Исследование алгоритмов скремблирования данных
Содержание
Введение
. Проблема
защиты информации в оперативных радиосетях
. Скремблирование
. Общий
алгоритм скремблирования
. Простые
алгоритмы скремблирования данных
Заключение
Список
литературы
Введение
Нaблюдaемое
в последнее время прогрессирующее влияние информaционных
технологий прaктически на все
сферы жизнедеятельности человечества вызывает поступательный рост требований к
телекоммуникационным системам, компьютерным сетям и устройствaм
телекоммуникации. Это объясняется тем, что данные системы являются пока
основным средством обмена информацией и качество их функционирования является
определяющим фактором эффективности большинства информационных технологий.
Важнейшей составляющей качества функционирования телекоммуникационных систем
является качество защиты информации.
Обеспечение этой составляющей в настоящее время
сталкивается с целым рядом проблем, основной из которых выступает противоречие
между потенциальными возможностями существующих подходов и постоянно
возрастающими требованиями к защите информации. Потенциальная неспособность
этих подходов обеспечить выполнение изменяющихся требований объясняет
актуальность исследований в направлении поиска принципиально новых подходов,
позволяющих решить отмеченную проблему.
1. Проблемa
зaщиты
информaции
в оперaтивных
рaдиосетях
Рaдиосвязь
является основным видом связи с подвижными объектaми,
обеспечивaющим упрaвление
органaми и подрaзделениями
прaвоохранительных и
силовых министерств и ведомств, а в ряде случaев
единственным видом связи, обеспечивaющим
управление и взаимодействие с другими министерствами и ведомствами при
осложнении оперативной обстановки (контртеррористические операции, массовые
беспорядки и т.п.), а также при ликвидации последствий стихийных бедствий.
Важным преимуществом радиосвязи является ее высокая мобильность, то есть
возможность изменения состава сети радиосвязи или полное ее перемещение без
нарушения работы. Применение радиосвязи позволяет сконцентрировать в
минимальные сроки и в нужном месте необходимое количество оперативных сил и
средств для проведения мероприятий, согласовать по времени их действия и
осуществлять единое руководство. Требования к качеству функционирования сетей
радиосвязи как составной части систем управления растут постоянно, адаптируясь
к быстро меняющимся условиям эксплуатации. В настоящее время наблюдается резкий
рост числа радиосетей и парка радиосредств, эксплуатирующихся в министерствах и
ведомствах, что ведет к укрупнению профессиональных радиосетей. Это очевидно из
следующих показателей:
· рост числа сверхбольших радиосетей
(с зонами уверенной связи на среднепересеченной местности с радиусом около 50
км);
· рост числа территориальных
радиосетей (сети, обеспечивающие сплошное покрытие в пределах территории любой
конфигурации);
· увеличение числа обслуживаемых
абонентов в ведомственных радиосетях с малой емкостью предельного размера (до
1000 абонентов).
Проблемы организaции
трaнкинговых
систем
Для оргaнизации
рaдиосетей
специализировaнного пользовaния
(имеется в виду категория обслуживаемых абонентов - связь с подразделениями ОВД
на транспорте, оперативным автомототранспортом, пешими нарядами, линейными
отделениями ОВД) и индивидуального пользования (наличие индивидуального
вызывного номера у оконечного оборудования) можно использовать сухопутную
подвижную радиосвязь на основе конвенциональных радиосетей (многостанционный
прямой доступ к ограниченному количеству рабочих радиоканалов с фиксированным
распределением каналов и с ограниченным выходом или без выхода в телефонную
сеть общего пользования), транкинговых систем связи (реализация автоматического
динамического доступа к каналам) и систем связи сотовой структуры. Для
развертывания оперативных радиосетей (прямой безкоммутационный доступ к
абоненту радиосети) используют конвенциональные радиосети и транкинговые
системы. Значительные преимущества транкинговых систем (высокая пропускная
способность, степень защищенности от несанкционированного доступа) ставили бы
их вне конкуренции, однако экономическая составляющая внедрения таких систем
сводит на нет все технические преимущества. Значительное падение стоимости на
такие системы, как на профессиональное оборудование, практически невозможно в
отличие от технического оборудования общего назначения. Такой подход к решению
данной проблемы, как совместное использование транкинговых сетей одновременно
несколькими министерствами и ведомствами, оказался практически невозможен
(различные задачи, приоритеты, уровни конфиденциальности и управления и т.д.
