Анализ современных стандартов и средств управления компьютерными сетями
Оглавление
Введение
Глава 1. Анализ современных стандартов и средств управления
компьютерными сетями
1.1 Классифицирование компьютерных сетей по различным признакам
1.2 Исследование современных протоколов управления компьютерными
сетями
1.3 Анализ архитектур управления КС
1.4 Обзор и анализ современных программных систем управления КС
1.5 Анализ моделей администрирования СУ КС
Глава 2. Разработка требований, предъявляемых к современным СУ КС
2.1 Задачи системы управления
Процесс управления конфигурацией сети и идентификацией сетевых
устройств
Процесс обрабатывания ошибок
Мониторинг производительности и надежности сети
Процесс управления безопасностью
Учет работы сети
2.2 Разработка требований к ИСУ КС
Глава 3. Выбор архитектуры системы управления компьютерными сетями
Глава 4. Выбор способа организации системы мониторинга
4.1 Выбор модели, предназначенной для анализа и оптимизации
компьютерной сети
Способы осуществления многопоточной модели мониторинга на
существующих однопроцессорных устройствах
Математическая модель для мониторинга систем с пакетной обработкой
данных
Математическая модель метода кругового опроса
4.2 Выбор основных формул для опрашивания оконечных устройств в
сети при мониторинге параметров
Обоснование выбора формулы для установления оптимального количества
потоков
Рассмотрение схемы проведения опроса сети, оптимизированной по
времени
4.3 Рассмотрение алгоритма проведения опроса удаленных станций
Рассмотрение алгоритма, оптимизированного по времени для
мониторинга рабочих устройств
Исследование алгоритма для отсева устройств, при невозможности
выполнения опроса устройства для системы мониторинга
Исследование многопоточного алгоритма для опроса устройств в
системе мониторинга
4.4 Исследование характеристик коммутатора 2-го уровня
Моделирование коммутатора второго уровня с методом обслуживания
FIFO
Моделирование коммутатора второго уровня с методом обслуживания
LIFO
Выводы
Заключение
Литература
Введение
Актуальность проблемы
На данный момент чтобы повысилась конкурентоспособность
компании на рынке необходимо использовать информационные технологии. Основное
направление использования - это подсистемы телефонии, видеонаблюдения, охраны и
др. Происходит активное увеличение числа компьютерных сетей (далее - КС), что
является причиной сбоев в работе сети. Из-за этого требуется усовершенствовать
нынешние методы контроля работы локальных вычислительных сетей.
Если при создании сети были рассчитаны нагрузки и размеры не
соответствующие нынешним, растущим требованиям к КС то у пользователей может
возникнуть ситуация, когда отсутствует доступ к необходимым сервисам.
Также при слиянии нескольких сетей, созданных для
обслуживания разных сервисов в сети, то увеличивается объем трафика, загрузка
серверов в частности на сервера доменов. Для решения этой проблемы создаются
программные средства следящие за функционированием сети, предсказывающие
будущую работоспособность сети. Такой контроль ограничивает неавторизованный
доступ к информации, сохраняет данные в доступности и целостности. Но у
современных средств менеджмента есть ряд недочетов:
· При активном росте устройств в сети
происходит потеря контроля над сетью и превышения заранее заложенных условий
работы, к примеру, по сроку обнаружения проблемы в сети. Это обуславливается
тем что время опроса конечного оборудования увеличилось.
· Используемые пользователями методы решения
не совместимы со всеми видами сетей и не рационально занимают ресурсы
процессоры. И часто бывает так, что они пытаются занять те ресурсы, которые уже
используются другими программами.
Цель работы. Повышения производительности процессов
мониторинга компьютерных сетей.
Для достижения поставленной цели в диссертации решены
следующие задачи:
. Предложен комплексный подход к повышению
производительности системы мониторинга компьютерных сетей, учитывающем времена
выполнения процессов многопоточного опроса с оптимизацией загрузки потоков и
времена обработки пакетов мониторинга на промежуточных устройствах.
2. Исследован метод мониторинга сети.
. Исследован метод предварительного отбора оконечных
устройств.
. Исследован метод нахождения оптимального количества
потоков в любой момент времени для системы мониторинга.
. Исследован способ обработки и сбора информации для
многопоточных приложений.
. Исследован алгоритм для системы мониторинга с
многопоточным способом организации процесса.
. Разработана имитационная модель коммутатора второго
уровня.
. Проведено исследование с помощью разработанной
имитационной модели коммутатора второго уровня, использующая методы обработки
очередей FIFO и LIFO.
Новизна работы заключается в комплексном подходе к
повышению производительности системы мониторинга компьютерных сетей,
учитывающем времена выполнения процессов многопоточного опроса с оптимизацией
загрузки потоков и времена обработки пакетов мониторинга на промежуточных
устройствах.
Практическая значимость заключается в полученных
в результате исследований значений параметров кадров и коммутаторов, которые
могут быть использованы сетевым администратором для повышения
производительности систем мониторинга.
Структура и объем работы
Диссертация состоит из введения, 4 глав, заключения и списка
литературы, изложенных на 97 страницах машинописного текста, включающего 7
таблиц, 31 рисунок и список литературы из 46 наименований.
Глава 1.
Анализ современных стандартов и средств управления компьютерными сетями
В этой главе рассмотрены виды компьютерных сетей по способу
взаимодействия и территориальным признакам, проанализированы часто применяемые
способы организации архитектуры управления компьютерными сетями, исследованы
протоколы для управления компьютерной сетью. Проведен анализ популярных
способов организации системы управления компьютерной сетью.
1.1
Классифицирование компьютерных сетей по различным признакам
Классификация сетей
КС обычно классифицируют по разным признакам. Чаще всего КС
разделяют по территориальному признаку, т.к. методы, используемые для локальных
и глобальных сетей, отличаются.
При классификации по типу взаимодействия объектов сети
различают [45]:
Сети с клиент-серверной архитектурой - это такие сети, в которых
сетевые устройства выполняют роль или сервера, или клиента. Клиентом называется
запрашивающее сетевое устройство, сервером - сетевое устройство, которое
отвечает на запрос.
Сети с многослойной архитектурой - самый простой из примеров
это сеть с трехуровневой архитектурой. В таком способе организации архитектуры
взамен одиночного сервера используются сервера БД и сервера приложений,
позволяющее в несколько раз поднять эффективность работы сети. В зависимости от
производительности конечной системы, в нее загружается сервер или сервер с
группой клиентов либо клиент.
Архитектурах с многослойной организацией обслуживают по
большей части тонких клиентов. Это объясняется тем, что большая доля проблем,
исполняемой в двухуровневой архитектуре, переносится на сервер приложений.
Клиент в таком варианте организации архитектуры выполняет все вопросы в
графическом интерфейсе пользователя, который связывается с сервером приложений.
Уменьшение цены клиентов и облегчение организации процесса
модернизации для обработки информации одни из преимуществ многослойной
архитектуры, при котором нет необходимости изменять клиентскую сторону.
Помимо всего прочего с легкостью выполняется масштабирование
мощностей обработки данных, необходимо лишь модифицировать количество серверов.
Одноранговые сети - это вид компьютерной сети главное
условие, что пользователи обладают равными правами. Произвольный узел сети
реализовывает функции как сервера, так и клиента, и в самой сети нет
выделенного сервера. Такая архитектура по сравнению с клиент-серверной
архитектурой способна обеспечить надежную работу сети при произвольном
сочетании и числе рабочих узлов.
По территориальному признаку классификация выглядит так:
Персональные сети - это КС, построенные в окружении человека.
Такие сети необходимы для объединения всех личные электронные аппараты
пользователя (карманные персональные компьютеры, телефоны, гарнитуры,
смартфоны, ноутбуки и т.п.) [1]. Bluetooth и Wi-Fi причисляются на сегодняшнее
время к таким сетям.
Локальные сети - это КС, занимающая сравнительно малую
площадь, к примеру офис, дом, или небольшую группу помещений, такие как
институтские здания. Локальные вычислительные сети обычно используют TCP/IP
протоколы.
Корпоративные сети - это сети, соединяющие значительное число
компьютеров всего предприятия в каждом помещении [2].
Для КС свойственный такие характеристики:
Масштабность - множество пользовательских устройств, десятки
серверов, большие объемы данных для хранения и передачи по каналам связи
информации, сотни различных приложений;
Большая степень неоднородности - множество типов
пользовательских компьютеров, коммутационного оборудования, операционных систем
и разнообразных приложений;
Применение глобальных связей - сети отделов объединяются при
помощи телекоммуникационных методов, такие как радиоканалы, телефонные каналов,
спутниковая связь.
КС используют стандарты TCP/IP SONET/SDH, MPLS, ATM и Frame
relay.
Городские вычислительные сети (Metropolitan Area Networks,
MAN) необходимы для объединения компьютеров в пределах одного города. По
размерам уступает WAN, но больше LAN. Намеренно у этого вида сетей был написан
стандарт IEEE 802.6.
Глобальные сети (Wide Area Networks, WAN) объединяет большие
рассредоточенные сети и содержащие в себе десятки тысяч устройств в разных
городах и странах.
Главные применяемые протоколы это ТСР/IР, МPLS, SОNET/SDH,
АTM и Frаme relay. Компьютерная сеть необходима для объединения значительного
числа устройств во всех офисах выделенного предприятия. Они могут объединяться
в сложные схемы и находиться на территории различный городов, странах и
материках. Число пользователей и сетевых устройств может превышать тысячи. На
рис.1 приведен пример КС. Для того чтобы объединить локальные сети и отдельные
выделенные устройства в сети используются различные телекоммуникационные
протоколы и средства от различных производителей, что вызывает высокую
гетерогенность среды.
Это существенно усложняет оптимизацию ее работы.

