нахождения эллипсов необходимо
производить операции в четырехмерном фазовом пространстве. Вычисление фазового
пространства для кривых высшего порядка представляет весьма трудоемкую
вычислительную задачу, поэтому базовое преобразование Хафа для таких примитивов
применяется крайне редко.
1.4 Модификации преобразования Хафа
Преобразование Хафа позволяет проводить полный
анализ пространства изображения, но существует ряд проблем, которые влияют на
результат и производительность такого подхода:
а) Дискретизация
На шаге 1 выбирается сетка дискретизации. В связи
с этим выбором возможны следующие проблемы:
1) Сетка выбрана слишком мелкой. Тогда, если в
исходном облаке точек присутствовал шум, то даже точки одной кривой будут
попадать в разные ячейки сетки, а значит, потенциальный максимум аккумулятора
(соответствующий этой кривой) будет размыт и его будет сложнее или вообще
невозможно найти.
2) Сетка выбрана слишком крупной. Тогда
существует вероятность того, что в одну ячейку попадут точки, лежащие на разных
кривых.
) При любой сетке дискретизации, если
точки облака  образуют кривую с
параметром j0, лежащим на
границе ячейки, то из-за шума точки этой кривой будут попадать в соседние
ячейки и будет наблюдаться размытие пика в аккумуляторе. Это вообще
фундаментальная проблема дискретизации.
образуют кривую с
параметром j0, лежащим на
границе ячейки, то из-за шума точки этой кривой будут попадать в соседние
ячейки и будет наблюдаться размытие пика в аккумуляторе. Это вообще
фундаментальная проблема дискретизации.
б) Сложность алгоритма.
Заполнение аккумулятора на шаге 2 является самой
трудоемкой частью алгоритма, сложность которой зависит от: размерности фазового
пространства и сетки дискретизации. Чем больше размерность фазового
пространства и меньше сетка, тем больше ячеек в аккумуляторе. Значит, тем
больше требуется памяти и времени для его хранения и заполнения. Именно поэтому
на практике чаще всего фазовое пространство представляет собой плоскость, а
преобразование Хафа применяется, в основном, для поиска прямых на плоскости
(изображениях).
В связи с вышеперечисленными проблемами были
разработаны некоторые модификации стандартного алгоритма (Standard Hough
Transform, SHT).
Комбинаторное преобразование Хафа (Combinatorial
Hough Transform)
разрабатывалось для быстрого поиска прямых линий на изображении. В таком случае
у нас имеется плоское бинарное изображение (на нем точки интереса одного цвета,
а точки фона другого). Поскольку производится поиск прямых линий, то
размерность фазового пространства равна 2.
Идея метода состоит в изменении шага 2
(заполнение аккумулятора):
а) Исходное бинарное изображение разбивается на
небольшие участки.
б) В каждом участке для каждой пары точек
определяются параметры (r,q) прямой,
проходящей через них.
в) Если (r,q)
попадают в некоторую ячейку, и ее счетчик соответственно увеличивается.
Первый шаг модификации необходим для сокращения
числа переборов.
Если точек в участке мало и сетка дискретизации
фазового пространства тоже мала, количество записей в аккумуляторе получается
меньше.
Иерархическое преобразование Хафа (Hierarchical
Hough Transform) -это еще одна модификации для поиска линий на бинарном
изображении. Приведем последовательность действий для иерархического
преобразования:
а) Исходное изображение разбивается регулярной
сеткой.
б) В каждом фрагменте изображения
выделяются прямые преобразованием Хафа.
в) Производится иерархическое слияние. На
каждом уровне рассматриваются 4 соседних фрагмента. Линии, выделенные на каждом
из фрагментов, объединяются на основании преобразования Хафа для объединения
фрагментов. Если линии не удалось слиться ни с одной линией из соседних
фрагментов, она удаляется из рассмотрения.
г) Слияние производится до получения
одного исходного изображения.
В результате сложность алгоритма снижается за
счет подразбиения изображения (можно использовать более грубую сетку в фазовом
пространстве и количество точек существенно меньше).
Недостаток состоит в том, что одна длинная линия
может быть в результате представлена несколькими близкими линиями, поскольку
разные концы отрезка могут быть неколлинеарными при близком рассмотрении, т.е.
на низких уровнях иерархического слияния.
Адаптивное преобразование Хафа (Adaptive Hough
Transform) - эта модификация позволяет использовать меньше места для хранения
аккумулятора и быстрее выделять кривые [14]. На протяжении всего процесса
поиска используется аккумулятор заранее выбранного маленького размера
(например, 9´9 или 3´3´3´3
в многомерном случае). Алгоритм выглядит следующим образом:
1) Выбор размера аккумулятора (маленький!).
