Архитектупа супер ЭВМ, построенная на принципах схемной эмуляции
Ковалев Сергей, г. Киев simula@ukr.net
Схемная
эмуляция как альтернатива
реконфигурируемым
суперкомпьютерам
"… если вы хотите добиться настоящего успеха в бизнесе, вы должны
иметь такую идею, которой нет у других".
Г.Форд
Суть
идеи
Очевидно,
что создание высокопроизводительных вычислительных систем входит в число
важнейших программ ведущих государств мира. Без суперкомпьютеров невозможно
обеспечить конкурентоспособность страны на мировом рынке, проводить
современные научные изыскания в самых различных областях знаний.
Как бы не
показалось странным на первый взгляд, но вычислительная мощность компьютерных
систем за время их существования выросла, главным образом, далеко не за счет технологического
развития. Ведь если со времен первых компьютеров (EDSAC, Кембридж, 1949 год) и
до наших дней (суперкомпьютер Hewlett-Packard V2600) время такта выросло с 2
микросекунд до 1,8 наносекунды и прирост составил 1000 раз, то
производительность выросла, соответственно, со 100 арифметических операций в
секунду до 77 миллиардов. Прирост составляет более чем семьсот миллионов раз.
Откуда же тогда взялась такая существенная разница? Ответ очевиден – от использования
новых решений в архитектуре компьютеров.
Тем не менее, в
настоящее время все отчетливее зреет понимание того, что и развитие
архитектурных решений близко к своему пределу. К тому же, эффективно
использовать все более усложняющиеся системы становится труднее. Назревающий
кризис толкает исследователей на поиск принципиально новых архитектурных
решений, основанных на нефоннеймановских принципах, которые отличались бы логической
простотой и регулярностью, пусть даже за счет увеличения общего объема
оборудования. При этом усилия части исследователей и разработчиков
сосредоточились на проектировании матричных структур с изменяемыми
межпроцессорными связями – так называемых реконфигурируемых вычислительных
структурах (РВС), которые должны обеспечить высокую
производительность вычислительной системы на уровне пиковой для широкого класса
задач, а также линейный рост производительности при увеличении числа
процессоров в системе.
Вообще
говоря, любой мультипроцессорной архитектуре с жесткими межпроцессорными
связями присущ один и тот же органический недостаток: наивысшей
производительности, близкой к пиковой, она способна достичь только для
какого-то узкого класса задач. И производительность которой имеет свойство
падать, уменьшаясь на порядок-два, для задач других классов.
Эта
проблема имеет системный характер и является следствием неадекватности каждой
конкретной архитектуры вычислительной системы внутренней структуре решаемой
задачи. Вообще говоря, любую задачу пользователя можно представить системой S,
процессы в которой описаны формой информационного графа (рис. 1а). Граф G(Q,X)
содержит множество вершин gi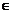 Q, каждой
из которых приписана некоторая операция Oi,
принадлежащая множеству допустимых операций O.
Q, каждой
из которых приписана некоторая операция Oi,
принадлежащая множеству допустимых операций O. Дуги графа определяют
последовательность выполнения операций, приписанных вершинам. Множество входных
дуг определяют источник входных данных, выходных – приемник результатов
решения.
Дуги графа определяют
последовательность выполнения операций, приписанных вершинам. Множество входных
дуг определяют источник входных данных, выходных – приемник результатов
решения.
При
исполнении задачи S в среде мультипроцессорной системы (S*), в
последней организуется вычислительный процесс, который можно описать
информационным графом G*(Q*,X*). Здесь множество вершин Q*
определяется множеством процессоров вычислительной системы, а множество дуг X*
представляет собой множество каналов коммуникаций между процессорами. В свою
очередь, входные и выходные дуги определяются каналами связи с источником
входных и приемником выходных данных.
Как
правило, графы G и G* существенно отличаются один
от другого. Объяснение этому можно найти в том, что жесткая архитектура
многопроцессорной вычислительной системы S* в
большинстве случаев значительно отличается от структуры пользовательской задачи
S. В результате,
системой S* приходится организовывать некоторый мультипроцедурный
процесс, который моделирует систему S, но структурно с ней не
совпадает. Результатом такого моделирования становится то, что граф G*
оказывается намного сложнее, чем исходный граф G. Все это
приводит к существенным потерям времени за счет операций распределения заданий
и процедур между процессорами вычислительной системы, очередей, конфликтов и
т.д.
Указанного
недостатка вычислительной системы с "жесткой" архитектурой можно
избежать, если обеспечить возможность ее реконфигурации таким образом, чтобы
граф G* вычислительного процесса как можно ближе совпадал с графом G решаемой
задачи.
Суть
концепции РВС в том и заключается, чтобы архитектура вычислительной системы
имела возможность адаптироваться под структуру решаемой задачи. В отличие от
многопроцессорных вычислительных систем с жесткими межпроцессорными связями, а
также кластерных систем, архитектура связей реконфигурируемых вычислителей
может изменяться в процессе их функционирования. В результате у пользователя
появляется возможность адаптации архитектуры вычислительной системы под
структуру решаемой задачи. В качестве наиболее подходящей среды реализации идеи
используются микросхемы программируемой логики (ПЛИС), как устройств наивысшей
степени параллельного действия, известных на сегодняшний день. К тому же
применение ПЛИС обеспечивает ускорение вычислительного процесса по сравнению с
микропроцессором от 5 до 100 раз вследствие адаптации внутренней вычислительной
структуры к информационной структуре решаемой задачи.
Можно
сказать, что идея РВС в настоящее время завоевывает все большее число
сторонников и более того, воспринимается многими именно той
"фишкой", которая ляжет в основу архитектуры ЭВМ нового типа. Тем
не менее, как на мой взгляд, "всенародная любовь" эта является скорее
вынужденной, что можно объяснить просто отсутствием должной альтернативы, чем
совершенством имеющегося метода. Потому как у изначально красивой идеи, на
этапе реализации обнаружилось немало системных проблем.
