Критерий согласия для распределения Парето
Введение
В математической статистике
значимость исследования выборки очень существенна. Выборка подвергается
обработке и выдвигается предположение о распределении, которому подчиняется
выборка.
Так как все предположения о
характере того или иного распределения - это гипотезы, то они должны быть
подвергнуты статистической проверке с помощью критериев согласия, которые дают
возможность установить, когда расхождения между теоретическими и эмпирическими
частотами следует признать несущественными, т.е. случайными, а когда -
существенными (неслучайными). Таким образом, критерии согласия позволяют
отвергнуть или подтвердить правильность выдвинутой при выравнивании ряда
гипотезы о характере распределения в эмпирическом ряду.
1. Теоретическая часть
1.1 Распределение Парето
Распределение Парето - это
двухпараметрическое семейство абсолютно непрерывных распределений.
Функция распределения F(x) имеет вид (1.1).
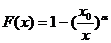 , (1.1)
, (1.1)
где α, x0
- параметры распределения, x
> x0
> 0, α > 0.
Функция плотности
распределения f(x) имеет вид (1.2).
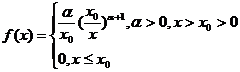 (1.2)
(1.2)
График функции
распределения приведен на рисунке 1. График функции плотности распределения
приведен на рисунке 2.
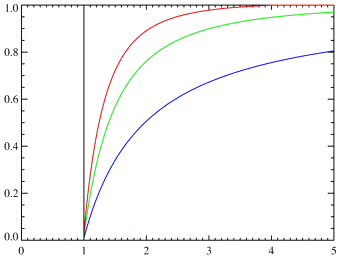
Рисунок 1 - График
функции распределения
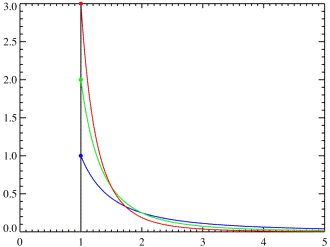
Рисунок 1 - График
функции плотности распределения
1.2 Критерий согласия χ2
Предположим, что по виду
гистограммы или полигона частот или из каких-либо других соображений удается
выдвинуть гипотезу о множестве функций определенного вида (нормальных,
показательных, биномиальных и т.п.), к которому может принадлежать функция
распределения исследуемой случайной величины X.
Критерий χ2 Пирсона (критерий согласия χ2)
позволяет производить проверку согласия эмпирической функции распределения F*(x)
с гипотетической функцией распределения F(x).
Для этого придерживаются
следующей последовательности действий:
) Диапазон изменения
экспериментальных данных разбивается на k
интервалов;
) На основании
гипотетической функции F(x) вычисляют вероятность попадания с.в. X
в частичные интервалы [xi-1,
xi] по формуле (1.3);
pi
= P(xi-1 ≤ X ≤ xi), i=1,2., k (1.3)
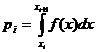
3) Умножая полученные
вероятности pi на объем выборки n, получают теоретические частоты npi
частичных интервалов [xi-1,
xi],
т.е. частоты, которые следует ожидать, если гипотеза справедлива;
) Вычисляю выборочную
статистику (критерий) χ2 по формуле (1.4).
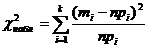 , (1.4)
, (1.4)
где mi - количество значений с.в.,
попавших в i-й интервал;
n
- объём выборки.
Если гипотеза верна, то
при n→∞ распределение выборочной статистики, независимо от
вида функции F(x), стремится к распределению χ2
с v= k-r-1 степенями свободы (k
- число частичных интервалов, r
- число параметров гипотетической функции F(x), оцениваемых по данной выборке).
Критерий χ2
сконструирован таким образом, что чем ближе к нулю наблюдаемое
значение критерия χ2, тем вероятнее, что гипотеза справедлива. Поэтому для проведения
гипотезы применяется критерий χ2
с правосторонней критической областью. Необходимо найти по таблице квантилей χ2-распределения
по заданному уровню значимости α и числу степеней
свободы v критическое значение χ2α,v, удовлетворяющее условию p(χ2
≥ χ2α,v) = α.