2) Достижение заданной точности. На каждой
итерации размер ячейки уменьшается. Цикл идет до достижения заранее заданного
размера ячейки.
) Заполнение аккумулятора. Как и в
стандартном варианте, однако меньшая сложность достигается за счет небольшого
размера аккумулятора.
) Поиск ячейки с максимальным значением
счетчика.
) Ячейка принимается за новое фазовое
пространство, переход на шаг 2. Таким образом, мы уменьшаем шаг дискретизации,
но только в области интереса (ячейке с максимальным счетчиком).
) Выделяем кривую.
Главными достоинствами адаптивного
преобразования Хафа являются:
а) Меньшая сложность по времени и по памяти.
б) Практическое решение проблемы
дискретизации, поскольку сетка дискретизации не регулярная и на каждой итерации
уточняется.
Основным недостатком алгоритма является
следующее. Если исходное облако точек образует
несколько кривых из заданного семейства, то для выделения каждой точки
необходимо повторить весь алгоритм сначала (предварительно устранив из
рассмотрения точки уже выделенных кривых).
Вероятностное преобразование Хафа (Probabilistic
Hough Transform) рассматривает только доля a точек из множества
X, при этом
результат с некоторой вероятностью получается такой же, как и у стандартного
алгоритма. Доля точек выбирается случайно с равномерной вероятностью [15].
Показано, что существует athreshold
такое, что при a > athreshold
ошибок (относительно стандартного алгоритма) происходит очень мало, а при a
< athreshold
их количество резко возрастает. Поэтому рекомендуется выбирать a
примерно равное athreshold,
которое находится в диапазоне 5% - 15% от всего количества точек.
Очевидное достоинство модификации заключается в
сокращении перебора на шаге 2 адаптивного преобразования Хафа. В качестве
недостатка можно отметить недетерминированность результата относительно входных
данных.
Прогрессивное вероятностное преобразование Хафа
(Progressive Probabilistic Hough Transform) состоит в следующем: пусть имеется
облако точек X и большое
количество точек образуют искомую кривую [11]. Тогда в соответствующей ячейке
фазового пространства значение счетчика будет иметь большое значение. Идея этой
модификации заключается в том, чтобы выделять кривые (шаг 4) при достижении
счетчиком порогового значения, не заполняя аккумулятор полностью (шаг 2). Для
вышеописанной кривой значение соответствующего счетчика довольно быстро наберет
пороговое значение.
Алгоритм формулируется следующим образом:
а) Если в облаке нет точек, окончание.
б) Аккумулятор пополняется случайно
выбранной точкой из множества X, а точка удаляется из рассмотрения.
в) Если максимальное значение аккумулятора
не превосходит порога, топереход на шаг 1.
г) Находится кривая максимальной длины.
Внутри некоторого коридора (определяемого
ячейкой с максимальным значением счетчика) производится поиск кривой с
максимальной длиной.
д) Все точки найденной кривой удаляются с
исходного изображения и аккумулятора.
е) Переход на шаг 1.
Достоинством этого метода так же является то,
что он постоянно пополняет результат, т.е. его выполнение можно прекратить при
достижении остаточного количества результатов или по истечении некоторого
времени.
Случайное преобразование Хафа
(Randomized Hough Transform) - эта модификация напоминает комбинаторную
преобразованию Хафа [15, 17]. Если параметры j кривой F(j,x)=0 можно
однозначно восстановить по K  точкам, то
алгоритм заполнения аккумулятора формулируется следующим образом (шаг 2):
точкам, то
алгоритм заполнения аккумулятора формулируется следующим образом (шаг 2):
а) Из облака точек X случайным
образом выбирается K точек.
случайным
образом выбирается K точек.
б) По выбранным точкам
определяются параметры кривой j.
в) Значение счетчика
соответствующей ячейки увеличивается.
Перед поиском следующей кривой необходимо
удалить из рассмотрения все точки, ассоциированные с предыдущими кривыми,
поскольку алгоритм носит случайный характер.
.5 Нахождение точечных особенностей изображения
Особая точка сцены или точечная особенность
(point feature) - это такая точка сцены, изображение которой можно отличить от
изображений всех соседних с ней точек сцены.
Для сравнения и описания точек можно
использовать ее окрестность. Тогда предыдущее определение уточняется следующим
образом. Под точечной особенностью понимается такая точка сцены M 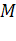 , лежащая на
плоском участке поверхности сцены PlaneSegment
, лежащая на
плоском участке поверхности сцены PlaneSegment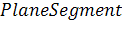 ,
изображение окрестности I(PlaneSegment)
,
изображение окрестности I(PlaneSegment) 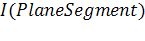 которой
можно отличить от изображений окрестностей всех других точек сцены N
которой
можно отличить от изображений окрестностей всех других точек сцены N 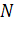 из некоторой
другой окрестности этой точки O(M)
из некоторой
другой окрестности этой точки O(M)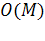 .
