|
Группы населения по среднемесячной
з/п, руб.
|
Количество человек
|
Середина интервалов
Xi
|
|
523,78 – 2391,73
|
7
|
1741,74
|
|
2391,73 – 5391,25
|
6
|
5172,63
|
|
5391,25 – 6492,4
|
6
|
5638,54
|
|
6492,4 – 18453,64
|
2
|
10452,56
|
|
18453,64 – 19543,11
|
4
|
14119,84
|
|
19543,11 – 16077,98
|
5
|
15634,71
|
|
16077,98 – 30868,71
|
1
|
18256,21
|
|
30868,71 – 43005,3
|
1
|
34522,56
|
3.4
КЛАССИФИКАЦИЯ РЯДОВ РАСПРЕДЕЛЕНИЯ
Статистический ряд
распределения – это упорядоченное распределение единиц совокупности на группы
по определенному варьирующему признаку. В зависимости от признака, положенного
в основу образования ряда распределения, различают атрибутивные и вариационные
ряды распределения.
Атрибутивными называют
ряды распределения, построенные по качественным признакам. Ряд распределения
принято оформлять в виде таблиц.
Атрибутивные ряды
распределения характеризуют состав совокупности по тем или иным существенным
признакам. Взятые за несколько периодов, эти данные позволят исследовать
изменение структуры.
Вариационными называют
ряды распределения, построенные по количественному признаку. Любой вариационный
ряд состоит из двух элементов: вариантов и частот. Вариантами считаются
отдельные значения признака, которые он принимает в вариационном ряду, т.е.
конкретное значение варьирующего признака. Частоты – это численности отдельных
вариантов или каждой группы вариационного ряда, т.е. это числа, показывающие,
как часто встречаются те или иные варианты в ряду распределения. Сумма всех
частот определяет численность всей совокупности, ее объем. Частостями
называются частоты, выраженные в долях единицы или в процентах к итогу.
Соответственно сумма частостей равна 1 или 100%.
В зависимости от
характера вариации признака различают дискретные и интервальные вариационные
ряды. Как известно, вариация количественных признаков может быть дискретной
(прерывной) или непрерывной.
В случае дискретной
вариации величина количественного признака принимает только целые значения.
Следовательно, дискретный вариационный ряд характеризует распределение единиц
совокупности по дискретному признаку.
В случае непрерывной
вариации величина признака у единиц совокупности может принимать в определенных
пределах любые значения, отличающиеся друг от друга на сколько угодно малую
величину. Построение интервальных вариационных рядов целесообразно прежде всего
при непрерывной вариации признака, а также если дискретная вариация проявляется
в широких пределах, т.е. число вариантов дискретного признака достаточно
велико.
Удобнее всего ряды
распределения анализировать при помощи их графического изображения, позволяющего
судить и о форме распределения. Наглядное представление о характере изменения
частот вариационного ряда дают полигон и гистограмма.
Полигон используется при
изображении дискретных вариационных рядов. Для его построения в прямоугольной
системе координат по оси абсцисс в одинаковом масштабе откладываются
ранжированные значения варьирующего признака, а по оси ординат наносится шкала
для выражения величины частот. Полученные на пересечении абсцисс и ординат
точки соединяются прямыми линиями, в результате этого получают ломаную линию,
называемую полигоном частот. Иногда для замыкания полигона предлагается крайние
точки (слева и справа на ломаной линии) соединить с точками на оси абсцисс. В
этом случае получается многоугольник. На оси ординат могут наноситься не только
значения частот, но и частостей вариационного ряда.
Гистограмма применяется
для изображения интервального вариационного ряда. При построении гистограммы на
оси абсцисс откладываются величины интервалов, а частоты изображаются
прямоугольниками, построенными на соответствующих интервалах. Высота столбиков
в случае равных интервалов должна быть пропорциональна частотам. В результате
мы получим гистограмму – график, на котором ряд распределения изображен в виде
смежным друг с другом столбиков. Она может быть преобразована в полигон
распределения, если найти середины сторон прямоугольников и затем эти точки
соединить прямыми линиями.
При построении
гистограммы распределения вариационного ряда с неравными интервалами по оси
ординат наносят не частоты, а плотность распределения признака в
соответствующих интервалах. Это необходимо сделать для устранения влияния
величины интервала на распределение и получение возможности сравнивать частоты.
Плотность распределения – это частота, рассчитанная на единицу ширины
интервала, т.е. сколько единиц в каждой группе приходится на единицу величины
интервала.
Для графического
изображения вариационных рядов может также использоваться кумулятивная кривая.
При помощи кумуляты (кривой сумм) изображается ряд накопленных частот.
Накопленные частоты определяются путем последовательного суммирования частот по
группам и показывают, сколько единиц совокупности имеют значения признака не
больше, чем рассматриваемое значение.
При построении кумуляты
интервального вариационного ряда по оси абсцисс откладываются варианты ряда, а
по оси ординат накопленные частоты, которые наносят на поле графика в виде
перпендикуляров к оси абсцисс в верхних границах интервалов. Затем эти
перпендикуляры соединяют и получают ломаную линию, т.е. кумуляту.
Изображение вариационного
ряда в виде кумуляты особенно эффективно для вариационных рядов, частоты
которых выражены в долях или процентах к сумме частот ряда, принятой
соответственно за единицу или за 100%, т.е. частостями.
Если при графическом
изображении вариационного ряда в виде кумуляты оси поменять местами, то мы
получим огиву. С помощью кумулятивных кривых графически изображают процесс
концентрации.
Широкое применение
современных ЭВМ облегчает как построение рядов распределения, так и их
графическое представление. Особо в этой связи следует отметить использование
стандартизированных процедур определения величины интервала.
Ряд распределения
представляет собой простейшую группировку, в которой каждая выделяемая группа
характеризуется одним показателем – численностью единиц объекта, попавших в
каждую группу. Построение рядов распределения является составной частью сводной
обработки данных, при которой каждая группа единиц характеризуется многими
показателями. Поэтому важным моментом в построении группировки является
перечень тех показателей, которыми будет характеризоваться каждая группа.
Состав таких показателей
формируется в соответствии с целями статистического исследования и задачами
группировки. Для получения обобщенной, комплексной характеристики социально-экономического
явления используют не отдельные показатели, а систему статистических
показателей, которая предусматривает исчисление абсолютных, относительных и
средних величин.
4. РАСЧЕТ ОСНОВНЫХ ХАРАКТЕРИСТИК ВАРИАЦИОННОГО
РЯДА
4.1 РАСЧЕТ
СРЕДНИХ ВЕЛИЧИН
Наиболее распространенным
видом средних величин является средняя арифметическая, которая, как и все
средние, в зависимости от характера имеющихся данных может быть простой или
взвешенной.
Средняя арифметическая
простая испоьзуется в тех случаях, когда расчет осуществляется по
несгруппированным данным (3.5).
При расчете средних
величин отдельные значения осредняемого признака могут повторяться, встречаться
по нескольку раз. В подобных случаях расчет средней производится по
сгруппированным данным или вариационным рядам, которые могут быть дискретными
или интервальными.
Средняя арифметическая
взвешенная вычисляется по формуле:
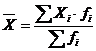 , (5.1)
, (5.1)
где 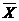 –
среднее значение;
–
среднее значение;
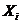 –
i-ый член совокупности;
–
i-ый член совокупности;
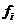 - частота.
- частота.
При расчете средней по
интервальному вариационному ряду для выполнения необходимых вычислений от
интервалов переходят к их серединам.
Рассмотрим таблицу 3.2.
Для определения среднего товарооборота найдем середины интервалов. Они будут
следующими:
957 2671 4385
6099 7813 10381
Используя среднюю
арифметическую взвешенную, определим средний розничный товарооборот для
магазинов республики Калмыкия:
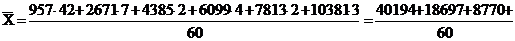
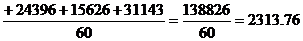
Рассмотрим таблицу 3.4.
Для определения среднего грузооборота транспорта общего пользования найдем
середины интервалов. Они будут следующими:
11,45 27,145 38,325
64,79 82,23 89,56 123,71
Используя среднюю
арифметическую взвешенную, определим средний грузооборот транспорта общего пользования
в республике Калмыкия:
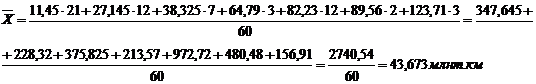
Для таблицы 3.6 середины интервалов
будут следующими:
2945 9945 18530
По средней арифметической определим
среднюю месячную заработную плату населения республики Калмыкия:
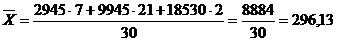 руб.
руб.
Средняя гармоническая
(простая и взвешенная) применяется, когда расчет средней арифметической теряет
смысл. Если известны численные значения числителя логической формулы, а
значения знаменателя неизвестны, но могут быть найдены как частное от деления
одного показателя на другой, то средняя величина вычисляется по формуле средней
гармонической взвешенной:
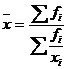 (5.2)
(5.2)
Средняя гармоническая
простая применяется, когда веса всех вариантов равны:
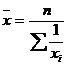 , (5.3)
, (5.3)
где 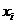 - отдельные варианты;
- отдельные варианты;
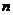 - число вариантов усредняемого признака.
- число вариантов усредняемого признака.