Поэтому
показательным выглядит то, что несмотря на большое число исследований в
области реконфигурируемых структур, они до сих пор так и не нашли широкого
применения. В том числе это объясняется специфичностью и достаточной сложностью
программирования таких систем, наличием нестандартных и сложнейших средств
программирования, а также требованием к нестандартному мышлению программиста.
Процесс разработки реконфигурируемой структуры трудоемкий, требующий от пользователя
больших временных затрат, а также специальных знаний и, по сути,
квалификации схемотехника. По степени сложности программирование РВС
сопоставимо с разработкой новой вычислительной среды. Отчего использование таких
систем структур для решения часто меняющихся задач оказывается малоэффективным.
В то же
время, преимущество идеи реконфигурирования в полной мере проявилось пока на
решениях только некоторых классов параллельных задач, таких как потоковые, в
которых большие массивы данных обрабатываются по одному и тому же алгоритму –
обработки сигналов, криптографии и т.п. Так что о широком классе решаемых
задач говорить пока тоже рановато. В особенности, если учесть, что современные
приложения зачастую образуют сложную иерархию параллельно-последовательных
процессов, да еще и меняющихся во времени.
Представляемая
на суд читателя статья является, по сути,
первой попыткой заявить вслуг, что нет смысла и дальше бороться с
"ветряными мельницами". Потому что на самом деле есть другой путь – более
дешевый, эффективный, надежный и доступный каждому! И, к тому же, свободный от
каких-либо системных "болезней". Путь, который почему-то совершенно
выпал из поля зрения идеологов и разработчиков вычислительных систем, имя
которому – моделирование.
Я
преднамеренно выше, при рассмотрении идеи несовпадения графов задачи и
исполняющей системы, выделил жирным курсивом слово "моделирует",
потому что все идеологи архитектур его видят (и пишут про него), но при этом
всеми силами с ним борются, выбрав за основу развития – реконфигурацию.
Притом, как оказалось, путь тернистый, усеянный множеством трудноразрешимых
преград.
Целью
данной статьи есть стремление показать, что именно идея моделирования,
предварительно развитая автором до понятия эмуляции алгоритмов и систем,
обладает поразительной возможностью к развитию. Она открывает альтернативный
подход к проектированию вычислительных систем, основанный на том, что
заниматься реконфигурированием их среды каждый раз заново от задачи к задаче –
как раз и не нужно! Достаточно только один раз "заточить" ее под
структуру авторского модуля схемной эмуляции, а потом просто эмулировать
задачи пользователей, элементарно загружая их в уже подготовленную среду. В
этом случае отпадает всякая необходимость ценой неимоверных аппаратно-программных
усилий стремиться подогнать структуру вычислительной системы (S*) к структуре
пользовательской задачи (S), потому что в среде эмуляции мы уже непосредственно
работаем с исходным информационным графом задачи пользователя (G). Предлагаемый
подход прост в реализации и совершенно свободен от недостатков, которыми в избытке
наделены абсолютно все известные архитектуры, включая и реконфигурируемые
вычислительные структуры.
Не менее
интересной прелестью предлагаемой к рассмотрению архитектуры является
практически абсолютная ее способность к так называемому масштабированию. Это
означает, что ее вычислительная мощность растет практически линейно включенному
в архитектуру оборудованию, состоящего, к тому же, из однотипных узлов. Можно
сказать, что высокая степень масштабирования с легкостью позволяет практически
разрешить наверно самый глобальный недостаток известных суперкомпьютеров –
чрезвычайно малый срок морального устаревания, составляющий примерно пять лет.
Для изделий,
чья стоимость начинается от сотен тысяч долларов и достигает десятков миллионов
– это очень важный фактор, заметно сдерживающий развитие суперкомпьютерной
отрасли в целом!
Суперкомпьютер,
спроектированный в соответствии с предлагаемой автором идеей, в заметно
меньшей степени будет зависеть от такого понятия как срок морального
устаревания.
Корнями
идея эмуляции алгоритмов и систем уходит к классу программных продуктов,
известных как схемные симуляторы. В качестве примера можно упомянуть такие,
как Micro-CAP от "Spectrum SoftWare", PSpice от "MicroSim
Corp." и т.д., которые у нас еще принято называть программами
моделирования электронных устройств.
Исторически
симуляторы появились в ответ на законное желание разработчиков иметь
возможность проверять работу спроектированной ими схемы до того, как она будет
реализована с помощью паяльника.
В таких программах
уровни входных сигналов, выбираемые из так называемого массива входных
воздействий, шаг за шагом подаются на вход программной модели устройства.
Разумеется, что само слово "массив" – это атрибут программистских
"штучек" и не имеет ни малейшего отношения к реальным сигналам.
Под моделированием
понимается этап имитации поведения схемы устройства (в масштабах условной
временной шкалы) на уровне ее программной модели с соблюдением всей динамики
протекающих в устройстве процессов.
Проектирование можно
считать выполненным правильно в случае, если получены правильные временные
соотношения для уровней сигналов во всех цепях устройства. Результатом
моделирования становится также некий массив уровней сигналов в цепях схемы,
который можно затем вывести на принтер или дисплей в виде графиков.
А что же тогда есть
эмуляция? Эмуляция – это моделирование, выполняемое в режиме реального времени
и в реальной среде окружения.
Для того чтобы
программа схемотехнического моделирования превратилась в программу схемной
эмуляции необходимо выполнение некоторых условий.
Первое - добиться
того, чтобы программа моделирования работала не с программными массивами, а с
реальными сигналами. В этом случае на вход программной модели должны подаваться
не комбинации входных событий, выбираемых из программного массива, а уровни
сигналов с реальных периферийных систем. В тоже время, отклики, снимаемые с
программной модели, опять-таки, должны подаваться в реальное окружение.
Второе - добиться того,
чтобы программа моделирования работала в режиме реального времени, а не
какой-либо условной временной шкале. Потому что эмуляция – это имитация
поведения электронного устройства, как будто его схема уже реализована с
помощью паяльника.