Если χ2набл.
≥ χ2α,v, то считается, что гипотетическая функция F(x) не согласуется с результатами эксперимента. Если χ2набл.
≤ χ2α,v, то считается, что гипотетическая функция F(x) согласуется с результатами эксперимента.
1.3 Алгоритм обработки
выборки
) Сортируем выборку по
возрастанию (преобразуем в вариационный ряд)
) Находим минимальный xmin и максимальный xmax элемент выборки
) Находим длину
интервалов группировки h
по формуле (1.5)
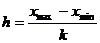 , (1.5)
, (1.5)
где k - число интервалов группировки.
) Находим левые xl и правые xr границы интервалов группировки по
формулам (1.6)
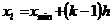 (1.6)
(1.6)
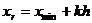
) Находим центры xk*
интервалов группировки по формуле (1.7)
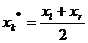 (1.7)
(1.7)
) Для каждого интервала
группировки (xk-1,
xk) находим число nk*
(абсолютная частота) элементов выборки, попавших в этот интервал.
Важно чтобы каждый элемент выборки был отнесен к одному и только к одному
интервалу, а если значение элемента попадает на границу интервала, то его
относят к интервалу с младшим номером. Минимальный элемент всегда относится к
первому интервалу, максимальный к последнему.
) Вычисляем
относительные частоты Otnk*
по формуле (1.8) как отношение абсолютной частоты к объему выборки. Убеждаемся,
что сумма всех относительных частот равна единице (допускается небольшое
отличие от единицы в рамках погрешности вычислений).
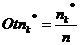 (1.8)
(1.8)
8) Строим гистограмму
относительных частот - фигуру, состоящую из k
прямоугольников, опирающихся на интервалы группировки. Площадь k-го прямоугольника полагают равной относительной частоте данного
интервала. Высота k-го прямоугольника Hk рассчитывается
по формуле (1.9).
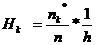 (1.9)
(1.9)
Убеждаемся, что сумма
всех высот Hk, умноженная на h, равна единице (допускается небольшое отличие от единицы в рамках
погрешности вычислений). На оси абсцисс выбираем начальную точку чуть левее
точки xmin, и такой масштаб, чтобы
на оси поместился интервал [xmin,
xmax] и отчетливо
различались точки xl,
xr. На оси ординат выбираем начало
отсчета в точке 0 и такой масштаб, чтобы отчетливо различались Hk. Для построения гистограммы
относительных частот на ось абсцисс наносим интервалы [xl, xr] и, используя каждый из них как
основание, строим прямоугольник с соответствующей высотой Hk. Получаем гистограмму.
) Вычисляем параметры
распределения Парето α и x0.
Для этого используем систему (1.10).
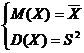 , (1.10)
, (1.10)
где 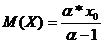 ,
,
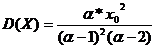 ,
,
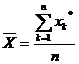 ,
,
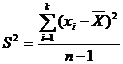 .
.
Получается система
(1.11):
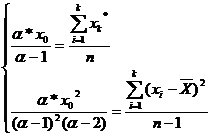 (1.11)
(1.11)
Решая систему уравнений,
находим параметры α и x0.
При этом должны выполняться условия α
> 0. Параметры распределения вычисляются по формулам (1.12).
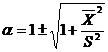 (1.12)
(1.12)
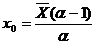
) Строим график функции
плотности распределения f(x) с вычисленными параметрами распределения α
и x0,
где x - это значения центров интервалов xk*.
) Проверяем выборку на
соответствие распределению Парето по критерию согласия χ2
по формуле (1.4), где mi
= nk*,
n - объем выборки, pi
= F(xr)
- F(xl),
или по формуле интеграла (pi
= x0α((xl)-α
- (xr)-α).