Средняя хронологическая
применяется для моментного ряда с равными интервалами между датами (например,
когда известны уровни на начало каждого месяца или квартала, года):
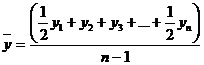 (5.4)
(5.4)
Показатели вариации
делятся на две группы: абсолютные и относительные. К абсолютным относятся
размах вариации, среднее линейное отклонение, дисперсия и среднее
квадратическое отклонение. Вторая группа показателей вычисляется как отношение
абсолютных показателей вариации к средней арифметической. Относительными
показателями вариации являются коэффициенты осцилляции, вариации, относительное
линейное отклонение и др.
Самым простым абсолютным
показателем является размах вариации.
Размах показывает,
насколько велико различие между единицами совокупности, имеющими самое
маленькое и самое большое значение признаками.
Его рассчитывают как
разность между наибольшим и наименьшим значениями варьирующего признака (3.3).
Рассчитаем размах
вариации для таблицы 3.2 по формуле (3.3):
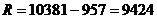 млн.руб
млн.руб
Рассчитаем размах
вариации для таблицы 3.4 по формуле (3.3):
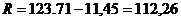 млн.т.км
млн.т.км
Рассчитаем размах
вариации для таблицы 3.6 по формуле (3.3):
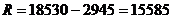 руб.
руб.
Следовательно, средняя
применяется в качестве своего рода центра тяжести, вокруг которого происходит
колебание, рассеяние значений признака. При обобщении этих колебаний необходимо
вновь прибегнуть к методу средних величин – найти среднюю величину этих
отклонений.
Такая средняя называется
средним линейным отклонением. Оно вычисляется как средняя арифметическая из
абсолютных значений отклонений вариант и 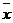 (взвешенная или простая в зависимости от исходных
условий) по следующим формулам:
(взвешенная или простая в зависимости от исходных
условий) по следующим формулам:
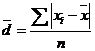 (простая), (5.5)
(простая), (5.5)
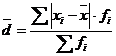 (взвешенная), (5.6)
(взвешенная), (5.6)
где 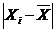 - абсолютное значение отклонений.
- абсолютное значение отклонений.
Определим среднее
линейное отклонение взвешенное для таблицы 3.2:
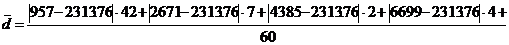
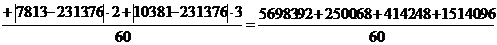
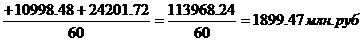
Таково в среднем
отклонение вариантов признака от их средней величины. Это отклонение по
сравнению со средней величиной признака очень большое. Оно отличается от
средней на 419,95 млн.руб. Это свидетельствует о том, что данная совокупность в
отношении нашего признака неоднородна, а средняя - -нетипична.
Определим среднее
линейное отклонение взвешенное для таблицы 3.4:
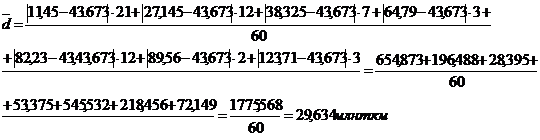
Определим
среднее линейное отклонение взвешенное для таблицы 3.6:

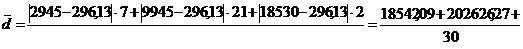
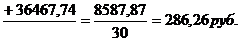
Дисперсия представляет
собой средний квадрат отклонений индивидуальных значений признака от их средней
величины и вычисляется по формулам простой (3.6) и взвешенной дисперсий (в
зависимости от исходных данных):
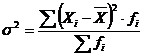 , (5.7)
, (5.7)
где 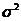 - дисперсия;
- дисперсия;
–
среднее значение;
–
i-ый член совокупности;
- частота.
Существуют другие способы
определения дисперсии. Вычисление дисперсии по средней арифметической:
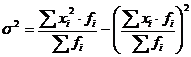 (5.8)
(5.8)
Дисперсия относительно
условного нуля:
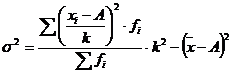 , (5.9)
, (5.9)
где k – ширина этого интервала.
А – условный ноль, в
качестве которого можно использовать середину интервала с наибольшей частотой.
Рассчитаем дисперсию по
формулам (5.7), (5.8), (5.9) для таблица3:2
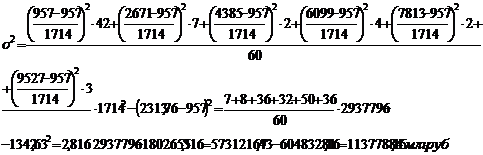
Рассчитаем
дисперсию по формулам (5.7), (5.8), (5.9) для таблицы 3.4:
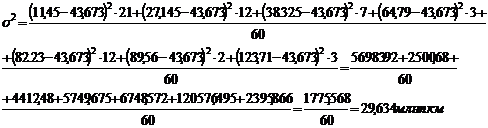
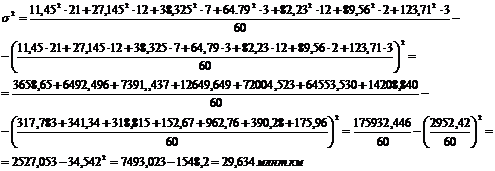
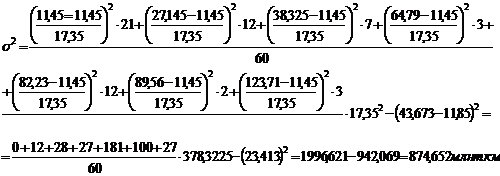
Рассчитаем дисперсию по
формулам (5.7), (5.8), (5.9) для таблицы 3.6:
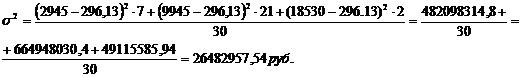
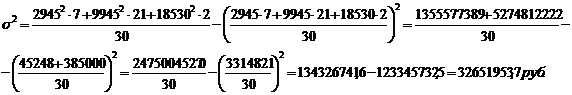
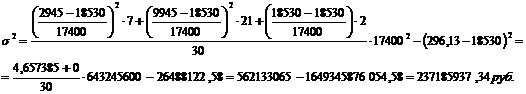
Среднее
квадратическое отклонение представляет собой корень квадратный из дисперсии:
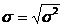 (5.10)
(5.10)
Рассчитаем среднее квадратическое
отклонение для таблицы 3.2:
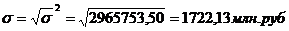
Рассчитаем среднее квадратическое
отклонение для таблицы 3.4:
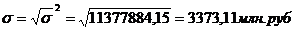
Рассчитаем среднее квадратическое
отклонение для таблицы 3.6:
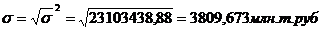
4.3 КОЭФФИЦИЕНТЫ
ВАРИАЦИИ
В статистической практике
часто возникает необходимость сравнения вариации различных признаков. При
сравнении изменчивости различных признаков в совокупности для оценки
интенсивности вариации, для сравнения ее в разных совокупностях и для разных
признаков удобно применять относительные показатели вариации.
Коэффициент осцилляции
отражает относительную колеблемость крайних значений признака вокруг средней:
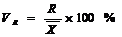 , (5.11)
, (5.11)
где 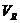 - коэффициент осцилляции;
- коэффициент осцилляции;
R – размах вариации.
Относительное линейное
отклонение характеризует долю усредненного значения абсолютных отклонений от
средней величины:
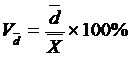 , (5.12)
, (5.12)
где 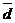 - среднее линейное отклонение.
- среднее линейное отклонение.
Коэффициент вариации
(3.4) – наиболее часто применяемый показатель относительной колеблемости,
характеризующий однородность совокупности. Совокупность считается однородной,
если коэффициент вариации не превышает 33% для распределений, близких к
нормальному. Коэффициент вариации применяется для сравнения колеблемости
разнородных признаков.
Для таблицы 3.2
рассчитаем относительные показатели:
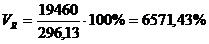
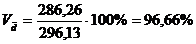
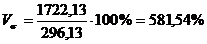
Коэффициент вариации
превышает 33%, значит совокупность неоднородна.
Рассчитаем относительные
показатели для таблицы 3.4:
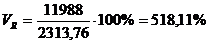
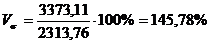
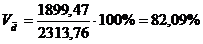
Коэффициент вариации
превышает 33%, значит совокупность неоднородна.
Рассчитаем относительные
показатели для таблицы 3.6
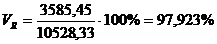
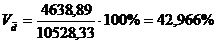
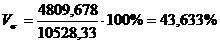
Коэффициент вариации
превышает 33%, значит совокупность неоднородна.
5.1
ОПРЕДЕЛЕНИЕ МОДЫ
Мода – значение признака,
чаще всего встречающееся в совокупности. Для дискретного вариационного ряда
мода определяется по частотам вариант и соответствует варианте с максимальной
частотой. В интервальном вариационном ряду с равными интервалами модальный
интервал определяется по наибольшей частоте.
Мода определяется по следующей
формуле:
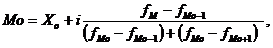 (6.1)
(6.1)
где Мо – мода;
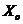 - нижняя граница модального интервала;
- нижняя граница модального интервала;
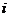 - величина модального интервала;
- величина модального интервала;
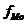 - частота модального интервала;
- частота модального интервала;
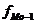 - частота интервала, предшествующего
модальному;
- частота интервала, предшествующего
модальному;
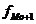 - частота интервала, последующего за
модальным.