Под "режимом
реального времени" следует понимать случай, когда скорость имитации становится
соизмеримой со скоростью изменения процессов в реальном объекте управления.
Другими словами, когда отклик, снимаемый с программной модели, будет
поспевать за процессами, протекающими в реальной среде окружения.
Третье – сделать так, чтобы
программа моделирования не требовала ресурсов PC. Соблюдение этого условия
позволит размещать ее не только на PC платформах, но и во встраиваемых системах.
Программу
схемотехнического моделирования, удовлетворяющую выполнению вышеперечислен-ных
условий, уже по праву можно назвать – программой схемной эмуляции. В основу
предлагаемой мною системы положен авторский алгоритм схемной
эмуляции, реализованный в авторском программном продукте - модуле
схемной эмуляции.
В тоже время,
разработанный и программно реализованный мною алгоритм, успешно выполняет еще одно условие – в основу его работы положен принцип
параллельных потоков.
Конечно
же, в среде PC платформ или встраиваемых микропроцессоров, принцип
многопоточности может только имитироваться. Для наиболее же полного раскрытия
свойств алгоритма требуется и среда параллельного действия. К счастью, в
настоящее время реализация такой среды известна – это т.н. матрицы вентильных
массивов FPGA (Field-Programmable
Gate Arrays) микросхем программируемой логики (ПЛИС).
Именно
соединение этих двух компонент – авторского модуля схемной эмуляции (реализованного
на принципах многопоточности), и матрицы вентильных массивов (как устройства
параллельного действия), открывает широчайшие возможности для создания
действительно принципиально новой вычислительной среды – системы эмуляции
задач пользователей, представленных в графическом виде.
В соответствии с
идеологией системы эмуляции, модуль схемной эмуляции, по сути, выполняет
функцию системы исполнения задач пользователей,
представленных в графическом виде.
Уровень представления
задач здесь допускается самый разный: от графов, сетей, алгоритмов и
специальных языков графического программирования - до функциональных и
структурных схем. В конце концов – это может быть принципиальная схема
электронного устройства, реализующего некий алгоритм. Поскольку в теории
реконфигурируемых систем отталкиваются от такого уровня как графы алгоритмов,
то и я в рамках данной статьи привяжусь именно к этому уровню. Да и пронаблюдать
сравнительный анализ двух архитектур в этом случае будет значительно проще.
Исполнить задачу в
системе эмуляции – означает эмулировать (имитировать поведение в режиме
реального времени и реальноой среды окружения) графический рисунок
пользователя, в соответствии с тем, как сам пользователь мог бы представить его
работу в своем воображении. Только модуль эмуляции сделает это точно и без
ошибок. Красота идеи состоит в том, что при этом пользователю не нужно браться
за паяльник, чтобы реализовать свою задачу аппаратно, или пытаться реализовать
ее программным способом.
Вообще говоря, возможность
реализовать алгоритмы аппаратными или программными способами издавна называется
дуализмом (Э.Э. Клингман). До сегодняшнего дня развитие технических систем
проходило именно в соответствии с этим принципом. Идея схемной эмуляции
впервые открывает пользователю новый (третий) путь реализации его проектов –
просто имитацией их поведения в принципиально новой среде – среде
графического исполнения, основанной на принципах схемной эмуляции.
Особенностью
архитектуры системы эмуляции, построенной на основе кристалла ПЛИС, есть то,
что в распоряжение пользователя предоставляется не "голый" кристалл,
который ему еще каким-то образом необходимо запрограммировать. А такой, в
котором рабочая область уже предварительно "отформатирована" структурой
модуля эмуляции, и в которую пользователю достаточно только загрузить описание
графической схемы своей задачи.
Однако
прежде чем переходить к презентации своей идеи, мне хотелось бы привести
краткое описание сути самих реконфигурируемых вычислительных структур. Потому
что именно в сравнительном анализе читателю в полной мере раскроются
преимущества представляемого мною подхода. С другой стороны, не смотря на то,
что в глобальной сети можно найти мегатонны текстов, посвященных реконфигурируемым
структурам, идея эта все еще остается достаточно специфической и вряд ли
знакомой широкому кругу специалистов. Поэтому я не вижу смысла отвлекать
внимание читателя на поиск и изучение материалов по данной теме, а предлагаю сразу,
в рамках данной статьи, ознакомиться с моей реферативной подборкой. Которая,
конечно, не претендует на глубину изложения, но для понятия сути вопроса является
вполне достаточной. Приведенный мною материал касательно реконфигурируемых
структур изложен на основании статей таких идеологов, как: И.А.
Каляев (НИИ многопроцессорных вычислительных систем Южного федерального
университета, г. Таганрог, Россия), И.И. Левин, Е.А. Семерников (Южный
научный центр РАН, г. Ростов-на-Дону, Россия), А.В
Палагин (Институт кибернетики им. В.М. Глушкова НАН Украины) и других.
Архитектура реконфигурируемых вычислительных структур
Таким
образом, регулярность вычислительной структуры еще не является залогом ее высокой
производительности на широком классе задач. Необходимым условием следует
считать также возможность ее реконфигурации, чтобы граф G* вычислительного
процесса как можно ближе совпадал с графом G решаемой задачи.
Суть
концепции РВС в том и заключается, чтобы архитектура вычислительной системы
имела возможность адаптироваться под структуру решаемой задачи. В отличие от
многопроцессорных вычислительных систем с жесткими межпроцессорными связями, а
также кластерных систем, архитектура связей реконфигурируемых вычислителей
может изменяться в процессе их функционирования. В результате у пользователя
появляется возможность адаптации архитектуры вычислительной системы под
структуру решаемой задачи.
В отличие
от традиционных методов организации параллельных вычислений РВС ориентируются
на абсолютно параллельную форму алгоритма задачи – ее информационный граф. Под
информационным графом понимается граф, вершинам которого соответствуют
арифметико-логические операции над операндами. Дуги информационного графа
соответствуют информационной зависимости между вершинами и, по сути, определяют
порядок соединения вычислителей.