При этом минимальное значение по левой границе равно значению больше нуля, а
максимальное значение по правой границе - бесконечность ∞, а также должны
выполняться условия функции распределения. Хи-квадрат крит. χ2α,v = χ2крит. находится по таблице, где v
= 3, α - выбирается из таблицы.
2. Практическая часть
Для автоматизации
обработки выборки была разработана программа Pareto_distribution.exe, в которую заложены алгоритмы обработки выборки и возможность
быстрого получения результата. Вид программы представлен на рисунке 3.
парето распределение
программа выборка
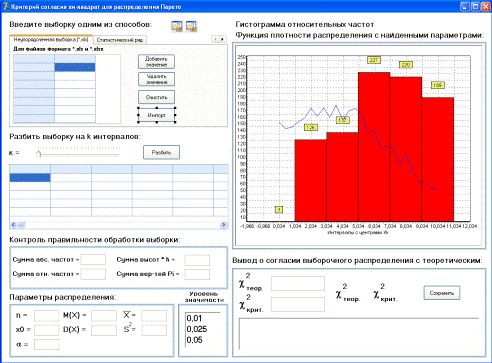
Рисунок 3 - Программа Pareto_distribution.exe
В программе заложена
возможность ввода либо неупорядоченной выборки, либо статистического ряда. Для
неупорядоченной выборки возможен импорт из внешнего файла с расширением *.xml и *.txt. Также
пользователь может сам вводить выборку.
Для разбиения выборки на
интервалы заложено определенное число интервалов, на которые можно разбить
выборку. Это число интервалов соответствует числу интервалов из таблицы χ2крит.
Для контроля
правильности обработки выборки и лучшего понимания самого процесса обработки
представлена таблица, в которой отображаются все вычисляемые данные, заложенные
в постановке задачи.
Под таблицей находится
область, в которой отображаются вычисленные параметры распределения Парето
полученной выборки.
Для визуального анализа
представлен график, на котором отображаются гистограмма относительных частот и
функция плотности распределения с вычисленными параметрами. Это уже позволяет
сделать вывод о соответствии исходной выборки распределению Парето.
Под графиком находится
область, отображающая значения χ2крит
и χ2теор.
Здесь уже делается окончательный вывод на соответствие исходной
выборки распределению Парето.
Для импорта выборки из
файла существуют некоторые правила:
выборка в поле
записывается в один столбик, начиная каждое значение с новой строки;
в импортируемом файле
выборка должна быть записана в один столбик, каждое значение с новой строки. В
файле не должно присутствовать лишних значений и заголовков. Пример файла с
выборкой представлен на рисунке 4.
Рисунок 4 - Импорт
текстового файла
2) Для файлов формата *.xls (MS
Excel):
для неупорядоченного
случая: выборка должна быть записана в столбик, каждое значение с новой строки.
Предполагается, что первая строка - заголовок столбца. Пример файла с выборкой
представлен на рисунке 5;
для статистического
ряда: выборка представляет собой два столбика, в первый из которых записано значение
выборки, а во второй записана частота этого значения. Предполагается, что
первая строка - заголовок столбца. Пример статистического ряда представлен на
рисунке 5.
Рисунок 5 - Импорт из
Excel
При импорте или вводе
выборке необходимо, чтобы в таблице в программе не было пустых или не
заполненных строк. Если такие строки остаются, необходимо встать на необходимую
ячейку и нажать кнопку «Удалить». Пример правильно заполнения таблицы приведен
на рисунке 6.
Рисунок 6 - Правильный
ввод выборки
2.1 Пример 1
Дана выборка, записанная
в файле формата *.txt. Сделать выводы
по соответствию данной выборке распределению Парето, используя различные
интервалы разбиения и уровень значимости α.