.
Воспользовавшись последним
определением можно дать определение точечной особенности изображения:
Точечная особенность изображения m - это такая
точка изображения, окрестность которой o(m) можно
отличить от окрестности любой другой точки изображения o(n) в
некоторой другой окрестности особой точки.
1.5.1 Детектор Харриса
За последние двадцать лет было создано довольно
много различных детекторов точечных особенностей изображений. Чаще всего
используется детектор Харриса [12].
Для каждого пикселя 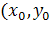 (x0, y0)
рассчитываем следующую матрицу:
(x0, y0)
рассчитываем следующую матрицу:
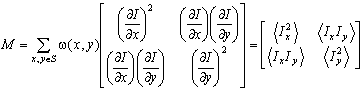
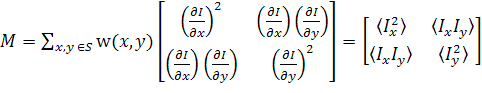 , (14)
, (14)
где I(x,y) - яркость
в точке (x,y);
w(x,y) - весовая
функция по окрестности S(x0,y0), в
качестве которой обычно берут распределение Гаусса.
У точки, окрестность которой похожа
на угол, матрица (14) будет иметь два больших положительных собственных
значения. Таким образом, условие похожести точки на угол запишется следующим
образом:
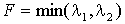
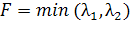 ,(15)
,(15)
Теперь остается найти локальные максимумы
функции отклика угла F(x,y),
которые и будут соответствовать особым точкам.
Чтобы упростить вычисления, Харрис предложил
отказаться от подсчета собственных значений матрицы, и вместо них ввел
следующую функцию отклика угла:
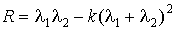 , (16)
, (16)
где k 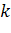 - параметр
Харриса, его величина обычно лежит в пределах 0,04-0,15 и определяется
эмпирически.
- параметр
Харриса, его величина обычно лежит в пределах 0,04-0,15 и определяется
эмпирически.
Далее с ней проводятся аналогичные
действия - поиск локальных максимумов, и введение порогового значения.
1.5.2 Масочный детектор
Данный детектор основан на применении оценочного
алгоритма соответствия маске того или иного фрагмента изображения. Для этого могут
использоваться маски 3´3, 5´5,
7´7
и т.д. Сравнение с масками большего размера позволяет добиться более точных
результатов, но отрицательно сказывается на быстродействии алгоритма. Работа
алгоритма заключается в следующем: для каждого пикселя изображения в
соответствии с размером маски извлекается фрагмент и сравнивается
непосредственно с маской. Особый случай представляет собой проверка пикселей,
находящихся на границе изображения. Для этого применяют следующий подход:
вокруг изображения прорисовывается мнимый контур, который закрашен фоновым
цветом и позволяет корректно детектировать углы на границы изображения.
.6 Сравнительная характеристика алгоритмов
детекции
Рассмотренные ранее методики имеют ряд
преимуществ и недостатков, что приводит их к определенной
"специализации" в области применения. Также следует отметить, что
некоторые модификации преобразования Хафа эффективны для нахождения одних видов
примитивов, но совершенно не подходят для поиска других.
Для
нахождения точечных особенностей применяется ряд подходов, в числе которых
преобразование Хафа (на основе анализа найденных отрезков), детектор Харриса и
масочный детектор. На рисунке 11 изображены результаты применения этих
алгоритмов.
|
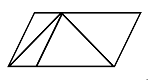
|

|
|
а
|
б
|
|

|

|
|
в
|
г
|
|
Рисунок
11 - Нахождение точечных особенностей изображения: а - исходное изображение,
б - результат преобразования Хафа, в - результат детектора Харриса, г -
результат масочного детектора
|
Как видно из рисунка 11 лучшие результаты
продемонстрировал детектор Харриса. Он обнаружил более качественные особенности
и количество их примерно соответствует углам фигуры. Преобразование Хафа
показало чуть худшие результаты, обнаружив множество ложных углов, но были
обнаружены и искомые углы. Масочный детектор отработал неэффективно, обнаружив
лишь часть искомых углов, однако не были зафиксированы и ложные углы.