Таким
образом, идея концепции РВС заключается в аппаратной реализации всех операций,
предписанных вершинами информационного графа, и всех каналов передачи данных
между вершинами, соответствующих дугам графа. Такое решение задачи принято
называть структурным.
Наиболее
наглядно идею РВС можно продемонстрировать на примере т.н. однородной
мультимикроконвейерной вычислительной среды, представляющую собой
матрицу однотипных (как правило однобитных) процессоров.
Суть этого подхода
заключается в создании мультиконвейера с жесткой архитектурой и обеспечении
коммутационных возможностей за счет придания каждому процессору дополнительных
функций транзитной передачи информации. В такую структуру можно отобразить
любой граф алгоритма G(Q,X), как показано на рис.1
При этом,
как можно заметить из рисунка, часть процессоров будет занята неэффективной
работой транзита входной информации к другим узлам структуры, а часть
процессоров не будут заняты никакими процессами вообще. К тому же, транзит
информации через процессоры вносит дополнительные временные задержки при
прохождении данных через мультиконвейер, снижая тем самым темп конвейерной
обработки. Кроме того, процесс отображения исходного графа в матричную
структуру с жесткой архитектурой является нетривиальной задачей. Очевидным
есть и то, что в такой структуре невозможно поместить граф реальной задачи,
состоящий из сотен, тысяч и миллионов вершин. Эффективность рассматриваемой
архитектуры можно было бы увеличить, применив полнодоступный коммутатор,
обеспечивающий возможность полнодоступной коммутации между всеми процессорами
мультимикроконвейера. Однако, аппаратные затраты на его реализацию будут
недопустимо велики, потому как пропорциональны квадрату числа процессоров.
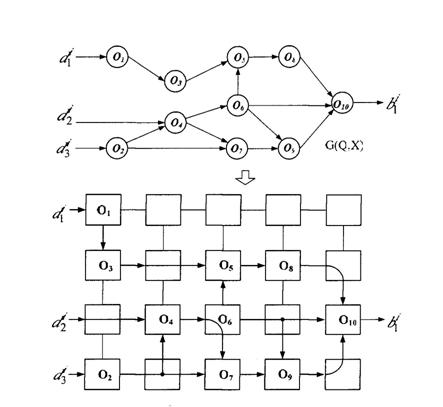
Рис. 1
Отображение графа G(Q,X) в матричную мультимикроконвейерную структуру
Поэтому более
перспективным направлением считается проектирование РВС на основе архитектуры мультимакроконвейерных
структур с программируемой логикой (рис. 2). Суть которого
состоит в том, чтобы создать архитектуру вычислительной системы, способную
реконфигурировать свою структуру к графу алгоритма. При этом, функции
коммутации перекладываются с процессоров, как в выше рассмотренном случае, на
отдельную коммутационную структуру. В отличие от однородных вычислительных
сред, авторы данной концепции предложили строить процессорный узел в виде
некоторого множества элементарных многоразрядных процессоров, объединенных
полнодоступной коммутационной шиной. При этом, как и в предыдущем случае,
процесс решения задачи сводится к организации мультиконвейерных цепочек,
отображающих информационный граф решаемой задачи.
Основными
вычислительными блоками в мультимакроконвейерной РВС являются макропроцессоры,
представляющие собой набор некоторого числа элементарных процессоров,
объединенных в единый вычислительный ресурс с помощью локального коммутатора.
Элементарные процессоры, в отличие от стандартного микропроцессора, не
управляют процессом обработки информации, а лишь реализуют операции над
поступающими на их входы операндами. В свою очередь, макропроцессоры реализуют
крупные операции, предписанные вершинам информационного графа. В каждый момент
времени макропроцессор может реализовать одну макрооперацию. Незадействованные
в макрооперации элементарные процессоры будут простаивать. Для реализации
всего информационного графа макропроцессоры объединяются с помощью системного
коммутатора (коммутатора второго уровня) в единую параллельно-конвейерную
структуру.
Таким
образом, совокупность вычислительных структур, созданных в рамках базовой
архитектуры РВС, образуют виртуальный проблемно-ориентированный вычислитель,
структура которого адекватна информационному графу решаемой задачи. При этом
считается, что именно при таком подходе будет достигнута реально высокая
производительность вычислительной системы на широком классе задач, а также
почти линейный рост производительности при увеличении числа процессоров. Правда,
говоря о широком классе задач, как на мое мнение, разработчики РВС немного
льстят себе. Потому что изначально такие системы позиционировались для решения
исключительно параллельных задач, да и то - потоковых. При том, что подавляющее
число практических приложений представляют собой сложную иерархию
параллельно-последовательных меняющихся во времени процессов.
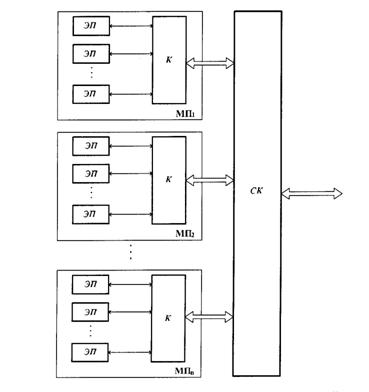
Рис. 2
Архитектура мультимакроконвейерной РВС с программируемой логикой.
Реализация
идеи реконфигурируемых МВС долгое время сдерживалось отсутствием подходящих
компонент. Появления в конце 90-х годов XX века программируемых логических
интегральных схем сверхвысокой степенью интеграции вдохнуло в идею второе
дыхание. Микросхемы ПЛИС представляет собой матрицу логических ячеек (FPGA – Field
Programmable Gates Array), путем программирования и
коммутации которых можно создавать аппаратные реализации различных структур,
причем перепрограммирование допускается многократно.