В программе переходим на
вкладку «Неупорядоченная выборка (*.txt)»
и нажимаем кнопку «Импорт». Появляется окошко, представленное на рисунке 7.
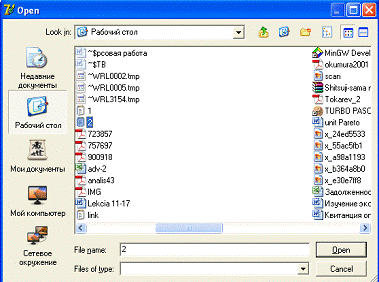
Рисунок 7 - Окно импорта
Выбираем нужный файл и
щелкаем кнопку «Open». Выборка,
записанная в файле, отобразится в окошечке программы, как показано на рисунке
8.

Рисунок 8 - Выборка из
файла
После этого с помощью
движка выбираем количество интервалов, на которое хотим разбить выборку. Пусть k=10. После этого нажимаем кнопку «Разбить». В таблице отобразятся
данные, полученные при разбивке выборки. Полученный результат показан на
рисунке 9. С помощью полосы прокрутки можно посмотреть всю таблицу. Для
контроля правильности обработки выборки в программу внедрен специальный блок.
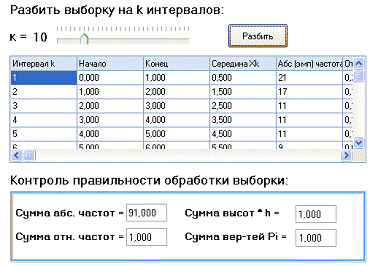
Рисунок 9 - Данные
разбивки
Для изменения уровня
значимости α щелкаем на нужное значение один раз. Выбираем, например первое
значение.
Получившиеся гистограмма
относительных частот и график функции плотности распределения представлены на
рисунке 10.
При данных значениях разбивки
делаем вывод, что данная выборка согласуется с распределением Парето, т.е.
выполнены условия критерия согласия Пирсона. Вывод указан на рисунке 11.
Для того, чтобы
сохранить полученные данные обработки выборки, в программе находится кнопка
«Сохранить». При ее нажатии, все полученные данные сохранятся в формате *.xml. Сохраненный файл представлен на рисунке 12.

Рисунок 10 - График

Рисунок 11 - Вывод
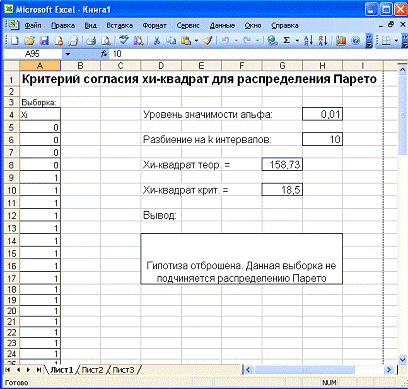
Рисунок 12 - Экспорт в Excel
2.2 Пример 2
Дана выборка в виде статистического
ряда. Нужно произвести произвольное разбиение выборки и посмотреть, при какой
значении k выборка подчиняется распределению Парето.
В программе переходим на вкладку «Статистический
ряд» и нажимаем кнопку «Импорт». Появляется диалоговое окно, с помощью которого
открываем файл с готовой выборкой. Нажимаем кнопку «Open».
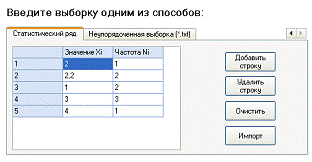
Рисунок 13 - Статистический ряд
После этого переходим к разбиению
выборки:
) Пусть k=10. Тогда получим данные,
приведенные на рисунке 14. По гистограмме относительных частот видно, что
выборка не подчиняется распределению Парето. Имеем χ2крит. > χ2теор., следовательно, не
выполнено условие Пирсона;
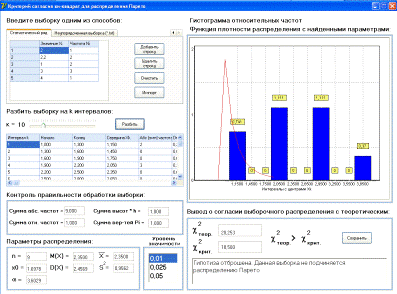
Рисунок 14 - Итоги обработки
) Пусть k=6. Имеем χ2крит. < χ2теор., следовательно,
условие Пирсона выполнено; а значит, выборка при таком разбиении подчиняется
закону распределения Парето.