Для
нахождения прямых (или в рассмотрении ограниченного пространства изображения отрезков)
применяются алгоритмы на основе преобразования Хафа. На рисунке 12 изображены
результат работы базового алгоритма и ряда его модификаций.
|
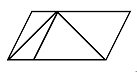
|

|
|
а
|
б
|
|

|

|
|
в
|
г
|
|

|

|
|
д
|
е
|
|
Рисунок
12 - Нахождение отрезков на изображении на основе преобразования Хафа: а -
исходное изображение, б - базовое, в - прогрессивно-вероятностное, г -
иерархическое, д - случайное, е - адаптивное
|
Из рисунка 12 можно сделать вывод, что со своей
задачей прекрасно справились 3 алгоритма: базовое, прогрессивно-вероятностное и
адаптивное преобразование Хафа. Результат их работы полностью отражает
возлагаемую на них задачу - были обнаружены все искомые отрезки. Чуть хуже
справился иерархический алгоритм, проявился его недостаток в решении задачи
иерархического слияния, а именно были потеряны длинные отрезки, располагающиеся
в нескольких ячейках. Самый худший результат продемонстрировало случайное
преобразование Хафа, не была найдена большая часть искомых отрезков.
Проведенный сравнительный анализ позволяет
судить об эффективности алгоритмов для простых изображений. В случае сложных
изображений особую роль имеет этап предварительной обработки, который позволяет
решить ряд проблем и получить более "простые" входные данные для
алгоритмов детекции изображение.
1.7 Анализ существующих программных решений
Задача нахождения графических примитивов решается
во многих системах компьютерного зрения. Проведение подобного исследования
позволяет проанализировать изображение с точки зрения его структурного состава
и получить начальные данные для проведения более узких экспериментов.
Система
"Cognitive Passport", основанная на технологиях "Cognitive
Forms" и "Scanify", была разработана в 2005 году. Система
предназначена для автоматизации процесса ввода и обработки документов,
удостоверяющих личность (паспортов, водительских удостоверений и др.),
построенных по стандартизованной форме и напечатанных на гербовой бумаге. Она
обеспечивает автоматизированный ввод документов, распознавание текстовой и
выделение графической информации, редактирование сомнительно распознанных полей
и преобразование считанной информации в согласованный формат экспорта-импорта
документов. Программное ядро
системы "Cognitive Passport" основано на использовании сложных
алгоритмов оптического распознавания, включающих Wavelet-фильтрацию,
преобразование Хафа, линейную спектральную модель цвета и др. Это позволяет
более качественно распознавать защищенные документы за счет фильтрации
"гербового" и текстурного фона.
|
|
|
Рисунок
13 - Интерфейс системы "Cognitive Passport"
|
Пакет "Image Processing Toolbox" - это
расширение MATLAB, содержащий полный набор типовых эталонных алгоритмов для
обработки и анализа изображений, в том числе функций фильтрации, частотного
анализа, улучшения изображений, морфологического анализа и распознавания. В
рамках данного пакета расширения применяется вероятностное преобразование Хафа
[10].
Все функции пакета написаны на открытом языке
MATLAB, что позволяет пользователю контролировать исполнение алгоритмов,
изменять исходный код, а также создавать свои собственные функции и процедуры.
Пакет "Image Processing Toolbox" применяется инженерами и учеными в
таких областях как разработка систем сжатия, передачи и улучшения изображений,
разработка систем наблюдения и распознавания, биометрика, тестирование
полупроводников, микроскопия, разработка сенсоров, материаловедение и др.
Система "Juno" является инструментом
для обработки, преобразования и статистического анализа больших массивов
экспериментальных данных (см. Рисунок 14). Программа обладает уникальными
возможностями, которые позволяют пользователю, практически незнакомому с
программированием осуществлять сложные манипуляции с данными, производить
построение одномерных и двухмерных статистических распределений, выполнять
выделение редких событий с помощью наложения условий и дополнительных
критериев.
|
|
|
Рисунок
14 - Интерфейс системы "Juno"
|
В рамках разработки математического обеспечения
для внешнего трекера для эксперимента HERA-B в рамках системы Juno
развит новый алгоритм быстрой инициализации программы распознавания треков
RANGER на основе метода преобразования Радона-Хафа. Алгоритм реализован в виде
программы на языке C++. Разработан и проверен на реальных данных алгоритм очень
быстрого робастного фитирования дуг окружностей по данным, учитывающим радиусы
дрейфа в XoZ плоскости камеры магнита.
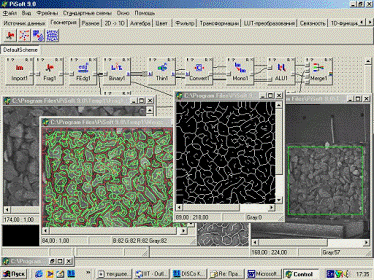
Программный пакет "Pisoft Image
Framework" предназначен для разработчиков и пользователей систем обработки
изображений, и может применяться для практических, исследовательских и учебных
целей в качестве интегрированной среды работы с изображениями (см. Рисунок 15).