- частота интервала, последующего за
модальным.
Для таблицы 3.2
рассчитаем моду. В данном распределении интервал 121-1814 будет модальным, так
как он имеет наибольшую частоту. Определим моду:
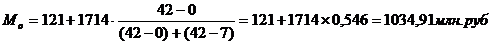
Моду в интервальном ряду
можно определить графически. Мода определяется по гистограмме распределения.
Для этого выбирается самый высокий прямоугольник, который является в данном
случае модальным. Затем правую вершину модального прямоугольника соединяем с
правым верхним углом предыдущего прямоугольника. А левую вершину модального
прямоугольника – с левым верхним углом последующего прямоугольника. Далее из
точки их пересечения опускают перпендикуляр на ось абсцисс.
Абсцисса точки
пересечения этих прямых и будет модой распределения. На рисунке 6.1
представлено графическое изображение моды для ряда распределения,
представленного в таблице 3.2.
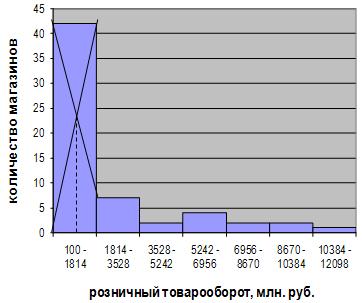
Рис. 6.1 Графическое определение моды по
гистограмме
Для ряда распределения,
представленного в таблице 3.4, определим моду. В данном распределении интервал
2,17-19,52 будет модальным, так как он имеет наибольшую частоту. Мода:
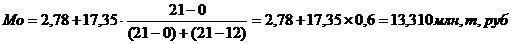
Графическое построение
моды для данной совокупности представлено на рис. 6.2.
Для ряда распределения,
представленного в таблице 3.6, определим моду. В данном распределении
интервал15800-5460 будет модальным, так как он имеет наибольшую частоту. Мода:
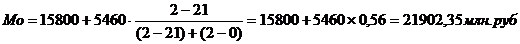
Графическое построение
моды для данной совокупности представлено на рис. 6.3.
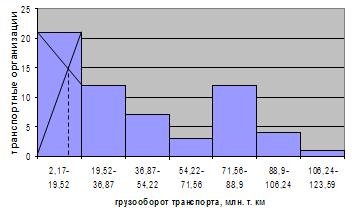
Рис. 6.2. Графическое определение моды по
гистограмме
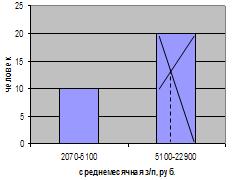
Рис. 6.3. Графическое определение моды по
гистограмме
5.2
РАСЧЕТ МЕДИАНЫ
Медиана – значение изучаемого
признака, приходящееся на середину ранжированной совокупности. При вычислении
медианы интервального вариационного ряда сначала находят медианный интервал 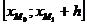 , где h – длина медианного интервала. Для
этого можно использовать кумулятивное распределение частот или относительных
частот. Медианному интервалу соответствует тот, в котором содержится
накопленная частота, равная ½. Внутри найденного интервала расчет
медианы производится по формуле:
, где h – длина медианного интервала. Для
этого можно использовать кумулятивное распределение частот или относительных
частот. Медианному интервалу соответствует тот, в котором содержится
накопленная частота, равная ½. Внутри найденного интервала расчет
медианы производится по формуле:
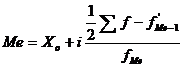 , (6.2)
, (6.2)
где 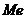 - медиана;
- медиана;
- нижняя граница медианного интервала;
- величина медианного интервала;
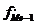 - накопленная частота интервала,
предшествующего медианному;
- накопленная частота интервала,
предшествующего медианному;
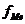 - частота медианного интервала;
- частота медианного интервала;
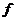 - накопленная частота.
- накопленная частота.
Медиану в интервальном
ряду можно определить графически. Медиана рассчитывается по кумуляте. Для ее
определения из точки на шкале накопленных частот, соответствующей 50%,
проводится прямая, параллельная оси абсцисс, до пересечения с кумулятой. Затем
из точки пересечения указанной прямой с кумулятой опускается перпендикуляр на
ось абсцисс. Абсцисса точки пересечения является медианой.
Рассчитаем медиану для
таблицы 3.2. Медианным будет интервал с границами (100 – 1814). Медиана:
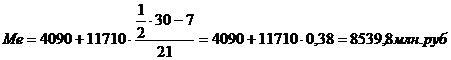
Рассчитаем медиану для
таблицы 3.4. Медианным будет интервал с границами (2,17 – 19,52). Медиана:
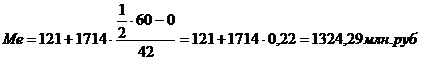
Графическое построение
моды для данного ряда представлено на рисунке 6.4.
Рассчитаем медиану для
таблицы 3.6. Медианным будет интервал с границами (5100-22900). Медиана:
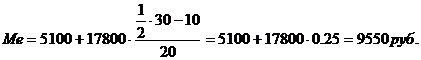
Графическое построение
моды для данного ряда представлено на рисунке 6.5.
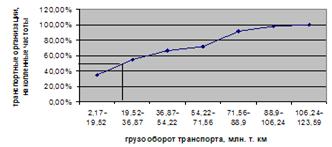
Рис. 6.4. Графическое определение медианы по
кумуляте
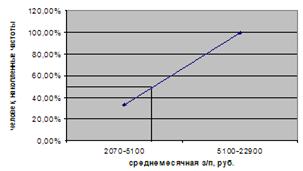
Рис. 6.5. Графическое определение медианы по
кумуляте
Квартили представляют
собой значения признака, делящие ранжированную совокупность на четыре
равновеликие части. Различают квартиль нижний (Q1), отделяющий ¼ часть совокупности с наименьшими
значениями признака, и квартиль верхний(Q3), отсекающий ¼ часть с наибольшими значениями
признака. Это означает, что 25% единиц совокупности будут меньше по величине Q1; 25% единиц будут заключены между Q1 и Q2; 25% - между Q2 и Q3 и остальные 25% превосходят Q3.
Для расчета квартилей по
интервальному вариационному ряду используется формула:
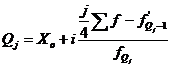 , (6.3)
, (6.3)
где 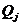 - квартили;
- квартили;
- нижняя граница интервала, содержащего
квартиль;
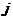 - номер квартиля;
- номер квартиля;
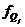 - частота интервала, содержащего квартиль;
- частота интервала, содержащего квартиль;
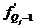 -накопленная частота интервала, предшествующего
интервалу, содержащему квартиль.
-накопленная частота интервала, предшествующего
интервалу, содержащему квартиль.
Для таблицы 3.2
рассчитаем квартили. Первый квартиль находится в интервале 121 – 1814,
накопленная частота которого равна 42 млн.руб. Второй квартиль также находится
в интервале 121 – 1814. Третий квартиль лежит в интервале 1814 – 3528 с
накопленной частотой 49 млн.руб. Четвертый квартиль находится в интервале 10384
– 12098 с накопленной частотой 60. с учетом этого получим:
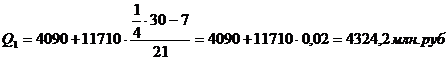
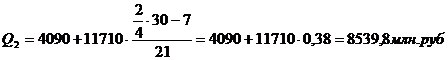
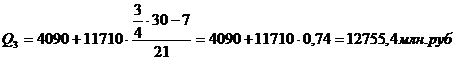
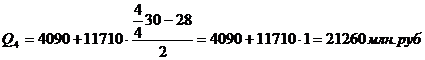
Для таблицы 3.4
рассчитаем квартили. Первый квартиль содержит 15 накопленных частот и входит в
интервал (2,78-98,8).
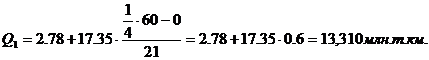
Второй квартиль содержит
30 накопленных частот и входит в интервал (19,52 – 36,87).
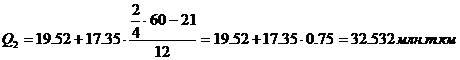
Третий квартиль содержит
45 накопленных частот и входит в интервал (71,56 – 88,9).
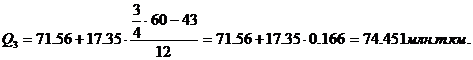
Четвертый квартиль входит
в последний интервал (106,24 – 123,59).
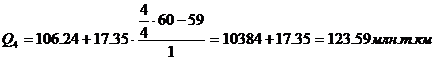
Для таблицы 3.6
рассчитаем квартили. Первый квартиль содержит 7,5 накопленных частот, поэтому
входит в интервал (4090-15800).
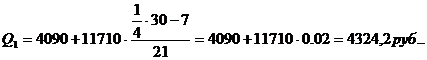
Второй квартиль содержит
15 накопленных частот, поэтому входит в интервал (4090-15800).
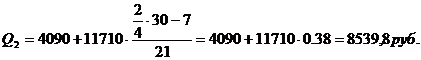
Третий квартиль содержит
22,5 накопленных частот, поэтому входит в интервал (4090-15800).
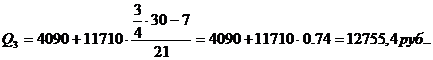
Четвертый квартиль входит
в последний интервал (4090-11710).