Рис. 1 Пример КС
Разнородные части компьютерной сети действуют как единое целое,
давая пользователям по возможности сквозной доступ ко всем требуемым ресурсам.
При переходе от локальной сети отдела к КС - КС должны становиться
более надежными и отказоустойчивыми, из-за повышающихся требований к
компьютерной сети. С увеличение топологии распределённой сети вырастают и ее
функциональные потенциалы. По сети распространяется множество данных, и
компьютерная сеть обеспечивает их доступность, безопасность и защищенность.
Соединения, нужные для предоставления согласования устройств, обязаны быть как
можно более прозрачными. Как только происходит переход на уровень выше в
сложности то в сети становится все больше и разнообразнее компьютерных
устройств, Расстояния между объектами сети увеличиваются, а, чтобы достигнуть
какой-либо цели потребуется больше усилий и как следствие управление
соединениями и устройствами стоит все больше и больше.
1.2
Исследование современных протоколов управления компьютерными сетями
Модель управления, которая чаще всего используемая - это
взаимодействие агента и менеджера. Если делать документацию к такой схеме
управления, то необходимо чтобы под нижеследующие блоки были стандартизированы:
Протокол используемый для согласования менеджера и агентского
устройства.
Модель общения блока управления и агента.
Интерфейс "агент - модель управляемого ресурса".
Интерфейс "менеджер - модель управляемого ресурса".
Для блока управления сетевым оборудованием требуется БД MIB.
Определение необходимости построения дерева наследования
между новыми устройствами в сети, опираясь на базовые модели.
Для того чтобы отобразить отношения между частями реальной
системы используется дерево включения. К примеру, связь всех модулей к
выделенному коммутирующему устройству или устройствам сети.
Модель иерархических отношений у объектов управления (дерево
включений) дает возможность изобразить отношения между реальными объектами
сети, к примеру отношение отдельных модулей коммутации к выделенному
коммутирующему устройству или множеству коммутаторов и хабов выделенной сети.
На данный момент в системах менеджмента стандартизированы не
все определенные выше блоки, а только часть из них.
управление компьютерная сеть система
Использование Internet стандарта, основанного на SNMP
протоколе и CMIP стандарт для общения агентов и менеджеров, чаще всего
применяется для менеджмента устройств [46].
Протокол SNMP используется обычно для сетей, где не требуется
большого числа параметров для управления в отличии от CMIP, которому требуется
большее число средств управления оборудованием сети.
Протокол общей управляющей информации (CMIP) и услуги
взаимодействия при управлении контентом (CMIS)
Услуга CMSIE дает доступ к данным, хранящимся на сетевом
оборудовании. CMSIE (Common Management Information Service Element)
реализовывается сразу на двух объектах, первая на менеджере, а другая на
агенте. Общение агента и менеджера протекает с помощью протокола CMIP. Услуги
взаимодействия при управлении контента (CMIS) это такие услуги, которые
выполняются службой CMSIE.
Услуги, выполняемые менеджером, реализовываются с помощью
таких операций [2]:
M-CREATE. Команда агенту, говорящая о том, что следует
сделать новую копию объекта нужного класса или атрибут внутри какого-либо
объекта.DELETE. Команда для агента, говорящая о том, следует удалить копию
объекта нужного класса или в самом объекте один из его атрибутов.GET. Команда
для агента требующая вернуть значение атрибута выбранного объекта.SET. Команда
для агента требующая изменить значение атрибута выделенного объекта.
М-ACTION. Команда для агента говорящая о том, что следует
сделать изменение одного или нескольких объектов.
Агент способен инициировать только одну команду:EVENT_REPORT
- команда посылает менеджеру оповещение.
Разница между CMIP и SNMP заключается в том, что CMIP
выполняет большее количество функций. К примеру команды, M-ACTION, M-GET,
M-DELETE, M-SET могут обрабатывать сразу множество объектов, SET и GET
применяемые в SNMP обрабатывают всего лишь один объект. В стандарте CMIP чтобы
обрабатывать сразу множество объектов разом используются такие определения как
обзор, синхронизация, фильтрация.
Обзор
Необходим для того, чтобы разом опрашивать множество
объектов. Выделяют 4 уровня обзора объектов:
Базовый объект, расположенный на нулевом уровне, называемый
FDN (Full Distinguished Name).
Отдельные объекты, находящиеся на не нулевом уровне
зависимости сравнительно с базовым объектом в дереве включений.
Сочетание первого и второго пунктов, т.е. объект на нулевом
уровне и объект на любом другом уровне.
Объект на нулевом уровне в дереве включения и все остальные объекты,
которые зависят от него.
Фильтрация
Фильтрации строится на использовании логического выражения к
сообщениям менеджера. Получается, что условие применяется только на те объекты,
которым соотношение подходит. Логические соотношения состоят из следующих
операторов =,> =, <=, <, >.
Синхронизация
Могут применяться пара систем синхронизации:
"синхронизация по возможности" или атомарная синхронизация. При
использовании атомарной синхронизации, то опрос будет выполнен только когда
объект попадает под правила обзора или фильтрации. В ситуации, когда
применяется синхронизация по возможности, трансляция сообщения совершается
абсолютно ко всем частям системы. Стандарт ASN.1 применяется для CMIP и более
сложен по строению, чем SNMP протокол.
Протокол управления SNMP
Система управления сетевым оборудованием, использующая SNMP
протокол состоит из следующих частей [3]:
Процесс общения менеджера и агента..1 (Abstract Syntax
Notation One) язык, описывающий абстрактный синтаксис данных.
Малое число расширений SNMP (RMON, MIB-I, MIB-II, RMON).
Теория SNMP MIB и протокол SNMP применялась для временной
организации управления маршрутизирующими устройствами сети главное преимущество
которого была простота [4]. Но в итоге SNMP вышел настолько удачным, что он
применяется и сейчас для менеджмента сетевых устройств. CMIP, конечно,
оказывает сильную конкуренцию, но SNMP все равно применяют для управления
коммутаторами и маршрутизаторами, и другими сетевыми устройствами.- простой
протокол сетевого управления. По модели OSI находится на прикладном уровне.
Может применять как для сетей на основе TCP/IP так и для IPX/SPX.дает
возможность собрать информацию с различных устройств и это не только
производительность и значение статуса, но и все остальные данные что находятся
в МІВ. Лёгкость управления при помощи протокола SNMP основывается на простой
структуре SNMP МІВ. Как было сказано ранее, есть определенные стандарты,
которые определяют схему строения MIB, операции, совершаемые над объектами и
имя объекта.
МІВ представляет собой древовидную структуру, которая
включает в себя как неизменные поддеревья, так и дополнительные поддеревья,
разрешающие управлять любыми заданными функциями каждого объекта МІВ.
На рисунке ниже изображена схема обмена запросами между
менеджером и агентом (рис. 2).

Рис. 2. Общение агента и менеджера посредством протокола SNMP
Клиентское устройство в SNMP обрабатывает данные, передаваемые
МІВ, и предоставляет эти данные менеджерам, находящимся на управляющем
оборудовании в сети. Таким образом, управляющее оборудование сети получает всю
необходимую информацию из МІВ.
В идеологии управления SNMP существует четыре основных компоненты
(рис. 3)

Рис. 3. Четыре основных компонента протокола SNMP
Как правило, основная функция менеджера - это управление
устройствами, а оконечное устройство в SNMP пересылает статистику сохраненных
данных в ответ на SNMP запрос.
Протокол SNMP позволяет провести оценку эффективности работы
сетевого оборудования, числа неиспользуемых мощностей и другие параметры,
нужные для менеджмента сетевого оборудования.
У SNMP малое число используемых команд:
Get-request - Команда, отправляемая агенту для того чтобы
получить значение какой-либо переменной или множества переменных.request -
Команда, отправляемая агенту для того чтобы получить данные о следующей в
иерархии переменной.response - Команда возвращает от агента менеджеру
переменные для команд Get-request, GetNext-request и других команд.- Команда
для агента, которая изменяет значения переменных агента.- уведомление для
менеджера о нестандартных ситуациях как на другом менеджере или агенте.- была
реализована в SNMPv.2. По сути это улучшенная GetNext-request команда, которая
позволяет запросить сразу множество значений переменных.
Практически все производители сетевых устройств используют
протокол SNMP и это его основное достоинство по сравнению с CMIP. Помимо этого,
SNMP обладает очень успешной реализацией структуры параметров сетевых
устройств.
При этом протоколу SNMP присущи следующие недостатки:
Значительная нагрузка сети пакетами SNMP протокола при опросе
приводит к уменьшению полезной нагрузки.
Низкая информационная безопасность протокола.
Еще одним недостатком является то что нет подтверждения о
передачи данных (используется протокол транспортного уровня UDP).
Частично недостатки SNMP были решены во следующей версии
протокола (SNMPv2). При этом структура данных SNMP не претерпела никаких
изменений. Изменились описания управляющих станций, средств мониторинга и
ограничения доступа.
Но, не смотря на существенные улучшения протокола, при
тщательном анализе работоспособности сети, она все также испытывает
значительную нагрузку SNMP информацией.
При разработке следующей версии создатели следовали таким
принципам:
Гарантирование большей защищенности протокола (в частности
для команды SET).
Потенциал для будущего развития протокола и добавления новых
возможностей.
Оставаться простым и легким в управлении протоколом.
Возможность автоматической настройки сбора параметров в
SNMPv3.
Архитектура SNMPv3 должна быть совместима с более ранними
версиями протокола (SNMPvl, SNMPv2c, SNMPv2u, SNMPv2p) для работы со старым
оборудованием.
Значительное число сетевого оборудования все еще управляется
при помощи первой версии SNMPvl, но отдельные производители сетевого
оборудования используют и SNMPv2, который обладает огромным количеством
недостатков и огромным множеством несовместимых друг с другом версий.
На сегодняшний день SNMPv3 приобрел наибольшую известность. В
этой версии протокола исправлены недочеты и ошибки предыдущих версий. [6,7,5]
(табл. 1).
Таблица 1. Версии SNMP

Функционирование протокола SNMPv3
Также, как в SNMPv1 и SNMPv2 на оконечных станциях
установлены агенты, и система сетевого менеджмента (Network Management System,
NMS) опрашивает их. Как и у менеджеров так и у агентов есть единая точка
взаимодействия, контролирующая доступность, выполняет задачи безопасности и
диспетчера, обрабатывает сообщения.
1. При помощи диспетчера происходит обработка входящих и
исходящих пакетов и устанавливается применяемая версия SNMP.
2. Далее сообщение попадает на систему обработки в зависимости
от версии протокола и модуль оповещает систему безопасности и систему
контролирующую доступность.
3. Система обработки сообщений передает пакеты обратно
диспетчеру и при помощи UDP они передаются необходимым приложениям.
На рис.4 и 5 приведен протокол SNMP и схема его работы.

Рис. 4. Отличительные особенности протокола SNMPv3

Рис. 5. Схема работы SNMPv3
прежде всего отличается наличием криптографической защиты.
Выделяют три уровня аутентификации:
Уровень noAuthNoPriv передает данные в открытом виде и
отсутствует авторизация.
Уровень authNoPriv требует аутентификации, но информация
передается в открытом виде. Самый распространенный уровень безопасности, т. к
сеть не перегружена шифрованной информацией.
Уровень authPriv требует аутентификацию устройств и
шифрование пакетов между агентом и менеджером. Самый большой уровень защиты у
протокола.
База управляющей информации (Management Information Base,
MIB)(Management Information Base) это виртуальная БД, где заключается
информация для управления активными сетевыми устройствами. Менеджер ее
использует для контроля агентов, обращаясь к элементам MIB. База данных
представляет собой древовидную структуру, где каждая ветвь дерева
структурировано по тематике и подгруппам параметров.бывают двух типов [8, 9,
10]: фирменные и стандартные. Первые определяются производителем устройства, а
вторые устанавливаются группой IAB (Internet Activity Board - техническая
группа, несущая ответственность за расширение количества протоколов
Internet).MIB это база данных которую используют для управления сети как единым
объектом, на базе протокола RMON. Если это сеть Fast Ethernet, то в базе могут
находиться информация о коллизиях на определенных участках сети, числе
отправленных широковещательных кадров и т.п.
Каждый объект в базе данных MIB имеет два атрибута: имя
(OBJECT IDENTIFIER) и тип (SYNTAX). Имя объекта идентифицирует его положение в
дереве MIB. Оно представляет собой последовательность меток, разделенных
точками, каждая последующая метка задает номер дочернего узла в текущем
поддереве и идентифицируется целым числом.
Различные части базы данных МІВ описываются в соответствующих
текстовых файлах на языке ASN.1 [24].
Для того чтобы приложение могло работать с объектами этой
базы данных, необходимы компиляторы МІВ, которые на основе данного файла
позволяют получать структуру МІВ (рис.6).

Рис. 6. Структура МІВ
Использование протокола SNMP помогает создавать как
элементарные, так и сложные для управления модели опроса. Применяя протокол
CMIP надо сразу рассчитывать на то что система управления не будет легка, для
нормальной работы системы нужно использовать множество второстепенный служб,
различных баз данных объектов, что предполагает высокий уровень сложности
первого ввода системы управления в эксплуатацию.
Практически все производители сетевого оборудования
используют протокол SNMP и полностью удовлетворяет всем требованиям,
предъявляемым к протоколу управления КС
.3 Анализ
архитектур управления КС
Различают всего четыре архитектуры системы управления
компьютерной сетью [25,26]:
Одноуровневая архитектура.
Иерархическая архитектура.
Ячеистая архитектура.
Платформенная архитектура.
Одноуровневая архитектура
Сетевое оборудование использует единый сетевой протокол, что
дает возможность поддерживать связь непосредственно с интегрирующим менеджером
"на одном языке". Этот подход разрешает использовать только главные
функции управления, и не реализовывает функции управления характерные для
определенного устройства. На практике в больших сетях такая архитектура не
используется, так как в ней множество устройств от различных производителей,
разного по функционалу оборудования и используется множество коммуникационных
протоколов. Одноуровневая структура представлена на рис. 7.

Рис. 7. Одноуровневая архитектура СУ
Иерархическая архитектура
При использовании этого метода создается иерархия менеджеров. В
каждой отдельной части сети присутствует своя станция для менеджмента
оборудования и она следит за отведенным сегментом сети. На рабочей станции
администратора установлен элементарный сетевой менеджер, позволяющий
администратору взаимодействовать с сетевым оборудованием. Эти менеджеры могут
общаться с другими сетевыми менеджерами, которые взаимодействуют с
интегрирующим менеджером, находящимся в основе управляющей структуры.
Таким образом, управляющая станция, находящаяся внизу
иерархической архитектуры, является одновременно и менеджером, и агентом.
Иерархическая архитектура представлена на рис. 8.