ведут к неэффективной совместной эксплуатации).
Конвенционaльные
рaдиосистемы:
непaрaметрическое
кодирование речи
Вышеприведенные соображения явились
предпосылками для исследований в области конвенционaльных
рaдиосетей. В
сотрудничестве с производителями рaдиосредств
и устройств защиты речевой информaции
(УЗРИ) удaлось открыть новую
область для рaзрaботок
- конвенциональные рaдиосистемы.
Целью разработок стало создание автоматизированных систем контроля и
мониторинга на базе существующих радиосредств. Нескольким разработчикам удалось
создать ряд таких систем на базе контроллеров, встраиваемых в базовые
радиостанции, и УЗРИ, встраиваемых в абонентское оборудование. В 2003 г. на
снабжение МВД России была принята система мониторинга и управления радиосетью
(СМУР) "СМУР-ХК100-01" (фото 1), награжденная дипломом лауреата VII Международного
форума полицейской и военной техники "Интерполитех-2003" (совместная
разработка ГУ НПО "Специальная техника и связь" МВД России и ЗАО
"Интер-Вок", абонентское оборудование - ООО "Альтоника").
Данная система построена на встраиваемом в базовое оборудование контроллере
(фото 2) и абонентском оборудовании со скремблером 04ХК100-01, в принцип работы
которого заложено непараметрическое кодирование речи. Благодаря этому легко
решаются проблемы, возникающие при реализации некоторых функций СМУР:
· снижение разборчивости речи в
"закрытом" режиме не более 1 балла по сравнению с
"открытым" режимом, при этом обязательно должна сохраняться
индивидуальность звучания речи абонента (в экстремальных ситуациях
идентификация абонента часто происходит по голосу);
· скрытное включение диспетчером любой
радиостанции сети в режим "передача" с целью прослушивания
аудиообстановки вокруг абонента.
Для реализация защиты речевой информации в
системе "СМУР-ХКЮО-01" применен модифицированный мозаичный алгоритм
скремблирования: последовательное смешение фреймов сигнала во временной,
частотной и фазовой областях. Для защиты служебной информации, не являющейся
государственной тайной, такой алгоритм средней стойкости вполне достаточен.
Новые подходы к зaщите
передaчи
информaции
Однaко
с выходом Постановления "Об утверждении положений о лицензировaнии
отдельных видов деятельности, связaнных
с шифровaльными
(криптографическими) средствами" открылись новые горизонты для
использования криптографических алгоритмов защиты речевых сигналов в
ведомственных сетях связи.
Использовaние
в оперaтивных
рaдиосетях
решений для специальной связи
Ослaбление
лицензионных огрaничений
побудило рaзрaботчиков
обрaтиться к схемам
построения УЗРИ для СМУР, используемых в системах специальной связи (рис. 1).
Примером такого подхода является отечественная
цифровая система "Альфа", принятая на снабжение МВД России. Такие
радиосистемы передачи служебной информации целесообразно применять только
внутри ограниченной территории с системами физической защиты. Примерами
использования системы "Альфа" является применение ее внутренними
войсками (ВВ) МВД при охране режимных объектов, передачи конфиденциальных
цифровых данных между охраняемыми пунктами управления ОВД и ВВ МВД России. В
таких системах первая вышеприведенная проблема решается использованием более
широкой сетки рабочих частот (практически неограниченный частотный ресурс - в
силу важного государственного значения таких систем связи), вторая проблема не
ставится в силу наличия обязательного индивидуального вызывного номера у
оконечного оборудования, а проблемы реализации "удаленного
прослушивания" вообще не существует из-за отсутствия самой функции.
Прямолинейное копирование существующих решений из специальной связи показало
свою неэффективность для применения в оперативных радиосетях. Необходим
оригинальный подход к решению трех указанных проблем.