Пакет реализован на базе оригинальной фрейм-ориентированной технологии, которая
обеспечивает ряд существенных преимуществ в управлении процессом обработки
видео данных и организации соответствующего интерфейса пользователя.
|
|
|
Рисунок
15 - Интерфейс программного пакета Pisoft
Image
Framework
|
Пакет "Pisoft
Image Framework"
позволяет проводить анализ профилей яркости, апертур, проекций и гистограмм,
различные средства геометрических измерений; линейные, нелинейные и
произвольные геометрические преобразования; алгебраические операции над одним
или несколькими изображениями; линейные, нелинейные и произвольные яркостные и
цветовые преобразования; линейную и нелинейную фильтрация изображений в
пространственной и частотной области; сегментация изображений, выделение и
анализ областей и контуров; математическая морфология Серра, wavelet transform;
преобразование Хафа, обнаружение прямолинейных структур; текстурный анализ, вычисление
статистик; выделение объектов, вычисление геометрических признаков.
Рассмотренные выше системы сведем в таблицу 3.
Таблица 3. Программные продукты, применяющие
преобразование Хафа
|
Система
|
Алгоритмы
|
|
Cognitive Passport
|
Базовое
преобразование Хафа, иерархическое преобразование Хафа
|
|
MATLAB Image Processing Toolbox
|
Прогрессивно-вероятностное
преобразование Хафа, градиентные модификации
|
|
Juno
|
Базовое
преобразование Хафа, адаптивное преобразование Хафа
|
|
Pisoft Image Framework
|
Случайное
преобразование Хафа, комбинаторное преобразование Хафа, иерархическое
преобразование Хафа
|
.8 Выводы по главе
В данной главе была проведена классификация
графических примитивов, выявлены параметры, характеризующие тот или иной
геометрический объект. Рассмотрены подходы к нахождению примитивов, оценены их
преимущества и недостатки. Построен общий алгоритм получения геометрического
описания пространства изображения на основе анализа входных данных и этапа
предварительной обработки. В рамках данного алгоритма проведен обзор
шумоподавляющих фильтров (свертка по маске, медианный, фильтр Гаусса),
операторов детектирования краев (операторы Робертса, Превитта, Собела, Лапласа,
Канни. Завершающим шагом алгоритма нахождения примитивов является применение
преобразования Хафа. Рассмотрены базовое преобразование Хафа для нахождения
примитивов различной сложности, а также его модификации (комбинаторное,
иерархическое, адаптивное, случайное, вероятностное, прогрессивно-вероятностное
преобразования). Для нахождения точечных особенностей изображения в дополнение
к подходу, основанному на преобразовании Хафа, изучены детекторы Харриса и
масочный детектор. Проведен сравнительный анализ методов на основе
преобразования Хафа. В заключение главы рассмотрены существующие аналоги
программных продуктов, позволяющие решать задачи нахождения геометрических
объектов в рамках определенной предметной области.
2.
РАЗРАБОТКА ПРОГРАММНОГО ПРОДУКТА
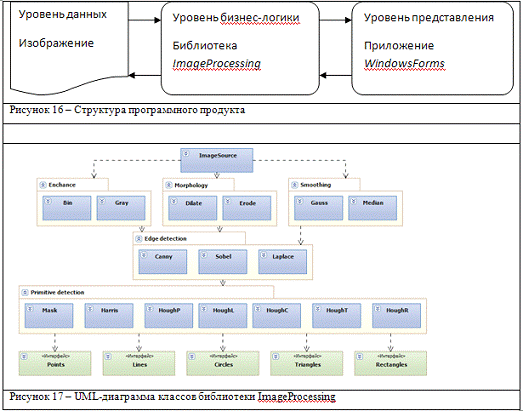
.1 Структура программного продукта
Программный продукт "HoughTransform"
выполнен в виде системы на основе трехуровневой архитектуры систем (см. Рисунок
16). В качестве источника данных в программе выступает само изображение,
уровень бизнес-логики реализован на основе библиотеки ImageProcessing
(см. Рисунок 17), уровень представления - приложение на основе WindowsForms.
.2 Руководство программиста
Характеристики программы
Программный продукт написан на языке C#
на .Net
Framework 4. В проекте
применялась сторонняя библиотека EmguCV
для эффективной работы с изображениями. Система состоит из трех основных
частей: исполняемый файл HoughTransformSystem.exe,
библиотека ImageProcessing.dll
и группа библиотек EmguCV.
Программный продукт реализует медианный и гауссов фильтр, операторы краев
Канни, Собела и Лапласа. Из детектирующих алгоритмов в системе реализованы
детектор Харриса, масочный детектор, детектор особенностей на основе
преобразования Хафа, базовое преобразование Хафа, прогрессивно-вероятностная и
иерархическая модификации преобразования Хафа.