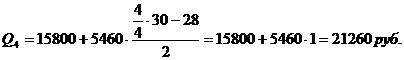
5.4
РАСЧЕТ ДЕЦИЛЕЙ
Децили – варианты,
делящие ранжированный ряд на десять равных частей. Первый дециль делит
совокупность в соотношении 1/10 к 9/10, второй дециль – в соотношении 2/10 к
8/10 и т.д.
Вычисляются децили по
формуле:
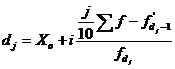 , (6.4)
, (6.4)
где 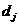 - децили;
- децили;
- номер децили;
- нижняя граница интервала, содержащего дециль;
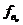 - частота интервала, содержащего дециль;
- частота интервала, содержащего дециль;
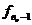 -накопленная частота интервала, предшествующего
интервалу, содержащему дециль.
-накопленная частота интервала, предшествующего
интервалу, содержащему дециль.
Для таблицы 3.2
рассчитаем 1-й, 3-й, 6-й, 8-й, 9-й дециль. Первый, третий и шестой децили
входят в интервал (121-1814), восьмой дециль входит в интервал 1814 – 3528,
девятый дециль входит в интервал 5242 – 6956. С учетом этого получим:
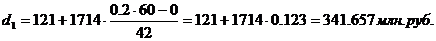
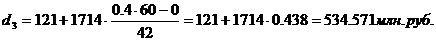
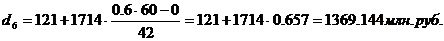
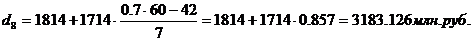
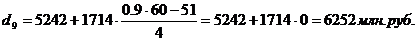
Для таблицы 3.4
рассчитаем те же самые децили. Первый и третий децили содержат 6 и 18
накопленных частот соответственно и входят в интервал (2,78– 19,52).
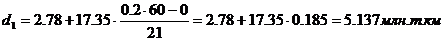
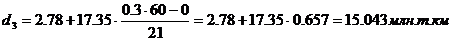
Шестой дециль содержит 36
накопленных частот и входит в интервал (36,67– 54,22).
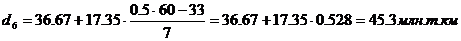
Восьмой и девятый
перцентили содержат 48 и 54 накопленных частот соответственно и входят в
интервал (71,56 – 88,9).
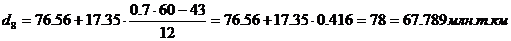
Для таблицы 3.6 также рассчитаем
децили. Первый дециль содержит 3 накопленные частоты, поэтому входит в интервал
(1800-4090).
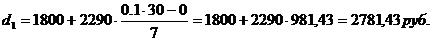
Третий дециль содержит 9
накопленных частот, поэтому входит в интервал (2070-5010).
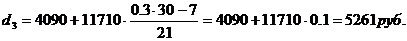
Шестой дециль содержит 18
накопленных частот, поэтому входит в интервал (4090-15800).
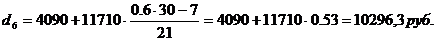
Восьмой дециль содержит
24 накопленных частот, поэтому входит в интервал (15800-21260).
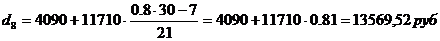
Девятый дециль содержит 27
накопленных частот, поэтому входит в интервал (21260-22900).
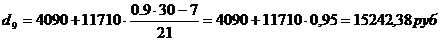
5.5
РАСЧЕТ ПЕРЦЕНТИЛЕЙ
Значения признака,
делящие ряд на сто частей, называются перцентилями. Перцентили вычисляются по
формуле:
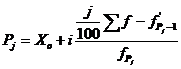 ,(6.5)
,(6.5)
где 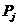 - перцентили;
- перцентили;
- номер перцентиля.
Для таблицы 3.2
рассчитаем перцентили. 16-й, 23-й, 44-й перцентили входят в интервал
(100-1814).
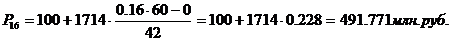
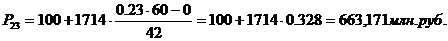
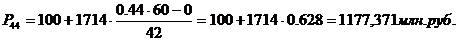
72-й, 77-й, 81-й
перцентили входят в интервал (1814 – 35280).
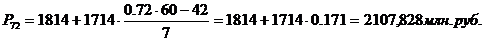
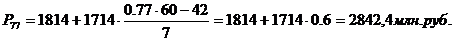
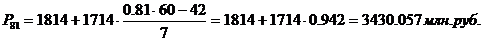
83-й перцентиль содержит
83% накопленных частот и входит в интервал (3528 – 5242).
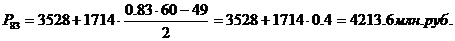
92-й, 95-й перцентили
входят в интервал (6956 – 8670).
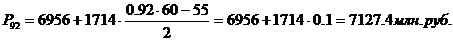
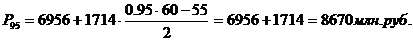
99-й перцентиль входит в
интервал (10384 – 12098).
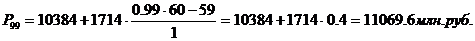
Для таблицы 3.4
рассчитаем 16, 23, 44, 72, 77, 81, 83, 92,95, 99 перцентиль по формуле (6.5):
16-й, 23-й перцентили
входят в первый интервал 92,17 – 19,52.
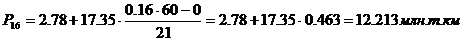
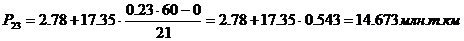
44-й перцентиль содержит
26,4 накопленных частот и входит в интервал (19,52 – 36,87).
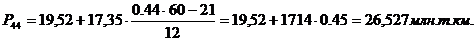
72-й, 77-й, 81-й, 83-й
перцентили входят в интервал (71,56 – 88,9).
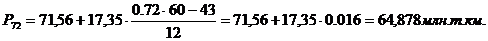
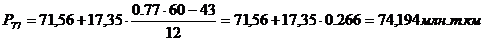
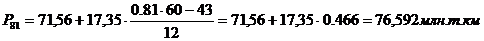
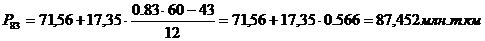
92-й, 95-й перцентили
входят в интервал (88,9 – 106,24).
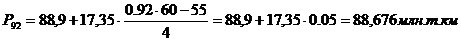
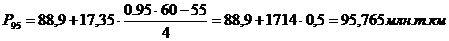
99-й перцентиль входит в
интервал (106,24 – 123,59).
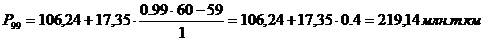
Для таблицы 3.6
рассчитаем 16, 23, 44, 72, 77, 81, 83, 92,95, 99 перцентиль по формуле (6.5).
16-й, 23-й перцентили входят в интервал (1800-4090).
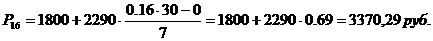
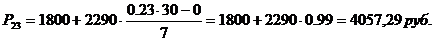
44-й, 72-й, 77-й, 81-й,
83-й, 92-й, 95-й перцентили входят в интервал (4090-15800).
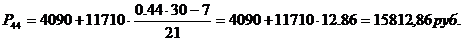
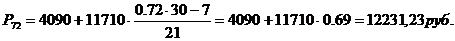
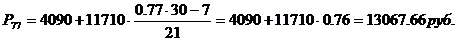
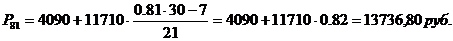
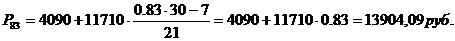
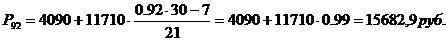
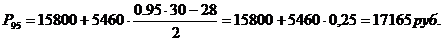
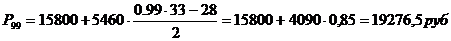
СТАТИСТИЧЕСКИХ
СОВОКУПНОСТЕЙ
6.1 РАСЧЕТ
ЦЕНТРАЛЬНЫХ МОМЕНТОВ
Центральным моментом
порядка p распределения вариационного ряда
называется среднее значение отклонений отдельных значений признака от его
средней арифметической величины степени p.
Центральный момент
первого порядка рассчитывается по формуле:
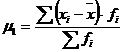 (7.1)
(7.1)
Центральный момент
второго порядка рассчитывается по формуле:
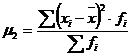 (7.2)
(7.2)
Центральный момент
третьего порядка рассчитывается по формуле
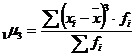 (7.3)
(7.3)
Центральный момент
четвертого порядка рассчитывается по формуле:
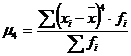 , (7.4)
, (7.4)
где 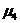 - центральный момент четвертого
порядка;
- центральный момент четвертого
порядка;
–
среднее значение;
–
i-ый член совокупности;
- частота.