Вот,
пожалуй, и вся идея организации архитектуры программируемых реконфигурируемых
вычислительных структур. Она является основополагающей и лежит в основе РВС
различных типов. Отличие подходов заключается лишь в той или иной степени
детализации конвейерной ступени, а также в том или ином способе
реконфигурирования связей между ними. Поэтому для дальнейших рассуждений
понимания рассмотренной сути представляемой идеи вполне достаточно.
Тем не
менее, изначально красивая идея оказалась труднореализуемой. И главным источником
преткновения стал факт того, что число операционных вершин в графе алгоритма
практически любой реальной задачи пользователя оказывается значительно больше
числа макропроцессоров в мультиконвейере. Поэтому информационные графы больших
задач не могут быть целиком отображены в имеющемся аппаратном ресурсе РВС.
Именно на
разрешение этой проблемы и была направлена львиная доля усилий исследователей и
разработчиков. Для этого информационный граф всей задачи предлагается
сегментировать на фрагменты – непересекающиеся базовые подграфы, физически
реализуемые в аппаратуре РВС. Размер подграфа выбирается таким образом, чтобы
ресурсов системы было достаточно для его структурной реализации. В таком случае
решение большой задачи выполняется структурно-процедурным способом, при
котором на аппаратный ресурс поочередно отображаются базовые подграфы всего
информационного графа. Весь процесс назван "структурно-процедурным"
оттого, что вычисления в соответствии с отображенным подграфом выполняются
структурно, а смена подграфов выполняется процедурно.
И
опять-таки, за внешне привлекательной идеей организации
структурно-процедурного способа обнаружилось множество подводных камней. Так,
многокритериальное разрезание графа G(Q,X) на подграфы оказалось
достаточно непростым процессом. В свою очередь, и процесс отображения каждого
подграфа Gi(Qi,Xi)
в мультиконвейер также оказался нетривиальной задачей. Требующей,
к тому же, организации механизма сохранения результатов обработки каждого
подграфа в некоторой промежуточной памяти. Соответствующих аппаратных ресурсов
требует и механизм формирования очереди подграфов.
К тому
же, не вызывает сомнения, что применение структурно-процедурного метода
замедляет скорость обработки данных, поступающих на вход мультиконвейера. Ведь
регулярной перезагрузки кадров в кристалл ПЛИС просто не избежать. Как выход
из создавшейся ситуации разработчиками РВС предложен механизм накопления
векторов входных данных в пакеты, которые затем уже поступают на вход
структуры. Но и в таком случае вполне реальной может сложиться ситуация, когда
время подготовки вычислений станет соизмеримым и даже заметно превышающим время
самих вычислений! До боли знакомая картина, уже наблюдаемая в архитектурах
универсальных ЭВМ с жесткими межпроцессорными связями.
Как метод
уменьшения зависимости от частой перезагрузки кадров было предложено
организовывать отдельные микросхемы программируемой логики в большие
решающие поля. В этом случае все вычислительные и коммутационные структуры
задачи разворачиваются не в отдельной микросхеме ПЛИС, а во всем решающем поле.
Однако реализация такой идеи также потребовала немалых аппаратных ресурсов.
В то же
время, построение больших решающих полей на ПЛИС требует преодоления ряда
проблем. Одна из которых – это негативный эффект границ, возникающих на
стыках отдельных ПЛИС при их объединении в решающее поле.
Архитектура вычислительной структуры, построенной на принципах
схемной эмуляции
Поскольку
целью данной статьи есть стремление донести идею применения принципов
схемной эмуляции к вопросу создания альтернативной вычислительной среды, то на
рис.3 такая среда представлена на уровне функциональной схемы без привязки к
структурам конкретных комплектующих каких-либо производителей.
Тем не
менее, за основу принимается, что базовым элементом такой архитектуры является
микросхема программируемой логики. Потому что именно соединение принципа
многопоточности авторского модуля схемной эмуляции с принципом параллельного
действия ПЛИС позволяет создать принципиально новую вычислительную среду
параллельного действия. В то же время, высокая степень регулярности
представляемой структуры позволяет использовать различные варианты ее
реализации, предоставляя тем самым разработчикам широкое поле деятельности при
поиске наиболее оптимальной конфигурации на этапе опытно-конструкторских работ.
На рис.3 отображены три варианта реализации авторской идеи, которые, тем не
менее, органично дополняют одна другую даже в пределах одной структуры.
Работа в
новой системе представляется следующим образом.
Изначально,
пользователь, находясь в среде графического редактора (установленного на ПК),
рисует граф алгоритма своей вычислительной задачи. После окончания этапа
рисования, специальный программный модуль "сворачивает" рисунок
проекта в так называемый файл описания схемы (ФОС), который и загружается в
рабочую область эмуляции кристалла ПЛИС, уже предварительно
"отформатированного" структурой модуля эмуляции. Модуль эмуляции
разворачивает в рабочей области эмуляции программную модель схемы проекта.
Именно
на уровне программной модели происходит эмуляция (имитация) работы схемы задачи
пользователя.
Модуль
эмуляции, с учетом динамики протекающих в программной модели процессов,
порождает в матрице FPGA множество потоков. Под процессами здесь подразумется волны изменения
значений идентификаторов в ветвях программной модели рисунка задачи
пользователя. Потоки – это реальные сигналы в матрице FPGA. В соответствии с
идеологией системы эмуляции одному процессу может соответствовать некоторое
множество потоков.
Одна
часть потоков "существует" исключительно в рабочей области эмуляции и
не выходит за ее пределы, назовем их внутренними. Предназначены они для обеспечения
функционирования самой модели. Другая часть потоков, для которой необходимо
выполнение каких-либо арифметических или логических операций, предписанных
вершинами графа задачи, посредством концентратора SW перенаправляются
в свободные исполнительные процессоры (Исполнительный процессор 1 –
Исполнительный процессор N). Назовем такие потоки внешними.
Каждый внешний процесс несет на себе необходимые операнды и номер (код)
операции, и возвращает результат операции в рабочее поле эмуляции. Исполнительные
процессоры, как и макропроцессоры для случая РВС, не управляют процессом
обработки информации, а лишь реализуют операции над поступающими на их входы
операндами.