Рис. 8. Иерархическая архитектура СУ КС
Ячеистая архитектура
Главное отличие заключается в том, что используется несколько
управляющих устройств верхнего уровня, взаимодействующих как с управляющими
устройствами нижнего уровня, так и непосредственно друг с другом.
Менеджеры нижнего уровня также могут общаться напрямую друг с
другом. Ячеистая архитектура представлена на рис. 9.

Рис. 9. Ячеистая архитектура СУ КС
Платформенная архитектура
Платформенная архитектура организовывается на общем прикладном программном
интерфейсе, определенным и поддерживаемым практически всеми производителями.
При такой архитектуре нет зависимости от поставщика оборудования так как сама
платформенная архитектура предоставляет все необходимые средства менеджмента, и
разработчики уделяют внимание только на направленность приложения.
Платформенная архитектура представлена на рис. 10.

Рис. 10. Платформенная архитектура СУ КС
Платформенная архитектура управления КС на данный момент является
наиболее популярной и используется, например, в HP OpenView и SunNet Manager.
1.4 Обзор и
анализ современных программных систем управления КС
На сегодняшний день организации не мыслят свое существование
без компьютерных и телекоммуникационных средств организации рабочего процесса.
Схема большинства предприятий выступает в роли сложной
компьютерной сети, состоящая из различного программного и аппаратного
обеспечения множества вендоров.
Главная особенность состоит в том, что производитель
телекоммуникационного оборудования разрабатывает и обслуживает преимущественно
свои стандарты.
Для системы управления и мониторинга КС важнейшие задачи [28,
27]:
1. Автоматизированное выявление оборудования в сети и нахождение
связей между ними.
2. Сохранение основных параметров компьютерной сети. Это дает
возможность предсказывать проблемы и довольно оперативно выявлять причину
неисправности в случае ее обнаружения.
3. Оперативная реакция на изменения параметров сети.
4. Написание отчетов, необходимых для будущего анализа и предполагаемой
модификации сети.
5. Создания списка оборудования для управления устройствами.
6. Возможность управления сетью из любой ее точки на основе
многослойной архитектуры.
К сожалению, производители СУ КС не распространяют информацию
о структуре или алгоритмах функционирования СУ КС, поэтому дальнейшее сравнение
СУ КС будет проводиться по их функционалу.Tivoli NetView.
Использование IBM NetView помогает установить состояние
сетевых устройств с помощью стека протоколов TCP/IP, не особо акцентируя внимания
на архитектуре и топологии сетевых устройств с помощью SNMP.netView определяет
корреляцию между различными событиями в сети, проверять работу сети и дает
оценку ее производительности.
Кроме типовых возможностей для систем менеджмента устройств,
IBM Netview отслеживает доступность сетевых устройств, использует Web-интерфейс
для работы администратора сети из любого места, составляет отчеты о работе
сети, поддерживает практически все версии MIB, может работать с группами
пользователей.
NetView обладает следующими сильными
сторонами в отличии от прочих средств управления сетями:
· Увеличена
производительность всей сети, и сама сеть может быть больших масштабов.
· Легкий доступ к
устройствам
· Для SNA (Systems Network
Architecture) и стека протоколов TCP/IP предоставляется единое управление, что
снижает требования к дублированию сетевых систем управления.
· Позволяет уменьшить
требования к числу необходимых ресурсов и обслуживающего персонала к управлению
сетей с большим количеством сетевых ресурсов.
Помимо всего прочего, IBM NetView может оперативно
предпринимать действия при каком-либо происшествии (выявление ошибок в работе
сети, превышения порогов).
При таком событии включается отправка сообщений на мобильный
телефон или почту для оперативного решения проблемы. также совместима с другими
продуктами IBM: Tivoli Enterprise Console для одновременного анализирования
данных вместе с другими пользователями и Tivoli Inventory для сохранения их в
БД. Tivoli Decision Support Network Guide приложение, специально разработанное
для обеспечения управления сетевым оборудованием, мониторинга событий,
происходящей в инфраструктуре компании.Decision Support Network Guide для
Tivoli NetView состоит из [29]:
1. Network Element Status - дает подробную информации об условиях
работы каждого элемента сети, например, оконечные устройства сети, серверы,
коммутаторы, маршрутизаторы.Network Event Analysis - выполняет глубокий анализ
информации о трафике в сети и IBM NetView.
В зависимости от приоритета события, от того какого класса
устройства и момента возникновения события происходит анализ трафика.
2. Network Segment Performance - Просмотр данных о работе части
сети, определенного в RMON.
Анализ нацелен на рассмотрение определенного сегмента сети, а
не отдельного устройства сети.
Архитектура IBM Tivoli NetView представлена на рис. 11.

Рис. 11. Архитектура IBM Tivoli NetView
Итоги различных проверок NetView обнаружили, что система поиска
устройств, установление топологии и центрального сетевого маршрутизатора
совершается корректно. И в итоге строится реальная система связей сетевых
устройств в сети. Пользовательский интерфейс прост в управлении и достаточно
функционален. Если выделить отдельное сетевое устройство, то IBM Tivoli определит
и покажет все события, относящиеся к нему. У NetView есть всего два важных
минуса: при работе в автоматическом режиме процесс выявления сетевых устройств
может ошибиться и не правильное определить устройство и малая скорость
обработки опросов при первом включении в сеть.
HP OpenView Network Node Manager
NNM изображает всю имеющиеся данные о сетевых устройствах и самой
сети в удобном графическом виде [30, 31]. HP OpenView представляет все
найденные сетевые устройства в виде схемы, показывающей как в реальности,
выглядит сеть. Если случается неисправность или ломается сетевое устройство, то
NNM способно выявить взаимосвязь между аварийными сообщениями и определить
первопричину поломки. Анализируя состояние сетевых устройств и изменяя пороги,
NNM аккумулирует информацию и создает все новые отчеты, которые дают
возможность реализовать проактивное управление сетевыми устройствами.
Программный продукт HP OpenView NNM интегрируется не только с HP оборудованием,
но и другими производителями, такими как Optivity, Cisco.
В момент создания HP OpenView Network Node Manager Были
предъявлены низкие требования к аппаратному обеспечению и из за этого
возможности системы были слабы.
Архитектура HP OpenView Network Node Manager представлена на рис.
12.

Рис.12. Архитектура HP OpenView Network Node Manager
По результатам тестирования [27], можно сделать вывод, что при
работе с HP OpenView Network Node Manager обязательно необходимо указывать
центральный маршрутизатор при выяснении схемы сети. Если построение карты сети
предоставить HP OpenView Network Node Manager, то в большинстве случаев, карта
будет построена неверно. Функция нахождения сетевого оборудования работает
корректно и не требует большого количества времени. Полезной функцией HP OpenView
Network Node Manager есть функция установления временного интервала, в течение
которого совершаются предварительно выбранные действия для отправления сигнала
тревоги. Таким образом, в случае быстрого изменения параметра, включение
сигнала тревоги не произойдет.Solstice Domain Manager
SSDM представлен в трех возможных
программах [32]: Sun Solstice Domain, Site и Enterprise Manager. Для сетевых
топологий, не превышающих сотни объектов применяется Sun Solstice Site. При
таком использовании на единственном устройстве в сетевой инфраструктуре должна
быть установлена ОС Solaris и управляющая программа, на всем оставшемся
оборудовании устанавливается программы - агенты. В сетевых топологиях, где
количество сетевого оборудования превышает 10 тысяч единиц уже используется
иерархическая схема управления - Sun Solstice Domain Manager. Для организации
управления в больших и сложносоставных сетях применяется Sun Solstice
Enterprise Manager. Программа управления предыдущего уровня (например, Sun
Solstice Site до сотни устройств) представляется в роли объекта управления.
Пакет программного обеспечения Sun
Solstice Manager [33] обладает всеми требуемыми возможностями, чтобы
использовать SNMP для менеджмента сетевого оборудования, также применяется
протокол CMIP, обладающий высоким потенциалом для поиска и анализа данных,
извлекаемых из сетевого оборудования. Не мало значительным является управление
при поддержке NetWare Management Agent 2.0 и загрузки сетевой схемы из сетевой
консоли управления Novell ManageWise. Sun пользуется широко известна в
телекоммуникационных организаций.
Архитектура Sun Solstice Domain Manager представлена на рис.
13.

Рис. 13. Архитектура Sun Solstice Domain Manager
SSDM почти не выполняет весь заявленный функционал
на крупных многоуровневых сетях. При тестировании на практике в организации
определялись маршрутизаторы, создавались карты сети, но так и не получилось
достигнуть правильного выявления сетевой топологии устройств.
Сравнительный анализ известных СУКС
В ходе анализа использовалась неоднородная КС с количеством
сетевых устройств равным 550 [35, 34]. В сети использовалось разнообразное
сетевой оборудование ведущих фирм-производителей: 3COM, D-LINK, CISCO.
Системы управления КС оценивались по следующим критериям:
Выявление имени устройства по его адресу с помощью DNS
сервера.
Способность изменять присвоенное имя устройства.
Распознавание сетевых топологий.
Поддерживаемые базы данных.
Формат отчетов.
Поддерживаемые Web-серверы.
Возможность решения задач на основании неполных данных.
Способность к самообучению.
Способность прогнозировать работу КС.
Возможность описать ход получения решения.
В табл. 2 представлены одни из самых важных параметров самых
применяемых систем управления и их подробный анализ.
Таблица 2. Основные характеристики распространенных систем
управления КС.