Заключение
Критерий согласия Пирсона является
очень удобным инструментом для определения, относится ли случайная выборка к
тому или иному распределению.
Одна и та же выборка может принимать
то или иное распределение. Это зависит от числа интервалов, на которое делится
выборка, а также от выбранного уровня значимости α.
Приложение А
Xls_To_StringGrid
(AGrid: TStringGrid; AXLSFile: string): Boolean;= $0000000B;, Sheet:
OLEVariant;: Variant;: OleVariant;, y, k, r: Integer;:integer;:= False;
// Create Excel-OLE
Object:= CreateOleObject ('Excel. Application');
// Hide Excel. Visible:=
False;
// Open the Workbook.
Workbooks. Open(AXLSFile);
// Sheet:= XLApp.
Workbooks[1].WorkSheets[1];:= XLApp. Workbooks
[ExtractFileName(AXLSFile)].WorkSheets[1];
// In order to know the
dimension of the WorkSheet, i.e the number of rows
// and the number of
columns, we activate the last non-empty cell of it. Cells. SpecialCells
(xlCellTypeLastCell, EmptyParam).Activate;
// Get the value of the
last row:= XLApp. ActiveCell. Row;
// Get the value of the
last column:= XLApp. ActiveCell. Column;
// Set Stringgrid's row
&col dimensions.. RowCount:= x;
// Assign the Variant
associated with the WorkSheet to the Delphi Variant:= XLApp. Range ['A1',
XLApp. Cells. Item [X, Y]].Value;
//XLApp. Quit;
// Define the loop for
filling in the TStringGrid
{K:= 1;R:= 1 to Y do.
Cells[(R), (K)]:= RangeMatrix [K+1, R];. RowCount:= K + 1;(K, 1);>=
(X-1);}:=1;K<X do beginR:= 1 to Y do //begin. Cells[(R), (K)]:= RangeMatrix
[K+1, R];. RowCount:= K + 1;(K, 1);
//end;;i:=1 to AGrid.
RowCount-1 do. Cells [0, i]:=IntToStr(i);
// Unassign the Delphi
Variant Matrix:= Unassigned;
// Quit Excelnot
VarIsEmpty(XLApp) then. DisplayAlerts:= False;. Quit;:= UnAssigned;:=
UnAssigned;:= True;;;;InsertFileInMemo (RzMemo1: TRzMemo; FileName: string;:
Boolean);: TMemoryStream;: Char;:= TMemoryStream. Create;.
LoadFromFile(FileName);. Seek (0, 2);:= #0;. Write (NullTerminator, 1);not
ReplaceSel then. SelLength:= 0;(RzMemo1. Handle, EM_ReplaceSel, 0,(Stream.
Memory));. Free;;;Sort;i:integer;: boolean;:real;:= FALSE;i:= 0 to n-2 doV[i]
> V [i+1] then begin:= V[i];[i]:=V [i+1];[i+1]:= buf;:=
TRUE;;changed;;Vkladka3;i:integer;:=Form1. RzMemo1. Lines. Count;(V, n);i:=0 to
n-1 do begin[i]:=StrToFloat (Form1. RzMemo1. Lines. Strings[i]);;;;Vkladka1;i:integer;:=Form1.SG.