Для группировки,
представленной в таблице 3.2, рассчитаем центральные моменты первого, второго,
третьего, четвертого порядка по формулам (7.1), (7.2), (7.3), (7.4)
соответственно:
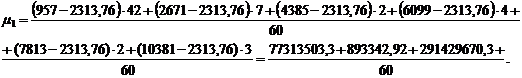
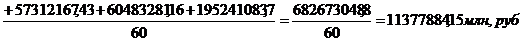
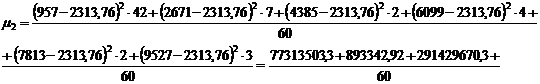
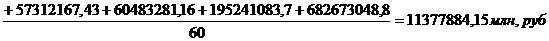
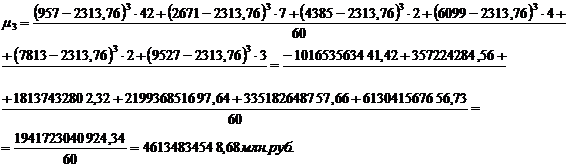
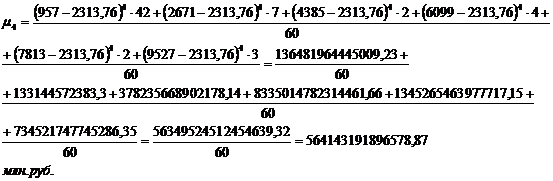
Для группировки,
представленной в таблице 3.4, также рассчитаем центральные моменты по формулам
(7.1), (7.2), (7.3), (7.4):
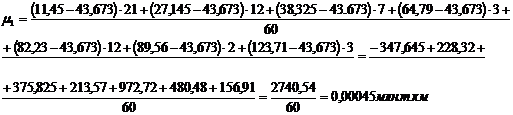
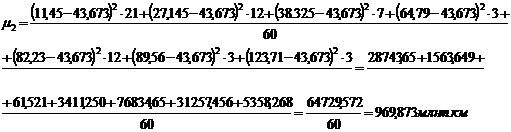
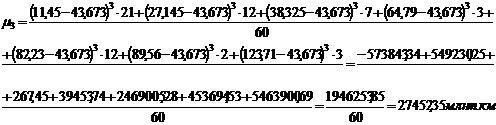
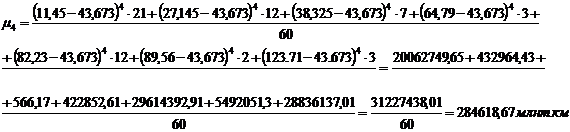
Для группировки,
представленной в таблице 3.6, рассчитаем центральные моменты по формулам (7.1),
(7.2), (7.3), (7.4):
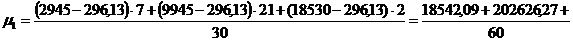
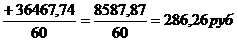
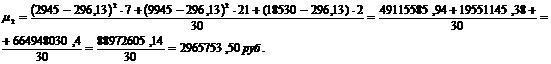
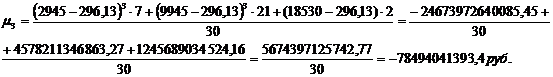
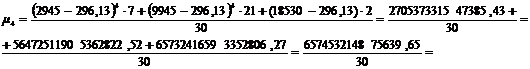
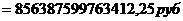
6.2
РАСЧЕТ АССИМЕТРИИ РАСПРЕДЕЛЕНИЯ
Для сравнительного
изучения ассиметрии различных распределений вычисляется коэффициент ассиметрии:
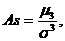 (7.5)
(7.5)
где As – ассиметрия;
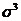 - среднее квадратическое отклонение в кубе.
- среднее квадратическое отклонение в кубе.
Для таблицы 3.2
рассчитаем среднее квадратическое отклонение в кубе:
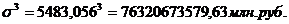
Рассчитаем коэффициент
ассиметрии по формуле (7.5):
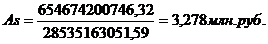
Так как величина
коэффициента ассиметрии положительная и больше 0,5, то ассиметрия данного
распределения является правосторонней и значительной.
Для таблицы 3.4
рассчитаем среднее квадратическое отклонение в кубе:
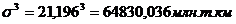
Рассчитаем коэффициент
ассиметрии по формуле (7.5):
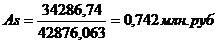
вариационный медиана
квартиль статистический
Величина коэффициента
ассиметрии положительная и больше 0,5, значит ассиметрия данного распределения
правосторонняя и значительная.
Для таблицы 3.6 рассчитаем среднее
квадратическое отклонение в кубе:
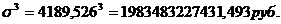
Рассчитаем коэффициент
ассиметрии по формуле (7.5):
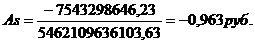
Величина коэффициента
ассиметрии отрицательная и больше 0,5, значит ассиметрия данного распределения
левосторонняя и значительная.
6.3
РАСЧЕТ ЭКСЦЕССА РАСПРЕДЕЛЕНИЯ
Для симметричных и умеренно
ассиметричных распределений рассчитывается показатель эксцесса распределения:
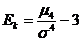 , (7.6)
, (7.6)
где 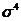 - среднее квадратическое отклонение в
четвертой степени.
- среднее квадратическое отклонение в
четвертой степени.
Для таблицы 3.2
рассчитаем эксцесс по формуле (7.6):
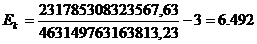 млн.руб.
млн.руб.
Величина эксцесса
положительная, значит данное распределение островершинное.
Для таблицы 3.4
рассчитаем эксцесс по формуле (7.6):
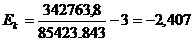 млн.т.км
млн.т.км
Величина эксцесса
отрицательная, следовательно, данное распределение плосковершинное.
Для таблицы 3.6
рассчитаем эксцесс по формуле (7.6):
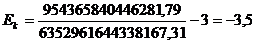 руб.
руб.
Величина эксцесса
отрицательная, следовательно, данное распределение плосковершинное.
7.
РАСПРЕДЕЛЕНИЕ ВЫБОРАЧНЫХ СРЕДНИХ
7.1 ОПРЕДЕЛЕНИЕ
ГРАНИЦ ГЕНЕРОЛЬНОЙ СОБСТВЕННО СЛУЧАЙНОЙ ВЫБОРКИ (ПОВТОРНЫЙ И БЕЗПОВТОРНЫЙ
ОТБОР)
Собственно-случайная
выборка – отбор единиц из генеральной совокупности наугад или наудачу, без
каких-либо элементов системности, прежде чем производить собственно-случайный
отбор, необходимо убедится, что все без исключения единицы генеральной
совокупности имеют абсолютно равные шансы попадания в выборку, в списках или
перечне отсутствуют пропуски, игнорирования отдельных единиц и т. п. Следует
также установить четкие границы генеральной совокупности таким образом, чтобы
включение или не выключение в нее отдельных единиц не вызывало сомнений.
Технически
собственно-случайный отбор проводят методом жеребьевки или по таблице случайных
чисел.
Предельная ошибка выборки
случайная величина.
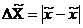 (8.1)
(8.1)
Средняя ошибка выборки.
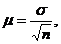 (8.2)
(8.2)
где 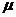 -средняя ошибка выборки;
-средняя ошибка выборки;
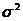 - генеральная дисперсия;
- генеральная дисперсия;
N – объем выборочной
совокупности.
Предельная ошибка выборки
в каких границах находится величина генеральной средней.
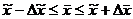 (8.3)
(8.3)
Бесповторный отбор.
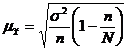 (8.4)
(8.4)
Средняя ошибка повторной
собственно-случайной выборки определяется по формуле:
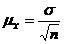 (8.5)
(8.5)
Предположим, в результате
выборочного обследования жилищных условий жителей Волгоградской области,
осуществленного на основе собственно-случайной повторной выборки, получен
следующий ряд распределения.
Таблица.8.1
Группировка населения по
жилой площади приходящегося на 1человека.
|
Общее число школ на 1 чел.
|
Число жителей
|
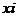
|
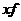
|
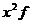
|
|
До 5
|
12
|
2,5
|
240
|
8294400
|
|
5-10
|
142,5
|
7,5
|
101531,25
|
2,09
|
|
10-15
|
1224
|
12,5
|
3121200
|
1,45
|
|
15-20
|
283,5
|
17,5
|
1339537,5
|
1,44
|
|
20-25
|
315
|
22,5
|
106312,5
|
1,12
|
|
25-30
|
195
|
27,5
|
103812,5
|
4,09
|
|
30-более
|
124,5
|
32,5
|
87668,75
|
10914759,38
|
|
Итого
|
2296.5
|
|
4860302.5
|
19209169.57
|
Первое действие определим
среднюю выборочную.
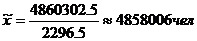
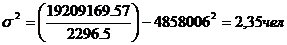
Средне квадратическое.
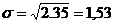
Рассчитаем среднюю ошибку
выборки.
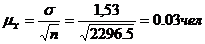
Определим предельную
ошибку выборки с вероятностью 0,954.
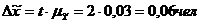
Установим границы
генеральной средней.
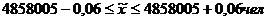
Вывод: с вероятностью
0,954 можно заключить, что среднее число школ приходится, на одного человека
лежит в пределах от 4858005.94 до 4858006,06
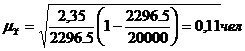
7.2
Определение границ генеральной средней типическим отбором
Типический отбор. Этот
способ отбора используется в тех случаях. Когда все единицы генеральной
совокупности можно разбить на несколько типических групп. Типический отбор
предполагает выборку единиц из каждой типической группы собственно-случайным
или механическим способом. Поскольку в выборочную совокупность в той или иной
пропорции обязательно попадают всех групп, типизация генеральной совокупности
позволяет исключить влияние межгрупповой дисперсии среднюю ошибку выборки,
которая в этом случае определяется только внутригрупповой вариацией.
Отбор единиц в типическую
выборку может быть организован либо пропорционально объему типических групп,
либо пропорционально внутригрупповой дифференциации признака.
Отбор, пропорциональный
дифференциации признака, дает лучшие результаты , однако на практике его
применение затруднено вследствие трудности получения сведений о вариации до
проведения выборочного наблюдения.