Рис. 3
Функциональная схема модуля вычислительной структуры,
построенной на принципах схемной
эмуляции.
Существенным
отличием представляемой архитектуры от идеологии реконфигурируемых
вычислительных структур является то, что здесь исполнительные процессоры ни коим
образом не привязаны к вершинам графа задачи пользователя.
В
соответствии с идеологией системы эмуляции, в каждый момент времени каждый из
исполнительных процессоров может быть занят обработкой данных, поступивших на
его входы вместе с любым внешним потоком. Поэтому в функциональном плане они
должны быть абсолютно идентичными, то есть, каждый должен быть способным
выполнить операцию, предписанную любой вершине графа задачи. Правило выбора
процессора потоком простое: поток, посредством сетевого концентратора,
выбирает первый же исполнительный процессор, который не занят обработкой
данных какого-либо другого протока.
Со времен
появления первых компьютеров стало очевидным, что для каждого уровня
технологического развития практически единственным путем увеличения мощности
вычислительной системы является соединение энного числа процессоров в единую
"упряжку", то есть создание мультипроцессорной системы. Казалось бы,
что может быть проще: превратить однопроцессорную машину в многопроцессорную
путем добавления на платформу некоторого числа точно таких же процессоров. Однако
на практике все оказалось гораздо сложнее и добавление в систему даже одного
процессора может уменьшить производительность системы. Ведь в этом случае
разработчик сталкивается с принципиально новым явлением – информационным и
алгоритмическим взаимодействием процессоров. И здесь важнейшим аспектом,
связанным с эффективностью работы вычислителя, начинает выступать организация
межпроцессорного обмена служебными потоками, а также проблемы распараллеливания
и синхронизации информационных потоков самой задачи. В свою очередь, поддержание
всего этого требует немалых аппаратных усилий. Все это привело к тому, что
современные процессора превратились в сложнейшие устройства, в которых
вспомогательные узлы - т.н. опережающей выборки команд, условных ветвлений,
блоков синхронизации и т.д. – занимают на кристалле значительно больше места,
чем непосредственно само арифметико-логическое устройство.
Идея
реконфигурируемых вычислительных структур, казалось бы, могла стать достойным
ответом на проблему. Но, как выяснилось, она оказалась не только
сложнореализуемой, но даже использование такой системы превратилась в
достаточно нетривиальную задачу. К тому же, такой ответ оказался не вполне
достаточным и потому, что наилучшим образом подходит только для решения потоковых
задач. Поэтому говорить о широком классе задач при работе с такой структурой не
приходится.
В
противоположность сказанному можно утверждать, что идея использования системы эмуляции
в основе вычислительной структуры, впервые открывает простейший путь соединения
любого числа процессоров в единую "упряжку", потому что никакого
информационного и алгоритмического взаимодействия процессоров здесь просто нет.
Вся работа по организации этих процессов переносится на уровень программной
модели задачи пользователя, что, в свою очередь, позволяет использовать в
системе процессора с элементарной внутренней архитектурой. Все что требуется в
такой структуре от процессора для организации мультипроцессорности – это подать
в сетевой концентратор сигнал готовности, после того как операнды, попавшие на
его входы вместе с потоком, обсчитаны и результат возвращен в рабочее поле
эмуляции.
Представляемая
вычислительная структура, основанная на принципах схемной эмуляции, по сути,
есть ни что иное, как машина потоков. Однако главное отличие ее от
архитектур традиционных потоковых машин состоит в том, что в ней порядок
операций, предписанный вершинами графа задачи, определяется не готовностью
данных, а информационными потоками в программной модели задачи пользователя.
К слову будет сказать, что именно это отличие, главным образом, и освобождает
представляемую мною архитектуру от массы проблем, сопутствующим традиционным
потоковым архитектурам. И от неразрешимости которых, те до сих пор так и не получили
развития дальше экспериментальных образцов.
Такая
система самым оптимальным образом подходит для решения как параллельных, так и
параллельно-последовательных задач. При том, что генерация всех процессов в
программной модели и их взаимная синхронизация происходит автоматически.
Фундаментальным
отличием представляемой идеологии от идеологии РВС состоит в том, что от
понятий "структура" и "реконфигурация" мы переходим к
оперированию понятиями – "эмуляция" и "рисунок задачи". В
соответствии с идеологией системы эмуляции, модуль схемной эмуляции, по сути,
выполняет функцию системы исполнения задач пользователей, представленных в
графическом виде.
Этапы
"программирования" и исполнения в представляемой архитектуре
полностью согласованы. "Общим знаменателем" такой согласованности
выступает работа с графическим образом проекта, как на этапе проектирования,
так и на этапе исполнения. Для машины потоков, построенной на принципах
схемной эмуляции, представление проектов в графическом виде является единственно
допустимым и естественным способом. Поэтому процесс ее
"программирования" до безобразия прост: начинается он с прорисовки
графа задачи в среде графического редактора, а заканчивается загрузкой файла
описания схемы задачи в саму платформу одним кликом мышки.
Вычислительная
структура,
основанная на принципах схемной эмуляции, является более однородной, чем структуры
РВС. Как видно на рис.3, в ней можно четко выделить три области: рабочую
область эмуляции, сетевой концентратор и блоки исполнительных процессоров. Увеличение
степени однородности открывает широкие возможности по увеличению
функциональной мощности базовой структуры.
Описание работы
представляемой вычислительной системы, приведенное выше, касалось только части
всей функциональной схемы – базовой структуры. В нем были задействованы
следующие узлы: рабочая область эмуляции, концентратор SW и модуль
исполнительных процессоров ИП 1-ИП N. Если принять, что
все они находятся в пределах одного кристалла микросхемы программируемой
логики, то такую архитектуру смело можно назвать закрытой.