Входные и выходные данные
В качестве выходных данных выступают файлы
изображений с указанными выше расширениями, являющиеся результатом некоторого
этапа обработки исходного изображения. Также к числу выходных данных относятся
текстовые файлы с расширением pvt,
содержащие в себе информацию о найденных примитивах, и текстовые файлы с
расширением tr,
представляющие собой результаты сравнения найденных примитивов с эталонными
объектами.
Основные классы
Все основные классы системы, образующие уровень
бизнес-логики приложения, расположены в библиотеке ImageProcessing.
Классы обеспечивают замкнутый цикл обработки изображения от считывания
изображения непосредственно из файла до нахождения множества примитивов.
Аргументы в классы передаются посредством методов классов. Опишем основные из
них:
public ImageSource Open (string
filename) - создает объект
класса
ImageSource, открывая файл
изображения.
Параметр
filename - полный путь
к
файлу
изображения.ImageSource
Rotate (double angle, Color background) - возвращает
изображение,
повернутое
на
угол
angle. Параметр
background задает цвет фона,
получаемого в результате поворота.
public
ImageSource
Resize (int
width, int
height) - возвращает
изображение с измененными размерами. Width
- ширина, height - высота.
public
ImageSource
Flip (FLIP
flip) - возвращает
изображение, отраженное относительно горизонтальной или вертикальной осей. Flip
задает ось отражения.
public
ImageSource
Erode (ImageSource
source, int
iteration) - возвращает
изображение, подвергнутое морфологической операции сужения. Iteration
- задает количество проходов морфологическим фильтром.
public
ImageSource
Dilate (ImageSource
source, int
iteration) - возвращает
изображение, подвергнутое морфологической операции расширения. Iteration
- задает количество проходов морфологическим фильтром.
public
ImageSource
MedianSmooth (ImageSource
source, int
windowSize) - возвращает
изображение, сглаженное медианным фильтром. WindowSize
задает размер скользящего окна.
public
ImageSource
GaussSmooth (ImageSource
source, int
width, int
height, double
sigma) - возвращает
изображение, сглаженное фильтром Гаусса. Параметры width
и height задают размер
скользящего окна. Sigma
задает значение гауссова среднеквадратичного отклонения в формуле (2).
public
ImageSource
Binarization (ImageSource
source, int
threshold, int
max) - возвращает изображение,
подвергнутое процедуры глобальной бинаризации. Threshold
задает значение интенсивности, являющееся порогом бинаризации, max
- значение интенсивности для пикселей выше порога.
public
ImageSource
Canny (ImageSource
source, int
threshold, int
link) - возвращает
изображение, обработанное оператором краев Канни. Threshold
задает порог для градиента, значения выше которого приравниваются к точке края,
link - порог для
градиента для связи контурных пикселей.
public
ImageSource
Sobel (ImageSource
source, int
orderX, int
orderY, int
size) - возвращает
изображение, обработанное оператором краев Собела. OrderX
и orderY задают порядок
производной по соответствующим направлениям, size
- размер скользящего окна.
public
ImageSource
Laplace (ImageSource
source, int
size) - возвращает
изображение, обработанное оператором краев Лапласа. Size
задает размер скользящего окна.
public
Point[] Harris
(ImageSource
source, int
maxFeatures, double
quality, double
minDist, double
k) - возвращает
множество особенных точек, найденных детектором Харриса на изображении source.
MaxFeatures задает
максимальное число особенностей, quality
- минимальное собственное значение, относящееся к углу, minDist
- минимальное расстояние между двумя углами, k
- значение параметра Харриса в формуле (16).
public
Point[] Mask
(ImageSource
source, int
quality) - возвращает
множество особенных точек, найденных масочным детектором на изображении source.
Quality - качество
найденных углов, характеризующееся степенью соответствия маске.
public
Point[] HouhPoints
(ImageSource
source, int
threshold, int
width, int
gap) - возвращает
множество особенных точек, найденных детектором на основе отрезков,
обнаруженных преобразованием Хафа. Threshold
- значение аккумулятора, при котором отрезок считается найденным, width
- минимальная длина, найденных отрезков, gap
- расстояние между ними.
public Line[] HoughLines(ImageSource
source, string type, int threshold, int width, int gap) - возвращает
множество
отрезков,
найденных
преобразованием
Хафа.
Тип
преобразования
задается
параметром
type.Circle[] HoughCircles (ImageSource source, double thresh, double acthresh,
double resol, int gap, int minR, int maxR) - возвращает
множество
окружностей,
найденных
преобразованием
Хафа.
Resol
задает размерность фазового пространства (если 1, то размерность фазового
пространства 2). MinR
и maxR - характеристики
радиуса, найденных окружностей.