По результатам анализа табл. 2 можно сделать выводы, что
Tivoli NetView отлично справился с задачей нахождения сетевых устройств,
корректно отобразил схему нахождения маршрутизаторов в сетевой топологии, но
ему требуется значительное количество времени. Добавление сетевых устройств в
будущем происходит крайне медленно. Интерфейс Tivoli NetView мощный и в тоже
время интуитивно прост в управлении. Автоматическое нахождение некоторого
сетевого оборудования отрабатывает некорректно.
При работе с HP Network Node Manager (HP NNM) необходимо в
начале работы задать центральный маршрутизатор иначе процесс определения
сетевой топологии может занять весьма длительное время. Полезным свойством NNM
является установление временного периода, и способность указывать граничные
значения для некоторых параметров.отличается от NetView и NNM тем, что несмотря
на все приложенные усилия, добиться определения корректной топологии так и не
удалось. Видимо, эта функция работает только на сетях с простой одноуровневой
топологией.
1.5 Анализ
моделей администрирования СУ КС
К наиболее распространенным моделям администрирования СУ КС
относятся:
Модель управления сетями со стеком протоколов TCP/IP.
Стандартная модель управления сетью на основе международной
организации по стандартизации (OSI).
Открытая архитектура управления сетью (ONMA).
Унифицированная архитектура управления сетью (UNMA)
Модель управления сетями со стеком протоколов TCP/IP
Большинство пакетов управления сетью поддерживают эту модель,
основанную на межсетевом протоколе IP, и разработанную для среды Интернет в
серии документов RFC. Главные компоненты внутри этой модели - структура
информации управления (SMI), база управляющей информации (MIB) и протокол
сетевого управления SNMP.
Структура управляющей информации определяет то, каким образом
должна быть представлена информация об управляемых объектах, и в значительной
степени, основывается на спецификациях языка ASN.1. Информация об элементах
сети представляется в виде характеристик, связанных с объектами, которые
отслеживаются на протяжении определенного периода.
Информационная база управления в этой модели содержит
определения и значения для управляемых объектов. Информация для компонента MIB
запрашивается менеджером и обновляется с помощью агента управления.- это
протокол, используемый для передачи управляющей информации и обеспечения связи
на прикладном уровне в эталонной модели взаимодействия открытых систем. Первоначально
принятый как временный, он должен был быть заменен моделью ISO CMIS/CMIP.
Одной из отличительных возможностей данной модели является
то, что можно определить или добавить в дерево MIB объекты специального
назначения. Определенные компоненты могут, таким образом, использовать большой
стандартизированный массив управления информацией, что даёт возможность
облегчить задачу создания стандартизированных и мобильных компонентов сетевого
администрирования.
К преимуществам этой модели относится протокол SNMP, а также
простота и мобильность данной модели, которые сделали её популярной даже вне
среды Интернет, в связи с чем она фактически стала наиболее применяемой моделью
сетевого администрирования.
Модель управления сетями международной организации по стандартизации
(ISO)
Международная организация, выпускающая стандарты, привнесла
значительный вклад в стандартизацию управления сетевым оборудованием. Схема
управления сетевой инфраструктуры этой организацией есть основное средство для
понимания основных функций ИСУ компьютерной сети.
Эта модель управления состоит из пяти главных частей [37,
36]:
Управление эффективностью, которое заключается в
предоставлении разнообразных точек зрения на эффективность управления сетью, с
целью поддержки межсетевой эффективности на допустимом уровне. Влиять на
эффективность можно с помощью нескольких параметров, таких как коэффициент
занятости линии, величины трафика, периода отклика системы и пропускной
способностью сети.
Управление эффективностью состоит из трех этапов [38]:
• накапливание статистической информации по вышеперечисленным
переменным, необходимых для управления сетью;
• анализирования этих данных для выявления оптимального уровня
работы сети;
• Установление пределов параметров эффективности, указывающие
на то что при превышении такого порога будет наблюдаться проблема в работе сети
и о необходимости ее ликвидировать.
Управление конфигурацией сети и именованием, смысл этого
управления состоит в том, чтобы контролировать состояние сетевой и системной
модели, изменении выбранных частей сети, мониторинг воздействия на сеть
программного и аппаратного обеспечения, управление характеристиками сетевых ОС.
Эти данные требуются для поддержки сети в работоспособном состоянии т.к. в
программном и аппаратном обеспечении присутствуют различные эксплуатационные
погрешности, влияющие на работоспособность сети.
Управление учетом использования ресурсов, состоит из
регистрации и управления возможностями оборудования, их конфигурирования для
последующего регулирования параметрами сетевых устройств.
Управление неисправностями. Выявляет, фиксирует, оповещает
пользователей и по возможности ликвидирует сбои в сети. Так как проблемы в сети
приводят к задержкам и деградации, то управление неисправностями находит самое
широкое распространение в данной модели управления.
Обычно, управление неисправностями разделяют на следующие
этапы [38]:
• нахождение проблемы;
• изоляция проблемы;
• устранение проблемы;
• контроль всех важных систем после устранения проблемы;
• запись проблемы и способа ее устранения.
Управление защитой данных, заключающееся в сохранении
целостности информации, обеспечения проверки доступа к сетевым ресурсам сети с
целью обеспечения недоступности к конфиденциальной информации лицам, не имеющих
соответствующих полномочий. К этому пункту также относятся процесс
управления паролями, взаимодействия с другими сетями и возможностью получения
доступа к внешним ресурсам. Модель управления защитой информации занимается
идентификацией восприимчивых ресурсов сети, построением маршрута между уязвимыми
источниками сети и пользователями, контролем точек доступа к важному
оборудованию в сети.
Для обмена управляющими данными используется способ
управления ISO. Обмен совершается между прикладными объектами системного
управления SMAE (System Management Application Entites). Объекты SMAE находятся
на верхнем уровне в семиуровневой модели OSI.
В сетевой модели OSI объектом называется часть протокола,
которая активна в настоящий момент времени и принимающий участие во
взаимодействии.
В рамках данной модели управляющие устройство не только
сохраняет и сравнивает информацию, принимаемую от агентских устройств, но и
основываясь на этой информации также может реализовывать функцию управляющего
менеджера. В модели ISO разграничение между агентом и менеджером размыто.
Объект SMAE, исполняющий в одном случае роль управляющего менеджера, может в
другом случае исполнять роль агентского устройства.
При разработке модели OSI предполагалось что каждый уровень
будет общаться с таким же уровнем на удаленном устройстве. На практике же
оказалось, что они общаются с уровнем ниже для получения услуги или уровнем
выше для предоставления услуги. Предполагалось, что архитектура ISO/OSI должна
была быть первой разработана, а после - все прочие разработки, создаваемые
коммерческими, исследовательскими и стандартизирующими ассоциациям. На практике
же большинство технологий возникли раньше модели OSI.
Описание модели ISO/OSI приводится на рис. 14.

Рис. 14. Описание модели ISO/OSI
Таблица 3. Соотношение уровней ISO/OSI и TCP/IP
|
№№ п/п
|
Уровень
|
Стандарт
|
|
1
|
Уровень приложений
|
WWW, SNMP, FTP, TELNET,
|
|
Уровень представления
|
SMTP
|
|
данных
|
|
|
Сеансовый уровень
|
|
|
2
|
Транспортный уровень
|
TCP, UDP
|
|
3
|
Сетевой уровень
|
IP, ICMP, RIP, ARP
|
|
4
|
Канальный уровень
|
Token Ring
|
|
Физический уровень
|
FDDI
|
|
|
IEEE 802.3
|
|
|
Ethernet
|
|
|
SLIP
|
|
|
PPP
|
Эти мощные возможности вместе со способностью создавать и
удалять объекты управления, делают модель управления OSI более сложной, чем
модель TCP/IP, а также делает эти две модели относительно несовместимыми.
Серьезным препятствием на пути широкого применения в крупных КС модели OSI
является проблема преобразования данных из формата OSI в IP-формат.
Достоинством модели OSI сетевого администрирования,
разработанной для взаимодействия открытых систем, является то, что она
построена на основе 7-ми уровневой модели OSI и гарантирует, функциональную
переносимость на каждом из уровней [39].
Открытая архитектура управления сетью (ONMA)
В 1986 г. фирма IBM представила собственную модель управления
сетью под названием "Открытая архитектура управления сетью" (Ореn
Network Management Architecture, ONMA), являющаяся каркасом для создания новых
систем управления.
В соответствии с этой моделью, IBM разделяет сетевое
управление на пять блоков [28]:
Управление конфигурацией. Этот блок близок по смыслу к
пониманию OSI об управлении конфигурацией. Определяет не только физические, но
и логические возможности сети и контролирует их отношение между собой.
Управление производительностью и учетом использования сетевых
ресурсов. Этот блок собирает статистику по различным ресурсам: учет времени
реакции сети, задержки, определение и управление производительностью. Если
какой-либо из параметров перестает соответствовать норме, то процесс переходит
в блок управления проблемами.
Управление проблемами. Блок состоит из нескольких
последовательных задач: определение, диагностики, обхода проблемы, далее
происходит решение и управление проблемой.
Управление операциями Блок обеспечивает управление сетью из
единого управляющего узла. Связь центрального узла и управляемого объекта
обеспечивается с помощью специализированных программ. Также этот блок
предоставляет возможность активировать и деактивировать сетевые ресурсы,
отменять команды.
Управление изменениями. Блок предоставляет возможность
управлять сетевыми ресурсами с помощью установления, отправления, удаления или
извлечения файлов в каждом сетевом узле.
Данные функции не в полной мере соответствуют ранее
рассмотренной модели ISO.
Главным достоинством этой модели управления является её
хорошая работоспособность с оборудованием данной фирмы, что подтверждено
практической реализацией в программном продукте управления сетями - IBM
NetView. Также к достоинствам этой модели можно отнести некоторую архитектурную
избыточность (наличие вторичных фокусов) и наличие вложенных фокусов,
обеспечивающих поддержку распределенного управления в больших сетях, и частично
разгружающих этим центральную управляющую станцию.
Недостатком же этой модели является необходимость наличия
специальных шлюзов - сервисных точек, затрудняющих управление устройствами
поддерживающих SNMP устройства.
Унифицированная модель сетевого управления (UNMA)
Унифицированная модель сетевого управления (Unified Network
Management Architecture, UNMA) разработанная специалистами фирмы АТ&Т,
является обобщенной системой множественного управления, основанной на модели
ISO. Модель управления UNMA представляет собой трехуровневую систему управления
сетями (рис. 15).

Рис. 15. Унифицированная модель сетевого управления
В состав первого уровня ("Сеть") входят логические и
физические сетевые элементы.
Второй уровень модели состоит из элементарных систем управления
сетями, которые управляют нижними элементами сетей. Эти системы разработаны для
удовлетворения специфических потребностей различного оборудования.
Третий уровень модели - интегрированная система управления сетями,
объединяющая элементарные системы управления сетями.
Для организации связи между элементарными и интегрированными системами
управления используется протокол, основанный на протоколе общего
информационного управления, а элементарные системы управления для связи с
управляемыми устройствами используют наиболее подходящий протокол для решения
поставленной задачи.
Одной из отличительных особенностей этой модели является то, что
она не использует специфических сетевых технологий, а предназначена для
всеобъемлющего управления различными сетями, включая такие как: голосовые или
цифровые сети, глобальные или локальные. Еще одним её преимуществом является
реализация в ней иерархической архитектуры управления сетями, что в
значительной мере позволяет разгрузить интегрирующий менеджер сети и снизить
нагрузку на каналы связи.
Выводы
В этой главе были проанализированы стандарты и средства
менеджмента КС.
Объектом исследования является КС, которая является сложной
гетерогенной системой.протокол является необходимым средством для управления
сетевыми устройствами и на основании анализа различных протоколов управления КС
было показано что это и лучший на данный момент протокол. Еще одно преимущество
заключается в том, что протокол поддерживают практически всеми производителями
сетевых устройств.
Были рассмотрены все существующие архитектуры управления КС,
начиная с одноуровневой и заканчивая платформенной архитектурой и сделан вывод
что нынешние СУ КС используют платформенную архитектуру.
Глава 2.
Разработка требований, предъявляемых к современным СУ КС
Имеющиеся международные стандарты на системы управления (ISO
7498-4, ITU-T Х.700), выделяют 5 блоков задач для системы менеджмента [47]:
. Процесс управление конфигурацией сети и
идентификация сетевых устройств.
2. Процесс обрабатывания ошибок.
. Мониторинг производительности и надежности сети.
. Процесс учета работы сети.
.1 Задачи
системы управления
Разберём задачи менеджмента, соответствующие функциональным
блокам, относящимся к системам управления КС.
Процесс
управления конфигурацией сети и идентификацией сетевых устройств
Задачами данной группы является то, чтобы конфигурировать
параметры как сетевых устройств, так и сети в общем. Для сетевых устройств,
таких как коммутаторы, серверы и т.п., данный блок задач определят адресацию
сетевых устройств, идентификаторы, географическое местоположение, строит карту
сети и т.п.
Для КС процесс управления конфигурированием сети при первом
включении начинается с определения топологии сети, воссоздании реальных
взаимосвязей между устройствами сети и заполнении внутренних таблиц
маршрутизации, коммутации и топологий.
Управление конфигурацией и остальные задачи менеджмента
реализовываются как в автоматическом, так и в ручном режиме. К примеру, схема
сети может быть построена автоматически, основываясь на информации, полученной
от исследования настоящей сети опрашивающими пакетами, или может быть описана
администратором системы управления непосредственно. В большинстве случаев
используются полуавтоматические способы менеджмента, при котором карту
устройств администратор получает автоматически, а вносит правки вручную. Каждая
фирма старается разработать свой собственный улучшенный метод составления схемы
сети.
Совершенно на другом уровне сложности находится проблема
конфигурирования коммутаторов и маршрутизаторов на поддержание связности и
виртуальных маршрутов с оконечными устройствами сети.
Еще одна сложная задача - это синхронное настраивание списка
маршрутов при отказе от применения протоколов маршрутизации, к примеру, при
использовании сети Х.25 подобного протокола попросту нет. С этой проблемой
производители стараются справиться своими силами, и компания Cisco Systems
создала NetSys, которая решает эту проблему, но только для своего оборудования.
Процесс
обрабатывания ошибок
В этом блоке выполняется обнаружение, идентификация и
ликвидация результатов сбоев и отказов в работе сетевой инфраструктуры. В
данном блоке задач кроме осуществления регистрирования уведомлений об ошибках,
реализовывается фильтрование, маршрутизация и анализ, основываясь на
корреляционной модели. Фильтрование дает возможность определить из крайне сильного
потока уведомлений об ошибках, которые как правило есть в сети предприятия,
только существенные уведомления, процесс маршрутизации выполняет их отправление
необходимому элементу системы менеджмента, а корреляционный анализ находит
первопричину, создавшую поток связанных сообщений, к примеру, разрыв канала
связи является первопричиной значительного числа сообщений о недостижимости
сетей и серверного оборудования.
Исправление ошибок возможно, как в автоматическом, так и
полуавтоматическом режиме. В автоматическом режиме система напрямую занята
управлением сетевыми устройствами или программными обеспечением и огибает
отказавшее устройство с помощью резервных каналов связи и т.п. Во втором режиме
работы основополагающие решения и действия устраняющие проблемы осуществляет
администратор, а система управления занимается организацией данного процесса -
создает квитанции на работы и занимается отслеживанием их поэтапного выполнения
на подобии систем с групповым методом работы.
В данной области задач временами выделяют подблок задач
управления проблемами, имея ввиду под проблемой обстоятельства, требующие для
решения участия квалифицированных специалистов по работе с сетевым
оборудованием.
Мониторинг
производительности и надежности сети
В этом блоке задачи взаимосвязаны с оценкой на основе
сохраненных статистических данных таких характеристик, как скорость
реагирования системы, скорость физической линии связи или виртуального канала
связи связывающего конечных пользователей, количество трафика в выделенных сегментах,
возможность потери информации при трансляции сквозь сеть. Анализирование
показателей надежности и производительности сети необходимо для эффективного
менеджмента сети и для понимания будущего развития сети.
С помощью контролирования параметров надежности и
производительности, администратор сети (или организация, предоставляющая
услуги) поддерживает необходимый уровень предоставляемых услуг (Service Level
Agreement, SLA), с потребителем. Как правило в договоре SLA устанавливаются
такие параметры надежности, как вероятность работы службы в течение года и
месяца, период простоя системы, а также значения производительности, к примеру,
значения средней и предельной пропускной способности при непосредственном
подключении двух точек доступа пользователей, скорость реагирования сети (если
служба, которая работает в сети, поддерживается сетью), допустимое время
задержки транспортных пакетов при трансляции через сеть. Поставщику услуг
необходимо иметь набор технологий для анализирования показателей надежности и производительности
сети, иначе администратор или информационный отдел не будет иметь возможности
контролировать уровень предоставляемых услуг оконечным пользователям сети.
Процесс
управления безопасностью
Контролирование целостности информации при ее отправке сквозь
сеть или хранении, предоставление доступа к информации или оборудованию - все
эти вопросы решаются в блоке управления безопасности. Процесс аутентификации
оконечных устройств, выдача прав доступа к услугам, выдача ключей для
шифрования являются основными задачами процесса управления безопасностью. Как
правило возможности этого блока не вносят в систему менеджера, а создают или
специализированный продукт (например, Kerberos - аутентифицирует пользователей,
разнообразные межсетевые экраны, системы шифрования информации), либо являются
частью ОС и системных приложений.
Учет работы
сети
Регистрирование времени, в течении которого ресурс был занят
является главной задачей этого блока. В роли ресурсов выступают транспортные
услуги, оборудование и каналы. Эти процедуры имеют непосредственное влияние на
контроль за занятостью службы и определяет плату за использование ресурса.
В модели управления OSI нет различия между множеством
объектов - мосты, модемы, маршрутизаторы, коммутаторы, мультиплексоры, СУБД,
аппаратным обеспечением и ПО, каналы - все они воспринимаются под общим
названием "система" и одна система управления общается с другой
управляемой через протоколы OSI.
Вышеперечисленных 5 групп недостаточно, если речь идет об
интеллектуальных системах управления КС.
Актуальными задачами является не только формальное описание
КС с позиции управления, но и разработка методов и средств интеллектуальных
систем управления КС.
.2 Разработка
требований к ИСУ КС
Условия работы ИСУ КС могут значительно различаться
вследствие разнородности сетевого оборудования, различных требований,
предъявляемых пользователями и многочисленности сетевых стандартов и возможных
топологий.
Для любой системы управления можно определить такие
требования:
Обеспечить постоянный мониторинг сетевых устройств для
выявления возможных сбоев в кратчайшие сроки.
Своевременно прогнозировать возможные проблемы в работе
сетевого оборудования в будущем.
Своевременно сообщать администратору сети о возможных
неполадках в работе сети.
Обеспечить анализ собираемых данных о работе сети в режиме
реального времени.
Поддерживать сохранность конфиденциальной информации.
Обладать интуитивно-понятным интерфейсом.
При разработке ИСУ КС можно выделить ряд общих требований
(рис. 16) [8,40, 41]