Современный
уровень интеграции ПЛИС позволяет при реализации структуры РВС размещать на
кристалле порядка 100 макропроцессоров. В системе эмуляции большую часть
ресурсов кристалла займет рабочее поле эмуляции. Поэтому обобщенная оценка
показывает, что оставшихся его ресурсов окажется достаточным для реализации
всего лишь с десяток исполнительных процессоров. Естественно, что такого их количества
явно недостаточно для полноценного обслуживания всех порожденных программной
моделью внешних потоков. В этом случае, потоки, которым не хватит
свободных ИП, будут переходить в состояние ожидания. Благо, произойдет это на
уровне программной модели и поэтому никаких аппаратных затрат в виде разного
рода буферов памяти здесь не потребуется.
Не
вызывает сомнений, что имеющегося числа ИП в такой структуре можно считать
более чем достаточным при реализации какой-нибудь системы управления (например,
бортового компьютера), но никак не суперЭВМ. Очевидно, что уменьшить влияние притормаживания
потоков на скорость решения задач пользователей можно только увеличением числа
ИП в системе. Разрешить проблему нехватки ресурсов одного кристалла ПЛИС поможет
все та же однородность структуры системы эмуляции. Для этого, внешние потоки с
выхода сетевого концентратора SW вместо внутреннего блока исполнительных
процессоров следует перенаправить в Блок Портов низкоскоростного
последовательного ввода-вывода. При этом сам модуль исполнительных процессоров
необходимо будет переместить в отдельные корпуса ПЛИС. При таком варианте
реализации структуры, каждый из внешних потоков будет использовать
соответствующий порт как транзитный узел.
На реализацию
рассмотренного варианта может накладываться ограничение только одним фактором
– ограничением по числу внешних контактов микросхемы ПЛИС, которые могут быть
задействованы под реализацию данной конфигурации.
Разрешить
проблему нехватки контактов можно достаточно простым способом, использовав
вместо блока низкоскоростных портов один порт высокоскоростного обмена (Порт 2).
Такой порт должен иметь в своем составе буфера памяти, принимающие в себя
информацию от каждого потока, и непосредственно узел высокоскоростного обмена.
Понятно, что в этом случае и сам модуль исполнительных процессоров должен иметь
в своем составе аналогичный порт.
Рассмотренные
варианты структуры системы эмуляции, в которых использован внешний модуль
исполнительных процессоров назовем открытой.
Здесь к
слову будет сказать, что вычислительная система, построенная на принципах
открытой структуры обладает широкими возможностями к развитию. Например, она
позволяет в
качестве исполнительных процессоров использовать обычные (к примеру - RISC)
коммерчески доступные микропроцессорные кристаллы.
В
рассмотренной выше функциональной схеме использование такого узла как сетевой
концентратор (SW) также несет высокую идейную нагрузку. Дело в том, что в
современных архитектурах вычислительных структур (не исключением которых стали
как потоковые машины, так и реконфигурируемые вычислительные структуры) широкое
применение находят сетевые коммутаторы (Hab). Конечно, реализация такого
устройства требует меньших аппаратных ресурсов, однако его принципиальным
недостатком является жесткий принцип действия. Это значит, что в момент программирования
в его структуре может быть реализована только одна схема коммутации. И замена
старой схемы на новую потребует очередного перепрограммирования. Принципиальным
отличием концентратора есть то, что по своей сути он является устройством
параллельного действия. Это значит, что в каждый момент времени такое
устройство в состоянии обеспечить гибкую коммутацию любого числа
непересекающихся (не имеющих коллизий) активных каналов.
Таким
образом, соединение во едино двух упомянутых компонент – авторского модуля
схемной эмуляции (построенного на принципах многопоточности) и сетевого
концентратора (как устройства параллельного действия) придает вычислительной структуре
абсолютную степень параллельности, а также высокую степень гибкости, которая, в
свою очередь, служит источником различных структурных вариаций.
Тем не
менее, принцип многопоточности модуля эмуляции – это, на самом деле, только
первое важное его свойство. Другим, не менее важным свойством, следует считать
высокую степень поддержки идеологии т.н. распределенного управления систем (Distributed
Control System). Что, в
свою очередь, позволяет на самом высоком уровне обеспечить высокую
степень масштабируемости структуры. Это означает, что если ресурсов
одной микросхемы программируемой логики окажется недостаточным для загрузки в
нее всего файла описания схемы, то достаточно будет всего лишь разбить последний
на нужное число фрагментов (частей). Притом, сделать это автоматически,
находясь в среде графического редактора схем. А после этого каждый фрагмент
загрузить в отдельный кристалл. Понятно, что размер фрагмента выбирается из
такого расчета, чтобы ресурсов одного кристалла ПЛИС стало достаточно для
загрузки одного фрагмента ФОС.
Положительный
эффект здесь достигается тем, что объединение фрагментов задачи пользователя
осуществляется не на физическом уровне кристаллов программируемой логики (как в
случае РВС), а на уровне программной модели всей задачи. Именно модули схемной
эмуляции, прошитые в структурах матриц программируемой логики, выступают теми
цементирующими кирпичиками, которые связывают всю систему воедино. Поэтому
таким "хроническим" проблемам, присущих РВС, как "негативный
эффект границ" и др. в представляемой архитектуре просто нет места.
Для целей
аппаратной поддержки принципа масштабируемости в структуре системы эмуляции
(рис.3) служит порт (Порт 1) низкоскоростного обмена потоками. В соответствии с
идеологией системы эмуляции считается, что в этот порт направляются потоки
(Q), образованные как раз на местах "разрезания" файла
описания схемы. Чтобы организовать обмен такими потоками между всеми
кристаллами ПЛИС, необходимо все выводы микросхем, соответствующих упомянутым
портам, соединить между собой посредством внешнего сетевого концентратора
(концентратора II уровня).
Здесь
резонно может возникнуть вопрос – а причем тут масштабируемость и зачем ее
поддерживать? А все дело в том, что идеология системы эмуляции свободна от
такого понятия как структурно-процедурный метод решения задачи и требует, чтобы
проект пользователя загружался в систему целиком до начала исполнения
(эмуляции).