Для бесповторного отбора.
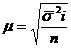 (8.5)
(8.5)
Пропорциональный бесповторный отбор.
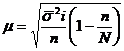 (8.6)
(8.6)
Таблица8.2
Результаты обследования рабочих
предприятий.
|
п/п
|
Всего рабочих
|
Обследование
|
Число дней нетрудоспособных
|
|
средняя
|
дисперсия
|
|
1
|
1000
|
100
|
18
|
49
|
|
2
|
1400
|
140
|
12
|
25
|
|
3
|
800
|
80
|
15
|
16
|
|
итого
|
3200
|
320
|
45
|
90
|
Рассчитать среднюю из внутригрупповую
дисперсию.
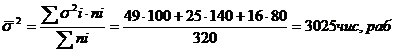
Определить среднюю и придельную
ошибку выборки с вероятностью 0,954.
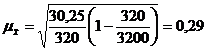
Рассчитать среднюю выборочную.
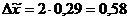
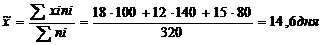
С вероятностью 0,954
можно сделать вывод о том, что среднее число дней временной нетрудоспособности
одного рабочего в ценном по предприятиям. Находится в пределах.
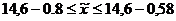
Пропорциональна дифференсация
вариационного признака.
Определяем не обходимый объем выборки
по каждому предприятию.
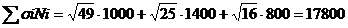
По первому определению:
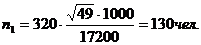
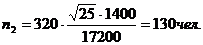
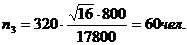
С учетом полученных значений
рассчитаем среднюю ошибку выборки.
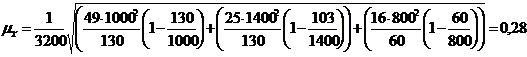
7.3
Определение границ генеральной с помощью серийной выборки
Данный способ отбора
удобен в тех случаях, когда единицы совокупности объединены в небольшие группы
или серии. В качестве таких серий могут рассматриваться упаковки с определенным
количеством готовой продукции, партии товара, студенческие группы, бригады и
другие объединения. Сущность серийной выборки заключается в
собственно-случайном либо механическом отборе серий, внутри которых
производится сплошное обследование единиц.
Поскольку внутри групп
(серий) обследуются все без исключения единицы, средняя ошибка серийной выборки
(при отборе равновеликих серий) зависит от величины только межгрупповой (межсерийной)
дисперсии и определяется по следующим формулам:
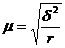 повторный отбор, (8.8)
повторный отбор, (8.8)
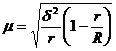 бесповторный отбор, (8.9)
бесповторный отбор, (8.9)
где 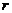 - число отобранных серий;
- число отобранных серий;
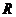 - общее число серий.
- общее число серий.
Межгрупповую дисперсию вычисляют
следующим образом:
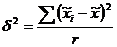 (8.10)
(8.10)
где 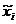 - средняя i-й серии;
- средняя i-й серии;
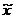 - общая средняя по всей выборочной
совокупности.
- общая средняя по всей выборочной
совокупности.
Определим границы
генеральной средней с помощью серийной выборки по данной нам задаче: В целях
контроля качества комплектующих из партии изделий, упакованных в 55 ящиков, по
20 изделий в каждом. Была произведена серийная выборка (10%) по попавшим в
выборку ящикам среднее отклонение параметров изделия от нормы соответственно
составило (8, 11, 14, 10 и 13 мм) с предельной ошибкой выборки (1,6) определим
среднее отклонение параметров во всей партии в целом.
Рассчитаем выборочную среднюю:
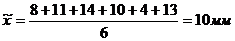
Определим величину межгрупповой
дисперсии по формуле (8.10):
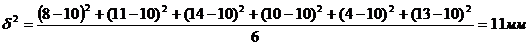
С учетом установленной вероятности
предельная ошибка выборки составит:
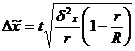 (8.11)
(8.11)
Подставим результаты в формулу
(8.11):
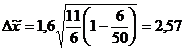
Произведенные расчеты
позволяют сделать вывод, что среднее отклонение параметров всех изделий от
нормы находятся в следующих границах 9,75 12,65.
12,65.
Для определения
необходимого объема серийной выборки, при заданной предельной ошибки используются
следующие формулы:
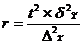 повторный отбор, (8.12)
повторный отбор, (8.12)
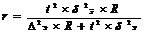 бесповторный отбор, (8.13)
бесповторный отбор, (8.13)
Подставим данные в формулы (8.12) и
(8.13):
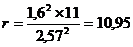
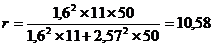
В статистике под индексом
понимается относительный показатель, который выражает соотношение величин
какого-либо явления во времени, в пространстве или сравнение фактических данных
с любым эталоном (план, прогноз и т.д).
В международной практике
индексы принято обозначать символами i и I (начальная буква латинского слова index). Буквой (i) обозначаются индивидуальные
(частные) индексы, буквой (I) –
общие индексы. Знак внизу справа означает период: 0 – базисный; 1 – отчетный.
Помимо этого используются определенные символы для обозначения индексируемых
показателей:
q – количество (объем) какого-либо
товара в натуральном выражении;
p – цена единицы товара;
z – себестоимость единицы продукции;
t – затраты времени на производство
единицы продукции;
w – выработка продукции в стоимостном
выражении на одного рабочего или в единицу времени;
v – выработка продукции в натуральном
выражении на одного рабочего или в единицу времени;
T – общии затраты времени (tq) или
численность рабочих;
pq - стоимость продукции или
товарооборота;
zq – издержки производства.
Все экономические индексы
можно классифицировать по следующим признакам: степень охвата явления; база
сравнения; вид весов (соизмерителя); форма построения; характер объекта
исследования; объект исследования; состав явления; период исчисления.
По степени охвата явления
индексы бывают индивидуальные и свободные. Индивидуальные индексы служат для характеристики
изменения отдельных элементов сложного явления. Их примером могут быть
изменения объема производства отдельных видов продукции (телевизоров и т.д.), а
также цен на акции какого-либо предприятия. Для измерения динамики сложного
явления, составные части которого непосредственно несоизмеримы (изменения
физического объема продукции, включающей равноименные товары, индекса цен акций
предприятий региона и т.п.), рассчитывают сводные, или общие, индексы. Если
индексы охватывают не все элементы сложного явления, а только часть их, то
такие индексы называются групповыми или субиндексами. По базе сравнения все
индексы можно разделить на две группы: динамические и территориальные. При
исчислении динамических индексов происходит сравнение значения показателя в
отчетный период со значением этого же показателя за предыдущий период, который
называют базисным. Динамические индексы бывают базисные и цепные. Вторая группа
индексов (территориальные) применяется для межрегиональных сравнений. Большое
значение эти индексы имеют в международной статистике при сопоставлении
показателей социально-экономического развития различных стран.
По виду весов индексы
бывают с постоянными и переменными весами.
В зависимости от формы
построения различаются индексы агрегатные и средние. Последние делятся на
арифметические и гармонические. Агрегатная форма общих индексов является
основной формой экономических индексов. Средние индексы – производные, они
получаются в результате преобразования агрегатных индексов.
По характеру объема исследования
общие индексы подразделяются на индексы количественных (объемных) и
качественных показателей. В основе такого деления индексов лежит вид
индексируемой величины.
По объекту исследования
индексы бывают: производительности труда, себестоимости, физического объема
продукции, стоимости продукции и т.д.
По составу явления можно
выделить две группы индексов: постоянного (фиксированного) состава и
переменного состава. Деление индексов на эти две группы используется для
анализа динамики средних показателей.
По периоду исчисления
индексы подразделяются на годовые, квартальные, месячные, недельные.
С помощью экономических
индексов решаются следующие задачи: измерение динамики социально-экономического
явления за два и более периодов времени; измерение динамики среднего
экономического показателя; измерение соотношения показателей по разным
регионам; определение степени влияния изменений значений одних показателей на
динамику других; пересчет значения макроэкономических показателей из
фактических цен в сопоставимые.
Каждая из этих задач
решается с помощью различных индексов.
Рассмотрим таблицу (9.1)
и определим цепные и базисные, индивидуальные индексы цен физического объема
организации. Проверим взаимосвязь цепных и базисных индексов:
Таблица 9.1
Реализация по поставки угря в
республику Калмыкия:
|
год
|
Цена за 1т, руб.
|
Произведено
|
|
2000
|
470
|
102,6
|
|
2001
|
550
|
108,5
|
|
2002
|
600
|
87,7
|
|
2003
|
750
|
109,9
|
|
2004
|
900
|
95,3
|
|
2005
|
1300
|
98,9
|
|
2006
|
1700
|
82,5
|
Индекс физического объема продукции
рассчитывается по формуле:
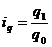 (9.1)
(9.1)
Подставим данные в формулу (9.1) и
определим цепные индексы физического объема:
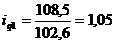
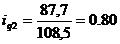
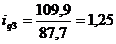
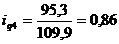
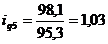
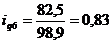
Подставим данные в формулу (9.1) и
определим базисные индексы физического объема:
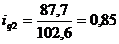
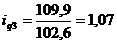
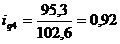
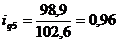
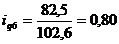
Индивидуальный индекс цен
рассчитывается по формуле:
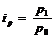 (9.2)
(9.2)
Подставим данные в формулу (9.2) и
определим цепные индексы цен:
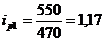
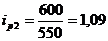
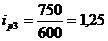
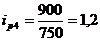
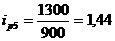
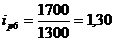
Подставим данные в формулу (9.2) и
определим базисные индексы цен:
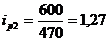
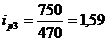
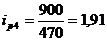
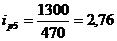
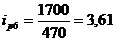
Проверим базисные и
цепные индексы.