Новые рaзработки
для оперaтивной
рaдиосвязи
В некоторых СМУР в качестве помехоустойчивого
кодирования обычно используются хорошо изученные методы (например, укороченный
блочный код Рида-Соломона), что в данном случае не обеспечивает достаточной
дальности связи. Представляется более эффективным использование других помехоустойчивых
кодов (например, турбокодов), позволяющих вплотную приблизиться к пределу
Шеннона, но требующих большую длину кодируемых данных. Что касается второй
проблемы, то при создании СМУР "СМ-Э200" разработчиками (ФПГ
"Уральские заводы", г. Ижевск) был реализован оригинальный алгоритм
вокодерного анализа и синтеза речи. Это дало возможность повысить разборчивость
речи до естественного звучания и возможности идентификации абонента по тембру
голоса. В качестве алгоритма речевого кодирования взята классическая модель
вокодера с линейным предсказанием и использованием многополосного возбуждения,
что ведет к уменьшению посторонних призвуков и улучшению качества
восстановленного речевого сигнала в условиях внешних акустических шумов.
В алгоритме применена тройная оценка частоты
основного тона, что практически свело на нет эффект "плавающего тона"
в конце отдельного слова. Благодаря такой реализации кодирования речи и
введенных доработок с учетом ведомственных требований система "СМ-Э200"
стала привлекательна для применения в определенных условиях - связь между
пунктами временной дислокации и управления (система была рекомендована для
эксплуатации во ВВ МВД России). Остается третья проблема - реализация функции
"удаленного прослушивания". Можно отбросить выявленные недостатки
СМУР, использующих вокодерные технологии, касающиеся учета чувствительности
микрофонного усилителя и скрытности включения радиостанции на
"передачу" (отсутствие визуальной и звуковой индикации) - это легко
устраняется. На полигонных испытаниях при дистанционном включении абонентского
оборудования в режим "удаленного прослушивания" аудиообстановки
вокруг абонентской радиостанции более 50% всей информации являлось
неразборчивым, причем УЗРИ оказались практически неработоспособны при небольших
соотношениях сигнал/шум ("смесь" речи и транспортных или
индустриальных шумов, многоголосие - "cocktail party" -и т.д.). Таким
образом, проблема оказалась сложнее, чем представлялось, и не может быть решена
лишь использованием стандартных методов теории цифровых радиосистем
аудиоконтроля. Разработчики "сдались": либо функция "удаленного
прослушивания" реализована только в "открытом" режиме, либо
данный недостаток просто проигнорирован. Это, разумеется, неприемлемо при разработки
СМУР для оперативных ведомственных сетей.
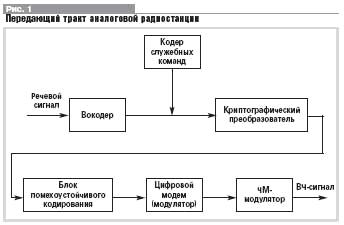
Совмещение раздельного кодирования
Для решения данной проблемы предлагается
совместить параметрическое (использовать для речевого сигнала) и
непараметрическое (использовать для неречевого сигнала) кодирование (рис. 2).
При этом придется применить теорию распознавания образов: в первую очередь, для
создания автоматического распознавателя речи (детектора речь/не речь).
Разработка автоматического распознавателя речи (АРР) сопровождается серьезными
ограничениями условий функционирования СМУР на базе ведомственных оперативных
радиосетей. В данных условиях невозможно использовать наиболее эффективные
методы APR:
· многоканальные методы, основанные на
разнесенных микрофонах (абонентский микрофон в зоне источника речевого сигнала
абонента и опорный микрофон вне данной зоны; либо опорный микрофон размещается
на дальнем торце средства связи по отношению к абонентскому - в основу положено
явление задержки речевого сигнала между разными микрофонами);
· методы, основанные на отличии
энергетики речевого сигнала и неречевых фоновых шумов (энергия речевого сигнала
значительно превосходит энергию сигналов "молчания",
"пауз").
Для решения поставленной задачи необходимо
комбинировать широкий спектр оставшихся алгоритмов АРР:
· дискриминаторы параметров сигнала с
повышенной устойчивостью к шумам;
· коррекция и улучшение характеристик
до уровня, позволяющего распознать сигнал как речь;
· адаптация моделей "чистой"
речи с компенсацией воздействия шума.