Методика нахождения прямоугольников и
треугольников, основывается на прямых найденных на основе класса HoughLines,
из которых строится заданный примитив с учетом аппроксимационного параметра approx.
.3 Руководство пользователя
Требование к программному и аппаратному
обеспечению
Для корректной и эффективной работы программного
продукта необходима система на базе Pentium
4 с тактовой частотой процессора не менее 2 ГГц, 512 Мб ОЗУ.
Программным обеспечением для данной системы
является .Net
Framework 4, а также
дополнительные библиотеки EmguCV.
Выполнение программы
Для запуска программы необходимо запустить
исполняемый файл HoughTransformSystem.exe.
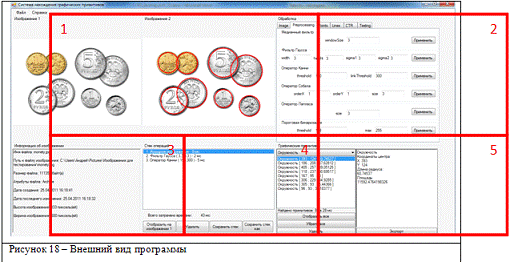
Внешний вид программы представлен на рисунке 18.
Главное окно программы состоит из 5 областей:
1) Изображения - исходное изображение и
результат обработки после каждой из операций.
2) Окно обработки - состоит из 6 вкладок с
различными фильтрами, а также с механизмами для осуществления преобразования
Хафа.
) Информация об изображении - отображает
полный набор сведений об изображении: имя файла, путь к нему, размер файла,
атрибуты и т.д.
) Стек операций - представлен в виде
списка, при выполнении каждой операции добавляется запись о ее совершении.
) Графические примитивы - отображает
информацию о найденных примитивах, позволяет экспортировать эту информацию в
виде pvt - файла.
2.4 Тестирование ПП
Тестирование ПП осуществляется методом
"черного ящика", в качестве входной последовательности будет
выступать ряд изображений с увеличением сложности фона. Оценка характеристик
быстродействия, точности, общей эффективности, а также задание эталонных
примитивов реализуется при помощи встроенного в программное средство модуля
тестирования.
Для оценки эффективности реализации проводится
следующая оценка: для входной последовательности рассчитывается время
нахождения примитивов (быстродействие), затем проводится оценка соответствия
найденных примитивов эталонным (точность).
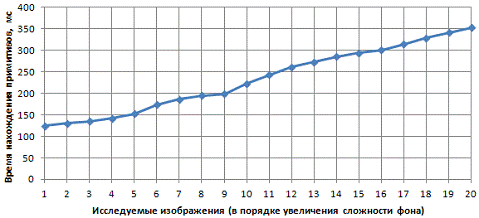
Рассчитаем указанные величины для нахождения
точечных особенностей, отрезков, окружностей, треугольников и прямоугольников и
изобразим эти результаты в виде графиков быстродействия (см. Рисунок 19),
точности (см. Рисунок 20), характеризующих систему в целом.
|
|
|
Рисунок
19 - Быстродействие системы (мс)
|
|
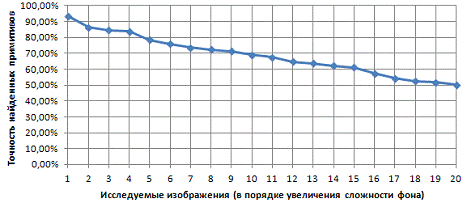
|
|
Рисунок
20 - Точность системы
|
Из приведенных графиков характеристик можно
сделать следующие выводы: быстродействие системы позволяет обрабатывать
изображения во временных отрезках близких к реальному времени; сложность
изображений значительно влияет на быстродействие системы, главным образом за
счет увеличения времени предварительного этапа обработки; при любой сложности
фона изображения удается добиться допустимой точности найденных примитивов.
Таким образом, данную систему можно считать эффективной и приемлемой для
решения ряда задач компьютерного зрения.
.5 Выводы по главе
В данной главе была приведена структура
программного продукта, рассмотрена архитектура и UML-диаграмма
классов системы. Особенности реализации методик по обработке изображения и
нахождения графических примитивов приведены в руководстве программиста.
Руководство пользователя содержит в себе основы работы с системой, а также
технические и программные требования для ее эффективной работы. В заключение
главы проведены результаты тестирования программного продукта, выявлены
характеристики быстродействия и точности системы.
ЗАКЛЮЧЕНИЕ
В ходе выполнения выпускной квалификационной
работы была разработана система нахождения графических примитивов на изображении.
Были решены следующие задачи:
– Проведена классификация графических
примитивов. Рассмотрены области применения определенных групп примитивов, а
также выявлены параметры, характеризующие тот или иной геометрический объект.