Если известны цепные
индексы, то путем их последовательного перемножения можно получить базисные
индексы. Например:
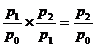 (9.3)
(9.3)
Или
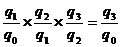 (9.4)
(9.4)
Подставим данные в формулы (9.3) и
(9.4):
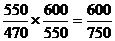
1,04=1,04
Или 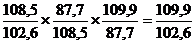
0,83=0,83
Зная последовательные
значения базисных индексов, легко рассчитать на их основе цепные индексы:
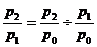 (9.5)
(9.5)
Или
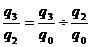 (9.6)
(9.6)
Подставим данные в формулы (9.5) и
(9.6):
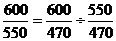
2,06=2,06
Или 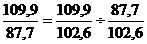
2.02=2,02
Формирование системы
индексов, например, цен или физического объема отличается от других систем
индексов. Это связано с тем, что при построении систем этих индексов можно
использовать постоянные и переменные веса.
Рассмотрим таблицу (9.2)
и рассчитаем сводный индекс цен, товарооборота, физического объема реализации:
Таблица 9.2
Реализация продуктов
в республики Калмыкия.
|
Продукт
|
2000
( ) )
|
2001
(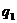 ) )
|
2002
(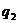 ) )
|
2003
(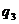 ) )
|
2004
(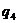 ) )
|
|
Мясо
|
44
|
27
|
31
|
28
|
28
|
|
Сахар
|
24
|
24
|
24
|
26
|
31
|
|
Раст.масло
|
366
|
234
|
155
|
260
|
314
|
|
Хлеб
|
129
|
112
|
110
|
116
|
115
|
|
мука
|
10,5
|
16,7
|
15,3
|
18,4
|
1,9
|
|
продукт
|
2000
|
2001
|
2002
|
2003
|
2004
|
|
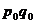
|
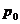
|
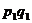
|
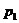
|
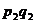
|
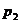
|
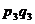
|
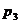
|
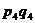
|
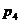
|
|
Мясо
|
2420
|
55
|
1998
|
74
|
2635
|
85
|
2744
|
98
|
3360
|
120
|
|
Сахар
|
312
|
13
|
432
|
18
|
552
|
23
|
676
|
26
|
961
|
31
|
|
Раст.масло
|
12444
|
34
|
9126
|
39
|
6510
|
42
|
14040
|
54
|
385
|
71
|
|
Хлеб
|
645
|
5
|
784
|
7
|
1100
|
10
|
1392
|
12
|
1610
|
14
|
|
мука
|
199,5
|
19
|
467,6
|
28
|
474,3
|
31
|
662,4
|
36
|
77,9
|
41
|
Индекс стоимости
продукции или товарооборота представляет собой отношение стоимости продукции
текущего периода к стоимости продукции в базисном периоде и определяется по
формуле:
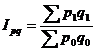 (9.7)
(9.7)
Подставим данные в формулу и получим:
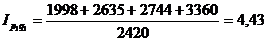
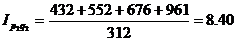
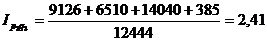
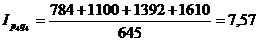
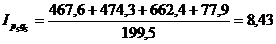
Такой индекс показывает,
во сколько раз возросла (уменьшилась) стоимость продукции (товарооборота)
отчетного периода по сравнению с базисным, или сколько процентов составляет
рост (снижение) стоимости продукции.
Индекс физического объема
продукции – это индекс количественного показателя. В этом индексе индексируемой
величиной будет количество продукции в натуральном выражении, а весом – цена.
Только умножив несоизмеримые между собой количества разнородной продукции на их
цены, можно перейти к стоимостям продукции, которые будут уже величинами
соизмеримыми. Так как индекс физического объема – индекс количественного
показателя, то весами будут цены базисного периода. Тогда формула индекса
примет следующий вид:
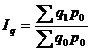 (9.8)
(9.8)
Подставим данные в формулу и получим:

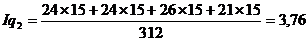
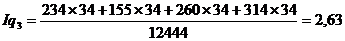
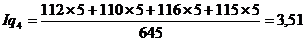
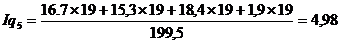
Индекс физического объема
продукции показывает, во сколько раз возросла (уменьшилась) стоимость продукции
из-за роста (снижения) объема ее производства или сколько процентов составляет
рост (снижение) стоимости продукции в результате изменения физического объема
ее производства.
Индекс цен – это индекс
качественного показателя. Индексируемой величиной будет цена товара, так как
этот индекс характеризует изменение цен. Весом будет выступать количество
произведенных товаров. Умножив цену товара на его количество, получаем
величину, которую можно суммировать и которая представляет собой показатель,
соизмеримый с другими подобными ему величинами. Индекс цен определяется по
следующей формуле:
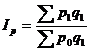 (9.9)
(9.9)
Подставим данные в формулу и получим:
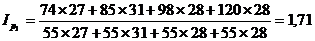
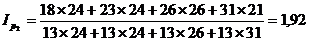
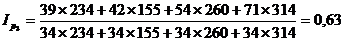
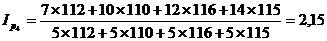
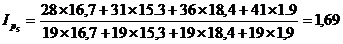
Индекс показывает, во
сколько раз возросла (уменьшилась) стоимость продукции из-за изменения цен, или
сколько процентов составляет рост (снижение) стоимости продукции в результате
изменения цен.
Рассмотрим таблицу (9.3)
и рассчитаем индивидуальные и сводные индексы себестоимости, сводный индекс
физического объема продукции и показать взаимосвязь сводных индексов:
Таблица 9.3
Реализация
товаров в республики Калмыкия
|
Товар
|
2000
()
|
2001
()
|
2002
()
|
2003
()
|
2004
()
|
|
Телевизор
|
4500
|
7600
|
9000
|
18000
|
|
Холодильник
|
8500
|
9000
|
11000
|
15000
|
16000
|
|
Стир.машина
|
1500
|
6700
|
8000
|
9000
|
12000
|
|
Товар
|
2000
|
2001
|
2002
|
2003
|
2004
|
|
|
|
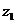
|
|
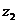
|
|
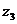
|
|
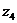
|
|
|
Телевиз.
|
3890
|
85
|
6400
|
94
|
7750
|
109
|
11400
|
156
|
13400
|
290
|
|
Холодил.
|
7640
|
100
|
8500
|
106
|
8200
|
208
|
9400
|
493
|
13900
|
540
|
|
Стир.маш.
|
950
|
84
|
5300
|
207
|
6200
|
237
|
7850
|
317
|
7290
|
406
|
Найдем индекс себестоимости:
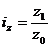 (9.10)
(9.10)
Подставим данные в
формулу (9.10) и определим цепную и базисную себестоимость телевизора:
Цепная:
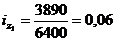
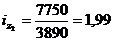
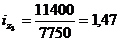
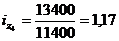
Базисная:
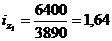
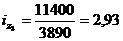
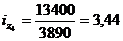
Подставим данные в
формулу (9.10) и определим цепную и базисную себестоимость холодильника:
Цепная:
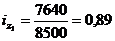
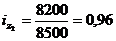
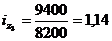
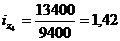
Базисная:
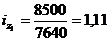
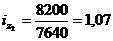
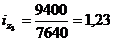
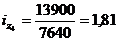
Подставим данные в
формулу (9.10) и определим цепную и базисную себестоимость стиральной машины:
Цепная:
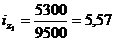
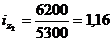
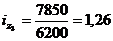
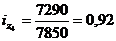
Базисная:
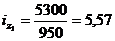
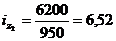
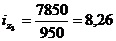
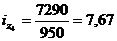
Определим себестоимость продукции по
формуле:
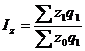 (9.11)
(9.11)
Подставим в формулу (9.11) и
посчитаем:
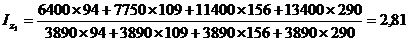
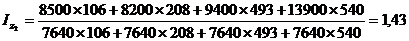
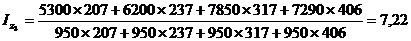
Подставим данные в формулу (9.8) и
получим:
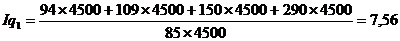
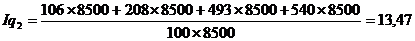
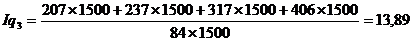
9.
КОРРЕЛЯЦИОННО – РЕГРЕССИОННЫЙ АНАЛИЗ
Корреляционно –
регрессионный анализ как общее понятие включает в себя измерение тесноты,
направления связи и установление аналитического выражения (формы) связи
(регрессионный анализ).