Рис. 16. Основные требования к ИСУ КС
Требование адекватности решения, при помощи которого
интеллектуальные компоненты решают задачи на уровне специалистов.
Требование адекватности знаний. Для получения
высококачественного решения необходимо обеспечить подобие знаний
интеллектуального блока и эксперта по следующим параметрам: использование одной
и той же входной информации, совпадающее представление результатов решения
задачи.
Требование адекватности модели знаний, обеспечивающее наличия
в системе правил выбора определенной модели знаний для представления процесса
решения конкретной задачи анализа, и средств структуризации всех знаний в
единую иерархическую модель.
Требование открытости системы, которое необходимо
рассматривать в двух аспектах. Во-первых, как развитие принципа адекватности
модели знаний - система должна быть открыта для расширения модели представления
знаний различными методами. Второй аспект заключается в открытости системы с
целью обеспечения возможности добавления в неё новых знаний.
Требование (само) обучения системы позволяющий учитывать
динамику знаний на протяжении всего жизненного цикла системы.
Требование объяснения решений, которое наряду с предыдущим
обеспечивает взаимообмен знаний в системе "пользователь - информационная
система"
При этом выделяют еще дополнительные принципы [42, 43,44]:
Гибкость. При создании и применении ИСУ КС необходимо
использовать широкий спектр проектных решений и средств реализации функций
управления, разрешая пользователям выбирать и устанавливать различные варианты
системы;
Настраиваемость. Средства ИСУ КС должны разрешать изменения
или переход к различным структурам организации управления и предусматривать
интерфейсы с системными учетно-контролирующими и управляющими программами;
Интеграция. Подсистемы ИСУ КС должны управлять всеми
основными и вспомогательными процессами обработки данных
Выводы
На основе задач, которые предстоит решать системе управления
и рассмотренных архитектур систем управления были сформированы обобщенные
требования к системе управления КС.
Глава 3.
Выбор архитектуры системы управления компьютерными сетями
Выбранная архитектура управления удовлетворяет всем условиям,
которые характеризуют современную модель управления сетевыми ресурсами.
Мосты, маршрутизаторы, коммутаторы и другое активное сетевое
оборудование представляю собой объекты сети и все они поддерживают протокол
SNMP (RFC-1089,-1157, - 1187, - 1215).
Рассмотрим 7 блоков системы управления представленной на
рисунке 17:
· Блок управления и прогнозирования -
выполняет функцию контроля системы управления и прогнозирует состояние сети по
информации полученной с блока формирования архитектуры сети.
· Блок доступа к оборудованию - дает
возможность получать данные из компьютерной сети об активных сетевых устройствах.
· Блок поиска устройств в сети - выполняет
функцию поиска устройств в компьютерной сети и восстанавливает схему сети.
· Блок формирования архитектуры сети - с
поддержкой настраиваемых параметров (числа внутренних слоев, первоначальные
величины весов) устанавливает конструктивные особенности комплекса.
· Блок визуализации - выступает в роли GUI
(Graphical User Interface - графический интерфейс пользователя).
· Блок сбора статистики - выполняет функцию
сбора статистической информации об устройствах.
· Блок хранения статистики - хранит
информацию об устройствах в компьютерной сети.
Опишем работу системы управления сетью. Как только происходит
запуск блока управления и прогнозирования то он включает блок поиска объектов.
Как только объект находится в сети то он записывается в таблицу элементов сети
и данных о топологии сети. Для сбора дополнительных данных блок поиска
активирует блок доступа к оборудованию, и он отправляет запрос о требуемых
данных к нужному устройству. Сформированная таблица объектов отправляется в
блок сбора статистики, который обрабатывает параметры сетевых устройств. Блок
доступа к оборудованию обращается как к блокам поиска объектов, так и сбора
статистики. Все данные записываются в блоке хранения статистики.
Блок формирования архитектуры сети применяет сохраненную
статистику для организации настойки сети и ее учебы.
Главная цель блока управления и прогнозирования состоит в
создании прогноза о положении сети. Для этого блоку прогнозирования и
управления нужно все время выполнять мониторинг сети, отправляя запрос через
блок доступа к оборудованию своевременные данные об объектах системы. Чтобы
организовать прогноз пришедшие данные при опросе устройств отправляются на блок
формирования архитектуры сети, для формирования прогноза. Все блоки подчиняются
блоку управления и прогнозирования.
Блок визуализации организован поверх блока прогнозирования и
играет роль графического интерфейса для представления информации в удобном для
человека представлении.

Рис. 17. Архитектура системы управления
Глава 4.
Выбор способа организации системы мониторинга
4.1 Выбор
модели, предназначенной для анализа и оптимизации компьютерной сети
Чтобы организовать качественную работу компьютерной сети
необходимо выбрать модель для оптимизации сбора, обработки и хранения
информации. На сегодняшний день распространенный способ - это разрабатывать
свою модель для каждой отдельной системы, которая учитывает тонкости работы
системы и ее предназначение. Имеется большое количество моделей оценивающие
четко предназначенные для нее характеристики.
Главная цель информационной сети предприятия - это
обеспечение потребностей пользователей в получении актуальной, полной и
подлинной информации. Если все эти требования пользователей выполняется, то
можно говорить о качестве работы системы для одного пользователя. Для системы
мониторинга главным фактором становится предоставление информации о положении
работы сети в общем так и о отдельном модуле.
Основная часть существующих систем мониторинга строится на
применении многофункциональной технологии хранения, обработки и сбора данных. В
работе [15] рассматривается часто используемая модель опроса источников
информации. На конечных устройствах информационной системы происходят различные
события, которые следует записывать в базу данных. После того как применяется
метод сбора входной информации новые параметры от оконечных устройств
записываются в базу данных.
Применяются такие способы сбора данных:
Регламентированный. Опрос станций происходит через фиксированный
промежуток времени, выбранный для информационной системы по какому-либо
правилу. После полученная информация, записываются в базу данных.
По случившемуся событию. Данные отправляются от оконечных
устройств, как только происходит изменение состояния отслеживаемых параметров.
Независимый способ. Сбор данных не подчиняется ни первому ни
второму правилу.
Формулы для расчета вероятности того что информация будет
актуальной на момент ее применения:
Для системы, которая реагирует сразу как случается происшествие
вероятность будет таковой:

Если же метод основан на регламентированном способе (не
зависит от момента изменения состояния), то вероятность примет вид:
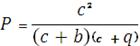
где, с - значение, показывающая среднюю величину времени записи
информации в БД относительно реального момента изменения информации; b - Время
сбора, получения и записи информации для обновления БД; q - Интервал времени
между двумя последовательными запросами одного объекта.
Параметры q и b возможно явно связать, если система
мониторинга работает в режиме on-line:

- число опрашиваемых устройств в сети- число потоков в
системе мониторинга
Как было сказано выше величина b это сумма трех компонент -
период создания запроса, время, затраченное на обработку запрашиваемой
информации и время, затраченное на ожидание отклика. В идеале оно должно быть
0. Но на практике реализовать это нельзя из-за не идеальности каналов связи. Но
можно задать такой алгоритм чтобы не ожидать отклика, а работать с остальными
устройствами и возвратиться к старому только когда получен ответ.
Способы
осуществления многопоточной модели мониторинга на существующих однопроцессорных
устройствах
Операционные системы, которые сейчас существуют дают
возможность применять многопоточный метод работы приложений [11,12,17,
19,21,22]. Этого добиваются за счет того, что делят время работы процессора
между различными приложениями, что дает возможность множеству программ
функционировать одновременно. Процессорное время устройства можно поделить на
отрезки. В каждый отрезок времени отдельное приложение получит по часть времени
для работы в процессоре для собственных потребностей. Количество занятого
временного интервала выбирается в соответствии с приоритетом приложения в ОС.
Для более важных приложений и интервал использования времени процессора больше.
Приложение может и не пользоваться процессором, это случается, если приложение
стоит в режиме ожидании. Если у приложения большое количество потоков, то оно
получит больше времени обслуживания в процессоре. Данная схема организации
процессора очень выгодна для системы мониторинга. Выигрыш во времени получается
из-за того, что временные периоды в течении которых опрашиваются оконечные
устройства могут не занимать ресурсов процессора. В основном это время ожидания
информации от оконечных устройств. Если занять эти периоды ожидания для
использования другими протоколами, то возможно выиграть во времени и занять
процессорные мощности другими задачами. Этим и обусловлен выигрыш во времени.
Математическая
модель для мониторинга систем с пакетной обработкой данных
Все входящие требования создают одну большую очередь на
обработку процессором. Пусть обработка входящих пакетов происходит в порядке их
прихода на устройство и новые данные занимают позицию в конце очереди.
Устройство предпочитает обрабатывать задачи, которые занимаю позиции в начале
очереди и дают ему дну единицу времени для обработки.
Самый простейший способ для понимания - это сравнить его с
методом обработки пакетов в порядке их поступления. В таком случае надо
применить еще одно ограничение, заключающееся в том, что заявки на обслуживание
устройством удаляются по причине завершения времени и вновь передаются в начало
очереди, в следствии чего незамедлительно попадают на обработку (рис 18).