– Рассмотрены существующие алгоритмы и
методы детектирования графических примитивов на изображении. Приведены их
достоинства и недостатки.
– Проведен обзор основных этапов
предварительной обработки изображения. Изучены шумоподавляющие фильтры
(медианный фильтр, фильтр Гаусса), операторы выделения краев (Собела, Лапласа,
Канни).
– Проведен анализ базового преобразования
Хафа и его модификаций. Выявлены их преимущества и недостатки. Рассмотрены
алгоритмы базового, адаптивного, иерархического, случайного, вероятностного,
прогрессивно-вероятностного преобразований Хафа. Проведен обзор алгоритмов
детектирования точечных особенностей изображения, в рамках которого рассмотрены
масочный детектор и детектор Харриса. Выполнено сравнение алгоритмов нахождения
точечных особенностей и отрезков.
– Разработан программный продукт для
нахождения графических примитивов на основе преобразования Хафа. В программном
продукте были реализованы подходы, подвергшиеся рассмотрению в предыдущих
главах, а именно: сглаживающие фильтры, детекторы краев, базовое преобразование
Хафа, прогрессивно-вероятностная и иерархическая модификации преобразования
Хафа, детектор Харриса и масочный детектор.
– Проведено тестирование программного
продукта. Выявлены недостатки и преимущества реализованных алгоритмов в части
быстродействия и точности.
При решении данных задач также был сформирован
подход для поиска более сложных графических примитивов (треугольников,
прямоугольников) на основе аппроксимационного алгоритма. Для поиска точек
наряду с преобразованием Хафа были применены детекторы Харриса и масочный
детектор. Данные точки представляют собой особые точки (features)
и применяются в задачах компьютерного зрения, например, в задачах отслеживания
точечных особенностей изображения.
В качестве дальнейших направлений исследования
можно указать оптимизацию алгоритмов для работы со сложными изображениями
различного качества, создание принципиально новых алгоритмов на основе
комбинирования преобразования Хафа с другими методами обнаружения объектов.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
. Абламейко С.В. Обработка
изображений: технология, методы, применение. Учебное пособие. - М.: Амалфея,
2000. - 304 с.
. Анисимов Б.В., Курганов
В.Д., Злобин В.К. Распознавание и цифровая обработка изображений: Учебное
пособие для студентов вузов. - М.: Высш.шк., 1983. - 295 с. ил.
. Гонсалес Р., Вудс Р.
Цифровая обработка изображений : Пер.с англ., М.: Техносфера, 2005. - 1072 с.
ил.
. Сойфер В.А. Методы
компьютерной обработки изображений. - 2-е изд., испр. - М.: ФИЗМАТЛИТ, 2003. -
784 с.
. Форсайт Д., Понс Ж.
Компьютерное зрение. Современный подход. : Пер. с англ. - М.: Издательский дом
"Вильямс", 2004. -928 с. ил.
. Яне Б. Цифровая обработка
изображений. : Пер.с англ. - М.: Техносфера, 2007. - 584 с.
7. Canny J. A
Computational Approach To Edge Detection // IEEE Trans. Pattern Analysis and
Machine Intelligence, 1986. - pp. 679-698.
. Duda R. O., Hart P. E.
Use of the Hough Transformation to Detect Lines and Curves in Pictures // Comm.
ACM, Vol. 15, 1972. - pp. 11-15.
. Galambos C., Kittler
J., Matas J. Gradient based progressive probabilistic Hough transform // IEE
Proc. Vision, Image and Signal Process., vol: 148, num: 3. - pp.158-165
. Gonsales R., Woods R.,
Eddins S. Digital Image Processing using MATLAB. - New Jersey, USA: Prentice
Hall, 2004. - 616 p.
. Harris C., Stephens M.
A combined corner and edge detector // Proceedings of the 4th Alvey Vision
Conference, 1988. - pp 147-151.
. Hough P. Machine
Analysis of Bubble Chamber Pictures, Proc. Int. Conf. High Energy Accelerators
and Instrumentation, 1959. - pp 153-163.
. Ecabert O., Thiran J.
Adaptive Hough transform for the detection of natural shapes under weak affine
transformation // Pattern Recognition Letters (25), No. 12, September 2004. -
pp. 1411-1419.
. Kiryati N. Randomized
or Probabilistic Hough Transform: Unified Performance Evaluation // Pattern
Recognition Letters, Vol. 21, 2000. - pp. 1157-1164.
. Serra J. Image
analysis and mathematical morphology. - London, England: Academic Press Inc.,
1982. - 610 p.
. Xu L., Oja E., and
Kultanan P. A new curve detection method: Randomized Hough transform (RHT) //
Pattern Recog. Lett. 11, 1990. - pp. 331-338.