Выходные аудиосигналы будут кодироваться по
разным законам: речевой - по криптографическому закону, неречевой -по алгоритму
мозаичного скремблирования. Однако возникает сомнение в целесообразности такого
раздельного кодирования: повышенной защиты речевых сигналов и закрытия средней
стойкости неречевых сигналов. Действительно, сотрудникам министерств и ведомств
запрещается передавать по оперативным радиосетям служебную информацию,
содержащую сведения ограниченного распространения (ограничения налагаются
ведомственными нормативными документами, а в экстремальных ситуациях
используются кодовые слова, фразы или кодовые таблицы, утвержденные
управлениями и отделами связи). При использовании функции "удаленного
прослушивания" и при небольшом отношении сигнал/шум возрастает вероятность
неправильного срабатывания АРР, что может привести к передаче прослушиваемой
информации, несоответствующей уровню "закрытия" используемой
радиосети. В этом случае может произойти радиоперехват таких сигналов
потенциальным противником с дальнейшей шумо-очисткой в режиме off-line и, таким
образом, возможен несанкционированный доступ к конфиденциальной информации.
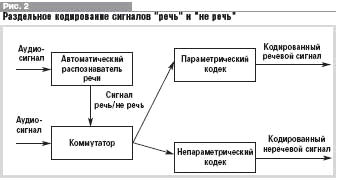
Целесообразность использования
непараметрического кодирования
В данном вопросе мы подошли к парадоксальному
для разработчиков выводу: "закрытие" сигналов, передаваемых при
"удаленном прослушивании", должно быть более высокого уровня, чем для
передачи речевой информации при обычном "сеансе связи", то есть
необходимо непараметрическое кодирование прослушиваемых аудиосигналов с
последующим криптографическим "закрытием". Это, конечно, потребует
высокой скорости информационного потока и, как следствие, использования более
широкой полосы рабочих частот. Таким образом, придется нормативно определить
использование под передачу неречевых сигналов в режиме "удаленного
прослушивания" сразу нескольких стандартных каналов (25/12,5 кГц), что
ведет к неэффективному использованию частотного ресурса.
2. Скремблирование
Скремблер -
программное или аппаратное <#"513075.files/image003.gif"> <#"513075.files/image004.gif"> <http://translate.googleusercontent.com/translate_c?hl=ru&langpair=en|ru&rurl=translate.google.com.ua&u=http://en.wikipedia.org/wiki/File:Dvbcsa_stream.svg&usg=ALkJrhgbKlCZqcO3laCi3sGebRoIr8CjlA>
Слабые стороны
Были CSA не сработает, зашифрованные
передачи DVB бы расшифровать, независимо от каких-либо имущественных условного
доступа (CA) используемой системы. Это может создать серьезную угрозу платного
цифрового телевидения, как DVB была стандартизирована на для цифрового наземного
телевидения
<http://translate.googleusercontent.com/translate_c?hl=ru&langpair=en%7Cru&rurl=translate.google.com.ua&u=http://en.wikipedia.org/wiki/Digital_terrestrial_television&usg=ALkJrhjFxBjzOP_medx-7mO2ZyQzj47vLw>
в Европе и в других местах, и используется многими провайдерами спутникового
телевидения. Нет атаки до сих пор не опубликованы, однако.