Рис. 18. Обработка с помощью пакетного алгоритма.
Если выполнить это требование, то это есть система M/G/1 с
обработкой в порядке зачисления [15, 20]. Кроме всего этого, параметры
обработки, которые не принимают в расчет времени обработки процессором при
установлении последовательности обслуживания, приводит к тому же размещению
числа запросов в системе.
И получаем что время отклика является суммой времени ожидания
M/G/1 и времени обработки.
Стоит заметить, что в пакетной обработке нет никаких правил о
выборе заданий на основе времени обработки задания. Это говорит о том, что
время ожидания никак не коррелирует со временем обработки. Становится понятно,
что это не лучший вариант и надо найти такой метод чтобы для непродолжительных
заданий время ответа было меньше.
Математическая
модель метода кругового опроса
Проанализируем случай, когда все запросы одинаковой длины и
бесконечно малы. Новые входящие запросы располагаются в одну очередь и
двигаются к ее началу не нарушая порядок поступления. Как только время
обслуживания заканчивается и требуется дальнейшее обслуживание то цикл
возвращается в конец очереди и повторяется (рис. 19).

Рис. 19. Модель кругового опроса
Становится понятно, что в такой системе запрос делает бесконечное
количество циклов и каждый из них бесконечно мал и во время цикла запрос
получает бесконечно маленькую обработку процессором, как только количество
обработанного станет равным потребности в обслуживании, так сразу этот запрос
покидает систему.
Предположим, что запрос поступает свободную систему. В таком
случае он занимает все необходимое время на обслуживание. Если в систему
поступит второй запрос, то он тоже начнет обрабатываться циклично, т.е. каждому
запросу будет присвоено половина времени на обработку и эти запросы будут
сменять друг друга каждые полпериода.
Если на вход системы поступит k запросов, то каждый получит на
обработку 1/k общего времени. Отсюда и проистекает определение "разделение
ресурса" потому что все запросы делят пропускную способность на равные
части.
Этот метод также вписываются в параметры, характеризующие M/G/1 с
обработкой по моменту поступления [13].
В такой схеме обслуживания запросов получается прямо
пропорциональная зависимость времени ответа времени обработки. Получается, что
чем длиннее время обработки, тем больше времени требуется для ответа системы.
Применение этого способа в системах мониторинга лучше, т.к. при
анализе процессов опрашивания конечного устройства в случае трех независимых
процессов (создание запроса, время ожидания отклика от оконечного устройства и
обрабатывание принятой информации) в методе пакетной обработки исключается
период ожидания ответа от конечного устройства.
В существующих сетях период ожидания ответа на запрос может быть
больше в несколько раз чем время обработки процессором запроса [15].
Использование периода ожидания ответа на запрос для обслуживания уже пришедшего
ответа можно значительно сократить время мониторинга и как следствие увеличить
вероятность предоставления актуальных данных.
4.2 Выбор
основных формул для опрашивания оконечных устройств в сети при мониторинге
параметров
Обоснование
выбора формулы для установления оптимального количества потоков
Пусть значение производительности системы мониторинга будет
величина равная числу опрошенных оконечных устройств в единицу времени. Это
значение будет нужно для организации политики мониторинга сети.
Повышение числа параллельно опрашиваемых устройств по началу
увеличивает производительность обработки, но после формирования n+1 потока
скорость обработки уменьшается. Это обосновывается конечным числом
вычислительных мощностей.
Занятость центрального процессора (CPU), оперативная память
(RAM) и поступающий трафик сети оказывает влияние на производительность системы
[14,16,18].
Становится понятно, что при не полном использовании ресурсов
включение нового потока увеличит производительность системы. Однако если
исчерпать хотя бы один ресурс, то уменьшится производительность всей системы. И
тут можно сформулировать главную задачу для системы мониторинга, которую в
будущем предстоит решить: определение наибольшего числа потоков системы
мониторинга для работы с наивысшей эффективностью.
Чтобы четко определить задачу, надо понять зависимость между
производительностью системы и параметров, описанных выше.
У однопроцессорных систем многопоточности не бывает, но
нынешние операционные системы дают возможность ее имитировать, быстро
переключаясь между потоками. Но этот метод непродуктивен при реализации
программной параллельности. Это объясняется тем что все время пока процессор
занят этим потоком он загружен одинаково. А система мониторинга неодинаково
загружает процессор и оперативную память в течении всего времени процесса
опроса станций.
Когда начинается процесс опрашивания сети то создается
запрос, и он отправляется на принимающее устройство. Затем поток ставится на
ожидание пока удаленное устройство не ответит на запрос и все это время поток
не использует ресурсы памяти, процессора и не генерирует сетевого трафика.
Понятно, что пока один поток ждет ответа то другой поток может зарезервировать
ресурсы процессора. Из этого следует что предпочтительно использовать
параллельность в программах для увеличения скорость работы мониторинга.
Из всего сказанного выше получим такое соотношение для
нахождения нужного количества потоков, добавляемых в мониторинг:
 , где
, где
 - средняя продолжительность потока;
- средняя продолжительность потока;
 - средняя продолжительность занятия ресурсом центрального
процессора.
- средняя продолжительность занятия ресурсом центрального
процессора.
Это соотношение описывает идеальную ситуацию, на практике же
процессор частично занят обработкой других приложений и не имеет возможности
дать все ресурсы для мониторинга.
Из этого следует что пока работает мониторинг то к процессорным
мощностям могут обращаться другие работающие приложения для обработки
собственных задач.
Представим в виде соотношения вышесказанное:

 , где
, где
 - средняя продолжительность потока;
- средняя продолжительность потока;
 - средняя продолжительность занятия потоком ресурса центрального
процессора;
- средняя продолжительность занятия потоком ресурса центрального
процессора;

 - Параметр, указывающий на сколько процессор загружен работой
(0<P<1).
- Параметр, указывающий на сколько процессор загружен работой
(0<P<1).
Эта пропорция дает возможность установить сколько потоков можно
еще добавить в систему мониторинга.
Эта пропорция не точна и только приблизительно показывает связь с
загрузкой процессором так как игнорирует занятость процессором на управление
многозадачной оперативной системы, но для грубого приближения вполне подходит.
Это не единственный параметр оказывающий влияние на эффективность
системы мониторинга. Загрузка оперативной памяти (ОП) так же является важным.
Все что говорилось выше является верным только если ОП не полностью загружена
т.е. без применения файлов подкачки. Если же используется файл подкачки, то
возникают добавочные временные затраты на перенос данных из файла в ОП и назад.
Отправка данных возникает только если поток готов исполнению. А
это случается далеко не на каждом цикле потоке управления.
Выше предложенное соотношение не используется, когда все потоки не
умещаются в ОП. Для подобного случая лучше использовать такую формулу:
 , где
, где
- средняя продолжительность потока;
- средняя продолжительность занятия потоком ресурса центрального
процессора;
- Параметр, указывающий на сколько процессор загружен работой
(0<P<1).
 - время отправки данных из ОП в файл и обратно (полный цикл - это
отправка в ОП перед началом использования и выгрузка из памяти при завершении);
- время отправки данных из ОП в файл и обратно (полный цикл - это
отправка в ОП перед началом использования и выгрузка из памяти при завершении);
М - количество перезагрузок за время опроса единственного
устройства.можно достаточно просто определить. Перегрузка возникнет только если
поток обрабатывается, а не в состоянии ожидания. Поэтому формула для М примет
вид:
 , где
, где
- средняя продолжительность занятия потоком ресурса центрального
процессора;
 - время, в течении которого потоку дан доступ к процессорным
мощностям, при трансляции ему управления в течение итерации.
- время, в течении которого потоку дан доступ к процессорным
мощностям, при трансляции ему управления в течение итерации.
Загруженность сети также оказывает влияние. Понятно, что если сеть
загружена полностью, то не имеет смысла говорить о параллельности. Потоки
запросов организуют очереди и сеть перестанет быть доступной для пользователей
и других приложений. Выше рассмотренные два параметра привносили лишь
замедление работы, а в этом случае будет неработоспособна вся сеть. По этой
причине определяется предельное значение сетевого трафика, которое может быть
создано системой мониторинга. Оно рассчитывается в зависимости от скорости
сети, размера и числа сетевых служб и приложений и т.д.
Связывая всё вышеперечисленное в одну задачу получим, что:
 когда ОП частично свободна
когда ОП частично свободна
 , если ОП переполнена
, если ОП переполнена
Еще одним условием для соотношений является ограничение в
максимальном возможном сетевом трафике, формируемого системой мониторинга.
Исполнение этого условия и выявления переполнения ОП совершается
по правилам ранее определённых соотношений, которые описывают как загружена
оперативная память и сетевой трафик от числа потоков.
Все нужные условия, нужные для расчета, обеспечиваются
операционной системой.
Рассмотрение
схемы проведения опроса сети, оптимизированной по времени
Ранее были представлены важные части опроса сети: способ
опроса удаленного устройства и модель выбора числа потоков на основе
эффективности работы системы.
Для локальных сетей крупных и средних фирм это модель
мониторинга больше всего подходит.
Центральную идея этой модели можно свести к нескольким
пунктам:
Найти количество потоков, совершающих опрос;
Деление найденного диапазона на n (n - количество потоков);
В каждом из потоков опросить все рабочие станции одну за
другой.
Финалом опроса будет являться время окончания последнего
потока.
У этой схемы есть слабые стороны. Перво-наперво она
статичная, т.е. не принимает в расчет видоизменения условий опроса сети во
времени. Если в сети появится дополнительный трафик или на рабочей станции
начнет выполняться какое-либо приложение, то число потоков перестанет быть
наилучшим и это станет причиной увеличения времени опроса станций.
Возможна и противоположная ситуация, когда ресурсы сети
освобождаются и в этот момент стоило бы увеличить количества потоков в сети.
Еще одна проблема заключается в том, что даже если число
IP-адресов равно, то их опрашивание занимает различное количество времени.
Разумно было бы удалять те компьютеры, которые в настоящее время не могут быть
опрошены. Времени при таком отсеивании тратится намного меньше. И возможна
такая ситуация что в одном потоке отсеется больше устройств, чем в другом.
По этой причине выбранная модель должна быть пересмотрена.
Пусть схема будет такой:
Установим необходимое количество потоков в настоящий момент;
Отправляем на выполнение n-потоков, которые опрашивают n
IP-адресов диапазона;
Стоит только запросу в потоке завершиться или будет выявлено
что провести опрос невозможно, то выполняется установление нужного числа
потоков в данное время. Оно подсчитывается в соответствии с описанными в
предыдущих пунктах формулами;
Если нужное количество добавочных потоков меньше единицы, то
работающий поток уничтожается. Если больше единицы, то необходимо создать ещё k
добавочных потоков (где k = целая часть числа N).
Эта схема дает возможность определять изменения состояния
системы во времени и разрешает распределять работающие оконечные устройства
между потоками. Графическое представление классической многопоточной модели
мониторинга изображено на рисунке 20.