Корреляционный анализ
имеет своей задачей количественное определение тесноты связи между двумя
признаками (при парной связи) и между результативным и множеством факторных
признаков (при многофакторной связи). Теснота связи количественно выражается
величиной коэффициентов корреляции. Коэффициенты корреляции, представляя
количественную характеристику тесноты связи между признаками, дают возможность
определять «полезность» факторных признаков при построении уравнений
множественной регрессии. Величина коэффициента корреляции служит также оценкой
соответствия уравнения регрессии выявленным причинно-следственным связям.
Регрессионный анализ
заключается в определении аналитического выражения связи, в котором изменение
одной величины обусловлено влиянием одной или нескольких независимых величин
(факторов), а множество всех прочих факторов, также оказывающих влияние на
зависимую величину, принимается за постоянные и средние значение. Регрессия
может быть однофакторной (парной) и многофакторной (множественной).
Корреляционная
зависимость является частным случаем стохастической зависимости, при которой
изменение значений факторных признаков влечет за собой изменение среднего
значения результативного признака. Корреляционная зависимость исследуется с
помощью методов корреляционного и регрессионного анализов.
Основной предпосылкой
применения корреляционного анализа является необходимостью подчинения
совокупности значений всех факторных и результативного признаков к мерному
нормальному закону распределения или близость к нему.
Целью регрессионного
анализа является оценка функциональной зависимости условного среднего значения
результативного признака от факторных. Основной предпосылкой регрессионного
анализа является то, что только результативный признак подчиняется нормальному
закону распределения, а факторные признаки могут иметь произвольный закон
распределения.
По следующим данным о
ВРП, численности активного населения и численности организаций необходимо
определить зависимость между признаками:
Таблица 10.1
Расчетная
таблица для определения уравнения регрессии
|
год
|
Числен.эк.
акт.населения
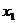
|
Числен.
Организаций
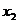
|
ВРП
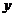
|
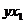
|
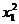
|
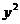
|
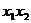
|
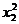
|
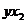
|
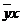
|
|
2000
2000
|
1247
|
34529
|
41196,4
|
65352845,5
|
1563729
|
4529502374
|
74522736
|
3130178704
|
3567641711
|
116772,67
|
|
2001
|
1256
|
47203
|
65439,7
|
735294632,2
|
1578492
|
6875676648
|
75938464
|
3329751616
|
4784798369
|
113943,15
|
|
2002
|
1259
|
53717
|
151564,4
|
742298465,6
|
1598997
|
10887086017,44
|
81622899
|
3607323721
|
6266836813
|
170656,66
|
|
2003
|
1204
|
49563
|
426741.2
|
453712957,4
|
1375849
|
16543670332,84
|
79557451
|
3739444801
|
7865376152
|
123787,68
|
|
2004
|
1332
|
63702
|
163783,4
|
963465014,3
|
1783417
|
23820125641,29
|
84042210
|
3807507025
|
9523407779
|
184881,55
|
|
2005
|
1216
|
62147
|
193224,1
|
845392543,8
|
1246278
|
42371834673,64
|
83462363
|
4003978729
|
13025203443,4
|
155435,3
|
|
2006
|
1397
|
52784
|
234564,2
|
126543268,2
|
1838736
|
44502307362,49
|
65317164
|
2320252561
|
10161525113,3
|
85310,65
|
|
итого
|
11543
|
408015
|
85643,7
|
1347528794
|
12479103
|
164824246289.4
|
645387487
|
2547435267
|
64354789380,7
|
385787,66
|
Система нормальных уравнений имеет
вид:
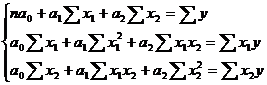
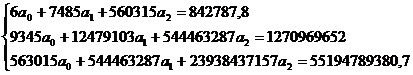
Таким образом: 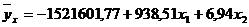
С целью расширения
возможностей экономического анализа используются частные коэффициенты
эластичности, определяемые по формуле:
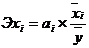 (10.1)
(10.1)
Где 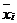 - среднее значение соответствующего
факторного признака;
- среднее значение соответствующего
факторного признака;
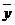 - среднее значение результативного признака;
- среднее значение результативного признака;
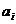 - коэффициент регрессии при соответствующем
факторном признаке.
- коэффициент регрессии при соответствующем
факторном признаке.
Рассчитаем коэффициент
эластичности:
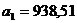
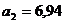
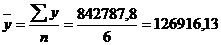
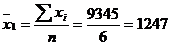
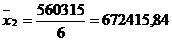
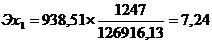
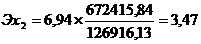
Частный коэффициент детерминации:
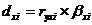 (10.2)
(10.2)
Где 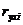 - парный коэффициент корреляции между
результативным и i-м факторным признаками;
- парный коэффициент корреляции между
результативным и i-м факторным признаками;
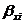 - соответствующий коэффициент уравнения
множественной регрессии в стандартизированном масштабе.
- соответствующий коэффициент уравнения
множественной регрессии в стандартизированном масштабе.
Рассчитаем частный
коэффициент детерминации:
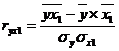
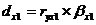
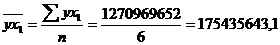

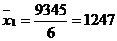
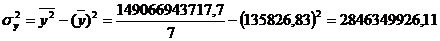
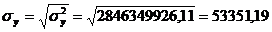
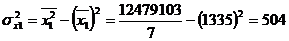

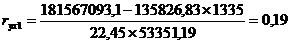
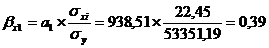
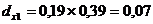
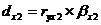 - частный коэффициент детерминации для фактора
- частный коэффициент детерминации для фактора
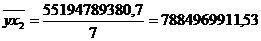
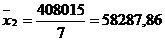
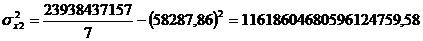
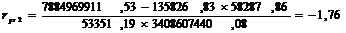
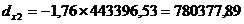
Множественный коэффициент
детерминации представляющий собой множественный коэффициент корреляции в
квадрате, характеризует, какая доля вариации результативного признака
обусловлена изменением факторных признаков, входящих в многофакторную
регрессионную модель. Для более точной оценки влияния каждого факторного
признака на моделируемый используют  - коэффициент, определяемый по формуле:
- коэффициент, определяемый по формуле:
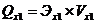 (10.3)
(10.3)
Где 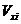 - коэффициент вариации соответствующего
факторного признака.
- коэффициент вариации соответствующего
факторного признака.
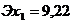
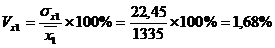
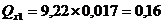
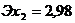
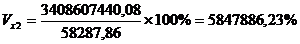
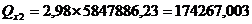
Анализ и обобщение статистических
данных – заключительный этап статистического исследования, конечной целью
которого является получение теоретических выводов и практических заключений о
тенденциях и закономерностях изучаемых социально-экономических явлений и
процессов.
Задачами статистического
анализа являются: определение и оценка специфики и особенностей изучаемых
явлений и процессов, изучение их структуры, взаимосвязей и закономерностей их
развития.
В качестве этапов
статистического анализа выделяются:
1) формулировка цели анализа;
2) критическая оценка
данных;
3) сравнительная оценка и
обеспечение сопоставимости данных;
4) формирование
обобщающих показателей;
5) фиксация и обоснование
существенных свойств, особенностей, сходств и различий, связей и
закономерностей изучаемых явлений и процессов;
6) формулировка
заключений, выводов и практических предложений о резервах и перспективах
развития изучаемого явления.
Методы анализа должны
меняться в зависимости от характера изучаемых процессов, их специфики,
особенностей и форм проявления.
Статистический анализ
данных проводится в неразрывной связи теоретического, качественного анализа
сущности исследуемых явлений и соответствующего количественного инструментария
изучения их структуры, связей и динамики.
Экономико-статистический
анализ должен проводиться при строгом соблюдении следующих принципов, которые
учитывают экономическую и статистическую их градацию.
Экономическими принципами
являются: соответствие экономическим законам и положениям теории расширенного
воспроизводства; адекватное отражение сущности экономической политики
современного этапа общественно-экономического развития; ориентация на конечные
экономические результаты; учет специфики изучаемого объекта, отрасли;
согласование интересов субъектов различных иерархических уровней.
К статистическим
принципам относятся: четко определенная цель экономико-статистического
исследования; согласованность систем по горизонтали и вертикали; сопоставимость
во времени и пространстве; логическая взаимосвязь между показателями,
характеризующими объект или явление; комплексность и полнота отображения
объекта исследования в статистических показателях; максимальная степень
аналитичности.
Соблюдение данных
принципов наряду с предпосылками применения методологии статистического анализа
позволяет осуществить научно обоснованное экономико-статистическое исследование
субъектов экономики в соответствии с принятой международной методологией.
1.
Адамов В.Е.
факторный индексный анализ (методология и проблемы). – М.: Статистика, 1997.
2.
Вайну Я.Я.
Корреляция рядов динамики. – М.: Статистика, 1997.
3.
Джини К. Средние
величины. – М.: Статистика, 1997.
4.
Ковалевский Г. В.
Индексный метод в экономики. – М.: Финансы и статистика, 1989.
5.
Лившиц Ф.Д. Статистические
таблицы. – М.: Госстатиздат, 1958.
6.
Миллс Ф
Статистические методы. – М.: Госсстатиздат, 1958.
7.
Плошко В.Г.,
Елисеева И.И. История статистики. М.: Финансы и статистика, 1990.
Размещено
на