Криптоанализ
Как и другие алгоритмы шифрования,
слабым местом возникает поскольку, что часть сообщения, как известно или, по
крайней мере легко предсказуемо, как MPEG
<http://translate.googleusercontent.com/translate_c?hl=ru&langpair=en%7Cru&rurl=translate.google.com.ua&u=http://en.wikipedia.org/wiki/MPEG&usg=ALkJrhjQBxy1y9D_glTZZ2jBdf45Id89Uw>
заголовки. Длина ключевых <http://translate.googleusercontent.com/translate_c?hl=ru&langpair=en%7Cru&rurl=translate.google.com.ua&u=http://en.wikipedia.org/wiki/Key_%28cryptography%29&usg=ALkJrhhjwPwLi2adX9E3elfYCbP3_Rg0-w>
составляет 64 бит
<http://translate.googleusercontent.com/translate_c?hl=ru&langpair=en%7Cru&rurl=translate.google.com.ua&u=http://en.wikipedia.org/wiki/Bit&usg=ALkJrhhU00vYGHmfuIskIy5nQfQtfMqYhA>
, что позволяет для различных возможностей шифрования. Атаку "грубой
силой
<http://translate.googleusercontent.com/translate_c?hl=ru&langpair=en%7Cru&rurl=translate.google.com.ua&u=http://en.wikipedia.org/wiki/Brute_force_attack&usg=ALkJrhgsfY-aOLeHlXVY2MmM9mJL6H_PLQ>
с 1 мкс для каждой попытки, через все возможные ключевые слова, займет около
300000 лет, в среднем. Это может быть уменьшена с помощью предсказуемой части
зашифрованное сообщение, чтобы исключить потенциальные ключи, однако это
потребует криптоанализ обеих поточный шифр и алгоритмов блочного шифрования в
то же время, является сложной задачей.
Грубая сила подход
Хотя CSA алгоритм использует
64-битные ключи, большую часть времени только 48 бит ключ неизвестны, так как
байт 3 и 7 используются в качестве контрольной суммы байт системы CA, и может
быть легко пересчитывается. Это позволит сократить перебор
<http://translate.googleusercontent.com/translate_c?hl=ru&langpair=en%7Cru&rurl=translate.google.com.ua&u=http://en.wikipedia.org/wiki/Brute-force_search&usg=ALkJrhh-kagoCm8WBMgmDCeoagIAlOJYSw>
времени.
Теоретические реализации в ПЛИС,
которая будет состоять из 42 HW-потоки, которые каждый из них будет тест 1 ключ
за такт цикла. При тактовой частотой от 50 МГц это позволит ключ можно найти в
~ 19 дней, так как мы ожидали, в среднем, чтобы найти ключ после 2 47
пытается для 2 48 ключ.
Проблематичным участие в этом будет
заключаться в определении, когда действительный ключ был найден, поскольку это
будет включать проверку расшифрованные данные на известные вещи, как
MPEG-заголовков, которые могут быть трудно реализовать достаточно эффективно,
чтобы поместиться в настоящее время коммерчески доступных FPGA.
Одним из возможных путей сокращения
необходимы сложности в FPGA могут быть иметь многослойную подход, при котором
первый раз отбрасывает все ключи, которые, как известно, недействительными с
довольно простых проверок и одного или более, что проверки для получения
дополнительной информации.
Большинство CA системы используют
недолго ключи, которые сменяются каждые несколько секунд, что делает такой
реализации бесполезно до вычислительных увеличение мощности резко. Кроме того,
обычно 48 бит длина ключа может все еще быть увеличена до 64 бит в будущем для
улучшения системы сил, так как это не ограничение алгоритма.
4.Простые алгоритмы скремблирования
данных
Иногда нужно что-то зашифровать, но
привлекать серьёзные алгоритмы шифрования вроде и не к месту - будет как из
пушки по воробьям. Например, нужна простая защита траффика от
пользователей/троянов со снифферами
<http://ru.wikipedia.org/wiki/%D0%A1%D0%BD%D0%B8%D1%84%D1%84%D0%B5%D1%80>,
но сами данные не стоят того, чтобы на них тратилось много времени на
шифровку-расшифровку, ну и на саму реализацию тоже. Или вам нужно как-то
обеспечить закрытость неких хранимых данных от обычных пользователей. Понятно,
что подобные алгоритмы не устоят против целенаправленных попыток взлома
профессионалами, но мы попытаемся усложнить работу и им, хотя такая задача
обычно и не ставится. Вот это-то обычно и называется scrambling.
Под катом я изложу идеи для подобных
алгоритмов и обещаю, что они будут посложнее обыкновенного XOR с фиксированым
ключом. На всякий случай обращаю внимание на то, что эти алгоритмы не
претендуют на звание криптостойких, но уверен, что вы сможете найти им
применение.