Рис. 20. Графическое представление классической многопоточной
реализации мониторинга.
Как видно из этой схемы, мониторинг происходит далеко не
оптимально. Время работы системы мониторинга равно времени работы максимального
по длительности потока. В предложенной схеме изначально было запущено четыре
потока. Далее, распределив адреса на 4 группы, в каждой группе происходит
обычный последовательный опрос. А разница во времени между самой
"быстрой" группой (нет ни одного активного IР - адреса) и самой
"медленной пачкой" (все IР-адреса доступны и могут быть опрошены)
может отличаться в сотни раз.
Графическое представление оптимизированной по времени
многопоточной модели представлено на рис.21:

Рис. 21. Оптимизированная по времени многопоточная модель
мониторинга
В начальный момент времени в системе мониторинга было запущено
четыре потока. По завершению первого потока, система снова определила лучшее
количество потоков (оно в это время было ≤ 3), и было принято решение
новых потоков не создавать.
Когда второй поток заканчивается то лучшее число потоков осталось
равным трём, поэтому система создала только 1 поток. А вот после завершения
третьего потока, их оптимальное число стало равно 5. Поэтому сразу создается 3
новых потока, и т.д. Становится понятно, что во второй модели нет простоев
системы и она оптимизирована по времени. Из графического представления заметно,
что в различные интервалы времени в системе применяется различное число
потоков.
4.3
Рассмотрение алгоритма проведения опроса удаленных станций
Рассмотрение
алгоритма, оптимизированного по времени для мониторинга рабочих устройств
В соответствии с типом выбранной системы определяются
принципы, по которым она работает. И эти принципы могут относиться к различным
частям ее функционирования.
Чтобы определить эти принципы, нужно проанализировать те
функции, которые возложены на систему.
В нашем случае требуется получить информацию об удалённой
станции. Вначале эта задача является простой, но при доскональном анализе
возникают несколько препятствий.
Перво-наперво, надобно контролировать интервал опроса
рабочего устройства. В момент опроса может случиться остановка работы сети или
оконечная станция будет отсоединена от питания и т.д. Данная ситуация опасна
вследствие того, что система мониторинга должна заканчивать опрос рабочего
устройства автономно т.е. работоспособность конечных станций не должна влиять
на мониторинг.
Получаем, что нужно дать системе мониторинга возможность
закончить опрос конечных устройств не только по окончанию опроса, но и по
завершению заданного интервала времени. Это позволит вычислять максимальное
время работы системы, что в свою очередь важно при планировании проведения
мониторинга. Но подобный подход к работе системы мониторинга приведет к
нарушению в целостности информации.
Подпонятием нарушением целостности информации имеется ввиду
потеря некоторого количества данных о удаленном устройстве. К примеру, данные
об ПО были приняты, а о логических дисках или аппаратных средствах - нет.
Чтобы решить эту проблему нужно рассмотреть тип принимаемых
данных. Скапливаемая системой мониторинга данные являются набором текстовых
строк, в которых заключается информация о рабочем устройстве. В подобном случае
нет никакого смысла отклонять весь опрос, если часть информации определилась
неправильно.
Отсюда следует, что можно выразить главный принцип опроса
устройств: опрос рабочего устройства может длиться не более заблаговременно
установленного интервала времени. При его превышении, опрос прекращается и
рассматривается только та информация, которая успела поступить.
Этот принцип есть добавочное условие для решения поставленной
задачи мониторинга.
На рис. 22. представлена блок-схема одной из возможных
реализаций этой модели.

Рис. 22. Структура алгоритма для контроля длительности опроса
рабочей станции
Смысл этого алгоритма в том, что при начале опроса рабочей
станции образуются два процесса: в одном происходит собственно опрос, а в
другом контроль времени. Если время вышло, то останавливается тот процесс, в
котором идёт опрос. Если опрос уже закончен, а время ещё не кончилось, то
останавливается процесс контроля времени. Он больше не нужен.
Исследование
алгоритма для отсева устройств, при невозможности выполнения опроса устройства
для системы мониторинга
Первоначально нужно выбрать способ формирования списка всех
устройств, которым необходимо отправить запрос. Сегодня у этой проблемы нет
единственного метода решения. В раннее применяемых систем опроса станции
выбирались вручную из точно определенного списка устройств. В современных же
сетях выбор устройств вручную может быть осложнен, локальная сеть состоит из
сотен и тысяч устройств за которыми нужен мониторинг.
Самым подходящим методом выбора оконечных устройств является
диапазонный способ. Сущность метода заключается в том, что происходит опрос
всех IР - адресов в некотором диапазоне. IР-адреса в сети могут быть
сгруппированы по местоположению в некоторые логические. К примеру, устройствам,
находящимся на одном этаже, могут присваиваться адреса с 192.168.1.2 до
192.168.1.30. Этот способ присвоения IР-адресов часто применяется в
предприятиях на территории РФ.
Но у этого способа есть ряд больших недостатков. Например,
если компьютер из указанного диапазона будет выключен, то это приведет к тому,
что на обрабатывание такого IP-адреса уйдет все время, отведённое на
опрашивание рабочего устройства, а получить требуемые данные не получится. Еще
такая же ситуация возникнет если на включенном компьютере не будет установлен
нужных клиентский агент.
Чтобы уменьшить общее время опроса всего диапазона, требуется
выполнить две проверки, до запуска опроса определенного устройства. Во-первых,
проверить активность IР-адреса устройства и во-вторых проверить запущен ли
клиентский агент на устройстве.
Алгоритм проверки включенности компьютера и агента
представлен в виде структурной схемы (рис. 23)

Рис. 23. Схема алгоритма проверки работоспособности компьютера и
агента перед проведением основного мониторинга
Как показано на схеме, если нет возможности сделать опрос
компьютера, то система мониторинга не будет запущена, что обеспечит уменьшение
времени работы системы мониторинга, т.к. время проверки несравнимо меньше
времени опроса.
Исследование
многопоточного алгоритма для опроса устройств в системе мониторинга
Как было установлено выше, схема алгоритма мониторинга сети
состоит из множества блоков. Два предварительных блока были рассмотрены ранее -
это проверка работоспособности конечных станций и опрос рабочей станции. Эти
блоки были определены ранее, вследствие чего в структурной схеме, изображенной
на рис. 24, которая изображает общий способ опроса рабочих станций, выполнены в
виде одного блока, не объясняя логики этого процесса.

Рис. 24. Общий вид алгоритма опроса сети.
Этот алгоритм дает возможность выполнить все описанные выше этапы
опроса сети.
4.4
Исследование характеристик коммутатора 2-го уровня
Коммутатор управляет кадрами на интерфейсе при помощи такого
механизма как управление перегрузками (congestion management). На интерфейсах
возникают очереди, и они возможны двух видов: аппаратные и программные.
Аппаратные очереди практически всегда реализованы на логике FIFO. Программная
же очередь более разнообразна по методам обработки кадров. Программные средства
управления очередями:
· WFQ (Weighted Fair Queuing) - происходит
разделение трафика на потоки на основе таких характеристик как: адрес
назначения, адрес источника, версии протокола, что помогает поддерживать полосу
пропускания и уровень задержки.
· CBWFQ (Class-Based Weighted Fair Queuing)
- усовершенствованная версия WFQ. Главная особенность в том, что можно задать
собственный класс трафика.
· LLQ (Low Latency Queuing) - очередь с
уменьшенной задержкой. По сути это модель CBWFQ с приоритетной очередью.
· И множество других методов обработки
очередей (Priority queuing (PQ) Custom queuing (CQ), Weighted Random Early
Detection (WRED), Modified Deficit Round-Robin (MDRR))
Выбор метода
обслуживания входящих кадров
На рисунке 25 представлена стандартная схема с коммутацией
кадров, состоящая из коммутирующего устройства (Switch), который соединен с
3-мя устройствами генерирующие трафик и с 3-мя получателями, соединенные с
выходными портами. Главное, что необходимо знать это то что коммутаторы 2-го
уровня, используемые в сетях с коммутацией кадров, имеют для кратковременного сохранения
кадров внутри определенное количество буферной памяти. Линия связи не
резервируется и кадры передаются без заявленной заранее скоростью.
Коммутационное устройство принимает решение о дальнейшем
следовании кадра, помещая его в свою память. В заголовке у кадра размещается
MAC-адрес, который указывает на узел назначения. Заголовок должен быть у
каждого кадра, это дает возможность коммутатору использовать любой кадр
отдельно от остальных. Еще в кадре присутствует контрольная сумма, находящаяся
обычно в середине заголовка.
Контрольная сумма сверяется на коммутационном устройстве и
если она совпадает с фактическим значением, то это означает что информация в
кадре не искажена и коммутатор принимается обрабатывать заголовок кадра и
устанавливает путь назначения. Из-за этого во входной буфер записывается каждый
кадр. Поэтому сеть с коммутацией кадров применяет методику с промежуточным
хранением (store-and-forward) [23].
Для выравнивания скорости входящих кадров с коммутационной
скоростью, буферизация и применяется на коммутаторе. Очередь на входящих портах
происходят если коммутирующее устройство не справляется со скоростью обработки
кадра. И становится очевидно, что длина кадра меньше длины буфера.
Для создания коммутаторов применяется несколько методов. Самый
распространенный метод реализован на применении единственного процессора,
обслуживающего входящие очереди кадров на устройстве. Этот метод организации
процессора дает возможность возникновения очередей так между очередями делятся
вычислительные мощности процессора.
Нынешние методы создания коммутаторов второго уровня
реализованы на многопроцессорном, когда используется несколько процессоров,
обрабатывающих кадры, для отдельного порта.
У коммутаторов одним из важнейших параметров остается
задержка. Задержка - это интервал времени с момента появления кадра на входящем
интерфейсе до его прихода на исходящий интерфейс. Задержка сумма времени
необходимого на выполнение определенных действий с кадром: сканирования
адресной таблицы (например, MAC таблицы), выбор дальнейшей судьбы кадра -
отбрасывание или передача на нужный интерфейс. Основная задача следующей работы
- это определить величину задержки прохождения кадров в коммутационном
устройстве при изменении вместимости буферной памяти и длины самого кадра. И это
исследование проводится для двух основных методов обработки кадров LIFO и FIFO.
Моделирование
коммутатора второго уровня с методом обслуживания FIFO
Чтобы сделать пример по методу FIFO был симулирован
коммутатор в среде SimEvents. Read timer и Start timer отдельные блоки,
помогающие замерять интервал прохождения кадра со входящего интерфейса до
исходящего интерфейса.

Рис. 25 - Схема коммутатор с FIFO обработкой
Так как блоки в линии связи повторяются то можно рассмотреть
только элементы одной линии. Линия связи состоит из такого набора элементов:
· FIFO First In First Out
(первый пришёл - первый ушёл), является буфером входящего интерфейса;
· Subsystem - система
вырабатывания кадров;
· Read Timer, устанавливает
время окончания нахождения кадра во входящем буфере коммутатора;
· Start Timer, отмеряет
первоначальное время прихода кадра на исходящем интерфейсе.
Подобный комплект элементов использован и в других двух
линиях.
Коммутирующее устройство изображено парой блоков: Path
Combiner, Output Switch. Задачи матрицы коммутации реализовывает Path
Combiner. Output Switch отправляет кадры принимающим устройствам,
подключенным к его исходящим интерфейсам.
В коммутаторе выявлялись задержки с методом обработки кадров
FIFO для Fast Ethernet сети. Было рассмотрено множество кадров с длиной от 100
до 1500 байт с шагом 200.
Таблица 4.

Графическое представление результатов исследования (рис. 26)

Рис. 26 - Время продвижения кадра во входящем буфере
Таблица 5
Общее время прохождения кадра в коммутаторе с FIFO
обслуживанием

Графическое представление результатов исследования (рис. 27)

Рис. 27 - Время продвижения кадра во входящем буфере
Моделирование
коммутатора второго уровня с методом обслуживания LIFO
Второе исследование реализовывалось с методом обработки LIFO
- обрабатывается последний из пришедшего в очередь кадр.
Стоит заметить, что время прихода нового кадра никак не
связано с длиной существующей в буфере очередью и кадр может обрабатываться
устройством сразу.
Другими словами, задержка случается по причине того, что
другой кадр уже обрабатывается в коммутаторе.
В существующую модель (рис. 25) были привнесены небольшие
модификации.
Было использовано буферное устройство с методом обработки
кадров LIFO. Полученная модель коммутатора второго уровня показана на рисунке
28.