RowCount-1;(V, n);i:=0 to n-1 do begin[i]:=StrToFloat (Form1.SG. Cells [1,
i+1]);;;;Vkladka2;i, j, m:integer;, k, r, w:integer;:integer;:array of
real;:array of integer;:=0;:=Form1.SG1. RowCount-1;i:=0 to m-1 do:=SummaEl+StrToInt
(Form1.SG1. Cells [2, i+1]);:=SummaEl;(MXi, m);(MNi, m);i:=0 to m-1 do
begin[i]:=StrToFloat (Form1.SG1. Cells [1, i+1]);[i]:=StrToInt (Form1.SG1.
Cells [2, i+1]);;(V, n);:=0;:=0;:=0;w<=n-1 do begini:=0 to m-1 do
begin:=MNi[i];j:=0 to r-1 do begin[w]:=MXi[i];:=w+1;;;;;;OcenkaParam;i:integer;,
alp2:real;:=0;:=0;i:=0 to k-1 do begin:=X+(Xk[i]*OtnCh[i]);;. RzLabel27.
Caption:=FloatToStrF (X, ffFixed, 10,4);i:=0 to k-1 do begin:=SKv+(sqr (Xk[i] -
X));;:=SKv/(n-1);:=sqrt(SKv);. RzLabel25. Caption:=FloatToStrF (SKv, ffFixed,
10,4);
// Находим параметр альфа
alp1:=1+sqrt (1+(sqr(X)/SKv));
alp2:=1-sqrt
(1+(sqr(X)/SKv));(alp1>0) then alp:=alp1begin(alp2>0) then
alp:=alp2ShowMessage ('Параметр альфа - отрицательный');;:=X*(alp-1)/alp;.
RzLabel16. Caption:=FloatToStrF (x0, ffFixed, 10,4);. RzLabel17.
Caption:=FloatToStrF (alp, ffFixed, 10,4);(alp>1) then
begin:=alp*x0/(alp-1);. RzLabel18. Caption:=FloatToStrF (Mx, ffFixed,
10,4);Form1. RzLabel18. Caption:='Мат.ожидания нет';(alp>2) then
begin:=alp*sqr(x0)/sqr (alp-1)*(alp-2);. RzLabel19. Caption:=FloatToStrF (Dx,
ffFixed, 10,4);Form1. RzLabel19. Caption:='Дисперсии нет';. RzLabel15.
Caption:=IntToStr(n);;F (x:real):real;:=(1 - (Power((x0/x),
alp)));;Pareto;i:integer;((alp>0) and (x0>0)) then begini:=0 to k-1 do
begin(Xk[i]>x0) then begin[i]:=(alp/x0) * (Power((x0/Xk[i]), alp+1));[i]:=F
(Xk[i]);begin[i]:=0;[i]:=0;;;Form1. RzMemo2. Lines. Text:='Параметры
распределения отрицательные';
//
Делаем нормировку
Rx [k-1]:=Infinity;
Lx[0]:=x0;((alp>0)
and (x0>0)) then begini:=0 to k-1 do begin(Lx[i]>x0) then begin[i]:=F
(Lx[i]);FLx[i]:=0;(Rx[i]>x0) then begin[i]:=F
(Rx[i]);FRgx[i]:=0;[i]:=FRgx[i] - FLx[i];;;:=0;i:=0 to k-1 do
begin:=Sp+Px[i];[i]:=n*Px[i];;. RzLabel49. Caption:=FloatToStrF (Sp, ffFixed,
10,3);i:=1 to k do begin. RzStringGrid2. Cells [7, i]:=FloatToStrF (Px[i-1],
ffFixed, 10,4);. RzStringGrid2. Cells [8, i]:=FloatToStrF (fx[i-1], ffFixed,
10,4);. RzStringGrid2. Cells [9, i]:=FloatToStrF (Frx[i-1], ffFixed, 10,4);.