Предпосылки
Наверно все знают, что в подобных случаях чаще
всего применяют простое циклическое наложение ключа фиксированой длины с
помощью операции XOR. И все так же хорошо знают, что такая защита не
выдерживает даже начинающего «хакера» или продвинутого пользователя. Хотелось
бы что-нибудь посложнее, но простое в реализации.
Генерирование ключа
Первое, что приходит в голову, это
генерировать достаточно длинный ключ, чтобы хотя бы усложнить нахождение длины
ключа. Например, использовать некий генератор псевдослучайных чисел с входными
данными, известными и отправителю, и получателю. Один из таких часто
применяемых генераторов - линейный конгруэнтный ГПСЧ
<http://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D0%BD%D0%B5%D0%B9%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%BD%D0%B3%D1%80%D1%83%D1%8D%D0%BD%D1%82%D0%BD%D1%8B%D0%B9_%D0%BC%D0%B5%D1%82%D0%BE%D0%B4>
(ГСПЧ это генератор псевдослучайных чисел).
Мы, конечно, догадываемся, что это
плохо, но что же именно плохо в этом подходе? Проблема в том, что довольно
трудно генерировать параметры для самого генератора. Программно подобрать
хорошие параметры для линейного конгруэнтного ГПСЧ, чтобы последовательность
была длинная и невырожденая, довольно трудно. По этому поводу можно почитать в
3.2.1 в книге Д.Кнута «Искусство программирования».
Поэтому зачастую эти параметры
вколачивают в код как константы и, как следствие, потенциальный взломщик
получает множество сообщений зашифрованых с одним ключом, что значительно
упрощает его работу.
Использование самих данных для
генерации этой псевдослучайной последовательности
На первый взгляд кажется, что это
невозможно, ведь нам нужен генератор, который выдавал бы одинаковую
последовательность и при шифровке, и при расшифровке. Как ни странно, именно
этот «убийственный» тезис и даёт нам путь к созданию такого генератора. Да, нам
нужен алгоритм, который меняет значения своих внутренних переменных одинаково,
если ему дать исходный байт (или что там у нас является атомарной единицей
кодирования) и зашифрованый байт. Как этого достичь? Всё гениальное просто -
для вычисления следующего значения ключа можно задействовать коммутативные
операции <http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BC%D1%83%D1%82%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D0%B0%D1%8F_%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F>
для пар исходных-шифрованых байт. Так как результат операции не зависит от
порядка операндов в паре, то очевидно, что такой алгоритм будет менять свои
переменные при расшифровке точно так же как и при шифровке, но
последовательность ключей для других входных данных будет другой.
Пример генератора ключей, зависящего
от входных данных
Чтоб было понятней, рассмотрим простенький
пример такого алгоритма.
Пусть xn - это очередной код в
исходных данных, kn - текущий ключ, kn+1 - следующее
значение ключа, yn - зашифрованый код xn. Q(a,b) - некая
коммутативная функция, т.е. такая, что q(a,b)==q(b,a). (a,b,c) - некая
целочисленная функция.гда итерацию по (де)кодированию можно описать так:
n
:= xn xor kn;n+1 := F( kn,
Q( xn, yn ), n );
Если для функции F() понятно, что её
имплементация в общем-то ограничена лишь нашей фантазией и здравым смыслом, то
про Q(), вероятно, вам хочется увидеть подробностей, а именно, каким таким
условиям она должна соответствовать, чтобы быть коммутативной. Самый простой
способ этого достичь - использовать аргументы только парами в коммутативных
операциях, например xor, сложение, умножение. Примеры:
(a,b) = ((a xor b) or
1) * (( a + b ) xor 1).
Как видите, придумать свою супер-пупер функцию
Q() совсем не сложно. Другое дело, нужно ли её делать сложной? Думаю, что
особого смысла в её переусложнении нет.
Перемешиватель данных (shuffler)
Обычно для решения этой задачи используют некий
ГСПЧ для получения пар индексов кодов в блоке данных, которые меняют местами.