Поэтому выглядит
естественным, что при решении больших практических задач может возникнуть
ситуация, которую и придется "исправлять" путем добавления в систему
некоторого числа точно таких же кристаллов ПЛИС. Тем не менее, пользователю
совершенно даже не придется браться за паяльник.
Как уже
говорилось, широкие возможности к развитию системы эмуляции и регулярность ее
структуры служит надежной базой для реализации различных структурных вариаций.
Все это открывает перед разработчиками широчайшие возможности по разработке
оптимальной конфигурации базовых конструктивных модулей. Я лично
больше склоняюсь к мнению, что применение принципов схемной эмуляции к вопросу
проектирования суперЭВМ приведет к разработке двух основных типов модулей
(платформ): модуля рабочей области эмуляции и модуля исполнительных
процессоров, в каждом из которых количество микросхем программируемой логики
будет подобрано оптимальным образом.
Таким
образом, пользователю предоставляется возможность простым добавлением базовых
платформ на общее шасси наращивать вычислительную мощность всей системы до
любого практически необходимого уровня и, что не менее важно, мощность такой
системы будет расти практически линейно числу добавляемых платформ. Притом, что
использование такой системы обеспечит наивысшую производительность при решении
действительно любых классов задач.
В
заключении хотелось бы отметить, что представляемая в данной статье система эмуляции
прошла успешную апробацию на практических внедрениях в области разработки
систем автоматизации на PC- платформах и самым полным образом подтвердила свою
работоспособность.
Архитектура
кластерной системы, построенной на принципах схемной
эмуляции
В основе
кластерной сети, построенной на принципах схемной эмуляции, лежит все та же
идея масштабирования. Представляемая мною идея организации структуры кластерной
сети отличается от выше рассмотренной мультиплатформенной вычислительной ПЛИС-
системы тем, что средой, в которой разворачивается рабочая область эмуляции,
является PC платформа. А вместо модулей блоков исполнительных процессоров
используется микропроцессор самой платформы.
В таком
случае на каждой PC-платформе, кроме непосредственно
фрагмента задачи, размещается и модуль схемной эмуляции. Совместная работа всех
модулей эмуляции и выступает в роли звена, "собирающего" все
фрагменты задачи в единую программную модель.
Существенным
отличием представляемой структуры от известных архитектур кластерных систем
состоит в том, что в ней все платформы абсолютно равноценны. Система абсолютно
гомогенная и никто – никем не управляет. То есть, в такой структуре нет места
основному серверу (с установленным на него ПО – т.н. менеджера кластера) и
узлам кластера (с клиентским ПО).
Полученную
кластерную систему с полным правом можно использовать для решения любого класса
задач, потому что по своей природе она является сильносвязанной системой.
В то время как известные кластерные структуры могут быть использованы для
решения слабосвязанных задач, не требующих интенсивного обмена данными между
процессорными узлами.
Работа
представляемой структуры до банальности проста: каждый модуль эмуляции
разворачивает в пределах платформы программную модель соответствующего
фрагмента задачи пользователя. Объединение фрагментов в единую модель
осуществляется благодаря соединению всех платформ в единое сетевое подключение
посредством сетевого концентратора.
Можно
сказать, что превратить одноплатформенную систему в мультиплатформенную –
задача не менее сложная, чем организация самой мультипроцессорной платформы. Ведь
в этом случае разработчик также сталкивается с информационным и
алгоритмическим взаимодействием на уровне платформ. И здесь важнейшим аспектом,
связанным с эффективностью работы вычислителя, начинает выступать организация
межплатформенного обмена служебными потоками, а также проблемы
распараллеливания и синхронизации информационных потоков самой задачи.
Вот
почему менеджер кластера и клиентское части традиционных кластерных систем
представляют собой чрезвычайно сложное и дорогостоящее программное обеспечение.
Представляемая
мною кластерная структура свободна от всего этого, потому что все задачи
организации межплатформенного взаимодействия берут на себя модули эмуляции,
установленные на каждой платформе, причем сделают это они совершенно
автоматически. Все что требуется от пользователя – это умение составить граф
задачи, тупо разбить его на фрагменты и загрузить каждый фрагмент в отдельную
платформу.
Понятно,
что недостатком представляемой кластерной структуры является то, что, как это
уже говорилось, в среде PC платформ всякая параллельность алгоритма работы авторского
модуля эмуляции может только имитироваться, потому как любой микропроцессор в состоянии
выполнять инструкции только последовательно. Единственным методом
"борьбы" с таким системным недостатком, свойственным архитектуре фон
Неймана, является как можно более глубокое распараллеливание задачи путем
добавления в систему как можно большего числа PC платформ. Благо, для
представляемой идеи это не представляет какой-либо проблемы, чего не скажешь о
традиционных кластерных системах.
Однако,
для тех приложений, где скорость выполнения задачи является принципиальным
параметром, – использование рассмотренной в предыдущем разделе
мультиплатформенной системы, построенной на микросхемах программируемой
логики, представляется единственно реальной альтернативой.
Список использованной
литературы:
"Архитектура семейства
реконфигурируемых вычислительных систем на основе ПЛИС"//
И.А.
Каляев, И.И. Левин, Е.А. Семерников – ж-л "Искусственный интеллект",
3' 2008, г. Харьков
"Реконфигурируемые
мультиконвейерные вычислительные структуры"//
И.А.
Каляев, И.И. Левин, Е.А. Семерников, В.И. Шмойлов – издательство ЮНЦ
РАН, г. Ростов-на-Дону, 2008 г.
"Реконфигурируемые
вычислительные системы с открытой масштабируемой архитектурой"//
И.И. Левин, РАСО 2010 г.
"Вычислительные системы с
реконфигурируемой (программируемой) архитектурой"//
А.В. Палагин, В.Н.
Опанасенко, В.Г. Сахарин – ж-л Проблемы информатизации и управления",
10' 2004 г.
"Будущее
высокопроизводительных систем"// Виктор Корнеев, "Открытые
системы", #5 / 2003 г.