RzStringGrid2. Cells [11, i]:=FloatToStrF (EmpCh[i-1], ffFixed,
10,4);;;Gipotiza;i:integer;. RzMemo2. Lines. Text:='';;:=0;i:=0 to k-1 do
begin(Px[i]<>0) then:=HiNabl+(Power((Nk[i] - n*Px[i]), 2))/(n*Px[i]);;.
RzLabel22. Caption:=FloatToStrF (HiNabl, ffFixed, 10,3);. RzLabel23.
Caption:=FloatToStrF (HiKrit, ffFixed, 10,3);:=
'Гипотиза отброшена. Данная выборка не подчиняется распределению Парето';
If (HiNabl>=HiKrit) then begin
Form1. RzMemo2.
Text:=a;. RzLabel40. Caption:='>';begin. RzMemo2. Text:=b;. RzLabel40.
Caption:='<';;;NewIntervals;i, m, l:integer;:real;Form1. RzPageControl1.
ActivePage=Form1. TabSheet1 then Vkladka1beginForm1. RzPageControl1.
ActivePage=Form1. TabSheet2 then Vkladka2beginForm1. RzPageControl1. ActivePage=Form1.
TabSheet3 then Vkladka3;;:=V[0];:=V [n-1];:=(Xmax-Xmin)/k;(Rx, k);(Lx, k);(Xk,
k);(Nk, k);(OtnCh, k);(Hk, k);(Px, k);(fx, k);(Frx, k);(FLx, k);(FRgx,
k);(Fremp, k);(EmpCh, k);i:=0 to k-1 do
begin[i]:=Xmin+i*h;[i]:=Xmin+(i+1)*h;[i]:=(Lx[i]+Rx[i])/2;;
// подсчитываем число элементов,
вошедших в интервал
m:=0;:=0;:=0;(m<=k-1)
do begini:=l to n-1 do begin(V[i]<=Rx[m]) then
begin:=Summa+1;:=l+1;begin[m]:=Summa;;[m]:=Summa;;:=0;:=m+1;;i:=0 to k-1 do
begin[i]:=Nk[i]/n;[i]:=OtnCh[i]/h;;:=0;:=0;:=0;i:=0 to k-1 do
begin:=Sotch+OtnCh[i];:=Shk+h*Hk[i];:=Sach+Nk[i];;. RzLabel46.
Caption:=FloatToStrF (Sach, ffFixed, 10,3);. RzLabel47. Caption:=FloatToStrF
(Sotch, ffFixed, 10,3);. RzLabel48. Caption:=FloatToStrF (Shk, ffFixed,
10,3);:=0;i:=0 to k-1 do begin[i]:=t+OtnCh[i];:=Fremp[i];;i:=1 to k do begin.
RzStringGrid2. Cells [0, i]:=IntToStr(i);. RzStringGrid2. Cells [1,
i]:=FloatToStrF (Lx[i-1], ffFixed, 10,3);. RzStringGrid2. Cells [2,
i]:=FloatToStrF (Rx[i-1], ffFixed, 10,3);. RzStringGrid2. Cells [3,
i]:=FloatToStrF (Xk[i-1], ffFixed, 10,3);. RzStringGrid2. Cells [4,
i]:=IntToStr (Nk[i-1]);. RzStringGrid2. Cells [5, i]:=FloatToStrF (OtnCh[i-1],
ffFixed, 10,4);. RzStringGrid2. Cells [6, i]:=FloatToStrF (Hk[i-1], ffFixed,
10,4);. RzStringGrid2. Cells [10, i]:=FloatToStrF (Fremp[i-1], ffFixed,
10,4);;i:=0 to k-1 do begin.diagr1. AddXY (Xk[i], Hk[i], FloatToStrF (Xk[i],
ffFixed, 10,4), clBlue);;;;i:=0 to k-1 do begin.diagr2. AddXY (Xk[i], fx[i],
FloatToStrF (fx[i], ffFixed, 10,3), clRed);;