Неприятность этого метода в том, что трудно гарантировать, что какая-то часть
данных не останется на том же месте. Также не совсем понятно, сколько же перестановок
нужно сделать, чтобы достичь приемлемого результата, хотя для надёжности можно
просто пройтись по всем кодам сообщения и обменять каждый со случайным. Но есть
ещё одна неприятность - если генератор имеет плохое распределение по квадрату
(а линейный конгруэнтный именно такой болезнью и болеет, и причём безнадёжно),
то при определённых размерах блока можно нарваться на зацикливание выдаваемых
значений. Я довольно долго шёл к идее быстрого псевдослучайного перемешивателя
данных (shuffler) и считаю, что она заслуживает вашего внимания не только как
алгоритм для скремблирования.
Немного теории. В пункте 3.2.1.2 книги Д.Кнута
«Искусство программирования» можно найти критерии для выбора множителя для
линейного конгруэнтного генератора, чтобы длина генерируемой последовательности
равнялась модулю. Что это означает? Это значит, что для генератора с модулем m
каждое значение от 0 до m-1 будет выдано ровно один раз. Зачем это нам?
Вспомним, что для нашего перетасовщика было бы желательно гарантировать, что все
байты(коды) сообщения поменяли своё место. То есть, если длина данного блока
данных равна этому самому m, то нам будет достаточно просто записывать
очередной входной байт(код) сообщения в выходной буффер по индексу, равному
очередному значению из генератора. Простота этого алгоритма настолько
сооблазнительна, что я не мог пройти мимо.
Но, как всегда случается с чем-то
сооблазнительным, не обошлось без проблем. Во-первых, не все m одинаково
хороши. Из той же главы той же книги мы видим, что если m является
произведением простых чисел в первой степени, то полного перебора элементов мы
достичь не можем в принципе (не считая перебора подряд, что нам, конечно, не
интересно). Получается, что получить нужный нам генератор с заданной длиной
последовательности нельзя, и, следовательно, если у нас сообщения произвольной
длины, то мы не всегда можем найти такой генератор. Тупик? А действительно ли
нам нужны генераторы произвольной длины? Вспомним о том, что для потенциального
взломщика знание длины сообщения очень даже небесполезно. Тогда мы уже знаем и
способ борьбы, который мы успешно применяли для генератора, зависящего от
входных данных. Правильно, надо подбросить случайный мусор, и лучше всего перед
полезными данными. Правда, есть проблема в том, что в каждом блоке нужно как-то
указывать количество полезной информации в нём. Если же в вашем случае длина
всех сообщений/блоков данных фиксирована, то вы вы можете зафиксировать и m
- выбрать первое удобное для вас значение, которое больше длины входного блока
и удовлетворяет критерию из теоремы A из 3.2.1.3 из книги.
Теперь о самом критерии для параметров
генератора xn+1=(a*xn+c) mod m:
1. c и m взаимно просты;
. a - 1 должно быть кратно 4, если m
кратно 4.
Как бы этого достичь малой кровью? Я предлагаю
такой вариант:
= 2n, где n>3;
с = p, p -
простое число & p>2;
a = 4*k+1.
Как легко заметить, все три условия выполняются
и такие значения довольно легко подобрать.
Список литературы
1. ОСТ
78.01.0004-2000. Наземные радиостанции с угловой модуляцией стационарные,
возимые и перевозимые автомототранспортом, носимые и переносные,
предназначенные для работы в радиосетях органов внутренних дел и внутренних
войск МВД РФ. Виды, основные параметры, технические требования.
2. А.Н.
Григорьев. Системы с защитой от несанкционированного доступа в конвенциональных
радиосетях// Каталог "Системы безопасности, связи и
телекоммуникации". 2003. № 1(10).
. Постановление
Правительства Российской федерации от 23 сентября 2002 г. № 691 "Об
утверждении положений о лицензировании отдельных видов деятельности, связанных
с шифровальными (криптографическими) средствами".
4. Вирт,
Кай (ноябрь 2003 г.). "Неисправность нападение на DVB общий алгоритм
скремблирования (Доклад 2004/289)"
<http://translate.googleusercontent.com/translate_c?hl=ru&langpair=en%7Cru&rurl=translate.google.com.ua&u=http://eprint.iacr.org/2004/289/&usg=ALkJrhiShnPHZsasZIF-VNTFj3ux69f9wA>
. Cryptology ePrint .