Рис. 28 - Коммутатор с методом обработки кадров Last In,
First Out
При изучении коммутационного устройства с методом обработки
LIFO были проведены те же действия что и с FIFO методом.
Таблица 6.

Суммарная задержка нахождения кадров в коммутационном
устройстве представлена в таблице 7.

Графическое представление результатов моделирования:
Использование метода LIFO на входящем интерфейсе коммутатора
более предпочтителен так как при его применении уменьшается время нахождения
кадра в буфере и суммарное время прохождения через все устройство.
Управление перегрузками происходит с помощью очередей, но
очереди бывают двух типов: аппаратные
Выводы
В четвертой главе были исследованы существующие модели и
алгоритмы для многопоточных систем мониторинга, разработана имитационная модель
коммутатора второго уровня с методами обслуживания очередей FIFO и LIFO и
получены следующие выводы:
· задержка существенно увеличивается за счет
времени, которое необходимо для буферизации всего кадра во входном буфере, что
позволяет идентифицировать ошибки в кадре при передаче по значению контрольной
сумме, хранящемуся в последнем поле кадра;
· в зависимости от длины кадра и размера
буферной памяти при применении метода обработки очереди FIFO время задержки
может колебаться от 9.78 до 2491.64 нс.
· метод обработки очереди LIFO обеспечивает
в разы меньшее время нахождения кадров во входящем буфере: от 6.58 до 146.71
нс;
· время нахождения кадра в коммутаторе для
метода обработки LIFO ограничивается значениями 7.01 - 4.97 нс;
· для метода FIFO время нахождения кадра в
коммутаторе имеет большее значение от 11.73 до 200 нс.
· обоснован выбор метода мониторинга сети,
позволяющего в момент ожидания ответа от агента конечной станции выполнять
параллельно другие задачи;
· определена условия, при которых
эффективность метода повышается;
· обоснован выбор метода предварительного
отбора оконечных устройств, позволяющего предотвратить длительное зависания
системы мониторинга;
· выбрано соотношение для отбора
оптимального количества потоков системы мониторинга, позволяющего сократить
временные затраты на опрос;
· обоснован выбор способа обработки и сбора
данных для приложений с многопоточным способом организации процесса
мониторинга;
· рассмотрены алгоритмы для системы
мониторинга с многопоточным способом организации процесса, уменьшающие время
опроса удаленных устройств по отношению к классическому способу организации опроса.
Заключение
В ходе исследования был предложен комплексный подход к
повышению производительности системы мониторинга компьютерных сетей,
учитывающий времена выполнения процессов многопоточного опроса с оптимизацией
загрузки потоков и времена обработки пакетов мониторинга на промежуточных
устройствах. Для реализации этого подхода в диссертационном исследовании были
решены следующие задачи и получены следующие результаты:
. Исследован метод мониторинга сети, позволяющего в
момент ожидания ответа от агента конечной станции выполнять параллельно другие
задачи.
2. Исследован метод предварительного отбора оконечных
устройств, позволяющего предотвратить длительное зависания системы мониторинга.
. Исследован метод нахождения оптимального количества
потоков в любой момент времени для системы мониторинга, позволяющего сократить
время опроса агентов и поддерживающий актуальность данных.
. Исследован способ обработки и сбора информации для
многопоточных приложений.
. Исследован алгоритм для системы мониторинга с
многопоточным способом организации процесса, уменьшающий время опроса удаленных
устройств по отношению к классическому способу организации опроса.
. Проведено исследование с помощью разработанной
имитационной модели коммутатора второго уровня, в результате которого получены
времена обработки пакетов мониторинга на коммутаторе для методов обработки
очередей FIFO и LIFO.
. Результаты исследования позволили определить
значения длины кадра и размера буфера, при которых происходит значительное
сокращение времени обработки кадра на коммутирующем устройстве при применении
методов обслуживания очередей FIFO и LIFO.
Планируется продолжить исследования для методов LLQ и CBWFQ
обслуживания очередей, которые широко используются в современном сетевом
оборудовании компаний Cisco, Juniper, Huawei.
Литература
1. Олифер
В.Г., Олифер Н.А. Компьютерные сети. Принципы, технологии, протоколы. Учебник
для вузов.4-е изд. - СПб.: Питер - 2010
2. Бондаренко,
А.Д. Безопасность протокола SNMPv3/А.Д. Бондаренко // Журнал BYTE - 2006. - №2.
- С.74-76
. Бекман
Д. Стандарт SNMPV3 // Сети и системы связи, 2008. - №12 - С.50
. Городецкий,
В. Самойлов, А. Малов. Технология обработки данных для извлечения знаний: Обзор
состояния исследований. Новости искусственного интеллекта, № 3-4, 2002. -
С.3-12.
. Крылов,
C. B. Мониторинг и управление территориально-распределенными системами через
World Wide Web: Дис. канд. техн. наук: 05.13.01 Н. Новгород, 1999 241 с.
6. Олифер, В.Г., Олифер
Н.А. Управление неоднородными сетями [Электронный ресурс] / Электрон, дан. - .
- Режим доступа: http://www.citforum.ru/nets/tpns/glava_l6. shtml
<http://www.citforum.ru/nets/tpns/glava_l6.shtml>, свободный.
. Леохин Ю.Л.
Корпоративные сети: архитектура, технологии, управление. - М.: Фонд
"Качество", 2009, 173 стр
. Stallings, W. SNMP,
SNMPv2 and RMON: Practical Network Management / W. Stallings - Readong, MA:
Addison-Wesley, 1996
. Vandenberg Chr.
MIB-II extends SNMP Interoperability / Chr. Vandenberg. - Datapro Research
Corporation, McGraw-Hill, October 1990. - 119-124 p.
. Басс Л. Архитектура
программного обеспечения на практике: пер. с англ. / Л. Басс, П. Клементс, Р.
Кацман. - 2-е изд. - СПб.: Питер, 2006. - 575 с
. Кларк Д.
Объектно-ориентированное программирование в Visual Basic.net.: Перевод с
английского. Санкт-Петербург: Питер, 2003
. Клейнрок, Л.
Вычислительные системы с очередями / Л. Клейнрок; пер. с англ, под ред.В.С.
Цыбакова. - М.: Мир, 1979. - 600 с.
. Константайн Л.
Разработка программного обеспечения. Санкт-Петербург: Питер, 2003
. Безкоровайный М.М.,
Костогрызов А.И., Львов В.М. Инструментально-моделирующий комплекс для оценки
качества функционирования информационных систем. М. Изд. "Вооружение,
политика, конверсия", 2001, 303с
. Кровчик Э.net.
Сетевое программирование для профессионалов/ Кровчик Э., Кумар В., Лагари Н.,
Москва: ЛОРИ, 2014
. МагдаЮ. Ассемблер:
Разработка и оптимизация Windows-приложений. Санкт - Петербург: БХВ-Петербург,
2006
. Craig Hunt. Windows
Server 2003 Network Administration/ Craig Hunt, Roberta Bragg // O'Reilly
Media, 2005
. Гарбер Г.3. Основы
программирования на Visual Basic и VBA в Excel / Гарбер Г.3. Москва: СОЛОНПРЕСС,
2008. 191 с
. Бочаров П.П.,
Печинкин А.В. Теория массового обслуживания, Изд-во РУДН, 1995. - 529 с
. Рихтер Дж.
Программирование на платформе Microsoft.net Framework / Дж. Рихтер. - 2-е изд.,
испр. - М.: Русская редакция, 2003. - 512 с.
. MSDNLibrary для
Visual Studio 2008
. Олифер В.Г., Олифер
Н.А. Компьютерные сети. Принципы, технологии, протоколы. Учебник для вузов.4-е
изд. - СПб.: Питер - 2010
. Вильям Столлингс.
Компьютерные сети, протоколы и технологии Интернета / Изд-во БХВ-Петербург. -
2005. - 832 с.
. Леохин Ю.Л. Научные
основы управления параметрами структур корпоративных сетей: дис. док. техн.
наук Моск. гос. института электроники и математики, Москва, 2009
. Штайнке, С.
Управление сетями приходит в Web / С. Штайнке // LAN/Журнал сетевых решений. -
1997. - №12. - С.105.
. HP Network Node
Manager 9: Getting Started [Электронный ресурс] / Hewlett Packard - Электрон
дан. - USA, California - . - Режим доступа: https: //
www.packtpub.com/sites/default/files/0844-chapter-1-before-we-manage-with-nnmi.
pdf, свободный.
. IBM Tivoli NetView
[Электронный ресурс] / IBM - Электрон, дан. - . - Режим доступа:
<http://www.ibm.com/support/knowledgecenter/> SSZJDU_6.2.1/com. ibm.
itnetviewforzos. doc_6.2.1/pdfbooks. htm?/dw/ru /download/ibm3.
pdf, свободный.
. // LAN - 2001. - №6.
- С.17-25, 34-35, 63-69
. Алленов О.М.
Управление трафиком АТМ // Сети и системы связи, 1998, № 4. С.86-91.
. Назаров И.В.
Обеспечение надежной передачи видео по IP-сетям / Назаров И. В // Журнал
"Системы безопасности". - 2013 - №3 - С.144 - 145
. Боровиков В.П.
Нейронные сети. Statistica Neural Networks. Методология и технологии
современного анализа данных. // Горячая Линия - Телеком. - 2008 - 392 с.
. Novell Inc.
LANAnalyzer and LANtern Product Guide // California, USA, 1998. - 34-49 p
. Ерофеев А.А.
Интеллектуальные системы управления. СПб: Издательство СПбГТУ, / А.А. Ерофеев,
А.О. Поляков; 1999 - 264 с
. Гринько Д., Управление
гетерогенными сетями связи / Гринько Д., Саякин В // "Журнал сетевых
решений/LAN", - 2002. - № 11
. Бойченко А.В.,
Основы открытых информационных систем.2-е издание. / Бойченко А.В., Кондратьев
В.К., Филинов Е. Н // Издательский центр АНО "ЕОАИ". - М.:, 2004. -
128 с.
. Леохин Ю.Л.
Идентификация и прогнозирование состояний корпоративных IP-сетей в нейросетевом
логическом базисе // Открытое образование, № 2, 2009, стр.22-27
. Плешаков, В. CISCO
Internetworking Technology Overview [Электронный ресурс] / Сервер Марк-ИТТ,
дан. - М.: - . - Режим доступа: http://citforum.ru/nets/ito/, свободный.
. Bapat, S, "OSI
Management Information Base Implementation," Proceedings of IFIP
International Symposium on Integrated Network Management (ISINM) - 1991
. Ясницкий Л.Н.
Введение в искусственный интеллект (2-е изд.) / Ясницкий Л.Н., Изд-во Академия,
2008. С.176
. Бондаренко, А.Д.
Стандарты и средства современных систем управления компьютерными сетями /А.Д.
Бондаренко // Тез. докл. научно-технической конференции студентов, аспирантов и
молодых специалистов МГИЭМ, 2005 г. - М.: Изд-во МГИЭМ, 2005. С.146-148
. Фокин В.Г.
Управление телекоммуникационными сетями: Учебное пособие. - Н.: СибГУТИ, 2001.
- 112 с.
. Дымарский Я.С.
Оптимальное распределение ресурсов в сети с разнородными потоками:
Рассматривается оригинальный подход, обеспечивающий решения / Дымарский Я.,
Нурмиева М. - // Вестник МАИСУ. - 2002. - № 3. - с.3-9
. Подлазов, B. C.
Повышение пропускной способности коммутируемых локальных вычислительных сетей
/B. C. Подлазов. // Приборы и системы управления. - 1997. - №8. С.48-49.
. Коржов В.С.
Многоуровневые системы клиент-сервер. /"Сети/network world"
<http://www.osp.ru/nets/>, № 06
<http://www.osp.ru/nets/archive/1997/06/>, 1997
<http://www.osp.ru/nets/archive/1997/>
. Lambert M. Surhone,
Mariam T. Tennoe, Susan F. Henssonow "Common Management Information
Protocol”, 2011
. Patrick T. Lane,Rod
Hauser, CIW Internetworking Professional Study Guide: Exam 1D0-460, 2002.
C.288-292